| БрМЭЦМі: |
БОЮФДгПЊЗЂКЭдЫЮЌСНИіЪгНЧЖрВуДЮЕФНВНтЪВУДГЁОАгІИУ
Dev КЭ OpsЃЌЪВУДГЁОАгІИУ DevOpsЃЌМД DevOps ЕФЗжгыКЯЃЌВЂЪЙгУвЛИі
Demo ЪОР§ИцЫпДѓМв DevOps жаЕФЙиМќВНжшГжајВПЪ№ШчКЮЪЕМљЁЃ
БОЮФРДздгкCSDN,гЩЛ№СњЙћШэМўAliceБрМЭЦМіЁЃ |
|
ГщЯѓЕФ DevOps
DevOps ЪЧЪЙШэМўПЊЗЂКЭ IT ЭХЖгжЎМфЕФСїГЬздЖЏЛЏЕФвЛзщЪЕМљЃЌвдБуЫћУЧПЩвдИќПьЃЌИќПЩППЕиЙЙНЈЃЌВтЪдКЭЗЂВМШэМўЁЃ
DevOpsЕФИХФюНЈСЂдкНЈСЂЭХЖгжЎМфазїЮФЛЏЕФЛљДЁЩЯЃЌетаЉЭХЖгЙ§ШЅвЛжБдкЯрЖдЙТЕКжадЫзїЁЃ
РрЫЦгкетжжЕФ DevOps ЯрЙиЕФУшЪіЬ§Ц№РДЬиБ№ГщЯѓЃЌЗЧГЃбЇЪѕЃЌЗЧГЃНЬПЦЪщЃЌШУШЫИаОѕЮоЗЈТфЕиЃЌВЛжЊЕРИУШчКЮШыЪжЁЃКмЖрЭХЖгдкСЫНт
DevOpsЃЌЪЕМљ DevOps ЕФЪБКђВЛФмКмКУЕФЖрЮЌЖШПДД§ DevOpsЃЌЪЕМљЕФЙ§ГЬвВКмЭДПрЃЌВЛжЊЕРетжжаТаЭЕФРэФюШчКЮЪЕМЪЬсЩ§здМКЭХЖгЕФеНЖЗСІЁЃ
DevOps ЕФСНИіЪгНЧ
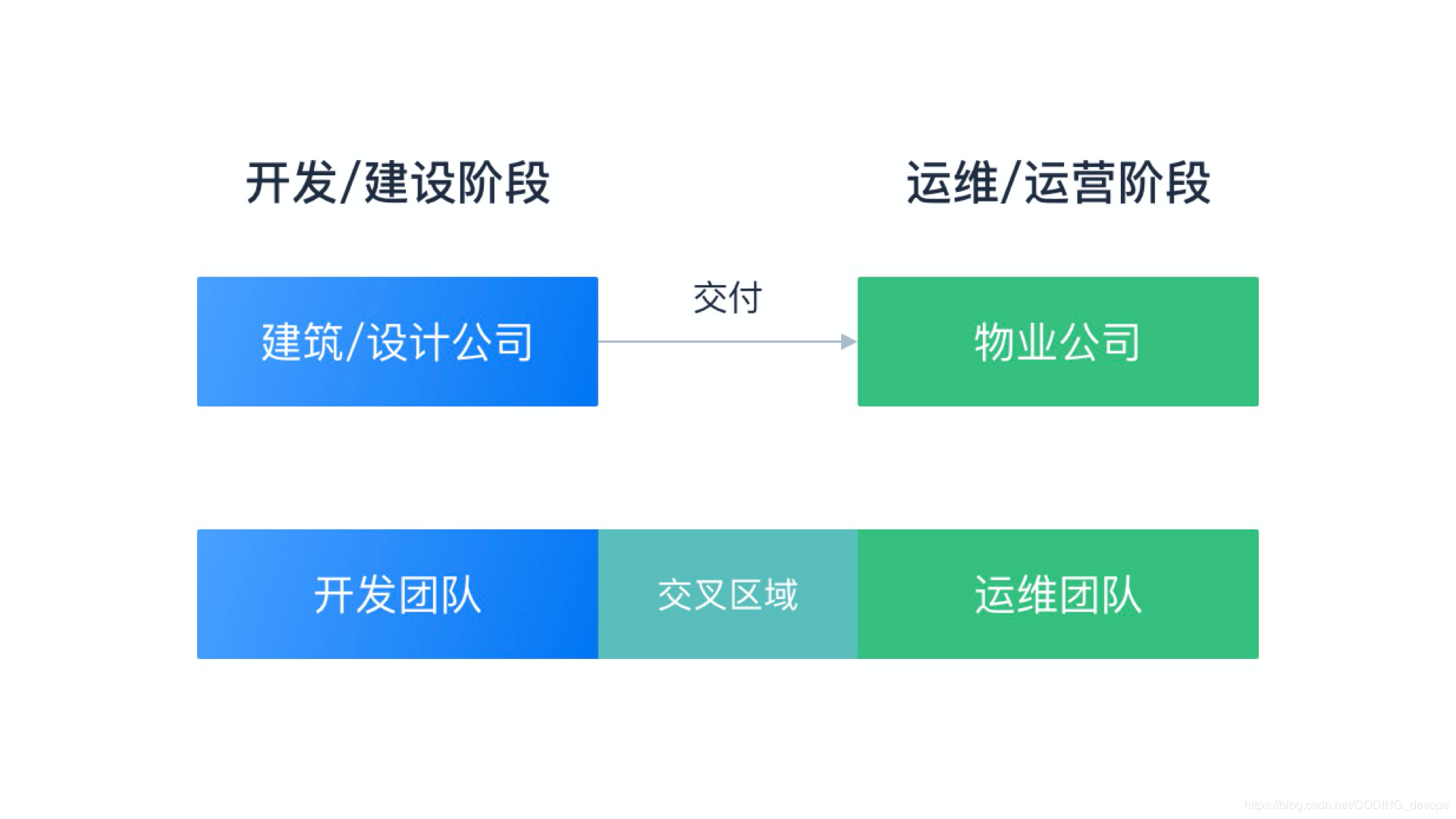
DevOps ДгзжУцЩЯПДОЭЪЧПЊЗЂКЭдЫЮЌЃЌвВгаЗвыЮЊПЊЗЂдЫЮЌЃЈдЫгЊЃЉвЛЬхЛЏЁЃЮвУЧетРяЕФСНИіЪгНЧВЛЪЧБ№ЕФЖЋЮїЃЌе§ЪЧПЊЗЂКЭдЫЮЌЁЃетРяЕФПЊЗЂЃЌВЛФмМђЕЅЕФРэНтЮЊПЊЗЂЙЄГЬЪІЃЌжИДњЕФЪЧећИіШэМўЕФбаЗЂЙ§ГЬЫљКЌЕФЫљгавЊЫиЃЌКИЧашЧѓЗжЮіЁЂПЊЗЂЁЂВтЪдЕШЕШЃЌЦфжеЕуЪЧПЩНЛИЖЕФШэМўжЦЦЗЁЃЭЌбљдЫЮЌВЛНіНіЪЧдЫЮЌЙЄГЬЪІЃЌжИДњЕФЪЧШэМўНЛИЖКѓЭЖВњЙ§ГЬвдМАКѓајЕФдЫгЊЃЌЗДРЁЕШЯЕСаЙ§ГЬЃЌЦфЦ№ЕуЪЧНгЪмНЛИЖЕФШэМўжЦЦЗЁЃ
етУДСНИіЪгНЧЕФЧјЗжЪЧвўКЌзХШэМўЙЄГЬБГКѓЕФТпМЕФЃЌОЭЯёвЛЖАДѓТЅЃЌЫћЕФНЈЩшЗНЪЧНЈжўКЭЩшМЦЙЋЫОЃЌЫћЕФдЫгЊЗНЪЧЮявЕЙЋЫОвЛбљЃЌСНепжЎМфгаЯрЖдЧхЮњЕФНчЯоЁЃ

ЮвУЧашвЊЛиЙЫШэМўаавЕЕФЗЂеЙЃЌРДПДЮЊЪВУД DevOps БЛЬсГіРДЃЌЮЊЪВУДЯждквЊЧПЕї
Dev КЭ Ops ЕФНєУмНсКЯвдМАЪВУДГЁОАвЊНєУмНсКЯЃЌЪВУДГЁОАВЛашвЊЁЃ
вдЯТЫФИіЗНУцДйЪЙСЫШэМўаавЕПЊЪМвтЪЖЕН DevOps ЕФзїгУЃК
ЭјТчЛЏЃКЕфаЭЕФДЋЭГШэМўДњБэ Office ЯЕСаЃЌPhotoshop
ЕШДѓЖМВЛашвЊЭјТчжЇГжЃЌЕЅЬхАВзАдкЕчФдЩЯМДПЩЪЙгУЃЌетРрШэМўВЛЧЃЩцдЫЮЌЃЌЫљвдИќУЛга DevOps ИХФюЁЃаТаЭЕФвдЛЅСЊЭјЮЊЛљДЁЕФШэМўЃЌР§ШчЮЂаХЃЌЬкбЖЛсвщЕШЖМЪЧНЈСЂдкЭјТчЛљДЁЩЯЕФЃЌетЪєгкЕфаЭЕФ
C/S ЕФМмЙЙЃЌC/S МмЙЙжаЗўЮёЦїЖЫШэМўЕиЮЛМЋЮЊживЊЃЌЗўЮёЦїЖЫШэМўЪЧвўВидкжкЖргУЛЇБГКѓЕФВЛПЩМћЕФЃЌашвЊЮШЖЈадЁЂАВШЋадЕШдЫЮЌЫпЧѓЃЌОЭв§ГіСЫПЊЗЂКЭдЫЮЌЙЄзїЕФаЭЌЛЏЫпЧѓЁЃ
Web ЛЏЃКЯрЖдгк C/S ЕФШэМўЃЌB/S ЕФШэМўдкгУЛЇЖЫЕФВПЗжЃЈC/S
ЪЧзРУцЛђепЪжЛњгІгУЃЌB/S ЪЧЭјвГЃЉЩЯгаИќИпЕФИќаТЗЂВМЦЕТЪЃЌашжЇГжИќаТЙ§ГЬВЛЭЃжЙЗўЮёЃЌЮоИаИќаТЕШЬиадЃЌЖдШэМўЕФНЛИЖЫйЖШКЭжЪСПгаСЫИќИпЕФвЊЧѓЃЌетвВв§ГіСЫПЊЗЂКЭдЫЮЌЙЄзїЕФаЭЌЛЏЫпЧѓЁЃ
дЦЛЏЃКДЋЭГЕФ ERPЃЌCRMЃЌHRMЃЌЪгЦЕЛсвщЯЕЭГЖМЪЧгаШэМўЙЉгІЩЬЖРСЂЪЕЪЉИјПЭЛЇЗНЃЌЖјетаЉШэМўвВЖМдкж№ВНдЦЛЏЃЌВњЩњСЫР§ШчЯњЪлвзЃЌЬкбЖЛсвщЃЌЖЄЖЄЃЌЦѓвЕЮЂаХЕШ
SaaS гІгУШэМўЃЌетРр SaaS ЛЏЕФШэМўЖд DevOps ЫпЧѓИќЮЊЦШЧаЁЃ
УєНнЛЏЃКДЋЭГЕФЭтАќШэМўНЛИЖФЃЪНвђЦфЗДРЁжмЦкГЄЃЌЪЕЪЉГЩБОИпЕШБзВЁвбОПЊЪМДѓЙцФЃЕФзЊЯђУєНнЁЂаЁВНПьХмЁЂИпЫйЕќДњЕФФЃЪНЃЌИќИпЕФНЛИЖЫйЖШвЊЧѓПЊЗЂКЭдЫЮЌжЎМфБиаыНЈЩшазїЮФЛЏЃЌСїГЬЃЌБъзМвдМАЙЄОпЁЃ
ШчЙћФуЕФШэМўВЛЗћКЯЩЯЪіЫФИіЗЂеЙЗНЯђЃЌПДЕНетРяОЭЙЛСЫЃЌФуВЛашвЊШЅЪЕМљШЫдЦврдЦЕФ
DevOpsЃЌГЂЪджЛЛсИјФуДјРДВЛБивЊЕФТщЗГЁЃ
