编辑推荐:
本文主要介绍了linux内核栈等相关内容。希望对你的学习有帮助。
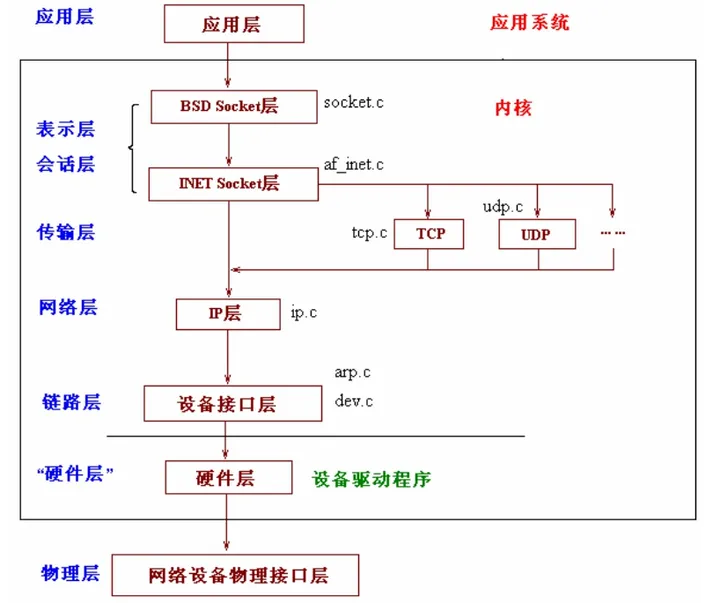
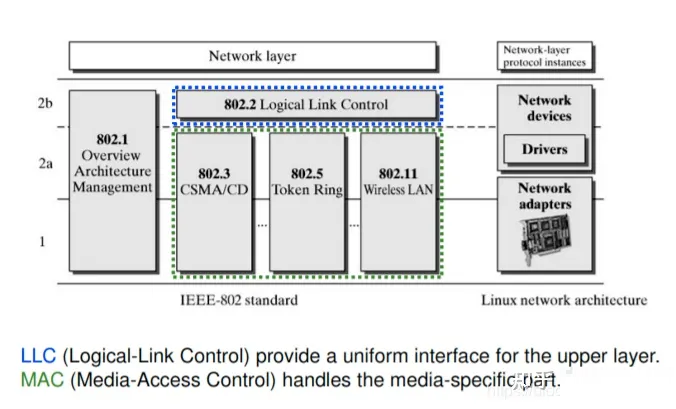
Linux 内核协议栈分层架构
驱动程序层(Physical device hardware):提供连接硬件设备的各种软件接口。
设备接口层(Device agnostic interface):提供驱动程序的各种抽象接口。作为驱动层和协议层之间的中间层,提供无关具体设备的统一接口定义。
网络协议层(Network protocols):提供 L3-4 TCP/IP 网络协议的具体实现。例如:ARP、IP、ICMP、TCP
等。
协议接口层(Protocol agnostic interface):也称为 BSD Socket
API 层,本质是 SCI(系统调用接口)的一部分,向上层应用程序提供各种网络编程接口。作为协议层和应用层之间的中间层,提供无关具体协议的统一
Socket 接口定义。
报文处理流程概览
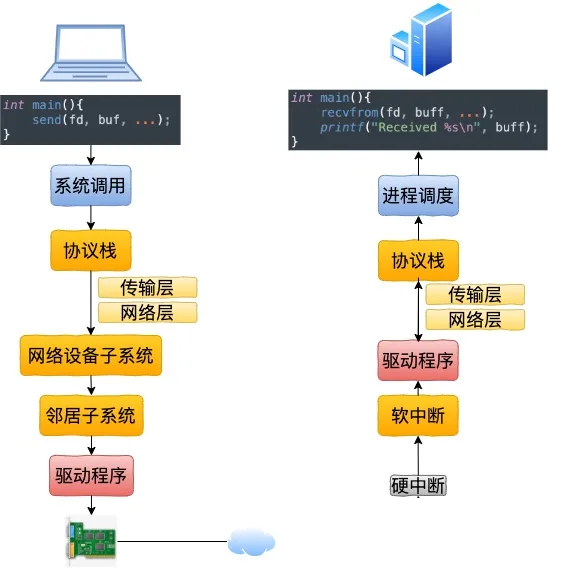
跨主机收发报文概览
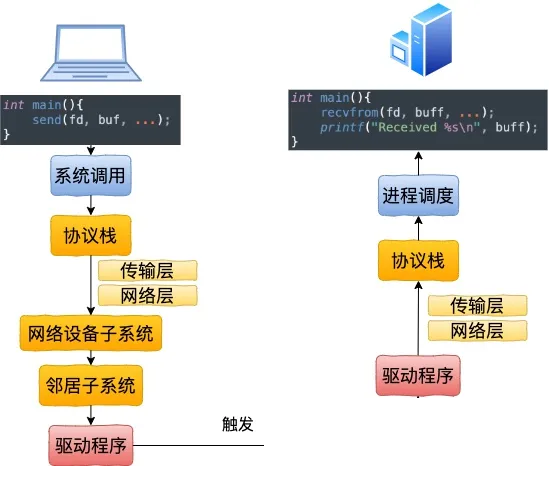
本地收发报文概览
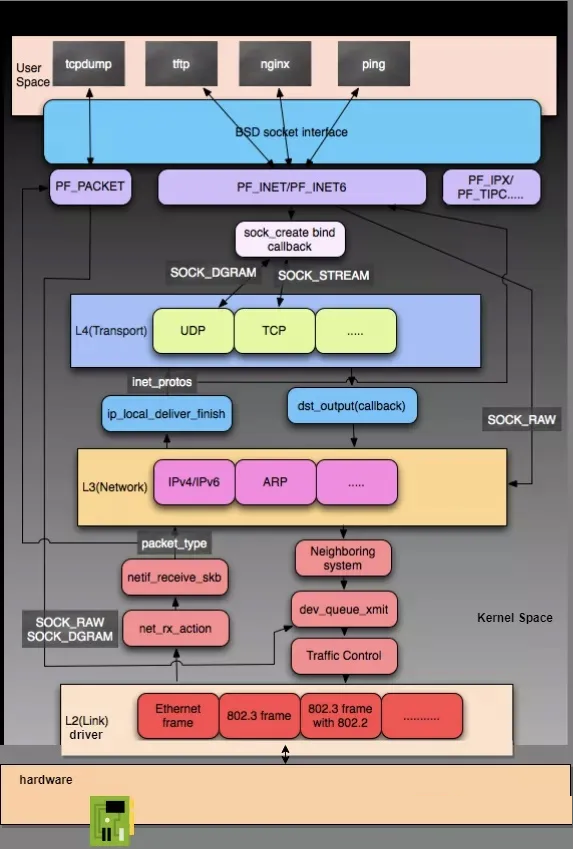
协议栈实现概览
内核协议栈关键技术
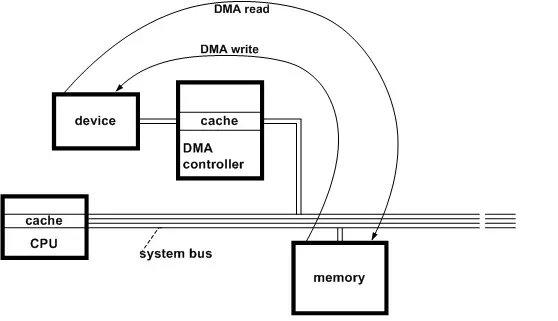
DMA
DMA(Direct Memory Access,直接内存访问)是一种硬件实现的外设
I/O 技术。在 DMA 技术出现之前,NIC 和 CPU 之间的 Frames(二层数据帧)收发依赖
CPU 先从 NIC Rx/Tx queue 逐个 Copy 到 Kernel space,然后再从
Kernel space 中 Copy 到 User space,单向两次 CPU Copy 的方式,非常消耗资源。DMA
技术出现后,NIC 增加了 DMA Control 功能,并将 NIC Rx/Tx queue 与
Main Memory 中的 ZONE_DMA 建立直接映射关系。当 Frames 进入 NIC Rx/Tx
