| 编辑推荐: |
本文介绍不同类型AI服务器之比较分析,选择GPU服务器的基本原则,AI超级计算机DGX系统详解,NGC云平台使用方法和价值等希望对您有所帮助
本文来自于csdn由火龙果软件Delores编辑推荐。 |
|
选择GPU服务器的五大基本原则
从性能、可编程性、灵活性等方面对CPU、GPU、FPGA、ASIC等不同类型的服务器进行了系统的比较分析,并给出了五条选择GPU服务器的基本原则:
1.考虑业务应用先选择GPU型号
2.考虑服务器的使用场景及数量(边缘/中心)
3.考虑客户自身的目标使用人群及IT运维能力
4.考虑服务器配套软件的价值以及服务的价值
5.考虑整体GPU集群系统的成熟度及工程效率
NVIDIA 高级系统架构师易成则从计算性能、互联互通、可扩展性、适用场景等方面系统讲解了DGX-1、DGX-2、DGX Station以及如何利用VNIDIA NGC高效的使用DGX系统。
不同类型AI服务器之比较分析

首先看下不同类型AI服务器的比较,通过上面这张二维图中我们可以对不同架构的服务器进行简单的比较。从左上方到右下角依次是CPU、GPU、FPGA、TPU、ASIC,从横轴来看,越往右性能(Performance)越好。纵轴Programmability/Flexibility是指服务器的可编程性和灵活性, ASIC的性能最好,因为它是将算法固化在芯片上,算法是比较固定的,所以它的性能最好的,但是它的编程性和灵活性就相对比较弱。而CPU的灵活性和编程性最好,但性能最弱。总的来说,GPU的灵活性比CPU弱,但它的性能更好。往下依次是FPGA、TPU以及ASIC。在实际选择时需要考虑到功耗、成本、性能、实时性等各方面因素,尤其是一些具有专用目的的处理器,如果算法已经固化并且很简单,可以考虑ASIC,因为ASIC性能好且功耗低。如果是在训练或者通用情况下,GPU则是更好的选择。
选择GPU服务器的基本原则
在介绍选择GPU服务器的基本原则之前,先来跟大家介绍下常见的GPU和GPU服务器。
常见的GPU,按总线接口类型,可以分为NV-Link接口、传统总线接口以及传统PCI-e总线三种。
NV-Link接口类型的GPU典型代表是NVIDIA V100,采用 SXM2接口。在DGX-2上有SXM3的接口。NV-Link总线标准的GPU服务器可以分为两类,一类是NVIDIA公司设计的DGX超级计算机,另一类是合作伙伴设计的NV-Link接口的服务器。DGX超级计算机不仅仅提供硬件,还有相关的软件和服务。
传统总线接口的GPU,目前主流的有这几款产品,比如 PCI-e接口的V100、 P40(P开头指的是上一代PASCAL架构)和P4,以及最新的图灵架构T4等。其中比较薄和只占一个槽位的P4和T4,通常用于Inference,目前也已经有成熟的模型进行推理和识别。
传统PCI-e总线的GPU服务器也分为两类,一类是OEM服务器,比如曙光、浪潮、华为等其他国际品牌;另一类是非OEM的服务器,也包括很多种类。选择服务器时除了分类,还要考虑性能指标,比如精度、显存类型、显存容量以及功耗等,同时也会有一些服务器是需要水冷、降噪或者对温度、移动性等等方面有特殊的要求,就需要特殊的服务器。
选择GPU服务器时首先要考虑业务需求来选择适合的GPU型号。在HPC高性能计算中还需要根据精度来选择,比如有的高性能计算需要双精度,这时如果使用P40或者P4就不合适,只能使用V100或者P100;同时也会对显存容量有要求,比如石油或石化勘探类的计算应用对显存要求比较高;还有些对总线标准有要求,因此选择GPU型号要先看业务需求。
GPU服务器人工智能领域的应用也比较多。在教学场景中,对GPU虚拟化的要求比较高。根据课堂人数,一个老师可能需要将GPU服务器虚拟出30甚至60个虚拟GPU,因此批量Training对GPU要求比较高,通常用V100做GPU的训练。模型训练完之后需要进行推理,因此推理一般会使用P4或者T4,少部分情况也会用V100。
