| ±ΨΈΡΡΩ¬ΦΘΚ
“ΜΓΔ±≥ΨΑ
ΕΰΓΔΈ“Ο«ΒΡ–η«σ « ≤Ο¥ΘΩ
»ΐΓΔΗ≈Ρν≥Έ«ε
ΥΡΓΔΗ≈ΡνΡΘ–Ά
ΈεΓΔΉήΧε…ηΦΤ
ΝυΓΔΙΊΦϋΒψ…ηΦΤ
ΤΏΓΔΉήΫα
“ΜΓΔ±≥ΨΑ
ΥΒΒΫΉ‘Ε·Μ·≤Ω πΘ§¥σΦ“ΩœΕ®ΕΦΜαœκΒΫ“Μ–©≈δ÷ΟΙήάμΙΛΨΏΘ§œώansible,chef,puppet, saltstack»»ΓΘΥδ»Μ’β–©ΙΛΨΏΗχ‘ΥΈ§–߬ ΚΆΑ≤»Ϊ–‘¥χά¥ΝΥΚήΕύΚΟ¥ΠΓΘΒΪ « ΒΦ ΙΛΉς÷–Θ§Έ“Ο«ΜΙ «Μα”ωΒΫ“Μ–©Έ ΧβΘΚ
’β–©ΙΛΨΏΈόΖ®Τ’ΦΑΒΫΩΣΖΔΓΔ≤β ‘»Υ‘±Θ§Ψ≠≥Θ’“‘ΥΈ§ΑοΟΠΘ§ΈόΖ®Ή‘÷ζΘΜ
œνΡΩ»Υ‘±ΈόΖ®÷±ΙέΒΡ≤ΈΩ¥ΒΫœΒΆ≥ΒΡ≤Ω πΦήΙΙ…ηΦΤΘ§ΦΑΦήΙΙΒΡ―ίΫχΙΐ≥ΧΘΜ
¥”ΈοάμΦήΙΙ…ηΦΤΒΫΉν÷’…œœΏΘ§ΈόΖ®–Έ≥…±’ΜΖΘΜ
ή≤ν“λ–‘ΒΡΜυ¥Γ…η ©”ΑœλΫœ¥σΓΘ
ΕΰΓΔΈ“Ο«ΒΡ–η«σ « ≤Ο¥ΘΩ
Έ“Ο«DevOpsΤΫΧ®ΒΡ≤Ω πΡΘΩιΨΆΩΥΖΰ…œΟφ’β–©Έ ΧβΘ§ΈΣ Βœ÷DevOps“‘≤ζΤΖΈΣΚΥ–ΡΘ§“‘œνΡΩΙήάμΈΣ«ΐΕ·Θ§ΫΪ–η«σΓΔ…ηΦΤΓΔΫΜΗΕΓΔ‘ΥΈ§’ϊΗωΝ¥¬Ζ¥ρΆ®’β“ΜΡΩ±ξΧαΙ©”–ΝΠ÷ß≥÷ΓΘΨΏΧεά¥Ω¥Τδ–η«σΚ≠Η«“Μœ¬ΦΗΒψΘΚ
ΫΪΦήΙΙ…ηΦΤΡ…»κDevOpsΙήάμΙΐ≥Χ÷–Θ§÷ß≥÷ΦήΙΙ…ηΦΤΑφ±ΨΜ·ΘΜ
“Μ¥ΈΦήΙΙ…ηΦΤΕύ¥Έ≤Ω πΘΜ
“‘ΉνΦ― ΒΦυΈΣΜυ¥ΓΘ§ Βœ÷ΦήΙΙ…ηΦΤΡΘΑφ÷Ί”ΟΘΜ
ΕύΜΖΨ≥≤Ω πΘ§Ά§ ±÷ß≥÷”Π”Ο‘Ύ–ιΡβΜζΓΔ»ίΤς…œΒΡ≤Ω πΘΜ
÷ß≥÷Εύ÷÷≤Ω πΡΘ ΫΘ®ΒΞΜζΓΔΗΏΩ…”ΟΘ©ΓΔ≤Ω π≤Ώ¬‘Θ®»Ϊ–¬ΓΔάΕ¬ΧΓΔΙωΕ·…ΐΦΕΓΔΜΊΙωΘ©
»ΐΓΔΗ≈Ρν≥Έ«ε
‘Ύ’ΐ ΫΫ≤ΫβΈ“Ο«ΒΡ…ηΦΤ÷°«ΑΘ§Έ“Ο«œκ≥Έ«εCI/CDΒΡΜυ±ΨΗ≈ΡνΘ§“ρΈΣ±Ψ¥ΈΒΡ÷ςΧβΚΆ≥÷–χΦ·≥…ΓΔ≥÷–χΫΜΗΕΚΆ≥÷–χ≤Ω π’β–©Οϊ¥ Ήή”––©‘®‘¥ΓΘ
1ΓΔ ≤Ο¥ «≥÷–χΦ·≥…ΘΩ
≥÷–χΦ·≥…Θ®Continuous IntegrationΘ©÷ΗΒΡ «Θ§ΤΒΖ±ΒΊΫΪ¥ζ¬κΦ·≥…ΒΫ÷ςΗ…Θ§“‘±ψΩλΥΌΖΔœ÷¥μΈσΓΔΖά÷ΙΖ÷÷ߥσΖυΕ»ΤΪάκ÷ςΗ…ΓΘ
≥÷–χΦ·≥…ΒΡΡΩΒΡΘ§ΨΆ «‘Ύ≤ζΤΖΩλΥΌΒϋ¥ζΒΡΆ§ ±±Θ≥÷¥ζ¬κ÷ ΝΩΘ§ΥϋΒΡΚΥ–Ρ¥κ ©÷ς“Σ”–ΝΫΒψΘΚ
1Θ©¥ζ¬κΦ·≥…ΒΫ÷ςΗ…÷°«ΑΘ§±Ί–κΆ®ΙΐΉ‘Ε·Μ·≤β ‘Θ§÷Μ“Σ”–“ΜΗω≤β ‘”Οάΐ ßΑήΘ§ΨΆ≤ΜΡήΦ·≥…ΓΘ
2Θ©Ά®ΙΐCode ReviewΓΔ¥ζ¬κ÷ ΝΩΖ÷ΈωΙΛΨΏΕ‘¥ζ¬κ÷ ΝΩΫχ––Α―ΙΊΘ§“‘±ψ»ΖΕ® «ΖώΡήΙΜΦ·≥…ΓΘ
Martin FlowerΥΒΙΐΘ§ ΓΑ≥÷–χΦ·≥…≤Δ≤ΜΡήœϊ≥ΐBugΘ§Εχ «»ΟΥϊΟ«Ζ«≥Θ»ί“ΉΖΔœ÷ΚΆΗΡ’ΐΓΘΓ±
2ΓΔ ≤Ο¥ «≥÷–χΫΜΗΕΘΩ
≥÷–χΫΜΗΕΘ®Continuous DeliveryΘ©÷ΗΒΡ «Θ§–¬Αφ±ΨΈΣΝΥΡήΙΜΩλΥΌΑ≤»ΪΒΡΫΜΗΕΒΫ…ζ≤ζΜΖΨ≥÷–Θ§–η“ΣΫΪ–¬Αφ±Ψœ»ΫΜΗΕΒΫάύ…ζ≤ζΘ®Production-likeΘ©ΜΖΨ≥÷–Θ®»γUATΘ·StagingΘ·LabΜΖΨ≥Θ©Θ§“‘±ψΫχ––œύ”ΠΒΡ“ΒΈώ―ι÷ΛΓΔΑ≤»Ϊ―ι÷ΛΓΔ–‘Ρή―ι÷ΛΒ»Ιΐ≥ΧΓΘ
