| ���Ľ�ѡ�Թ����ȱ����ġ�KubernetesȨ��ָ�ϡ����ý���Ҫ�Գ��õ�Kubernetesϵͳ��ά�����ͼ��ɽ�����ϸ˵����
Node�ĸ���ͻָ�
apiVersion: v1
kind: Node
metadata:
name: kubernetes-minion1
labels:
kubernetes.io/hostname: kubernetes-minion1
spec:
unschedulable: true |
Ȼ��ͨ��kubectl replace������ɶ�Node״̬���ģ�
$ kubectl replace -f unschedule_node.yaml
nodes/kubernetes-minion1 |
�鿴Node��״̬�����Թ۲쵽��Node��״̬��������һ��SchedulingDisabled��

���ں���������Pod��ϵͳ�����������Node���е��ȡ�
��һ�ַ����Dz�ʹ�������ļ���ֱ��ʹ��kubectl patch������ɣ�
$ kubectl patch node kubernetes-minion1 -p
'{��spec��:{��unschedulable��:true}}' |
��Ҫע����ǣ���ij��Node������ȷ�Χʱ�����������е�Pod�������Զ�ֹͣ������Ա��Ҫ�ֶ�ֹͣ�ڸ�Node�����е�Pod��
ͬ���������Ҫ��ij��Node�������뼯Ⱥ���ȷ�Χ����unschedulable����Ϊfalse���ٴ�ִ��kubectl
replace��kubectl patch������ָܻ�ϵͳ�Ը�Node�ĵ��ȡ�
Node������
��ʵ������ϵͳ�лᾭ����������������������������ʱ����Ҫ�����µķ�������Ȼ��Ӧ��ϵͳ����ˮƽ��չ����ɶ�ϵͳ�����ݡ�
��Kubernetes��Ⱥ�У�����һ����Node�ļ����Ƿdz��ġ�������Node�ڵ��ϰ�װDocker��Kubelet��kube-proxy����Ȼ��Kubelet��kube-proxy�����������е�Master
URLָ��Ϊ��ǰKubernetes��ȺMaster�ĵ�ַ�����������Щ������Kubelet���Զ�ע����ƣ��µ�Node�����Զ��������е�Kubernetes��Ⱥ�У���ͼ1��ʾ��
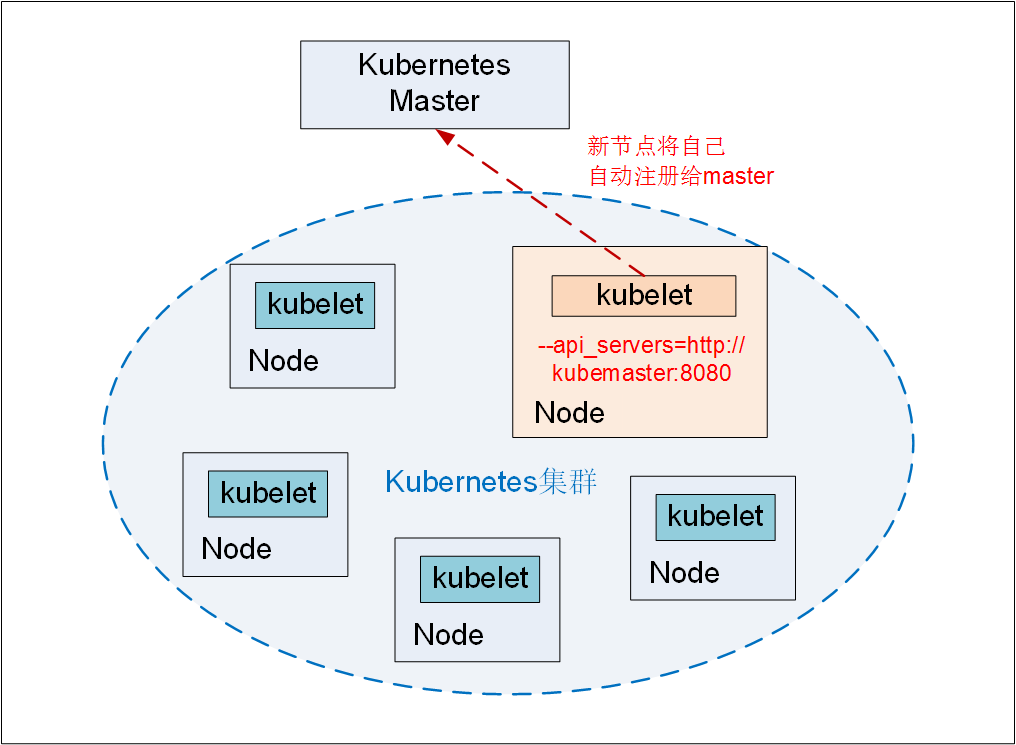
ͼ1 �½ڵ��Զ�ע���������
Kubernetes Master�ڽ�������Node��ע��֮���Զ��������뵱ǰ��Ⱥ�ĵ��ȷ�Χ�ڣ���֮������ʱ���Ϳ������µ�Node���е����ˡ�
ͨ�����ֻ��ƣ�Kubernetesʵ���˼�Ⱥ�����ݡ�
Pod��̬���ݺ�����
��ʵ������ϵͳ�У����Ǿ���������ij��������Ҫ���ݵij�����Ҳ���ܻ�����������Դ���Ż��߹������ؽ��Ͷ���Ҫ���ٷ���ʵ�����ij�������ʱ���ǿ�����������kubectl
scale rc�������Щ������Redis-slave RCΪ�����Ѷ���������������Ϊ2��ͨ��ִ����������redis-slave
RC���Ƶ�Pod���������ӳ�ʼ��2����Ϊ3��
$ kubectl scale rc redis-slave --replicas=3
scaled |
ִ��kubectl get pods��������֤Pod�ĸ����������ӵ�3��
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
redis-slave-4na2n 1/1 Running 0 1h
redis-slave-92u3k 1/1 Running 0 1h
redis-slave-palab 1/1 Running 0 2m |
��--replicas����Ϊ�ȵ�ǰPod����������С�����֣�ϵͳ���ᡰɱ����һЩ�����е�Pod������ʵ��Ӧ�ü�Ⱥ���ݣ�
$ kubectl scale rc redis-slave --replicas=1
scaled
