| 编辑推荐: |
本文主要介绍了CPU缓存:性能优化的关键相关内容。 希望对你的学习有帮助。
本文来自于微信公众号深度Linux,由火龙果软件Linda编辑、推荐。 |
|
作为计算机的核心部件,其缓存结构犹如一座高效的数据桥梁,在提升计算机性能方面发挥着关键作用。而原子操作,则以其独特的不可分割性,为程序的正确性和稳定性提供了坚实的保障。
在接下来的时间里,我们将逐步揭开 CPU 缓存结构的神秘面纱,深入了解其工作原理和设计理念。同时,我们也将一同探寻原子操作的奥秘,明白它在多线程编程等场景中的重要意义。让我们共同开启这场充满智慧与挑战的科技之旅。
一、初识CPU缓存
1.1多级缓存体系
现代 CPU 为了弥合处理器与主内存之间巨大的速度差异,引入了多级缓存体系。
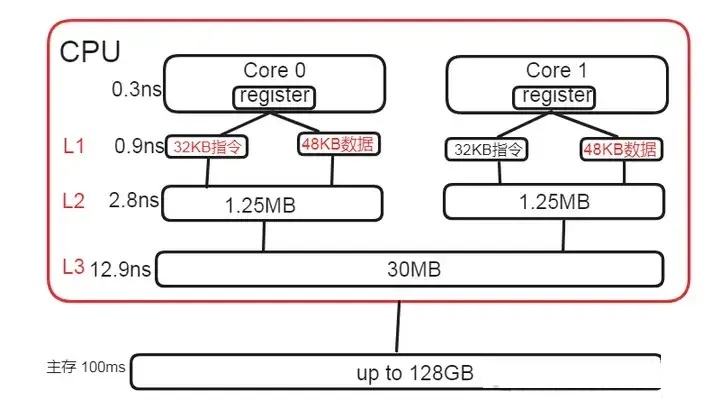
L1 缓存距离 CPU 核心最近,速度最快但容量较小。它通常可以在几个 CPU 时钟周期内完成数据的读取和写入,能够为
CPU 核心提供最快速的数据访问。这就像是 CPU 的贴身助手,随时准备着为其提供最急需的数据。
L2 缓存容量相对 L1 缓存更大一些,速度稍慢。它起到了一个中间缓冲的作用,当 L1 缓存未命中时,CPU
会尝试从 L2 缓存中获取数据。可以把 L2 缓存想象成一个小型的数据仓库,存储着更多可能被 CPU
核心频繁使用的数据。
L3 缓存则通常具有更大的容量,但速度相对较慢。它在多核心处理器中扮演着重要的角色,多个核心可以共享
L3 缓存中的数据。L3 缓存就像是一个大型的公共数据存储区,为多个核心协同工作提供支持。
1.2缓存行解析
缓存行是缓存与主内存之间数据传输的基本单位。它由标志位、标记和数据区域组成。
标志位用于指示缓存行的状态,例如是否有效、是否被修改等。标记则用于唯一标识缓存行中的数据在主内存中的位置。当
CPU 需要访问某个内存地址的数据时,首先会根据地址计算出对应的缓存行标记,然后检查缓存中是否有匹配的缓存行。如果有,并且标志位显示该缓存行有效,那么就可以直接从缓存行的数据区域中获取数据。
缓存行的大小通常为几十到几百个字节不等。不同的处理器架构可能会有不同的缓存行大小。在读取数据时,CPU
会以缓存行为单位进行读取,即使只需要访问一个字节的数据,也可能会将整个缓存行加载到缓存中。这样做的目的是为了提高后续访问同一缓存行中其他数据的速度。
当CPU访问内存时,如果所需数据在缓存中已经存在于一个Cache Line中,那么CPU可以直接从缓存中读取数据,而无需访问主存,从而提高了数据传输的速度。

标志位(flag):用于指示Cache Line当前是否有效。当一个Cache Line中存储的数据被更新或替换时,标志位会被清除,表示该Cache
Line不再有效。(存MESI 的状态)
标记(tag):用于标识数据区域中存储的数据块是来自哪个主存地址。当CPU需要读取或写入特定地址的数据时,它会将该地址的一部分作为标记,并与Cache
Line中存储的标记进行比较,以确定是否命中缓存。
数据区域(data):用于存储从主存中读取的数据块。
在数据读取方面,CPU 以缓存行为单位进行读取。即使只需要访问一个字节的数据,也可能会将整个缓存行加载到缓存中。这是因为在实际应用中,程序的局部性原理使得后续很可能会访问同一缓存行中的其他数据。这样一次读取整个缓存行可以提高后续访问的速度,减少对主内存的访问次数,从而提升系统性能。
在数据一致性方面,缓存行的存在使得多个处理器在访问共享数据时需要考虑缓存一致性问题。当一个处理器修改了某个缓存行中的数据,其他处理器需要通过一定的机制(如总线嗅探等)来保证自己缓存中的副本数据也得到更新,以维持数据的一致性。
二、理解写回策略
2.1写回策略概述
写回策略的核心思想是先将更新的数据写入缓存,而不是立即写回主内存。当缓存中的数据被修改后,该缓存行被标记为
“脏数据”,表示与主内存中的数据不一致。只有在特定的情况下,比如缓存行需要被替换或者系统显式地要求将数据写回主内存时,才会将脏数据写回主内存。
这种策略的主要优点在于减少了对主内存的访问次数。由于主内存的访问速度相对较慢,通过延迟写回操作,可以让
CPU 在处理数据时更加高效。同时,对于那些在短时间内可能会被再次修改的数据,避免了频繁地写入主内存,从而提高了系统的整体性能。
2.2读写请求处理
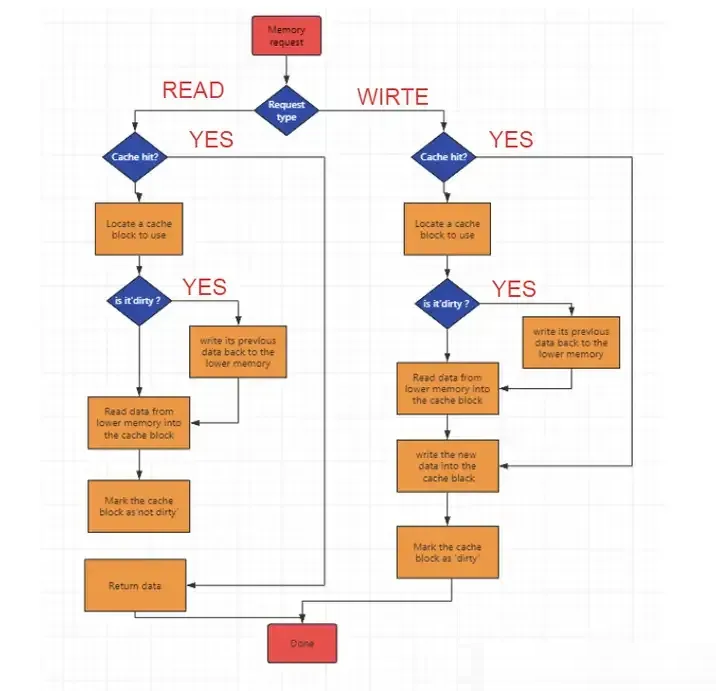
写请求处理:当 CPU 发出写请求时,首先会检查要写入的数据是否已经在缓存中。如果在缓存中,就直接将数据写入对应的缓存行,并将该缓存行标记为脏数据。如果数据不在缓存中,可能会根据缓存替换策略从主内存中加载包含该数据的缓存行到缓存中,然后再进行写入操作。
