| 编辑推荐: |
| 本文来自于csdn,深度学习的兴起,使得多线程以及GPU编程逐渐成为算法工程师无法规避的问题。这里主要记录自己的GPU自学历程。 |
|
《GPU编程自学1 —— 引言》
《GPU编程自学2 —— CUDA环境配置》
《GPU编程自学3 —— CUDA程序初探》
《GPU编程自学4 —— CUDA核函数运行参数》
《GPU编程自学5 —— 线程协作》
《GPU编程自学6 —— 函数与变量类型限定符》
《GPU编程自学7 —— 常量内存与事件》
《GPU编程自学8 —— 纹理内存》
《GPU编程自学9 —— 原子操作》
《GPU编程自学10 —— 流并行》
一、 引言
传统的中央处理器(CPU,Central Processing Unit) 内部结构异常复杂,主要是因为其需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。
为了提高计算能力,CPU通常会采取提高时钟频率或增加处理器核数量的策略。
为了进一步获得更高效的计算,图形处理器(GPU, Graphics Processing Unit)应运而生。
GPU可以在无需中断的纯净环境下处理类型高度统一的、相互无依赖的大规模数据。
如下图所示:

GPU的高效在于可以高度并行处理。 以两个向量相加为例,CPU可能采取循环处理,每个循环对一个分量做加法。GPU则可以开多个线程,每个线程同时对一个分量做加法。CPU加法的速度一般快于GPU,但因为GPU可以同时开大量线程并行跑,因此更加高效。
为了降低GPU程序的开发难度,NVIDIA推出了 CUDA(Compute Unified Device
Architecture,统一计算设备架构)这一编程模型。
二、 CUDA环境配置
首先说明一下我的基础环境: 联想小新超极本;Win10 X64 专业版; NVIDIA GeForce
940MX; VS2013。
2.1 安装CUDA Toolkit
在保证NVIDIA显卡驱动成功安装的条件下,从下面链接下载并安装对应版本的CUDA Toolkit.(注意:最好已经安装好VS)
https://developer.nvidia.com/cuda-downloads。 建议右键复制下载链接然后迅雷下载。

通过在命令窗中执行 nvcc -V初步判断是否安装成功:

安装成功后(默认安装)系统会增加如下环境变量:
CUDA_PATH: C:\Program
Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0
CUDA_PATH_V8_0: C:\Program Files\NVIDIA GPU Computing
Toolkit\CUDA\v8.0
NUMBER_OF_PROCESSORS: 4
NVCUDASAMPLES_ROOT: C:\ProgramData\NVIDIA Corporation\CUDA
Samples\v8.0
NVCUDASAMPLES8_0_ROOT: C:\ProgramData\NVIDIA Corporation\CUDA
Samples\v8.0
NVTOOLSEXT_PATH: C:\Program Files\NVIDIA Corporation\NvToolsExt\ |
2.2 VS测试工程
CUDA Toolkit安装成功后会自动和系统的编译器进行绑定。 以我的VS2013为例,“新建项目”下增加了
“NVIDIA”选项。

CUDA Toolkit已经为我们提供了一些简单的样例,位于 环境变量 “NVCUDASAMPLES_ROOT”所指向的目录下。
注意,该目录通常为隐藏目录。

随便选择其中的一个子项目,如果可以成功运行,则表明CUDA确实已经安装成功。
三、 CUDA程序初探
3.1 主机与设备
通常将CPU及其内存称之为主机,GPU及其内存称之为设备。
如下图所示,新建一个NVIDIA CUDA工程,并命名为 “1-helloworld”

之后发现项目里多了一个 “kernel.cu”的文件,该文件内容是一个经典的 矢量相加 的GPU程序。
可以暂时全部注释该代码,并尝试编译运行下面的我们经常见到的编程入门示例:
| #include <iostream>
int main()
{
std::cout<<"Hello, World!"<<std::endl;
system("pause");
return 0;
} |
这看起来和普通的C++程序并没什么区别。 这个示例只是为了说明CUDA C编程和我们熟悉的标准C在很大程度上是没有区别的。
同时,这段程序直接运行在 主机上。
接下来,我们看看如何使用GPU来执行代码。如下:
| #include <iostream>
__global__ void mkernel(void){}
int main()
{
mkernel <<<1,1>>>();
std::cout<<"Hello, World!"<<std::endl;
system("pause");
return 0;
} |
与之前的代码相比, 这里主要增加了
一个空的函数mkernel(), 并带有修饰符 global
对空函数的调用, 并带有修饰符 <<<1,1>>>
_global_ 为CUDA C为标准C增加的修饰符,表示该函数将会交给编译设备代码的编译器(NVCC)并最终在设备上运行。
而 main函数则依旧交给系统编译器(VS2013)。
其实,CUDA就是通过直接提供API接口或者在语言层面集成一些新的东西来实现在主机代码中调用设备代码。
3.2 第一个GPU程序: 矢量相加
下面主要通过代码解读的形式来进行我们的第一个GPU程序。
程序遵循以下流程:
主机端准备数据 -> 数据复制到GPU内存中 -> GPU执行核函数 -> 数据由GPU取回到主机
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
// 接口函数: 主机代码调用GPU设备实现矢量加法 c = a + b
cudaError_t addWithCuda(int *c, const int *a,
const int *b, unsigned int size);
// 核函数:每个线程负责一个分量的加法
__global__ void addKernel(int *c, const int
*a, const int *b)
{
int i = threadIdx.x; // 获取线程ID
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50
};
int c[arraySize] = { 0 };
// 并行矢量相加
cudaError_t cudaStatus = addWithCuda(c, a, b,
arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50}
= {%d,%d,%d,%d,%d}\n",
c[0], c[1], c[2], c[3], c[4]);
// CUDA设备重置,以便其它性能检测和跟踪工具的运行,如Nsight and Visual
Profiler to show complete traces.traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
// 接口函数实现: 主机代码调用GPU设备实现矢量加法 c = a + b
cudaError_t addWithCuda(int *c, const int *a,
const int *b, unsigned int size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// 选择程序运行在哪块GPU上,(多GPU机器可以选择)
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed!
Do you have a CUDA-capable GPU installed?");
goto Error;
}
// 依次为 c = a + b三个矢量在GPU上开辟内存 .
cudaStatus = cudaMalloc((void**)&dev_c,
size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a,
size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b,
size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// 将矢量a和b依次copy进入GPU内存中
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int),
cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int),
cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// 运行核函数,运行设置为1个block,每个block中size个线程
addKernel<<<1, size>>>(dev_c,
dev_a, dev_b);
// 检查是否出现了错误
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed:
%s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// 停止CPU端线程的执行,直到GPU完成之前CUDA的任务,包括kernel函数、数据拷贝等
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize
returned error code %d after launching addKernel!\n",
cudaStatus);
goto Error;
}
// 将计算结果从GPU复制到主机内存
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int),
cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
} |
四、 CUDA核函数运行参数
在前面的章节中,我们不止一次看到了在调用定义的核函数时采用了类似下面的形式:
| kernel<<<1,1>>>(param1,param2,...) |
“<<< >>>”中参数的作用是告诉我们该如何启动核函数(比如如何设置线程)。
下面我们先直接介绍参数概念,然后详细说明其意义。
4.1 核函数运行参数
当我们使用 gloabl 声明核函数后
| __global__ void
kernel(param list){ } |
在主机端(Host)调用时采用如下的形式:
| kernel<<<Dg,Db,
Ns, S>>>(param list); |
Dg: int型或者dim3类型(x,y,z)。 用于定义一个grid中的block是如何组织的。
int型则直接表示为1维组织结构。
Db: int型或者dim3类型(x,y,z)。 用于定义一个block中的thread是如何组织的。
int型则直接表示为1维组织结构。
Ns: size_t类型,可缺省,默认为0。 用于设置每个block除了静态分配的共享内存外,最多能动态分配的共享内存大小,单位为byte。
0表示不需要动态分配。
S: cudaStream_t类型,可缺省,默认为0。 表示该核函数位于哪个流。
4.2 线程结构
关于CUDA的线程结构,有着三个重要的概念: Grid, Block, Thread
GPU工作时的最小单位是 thread。
多个 thread 可以组成一个 block,但每一个 block 所能包含的 thread 数目是有限的。因为一个block的所有线程最好应当位于同一个处理器核心上,同时共享同一块内存。
于是一个 block中的所有thread可以快速进行同步的动作而不用担心数据通信壁垒。
执行相同程序的多个 block,可以组成 grid。 不同 block 中的 thread 无法存取同一块共享的内存,无法直接互通或进行同步。因此,不同
block 中的 thread 能合作的程度是比较低的。不过,利用这个模式,可以让程序不用担心显示芯片实际上能同时执行的
thread 数目限制。例如,一个具有很少量执行单元的显示芯片,可能会把各个 block 中的 thread
顺序执行,而非同时执行。不同的 grid 则可以执行不同的程序(即 kernel)。
下图是一个结构关系图:
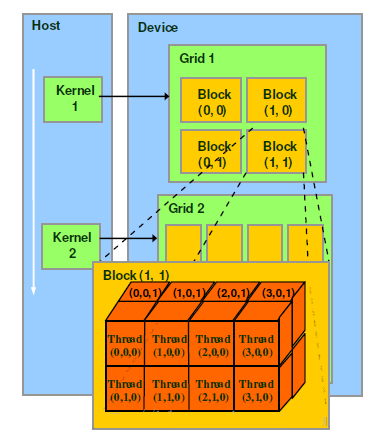
此外,Block, Thread的组织结构可以是可以是一维,二维或者三维。以上图为例,Block,
Thread的结构分别为二维和三维。
CUDA中每一个线程都有一个唯一标识ThreadIdx,这个ID随着组织结构形式的变化而变化。 (注意:ID的计算,同计算行优先排列的矩阵元素ID思路一样。)
回顾之前我们的矢量加法:
// Block是一维的,Thread也是一维的
__global__ void addKernel(int *c, const int *a,
const int *b)
{
int i = blockIdx.x *blockDim.x + threadIdx.x;
c[i] = a[i] + b[i];
} |
| // Block是一维的,Thread是二维的
__global__ void addKernel(int *c, int *a, int
*b)
{
int i = blockIdx.x * blockDim.x * blockDim.y
+ threadIdx.y * blockDim.x + threadIdx.x;
c[i] = a[i] + b[i];
} |
// Block是二维的,Thread是三维的
__global__ void addKernel(int *c, int *a, int
*b)
{
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int i = blockId * (blockDim.x * blockDim.y * blockDim.z)
+ (threadIdx.z * (blockDim.x * blockDim.y))
+ (threadIdx.y * blockDim.x) + threadIdx.x;
c[i] = a[i] + b[i];
} |
下表是不同计算能力的GPU的技术指标(更多可参见 CUDA Toolkit Documentation)