“ΜΒ©άύ…ζ≤ζΜΖΨ≥―ι÷ΛΆ®ΙΐΘ§–¬Αφ±ΨΨΆΫχ»κΒΫ…ζ≤ζΫΉΕΈΓΘ
≥÷–χΫΜΗΕΩ…“‘Ω¥Ής «≥÷–χΦ·≥…ΒΡΫχ“Μ≤ΫΓΘΥϋ«ΩΒςΒΡ «Θ§≤ΜΙή‘θΟ¥Ηϋ–¬Θ§»μΦΰ «Υφ ±ΥφΒΊΩ…“‘ΫΜΗΕΒΡΓΘ
3ΓΔ ≤Ο¥ «≥÷–χ≤Ω πΘΩ
≥÷–χ≤Ω πΘ®Continuous DeploymentΘ©÷ΗΒΡ «Θ§–¬Αφ±ΨΆ®Ιΐάύ…ζ≤ζΜΖΨ≥ΒΡ―ι÷ΛΚσΘ§Ή‘Ε·≤Ω πΒΫ…ζ≤ζΜΖΨ≥÷–ΓΘ
≥÷–χ≤Ω πΩ…“‘Ω¥≥…≥÷–χΫΜΗΕΒΡΫχ“Μ≤ΫΓΘ≥÷–χ≤Ω πΒΡ«ΑΧα «Ή‘Ε·Μ·Άξ≥…≤β ‘ΓΔΙΙΫ®ΓΔ―ι÷ΛΒ»≤Ϋ÷ηΓΘ
≥÷–χ≤Ω πΒΡΡΩ±ξ «Θ§¥ζ¬κ‘Ύ»ΈΚΈ ±ΩΧΕΦΩ…“‘Ϋχ»κΉ‘Ε·ΒΊΫχ»κ…ζ≤ζΫΉΕΈΘ§ΈΣΉν÷’”ΟΜßΧαΙ©ΖΰΈώΓΘ
≥÷–χΫΜΗΕΚΆ≥÷–χ≤Ω πΒΡ«χ±πΩ…“‘≤ΈΩΦœ¬ΆΦΘΚΆΦΤ§Οη ω

¥”…œΆΦ÷–Θ§Έ“Ο«Ω…“‘Ω¥≥ωΘΚ
≥÷–χΫΜΗΕΝς≥ΧΫΪΉ‘Ε·ΒΡ≤β ‘–¬Αφ±Ψ”Π”ΟΘ§ΒΪ «ΖώΫΪ–¬Αφ±ΨΫΜΗΕΒΫ…ζ≤ζΜΖΨ≥÷– «“ΜΗω ÷Ε·Ιΐ≥ΧΓΘ≥÷–χ≤Ω π‘ρ «Ή‘Ε·ΒΊΫΪ–¬Αφ±ΨΫΜΗΕΒΫ…ζ≤ζΜΖΨ≥÷–»ΞΓΘ
ΙΊ”Ύ≥÷–χΫΜΗΕΘ·≥÷–χ≤Ω πΘ§Έ“Ο«≤ΜΡήΥΒΡΡ“ΜΗω «ΉνΚΟΒΡΖΫΑΗΓΘΕ‘”Ύ≤ΜΆ§ΒΡΉι÷·Θ§ ΚœΒΡΨΆ «ΉνΚΟΒΡΓΘ
4ΓΔ ≤Ο¥ «Ή‘Ε·Μ·≤Ω πΘΩ
Ή‘Ε·Μ·≤Ω πΘ®Automatic DeploymentΘ©÷ΗΒΡ «Θ§Ά®ΙΐΉ‘Ε·Μ·ΙΛΨΏΫΪ”Π”ΟΫι÷ ≤Ω πΒΫ÷ΗΕ®ΜΖΨ≥÷–»ΞΓΘ
Ή‘Ε·Μ·≤Ω π÷Μ «≥÷–χΫΜΗΕΚΆ≥÷–χ≤Ω πΝς≥Χ÷–ΒΡ“ΜΗωΙΠΡήΒΞ‘ΣΓΘ
Ή‘Ε·Μ·≤Ω πΙΛΨΏΘΚAnsibleΓΔPuppetΓΔSaltStack»»ΓΘ
Ά®Ιΐ“‘…œΗ≈ΡνΒΡ≥Έ«εΘ§Έ“Ο«ΝΥΫβΝΥ ≤Ο¥ «≥÷–χΦ·≥…ΓΔ≥÷–χΫΜΗΕΓΔ≥÷–χ≤Ω π“‘ΦΑΉ‘Ε·Μ·≤Ω πΓΘ
±ΨΈΡΒΡ÷ςΧβ≤Μ «Ϋι…ή≥÷–χΦ·≥…ΓΔ≥÷–χΫΜΗΕΓΔ≥÷–χ≤Ω πΒΡPipeline”κ Βœ÷Θ§Εχ «Ϋι…ήDevOpsΤΫΧ®÷–Θ§‘Ύ¥ΪΆ≥Ή‘Ε·Μ·≤Ω πΙΛΨΏ÷°…œΒΡΉ‘Ε·Μ·≤Ω πΩρΦήΒΡ…ηΦΤ”κ Βœ÷ΓΘΕχΉ‘Ε·Μ·≤Ω πΡΘΩι“≤ «Έ“Ο«DevOpsΤΫΧ®÷–ΒΡCI/CDΒΡΒΉ≤ψΡήΝΠΓΘ
œ¬ΟφΈ“Ο«ΨΆά¥ΝΡΝΡΨΏΧεΒΡ…ηΦΤΓΘ
ΥΡΓΔΗ≈ΡνΡΘ–Ά
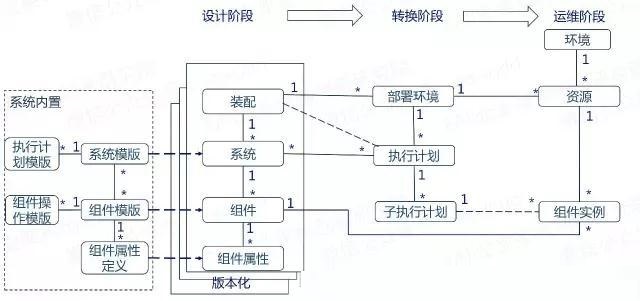
≥ΐΝΥœΒΆ≥ΡΎ÷ΟΒΡ“Μ–©ΡΘΑφΗ≈ΡνΘ§Έ“Ο«ΫΪΉ‘Ε·Μ·≤Ω πΝς≥ΧΖ÷ΈΣ»ΐΗωΫΉΕΈΘ§Φ¥…ηΦΤΓΔΉΣΜΜΓΔ‘ΥΈ§ΓΘΟΩΗωΫΉΕΈΕΦΜα”–œύ”ΠΒΡΜυ±ΨΡΘ–ΆΓΘ
œ¬ΟφΘ§Έ“Ο«Ζ÷ΫΉΕΈΒΡ»ΞΫβ Ά“Μœ¬’β–©Η≈ΡνΡΘ–ΆΓΘ
1ΓΔ…ηΦΤΫΉΕΈ
…ηΦΤΘ®DesignΘ©Θ§ «‘ΎΉΑ≈δΘ®AssemblyΘ©ΡΎΕ‘”Π”Ο/œΒΆ≥ΒΡΦήΙΙΒΡΟη ωΘΜΕχ”Π”Ο/œΒΆ≥Θ§ «”…Κ§”–ΕύΗωΉιΦΰΘ®ComponentΘ©ΒΡœΒΆ≥Θ®PlatformΘ©Ήι≥…ΒΡΓΘ
DesignΫΉΕΈΒΡΜυ±ΨΝς≥ΧΘΚ
Θ®1Θ©¥¥Ϋ®ΉΑ≈δΘ®AssemblyΘ©
