| 编辑推荐: |
本文主要介绍了
Linux系统的4个主要部分:内核、shell、文件系统和应用程序。内核、shell和文件系统一起形成了基本的操作系统结构,它们使得用户可以运行程序、管理文件并使用系统
,
希望对你的学习有帮助。
本文来自于 深度Linux ,由火龙果软件Alice编辑、推荐。 |
|
一、Linux内核
内核是操作系统的核心,具有很多最基本功能,它负责管理系统的进程、内存、设备驱动程序、文件和网络系统,决定着系统的性能和稳定性。Linux
内核由如下几部分组成:内存管理、进程管理、设备驱动程序、文件系统和网络管理等。如图:
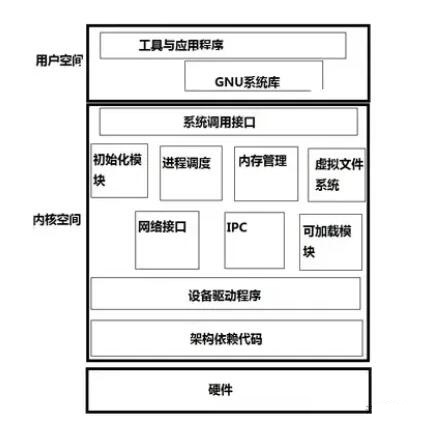
系统调用接口:SCI 层提供了某些机制执行从用户空间到内核的函数调用。这个接口依赖于体系结构,甚至在相同的处理器家族内也是如此。SCI
实际上是一个非常有用的函数调用多路复用和多路分解服务。在 ./linux/kernel 中您可以找到
SCI 的实现,并在 ./linux/arch 中找到依赖于体系结构的部分。
(1)内存管理
对任何一台计算机而言,其内存以及其它资源都是有限的。为了让有限的物理内存满足应用程序对内存的大需求量,Linux
采用了称为“虚拟内存”的内存管理方式。Linux 将内存划分为容易处理的“内存页”(对于大部分体系结构来说都是
4KB)。Linux 包括了管理可用内存的方式,以及物理和虚拟映射所使用的硬件机制。
不过内存管理要管理的可不止 4KB 缓冲区。Linux 提供了对 4KB 缓冲区的抽象,例如 slab
分配器。这种内存管理模式使用 4KB 缓冲区为基数,然后从中分配结构,并跟踪内存页使用情况,比如哪些内存页是满的,哪些页面没有完全使用,哪些页面为空。这样就允许该模式根据系统需要来动态调整内存使用。为了支持多个用户使用内存,有时会出现可用内存被消耗光的情况。
由于这个原因,页面可以移出内存并放入磁盘中。这个过程称为交换,因为页面会被从内存交换到硬盘上。内存管理的源代码可以在
./linux/mm 中找到。
(2)进程管理
进程实际是某特定应用程序的一个运行实体。在 Linux 系统中,能够同时运行多个进程,Linux
通过在短的时间间隔内轮流运行这些进程而实现“多任务”。这一短的时间间隔称为“时间片”,让进程轮流运行的方法称为“进程调度”
,完成调度的程序称为调度程序。进程调度控制进程对CPU的访问。
当需要选择下一个进程运行时,由调度程序选择最值得运行的进程。可运行进程实际上是仅等待CPU资源的进程,如果某个进程在等待其它资源,则该进程是不可运行进程。Linux使用了比较简单的基于优先级的进程调度算法选择新的进程。通过多任务机制,每个进程可认为只有自己独占计算机,从而简化程序的编写。每个进程有自己单独的地址空间,并且只能由这一进程访问,这样,操作系统避免了进程之间的互相干扰以及“坏”程序对系统可能造成的危害。
为了完成某特定任务,有时需要综合两个程序的功能,例如一个程序输出文本,而另一个程序对文本进行排序。为此,操作系统还提供进程间的通讯机制来帮助完成这样的任务。Linux
中常见的进程间通讯机制有信号、管道、共享内存、信号量和套接字等。
内核通过 SCI 提供了一个应用程序编程接口(API)来创建一个新进程(fork、exec 或 Portable
Operating System Interface [POSⅨ] 函数),停止进程(kill、exit),并在它们之间进行通信和同步(signal
或者 POSⅨ 机制)。
(3)文件系统
和 DOS 等操作系统不同,Linux 操作系统中单独的文件系统并不是由驱动器号或驱动器名称(如
A: 或 C: 等)来标识的。相反,和 UNIX 操作系统一样,Linux 操作系统将独立的文件系统组合成了一个层次化的树形结构,并且由一个单独的实体代表这一文件系统。
Linux 将新的文件系统通过一个称为“挂装”或“挂上”的操作将其挂装到某个目录上,从而让不同的文件系统结合成为一个整体。Linux
操作系统的一个重要特点是它支持许多不同类型的文件系统。
Linux 中最普遍使用的文件系统是 Ext2,它也是 Linux 土生土长的文件系统。但 Linux
也能够支持 FAT、VFAT、FAT32、MINIX 等不同类型的文件系统,从而可以方便地和其它操作系统交换数据。
由于 Linux 支持许多不同的文件系统,并且将它们组织成了一个统一的虚拟文件系统.虚拟文件系统(VirtualFileSystem,VFS):隐藏了各种硬件的具体细节,把文件系统操作和不同文件系统的具体实现细节分离了开来,为所有的设备提供了统一的接口,VFS提供了多达数十种不同的文件系统。