当然也可以通过下面的代码来直接查询自己GPU的具体指标:
#include "cuda_runtime.h"
#include <iostream>
int main()
{
cudaError_t cudaStatus;
// 初获取设备数量
int num = 0;
cudaStatus = cudaGetDeviceCount(&num);
std::cout << "Number of GPU: "
<< num << std::endl;
// 获取GPU设备属性
cudaDeviceProp prop;
if (num > 0)
{
cudaGetDeviceProperties(&prop, 0);
// 打印设备名称
std::cout << "Device: " <<prop.name
<< std::endl;
}
system("pause");
return 0;
} |
其中 cudaDeviceProp是一个定义在driver_types.h中的结构体,大家可以自行查看其定义。
4.3 内存结构
如下图所示,每个 thread 都有自己的一份 register 和 local memory 的空间。同一个
block 中的每个 thread 则有共享的一份 share memory。此外,所有的 thread(包括不同
block 的 thread)都共享一份 global memory、constant memory、和
texture memory。不同的 grid 则有各自的 global memory、constant
memory 和 texture memory。
这种特殊的内存结构直接影响着我们的线程分配策略,因为需要通盘考虑资源限制及利用率。 这些后续再进行讨论。

4.4 异构编程
如下图所示,是常见的GPU程序的处理流程,其实是一种异构程序,即CPU和GPU的协同。
主机上执行串行代码,设备上则执行并行代码。
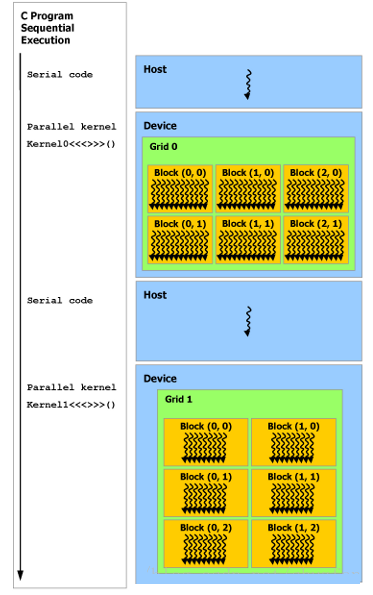
五、 线程协作
5.1 并行程序块的分解
首先回顾我们之前实现的矢量相加程序:
// 核函数:每个线程负责一个分量的加法
__global__ void addKernel(int *c, const int *a,
const int *b)
{
int i = threadIdx.x; // 获取线程ID
c[i] = a[i] + b[i];
}
// 运行核函数,运行设置为1个block,每个block中size个线程
addKernel << <1, size >> >(dev_c,
dev_a, dev_b); |
通过前面小节,我们知道一个Block中的可开辟的线程数量是有限的(不超过1024)。
如果矢量特别长,上面的操作是会出现问题的。于是我们可以采用多个线程块(Block)来解决线程不足的问题。
假如我们设定每个线程块包含128个线程,则需要的线程块的数量为 size / 128。 为了避免不能整除带来的问题,我们可以稍微多开一点
(size + 127) / 128,但需要增加判断条件来避免越界。
// 核函数:每个线程负责一个分量的加法
__global__ void addKernel(int *c, const int *a,
const int *b, const int size)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
// 获取线程ID
if (i < size)
c[i] = a[i] + b[i];
}
// 运行核函数,运行设置为多个block,每个block中128个线程
addKernel <<<(size + 127) / 128, 128
>>>(dev_c, dev_a, dev_b, size); |
通过前面小节,我们同时也知道一个Grid中可开辟的Block数量也是有限的。
如果数据量大于 Block_num * Thread_num,那么我们就无法为每个分量单独分配一个线程了。
不过,一个简单的解决办法就是在核函数中增加循环。
// 核函数:每个线程负责多个分量的加法
__global__ void addKernel(int *c, const int *a,
const int *b, const int size)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
while (i < size)
{
c[i] = a[i] + b[i];
// 偏移分量等于一个Grid中包含的线程数量
i += blockDim.x * gridDim.x;
}
}
// 运行核函数,运行设置为1个Grid包含128个block,每个block包含128个线程
// 其中已经假设 size > 128*128
addKernel <<<128, 128 >>>(dev_c,
dev_a, dev_b, size); |
5.2 共享内存与同步
上面提到线程块的分解似乎是为了增加可用的线程数量,但这种说法并不靠谱,因为这完全可以由CUDA在幕后全权控制。
其实,分解线程块的重要原因是因为内存。
在“4.3 内存结构”中我们已经知道,同一个Block中的线程可以访问一块共享内存。由于共享内存缓冲区驻留在物理GPU上,而不是GPU之外的系统内存上,因此访问共享内存的延迟要远远低于访问普通缓冲区的延迟。
不同Block之间存在隔离,如果我们需要不同线程之间进行通信,那么还需要考虑线程同步的问题。比如线程A将某个数值写入内存,然后线程B会对该数值进行一些操作,那么显然必须等A完成之后B才可以操作,如果没有同步,程序将会因进入“竞态条件”而产生意想不到的错误。
接下来我们通过一个矢量点积的例子来说明上述问题。
矢量点积的定义如下:
(x1,x2,x3,x4)?(y1,y2,y3,y4)=x1y1+x2y2+x3y3+x4y4(x1,x2,x3,x4)?(y1,y2,y3,y4)=x1y1+x2y2+x3y3+x4y4
由上面的定义来看,点积的实现可以分为两步:
(1)计算每个分量的乘积,并暂存该结果;
(2)将所有临时结果加和。
我们先来简单实现下第一步:
// 定义我们的矢量长度
const int N = 64 * 256;
// 定义每个Block中包含的Thread数量
const int threadsPerBlock = 256;
// 定义每个Grid中包含的Block数量, 这里32 < 64, 是为了模拟线程数量不足的情况
const int blocksPerGrid = 32;
__global__ void dot( float *a, float *b, float
*c )
{
// 声明共享内存用于存储临时乘积结果,内存大小为1个Block中的线程数量
// PS. 每个Block都相当于有一份程序副本,因此相当于每个Block都有这样的一份共享内存
__shared__ float cache[threadsPerBlock];
// 线程索引
int tid = threadIdx.x + blockIdx.x * blockDim.x;
// 一个Block中的线程索引
int cacheIndex = threadIdx.x;
// 计算分量乘积,同时处理线程不足的问题
float temp = 0;
while (tid < N) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
// 存储临时乘积结果
cache[cacheIndex] = temp;
} |
执行完上面的部分,我们剩下的就是把cache中的值相加求和。 但是,我们必须要保证所有乘积都已经计算完成,才能去计算求和。
命令如下:
// 对线程块中的所有线程进行同步
// 线程块中的所有线程都执行完前面的代码后才会继续往后执行
__syncthreads(); |
求和最直接的方式就是循环累加,此时复杂度与数组长度成正比。不过我们可以再用一种更加高效的方法,其复杂度与数组长度的log成正比:将值两两合并,于是数据量减小一半,再重复两两合并直至全部计算完成。代码如下:
// 合并算法要求长度为2的指数倍
int i = blockDim.x/2;
while (i != 0)
{
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
// 最后将一个Block的求和结果进行保存
if (cacheIndex == 0)
c[blockIdx.x] = cache[0]; |
下面给出完整的代码(简单起见,不再做错误检查):
| #include <iostream>
#include "cuda_runtime.h"
//定义矢量长度
const int N = 64 * 256;
// 定义每个Block中包含的Thread数量
const int threadsPerBlock = 256;
// 定义每个Grid中包含的Block数量, 这里32 < 64, 是为了模拟线程数量不足的情况
const int blocksPerGrid = 32;
// 核函数:矢量点积
__global__ void dot(float* a, float* b, float*
c)
{
// 声明共享内存用于存储临时乘积结果,内存大小为1个Block中的线程数量
// PS. 每个Block都相当于有一份程序副本,因此相当于每个Block都有这样的一份共享内存
__shared__ float cache[threadsPerBlock];
// 线程索引
int tid = blockIdx.x * blockDim.x + threadIdx.x;
// 一个Block中的线程索引
int cacheIndex = threadIdx.x;
// 计算分量乘积,同时处理线程不足的问题
float temp = 0.0f;
while (tid < N)
{
temp += a[tid] * b[tid];
tid += gridDim.x * blockDim.x;
}
// 存储临时乘积结果
cache[cacheIndex] = temp;
// 对线程块中的所有线程进行同步
// 线程块中的所有线程都执行完前面的代码后才会继续往后执行
__syncthreads();
// 合并算法要求长度为2的指数倍
int i = threadsPerBlock / 2;
while (i != 0)
{
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];
}
int main()
{
// 在主机端创建数组
float a[N];
float b[N];
float c[threadsPerBlock];
for (size_t i = 0; i < N; i++)
{
a[i] = 1.f;
b[i] = 1.f;
}
// 申请GPU内存
float* dev_a = nullptr;
float* dev_b = nullptr;
float* dev_c = nullptr;
cudaMalloc((void**)&dev_a, N * sizeof(float));
cudaMalloc((void**)&dev_b, N * sizeof(float));
cudaMalloc((void**)&dev_c, blocksPerGrid
* sizeof(float));
//将数据从主机copy进GPU
cudaMemcpy(dev_a, a, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N * sizeof(float), cudaMemcpyHostToDevice);
//进行点积计算
dot<<<32, 256>>>(dev_a, dev_b,
dev_c);
//将计算结果copy回主机
cudaMemcpy(c, dev_c, blocksPerGrid * sizeof(float),
cudaMemcpyDeviceToHost);
//将每个block的结果进行累加
for (size_t i = 1; i < blocksPerGrid; i++)
c[0] += c[i];
// 输出结果
std::cout << "The ground truth is
16384, our answer is " << c[0] <<
std::endl;
//释放内存
cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c);
system("pause");
return 0;
} |
六、 函数与变量类型限定符
在之前的小节中,我们已经遇到了 __global__ 和 __shared__这两种类型限定符。 前者属于函数类型限定符,后者则属于变量类型限定符。
接下来,我们来来了解一下这两类限定符。
6.1 函数类型限定符
函数类型限定符用来标识函数运行在主机还是设备上,函数由主机还是设备调用。
__global__
__global__修饰的函数为 核函数。
运行在设备上;
可以由主机调用;
可以由计算能力大于3.2的设备调用;
必须有void返回类型;
调用时必须制定运行参数(<<< >>>)
该函数的调用时异步的,即可以不必等候该函数全部完成,便可以在CPU上继续工作;
__device__
运行在设备上;
只能由设备调用;
