| 编辑推荐: |
本期主要介绍了程序是如何控制GPU做事情的。希望对您的学习有所帮助。
本文来自于微信公众号TrustZone,由火龙果软件Linda编辑、推荐。 |
|
前言
之前几期我们过了一遍,现在的GPU都有什么功能模块。以及如何用可控的方式把它们部署到硬件上,但是光有硬件不行啊,总得让软件能用得上。本期就来看看程序是如何控制GPU做事情的。
程序需要通过操作系统提供的的硬件端口读写,直接操作图形硬件。
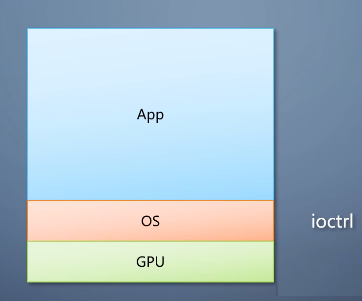
如果每个程序都需要对每个操作系统的每个硬件写一遍。开发效率非常低,
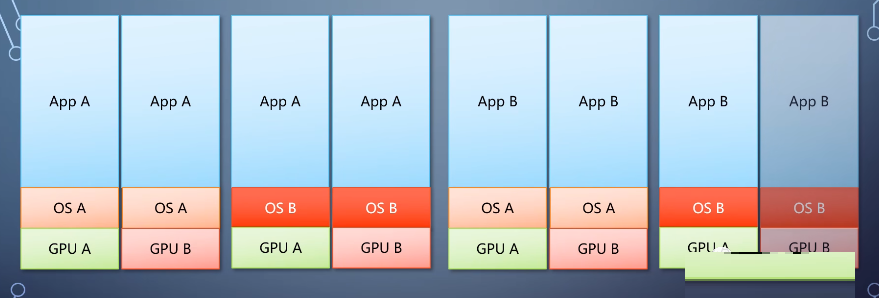
他们自然用的抽象的思路,通过抽象形成一个公共的接口层。程序使用这个接口来告诉底下做什么,底下负责怎么做,这个接口就成为应用程序编程接口api。
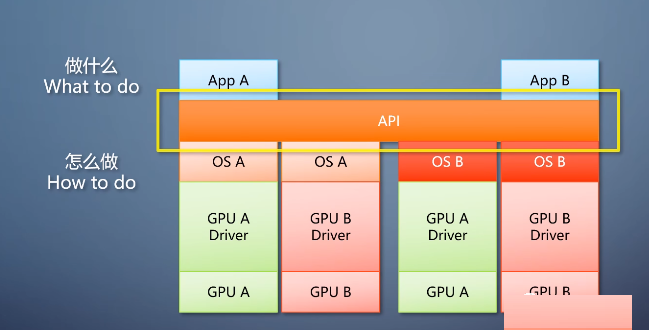
程序只要针对图形API写一遍就行,几乎不必考虑操作系统和硬件的区别。图形API由硬件厂商实现往下翻译成对应件的操作。
