| 编辑推荐: |
文章通过对内核主要模块的介绍
,包括进程管理,内存管理,虚拟文件系统,设备驱动,网络等相关内容介绍。
本文来自于微信公众号:从零开始学架构,由火龙果软件依然编辑推荐。 |
|
28年前(1991年8月26日)Linus公开Linux的代码,开启了一个伟大的时代。这篇文章从进程调度,内存管理,设备驱动,文件系统,网络等方面讲解Linux内核系统架构。Linux的系统架构是一个经典的设计,它优秀的分层和模块化,融合了数量繁多的设备和不同的物理架构,让世界各地的内核开发者能够高效并行工作。先来看看Linus在多年前公开Linux的邮件。
"Hello everybody out there using minix - I’m
doing a (free) operating system (just a hobby, won’t
be big and professional like gnu) for 386(486) AT
clones. This has been brewing since april, and is
starting to get ready. I’d like any feedback on things
people like/dislike in minix, as my OS resembles it
somewhat (same physical layout of the ?le-system (due
to practical reasons) among other things).
I’ve currently ported bash(1.08) and gcc(1.40), and
things seem to work. This implies that I’ll get something
practical within a few months, and I’d like to know
what features most people would want. Any suggestions
are welcome, but I won’t promise I’ll implement them
:-)
Linus (torv...@kruuna.helsinki.?)"
事实上,从那一天开始,Linux便是博采众长,融合了非常多的优秀设计。在了解操作系统的时候,我们至少需要知道:1.
操作系统是如何管理各种资源的?2. 软硬件如何协同工作?3. 如何通过抽象化屏蔽差异 4. 软硬件如何分工?这篇文章通过对内核主要模块的介绍,希望能为大家寻找这些问题的答案起一个抛砖引玉的作用。实际上,建议每一个希望成为技术专家的人都读一遍Linux的源代码。
先来看看Linux内核一个高阶架构图:
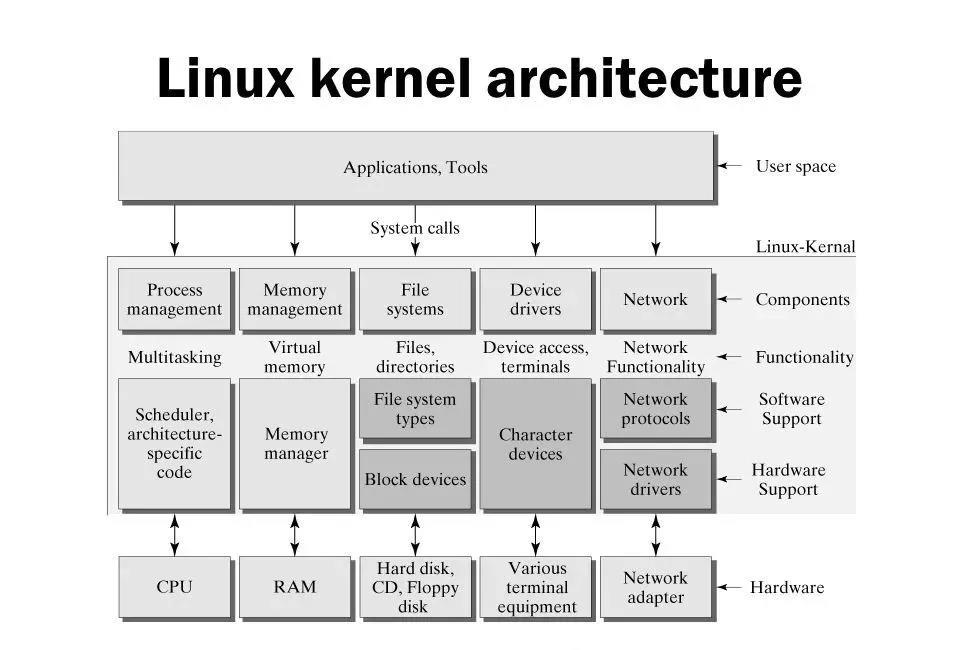
Linux系统架构图
架构非常清晰,从硬件层,硬件抽象层,内核基础模块(进程调度,内存管理,网络协议栈等)到应用层,这个基本上也是各类软硬件结合的系统架构的基础设计,例如物联网系统(从单片机,MCU等小型嵌入式系统,到智能家居,智慧社区甚至智慧城市)在接入端设备的可参考架构模型。
Linux最初是运行在PC机上的,使用的x86架构处理器相对来说比较强大,各类指令和模式也比较齐全。例如我们看到的用户态和内核态,在一般的小型嵌入式处理器上是没有的,它的好处是通过将代码和数据段(segment)给予不同的权限,保护内核态的代码和数据(包括硬件资源)必须通过类似系统调用(SysCall)的方式才能访问,确保内核的稳定。
想象一下,如果需要你写一个操作系统,有哪些因素需要考虑?
