| 编辑推荐: |
代码整洁是软件长期稳定和可扩展的基础,本文从现实中的代码、重构、设计模式谈论代码整洁之道,总结出如何做一个有思想的程序员。希望对你的学习有帮助。
本文来自于微信公众号阿里云开发者,由火龙果软件Linda编辑、推荐。 |
|
我心中理想的代码
软件开发是一个需要团队协作、长期维护的过程,代码整洁是软件长期稳定和可扩展的基础。整洁的代码具备清晰的代码结构和规范的命名,具有良好的可读性和可维护性,便于快速定位和修复问题,有利于新功能的快速迭代。团队成员也可以更高效地协作,减少沟通成本,整体提高项目的研发效率。
首先我们可以来看下C++之父Bjarne Stroustrup对于好代码的定义。
我喜欢我的代码优雅且高效。 逻辑应该简单明了,这样 bug 就很难隐藏;依赖关系最小化,以便于维护;错误处理应该根据明确的策略完成;性能应该接近最佳,以免诱使人们通过无原则的优化使代码变得混乱。
干净的代码可以很好地完成一件事。
总体来说,优雅的代码具备如下特点:
阅读上赏心悦目,修改上得心应手。
代码简洁明了,尽量减少冗余和复杂性。
模块化,高内聚低耦合,便于维护和扩展。
可测试性,需要有UT、E2E保证代码的可修改性。
适当的注释和文档,解释代码的意图和实现细节。
现实中的代码
圈复杂度
圈复杂度(Cyclomatic Complexity)是一种代码复杂度的度量指标,用于衡量代码中的控制流路径的数量和复杂程度。它通过统计代码中的决策点(如条件语句和循环语句)来计算。
圈复杂度的值可以用于判断代码的复杂程度和测试的覆盖范围。较高的圈复杂度表示代码中存在更多的路径和可能的执行情况,增加了理解、维护和测试代码的难度。
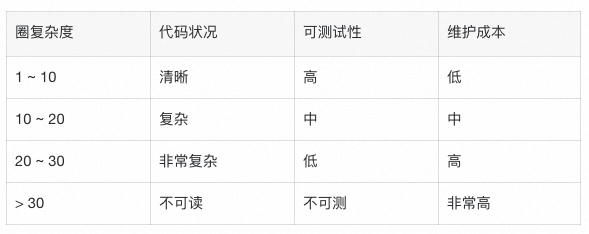
iLogtail代码复杂度探讨
iLogtail 作为一款阿里云日志服务(SLS)团队自研的可观测数据采集器,目前已经在 Github
开源,其核心定位是帮助开发者构建统一的数据采集层。不仅仅是在功能、性能上表现突出,代码层面也一直在追求整洁优雅,详见《跟着iLogtail学习设计模式》。
iLogtail部分关键模块代码,代码行数跟圈复杂度基本是控制在比较合理的范畴。

但是也存在少数代码,整体复杂度已经到了极度复杂的程度,严重影响了代码的可扩展性。例如,下图两个函数,563行代码/169圈复杂度
代码[1], 332行代码/71圈复杂度 代码[2]。

备注:以上圈复杂度基于 VSCode 插件 Codalyze [3]获取。
综上我们可以看出,对于一些简单的代码往往是比较容易控制好结构的;但是拥有着比较复杂的业务逻辑的代码,往往会不是那么优雅,而且随着时间的推移,复杂度会变得越来越高。
为什么造成这种局面?主要有以下几个原因:
业务逻辑复杂:业务逻辑复杂的代码,如果初期没有很好的设计导致不易扩展;后期又不断引入新的特性,加剧了代码的复杂度。
开发阶段时间紧张:为了快速开发使用重复或结构差的代码来实现,以及后面再补的思维。
缺乏代码重构:当代码不断变得不易维护时,开发人员没有进行及时意识到代码的坏味道,并进行有效的重构,导致代码越来越复杂。
缺乏单元测试和集成测试:导致历史代码没人敢动,只能维持现状。
接下来,我们结合实战手段介绍如何合理地利用重构跟设计模式两种手段避免代码腐化的问题。
重构
重构实际上是对代码的一种调整,目的是在不改变软件可观察行为的前提下,提升代码的扩展性和可理解性,降低维护成本。
识别代码的坏味道
就像破窗效应中提到的一样,干净优雅的代码会让开发者心生敬畏;而一旦代码中出现了一些小的问题或坏味道,如果不及时修复,日积月累最终将会导致代码的腐化。
因此,为了保证代码的质量,首先需要对代码中的坏味道有敏锐的识别能力。常见的坏味道:
过长函数
重复代码
过长参数列表
过多全局变量
霰弹式修改
冗余的注释
重构的方式
重新组织函数
/////////////////////
原始代码 /////////////////////
void printOwing() {
Enumeration e = _orders.elements();
double outstanding = 0.0;
// print banner
System.out.println("***************************");
System.out.println("******** Custor Owes
******");
System.out.println("***************************");
// calculate outstanding
while (e.hasMoreElements()) {
Order each = (Order) e.nextElement();
outstanding += each.getAmount();
}
// print details
System.out.println("name:" + _name);
System.out.println("amount" + outstanding);
}
|
///////////////////// 重构后 /////////////////////
void printBanner() {
System.out.println("***************************");
System.out.println("******** Custor Owes