编译器会内联所有认为合适的__device__修饰的函数;
__host__
运行在主机上;
只能由主机调用;
效果等同于函数不加任何限定符;
不能与__global__共同使用, 但可以和__device__联合使用;
__noinline__
声明不允许内联
__forceinline__
强制编译器内联该函数
6.2 变量类型限定符
变量类型限定符用来标识变量在设备上的内存位置。
__device__ (单独使用时)
位于 global memory space
生命周期为整个应用期间(即与application同生死)
可以被grid内的所有threads读取
可以在主机中由以下函数读取
cudaGetSymbolAddress()
cudaGetSymbolSize()
cudaMemcpyToSymbol()
cudaMemcpyFromSymbol()
__constant__
可以和 __device__ 联合使用
位于 constant memory space
生命周期为整个应用期间
可以被grid内的所有threads读取
可以在主机中由以下函数读取
cudaGetSymbolAddress()
cudaGetSymbolSize()
cudaMemcpyToSymbol()
cudaMemcpyFromSymbol()
__shared__
可以和 __device__ 联合使用
位于一个Block的shared memory space
生命周期为整个Block
只能被同一block内的threads读写
__managed__
可以和 __device__ 联合使用
可以被主机和设备引用,主机或者设备函数可以获取其地址或者读写其值
生命周期为整个应用期间
__restrict__
该关键字用来对指针进行限制性说明,目的是为了减少指针别名带来的问题。
C99标准中引入了restricted指针,用以缓解C语言中指针二义性的问题。缓解指针二义性问题可用于编译器的代码优化。下面是一个指针二义性的例子:
void foo(const
float* a,
const float* b,
float* c)
{
c[0] = a[0] * b[0];
c[1] = a[0] * b[0];
c[2] = a[0] * b[0] * a[1];
c[3] = a[0] * a[1];
c[4] = a[0] * b[0];
c[5] = b[0];
...
} |
在C语言中,指针a, b, 和c可能有二义性(别名),因而对数组c的写入可能会更改数组a和b的元素的值。这就意味着,为了保证程序的正确性,编译器不能把a[0]和b[0]装载入寄存器,对它们做乘法,然后把结果写入c[0]和c[1],这是因为有这种可能a[0]和c[0]是同一个地址。故而编译器无法对相同的表达式进行优化。
通过把a, b, c声明为restricted指针,程序员可以断言这些指针实际上没有二义性(这里,所有的指针参数都要被设为restrict)
void foo(const
float* __restrict__a,
const float* __restrict__ b,
float* __restrict__ c) |
在增加了restrict关键字以后,编译器可以根据需要对代码进行优化:
void foo(const
float* __restrict__ a,
const float* __restrict__ b,
float* __restrict__ c)
{
float t0 = a[0];
float t1 = b[0];
float t2 = t0 * t2;
float t3 = a[1];
c[0] = t2;
c[1] = t2;
c[4] = t2;
c[2] = t2 * t3;
c[3] = t0 * t3;
c[5] = t1;
...
} |
这样便可以减少访存次数和计算量,而代价是增加寄存器的使用量。考虑到额外的寄存器使用可能会降低occupancy,因此这种优化也可能会带来负面效果。
七、 常量内存与事件
GPU通常包含大量的数学计算单元,因此性能瓶颈往往不在于芯片的数学计算吞吐量,而在于芯片的内存带宽,即有时候输入数据的速率甚至不能维持满负荷的运算。
于是我们需要一些手段来减少内存通信量。 目前的GPU均提供了64KB的常量内存,并且对常量内存采取了不同于全局内存的处理方式。
在某些场景下,使用常量内存来替换全局内存可以有效地提高通信效率。
7.1 常量内存
常量内存具有以下特点:
需要由 __constant__ 限定符来声明
只读
硬件上并没有特殊的常量内存块,常量内存只是只是全局内存的一种虚拟地址形式
目前的GPU常量内存大小都只有64K,主要是因为常量内存采用了更快速的16位地址寻址(2^16 =
65536 = 64K)
对于数据不太集中或者重用率不高的内存访问,尽量不要使用常量内存,否则甚至会慢于使用全局内存
常量内存无需cudaMalloc()来开辟,而是在声明时直接提交一个固定大小,比如 __constant__
float mdata[1000]
常量内存的赋值不能再用cudaMemcpy(),而是使用cudaMemcpyToSymbol()
常量内存带来性能提升的原因主要有两个:
对常量内存的单次读操作可以广播到其他的“邻近(nearby)”线程,这将节约15次读取操作
常量内存的数据将缓存起来,因此对于相同地址的连续操作将不会产生额外的内存通信量。
对于原因1,涉及到 线程束(Warp)的概念。
在CUDA架构中,线程束是指一个包含32个线程的集合,这个线程集合被“编织在一起”并且以“步调一致(Lockstep)”的形式执行。
即线程束中的每个线程都将在不同数据上执行相同的指令。
当处理常量内存时,NVIDIA硬件将把单次内存读取操作广播到每个半线程束(Half-Warp)。在半线程束中包含16个线程,即线程束中线程数量的一半。如果在半线程束中的每个线程从常量内存的相同地址上读取数据,那么GPU只会产生一次读取请求并在随后将数据广播到每个线程。如果从常量内存中读取大量数据,那么这种方式产生的内存流量只是使用全局内存时的1/16。
对于原因2,涉及到缓存的管理
由于常量内存的内容是不发生变化的,因此硬件将主动把这个常量数据缓存在GPU上。在第一次从常量内存的某个地址上读取后,当其他半线程束请求同一个地址时,那么将命中缓存,这同样减少了额外的内存流量。
另一方面, 常量内存的使用也可能会对性能产生负面的影响。半线程束广播功能实际上是一把双刃剑。虽然当所有16个线程都读取相同地址时,这个功能可以极大提升性能,但当所有16个线程分别读取不同的地址时,它实际上会降低性能。因为这16次不同的读取操作会被串行化,从而需要16倍的时间来发出请求。但如果从全局内存中读取,那么这些请求会同时发出。
7.2 常量内存应用实例 —— 光线跟踪
下面通过一个光线跟踪的实例来说明一下常量内存的使用效果。
下面的光线跟踪不涉及光源以及光线反射,只是简单的类似于“投影”的操作,如下图所示。
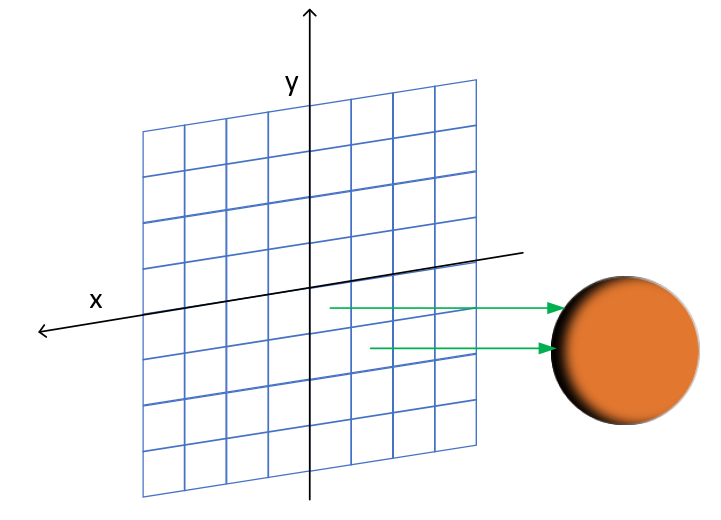
投影平面前面会有大量存在重叠的球体(这里我只画了1个),投影平面上每个像素点会发射出一条射线(射线方向认为是Z方向),我们需要和所有球体判断相交情况。
如果和多个球体相交,则选择最近的交点(即无法看到遮挡的球体)。 根据交点到对应球心的距离(Z方向距离)确定投影点的像素值,距离越远则越亮。
如果距离为无穷大,则表明没有相交,则置为黑色背景。
由于每个像素都会射出一条射线,然后和所有球体计算相交,因此需要经常访问固定的球体参数。 因此,为了提高访问效率,我们将球体信息定义到常量内存。
代码如下(需要OpenCV):
#include "cuda_runtime.h"
#include "highgui.hpp"
#include <time.h> using namespace cv;
#define INF 2e10f // 定义无穷远距离(用于表示没有球体相交)
#define rnd(x) (x*rand()/RAND_MAX)
#define SPHERES 100 //球体数量
#define DIM 1024 //图像大小
// 球体信息结构体
struct Sphere
{
float r, g, b; // 球体颜色
float radius; // 球体半径
float x, y, z; // 球体空间坐标
// 计算从(ox, oy)发出的射线与球体的交点
// n为交点到球心的距离(Z方向距离)与球半径的比值
__device__ float hit(float ox, float oy, float
*n)
{
float dx = ox - x;
float dy = oy - y;
if (dx*dx + dy*dy < radius*radius)
{
float dz = sqrt(radius*radius - dx*dx - dy*dy);
*n = dz / sqrt(radius*radius);
return dz + z;
}
return -INF;
}
};
// 声明球体数组
__constant__ Sphere s[SPHERES];
// 光线跟踪核函数
//__global__ void rayTracing(unsigned char*
ptr, Sphere* s)
__global__ void rayTracing(unsigned char* ptr)
{
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
// 以图像中心为坐标原点
float ox = (x - DIM / 2);
float oy = (y - DIM / 2);
float r = 0, g = 0, b = 0;
float maxz = -INF;
for (int i = 0; i < SPHERES; i++)
{
float n;
float t = s[i].hit(ox, oy, &n);
// 判断是否存在相交球体
if (t > maxz)
{
float fscale = n;
r = s[i].r * fscale;
g = s[i].g * fscale;
b = s[i].b * fscale;
maxz = t;
}
}
ptr[offset * 3 + 2] = (int)(r * 255);
ptr[offset * 3 + 1] = (int)(g * 255);
ptr[offset * 3 + 0] = (int)(b * 255);
}
int main(int argc, char* argv[])
{
// 建立事件用于计时
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
Mat bitmap = Mat(Size(DIM, DIM), CV_8UC3,
Scalar::all(0));
unsigned char *devBitmap;
(cudaMalloc((void**)&devBitmap, 3 * bitmap.rows*bitmap.cols));
// cudaMalloc((void**)&s, sizeof(Sphere)*SPHERES);
// 创建随机球体
Sphere *temps = (Sphere*)malloc(sizeof(Sphere)*SPHERES);
srand(time(0)); //随机数种子
for (int i = 0; i < SPHERES; i++)
{
temps[i].r = rnd(1.0f);
temps[i].g = rnd(1.0f);
temps[i].b = rnd(1.0f);
temps[i].x = rnd(1000.0f) - 500;
temps[i].y = rnd(1000.0f) - 500;
temps[i].z = rnd(1000.0f) - 500;
temps[i].radius = rnd(100.0f) + 20;
}
// cudaMemcpy(s, temps, sizeof(Sphere)*SPHERES,
cudaMemcpyHostToDevice);
// 将球体参数copy进常量内存
cudaMemcpyToSymbol(s, temps, sizeof(Sphere)*SPHERES);
free(temps);
dim3 grids(DIM / 16, DIM / 16);
dim3 threads(16, 16);
// rayTracing<<<grids, threads>>>(devBitmap,
s);
rayTracing << <grids, threads >>
> (devBitmap);
cudaMemcpy(bitmap.data, devBitmap, 3 * bitmap.rows*bitmap.cols,
cudaMemcpyDeviceToHost);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start,
stop);
printf("Processing time: %3.1f ms\n",
elapsedTime);
imshow("Ray Tracing", bitmap);
waitKey();
cudaFree(devBitmap);
// cudaFree(s);
return 0;
} |
实验效果如下图:

7.3 使用事件来测量性能
为了直观地看到常量内存带来的增益,我们需要测量程序运行的时间。
以往的话我们大多采用CPU或者操作系统中的某个计时器,但是这很容易带来各种延迟(包括操作系统线程调度、高精度CPU计时器可用性等)。
特别地,核函数与CPU程序是异步执行的,这更易带来意想不到的延迟。当然,针对这个问题,我们可以使用cudaThreadSynchronize()函数进行同步然后再利用CPU计时。
除了采用CPU主机端计时之外,更准确的方法应该是利用CUDA的事件API。
计时模板如下:
cudaEvent_t start,
stop;
float time = 0.f;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
/*****************************************
*********** 需要计时的代码部分**************
******************************************/
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&ime, start, stop);
std::cout << time << std::endl;
cudaEventDestroy(start);
cudaEventDestroy(stop); |
八、 纹理内存
同常量内存一样,纹理内存(Texture Memory)也是一种只读内存。 之所以称之为 “纹理”,是因为最初是为图形应用设计的。
当程序中存在大量局部空间操作时,纹理内存可以提高性能。
8.1 为什么纹理内存可以加速
纹理内存可以加速应用主要原因有两方面:
1. 纹理内存也是缓存在片上的,因此一些情况下相比从芯片外的DRAM上获取数据,纹理内存可以通过减少内存请求来提高带宽。
2. 纹理内存是针对图形应用设计的,可以更高效地处理局部空间的内存访问。