Ά®Ιΐ―Γ‘ώΩ…”ΟΒΡœΒΆ≥ΡΘΑφ(Platform Template)Θ§ΧμΦ”“ΜΗω–¬ΒΡPlatformΘΜ
ΟΩ“ΜΗωPlatformΕΦΕ‘”Π“Μ÷÷”Π”ΟΘ®»γmysqlΘ§tomcatΘ§springbootΘ§nginxΘ©ΘΜ
ΟΩ“ΜΗωPlatformΕΦ «”–“ΜΉιΉιΦΰΘ®ComponentΘ©Ήι≥…ΒΡΘ§≤Δ«““―Ε®“εΚΟΝΥΉιΦΰ÷°ΦδΒΡ“άάΒΙΊœΒΘΜ
‘ΎAssemblyΡΎΘ§”ΟΜßΩ…“‘Ά®Ιΐ…η÷ΟPlatform Link…η÷ΟΗςΗωPlatform÷°ΦδΒΡΙΊœΒ
Θ®2Θ©≈δ÷ΟœΒΆ≥Θ®PlatformΘ©ΡΎΒΡΉιΦΰΘ®ComponentΘ©ΒΡ τ–‘÷Β
Component «ΉνΒΉ≤ψΒΡ≤Ω πΘ®Μρ’Ώ≈δ÷ΟΘ©ΒΞ‘ΣΘ§»γspringboot÷–ΒΡsecgroup, compute,
os, jdk, fatjar, lbΕΦ «“ΜΗωΉιΦΰΘΜ
ΟΩ“ΜΗωComponentΕΦ”–œύ”ΠΒΡ≈δ÷ΟΡΘΑφ
Θ®3Θ©ΧαΫΜ…ηΦΤ
ΧαΫΜΒΡΙΐ≥Χ «ΫΪ“―Ψ≠Άξ≥…ΒΡ…ηΦΤΉω“Μ¥ΈCommitΘ§Ήω“Μ¥ΈΙιΒΒΓΘ
2ΓΔΉΣΜΜΫΉΕΈ
ΉΣΜΜΘ®TransitionΘ©Θ§ «‘ΎAssemblyΡΎΕ‘”Π”Ο/œΒΆ≥‘ΎΡ≥“ΜEnvironmentΡΎΒΡ≤Ω πΙΐ≥ΧΓΘ
TransitionΫΉΕΈΒΡΜυ±ΨΝς≥ΧΘΚ
Θ®1Θ©¥¥Ϋ®≤Ω πΜΖΨ≥Θ®Deploy EnvironmentΘ©
ΗυΨίΜΖΨ≥άύ–Ά(»γdev, test, prodΒ»)Θ§ΧμΦ” τ”ΎΡ≥ΗωAssemblyΒΡ≤Ω πΜΖΨ≥
≤Ω π÷°«ΑΘ§≤Ω πΜΖΨ≥ «”Π”Ο/œΒΆ≥”Ο”Ύ≤Ω πΒΡ≈δ÷ΟΒΡ≥ιœσ
≤Ω π÷°ΚσΘ§≤Ω πΜΖΨ≥ΨΆ «ΙήάμΚΆΦύΩΊ”Π”Ο/œΒΆ≥ΒΡΨΏΧε ΒάΐΒΡΦ·Κœ
Θ®2Θ©≈δ÷Ο≤Ω πΜΖΨ≥
…η÷ΟΟΩΗωPlatformΙΊΝΣΒΡΉ ‘¥Θ®vm/containerΘ©ΓΔ≤Ω πΡΘ ΫΘ®ΒΞΒψΘ§ΗΏΩ…”ΟΘ©
Θ®3Θ©―Γ‘ώAssemblyΡΎΒΡ“ΜΗωΜρΕύΗωPlatform…ζ≥…≤ΔΧαΫΜ÷¥––ΦΤΜ°
ΗυΨί≤Ω π≤Ώ¬‘≤ΜΆ§Θ§“ΜΗωPlatformΒΡ÷¥––ΦΤΜ°Ω…ΡήΑϋΚ§ΦΗΗωΉ”ΦΤΜ°
Θ®4Θ©÷¥––≤Ω π
ΟΩΗωAssembly/Environment/Platformœ¬ΟφΒΡΟΩΗωComponentΕΦ”–“ΜΗωinstanceΘ§’β–©instanceΩ…“‘Ϋχ––ΒΞΕάRepair
3ΓΔ‘ΥΈ§ΫΉΕΈ
‘ΥΈ§Θ®OperationΘ©Θ§ «‘ΎAssemblyΡΎΕ‘ΗςΗω≤Ω πΜΖΨ≥ΡΎInstancesΒΡΙήάμΚΆΦύΩΊΓΘ
OperationΫΉΕΈΒΡΜυ±Ψ»ΈΈώΘΚ
Θ®1Θ©ΉιΦΰ Βάΐ‘ΥΈ§Θ§άΐ»γ
Compute: Status, Reboot, upgrade-os-security, powercycel,
repair, upgrade-os-all
Tomcat/Jboss: Status, Stop, Start, Restart, Repair,
Debug
Artifact: Repair, Redeploy, Custom User Attachment
Θ®2Θ©’Ιœ÷’ΐ‘Ύ≤Ω πΒΡ≤ΌΉςΘ§”–Ω…ΡήΜΙΜαReplaceΜρCancelΤδ÷–“ΜœνΉιΦΰ≤Ω πΜρ’ϊΗω≤Ω π
Θ®3Θ©’Ι ΨAssemblyΡ≥“ΜEnvironmentœ¬ΒΡΉιΦΰ ΒάΐΆΦΤΉ
Θ®4Θ©»’÷Ψ≤ι―·
Ε‘Μυ±ΨΒΡΗ≈ΡνΡΘ–Ά”–ΝΥΜυ±Ψ»œ ΕΚσΘ§Έ“Ο«ά¥Ω¥“Μœ¬Ή‘Ε·Μ·≤Ω πΩρΦήΒΡΉήΧεΥΦ¬ΖΓΘ