******");
System.out.println("***************************");
}
void printDetails(double outstanding) {
System.out.println("name:" + _name);
System.out.println("amount" + outstanding);
}
double getOutstanding() {
Enumeration e = _orders.elements();
double outstanding = 0.0;
while (e.hasMoreElements()) {
Order each = (Order) e.nextElement();
outstanding += each.getAmount();
}
return outstanding;
}
void printOwing() {
printBanner();
double outstanding = getOutstanding();
printDetails(outstanding);
}
|
避免函数参数过多
///////////////// 重构前 /////////////////
// 1
public User getUser(String username, String
telephone, String email);
// 2
public void postBlog(String title, String summary,
String keywords, String content, String category,
long authorId);
///////////////// 重构后 /////////////////
// 考虑函数是否职责单一,是否能通过拆分成多个函数的方式来减少参数。
public User getUserByUsername(String username);
public User getUserByTelephone(String telephone);
public User getUserByEmail(String email);
// 将函数的参数封装成对象
public class Blog {
private String title;
private String summary;
private String keywords;
private Strint content;
private String category;
private long authorId;
}
public void postBlog(Blog blog);
|
学会使用解释性变量
///////////////// 重构前 /////////////////
if (date.after(SUMMER_START) && date.before(SUMMER_END))
{
// ...
} else {
// ...
}
///////////////// 重构后 /////////////////
// 引入解释性变量后逻辑更加清晰
boolean isSummer = date.after(SUMMER_START)&&date.before(SUMMER_END);
if (isSummer) {
// ...
} else {
// ...
}
|
移除过深的嵌套层次。嵌套最好不超过两层,超过两层之后就要思考一下是否可以减少嵌套。
//
重构前的代码
public List<String> matchStrings(List<String>
strList,String substr) {
List<String> matchedStrings = new ArrayList<>();
if (strList != null && substr != null)
{
for (String str : strList) {
if (str != null) {
if (str.contains(substr)) {
matchedStrings.add(str);
}
}
}
}
return matchedStrings;
}
// 重构后的代码:先执行判空逻辑,再执行正常逻辑
public List<String> matchStrings(List<String>
strList,String substr) {
if (strList == null || substr == null) { //先判空
return Collections.emptyList();
}
List<String> matchedStrings = new
ArrayList<>();
for (String str : strList) {
if (str != null && str.contains(substr))
{
matchedStrings.add(str);
}
}
return matchedStrings;
}
|
重构的方法很多,这里无法一一列举。
重构的时机
微重构
开发新功能时:让新功能更易扩展。一般可以秉承事不过三的原则。
阅读一段代码时:让代码读起来更简单。
Bugfix 和 CodeReview 时:发现旧代码的质量问题,并按计划根治解决。
模块级重构
代码已经不堪重负,可维护性极差,严重阻碍开发迭代进度。
架构级重构
代码结构已经跟不上架构发展的需求。
重构从“战胜对老代码的恐惧”开始!
