| БрМЭЦМі: |
| БОЮФРДздгкcnblogsЃЌБОЮФжївЊвдARMЬхЯЕНсЙЙЯТЕФжаЖЯДІРэЮЊР§ЃЌНВЪіећИіжаЖЯДІРэЙ§ГЬжаЕФгВМўааЮЊКЭШэМўЖЏзїЁЃ |
|
вЛЁЂЧАбд
БОЮФжївЊвдARMЬхЯЕНсЙЙЯТЕФжаЖЯДІРэЮЊР§ЃЌНВЪіећИіжаЖЯДІРэЙ§ГЬжаЕФгВМўааЮЊКЭШэМўЖЏзїЁЃОпЬхећИіДІРэЙ§ГЬЗжГЩШ§ИіВНжшРДУшЪіЃК
1ЁЂЕкЖўеТУшЪіСЫжаЖЯДІРэЕФзМБИЙ§ГЬ
2ЁЂЕкШ§еТУшЪіСЫЕБЗЂЩњжаЕФЪБКђЃЌARMгВМўЕФааЮЊ
3ЁЂЕкЫФеТУшЪіСЫARMЕФжаЖЯНјШыЙ§ГЬ
4ЁЂЕкЮхеТУшЪіСЫARMЕФжаЖЯЭЫГіЙ§ГЬ
БОЮФЩцМАЕФДњТыРДзд3.14ФкКЫЁЃСэЭтЃЌБОЮФзЂвтУшЪіARMжИСюМЏЕФФкШнЃЌгааЉsource codeЮЊСЫМђЖЬвЛаЉЃЌЩОГ§СЫTHUMBЯрЙиЕФДњТыЃЌГ§ДЫжЎЭтЃЌгааЉdebugЯрЙиЕФФкШнвВЛсЩОГ§ЁЃ
ЖўЁЂжаЖЯДІРэЕФзМБИЙ§ГЬ
1ЁЂжаЖЯФЃЪНЕФstackзМБИ
ARMДІРэЦїгаЖржжprocessor modeЃЌР§Шчuser modeЃЈгУЛЇПеМфЕФAPЫљДІгкЕФФЃЪНЃЉЁЂsupervisor
modeЃЈМДSVC modeЃЌДѓВПЗжЕФФкКЫЬЌДњТыЖМДІгкетжжmodeЃЉЁЂIRQ modeЃЈЗЂЩњжаЖЯКѓЃЌДІРэЦїЛсЧаШыЕНИУmodeЃЉЕШЁЃЖдгкlinux
kernelЃЌЦфжаЖЯДІРэДІРэЙ§ГЬжаЃЌARM ДІРэЦїДѓВПЗжЖМЪЧДІгкSVC modeЁЃЕЋЪЧЃЌЪЕМЪЩЯВњЩњжаЖЯЕФЪБКђЃЌARMДІРэЦїЪЕМЪЩЯЪЧНјШыIRQ
modeЃЌвђДЫдкНјШыеце§ЕФIRQвьГЃДІРэжЎЧАЛсгавЛаЁЖЮIRQ modeЕФВйзїЃЌжЎКѓЛсНјШыSVC modeНјааеце§ЕФIRQвьГЃДІРэЁЃгЩгкIRQ
modeжЛЪЧвЛИіЙ§ЖШЃЌвђДЫIRQ modeЕФеЛКмаЁЃЌжЛга12ИізжНкЃЌОпЬхШчЯТЃК
struct stack
{
u32 irq[3];
u32 abt[3];
u32 und[3];
} ____cacheline_aligned;
static struct stack stacks[NR_CPUS]; |
Г§СЫirq modeЃЌlinux kernelдкДІРэabt modeЃЈЕБЗЂЩњdata
abort exceptionЛђепprefetch abort exceptionЕФЪБКђНјШыЕФФЃЪНЃЉКЭund
modeЃЈДІРэЦїгіЕНвЛИіЮДЖЈвхЕФжИСюЕФЪБКђНјШыЕФвьГЃФЃЪНЃЉЕФЪБКђвВЪЧВЩгУСЫЯрЭЌЕФВпТдЁЃвВОЭЪЧОЙ§вЛИіМђЖЬЕФabtЛђепund
modeжЎКѓЃЌstackЧаЛЛЕНsvc modeЕФеЛЩЯЃЌетИіеЛОЭЪЧЗЂЩњвьГЃФЧИіЪБМфЕуcurrent threadЕФФкКЫеЛЁЃanywayЃЌдкirq
modeКЭsvc modeжЎМфзмЪЧашвЊвЛИіstackБЃДцЪ§ОнЃЌетОЭЪЧжаЖЯФЃЪНЕФstackЃЌЯЕЭГГѕЪМЛЏЕФЪБКђЃЌcpu_initКЏЪ§жаЛсНјаажаЖЯФЃЪНstackЕФЩшЖЈЃК
void notrace
cpu_init(void)
{
unsigned int cpu = smp_processor_id();ЃЃЃЃЃЃЛёШЁCPU
ID
struct stack *stk = &stacks[cpu];ЃЃЃЃЃЃЃЃЃЛёШЁИУCPUЖдгкЕФirq
abtКЭundЕФstackжИеы
ЁЁ
#ifdef CONFIG_THUMB2_KERNEL
#define PLC "r"ЃЃЃЃЃЃThumb-2ЯТЃЌmsrжИСюВЛдЪаэЪЙгУСЂМДЪ§ЃЌжЛФмЪЙгУМФДцЦїЁЃ
#else
#define PLC "I"
#endif
__asm__ (
"msr cpsr_c, %1\n\t"ЃЃЃЃЃЃШУCPUНјШыIRQ
mode
"add r14, %0, %2\n\t"ЃЃЃЃЃЃr14МФДцЦїБЃДцstk->irq
"mov sp, r14\n\t"ЃЃЃЃЃЃЃЃЩшЖЈIRQ
modeЕФstackЮЊstk->irq
"msr cpsr_c,
%3\n\t"
"add r14, %0, %4\n\t"
"mov sp, r14\n\t"ЃЃЃЃЃЃЃЃЩшЖЈabt
modeЕФstackЮЊstk->abt
"msr cpsr_c,
%5\n\t"
"add r14, %0, %6\n\t"
"mov sp, r14\n\t"ЃЃЃЃЃЃЃЃЩшЖЈund
modeЕФstackЮЊstk->und
"msr cpsr_c,
%7"ЃЃЃЃЃЃЃЃЛиЕНSVC mode
:ЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЩЯУцЪЧcodeЃЌЯТУцЕФoutputВПЗжЪЧПеЕФ
: "r" (stk),ЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЖдгІЩЯУцДњТыжаЕФ%0
PLC (PSR_F_BIT | PSR_I_BIT | IRQ_MODE),ЃЃЃЃЃЃЖдгІЩЯУцДњТыжаЕФ%1
"I" (offsetof(struct stack, irq[0])),ЃЃЃЃЃЃЃЃЃЃЃЃЖдгІЩЯУцДњТыжаЕФ%2
PLC (PSR_F_BIT | PSR_I_BIT | ABT_MODE),ЃЃЃЃЃЃвдДЫРрЭЦЃЌЯТУцВЛзИЪі
"I" (offsetof(struct stack, abt[0])),
PLC (PSR_F_BIT | PSR_I_BIT | UND_MODE),
"I"
(offsetof(struct stack, und[0])),
PLC (PSR_F_BIT | PSR_I_BIT | SVC_MODE)
: "r14");ЃЃЃЃЃЃЃЃЩЯУцЪЧinputВйзїЪ§СаБэЃЌr14ЪЧвЊclobbered
registerСаБэ
} |
ЧЖШыЪНЛуБрЕФгяЗЈИёЪНЪЧЃКasm(code : output operand list : input
operand list : clobber list);ДѓМвЖдзХЩЯУцЕФcodeОЭПЩвдЗжПЊИїЖЮФкШнСЫЁЃдкinput
operand listжаЃЌгаСНжжЯожЦЗћЃЈconstraintЃЉЃЌ"r"Лђеп"I"ЃЌ"I"БэЪОСЂМДЪ§ЃЈImmediate
operandsЃЉЃЌ"r"БэЪОгУЭЈгУМФДцЦїДЋЕнВЮЪ§ЁЃclobber listжагавЛИіr14ЃЌБэЪОдкЛуБрДњТыжааоИФСЫr14ЕФжЕЃЌетаЉаХЯЂЪЧБрвыЦїашвЊЕФФкШнЁЃ
ЖдгкSMPЃЌbootstrap CPUЛсдкЯЕЭГГѕЪМЛЏЕФЪБКђжДааcpu_initКЏЪ§ЃЌНјааБОCPUЕФirqЁЂabtКЭundШ§жжФЃЪНЕФФкКЫеЛЕФЩшЖЈЃЌОпЬхЕїгУађСаЪЧЃКstart_kernel--->setup_arch--->setup_processor--->cpu_initЁЃЖдгкЯЕЭГжаЦфЫћЕФCPUЃЌbootstrap