queue 之后,就会直接被 DMA Controller Copy 到 ZONE_DMA,这一次
Copy 完全不需要 CPU 的参与。并且由于 ZONE_DMA 是一块物理映射区,所以 Kernel
space 也可以直接访问。DMA 技术在单向的外设 I/O 的流程中,减少了一次 CPU Copy
的工作,也以此减轻了 CPU 的工作负载。在 32bit Linux 中,ZONE_DMA 默认只有
16MB;而在 64bit Linux 中,ZONE_DMA 默认可以有 4GB,得到了非常大的提升。
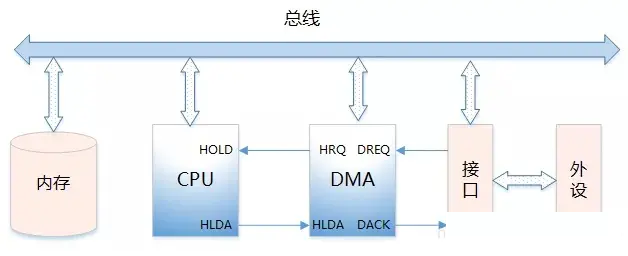
DMA Controller 的功能:
向 CPU 发出 HOLD(保持)信号,提出 Bus(总线)接管请求。
当 CPU 发出允许接管信号后,负责对 Bus 的控制,进入 DMA I/O 模式。
通过对 Main Memory 进行寻址以及修改地址指针,实现对 Memory 的读写操作。
向 CPU 发出 DMA 结束信号,CPU 恢复正常工作模式。
DMA 信号类型:
DREQ(外设请求信号):I/O 外设向 DMA Controller 发起请求。
DACK(DMA 响应信号):DMA Controller 向 I/O 外设的响应信号
HRQ/HOLD(DMA 请求信号):DMA Controller 向 CPU 发出,要求接管 Bus。
HLDA(CPU 响应信号):CPU 响应允许 DMA Controller 接管 Bus。
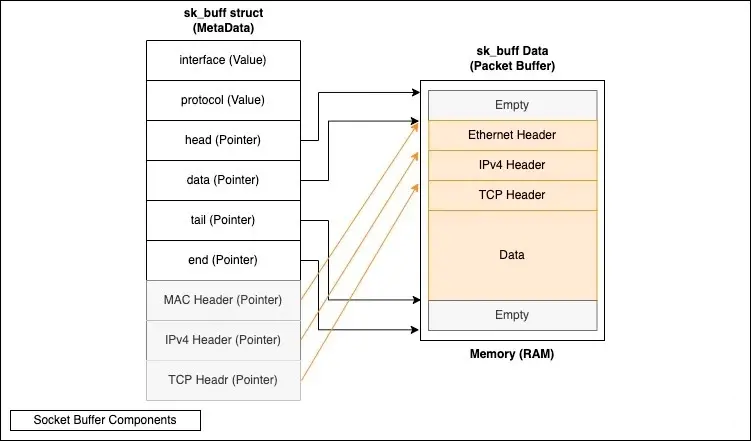
sk_buff 结构体
sk_buff 结构体是 Kernel 定义的一个用于描述 Frame 的数据结构。Net
driver 的初始化流程中包括对 DMA 空间进行初始化,主要的工作就是在 ZONE_DMA 中分配好用于存储sk_buff的内存空间。当
Frame 到达 NIC 后,DMA Controller 就会将 Frame 的数据 Copy 到
sk_buff 结构体中,以此来完成 Frame => sk_buff 数据格式的封装。在后续的流程中,sk_buff
还会从 ZONE_DMA Copy 到 Kernel Socket Receive Buffer 中,等待
Application 接收。
struct igb_ring {
...