若命中,直接将新数据写入缓存,并且标记为脏数据dirty(缓存中修改过但尚未写回到更高级别缓存或主内存中的数据)。注意此时不会写入内存。
若未命中,分配一个缓存块Cache Line,判断当前缓存块是不是脏数据。如果是,先将缓存块的数据写回内存中,再将新数据写入缓存块。如果不是脏数据,直接从内存中读到缓存块中(建立内存块与缓存块的索引关系),再将新数据写入缓存块,并标记为dirty。
例如,在一个多线程的程序中,一个线程修改了某个变量的值。这个变量可能已经被缓存在 CPU 的某个级别的缓存中。此时,CPU
会直接将新的值写入缓存行,并标记为脏数据。后续如果其他线程需要读取这个变量,首先会在缓存中查找,如果找到,就可以直接使用缓存中的数据,而无需访问主内存。
读请求处理:当 CPU 发出读请求时,会依次在各级缓存中查找所需的数据。如果在某一级缓存中找到数据,并且该缓存行有效,就直接从该缓存行中读取数据。如果在所有缓存中都未找到数据,就需要从主内存中读取数据,并将其加载到缓存中,以便后续的访问能够更快地获取数据。
若命中,直接返回其数据;
若未命中时,分配一个缓存块,判断当前缓存块是不是脏数据。如果是,先将缓存块的数据写回下一级存储中,再从内存读取新数据到缓存块中。如果不是脏数据,直接从内存中读到缓存块中,修改dirty位为clean(未被修改)。最后返回数据。
例如,当一个程序首次访问某个数据时,CPU 会从主内存中读取该数据,并将包含该数据的缓存行加载到
L1 缓存中。如果后续再次访问这个数据,由于数据已经在缓存中,就可以直接从 L1 缓存中快速读取,大大提高了访问速度。
这种策略的主要优势在于减少了向主内存写入数据的次数。相比于每次数据修改都直接写入主内存(写直达,Write
Through),写回策略可以将多次对同一块数据的修改累积起来,一次性地写回主内存,减少了对主内存的访问,提高了效率。
三、应对缓存一致性问题
3.1问题的产生
上面介绍的写回策略,延迟数据写入主内存的时机,可能会带来数据一致性的问题。因为CPU是多核的,在数据被修改后,尚未写回主内存之前,如果发生了缓存替换或其他操作,主内存上的数据可能是过期的。
比如在多处理器系统下,核心A和核心A共享一块主存。假如核心A从主存中读取到 x,并对其加 1 ,此时还没有写回主存。与此同时,核心B
也从主存中读取 x ,并加 1 。但是它们都不知道对方的存在,也不可以读取对方的缓存。若这时都将 x
写回主存,那此时 x 的值就少了 1 ,出现了数据不一致的问题。
3.2解决方案探索
(1)硬件层面的措施
①总线监听(Bus Snooping)
每个 CPU 核心都通过总线监听其他核心对内存的访问。当一个核心修改了共享数据并将其写入自己的缓存时,会在总线上发出一个信号。其他核心通过监听总线,检测到这个信号后,会检查自己的缓存中是否有该数据的副本。如果有,就将其标记为无效或者更新为新的数据。
例如,在一个多线程的程序中,线程 A 在核心 1 上运行,线程 B 在核心 2 上运行。如果线程
A 修改了一个共享变量,核心 1 会将新值写入自己的缓存,并通过总线发出一个更新信号。核心 2 监听到这个信号后,会检查自己的缓存中是否有该变量的副本。如果有,就将其标记为无效,以便下次访问时从主内存中重新获取最新的值。
②缓存一致性协议(Cache Coherence Protocol)
常见的缓存一致性协议有 MESI(Modified、Exclusive、Shared、Invalid)协议等。这些协议定义了缓存行的不同状态以及状态之间的转换规则,以确保多个核心的缓存与主内存之间的数据一致性。
例如,在 MESI 协议中,当一个缓存行处于 Modified 状态时,表示该缓存行被当前核心修改过,并且与主内存中的数据不一致。其他核心如果需要访问这个数据,必须先从当前核心获取最新的值,并将自己的缓存行状态设置为
Invalid。
③缓存锁定(Cache Locking)
在某些情况下,CPU 需要确保对特定数据的操作是原子性的,即不能被其他核心中断。这时可以使用缓存锁定机制,将包含该数据的缓存行锁定在当前核心的缓存中,直到操作完成。
例如,在对一个共享计数器进行递增操作时,可以使用缓存锁定来确保这个操作是原子的,避免其他核心在操作过程中读取到不一致的数据。
(2)软件层面的措施
④使用同步原语(Synchronization Primitives)
编程语言提供了一些同步原语,如锁、信号量等,可以用于协调多个线程对共享数据的访问。这些同步原语通常会在底层使用硬件提供的原子操作和缓存一致性机制来确保数据的一致性。