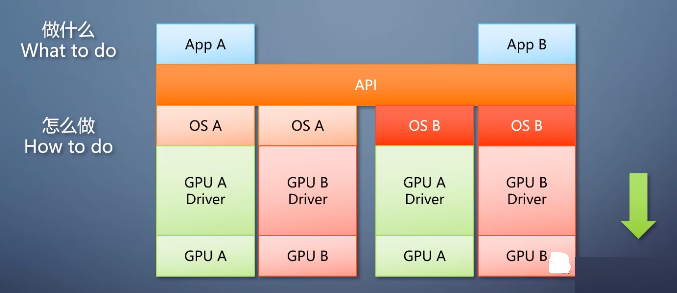
久久之人们发现同一个API的不同实现也存在大量可以公用的部分。于是API的实现又进行了分层,增加的一个抽象层称为设备驱动接口DDI。
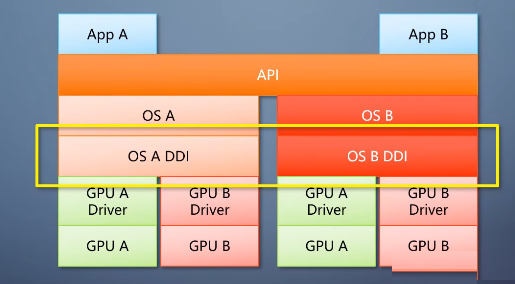
DDI往上属于操作系统,负责数据有效性检查,内存分配等。
DDI往下是驱动,负责各个硬件特别的部分。
相当于操作系统把API翻译成DDI驱动,驱动把DDI翻译成对硬件的操作。
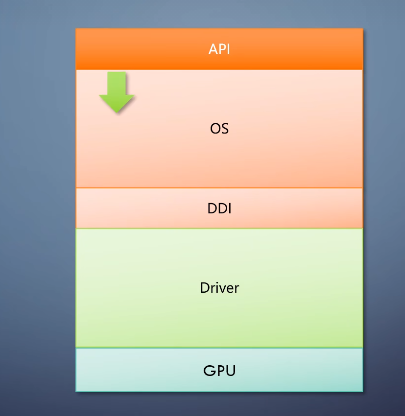
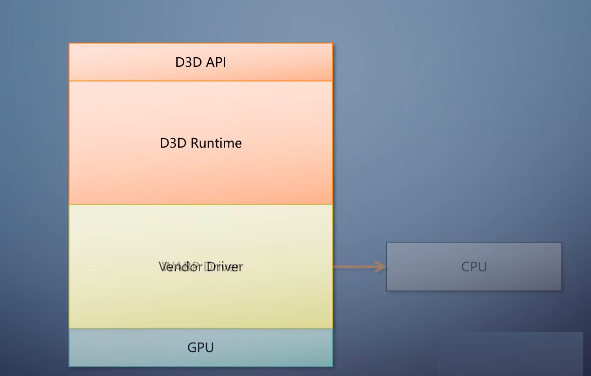
这就是图形API软件栈的架构。
图形API软件栈的架构
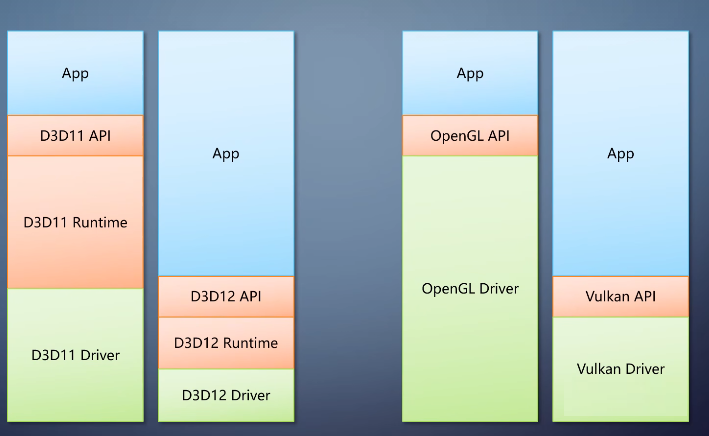
1-Direct3Dd->D3D
当然上面这只是理想状况,现实中往往会有所调整,尤其是操作系统本身就分为用户态和内个态,使得组合更为复杂。下面我会以几个有代表性的api为例,看看他们现实中的架构。第一个是微软的Direct3Dd,D3D。这里只讨论Windows上的官方实现。