从数学的角度,上图中的4个地址并非连续的,在一般的CPU缓存中,这些地址将不会缓存。但由于GPU纹理缓存是专门为了加速这种访问模式而设计的,因此如果在这种情况中使用纹理内存而不是全局内存,那么将会获得性能的提升。
8.2 纹理内存的数据限制
下图是常见内存的存储位置,以及读取模式:

由上图可以看出,纹理内存是只读的,而且可以同时被主机和设备读取。
此外,纹理内存可以被声明为1D、2D或者3D数组,但数组的大小有限制,具体可以点击链接查看《不同计算能力GPU的指标》。
同时纹理内存中存储的数据也必须声明为固定类型,即各种对齐类型中的一种,如(char、short、int、long、float、double等)。
8.3 纹理内存使用
纹理内存的使用依赖于API函数。下面直接给出常见的使用流程:
8.3.1 声明纹理变量
texture<Type,
Dim, ReadMode> VarName;
//Type: 前面提到的基本的整型和浮点类型,以及其它的对齐类型
//Dim: 纹理数组的维度,值为1或2或3,默认缺省为1
//ReadMode:cudaReadModelNormalizedFloat 或 cudaReadModelElementType(默认) |
cudaReadModelNormalizedFloat:如果Type为整型(8bit或者16bit),则读取数据时会自动将整型数据转化为浮点数。具体地,如果是无符号整型,则转化为[0
1]之间的浮点数;如果是有符号整型,则转化为[-1 1]之间的浮点数。
cudaReadModelElementType:默认值,不进行任何转换
8.3.2 开辟内存
分配内存,内存形式有两种 线性内存 和 CUDA数组。
线性内存通过cudaMalloc()、cudaMallocPitch()或者cudaMalloc3D()分配;
CUDA数组可以通过cudaMalloc3DArray()或者cudaMallocArray()分配。前者可以分配1D、2D、3D的数组,后者一般用于分配2D的CUDA数组。
比如开辟一个二维CUDA数组ArrayName(64 x 64):
cudaChannelFormatDesc
channelDesc = cudaCreateChannelDesc<float>();
cudaArray *ArrayName;
cudaMallocArray(&ArrayName, &channelDesc,
64, 64); |
8.3.3 绑定纹理内存
纹理绑定(texture binding)的作用有两个:
将指定的缓冲区作为纹理来使用;
纹理引用作为纹理的“名字”
通常使用cudaBindTexture() 或 cudaBindTexture2D() 分别将线性内存绑定到1D和2D纹理内存,使用cudaBindTextureToArray()将CUDA数组与纹理绑定。
注意: 线性内存只能与一维或二维纹理绑定;CUDA数组则可以与一维、二维、三维纹理绑定。切两种绑定有着一些不同的特性。