例如,在 Java 中,可以使用 synchronized 关键字来对一段代码进行同步,确保在同一时间只有一个线程可以执行这段代码,从而避免了对共享数据的竞争条件。
⑤优化数据访问模式(Optimizing Data Access Patterns)
在程序设计中,可以通过优化数据访问模式来减少缓存一致性问题的发生。例如,可以尽量减少不同核心之间对共享数据的频繁访问,或者将数据按照一定的规则进行划分,使得不同核心访问不同的数据区域,减少冲突。
例如,在一个并行计算的程序中,可以将数据分成多个小块,每个核心处理一个小块的数据,这样可以减少核心之间对共享数据的竞争,提高缓存的利用率。
四、原子操作与缓存关系
4.1 什么是原子操作
原子操作是指一个操作在执行过程中不可被中断,要么完全执行,要么完全不执行,不会出现执行到一半的中间状态。在多线程编程或并发环境中,原子操作至关重要。如果一个操作不是原子的,那么在多个线程同时访问和修改共享数据时,可能会出现数据不一致的情况。例如,一个线程正在读取一个变量的值,而另一个线程同时在修改这个变量,可能会导致读取到错误的值。而原子操作可以确保在并发环境下,对共享数据的操作是安全的,不会出现数据竞争和不一致的问题。
(1)原子操作的实现方式
硬件支持:许多现代处理器提供了原子操作的指令,例如比较并交换(Compare and Swap,CAS)指令、加载链接
/ 存储条件(Load Linked/Store Conditional,LL/SC)指令等。这些指令可以在硬件层面上保证操作的原子性。例如,CAS
指令用于比较一个内存位置的值与给定的值,如果相等,则将该内存位置的值更新为新的值,并返回成功标志;否则,不进行任何操作,并返回失败标志。通过不断地尝试
CAS 操作,直到成功为止,可以实现原子的更新操作。
软件实现:在一些没有硬件支持原子操作的环境中,可以通过软件的方式来实现原子操作。例如,可以使用锁机制来确保一个操作在执行过程中不会被其他线程中断。当一个线程获得锁后,其他线程必须等待,直到该线程释放锁。这样可以保证在锁的保护范围内的操作是原子的。不过,软件实现的原子操作通常比硬件实现的原子操作效率低,因为锁机制会带来一定的开销。
(2)原子操作的应用场景
计数器更新:在多线程环境下,需要对一个计数器进行递增或递减操作时,可以使用原子操作来确保计数器的值是正确的。例如,在一个并发的网络服务器中,需要统计连接的客户端数量,可以使用原子操作来更新计数器,避免出现计数错误的情况。
并发数据结构:许多并发数据结构,如并发队列、并发栈等,都需要使用原子操作来确保数据的一致性。例如,在一个并发队列中,入队和出队操作都需要是原子的,以避免出现数据丢失或混乱的情况。
4.2 C++标准库的原子类型
C++ 标准库的<atomic>头文件中提供了多种原子类型,用于在多线程环境下保证对数据的原子操作,以下是一些常见的原子类型及代码演示:
(1)基本整型原子类型
std::atomic_bool:用于原子操作的布尔类型。
#include <iostream>
#include <atomic>
#include <thread>
std::atomic_bool flag(false);
void setFlagTrue() {
flag.store(true);
}
void checkFlag() {
while (!flag.load()) {
// 等待 flag 被设置为 true
}
std::cout << "Flag is true!" << std::endl;
}
int main() {
std::thread t1(setFlagTrue);
std::thread t2(checkFlag);
t1.join();
t2.join();
return 0;
}
|
std::atomic_int、std::atomic_uint 等:用于整数的原子操作。
#include <iostream>
#include <atomic>
#include <thread>
std::atomic<int> counter(0);
void incrementCounter() {
for (int i = 0; i < 1000; ++i) {
counter.fetch_add(1);
}
}
int main() {
std::thread t1(incrementCounter);
std::thread t2(incrementCounter);
t1.join();
t2.join();
std::cout << "Counter value: " << counter << std::endl;