CPUЛсдкЯЕЭГГѕЪМЛЏЕФзюКѓЃЌЖдУПвЛИіonlineЕФCPUНјааГѕЪМЛЏЃЌОпЬхЕФЕїгУађСаЪЧЃКstart_kernel--->rest_init--->kernel_init--->kernel_init_freeable--->kernel_init_freeable--->smp_init--->cpu_up--->_cpu_up--->__cpu_upЁЃ__cpu_upКЏЪ§ЪЧКЭCPU
architectureЯрЙиЕФЁЃЖдгкARMЃЌЦфЕїгУађСаЪЧ__cpu_up--->boot_secondary--->smp_ops.smp_boot_secondary(SOCЯрЙиДњТы)--->secondary_startup--->__secondary_switched--->secondary_start_kernel--->cpu_initЁЃ
Г§СЫГѕЪМЛЏЃЌЯЕЭГЕчдДЙмРэвВашвЊirqЁЂabtКЭund stackЕФЩшЖЈЁЃШчЙћЮвУЧЩшЖЈЕФЕчдДЙмРэзДЬЌдкНјШыsleepЕФЪБКђЃЌCPUЛсЖЊЪЇirqЁЂabtКЭund
stack pointМФДцЦїЕФжЕЃЌФЧУДдкCPU resumeЕФЙ§ГЬжаЃЌвЊЕїгУcpu_initРДжиаТЩшЖЈетаЉжЕЁЃ
2ЁЂSVCФЃЪНЕФstackзМБИ
ЮвУЧОГЃЫЕНјГЬЕФгУЛЇПеМфКЭФкКЫПеМфЃЌЖдгквЛИігІгУГЬађЖјбдЃЌПЩвддЫаадкгУЛЇПеМфЃЌвВПЩвдЭЈЙ§ЯЕЭГЕїгУНјШыФкКЫПеМфЁЃдкгУЛЇПеМфЃЌЪЙгУЕФЪЧгУЛЇеЛЃЌвВОЭЪЧЮвУЧШэМўЙЄГЬЪІБраДгУЛЇПеМфГЬађЕФЪБКђЃЌБЃДцОжВПБфСПЕФstackЁЃЯнШыФкКЫКѓЃЌЕБШЛВЛФмгУгУЛЇеЛСЫЃЌетЪБКђОЭашвЊЪЙгУЕНФкКЫеЛЁЃЫљЮНФкКЫеЛЦфЪЕОЭЪЧДІгкSVC
modeЪБКђЪЙгУЕФеЛЁЃ
дкlinuxзюПЊЪМЦєЖЏЕФЪБКђЃЌЯЕЭГжЛгавЛИіНјГЬЃЈИќзМШЗЕФЫЕЪЧkernel
threadЃЉЃЌОЭЪЧPIDЕШгк0ЕФФЧИіНјГЬЃЌНазіswapperНјГЬЃЈЛђепНазіidleНјГЬЃЉЁЃИУНјГЬЕФФкКЫеЛЪЧОВЬЌЖЈвхЕФЃЌШчЯТЃК
union thread_union
init_thread_union __init_task_data =
{ INIT_THREAD_INFO(init_task) };
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
}; |
ЖдгкARMЦНЬЈЃЌTHREAD_SIZEЪЧ8192ИіbyteЃЌвђДЫеМОнСНИіpage
frameЁЃЫцзХГѕЪМЛЏЕФНјааЃЌuser spaceЕФНјГЬвВЛсДДНЈНјГЬЛђепЯпГЬЁЃLinux kernelдкДДНЈНјГЬЃЈАќРЈгУЛЇНјГЬКЭФкКЫЯпГЬЃЉЕФЪБКђЖМЛсЗжХфвЛИіЃЈЛђепСНИіЃЌКЭХфжУЯрЙиЃЉpage
frameЃЌОпЬхДњТыШчЯТЃК
static struct
task_struct *dup_task_struct(struct task_struct
*orig)
{
......
ti = alloc_thread_info_node(tsk, node);
if (!ti)
goto free_tsk;
......
} |
ЕзВПЪЧstruct thread_infoЪ§ОнНсЙЙЃЌЖЅВПЃЈИпЕижЗЃЉОЭЪЧИУНјГЬЕФФкКЫеЛЁЃЕБНјГЬЧаЛЛЕФЪБКђЃЌећИігВМўКЭШэМўЕФЩЯЯТЮФЖМЛсНјааЧаЛЛЃЌетРяОЭАќРЈСЫsvc
modeЕФspМФДцЦїЕФжЕБЛЧаЛЛЕНЕїЖШЫуЗЈбЁЖЈЕФаТЕФНјГЬЕФФкКЫеЛЩЯРДЁЃ
3ЁЂвьГЃЯђСПБэЕФзМБИ
ЖдгкARMДІРэЦїЖјбдЃЌЕБЗЂЩњвьГЃЕФЪБКђЃЌДІРэЦїЛсднЭЃЕБЧАжИСюЕФжДааЃЌБЃДцЯжГЁЃЌзЊЖјШЅжДааЖдгІЕФвьГЃЯђСПДІЕФжИСюЃЌЕБДІРэЭъИУвьГЃЕФЪБКђЃЌЛжИДЯжГЁЃЌЛиЕНдРДЕФФЧЕуШЅМЬајжДааГЬађЁЃЯЕЭГЫљгаЕФвьГЃЯђСПЃЈЙВМЦ8ИіЃЉзщГЩСЫвьГЃЯђСПБэЁЃЯђСПБэЃЈvector
tableЃЉЕФДњТыШчЯТЃК
.section .vectors,
"ax", %progbits
__vectors_start:
W(b) vector_rst
W(b) vector_und
W(ldr) pc, __vectors_start + 0x1000
W(b) vector_pabt
W(b) vector_dabt
W(b) vector_addrexcptn
W(b) vector_irq ---------------------------IRQ
Vector
W(b) vector_fiq |
ЖдгкБОЮФЖјбдЃЌЮвУЧжиЕуЙизЂvector_irqетИіexception vectorЁЃвьГЃЯђСПБэПЩФмБЛАВЗХдкСНИіЮЛжУЩЯЃК
ЃЈ1ЃЉвьГЃЯђСПБэЮЛгк0x0ЕФЕижЗЁЃетжжЩшжУНазіNormal vectorsЛђепLow vectorsЁЃ
ЃЈ2ЃЉвьГЃЯђСПБэЮЛгк0xffff0000ЕФЕижЗЁЃетжжЩшжУНазіhigh vectors
ОпЬхЪЧlow vectorsЛЙЪЧhigh vectorsЪЧгЩARMЕФвЛИіНазіЕФSCTLRМФДцЦїЕФЕк13Иіbit
ЃЈvector bitЃЉПижЦЕФЁЃЖдгкЦєгУMMUЕФARM LinuxЖјбдЃЌЯЕЭГЪЙгУСЫhigh vectorsЁЃЮЊЪВУДВЛгУlow
vectorФиЃПЖдгкlinuxЖјбдЃЌ0ЁЋ3GЕФПеМфЪЧгУЛЇПеМфЃЌШчЙћЪЙгУlow vectorЃЌФЧУДвьГЃЯђСПБэдк0ЕижЗЃЌФЧУДдђЪЧгУЛЇПеМфЕФЮЛжУЃЌвђДЫlinuxбЁгУhigh
vectorЁЃЕБШЛЃЌЪЙгУLow vectorвВПЩвдЃЌетбљLow vectorЫљдкЕФПеМфдђЪєгкkernel
spaceСЫЃЈвВОЭЪЧЫЕЃЌ3GЁЋ4GЕФПеМфМгЩЯLow vectorЫљеМЕФПеМфЪєгкkernel spaceЃЉЃЌВЛЙ§етЪБКђвЊзЂвтвЛЕуЃЌвђЮЊЫљгаЕФНјГЬЙВЯэkernel
spaceЃЌЖјгУЛЇПеМфЕФГЬађОГЃЛсЗЂЩњПежИеыЗУЮЪЃЌетЪБКђЃЌФкДцБЃЛЄЛњжЦгІИУПЩвдВЖЛёетжжДэЮѓЃЈДѓВПЗжЕФMMUЖМПЩвдзіЕНЃЌР§ШчЃКНћжЙuserspaceЗУЮЪkernel
spaceЕФЕижЗПеМфЃЉЃЌЗРжЙvector tableБЛЗУЮЪЕНЁЃЖдгкФкКЫжагЩгкГЬађДэЮѓЕМжТЕФПежИеыЗУЮЪЃЌФкДцБЃЛЄЛњжЦвВашвЊПижЦvector
