| ±ύΦ≠ΆΤΦω: |
CPU
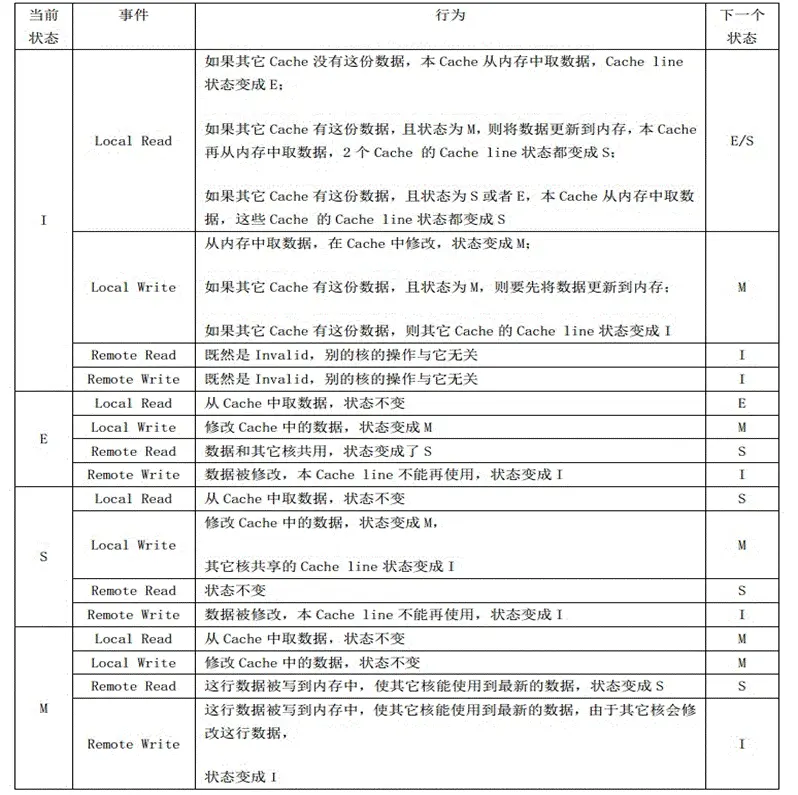
ΡΎ÷Ο…ΌΝΩΒΡΗΏΥΌΜΚ¥φΒΡ÷Ί“Σ–‘≤Μ―‘Εχ”ςΘ§‘ΎΧεΜΐΓΔ≥…±ΨΓΔ–ß¬ Β»“ρΥΊœ¬≤ζ…ζΝΥΒ±Ϋώ”ΟΒΫΒΡΦΤΥψΜζΒΡ¥φ¥ΔΫαΙΙΓΘ
±ΨΈΡά¥Ή‘”ΎinfoqΘ§”…ΜπΝζΙϊ»μΦΰAnna±ύΦ≠ΓΔΆΤΦωΓΘ |
|
CPU ΤΒ¬ ΧΪΩλΘ§Τδ¥ΠάμΥΌΕ»‘ΕΩλ”Ύ¥φ¥ΔΫι÷ ΒΡΕΝ–¥ΓΘ“ρ¥ΥΘ§ΒΦ÷¬ CPU
Ή ‘¥ΒΡάΥΖ―Θ§–η“Σ”––ßΫβΨω IO ΥΌΕ»ΚΆ CPU ‘ΥΥψΥΌΕ»÷°ΦδΒΡ≤ΜΤΞ≈δΈ ΧβΓΘ–ΨΤ§ΦΕΗΏΥΌΜΚ¥φΩ…¥σ¥σΦθ…Ό÷°ΦδΒΡ¥Πάμ―”≥ΌΓΘCPU
÷Τ‘λΙΛ“’ΒΡΫχ≤Ϋ ΙΒΟ‘Ύ±»“‘«ΑΗϋ–ΓΒΡΩ’Φδ÷–Α≤ΉΑ ΐ °“ΎΗωΨßΧεΙήΘ§»γ¥ΥΩ…ΈΣΜΚ¥φΝτ≥ωΗϋΕύΩ’ΦδΘ§ ΙΤδΨΓΩ…ΡήΒΊΩΩΫϋΚΥ–ΡΓΘ
CPU ΡΎ÷Ο…ΌΝΩΒΡΗΏΥΌΜΚ¥φΒΡ÷Ί“Σ–‘≤Μ―‘Εχ”ςΘ§‘ΎΧεΜΐΓΔ≥…±ΨΓΔ–ß¬ Β»“ρΥΊœ¬≤ζ…ζΝΥΒ±Ϋώ”ΟΒΫΒΡΦΤΥψΜζΒΡ¥φ¥ΔΫαΙΙΓΘ
Ϋι …ή
ΦΤΥψΜζΒΡΡΎ¥φΨΏ”–Μυ”ΎΥΌΕ»ΒΡ≤ψ¥ΈΫαΙΙΘ§CPU ΗΏΥΌΜΚ¥φΈΜ”ΎΗΟ≤ψ¥ΈΫαΙΙΒΡΕΞ≤ΩΘ§ «Ϋι”Ύ CPU ΡΎΚΥΚΆΈοάμΡΎ¥φ(Ε·Χ§ΡΎ¥φ
DRAM)÷°ΦδΒΡ»τΗ…ΩιΨ≤Χ§ΡΎ¥φΘ§ «ΉνΩλΒΡΓΘΥϋ“≤ «ΉνΩΩΫϋ÷–―κ¥ΠάμΒΡΒΊΖΫΘ§ « CPU ±Ψ…μΒΡ“Μ≤ΩΖ÷Θ§“ΜΑψ÷±Ϋ”Ηζ
CPU –ΨΤ§Φ·≥…ΓΘ
CPU ΦΤΥψΘΚ≥Χ–ρ±Μ…ηΦΤΈΣ“ΜΉι÷ΗΝνΘ§Ήν÷’”… CPU ‘Υ––ΓΘ

ΉΑ‘Ί≥Χ–ρΚΆ ΐΨίΘ§œ»¥”ΉνΫϋΒΡ“ΜΦΕΜΚ¥φΕΝ»ΓΘ§»γ”–ΨΆ÷±Ϋ”ΖΒΜΊΘ§÷π≤ψΕΝ»ΓΘ§÷±÷Ν¥”ΡΎ¥φΦΑΤδΥϋΆβ≤Ω¥φ¥Δ÷–Φ”‘ΊΘ§≤ΔΫΪΦ”‘ΊΒΡ ΐΨί“ά¥ΈΖ≈»κΜΚ¥φΓΘ
ΗΏΥΌΜΚ¥φ÷–ΒΡ ΐΨί–¥ΜΊ÷ς¥φ≤ΔΖ«ΝΔΦ¥÷¥––Θ§–¥ΜΊ÷ς¥φΒΡ ±ΜζΘΚ
1.ΜΚ¥φ¬ζΝΥΘ§≤…”Οœ»Ϋχœ»≥ωΜρΉνΨΟΈ¥ Ι”ΟΒΡΥ≥–ρ–¥ΜΊΘΜ
2.#Lock –≈Κ≈Θ§ΜΚ¥φ“Μ÷¬–‘–≠“ιΘ§Ος»Ζ“Σ«σ ΐΨίΦΤΥψΆξ≥…Κσ“ΣΝΔ¬μΆ§≤ΫΜΊ÷ς¥φΓΘ
CPU ΜΚ¥φΒΡΫαΙΙ
œ÷¥ζΒΡ CPU ΜΚ¥φΫαΙΙ±ΜΖ÷ΈΣΕύ¥ΠάμΓΔΕύΚΥΓΔΕύΦΕΒΡ≤ψ¥ΈΓΘ
2.1 ΕύΦΕΜΚ¥φΫαΙΙ
Ζ÷ΈΣ»ΐΗω÷ς“ΣΦΕ±πΘ§Φ¥ L1Θ§L2 ΚΆ L3ΓΘάκ CPU ‘ΫΫϋΒΡΜΚ¥φΘ§ΕΝ»Γ–ß¬ ‘ΫΗΏΘ§¥φ¥Δ»ίΝΩ‘Ϋ–ΓΘ§‘λΦέ‘ΫΗΏΓΘ
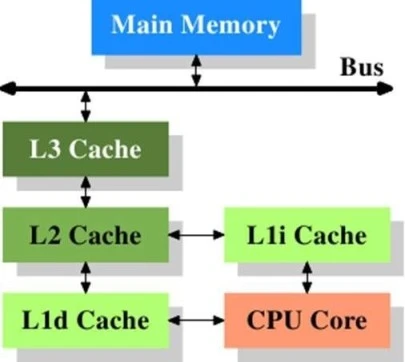
L1 ΗΏΥΌΜΚ¥φ «œΒΆ≥÷–¥φ‘ΎΒΡΉνΩλΒΡΡΎ¥φΓΘΨΆ”≈œ»ΦΕΕχ―‘Θ§L1 ΜΚ¥φΨΏ”– CPU ‘ΎΆξ≥…ΧΊΕ®»ΈΈώ ±ΉνΩ…Ρή–η“ΣΒΡ ΐΨίΘ§¥σ–ΓΆ®≥ΘΩ…¥ο
256KBΘ§“Μ–©ΙΠΡή«Ω¥σΒΡ CPU ’Φ”ΟΫϋ 1MBΓΘΡ≥–©ΖΰΈώΤς–ΨΤ§Ήι(»γ Intel ΗΏΕΥ Xeon
CPU)ΨΏ”– 1-2MBΓΘL1 ΜΚ¥φΆ®≥Θ”÷Ζ÷ΈΣ÷ΗΝνΜΚ¥φΚΆ ΐΨίΜΚ¥φΓΘ÷ΗΝνΜΚ¥φ¥Πάμ”–ΙΊ CPU ±Ί–κ÷¥––ΒΡ≤ΌΉςΒΡ–≈œΔΘ§ ΐΨίΜΚ¥φ‘ρ±ΘΝτ“Σ‘ΎΤδ…œ÷¥––≤ΌΉςΒΡ ΐΨίΓΘ»γ¥ΥΘ§Φθ…ΌΝΥ’υ”Ο
Cache Υυ‘λ≥…ΒΡ≥εΆΜΘ§ΧαΗΏΝΥ¥ΠάμΤς–ßΡήΓΘ
L2 ΦΕΜΚ¥φ±» L1 ¬ΐΘ§ΒΪ¥σ–ΓΗϋ¥σΘ§Ά®≥Θ‘Ύ 256KB ΒΫ 8MB ÷°ΦδΘ§ΙΠΡή«Ω¥σΒΡ CPU ΆυΆυΜα≥§Ιΐ¥Υ¥σ–ΓΓΘL2
ΗΏΥΌΜΚ¥φ±Θ¥φœ¬“Μ≤ΫΩ…Ρή”… CPU ΖΟΈ ΒΡ ΐΨίΓΘ¥σΕύ ΐ CPU ÷–Θ§L1 ΚΆ L2 ΗΏΥΌΜΚ¥φΈΜ”Ύ CPU
ΡΎΚΥ±Ψ…μΘ§ΟΩΗωΡΎΚΥΕΦ”–Ή‘ΦΚΒΡΗΏΥΌΜΚ¥φΓΘ
L3 ΦΕΗΏΥΌΜΚ¥φ «Ήν¥σΒΡΗΏΥΌ¥φ¥ΔΒΞ‘ΣΘ§“≤ «Ήν¬ΐΒΡΓΘ¥σ–Γ¥” 4MB ΒΫ 50MB “‘…œΓΘœ÷¥ζ CPU
‘Ύ CPU ¬ψΤ§…œΨΏ”–”Ο”Ύ L3 ΗΏΥΌΜΚ¥φΒΡΉ®”ΟΩ’ΦδΘ§«“’Φ”ΟΝΥΚή¥σ“Μ≤ΩΖ÷Ω’ΦδΓΘ
