| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌНщЩмСЫGPUБрГЬФЃаЭЃЌгВМўЯрЙиЕФБГОАЃЌШэМўЕФПђМмЃЌGPUЕФФкДцФЃаЭЕШЁЃ |
|
GPUМђНщ
GPUЃЈgraphical processing unitЃЉЪЧЯдПЈФкгУгкЭМаЮДІРэЕФЦїМўЁЃКЭCPUЯрБШЃЌCPUЪЧДЎаажДааЃЌЖјGPUЪЧЖрИіКЫВЂаажДааЁЃGPUЪЧвЛИіИпадФмЕФЖрКЫДІРэЦїЃЌгаКмИпЕФМЦЫуЫйЖШКЭЪ§ОнЭЬЭТТЪЁЃдкGPUЩЯЕФдЫЫуФмЛёЕУЯрЖдгкCPUЖјбдКмИпЕФМгЫйБШЁЃЕквЛЁЂЕкЖўДњGPUГіЯжЕФЪБКђЃЌGPUВЛЪЧПЩБрГЬЕФ[4]ЁЃЕБЕкШ§ДњGPUГіЯжЕФЪБКђЃЌGPUПЊЪМгУгкЭМаЮБрГЬЃЌбаОПепУЧИјGPUЩежЦГЬађЃЌНјааЭМЯёДІРэЁЃGPUЕФВЂааСїДІРэФмСІЮќв§СЫВЂааМЦЫуЕФбаОПепЃЌбаОПепУЧНшжњЭМаЮБрГЬЕФИХФюЃЌАбМЦЫуВйзїзЊЛЏГЩЭМаЮЮЦРэВйзїЁЃетИіЪБКђGPUМЦЫуЃЌашвЊЖдЭМаЮИХФюгаБШНЯЩюЕФСЫНтЃЌБрГЬБШНЯИДдгЁЃЕкЫФДњGPUвдNVIDIAЕФGeForceЯЕСаЯдПЈЮЊДњБэЃЌПЊЪМЬсЙЉзЈУХгУгкЭЈгУМЦЫуЕФММЪѕЃЌВЂЧвГіЯжСЫCUDA[17]ЁЂopenCL[6]ЕШЛљгкcгябдЕФЭЈгУБрГЬгябдЁЃGPUгУгкВЂааМЦЫуЕФММЪѕГЦЮЊGPGPUЃЈgeneral
purpose GPUЃЉ[4]ЁЃGPGPUЩцМАЕФЗЖЮЇКмЙуЃЌАќРЈСЫМИКЮМЦЫуЁЂЕААзжЪФЃФтЁЂгХЛЏМЦЫуЁЂЦЋЮЂЗжЗНГЬЕШЁЃ
ФПЧАЕФЯдПЈЪаГЁЃЌжївЊгаСНМвЙЋЫОЕФВњЦЗЃЌвЛИіЪЧNVIDIAЯдПЈЃЌСэвЛИіЪЧATIЯдПЈЁЃЭЈгУМЦЫугябдгаСНИіБъзМЃЌЕквЛИіЪЧNVIDIAЙЋЫОЕФCUDAММЪѕЃЌСэвЛИіЪЧгЩappleЙЋЫОЬсГіЁЂЖрМвЙЋЫОЙВЭЌПЊЗЂЕФПЊЗХБъзМopenCLЁЃCUDAММЪѕЪЧNVIDIAЙЋЫОЕФЫНгаБъзМЁЃгЩгкNVIDIAЙЋЫОзюЯШГЂЪдGPUЭЈгУМЦЫуЃЌЦфбаЗЂЕФгУгкЭЈгУМЦЫуЕФЯдПЈКЭгУгкЭЈгУМЦЫуЕФБрГЬгябдCUDAзюдчГіЯждкЪаГЁЩЯЁЃвђДЫЃЌCUDAММЪѕЯрЖдгкЦфЫћЕФММЪѕЖјбдЃЌгЕгаКмЧПЕФгХЪЦЃЌЙигкCUDAММЪѕЕФзЪСЯКЭЬжТлвВБШНЯЖрЁЃЖјopenCLЪЧвЛИіПЊЗХБъзМЃЌЖрМвЙЋЫОЕФВњЦЗЖМжЇГжИУБъзМЃЌАќРЈNVIDIAЯдПЈЃЌЛЙгаATIЯдПЈЕФstreamММЪѕвВжЇГжИУБъзМЁЃгЩгкopenCLПЊЗЂЕФБШНЯЭэЃЌдкЦфПЊЗЂЪБЃЌCUDAММЪѕвбОКмГЩЪьСЫЃЌвђДЫopenCLдкКмЖрИХФюЩЯНшМјСЫCUDAММЪѕЁЃ
GPUгВМўМмЙЙ
дкGPUБрГЬЕФгВМўНсЙЙжаЃЌећЬхЩшБИБЛЗжЮЊСНИіВПЗжЁЃЕквЛИіВПЗжЪЧПижЦЩшБИЃЌГЦЮЊHostЃЈжїЛњЃЉЁЃЕкЖўВПЗжЪЧМЦЫуЩшБИЃЌГЦЮЊdeviceЁЃ
Host ИКд№ЙмРэGPUЕФдЫааЃЌвдМАзЪдДЕФЗжХфЙмРэЁЃзМШЗЕФЫЕЃЌбаОПепЪЧЭЈЙ§КЭHostНЛСїЃЌРДПижЦGPUЁЃHostЭЈЙ§openCL
api РДКЭМЦЫуЩшБИНЛЛЅЁЃHostЪЧдЫаагкCPUЩЯЕФЁЃдЫаагкHostЩЯЕФГЬађГЦЮЊhost programЁЃ
МЦЫуЩшБИЕФећЬхгжЛЎЗжСЫКмЖрЕФМЦЫуЕЅдЊЃЈcompute UnitЃЉЁЃУПИіМЦЫуЕЅдЊгавЛаЉЙВЯэзЪдДЃЌЭЌвЛИіМЦЫуЕЅдЊФкЕФДІРэдЊПЩвдЪЕЯжЭЌВНЁЃУПИіМЦЫуЕЅдЊгжЛЎЗжГЩШєИЩИіДІРэдЊЁЃеце§ЕФМЦЫуЗЂЩњдкДІРэдЊЩЯЁЃдЫаадкУПИіДІРэдЊЩЯЕФЪЕР§ГЦЮЊkernelЁЃ
МйЩшгаNИіМЦЫуЕЅдЊЃЌУПИіМЦЫуЕЅдЊгаMИіДІРэдЊЁЃФЧУДзмЙВгаN*MИіКЫЁЃЭЌвЛЪБПЬЃЌОЭПЩвддйЩшБИЩЯдЫааN*MИіЪЕР§ЁЃвђДЫЃЌШчЙћВЛПМТЧI/OЕШЦфЫћвђЫиЃЌМгЫйБШЕФРэТлЩЯЯоЪЧN*MЁЃ
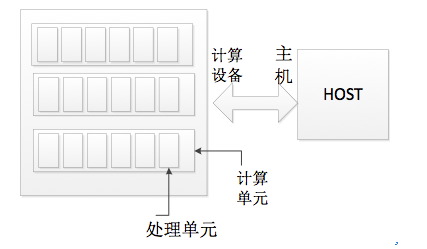
ЭМ 2-1 GPUгВМўГщЯѓФЃаЭ
GPUШэМўМмЙЙ
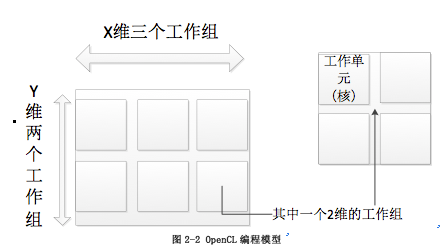
ЭМ2-2 OpenCLБрГЬФЃаЭ
openCLАбећИіМЦЫуЩшБИЕФПеМфЛЎЗжГЩNЮЌЃЈN=1ЁЂ2ЁЂ3ЃЉЃЌГЦЮЊNDRangeЁЃУПвЛИіЮЌЖШЩЯЕФгжЛЎЗжГЩШєИЩИіЙЄзїзщЃЈwork