进程管理:如何在多任务系统中按照调度算法分配CPU的时间片。
内存管理:如何实现虚拟内存和物理内存的映射,分配和回收内存。
文件系统:如何将硬盘的扇区组织成文件系统,实现文件的读写等操作。
设备管理:如何寻址,访问,读,写设备配置信息和数据。
这些概念是操作系统的核心概念,由于篇幅原因,本文章主要从高阶的角度来讲,更多细节不在本文覆盖。
进程管理
进程在不同的操作系统中有些称为process,有些称为task。操作系统中进程数据结构包含了很多元素,往往用链表连接。
进程相关的内容主要包括:虚拟地址空间,优先级,生命周期(阻塞,就绪,运行等),占有的资源(例如信号量,文件等)。
CPU在每个系统滴答(Tick)中断产生的时候检查就绪队列里面的进程(遍历链表中的进程结构体),如有符合调度算法的新进程需要切换,保存当前运行的进程的信息(包括栈信息等)后挂起当前进程,选择新的进程运行,这就是进程调度。
进程的优先级差异是CPU调度的基本依据,调度的终极目标是让高优先级的活动能够即时得到CPU的计算资源(即时响应),低优先级的任务也能公平分配到CPU资源。因为需要保存进程运行的上下文(process
context)等,进程的切换本身是有成本的,调度算法在进程切换频率上也需要考虑效率。
在早期的Linux操作系统中,主要采用的是时间片轮转算法(Round-Robin),内核在就绪的进程队列中选择高优先级的进程运行,每次运行相等的时间。该算法简单直观,但仍然会导致某些低优先级的进程长时间无法得到调度。为了提高调度的公平性,在Linux
2.6.23之后,引入了称为完全公平调度器CFS(Completely Fair Scheduler)。
CPU在任何时间点只能运行一个程序,用户在使用优酷APP看视频时,同时在微信中打字聊天,优酷和微信是两个不同的程序,为什么看起来像是在同时运行?CFS的目标就是让所有的程序看起来都是以相同的速度在多个并行的CPU上运行,即nr_running个运行的进程,每个进程以1/nr_running的速度并发执行,例如如有2个可运行的任务,那么每个以50%的CPU物理能力并发执行。
CFS引入了"虚拟运行时间"的概念,虚拟运行时间用p->se.vruntime
(nanosec-unit) 表示,通过它记录和度量任务应该获得的"CPU时间"。在理想的调度情况下,任何时候所有的任务都应该有相同的p->se.vruntime值(上面提到的以相同的速度运行)。因为每个任务都是并发执行的,没有任务会超过理想状态下应该占有的CPU时间。CFS选择需要运行的任务的逻辑基于p->se.vruntime值,非常简单:它总是挑选p->se.vruntime值最小的任务运行(最少被调度到的任务)。