DevOps е§ж№НЅАбПЊЗЂКЭдЫЮЌжаМфЕФНчЯоФЃК§ЕєЃК
БОЮФдкЬНЬжЭъБЯСНИіЪгНЧЁЂЫЋЯђвЦЖЏЁЂЫФИіВуУцКѓЛсАбПЊЗЂКЭдЫЮЌЕФжаМфжиЕўВПЗжЃЈШэМўНЛИЖЃЉЮЊжїЬтРДЯъЯИВћЪіетвЛ
DevOps ЪЕМљЕФзюДѓФбЬтЁЃ
ПЊЗЂЪгНЧ
ПЊЗЂНзЖЮЙизЂЕФаХЯЂКЭИХФюИњдЫЮЌдЫгЊНзЖЮгаЯрЕБДѓЕФВювьгжгаВПЗжЕФжиЕўЃК

дЫЮЌЪгНЧ
ЭЌбљЕФЃЌдЫЮЌНзЖЮЙизЂЕФаХЯЂКЭИХФюгыПЊЗЂНзЖЮгаЯрЕБДѓЕФВювьЃЌгжгаВПЗжжиЕўЃК

ЪгНЧЕФОлНЙ
дкЖд DevOps ИХФюНјааРэНтЃЌШЋОжПМТЧЕФЪБКђашвЊФмЯёЩЯЮФжаЬсЕФвЛбљРэНтПЊЗЂНзЖЮКЭдЫЮЌНзЖЮЕФЙувхадЃЌЕЋдкБОЮФЩшМЦЕФГжајВПЪ№ЛАЬтЃЌвђЦЊЗљЯожЦЃЌЛсАбЪгНЧОлНЙдкПЊЗЂНзЖЮЕФНсЪјКЭдЫЮЌНзЖЮЃЌПМТЧЯСвхЕФдЫЮЌИХФюЃЈМДДЋЭГРэНтЕФдЫЮЌЙЄГЬЪІЕФЙЄзїЗЖГыЃЉЭЈЙ§ЦЪЮідЫЮЌЙЄГЬЪІЕФЙЄзїФкШнБфЛЏРДЬжТл
DevOps ЕФЗжгыКЯЁЃ
ФЧУДЖдгкдЫЮЌЙЄГЬЪІЕФЛљБОЙЄзїЖјбдЃЌПЩвдАбФЃаЭМђЛЏЮЊШчЯТСНИіЗНУцЃК
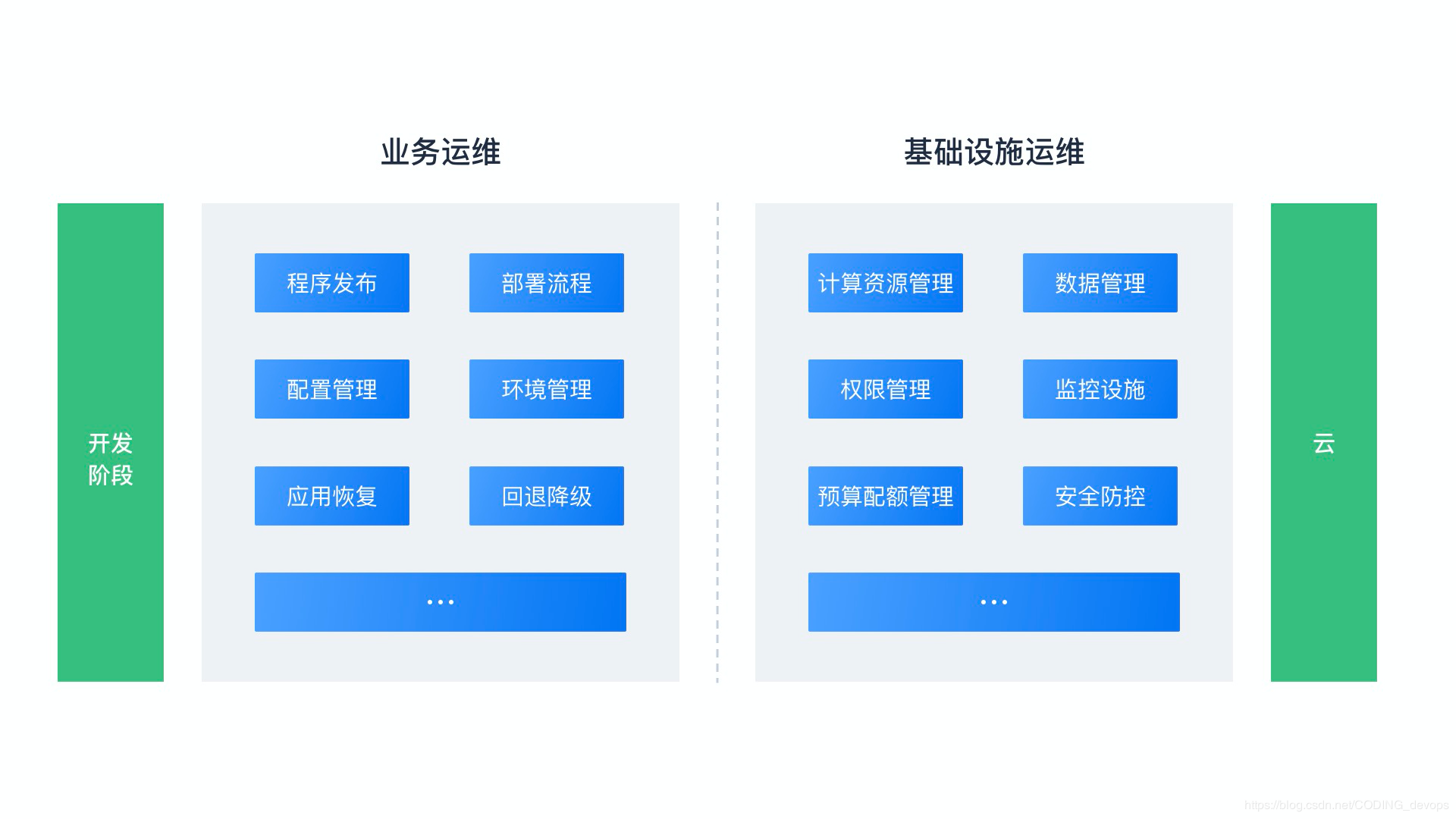
вЕЮёдЫЮЌЕФзѓвЦ
дкИпЦЕДЮЕФГЬађЗЂВМЃЌБЌЗЂЪНвЕЮёдіГЄЕФГЁОАЯТЃЌдЫЮЌЭХЖгдНРДдНЭДПрЃЌдкМгЩЯКмЖрЭХЖгУЛгаКЯЪЪЕФЙЄОпЯЕЭГКЭБъзМЛЏЕФВПЪ№СїГЬЃЌОГЃЛсПДЕНЭХЖгФкЕФЫЋЯђЭТВлЃК
ПЊЗЂЭХЖгЫЕЃК
ЮЊЪВУДЮвУЧетБпаоКУСЫ bug НёЬьВЛФмИјЮвЗЂВМЃПЮвашвЊВщвЛЯТЩњВњЛЗОГШежОвЊЕШ
3 ИіаЁЪБЃПдЫЮЌЭЌбЇФмВЛФмВЛвЊзмЪЧГДэХфжУЯюЃП
дЫЮЌЭХЖгЫЕЃК
ЧыгУЮФЕЕЯъЯИзЋаДЧхГўЗЂВМВНжшКЭзЂвтЪТЯюВЂзаЯИЦРЙРЗЂВМЗчЯеЁЃдЫЮЌЭХЖгвбОХХТњСЫЫљгаЗЂВММЦЛЎЃЌФуетИіаоИДЮЪЬтВЛбЯжиЃЌЧыЕШЯТжмдйХХЁЃ
дЫЮЌЭХЖгЯнШыЮоЯоЕФЛњаЕаджиИДРЭЖЏжаЃЌЖјЦфжаДѓВПЗжЙЄзїЖМЪЧЕЭИмИЫЕФжДааЗЂВМЃЌВщбЏШежОЃЌжДааЛиЭЫЕШЁЃ
етЪєгк DevOps ЕФЗжРыЕФГЁОАЃЌЭХЖггыЭХЖгжЎМфгаЙЄзїбЙСІВЛОљЃЌаХШЮИаШБЪЇЃЌФПБъВЛвЛжТЕШЮЪЬтЃЌНЈвщГЂЪдзівЛаЉвЕЮёдЫЮЌЕФзѓвЦЃЌвВМДдкКЯЪЪЕФЙЄОпЯЕЭГЛљДЁЩЯАбвЕЮёдЫЮЌЕФВПЗжШЈСІЛђепШЫдБЗжХфЕНПЊЗЂЭХЖгЃЌЪЙжЎПЩвдЭъГЩДѓВПЗжЕФГЬађЗЂВМЁЂХфжУИќаТЁЂШежОВщбЏЕШЙЄзїЃЌНтЗХдЫЮЌЁЃ
аЮГЩЯТЭМаЇЙћЃЌДгШЫдБЩЯПЩвдЪЧПЊЗЂМцжАвЕЮёдЫЮЌЃЌвВПЩвдЪЧПЊЗЂЭХЖггазЈжАвЕЮёдЫЮЌШЫдБЃЌЦфБОжЪЪЧвЕЮёдЫЮЌЕФжївЊЙЄзїБеЛЗдкПЊЗЂЭХЖгФкВПЃЌЪЕЯжИпаЇдЫзЊЁЃ

етбљМДдкФГжжГЬЖШЩЯЪЕЯжСЫ Dev КЭ Ops ЕФКЯЁЃ
ЛљДЁЩшЪЉдЫЮЌЕФгввЦ
аХЯЂЪ§ОнЕФАВШЋЫпЧѓЃЌвддЦЮЊДњБэЕФЛљДЁЩшЪЉЕФащФтЛЏЁЂЕЏадЛЏЁЂЩѕжСгкДњТыЛЏЕФЗЂеЙвВИјдЫЮЌЭХЖгЕФЛљДЁЩшЪЉдЫЮЌЙЄзїДјРДСЫаТЕФЬєеНКЭЛњгіЁЃЮвУЧЛсЗЂЯжЛљДЁЩшЪЉдЫЮЌЭХЖгдкдЦЕФЗЂеЙЯТНЅНЅЕФЪЕЯжСЫгввЦЃЈАбЛљДЁЩшЪЉШЋаХШЮЕФНЛИјдЦДІРэЃЉЁЃ
дкУЛгадЦжїЛњЕФФъДњЃЌдЫЮЌЭХЖгВЛЕУВЛПИзХГСжиЕФЗўЮёЦїШЅЛњЗПРяЃЌЖдеезХЙйЗНжИФЯЃЌАВзАВйзїЯЕЭГЁЂХфжУЭјТчВпТдЃЛдЦжїЛњЪБДњЃЌШнЦїЛЙЮДЕНРДжЎЪБЃЌдЫЮЌЭХЖгАкЭбСЫЮяРэЗўЮёЦїЃЌШДВЛЕУВЛЮЌЛЄДѓСПЕФЗўЮёЦїШэМўЃЌАВзАЁЂаЖдиЁЂХњСПЗЂВМЕШЃЌШЅЮЌЛЄвЕЮёдЫааЕФЛљДЁШэМўЛЗОГЃЛдкгаСЫ
KubernetesЃЌDocker ЕШШнЦїММЪѕжЎКѓЃЌдЫЮЌЙЄГЬЪІДгЮЌЛЄШэМўдЫааЛљДЁЛЗОГжаНтЭбЃЌзЊЖјзіИќЩЯВуЕФЛљДЁЩшЪЉЃКМрПиЬхЯЕЁЂИКдиОљКтЕШЃЛВЛдЖЕФНЋРДЃЌЕБ
Serverless жиЙЙдЦМЦЫуЬхЯЕЕФЪБКђЃЌдЫЮЌШЫдБСЌМрПиЬхЯЕЁЂИКдиОљКтЕШЖМВЛашвЊЙизЂСЫЃЌШЋСПНЛИјдЦРДНтОіЁЃ
дЦЕФВЛЖЯЗЂеЙЕФРњГЬвВЪЧвЛИіж№ВНЭЬЪЩЛљДЁЩшЪЉдЫЮЌШЫдБЙЄзїЕФРњГЬЃЌШчНёдЫЮЌШЫдБдкдЦЕФЛљДЁЩЯгаСЫдЦ
LB ВЛашвЊдйдЫЮЌ HAProxyЃЌNginx ЕШЃЌгаСЫдЦЪ§ОнПтВЛашвЊдйдЫЮЌ MySQLЁЂRedis