groupЃЉЃЌУПИіЙЄзїзщгжАќКЌСЫШєИЩИіЙЄзїЕЅдЊЃЈwork itemЃЉЁЃдкУПвЛИіЮЌЖШФкЃЌУПвЛИіЙЄзїзщЖМгавЛИіЮЈвЛgroup
idБъЪЖЁЃУПвЛИіЙЄзїЕЅдЊЖМгавЛИіЮЈвЛЕФglobal idЁЃдкУПвЛИіЮЌЖШЕФУПвЛИіЙЄзїзщФкЃЌУПИіЙЄзїЕЅдЊЖМгавЛИіЮЈвЛЕФlocal
idБъЪЖЁЃУПвЛИіЙЄзїЕЅдЊЕФglobal idПЩвдКЭЫљЪєЙЄзїзщЕФgroup idКЭlocal idЛЛЫуЁЃ
КЭЩЯвЛаЁНкЯрБШЃЌдкЩЯвЛаЁНкжаЬсЕНЕФМЦЫуЕЅдЊКЭДІРэдЊЕФИХФюЖМЪЧгВМўИХФюЁЃЖјБОаЁНкЬсЕНЕФЮЌЖШЁЂЙЄзїзщЁЂЙЄзїЕЅдЊЕФИХФюЪЧГщЯѓИХФюЃЌКЭгВМўИХФюжЎМфУЛгаЙиСЊЁЃУПвЛИіЙЄзїЕЅдЊЃЌПЩвдгЩвЛИіЛђепЖрИіДІРэдЊЙЙГЩЁЃ
УПвЛИіЮЌЖШЩЯЕФУПИіЙЄзїзщЕФДѓаЁгавЛЖЈЕФЯожЦ ,ЫљгаЮЌЖШФкЪєгкЭЌвЛИіЙЄзїзщЕФЙЄзїЕЅдЊЕФЪ§ФПВЛФмГЌЙ§гВМўвЛИіМЦЫуЛњШКЕФДѓаЁЁЃМйЩшУПИіЮЌЖШЕФЙЄзїзщДѓаЁЗжБ№ЪЧN1ЃЌN2ЃЌN3ЃЌМЦЫуЕЅдЊЕФДѓаЁЪЧsizeЃЌФЧУДгаN1*N2*N3<=sizeЁЃ
ЭМ2-2жаеЙЪОЕФЪЧвЛИіЖўЮЌПеМфЁЃЦфаЮЪНРрЫЦгкЖўЮЌОиеѓЃЌжЛЪЧУПИіЮЌЖШЩЯЛЙгаЙЄзїзщЕФИХФюЁЃ
openCLДцДЂФЃаЭ
openCLЕФДцДЂИљОнзїгУгђПЩвдЗжГЩЫФИіМЖБ№ЁЃвРДЮЪЧЃКШЋОжФкДцЃЌГЃСПФкДцЃЌОжВПФкДцЃЌЫНгаФкДцЁЃ
ШЋОжФкДцЃЌЖдгкЫљгаЙЄзїзщФкЕФЫљгаЙЄзїЕЅдЊЖМПЩЖСКЭПЩаДЁЃЕЋЪЧЖдетВПЗжФкДцЕФЖСаДПЩФмЛсБЛЛКДцЃЌвђДЫЖрИіДІРэЕЅдЊДІРэЭЌвЛПщФкДцЪБЃЌвЊзЂвтНјааЭЌВНЁЃ
ГЃСПФкДцЃЌзїгУгђКЭШЋОжФкДцвЛбљЃЌЕЋЪЧжЛПЩЖСЃЌВЛПЩаДЁЃШЋОжФкДцКЭГЃСПФкДцЖМЪЧгЩhostНјааЗжХфПеМфКЭГѕЪМЛЏЕФЁЃ
ОжВПФкДцЃЌЙЫУћЫМвхЃЌжЛЖдВПЗжДІРэЕЅдЊПЩВйзїЁЃЦфзїгУгђдкЭЌвЛИіЙЄзїзщФкЁЃетВПЗжЕФгВМўЮЛгкМЦЫуЕЅдЊФкВПЁЃ