tableБЛаоИФЃЌвђДЫvector tableЫљдкЕФПеМфБЛЩшжУГЩread onlyЕФЁЃдкЪЙгУСЫMMUжЎКѓЃЌОпЬхвьГЃЯђСПБэЗХдкФЧИіЮяРэЕижЗвбОВЛживЊСЫЃЌживЊЕФЪЧАбЫќгГЩфЕН0xffff0000ЕФащФтЕижЗОЭOKСЫЃЌОпЬхДњТыШчЯТЃК
static void
__init devicemaps_init(const struct machine_desc
*mdesc)
{
ЁЁ
vectors = early_alloc(PAGE_SIZE * 2); ЃЃЃЃЃЗжХфСНИіpageЕФЮяРэвГжЁ
early_trap_init(vectors); ЃЃЃЃЃЃЃcopyЯђСПБэвдМАЯрЙиhelp
functionЕНИУЧјгђ
ЁЁ
map.pfn = __phys_to_pfn(virt_to_phys(vectors));
map.virtual = 0xffff0000;
map.length = PAGE_SIZE;
#ifdef CONFIG_KUSER_HELPERS
map.type = MT_HIGH_VECTORS;
#else
map.type = MT_LOW_VECTORS;
#endif
create_mapping(&map); ЃЃЃЃЃЃЃЃЃЃгГЩф0xffff0000ЕФФЧИіpage
frame
if (!vectors_high()) {ЃЃЃШчЙћSCTLR.VЕФжЕЩшЖЈЮЊlow vectorsЃЌФЧУДЛЙвЊгГЩф0ЕижЗПЊЪМЕФmemory
map.virtual = 0;
map.length = PAGE_SIZE * 2;
map.type = MT_LOW_VECTORS;
create_mapping(&map);
}
map.pfn += 1;
map.virtual = 0xffff0000 + PAGE_SIZE;
map.length = PAGE_SIZE;
map.type = MT_LOW_VECTORS;
create_mapping(&map); ЃЃЃЃЃЃЃЃЃЃгГЩфhigh vecotrПЊЪМЕФЕкЖўИіpage
frame
ЁЁ
} |
ЮЊЪВУДвЊЗжХфСНИіpage frameФиЃПетРяvectors tableКЭkuser helperКЏЪ§ЃЈФкКЫПеМфЬсЙЉЕФКЏЪ§ЃЌЕЋЪЧгУЛЇПеМфЪЙгУЃЉеМгУСЫвЛИіpage
frameЃЌСэЭтвьГЃДІРэЕФstubКЏЪ§еМгУСЫСэЭтвЛИіpage frameЁЃЮЊЪВУДЛсгаstubКЏЪ§ФиЃПЩдКѓЛсНВЕНЁЃ
дкearly_trap_initКЏЪ§жаЛсГѕЪМЛЏвьГЃЯђСПБэЃЌОпЬхДњТыШчЯТЃК
void __init
early_trap_init(void *vectors_base)
{
unsigned long vectors = (unsigned long)vectors_base;
extern char __stubs_start[], __stubs_end[];
extern char __vectors_start[], __vectors_end[];
unsigned i;
vectors_page = vectors_base;
НЋећИіvector tableФЧИіpage frameЬюГфГЩЮДЖЈвхЕФжИСюЁЃЦ№ЪМvector
tableМгЩЯkuser helperКЏЪ§ВЂВЛФмЭъШЋЕФГфТњетИіpageЃЌгааЉЗьЯЖЁЃШчЙћВЛетУДДІРэЃЌЕБМЋЖЫЧщПіЯТЃЈГЬађДэЮѓЛђепHWЕФissueЃЉЃЌCPUПЩФмДгетаЉЗьЯЖжаШЁжИжДааЃЌДгЖјЕМжТВЛПЩжЊЕФКѓЙћЁЃШчЙћНЋетаЉЗьЯЖЬюГфЮДЖЈвхжИСюЃЌФЧУДCPUПЩвдВЖЛёетжжвьГЃЁЃ
for (i = 0; i < PAGE_SIZE / sizeof(u32); i++)
((u32 *)vectors_base)[i] = 0xe7fddef1;
ПНБДvector tableЃЌПНБДstub function
memcpy((void *)vectors, __vectors_start, __vectors_end
- __vectors_start);
memcpy((void *)vectors + 0x1000, __stubs_start,
__stubs_end - __stubs_start);
kuser_init(vectors_base); ЃЃЃЃcopy kuser helper
function
flush_icache_range(vectors, vectors + PAGE_SIZE
* 2);
modify_domain(DOMAIN_USER, DOMAIN_CLIENT);
} |
НЋећИіvector tableФЧИіpage frameЬюГфГЩЮДЖЈвхЕФжИСюЁЃЦ№ЪМvector
tableМгЩЯkuser helperКЏЪ§ВЂВЛФмЭъШЋЕФГфТњетИіpageЃЌгааЉЗьЯЖЁЃШчЙћВЛетУДДІРэЃЌЕБМЋЖЫЧщПіЯТЃЈГЬађДэЮѓЛђепHWЕФissueЃЉЃЌCPUПЩФмДгетаЉЗьЯЖжаШЁжИжДааЃЌДгЖјЕМжТВЛПЩжЊЕФКѓЙћЁЃШчЙћНЋетаЉЗьЯЖЬюГфЮДЖЈвхжИСюЃЌФЧУДCPUПЩвдВЖЛёетжжвьГЃЁЃ
вЛЕЉЩцМАДњТыЕФПНБДЃЌЮвУЧОЭашвЊЙиаФЦфБрвыСЌНгЪБЕижЗЃЈlink-time address)КЭдЫааЪБЕижЗЃЈrun-time
addressЃЉЁЃдкkernelЭъГЩСДНгКѓЃЌ__vectors_startгаСЫЦфlink-time
addressЃЌШчЙћlink-time addressКЭrun-time addressвЛжТЃЌФЧУДетЖЮДњТыдЫааЪБКСЮобЙСІЁЃЕЋЪЧЃЌФПЧАЖдгкvector
tableЖјбдЃЌЦфБЛcopyЕНЦфЫћЕФЕижЗЩЯЃЈЖдгкHigh vectorЃЌетЪЧЕижЗОЭЪЧ0xffff00000ЃЉЃЌвВОЭЪЧЫЕЃЌlink-time
addressКЭrun-time addressВЛвЛбљСЫЃЌШчЙћШдШЛЯывЊетаЉДњТыПЩвде§ШЗдЫааЃЌФЧУДашвЊетаЉДњТыЪЧЮЛжУЮоЙиЕФДњТыЁЃЖдгкvector
tableЖјбдЃЌБиаывЊЮЛжУЮоЙиЁЃBетИіbranch instructionБОЩэОЭЪЧЮЛжУЮоЙиЕФЃЌЫќПЩвдЬјзЊЕНвЛИіЕБЧАЮЛжУЕФoffsetЁЃВЛЙ§ВЂЗЧЫљгаЕФvectorЖМЪЧЪЙгУСЫbranch
instructionЃЌЖдгкШэжаЖЯЃЌЦфvectorЕижЗЩЯжИСюЪЧЁАW(ldr) pc, __vectors_start
+ 0x1000 ЁБЃЌетЬѕжИСюБЛБрвыЦїБрвыГЩldr pc, [pc, #4080]ЃЌетжжЧщПіЯТЃЌИУжИСювВЪЧЮЛжУЮоЙиЕФЃЌЕЋЪЧгаИіЯожЦЃЌoffsetБиаыдк4KЕФЗЖЮЇФкЃЌетвВЪЧЮЊКЮДцдкstub
sectionЕФдвђСЫЁЃ
4ЁЂжаЖЯПижЦЦїЕФГѕЪМЛЏ
ОпЬхПЩвдВЮПМGICДњТыЗжЮіЁЃ