ЕШЁЃШчДЫжжжжЃЌЛљДЁЩшЪЉдЫЮЌЕФЙЄзїЖМгввЦИјСЫдЦЁЃ
ЕБШЛетИігввЦВЛЪЧвЛѕэЖјОЭЕФЃЌЪЧИіНЅНјЕФЙ§ГЬЃЌашвЊаавЕТ§Т§ШЅНгЪмЃЌвВашвЊдЦЕФГЩЪьгыЗЂеЙЁЃзюНќЗаЗабябяЕФЮЂУЫдЫЮЌШЫдБЩОПтХмТЗЪТМўЪЧвЛИіКмКУЕФзєжЄЃЌЫћУЧЪЙгУСЫЬкбЖдЦЃЌЬкбЖдЦзюжеАяЫћУЧевЛиСЫЪ§ОнЃЌЕЋЫћУЧЛљДЁЩшЪЉдЫЮЌЕФгввЦГЬЖШВЛЙЛИпЃЌЛЛОфЛАЫЕНазідЦдЩњЩјЭИВЛЙЛЩюЃЌШчЙћЪЙгУЕФЪЧРрЫЦгкдЦЪ§ОнПтетРрдЦЬсЙЉЕФЪ§ОнПтЛљДЁЩшЪЉЃЌФЧвВаэДѓПЩВЛБиЪЙгУгВХЬЛжИДММЪѕРДевЛиЪ§ОнЁЃ
ГЯШЛЃЌдЦВњЦЗЛЙгаГЄдЖЕФТЗвЊЗЂеЙЃЌЕЋдкЯжгаЕФдЦЕФФмСІЯТЃЌИїЮЛПЩвдЫМПМЯТЃЌздМКЭХЖгЕФЛљДЁЩшЪЉдЫЮЌгввЦСЫЖрЩйЃЌзшАгввЦЕФЮЪЬтЪЧЪВУДЃЌгввЦВЛЙЛЕМжТРЫЗбСЫЖрЩйШЫдБОЋСІЃЌДјРДСЫЖрЩйЗчЯеЁЃ
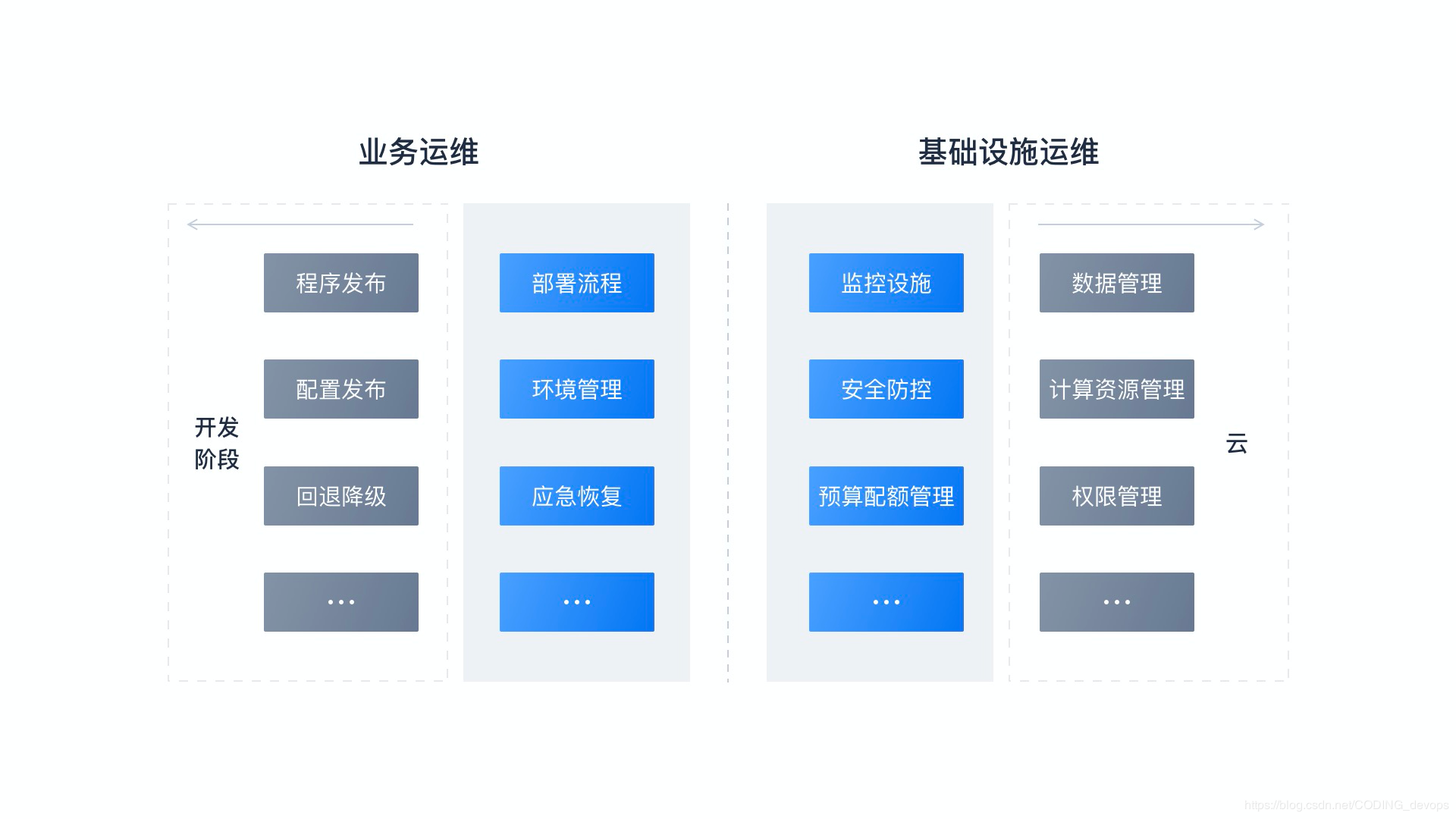
DevOps ЕФЫФИіживЊВуУц
ШЯецЦРЙРФуЕФШэМўЕФНЛИЖЛњжЦвдМАдЫЮЌЭХЖгзѓвЦКЭгввЦЕФГЬЖШЪЧФубЁдёВЩгУКЮжж
DevOps ЗжКЯВпТдЃЌвдМА DevOps ЪЕМљЪЧЗёГЩЙІЕФЙиМќвђЫиЁЃ
DevOps ЕФЗжгыКЯЃЌгыдЫЮЌЙЄзїЕФзѓвЦгввЦЃЌдЦММЪѕЕФЗЂеЙЃЌдЦдЩњБъзМЕФЭГвЛгаМЋДѓЙиЯЕЃЌDevOps
ИХФюПЩвддкКмЖрВуУцЩЯЕУЕНЬхЯжЃЌБОЮФОЭЦфжажївЊЕФЃЌПЩвдШУ DevOps ЭХЖгецЧаИажЊЕФЫФИіВуУцРДзіМђвЊНщЩмЃК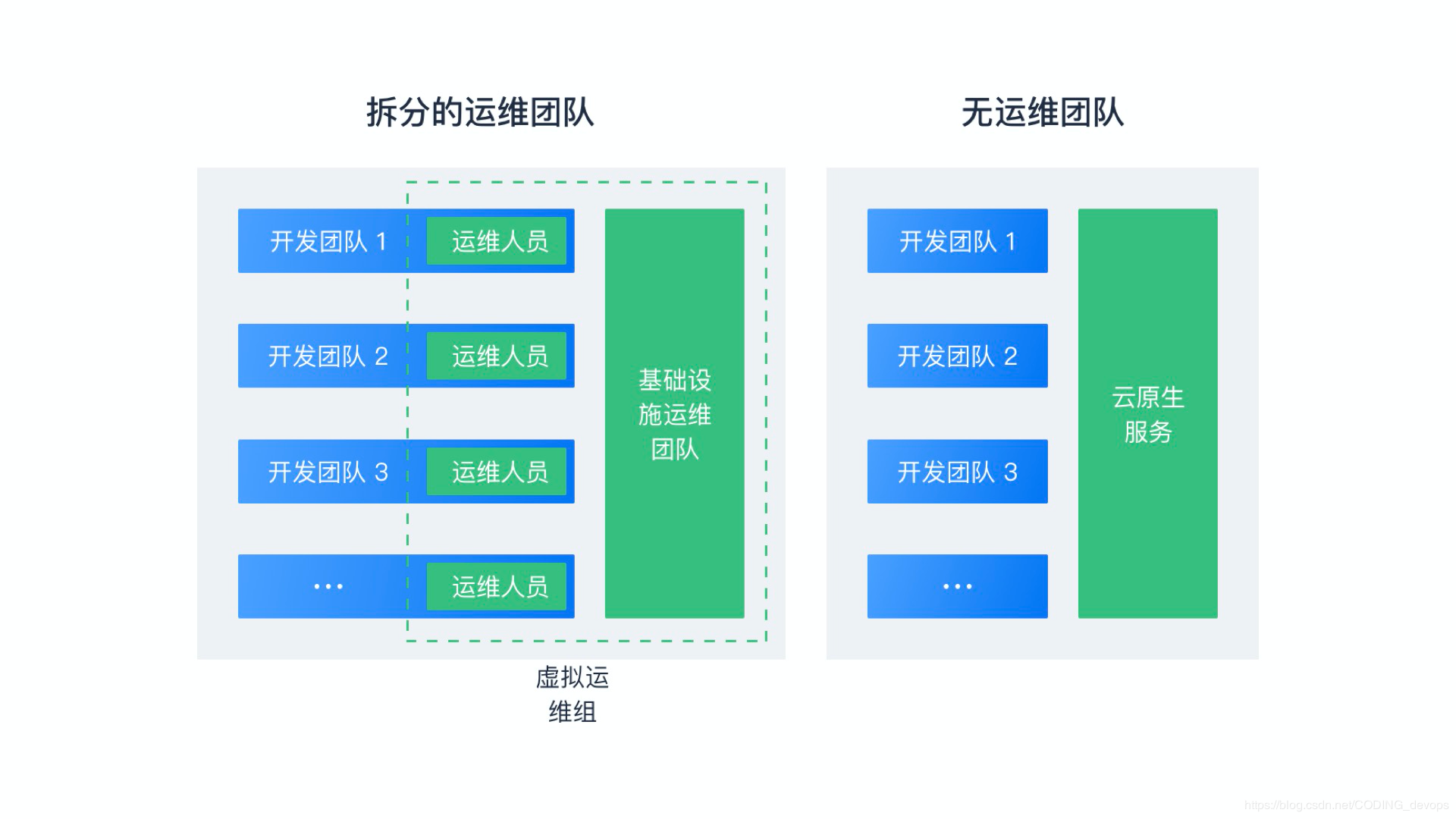
ДгШЫдБЙмРэВуУцПД DevOps
вЊЯыЪЕМљ DevOps ЕФЗжгыКЯЃЌБиаывЊХфжУЩЯКЯЪЪЕФЭХЖгХфжУЁЃетРягаШєИЩжжХфжУЕФЗжРрЃК
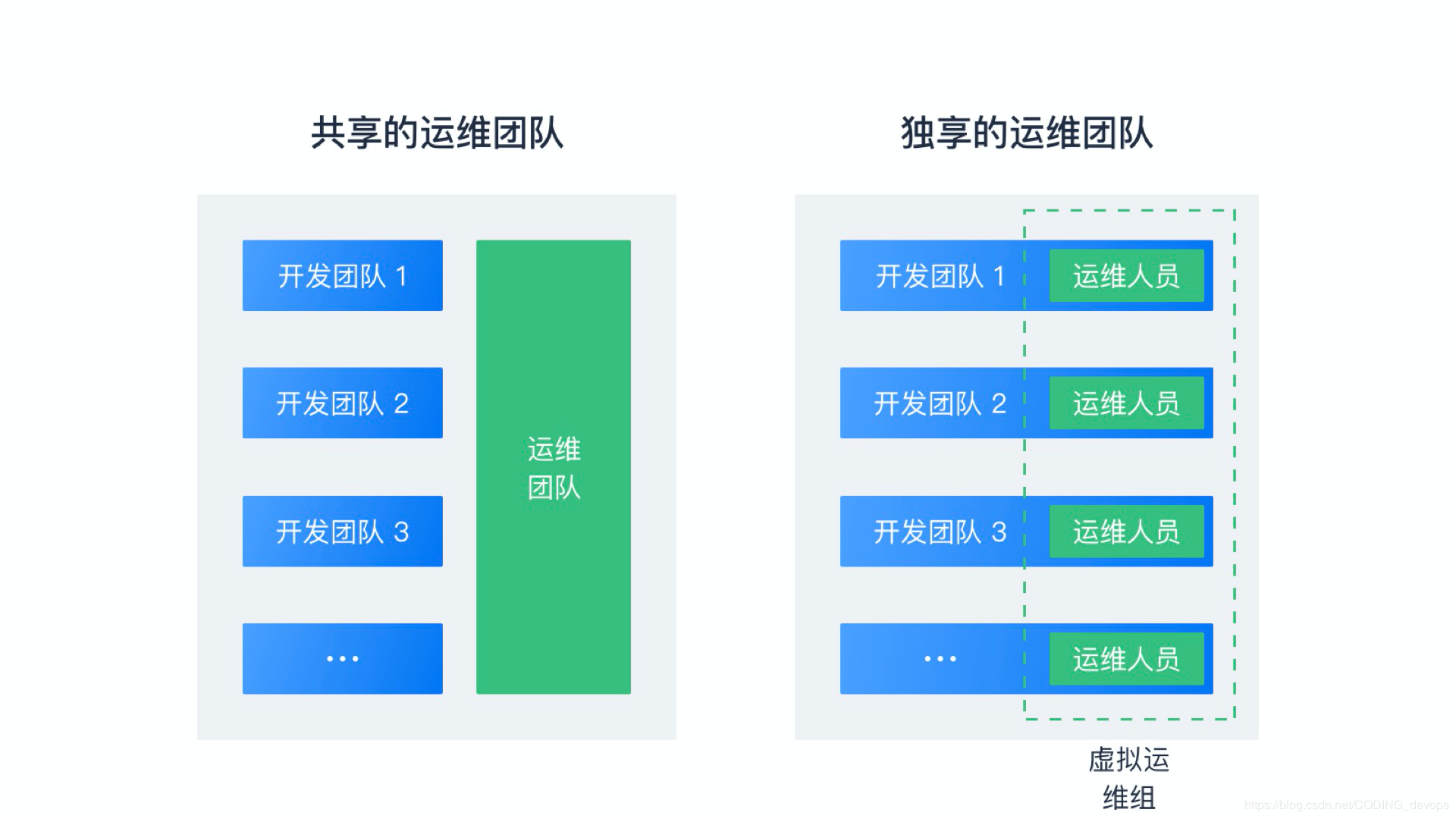
ЕквЛжжФЃЪНЪєгк Dev КЭ Ops ЗжЕФБШНЯГЙЕзЕФРраЭЃЌетжжШЫдБФЃаЭПЩвдЪЪХфвЕЮёдЫЮЌзѓвЦГЬЖШНЯЩйЃЌНЛИЖСїГЬНЯЮЊБъзМЛЏЕФГЁОАЃЌдЫЮЌЭХЖгжЦЖЈСїГЬЃЌСїГЬКЭдЫЮЌЗўЮёЙВЯэИјЫљгаПЊЗЂЭХЖгЁЃ
ЕкЖўжжФЃЪНЪєгк Dev КЭ Ops КЯЕФБШНЯГЙЕзЕФРраЭЃЌетжжШЫдБФЃаЭПЩвдЪЪХфвЕЮёдЫЮЌзѓвЦГЬЖШКмИпЃЌЛљДЁЩшЪЉдЫЮЌгввЦГЬЖШвВКмИпЕФГЁОАЃЌЛљБОЩЯЪЕЯжСЫУПИіПЊЗЂЭХЖгХфКЯдЦОЭФмЭъећЪЕЯжБеЛЗЃЌвбОУЛгаДЋЭГвтвхЕФЖРСЂдЫЮЌВПУХЁЃ
ЕкШ§жжФЃЪНЪєгк Dev КЭ Ops ВПЗжЗжПЊЁЂВПЗжКЯВЂЕФРраЭЃЌетжжШЫдБФЃаЭПЩвдЪЪХфвЕЮёдЫЮЌзѓвЦГЬЖШНЯЖрЃЌЕЋЛљДЁЩшЪЉдЫЮЌгввЦГЬЖШНЯЩйЕФГЁОАЃЌЪЪгУгкЯЃЭћФмЪЕЯжПЊЗЂЭХЖгБеЛЗЃЌгжЖддЦЛљДЁЩшЪЉгааХШЮЮЪЬтЃЌашвЊздНЈЛљДЁЩшЪЉЃЈР§ШчЫНгадЦЃЌЛђЛљгкЙЋгадЦЕФЫНгаЛљДЁЩшЪЉЃЉРраЭЕФЭХЖгЃЌетжжФЃЪНИњЕкЖўжжФЃЪНЕФЮЈвЛВювьЪЧЪЧЗёгазджїЛљДЁЩшЪЉдЫЮЌЭХЖгЃЌдкГЌДѓЙцФЃ
DevOps НЈЩшЫНгадЦЕФГЁОАЖрМћЁЃ
ЕкЫФжжФЃЪНЪєгк Dev КЭ Ops ЕФКЯВЂвбОДяЕНМЋжТЃЌПЩвдЭъШЋЮодЫЮЌЭХЖгЙЄзїЃЌдкЪЙгУдЦЛљДЁЩшЪЉКЭКЯЪЪЕФПЊЗЂЙЄОпЛљДЁЩЯОЭПЩвдЪЕЯжПЊЗЂЭХЖгФкЭъећБеЛЗЃЌР§ШчШЋСПЪЙгУ
Serverless ММЪѕЃЌЮоашЕЃаФИКдиОљКтЃЌЕЏадРЉЫѕШнЃЌМрПиЕШЛљДЁЩшЪЉЙЄзїЁЃ
УЛгаФФИіФЃЪНЪЧЭъУРЕФЃЌдкЪЕМљздМКЕФ DevOps ШЫдБХфжУЕФЪБКђЃЌвЊЯыЧхГўздМКЕФЪЕМЪГЁОАЃЌЕБЯыЧхГўздМКЕФШЫдБХфжУЕФЪБКђЃЌвЊЯыБЃГжИпаЇОЭвЊПМТЧетаЉШЫгыШЫжЎМфаХЯЂШчКЮСїзЊЫГГЉЁЃ
ДгаХЯЂСїзЊВуУцПД DevOps
DevOps ЪЧвЛжжазїЮФЛЏЃЌазїСїГЬЃЌЖјазїЕФБОжЪЪЧЫГГЉЁЂОЋзМЕФаХЯЂСїзЊЁЃ
вЛИіМђЛЏЕФЕфаЭЕФ DevOps аХЯЂСїзЊФЃаЭДѓжТШчЯТЃК

аХЯЂСїзЊЫГГЉКЭОЋзМЕФИљБОдкгкаХЯЂЪЧЗёЪЧНсЙЙЛЏЁЂСїГЬЛЏЁЂБъзМЛЏЕФЁЃвЛИіЫљгааХЯЂСїзЊЖМвРРЕСФЬьШКЁЂПЊЛсЁЂгЪМўЕШаЮЪННтОіЃЌПДЫЦФмЙЛвЛДЅМДДяЕФаХЯЂСїзЊЃЌЭљЭљЛсгажиЕуВЛЭЛГіЃЌаХЯЂвХТЉЃЌаХЯЂвРРЕШЫЮЊИњНјЕШЮЪЬтЃЌЦфЪЕЪЧВЛЫГГЉвВВЛОЋШЗЕФЁЃ