union {
...
/* RX */
struct {
struct sk_buff *skb;
struct igb_rx_queue_stats rx_stats;
struct u64_stats_sync rx_syncp;
};
...
}
sk_buff 的结构体定义如下图所示,它包含了一个 Frame 的 Interface(网络接口)、Protocol(协议类型)、Headers(协议头)指针、Data(业务数据)指针等信息。
值得留意的是,在 Kernel 中,一个 Frame 的 Headers 和 Payload 可能是分开存放到不同内存块种的。有以下几点原因:
两者具有不同的特征和用途:Headers 包含了网络协议的元数据信息,而 Payload 包含了 Application
的业务信息。
两者具有不同的大小和格式:Headers 的格式通常是标准的,而且数据量比 Payload 小的多。
两者具有不同的处理逻辑:Headers 需要被快速识别、分析和校验,而 Payload 则需要被快速的传输和存储。
分开存储和处理的方式,可以有效提高网络传输的效率和可靠性。同时,sk_buff 是一个双向链表数据结构,支持链表操作。
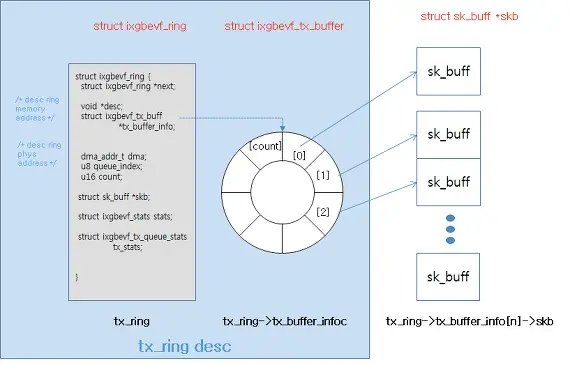
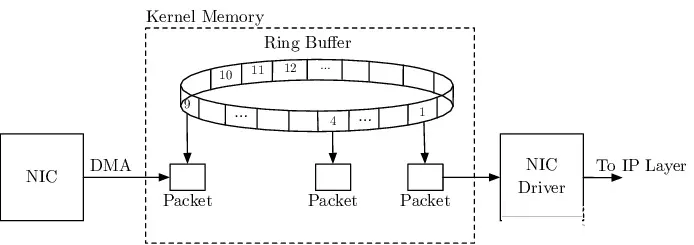
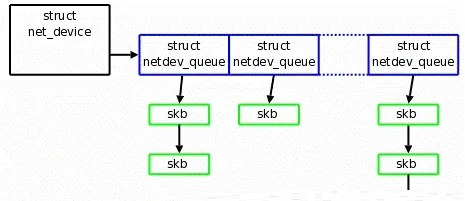
Net driver Rx/Tx Ring Buffer
Netdriver实现了 2 个 Ring
Buffer 用于数据报文的收发处理。Ring queue 是高性能数据包处理场景中常见的数据结构,它将
Buffer 内存空间设计成一个首尾相连的环。当 Buffer 空间溢满后,新来的 Frames 会从头开始存放,而不是为其分配新的内存空间。相较于传统的
FIFO queue 数据结构,Ring queue 可以避免频繁的内存分配和数据复制,从而提高传输效率。此外还具有缓存友好、易于并行处理等优势。值得注意的是,Rx/Tx
Ring Buffer 中存储的是 sk_buff 的 Descriptor,而不是 sk_buff
本身,本质是一个指针,也称为 Packet Descriptor。