虚拟文件系统可以分为逻辑文件系统和设备驱动程序。逻辑文件系统指Linux所支持的文件系统,如ext2,fat等,设备驱动程序指为每一种硬件控制器所编写的设备驱动程序模块。虚拟文件系统(VFS)是
Linux 内核中非常有用的一个方面,因为它为文件系统提供了一个通用的接口抽象。
VFS 在 SCI 和内核所支持的文件系统之间提供了一个交换层。即VFS 在用户和文件系统之间提供了一个交换层。
在 VFS 上面,是对诸如 open、close、read 和 write 之类的函数的一个通用
API 抽象。在 VFS 下面是文件系统抽象,它定义了上层函数的实现方式。它们是给定文件系统(超过
50 个)的插件。
文件系统的源代码可以在 ./linux/fs 中找到。文件系统层之下是缓冲区缓存,它为文件系统层提供了一个通用函数集(与具体文件系统无关)。这个缓存层通过将数据保留一段时间(或者随即预先读取数据以便在需要是就可用)优化了对物理设备的访问。
缓冲区缓存之下是设备驱动程序,它实现了特定物理设备的接口。因此,用户和进程不需要知道文件所在的文件系统类型,而只需要象使用
Ext2 文件系统中的文件一样使用它们。
(4)设备驱动程序
设备驱动程序是 Linux 内核的主要部分。和操作系统的其它部分类似,设备驱动程序运行在高特权级的处理器环境中,从而可以直接对硬件进行操作,但正因为如此,任何一个设备驱动程序的错误都可能导致操作系统的崩溃。
设备驱动程序实际控制操作系统和硬件设备之间的交互。设备驱动程序提供一组操作系统可理解的抽象接口完成和操作系统之间的交互,而与硬件相关的具体操作细节由设备驱动程序完成。一般而言,设备驱动程序和设备的控制芯片有关,例如,如果计算机硬盘是
SCSI 硬盘,则需要使用 SCSI 驱动程序,而不是 IDE 驱动程序。
(5)网络接口(NET)
提供了对各种网络标准的存取和各种网络硬件的支持。网络接口可分为网络协议和网络驱动程序。网络协议部分负责实现每一种可能的网络传输协议。众所周知,TCP/IP
协议是 Internet 的标准协议,同时也是事实上的工业标准。Linux 的网络实现支持 BSD
套接字,支持全部的TCP/IP协议。
Linux内核的网络部分由BSD套接字、网络协议层和网络设备驱动程序组成。网络设备驱动程序负责与硬件设备通讯,每一种可能的硬件设备都有相应的设备驱动程序。
二、Linux shell
2.1什么是 shell
Shell 是系统的用户界面,提供了用户和内核进行交互操作的一种接口。同时,Shell 也是一个命令解释器,它解释由用户输入的命令并且把它们送到内核。不仅如此,Shell
有自己的编程语言用于对命令的编辑,它允许用户编写由 shell 命令组成的程序。
通常在图形界面中对实际体验带来差异的不是不同发行版的各种终端模拟器,而是这个 Shell(壳)。有壳就有核,这里的核就是指
UNIX/Linux 内核,Shell 是指“提供给使用者使用界面”的软件(命令解析器),类似于 DOS
下的 command(命令行)和后来的 cmd.exe 。
UNIX/Linux 操作系统下的 Shell 既是用户交互的界面,也是控制系统的脚本语言。当然这一点有别于
Windows 下的命令行,虽然该命令行也提供很简单的控制语句。在 Windows 操作系统下,有些用户从来都不会直接使用
Shell。然而在 UNIX 系列操作系统下,Shell 仍然是控制系统启动和其它很多实用工具的脚本解释程序。
2.2shell 类别
在UNIX/Linux 中比较常见的 Shell:
Bourne Again Shell (简称 bash)
Bourne Shell(简称 sh)
C-Shell(简称 csh)
Korn Shell(简称 ksh)
Z shell(简称 zsh)
Ubuntu 终端默认使用的是 bash,默认的桌面环境是GNOME 或者 Unity(基于 GNOME),我们的环境中使用的分别是
zsh 和 xfce。
还可以通过 cat /etc/shells 来查看我们主机上的 shell 类型。
目前主要有下列版本的shell:
1、Bourne Shell:是贝尔实验室开发的。
2、BASH:是GNU的Bourne Again Shell,是GNU操作系统上默认的shell,大部分linux的发行套件使用的都是这种shell。
3、Korn Shell:是对Bourne SHell的发展,在大部分内容上与Bourne Shell兼容。
4、C Shell:是SUN公司Shell的BSD版本。
三、Linux系统文件
3.1文件系统的概念
首先我们来想一个问题,磁盘等存储设备上存储的不过是01100111这样的字符数据,但是为什么我们在电脑上打开某盘访问时看到的却是整齐的目录结构呢,一块磁盘上的数据是怎样被操作系统识别为一棵目录树然后被我们读写访问的?这其中就离不开文件系统。
文件系统是用于在存储设备或分区上组织管理文件的方法和数据结构,每一个系统可读写文件的设备上都包含了一个完整的系统可识别的文件系统用来组织设备上的文件,比如我们常用的U盘,里面就有一个FAT32、NTFS或者exFAT等其它类型的文件系统,再比如我们打开Linux系统中的设备目录/dev,其中每一个可读取的块设备上都有一个文件系统,正因如此我们才可以把这样的块设备挂载到系统的某个目录然后访问其中的文件。另外我们也可以注意到,一个可读取设备即使没有存储任何文件,它的存储空间也已经被使用了一部分,这部分就是文件系统所占用的空间。
我们常常对一个设备进行格式化操作,这里的格式化就是指采用指定文件系统类型对设备空间进行登记索引并建立相应的管理表格的一个过程。
在Linux中,正因为有文件系统,我们可以把任何设备一视同仁当作一个文件看待,这也是Linux的设计哲学之一:一切皆文件。
文件类型
Linux下面的文件类型主要有:
1) 普通文件:C语言元代码、SHELL脚本、二进制的可执行文件等。分为纯文本和二进制。
2) 目录文件:目录,存储文件的唯一地方。
3) 链接文件:指向同一个文件或目录的的文件。
4) 设备文件:与系统外设相关的,通常在/dev下面。分为块设备和字符设备。5)管道(FIFO)文件
: 提供进程建通信的一种方式
6)套接字(socket) 文件: 该文件类型与网络通信有关可以通过ls –l, file, stat几个命令来查看文件的类型等相关信息。
Linux目录
文件结构是文件存放在磁盘等存贮设备上的组织方法。主要体现在对文件和目录的组织上。目录提供了管理文件的一个方便而有效的途径。Linux使用标准的目录结构,在安装的时候,安装程序就已经为用户创建了文件系统和完整而固定的目录组成形式,并指定了每个目录的作用和其中的文件类型。
完整的目录树可划分为小的部分,这些小部分又可以单独存放在自己的磁盘或分区上。这样,相对稳定的部分和经常变化的部分可单独存放在不同的分区中,从而方便备份或系统管理。目录树的主要部分有
root、/usr、/var、/home 等(图2) 。这样的布局可方便在 Linux 计算机之间共享文件系统的某些部分。
Linux采用的是树型结构。最上层是根目录,其他的所有目录都是从根目录出发而生成的。微软的DOS和windows也是采用树型结构,但是在DOS和
windows中这样的树型结构的根是磁盘分区的盘符,有几个分区就有几个树型结构,他们之间的关系是并列的。
最顶部的是不同的磁盘(分区),如:C,D,E,F等。但是在linux中,无论操作系统管理几个磁盘分区,这样的目录树只有一个。从结构上讲,各个磁盘分区上的树型目录不一定是并列的。
3.2虚拟文件系统(VFS)的概念
在Linux中支持多达数十套文件系统,不同设备上的文件系统可能都不一样,那么为什么我们在实际操作时可以不用理会设备上的文件系统类型,就能用统一的命令对不同设备上的文件进行读写呢?这就涉及到在文件系统上层的抽象层,虚拟文件系统。
学过面向对象就很好理解,虚拟文件系统作为抽象层规定了一个文件系统要实现哪些接口和数据结构,文件系统研发人员就依据这些标准去研发,因此即使不同文件系统内部实现各有不同,但是都实现了可供上层虚拟文件系统进行统一调用的接口,用户不需要关心各个文件系统内部的实现细节,只要通过统一的系统调用(比如open()、read()、write())就可以读取不同文件系统上的文件数据,从用户的角度看就好像只有一个文件系统一样。
3.3Unix文件系统
VFS提供了一个通用的文件系统模型,该模型囊括了任何文件系统的常用功能集和行为,该模型偏重于Unix风格的文件系统。
Unix文件系统主要有四个抽象概念:文件、目录项、索引节点和安装点。
(1)安装点
当我们运行一个Linux操作系统时,我们可以发现整个操作系统看起来就是一棵目录树,最顶层的目录为根目录"/",所有文件都组织在这个目录树中,这个最顶层的文件系统就称为根文件系统,所有已安装的文件系统都作为根文件系统树的枝叶出现在系统中,当我们新增一个设备(文件系统)时,需要将其挂载到目录树中的某个目录中才能进行访问,这个目录就称为安装点。
(2)文件
文件就是一个有序字节串,字节串中第一个字节就是文件的头,最后一个字节就是文件的尾。
(3)目录项
目录也是文件,也是用索引节点唯一标识,和普通文件不同的是,普通文件在磁盘里面保存的是文件数据,而目录文件在磁盘里面保存子目录或文件。
目录项和目录是一个东西吗?