CFS使用了基于时间排序的红黑树来为将来任务的执行排时间线。所有的任务按p->se.vruntime关键字排序。CFS从树中选择最左边的任务执行。随着系统运行,执行过的任务会被放到树的右边,逐步地地让每个任务都有机会成为最左边的任务,从而在一个可确定的时间内获得CPU资源。
总结来说,CFS首先运行一个任务,当任务切换(或者Tick中断发生的时候)时,该任务使用的CPU时间会加到p->se.vruntime里,当p->se.vruntime的值逐渐增大到别的任务变成了红黑树最左边的任务时(同时在该任务和最左边任务间增加一个小的粒度距离,防止过度切换任务,影响性能),最左边的任务被选中执行,当前的任务被抢占。
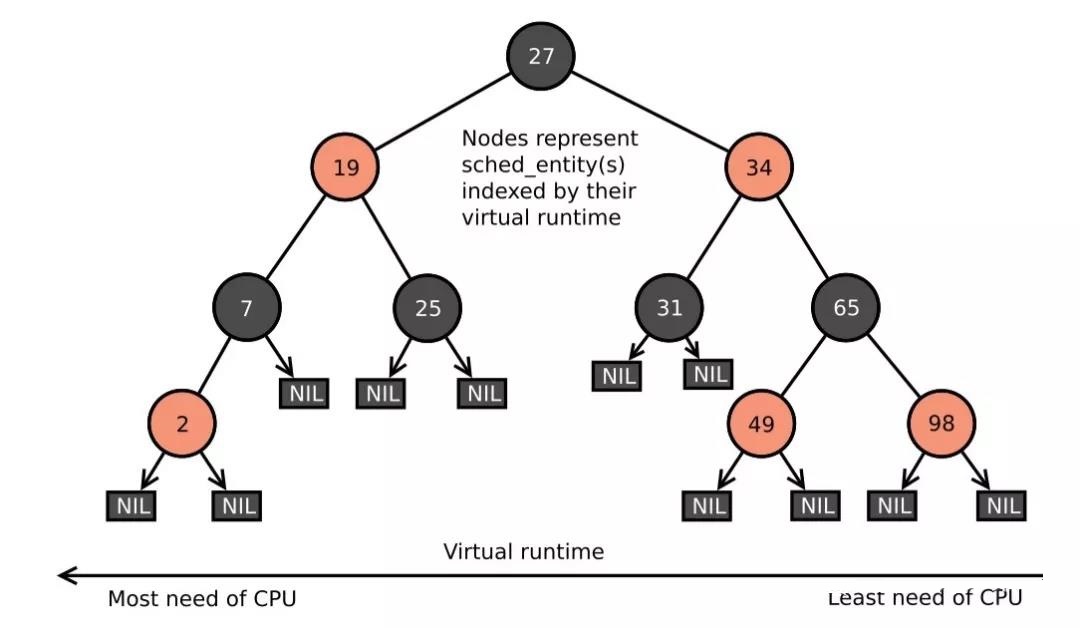
CFS红黑树
一般来说,调度器处理单个任务,且尽可能为每个任务提供公平的CPU时间。某些时候,可能需要将任务分组,并为每个组提供公平的CPU时间。例如,系统可以为每个用户分配平均的CPU时间后,再为每个用户的每个任务分配平均的CPU时间。
内存管理
内存本身是一个外部存储设备,系统需要对内存区域寻址,找到对应的内存单元(memory cell),读写其中的数据。
内存区域通过指针寻址,CPU的字节长度(32bit机器,64bit机器)决定了最大的可寻址地址空间。在32位机器上最大的寻址空间是4GBtyes。在64位机器上理论上有2^64Bytes。
最大的地址空间和实际系统有多少物理内存无关,所以称为虚拟地址空间。对系统中所有的进程来说,看起来每个进程都独立占有这个地址空间,且它无法感知其它进程的内存空间。事实上操作系统让应用程序无需关注其它应用程序,看起来每个任务都是这个电脑上运行的唯一进程。
Linux将虚拟地址空间分为内核空间和用户空间。每个用户进程的虚拟空间范围从0到TASK_SIZE。从TASK_SIZE到2^32或2^64的区域保留给内核,不能被用户进程访问。TASK_SIZE可以配置,Linux系统默认配置3:1,应用程序使用3GB的空间,内核使用1GB的空间,这个划分并不依赖实际RAM的大小。在64位机器上,虚拟地址空间的范围可以非常大,但实际上只使用其中42位或47位(2^42或2^47)。
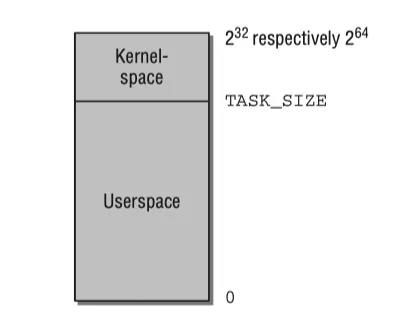
虚拟地址空间
绝大多数情况下,虚拟地址空间比实际系统可用的物理内存(RAM)大,内核和CPU必须考虑如何将实际可用的物理内存映射到虚拟地址空间。