return 0;
}
|
(2)指针类型的原子操作
std::atomic<T*>,其中 T 是指针指向的类型。
#include <iostream>
#include <atomic>
#include <thread>
int data = 0;
std::atomic<int*> ptr(&data);
void updatePointer() {
int* newData = new int(42);
int* oldPtr = ptr.exchange(newData);
delete oldPtr;
}
void readPointer() {
int* localPtr = ptr.load();
std::cout << "Data pointed by the pointer: " << *localPtr << std::endl;
}
int main() {
std::thread t1(updatePointer);
std::thread t2(readPointer);
t1.join();
t2.join();
delete ptr.load();
return 0;
}
|
(3)其他原子类型
std::atomic_size_t:用于 size_t 类型的原子操作,常用于表示数据结构的大小等。
std::atomic_char、std::atomic_short、std::atomic_long
等:分别用于字符、短整型、长整型等的原子操作。
在使用原子类型时,需要注意内存序的问题,不同的内存序会影响原子操作的可见性和顺序。例如,std::memory_order_relaxed
是最宽松的内存序,只保证原子操作本身的原子性,不保证其他线程对该操作的可见性顺序;而 std::memory_order_seq_cst
是最强的内存序,保证所有线程看到的操作顺序是一致的。在实际应用中,需要根据具体情况选择合适的内存序来保证程序的正确性和性能。
五、内存序问题
5.1什么是内存序问题
在多线程编程中,内存序问题指的是不同线程对内存中共享数据的访问顺序的不确定性。内存序决定了在多线程环境下,对共享内存的读写操作的可见性和顺序性。不同的内存序选项会影响编译器和处理器对代码的优化方式,从而导致不同线程可能看到不同的内存操作顺序。
例如,在一个多线程程序中,线程 A 写入一个变量,线程 B 读取这个变量。如果没有明确指定内存序,编译器和处理器可能会对这些操作进行重排序,使得线程
B 在变量还未被线程 A 写入时就读取了该变量,从而导致错误的结果。比如下面一段代码:
int i=10;
int j=20;
i+=2;
j+=3;
|
我们以为执行顺序是从上往下,但编译器任务i和j没有关联,可能会优化成:
int i=10;
i+=2;
int j=20;
j+=3;
|
在单核处理器的情况下,这种优化没问题,因为执行的结果不会变。但是如果是多核处理器,多线程并行执行,就会出现一些难以预知的问题。比如编译器和处理器可能会重排共享变量的写操作,使得其中一个线程的写操作先于另一个线程的写操作执行。这样会导致增量值丢失或重复计算,最终的结果可能小于预期的值。
总结来说,就是编译器和CPU会优化重排指令,改变原始程序中指令的执行顺序。这可能会导致多线程间的竞态条件和数据依赖关系出现问题,从而使得程序的行为产生难以预测的结果,需要使用适当的内存序来指定对共享变量的读写操作的顺序和同步行为。
常见的内存序类型
std::memory_order_relaxed:这是最宽松的内存序。只保证单个原子操作的原子性,不提供任何关于操作顺序或可见性的保证。编译器和处理器可以自由地对这些操作进行重排序。
std::memory_order_consume:该内存序用于依赖关系的传递。一个线程对某个原子变量的读取操作(使用
std::memory_order_consume),只会保证该变量的依赖关系在该线程中被正确传递。也就是说,如果一个变量的读取依赖于另一个变量的写入,那么在使用
std::memory_order_consume 时,只有这个依赖关系会被保证,而其他没有依赖关系的操作可能会被重排序。
std::memory_order_acquire:用于获取操作。一个线程对某个原子变量的读取操作(使用
std::memory_order_acquire),保证该操作之后的所有内存访问都不会被重排序到该读取操作之前。这意味着在这个读取操作之后的所有对共享内存的访问都能看到该读取操作所获取的值。
std::memory_order_release:用于释放操作。一个线程对某个原子变量的写入操作(使用