虽然名字很相近,但是它们不是一个东西,目录是个文件,持久化存储在磁盘,而目录项是内核一个数据结构,缓存在内存。
如果查询目录频繁从磁盘读,效率会很低,所以内核会把已经读过的目录用目录项这个数据结构缓存在内存,下次再次读到相同的目录时,只需从内存读就可以,大大提高了文件系统的效率。
(4)索引节点(inode)
Unix文件系统将文件的相关信息和文件本身这两个概念加以区分,例如访问控制权限、文件大小、拥有者和创建时间等就属于文件相关信息,存储在一个单独的数据结构当中,该结构称为索引节点
3.4文件系统特点
文件系统要有严格的组织形式,使得文件能够以块为单位进行存储。
文件系统中也要有索引区,用来方便查找一个文件分成的多个块都存放在了什么位置。
如果文件系统中有的文件是热点文件,近期经常被读取和写入,文件系统应该有缓存层。
文件应该用文件夹的形式组织起来,方便管理和查询。
Linux内核要在自己的内存里面维护一套数据结构,来保存哪些文件被哪些进程打开和使用。
总体来说,文件系统的主要功能梳理如下:
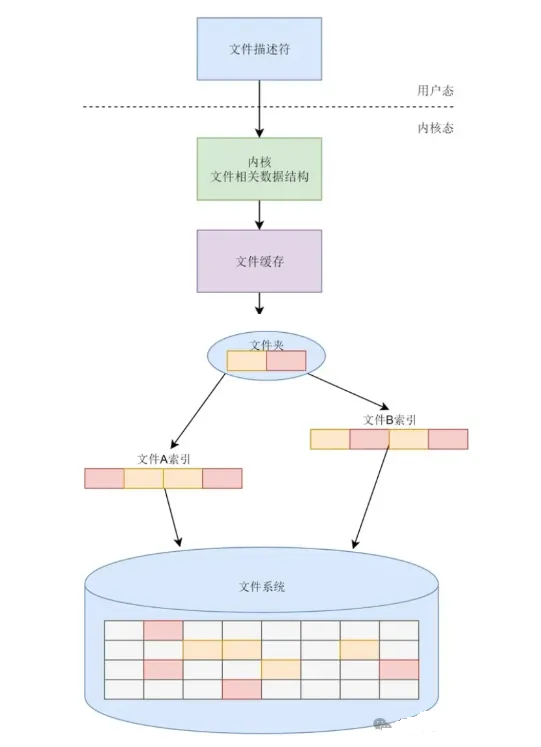
3.5EXT系列的文件系统的格式
inode与块的存储
硬盘分成相同大小的单元,我们称为块(Block)。一块的大小是扇区大小的整数倍,默认是4K。在格式化的时候,这个值是可以设定的。
一大块硬盘被分成了一个个小的块,用来存放文件的数据部分。这样一来,如果我们像存放一个文件,就不用给他分配一块连续的空间了。我们可以分散成一个个小块进行存放。这样就灵活得多,也比较容易添加、删除和插入数据。
inode就是文件索引的意思,我们每个文件都会对应一个inode;一个文件夹就是一个文件,也对应一个inode。
inode数据结构如下:
struct ext4_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size_lo; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Inode Change time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks_lo; /* Blocks count */
__le32 i_flags; /* File flags */
......
__le32 i_block[EXT4_N_BLOCKS];/* Pointers to blocks */
__le32 i_generation; /* File version (for NFS) */
__le32 i_file_acl_lo; /* File ACL */
__le32 i_size_high;
......
};
|
inode里面有文件的读写权限i_mode,属于哪个用户i_uid,哪个组i_gid,大小是多少i_size_io,占用多少个块i_blocks_io,i_atime是access
time,是最近一次访问文件的时间;i_ctime是change time,是最近一次更改inode的时间;i_mtime是modify
time,是最近一次更改文件的时间等。
所有的文件都是保存在i_block里面。具体保存规则由EXT4_N_BLOCKS决定,EXT4_N_BLOCKS有如下的定义:
#define EXT4_NDIR_BLOCKS 12
#define EXT4_IND_BLOCK EXT4_NDIR_BLOCKS
#define EXT4_DIND_BLOCK (EXT4_IND_BLOCK + 1)
#define EXT4_TIND_BLOCK (EXT4_DIND_BLOCK + 1)