面对复杂臃肿的老代码,开发者往往心生畏惧。但是只要秉承如下原则,重构也不再可怕。
重构前需要对整体有清晰的认识:架构设计梳理、模块间交互、周边交互。进而指导后续的重构过程。
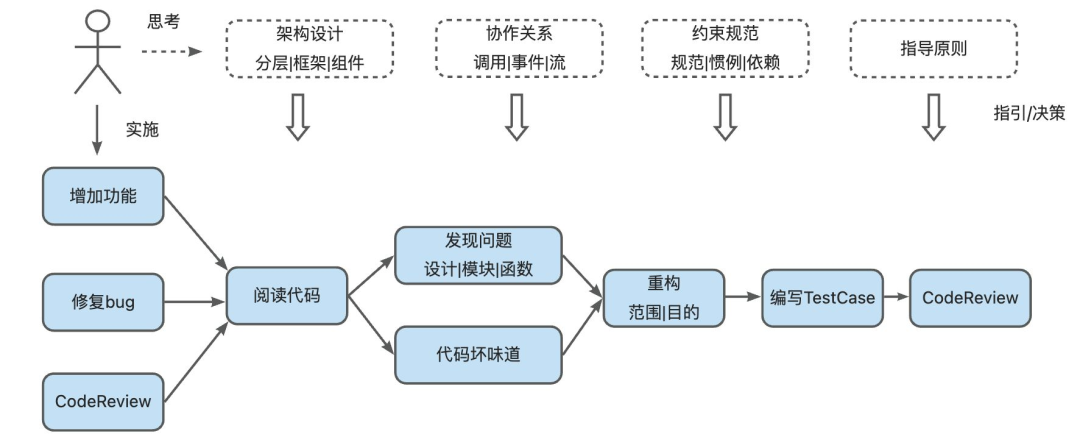
最主要的是测试先行,良好的测试体系是进行重构的关键。当然最理想的是测试(UT、E2E、Benchmark等)应该做到首次开发时、做到平时。
核心场景梳理,特别是可靠性场景、异常场景的处理以及微小的长尾细节。放过任何一处都可能是一个bug,而且有些微小细节的问题可能暴露的时间会很长。
最后,牢记细致认真是代码重构最重要的素养。
设计模式
抽象与分层
众所周知,程序员往往自嘲为码农。但是我认为码农跟程序员还是有本质区别的,这个区别就是抽象思维。码农只会CRUD,单点解决问题,导致只能埋头苦干;而程序员可以通过抽象思维解决,进行产品跟技术实现的归纳总结,一次解决更多通用需求。而软件技术本质上也是一门抽象的艺术。
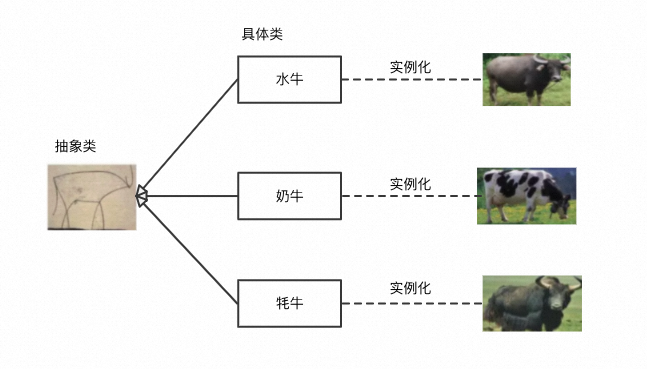
抽象思维是程序员最重要的思维能力,抽象的过程就是寻找共性、归纳总结、综合分析,提炼出相关概念的过程。
抽象是忽略细节的。抽象类是最抽象的,忽略的细节也最多,就像抽象牛,只是几根线条而已。在代码中可以类比到
Abstract Class 或者 Interface。
抽象代表了共同性质。类(Class)代表了一组实例(Instance)的共同性质,抽象类(Abstract
Class)代表了一组类的共同性质。
抽象具有层次性。抽象层次越高,内涵越小,外延越大,也就是说它的涵义越小,泛化能力越强。比如,牛就要比水牛更抽象,因为它可以表达所有的牛,水牛只是牛的一个种类(Class)。
而设计模式是软件开发中抽象化思维的重要经验总结。总体上可以分为三类:
创建型模式:这些模式关注于对象的创建和初始化方式,用于解决对象创建的复杂性问题。创建型模式包括单例模式、工厂模式、抽象工厂模式、建造者模式和原型模式等。
结构型模式:这些模式关注于对象之间的关系,用于解决对象的组合和属性之间的问题。结构型模式包括适配器模式、桥接模式、组合模式、装饰器模式、外观模式、享元模式和代理模式等。
行为型模式:这些模式关注于对象之间的通信、交互和责任分配,用于解决对象之间的复杂交互问题。行为型模式包括责任链模式、命令模式、解释器模式、迭代器模式、中介者模式、备忘录模式、观察者模式、状态模式、策略模式、模板方法模式和访问者模式等。
在《跟着iLogtail学习设计模式》一文中,深入阐述了多种设计模式的应用实践,这里不再一一介绍,而是从几个场景问题触发,探讨如何解决。
场景1:如何避免冗长的if-else
相信大家都见过如下代码,将处理逻辑的定义、创建、使用直接耦合在一起,代码特别冗长。
public class OrderService {
public double discount(Order order) {
double discount = 0.0;
OrderType type = order.getType();
if (type.equals(OrderType.NORMAL)) { // 普通订单
//...省略折扣计算算法代码
} else if (type.equals(OrderType.GROUPON)) {
// 团购订单
//...省略折扣计算算法代码
} else if (type.equals(OrderType.PROMOTION))
{ // 促销订单
//...省略折扣计算算法代码
}
return discount;
}
}
|
使用策略模式避免冗长的if-else/switch分支:将不同类型订单的打折策略设计成策略类,并由工厂类来负责创建策略对象。
// 定义策略接口
public interface DiscountStrategy {
double calDiscount(Order order);
}
// 具体策略实现
// 省略NormalDiscountStrategy、GrouponDiscountStrategy、PromotionDiscountStrategy类代码...