当GPU型号选定后,再考虑用什么样GPU的服务器。这时我们需要考虑以下几种情况:
第一、 在边缘服务器上需要根据量来选择T4或者P4等相应的服务器,同时也要考虑服务器的使用场景,比如火车站卡口、机场卡口或者公安卡口等;在中心端做Inference时可能需要V100的服务器,需要考虑吞吐量以及使用场景、数量等。
第二、 需要考虑客户本身使用人群和IT运维能力,对于BAT这类大公司来说,他们自己的运营能力比较强,这时会选择通用的PCI-e服务器;而对于一些IT运维能力不那么强的客户,他们更关注数字以及数据标注等,我们称这类人为数据科学家,选择GPU服务器的标准也会有所不同。
第三、 需要考虑配套软件和服务的价值。
第四、 要考虑整体GPU集群系统的成熟程度以及工程效率,比如像DGX这种GPU一体化的超级计算机,它有非常成熟的从底端的操作系统驱动Docker到其他部分都是固定且优化过的,这时效率就比较高。
AI超级计算机DGX系统详解
目前DGX产品主要包含DGX工作站(DGX Station)、DGX-1服务器以及今年刚发布的DGX-2服务器三款产品。它们都是NVIDIA推出的软硬一体机产品,主要包括操作系统、相关软件以及配套的硬件。以往我们买服务器或工作站时,通常需要自己在服务器中安装操作系统并部署应用软件,而在DGX一体机上就不需要这个过程了,所有的软件出厂时就已经完成了安装配置,开机就可以使用,非常适合开发人员做深度学习或高性能计算的应用。
在介绍DGX超级计算机之前,先了解一下超级计算机的计算核心V100 GPU。在DGX中使用的是NVLink GPU,包含5120个CUDA核心,640个TensorCore,双精度的计算能力瀀??
达到7.8万亿次,深度学习的计算能力达到125万亿次。GPU之间可以通过NVLink进行互相访问,带宽可以达到300GB/s。而PCI-e的GPU只能通过PCI-e总线进行GPU之间的互相访问,带宽为32GB。因此相比较而言,NVLink版V100是目前性能最强的GPU。
与上一代GPU相比,V100 GPU采用最新的Volta架构,采用SM流多处理器架构,首次引进了Tensor Core计算核心,这也是以前Pascal架构所没有的,大大增强了GPU的深度学习计算性能。V100采用了新一代的NVLink 2.0技术,双向总带宽可以达到300GB/s,并且采用了新的HBM2显存,可以达到900GB/s的IO带宽。V100引入了新的MPS多进程服务技术,以提高GPU的利用率,还改进了SMIT的计算模型。
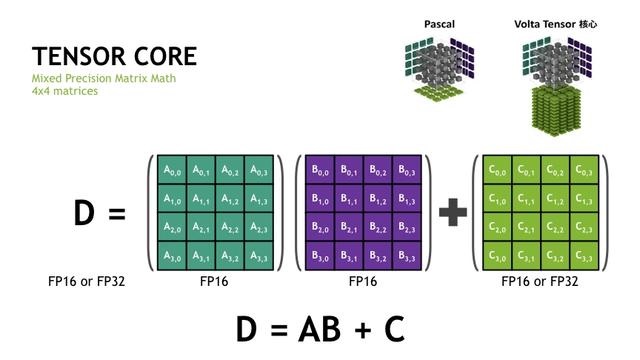
Tensor Core是V100非常重要的特性,支持混合精度计算,如上图所示的D=A*B+ C的混合矩阵乘加计算。在矩阵中,矩阵A和矩阵B要求是半精度的FP16类型,而加法矩阵C可以是半精度FP16或者是单精度FP32类型,左边的计算结果也可以是FP16或FP32类型。
DGX-1服务器主要用于数据中心的深度学习或者高性能计算应用,整机的计算峰值可以达到1000万亿次。我们都知道,深圳超算中心的计算能力大约是1200万亿次,也就是一台DGX-1的计算能力和一个超算中心的计算能力相当,之所以说适合于数据中心,是因为DGX-1服务器需要安装在机柜中,功耗达到3200瓦,噪音也比较大,因此只能放在数据中心的机房。
DGX-1配置了8块最新的NVLink V100 GPU,每块GPU是32GB显存,配置了大容量的内存,一共是512GB,可以将大量的数据读入内存。配置了7TB的SSD作为本地缓存,SSD配置的是RAID 0模式,仅仅作为本地的缓存,可以实现高速存储的IO性能。另外,DGX-1配置了4个100Gb的网卡,并且可以选择InfiniBand或以太网模式,是为了配置GPU集群预留的网络接口,可以作为节点间通讯的计算网络或存储网络。