以cudaBindTexture()为例(有两种级别的调用)
high-level API
cudaBindtexture
(size *t offset, const struct texture<T, dim,
readMode> & tex , const void * devptr,
size_t size= UINT_MAX)
// offset: 字节偏移量
// tex: 待绑定的纹理
// devPtr: 设备上已开辟的内存地址
// size : 开辟的内存大小 |
调用例子如下:
texture<Type,
Dim, ReadMode> tex;
cudaMalloc((void**)&devPtr, size);
cudaBindTexture(NULL, tex, devPtr, size); |
low-level API
此种情况稍微复杂一点, 是将开辟的缓存与“纹理参考系”绑定。
纹理参照系(texture reference)约定从数据的地址到纹理坐标的映射方式,其定义如下:
struct textureReference
{
int normalized;
enum cudaTextureFilterMode filterMode;
enum cudaTextureAddressMode addressMode[3];
struct cudaChannelFormatDesc channelDesc;
...
} |
可能用到的主要有下面3个参数:
normalized设置是否对纹理坐标归一化(纹理内存支持浮点坐标索引,[0 ~ N]的坐标索引会被归一化到
[0 1-1/N])
filterMode用于设置纹理的滤波模式(纹理缓存一次预取拾取坐标对应位置附近的几个象元,可以实现滤波模式)
addressMode说明了寻址方式
此时纹理内存被声明为引用形式:
| texture<DataType,
Type, ReadMode> texRef; |
完整的使用示例如下:
texture<float,
cudaTextureType1D, cudaReadModeElementType>
texRef; textureReference* texRefPtr;
cudaGetTextureReference(&texRefPtr, &texRef);
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
size_t offset;
cudaBindTexture2D(&offset, texRefPtr, devPtr,
&channelDesc, width, height, pitch); |
8.3.4 拾取纹理内存
在kernel中访问纹理内存称为纹理拾取(texture fetching)。 访问纹理内存必须使用API函数,而不能使用方括号索引的形式。因为我们需要API函数将读取请求转发到纹理内存而不是全局内存。
对于线性存储器绑定的纹理,使用tex1Dfetch()访问,采用的纹理坐标是整型。 对与一维、二维、三维cuda数组绑定的纹理,分别使用tex1D(),
tex2D() 和 tex3D()函数访问,并且使用浮点型纹理坐标。
此外,tex1Dfetch()是一个编译器内置函数,因此纹理引用必须声明为文件域内的全局变量,因为编译器在编译阶段需要知道tex1Dfetch()对哪些纹理采样。
8.3.5 解绑纹理内存
最后当程序结束时,我们需要释放之前开辟的内存并解除纹理内存的绑定。
示例代码如下:
cudaUnbindTexture
(tex);
cudaFree(devPtr); |
8.4 使用纹理内存实现均值滤波
下面给出一个我实现的简单的3x3均值滤波,即滤波后的一个像素值是其周围3x3范围内9个像素值的平均值。
均值滤波可以有效去除高斯噪声。
#include "cuda_runtime.h"
#include "opencv.hpp"
#include "highgui.hpp"
// 声明2D纹理内存引用
texture<uchar, 2, cudaReadModeElementType>
texRef;
// 核函数, 用于均值滤波
__global__ void meanfilter_kernel(uchar* dstcuda,
int width)
{
unsigned int x = blockIdx.x * blockDim.x + threadIdx.x;
unsigned int y = blockIdx.y * blockDim.y + threadIdx.y;
// 3x3范围内求和, 然后计算均值
// 注意tex2D会自动对索引越界进行处理,因此不用判断x-1是否小于0
dstcuda[y * width + x] = ( tex2D(texRef, x -
1, y - 1) + tex2D(texRef, x, y - 1) + tex2D(texRef,
x + 1, y - 1) +
tex2D (texRef, x - 1, y) + tex2D(texRef, x, y)
+ tex2D(texRef, x + 1, y) +
tex2D(texRef, x - 1, y + 1) + tex2D(texRef,
x, y + 1) + tex2D(texRef, x + 1, y + 1)) / 9;
}
int main()
{
// 读取待滤波图片(1024x640含高斯噪声灰度图)
cv::Mat srcImg = cv::imread ("gray_scarleet_noisy.jpg", cv::IMREAD_GRAYSCALE);
// 开辟系统内存
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc
(8,0,0,0,cudaChannelFormatKindUnsigned);
cudaArray* srcArray;
cudaMallocArray (&srcArray, &channelDesc,
srcImg.cols, srcImg.rows);
// 将图像copy进内存
cudaMemcpyToArray (srcArray, 0, 0, srcImg.data,
srcImg.cols * srcImg.rows, cudaMemcpyHostToDevice);
// 将内存与纹理引用绑定
cudaBindTextureToArray (&texRef,srcArray,&channelDesc);
// 声明用于储存滤波后的图像
cv::Mat dstImg = cv::Mat(cv::Size (srcImg.cols,
srcImg.rows), CV_8UC1);
uchar * dstcuda;
cudaMalloc((void**)& dstcuda, srcImg.cols
* srcImg.rows * sizeof(uchar));
// 运行核函数
dim3 dimBlock(32, 32);
dim3 dimGrid ((srcImg.cols + dimBlock.x - 1)
/ dimBlock.x, (srcImg.rows + dimBlock.y - 1)
/ dimBlock.y);
meanfilter_kernel << <dimGrid, dimBlock
>> > (dstcuda, srcImg.cols);
// 线程同步
cudaThreadSynchronize();
// 将数据copy回主机
cudaMemcpy (dstImg.data, dstcuda, srcImg.cols
* srcImg.rows * sizeof(uchar), cudaMemcpyDeviceToHost);
// 解除绑定并释放内存
cudaUnbindTexture(&texRef);
cudaFreeArray(srcArray);
cudaFree(dstcuda);
// 显示效果图
cv::imshow("Source Image", srcImg);
cv::imshow("Result Image", dstImg);
cvWaitKey();
return 0;
} |
效果如下:
高斯噪声图