КЫаФвЊАбЮе DevOps ЪЕМљЭХЖгЕФШчЯТНкЕуЪЧЗёаХЯЂДЋЪфЫГГЉЧвОЋзМЃК
ПЊЗЂНЛИЖВтЪдНзЖЮЃКаХЯЂЬсЙЉЗНЪЧПЊЗЂЁЂжїНгЪеЗНЪЧВтЪдЁЂГЫЭЗНЪЧВњЦЗОРэЁЂЯюФПОРэЁЂдЫЮЌЕШЃЌетИіЬсВтЩъЧыЪЧЗёНсЙЙЛЏЃПЪЧЗёОпБИБъзМЃПгаУЛгаСїГЬЃПЪЧЗёгазЈгУЙЄОпжЇГХЃП
ВтЪдЛиРЁЃКаХЯЂЬсЙЉЗНЪЧВтЪдЃЌжїНгЪеЗНЪЧПЊЗЂЁЂГЫЭЗНВњЦЗОРэЁЂЯюФПОРэЕШЃЌетИіаХЯЂзюМђЕЅЕФЗНЪНЪЧВЩгУЬхЯЕЛЏЕФШБЯнЙмРэЯЕЭГХфКЯЩЯЯТгЮРДвЛЦ№ЙмРэЃЌЯИЛЏСїГЬКЭБъзМКѓМДПЩЪЕЯжЫГГЉЃЌОЋзМДЋДя
НЛИЖЗЂВМЃКаХЯЂжїЬсЙЉЗНЪЧПЊЗЂЃЌжїНгЪеЗНЪЧдЫЮЌЃЌГЫЭЗНЪЧВњЦЗОРэЁЂВтЪдЁЂЯюФПОРэЕШЃЌетИіНзЖЮЕФздЖЏЛЏГЬЖШЪЧЯрЕБживЊЕФЃЌвЊЯыЪЕЯжздЖЏЛЏЃЌЧАЬсЪЧНсЙЙЛЏЁЂСїГЬЛЏЁЂБъзМЛЏЯШааЁЃдкБОЮФЕФКѓајЖЮТфжаЛсвд
Kubernetes ЬхЯЕЕФздЖЏВПЪ№ЮЊЪЕеНРДНщЩмШчКЮНсЙЙЛЏЁЂСїГЬЛЏЁЂБъзМЛЏзюжеЪЕЯжздЖЏЛЏ
етМИИіЙиМќЛЗНкЖМЖЈвхКУБъзМКЭСїГЬЕФЪБКђЃЌдйДЮвЊШЅПДЦфЫћЛЗНкЕФЯИЛЏаХЯЂСїзЊЮЪЬтЃЌНгЯТРДОЭЪЧашвЊПМТЧЪЙгУКЮжжЙЄОпЯЕЭГЮЊДЫБъзМКЭСїГЬЬсЫйЕФЪБКђСЫЁЃ
ДгЙЄОпЯЕЭГВуУцПД DevOps
DevOps ЕФазїЮФЛЏФПЕФЪЧЬсЩ§ЭХЖгЕФаЇФмЃЌЖјздЖЏЛЏЙЄОпЪЧБиБИЕФЃЌКУЕФЙЄОпЬхЯЕгІИУЪЧећКЯЕФЁЂНЧЩЋЧаУцЕФЁЂздЖЏСїзЊЕФЁЃЙЄОпЯЕЭГФПБъЪЧЫГГЉОЋзМЕФДЋЪфаХЯЂВЂЧвИпаЇЕФжДааЛњаЕЛЏВйзїЁЃ
ећКЯадЃКDevOps ЕФПЊдДЁЂЩЬвЕШэМўгаКмЖрПюЃЌШЛЖјДѓЖрЪ§ШэМўЯЕЭГжЎМфЖМЪЧШѕећКЯзДЬЌЃЌКмЖрЖМЪЧаћГЦжЇГж
OAuth Лђеп LDAP гУЛЇЬхЯЕОЭЫуећКЯСЫЃЌетРяУцЕФВюОрЛЙКмДѓЃЌР§Шч Jira ЕФЯюФПКЭ GitLab
ЕФЯюФПЃЌGitLab ЕФЯюФПгы TestLink ЕФВтЪдМЦЛЎЃЌетаЉЪЕМЪЕФИХФюдкВЛЭЌЕФЯЕЭГжЎМфЖМзёДгзХВЛЭЌЕФВњЦЗЩшМЦембЇЃЌЪЕМЪЩЯШѕећКЯЕФЙЄОпЯЕЭГдкЬсЩ§ЭХЖгаХЯЂСїзЊаЇТЪЩЯВЂУЛгаЬЋДѓАяжњЁЃ
НЧЩЋЧаУцЃККУЕФ DevOps ЙЄОпЯЕЭГгІИУЯёЪЧвЛИіЮЊЙЄГЇСПЩэЖЈжЦЕФЩњВњСїЫЎЯпЃЌИїИіНЧЩЋИїЫОЦфжАЃЌЙизЂОЋзМЕФаХЯЂЃЌжДааБъзМЕФВйзїЃЌЪфГіБъзМЕФНсЙћЁЃдкШѕећКЯЕФЙЄОпЯЕЭГРяПЩФмВЛЭЌЯЕЭГЕФгУЛЇЁЂНЧЩЋЁЂШЈЯоЩшМЦЖМгаКмДѓВювьЃЌФбвдЪЕЯжНЧЩЋЧаУцЁЃР§ШчвЛЬзЛљгк
Jira + GitLab + Jenkins + Kubernetes ЕФЬхЯЕЃЌдЫЮЌНЧЩЋгІИУМгШы
Jira ЕФЯюФПжаУДЃПВњЦЗОРэЪЧЗёашвЊЙизЂ Jenkins ЕФJob жДаазДЬЌЃП
здЖЏСїзЊЃКздЖЏСїзЊЪЧЮЊСЫНтОіжиИДадЕФЛњаЕРЭЖЏЖјЩшМЦЕФЃЌвЊЯыОпБИздЖЏСїзЊЕФЬиадЃЌећКЯадКЭНЧЩЋЧаУцвВБиаыЩшМЦЕФЗЧГЃКУЃЌПЊЗЂЭъБЯЕНЬсВтздЖЏВПЪ№ЃЌВтЪдЭЈЙ§ЕНздЖЏЗЂВМЃЌдкЩшМЦКУСїГЬКЭБъзМКѓЖМЪЧвЛаЉЛњаЕЛЏЕФжиИДРЭЖЏ
ЙЄОпЯЕЭГВЛЪЧЭђФмЕФЃЌгаЪБКђФуЛсЗЂЯжгаСЫКУЕФШЫдБНсЙЙЁЂаХЯЂСїзЊЗНЪНЁЂећКЯадЕФЙЄОпЯЕЭГЃЌЪЕМљЦ№
DevOps ЛЙЪЧгавЛЖЈРЇФбЃЌФЧФуПЩвдПДПДШчЯТетИіЕуЃКММЪѕМмЙЙЁЃ
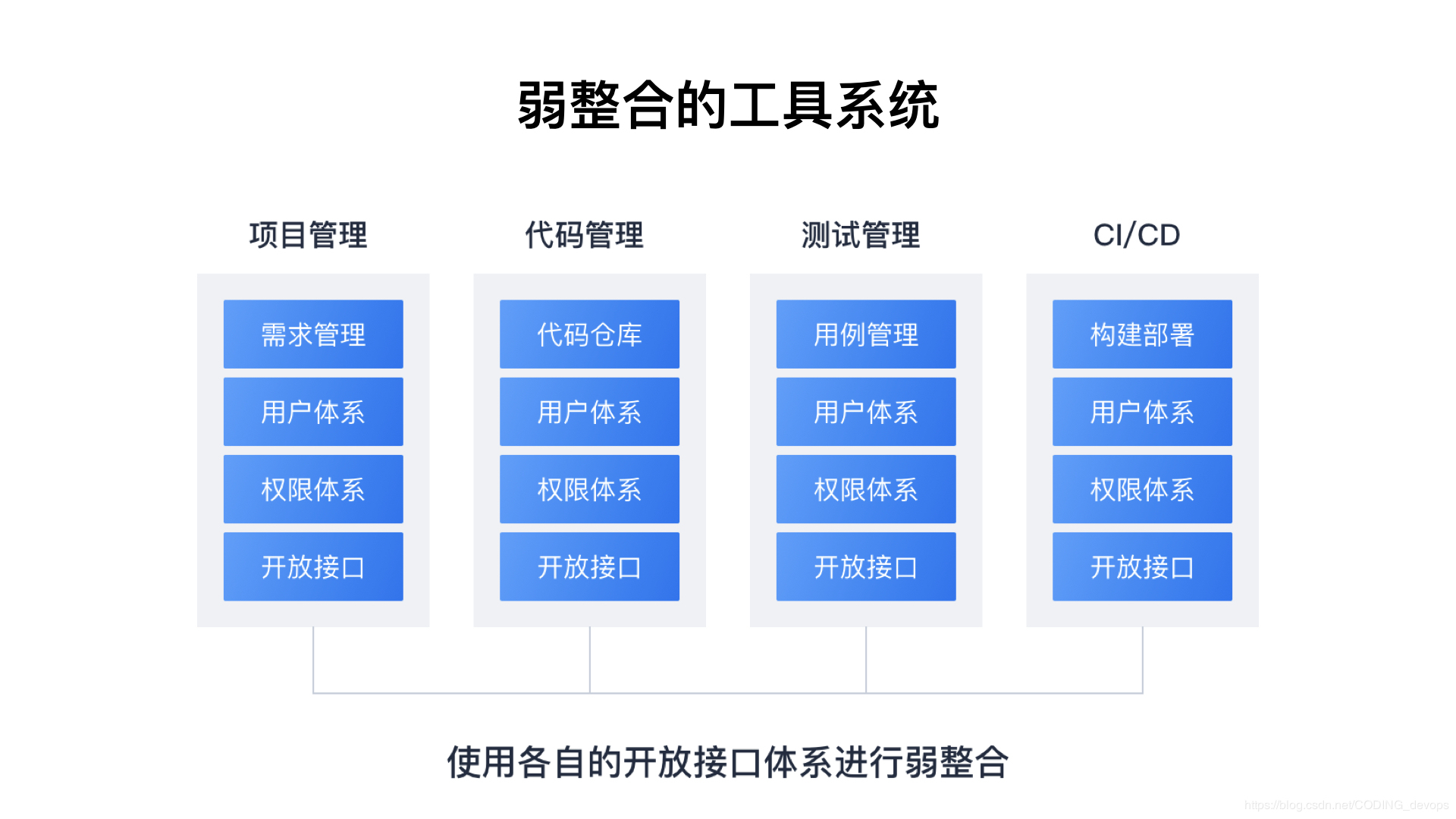
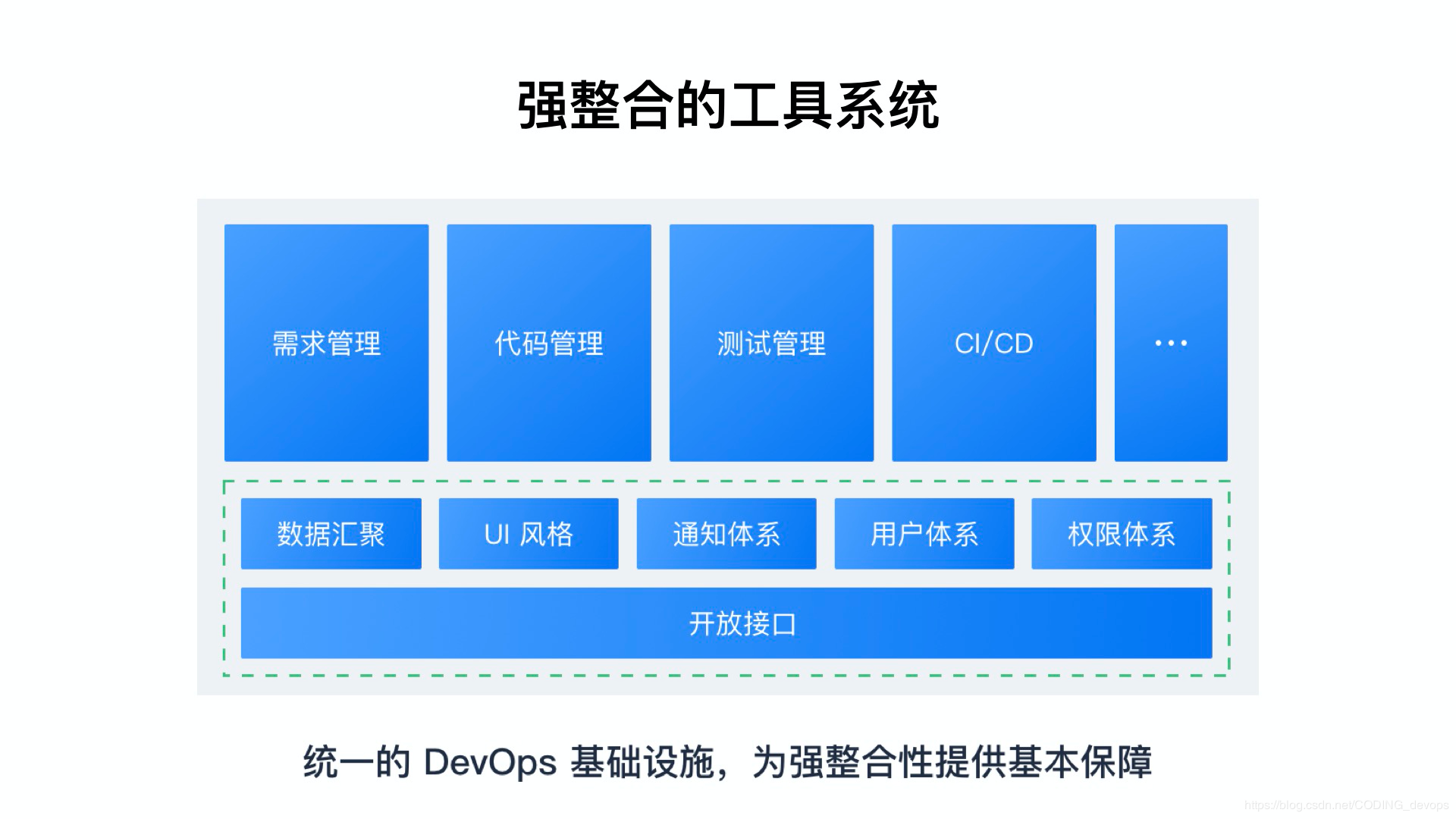
ДгММЪѕМмЙЙВуУцПД DevOps
ММЪѕМмЙЙЖд DevOps ЕФгАЯьжївЊЬхЯждкЙЙНЈЁЂВПЪ№ЁЂдЫЮЌЛЗНкЁЃВЛЭЌЕФШэМўРраЭЃЌММЪѕМмЙЙдкетШ§ЗНУцЪЧгаКмДѓВювьЕФЁЃР§ШчЕЅЛњЪжгЮЃЌжЛгаЙЙНЈКЭЗЂВМЪаГЁЃЌЛљБОВЛДцдкВПЪ№ЁЂдЫЮЌЛЗНкЁЃЖјЮЂЗўЮёМмЙЙ
SaaS ЛЏЕФЖрзтЛЇдЦЗўЮёдкетЗНУцОЭИДдгЕФЖрЁЃ
етРявдЕфаЭЕФЗўЮёЦїЖЫгІгУЕФММЪѕМмЙЙЩ§МЖЙ§ГЬРДзїМђвЊЗжЮіЃЌР§ШчЖдгквЛИіЛљгк
Spring ПђМмаДГЩЕФ Java Web гІгУЃЌЦфЗЂеЙРњГЬПЩФмЪЧетбљЕФЃК