// 建立策略工厂
public class DiscountStrategyFactory {
private static final Map<OrderType, DiscountStrategy>
strategies = new HashMap<>();
static {
strategies.put(OrderType.NORMAL, new NormalDiscountStrategy());
strategies.put(OrderType.GROUPON, new GrouponDiscountStrategy());
strategies.put(OrderType.PROMOTION, new PromotionDiscountStrategy());
}
public static DiscountStrategy getDiscountStrategy(OrderType
type) {
return strategies.get(type);
}
}
// 策略的使用
public class OrderService {
public double discount(Order order) {
OrderType type = order.getType();
DiscountStrategy discountStrategy = DiscountStrategyFactory.getDiscountStrategy(type);
return discountStrategy.calDiscount(order);
}
}
|
场景2:善用组合
假如有一个几何形状Shape类, 扩展出两个子类: 圆形Circle和 方形Square 。 现在需要引入颜色的因素,该如何实现?
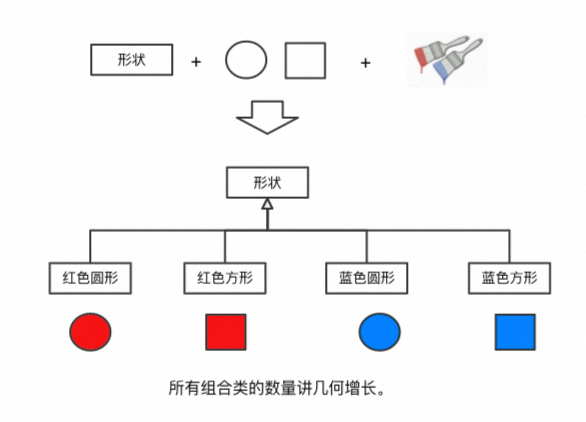
桥接模式可将一个大类或一系列紧密相关的类拆分为抽象和实现两个独立的层次结构, 从而能在开发时分别使用。一个类存在两个(或多个)独立变化的维度,可以通过组合的方式,让这两个(或多个)维度可以独立进行扩展。

场景3:巧用适配器模式提高系统的可扩展性
适配器模式将一种类型的接口转换成希望的另一类接口,使得原本接口不兼容对象能够一起配合工作。适配器接受客户端通过适配器接口发起的调用,
并将其转换为适用于被封装服务对象的调用。
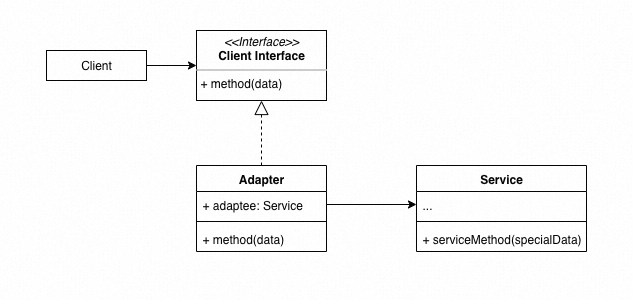
我们的系统当中,往往会依赖各种各样的外部系统,合理地利用适配器模式可以达到如下效果:
外部系统的可替代性:当需要把项目中依赖的一个外部系统替换为另一个外部系统的时候(例如日志系统从Elasticsearch切换到SLS),利用适配器模式可以减少对代码的改动及测试复杂度。
多外部系统接口统一:某个功能的实现依赖多个外部系统,通过适配器模式,将它们的接口适配为统一的接口定义,然后就可以使用多态的特性来复用代码逻辑。
兼容老版本接口:在做版本升级的时候,对于一些要废弃的接口,往往不直接将其删除,而是暂时保留,并且标注为deprecated,并将内部实现逻辑委托为新的接口实现。这样做的好处是,让使用它的项目有个过渡期,而不是强制进行代码修改。
结束语:为了更美好的生活,请写好代码!
|