2.2 Εύ¥ΠάμΤςΜΚ¥φΫαΙΙ
ΦΤΥψΜζ‘γ“―Ϋχ»κΕύΚΥ ±¥ζΘ§»μΦΰ“≤‘Υ––‘ΎΕύΚΥΜΖΨ≥ΓΘ“ΜΗω¥ΠάμΤςΕ‘”Π“ΜΗωΈοάμ≤ε≤έΓΔΑϋΚ§ΕύΗωΚΥΘ®“ΜΗωΚΥΑϋΚ§ΦΡ¥φΤςΓΔL1
CacheΓΔL2 CacheΘ©Θ§ΕύΚΥΦδΙ≤œμ L3 CacheΘ§Εύ¥ΠάμΤςΦδΆ®Ιΐ QPI ΉήœΏœύΝ§ΓΘ
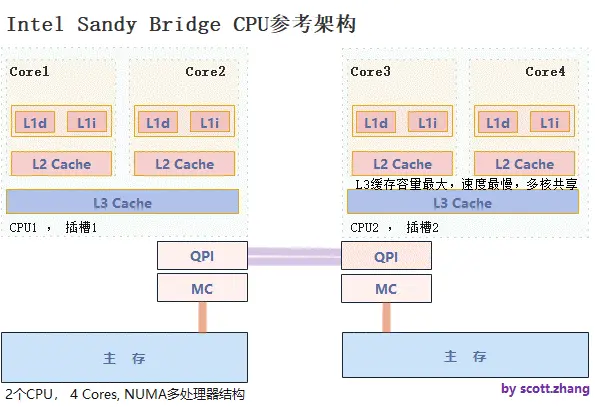
L1 ΚΆ L2 ΜΚ¥φΈΣ CPU ΒΞΗωΚΥ–ΡΥΫ”–ΒΡΜΚ¥φΘ§L3 ΜΚ¥φ «Ά§≤ε≤έΒΡΥυ”–ΚΥ–ΡΕΦΙ≤œμΒΡΜΚ¥φΓΘ
L1 ΜΚ¥φ±ΜΖ÷≥…ΕάΝΔΒΡ 32K ΐΨίΜΚ¥φΚΆ 32K ÷ΗΝνΜΚ¥φΘ§L2 ΜΚ¥φ±Μ…ηΦΤΈΣ L1 ”κΙ≤œμΒΡ
L3 ΜΚ¥φ÷°ΦδΒΡΜΚ≥εΓΘ¥σ–ΓΈΣ 256KΘ§÷ς“ΣΉςΈΣ L1 ΚΆ L3 ÷°ΦδΒΡΗΏ–ßΡΎ¥φΖΟΈ Ε”Ν–,Ά§ ±ΑϋΚ§ ΐΨίΚΆ÷ΗΝνΓΘL3
ΜΚ¥φΑϋά®ΝΥ‘ΎΆ§“ΜΗω≤έ…œΒΡΥυ”– L1 ΚΆ L2 ΜΚ¥φ÷–ΒΡ ΐΨίΓΘ’β÷÷…ηΦΤœϊΚΡΝΥΩ’ΦδΘ§ΒΪΩ…άΙΫΊΕ‘ L1 ΚΆ
L2 ΜΚ¥φΒΡ«κ«σΘ§Φθ«αΝΥΗςΗωΚΥ–ΡΥΫ”–ΒΡ L1 ΚΆ L2 ΜΚ¥φΒΡΗΚΒΘΓΘ
2.3 Cache Line
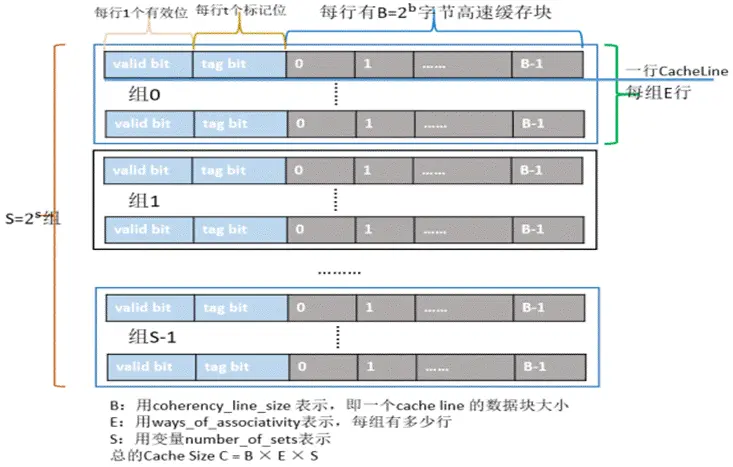
Cache ¥φ¥Δ ΐΨί“‘ΙΧΕ®¥σ–ΓΈΣΒΞΈΜΘ§≥ΤΈΣ Cache Line/BlockΓΘΗχΕ®»ίΝΩΚΆ Cache
Line sizeΘ§‘ρΨΆΙΧΕ®ΝΥ¥φ¥ΔΒΡΧθΡΩΗω ΐΓΘΕ‘”Ύ X86Θ§Cache Line ¥σ–Γ”κ DDR “Μ¥ΈΖΟ¥φΡήΒΟΒΫΒΡ ΐΨί¥σ–Γ“Μ÷¬Θ§Φ¥
64BΓΘΨ…ΒΡ ARM ΦήΙΙΒΡ Cache Line « 32BΘ§“ρ¥ΥΨ≠≥Θ «“Μ¥ΈΧνΝΫΗω Cache LineΓΘCPU
¥” Cache Μώ»Γ ΐΨίΒΡΉν–ΓΒΞΈΜΈΣΉ÷ΫΎΘ§Cache ¥” Memory Μώ»ΓΒΡΉν–ΓΒΞΈΜ « Cache
LineΘ§Memory ¥”¥≈≈ΧΜώ»Γ ΐΨίΆ®≥ΘΉν–Γ « 4KΓΘ
Cache Ζ÷≥…ΕύΗωΉιΘ§ΟΩΉιΖ÷≥…ΕύΗω Cache Line ––Θ§¥σ÷¬»γœ¬ΆΦΘΚ
Linux œΒΆ≥œ¬ Ι”Ο“‘œ¬ΟϋΝν≤ιΩ¥ Cache –≈œΔΘ§lscpu ΟϋΝν“≤Ω…ΓΘ

ΜΚ¥φΒΡ¥φ»Γ”κ“Μ÷¬
œ¬Οφ±μΗώΟη ωΝΥ≤ΜΆ§¥φ¥ΔΫι÷ ΒΡ¥φ»Γ–≈œΔΘ§Ι©≤ΈΩΦΓΘ
¥φ»ΓΥΌΕ»ΘΚΦΡ¥φΤς > cache(L1~L3) > RAM > Flash >
”≤≈Χ > Άχ¬γ¥φ¥Δ
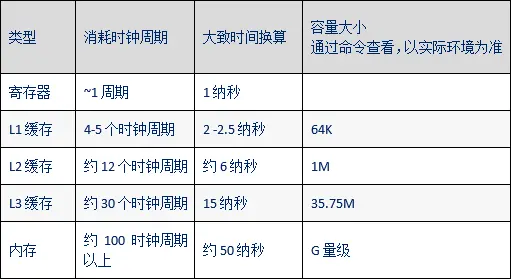
“‘ 2.2Ghz ΤΒ¬ ΒΡ CPU ΈΣάΐΘ§ΟΩΗω ±÷”÷ήΤΎ¥σΗ≈ « 0.5 Ρ…ΟκΓΘ
3.1 ΕΝ»Γ¥φ¥ΔΤς ΐΨί
Α¥ CPU ≤ψΦΕΜΚ¥φΫαΙΙΘ§»Γ ΐΨίΒΡΥ≥–ρ «œ»ΜΚ¥φ‘Ό÷ς¥φΓΘΒ±»ΜΘ§»γ ΐΨίά¥Ή‘ΦΡ¥φΤςΘ§÷Μ–η÷±Ϋ”ΕΝ»ΓΖΒΜΊΦ¥Ω…ΓΘ
1) »γ CPU “ΣΕΝΒΡ ΐΨί‘Ύ L1 cacheΘ§ΥχΉΓ cache ––Θ§ΕΝ»ΓΚσΫβΥχΓΔΖΒΜΊ
2) »γ CPU “ΣΕΝΒΡ ΐΨί‘Ύ L2 cacheΘ§ ΐΨί‘Ύ L2 άοΦ”ΥχΘ§ΫΪ ΐΨίΗ¥÷ΤΒΫ L1Θ§‘Ό÷¥––ΕΝ
L1
3) »γ CPU “ΣΕΝΒΡ ΐΨί‘Ύ L3 cacheΘ§“≤“Μ―υΘ§÷Μ≤ΜΙΐœ»”… L3 Η¥÷ΤΒΫ L2Θ§‘Ό¥” L2
Η¥÷ΤΒΫ L1Θ§ΉνΚσ¥” L1 ΒΫ CPU
4) »γ CPU –ηΕΝ»ΓΡΎ¥φΘ§‘ρ Ήœ»Ά®÷ΣΡΎ¥φΩΊ÷ΤΤς’Φ”ΟΉήœΏ¥χΩμΘ§ΚσΡΎ¥φΦ”ΥχΓΔΖΔΤπΕΝ«κ«σΓΔΒ»¥ΐΜΊ”ΠΘ§ΜΊ”Π ΐΨί±Θ¥φ÷Ν
L3Θ§L2,L1Θ§‘Ό¥” L1 ΒΫ CPU ΚσΫβ≥ΐΉήœΏΥχΕ®ΓΘ
3.2 ΜΚ¥φΟϋ÷–”κ―”≥Ό
”…”Ύ ΐΨίΒΡΨ÷≤Ω–‘‘≠άμΘ§CPU ΆυΆυ–η“Σ‘ΎΕΧ ±ΦδΡΎ÷ΊΗ¥Εύ¥ΈΕΝ»Γ ΐΨίΘ§ΡΎ¥φΒΡ‘Υ––ΤΒ¬ ‘ΕΗζ≤Μ…œ CPU
ΒΡ¥ΠάμΥΌΕ»Θ§ΜΚ¥φΒΡ÷Ί“Σ–‘±ΜΆΙœ‘ΓΘCPU Ω…±ήΩΣΡΎ¥φ‘ΎΜΚ¥φάοΕΝ»ΓΒΫœκ“ΣΒΡ ΐΨίΘ§≥Τ÷°ΈΣΟϋ÷–ΓΘL1 ΒΡ‘Υ––ΥΌΕ»ΚήΩλΘ§ΒΪ»ίΝΩΚή–ΓΘ§‘Ύ