#define EXT4_N_BLOCKS (EXT4_TIND_BLOCK + 1)
|
在ext2和ext3中,其中前12项直接保存了块的位置,也就是说,我们可以通过i_block[0-11],直接得到保存文件内容的块。
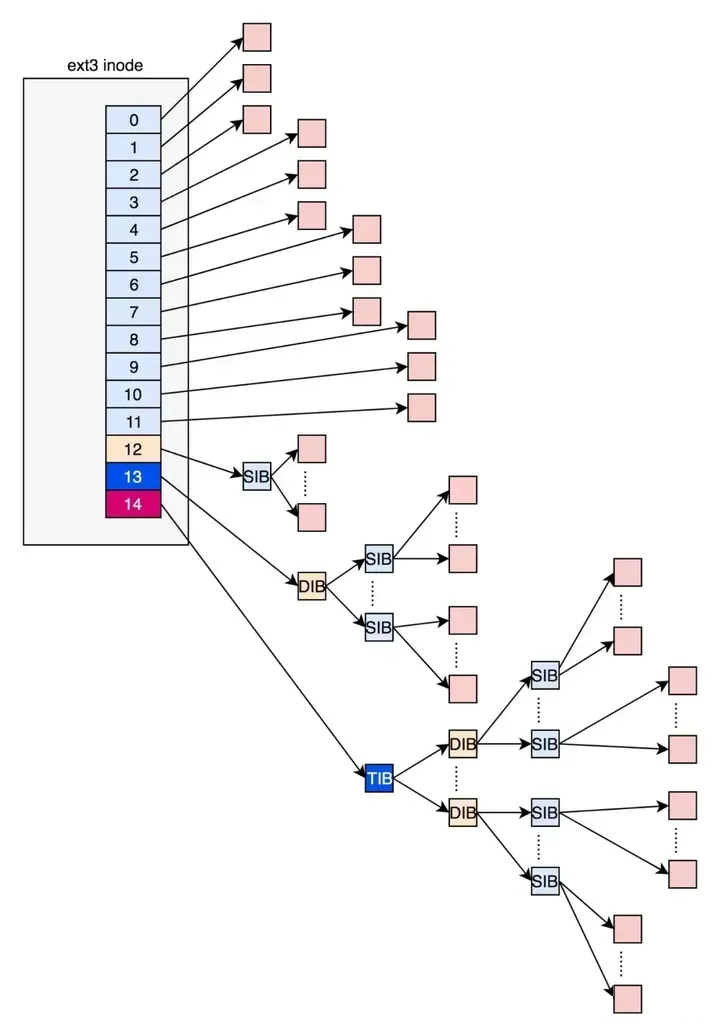
但是,如果一个文件比较大,12块放不下。当我们用到i_block[12]的时候,就不能直接放数据块的位置了,要不然i_block很快就会用完了。
那么可以让i_block[12]指向一个块,这个块里面不放数据块,而是放数据块的位置,这个块我们称为间接块。如果文件再大一些,i_block[13]会指向一个块,我们可以用二次间接块。二次间接块里面存放了间接块的位置,间接块里面存放了数据块的位置,数据块里面存放的是真正的数据。如果文件再大点,那么i_block[14]同理。
这里面有一个非常显著的问题,对于大文件来讲,我们要多次读取硬盘才能找到相应的块,这样访问速度就会比较慢。
为了解决这个问题,ext4做了一定的改变。它引入了一个新的概念,叫作Extents。比方说,一个文件大小为128M,如果使用4k大小的块进行存储,需要32k个块。如果按照ext2或者ext3那样散着放,数量太大了。但是Extents可以用于存放连续的块,也就是说,我们可以把128M放在一个Extents里面。这样的话,对大文件的读写性能提高了,文件碎片也减少了。
Exents是一个树状结构:
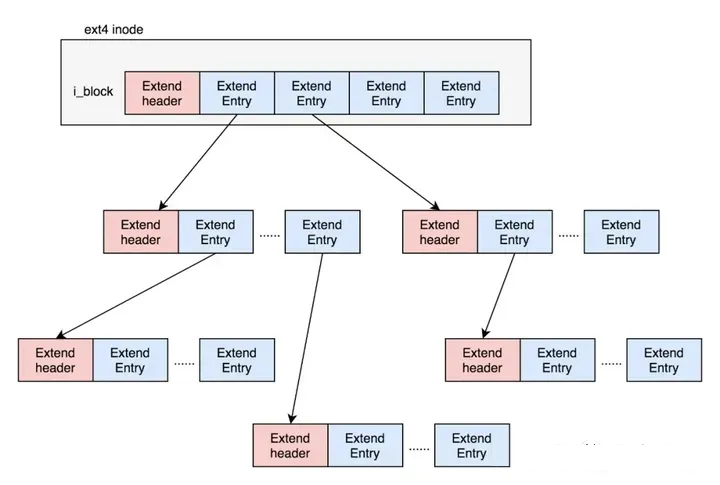
每个节点都有一个头,ext4_extent_header可以用来描述某个节点:
struct ext4_extent_header {
__le16 eh_magic; /* probably will support different formats */
__le16 eh_entries; /* number of valid entries */
__le16 eh_max; /* capacity of store in entries */
__le16 eh_depth; /* has tree real underlying blocks? */
__le32 eh_generation; /* generation of the tree */
};
|
eh_entries表示这个节点里面有多少项。这里的项分两种,如果是叶子节点,这一项会直接指向硬盘上的连续块的地址,我们称为数据节点ext4_extent;如果是分支节点,这一项会指向下一层的分支节点或者叶子节点,我们称为索引节点ext4_extent_idx。这两种类型的项的大小都是12个byte。
/*
* This is the extent on-disk structure.
* It's used at the bottom of the tree.
*/
struct ext4_extent {
__le32 ee_block; /* first logical block extent covers */
__le16 ee_len; /* number of blocks covered by extent */
__le16 ee_start_hi; /* high 16 bits of physical block */
__le32 ee_start_lo; /* low 32 bits of physical block */
};
/*
* This is index on-disk structure.
* It's used at all the levels except the bottom.