这个API不跨平台,但跨厂商。

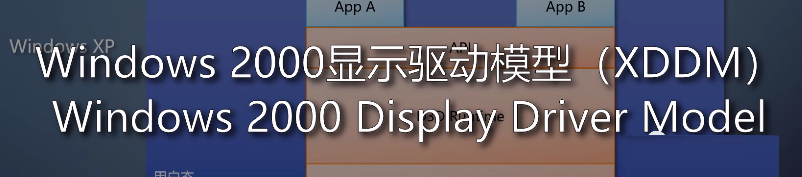
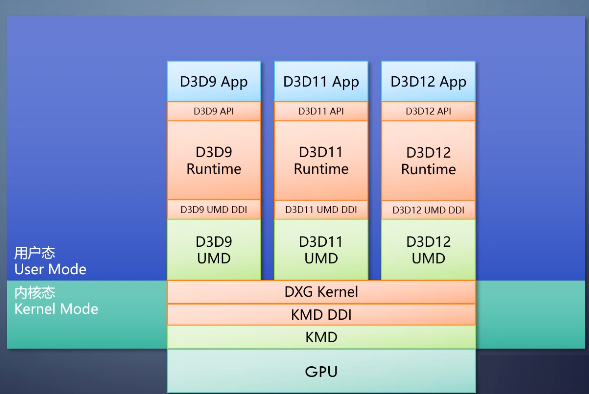
在Windows xp的时代,软件站就和理想状况不一样。操作系统提供一个D3D runtime,往上是API,往下是DDI
厂商提供一个内核态驱动,这个框架称为xdm。
而随着对稳定性,性能,共享资源的需求不断增加,到了vista时代,runtime和厂商驱动都进一步分成了用户态和内核态两部分。这两部分里分别有自己的DDI。

当程序调用D3D api的时候,D3D runtime会进行一些数据验证。通过用户态的DDI到达厂商提供的用户态驱动UMD。

UMD把shader字节码编译成厂商专用的指令,转换命令队列等,传到内核态。内核里的runtime部分叫做dxg
kernel。做显存分配、设备中断管理等。
经过内核态DDI调用厂商提供的内核态驱动KMD,
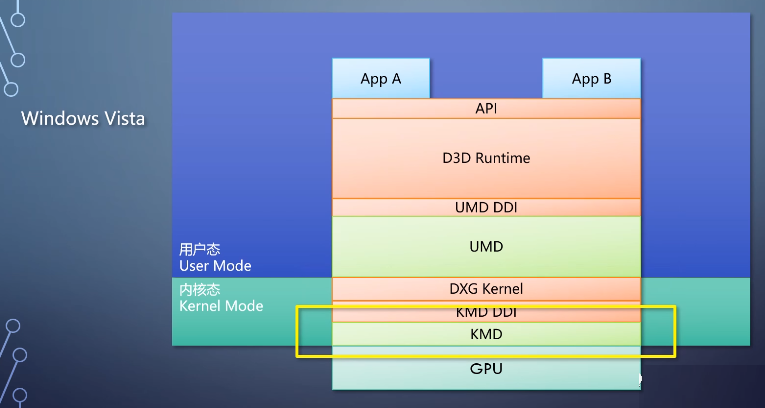

做一些地址翻译等厂商专用的操作,最后传给GPU执行。
这个架构称为WDDM。

把驱动分为用户态和内核态,并把大部分代码移到用户态,能大大提高稳定性。
就因为D3D runtime和dxg kernel这两个操作系统组件的存在,厂商开发驱动的过程从作文题直接变成了填空题。工作量大大减少,这还使得不同厂商之间的区别变小,总体质量有所提升。
结果vista之后因为驱动造成的蓝屏远少于xp的时代,多年以来D3D发展出了很多版本,目前最常用的是9
11 12。
2-OpenGL
每个版本之间的API和用户DDI大不相同,代码没有多少兼容性。每出一版,程序和UMD都得大改甚至重写才能用上。
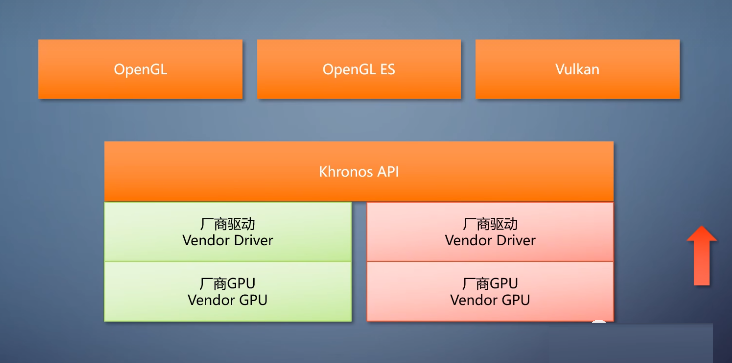
第二个例子是跨平台,而且跨厂商的图形API。opengl,它由Khronos发布。
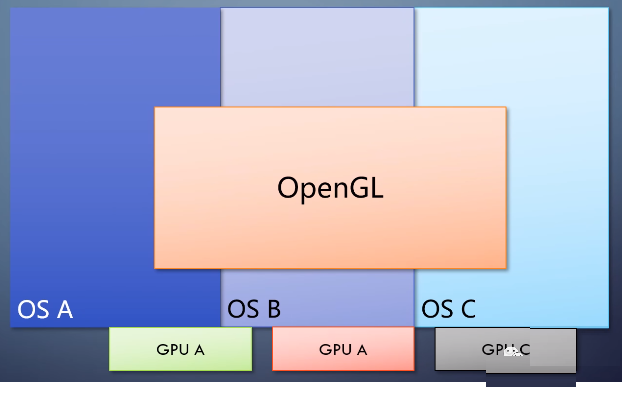
Khronos只组织标准协商会议,