L1 άοΟϋ÷–ΒΡΗ≈¬ ¥σΗ≈‘Ύ 80%Ήσ”“Θ§L2ΓΔL3 ΒΡΜζ÷Τ“≤άύΥΤΓΘ’β―υ“Μά¥Θ§CPU –η“Σ‘Ύ÷ς¥φ÷–ΕΝ»ΓΒΡ ΐΨί¥σΗ≈ΈΣ
5%-10%Θ§Τδ”ύΟϋ÷–»Ϊ≤ΩΩ…“‘‘Ύ L1ΓΔL2ΓΔL3 ÷–Μώ»ΓΘ§¥σ¥σΦθ…ΌΝΥœΒΆ≥ΒΡœλ”Π ±ΦδΓΘ
ΗΏΥΌΜΚ¥φ÷Φ‘ΎΦ”Ωλ÷ςΡΎ¥φΚΆ CPU ÷°ΦδΒΡ ΐΨί¥Ϊ δΓΘ¥”ΡΎ¥φΖΟΈ ΐΨίΥυ–ηΒΡ ±Φδ≥ΤΈΣ―”≥ΌΘ§L1 ΨΏ”–ΉνΒΆ―”≥Ό«“ΉνΫ”ΫϋΚΥ–ΡΘ§Εχ
L3 ΨΏ”–ΉνΗΏΒΡ―”≥ΌΓΘΜΚ¥φΈ¥Οϋ÷– ±Θ§”…”Ύ CPU –η¥”÷ς¥φ¥ΔΤς÷–Μώ»Γ ΐΨίΘ§ΒΦ÷¬―”≥ΌΜαΗϋΕύΓΘ
3.3 ΜΚ¥φΧφΜΜ≤Ώ¬‘
Cache άοΒΡ ΐΨί « Memory ÷–≥Θ”Ο ΐΨίΒΡ“ΜΗωΩΫ±¥Θ§¥φ¬ζΚσ‘Ό¥φ»κ“ΜΗω–¬ΒΡΧθΡΩ ±Θ§ΨΆ–η“ΣΑ―“ΜΗωΨ…ΒΡΧθΡΩ¥”ΜΚ¥φ÷–ΡΟΒτΘ§’βΗωΙΐ≥Χ≥ΤΈΣ
evictΓΘΜΚ¥φΙήάμΒΞ‘ΣΆ®Ιΐ“ΜΕ®ΒΡΥψΖ®ΨωΕ®ΡΡ–© ΐΨί–η“Σ¥” Cache άο“Τ≥ω»ΞΘ§≥ΤΈΣΧφΜΜ≤Ώ¬‘ΓΘΉνΦρΒΞΒΡ≤Ώ¬‘ΈΣ
LRUΘ§‘Ύ CPU …ηΦΤΒΡΙΐ≥Χ÷–Θ§Ά®≥ΘΜαΕ‘ΧφΜΜ≤Ώ¬‘Ϋχ––ΗΡΫχΘ§ΟΩ“ΜΩν–ΨΤ§ΦΗΚθΕΦ Ι”ΟΝΥ≤ΜΆ§ΒΡΧφΜΜ≤Ώ¬‘ΓΘ
3.4 MESI ΜΚ¥φ“Μ÷¬–‘
‘ΎΕύ CPU ΒΡœΒΆ≥÷–Θ§ΟΩΗω CPU ΕΦ”–Ή‘ΦΚΒΡ±ΨΒΊ CacheΓΘ“ρ¥ΥΘ§Ά§“ΜΗωΒΊ÷ΖΒΡ ΐΨίΘ§”–Ω…Ρή‘ΎΕύΗω
CPU ΒΡ±ΨΒΊ Cache άο¥φ‘ΎΕύΖίΩΫ±¥ΓΘΈΣΝΥ±Θ÷Λ≥Χ–ρ÷¥––ΒΡ’ΐ»Ζ–‘Θ§ΨΆ±Ί–κ±Θ÷ΛΆ§“ΜΗω±δΝΩΘ§ΟΩΗω CPU
Ω¥ΒΫΒΡ÷ΒΕΦ «“Μ―υΒΡΓΘ“≤ΨΆ «ΥΒΘ§±Ί–κ“Σ±Θ÷ΛΟΩΗω CPU ΒΡ±ΨΒΊ Cache ÷–ΡήΙΜ»γ ΒΖ¥”≥ΡΎ¥φ÷–ΒΡ’φ Β ΐΨίΓΘ
ΦΌ…η“ΜΗω±δΝΩ‘Ύ CPU0 ΚΆ CPU1 ΒΡ±ΨΒΊ Cache ÷–ΕΦ”–“ΜΖίΩΫ±¥Θ§Β± CPU0 –όΗΡΝΥ’βΗω±δΝΩ ±Θ§ΨΆ±Ί–κ“‘Ρ≥÷÷ΖΫ ΫΆ®÷Σ
CPU1Θ§“‘±ψ CPU1 ΡήΙΜΦΑ ±Ηϋ–¬Ή‘ΦΚ±ΨΒΊ Cache ÷–ΒΡΩΫ±¥Θ§’β―υ≤≈Ρή‘ΎΝΫΗω CPU ÷°Φδ±Θ≥÷ ΐΨίΒΡΆ§≤ΫΘ§CPU
÷°ΦδΒΡ’β÷÷Ά§≤Ϋ”–Ϋœ¥σΩΣœζΓΘ
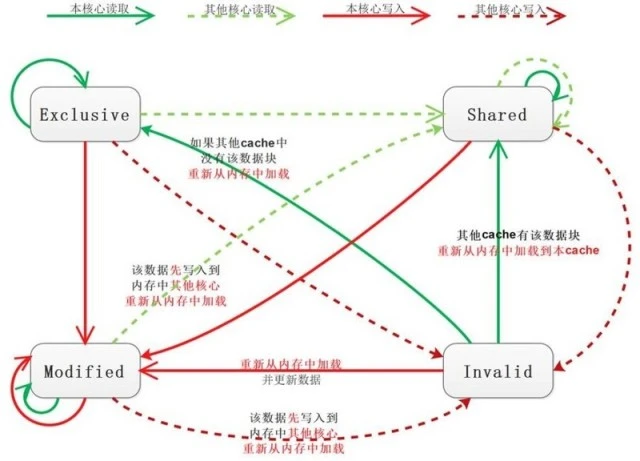
ΈΣ±Θ÷ΛΜΚ¥φ“Μ÷¬Θ§œ÷¥ζ CPU Βœ÷ΝΥΖ«≥ΘΗ¥‘”ΒΡΕύΚΥΓΔΕύΦΕΜΚ¥φ“Μ÷¬–‘–≠“ι MESI, MESI ΨΏΧεΒΡ≤ΌΉς…œΜα’κΕ‘ΒΞΗωΜΚ¥φ––Ϋχ––Φ”ΥχΓΘ
MESIΘΚModified Exclusive Shared or Invalid
1) –≠“ι÷–ΒΡΉ¥Χ§
CPU ÷–ΟΩΗωΜΚ¥φ–– Ι”Ο 4 ÷÷Ή¥Χ§Ϋχ––±ξΦ«( Ι”ΟΕνΆβΒΡΝΫΈΜ bit ±μ Ψ)
M: Modified
ΗΟΜΚ¥φ––÷Μ±ΜΜΚ¥φ‘ΎΗΟ CPU ΒΡΜΚ¥φ÷–Θ§«“±Μ–όΗΡΙΐ(dirty),Φ¥”κ÷ς¥φ÷–ΒΡ ΐΨί≤Μ“Μ÷¬Θ§ΗΟΜΚ¥φ––÷–ΒΡΡΎ»ί–η‘ΎΈ¥ά¥ΒΡΡ≥Ηω ±ΦδΒψ(‘ –μΤδΥϋ
CPU ΕΝ»Γ÷ς¥φ÷–œύ”ΠΡΎ¥φ÷°«Α)–¥ΜΊ÷ς¥φΓΘΒ±±Μ–¥ΜΊ÷ς¥φ÷°ΚσΘ§ΗΟΜΚ¥φ––ΒΡΉ¥Χ§±δ≥…Εάœμ(exclusive)Ή¥Χ§
E: Exclusive
ΗΟΜΚ¥φ––÷Μ±ΜΜΚ¥φ‘ΎΗΟ CPU ΒΡΜΚ¥φ÷–Θ§Έ¥±Μ–όΗΡΘ§”κ÷ς¥φ÷– ΐΨί“Μ÷¬ΓΘ‘Ύ»ΈΚΈ ±ΩΧΒ±”–ΤδΥϋ CPU ΕΝ»ΓΗΟΡΎ¥φ ±±δ≥…
shared Ή¥Χ§ΓΘΆ§―υΘ§Β±–όΗΡΗΟΜΚ¥φ––÷–ΡΎ»ί ±Θ§ΗΟΉ¥Χ§Ω…“‘±δ≥… Modified Ή¥Χ§.
S: Shared
“βΈΕΗΟΜΚ¥φ––Ω…Ρή±ΜΕύΗω CPU ΜΚ¥φΘ§ΗςΗωΜΚ¥φ÷–ΒΡ ΐΨί”κ÷ς¥φ ΐΨί“Μ÷¬Θ§Β±”–“ΜΗω CPU –όΗΡΗΟΜΚ¥φ––÷–Θ§ΤδΥϋ
CPU ÷–ΗΟΜΚ¥φ––Ω…“‘±ΜΉςΖœ(Invalid).