Packet Descriptor 有 Ready 和 Used 这 2 种状态。初始时 Descriptor
指向一个预先分配好且是空的 sk_buff 空间,处在 Ready 状态。当有 Frame 到达时,DMA
Controller 从 Rx Ring Buffer 中按顺序找到下一个 Ready 的 Descriptor,将
Frame 的数据 Copy 到该 Descriptor 指向的 sk_buff 空间中,最后标记为
Used 状态。这样设计的原因是 Rx/Tx Ring Buffer 作为 I/O 控制单元,不应该持有太多数据量。数据传输由
DMA 实现会非常快,而 Ring Buffer 也只需要记录相应的指针即可。
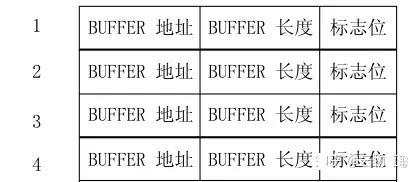
Buffer Descriptor Table
Rx/Tx Ring Buffer 的具体实现为一张
Buffer Descriptor Table(BDT)。BDT 是一个 Table 数据结构,拥有多个
Entries,每条 Entry 都对应了 Ring Buffer 中的一个 Rx/Tx Desc,它们记录了存放
sk_buff 的入口地址、长度以及状态标志位。
收包时:DMA Controller 搜索 Rx BDT,取出空闲的 DB Entry,将 Frame
存放到 Entry 指向的 sk_buff,修改 Entry 为 Ready。然后 DBT 指针下移一项。
发包时:DMA Controller 搜索 Tx BDT,取出状态为 Ready 的 DB Entry
所指向的 sk_buff 并转化为 Frame 发送出去。然后 DBT 指针下移一项。
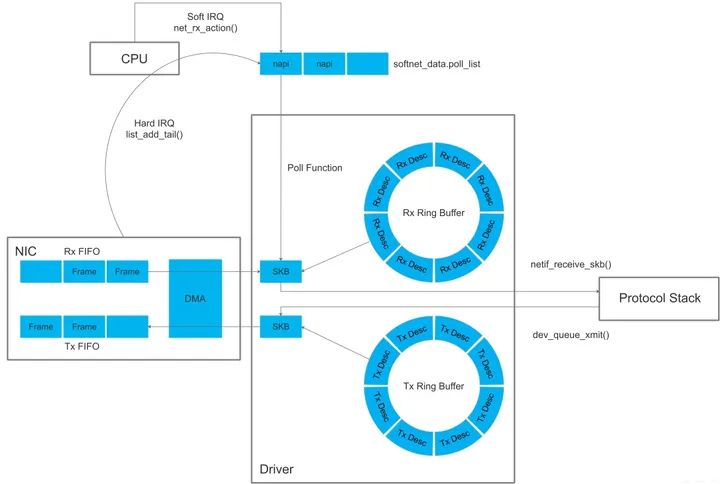
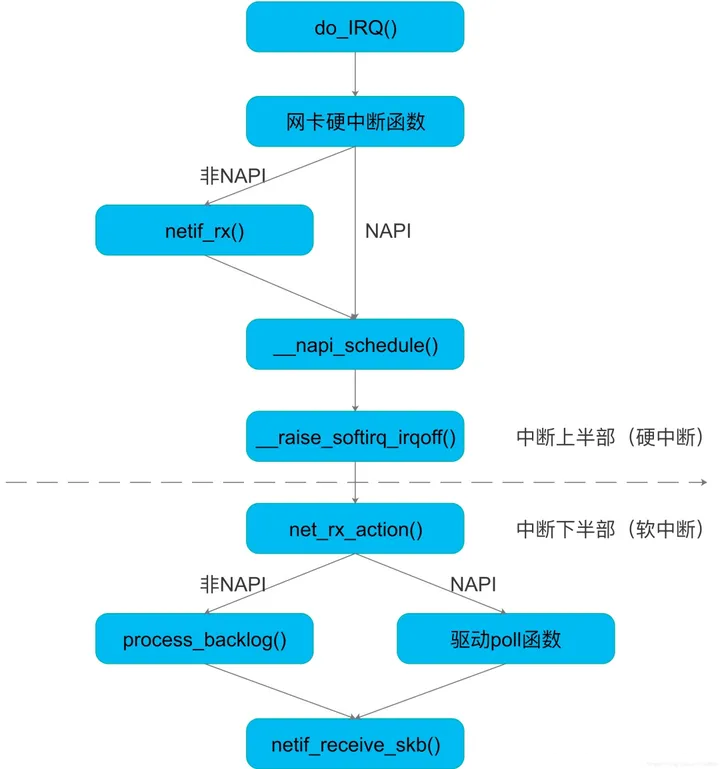
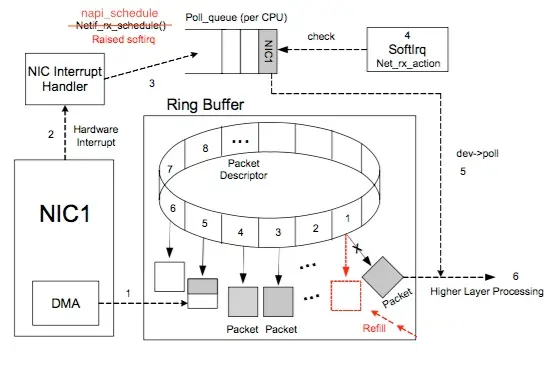
NAPI 收包机制
NAPI(New API)是一种 “中断 + 轮训” 收包机制,相较于传统的单一中断(硬中断
+ 软中断)收包的方式效率更高。
NAPI 的工作流程如下:
Net driver 初始化流程中,注册 NAPI 收包机制所必须的 poll() 函数到 ksoftirqd(软中断处理)内核线程。