滤波后

九、 原子操作
原子操作 是指对全局和共享内存中的32位或者64位数据进行 “读取-修改-覆写”这一操作。
原子操作可以看作是一种最小单位的执行过程。 在其执行过程中,不允许其他并行线程对该变量进行读取和写入的操作。
如果发生竞争,则其他线程必须等待。
下面先给出原子操作函数的列表,后续会给出一个应用例子。
9.1 原子操作函数列表
9.1.1 atomicAdd()
int atomicAdd(int*
address, int val);
unsigned int atomicAdd(unsigned int* address,
unsigned int val);
unsigned long long int atomicAdd(unsigned long
long int* address, unsigned long long int val);
float atomicAdd(float* address, float val);
double atomicAdd(double* address, double val); |
读取位于全局或共享存储器中地址address处的32位或64位字old,计算(old + val),并将结果存储在存储器的同一地址中。这三项操作在一次原子事务中执行。该函数将返回old。
注意:
32位浮点数的操作只适用于计算能力大于2.0的GPU
64位浮点数的操作只适用于计算能力大于6.0的GPU
但可以通过以下操作在计算能力不足的GPU上实现浮点数原子操作:
#if __CUDA_ARCH__
< 600
__device__ double atomicAdd(double* address, double
val)
{
unsigned long long int* address_as_ull = (unsigned
long long int*)address; unsigned long long int
old = *address_as_ull, assumed;
do {
assumed = old;
old = atomicCAS(address_as_ull, assumed, __double_as_longlong(val
+ __longlong_as_double(assumed)));
// Note: uses integer comparison to avoid hang
in case of NaN (since NaN != NaN)
}
while (assumed != old);
return __longlong_as_double(old);
}
#endif |
9.1.2 atomicSub()
int atomicSub(int*
address, int val);
unsigned int atomicSub(unsigned int* address,
unsigned int val); |
读取位于全局或共享存储器中地址address处的32位字old,计算(old - val),并将结果存储在存储器的同一地址中。这三项操作在一次原子事务中执行。该函数将返回old。
9.1.3 atomicExch()
int atomicExch(int*
address, int val);
unsigned int atomicExch(unsigned int* address,
unsigned int val);
unsigned long long int atomicExch(unsigned long
long int* address, unsigned long long int val);
float atomicExch(float* address, float val); |
读取位于全局或共享存储器中地址address处的32位或64位字old,并将val 存储在存储器的同一地址中。这两项操作在一次原子事务中执行。该函数将返回old。
9.1.4 atomicMin()
int atomicMin(int*
address, int val);
unsigned int atomicMin(unsigned int* address,
unsigned int val);
unsigned long long int atomicMin(unsigned long
long int* address, unsigned long long int val); |
读取位于全局或共享存储器中地址address处的32位字或64位字old,计算old 和val 的最小值,并将结果存储在存储器的同一地址中。这三项操作在一次原子事务中执行。该函数将返回old>
注意:
64位的操作只适用于计算能力大于3.5的GPU
9.1.5 atomicMax()
同atomicMin()。
9.1.6 atomicInc()
| unsigned int atomicInc(unsigned
int* address, unsigned int val); |
读取位于全局或共享存储器中地址address处的32位字old,计算 ((old >= val)
? 0 : (old+1)),并将结果存储在存储器的同一地址中。这三项操作在一次原子事务中执行。该函数将返回old。
9.1.7 atomicDec()
| unsigned int
atomicDec(unsigned int* address, unsigned int
val); |
读取位于全局或共享存储器中地址address处的32位字old,计算 (((old == 0) |
(old > val)) ? val : (old-1)),并将结果存储在存储器的同一地址中。这三项操作在一次原子事务中执行。该函数将返回old。
9.1.8 atomicCAS()
int atomicCAS(int*
address, int compare, int val);
unsigned int atomicCAS(unsigned int* address,
unsigned int compare, unsigned int val);
unsigned long long int atomicCAS(unsigned long
long int* address, unsigned long long int compare,
unsigned long long int val); |
读取位于全局或共享存储器中地址address处的32位或64位字old,计算 (old == compare
? val : old),并将结果存储在存储器的同一地址中。这三项操作在一次原子事务中执行。该函数将返回old(比较并交换)。
9.1.9 atomicAnd()
int atomicAnd(int*
address, int val);
unsigned int atomicAnd(unsigned int* address,
unsigned int val);
unsigned long long int atomicAnd(unsigned long
long int* address, unsigned long long int val); |
读取位于全局或共享存储器中地址address处的32位字或64位字old,计算 (old &
val),并将结果存储在存储器的同一地址中。这三项操作在一次原子事务中执行。该函数将返回old。
注意:
64位的操作只适用于计算能力大于3.5的GPU
9.1.10 atomicOr()
int atomicOr(int*
address, int val);
unsigned int atomicOr(unsigned int* address, unsigned
int val);
unsigned long long int atomicOr(unsigned long
long int* address, unsigned long long int val); |
读取位于全局或共享存储器中地址address处的32位字或64位字old,计算 (old | val),并将结果存储在存储器的同一地址中。这三项操作在一次原子事务中执行。该函数将返回old。
注意:
64位的操作只适用于计算能力大于3.5的GPU
9.1.11 atomicXor()
int atomicXor(int*
address, int val);
unsigned int atomicXor(unsigned int* address,
unsigned int val);
unsigned long long int atomicXor(unsigned long
long int* address, unsigned long long int val); |
读取位于全局或共享存储器中地址address处的32位字或64位字old,计算 (old ^ val),并将结果存储在存储器的同一地址中。这三项操作在一次原子事务中执行。该函数将返回old。
注意:
64位的操作只适用于计算能力大于3.5的GPU
9.2 直方图统计
在一开始我们就提到过,原子操作是为了保证每次只能有一个线程对变量进行读写,而其它线程必须等待。 这样可以有效地避免多个线程访问和修改一个变量带来的不确定问题。
下面我们的例子就是对一堆范围在[0 255]的数进行直方图统计。由于每遇到一个数我们就要在对应统计值处加1,因此多线程操作往同一位置加1的时候很容易出现问题。因此我们采用原子操作。
关于下面的简单程序还有几点说明:
为了验证GPU结果的准确性,我首先采用CPU进行直方图统计,然后在GPU中对数据进行 减计数,如果最后统计结果均为0,则说明GPU和CPU统计结果一致。
程序中每一个block包含256个线程,然后我在每一个block中开辟了一块共享内存temp,并将一个block中的统计结果存储到temp上,最后在对所有block的结果进行整合。这些操作主要是为了避免在全局内存上进行原子操作,否则速度会非常慢。
对于GPU的计算时间我没有考虑数据在主机和设备之间的通信所花费的时间。 事实上,这里的通信是一件相对很慢的工作。读者可以自己测量下整个包含通信所花费的时间。
#include <iostream>
#include "cuda_runtime.h"
#include "time.h"
using namespace std;
#define num (256 * 1024 * 1024)
// 核函数
// 注意,为了方便验证GPU的统计结果,这里采用了"逆直方图",
// 即每发现一个数字,就从CPU的统计结果中减1
__global__ void hist (unsigned char* inputdata,
int* outputhist, long size)
{
// 开辟共享内存,否则在全局内存采用原子操作会非常慢(因为冲突太多)
__shared__ int temp[256];
temp[threadIdx.x] = 0;
__syncthreads();
// 计算线程索引及线程偏移量
int ids = blockIdx.x * blockDim.x + threadIdx.x;
int offset = blockDim.x * gridDim.x;
while (ids < size)
{
//采用原子操作对一个block中的数据进行直方图统计
atomicAdd(&temp[inputdata[ids]],1);
ids += offset;
}
// 等待统计完成,减去统计结果
__syncthreads();
atomicSub (&outputhist[threadIdx.x], temp[threadIdx.x]);
}
int main()
{
// 生成随机数据 [0 255]
unsigned char* cpudata = new unsigned char[num];
for (size_t i = 0; i < num; i++)
cpudata[i] = s tatic_cast<unsigned char> (rand()
% 256);
// 声明数组用于记录统计结果
int cpuhist[256];
memset(cpuhist, 0, 256 * sizeof(int));
/******************************* CPU测试代码 *********************************/
clock_t cpu_start, cpu_stop;
cpu_start = clock();
for (size_t i = 0; i < num; i++)
cpuhist[cpudata[i]] ++;
cpu_stop = clock();
cout << "CPU time: " <<
(cpu_stop - cpu_start) << "ms"
<< endl;
/******************************* GPU测试代码 *********************************/
//定义事件用于计时
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
//开辟显存并将数据copy进显存
unsigned char* gpudata;
cudaMalloc((void**)& gpudata,num*sizeof(unsigned
char));
cudaMemcpy (gpudata, cpudata, num*sizeof(unsigned
char), cudaMemcpyHostToDevice);
// 开辟显存用于存储输出数据,并将CPU的计算结果copy进去
int* gpuhist;
cudaMalloc((void**) &gpuhist, 256*sizeof(int));
cudaMemcpy (gpuhist, cpuhist, 256*sizeof(int),
cudaMemcpyHostToDevice);
// 执行核函数并计时
cudaEventRecord(start, 0);
hist << <1024, 256 >> > (gpudata,gpuhist,num);
cudaEventRecord(stop, 0);
// 将结果copy回主机
int histcpu[256];
cudaMemcpy (cpuhist,gpuhist,256*sizeof(int), cudaMemcpyDeviceToHost);
// 销毁开辟的内存
cudaFree(gpudata);
cudaFree(gpuhist);
delete cpudata;
// 计算GPU花费时间并销毁计时事件
cudaEventSynchronize(stop);
float gputime;
cudaEventElapsedTime (&gputime, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cout << "GPU time: " <<
gputime << "ms" << endl;
// 验证结果
long result = 0;
for (size_t i = 0; i < 256; i++)
result += cpuhist[i];
if (result == 0)
cout << " GPU has the same result
with CPU." << endl;
else
cout << " Error: GPU has a different
result with CPU." << endl;
system("pause");
return 0;
} |
上面的执行结果为:
CPU time: 188ms
GPU time: 26.7367ms
GPU has the same result with CPU. |
十、 流并行
我们前面学习的CUDA并行程序设计,基本上都是在一批数据上利用大量线程实现并行。 除此之外, NVIDIA系列GPU还支持另外一种类型的并行性
—— 流。
GPU中的流并行类似于CPU上的任务并行,即每个流都可以看作是一个独立的任务,每个流中的代码操作顺序执行。
下面从流并行的基础到使用来说明。
10.1 页锁定内存
流并行的使用需要有硬件支持:即必须是支持设备重叠功能的GPU。
通过下面的代码查询设备是否支持设备重叠功能:
cudaDeviceProp
mprop;
cudaGetDeviceProperties(&mprop,0);
if (!mprop.deviceOverlap)
{
cout << "Device not support overlaps,
so stream is invalid!" << endl;
} |
只有支持设备重叠,GPU在执行一个核函数的同时,才可以同时在设备与主机之间执行复制操作。 当然,这种复制操作需要在一种特殊的内存上才可以进行
—— 页锁定内存。
页锁定内存: 需要由cudaHostAlloc()分配,又称为固定内存(Pinned Memory)或者不可分页内存。
操作系统将不会对这块内存分页并交换到磁盘上,从而确保了该内存始终驻留在物理内存中,因为这块内存将不会被破坏或者重新定位。
由于gpu知道内存的物理地址,因此可以通过“直接内存访问(Direct Memory Access,DMA)”
直接在gpu和主机之间复制数据。
可分页内存: malloc()分配的内存是标准的、可分页的(Pagable)主机内存。 可分页内存面临着重定位的问题,因此使用可分页内存进行复制时,复制可能执行两次操作:从可分页内存复制到一块“临时”页锁定内存,然后从页锁定内存复制到GPU。
虽然在页锁定内存上执行复制操作效率比较高,但消耗物理内存更多。因此,通常对cudaMemcpy()调用的源内存或者目标内存才使用,而且使用完毕立即释放。
10.2 流并行机制
流并行是指我们可以创建多个流来执行多个任务, 但每个流都是一个需要按照顺序执行的操作队列。 那么我们如何实现程序加速?
其核心就在于,在页锁定内存上的数据复制是独立于核函数执行的,即我们可以在执行核函数的同时进行数据复制。
这里的复制需要使用cudaMemcpyAsync(),一个以异步执行的函数。调用cudaMemcpyAsync()时,只是放置一个请求,表示在流中执行一次内存复制操作。当函数返回时,我们无法确保复制操作已经结束。我们能够得到的保证是,复制操作肯定会当下一个被放入流中的操作之前执行。(相比之下,cudaMemcpy()是一个同步执行函数。当函数返回时,复制操作已完成。)
以计算 a + b = c为例,假如我们创建了两个流,每个流都是按顺序执行:
| 复制a(主机到GPU) ->
复制b(主机到GPU) -> 核函数计算 -> 复制c(GPU到主机) |