I: InvalidΘ§ΜΚ¥φΈό–ß(Ω…ΡήΤδΥϋ CPU –όΗΡΝΥΗΟΜΚ¥φ––)
2) Ή¥Χ§«–ΜΜΙΊœΒ
”…œ¬ΆΦΩ…Ω¥≥ω cache «»γΚΈ±Θ÷ΛΥϋΒΡ ΐΨί“Μ÷¬–‘ΒΡΓΘ
Τ©»γΘ§Β±«ΑΚΥ–Ρ“ΣΕΝ»ΓΒΡ ΐΨίΩι‘ΎΤδΚΥ–ΡΒΡ cache Ή¥Χ§ΈΣ InvalidΘ§‘ΎΤδΥϊΚΥ–Ρ…œ¥φ‘Ύ«“Ή¥Χ§ΈΣ
Modified ΒΡ«ιΩωΓΘΩ…“‘¥”Β±«ΑΚΥ–ΡΚΆΤδΥϋΚΥ–ΡΝΫΗωΫ«Ε»Ιέ≤λΘ§ΤδΥϋΚΥ–ΡΫ«Ε»ΘΚΒ±«ΑΉ¥Χ§ΈΣ ModifiedΘ§ΤδΥϋΚΥ–ΡœκΕΝ’βΗω ΐΨίΩι(ΆΦ÷–
Modified ΒΫ Shared ΒΡ¬Χ…Ϊ–ιœΏ)ΘΚœ»Α―ΗΡ±δΚσΒΡ ΐΨί–¥»κΒΫΡΎ¥φ÷–(œ»”ΎΤδΥϋΚΥ–ΡΒΡΕΝ)Θ§≤ΔΗϋ–¬ΗΟ
cache Ή¥Χ§ΈΣ Share.Β±«ΑΚΥ–ΡΫ«Ε»ΘΚΒ±«ΑΉ¥Χ§ΈΣ InvalidΘ§œκΕΝ’βΗω ΐΨίΩι(ΆΦ÷– Invalid
ΒΫ Shared ΒΡ¬Χ…Ϊ ΒœΏ)ΘΚ’β÷÷«ιΩωœ¬Μα¥”ΡΎ¥φ÷–÷Ί–¬Φ”‘ΊΘ§≤ΔΗϋ–¬ΗΟ cache Ή¥Χ§ Share
“‘œ¬±μΗώ¥”’βΝΫΗωΫ«Ε»Ν–ΨΌΝΥΥυ”–«ιΩωΘ§Ι©≤ΈΩΦΘΚ
3) ΜΚ¥φΒΡ≤ΌΉςΟη ω
“ΜΗωΒδ–ΆœΒΆ≥÷–Μα”–ΦΗΗωΜΚ¥φ(ΟΩΗωΚΥ–ΡΕΦ”–)Ι≤œμ÷ς¥φΉήœΏΘ§ΟΩΗωœύ”ΠΒΡ CPU ΜαΖΔ≥ωΕΝ–¥«κ«σΘ§ΕχΜΚ¥φΒΡΡΩΒΡ «ΈΣΝΥΦθ…Ό
CPU ΕΝ–¥Ι≤œμ÷ς¥φΒΡ¥Έ ΐΓΘ
“ΜΗωΜΚ¥φ≥ΐ‘Ύ Invalid Ή¥Χ§ΆβΕΦΩ…“‘¬ζΉψ CPU ΒΡΕΝ«κ«σΘ§“ΜΗω Invalid ΒΡΜΚ¥φ––±Ί–κ¥”÷ς¥φ÷–ΕΝ»Γ(±δ≥…
S Μρ E Ή¥Χ§)ά¥¬ζΉψΗΟ CPU ΒΡΕΝ«κ«σΓΘ
“ΜΗω–¥«κ«σ÷Μ”–‘ΎΗΟΜΚ¥φ–– « M Μρ E Ή¥Χ§ ±≤≈Ρή±Μ÷¥––Θ§»γΙϊΜΚ¥φ––¥Π”Ύ S Ή¥Χ§Θ§±Ί–κœ»ΫΪΤδΥϋΜΚ¥φ÷–ΗΟΜΚ¥φ––±δ≥…
Invalid(≤Μ‘ –μ≤ΜΆ§ CPU Ά§ ±–όΗΡΆ§“ΜΜΚ¥φ––Θ§Φ¥ Ι–όΗΡΗΟΜΚ¥φ––÷–≤ΜΆ§ΈΜ÷ΟΒΡ ΐΨί“≤≤ΜΩ…)Θ§ΗΟ≤ΌΉς≥Θ“‘Ιψ≤ΞΖΫ Ϋά¥Άξ≥…ΓΘ
ΜΚ¥φΩ…“‘Υφ ±ΫΪ“ΜΗωΖ« M Ή¥Χ§ΒΡΜΚ¥φ––ΉςΖœΘ§Μρ±δ≥… InvalidΘ§Εχ“ΜΗω M Ή¥Χ§ΒΡΜΚ¥φ––±Ί–κœ»±Μ–¥ΜΊ÷ς¥φΓΘ“ΜΗω¥Π”Ύ
M Ή¥Χ§ΒΡΜΚ¥φ––±Ί–κ ±ΩΧΦύΧΐΥυ”– ‘ΆΦΕΝΗΟΜΚ¥φ––œύΕ‘÷ς¥φΒΡ≤ΌΉςΘ§≤ΌΉς±Ί–κ‘ΎΜΚ¥φΫΪΗΟΜΚ¥φ–––¥ΜΊ÷ς¥φ≤ΔΫΪΉ¥Χ§±δ≥…
S Ή¥Χ§÷°«Α±Μ―”≥Ό÷¥––ΓΘ
“ΜΗω¥Π”Ύ S Ή¥Χ§ΒΡΜΚ¥φ–––ηΦύΧΐΤδΥϋΜΚ¥φ ΙΗΟΜΚ¥φ––Έό–ßΜρΕάœμΗΟΜΚ¥φ––ΒΡ«κ«σΘ§≤ΔΫΪΗΟΜΚ¥φ––±δ≥…Έό–ßΓΘ
“ΜΗω¥Π”Ύ E Ή¥Χ§ΒΡΜΚ¥φ––“≤±Ί–κΦύΧΐΤδΥϋΕΝ÷ς¥φ÷–ΗΟΜΚ¥φ––ΒΡ≤ΌΉςΘ§“ΜΒ©”–’β÷÷≤ΌΉςΘ§ΗΟΜΚ¥φ–––η±δ≥…
S Ή¥Χ§ΓΘ
Ε‘”Ύ M ΚΆ E Ή¥Χ§Εχ―‘Ήή «ΨΪ»ΖΒΡΘ§ΚΆΗΟΜΚ¥φ––ΒΡ’φ’ΐΉ¥Χ§ «“Μ÷¬ΒΡΓΘΕχ S Ή¥Χ§Ω…Ρή «Ζ«“Μ÷¬ΒΡΘ§»γΙϊ“ΜΗωΜΚ¥φΫΪ¥Π”Ύ
S Ή¥Χ§ΒΡΜΚ¥φ––ΉςΖœΝΥΘ§ΕχΝμ“ΜΗωΜΚ¥φ ΒΦ …œΩ…Ρή“―Ψ≠ΕάœμΝΥΗΟΜΚ¥φ––Θ§ΒΪ «ΗΟΜΚ¥φ»¥≤ΜΜαΫΪΗΟΜΚ¥φ––…ΐ«®ΈΣ
E Ή¥Χ§Θ§ «“ρΈΣΤδΥϋΜΚ¥φ≤ΜΜαΙψ≤ΞΉςΖœΒτΗΟΜΚ¥φ––ΒΡΆ®÷ΣΘ§Ά§―υΘ§”…”ΎΜΚ¥φ≤ΔΟΜ”–±Θ¥φΗΟΜΚ¥φ––ΒΡ copy
ΒΡ ΐΝΩΘ§“ρ¥Υ“≤ΟΜ”–ΑλΖ®»ΖΕ®Ή‘ΦΚ «Ζώ“―Ψ≠ΕάœμΝΥΗΟΜΚ¥φ––ΓΘ
¥”…œΟφΒΡ“β“εά¥Ω¥Θ§E Ή¥Χ§ «“Μ÷÷ΆΕΜζ–‘ΒΡ”≈Μ·ΘΚ»γΙϊ“ΜΗω CPU œκ–όΗΡ“ΜΗω¥Π”Ύ S Ή¥Χ§ΒΡΜΚ¥φ––Θ§ΉήœΏ ¬Έώ–η“ΣΫΪΥυ”–ΗΟΜΚ¥φ––ΒΡ
copy ±δ≥… Invalid Ή¥Χ§Θ§Εχ–όΗΡ E Ή¥Χ§ΒΡΜΚ¥φ≤Μ–η“Σ Ι”ΟΉήœΏ ¬ΈώΓΘ
¥ζ¬κ…ηΦΤΒΡΩΦΝΩ
άμΫβΦΤΥψΜζ¥φ¥ΔΤς≤ψ¥ΈΫαΙΙΕ‘”Π”Ο≥Χ–ρΒΡ–‘Ρή”ΑœλΓΘ»γΙϊ–η“ΣΒΡ≥Χ–ρ‘Ύ CPU ΦΡ¥φΤς÷–Θ§÷ΗΝν÷¥–– ± 1
Ηω÷ήΤΎΡΎΨΆΡήΖΟΈ ΒΫΘΜ»γΙϊ‘Ύ CPU Cache ÷–Θ§–η 1~30 Ηω÷ήΤΎΘΜ»γΙϊ‘Ύ÷ς¥φ÷–Θ§–η“Σ 50~200
Ηω÷ήΤΎΘΜ‘Ύ¥≈≈Χ…œΘ§¥σΗ≈–η“ΣΆρΦΕ÷ήΤΎΓΘΝμΆβΘ§Cache Line ΒΡ¥φ»Γ“≤ «¥ζ¬κ…ηΦΤ’Ώ–η“ΣΙΊΉΔΒΡ≤ΩΖ÷,
“‘Ιφ±ήΈ±Ι≤œμΒΡ÷¥––≥ΓΨΑΓΘ“ρ¥ΥΘ§≥δΖ÷άϊ”ΟΜΚ¥φΒΡΫαΙΙΚΆΜζ÷ΤΩ…”––ßΧαΗΏ≥Χ–ρΒΡ÷¥–––‘ΡήΓΘ
4.1 Ψ÷≤Ω–‘ΧΊ–‘
“ΜΒ© CPU “Σ¥”ΡΎ¥φΜρ¥≈≈Χ÷–ΖΟΈ ΐΨίΨΆΜα≤ζ…ζ“ΜΗωΚή¥σΒΡ ±―”Θ§≥Χ–ρ–‘Ρήœ‘÷χΫΒΒΆΘ§ΈΣ¥ΥΈ“Ο«≤ΜΒΟ≤ΜΧαΗΏ
Cache Οϋ÷–¬ Θ§“≤ΨΆ «≥δΖ÷ΖΔΜ”Ψ÷≤Ω–‘‘≠άμΓΘ“ΜΑψά¥ΥΒΘ§ΨΏ”–ΝΦΚΟΨ÷≤Ω–‘ΒΡ≥Χ–ρΜα±»Ψ÷≤Ω–‘Ϋœ≤νΒΡ≥Χ–ρ‘Υ––ΒΟΗϋΩλΘ§≥Χ–ρ–‘ΡήΗϋΚΟΓΘ
Ψ÷≤Ω–‘Μζ÷Τ»Ζ±Θ‘ΎΖΟΈ ¥φ¥Δ…η±Η ±Θ§¥φ»Γ ΐΨίΜρ÷ΗΝνΕΦ«ς”ΎΨέΦ·‘Ύ“ΜΤ§Ν§–χΒΡ«χ”ρΓΘ“ΜΗω…ηΦΤ”≈ΝΦΒΡΦΤΥψΜζ≥Χ–ρΆ®≥ΘΨΏ”–ΚήΚΟΒΡΨ÷≤Ω–‘Θ§ ±ΦδΨ÷≤Ω–‘ΚΆΩ’ΦδΨ÷≤Ω–‘ΓΘ