API要支持什么,还得看组织里的软硬件厂商。

在Windows上,OpenGL和微软自己的D3D存在直接竞争关系,以至于微软一直想方设法要在Windows上掐OpenGL。很多次尝试都因为用户的强烈反对而作罢。
Windows并没有为OpendGL做多少事情,只是提供了一个框架叫做可安装用户驱动,ICD。
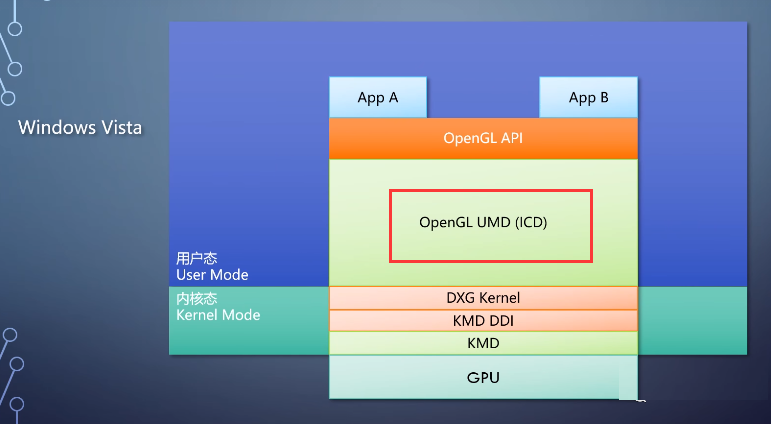

让硬件厂商实现OpenGL runtime的UMD。到了内核态,也要经过dxg kernel和同一个KMD。
到了Linux,OpenGL有两种实现方式,一种是完全由厂商实现整个OpenGL,另一种方式是基于Mesa的框架。Mesa提供了一个开源的OpenGL
runtime,并通过DDI调用厂商驱动来操作GPU。
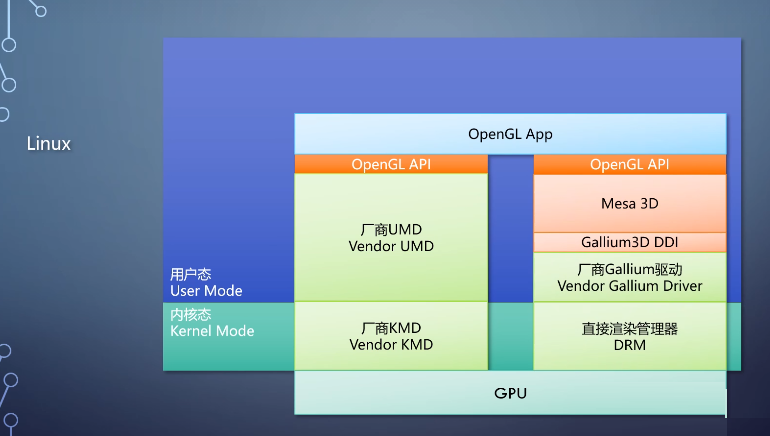
后来进一步扩展出了对OpenGL ES、Vulkan等API的支持。