一个方法是通过页表(Page Table)将虚拟地址映射到物理地址。虚拟地址与进程使用的用户&内核地址相关,物理地址用来寻址实际使用的RAM。
如下图所示,进程A和B的虚拟地址空间被分为大小相等的部分,称为页(page)。物理内存同样被分割为大小相等的页(page
frame)。

虚拟和物理地址空间映射
进程A第1个内存页映射到物理内存(RAM)的第4页;进程B第1个内存页映射到物理内存第5页。进程A第5个内存页和进程B第1个内存页都映射到物理内存的第5页(内核可决定哪些内存空间被不同进程共享)。
如图所示,并不是每个虚拟地址空间的页都与某个page frame关联,该页可能并未使用或者数据还没有被加载到物理内存(暂时不需要),也可能因为物理内存页被置换到了硬盘上,后续实际再需要的时候再被置换回内存。
页表(page table)将虚拟地址空间映射到物理地址空间。最简单的做法是用一个数组将虚拟页和物理页一一对应,但是这样做可能需要消耗整个RAM本身来保存这个页表,假设每个页大小为4KB,虚拟地址空间大小为4GB,需要一个1百万个元素的数组来保存页表。
因为虚拟地址空间的绝大多数区域实际并没有使用,这些页实际并没有和page frame关联,引入多级页表(multilevel
paging)能极大降低页表使用的内存,提高查询效率。关于多级页表的细节描述可以参考文后参考资料。
内存映射(memory mapping)是一个重要的抽象方法,被运用在内核和用户应用程序等多个地方。映射是将来自某个数据源的数据(也可以是某个设备的I/O端口等)转移到某个进程的虚拟内存空间。对映射的地址空间的操作可以使用处理普通内存的方法(对地址内容直接进行读写)。任何对内存的改动会自动转移到原数据源,例如将某个文件的内容映射到内存中,只需要通过读该内存来获取文件的内容,通过将改动写到该内存来修改文件的内容,内核确保任何改动都会自动体现到文件里。
另外,在内核中,实现设备驱动时,外设(外部设备)的输入和输出区域可以被映射到虚拟地址空间,读写这些空间会被系统重定向到设备,从而对设备进行操作,极大地简化了驱动的实现。
内核必须跟踪哪些物理页已经被分配了,哪些还是空闲的,避免两个进程使用RAM中的同一个区域。内存的分配和释放是非常频繁的任务,内核必须确保完成的速度尽量快,内核只能分配整个page
frame,它将内存分为更小的部分的任务交给了用户空间,用户空间的程序库可以将从内核收到的page
frame分成更小的区域后分配给进程。
虚拟文件系统
Unix系统是建立在一些有见地的理念上的,一个非常重要的隐喻是:
Everything is a ?le.