std::memory_order_release),保证该操作之前的所有内存访问都不会被重排序到该写入操作之后。这意味着在这个写入操作之前的所有对共享内存的修改都对其他使用
std::memory_order_acquire 或更强内存序进行读取的线程可见。
std::memory_order_acq_rel:结合了 std::memory_order_acquire
和 std::memory_order_release 的特性,用于既需要获取又需要释放的操作,例如原子的读
- 修改 - 写操作。
std::memory_order_seq_cst:顺序一致性内存序。这是最强的内存序,保证所有线程看到的内存操作顺序是一致的,并且不会对操作进行重排序,除非重排序不会改变程序的可观察行为。
内存序的选择
选择合适的内存序取决于程序的具体需求。如果对性能要求较高,可以考虑使用较宽松的内存序,但需要仔细分析代码中的依赖关系,以确保不会出现错误的结果。如果需要确保程序的正确性和可预测性,可能需要使用更强的内存序,如
std::memory_order_seq_cst,但这可能会带来一定的性能开销。
5.2内存序原理
内存序的原理涉及到编译器优化、处理器执行以及多线程环境下对共享内存的访问规则。
(1)编译器优化与重排序
编译器在编译代码时,为了提高程序的性能,可能会对指令进行重排序。这种重排序在单线程环境下通常不会影响程序的正确性,因为最终的结果是一致的。但是在多线程环境下,如果没有明确的内存序约束,不同线程可能会看到不同的指令执行顺序,从而导致数据不一致的问题。例如,考虑以下代码:
int a = 0;
int b = 0;
void thread1() {
a = 1;
b = 2;
}
void thread2() {
if (b == 2) {
assert(a == 1);
}
}
|
在没有内存序约束的情况下,编译器可能会将 thread1 中的 a = 1 和 b = 2 的顺序进行重排序,使得在
thread2 中可能会出现 b == 2 为真但 a == 1 为假的情况,从而导致断言失败。
(2)处理器执行与内存模型
处理器也可能会对内存操作进行重排序。处理器通常有自己的缓存和内存层次结构,为了提高性能,它可能会在不影响单线程程序正确性的前提下,对内存读写操作进行重新排序。
例如,处理器可能会先将一个变量的值写入缓存,然后再将另一个变量的值写入主内存,而不是按照程序中的顺序依次执行。在多线程环境下,如果没有适当的内存序约束,其他处理器可能会看到不一致的内存状态。
(3)内存序的作用
内存序的作用就是为了在多线程环境下控制编译器和处理器对内存操作的重排序行为,确保不同线程对共享内存的访问按照预期的顺序进行。
不同的内存序选项提供了不同程度的约束:
std::memory_order_relaxed:只保证单个原子操作的原子性,不限制编译器和处理器的重排序。
std::memory_order_consume:确保依赖于特定原子操作的内存访问不会被重排序到该操作之前,但对其他没有依赖关系的操作没有限制。
std::memory_order_acquire:阻止该操作之后的内存访问被重排序到该操作之前,确保后续的读取操作能看到该操作之前的所有写入操作。
std::memory_order_release:阻止该操作之前的内存访问被重排序到该操作之后,确保该操作之前的所有写入操作对其他使用
std::memory_order_acquire 或更强内存序进行读取的线程可见。
std::memory_order_acq_rel:结合了获取和释放的特性,用于原子的读 - 修改
- 写操作。
std::memory_order_seq_cst:提供最强的顺序一致性保证,所有线程看到的内存操作顺序都是一致的。
通过选择合适的内存序,可以在保证程序正确性的前提下,最大限度地提高程序的性能。例如,如果确定两个线程之间的操作没有依赖关系,可以使用较宽松的内存序来减少性能开销;如果需要严格的顺序保证,则可以使用
std::memory_order_seq_cst。
5.3内存屏障
内存屏障,也称为内存栅栏(memory barrier),是一种用于确保在多线程环境下内存操作顺序的机制。创建一个内存屏障,用于限制内存访问的重新排序和优化。它可以保证在屏障之前的所有内存操作都在屏障完成之前完成。
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<bool> flag(false);
std::atomic<int> data(0);
void writerThread() {