*/
struct ext4_extent_idx {
__le32 ei_block; /* index covers logical blocks from 'block' */
__le32 ei_leaf_lo; /* pointer to the physical block of the next *
* level. leaf or next index could be there */
__le16 ei_leaf_hi; /* high 16 bits of physical block */
__u16 ei_unused;
};
|
如果文件不大,inode里面的i_block中,可以放得下一个ext4_extent_header和4项ext4_extent。所以这个时候,eh_depth为0,也即inode里面的就是叶子节点,树高度为0。
如果文件比较大,4个extent放不下,就要分裂成为一棵树,eh_depth>0的节点就是索引节点,其中根节点深度最大,在inode中。最底层eh_depth=0的是叶子节点。
除了根节点,其他的节点都保存在一个块4k里面,4k扣除ext4_extent_header的12个byte,剩下的能够放340项,每个extent最大能表示128MB的数据,340个extent会使你的表示的文件达到42.5GB。
inode位图和块位图
inode的位图大小为4k,每一位对应一个inode。如果是1,表示这个inode已经被用了;如果是0,则表示没被用。block的位图同理。
在Linux操作系统里面,想要创建一个新文件,会调用open函数,并且参数会有O_CREAT。这表示当文件找不到的时候,我们就需要创建一个。那么open函数的调用过程大致是:要打开一个文件,先要根据路径找到文件夹。如果发现文件夹下面没有这个文件,同时又设置了O_CREAT,就说明我们要在这个文件夹下面创建一个文件。
创建一个文件,那么就需要创建一个inode,那么就会从文件系统里面读取inode位图,然后找到下一个为0的inode,就是空闲的inode。对于block位图,在写入文件的时候,也会有这个过程。
3.6文件系统的格式
数据块的位图是放在一个块里面的,共4k。
这个时候就需要用到块组,数据结构为ext4_group_desc,这里面对于一个块组里的inode位图bg_inode_bitmap_lo、块位图bg_block_bitmap_lo、inode列表bg_inode_table_lo,都有相应的成员变量。
这样一个个块组,就基本构成了我们整个文件系统的结构。因为块组有多个,块组描述符也同样组成一个列表,我们把这些称为块组描述符表。
我们还需要有一个数据结构,对整个文件系统的情况进行描述,这个就是超级块ext4_super_block。里面有整个文件系统一共有多少inode,s_inodes_count;一共有多少块,s_blocks_count_lo,每个块组有多少inode,s_inodes_per_group,每个块组有多少块,s_blocks_per_group等。这些都是这类的全局信息。
最终,整个文件系统格式就是下面这个样子
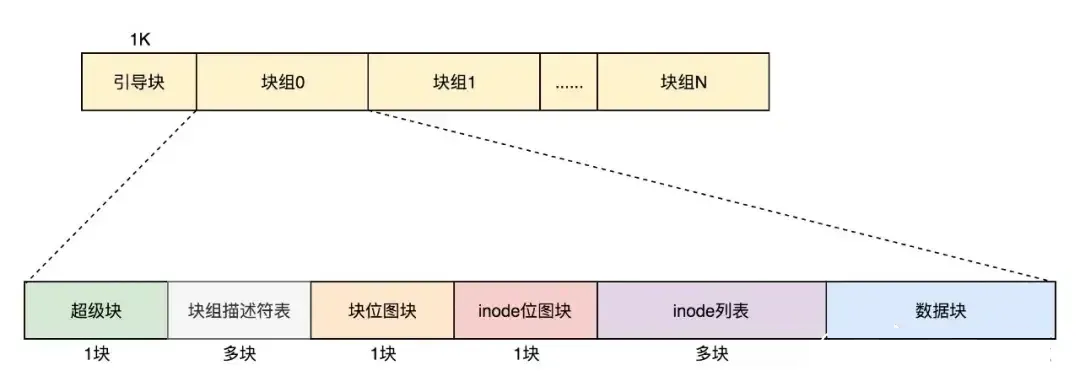
默认情况下,超级块和块组描述符表都有副本保存在每一个块组里面。防止这些数据丢失了,导致整个文件系统都打不开了。
由于如果每个块组里面都保存一份完整的块组描述符表,一方面很浪费空间;另一个方面,由于一个块组最大128M,而块组描述符表里面有多少项,这就限制了有多少个块组,128M
* 块组的总数目是整个文件系统的大小,就被限制住了。
因此引入Meta Block Groups特性。
首先,块组描述符表不会保存所有块组的描述符了,而是将块组分成多个组,我们称为元块组(Meta Block
Group)。每个元块组里面的块组描述符表仅仅包括自己的,一个元块组包含64个块组,这样一个元块组中的块组描述符表最多64项。
我们假设一共有256个块组,原来是一个整的块组描述符表,里面有256项,要备份就全备份,现在分成4个元块组,每个元块组里面的块组描述符表就只有64项了,这就小多了,而且四个元块组自己备份自己的。
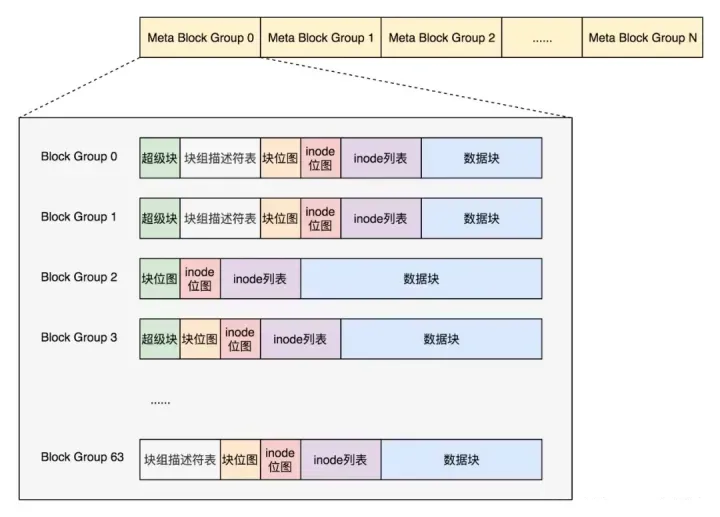
根据图中,每一个元块组包含64个块组,块组描述符表也是64项,备份三份,在元块组的第一个,第二个和最后一个块组的开始处。