即系统几乎所有的资源都可以看成是文件。为了支持不同的本地文件系统,内核在用户进程和文件系统实现间包含了一层虚拟文件系统(Virtual
File System)。大多数的内核提供的函数都能通过VFS(Virtual File System)定义的文件接口访问。例如内核子系统:字符和块设备,管道,网络Socket,交互输入输出终端等。
另外用于操作字符和块设备的设备文件是在/dev目录下的真实文件,当读写操作执行的时候,其的内容会被对应的设备驱动动态创建。
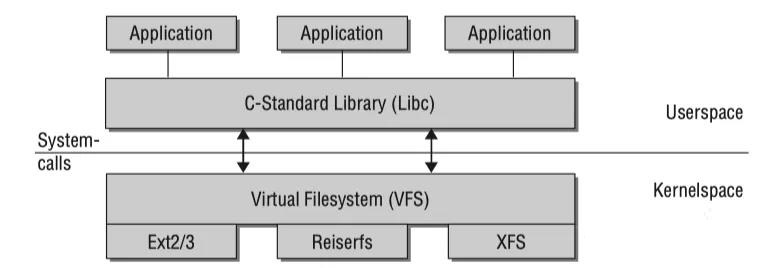
VFS系统
在虚拟文件系统中,inode用来表示文件和文件目录(对于系统来说,目录是一种特殊的文件)。inode的元素包含两类:1.
Metadata用于描述文件的状态,例如读写权限。2. 用于保存文件内容的数据段。
每个inode都有一个特别的号码用于唯一识别,文件名和inode的关联建立在该编号基础上。以内核查找/usr/bin/emacs为例,讲解inodes如何组成文件系统的目录结构。从根inode开始查找(即根目录‘/’),该目录使用一个inode表示,inode的数据段没有普通的数据,只包含了根目录存的一些文件/目录项,这些项可以表示文件或其它目录,每项包含两个部分:1.
下一个数据项所在的inode编号 2. 文件或目录名
首先扫描根inode的数据区域直到找到一个名为‘usr’的项,查找子目录usr的inode。通过‘usr’
inode编号找到关联的inode。重复以上步骤,查找名为‘bin’的数据项,然后在其数据项的‘bin’对应的inode中搜索名字‘emacs’的数据项,最后返回的inode表示一个文件而不是一个目录。最后一个inode的文件内容不同于之前,前三个每个都表示了一个目录,包含了它的子目录和文件清单,和emacs文件关联的inode在它的数据段保存了文件的实际内容。
尽管在VFS查找某个文件的步骤和上面的描述一样,但细节上还是有些差别。例如因为频繁打开文件是一个很慢的操作,引入缓存加速查找。
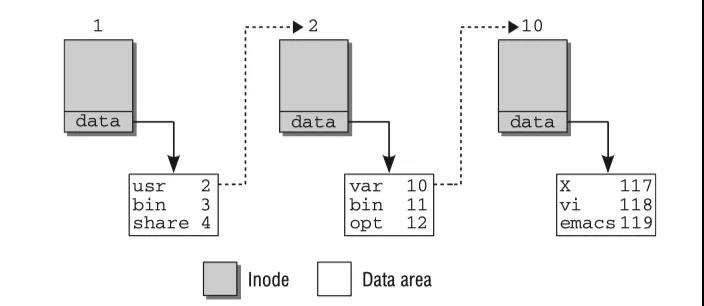
通过inode机制查找某个文件
设备驱动
与外设通信往往指的是输入(input)和输出(output)操作,简称I/O。实现外设的I/O内核必须处理三个任务:第一,必须针对不同的设备类型采用不同的方法来寻址硬件。第二,内核必须为用户应用程序和系统工具提供操作不同设备的方法,且需要使用一个统一的机制来确保尽量有限的编程工作,和保证即使硬件方法不同应用程序也能互相交互。第三,用户空间需要知道在内核中有哪些设备。
与外设通信的层级关系如下:

设备通信层级图
外部设备大多通过总线与CPU连接,系统往往不止一个总线,而是总线的集合。在很多PC设计中包含两个通过一个bridge相连的PCI总线。某些总线例如USB不能当作主总线使用,需要通过一个系统总线将数据传递给处理器。下图显示不同的总线是如何连接到系统的。

系统总线拓扑图
系统与外设交互主要有以下方式:
I/O端口:使用I/O端口通信的情况下,内核通过一个I/O控制器发送数据,每个接收设备有唯一的端口号,且将数据转发给系统附着的硬件。有一个由处理器管理的单独的虚拟地址空间用来管理所有的I/O地址。
I/O地址空间并不总是和普通的系统内存关联,考虑到端口能够映射到内存中,这往往不好理解。
