| һ������Linux����ϵͳ�ķ��������е�ͬʱ��Ҳ����������ָ���������Ϣ��ͨ����˵��ά��Ա��ϵͳ����Ա�����Щ���ݻἫΪ���У�������Щ�������ڿ�������˵Ҳʮ����Ҫ�����䵱��ij��������������ʱ����Щ��˿����������������ٶ�λ�������⡣
����ֻ��һЩ�Ĺ��߲鿴ϵͳ����ز�������Ȼ�ܶ��Ҳ��ͨ�������ӹ�/proc��/sys�µ������������ģ�����Щ����ϸ�¡�רҵ�����ܼ��͵��ţ����ܻ���Ҫ����רҵ�Ĺ���(perf��systemtap��)�ͼ����������Ŷ���Ͼ���˵��ϵͳ���ܼ�ر������Ǹ���ѧ�ʡ�
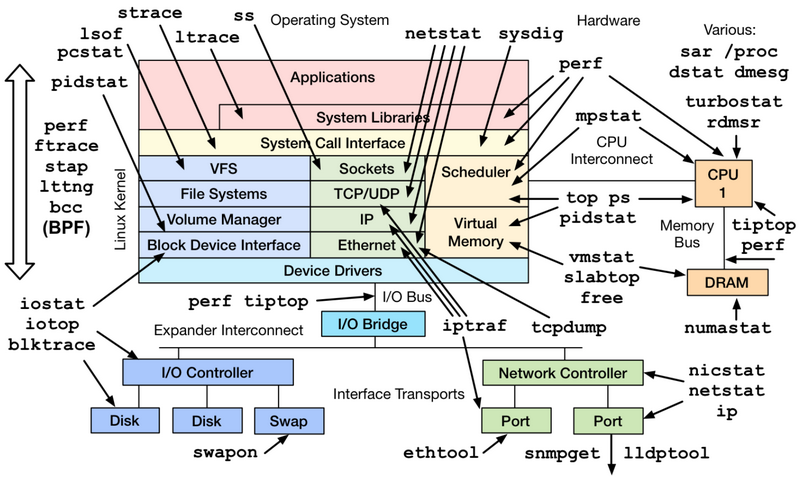
һ��CPU���ڴ���
1.1 top
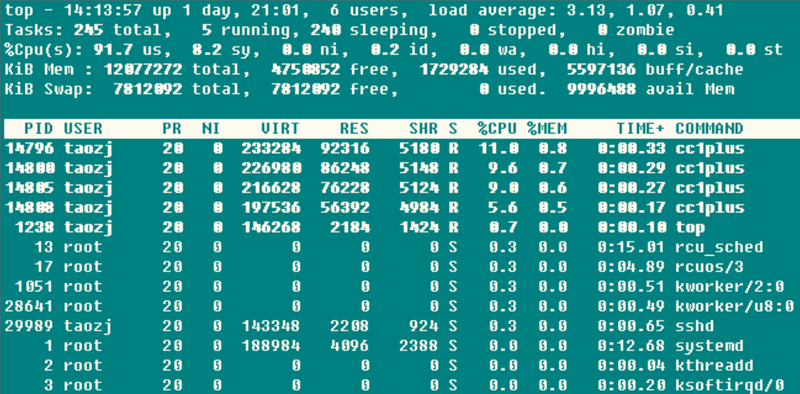
��һ�к��������ֵ��ϵͳ��֮ǰ1��5��15��ƽ�����أ�Ҳ���Կ���ϵͳ������������ƽ�ȡ��½������ƣ������ֵ����CPU��ִ�е�Ԫ����Ŀ�����ʾCPU�������Ѿ����ͳ�Ϊƿ���ˡ�
�ڶ���ͳ����ϵͳ������״̬��Ϣ��running����Ȼ���ض�˵����������CPU�����еĺͽ�Ҫ���������еģ�sleepingͨ���ǵȴ��¼�(����IO����)��ɵ�����ϸ�ֿ�����interruptible��uninterruptible�����ͣ�stopped��һЩ����ͣ������ͨ������SIGSTOP���߶�һ��ǰ̨�������Ctrl-Z���Խ�����ͣ��zombie��ʬ������Ȼ������ֹ��Դ�ᱻ�Զ����գ����Ǻ����˳������task
descriptor��Ҫ�����̷��ʺ�����ͷţ����ֽ�����ʾΪdefunct״̬����������Ϊ��������ǰ�˳�����δwait���ã��������ֽ��̶�Ӧ�ø���ע������Ƿ��������
������CPUռ���ʸ������������¼��������
(us) user: CPU�ڵ�niceֵ(�����ȼ�)�û�̬��ռ�õ�ʱ��(nice<=0)�����������ֻҪ���������Ǻ��У���ô�ֵ�CPUʱ��Ӧ�ö��ڴ�ִ���������
(sy) system: CPU�����ں�̬��ռ�õ�ʱ�䣬����ϵͳͨ��ϵͳ����(system call)���û�̬�����ں�̬����ִ���ض��ķ���ͨ������¸�ֵ��Ƚ�С�����ǵ�������ִ�е�IO�Ƚ��ܼ���ʱ��ֵ��Ƚϴ�
(ni) nice: CPU�ڸ�niceֵ(�����ȼ�)�û�̬�Ե����ȼ�����ռ�õ�ʱ��(nice>0)��Ĭ���������Ľ���nice=0���Dz����������ģ������ֶ�ͨ��renice����setpriority()�ķ�ʽ�ij����niceֵ
(id) idle: CPU�ڿ���״̬(ִ��kernel idle handler)��ռ�õ�ʱ��
(wa) iowait: �ȴ�IO�����ռ�õ�ʱ��
(hi) irq: ϵͳ����Ӳ���ж������ĵ�ʱ��
(si) softirq: ϵͳ�������ж������ĵ�ʱ�䣬��ס���жϷ�Ϊsoftirqs��tasklets(��ʵ��ǰ�ߵ�����)��work
queues����֪��������ͳ�Ƶ�����Щ��ʱ�䣬�Ͼ�work queues��ִ���Ѿ������ж���������
(st) steal: �����������²������壬��Ϊ�������CPUҲ�ǹ�������CPU�ģ��������ʱ�����������ȴ�hypervisor����CPU��ʱ�䣬Ҳ��ζ�����ʱ��hypervisor��CPU���ȸ����CPUִ�У����ʱ�ε�CPU��Դ����stolen���ˡ����ֵ����KVM��VPS�������Dz�Ϊ0�ģ���Ҳֻ��0.1������������Dz��ǿ��������ж�VPS���۵������
CPUռ���ʸߺܶ��������ζ��һЩ��������Ҳ��������CPUʹ���ʹ��������ָ������Ӧ���Ų�˼·��
(a) ��userռ���ʹ��ߵ�ʱ��ͨ����ijЩ����Ľ���ռ���˴�����CPU����ʱ�������ͨ��top�ҵ��ó���ʱ������ɳ����쳣������ͨ��perf��˼·�ҳ��ȵ���ú�������һ���Ų飻
(b) ��systemռ���ʹ��ߵ�ʱ�����IO����(�����ն�IO)�Ƚ϶࣬���ܻ�����ⲿ�ֵ�CPUռ���ʸߣ�������file
server��database server�����͵ķ������ϣ�����(����>20%)�ܿ�����Щ���ֵ��ںˡ�����ģ�������⣻
(c) ��niceռ���ʹ��ߵ�ʱ��ͨ����������Ϊ�������̵ķ�����֪��ijЩ����ռ�ýϸߵ�CPU����������niceֵȷ��������û�������̶�CPU��ʹ������
(d) ��iowaitռ���ʹ��ߵ�ʱ��ͨ����ζ��ijЩ�����IO����Ч�ʺܵͣ�����IO��Ӧ�豸�����ܺܵ������ڶ�д������Ҫ�ܳ���ʱ������ɣ�
(e) ��irq/softirqռ���ʹ��ߵ�ʱ�ܿ���ijЩ����������⣬���²���������irq������ʱ��ͨ�����/proc/interrupts�ļ�����������ڣ�
(f) ��stealռ���ʹ��ߵ�ʱ���ij�������������˰ɣ�
�����к͵������������ڴ�������ڴ�(��������)����Ϣ:
total = free + used + buff/cache������buffers��cached Mem��Ϣ�ܺ͵�һ���ˣ�����buffers��cached
Mem�Ĺ�ϵ�ܶ�ط���û˵�������ʵͨ���Ա����ݣ�������ֵ����/proc/meminfo�е�Buffers��Cached�ֶΣ�Buffers�����raw
disk�Ŀ黺�棬��Ҫ����raw block�ķ�ʽ�����ļ�ϵͳ��Ԫ����(���糬������Ϣ��)�����ֵһ��Ƚ�С(20M����)����Cached�������ijЩ������ļ����ж����棬�������ļ��ķ���Ч�ʶ�ʹ�õģ�����˵�������ļ�ϵͳ���ļ�����ʹ�á�
��avail Mem��һ���µIJ���ֵ������ָʾ�ڲ����н���������£����Ը��¿����ij�������ڴ�ռ䣬���º�free
+ buff/cached�൱������Ҳӡ֤�������˵����free + buffers + cached
Mem�����������õ������ڴ档���ң�ʹ�ý��������������ǻ����飬���Խ�������ʹ���ʲ���ʲô���صIJ���������Ƶ����swap
in/out�Ͳ��Ǻ������ˣ����������Ҫע�⣬ͨ����ʾ�����ڴ��ȱ�������
�����ÿ���������Դռ���б�������CPU��ʹ����������CPU coreռ���ʵ��ܺ͡�ͨ��ִ��top��ʱ�����ó��������Ķ�ȡ/proc���������Ի�����top������Ҳ��������ǰé�ġ�
top��Ȼ�dz�ǿ����ͨ�����ڿ���̨ʵʱ���ϵͳ��Ϣ�����ʺϳ�ʱ��(���졢������)���ϵͳ�ĸ�����Ϣ��ͬʱ���ڶ����Ľ���Ҳ����©������ͳ����Ϣ��
1.2 vmstat
vmstat�dz�top֮����һ�����õ�ϵͳ���ߣ������ͼ������-j4����boost��ϵͳ���ء�
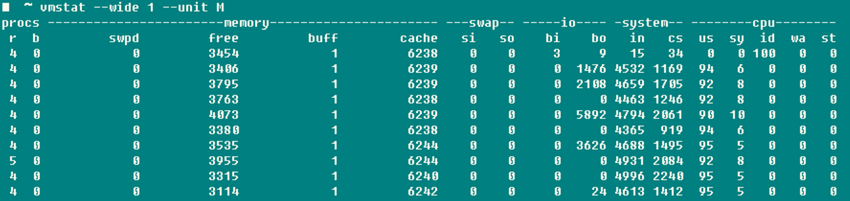
r��ʾ�����н�����Ŀ�����ݴ����������b��ʾ����uninterruptible˯�ߵĽ�����Ŀ��swpd��ʾʹ�õ��������ڴ���������top-Swap-used����ֵ��һ�����壬�����ֲ���˵��ͨ�������buffers��ĿҪ��cached
MemС�Ķ࣬buffersһ��20M��ô����������io���bi��bo����ÿ��������̽��պͷ��͵Ŀ���Ŀ(blocks/s)��system���in����ÿ���ӵ�ϵͳ�ж���(����ʱ���ж�)��cs������Ϊ�����л������������л�����Ŀ��
˵������뵽��ǰ�ܶ��˾������linux kernel��ʱ��-j����������CPU Core����CPU
Core+1��ͨ��������-j����ֵ����boost��linux kernel��ͬʱ����vmstat��أ��������������context
switch����û�б仯����Ҳֻ����������-jֵ��context switch�Ż������������ӣ��������ع��ھ�����������ˣ���Ȼ�������ʱ�䳤���һ�û�в��ԡ�����˵���������ϵͳ��������benchmark��״̬������context
switch>100000����϶������⡣
1.3 pidstat
������ij�����̽���ȫ�������٣�û��ʲô��pidstat�����ʵ��ˡ���ջ�ռ䡢ȱҳ������������л�����Ϣ�����۵ס�������������õIJ�����-t�����Խ������и����̵߳���ϸ��Ϣ���г�����
-r�� ��ʾȱҳ������ڴ�ʹ��״����ȱҳ�����dz�����Ҫ����ӳ���������ڴ�ռ��е��ǻ���δ�����ص������ڴ��е�һ����ҳ��ȱҳ����������Ҫ������
(a). minflt/s ָ��minor faults������Ҫ���ʵ�����ҳ����ΪijЩԭ��(���繲��ҳ�桢������Ƶ�)�Ѿ������������ڴ����ˣ�ֻ���ڵ�ǰ���̵�ҳ����û�����ã�MMUֻ��Ҫ���ö�Ӧ��entry�Ϳ����ˣ�����������൱С��
(b). majflt/s ָ��major faults��MMU��Ҫ�ڵ�ǰ���������ڴ�������һ����е�����ҳ��(���û�п��õĿ���ҳ�棬����Ҫ���������ҳ���л��������ռ�ȥ���ͷŵõ���������ҳ��)��Ȼ����ⲿ�������ݵ�������ҳ���У������úö�Ӧ��entry������������൱�ߵģ���ǰ���м������ݼ��IJ���
-s��ջʹ��״��������StkSizeΪ�̱߳�����ջ�ռ䣬�Լ�StkRefʵ��ʹ�õ�ջ�ռ䡣ʹ��ulimit
-s����CentOS 6.x����Ĭ��ջ�ռ���10240K����CentOS 7.x��Ubuntuϵ��Ĭ��ջ�ռ��СΪ8196K
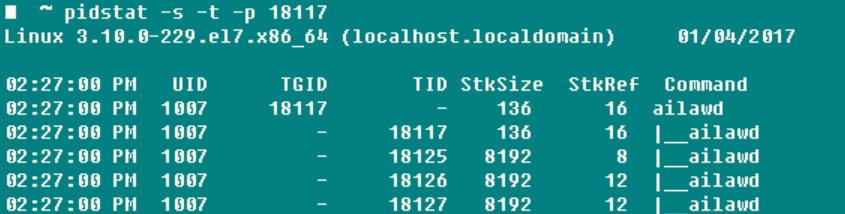
-u��CPUʹ�������������ͬǰ������
-w���߳��������л�����Ŀ����ϸ��Ϊcswch/s��Ϊ�ȴ���Դ�����ص��µ������л����Լ�nvcswch/s�߳�CPUʱ�䵼�µı����л���ͳ��
���ÿ�ζ���ps�õ������pid���ٲ���pidstat���Եú��鷳���������ɱ��ﵵ�-C����ָ��ij���ַ�����Ȼ��Command�������������ַ�������ô�ó������Ϣ�ͻᱻ��ӡͳ�Ƴ�����-l������ʾ�����ij������Ͳ���
~ pidstat -w -t -C ��ailaw�� -l |
��ô����������鿴���������Ƕ��̵߳�����ʱ��pidstat�ȳ��õ�ps����ʹ��
1.4 ����
����Ҫ������ⵥ��CPU�����ʱ����htop������ʹ��mpstat���鿴��SMP�������ϸ���Core�Ĺ������Ƿ��ؾ��⣬�Ƿ���ijЩ�ȵ��߳�ռ��Core��
�����ֱ�Ӽ��ij������ռ�õ���Դ���ȿ���ʹ��top -u taozj�ķ�ʽ���˵������û��ؽ��̣�Ҳ���Բ�������ķ�ʽ����ѡ��ps��������Զ�����Ҫ��ӡ����Ŀ��Ϣ��
while :; do ps -eo user,pid,ni,pri,pcpu,psr,comm | grep 'ailawd'; sleep 1; done |
��������̳й�ϵ������һ�����õIJ�������������ʾ�������ṹ����ʾЧ����pstree��ϸ���۵Ķ�
��������IO��
iotop����ֱ�۵���ʾ�������̡��̵߳Ĵ��̶�ȡʵʱ���ʣ�lsof����������ʾ��ͨ�ļ��Ĵ���Ϣ(ʹ����)�������Բ���/dev/sda1�����豸�ļ��Ĵ���Ϣ����ô���統������umount��ʱ�Ϳ���ͨ��lsof�ҳ����̸÷�����ʹ��״̬�ˣ���������+fg���������Զ�����ʾ�ļ���flag��ǡ�
2.1 iostat
��ʵ����ʹ��iostat -xz 1����ʹ��sar -d 1�����ڴ�����Ҫ�IJ����ǣ�
avgqu-sz: �����豸I/O����ĵȴ�����ƽ�����ȣ����ڵ����������ֵ>1�����豸���ͣ����ڶ���������е�������������⣻
await(r_await��w_await): ƽ��ÿ���豸I/O��������ĵȴ�ʱ��(ms)���������������ڶ����кͱ������ʱ��֮�ͣ�
svctm: �����豸I/O�����ƽ������ʱ��(ms)�����svctm��await�ܽӽ�����ʾ����û��I/O�ȴ����������ܺܺã�������̶��еȴ�ʱ��ϳ���������Ӧ�ϲ
%util: �豸��ʹ���ʣ�����ÿ��������I/O����ʱ���ռ�ȣ��������̵�%util>60%��ʱ�����ܾͻ��½�(������awaitҲ������)�����ӽ�100%ʱ����豸�����ˣ��������ж���������е�������������⣻
���У���Ȼ���Ĵ������ܱȽϲ���Dz�һ�����Ӧ�ó������Ӧ���Ӱ�죬�ں�ͨ��ʹ��I/O asynchronously������ʹ�ö�д���漼�����������ܣ��������ָ�����������ڴ����������Լ�ˡ�
�������Щ�������������ļ�ϵͳҲ�����õġ�
����������
�������ܶ��ڷ���������Ҫ�Բ��Զ���������iptraf����ֱ�۵���ʵ�������շ��ٶ���Ϣ���Ƚϵļ���ͨ��sar
-n DEV 1Ҳ���Եõ����Ƶ���������Ϣ�������������������������Ϣ�������������ǧ�������������ײ鿴�豸�������ʡ�
ͨ���������Ĵ������ʲ��������翪������Ϊ���еģ���������ض���UDP��TCP���ӵĶ����ʡ��ش��ʣ��Լ�������ʱ����Ϣ��
3.1 netstat
��ʾ�Դ�ϵͳ��������������Э�������������Ϣ����Ȼ������Ϣ�ȽϷḻ���ã������ۼ�ֵ��������������������ܵó���ǰϵͳ������״̬��Ϣ�������ʹ��watch�۾�ֱ������ֵ�仯���ơ�����netstatͨ���������˿ں�������Ϣ�ģ�
netstat �Call(a) �Cnumeric(n) �Ctcp(t) �Cudp(u) �Ctimers(o) �Clistening(l) �Cprogram(p) |
�Ctimers����ȡ�����������ѯ���ӿ���ʾ�ٶȣ��Ƚϳ��õ���
~ netstat -antp #�����TCP������
~ netstat -nltp #�г���������TCP�������֣���Ҫ��-a���� |
3.2 sar