DGX-1服务器的内部网络拓朴架构中有8个GPU服务器,这8个GPU互联成一个立方体的拓朴架构,每一个顶点是一块GPU。另外,从图中可以看到还有NVLink、PCI-E、QPI 三种互联通道,绿色的粗线条代表NVLink,紫色的细线条代表PCI-E总线,黑色的线条代表QPI线。在做GPU并行计算时,GPU之间的通信可以选择两种方案:
第一、 GPU通过PCI-E总线进行通信,这种通讯的方效率比较低的。
第二、 通过NVLink实现GPU之间直接通信,很显然这种方式的通讯效率会很高。

接下来为大家介绍下DGX-1服务器中GPU的计算速度和扩展性。图中柱状图表示计算速度,曲线代表扩展性,灰色的柱状图表示PCIe的GPU计算性能,绿色的柱状图表示NVLink GPU的性能。上图展示的数据是以神经网络翻译训练为例,从计算速度的角度看,与PCIe的GPU卡相比,GPU越多,NVLink GPU速度的优势越明显,8块NVLink GPU有20%的性能提升。从扩展性的角度看,8块NVLink GPU的加速比PCIe GPU高20%左右。从图中可以看出,8块DGX-1的服务器和普通的PCIe GPU服务器相比还是有比较大的性能优势,尤其是在深度学习框架或模型算法不支持集群计算的时候,使用DGX-1服务器会有比较大的优势。
NVIDIA DGX STATION是一个非常强大的工作站,可以达到480万亿次的计算能力,采用了最新的32GB V100 GPU。另一个特点是超静音设计,因为采用的是水冷模式而不是通常采用的风扇冷却方式,因此不需要机房,在办公室环境也可以使用,是特别为研发人员设计的个人超级计算机。

上图展示了DGX工作站的详细配置,包括GPU内存、SSD详细的配置情况等。可以看到,它的配置还是非常高的,完全满足开发研究人员做深度学习和高性能计算的需求。
最新发布的DGX-2服务器的计算能力是2000万亿次,是目前世界上性能最强的深度学习单机系统。
DGX-2的内部架构与DGX-1相比,在配置有比较大的提升,其中包括2个GPU主板,每个主板包括8块32GB V100 GPU和6个NVSwitch,采用全线速互联的方式,任意两块GPU之间通信总带宽可以达到300GB每秒,系统配置最新的Intel Xeon CPU,配置1.5TB的主机内存,8个100Gb的网卡,可以支持InfiniBand和以太网模式互相切换。这8个网卡主要用于做计算网络,另外还配置两个100Gb的网络接口作为存储网络,也可以支持InfiniBand和以太网的切换模式。DGX-2配置30TB NVME SSDs,和DGX-1一样,也是作为本地缓存使用。

从这张图我们可以看到DGX-2的内部结构,包括GPU主板以及其他配置。先来看下DGX-2中GPU互联的网络拓朴结构,DGX-2有两个GPU主板,每个主板包含8块GPU,6个NVSwitch,这是因为每个GPU有六个NVLink通道,每个通道连接一个NVSwitch。对于NVSwitch,我们可以把它理解成18端口的NVLink交换机,因为每个NVSwitch和八个GPU相连,一个GPU主板上所有NVSwitch通过背板和另外一个主板上的GPU互联,这样就能实现所有GPU都达到全互联状态,任意两个GPU之间的带宽都可以达到300GB/s。每个NVSwitch和8个GPU相连,有8个GPU NVLink接入,然后会有8个端口连出到背板上,因此一共占用了16个端口,还有两个端口剩余。
一台DGX-2服务器和两台DGX-1服务器相比,在相同数量GPU卡的情况下,在高性能计算深度学习应用中, DGX-2服务器相较DGX-1会有两倍以上的性能加速,之所以能超过两倍,是因为GPU数量增加两倍,而性能超过两倍是因为DGX-2 GPU之间的通讯效率比DGX-1要高,因此它的并行效率会更高。
NGC云平台使用方法和价值
DGX工作站和服务器都是软硬一体的计算平台,因此DGX不仅仅是一台硬件设备,还是一套完整的深度学习和高性能计算平台。DGX系统预装了NVIDIA优化的操作系统、Driver、SDK以及NVIDIA Docker引擎,也预装了各种深度学习框架和高性能计算的应用软件,并且所有的应用软件都会定期更新,一般每个月都会更新一次,这些更新都会发布在NGC云平台上。这里所说的应用都是以Docker容器镜像的方式提供。Docker容器是一个非常有用的工具,跟虚拟机有很多相似的地方,但是容器是一个效率更高更方便的工具。
NGC云平台上所提供的资源,包括深度学习的框架以及高性能计算资源,这些软件都是以容器镜像的方式提供。比如一些搞AI研究的研究员或者数据科学家经常会在网站或者论文上看到一些新的模型,并且想要验证一下效果。但这些模型需要的一些框架不一定是现在已经在用的,或者版本也不一定有。如果要下载一个最新的版本的框架,比如Caffe框架来进行测试,自己手动去安装这些软件会非常麻烦,需要安装cuDNN、OpenCV、Python等这些软件,另外还可能会存在一些版本的冲突,可能在软件部署上就会浪费一两天甚至一周的时间。而如果我们可以从NGC上去下载一个Caffe版本,就可以直接把我们的模型导入进去运行,这对于我们验证和测试环境的软件都是非常有用的,当然,对于生产环境,也可以自己去部署软件。