如果开启了sparse_super特性,超级块和块组描述符表的副本只会保存在块组索引为0、3、5、7的整数幂里。所以上图的超级块只在索引为0、3、5、7等的整数幂里。
四、目录的存储格式
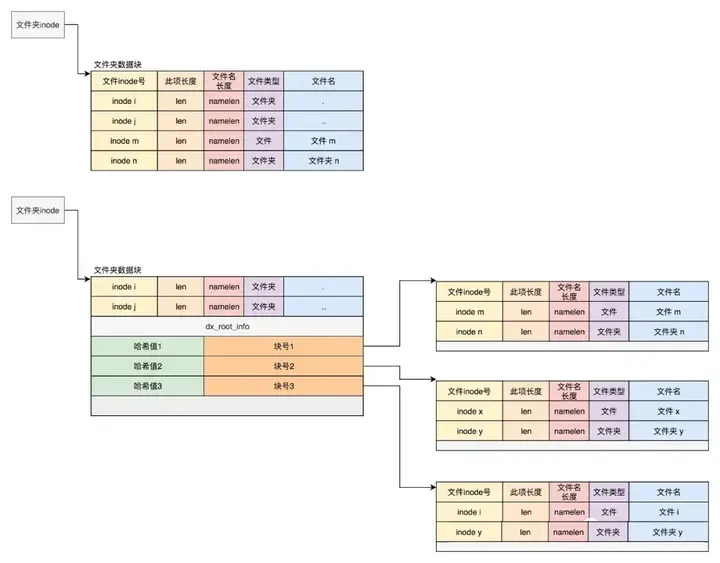
其实目录本身也是个文件,也有inode。inode里面也是指向一些块。和普通文件不同的是,普通文件的块里面保存的是文件数据,而目录文件的块里面保存的是目录里面一项一项的文件信息。这些信息我们称为ext4_dir_entry。
在目录文件的块中,最简单的保存格式是列表,每一项都会保存这个目录的下一级的文件的文件名和对应的inode,通过这个inode,就能找到真正的文件。第一项是“.”,表示当前目录,第二项是“…”,表示上一级目录,接下来就是一项一项的文件名和inode。
如果在inode中设置EXT4_INDEX_FL标志,那么就表示根据索引查找文件。索引项会维护一个文件名的哈希值和数据块的一个映射关系。
如果我们要查找一个目录下面的文件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个文件的信息在相应的块里面。然后打开这个块,如果里面不再是索引,而是索引树的叶子节点的话,那里面还是ext4_dir_entry的列表,我们只要一项一项找文件名就行。通过索引树,我们可以将一个目录下面的N多的文件分散到很多的块里面,可以很快地进行查找。
五、Linux中的文件缓存
5.1ext4文件系统层
对于ext4文件系统来讲,内核定义了一个ext4_file_operations
const struct file_operations ext4_file_operations = {
......
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
......
}
|
generic_file_read_iter和__generic_file_write_iter有相似的逻辑,就是要区分是否用缓存。因此,根据是否使用内存做缓存,我们可以把文件的I/O操作分为两种类型。
第一种类型是缓存I/O。大多数文件系统的默认I/O操作都是缓存I/O。对于读操作来讲,操作系统会先检查,内核的缓冲区有没有需要的数据。如果已经缓存了,那就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中。对于写操作来讲,操作系统会先将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说,写操作就已经完成。至于什么时候再写到磁盘中由操作系统决定,除非显式地调用了sync同步命令。
第二种类型是直接IO,就是应用程序直接访问磁盘数据,而不经过内核缓冲区,从而减少了在内核缓存和用户程序之间数据复制。
如果在写的逻辑__generic_file_write_iter里面,发现设置了IOCB_DIRECT,则调用generic_file_direct_write,里面同样会调用address_space的direct_IO的函数,将数据直接写入硬盘。
带缓存的写入操作
我们先来看带缓存写入的函数generic_perform_write。
ssize_t
generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
......
if (iocb->ki_flags & IOCB_DIRECT) {
......
struct address_space *mapping = file->f_mapping;
......
retval = mapping->a_ops->direct_IO(iocb, iter);
}
......
retval = generic_file_buffered_read(iocb, iter, retval);
}
ssize_t __generic_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
......
if (iocb->ki_flags & IOCB_DIRECT) {
......
written = generic_file_direct_write(iocb, from);
......
} else {
......
written = generic_perform_write(file, from, iocb->ki_pos);
......