sar�������̫ǿ���ˣ�ʲôCPU�����̡�ҳ�潻��ɶ���ܣ�����ʹ��-n��Ҫ����������������Ȼ������������ϸ����NFS��IP��ICMP��SOCK�ȸ��ֲ�θ���Э���������Ϣ������ֻ����TCP��UDP����������������ʾ��������¶Ρ����ݱ����շ������������
TCP
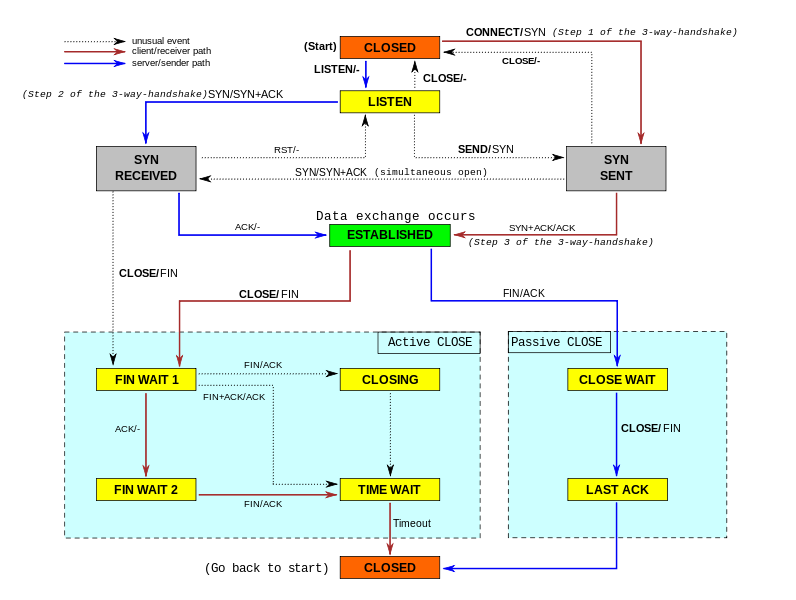
active/s�����ط����TCP���ӣ�����ͨ��connect()��TCP��״̬��CLOSED ->
SYN-SENT
passive/s����Զ�̷����TCP���ӣ�����ͨ��accept()��TCP��״̬��LISTEN ->
SYN-RCVD
retrans/s(tcpRetransSegs)��ÿ����TCP�ش���Ŀ��ͨ����������������߷��������غ�������£�����TCP��ȷ���ش����ƻᷢ���ش�����
isegerr/s(tcpInErrs)��ÿ���ӽ��յ����������ݰ�(����checksumʧ��)
UDP
noport/s(udpNoPorts)��ÿ���ӽ��յ��ĵ���ȴû��Ӧ�ó�����ָ��Ŀ�Ķ˿ڵ����ݱ�����
idgmerr/s(udpInErrors)����������ԭ��֮��ı������յ���ȴ���ɷ������ݱ�����
��Ȼ����Щ����һ���̶��Ͽ���˵������ɿ��ԣ���Ҳֻ��ͬ�����ҵ��������������ž������塣
3.3 tcpdump
tcpdump���ò�˵�Ǹ��ö�������Ҷ�֪�����ص��Ե�ʱ��ϲ��ʹ��wireshark���������Ϸ���˳���������ôŪ�أ���¼�IJο���������˼·����ԭ������ʹ��tcpdump����ץ���������⸴��(������־��ʾ����ij��״̬����)��ʱ�Ϳ��Խ���ץ���ˣ�����tcpdump��������-C/-W��������������ץȡ���洢�ļ��Ĵ�С�����ﵽ���������Ƶ�ʱ��İ������Զ�rotate������ץ���������廹�ǿɿصġ��˺����ݰ�������������wireshark����ô������ô���������գ�tcpdump��Ȼû��GUI���棬����ץ���Ĺ���˿������������ָ���������������˿ڡ�Э��ȸ�����˲�����ץ�����İ������ִ���ʱ������������ϳ�������ݰ�����Ҳ������ô��
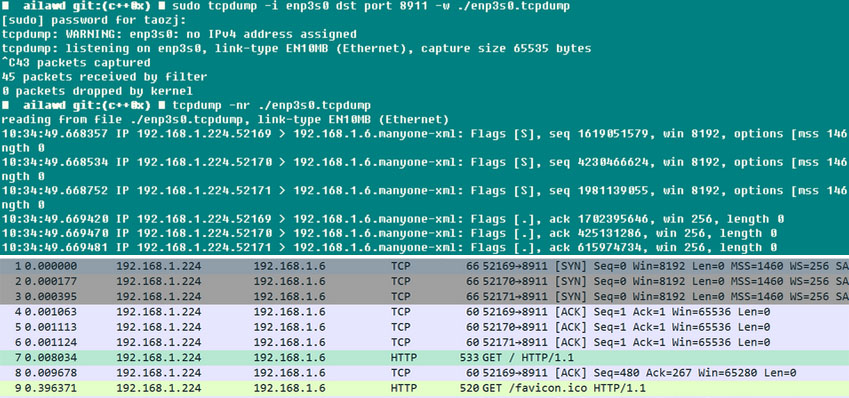
�������һ��С�IJ��ԣ��ɼ�Chrome����ʱ���Զ���Webserver���������������ӣ���������������dst
port���������Է���˵�Ӧ��������˵��ˣ���������wireshark��SYNC��ACK�������ӵĹ��̻��Ǻ����Եģ���ʹ��tcpdump��ʱ����Ҫ�����ܵ�����ץȡ�Ĺ���������һ������ڽ������ķ���������tcpdump�������������ϵͳ�����ܻ���Ӱ�죬������Ӱ�쵽����ҵ������ܡ�
�����꣡ |