data.store(42, std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_release);
flag.store(true, std::memory_order_relaxed);
}
void readerThread() {
while (!flag.load(std::memory_order_relaxed)) {
// 等待 flag 被设置
}
std::atomic_thread_fence(std::memory_order_acquire);
int value = data.load(std::memory_order_relaxed);
std::cout << "Read value: " << value << std::endl;
}
int main() {
std::thread t1(writerThread);
std::thread t2(readerThread);
t1.join();
t2.join();
return 0;
}
|
在这个例子中,writerThread先写入data,然后设置flag。通过使用内存屏障,确保在readerThread中,当flag被读取为true时,data的读取一定能看到writerThread中对data的写入结果。
常见的 memory_order 参数包括
std::memory_order_relaxed:最轻量级的内存顺序,允许重排和优化。
std::memory_order_acquire:在屏障之前的内存读操作必须在屏障完成之前完成。
std::memory_order_release:在屏障之前的内存写操作必须在屏障完成之前完成。
std::memory_order_acq_rel:同时具有 acquire 和 release
语义,适用于同时进行读写操作的屏障。
std::memory_order_seq_cst:对于读操作相当于获得,对于写操作相当于释放。
在多线程编程中,由于编译器优化和处理器的乱序执行,不同线程对内存的读写操作可能会以意想不到的顺序执行,从而导致数据不一致的问题。内存屏障的作用就是强制处理器或编译器在特定的位置插入一些特殊的指令,以确保特定的内存操作按照预期的顺序执行,有以下类型:
写屏障(Write Barrier):确保在屏障之前的所有写操作先于屏障之后的写操作完成。例如,在一个多线程程序中,一个线程对共享数据进行了一系列的写入操作,然后插入一个写屏障,确保这些写入操作对其他线程可见。
读屏障(Read Barrier):确保在屏障之后的所有读操作能够看到屏障之前的所有写操作的结果。例如,在一个多线程程序中,一个线程插入一个读屏障,确保它能够看到其他线程在屏障之前对共享数据的写入操作。
全屏障(Full Barrier):同时具有写屏障和读屏障的作用,确保在屏障之前的所有读写操作先于屏障之后的所有读写操作完成,并且在屏障之后的读操作能够看到屏障之前的所有写操作的结果。
在不同的硬件架构和编程语言中,内存屏障的实现方式可能会有所不同:
在一些编程语言中,如 C++ 和 Java,提供了一些特定的关键字或函数来实现内存屏障。例如,在
C++ 中,可以使用 std::atomic_thread_fence 函数来插入内存屏障;在 Java
中,可以使用 volatile 关键字或 java.util.concurrent.atomic 包中的原子类来实现内存屏障的效果。
在硬件层面,处理器通常提供了一些特定的指令来实现内存屏障。例如,x86 架构中的 mfence、sfence
和 lfence 指令分别用于实现全屏障、写屏障和读屏障。
应用场景
多线程同步:在多线程编程中,内存屏障可以用于确保不同线程对共享数据的访问顺序正确,避免数据竞争和不一致的问题。
硬件设备驱动程序:在与硬件设备交互时,内存屏障可以确保对设备寄存器的读写操作按照正确的顺序执行,避免出现错误的设备状态。
优化编译器:编译器在优化代码时,可能会对内存操作进行重排序。通过插入内存屏障,可以告诉编译器不要对特定的内存操作进行重排序,以确保程序的正确性。
六、案例分析
6.1 多线程加锁
在多线程编程中,加锁是一种常用的同步机制,用于确保多个线程对共享资源的互斥访问,避免数据竞争和不一致的问题。以下是用
C++ 语言演示多线程加锁的示例代码:
#include <iostream>
#include <thread>
#include <mutex>
std::mutex mutexLock;
int sharedData = 0;