ΈεΓΔΉήΧεΥΦ¬Ζ
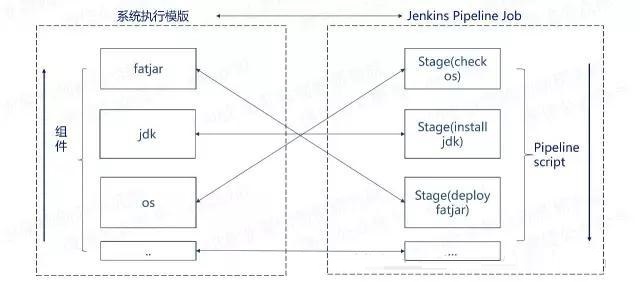
DevOpsΉ‘Ε·Μ·≤Ω πΩρΦή≤…”ΟDevOpsΤΫΧ®Θ®…ηΦΤΘ©ΘΪJenkinsΘ®÷¥––Θ©ΒΡΖΫ ΫΆξ≥…ΓΘ
DevOpsΒΡ÷Α‘π
Άξ≥…≤Ω πΦήΙΙ…ηΦΤΘΜ
ΗυΨί≤Ω πΦήΙΙ…ηΦΤΚΆ≤Ω πΜΖΨ≥ΒΡ≈δ÷Ο¥¥Ϋ®…ζ≥…œύ”ΠΒΡ÷¥––ΦΤΜ°ΦΑΉ”÷¥––ΦΤΜ°Θ§ΟΩ“ΜΗωΉ”ΦΤ Μ°Ε‘”Π“ΜΗωJenkins
pipeline job≈δ÷ΟΈΡΦΰ(config.xml)ΘΜ
≤ι―·Jenkins÷¥––jobΒΡ Β ±ΫχΕ»”κΫαΙϊΓΘ
JenkinsΒΡ÷Α‘π
ΗυΨίconfig.xml¥¥Ϋ®Jenkins Pipeline JobΘΜ
÷¥––pipeline jobΘΜ
Jenkins job Ά®Ιΐpipeline script÷–ansibleΘ·openshiftΟϋΝνΫχ––œύ”ΠΒΡ≤Ω πΒ»÷¥––≤ΌΉςΘΜ
ΧαΙ©≤ι―·job÷¥––«ιΩωΒΡRest APIΓΘ
ΫαΚœ…œΟφΧαΒΫΒΡ»ΐΗωΫΉΕΈΘ§ΨΏΧεΒΡΝς≥Χ»γœ¬Υυ ΨΘΚ
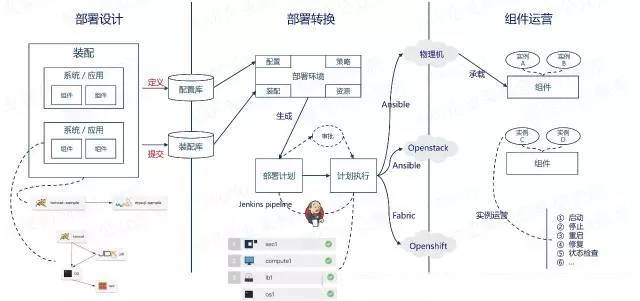
œ¬Οφ «ΨΏΧεΒΡ≤Ω π ”ΆΦΘΚ
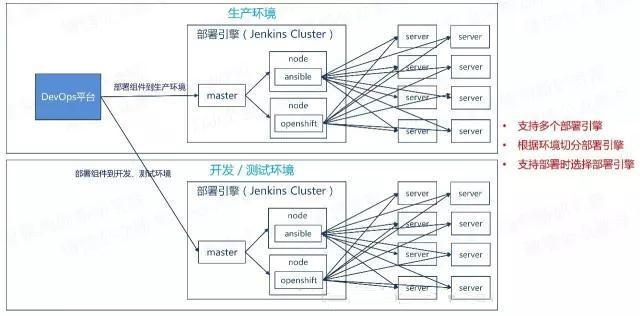
Ω¥Άξ’ϊΧεΥΦ¬ΖΚΆ≤Ω π ”ΆΦΘ§¥σΦ“ΩœΕ®ΜαΈ ΈΣ ≤Ο¥―Γ‘ώjenkinsΉςΈΣΨΏΧεΒΡ÷¥––“ΐ«φΘΩ
Ήœ»Θ§jenkins÷ß≥÷master/slaveΦήΙΙΘ§ΡήΗυΨί–‘Ρή–η«σΥ°ΤΫά©’≈Θ§slave”÷Ω…“‘÷ß≥÷Εύ÷÷ΜΖΨ≥Θ§Ω…“‘ΫΪ≤ΜΆ§ΒΡjobΖ÷≈δΒΫ≤ΜΆ§ΒΡslaveΫΎΒψΓΘ
ΜΙ”–Ζ«≥Θ÷Ί“ΣΒΡ“ΜΒψΘ§ΨΆ «Jenkins PipelineΒΡΡήΝΠΓΘ
Jenkins÷–pipelineΒΡ…ηΦΤάμΡν « Βœ÷Μυ”ΎgroovyΫ≈±ΨΘ§ΝιΜνΘ§Ω…ά©’ΙΒΡΙΛΉςΝςΓΘ
durable≥÷ΨΟ–‘ΘΚ‘ΎjenkinsΒΡmasterΑ¥ΦΤΜ°ΚΆΖ«ΦΤΜ°ΒΡ÷ΊΤτΚσΘ§pipelineΒΡjob»‘»ΜΡήΙΜΙΛΉςΘ§≤Μ ή”ΑœλΓΘ
Ω…‘ίΆΘ–‘ΘΚpipelineΜυ”ΎgroovyΩ…“‘ Βœ÷jobΒΡ‘ίΆΘΚΆΒ»¥ΐ”ΟΜßΒΡ δ»κΜρ≈ζΉΦ»ΜΚσΦΧ–χ÷¥––ΓΘ
ΗϋΝιΜνΒΡ≤Δ––÷¥––Θ§Ηϋ«ΩΒΡ“άάΒΩΊ÷ΤΘ§Ά®ΙΐgroovyΫ≈±ΨΩ…“‘ Βœ÷stepΘ§stageΦδΒΡ≤Δ––÷¥––Θ§ΚΆΗϋΗ¥‘”ΒΡœύΜΞ“άάΒΙΊœΒΓΘ
Ω…ά©’Ι–‘ΘΚΆ®ΙΐgroovyΒΡ±ύ≥ΧΗϋ»ί“ΉΒΡά©’Ι≤εΦΰΓΘ
ΖαΗΜ≤εΦΰΘΚJenkins“―Ψ≠÷ß≥÷Ά®ΙΐgroovyΟϋΝνΒς”ΟgitΓΔmavenΓΔnpmΓΔgradleΓΔshellΓΔjunitΓΔsonarqubeΓΔansibleΓΔdockerΓΔopenshiftΓΔkubernetesΒ»≤εΦΰΘ§≤Μ–η“ΣΈ“Ο«‘ΌΒΞΕά Βœ÷Φ·≥…ΓΘ
Rest APIΘΚJenkinsΧαΙ©Ά®ΙΐRest APIΒΡΖΫ ΫΜώ»ΓΟΩ“ΜΗωstageΒΡ÷¥––«ιΩωΓΘ
”…”ΎΈ“Ο«Ήν÷’ΜαΫΪ”Π”Ο≤Ω πΒΫ–ιΡβΜζΚΆ»ίΤς‘Τ÷–Θ§–ιΡβΜζ≤Ω π÷ς“ΣΆ®Ιΐjenkins÷–ΧαΙ©ΒΡansible≤εΦΰΘΪjenkins