接下来介绍一下NGC资源的使用流程。首先,免费注册并登录NGC平台(ngc.nvidia.com),登录后需要获取账号和密码,点击右上角Get API Key进入一个新的页面。在这个页面上点击右上角的Generate API key,这时候会弹出一个要确认的信息,我们点击Confirm就可以生成图4所示的账号和密码。获得账号和密码后,就可以在DGX系统中进行登录。
图5是一个范例,输入用户名和密码,需要注意的是,输入密码时不要加入空格,显示登录成功后,就可以输入我们需要下载应用软件的一些下载命令,输入 “docker pull nvcr.io/nvidia/caffe:18.09-py3”命令,这些应用的下载都非常简单,按照这张图中的操作步骤就可以完成下载,使用也非常方便。
DGX系统快速上手的最佳攻略

那么如何用好DGX系统呢?首先要用好V100的混合精度计算性能,在前面我们已经介绍了Tensor Core,可以支持混合精度的计算,也就是上图左上角的混合精度矩阵的乘加计算。有很多用户反映,他们买了DGX-1后发现和相同数量GPU P100相比,性能也没有特别大的提升。后来发现他们用的是单精度做训练,也就是将P100上运行的代码直接拿到DGX-1上运行,而并没有做修改,这样一来还是单精度的训练,并不会自动使用混合精度。
为了用好V100的混合精度计算性能,我们需要在源代码上做一些小的修改。比如在做训练时,需要把有些权重副本、梯度或者激活值等变量改为半精度FP16,可以提高它的计算速度,还可以减小内存的占用。在更新权重时,我们把它强制转化为FP32的单精度,可以保证训练模型的精度不会下降,因此在采用了一些小的修改后,再去做一些训练的计算才会获得比较高的计算速度。
缩短数据读写的时间也是提高计算速度比较重要的一点。在训练时都需要从网络文件系统读写数据,通常延时会比较大,因此DGX-1会配置文件系统的缓存功能,将数据缓存到系统的本地,而这一点不需要用户考虑,系统会自动配置好。当然有些用户会自己把数据拷贝到本地,这也是一个不错的办法。另外,由于本地SSD配置为RAID 0,它的可靠性比较低,因此不建议将重要数据长期存放在缓存里面,这将会很不安全。
在搭建GPU集群的时候,网络不一定是InfiniBand类型,经常会遇到40Gb的以太网,这时我们可以将DGX-1的网络接口切换为以太网模式,这样就可以接入到40Gb的以太网络环境中。

