| 编辑推荐: |
本文讲述了什么限制了应用程序的可伸缩性(Scalability )?朴素矩阵乘法(
naïve matrix multiplication )算法的实现等。希望能够帮助大家。
本文来自于微信公众号Linux阅码场 ,由火龙果软件Linda编辑、推荐。 |
|
现代计算机系统的计算核心的数量不断增加,我们希望高度并行化软件的性能可以随着系统核心数量的增加而线性提高。但是,有些因素限制了多核系统上的并行性和可伸缩性。本文将不会介绍所有这些内容,不过大多数情况下,该限制是由并行性的实现所致:
负载不均衡导致线程和CPU核心闲置。
同步过多导致自旋等待和其他无效工作浪费CPU时间。
API的滥用引起的并行运行时调用库的开销
如果消除了这些限制因素,那么所有的 CPU 核心都在忙着做有用的工作,程序的并行效率将会大大提高。在调整良好的benchmarks(如STREAM
or LINPACK)上可以看到性能的增长速度接近线性。但是,随着系统核心数量的增加(或在较新的拥有更多核心的系统上运行代码),可以看到应用程序的性能并没有线性提高,或者并行性开始趋向于不再稳定增长,如图一所示。

图一 核心数量变化对性能的影响
根据自顶向下性能分析方法(注释1),首先应检查其他组件是否在限制性能。确保:
系统不要总是忙于其他可能消耗资源的事情,例如消耗计算时间的其它应用程序或服务。
应用程序不是IO绑定(bound)的(例如等待磁盘或其它文件系统或网络系统操作)。
系统有足够的物理内存,避免与硬盘频繁交换内存。
通常你需要知道硬件配置是否正确以及内存子系统是否提供了预期的性能特征。例如,所有内存插槽都装有与主板特性(例如通道数,内存速度)相对应的DIMM。可以用已知的benchmarks轻松检查硬件的性能,进行此类的检查非常重要,因为使用硬件解决问题比使用软件优化要容易得多。
这些检查完成后,我们可以进一步检查作为并行缩放不佳主要原因之一的内存延时。在x86系统体系结构中,CPU从其缓存子系统中检索数据。理想情况下,数据在指令需要时驻留在最靠近CPU的缓存中(L1
Cache)(如图2)。CPU请求的数据所在的位置越远,传输到CPU核心执行单元所花费的时间就越长(缓存等级越高,速度越慢)。CPU硬件预取器有助于更快的引入数据,但这并不总是能够发生。通常数据延迟会使CPU
stall。(注释2)

图二 内存子系统中的数据读取
基本上,数据延迟可能有两个原因:1.当在CPU的EXE单元中执行一条指令请求数据时,数据位从主存或其他缓存到CPU的L1D经过很长时间(预取(prefetcher)失败)。这会产生内存延迟问题。2.数据预取成功,但由于硬件速度有限,数据在进入CPU时拥堵。这会产生内存带宽问题。
当然,如果在不同的源头提出不同的数据访问请求,则可能同时存在这两个问题。为了避免这些问题,就要明智地使用数据。要解决内存延迟问题,需要确保按地址递增的方式访问数据。顺序数据访问(甚至是间距很小的常量单位步幅)使得预取工作更轻松,并且数据访问速度更快。要解决内存带宽问题,需尽可能的重复使用数据并且在高速缓存中保持其热度。两种解决方案都需要重新考虑数据访问模式,甚至需要重新考虑整个算法的实现。
什么限制了应用程序的可伸缩性(Scalability )?
当我们的代码在CPU上执行效率低下,且观测到大多数stall是受内存限制,我们就需要进一步确定具体的内存问题,确定问题是内存延迟还是内存带宽引起的,不同的问题解决方案不同。我们将使用
Intel® VTune™ Amplifier 内存分析工具对内存问题进行详细分析。
我们不妨考虑一些改进简化的矩阵乘法benchmark的迭代。尽管它很简单,但它有效地指明了可能发生的内存问题,具体问题取决于算法的实现。为了进行测量,我们将使用
Intel® Xeon® processor E5-2697 v4 (代号为Broadwell,36核)的系统,理论上内存带宽
= 76.8 GB / s,双精度(DP)每秒浮点运算次数(FLOPS)= 662 GFLOPS /
s。
朴素矩阵乘法( naïve matrix multiplication )算法的实现
朴素矩阵乘法( naïve matrix multiplication )(图3,multiply1)的性能不会随着cpu核数量线性伸缩。但是出于教学目的,这是一个定位性能不佳的原因很好的例子。我们改进时可以添加
–no-alias 编译器选项来允许矢量化,不然标量实现将会慢10倍左右。表1中列出了 9216 x
9216 的矩阵运行矢量化 benchmark multiply1的结果。要注意的是最佳性能远低于理论上的最大
FLOPS 。
1. void multiply2(int
msize, int tidx, int numt, TYPE a[][NUM], TYPE
b[][NUM], TYPE c[][NUM], TYPE t[][NUM])
2. {
3. int i,j,k;
4. // Loop interchange
5. for(i=tidx; i<msize; i=i+numt) {
6. for(k=0; k<msize; k++) {
7. #pragma ivdep
8. for(j=0; j<msize; j++) {
9. c[i][j] = c[i][j] + a[i][k] * b[k][j];
10. }}}}
|
图三 优化后的矩阵乘法算法(multiply2)的实现