}
}
|
循环中主要做了这几件事:
对于每一页,先调用address_space的write_begin做一些准备;
调用iov_iter_copy_from_user_atomic,将写入的内容从用户态拷贝到内核态的页中;
调用address_space的write_end完成写操作;
调用balance_dirty_pages_ratelimited,看脏页是否太多,需要写回硬盘。所谓脏页,就是写入到缓存,但是还没有写入到硬盘的页面。
对于第一步,调用的是ext4_write_begin来说,主要做两件事:
第一做日志相关的工作
ext4是一种日志文件系统,是为了防止突然断电的时候的数据丢失,引入了日志(Journal)模式。日志文件系统比非日志文件系统多了一个Journal区域。文件在ext4中分两部分存储,一部分是文件的元数据,另一部分是数据。元数据和数据的操作日志Journal也是分开管理的。你可以在挂载ext4的时候,选择Journal模式。这种模式在将数据写入文件系统前,必须等待元数据和数据的日志已经落盘才能发挥作用。这样性能比较差,但是最安全。
另一种模式是order模式。这个模式不记录数据的日志,只记录元数据的日志,但是在写元数据的日志前,必须先确保数据已经落盘。这个折中,是默认模式。
还有一种模式是writeback,不记录数据的日志,仅记录元数据的日志,并且不保证数据比元数据先落盘。这个性能最好,但是最不安全。
第二调用
grab_cache_page_write_begin来,得到应该写入的缓存页。
ssize_t generic_perform_write(struct file *file,
struct iov_iter *i, loff_t pos)
{
struct address_space *mapping = file->f_mapping;
const struct address_space_operations *a_ops = mapping->a_ops;
do {
struct page *page;
unsigned long offset; /* Offset into pagecache page */
unsigned long bytes; /* Bytes to write to page */
status = a_ops->write_begin(file, mapping, pos, bytes, flags,
&page, &fsdata);
copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes);
flush_dcache_page(page);
status = a_ops->write_end(file, mapping, pos, bytes, copied,
page, fsdata);
pos += copied;
written += copied;
balance_dirty_pages_ratelimited(mapping);
} while (iov_iter_count(i));
}
|
在内核中,缓存以页为单位放在内存里面,每一个打开的文件都有一个struct file结构,每个struct
file结构都有一个struct address_space用于关联文件和内存,就是在这个结构里面,有一棵树,用于保存所有与这个文件相关的的缓存页。
对于第二步,调用
iov_iter_copy_from_user_atomic。先将分配好的页面调用kmap_atomic映射到内核里面的一个虚拟地址,然后将用户态的数据拷贝到内核态的页面的虚拟地址中,调用kunmap_atomic把内核里面的映射删除。
size_t iov_iter_copy_from_user_atomic(struct page *page,
struct iov_iter *i, unsigned long offset, size_t bytes)
{
char *kaddr = kmap_atomic(page), *p = kaddr + offset;
iterate_all_kinds(i, bytes, v,
copyin((p += v.iov_len) - v.iov_len, v.iov_base, v.iov_len),
memcpy_from_page((p += v.bv_len) - v.bv_len, v.bv_page,
v.bv_offset, v.bv_len),
memcpy((p += v.iov_len) - v.iov_len, v.iov_base, v.iov_len)
)
kunmap_atomic(kaddr);
return bytes;
}
|
第三步中,调用ext4_write_end完成写入。这里面会调用ext4_journal_stop完成日志的写入,会调用block_write_end->__block_commit_write->mark_buffer_dirty,将修改过的缓存标记为脏页。可以看出,其实所谓的完成写入,并没有真正写入硬盘,仅仅是写入缓存后,标记为脏页。
第四步,调用
balance_dirty_pages_ratelimited,是回写脏页
/**
* balance_dirty_pages_ratelimited - balance dirty memory state
* @mapping: address_space which was dirtied
*
* Processes which are dirtying memory should call in here once for each page
* which was newly dirtied. The function will periodically check the system's
* dirty state and will initiate writeback if needed.
*/
void balance_dirty_pages_ratelimited(struct address_space *mapping)
{
struct inode *inode = mapping->host;
struct backing_dev_info *bdi = inode_to_bdi(inode);
struct bdi_writeback *wb = NULL;
int ratelimit;
......
if (unlikely(current->nr_dirtied >= ratelimit))
balance_dirty_pages(mapping, wb, current->nr_dirtied);
......
}
|
在balance_dirty_pages_ratelimited里面,发现脏页的数目超过了规定的数目,就调用balance_dirty_pages->wb_start_background_writeback,启动一个背后线程开始回写。
另外还有几种场景也会触发回写:
用户主动调用sync,将缓存刷到硬盘上去,最终会调用wakeup_flusher_threads,同步脏页;
当内存十分紧张,以至于无法分配页面的时候,会调用free_more_memory,最终会调用wakeup_flusher_threads,释放脏页;
脏页已经更新了较长时间,时间上超过了设定时间,需要及时回写,保持内存和磁盘上数据一致性。
5.2带缓存的读操作
看带缓存的读,对应的是函数generic_file_buffered_read。
static ssize_t generic_file_buffered_read(struct kiocb *iocb,
struct iov_iter *iter, ssize_t written)
{
struct file *filp = iocb->ki_filp;
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
for (;;) {
struct page *page;
pgoff_t end_index;
loff_t isize;
page = find_get_page(mapping, index);
if (!page) {
if (iocb->ki_flags & IOCB_NOWAIT)
goto would_block;
page_cache_sync_readahead(mapping,
ra, filp,
index, last_index - index);
page = find_get_page(mapping, index);
if (unlikely(page == NULL))
goto no_cached_page;
}
if (PageReadahead(page)) {
page_cache_async_readahead(mapping,
ra, filp, page,
index, last_index - index);
}
/*
* Ok, we have the page, and it's up-to-date, so
* now we can copy it to user space...
*/
ret = copy_page_to_iter(page, offset, nr, iter);
}
}
|
在generic_file_buffered_read函数中,我们需要先找到page cache里面是否有缓存页。如果没有找到,不但读取这一页,还要进行预读,这需要在page_cache_sync_readahead函数中实现。预读完了以后,再试一把查找缓存页。
如果第一次找缓存页就找到了,我们还是要判断,是不是应该继续预读;如果需要,就调用
page_cache_async_readahead发起一个异步预读。
最后,copy_page_to_iter会将内容从内核缓存页拷贝到用户内存空间。
六、linux 应用
标准的Linux系统一般都有一套都有称为应用程序的程序集,它包括文本编辑器、编程语言、X Window、办公套件、Internet工具和数据库等。
|