Frame 到达 NIC;
DMA Controller 写入 sk_buff;
NIC Controller 发起硬中断,进入 Net driver 的 napi_schedule()
硬中断处理函数,然后将一个 napi_struct 结构体加入到 poll_queue(NAPI 软中断队列)中。此时
NIC Controller 立即禁用了硬中断,开始切换到 NAPI “轮训“ 收包工作模式。
再进入 raise_softirq_irqoff(NET_RX_SOFTIRQ) 软中断处理程序,唤醒
NAPI 子系统,新建ksoftirqd内核线程。
ksoftirqd 线程调用 Net driver 注册的 poll() 函数。
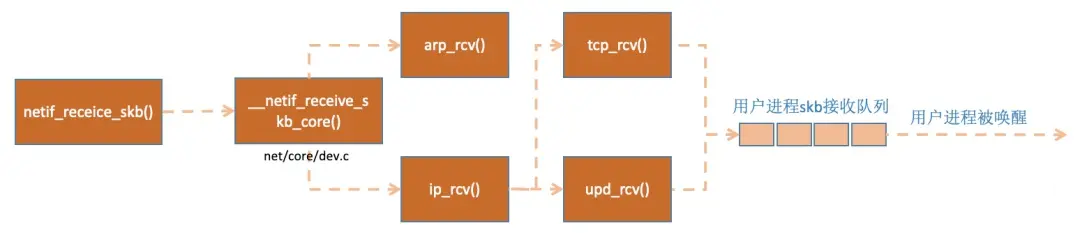
poll() 调用 netif_receive_skb() 开始从 sk_buff 空间中收包,并将它传递给网络协议栈进行处理。
直到一段时间内没有 Frame 到达为止,关闭 ksoftirqd 内核线程,NIC Controller
重新切换到 NAPI “中断” 收包工作模式。
在具体的实现中,poll() 会轮训检查 BDT Entries 的状态,如果发现当前 BDT 指针指向的
Entry Ready,则将该 Entry 对应的 sk_buff 取出来,并恢复该 Entry 的空闲状态。可见,和传统方式相比,NAPI
一次中断就可以接收多个包,因此可以减少硬件中断的数量。
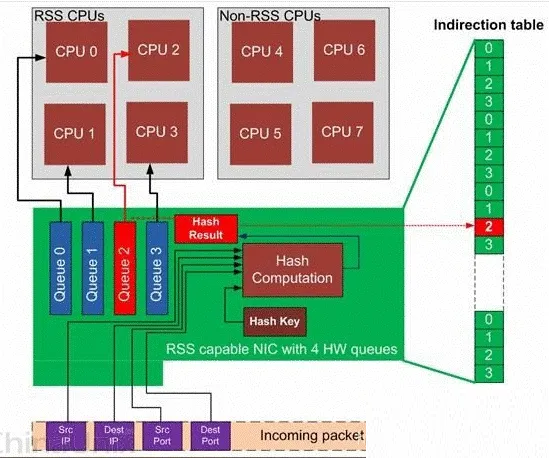
网卡多队列
在以往,一张 NIC 只会提供一组 HW Rx/Tx Ring queue,对应一个 CPU
来进行处理。在多核时代,NIC 也相应的提供了 Multi-Queue 功能,可以将多个 Queue
通过硬中断绑定到不同的 CPU Cores 上处理。以Intel 82575为例。
在硬件层面:它拥有 4 组硬件队列,它们的硬中断分别绑定到 4 个 Core 上,并通过 RSS(Receive
Side Scaling)技术实现负载均衡。RSS 技术通过 HASH Packet Header
IP 4-tuple(srcIP、srcPort、dstIP、dstPort),将同一条 Flow
总是送到相同的队列,从而避免了报文乱序问题。