Ш§ЁЂARM HWЖджаЖЯЪТМўЕФДІРэ
ЕБвЛЧазМБИКУжЎКѓЃЌвЛЕЉДђПЊДІРэЦїЕФШЋОжжаЖЯОЭПЩвдДІРэРДздЭтЩшЕФИїжжжаЖЯЪТМўСЫЁЃ
ЕБЭтЩшЃЈSOCФкВПЛђепЭтВПЖМПЩвдЃЉМьВтЕНСЫжаЖЯЪТМўЃЌОЭЛсЭЈЙ§interrupt requestion
lineЩЯЕФЕчЦНЛђепБпбиЃЈЩЯЩ§биЛђепЯТНЕбиЛђепbothЃЉЭЈжЊЕНИУЭтЩшСЌНгЕНЕФФЧИіжаЖЯПижЦЦїЃЌЖјжаЖЯПижЦЦїОЭЛсдкЖрИіДІРэЦїжабЁдёвЛИіЃЌВЂАбИУжаЖЯЭЈЙ§IRQЃЈЛђепFIQЃЌБОЮФВЛЬжТлFIQЕФЧщПіЃЉЗжЗЂИјИУprocessorЁЃARMДІРэЦїИажЊЕНСЫжаЖЯЪТМўКѓЃЌЛсНјааЯТУцвЛЯЕСаЕФЖЏзїЃК
1ЁЂаоИФCPSRЃЈCurrent Program Status RegisterЃЉМФДцЦїжаЕФM[4:0]ЁЃM[4:0]БэЪОСЫARMДІРэЦїЕБЧАДІгкЕФФЃЪНЃЈ
processor modesЃЉЁЃARMЖЈвхЕФmodeАќРЈЃК
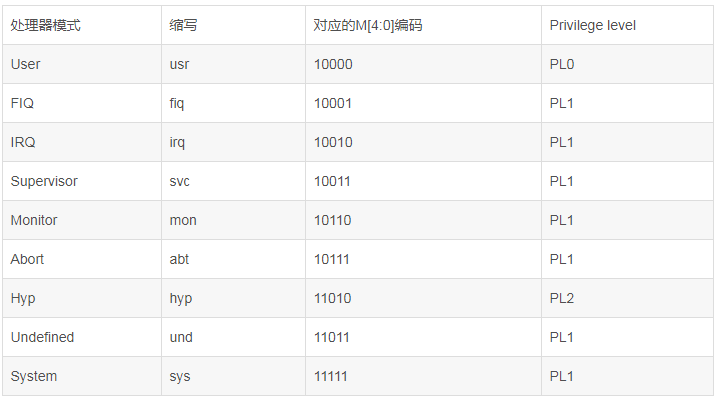
вЛЕЉЩшЖЈСЫCPSR.MЃЌARMДІРэЦїОЭЛсНЋprocessor modeЧаЛЛЕНIRQ modeЁЃ
2ЁЂБЃДцЗЂЩњжаЖЯФЧвЛЕуЕФCPSRжЕЃЈstep 1жЎЧАЕФзДЬЌЃЉКЭPCжЕ
ARMДІРэЦїжЇГж9жжprocessor modeЃЌУПжжmodeПДЕНЕФARM
core registerЃЈR0ЁЋR15ЃЌЙВМЦ16ИіЃЉЖМЪЧВЛЭЌЕФЁЃУПжжmodeЖМЪЧДгвЛИіАќРЈЫљгаЕФBanked
ARM core registerжабЁШЁЁЃШЋВПBanked ARM core registerАќРЈЃК
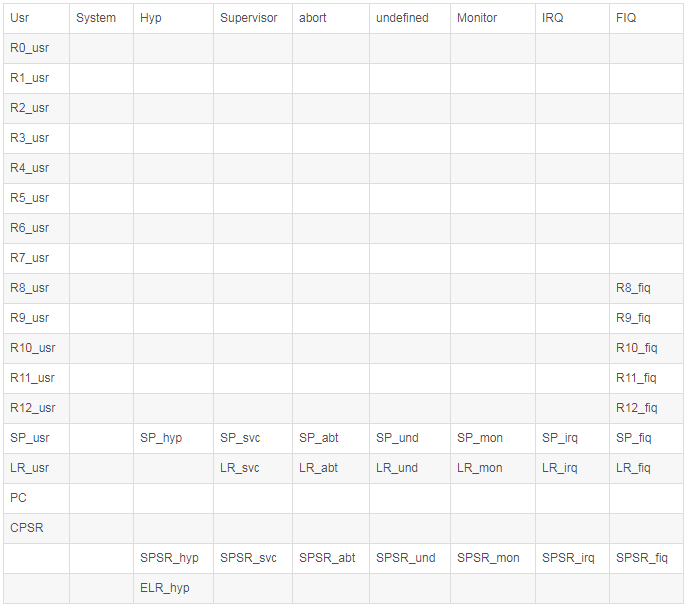
дкIRQ modeЯТЃЌCPUПДЕНЕФR0ЁЋR12МФДцЦїЁЂPCвдМАCPSRЪЧКЭusr modeЃЈuserspaceЃЉЛђепsvc
modeЃЈkernel spaceЃЉЪЧвЛбљЕФЁЃВЛЭЌЕФЪЧIRQ modeЯТЃЌгаздМКЕФR13(SPЃЌstack
pointerЃЉЁЂR14ЃЈLRЃЌlink registerЃЉКЭSPSRЃЈSaved Program
Status RegisterЃЉЁЃ
CPSRЪЧЙВгУЕФЃЌЫфШЛжаЖЯПЩФмЗЂЩњдкusr modeЃЈгУЛЇПеМфЃЉЃЌвВПЩФмЪЧsvc modeЃЈФкКЫПеМфЃЉЃЌВЛЙ§етаЉаХЯЂЖМЪЧЬхЯждкCPSRМФДцЦїжаЁЃгВМўЛсНЋЗЂЩњжаЖЯФЧвЛПЬЕФCPSRБЃДцдкSPSRМФДцЦїжаЃЈгЩгкВЛЭЌЕФmodeЯТгаВЛЭЌЕФSPSRМФДцЦїЃЌвђДЫИќзМШЗЕФЫЕгІИУЪЧSPSR-irqЃЌвВОЭЪЧIRQ
modeжаЕФSPSRМФДцЦїЃЉЁЃ
PCвВЪЧЙВгУЕФЃЌгЩгкКѓајPCЛсБЛаоИФЮЊirq exception vectorЃЌвђДЫгаБивЊБЃДцPCжЕЁЃЕБШЛЃЌгыЦфЫЕБЃДцPCжЕЃЌВЛШчЫЕЪЧБЃДцЗЕЛижДааЕФЕижЗЁЃЖдгкIRQЖјбдЃЌЮвУЧЦкЭћЗЕЛиЕижЗЪЧЗЂЩњжаЖЯФЧвЛЕужДаажИСюЕФЯТвЛЬѕжИСюЁЃОпЬхЕФЗЕЛиЕижЗБЃДцдкlrМФДцЦїжаЃЈзЂвтЃКетИіlrМФДцЦїЪЧIRQ
modeЕФlrМФДцЦїЃЌПЩвдБэЪОЮЊlr_irqЃЉЃК
ЃЈ1ЃЉЖдгкthumb stateЃЌlr_irq ЃН PC
ЃЈ2ЃЉЖдгкARM stateЃЌlr_irq ЃН PC Ѓ 4
ЮЊКЮвЊМѕШЅ4ЃПЮвЕФРэНтЪЧетбљЕФЃЈВЛвЛЖЈЖдЃЉЁЃгЩгкARMВЩгУСїЫЎЯпНсЙЙЃЌЕБCPUе§дкжДааФГвЛЬѕжИСюЕФЪБКђЃЌЦфЪЕШЁжИЕФЖЏзїдчОЭжДааСЫЃЌетЪБКђPCжЕЃНе§дкжДааЕФжИСюЕижЗ
ЃЋ 8ЃЌШчЯТЫљЪОЃК
ЃЃЃЃ> ЗЂЩњжаЖЯЕФжИСю
ЗЂЩњжаЖЯЕФжИСюЃЋ4
ЃPCЃЃ>ЗЂЩњжаЖЯЕФжИСюЃЋ8
ЗЂЩњжаЖЯЕФжИСюЃЋ12
вЛЕЉЗЂЩњСЫжаЖЯЃЌЕБЧАе§дкжДааЕФжИСюЕБШЛвЊжДааЭъБЯЃЌЕЋЪЧвбОЭъГЩШЁжИЁЂвыТыЕФжИСюдђжежЙжДааЁЃЕБЗЂЩњжаЖЯЕФжИСюжДааЭъБЯжЎКѓЃЌдРДжИЯђЃЈЗЂЩњжаЖЯЕФжИСюЃЋ8ЃЉЕФPCЛсМЬајдіМг4ЃЌвђДЫЗЂЩњжаЖЯКѓЃЌARM
coreЕФгВМўзХЪжДІРэИУжаЖЯЕФЪБКђЃЌгВМўЯжГЁШчЯТЭМЫљЪОЃК
ЃЃЃЃ> ЗЂЩњжаЖЯЕФжИСю
ЗЂЩњжаЖЯЕФжИСюЃЋ4 <-------жаЖЯЗЕЛиЕФжИСюЪЧетЬѕжИСю
ЗЂЩњжаЖЯЕФжИСюЃЋ8
ЃPCЃЃ>ЗЂЩњжаЖЯЕФжИСюЃЋ12
етЪБКђЕФPCжЕЦфЪЕЪЧБШЗЂЩњжаЖЯЪБКђЕФжИСюГЌЧА12ЁЃМѕШЅ4жЎКѓЃЌlr_irqжаБЃДцСЫЃЈЗЂЩњжаЖЯЕФжИСюЃЋ8ЃЉЕФЕижЗЁЃЮЊЪВУДHWВЛАяУІжБНгМѕШЅ8ФиЃПетбљЃЌКѓајШэМўВЛОЭВЛгУдйМѕШЅ4СЫЁЃетРяЮвУЧВЛФмЙТСЂЕФПДД§ЮЪЬтЃЌЪЕМЪЩЯARMЕФвьГЃДІРэЕФгВМўТпМВЛНіНіДІРэIRQЕФexceptionЃЌЛЙвЊДІРэИїжжexceptionЃЌКмвХКЖЃЌВЛЭЌЕФexceptionЦкЭћЕФЗЕЛиЕижЗВЛЭГвЛЃЌвђДЫЃЌгВМўжЛЪЧАяУІМѕШЅ4ЃЌЪЃЯТЕФНЛИјШэМўШЅЕїећЁЃ
3ЁЂmask IRQ exceptionЁЃвВОЭЪЧЩшЖЈCPSR.I = 1
4ЁЂЩшЖЈPCжЕЮЊIRQ exception vectorЁЃЛљБОЩЯЃЌARMДІРэЦїЕФгВМўОЭжЛФмАяФуАяЕНетРяСЫЃЌвЛЕЉЩшЖЈPCжЕЃЌARMДІРэЦїОЭЛсЬјзЊЕНIRQЕФexception
vectorЕижЗСЫЃЌКѓајЕФЖЏзїЖМЪЧШэМўааЮЊСЫЁЃ
ЫФЁЂШчКЮНјШыARMжаЖЯДІРэ
1ЁЂIRQ modeжаЕФДІРэ
IRQ modeЕФДІРэЖМдкvector_irqжаЃЌvector_stubЪЧвЛИіКъЃЌЖЈвхШчЯТЃК
.macro vector_stub,
name, mode, correction=0
.align 5
vector_\name:
.if \correction
sub lr, lr, #\correctionЃЃЃЃЃЃЃЃЃЃЃЃЃЃЈ1ЃЉ
.endif
@
@ Save r0, lr_ (parent PC) and spsr_
@ (parent CPSR)
@
stmia sp, {r0, lr} @ save r0, lrЃЃЃЃЃЃЃЃЃЈ2ЃЉ
mrs lr, spsr
str lr, [sp, #8] @ save spsr
@
@ Prepare for SVC32 mode. IRQs remain disabled.