ЕЅЬх TomcatЃКЙЙНЈвЛАуЪЙгУ IDE ХфКЯ Maven/GradleЃЌЩйаэЭХЖгЛсЪЙгУ
Jenkins жЎРрЕФНјааздЖЏЛЏЙЙНЈ war АќЃЌВПЪ№ЭљЭљбЁдё scp/sftp аЮЪННјааЗЂВМЃЌЭЃЛњВПЪ№ЃЌашвЊдЫЮЌШЫдБзЈУХШЫЙЄВйзїЃЌШнвзГіЯжДэЮѓ
ЖрЪЕР§ Tomcat + Nginx ИКдиОљКт + ЖЏОВЗжРыЃКЙЙНЈПЊЪМБфЕФИДдгЃЌЧАЖЫЕФ
js css ЕШашвЊНјааЖРСЂЕФбЙЫѕКЭЩЯДЋЃЌВПЪ№Й§ГЬгаКмЖрдЫЮЌЭХЖгПЊЪМбЁгУ Ansible жЎРрЕФБугкЙмРэ
Nginx ЕФИДдгХфжУЮФМўКЭЖрЪЕЧ€ааЗЂВМЃЌAnsible ЕШЙЄОпЮЊздЖЏЛЏЕФЗЂВМЬсЙЉСЫжюЖрБуРћЃЌЕЋШдШЛвЊЧѓдЫЮЌШЫдБШЅзЋаДФбвдЮЌЛЄЕФ
playbook КЭЗўЮёЦїЕФЛљДЁШэМўЛЗОГ
ЧАКѓЖЫЗжРы + ШнЦїЛЏЃКЕБвд Docker ЮЊДњБэЕФШнЦїММЪѕПЊЪМСїааЕФЪБКђЃЌЭХЖгПЊЪМГЂЪдЙЙНЈЕФНсЙћВЛдйОжЯоЕН
war АќВуУцЃЌПЩвдАбЧАЖЫКЭКѓЖЫЗжБ№ЙЙНЈГі Docker ОЕЯёЃЌвд Docker ОЕЯёзїЮЊБъзМНЛИЖЃЌЕЋЗўЮёЕФХфжУаХЯЂЁЂРЉЫѕШнФмСІЃЌНЁПЕМьВщЕШЮЪЬтШдШЛРЇШХзХдЫЮЌЭХЖг
ЮЂЗўЮёЛЏМмЙЙ + ШнЛ§МЏШКВПЪ№ЃКвд KubernetesЃЌIstio
Service MeshЕШЮЊДњБэЕФШнЦїМЏШКБрХХКЭЮЂЗўЮёММЪѕПЊЪМж№ВННјШыДѓМвЕФЪгвАЃЌВПЗжЭХЖгПЊЪМГЂЪдШУПЊЗЂЭХЖгзджїЭЈЙ§
Kubernetes ЙЄзїИКди Yaml ЮФМўЁЂConfigMap ЕШаЮЪНЙмРэХфжУаХЯЂЃЌЪЙгУ Service
ХфКЯЮЂЗўЮёЕФСїСППижЦЬхЯЕНјааЛвЖШПижЦЁЂЗўЮёНЕМЖЁЂШлЖЯДІРэЁЂБъзМЛЏНЁПЕМьВщМрПиЕШЁЃ
Serverless ЮоЗўЮёЦїМмЙЙЃКвд Serverless FrameworkЁЂAWS
LambdaЁЂKnative ЕШЮЊДњБэЕФаТвЛДњЮоЗўЮёЦїМмЙЙЕФЗўЮёЦїЖЫгІгУвбОАяжњвЛаЉММЪѕСьЯШЕФЭХЖгЪЕЯжСЫНјвЛВНЕФШЅдЫЮЌЛЏЃЌКѓЖЫПЊЗЂжЛашвЊАДеедЦКЏЪ§ЕФЖЈвхвЊЧѓНјааЩйСПЕФЩљУїЛђепХфжУЃЌМДПЩЪЕЯжШЋЬзЕФ
CI/CDЁЂИКдиОљКтЁЂЕЏадЩьЫѕЁЂЩњВњМЖБ№ИпПЩгУЕШФмСІЁЃШчЙћФуЛЙВЛжЊЕРЪВУДЪЧ ServerlessЃЌЛЖгРДетРяСЫНтЃКhttps://cloud.tencent.com/product/sls
дЦЕФЗЂеЙвВгГЩфзХММЪѕМмЙЙЕФБфЧЈЃЌвВв§СьзХЛљДЁЩшЪЉдЫЮЌЕФгввЦЃЌДѓжТЗжЮЊШ§ИіНзЖЮЃК
VM/ащФтЛњ ЪЕЯжСЫШЅгВМўЛЏ Hardwareless
Container/ШнЦї ЪЕЯжСЫШЅВйзїЯЕЭГЛЏ OSless
дЦКЏЪ§/Serverless ЪЕЯжСЫШЅЗўЮёЛЏ Serverless
УПвЛжжММЪѕМмЙЙЕФ DevOps ЕФЪЕМљФЃЪНЪЧгаВювьЕФЃЌЗжгыКЯЕФГЬЖШвВВЛвЛбљЁЃзаЯИЦЗЮЖетаЉММЪѕМмЙЙЕФЬиЕуЃЌШЯецЦРЙРздЩэЭХЖгвЕЮёдЫЮЌзѓвЦКЭгввЦЕФГЬЖШЃЌОЭПЩвдбЁдёГіКЯЪЪЕФШЫдБЙмРэФЃЪНЁЂбЁдёЪЪКЯздМКЕФЙЄОпЯЕЭГЃЌаЮГЩЫГГЉЁЂОЋзМЕФаХЯЂСїзЊЃЌДгЖјШУ
DevOps ЕФЪЕМљШЁЕУЪЕжЪадГЩЙћЁЃ
DevOps ЕФеГКЯМСЃКГжајВПЪ№
ГжајВПЪ№ЪЧШэМўНЛИЖЕФвЛжжаЮЪНЃЌГЃгУгкЗўЮёЦїЖЫШэМўЕФНЛИЖЃЌдкетРяЮвУЧвд
CODING CD + Kubernetes РДМђвЊНВЪівЛИіЗўЮёЦїШэМўГжајВПЪ№ФЃЪНЃЌЮвУЧМйЖЈЭХЖгЯждкЕФИїЗНУцЛљБОЧщПіШчЯТЃК
вЕЮёдЫЮЌВПЗжзѓвЦЃКГЃЙцЗЂВМЁЂХфжУЙмРэЕШЛљДЁвЕЮёдЫЮЌзѓвЦЕНПЊЗЂЭХЖг
ЛљДЁЩшЪЉдЫЮЌВПЗжгввЦЃКЛљДЁМЦЫузЪдДгЩдЦШЋЭаЙмЃЌжБНгЪЙгУдЦЕФ Kubernetes
МЏШКЃЌИКдиОљКтЦїЃЌЪ§ОнПтЕШ
ПЊЗЂЭХЖгКЭдЫЮЌЭХЖгЗжРыЃКдЫЮЌЭХЖгИќЖрЕФЪЧжЦЖЈвЕЮёдЫЮЌЙцЗЖБъзМКЭСїГЬЃЌдкдЦЕФЛљДЁЩЯВуНјааИќИпВуДЮЕФЛљДЁЩшЪЉдЫЮЌЃЌШчжЦзївЕЮёМрПиЬхЯЕЃЌаХЯЂАВШЋЃЌШежОЯЕЭГЕШ
ећКЯЪН DevOps ЯЕЭГЃКжБНгЪЙгУ CODING ЬсЙЉЕФМЏУєНнЯюФПЙмРэЃЌВтЪдЙмРэЃЌДњТыЙмРэЃЌГжајМЏГЩЃЌжЦЦЗПтЃЌГжајВПЪ№ЮЊвЛЬхЕФ
SaaS ЗўЮё
МђЕЅЕФЮЂЗўЮёММЪѕМмЙЙЃКЮДв§ШыШч Istio ЕШИпМЖЮЂЗўЮёМмЙЙЃЈв§ШыЮЂЗўЮёМмЙЙЕФГжајВПЪ№ИњДЫЪОР§РрЫЦЃЌЕЋЯИНкЙ§ЖрЃЌВЛЪЪгкдкДЫЮФЯъЪіЃЉЃЌЪЙгУ