OpenGL从90年代初的1.0到最后一版4.6,都是向下兼容的。

当时的代码现在也能用,不管在哪个平台上,OpenGL本身都是一样的。是和窗口打交道的部分略有不同,程序的平台适配并不难。
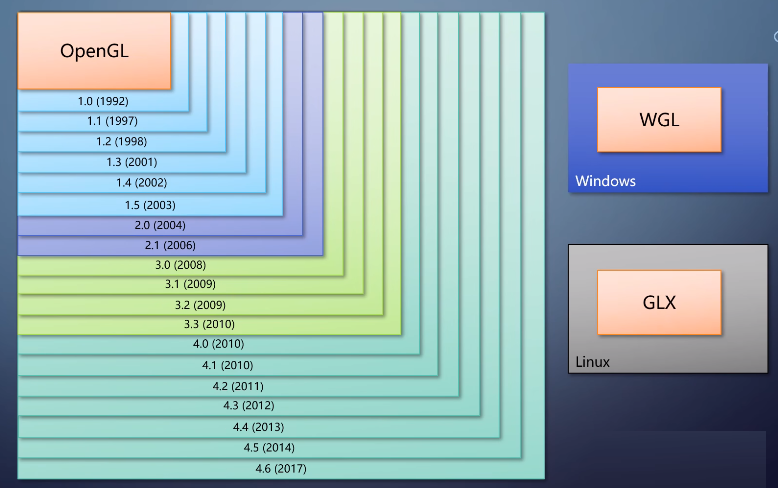
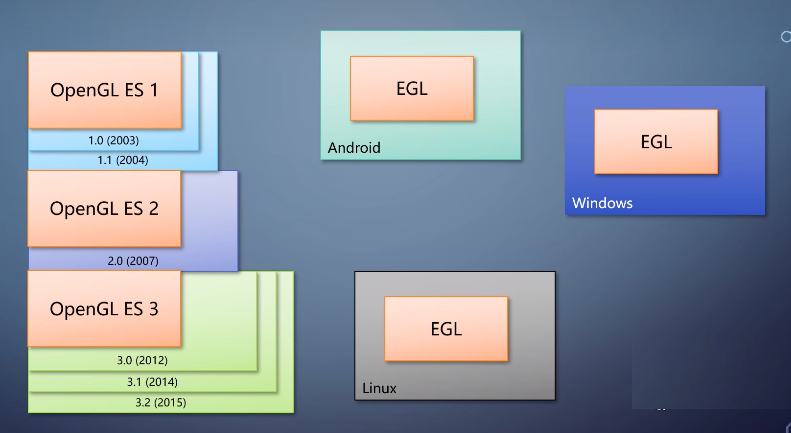
OpenGL ES甚至把窗口系统给抽象出来,成为EGL。进一步简化了跨平台。
注意,虽然OpenGL 和 OpenGL ES非常相似,
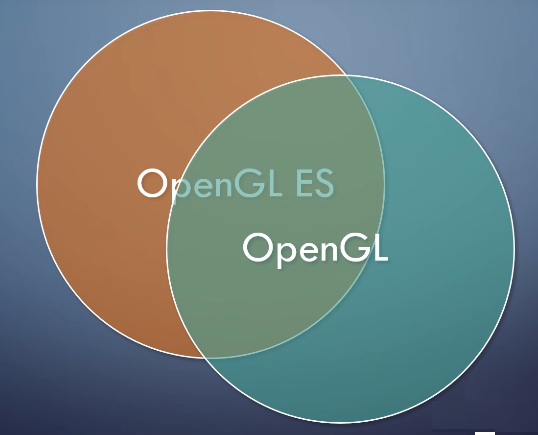
但只要提到他们,几乎总是只涉及他们不同的部分。因此应该把他们当做两个不同的api来看待。
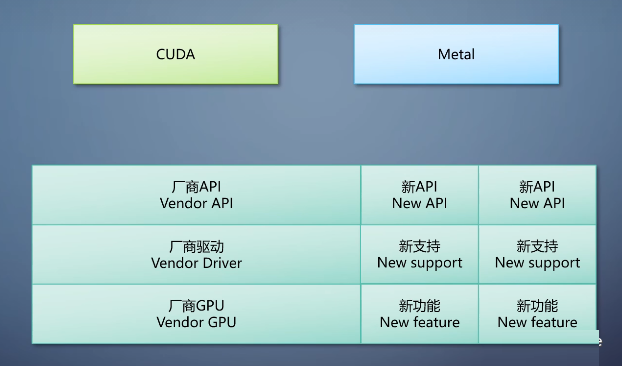
还有个代表性的API 是NVIDIA的CUDA,它是跨平台的,但不跨厂商。正式来说只能在NVIDIA的GPU上跑。这是一个只有计算的API,需要的话可以和其他的图形API交互,还计算的结果交给图形流水线。