表一 朴素矩阵乘法的性能和可伸缩性(36 核心, Intel® Xeon® processor E5-2697
v4, 双卡槽 2300 MHz 内存)
如表一所示,并行benchmark测试的性能随着线程数量的增加几乎在线性伸缩。超过30个核心时,性能伸缩趋于平稳。表1中的数据可能会让你对multiply1
benchmark的可伸缩性盲目自信。知道所用的benchmark占用多少计算机的计算资源是很重要的。在我们的例子中,得出的
FLOPS (由benchmark决定)与之前计算出的理论值相差甚远(大约小10倍)。并行可伸缩性不受限制,而串行性能则受到限制。需要注意的是,Intel
VTune Amplifier 指明循环内的代码执行效率低下(如图4)。较低的 Retiring 和较高的
CPI rates 有助于估算我们离实际限制的距离。

图4 朴素矩阵乘法并行benchmark测试的性能
接下来,我们将研究矩阵乘法优化算法(图3,multiply2)的实现。如果算法足够简单,并且编译器足够智能,它将识别效率低下的索引步长并自动生成
interchanged loops 的版本。(也可以手动操作)。

表二 优化后矩阵乘法的性能和可伸缩性(36 核心, Intel® Xeon® processor
E5-2697 v4, 双卡槽 2300 MHz 内存)
从表2中可以看到,性能数据稍好一些,但仍远非理想。
试想是什么限制了性能和可伸缩性。这次对于CPU微体系结构(注释3)实行常规的自顶向下法来分析结果(图5)。我们可以看到一些有趣的事情。

图5 常规方法分析结果
首先,可以看到数据从DRAM传到CPU的内存延迟减少了。这是预料之中的,因为我们在算法中实现了连续地址访问。考虑到内存带宽很大,我们应该检查主数据路径上的
bandwidth numbers,以确保DRAM控制器和 Intel®QuickPathInterconnect(QPI)不是瓶颈。其次,需要注意的是即使在连续地址访问数据,L3
缓存的延迟也很高。我们需要考虑其他问题,L3 延迟高意味着 L2 cache 频繁地没有命中,这很奇怪,因为
L2 预取应该可以正常工作(L2 确实在正常工作,因为 DRAM 延迟不会随着连续访问而减少)。第三,Remote
DRAM 延迟很大。这展示了非均匀访存模型 (NUMA)的效果,从 Remote DRAM 为每个节点获取部分数据。因此,为了使数据传输的整体情况更清晰明了,我们需要测量
DRAM 内存控制器和卡槽之间 QPI 总线上的数据流量。为此,我们使用VTune内存分析工具。
图6显示了72个线程情况下的分析结果。只有一个 DRAM 控制器装载了数据(package1),平均数据速率接近50
GB /秒,大约是最大带宽的三分之二。在package0的内存控制器上,流量可以忽略不计。

图6 72线程情况下 multipli2 上收集的内存访问分析结果
在同一时间段内,我们看到传出 QPI 通道中一半的数据流组成了 package1。这说明了数据如何从
package1 DRAM 到 package_0 CPU 核心(如图7)。这种跨 QPI 的数据流产生了额外的延迟,因为数据要么由预取器(prefetcher)从远端DRAM取得,要么由一个CPU核从远端LLC获得。对于benchmark测试来说,数据结构化且在线程之间平均分布可以很容易消除
NUMA 的影响。我们只需要把线程绑定到某个 CPU 核上,并让每个线程初始化a,b和c矩阵。但是我们需要谨慎地假设在每个线程内分配的数据会消除所有
NUMA 的影响。