Docker ОЕЯё + Kubernetes
етжжФЃЪНПЩФмЪЧЪЪКЯФПЧАЙњФкДѓЖрЪ§ЭХЖгЕФЯжзДЕФФЃЪНЃЌОпБИЯрЕБЕФДњБэадЃЌИњДЫФЃЪНгаВювьЕФЭХЖгвВПЩвдЭЈЙ§ДЫФЃЪНРДЦЗЮЖБОЮФЕФ
DevOps ЫМПМЃЌШЅИФНјздЩэЕФЪЕМљЁЃ
ЧАЬсзМБИЃК
ЪЙгУЬкбЖдЦ TKE ДДНЈвЛИі Kubernetes МЏШКЃКhttps:
//cloud.tencent.com/document /product /457 / 11741
зМБИКУвЛЬзПЩвдЙЙНЈГі Docker ОЕЯёЕФдДДњТыЃЌВЂЬсЙЉЖдгІЕФ Kubernetes
Manifest ЮФМўЃЌЪОР§ДњТыПтЃКhttps://wzw-test.coding.net/p/demo-for-cd/d
/ demo-for - cd /git
ХфжУКУздЖЏЙЙНЈЙ§ГЬЃКhttps://help.coding.net/docs/devops/ci
/manual . html
БОЪОР§ДњТыБШНЯМђЕЅЃЌЮвжБНгЬљГіМИИіЖдгІЕФКЫаФЮФМўЃК
app.py
from flask
import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "<h1>ЛЖгЪЙгУ CODING CD!ЃЁ</h1>"
if __name__ == '__main__':
app.run(debug=True,host='0.0.0.0')
|
Dockerfile
FROM python:3.7
COPY . /app
COPY pip.conf /etc/
WORKDIR /app
RUN pip install -r requirements.txt
ENTRYPOINT ["python"]
CMD ["app.py"]
|
Jenkinsfile
pipeline {
agent any
environment {
ENTERPRISE = "wzw-test"
PROJECT = "demo-for-cd"
ARTIFACT = "demo-for-cd"
CODE_DEPOT = "demo-for-cd"
ARTIFACT_BASE = "${ENTERPRISE}-docker.pkg.coding.net"
ARTIFACT_IMAGE="${ARTIFACT_BASE}/${PROJECT}
/${ARTIFACT}/${CODE_DEPOT}"
}
stages {
stage('МьГі') {
steps {
checkout([$class: 'GitSCM', branches: [[name:
env.GIT_BUILD_REF]],
userRemoteConfigs: [[url: env.GIT_REPO_URL,
credentialsId: env.CREDENTIALS_ID]]])
}
}
stage('ДђАќОЕЯё') {
steps {
sh "docker build -t ${ARTIFACT_IMAGE}:
${env.GIT_BUILD_REF}
."
sh "docker tag ${ARTIFACT_IMAGE}:${env.GIT_BUILD_REF}
${ARTIFACT_IMAGE}:latest"
}
}
stage('ЭЦЫЭЕНжЦЦЗПт') {
steps {
script {
docker.withRegistry("https://${ARTIFACT_BASE}",
"${env.DOCKER_REGISTRY_CREDENTIALS_ID}")
{
docker.image("${ARTIFACT_IMAGE}:${env.GIT_BUILD_REF}")
.push()
}
}
}
}
}
}
|
deployment.yaml
apiVersion:
apps/v1
kind: Deployment
metadata:
labels:
app: demo-for-cd
name: demo-for-cd-deployment
spec:
replicas: 3
selector:
matchLabels:
app: demo-for-cd
template:
metadata:
labels:
app: demo-for-cd
spec:
containers:
- image: demo-for-cd-image
name: demo-for-cd
ports:
- containerPort: 5000
imagePullSecrets:
- name: coding-registry
|
service.yaml
apiVersion:
v1
kind: Service
metadata:
labels:
name: demo-for-cd-service
spec:
ports:
- name: http
port: 5000
protocol: TCP
selector:
app: demo-for-cd
type: LoadBalancer
|
дк CODING ЦНЬЈЪЕЯжМђЕЅЕФПЊЗЂгыдЫЮЌЕФЧаУц
CODING ЬсЙЉСЫЭХЖгКЭЯюФПСНИіВуУцЕФЛљгкНЧЩЋЕФШЈЯоПижЦПЩвдЗНБуЕФЪЕЯжВЛЭЌНЧЩЋЕФЧаУцаЇЙћЃК

ОпЬхРДНВПЩвддкЭХЖгГЩдБЙмРэКЭЯюФПГЩдБЙмРэНјааОпЬхНЧЩЋЕФЗжХфЁЃ
дкДЫЪОР§жаЮвУЧЕФЯюФПУћГЦНазі demo-for-cd, гІгУУћГЦНазі
flaskapp.