pipeline scriptά¥ Βœ÷ΘΜ»ίΤς‘Τ≤Ω π‘ρΗυΨίΨΏΧεΒΡ»ίΤς‘ΤΘ§Ά®Ιΐopenshift≤εΦΰΘ®Μα”–“ΜΕ®ά©’ΙΘ©Μρ’Ώhttp
request≤εΦΰΘΪjenkins pipeline scriptά¥ Βœ÷ΓΘ
œ¬ΟφΈ“Ο«ά¥Ω¥“Μœ¬Jenkins2ΒΡ÷ς“ΣΗ≈ΡνΓΘ
step, Τδ ΒΗζjenkins1÷–ΒΡΗ≈Ρν“Μ―υΘ§ «jenkinsάοjob÷–ΒΡΉν–ΓΒΞΈΜΘ§Ω…“‘»œΈΣ «“ΜΗωΫ≈±ΨΒΡΒς”ΟΚΆ“ΜΗω≤εΦΰΒΡΒς”ΟΓΘ±»»γΆ®Ιΐgitά≠»Γ¥ζ¬κΨΆ «“ΜΗωstepΘ§mvn
clean package“≤ «“ΜΗωstepΘ§“ΜΗωhttp‘Ε≥ΧΒς”Ο»»ΓΘ
node, «piplelineάοgroovyΒΡ“ΜΗωΗ≈ΡνΘ§nodeΩ…“‘ΗχΕ®≤Έ ΐ”Οά¥―Γ‘ώagentΘ§nodeάοΒΡstepsΫΪΜα‘Υ––‘Ύnode―Γ‘ώΒΡagent…œΓΘ’βάο”κjenkins1ΒΡ«χ±π «Θ§“ΜΗω
jobάοΩ…“‘”–ΕύΗωnodeΘ§ΫΪjobΒΡstepsΑ¥’’–η«σ‘Υ––‘Ύ≤ΜΆ§ΒΡΜζΤς…œΓΘάΐ»γ“ΜΗωjobάο”–ΚΟΦΗΗω≤β ‘Φ·Κœ–η“ΣΆ§ ±‘Υ––‘Ύ≤ΜΆ§ΒΡΜζΤς…œΓΘ
stage, «pipelineάοgroovyάο“ΐ»κΒΡ“ΜΗω–ιΡβΒΡΗ≈ΡνΘ§ «“Μ–©stepΒΡΦ·ΚœΘ§Ά®ΙΐstageΈ“Ο«Ω…“‘ΫΪjobΒΡΥυ”–stepsΜ°Ζ÷ΈΣ≤ΜΆ§ΒΡstageΘ§ ΙΒΟ’ϊΗωjobœώΙήΒά“Μ―υΗϋ»ί“ΉΈ§ΜΛΓΘpiplelineΜΙ”–’κΕ‘stageΗΡΫχΙΐΒΡviewΘ§ ΙΒΟΦύΩΊΗϋ«ε≥ΰΓΘ’βάο≤Ι≥δ“ΜΨδΘ§ΕύΗωstageΩ…“‘‘Ύ“ΜΗωnodeάοΕ®“εΦΑ÷¥––Θ§“ΜΗωstageΡΎΒΡΕύΗωstepΩ…“‘Ζ÷ΒΫ≤ΜΆ§ΒΡnode…œ÷¥––ΓΘ
ΝυΓΔΙΊΦϋΒψ…ηΦΤ
«ΑΟφΈ“Ο«ΥΒΒΡΕΦ «Η≈ΡνΚΆΝς≥Χ…œΒΡΕΪΈςΘ§Ρ«Ο¥”ΟΜßΗΟ»γΚΈΫχ––≤Ω πΦήΙΙ…ηΦΤΘΩ≤Ω πΦήΙΙ…ηΦΤΆξ≥…ΚσΘ§»γΚΈΧαΫΜΡΊΘΩ
»γΚΈΫΪΧαΫΜΒΡ…ηΦΤ‘ΎΨΏΧεΒΡ≤Ω πΜΖΨ≥÷–ΉΣΜΜ≥…÷¥––ΦΤΜ°”κΉ”÷¥––ΦΤΜ°ΡΊΘΩΉ”ΦΤΜ°”÷»γΚΈ”κjenkins pipeline
job”≥…δΡΊΘΩ’βΨΆ «Έ“Ο«œ¬Οφ“ΣΫι…ήΒΡ“Μ–©ΙΊΦϋΒψ…ηΦΤΓΘ
1ΓΔΡΘΩιΜ·
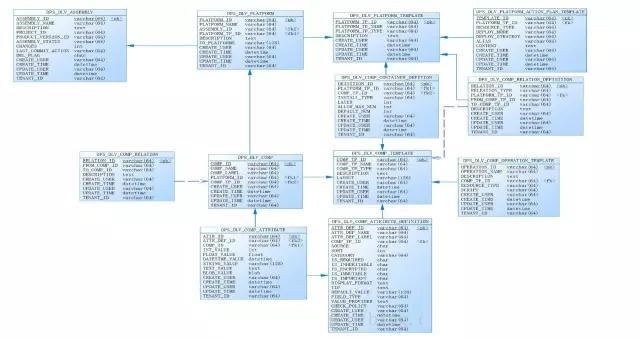
«ΑΟφΧαΒΫΘ§Β±”ΟΜߥ¥Ϋ®Platform ±Θ§Έ“Ο«ΒΡDevOpsΤΫΧ®ΧαΙ©Ω…―ΓΒΡPlatform TemplateΘ§Platform
TemplateΕ®“εΝΥΤδ÷–Ω…“‘ΑϋΚ§ΒΡΉιΦΰάύ–Ά(Component Template)Β»–≈œΔΓΘ“≤ΨΆ «ΥΒΘ§Έ“Ο«ΒΡΤΫΧ®ΧαΙ©ΝΥ“Μ÷÷Μυ”ΎΉνΦ― ΒΦυΒΡΖΫ ΫΘ§Αο÷ζ”ΟΜßΆξ≥…œΒΆ≥ΒΡΦήΙΙ…ηΦΤΓΘ≤ΜΫω»γ¥ΥΘ§Ά®ΙΐΕ‘Platform
Template/Component TemplateΒ»œύΙΊ ΐΨίΉΦ±ΗΒΡΫι…ήΘ§“≤Ε‘“‘Κσ”ΟΜßά©’ΙΧμΦ”–¬ΒΡΉιΦΰάύ–ΆΘ§ΧαΙ©ΝΥ≥δΉψ“άΨίΓΘΜυ±ΨΥΦ¬Ζ»γœ¬ΘΚ
1Θ©Ε®“ε≤ΜΆ§ΒΡœΒΆ≥ΡΘΑφPlatform Template(Φϊ±μDPS_DLV_PLATFORM_TEMPLATE)ΓΘœΒΆ≥ΡΘΑφΨΆ «Έ“Ο«Ά®ΙΐΉνΦ― ΒΦυΒΡΖΫ ΫΧαΙ©ΝΥ“ΜΧΉ”Π”ΟΘ·÷–ΦδΦΰœΒΆ≥ΒΡΡΘΑφΓΘ»γtomcatΘ§nginxΓΔspringbootΓΔmysqlΒ»ΓΘ