void incrementData() {
for (int i = 0; i < 1000; ++i) {
std::lock_guard<std::mutex> guard(mutexLock);
sharedData++;
}
}
int main() {
std::thread t1(incrementData);
std::thread t2(incrementData);
t1.join();
t2.join();
std::cout << "Final value of sharedData: " << sharedData << std::endl;
return 0;
}
|
在这个例子中,std::mutex 用于创建一个互斥锁,std::lock_guard 是一个 RAII(Resource
Acquisition Is Initialization,资源获取即初始化)风格的类,在构造时自动获取锁,在析构时自动释放锁,确保了锁的正确使用和及时释放,即使在函数执行过程中发生异常也能保证锁被正确释放。
两个线程分别调用 incrementData 函数,对共享变量 sharedData 进行递增操作。由于使用了互斥锁,每次只有一个线程能够访问和修改
sharedData,从而避免了数据竞争问题。
多线程加锁虽然可以解决数据竞争问题,但也可能带来一些性能开销,并且如果使用不当可能会导致死锁等问题。因此,在使用加锁机制时,需要仔细考虑锁的粒度、避免不必要的锁竞争以及正确处理可能出现的异常情况。
6.2 内存序问题
内存序问题在多线程编程中至关重要,它涉及到不同线程对共享内存的访问顺序以及编译器和处理器对内存操作的优化。在没有明确指定内存序的情况下,编译器和处理器可能会对内存操作进行重排序,以提高程序的性能。例如,一个线程可能会先执行对变量的写入操作,然后执行另一个无关的操作,但在另一个线程看来,这两个操作的顺序可能被颠倒了。这种重排序在单线程环境下通常不会影响程序的正确性,但在多线程环境下,可能会导致数据不一致和难以调试的错误。以下是一个
C++ 代码案例,用于分析内存序问题:
#include <iostream>
#include <atomic>
#include <thread>
std::atomic<bool> x(false), y(false);
std::atomic<int> z(0);
void write_x() {
x.store(true, std::memory_order_relaxed);
}
void write_y() {
y.store(true, std::memory_order_relaxed);
}
void read_x_then_y() {
while (!x.load(std::memory_order_relaxed)) {}
if (y.load(std::memory_order_relaxed))
z++;
}
void read_y_then_x() {
while (!y.load(std::memory_order_relaxed)) {}
if (x.load(std::memory_order_relaxed))
z++;
}
int main() {
std::thread a(write_x);
std::thread b(write_y);
std::thread c(read_x_then_y);
std::thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
std::cout << "z = " << z << std::endl;
return 0;
}
|
在这个例子中,有四个线程:a和b分别写入原子变量x和y,c先读取x再读取y,如果y为真则增加z,d先读取y再读取x,如果x为真则增加z。如果没有明确的内存序约束,c和d线程中的读取操作可能会以不同的顺序执行,导致z的最终值不确定。如果使用std::memory_order_seq_cst顺序一致性内存序,那么所有线程看到的内存操作顺序将是一致的,z的结果将更加可预测。
例如,如果使用std::memory_order_seq_cst来存储和加载原子变量:
void write_x() {
x.store(true, std::memory_order_seq_cst);
}
void write_y() {
y.store(true, std::memory_order_seq_cst);
}
void read_x_then_y() {
while (!x.load(std::memory_order_seq_cst)) {}