@
mrs r0, cpsrЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЈ3ЃЉ
eor r0, r0, #(\mode ^ SVC_MODE | PSR_ISETSTATE)
msr spsr_cxsf, r0
@
@ the branch table must immediately follow this
code
@
and lr, lr, #0x0fЃЃЃlrБЃДцСЫЗЂЩњIRQЪБКђЕФCPSRЃЌЭЈЙ§andВйзїЃЌПЩвдЛёШЁCPSR.M[3:0]ЕФжЕ
етЪБКђЃЌШчЙћжаЖЯЗЂЩњдкгУЛЇПеМфЃЌlr=0ЃЌШчЙћЪЧФкКЫПеМфЃЌlr=3
THUMB( adr r0, 1f )ЃЃЃЃИљОнЕБЧАPCжЕЃЌЛёШЁlable 1ЕФЕижЗ
THUMB( ldr lr, [r0, lr, lsl #2] )ЃlrИљОнЕБЧАmodeЃЌвЊУДЪЧ__irq_usrЕФЕижЗ
ЃЌвЊУДЪЧ__irq_svcЕФЕижЗ
mov r0, spЃЃЃЃЃЃНЋirq modeЕФstack pointЭЈЙ§r0ДЋЕнИјМДНЋЬјзЊЕФКЏЪ§
ARM( ldr lr, [pc, lr, lsl #2] )ЃЃЃИљОнmodeЃЌИјlrИГжЕЃЌ__irq_usrЛђеп__irq_svc
movs pc, lr @ branch to handler in SVC modeЃЃЃЃЃЃЈ4ЃЉ
ENDPROC(vector_\name)
.align 2
@ handler addresses follow this label
1:
.endm |
ЃЈ1ЃЉЮвУЧЦкЭћдкеЛЩЯБЃДцЗЂЩњжаЖЯЪБКђЕФгВМўЯжГЁЃЈHW contextЃЉЃЌетРяОЭАќРЈARMЕФcore
registerЁЃЩЯвЛеТЮвУЧвбОСЫНтЕНЃЌЕБЗЂЩњIRQжаЖЯЕФЪБКђЃЌlrжаБЃДцСЫЗЂЩњжаЖЯЕФPCЃЋ4ЃЌШчЙћМѕШЅ4ЕФЛАЃЌЕУЕНЕФОЭЪЧЗЂЩњжаЖЯФЧвЛЕуЕФPCжЕЁЃ
ЃЈ2ЃЉЕБЧАЪЧIRQ modeЃЌSP_irqдкГѕЪМЛЏЕФЪБКђвбОЩшЖЈЃЈ12ИізжНкЃЉЁЃдкirq modeЕФstackЩЯЃЌвРДЮБЃДцСЫЗЂЩњжаЖЯФЧвЛЕуЕФr0жЕЁЂPCжЕвдМАCPSRжЕЃЈОпЬхВйзїЪЧЭЈЙ§spsrНјааЕФЃЌЦфЪЕгВМўвбОАяЮвУЧБЃДцСЫCPSRЕНSPSRжаСЫЃЉЁЃЮЊКЮвЊБЃДцr0жЕЃПвђЮЊЫцКѓЕФДњТывЊЪЙгУr0МФДцЦїЃЌвђДЫЮвУЧвЊАбr0ЗХЕНеЛЩЯЃЌжЛгаетбљВХФмЭъЭъШЋШЋЛжИДгВМўЯжГЁЁЃ
ЃЈ3ЃЉПЩСЏЕФIRQ modeЩдзнМДЪХЃЌетЖЮДњТыОЭЪЧзМБИНЋARMЭЦЫЭЕНSVC modeЁЃШчКЮзМБИЃПЦфЪЕОЭЪЧаоИФSPSRЕФжЕЃЌSPSRВЛЪЧCPSRЃЌВЛЛсв§Ц№processor
modeЕФЧаЛЛЃЈБЯОЙетвЛВНжЛЪЧзМБИЖјвбЃЉЁЃ
ЃЈ4ЃЉКмЖрвьГЃДІРэЕФДњТыЗЕЛиЕФЪБКђЖМЪЧЪЙгУСЫstackЯрЙиЕФВйзїЃЌетРяУЛгаЁЃЁАmovs pc, lr
ЁБжИСюГ§СЫзжУцЩЯвтЫМЃЈАбlrЕФжЕИЖИјpcЃЉЃЌЛЙгавЛИівўКЌЕФВйзїЃЈmovsжаЁЎsЁЏЕФКЌвхЃЉЃКАбSPSR
copyЕНCPSRЃЌДгЖјЪЕЯжСЫФЃЪНЕФЧаЛЛЁЃ
2ЁЂЕБЗЂЩњжаЖЯЕФЪБКђЃЌДњТыдЫаадкгУЛЇПеМф
Interrupt dispatcherЕФДњТыШчЯТЃК
vector_stub
irq, IRQ_MODE, 4 ЃЃЃЃЃМѕШЅ4ЃЌШЗБЃЗЕЛиЗЂЩњжаЖЯжЎКѓЕФФЧЬѕжИСю
.long __irq_usr @ 0 (USR_26 / USR_32) <--------------------->
base address + 0
.long __irq_invalid @ 1 (FIQ_26 / FIQ_32)
.long __irq_invalid @ 2 (IRQ_26 / IRQ_32)
.long __irq_svc @ 3 (SVC_26 / SVC_32)<--------------------->
base address + 12
.long __irq_invalid @ 4
.long __irq_invalid @ 5
.long __irq_invalid @ 6
.long __irq_invalid @ 7
.long __irq_invalid @ 8
.long __irq_invalid @ 9
.long __irq_invalid @ a
.long __irq_invalid @ b
.long __irq_invalid @ c
.long __irq_invalid @ d
.long __irq_invalid @ e
.long __irq_invalid @ f |
етЦфЪЕОЭЪЧвЛИіlookup tableЃЌИљОнCPSR.M[3:0]ЕФжЕНјааЬјзЊЃЈВЮПМЩЯвЛНкЕФДњТыЃКand
lr, lr, #0x0fЃЉЁЃвђДЫЃЌИУlookup tableЙВЩшЖЈСЫ16ИіШыПкЃЌЕБШЛжЛгаСНЯюгааЇЃЌЗжБ№ЖдгІuser
modeКЭsvc modeЕФЬјзЊЕижЗЁЃЦфЫћШыПкЕФ__irq_invalidвВЪЧЗЧГЃЙиМќЕФЃЌетБЃжЄСЫдкЦфФЃЪНЯТЗЂЩњСЫжаЖЯЃЌЯЕЭГПЩвдВЖЛёЕНетбљЕФДэЮѓЃЌЮЊdebugЬсЙЉгагУЕФаХЯЂЁЃ
.align 5
__irq_usr:
usr_entryЃЃЃЃЃЃЃЃЃЧыВЮПМБОеТЕквЛНкЃЈ1ЃЉБЃДцгУЛЇЯжГЁЕФУшЪі
kuser_cmpxchg_checkЃЃЃКЭБОЮФУшЪіЕФФкШнЮоЙиЃЌетаЉВЛОЭНщЩмСЫ
irq_handlerЃЃЃЃЃЃЃЃЃЃКЫаФДІРэФкШнЃЌЧыВЮПМБОеТЕкЖўНкЕФУшЪі
get_thread_info tskЃЃЃЃЃЃtskЪЧr9ЃЌжИЯђЕБЧАЕФthread infoЪ§ОнНсЙЙ
mov why, #0ЃЃЃЃЃЃЃЃwhyЪЧr8
b ret_to_user_from_irqЃЃЃЃжаЖЯЗЕЛиЃЌЯТвЛеТЛсЯъЯИУшЪі |
whyЦфЪЕОЭЪЧr8МФДцЦїЃЌгУРДДЋЕнВЮЪ§ЕФЃЌБэЪОБОДЮЗХЛигУЛЇПеМфЯрЙиЕФЯЕЭГЕїгУЪЧФФИіЃПжаЖЯДІРэетИіГЁОАКЭЯЕЭГЕїгУЮоЙиЃЌвђДЫЩшЖЈЮЊ0ЁЃ
ЃЈ1ЃЉБЃДцЗЂЩњжаЖЯЪБКђЕФЯжГЁЁЃЫљЮНБЃДцЯжГЁЦфЪЕОЭЪЧАбЗЂЩњжаЖЯФЧвЛПЬЕФгВМўЩЯЯТЮФЃЈИїИіМФДцЦїЃЉБЃДцдкСЫSVC
modeЕФstackЩЯЁЃ
.macro usr_entry
sub sp, sp, #S_FRAME_SIZEЃЃЃЃЃЃЃЃЃЃЃЃЃЃA