端口有不同的类型。一些是只读的,一些是只写的,一般情况下它们是可以双向操作的,数据能够在处理器和外设间双向交换。
在IA-32架构体系中,端口的地址空间包含了2^16个不同的8位地址,这些地址可以通过从0x0到0xFFFFH间的数唯一识别。每个端口都有一个设备分配给它,或者空闲没有使用,多个外设不能共享一个端口。很多情况下,交换数据使用8位是不够用的,基于这个原因,可以将两个连续的8位端口绑定为一个16位的端口。两个连续的16位端口能够被当作一个32位的端口,处理器可以通过组装语句来做输入输出操作。
不同处理器类型在实现操作端口时有所不同,内核必须提供一个合适的抽象层,例如outb(写一个字节),outw(写一个字)和inb(读一个字节)这些命令可以用来操作端口。
I/O内存映射:必须能够像访问RAM内存一样寻址许多设备。因此处理器提供了将外设对应的I/O端口映射到内存中,这样就能像操作普通内存一样操作设备了。例如显卡使用这样的机制,PCI也往往通过映射的I/O地址寻址。
为了实现内存映射,I/O端口必须首先被映射到普通系统内存中(使用处理器特有的函数)。因为平台间的实现方式差异比较大,所以内核提供了一个抽象层来映射和去映射I/O区域。
除了如何访问外设,什么时候系统会知道是否外设有数据可以访问?主要通过两种方式:轮询和中断。
轮询周期性地访问查询设备是否有准备好的数据,如果有,便获取数据。这种方法需要处理器在设备没有数据的情况下也不断去访问设备,浪费了CPU时间片。
另一种方式是中断,它的理念是外设把某件事情做完了后,主动通知CPU,中断的优先级最高,会中断CPU的当前进程运行。每个CPU都提供了中断线(可被不同的设备共享),每个中断由唯一的中断号识别,内核为每个使用的中断提供一个服务方法(ISR,Interrupt
Service Routine,即中断发生后,CPU调用的处理函数),中断本身也可以设置优先级。
中断会挂起普通的系统工作。当有数据已准备好可以给内核或者间接被一个应用程序使用的时候,外设出发一个中断。使用中断确保系统只有在外设需要处理器介入的时候才会通知处理器,有效提高了效率。
通过总线控制设备:不是所有的设备都是直接通过I/O语句寻址操作的,很多情况下是通过某个总线系统。
不是所有的设备类型都能直接挂接在所有的总线系统上,例如硬盘挂到SCSI接口上,但显卡不可以(显卡可以挂到PCI总线上)。硬盘必须通过IDE间接挂到PCI总线上。
总线类型可分为系统总线和扩展总线。硬件上的实现差别对内核来说并不重要,只有总线和它附着的外设如何被寻址才相关。对于系统总线来说,例如PCI总线,I/O语句和内存映射用来与总线通信,也用于和它附着的设备通信。内核还提供了一些命令供设备驱动来调用总线函数,例如访问可用的设备列表,使用统一的格式读写配置信息。
扩展总线例如USB,SCSI通过清晰定义的总线协议与附着的设备来交换数据和命令。内核通过I/O语句或内存映射来与总线通信,通过平台无关的函数来使总线与附着的设备通信。
与总线附着的设备通信不一定需要通过在内核空间的驱动进行,在某些情况下也可以通过用户空间实现。一个主要的例子是SCSI
Writer,通过cdrecord工具来寻址。这个工具产生所需要的SCSI命令,在内核的帮助下通过SCSI总线将命令发送到对应的设备,处理和回复设备产生或返回的信息。