在软件层面:Linux Kernel v2.6.21 开始支持网卡多队列特性。在 Net driver
初始化流程中,Kernel 获悉 Net device 所支持的硬件队列数量。然后结合 CPU Cores
的数量,通过 Sum=Min(NIC queue, CPU core) 公式计算得出应该被激活 Sum
个硬件队列,并申请 Sum 个中断号,分配给激活的每个队列。
如上图所示,当某个硬件队列收到 Frames 时,就触发相应的硬中断,收到中断的 CPU Core
就中断处理任务下发给该 Core 的 NET_RX_SOFTIRQ 实例处理(每个 Core 都有一个
NET_RX_SOFTIRQ 实例)。在 NET_RX_SOFTIRQ 中调用 NAPI 的收包接口,将
Frames 收到具有多个 netdev_queue 的 net_device 结构体中。
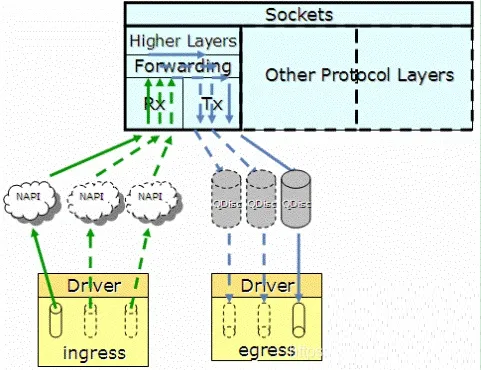
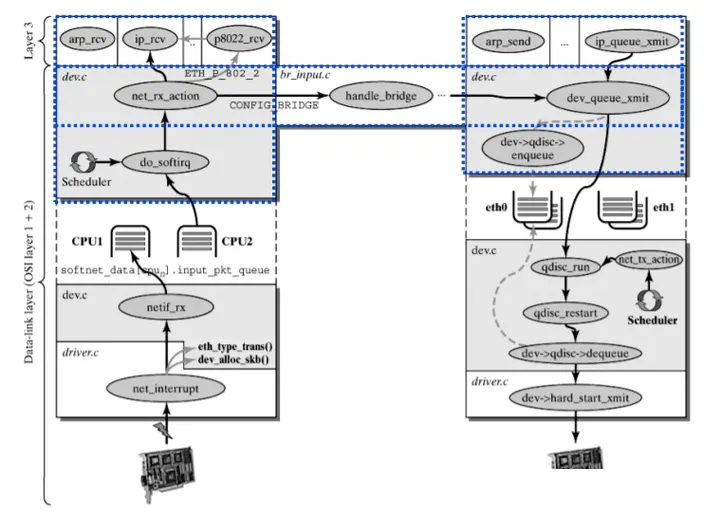
内核协议栈收包/发包流程概览
收包流程:
发包流程:
内核协议栈收包流程详
解驱动程序层(数据链路层)
NIC Controller 接收到高低电信号,表示 Frame 到达。PHY 芯片首先将电信号转换为比特流,然后
MAC 芯片再将比特流转换为 Frame 格式。
DMA Controller 将 Frame Copy 到 Rx Ring Buffer 中的一个
Rx Desc 指向的 sk_buff 空间。
DMA Controller 更新相应的 BD Entry 状态为 Ready,并将 BDT 指针下移一项。
NIC Controller 给 CPU 的相关引脚上触发一个电压变化,硬中断 CPU。每个硬中断都对应一个中断号,CPU
开始收包硬中断处理程序。硬中断处理程序由 Kernel 回调 Net driver 具体实现的注册函数,根据是否开启了
NAPI 有两条不同的执行路径。
以 NAPI 模式为例,Net driver 执行 napi_schedule() 硬中断处理函数,然后将一个
napi 结构体加入到 poll_queue(NAPI 软中断队列)中。此时 NIC Controller
立即禁用了硬中断,开始切换到 “NAPI 轮训“ 收包工作模式。