if (y.load(std::memory_order_seq_cst))
z++;
}
void read_y_then_x() {
while (!y.load(std::memory_order_seq_cst)) {}
if (x.load(std::memory_order_seq_cst))
z++;
}
|
在这种情况下,z的最终值将更有可能是 2,因为所有线程的操作顺序是一致的,不会出现混乱的重排序情况,这个例子展示了内存序问题如何影响多线程程序的结果,以及如何通过选择合适的内存序来确保程序的正确性。
6.3 多线程同步问题
多线程同步问题是在多线程编程中需要重点关注的问题,它主要涉及到多个线程对共享资源的正确访问和操作,以避免数据竞争、不一致性和其他错误。在多线程环境下,多个线程可能同时访问和修改共享资源。如果没有适当的同步机制,就可能出现以下问题:
数据竞争:当两个或多个线程同时对同一个共享变量进行读写操作时,可能会导致数据不一致。例如,一个线程正在读取一个变量的值,而另一个线程同时在修改这个变量,可能会导致读取到错误的值。
不一致状态:如果多个线程对共享资源的操作没有按照正确的顺序执行,可能会导致资源处于不一致的状态。例如,一个线程正在初始化一个对象,而另一个线程同时在使用这个对象,可能会导致程序出现错误。
死锁:当多个线程相互等待对方释放资源时,就可能会发生死锁。例如,线程 A 持有资源 X,等待资源
Y,而线程 B 持有资源 Y,等待资源 X,这样两个线程就会永远等待下去,导致程序无法继续执行。
以下是一个用 C++ 语言展示多线程同步问题的代码案例分析:
(1)没有同步机制的情况
#include <iostream>
#include <thread>
int sharedVariable = 0;
void incrementWithoutSync() {
for (int i = 0; i < 1000; ++i) {
sharedVariable++;
}
}
int main() {
std::thread t1(incrementWithoutSync);
std::thread t2(incrementWithoutSync);
t1.join();
t2.join();
std::cout << "Shared variable value without synchronization: " << sharedVariable << std::endl;
return 0;
}
|
在这个例子中,两个线程同时对sharedVariable进行递增操作。由于没有同步机制,可能会出现数据竞争问题。不同的运行环境下,sharedVariable的最终值可能不是预期的
2000,因为两个线程对sharedVariable的读写操作可能会交错进行,导致部分操作被覆盖。
(2)使用互斥锁进行同步
#include <iostream>
#include <thread>
#include <mutex>
int sharedVariable = 0;
std::mutex mutexLock;
void incrementWithSync() {
for (int i = 0; i < 1000; ++i) {
std::lock_guard<std::mutex> guard(mutexLock);
sharedVariable++;
}
}
int main() {
std::thread t1(incrementWithSync);
std::thread t2(incrementWithSync);
t1.join();
t2.join();
std::cout << "Shared variable value with synchronization: " << sharedVariable << std::endl;
return 0;
}
|
这里使用了std::mutex和std::lock_guard来确保在任何时候只有一个线程可以访问和修改sharedVariable。这样就避免了数据竞争问题,sharedVariable的最终值将是预期的
2000。
在多线程编程中,如果不使用同步机制,多个线程对共享资源的并发访问可能会导致不可预测的结果。而通过使用适当的同步机制,如互斥锁,可以确保线程之间对共享资源的访问是有序的和互斥的,从而保证程序的正确性。但需要注意的是,同步机制也会带来一定的性能开销,因为它们需要进行额外的操作来协调线程之间的访问。因此,在设计多线程程序时,需要权衡同步机制的必要性和性能影响,选择合适的同步策略。
|






 订阅
订阅