дЫЮЌНЧЩЋНјаадЄХфжУ
1.ХфжУдЦеЫКХЃЈШУ CODING ГжајВПЪ№Ињ Kubernetes
МЏШКДђЭЈЃЉ
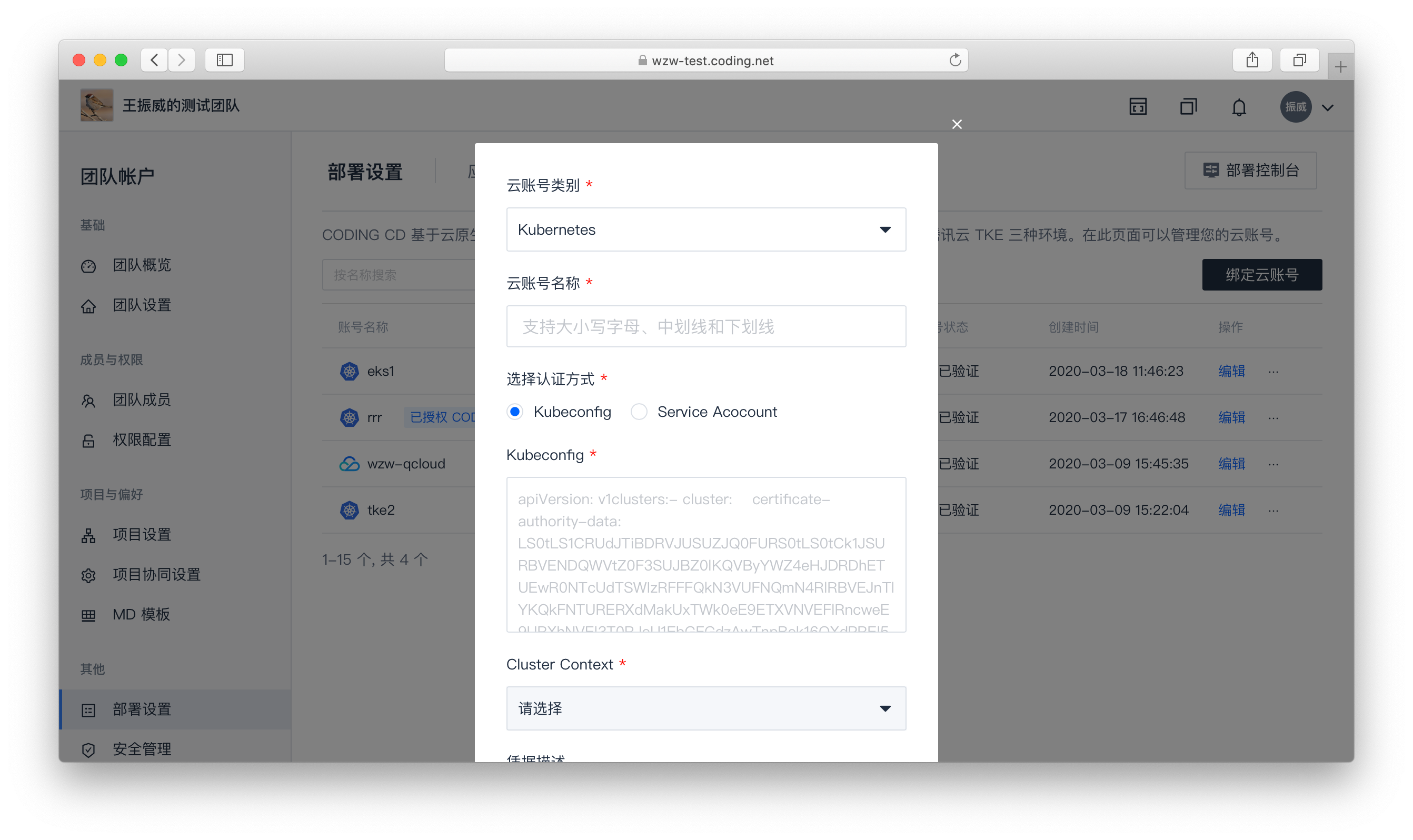
2.ДДНЈгІгУ flaskapp

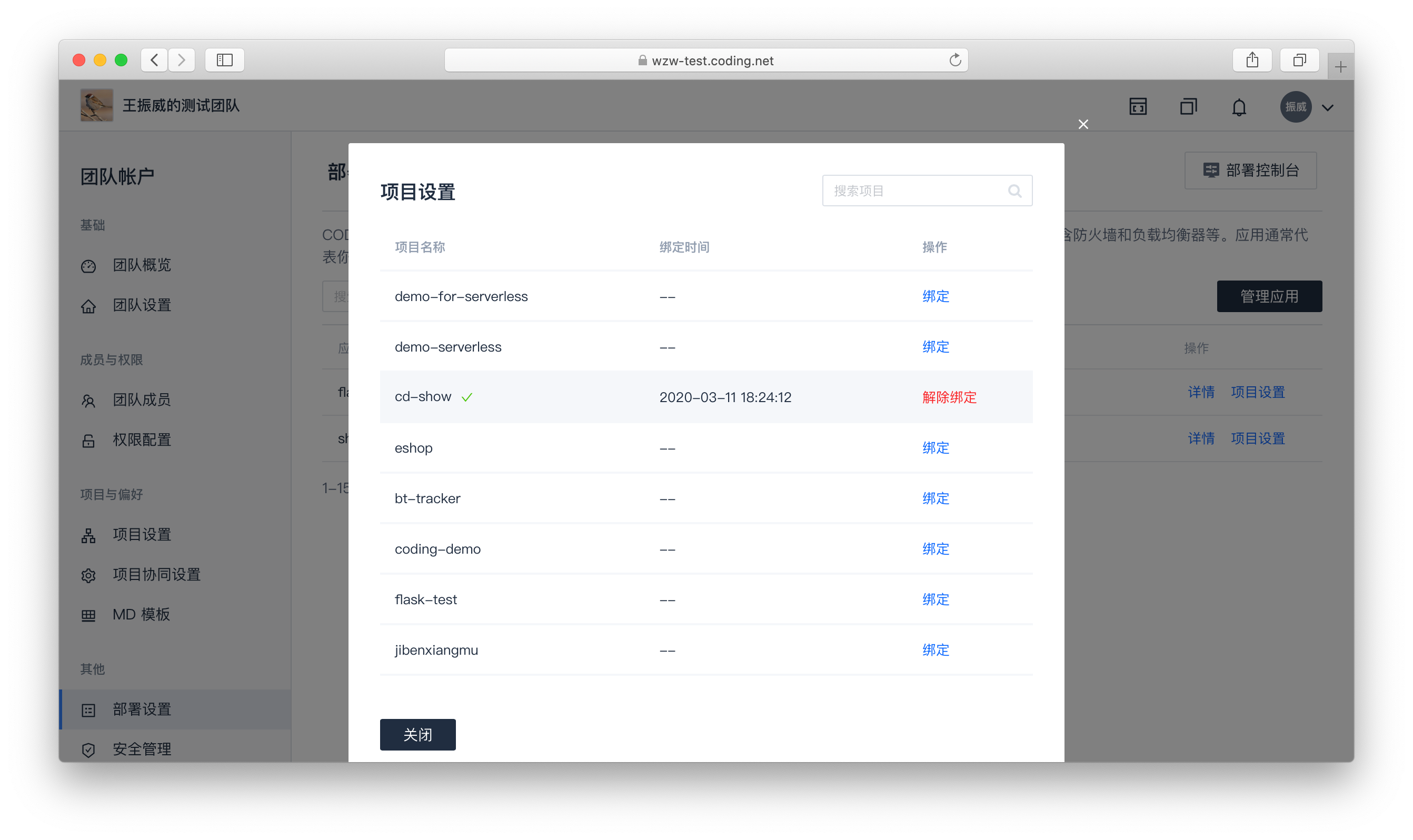
3.АбгІгУ flaskapp ИњЯюФП demo-for-cd ЙиСЊЃКЙиСЊКѓПЩвдРэНтЮЊетИігІгУЕФЯрЙиЗЂВМШЈЯоКЭХфжУЙмРэШЈЯоЯТЗХЕНЯюФПжаЃЌгГЩфЮвУЧЬсЕФЁАвЕЮёдЫЮЌзѓвЦЁБЫМЯы
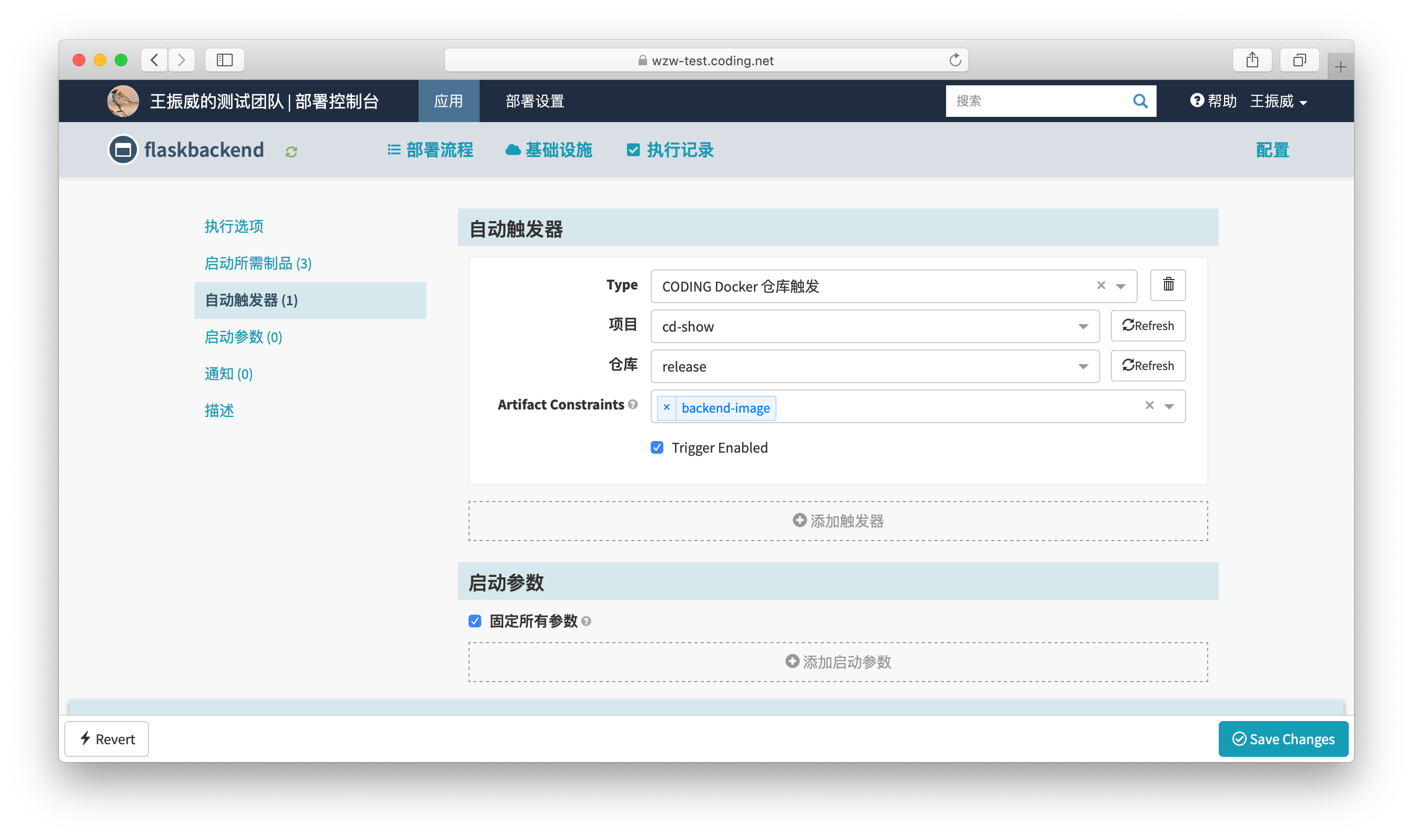
4.дкгІгУФкДДНЈВПЪ№СїГЬЃКгІгУИУдѕУДВПЪ№ЃЌдкЪВУДЬѕМўЯТВПЪ№ЃЌашвЊЪВУДзЪдДетаЉгЩдЫЮЌЭХЖгжЦЖЈЃЌгГЩфЮвУЧЬсЕФЁАНЛИЖЗЂВМЁБвЊБъзМЛЏЃЌСїГЬЛЏ

етРягаМИИіЯИНкашвЊзЂвтЃК
дЫЮЌдкХфжУВПЪ№СїГЬЕФЪБКђашвЊжЦЖЈСїГЬЦєЖЏЫљашжЦЦЗБъзМЃЈДЫДІгГЩфЮвУЧЬсЕФНЛИЖСїГЬЕФаХЯЂвЊНсЙЙЛЏЃЉЃЌЮвУЧЩљУїСЫЦєЖЏСїГЬашвЊШ§ИіжЦЦЗЗжБ№ЪЧ:
вЛИі Docker ОЕЯёЃЌвЛИі Deployment Manifest ЮФМўЃЌвЛИі Service
Manifest ЮФМўЁЃ

дЫЮЌПЩбЁХфжУШєИЩИіздЖЏДЅЗЂЦїРДздЖЏЦєЖЏетИіСїГЬЃЈДЫДІгГЩфЮвУЧЬсЕФНЛИЖСїГЬЕФаХЯЂдкНсЙЙЛЏЕФЛљДЁЩЯЪЕЯжздЖЏЛЏЃЉЃЌЮвУЧЩшжУСЫЕБ
Docker ОЕЯёПтГіЯжаТОЕЯёАцБОЪБздЖЏДЅЗЂДЫСїГЬЁЃ
ПЩвдИјВПЪ№СїГЬЬэМгЖюЭтЕФЭЈжЊЭЦЫЭгУвдИцжЊЯрЙиШЫдБЃЈДЫДІгГЩфЮвУЧЬсЕФаХЯЂСїзЊвЊОЋзМЃЌЧјЗжжїНгЪеШЫКЭГЫЭЖЉдФЃЉЃЌетРяПЩвдАбЗЂВМЪТМўаХЯЂЭЌВНЕНВњЦЗОРэЁЂЯюФПОРэЕШ
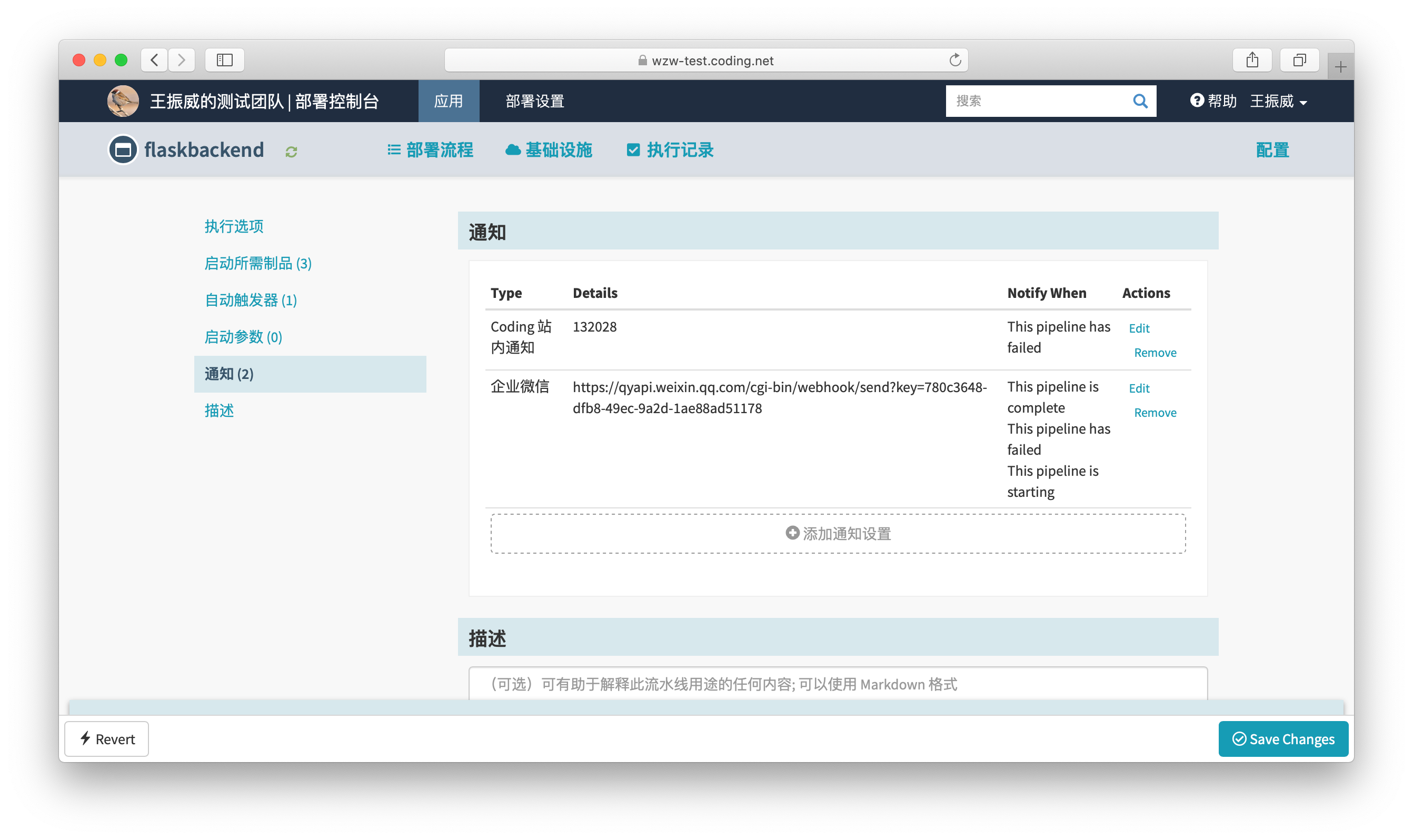
МИИізюМбЪЕМљЬсЪОЃК
ОЁСПзіЕНАцБОЛЏЙмРэвЛЧазЪдДЃКАцБОЛЏЙмРэ Kubernetes ХфжУЮФМўЃЌЙмРэШнЦїОЕЯёЃЌЙмРэВПЪ№СїГЬХфжУЕШЕШЃЌетбљгажњгкПьЫйЕФджФбЛжИДЃЌЮЪЬтзЗЫнЕШЃЌетаЉФмСІ
CODING ЖМвбЬсЙЉЃЌПЩвдКмЗНБуЕФЪЕЯжЁЃ
ПЩдкСїГЬжаВхШы Kubernetes JobЃЌЪЙгУ run job
РДДІРэЗЂВМЙ§ГЬжаЕФжюШчЪ§ОнПтБэНсЙЙИќаТЃЌЪ§ОнЧЈвЦЃЌОВЬЌзЪдДдЄБрвыЕШЙ§ГЬ
ЪЙгУ Kubernetes ConfigMap РДЙмРэХфжУЯюКЭХфжУЮФМўЃЌетбљЫљгаЕФПЩНЛИЖжЦЦЗРраЭОЭБЛЯожЦЮЊ
Docker ОЕЯёКЭ Kubernetes ManifestЃЌБугкЙмПи
ПЩбЁЪЙгУЖРСЂ Git ВжПтРДЙмРэ Kubernetes ЮФМўЃЌжївЊгЩдЫЮЌЭХЖгРДЙмРэЃЌНгЪмПЊЗЂЭХЖгЕФКЯВЂЧыЧѓЃЈПЩздгЩОіЖЈХфжУЙмРэЪЧЗёзѓвЦжСПЊЗЂЭХЖгЃЉ
ПЊЗЂНЧЩЋЭъГЩПЊЗЂКЭЗЂВМ