stmib sp, {r1 - r12} ЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃB
ldmia r0, {r3 - r5}ЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃC
add r0, sp, #S_PCЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃD
mov r6, #-1ЃЃЃЃorig_r0ЕФжЕ
str r3, [sp] ЃЃЃЃБЃДцжаЖЯФЧвЛПЬЕФr0
stmia r0, {r4 - r6}ЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃE
stmdb r0, {sp, lr}^ЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃF
.endm |
AЃКДњТыжДааЕНетРяЕФЪБКђЃЌARMДІРэвбОЧаЛЛЕНСЫSVC modeЁЃвЛЕЉНјШыSVC modeЃЌARMДІРэЦїПДЕНЕФМФДцЦївбОЗЂЩњБфЛЏЃЌетРяЕФspвбОБфГЩСЫsp_svcСЫЁЃвђДЫЃЌКѓајЕФбЙеЛВйзїЖМЪЧбЙШыСЫЗЂЩњжаЖЯФЧвЛПЬЕФНјГЬЕФЃЈЛђепФкКЫЯпГЬЃЉФкКЫеЛЃЈsvc
modeеЛЃЉЁЃОпЬхБЃДцЖрЩйИіМФДцЦїжЕЃПS_FRAME_SIZEвбОИјГіСЫД№АИЃЌетИіжЕЪЧ18ИіМФДцЦїЁЃr0ЁЋr15дйМгЩЯCPSRвВжЛга17ИіЖјвбЁЃЯШБЃСєетИівЩЮЪЃЌЮвУЧЩдКѓЛиД№ЁЃ
BЃКбЙеЛЪзЯШбЙШыСЫr1ЁЋr12ЃЌетРяЮЊКЮВЛДІРэr0ЃПвђЮЊr0дкirq modeЧаЕНsvc modeЕФЪБКђБЛЮлШОСЫЃЌВЛЙ§ЃЌдЪМЕФr0БЛБЃДцЕФirq
modeЕФstackЩЯСЫЁЃr13ЃЈspЃЉКЭr14ЃЈlrЃЉашвЊБЃДцТ№ЃЌЕБШЛашвЊЃЌЩдКѓдйБЃДцЁЃжДааЕНетРяЃЌФкКЫеЛЕФВМОжШчЯТЭМЫљЪОЃК
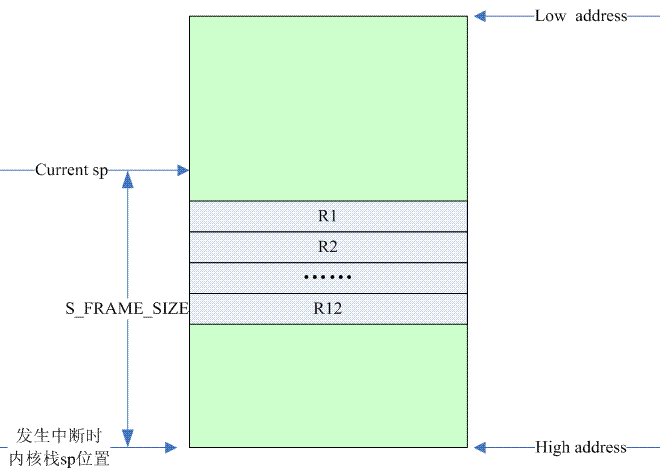
stmibжаЕФibБэЪОincrement beforeЃЌвђДЫЃЌдкбЙШыR1ЕФЪБКђЃЌstack pointerЛсЯШдіМг4ЃЌживЊЪЧдЄСєr0ЕФЮЛжУЁЃstmib
sp, {r1 - r12}жИСюжаЕФspУЛгаЁАЃЁЁБЕФаоЪЮЗћЃЌБэЪОбЙеЛЭъГЩКѓВЂВЛЛсеце§ИќаТstack
pointerЃЌвђДЫspБЃГждРДЕФжЕЁЃ
CЃКзЂвтЃЌетРяr0жИЯђСЫirq stackЃЌвђДЫЃЌr3ЪЧжаЖЯЪБКђЕФr0жЕЃЌr4ЪЧжаЖЯЯжГЁЕФPCжЕЃЌr5ЪЧжаЖЯЯжГЁЕФCPSRжЕЁЃ
DЃКАбr0ИГжЕЮЊS_PCЕФжЕЁЃИљОнstruct pt_regsЕФЖЈвхЃЈетИіЪ§ОнНсЙЙЗДгІСЫФкКЫеЛЩЯЕФБЃДцЕФМФДцЦїЕФХХСааХЯЂЃЉЃЌДгЕЭЕижЗЕНИпЕижЗвРДЮЮЊЃК
ARM_r0
ARM_r1
ARM_r2
ARM_r3
ARM_r4
ARM_r5
ARM_r6
ARM_r7
ARM_r8
ARM_r9
ARM_r10
ARM_fp
ARM_ip
ARM_sp
ARM_lr
ARM_pc<---------add r0, sp, #S_PCжИСюЪЙЕУr0жИЯђСЫетИіЮЛжУ
ARM_cpsr
ARM_ORIG_r0 |
ЮЊЪВУДвЊИјr0ИГжЕЃПвђДЫkernelВЛЯыаоИФspЕФжЕЃЌБЃГжspжИЯђеЛЖЅЁЃ
EЃКдкФкКЫеЛЩЯБЃДцЪЃгрЕФМФДцЦїЕФжЕЃЌИљОнДњТыЃЌвРДЮЪЧr0ЃЌPCЃЌCPSRКЭorig r0ЁЃжДааЕНетРяЃЌФкКЫеЛЕФВМОжШчЯТЭМЫљЪОЃК
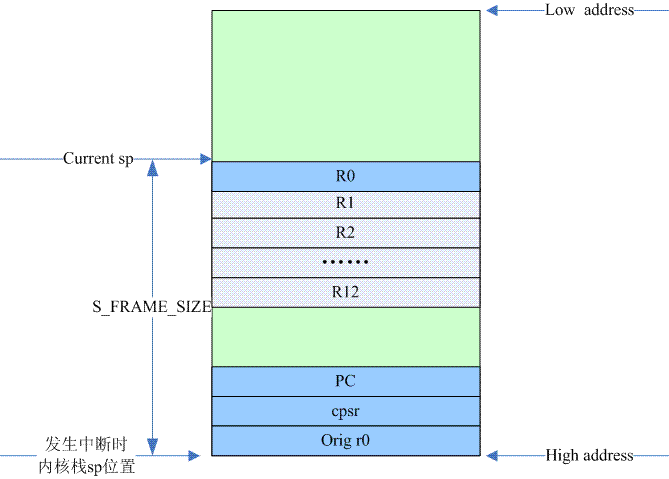
R0ЃЌPCКЭCPSRРДздIRQ modeЕФstackЁЃЪЕМЪЩЯетЖЮВйзїОЭЪЧДгirq stackОЭжаЖЯЯжГЁАсвЦЕНФкКЫеЛЩЯЁЃ
FЃКФкКЫеЛЩЯЛЙгаСНИіМФДцЦїУЛгаБЃГжЃЌЗжБ№ЪЧЗЂЩњжаЖЯЪБКђspКЭlrетСНИіМФДцЦїЁЃетЪБКђЃЌr0жИЯђСЫБЃДцPCМФДцЦїФЧИіЕижЗЃЈadd
r0, sp, #S_PCЃЉЃЌstmdb r0, {sp, lr}^жаЕФЁАdbЁБЪЧdecrement
beforeЃЌвђДЫЃЌНЋspКЭlrбЙШыstackжаЕФЪЃгрЕФСНИіЮЛжУЁЃашвЊзЂвтЕФЪЧЃЌЮвУЧБЃДцЕФЪЧЗЂЩњжаЖЯФЧвЛПЬЃЈЖдгкБОНкЃЌетЪЧЕБЪБuser
modeЕФspКЭlrЃЉЃЌжИСюжаЕФЁА^ЁБЗћКХБэЪОЗУЮЪuser modeЕФМФДцЦїЁЃ
ЃЈ2ЃЉКЫаФДІРэ
irq_handlerЕФДІРэгаСНжжХфжУЁЃвЛжжЪЧХфжУСЫCONFIG_MULTI_IRQ_HANDLERЁЃетжжЧщПіЯТЃЌlinux
kernelдЪаэrun timeЩшЖЈirq handlerЁЃШчЙћЮвУЧашвЊвЛИіlinux kernel
imageжЇГжЖрИіЦНЬЈЃЌетЪЧОЭашвЊХфжУетИібЁЯюЁЃСэЭтвЛжжЪЧДЋЭГЕФlinuxЕФзіЗЈЃЌirq_handlerЪЕМЪЩЯОЭЪЧarch_irq_handler_defaultЃЌОпЬхДњТыШчЯТЃК
.macro irq_handler
#ifdef CONFIG_MULTI_IRQ_HANDLER
ldr r1, =handle_arch_irq
mov r0, spЃЃЃЃЃЃЃЃЩшЖЈДЋЕнИјmachineЖЈвхЕФhandle_arch_irqЕФВЮЪ§
adr lr, BSYM(9997f)ЃЃЃЃЩшЖЈЗЕЛиЕижЗ
ldr pc, [r1]
#else
arch_irq_handler_default
#endif
9997:
.endm |
ЖдгкЧщПівЛЃЌmachineЯрЙиДњТыашвЊЩшЖЈhandle_arch_irqКЏЪ§жИеыЃЌетРяЕФЛуБржИСюжЛашвЊЕїгУетИіmachineДњТыЬсЙЉЕФirq
handlerМДПЩЃЈЕБШЛЃЌвЊзМБИКУВЮЪ§ДЋЕнКЭЗЕЛиЕижЗЩшЖЈЃЉЁЃ
ЧщПіЖўвЊЩдЮЂИДдгвЛаЉЃЈЖјЧвЃЌПДЦ№РДkernelжаЪЙгУЕФдНРДдНЩйЃЉЃЌДњТыШчЯТЃК
.macro arch_irq_handler_default
get_irqnr_preamble r6, lr
1: get_irqnr_and_base r0, r2, r6, lr
movne r1, sp
@
@ asm_do_IRQ ашвЊСНИіВЮЪ§ЃЌвЛИіЪЧ irq numberЃЈБЃДцдкr0ЃЉ