ЫНгаФкДцЃЌНіЯогкЕЅИіЙЄзїЕЅдЊПЩЖСаДЃЌЦфгВМўЮЛгкДІРэЕЅдЊФкВПЁЃЭЈГЃЃЌдкЙЄзїЕЅдЊЩЯдЫааЕФkernelЪЕР§ЃЌЦфКЏЪ§ОжВПБфСПЪЧЗжХфдкЫНгаФкДцЩЯЕФЁЃ
openCLЕФШЋОжФкДцЭЈГЃгУгкЗХжУgpuЕФШыПкВЮЪ§ЃЌвдМАGPUЕФдЫааНсЙћЁЃopenCLЕФГЬађБОЩэЪЧВЛЬсЙЉЗЕЛижЕЕФЃЌвђДЫШчЙћвЊЛёЕУЗЕЛижЕЃЌОЭашвЊАбдЫааНсЙћЗХШыШЋОжФкДцЁЃдкГЬађНсЪјКѓЃЌгЩhostГЬађЖСШЁШЋОжФкДцЧјЕФЪ§ОнЃЌДгЖјЛёЕУЗЕЛижЕЁЃ
openCLЕФжДааФЃаЭ
ЖдгкopenClЖјбдЃЌгаСНжжРраЭЕФжДааЗНЪНЃЌЕквЛжжЪЧШЮЮёВЂааФЃаЭЃЌЕкЖўжжЪЧЪ§ОнВЂааФЃаЭЁЃ
ШЮЮёВЂааФЃаЭЪЧжИЃЌУПИіЙЄзїЕЅдЊФкЃЌдЫаавЛИіkernelЪЕР§ЃЌЕЋЪЧВЛЭЌЕФЕЅдЊдЫааЕФЪЕР§ПЩФмВЛвЛбљЁЃ
Ъ§ОнВЂааФЃаЭЪЧжИЃЌУПИіЙЄзїЕЅдЊФкЃЌдЫааЕФЪЧЭЌвЛИіkernelЪЕР§ЃЌжЛЪЧУПИіЕЅдЊДІРэЕФЪ§ОнВЛвЛбљЃЌгЩгкУПИіЕЅдЊЖМгавЛИіЮЈвЛЕФidБъЪЖЃЌЫљвдЃЌПЩвдЭЈЙ§етИіidРДжИЖЈетИіЕЅдЊДІРэЕФЪЧФФаЉЪ§ОнЁЃ
дквХДЋЫуЗЈЕФЪЕЯжЗНЪНжаЃЌБОЮФВЩШЁСЫЪ§ОнВЂааФЃаЭЁЃ
ЭЌВН
дквХДЋЫуЗЈжаЃЌЖдгкУПвЛДЮЕќДњЃЌгааЉВйзїашвЊЕШД§ЫљгаЕФЙЄзїЕЅдЊЭъГЩКѓВХФмНјааЁЃБШШчЃЌЖдгкДЋЭГвХДЋЫуЗЈЃЌдкбЁдёВйзїЧАЃЌашвЊЫљгаЕФИіЬхЭЌЪБЭъГЩИіЬхЪЪгІжЕЕФЦРМлЁЃвђДЫашвЊЭЌВНВйзїЁЃ
дкopenCLжаЃЌДцдквЛИіAPIЃКbarrierЃЈcl_mem_fence_flagЃЉЁЃБъжОЮЛгаСНИібЁЯюЃЌLOCAL_MEM_FENCE
КЭGLOBAL_MEM_FENCEЃЌЗжБ№гУгкЭЌВНОжВПФкДцКЭШЋОжФкДцЁЃЭЌВНЕФДІРэЕЅдЊБиаыдкЕШД§ЫљгаЕФДІРэЕЅдЊЖМжДааЕНИУКЏЪ§ЪБЃЌВХФмжДааЯТвЛЬѕгяОфЁЃ