如上图,复制操作和核函数执行是分开的,但由于每个流内部需要按顺序执行,因此复制c的操作需要等待核函数执行完毕。
于是,整个程序执行的时间线如下图:(箭头表示需要等待)

从上面的时间线我们可以启发式的思考下:如何调整每个流当中的操作顺序来获得最大的收益? 提高重叠率。
如下图所示,假如复制一份数据的时间和执行一次核函数的时间差不多,那么我们可以采用交叉执行的策略:

由于流0的a和b已经准备完成,因此当复制流1的b时,可以同步执行流0的核函数。 这样整个时间线,相较于之前的操作很明显少掉了两块操作。
10.3 流并行示例
与流相关的常用函数如下:
// 创建与销毁
cudaStream_t stream//定义流
cudaStreamCreate(cudaStream_t * s)//创建流
cudaStreamDestroy(cudaStream_t s)//销毁流
//同步
cudaStreamSynchronize()//同步单个流:等待该流上的命令都完成
cudaDeviceSynchronize()//同步所有流:等待整个设备上流都完成
cudaStreamWaitEvent()//等待某个事件结束后执行该流上的命令
cudaStreamQuery()//查询一个流任务是否完成
//回调
cudaStreamAddCallback()//在任何点插入回调函数
//优先级
cudaStreamCreateWithPriority()
cudaDeviceGetStreamPriorityRange() |
下面给出一个2个流执行a + b = c的示例, 我们假设数据量非常大,需要将数据拆分,每次计算一部分。
#include <iostream>
#include "cuda_runtime.h"
using namespace std;
#define N (1024*256) // 每次处理的数据量
#define SIZE (N*20) //数据总量
// 核函数,a + b = c
__global__ void add(int* a, int* b, int* c)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N)
c[i] = a[i] + b[i];
}
int main()
{
// 获取0号GPU的属性并判断是否支持设备重叠功能
cudaDeviceProp mprop;
cudaGetDeviceProperties(&mprop,0);
if (!mprop.deviceOverlap)
{
cout << "Device not support overlaps,
so stream is invalid!" << endl;
return 0;
}
// 创建计时事件
cudaEvent_t start, stop;
cudaEventCreate(&start); cudaEventCreate(&stop);
float elapsedTime;
// 创建流
cudaStream_t stream0, stream1;
cudaStreamCreate(&stream0);
cudaStreamCreate(&stream1);
// 开辟主机页锁定内存,并随机初始化数据
int *host_a, *host_b, *host_c;
cudaHostAlloc((void**)&host_a, SIZE*sizeof(int),
cudaHostAllocDefault);
cudaHostAlloc((void**)&host_b, SIZE*sizeof(int),
cudaHostAllocDefault);
cudaHostAlloc((void**)&host_c, SIZE*sizeof(int),
cudaHostAllocDefault);
for (size_t i = 0; i < SIZE; i++)
{
host_a[i] = rand();
host_b[i] = rand();
}
// 声明并开辟相关变量内存
int *dev_a0, *dev_b0, *dev_c0; //用于流0的数据
int *dev_a1, *dev_b1, *dev_c1; //用于流1的数据
cudaMalloc((void**)&dev_a0,N*sizeof(int));
cudaMalloc((void**)&dev_b0, N*sizeof(int));
cudaMalloc((void**)&dev_c0, N*sizeof(int));
cudaMalloc((void**)&dev_a1, N*sizeof(int));
cudaMalloc((void**)&dev_b1, N*sizeof(int));
cudaMalloc((void**)&dev_c1, N*sizeof(int));
/************************ 核心计算部分 ***************************/
cudaEventRecord(start, 0);
for (size_t i = 0; i < SIZE; i += 2*N)
{
// 复制流0数据a
cudaMemcpyAsync(dev_a0, host_a + i, N*sizeof(int),
cudaMemcpyHostToDevice, stream0);
// 复制流1数据a
cudaMemcpyAsync(dev_a1, host_a + i+N, N*sizeof(int),
cudaMemcpyHostToDevice, stream1);
// 复制流0数据b
cudaMemcpyAsync(dev_b0, host_b + i, N*sizeof(int),
cudaMemcpyHostToDevice, stream0);
// 复制流1数据b
cudaMemcpyAsync(dev_b1, host_b + i+N, N*sizeof(int),
cudaMemcpyHostToDevice, stream1);
// 执行流0核函数
add << <N / 256, 256, 0, stream0 >>
>(dev_a0, dev_b0, dev_c0);
// 执行流1核函数
add << <N / 256, 256, 0, stream1 >>
>(dev_a1, dev_b1, dev_c1);
// 复制流0数据c
cudaMemcpyAsync(host_c + i*N, dev_c0, N*sizeof(int),
cudaMemcpyDeviceToHost, stream0);
// 复制流1数据c
cudaMemcpyAsync(host_c + i*N+N, dev_c1, N*sizeof(int),
cudaMemcpyDeviceToHost, stream1);
}
// 流同步
cudaStreamSynchronize(stream0);
cudaStreamSynchronize(stream1);
// 处理计时
cudaEventSynchronize(stop);
cudaEventRecord(stop, 0);
cudaEventElapsedTime(&elapsedTime, start,
stop);
cout << "GPU time: " <<
elapsedTime << "ms" <<
endl;
// 销毁所有开辟的内存
cudaFreeHost(host_a); cudaFreeHost(host_b);
cudaFreeHost(host_c);
cudaFree(dev_a0); cudaFree(dev_b0); cudaFree(dev_c0);
cudaFree(dev_a1); cudaFree(dev_b1); cudaFree(dev_c1);
// 销毁流以及计时事件
cudaStreamDestroy(stream0); cudaStreamDestroy(stream1);
cudaEventDestroy(start); cudaEventDestroy(stop);
return 0;
} |
|