дкдЫЮЌНјааЭъЩЯЪіХфжУКѓЃЌПЊЗЂШЫдБОЭПЩвддкЯюФПРяЖРСЂНјааЗЂВМВйзїСЫЃЈгГЩфЮвУЧЬсЕФвЕЮёдЫЮЌзѓвЦжСПЊЗЂЭХЖгЃЉЁЃ
ПЊЗЂЭХЖгдкШЗШЯаТАцБОЕФШ§ИіжЦЦЗЃЈвЛИі Docker ОЕЯёЃЌСНИі Kubernetes
Yaml ЮФМўЃЉзМБИКУКѓжБНгПЩвдаТНЈЗЂВМЕЅРДжДааЗЂВМЃЌвђЪТЯШдЄХфжУКУСЫСїГЬБъзМЃЌетРяПЊЗЂЮоашИњдЫЮЌЭХЖгНјааЕЭаЇЕФЮовтвхЕФЦфЫћаЮЪНЕФЙЕЭЈЃЌжБНгбЁЖЈШ§ИізЪдДЕФАцБОМДПЩжДааЗЂВМЁЃ
ПЊЗЂвВПЩвдЭЈЙ§ЩЯгЮЕФДњТыВжПтЁЂГжајМЏГЩКЭжЦЦЗПтЕФХфКЯЭъГЩШЋздЖЏЛЏЗЂВМЃЌЪЕЯжЗжжгМЖздЖЏЩЯЯпЁЃ
ЦфЫћГЁОАЕФГжајВПЪ№
ГжајВПЪ№ЪЧ DevOps ЕФЙиМќЛЗНкЃЌИњ DevOps вЛбљгыЭХЖгЕФдЫЮЌзѓвЦгввЦГЬЖШЃЌММЪѕМмЙЙЕШгаКмДѓЙиЯЕЃЌУЛгаФФИіГжајВПЪ№ЙЄОпЯЕЭГЪЧПЩвдКИЧЫљгаЕФГЁОАЕФЁЃCODING
ГжајВПЪ№ЯЃЭћФмКИЧДѓЖрЪ§НЯаТЕФММЪѕЬхЯЕЃЌвдМАгЕБЇдЦдЩњЕФВПЪ№ГЁОАЁЃетРяИјГіМИЕуЙигкЦфЫћГЃМћЕФГжајВПЪ№ЕФзіЗЈЬсЪОЃК
Ansible + БЄРнЛњГЁОАЃКетРрГжајВПЪ№ЕФКЫаФдкгк Ansible
ЕФ Playbook ЕФзЋаДжЪСПЃЌПЩвдбЁдёжБНгНгШы CI ЃЈШч CODING ГжајМЏГЩЁЂJenkinsЃЉЬхЯЕЪЙгУЃЌЪЕЯжПьЫйВПЪ№ЁЃ
дЦжїЛњЕФЕЏадЩьЫѕзщЃКCODING ГжајВПЪ№жЇГжЛљгкдЦжїЛњОЕЯёХфКЯЕЏадЩьЫѕзщЕФФЃЪННјааЗЂВМЃЌДЫФЃЪННЯжиЃЌПЩвдИљОнздМКЪЕМЪЧщПіНјаабЁдёЁЃ
scp/sftpЃЌGit/SVNЃКНЈвщОЁПьЩ§МЖжСШнЦїЕШаЮЬЌЕФЗНЪНЗЂВМЃЌдкЮДЩ§МЖЧАвВПЩвдПМТЧжБНгЧЖШыЕН
CI жажДааЁЃ
Serverless ГЁОАЃКетжжЪєгкЛљДЁЩшЪЉгввЦЗЧГЃГЙЕзЕФРраЭЃЌДѓЖрЪ§ЧщПіЯТВЛашвЊв§ШыЖРСЂЕФГжајВПЪ№ЙЄОпЬхЯЕЃЌПЩвдПМТЧжБНгдк
CI ЩѕжСгк IDE ПЊЗЂНзЖЮЪЙгУВхМўЕШЛњжЦЬэМгВПЪ№ФмСІЃЌЮоашНјааЙ§ЖШИДдгЕФЩшжУЁЃCODING ГжајВПЪ№ВЛХХГ§ЮДРДЛсеыЖд
Serverless ВПЪ№ГЁОАЬэМгИќЖрЕФЦфЫћЗНУцФмСІЃЌШчЩѓХњЃЌЭЈжЊЕШЃЌвджЇГжИќАВШЋЮШЖЈЕФЗЂВМааЮЊЙмПиЁЃ
зюКѓЕФзмНсЃКИУЗжЛЙЪЧИУКЯЃП
ПДЕНетРяЃЌЮвЯраХФувбОФмЙЛАбЮезЁ DevOps ЕФМИИіЪЕМљЕФКЫаФвЊЫиЃЌDevOps
ВЛЪЧЗЧКкМДАзЕФЃЌжЛвЊгаПЊЗЂКЭдЫЮЌЕФЭХЖгздЪМжСжеЖМвЛжБдкЪЕМљзХ DevOpsЃЌжЛЪЧаЇЙћгаКУЛЕЃЌЫЎЦНгаИпЕЭЁЃвЕЮёЬхЯЕЁЂЭХЖгХфжУЁЂММЪѕМмЙЙЁЂЙЄОпЯЕЭГЖМгаВювьЃЌЭбРыетаЉЛљБОЯжЪЕШЅКАПкКХЃЌСФМлжЕЪЧЮовтвхЕФЁЃФуЕФ
DevOps ЭХЖгвЊЗжЛЙЪЧвЊКЯЃЌЗжКЯЕНЪВУДГЬЖШЃЌЧыРфОВЫМПМЮФжаЬсЕНЕФМИИіКЯЁЃ |