当然,更多时候CUDA被用来做纯计算,比如有限元模拟,神经网络训练等。CUDA提供的一些功能并不存在于图形API里,并不是更高层的抽象。比如CUDA一开始就提出了shared
memory这个概念。用好的话可显著提高GPU的效率。
就在当时的图形API里是没有的,只能通过CUDA。后来的compute shader也是受到CUDA的影响而设计出来的。

横向比较一下现在的api,有这么一个规律。

CUDA和Metal这种从软件到硬件都是一个厂商拥有的API。在硬件有个新功能之后,可以直接通过API暴露出来。不需要跟别的厂商讨论,反应很快。
OpenGL、OpenGL ES、Vulkan这三个API的模式。都是Khronos拥有接口,硬件厂商拥有实现。在设计中使用了自己向上的方式。
他们都提供了扩展机制,可以在不更新api版本的情况下扩充api。

顺着时间纵向来看API,可以看到他们发展趋势是变薄。把更多的事情交给程序去做,而不是runtime和驱动。
因为程序知道自己的意图,不需要让API去猜。这个改进的结果就是执行效率更多。这几年出现的D3D12和Vulkan,都是响应了这个趋势。

这样的API,显得更底层,而用它们来开发更像是在写驱动,要做大量的细节操作。还好,一般来说API往上还有个渲染引擎的抽象层。可以把不同API抽象成同样的接口,这就把新API使用麻烦的缺点抹平了,同时获得新API带来的效率优势。
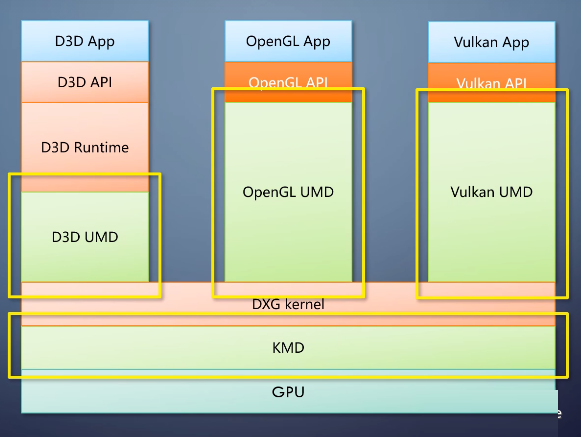
从前面说的分层架构可以看到,GPU执行的是驱动发来的操作,并不知道来自于哪个API,所谓的GPU支持哪个API。其实指的是GPU厂商提供了哪个API的驱动。所以说,GPU支持什么API的什么功能,都取决于驱动。
以前出现过这种情况:NVIDIA GeForce 6800硬件并不支持32位浮点混合,但它的OpenGL驱动说支持。当程序用到这个功能的时候,驱动切换到软件模式,模拟实现浮点混合。这没有任何问题,仍然是个有效的实现,只是效率有严重损失。
另一方面,驱动和操作系统高度相关。即便是同一个API,在不同操作系统上,驱动也完全不一样的。

换一个操作系统就得重写一次驱动。

比如高通的Adreno GPU,在Android上支持OpenGL ES,而在Windows上支持D3D,就是因为它们在不同平台提供了不同的驱动。并不能因为在Android上支持OpenGL
ES,这一点上,很多自以为是的人都翻过车。