“ΜΗωPlatform TemplateΕ®“εΝΥ’βΗωΡΘΑφ÷–ΑϋΚ§ΒΡΉιΦΰΡΘΑφΘ§Ε®“εΝΥΉιΦΰΡΘΑφ÷°ΦδΒΡ“άάΒΙΊœΒ(Φϊ±μDPS_DLV_COM_RELATION_DEFINITION)Θ§“‘ΦΑΟΩ“Μ÷÷ΉιΦΰάύ–ΆΥυ‘ΎΒΡ≤ψ“‘ΦΑΟΩ“Μ÷÷ΉιΦΰάύ–Ά‘ –μΧμΦ”ΒΡΉιΦΰΒΡΗω ΐ(Φϊ±μDPS_DLV_COMP_CONTAINER_DEFINITION)ΓΘΒ±”ΟΜßΧμΦ”“ΜΗωPlatform ±Θ§±Ί–κ“Σ―Γ‘ώ“Μ÷÷Platform
TemplateΓΘ
2Θ©ΗυΨί≤ΜΆ§ΒΡ≤Ω πΡΘ ΫΘ®ΒΞΫΎΒψΓΔΗΏΩ…”ΟΘ©ΓΔ≤ΜΆ§ΒΡΡΩ±ξΉ ‘¥Θ®–ιΡβΜζΓΔ»ίΤςΘ©ΓΔ≤ΜΆ§ΒΡ≤Ω π≤Ώ¬‘Θ®»Ϊ–¬ΓΔάΕ¬ΧΓΔΙωΕ·…ΐΦΕΓΔΜΊΙωΘ©Θ§“ΜΗωœΒΆ≥ΡΘΑφΜαΕ‘”ΠΒΫΕύΗω÷¥––ΦΤΜ°ΡΘΑφ
(Φϊ±μDPS_DLV_PLATFORM_ACTION_PLAN_TEMPLATE)ΓΘ
3Θ©“ΜΗωœΒΆ≥”…ΕύΗωΉιΦΰΉι≥…Θ§“ρ¥ΥœΒΆ≥ΡΘΑφΚΆΉιΦΰΡΘΑφ÷°Φδ“≤ «ΕύΕ‘ΕύΒΡΙΊœΒΓΘάΐ»γspringbootΡΘΑφΕ‘”ΠΒΡΉιΦΰΡΘΑφ”–ΘΚsecgroupΡΘΑφΓΔosΡΘΑφΓΔjdkΡΘΑφΓΔjava
applicationΡΘΑφ»»ΓΘ
ΉιΦΰΡΘΑφComponent Template(Φϊ±μDPS_DLV_COMP_TEMPLATE)“‘ΦΑΉιΦΰΒΡΥυ”– τ–‘(Φϊ±μDPS_DLV_COMP_ATTRIBUTE_DEFINITION)ΓΘΉιΦΰΡΘΑφΨΆ «ΉιΦΰΒΡ‘Σ ΐΨίΘ§ΈΣPlatformΧμΦ”ΒΡComponentΕΦ «‘¥”ΎComponent
TemplateΓΘ
4Θ©ΈΣΟΩΗωComponent TemplateΕ®“εOperationΡΘΑφ(Φϊ±μDPS_DLV_COMP_OPERATION)Θ§“‘±ψΕ‘ΒΞΗωΉιΦΰ ΒάΐΫχ––≤ΌΉςΘ§»γrestart,
repair, stopΒ»ΓΘ
Ά®Ιΐ“‘…œ4≤ΫœΒΆ≥‘Λ÷ΟΒΡPlatform TemplateΚΆComponent Template“‘ΦΑœύ”ΠΒΡ ΐΨίΘ§ΨΆΩ…“‘ΧαΙ©Ηχ”ΟΜßΧμΦ”“ΜΗωPlatformΝΥΓΘ’β–©‘Λ÷Ο ΐΨί“≤ΈΣΚσΟφ…ζ≥…≤Ω πΦΤΜ°Deploy
PlanΉωΚΟΒΡΉΦ±ΗΓΘ
2ΓΔ±δΝΩΙήάμ
‘Ύ–η«σΖ÷Έω÷–Θ§Έ“Ο«ΨΆΧα≥ωœΘΆϊ“Μ¥Έ…ηΦΤΕύ¥Έ≤Ω πΓΘΒΪ «‘Ύ…ηΦΤΫΉΕΈ…η÷ΟΗςΗωΉιΦΰ τ–‘ ±Θ§≤Δ≤ΜΡή»ΖΕ®‘Ύ≤ΜΆ§ΒΡ≤Ω πΜΖΨ≥÷–Τδ÷Β «“Μ÷¬ΒΡΘ§≤Δ«““ΜΗωœΒΆ≥ΒΡ≤ΜΆ§ΉιΦΰΒΡ τ–‘“≤Ω…Ρή «Ι≤”Ο“ΜΗω÷ΒΓΘ’β ±ΚρΈ“Ο«ΨΆ–η“Σ“ΐ»κ±δΝΩΙήάμΓΘ±δΝΩΙήάμΒΡ÷ς“ΣΥΦ¬Ζ»γœ¬ΘΚ
1Θ©…ηΦΤΫΉΕΈΘ§ΈΣœΒΆ≥Ε®“ε“Μ–©±δΝΩΘ®ConfigMetaΘ©≤Δ…η÷Ο“ΜΗωΡ§»œ÷ΒΘ§»γinstall_dirΓΘ»ΜΚσ‘Ύ…η÷ΟΡ≥ΗωΉιΦΰ τ–‘÷Β ±Ω…“‘”Ο@P{install_dir}ά¥±μ ΨΓΘ
2Θ©ΧαΫΜ…ηΦΤ ±Θ§“≤“ΜΆ§ΫΪ±δΝΩΕ®“εΉςΈΣ…ηΦΤΒΡ“Μ≤ΩΖ÷Ϋχ––ΧαΫΜΓΘ