1) ±ΦδΨ÷≤Ω–‘
»γΙϊ“ΜΗω ΐΨί/–≈œΔœν±ΜΖΟΈ Ιΐ“Μ¥ΈΘ§Ρ«Ο¥Κή”–Ω…ΡήΥϋΜα‘ΎΚήΕΧΒΡ ±ΦδΡΎ‘Ό¥Έ±ΜΖΟΈ ΓΘ±»»γ―≠ΜΖΓΔΒίΙιΓΔΖΫΖ®ΒΡΖ¥Η¥Βς”ΟΒ»ΓΘ
2) Ω’ΦδΨ÷≤Ω–‘
“ΜΗω Cache Line ”– 64 Ή÷ΫΎΩιΘ§Ω…“‘≥δΖ÷άϊ”Ο“Μ¥ΈΦ”‘Ί 64 Ή÷ΫΎΒΡΩ’ΦδΘ§Α―≥Χ–ρΚσ–χΜαΖΟΈ ΒΡ ΐΨίΘ§“Μ¥Έ–‘»Ϊ≤ΩΦ”‘ΊΫχά¥Θ§¥”ΕχΧαΗΏ
Cache Line Οϋ÷–¬ Θ®ΕχΖ«÷Ί–¬»Ξ―Α÷ΖΕΝ»ΓΘ©ΓΘ»γΙϊ“ΜΗω ΐΨί±ΜΖΟΈ Θ§Ρ«Ο¥Κή”–Ω…ΡήΈΜ”Ύ’βΗω ΐΨίΗΫΫϋΒΡΤδΥϋ ΐΨί“≤ΜαΚήΩλ±ΜΖΟΈ ΒΫΓΘ±»»γΥ≥–ρ÷¥––ΒΡ¥ζ¬κΓΔΝ§–χ¥¥Ϋ®ΒΡΕύΗωΕ‘œσΓΔ ΐΉιΒ»ΓΘ ΐΉιΨΆ «“Μ÷÷Α―Ψ÷≤Ω–‘‘≠άμάϊ”ΟΒΫΦΪ÷¬ΒΡ ΐΨίΫαΙΙΓΘ
3) ¥ζ¬κ Ψάΐ
Ψάΐ 1Θ§(C ”ο―‘)
//≥Χ–ρ array1.c
ΕύΈ§ ΐΉιΫΜΜΜ––Ν–ΖΟΈ Υ≥–ρ
char array[10240][10240];
int main(int argc, char *argv[]){
int i = 0;
int j = 0;
for(i=0; i < 10240 ; i++) {
for(j=0; j < 10240 ; j++) {
array[i][j] = Γ°AΓ·; //Α¥––Ϋχ––ΖΟΈ
}
}
return 0;
} |
Κλ…ΪΉ÷ΧεΒΡ¥ζ¬κΒς’ϊΈΣΘΚ arrayj = Γ°AΓ·; //Α¥Ν–Ϋχ––ΖΟΈ
±ύ“κΓΔ‘Υ––ΫαΙϊ»γœ¬ΘΚ
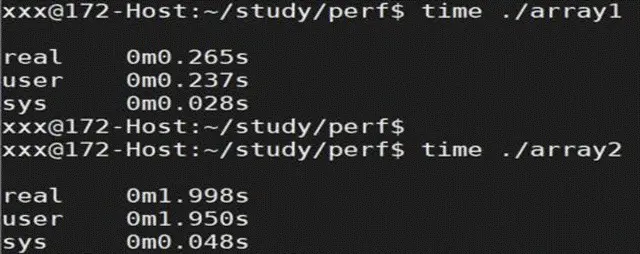
¥”≤β ‘ΫαΙϊΩ¥Θ§ΒΎ“ΜΗω≥Χ–ρ‘Υ––ΚΡ ± 0.265 ΟκΘ§ΒΎΕΰΗω 1.998
ΟκΘ§ «ΒΎ“ΜΗω≥Χ–ρΒΡ 7.5 ±ΕΓΘ
ΫαΙϊΖ÷Έω
ΐΉι‘ΣΥΊ¥φ¥Δ‘ΎΒΊ÷ΖΝ§–χΒΡΡΎ¥φ÷–Θ§ΕύΈ§ ΐΉι‘ΎΡΎ¥φ÷– «Α¥––Ϋχ––¥φ¥ΔΓΘΒΎ“ΜΗω≥Χ–ρΑ¥––ΖΟΈ Ρ≥Ηω‘ΣΥΊ ±Θ§ΗΟ‘ΣΥΊΗΫΫϋΒΡ“ΜΗω
Cache Line ¥σ–ΓΒΡ‘ΣΥΊΕΦΜα±ΜΦ”‘ΊΒΫ Cache ÷–Θ§’β―υ“Μά¥Θ§‘ΎΖΟΈ ΫτΑΛΉ≈ΒΡœ¬“ΜΗω‘ΣΥΊ ±Θ§ΨΆΩ…÷±Ϋ”ΖΟΈ
Cache ÷–ΒΡ ΐΨίΘ§≤Μ–η‘Ό¥”ΡΎ¥φ÷–Φ”‘ΊΓΘ“≤ΨΆ «ΥΒΘ§Ε‘ ΐΉιΑ¥––Ϋχ––ΖΟΈ ±Θ§ΨΏ”–ΗϋΚΟΒΡΩ’ΦδΨ÷≤Ω–‘Θ§Cache
Οϋ÷–¬ ΗϋΗΏΓΘ
ΒΎΕΰΗω≥Χ–ρΑ¥Ν–ΖΟΈ Ρ≥Ηω‘ΣΥΊΘ§Υδ»ΜΗΟ‘ΣΥΊΗΫΫϋΒΡ“ΜΗω Cache Line ¥σ–ΓΒΡ‘ΣΥΊ“≤Μα±ΜΦ”‘ΊΫχ Cache
÷–Θ§ΒΪΫ”œ¬ά¥“ΣΖΟΈ ΒΡ ΐΨί»¥≤Μ «ΫτΑΛΉ≈ΒΡΡ«Ηω‘ΣΥΊΘ§“ρ¥ΥΚή”–Ω…ΡήΜα‘Ό¥Έ≤ζ…ζ Cache missΘ§Εχ≤ΜΒΟ≤Μ¥”ΡΎ¥φ÷–Φ”‘Ί ΐΨίΓΘΕχ«“Θ§Υδ»Μ
Cache ÷–ΜαΨΓΝΩ±Θ¥φΉνΫϋΖΟΈ ΙΐΒΡ ΐΨίΘ§ΒΪ Cache ¥σ–Γ”–œόΘ§Β± Cache ±Μ’Φ¬ζ ±Θ§ΨΆ≤ΜΒΟ≤ΜΑ―“Μ–© ΐΨίΗχΧφΜΜΒτΓΘ’β“≤ «Ω’ΦδΨ÷≤Ω–‘≤νΒΡ≥Χ–ρΗϋ»ί“Ή≤ζ…ζ
Cache miss ΒΡ÷Ί“Σ‘≠“ρ÷°“ΜΓΘ
Ψάΐ 2Θ§Θ®JavaΘ©
“‘œ¬¥ζ¬κ÷–≥ΛΕ»ΈΣ 16 ΒΡ row ΚΆ column ΐΉιΘ§‘Ύ Cache
Line 64 Ή÷ΫΎ ΐΨίΩι…œΡΎ¥φΒΊ÷Ζ «Ν§–χΒΡΘ§Ρή±Μ“Μ¥ΈΦ”‘ΊΒΫ Cache Line ÷–Θ§‘ΎΖΟΈ ΐΉι ±Οϋ÷–¬ ΗΏΘ§–‘ΡήΖΔΜ”ΒΫΦΪ÷¬ΓΘ
public int run(int[]
row, int[] column) {
int sum = 0;
for(int i = 0; i < 16;i++ ) {
sum += row[i] * column[i];
}
return sum;
} |
±δΝΩ i Χεœ÷ΝΥ ±ΦδΨ÷≤Ω–‘Θ§ΉςΈΣΦΤ ΐΤς±ΜΤΒΖ±≤ΌΉςΘ§“Μ÷±¥φΖ≈‘ΎΦΡ¥φΤς÷–Θ§ΟΩ¥Έ¥”ΦΡ¥φΤςΖΟΈ Θ§Εχ≤Μ «¥”ΜΚ¥φΜρ÷ς¥φΖΟΈ ΓΘ
4.2 ΜΚ¥φ––ΒΡΥχΨΚ’υ
‘ΎΕύ¥ΠάμΤςœ¬Θ§ΈΣ±Θ÷ΛΗςΗω¥ΠάμΤςΒΡΜΚ¥φ“Μ÷¬Θ§Μα Βœ÷ΜΚ¥φ“Μ÷¬–‘–≠“ιΘ§ΟΩΗω¥ΠάμΤςΆ®Ιΐ–αΧΫ‘ΎΉήœΏ…œ¥Ϊ≤ΞΒΡ ΐΨίά¥Φλ≤ιΉ‘ΦΚΜΚ¥φΒΡ÷Β «≤Μ «ΙΐΤΎΘ§Β±¥ΠάμΤςΖΔœ÷Ή‘ΦΚΜΚ¥φ––Ε‘”ΠΒΡΡΎ¥φΒΊ÷Ζ±Μ–όΗΡΘ§ΨΆΜαΫΪΒ±«Α¥ΠάμΤςΒΡΜΚ¥φ––÷Ο≥…Έό–ßΉ¥Χ§Θ§Β±¥ΠάμΤς“ΣΕ‘’βΗω ΐΨίΫχ–––όΗΡ≤ΌΉςΒΡ ±ΚρΘ§Μα«Ω÷Τ÷Ί–¬¥”œΒΆ≥ΡΎ¥φάοΑ― ΐΨίΕΝΒΫ¥ΠάμΤςΜΚ¥φάοΓΘ
Β±ΕύΗωœΏ≥ΧΕ‘Ά§“ΜΗωΜΚ¥φ––ΖΟΈ ±Θ§»γΤδ÷–“ΜΗωœΏ≥ΧΥχΉΓΜΚ¥φ––Θ§»ΜΚσ≤ΌΉςΘ§’β ±ΤδΥϋœΏ≥Χ‘ρΈόΖ®≤ΌΉςΗΟΜΚ¥φ––ΓΘ’β÷÷«ιΩωœ¬Θ§Έ“Ο«‘ΎΫχ––≥Χ–ρ¥ζ¬κ…ηΦΤ ± «“ΣΨΓΝΩ±ήΟβΒΡΓΘ
4.3 Έ±Ι≤œμΒΡΙφ±ή
Ν§–χΫτ¥’ΒΡΡΎ¥φΖ÷≈δ¥χά¥ΗΏ–‘ΡήΘ§ΒΪ≤Δ≤Μ¥ζ±μΥϋ“Μ÷±ΕΦ––÷°”––ßΘ§Έ±Ι≤œμΨΆ «Έό…υΒΡ–‘Ρή…± ÷ΓΘΥυΈΫΈ±Ι≤œμ(False
SharingΘ©Θ§ «”…”Ύ‘Υ––‘Ύ≤ΜΆ§ CPU …œΒΡ≤ΜΆ§œΏ≥ΧΘ§Ά§ ±–όΗΡ¥Π‘ΎΆ§“ΜΗω Cache Line
…œΒΡ ΐΨί“ΐΤπΓΘΜΚ¥φ––…œΒΡ–¥ΨΚ’υ «‘Υ––‘Ύ SMP œΒΆ≥÷–≤Δ––œΏ≥Χ Βœ÷Ω……λΥθ–‘Ήν÷Ί“ΣΒΡœό÷Τ“ρΥΊΘ§“ΜΑψά¥ΥΒΘ§¥”¥ζ¬κ÷–ΚήΡ―Ω¥«ε «ΖώΜα≥ωœ÷Έ±Ι≤œμΓΘ