@ СэвЛИіЪЧ struct pt_regs *ЃЈБЃДцдкr1жаЃЉ
adrne lr, BSYM(1b)ЃЃЃЃЃЃЃЗЕЛиЕижЗЩшЖЈЮЊЗћКХ1ЃЌвВОЭЪЧЫЕвЊВЛЖЯЕФНтЮіirqзДЬЌМФДцЦїЕФФкШнЃЌЕУЕНIRQ
numberЃЌжБЕНЫљгаЕФirq numberДІРэЭъБЯ
bne asm_do_IRQ
.endm |
етРяЕФДњТывбОЪЧКЭmachineЯрЙиЕФДњТыСЫЃЌЮвУЧетРяжЛЪЧМђЖЬУшЪівЛЯТЁЃЫљЮНmachineЯрЙивВОЭЪЧЫЕКЭЯЕЭГжаЕФжаЖЯПижЦЦїЯрЙиСЫЁЃget_irqnr_preambleЪЧЮЊжаЖЯДІРэзізМБИЃЌгааЉЦНЬЈИљБОВЛашвЊетИіВНжшЃЌжБНгЖЈвхЮЊПеМДПЩЁЃget_irqnr_and_base
гаЫФИіВЮЪ§ЃЌЗжБ№ЪЧЃКr0БЃДцСЫБОДЮНтЮіЕФirq numberЃЌr2ЪЧirqзДЬЌМФДцЦїЕФжЕЃЌr6ЪЧirq
controllerЕФbase addressЃЌlrЪЧscratch registerЁЃ
ЖдгкARMЦНЬЈЖјбдЃЌЮвУЧЭЦМіЪЙгУЕквЛжжЗНЗЈЃЌвђЮЊДгТпМЩЯНВЃЌжаЖЯДІРэОЭЪЧашвЊИљОнЕБЧАЕФгВМўжаЖЯЯЕЭГЕФзДЬЌЃЌзЊЛЛГЩвЛИіIRQ
numberЃЌШЛКѓЕїгУИУIRQ numberЕФДІРэКЏЪ§МДПЩЁЃЭЈЙ§get_irqnr_and_baseетбљЕФКъЖЈвхРДЛёШЁIRQЪЧОЩЕФARM
SOCЯЕЭГЪЙгУЕФЗНЗЈЃЌЫќЪЧМйЩшSOCЩЯгавЛИіжаЖЯПижЦЦїЃЌгВМўзДЬЌКЭIRQ numberжЎМфЕФЙиЯЕЗЧГЃМђЕЅЁЃЕЋЪЧЪЕМЪЩЯЃЌARMЦНЬЈЩЯЕФгВМўжаЖЯЯЕЭГвбОЪЧдНРДдНИДдгСЫЃЌашвЊв§Шыinterrupt
controllerМЖСЊЃЌirq domainЕШЕШИХФюЃЌвђДЫЃЌЪЙгУЕквЛжжЗНЗЈгХЕуИќЖрЁЃ
3ЁЂЕБЗЂЩњжаЖЯЕФЪБКђЃЌДњТыдЫаадкФкКЫПеМф
ШчЙћжаЖЯЗЂЩњдкФкКЫПеМфЃЌДњТыЛсЬјзЊЕН__irq_svcДІжДааЃК
.align 5
__irq_svc:
svc_entryЃЃЃЃБЃДцЗЂЩњжаЖЯФЧвЛПЬЕФЯжГЁБЃДцдкФкКЫеЛЩЯ
irq_handler ЃЃЃЃОпЬхЕФжаЖЯДІРэЃЌЭЌuser modeЕФДІРэЁЃ
#ifdef CONFIG_PREEMPTЃЃЃЃЃЃЃЃКЭpreemptЯрЙиЕФДІРэ
get_thread_info tsk
ldr r8, [tsk, #TI_PREEMPT] @ get preempt count
ldr r0, [tsk, #TI_FLAGS] @ get flags
teq r8, #0 @ if preempt count != 0
movne r0, #0 @ force flags to 0
tst r0, #_TIF_NEED_RESCHED
blne svc_preempt
#endif
svc_exit r5, irq = 1 @ return from exception |
вЛИіtaskЕФthread infoЪ§ОнНсЙЙЖЈвхШчЯТЃЈжЛБЃСєКЭБОГЁОАЯрЙиЕФФкШнЃЉЃК
struct thread_info
{
unsigned long flags; /* low level flags */
int preempt_count; /* 0 => preemptable, <0
=> bug */
ЁЁ
}; |
flagГЩдБгУРДБъМЧвЛаЉlow levelЕФflagЃЌЖјpreempt_countгУРДХаЖЯЕБЧАЪЧЗёПЩвдЗЂЩњЧРеМЃЌШчЙћpreempt_countВЛЕШгк0ЃЈПЩФмЪЧДњТыЕїгУpreempt_disableЯдЪНЕФНћжЙСЫЧРеМЃЌвВПЩФмЪЧДІгкжаЖЯЩЯЯТЮФЕШЃЉЃЌЫЕУїЕБЧАВЛФмНјааЧРеМЃЌжБНгНјШыЛжИДЯжГЁЕФЙЄзїЁЃШчЙћpreempt_countЕШгк0ЃЌЫЕУївбООпБИСЫЧРеМЕФЬѕМўЃЌЕБШЛОпЬхЪЧЗёвЊЧРеМЕБЧАНјГЬЛЙЪЧвЊПДПДthread
infoжаЕФflagГЩдБЪЧЗёЩшЖЈСЫ_TIF_NEED_RESCHEDетИіБъМЧЃЈПЩФмЪЧЕБЧАЕФНјГЬЕФЪБМфЦЌгУЭъСЫЃЌвВПЩФмЪЧгЩгкжаЖЯЛНабСЫгХЯШМЖИќИпЕФНјГЬЃЉЁЃ
БЃДцЯжГЁЕФДњТыКЭuser modeЯТЕФЯжГЁБЃДцЪЧРрЫЦЕФЃЌвђДЫетРяВЛдйЯъЯИУшЪіЃЌжЛЪЧдкЯТУцЕФДњТыжаФкЧЖвЛаЉзЂЪЭЁЃ
.macro svc_entry,
stack_hole=0
sub sp, sp, #(S_FRAME_SIZE + \stack_hole - 4)ЃЃЃЃspжИЯђstruct
pt_regsжаr1ЕФЮЛжУ
stmia sp, {r1 - r12} ЃЃЃЃЃЃМФДцЦїШыеЛЁЃ
ldmia r0, {r3 - r5}
add r7, sp, #S_SP - 4 ЃЃЃЃЃЃr7жИЯђstruct pt_regsжаr12ЕФЮЛжУ
mov r6, #-1 ЃЃЃЃЃЃЃЃЃЃorig r0ЩшЮЊ-1
add r2, sp, #(S_FRAME_SIZE + \stack_hole - 4)ЃЃЃЃr2ЪЧЗЂЯжжаЖЯФЧвЛПЬstackЕФЯжГЁ
str r3, [sp, #-4]! ЃЃЃЃБЃДцr0ЃЌзЂвтгавЛИіЃЁЃЌspЛсМгЩЯ4ЃЌетЪБКђspОЭжИЯђеЛЖЅЕФr0ЮЛжУСЫ
mov r3, lr ЃЃЃЃБЃДцsvc modeЕФlrЕНr3
stmia r7, {r2 - r6} ЃЃЃЃЃЃЃЃЃбЙеЛЃЌдкеЛЩЯаЮГЩаЮГЩstruct
pt_regs
.endm |
жСДЫЃЌдкФкКЫеЛЩЯБЃДцСЫЭъећЕФгВМўЩЯЯТЮФЁЃЪЕМЪЩЯВЛЕЋЭъећЃЌЖјЧвЛЙгааЉШпгрЃЌвђЮЊЦфжагавЛИіorig_r0ЕФГЩдБЁЃЫљЮНoriginal
r0ОЭЪЧЗЂЩњжаЖЯФЧвЛПЬЕФr0жЕЃЌАДРэЫЕЃЌARM_r0КЭARM_ORIG_r0ЖМгІИУЪЧгУЛЇПеМфЕФФЧИіr0ЁЃ
ЮЊКЮвЊБЃДцСНИіr0жЕФиЃПЮЊКЮжаЖЯНЋ-1БЃДцЕНСЫARM_ORIG_r0ЮЛжУФиЃПРэНтетИіЮЪЬташвЊЬјЭбжаЖЯДІРэетИіжїЬтЃЌЮвУЧРДПДARMЕФЯЕЭГЕїгУЁЃЖдгкЯЕЭГЕїгУЃЌЫќ
КЭжаЖЯДІРэЫфШЛЖМЪЧcpuвьГЃДІРэЗЖГыЃЌЕЋЪЧвЛИіУїЯдЕФВЛЭЌЪЧЯЕЭГЕїгУашвЊДЋЕнВЮЪ§ЃЌЗЕЛиНсЙћЁЃШчЙћНјааетбљЕФВЮЪ§ДЋЕнФиЃПЖдгкARMЃЌЕБШЛЪЧМФДцЦїСЫЃЌ