3Θ©ΉΣΜΜΫΉΕΈΘ§‘Ύ≤Ω πΜΖΨ≥÷–Θ§ΈΣΟΩ“ΜΗω±δΝΩ…η÷ΟΒ±«ΑΜΖΨ≥œ¬ΒΡ÷ΒΘ®ConfigValueΘ©ΓΘΒ±¥¥Ϋ®÷¥––ΦΤΜ° ±Θ§ΜαΫΪ τ–‘@P{install_dir}ΧφΜΜΈΣΒ±«ΑΜΖΨ≥ΒΡ÷ΒΓΘ
≤ΜΫωPlatformΡΎΩ…“‘Ε®“ε±δΝΩΙ©ΗΟPlatformœ¬ΒΡComponent Ι”ΟΘ§Έ“Ο«“≤Ω…“‘ΗχAssemblyΕ®“ε±δΝΩΙ©Υυ”–PlatformΦΑΤδΉιΦΰ Ι”Ο,
–Έ»γ@A{assembly_var}ΓΘ
3ΓΔ…ηΦΤΧαΫΜ

Β±”ΟΜß…ηΦΤΆξ≤Ω πΦήΙΙΓΔ…η÷ΟΟΩΗωΉιΦΰ τ–‘ΦΑ±δΝΩΚσΘ§–η“ΣΫΪΒ±«ΑΒΡ…ηΦΤ÷ΗΕ®ΚΟΑφ±ΨΫχ––ΧαΫΜΘ§Φ¥ΙιΒΒΓΘ÷Μ”–ΧαΫΜΒΡ…ηΦΤΘ§≤≈Ρή‘Ύ≤Ω πΜΖΨ≥÷–Μώ»ΓΒΡΒΫ÷ΗΕ®ΒΡΑφ±ΨΓΘΆ®ΙΐΑφ±ΨΜ·Θ§Έ“Ο«Ω…“‘…ηΦΤΒΡ≤ΜΆ§Αφ±ΨΉωœύΙΊΒΡΕ‘±»ΓΘ
…œΟφΒΡ±μΫαΙΙ «±»Ϋœ«εΈζΒΡ±μ ωΓΘ
4ΓΔ÷¥––ΦΤΜ°
ΗυΨί≤ΜΆ§ΒΡ≤Ω πΡΘ ΫΘ®ΒΞΫΎΒψΓΔΗΏΩ…”ΟΘ©ΓΔ≤ΜΆ§ΒΡΡΩ±ξΉ ‘¥Θ®–ιΡβΜζΓΔ»ίΤςΘ©ΓΔ≤ΜΆ§ΒΡ≤Ω π≤Ώ¬‘Θ®»Ϊ–¬ΓΔάΕ¬ΧΓΔΙωΕ·…ΐΦΕΓΔΜΊΙωΘ©Θ§“ΜΗωœΒΆ≥ΡΘΑφΜαΕ‘”ΠΒΫΕύΗω÷¥––ΦΤΜ°ΡΘΑφΘ§≤Δ«“ΦΤΜ°ΡΘΑφ÷°Φδ”–ΗΗΉ”ΙΊœΒΓΘ
ΟΩ“ΜΗωΉ”÷¥––ΡΘΑφΨΆ «“ΜΗωjenkins pipeline scriptΡΘΑφΓΘ
Β±”ΟΜß‘Ύ≤Ω πΜΖΨ≥÷–―Γ‘ώΡ≥ΗωΨΏΧεœΒΆ≥ΦΑ≤Ω π≤Ώ¬‘…ζ≥…œύ”ΠΒΡ÷¥––ΦΤΜ°Θ®Κ§Ή”ΦΤΜ°Θ© ±Θ§ΟΩ“ΜΗωΉ”ΦΤΜ°ΒΡjenkins
pipeline scriptΨΆ «ΫΪΨΏΧεΒΡΉιΦΰ τ–‘ΉΔ»κΒΫ÷¥––ΡΘΑφ÷–…ζ≥…ΒΡΓΘ
ΝμΆβΘ§ΈΣ ≤Ο¥–η“Σœ‘ ΨΒΡ¥¥Ϋ®≥ωΉ”ΦΤΜ°ΡΊΘΩάΐ»γΘ§Ε‘”Ύ“ΜΗωΗΏΩ…”ΟΒΡ”Π”ΟΘ§≥ΐΝΥ“Σ≤Ω πΨΏΧεΒΡ”Π”ΟΘ§ΜΙ–η“ΣΗϋ–¬load
balance≈δ÷ΟΘ§Εχ’βΝΫ’Ώ÷°ΦδΩ…Ρή–η“ΣΦ”»κ“Μ–©»ΥΙΛΜνΕ·ΓΘΥυ“‘Έ“Ο«Ά®Ιΐœ‘ ΨΒΡ¥¥Ϋ®¥ΠΉ”ΦΤΜ°Θ§÷ß≥÷”ΟΜßΑ¥Ή”ΦΤΜ°“Μ≤Ϋ≤ΫΒΡά¥ΉωΓΘ
Εχjenkins pipeline scriptΒΡstageΦΗΚθΕΦΕ‘”ΠΒΫ“ΜΗωΨΏΧεΒΡΉιΦΰΘ§ΨΏΧεΩ…“‘Ω¥œ¬ΆΦΓΘ
5ΓΔ≤Ω π≤Ώ¬‘
«ΑΟφΈ“Ο«ΧαΒΫΝΥΓΑ≤Ω π≤Ώ¬‘Γ±’βΗω¥ Θ§≥ΐΝΥ»Ϊ–¬≤Ω πΘ§Έ“Ο«≥ΘΦϊΒΡ≤Ω π≤Ώ¬‘”–άΕ¬ΧΖΔ≤ΦΓΔΙωΕ·…ΐΦΕΓΔΜ“Ε»ΖΔ≤ΦΘ·ΫπΥΩ»ΗΖΔ≤ΦΓΔΜΊΙωΓΘœ¬Οφά¥Ω¥Ω¥Έ“Ο«ΒΡœύ”ΠΫβΨωΖΫΑΗΓΘΟΩ“Μ÷÷≤Ω π≤Ώ¬‘ΕΦΜα”–œύ”ΠΒΡ÷¥––ΦΤΜ°ΡΘΑφΘ®Κ§Ή”ΦΤΜ°Θ©ΓΘ
άΕ¬ΧΖΔ≤Φ
≤Ο¥ «άΕ¬ΧΖΔ≤ΦΘΩ
‘ΎΖΔ≤ΦΒΡΙΐ≥Χ÷–”ΟΜßΈόΗ–÷ΣΖΰΈώΒΡ÷ΊΤτΘ§Ά®≥Θ«ιΩωœ¬ «Ά®Ιΐ–¬Ψ…Αφ±Ψ≤Δ¥φΒΡΖΫ Ϋ Βœ÷Θ§“≤ΨΆ «ΥΒ‘ΎΖΔ≤ΦΒΡΝς≥Χ÷–Θ§–¬ΒΡΑφ±ΨΚΆΨ…ΒΡΑφ±Ψ «œύΜΞ»»±ΗΒΡΘ§Ά®Ιΐ«–ΜΜ¬Ζ”…»®÷ΊΒΡΖΫ ΫΘ®Ζ«0Φ¥100Θ© Βœ÷≤ΜΆ§ΒΡ”Π”ΟΒΡ…œœΏΜρ’Ώœ¬œΏΓΘ
«ΑΧαΧθΦΰ
ΥΪΖίΉ ‘¥ or ÷ß≥÷ΥΪΕΥΩΎΡΘ Ϋ
ΗΚ‘ΊΨυΚβΖΰΈώ ΘΪ ≤ΌΉςAPIΫ”ΩΎ
Β ©ΖΫΑΗ