再进入 raise_softirq_irqoff() 软中断处理程序,唤醒 NAPI 子系统,新建
ksoftirqd 内核线程。
ksoftirqd 线程调用 Net driver 注册的 poll() 函数。
// linux/drivers/net/ethernetnapi
poll() 调用 netif_receive_skb() 开始从 sk_buff 空间中收包,并将它传递给
TCP/IP 网络协议栈进行处理。
// linux/net/core/dev.c
int netif_receive_skb
直到一段时间内没有 Frame 到达为止,关闭 ksoftirqd 内核线程,NIC Controller
重新切换到硬中断收包工作模式。
VLAN 协议族
Linux Bridge 子系统
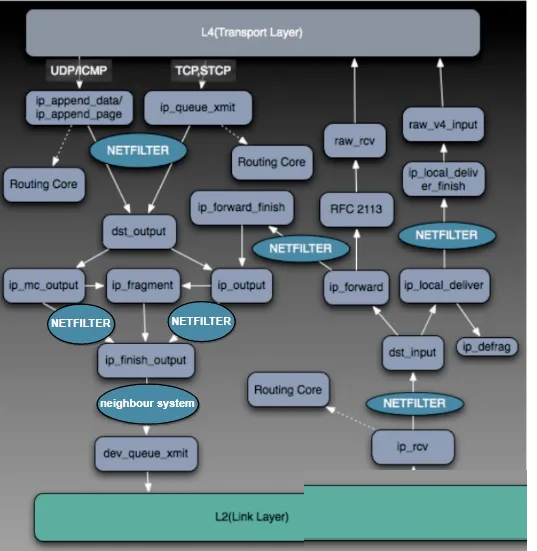
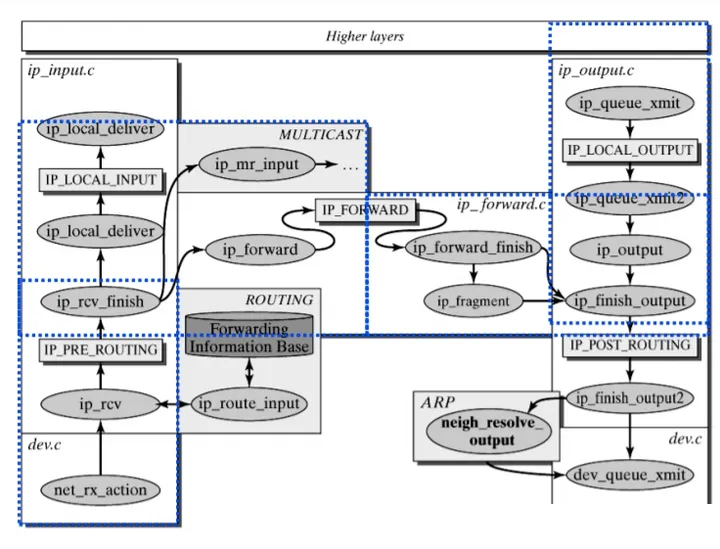
网络协议层(L3 子系统)
Net driver 调用 netif_receive_skb() 将 sk_buff 从 ZONE_DMA
Ring Buffer 中取出并交给 TCP/IP 协议栈处理的过程中,首先会根据 sk_buff
内层 Header 的 Protocol Type 选择相应的处理函数,如果是 IP 协议,则调用
ip_rcv() 进行处理。
ip_rcv() 首先会解析 IP Header,根据 srcIP 和 dstIP 进入路由子系统处理流程。如果
dstIP 是本机地址,则根据内层 Header 的 Protocol Type 选择相应的传输层处理函数。UDP
对应 udp_rcv()、TCP 对应 tcp_rcv()、ICMP 对应 icmp_rcv()、IGMP
对应 igmp_rcv()。
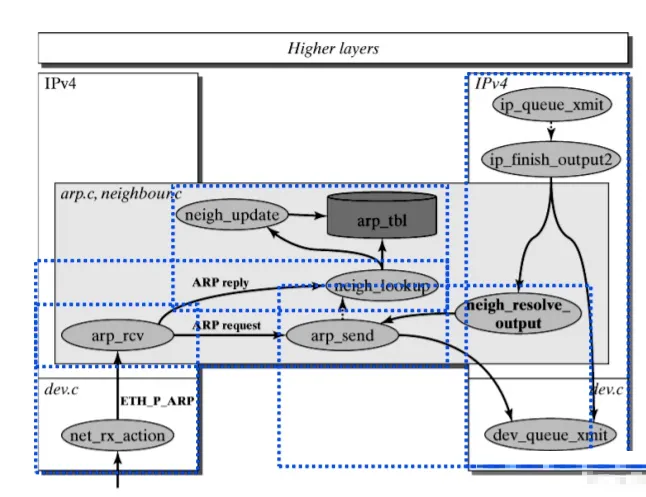
ARP 子系统
IP 子系统
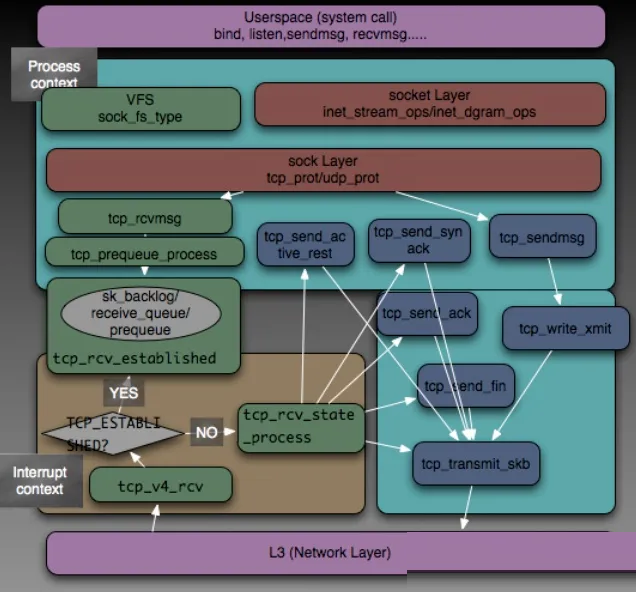
网络协议层(L4 子系统)
在使用 socket() 创建一个 TCP Socket 之后,Socket 对应的 Sock 结构体会被注册到一个
tcp_prot 全局变量中,并以 tcp_port 作为 Index。