前面看了软件栈的架构和一些常规实现,接下来来看一些不一样的做法。实际上,在整个架构里面,每一层做的事情就是往下翻译。

上下层之间通过接口隔离开来,上层并不需要知道下层是怎么做的。所以API不一定总是要往下到达DDI,比如ANGLE是个在Windows上最常用的OpenGL
ES实现。

它只是个用户态的库,把OpenGL ES翻译成,D3D11、OpenGL、Vulkan这些。
这样就能在不改操作系统和驱动的情况下
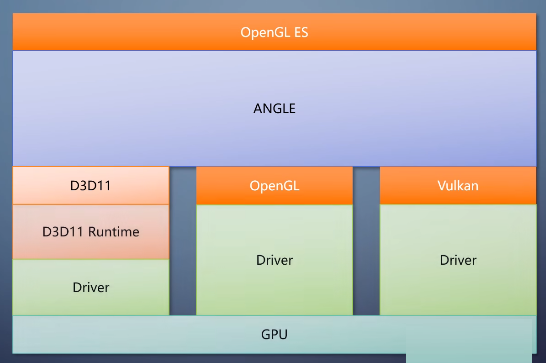
提供OpenGL ES的支持。同类的还有MoltenVK,把Vulkan翻译成Metal。
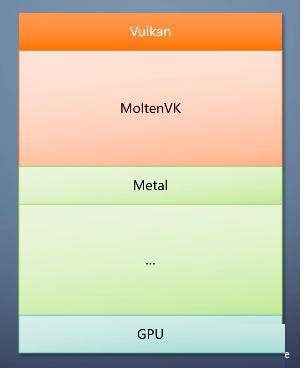
解决苹果的平台不支持Vulkan的问题。还有更奇葩的D3D11on12。它不是在上面加一个翻译层,而是用D3D12实现了一个D3D11的UMD。
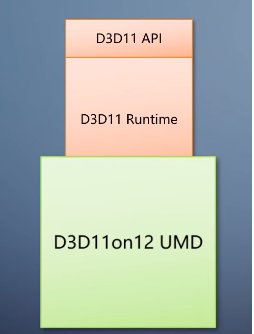
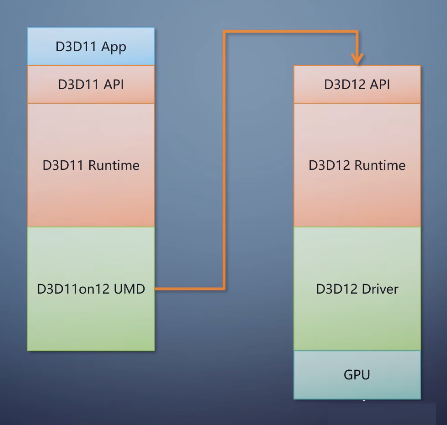
程序还是调用原来的D3D11 runtime,但到了UMD之后往上返回到D3D12 API,再往下走。
另一类非常规的,是软件模拟GPU。这样的驱动并不连到GPU硬件,而是在CPU上做了所有的事情。

Mesa就内置了一个软件模拟的驱动。

D3D也有一个,叫做WARP。
注意别和上一期说的GPU线程的warp搞混了,是完全不同的东西,

只是故意蹭曲速引摩的名字而已,同时也暗示速度很快。这样的CPU模拟GPU,可以辅助软硬件开发调试。
比如发明一个新功能,硬件还没做出来之前,可以模拟一把,以此定义这个功能的细节:作为硬件设计的参考。在没有安装GPU的服务器上,这样的软件模拟也可以临时用来跑一些GPU程序。