ШЛЖјЃЌе§ШчЧАЮФНВЕНЕФЃЌвЛИіЙЄзїзщЕФДѓаЁЪЧгаЯожЦЕФЃЌетИіЯожЦОЭЪЧвЛИіМЦЫуЕЅдЊЕФДѓаЁЁЃМЦЫуЕЅдЊЕФЛЎЗжЪЧгВМўЯожЦЃЌЪєгкЭЌвЛИіМЦЫуЕЅдЊЕФДІРэЕЅдЊЙВЯэМЦЫуЕЅдЊФкЕФФкДцКЭЦфЫћзЪдДЁЃGPUЖдЭЌВНЕФЪЕЯжвВвРРЕгкгВМўЃЌвђДЫЃЌжЛгаЪєгкЭЌвЛИіМЦЫуЕЅдЊЕФДІРэЕЅдЊВХФмЙЛЪЕЯжЭЌВНЁЃЖдгкГЬађПЊЗЂепЖјбдЃЌopenCLШѕЛЏСЫгВМўМмЙЙЃЌПЊЗЂепжЛжЊЕРЙЄзїзщетвЛИХФюЃЌВЛЧхГўМЦЫуЛњШКетвЛИХФюЁЃвђДЫЃЌopenCLЕФЭЌВНжЛЗЂЩњдкЭЌвЛИіЙЄзїзщжаЁЃ
дквХДЋЫуЗЈжаЃЌЫцЛњЙ§ГЬЭљЭљашвЊКмДѓЕФЛљЪ§ВХФмБЃжЄвЛаЉаЁИХТЪЪТМўЕФЗЂЩњЁЃБШШчБфвьВйзїЃЌетИіВйзїЕФИХТЪКмаЁЃЌШчЙћбљБОЪ§СПаЁЕФЛАЃЌКмФбБЃжЄЛсЗЂЩњБфвьЁЃЕЋЪЧЃЌШчЙћбљБОЪ§СПГЌЙ§СЫвЛИіМЦЫуЕЅдЊЕФДѓаЁЃЌФЧУДОЭЛсЕМжТЭЌВНЮЪЬтЁЃвђДЫдкетвЛЕуашвЊелжаПМТЧЁЃЭЌвЛИіШКЬхЕФИіЬхПЩвдЗХЕНЭЌвЛИіМЦЫуЕЅдЊжадЫааЃЌВЛЭЌЕФШКЬхЗХЕНВЛЭЌЕФМЦЫуЕЅдЊЩЯЁЃжжШКМфЮоашЭЌВНЁЃетбљМШТњзуСЫбљБОЕФЪ§СПашЧѓЃЌвВТњзуСЫЭЌВНвЊЧѓЁЃ
2.6. GPUГЬађЕФжДааСїГЬ
GPUГЬађЗжСНВПЗжЃЌвЛВПЗждкCPUЩЯжДааЃЌетВПЗжГЬађГЦЮЊhost programЃЌвЛВПЗждкGPUЩЯжДааЃЌетВПЗжГЬађГЦЮЊkernel
ЁЃHost ГЬађИКд№ГѕЪМЛЏЛЗОГЃЌАќРЈGPUдЫааЛЗОГКЭВЮЪ§ЁЃKernelдђИКд№МЦЫуЃЌВЂАбМЦЫуНсЙћаДШыФкДцЃЌгЩhostЖСШЁЁЃЭъећСїГЬШчЭМ2-3ЃК
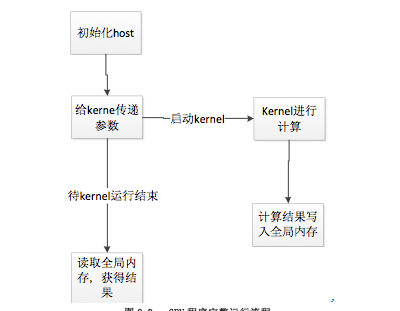
ЭМ2-3ЃК GPUГЬађЭъећдЫааСїГЬ
БОеТаЁНс
БОеТЯъЯИНщЩмСЫGPUБрГЬФЃаЭЃЌАќРЈGPUЕФгВМўПђМмЃЌНщЩмгВМўЯрЙиЕФБГОАЃЛБрГЬФЃаЭНщЩмШэМўЕФПђМмЃЛДцДЂФЃаЭНВЪіGPUЕФФкДцФЃаЭЃЌжДааФЃаЭНВЪіGPUЕФБрГЬПђМмЁЃДЫЭтЛЙгадкGPUжаБрГЬашвЊзЂвтЕФвЛаЉЮЪЬтЃЌБШШчЫцЛњЪ§ЃЌЭЌВНЮЪЬтЁЃзюКѓНщЩмСЫвЛИіЭъећЕФGPUВЂааГЬађЕФСїГЬЁЃ |