充分利用NVLINK网络通信的功能也是用好DGX一个很重要的点。如果使用普通的MPI模式进行通信,GPU之间采用PCIe,它的通信效率会比较低。为了采用NVLink通信,我们可以使用NCCL库,在Horovod软件中集成了NVIDIA NCCL库,它是一个采用的如右边这张图的算法,这个算法是百度最先提出来的。
从左边图上我们可以看到普通的TensorFlow并行和Horovod相比,GPU卡越多性能差距越明显,因此我们建议,在做多GPU并行或者多节点并行时,使用NCCL库作为通讯方式。另外,我们在NGC平台上提供的深度学习框架的资源中也已经集成了NCCL库,因此建议大家尽量使用NGC中的深度学习框架资源。
NVIDIA DGX服务器和工作站是软硬一体的产品,而且软件和硬件都出自NVIDIA,可以给用户提供一个高性能、高可靠的系统,提供完善的软件和硬件服务,包括故障处理、性能调优、应用移植等。NVIDIA有强大的AI专家团队,也可以快速解决大家在使用过程中的问题,提供一些AI算法等层面的支持。这对大家节省时间、快速迭代、缩短产品研发周期也是非常有帮助的,这也是NVIDIA服务的优势。
DGX系统各行业应用案例
DGX在互联网行业的应用,比如美国社交网络公司Facebook,去年采购了几百台DGX-1用于Deep Text和图像识别等。我们也知道,Facebook可以识别很多用户的政治倾向等方面的信息,同时他们也有很大的能力去做更多各种各样的分析。
DGX在智慧城市领域的应用,中国第一台DGX-1是海康威视所采购的,海康威视是全世界最大的监控设备厂商,他们使用DGX训练神经网络,但在识别时会用到另外的边缘服务器,同时还不是通用的PCIe卡,而是用Tegra X2,多个Tegra X2集成到一块卡中,并插在一个比较小的前端边缘服务器上。
DGX在初创公司的应用,Face++在使用大量的DGX和传统的PCIe服务器结合应用于在智能监控领域。商汤科技采用DGX用于人脸识别、车辆识别等。商汤科技在第一批DGX产生时就和NVIDIA有合作了。另外还有国内非常著名的手机厂商,他们也采用DGX用于数据分析或语音识别等。
DGX在教育科研行业的应用,以冷冻电镜为例,使用Relion GPU版,可以帮他们缩短分析计算的时间和成本。而国外用的最多的是美国的橡树岭国家实验室,它和IBM公司合作使用DGX打造了超级计算机Summit,总共有4608个节点,它的计算性能比神威·太湖之光还高一倍,其中NVIDIA V100的性能占据了95%的计算力。
DGX在制造业的应用,主要用在一些品质控制,比如原来有150多名检查员用眼睛去看那些产品的品质,要检查20-30分钟,如果使用DGX DeepLearning的方式来取代人来做识别,可以在4分钟内完成150人接近半个小时的工作。人有时候是会疲劳的,对眼睛伤害也很大。另一方面,在机器人上不仅是DGX的应用,DGX主要负责训练,训练好的模型会用到机器人上。另外还有国内物流产业的小车等在室外做识别都会用到DGX。

DGX在医疗行业的应用,应用最多是医学影像识别。如上图所示,黄颜色是人类有经验的医师给出的诊断,浅颜色是机器进行了训练后得到诊断。比如上海长征医院,有的医生一天要看一百多个病人,将近200张片子,同时有的肺片CT是32线或者64线。在排查时,医生需要从肺的底端到顶端进行排查。尤其人到下午的时间,疲劳度各个方面都会受到比较大的影响,同时准确率也会受到一些影响。在有了机器诊断后,不仅可以降低医学影像师的工作量,对医生也有很大帮助。另外,机器可学习的种类更多,学习效率更高,因此诊断结果也会更精准。
DGX在癌症研究方面的应用,比如美国能源部下属的国家癌症研究中心有一个癌症登月计划的项目,采用了124台DGX-1,主要进行加速癌症治疗方案的研究、预测药物治疗效果和分析病人对药物的效果等。
DGX在金融行业的应用,目前几个主要的银行或者大保险公司都在使用GPU服务器,少部分已经开始使用DGX。主要用于快速处理数据,以增加对损失的评估准确率。
NVIDIA在汽车自动驾驶方面有很多的应用,我们公司也有自己的DGX集群,总共有660台DGX-1,其中160台用于自动驾驶领域。利用这个集群我们可以做很多的训练,比如车辆识别、人员识别、交通识别以及模拟。自从出现过一些自动驾驶事故后,NVIDIA就不再进行实际路况的测试,而是放到模拟环境下进行测试,在模拟情况下的学习效率也会更高。
DGX在电信行业的应用,主要用于移动边缘计算。边缘计算主要是在雾端,目的是在雾端、边缘端可以有相关的Inference GPU服务器。所有物联网的设备比如红绿灯、探头、无人机、VR头盔等都可以通过5G进行识别。换句话说,不再需要IOT设备上的嵌入式GPU,因为5G会使网络成本变得很低,完全可以利用边缘服务器中的GPU来做Inference,从而获取更好的结果。
|