当 tcp_rcv() 收到 sk_buff 之后,根据 TCP Header 中的 dstPort
字段索引到相应的 Sock。
然后将 sk_buff 加入到该 Sock 的 receive_queue 成员所指向的 Socket
Receive Buffer 缓冲队列中,等待 Application 通过 read() 等 SCI
来进行读取。
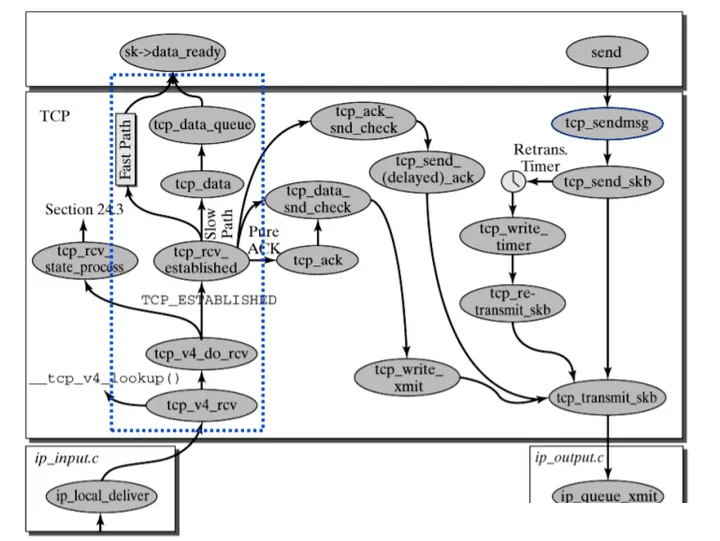
TCP 子系统
协议接口层(BSD Socket 层)
当 Application 调用 read() 来进行读取时:
首先会根据 socket fd 查询 file inode,并从中得到相应的 Sock 结构体;
然后从 Sock 结构体成员 recieve_queue 指向的 Socket Receive Buffer
发起一次 CPU Copy;
CPU 从用户模式转为内核模式,将数据包从 Kernel space Copy 到 User space。
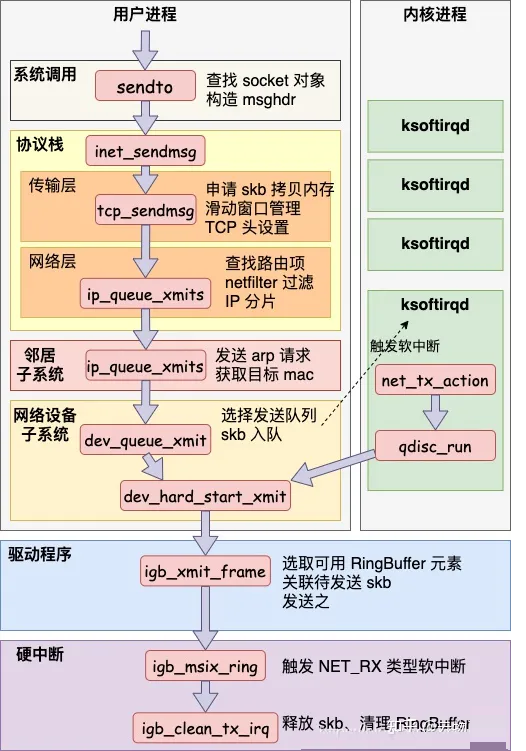
内核协议栈发包流程详解
以 UDP 数据报为例:
协议接口层:BSD socket 层的 sock_write() 会调用 INET socket 层的
inet_wirte()。INET socket 层会调用具体传输层协议的 write 函数,该函数是通过调用本层的
inet_send() 来实现的,inet_send() 的 UDP 协议对应的函数为 udp_write()。
L4 子系统:udp_write() 调用本层的 udp_sendto() 完成功能。udp_sendto()
完成 sk_buff 结构体相应的设置和 Header 的填写后会调用 udp_send() 来发送数据。而在
udp_send() 中,最后会调用 ip_queue_xmit() 将数据包下放的网络层。
L3 子系统:函数 ip_queue_xmit() 的功能是将数据包进行一系列复杂的操作,比如是检查数据包是否需要分片,是否是多播等一系列检查,最后调用
dev_queue_xmit() 发送数据。
驱动程序层:函数调用会调用具体设备提供的发送函数来发送数据包,e.g. hard_start_xmit(skb,
dev)。具体设备的发送函数在协议栈初始化的时候已经设置了。