‘ΎΟΩΗω CPU ά¥Ω¥Θ§ΗςΉ‘–όΗΡΒΡ «≤ΜΆ§ΒΡ±δΝΩΘ§ΒΪ”…”Ύ’β–©±δΝΩ‘ΎΡΎ¥φ÷–±Υ¥ΥΫτΑΛΉ≈Θ§“ρ¥ΥΥϋΟ«¥Π”ΎΆ§“ΜΗω
Cache Line …œΓΘΒ±“ΜΗω CPU –όΗΡ’βΗω Cache Line ÷°ΚσΘ§ΈΣΝΥ±Θ÷Λ ΐΨίΒΡ“Μ÷¬–‘Θ§±Ί»ΜΒΦ÷¬Νμ“ΜΗω
CPU ΒΡ±ΨΒΊ Cache ΒΡΈό–ßΘ§“ρΕχ¥ΞΖΔ Cache missΘ§»ΜΚσ¥”ΡΎ¥φ÷–÷Ί–¬Φ”‘Ί±δΝΩ±Μ–όΗΡΚσΒΡ÷ΒΓΘΕύΗωœΏ≥ΧΤΒΖ±ΒΡ–όΗΡ¥Π”ΎΆ§“ΜΗω
Cache Line ΒΡ ΐΨίΘ§ΜαΒΦ÷¬¥σΝΩΒΡ Cache missΘ§“ρΕχ‘λ≥…≥Χ–ρ–‘ΡήΒΡ¥σΖυœ¬ΫΒΓΘ
œ¬ΆΦΥΒΟςΝΥΝΫΗω≤ΜΆ§ Core ΒΡœΏ≥ΧΗϋ–¬Ά§“ΜΜΚ¥φ––ΒΡ≤ΜΆ§–≈œΔœνΘΚ
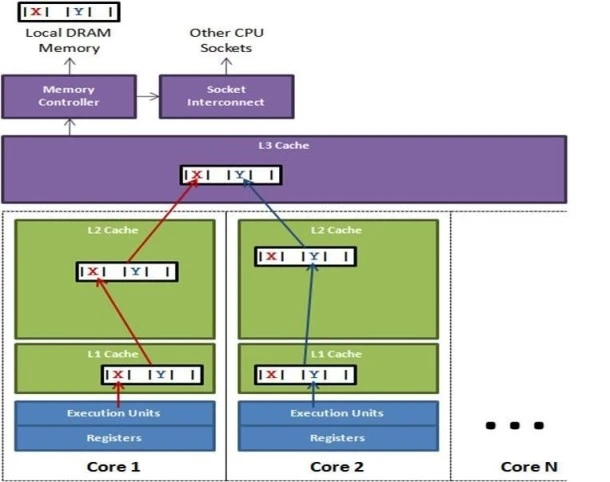
…œΆΦΥΒΟςΝΥΈ±Ι≤œμΒΡΈ ΧβΓΘ‘Ύ Core1 …œ‘Υ––ΒΡœΏ≥ΧΉΦ±ΗΗϋ–¬±δΝΩ XΘ§Ά§ ± Core2 …œΒΡœΏ≥ΧΉΦ±ΗΗϋ–¬±δΝΩ
YΓΘ»ΜΕχΘ§’βΝΫΗω±δΝΩ‘ΎΆ§“ΜΗωΜΚ¥φ––÷–ΓΘΟΩΗωœΏ≥ΧΕΦ“Σ»ΞΨΚ’υΜΚ¥φ––ΒΡΥυ”–»®ά¥Ηϋ–¬±δΝΩΓΘ»γΙϊ Core1
ΜώΒΟΝΥΥυ”–»®Θ§ΜΚ¥φΉ”œΒΆ≥ΫΪΜα Ι Core2 ÷–Ε‘”ΠΒΡΜΚ¥φ–– ß–ßΓΘΒ± Core2 ΜώΒΟΝΥΥυ”–»®»ΜΚσ÷¥––Ηϋ–¬≤ΌΉςΘ§Core1
ΨΆ“Σ ΙΉ‘ΦΚΕ‘”ΠΒΡΜΚ¥φ–– ß–ßΓΘά¥ά¥ΜΊΜΊΒΡΨ≠Ιΐ L3 ΜΚ¥φΘ§¥σ¥σ”ΑœλΝΥ–‘ΡήΓΘ»γΙϊΜΞœύΨΚ’υΒΡ Core ΈΜ”Ύ≤ΜΆ§ΒΡ≤ε≤έΘ§ΨΆ“ΣΕνΆβΚαΩγ≤ε≤έΝ§Ϋ”Θ§Έ ΧβΩ…ΡήΗϋΦ”―œ÷ΊΓΘ
1) Ιφ±ή¥ΠάμΖΫ Ϋ
l ‘ω¥σ ΐΉι‘ΣΥΊΒΡΦδΗτ ΙΒΟ≤ΜΆ§œΏ≥Χ¥φ»ΓΒΡ‘ΣΥΊΈΜ”Ύ≤ΜΆ§ cache lineΘ§Ω’ΦδΜΜ ±Φδ
l ‘ΎΟΩΗωœΏ≥Χ÷–¥¥Ϋ®»ΪΨ÷ ΐΉιΗςΗω‘ΣΥΊΒΡ±ΨΒΊΩΫ±¥Θ§»ΜΚσΫα χΚσ‘Ό–¥ΜΊ»ΪΨ÷ ΐΉι
2) ¥ζ¬κ ΨάΐΥΒΟς
Ψάΐ 3Θ§(JAVA)
¥”¥ζ¬κ…ηΦΤΫ«Ε»Θ§“ΣΩΦ¬««ε≥ΰάύΫαΙΙ÷–ΡΡ–©±δΝΩ «≤Μ±δΘ§ΡΡ–© «Ψ≠≥Θ±δΜ·Θ§ΡΡ–©±δΜ· «Άξ»ΪœύΜΞΕάΝΔΘ§ΡΡ–© τ–‘“ΜΤπ±δΜ·ΓΘΦΌ»γ“ΒΈώ≥ΓΨΑ÷–Θ§œ¬ΟφΒΡΕ‘œσ¬ζΉψΦΗΗωΧΊΒψ
public class
Data{
long modifyTime;
boolean flag;
long createTime;
char key;
int value;
} |
Β± value ±δΝΩΗΡ±δ ±Θ§modifyTime ΩœΕ®ΜαΗΡ±δ
createTime ±δΝΩΚΆ key ±δΝΩ‘Ύ¥¥Ϋ®ΚσΨΆ≤ΜΜα‘Ό±δΜ·
flag “≤Ψ≠≥ΘΜα±δΜ·Θ§≤ΜΙΐ”κ modifyTime ΚΆ value
±δΝΩΚΝΈόΙΊΝΣ
Β±…œΟφΒΡΕ‘œσ–η“Σ”…ΕύΗωœΏ≥ΧΆ§ ±ΖΟΈ ±Θ§¥” Cache Ϋ«Ε»Θ§Β±Έ“Ο«ΟΜ”–Φ”»ΈΚΈ¥κ © ±Θ§Data
Ε‘œσΥυ”–ΒΡ±δΝΩΦΪ”–Ω…Ρή±ΜΦ”‘Ί‘Ύ L1 ΜΚ¥φΒΡ“Μ–– Cache Line ÷–ΓΘ‘ΎΗΏ≤ΔΖΔΖΟΈ œ¬Θ§Μα≥ωœ÷’β÷÷Έ ΧβΘΚ
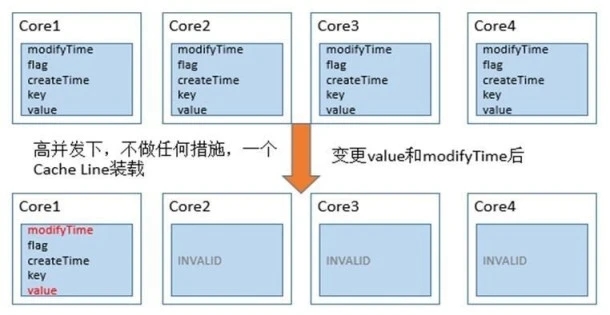
»γ…œΆΦΥυ ΨΘ§ΟΩ¥Έ value ±δΗϋ ±Θ§ΗυΨί MESI –≠“ιΘ§Ε‘œσΤδΥϊ CPU …œœύΙΊΒΡ Cache
Line »Ϊ≤Ω±Μ…η÷ΟΈΣ ß–ßΓΘΤδΥϊΒΡ¥ΠάμΤςœκ“ΣΖΟΈ Έ¥±δΜ·ΒΡ ΐΨί(key ΚΆ createTime) ±Θ§±Ί–κ¥”ΡΎ¥φ÷–÷Ί–¬ά≠»Γ ΐΨίΘ§‘ω¥σΝΥ ΐΨίΖΟΈ ΒΡΩΣœζΓΘ
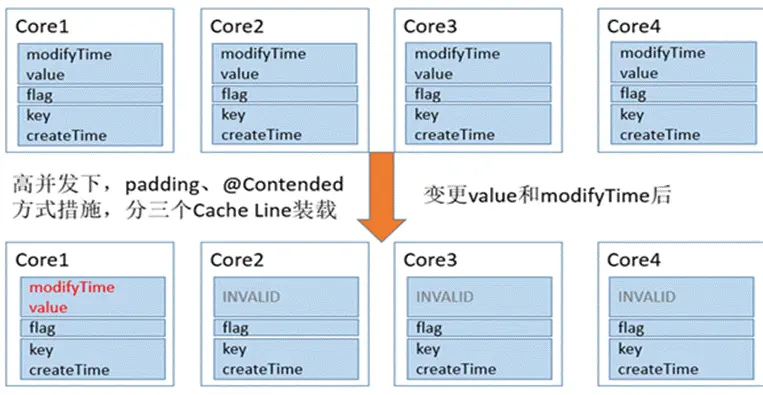
”––ßΒΡ Padding ΖΫ Ϋ
’ΐ»ΖΖΫ Ϋ «ΫΪΗΟΕ‘œσ τ–‘Ζ÷ΉιΘ§ΫΪ“ΜΤπ±δΜ·ΒΡΖ≈‘Ύ“ΜΉιΘ§”κΤδΥϊΈόΙΊΒΡΖ≈“ΜΉιΘ§ΫΪ≤Μ±δΒΡΖ≈ΒΫ“ΜΉιΓΘ’β―υΒ±ΟΩ¥ΈΕ‘œσ±δΜ· ±Θ§≤ΜΜα¥χΕ·Υυ”–ΒΡ τ–‘÷Ί–¬Φ”‘ΊΜΚ¥φΘ§Χα…ΐΝΥΕΝ»Γ–ß¬ ΓΘ‘Ύ
JDK1.8 «ΑΘ§“ΜΑψ‘Ύ τ–‘Φδ‘ωΦ”≥Λ’ϊ–Ά±δΝΩά¥Ζ÷ΗτΟΩ“ΜΉι τ–‘ΓΘ±Μ≤ΌΉςΒΡΟΩ“ΜΉι τ–‘’ΦΒΡΉ÷ΫΎ ΐΦ”…œ«ΑΚσΧν≥δ τ–‘Υυ’ΦΒΡΉ÷ΫΎ ΐΘ§≤Μ–Γ”Ύ“ΜΗω
cache line ΒΡΉ÷ΫΎ ΐΨΆΩ…¥οΒΫ“Σ«σΓΘ
public class
DataPadding{
long a1,a2,a3,a4,a5,a6,a7,a8;//Ζά÷Ι”κ«Α“ΜΗωΕ‘œσ≤ζ…ζΈ±Ι≤œμ
int value;
long modifyTime;
long b1,b2,b3,b4,b5,b6,b7,b8;//Ζά÷Ι≤ΜœύΙΊ±δΝΩΈ±Ι≤œμ;
boolean flag;
long c1,c2,c3,c4,c5,c6,c7,c8;//
long createTime;
char key;
long d1,d2,d3,d4,d5,d6,d7,d8;//Ζά÷Ι”κœ¬“ΜΗωΕ‘œσ≤ζ…ζΈ±Ι≤œμ
} |
≤…»Γ…œ ω¥κ ©ΚσΒΡΆΦ ΨΘΚ
‘Ύ Java ÷–
Java8 Βœ÷Ή÷ΫΎΧν≥δ±ήΟβΈ±Ι≤œμΘ§ JVM ≤Έ ΐ -XX:-RestrictContended
@Contended ΈΜ”Ύ sun.misc ”Ο”ΎΉΔΫβ java τ–‘Ή÷ΕΈΘ§Ή‘Ε·Χν≥δΉ÷ΫΎΘ§Ζά÷ΙΈ±Ι≤œμΓΘ