同样的道理,驱动也可以把硬件操作发到另一台机器,远程执行。这就开启了虚拟GPU和云GPU的途径。
那么,程序调用了图形API,走完整个栈,让GPU渲染之后,就直接写入帧缓存吗?
其实不总是这样。在同个系统中,多个程序同时运行,谁写入帧缓存的什么位置?如何保证不冲突?
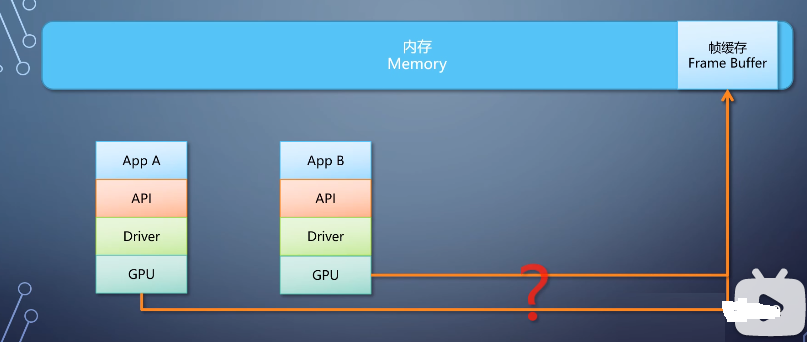
这里还有一个往往被忽略的东西,叫做合成器,compositor。
在不同系统上有不同组件来充当这个角色

Windows上是DWM,Android上是SurfaceFlinger。
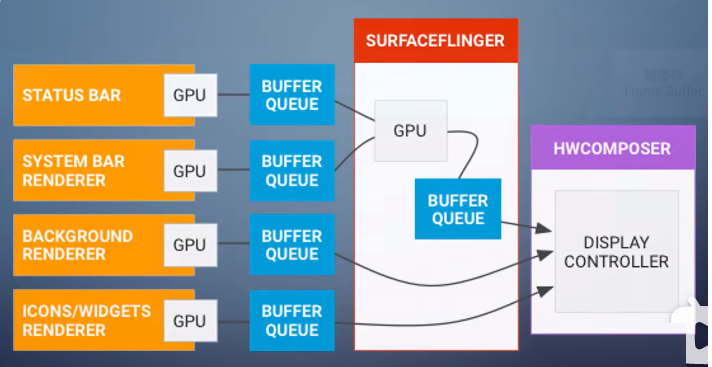
每个程序渲染出自己的内容,不写入帧缓存,而是写入一张纹理。这张纹理提交给操作系统,compositor拿到之后,

再次调用图形API,把它们合成到帧缓存,送去显示。
这叫做窗口模式,每个程序有自己的窗口,所有程序共存于桌面。
有的游戏会启用全屏独占模式,性能高一点点,
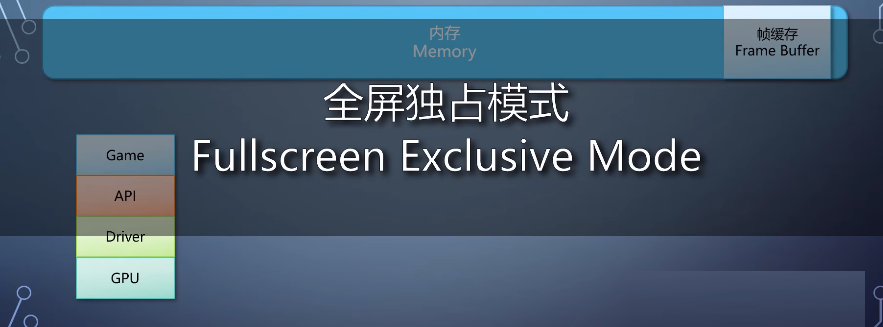
就是因为绕过了compositor,直接到达帧缓存。

但因为独占了,其他窗口就没法显示,甚至输入法都可能显示不正常。Compositor在各个操作系统里都对程序透明,
一般程序根本不需要知道它的存在。以至于在图形软件栈里,很少有提到compositor的。但在系统中,compositor的意义是肉眼可见的。
Windows上的毛玻璃窗体、macOS上的窗口动画特效这些,也都是compositor进行的渲染。至此,GPU的软硬栈已经补全,我们看到了从上到下的整条通路。下一期将来看GPU图形流水线里的一些细节。尤其是光栅化这个操作。 |