ЬиБ№ЪЧЗЕЛиНсЙћЃЌБЃДцдкСЫr0жаЁЃЖдгкARMЃЌr0ЁЋr7ЪЧИїжжcpu modeЖМЯрЭЌЕФЃЌгУгкДЋЕнВЮЪ§ЛЙЪЧКмЗНБуЕФЁЃвђДЫЃЌНјШыЯЕЭГЕїгУЕФЪБКђЃЌдкФкКЫеЛЩЯБЃДцСЫЗЂЩњЯЕЭГЕїгУЯжГЁЕФЫљгаМФДцЦїЃЌвЛЗНУцБЃДцСЫhardware
contextЃЌСэЭтвЛЗНУцЃЌвВОЭЪЧЛёШЁСЫЯЕЭГЕїгУЕФВЮЪ§ЁЃЗЕЛиЕФЪБКђЃЌНЋЗЕЛижЕЗХЕНr0ОЭOKСЫЁЃ
ИљОнЩЯУцЕФУшЪіЃЌr0гаСНИізїгУЃЌДЋЕнВЮЪ§ЃЌЗЕЛиНсЙћЁЃЕБАбЯЕЭГЕїгУЕФНсЙћЗХЕНr0ЕФЪБКђЃЌЭЈЙ§r0ДЋЕнЕФВЮЪ§жЕОЭБЛИВИЧСЫЁЃБОРДЃЌетвВУЛгаЪВУДЃЌЕЋЪЧгааЉГЁКЯЪЧашвЊашвЊетСНИіжЕЕФЃК
1ЁЂptrace ЃЈКЭdebuggerЯрЙиЃЌетРяОЭВЛдйЯъЯИУшЪіСЫЃЉ
2ЁЂsystem call restart ЃЈКЭsignalЯрЙиЃЌетРяОЭВЛдйЯъЯИУшЪіСЫЃЉ
е§вђЮЊШчДЫЃЌгВМўЩЯЯТЮФЕФМФДцЦїжаr0гаСНЗнЃЌARM_r0ЪЧДЋЕнЕФВЮЪ§ЃЌВЂИДжЦвЛЗнЕНARM_ORIG_r0ЃЌЕБЯЕЭГЕїгУЗЕЛиЕФЪБКђЃЌARM_r0ЪЧЯЕЭГЕїгУЕФЗЕЛижЕЁЃ
OKЃЌЮвУЧдйЛиЕНжаЖЯетИіжїЬтЃЌЦфЪЕдкжаЖЯДІРэЙ§ГЬжаЃЌУЛгаЪЙгУARM_ORIG_r0етИіжЕЃЌЕЋЪЧЃЌЮЊСЫЗРжЙsystem
call restartЃЌПЩвдИГжЕЮЊЗЧЯЕЭГЕїгУКХЕФжЕЃЈР§Шч-1ЃЉЁЃ
ЮхЁЂжаЖЯЭЫГіЙ§ГЬ
ЮоТлЪЧдкФкКЫЬЌЃЈАќРЈЯЕЭГЕїгУКЭжаЖЯЩЯЯТЮФЃЉЛЙЪЧгУЛЇЬЌЃЌЗЂЩњСЫжаЖЯКѓЖМЛсЕїгУirq_handlerНјааДІРэЃЌетРяЛсЕїгУЖдгІЕФirq
numberЕФhandlerЃЌДІРэsoftirqЁЂtaskletЁЂworkqueueЕШЃЈетаЉФкШнСэПЊвЛИіЮФЕЕУшЪіЃЉЃЌЕЋЮоТлШчКЮЃЌзюжеЖМЪЧвЊЗЕЛиЗЂЩњжаЖЯЕФЯжГЁЁЃ
1ЁЂжаЖЯЗЂЩњдкuser modeЯТЕФЭЫГіЙ§ГЬЃЌДњТыШчЯТЃК
ENTRY(ret_to_user_from_irq)
ldr r1, [tsk, #TI_FLAGS]
tst r1, #_TIF_WORK_MASKЃЃЃЃЃЃЃЃЃЃЃЃЃЃЃA
bne work_pending
no_work_pending:
asm_trace_hardirqs_on ЃЃЃЃЃЃКЭirq flag traceЯрЙиЃЌднЧвТдЙ§
/* perform architecture specific actions before
user return */
arch_ret_to_user r1, lrЃЃЃЃгааЉгВМўЦНЬЈашвЊдкжаЖЯЗЕЛигУЛЇПеМфзівЛаЉЬиБ№ДІРэ
ct_user_enter save = 0 ЃЃЃЃКЭtrace contextЯрЙиЃЌднЧвТдЙ§
restore_user_regs fast = 0, offset = 0ЃЃЃЃЃЃЃЃЃЃЃЃB
ENDPROC(ret_to_user_from_irq)
ENDPROC(ret_to_user) |
AЃКthread_infoжаЕФflagsГЩдБжагавЛаЉlow levelЕФБъЪЖЃЌШчЙћетаЉБъЪЖЩшЖЈСЫОЭашвЊНјаавЛаЉЬиБ№ЕФДІРэЃЌетРяМьВтЕФflagжївЊАќРЈЃК
| #define _TIF_WORK_MASK
(_TIF_NEED_RESCHED | _TIF_SIGPENDING | _TIF_NOTIFY_RESUME) |
етШ§ИіflagЗжБ№БэЪОЪЧЗёашвЊЕїЖШЁЂЪЧЗёгааХКХДІРэЁЂЗЕЛигУЛЇПеМфжЎЧАЪЧЗёашвЊЕїгУcallbackКЏЪ§ЁЃжЛвЊгавЛИіflagБЛЩшЖЈСЫЃЌГЬађОЭНјШыwork_pendingетИіЗжжЇЃЈwork_pendingКЏЪ§ашвЊДЋЕнШ§ИіВЮЪ§ЃЌЕкШ§ИіЪЧВЮЪ§whyЪЧБъЪЖФФвЛИіЯЕЭГЕїгУЃЌЕБШЛЃЌЮвУЧетРяДЋЕнЕФЪЧ0ЃЉЁЃ
BЃКДгзжУцЕФвтЫМвВПЩвдПДГЩЃЌетВПЗжЕФДњТыОЭЪЧНЋНјШыжаЖЯЕФЪБКђБЃДцЕФЯжГЁЃЈМФДцЦїжЕЃЉЛжИДЕНЪЕМЪЕФARMЕФИїИіМФДцЦїжаЃЌДгЖјЭъШЋЗЕЛиЕНСЫжаЖЯЗЂЩњЕФФЧвЛЕуЁЃОпЬхЕФДњТыШчЯТЃК
.macro restore_user_regs,
fast = 0, offset = 0
ldr r1, [sp, #\offset + S_PSR] ЃЃЃЃr1БЃДцСЫpt_regsжаЕФspsrЃЌвВОЭЪЧЗЂЩњжаЖЯЪБЕФCPSR
ldr lr, [sp, #\offset + S_PC]! ЃЃЃЃlrБЃДцСЫPCжЕЃЌЭЌЪБspвЦЖЏЕНСЫpt_regsжаPCЕФЮЛжУ
msr spsr_cxsf, r1 ЃЃЃЃЃЃЃЃЃИГжЕИјspsrЃЌНјааЗЕЛигУЛЇПеМфЕФзМБИ
clrex @ clear the exclusive monitor
.if \fast
ldmdb sp, {r1 - lr}^ @ get calling r1 - lr
.else
ldmdb sp, {r0 - lr}^ ЃЃЃЃЃЃНЋБЃДцдкФкКЫеЛЩЯЕФЪ§ОнБЃДцЕНгУЛЇЬЌЕФr0ЁЋr14МФДцЦї
.endif
mov r0, r0 ЃЃЃЃЃЃЃЃЃNOPВйзїЃЌARMv5TжЎЧАЕФашвЊетИіВйзї
add sp, sp, #S_FRAME_SIZE - S_PCЃЃЃЃЯжГЁвбОЛжИДЃЌвЦЖЏsvc
modeЕФspЕНдРДЕФЮЛжУ
movs pc, lr ЃЃЃЃЃЃЃЃЗЕЛигУЛЇПеМф
.endm |
2ЁЂжаЖЯЗЂЩњдкsvc modeЯТЕФЭЫГіЙ§ГЬЁЃОпЬхДњТыШчЯТЃК
.macro svc_exit,
rpsr, irq = 0
.if \irq != 0
@ IRQs already off
.else
@ IRQs off again before pulling preserved data
off the stack
disable_irq_notrace
.endif
msr spsr_cxsf, \rpsrЃЃЃЃЃЃЃНЋжаЖЯЯжГЁЕФcpsrжЕБЃДцЕНspsrжаЃЌзМБИЗЕЛижаЖЯЗЂЩњЕФЯжГЁ
ldmia sp, {r0 - pc}^ ЃЃЃЃЃетЬѕжИСюЪЧldmвьГЃЗЕЛижИСюЃЌетЬѕжИСюГ§СЫзжУцЩЯЕФВйзїЃЌ
ЛЙАќРЈСЫНЋspsr copyЕНcpsrжаЁЃ
.endm |
|