Ψάΐ 4Θ§(C ”ο―‘)
**//****≥Χ–ρ thread1.c**
**ΕύœΏ≥ΧΖΟΈ ΐΨίΫαΙΙΒΡ≤ΜΆ§Ή÷ΕΈ**
#include <stdio.h>
#include <pthread.h>
struct {
int a;
// charpadding[64]; // thread2.c¥ζ¬κ
int b;
}data;
void *thread_1(void) {
int i = 0;
for(i=0; i < 1000000000; i++){
data.a = 0;
}
}
void *thread_2(void) {
int i = 0;
for(i=0; i < 1000000000; i++){
data.b = 0;
}
}
|
//≥Χ–ρ thread2.c
Thread1.c ÷–ΒΡΚλ…ΪΉ÷Χε––Θ§¥ρΩΣΉΔ ΆΦ¥ΈΣ thread2.c
main()Κ· ΐΚήΦρΒΞΘ§¥¥Ϋ®ΝΫΗωœΏ≥Χ≤Δ‘Υ––,≤ΈΩΦ¥ζ¬κ»γœ¬ΘΚ
pthread_t id1;
int ret = pthread_create (&id1,NULL, (void*)thread_1,NULL); |
±ύ“κΓΔ‘Υ––ΫαΙϊ»γœ¬ΘΚ

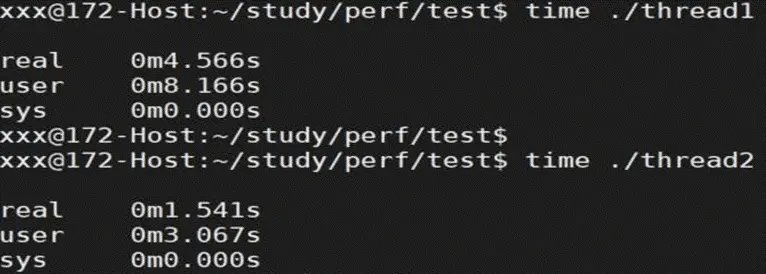
¥”≤β ‘ΫαΙϊΩ¥Θ§ΒΎ“ΜΗω≥Χ–ρœϊΚΡΒΡ ±Φδ «ΒΎΕΰΗω≥Χ–ρΒΡ 3 ±Ε
ΫαΙϊΖ÷Έω
¥Υ Ψάΐ…φΦΑΒΫ Cache Line ΒΡΈ±Ι≤œμΈ ΧβΓΘΝΫΗω≥Χ–ρΈ®“ΜΒΡ«χ±π «Θ§ΒΎΕΰΗω≥Χ–ρ÷–Ή÷ΕΈ a ΚΆ
b ÷–Φδ”–“ΜΗω¥σ–ΓΈΣ 64 ΗωΉ÷ΫΎΒΡΉ÷Ζϊ ΐΉιΓΘΒΎ“ΜΗω≥Χ–ρ÷–Θ§Ή÷ΕΈ a ΚΆΉ÷ΕΈ b ¥Π”ΎΆ§“ΜΗω Cache
Line …œΘ§Β±ΝΫΗωœΏ≥ΧΆ§ ±–όΗΡ’βΝΫΗωΉ÷ΕΈ ±Θ§Μα¥ΞΖΔ Cache Line Έ±Ι≤œμΈ ΧβΘ§‘λ≥…¥σΝΩΒΡ
Cache missΘ§ΫχΕχΒΦ÷¬≥Χ–ρ–‘Ρήœ¬ΫΒΓΘ
ΒΎΕΰΗω≥Χ–ρ÷–Θ§Ή÷ΕΈ a ΚΆ b ÷–ΦδΦ”ΝΥ“ΜΗω 64 Ή÷ΫΎΒΡ ΐΉιΘ§’β―υΨΆ±Θ÷ΛΝΥ’βΝΫΗωΉ÷ΕΈ¥Π‘Ύ≤ΜΆ§ΒΡ
Cache Line …œΓΘ»γ¥Υ“Μά¥Θ§ΝΫΗωœΏ≥ΧΦ¥±ψΆ§ ±–όΗΡ’βΝΫΗωΉ÷ΕΈΘ§ΝΫΗω cache line “≤ΜΞ≤Μ”ΑœλΘ§cache
Οϋ÷–¬ ΚήΗΏΘ§≥Χ–ρ–‘ΡήΜα¥σΖυΧα…ΐΓΘ
Ψάΐ 5Θ§(C ”ο―‘)
‘Ύ…ηΦΤ ΐΨίΫαΙΙΒΡ ±ΚρΘ§ΨΓΝΩΫΪ÷ΜΕΝ ΐΨί”κΕΝ–¥ ΐΨίΖ÷ΩΣΘ§≤ΔΨΏΨΓΝΩΫΪΆ§“Μ ±ΦδΖΟΈ ΒΡ ΐΨίΉιΚœ‘Ύ“ΜΤπΓΘ’β―υ
CPU Ρή“Μ¥ΈΫΪ–η“ΣΒΡ ΐΨίΕΝ»κΓΘΤ©»γΘ§œ¬ΟφΒΡ ΐΨίΫαΙΙΨΆΚή≤ΜΚΟΓΘ
struct __a
{
int id; // ≤Μ“Ή±δ
int factor;// “Ή±δ
char name[64];// ≤Μ“Ή±δ
int value;// “Ή±δ
};
|
‘Ύ X86 œ¬Θ§Ω…“‘ ‘Ή≈–όΗΡΚΆΒς’ϊΥϋ
#define CACHE_LINE_SIZE
64 //ΜΚ¥φ––≥ΛΕ»
struct __a
{
int id; // ≤Μ“Ή±δ
char name[64];// ≤Μ“Ή±δ
char __align[CACHE_LINE_SIZE ®C sizeof(int)+sizeof(name)
* sizeof(name[0]) %
CACHE_LINE_SIZE]
int factor;// “Ή±δ
int value;// “Ή±δ char __align2 [CACHE_LINE_SIZE
®C2* sizeof(int)%CACHE_LINE_SIZE ]}; |
CACHE_LINE_SIZE®Csizeof(int)+sizeof
(name)*sizeof (name[0])%CACHE_LINE_SIZE Ω¥Τπά¥≤ΜΚΆ–≥Θ§CACHE_LINE_SIZE
±μ ΨΗΏΥΌΜΚ¥φ––(64B ¥σ–Γ)ΓΘ__align ”Ο”Ύœ‘ ΫΕ‘ΤκΘ§’β÷÷ΖΫ Ϋ ΙΒΟΫαΙΙΧεΉ÷ΫΎΕ‘ΤκΒΡ¥σ–ΓΈΣΜΚ¥φ––ΒΡ¥σ–ΓΓΘ
4.4 ΜΚ¥φ”κΡΎ¥φΕ‘Τκ
1Θ©Ή÷ΫΎΕ‘Τκ
attribute ((packed))ΗφΥΏ±ύ“κΤς»ΓœϊΫαΙΙ‘Ύ±ύ“κΙΐ≥Χ÷–ΒΡ”≈Μ·Ε‘Τκ,Α¥’’ ΒΦ ’Φ”ΟΉ÷ΫΎ ΐΫχ––Ε‘ΤκΘ§ «
GCC ΧΊ”–ΒΡ”οΖ®;
__attribute__((aligned(n)))±μ ΨΥυΕ®“εΒΡ±δΝΩΈΣ n Ή÷ΫΎΕ‘Τκ;
struct B{ char b;int a;short c;}; (Ρ§»œ 4 Ή÷ΫΎΕ‘Τκ)
’β ±ΚρΆ§―υ «ΉήΙ≤ 7 ΗωΉ÷ΫΎΒΡ±δΝΩΘ§ΒΪ « sizeof(struct B)ΒΡ÷Β»¥ « 12ΓΘ
Ή÷ΫΎΕ‘ΤκΒΡœΗΫΎΚΆ±ύ“κΤς Βœ÷œύΙΊΘ§ΒΪ“ΜΑψΕχ―‘Θ§¬ζΉψ»ΐΗωΉΦ‘ρΘΚ
1)(ΫαΙΙΧε)±δΝΩΒΡ ΉΒΊ÷ΖΡήΙΜ±ΜΤδ(ΉνΩμ)Μυ±Ψάύ–Ά≥…‘±ΒΡ¥σ–ΓΥυ’ϊ≥ΐΘΜ
2)ΫαΙΙΧεΟΩΗω≥…‘±œύΕ‘”Ύ ΉΒΊ÷ΖΒΡΤΪ“ΤΝΩΕΦ «≥…‘±¥σ–ΓΒΡ ΐ±ΕΘ§»γ”––η“Σ,±ύ“κΤςΜα‘Ύ≥…‘±÷°ΦδΦ”…œΧν≥δΉ÷ΫΎ(internal
adding)
3)ΫαΙΙΧεΒΡΉή¥σ–ΓΈΣΫαΙΙΧεΉνΩμΜυ±Ψάύ–Ά≥…‘±¥σ–ΓΒΡ ΐ±ΕΘ§»γ”––η“Σ,±ύ“κΤςΜα‘ΎΉνΡ©“ΜΗω≥…‘±÷°ΚσΦ”…œΧν≥δΉ÷ΫΎ(trailing
padding)
2Θ©ΜΚ¥φ––Ε‘Τκ
ΐΨίΩγ‘ΫΝΫΗω cache lineΘ§“βΈΕΉ≈ΝΫ¥Έ load ΜρΝΫ¥Έ storeΓΘ»γΙϊ ΐΨίΫαΙΙ « cache