图7 跨 QPI 数据流
图8显示了一个在以前的假设下无法提高性能的示例,以及使用 Intel VTune Amplifier
工具检测内存问题的方法。在benchmark测试源代码中,我们引入了一个绑定线程到CPU的函数。图8展示了部分代码。
1. CreateThreadPool(
… )
2. {
3. pthread_t ht[NTHREADS];
4. pthread_attr_t attr;
5. cpu_set_t cpus;
6. pthread_attr_init(&attr);
7.
8. for (tidx=0; tidx<NTHREADS; tidx++) {
9. CPU_ZERO(&cpus);
10. CPU_SET(tidx, &cpus);
11. pthread_attr_setaffinity_np(&attr, sizeof(cpu_set_t),
&cpus);
12. pthread_create( &ht[tidx], &attr,
(void*)start_routine, (void*) &par[tidx]);
13. }
14. for (tidx=0; tidx<NTHREADS; tidx++)
15. pthread_join(ht[tidx], (void **)&status);
16. }
|
图8 绑定线程到CPU部分代码
在数据初始化函数中,数组乘法应该分配到各线程,在乘法函数中以相同的方法相乘。图9显示了在优化支持
NUMA 功能中所做的修改。在初始化函数中,数组除以大小为 msize / numt 的块,这个块是指矩阵的大小除以线程数。矩阵的大小除以线程数
msize/numt。在图10中的乘法函数中也执行了同样的操作。令人意外的是,benchmark测试的运行时间并不比不支持NUMA的版本好很多,因此让我们使用
VTune 工具对内存访问进行分析(如图11)。
1. InitMatrixArrays
(int msize, int tidx, int numt, … )
2. {
3. int i,j,k,ibeg,ibound,istep;
4. istep = msize / numt;
5. ibeg = tidx * istep;
6. ibound = ibeg + istep;
7.
8. for(i=ibeg; i<ibound; i++) {
9. for (j=0; j<msize;j++) {
10. a[i][j] = 1.0*i+2.0*j+3.0;
11. b[i][j] = 2.0*i+1.0*j+3.0;
12. c[i][j] = 0.0;
13. }
14. }
15. }
|
图9 优化支持 NUMA 功能的函数
1. multiply2(int
msize, int tidx, int numt, … )
2. {
3. int i,j,k,ibeg,ibound,istep;
4. istep = msize / numt;
5. ibeg = tidx * istep;
6. ibound = ibeg + istep;
7.
8. for(i=ibeg; i<ibound; i++) {
9. for(k=0; k<msize; k++) {
10. for(j=0; j<msize; j++) {
11. c[i][j] = c[i][j] + a[i][k] * b[k][j];
12. }}}}
|

图10 乘法函数
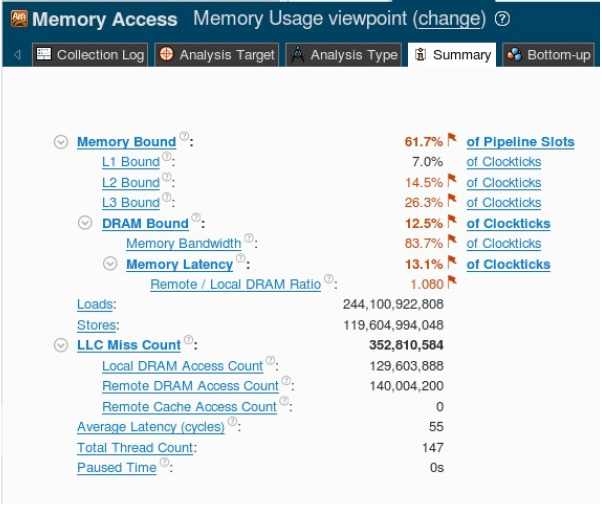
图11 内存访问分析
概述页告诉我们还是内存限制了程序(内存和数据流中的数据延迟导致 stall),而延迟主要由 LLC
引起的,DRAM 影响较少。另外,Remote DRAM 和 Local DRAM 之间的访问比率很高,这意味着有NUMA意识的那个途径失败了。如果我们按时间线查看通过
DRAM 和 QPI 的流量(如图12),会发现 DRAM 的数据流几乎未达到峰值带宽的30%,但是
QPI 在每个方向上的容量基本饱和了,达到了总容量的90%(此系统的QPI实际限制为29.2 GB
/ s)。

图12 按时间线查看通过DRAM控制器和QPI的流量
远程访问(不管是DRAM还是LLC)由于读取内存块使得CPU stall 而增加延迟。这些延迟可以用
Intel VTune Amplifier 工具的内存访问功能来计算,进而可以定位到哪些数据(matrix)仍然在以低效的方式被访问。如果我们查看内存分析的概述页(如图13),可以看到延迟很大的内存对象。

图13 延迟大的内存对象排行
在前三个内存对象中(由分配它们的函数表示),我们可以看到一个延迟明显很大的部分,它内部有大量的 load
操作(如图14)。需要注意的是,仅有一个内存对象平均延迟很高,足以推断出数据来自 LLC 的 RemoteDRAM
。我们可以通过 “Remote DRAM Access” 列表中的数据来确认该结论。