块设备(block)和字符设备(character)在3个方面显著不同:
块设备中的数据能够在任何点操作,而字符设备不能也没这个要求。
块设备数据传输的时候总是使用固定大小的块。即使只请求一个字节的情况下,设备驱动也总是从设备获取一个完整的块。相反,字符设备能够返回单个字节。
读写块设备会使用缓存。读操作方面,数据缓存在内存中,能够在需要的时候重新访问。写操作方面,也会被缓存,延时写入设备。使用缓存对于字符设备(例如键盘)来说不合理,每个读请求都必须被可靠地交互到设备。
块和扇区的概念:块是一个指定大小的字节序列,用于保存在内核和设备间传输的数据,块的大小可以被设置。扇区是固定大小的,能被设备传输的最小的数据量。块是一段连续的扇区,块大小是扇区的整数倍。
网络
Linux的网络子系统为互联网的发展提供了坚实的基础。网络模型基于ISO的OSI模型,如下图右半部分。但在具体应用中,往往会把相应层级结合以简化模型,下图左半部分为Linux运用的TCP/IP参考模型。(由于介绍Linux网络部分的资料比较多,在本文中只对大的层级简单介绍,不展开说明。)

网络模型
Host-to-host层(Physical Layer和Data link layer,即物理层和数据链路层)负责将数据从一个计算机传输到另一台计算机。这一层处理物理传输介质的电气和编解码属性,也将数据流拆分成固定大小的数据帧用于传输。如多个电脑共享一个传输路线,网络适配器(网卡等)必须有一个唯一的ID(即MAC地址)来区分。从内核的角度,这一层是通过网卡的设备驱动实现的。
OSI模型的网络层在TCP/IP模型中称为网络层,网络层使网络中的计算机之间能交换数据,而这些计算机不一定是直接相连的。
如下图,A和B之间物理上并没有直接相连,所以也没有直接的数据交换。网络层的任务是为网络中各机器之间通信找到路由。
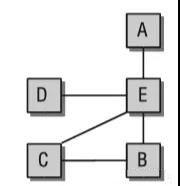
网络连接的电脑
网络层也负责将要传输的包分成指定的大小,因为包在传输路径上每个电脑支持的最大的数据包大小可能不一样,在传输时,数据流被分割成不同的包,在接收端再被组合。
网络层为网络中的电脑分配了唯一的网络地址以便他们能互相通信(不同于硬件的MAC地址,因为网络往往由子网络组成)。在互联网中,网络层由IP网络组成,有V4和V6版本。
传输层的任务是规范在两个连接的电脑上运行的应用程序之间的数据传输。例如两台电脑上的客户端和服务端程序,包括TCP或UDP连接,通过端口号来识别通信的应用程序。例如端口号80用于web
server,浏览器的客户端必须将请求发送到这个端口来获取需要的数据。而客户端也需要有一个唯一的端口号以便web
server能将回复发送给它。
这一层还负责为数据的传输提供一个可靠的连接(TCP情况下)。
TCP/IP模型中的应用层在OSI模型中包含(session层,展现层,应用层)。当通信连接在两个应用之间建立起来后,这一层负责实际内容的传输。例如web
server与它的客户端传输时的协议和数据,不同与mail server与它的客户端之间。
大多数的网络协议在RFC(Request for Comments)中定义。
网络实现分层模型:内核对网络层的实现类似TCP/IP参考模型。它是通过C代码实现的,每个层只能和它的上下层通信,这样的好处是可以将不同的协议和传输机制结合。如下图所示:

网络实现分层图
|