line Ε‘ΤκΒΡΘ§ΨΆ”–Ω…ΡήΦθ…Ό“Μ¥ΈΕΝ–¥ΓΘ ΐΨίΫαΙΙΒΡ ΉΒΊ÷Ζ cache line Ε‘ΤκΘ§“βΈΕΉ≈Ω…Ρή”–ΡΎ¥φάΥΖ―(ΧΊ±π « ΐΉι’β―υΝ§–χΖ÷≈δΒΡ ΐΨίΫαΙΙΘ©Θ§Υυ“‘–η“Σ‘ΎΩ’ΦδΚΆ ±ΦδΝΫΖΫΟφ»®ΚβΓΘ±»»γœ÷‘Ύ“ΜΑψΒΡ
malloc()Κ· ΐΘ§ΖΒΜΊΒΡΡΎ¥φΒΊ÷ΖΜα“―Ψ≠ « 8 Ή÷ΫΎΕ‘ΤκΒΡΘ§’βΨΆ «ΈΣΝΥΡήΙΜ»Ο¥σ≤ΩΖ÷≥Χ–ρ”–ΗϋΚΟΒΡ–‘ΡήΓΘ
‘Ύ C ”ο―‘÷–Θ§ΈΣΝΥ±ήΟβΈ±Ι≤œμΘ§±ύ“κΤςΜαΉ‘Ε·ΫΪΫαΙΙΧεΘ§Ή÷ΫΎ≤Ι»ΪΚΆΕ‘ΤκΘ§Ε‘ΤκΒΡ¥σ–ΓΉνΚΟ «ΜΚ¥φ––ΒΡ≥ΛΕ»ΓΘΉήΒΡά¥ΥΒΘ§ΫαΙΙΧε ΒάΐΜαΚΆΥϋΒΡΉνΩμ≥…‘±“Μ―υΕ‘ΤκΓΘ±ύ“κΤς’β―υΉω «“ρΈΣ’β «±Θ÷ΛΥυ”–≥…‘±Ή‘Ε‘Τκ“‘ΜώΒΟΩλΥΌ¥φ»ΓΒΡΉν»ί“ΉΖΫΖ®ΓΘ
__attribute__((aligned(cache_line)))Ε‘Τκ Βœ÷ struct syn_str
{ ints_variable;
};__attribute__((aligned(cache_line)))ΘΜ
Ψάΐ 6Θ§(C ”ο―‘)
struct
syn_str { int s_variable; };void
*p = malloc ( sizeof (struct syn_str) + cache_line
);syn_str
*align_p=(syn_str*)((((int)p)+ (cache_line-1))&~(cache_line-1); |
4.5 CPU Ζ÷÷ß‘Λ≤β
¥ζ¬κ‘ΎΡΎ¥φάοΟφ «Υ≥–ρ≈≈Ν–ΒΡΘ§Ω…“‘Υ≥–ρΖΟΈ Θ§”––ßΧαΗΏΜΚ¥φΟϋ÷–ΓΘΕ‘”ΎΖ÷÷ß≥Χ–ρά¥ΥΒΘ§»γΙϊΖ÷÷ß”οΨδ÷°ΚσΒΡ¥ζ¬κ”–Ηϋ¥σΒΡ÷¥––ΦΗ¬ Θ§ΨΆΩ…“‘Φθ…ΌΧχΉΣΘ§“ΜΑψ
CPU ΕΦ”–÷ΗΝν‘Λ»ΓΙΠΡήΘ§’β―υΩ…“‘ΧαΗΏ÷ΗΝν‘Λ»ΓΟϋ÷–ΒΡΦΗ¬ ΓΘΖ÷÷ß‘Λ≤β”ΟΒΡΨΆ « likely/unlikely
’β―υΒΡΚξΘ§“ΜΑψ–η“Σ±ύ“κΤςΒΡ÷ß≥÷Θ§ τΨ≤Χ§ΒΡΖ÷÷ß‘Λ≤βΓΘœ÷‘Ύ“≤”–ΚήΕύ CPU ÷ß≥÷‘ΎΡΎ≤Ω±Θ¥φ÷¥––ΙΐΒΡΖ÷÷ß÷ΗΝνΒΡΫαΙϊ(Ζ÷÷ß÷ΗΝν
cache)Θ§Υυ“‘Ψ≤Χ§ΒΡΖ÷÷ß‘Λ≤βΨΆΟΜ”–ΧΪΕύΒΡ“β“εΓΘ
Ψάΐ 7Θ§(C ”ο―‘)
int
testfun(int x)
{
if(__builtin_expect(x, 0)) {
^^^--- We instruct the compiler , "else"
block
is more probable
x = 5;
x = x * x;
} else {
x = 6;
}
return x;
}` |
‘Ύ’βΗωάΐΉ”÷–Θ§x ΈΣ 0 ΒΡΩ…Ρή–‘Ηϋ¥σΘ§±ύ“κΚσΙέ≤λΜψ±ύ÷ΗΝνΘ§ΫαΙϊ»γœ¬ΘΚ
`Disassembly
of section .textΘΚ
00000000 <testfun>:
0: 55 push %ebp
1: 89e5 mov %esp,%ebp
3: 8b 45 08 mov 0x8(%ebp),%eax
6: 85 c0 test %eax,%eax
8: 75 07 jne 11 <testfun+0x11>
a: b8 06 00 00 00 mov $0x6,%eax
f: c9 leave
10: c3 ret
11: b8 19 00 00 00 mov $0x19,%eax
16: eb f7 jmp f <testfun+0xf>` |
Ω…“‘Ω¥ΒΫΘ§±ύ“κΤς Ι”ΟΒΡ « jne ÷ΗΝνΘ§«“ else block
÷–ΒΡ¥ζ¬κΫτΗζ‘ΎΚσΟφ
8: 75 07 jne
11 < testfun+0x11>
a: b8 06 00 00 00 mov $0x6,%eax |
4.6 Οϋ÷–¬ ΒΡΦύΩΊ
≥Χ–ρ…ηΦΤ“ΣΉΖ«σΗϋΚΟΒΡάϊ”Ο CPU ΜΚ¥φΘ§ά¥Φθ…Ό¥”ΡΎ¥φΕΝ»Γ ΐΨίΒΡΒΆ–ßΓΘ‘Ύ≥Χ–ρ‘Υ–– ±Θ§Ά®≥Θ–η“ΣΙΊΉΔΜΚ¥φΟϋ÷–¬ ’βΗω÷Η±ξΓΘ
ΦύΩΊΖΫΖ®(Linux)ΘΚ≤ι―· CPU ΜΚ¥φΈόΟϋ÷–¥Έ ΐΦΑΜΚ¥φ«κ«σ¥Έ ΐΘ§ΦΤΥψΜΚ¥φΟϋ÷–¬
| perf stat -e
cache- references -e cache-misses |
4.7 –Γ Ϋα
≥Χ–ρ¥”ΡΎ¥φΜώ»Γ ΐΨί ±Θ§ΟΩ¥Έ≤ΜΫω»ΓΜΊΥυ–η ΐΨίΘ§ΜΙΜαΗυΨίΜΚ¥φ––ΒΡ¥σ–ΓΦ”‘Ί“ΜΕΈΝ§–χΒΡΡΎ¥φ ΐΨίΒΫΜΚ¥φ÷–Θ§≥Χ–ρ…ηΦΤ÷–ΒΡ”≈Μ·ΖΕ Ϋ≤ΈΩΦ»γœ¬ΓΘ
‘ΎΦ·Κœ±ιάζΒΡ≥ΓΨΑΘ§Ω… Ι”Ο”––ρ ΐΉιΘ§ ΐΉι‘ΎΡΎ¥φ÷– «“ΜΕΈΝ§–χΒΡΩ’Φδ;
Ή÷ΕΈΨΓΝΩΕ®“εΈΣ’Φ”ΟΉ÷ΫΎ–ΓΒΡάύ–ΆΘ§»γ int Ω…¬ζΉψ ±Θ§≤Μ Ι”Ο longΓΘ’β―υΒΞ¥ΈΩ…Φ”‘ΊΗϋΕύΒΡ ΐΨίΒΫΜΚ¥φ÷–;
Ε‘œσΜρΫαΙΙΧε¥σ–ΓΨΓΩ…Ρή…η÷ΟΈΣ CPU ΚΥ–ΡΜΚ¥φ––ΒΡ’ϊ ΐ±ΕΓΘΜυ”Ύ 64B
¥σ–ΓΒΡΜΚ¥φ––Θ§»γΕΝ»ΓΒΡ ΐΨί « 50BΘ§ΉνΜΒ«ιΩωœ¬–η“ΣΝΫ¥Έ¥”ΡΎ¥φΦ”‘ΊΘΜΒ±ΈΣ 70B ±Θ§ΉνΜΒ«ιΩω–η“Σ»ΐ¥ΈΡΎ¥φΕΝ»ΓΘ§≤≈ΡήΦ”‘ΊΒΫΜΚ¥φ÷–;
Ε‘Ά§“ΜΕ‘œσ/ΫαΙΙΧεΒΡΕύΗω τ–‘Θ§Ω…Ρή¥φ‘Ύ”ΎΆ§“ΜΜΚ¥φ––÷–Θ§ΒΦ÷¬Έ±Ι≤œμΈ ΧβΘ§–ηΈΣ τ–‘ΒΡ≤Μ±δ”κ≥Θ±δΘ§±δΜ·ΒΡΕάΝΔ”κΙΊΝΣΕχΗτάκ…ηΦΤΘ§ΦΑΜΚ¥φ––Ε‘ΤκΘ§ΫβΨωΕύœΏ≥ΧΗΏ≤ΔΖΔΜΖΨ≥œ¬ΜΚ¥φ ß–ßΓΔ±Υ¥Υ«Θ÷ΤΈ ΧβΘΜ
CPU ”–Ζ÷÷ß‘Λ≤βΡήΝΠΘ§‘Ύ Ι”Ο ifelse case when
Β»―≠ΜΖ≈–ΕœΒΡ≥ΓΨΑ ±Θ§Ω…“‘Υ≥–ρΖΟΈ Θ§”––ßΧαΗΏΜΚ¥φΒΡΟϋ÷– |