ΒΎ“Μ≤ΫΘ§…η÷ΟœΒΆ≥ΫΪ“Σ≤Ω πΒΡΉ ‘¥Ν–±μΓΘ
ΒΎΕΰ≤ΫΘ§ΫΪ–¬Αφ±Ψ≤Ω π»ίΤς≤Ω πΒΫΉ ‘¥Ν–±μ÷–ΓΘ
ΒΎ»ΐ≤ΫΘ§Βς”ΟΗΚ‘ΊΨυΚβΖΰΈώΒΡAPIΫ”ΩΎΗϋ–¬ΗΚ‘πΨυΚβ≈δ÷ΟΓΘΒΎΥΡ≤ΫΘ§Ηϋ–¬Ή ‘¥ΒΡ±ξ«©ΓΘ
ΩΦ¬«ΒΫ”ΟΜßΩ…ΡήΜα ÷ΙΛΫι»κ»ΖΕ® «Ζώ–η“ΣΗϋ–¬ΗΚ‘Ί≈δ÷ΟΘ§Έ“Ο«ΜαΫΪΒΎΕΰ≤ΫΓΔΒΎ»ΐ≤ΫΖ÷ΈΣΝΫΗωΉ”÷¥––ΦΤΜ°ΓΘ
ΙωΕ·…ΐΦΕ
≤Ο¥ «ΙωΕ·…ΐΦΕΘΩ
ΙωΕ·ΖΔ≤ΦΘ§“ΜΑψ «»Γ≥ω“ΜΗωΜρ’ΏΕύΗωΖΰΈώΤςΆΘ÷ΙΖΰΈώΘ§÷¥––Ηϋ–¬Θ§≤Δ÷Ί–¬ΫΪΤδΆΕ»κ Ι”ΟΓΘ÷ήΕχΗ¥ ΦΘ§÷±ΒΫΦ·»Κ÷–Υυ”–ΒΡ ΒάΐΕΦΗϋ–¬≥…–¬Αφ±ΨΓΘ
’β÷÷≤Ω πΖΫ ΫœύΕ‘”ΎάΕ¬Χ≤Ω πΘ§ΗϋΦ”ΫΎ‘ΦΉ ‘¥ΓΣΓΣΥϋ≤Μ–η“Σ‘Υ––ΝΫΗωΦ·»ΚΓΔΝΫ±ΕΒΡ Βάΐ ΐΓΘΈ“Ο«Ω…“‘≤ΩΖ÷≤Ω πΘ§άΐ»γΟΩ¥Έ÷Μ»Γ≥ωΦ·»ΚΒΡ20%Ϋχ––…ΐΦΕΓΘ
«ΑΧαΧθΦΰ
ΗΚ‘ΊΨυΚβΖΰΈώ ΘΪ ≤ΌΉςAPI Ϋ”ΩΎ
Β ©ΖΫΑΗ
ΒΎ“Μ≤ΫΘ§…η÷ΟΙωΕ·…ΐΦΕœΒ ΐΘ®≤ΫΫχΘ©Θ§»γ20%Θ·nΗωΓΘ
ΒΎΕΰ≤ΫΘ§“ά¥ΈΫΪ20%ΒΡ≤Ω π»ίΤς“Τ≥ΐΗΚ‘ΊΘ§»ΜΚσ‘Ύ‘≠Ή ‘¥¥Π≤Ω π–¬Αφ±ΨΘ§»ΜΚσΦ”»κΗΚ‘ΊΓΘ
Μ“Ε»ΖΔ≤ΦΘ·ΫπΥΩ»ΗΖΔ≤Φ
≤Ο¥ «Μ“Ε»ΖΔ≤ΦΘ·ΫπΥΩ»ΗΖΔ≤ΦΘΩ
Μ“Ε»ΖΔ≤Φ «‘ωΝΩΖΔ≤ΦΒΡ“Μ÷÷άύ–ΆΘ§ΥϋΒΡ÷¥––ΖΫ Ϋ «‘Ύ‘≠”–»μΦΰ…ζ≤ζΑφ±ΨΩ…”ΟΒΡ«ιΩωœ¬Θ§Ά§ ±≤Ω π“ΜΗω–¬ΒΡΑφ±ΨΓΘΆ§ ±‘Υ––Ά§“ΜΗω»μΦΰ≤ζΤΖΒΡΕύΗωΑφ±ΨΓΘ
Τδ ΒΘ§Μ“Ε»ΖΔ≤Φ «ΙωΕ·…ΐΦΕΒΡ“Μ÷÷±δΧεΘ§Τδ ΒΜ“Ε»ΖΔ≤Φ «œ»Μ°Ζ÷≥ω–¬Αφ±ΨΒΡ¬Ζ”…»®÷ΊΘ§–¬Αφ±Ψ‘Ύ’φ Β ΐΨί―ι÷ΛΆ®ΙΐΚσΘ§‘ΎΫχ–– Θ”ύάœΑφ±ΨΒΡ…ΐΦΕΓΘ
«ΑΧαΧθΦΰ
ΗΚ‘ΊΨυΚβΖΰΈώ ΘΪ ≤ΌΉςAPI Ϋ”ΩΎ
Β ©ΖΫΑΗ
ΒΎ“Μ≤ΫΘ§…η÷Ο–¬άœΑφ±ΨΒΡ¬Ζ”…»®÷ΊΘ§»γ90%ΒΡ”ΟΜßΈ§≥÷ Ι”ΟάœΑφ±ΨΘ§10%ΒΡ”ΟΜß Ι”Ο–¬Αφ±ΨΓΘ
ΒΎΕΰ≤ΫΘ§ΫΪ10%ΒΡ≤Ω π»ίΤς“Τ≥ΐΗΚ‘ΊΘ§»ΜΚσ‘Ύ‘≠Ή ‘¥¥Π≤Ω π–¬Αφ±ΨΘ§»ΜΚσΦ”»κΗΚ‘ΊΓΘ
ΒΎ»ΐ≤ΫΘ§¥ΐ’φ Β ΐΨί―ι÷ΛΆ®ΙΐΚσΘ§‘ΌΫχ–– Θ”ύάœΑφ±ΨΒΡΙωΕ·…ΐΦΕΓΘ
ΜΊΙω
≤Ο¥ «ΜΊΙωΘΩ
ΜΊΙω «÷ΗΫΪ”Π”ΟΘ·ΖΰΈώΜΊΆΥΒΫ…œ“ΜΩ…”ΟΑφ±ΨΘ§≤Δ Ι÷°Ω…”ΟΓΘ
Έ“Ο«‘ί ±÷Μ÷ß≥÷’κΕ‘άΕ¬ΧΖΔ≤ΦΒΡΜΊΙωΓΘ
«ΑΧαΧθΦΰ
–¬Αφ±Ψ «Μυ”ΎάΕ¬ΧΖΔ≤Φ≤Ώ¬‘Άξ≥…ΒΡ≤Ω πΓΘ
ΗΚ‘ΊΨυΚβΖΰΈώΘΪ≤ΌΉςAPIΫ”ΩΎΓΘ
Β ©ΖΫΑΗ
Ηϋ–¬ΗΚ‘Ί≈δ÷Ο
ΤΏΓΔΉήΫα
±ΨΈΡ¥σ÷¬œρ¥σΦ“Ϋι…ήΝΥΈ“Ο«ΒΡDevOpsΤΫΧ®÷–Ή‘Ε·Μ·≤Ω πΩρΦήΒΡœύΙΊ…ηΦΤΘ§÷ς“ΣΦρΒΞΫι…ήΝΥ Βœ÷ΥΦ¬ΖΚΆΦΗΗωΙΊΦϋΒψΓΘ
Τδ÷–ΜΙ”–ΚήΕύœΗΫΎΘ§±»»γ»γΚΈ”κCMDBΦ·≥…Θ§»γΚΈ”κΗς÷÷»ίΤς‘ΤΦ·≥…Θ§“‘ΦΑΈ“Ο« ΒΦυΙΐ≥Χ÷–”ωΒΫΒΡΗς÷÷ٔ»»ȧ’βάο≤Μ‘Ό“Μ“ΜΉΗ ωΓΘ
|