图14 分配函数表示的内存对象
很容易确定这三个对象就是a,b和c矩阵。矩阵c占用的存储量最大。为了定位哪个矩阵的数据延迟很高,只需要在
Intel VTune Amplifier 工具中的栈窗格中检查内存对象的栈(如图15)。通过用户代码中的栈,我们可以在
Intel VTune Amplifier Source View (如图16)中深入到数据分配的源代码的具体行。在这个例子中,矩阵b的数据导致延迟抖动和负载增加。现在,尽管数组数据是在和CPU绑定过的线程中分配和初始化的,但我们依然需要了解为什么会发生这种情况。

图15 栈窗格中的内存对象

图16 Intel® VTune™ Amplifier 源码视图
转置矩阵算法的研究表明了数据访问模式的低效(如图17)。要读取矩阵的一行,整个矩阵b必须完全从存储器中读取。

图17 转置矩阵算法
矩阵在一列/行中包含约9K个元素。因此,整个矩阵存储容量将超过CPU缓存容量,导致cache剔除和新数据reload。即使通过之前绑定到CPU核上的用来分配矩阵c和a的线程来访问它们的行,这也并不能完全运用到矩阵b。在此算法实现中,矩阵b的一半数据是线程从远程端口读取的。甚至更糟的是,为了读取矩阵的某一行要读取整个矩阵b,这样就制造了多余的加载操作(比所需大N倍),访问远程数据时
QPI 产生了过多的流量。
同样,你可以确定 Intel Xeon Phi 处理器系统上的 DRAM 或 MCDRAM 导致哪些数据对象流量增加。你只需要选择想要分析的内存域流量即可。你可以得到这些要分析的内存域的引用和分配的栈信息(如图18),当按照带宽域和带宽利用率进行分组时,你可以定位
L2 Miss Count 最大的内存对象(如图19)。

图18 分析内存域流量

图19 带宽域
数据分块
通过修改乘法算法来减少 CPU stall 进而减少数据延迟。我们希望运行在本地插槽上的线程访问三个矩阵中的所有数据。数据分块是一种普遍使用的修改方式(如图20)。它允许处理每个矩阵中的子矩阵,使它们在高速缓存中保持热度并由
CPU 复用(针对 CPU 高速缓存大小通过优化数据块进一步提高性能)。这也使得在线程之间分配块变得更加容易,并防止了大量的远程数据访问和
重新加载。

图20 矩阵数据分块
如果我们看一下高速缓存数据分块修改后的结果(如图21),我们能够看到,即使不修复NUMA的影响,内存延迟依然小了很多,执行速度也快了不少。

图21 缓存分块调整(multiply3)
根据 General Exploration 配置页面(图22),pipeline slots 的
Retiring 增加到 20%,而其余的CPU stall 是在Memory Bound 和 Core
Bound 之间的。

图22 General Exploration 配置页面(multiply3)
根据延迟数据直方图 (如图23),大多数延迟集中在L2访问值附近,而其他延迟则在50到100执行周期的范围内,这在
LLC 命中延迟数范围内。按时间线带宽图(如图24)显示,大多数数据来自本地 DRAM,QPI上的流量略有增加。这与Intel®
Math Kernel Library (Intel® MKL)双精度矩阵乘法(dgemm)的实现相比,它的性能仍然较低,但对于这样大小的矩阵它们的性能已经很接近了(如图25)。因此,我们最终的优化可以做的就是修改算法去分块数据并且要充分了解
NUMA 模式。最终性能请看表3和图26。

图23 延迟数据直方图 (multiply3)

图24 按时间线带宽图

图25 Intel® MKL-based multiply5 性能评估

表3 最终Matrix3优化的性能(36核,Intel® Xeon® processor E5-2697
v4,双卡槽 2300 MHz 内存)

图26 矩阵乘法benchmark测试结果
我们在性能可伸缩性曲线图中注意到下面几点:
由于高速缓存数据分块,矩阵3的曲线超过了理想曲线,这使单线程比普通实现的执行速度更快。
在线程数等于物理核心数之前,矩阵3的曲线会更接近理想曲线,而添加超线程并不能进一步提高可伸缩性。
结论
由于CPU微体系结构的限制,某些内存访问模式似乎使得并行程序的可伸缩性很差。为避免这些限制,你需要准确定位哪些数据导致CPU
stall。借助Intel VTune Amplifier内存访问分析工具,可以定位引起最大延迟的数据对象,用
CPU tick 计量的延迟量,数据所在的高速缓存级别,以及数据对象分配和延迟访问的源代码。此信息应该能帮助你优化算法来产生更好的内存访问模式。
| 