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
redis-slave-4na2n 1/1 Running 0 1h |
������Դ�����Label
Label����ǩ����Ϊ�û�������Ķ������ԣ����Ѵ����Ķ����ϣ���Ȼ������ʱͨ��kubectl label�������������ӡ��ġ�ɾ���Ȳ�����
���磬����Ҫ���Ѵ�����Pod��redis-master-bobr0������һ����ǩrole=backend��
$ kubectl label pod redis-master-bobr0 role=backend |
�鿴��Pod��Label��
$ kubectl get pods -Lrole
NAME READY STATUS RESTARTS AGE ROLE
redis-master-bobr0 1/1 Running 0 3m backend |
ɾ��һ��Label��ֻ�������������ָ��Label��key������һ�������������ɣ�
$ kubectl label pod redis-master-bobr0 role- |
��һ��Label��ֵ����Ҫ����--overwrite������
$ kubectl label pod redis-master-bobr0 role=master --overwrite |
��Pod���ȵ�ָ����Node
����֪����Kubernetes��Scheduler����kube-scheduler���̣�����ʵ��Pod�ĵ��ȣ��������ȹ���ͨ��ִ��һϵ�и��ӵ��㷨����Ϊÿ��Pod�����һ����ѵ�Ŀ��ڵ㣬��һ�������Զ���ɵģ�������֪��Pod���ջᱻ���ȵ��ĸ��ڵ��ϡ���ʱ���ǿ�����Ҫ��Pod���ȵ�һ��ָ����Node�ϣ���ʱ�����ǿ���ͨ��Node�ı�ǩ��Label����Pod��nodeSelector������ƥ�䣬���ﵽ����Ŀ�ġ�
���ȣ����ǿ���ͨ��kubectl label�����Ŀ��Node����һ���ض��ı�ǩ�������Ǵ�����������÷���
kubectl label nodes <node-name> <label-key>=<label-value> |
�������Ϊkubernetes-minion1�ڵ����һ��zone=north�ı�ǩ���������ǡ���������һ���ڵ㣺

���������в���Ҳ����ͨ������Դ�����ļ��ķ�ʽ����ִ��kubectl replace -f xxx.yaml��������ɡ�
Ȼ����Pod�������ļ��м���nodeSelector���壬��redis-master-controller.yamlΪ����
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master
labels:
name: redis-master
spec:
replicas: 1
selector:
name: redis-master
template:
metadata:
labels:
name: redis-master
spec:
containers:
- name: master
image: kubeguide/redis-master
ports:
- containerPort: 6379
nodeSelector:
zone: north |
����kubectl create -f�����Pod��scheduler�ͻὫ��Pod���ȵ�ӵ��zone=north��ǩ��Node��ȥ��
ʹ��kubectl get pods -o wide���������֤Pod���ڵ�Node��

������Ǹ����Node����������ͬ�ı�ǩ������zone=north������scheduler������ݵ����㷨������Node����ѡһ�����õ�Node����Pod���ȡ�
���ֻ���Node��ǩ�ĵ��ȷ�ʽ����Ժܸߣ��������ǿ���һ��Node�ֱ����ϡ�������������������֤���������û����ջ������������ǩ�е�һ�֣���ʱһ��Kubernetes��Ⱥ�ͳ�����3���������⽫�����߿���Ч�ʡ�
��Ҫע����ǣ��������ָ����Pod��nodeSelector�������Ҽ�Ⱥ�в����ڰ�����Ӧ��ǩ��Nodeʱ����ʹ���������ɹ����ȵ�Node�����PodҲ���ջ����ʧ�ܡ�
Ӧ�õĹ�������
����Ⱥ�е�ij��������Ҫ����ʱ��������ҪֹͣĿǰ��÷�����ص�����Pod��Ȼ��������ȡ���������������Ⱥ��ģ�Ƚϴ�����������ͱ����һ����ս��������ȫ��ֹͣȻ���������ķ�ʽ�ᵼ�½ϳ�ʱ��ķ����á�Kubernetes�ṩ��rolling-update����������������������������⡣
��������ͨ��ִ��kubectl rolling-update����һ����ɣ����������һ���µ�RC��Ȼ���Զ����ƾɵ�RC�е�Pod�����������ٵ�0��ͬʱ�µ�RC�е�Pod����������0�����ӵ�Ŀ��ֵ������ʵ����Pod����������Ҫע����ǣ�ϵͳҪ���µ�RC��Ҫ��ɵ�RC����ͬ�������ռ䣨Namespace���ڣ������ܰѱ��˵��ʲ�͵͵ת�Ƶ��Լ����¡�
��redis-masterΪ�������赱ǰ���е�redis-master Pod��1.0�汾����������Ҫ������2.0�汾��
����redis-master-controller-v2.yaml�������ļ����£�
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master-v2
labels:
name: redis-master
version: v2
spec:
replicas: 1
selector:
name: redis-master
version: v2
template:
metadata:
labels:
name: redis-master
version: v2
spec:
containers:
- name: master
image: kubeguide/redis-master:2.0
ports:
- containerPort: 6379 |
�������ļ����м�����Ҫע�⣺
��1��RC�����֣�name��������ɵ�RC��������ͬ��
��2����selector��Ӧ������һ��Label��ɵ�RC��Label��ͬ���Ա�ʶ��Ϊ�µ�RC��
������������һ����Ϊversion��Label������ɵ�RC�������֡�
����kubectl rolling-update�������Pod����������
kubectl rolling-update redis-master -f redis-master-controller-v2.yaml |
Kubectl��ִ�й������£�
Creating redis-master-v2
At beginning of loop: redis-master replicas: 2, redis-master-v2 replicas: 1
Updating redis-master replicas: 2, redis-master-v2 replicas: 1
At end of loop: redis-master replicas: 2, redis-master-v2 replicas: 1
At beginning of loop: redis-master replicas: 1, redis-master-v2 replicas: 2
Updating redis-master replicas: 1, redis-master-v2 replicas: 2
At end of loop: redis-master replicas: 1, redis-master-v2 replicas: 2
At beginning of loop: redis-master replicas: 0, redis-master-v2 replicas: 3
Updating redis-master replicas: 0, redis-master-v2 replicas: 3
At end of loop: redis-master replicas: 0, redis-master-v2 replicas: 3
Update succeeded. Deleting redis-master
redis-master-v2 |
�������µ�Pod������ɺɵ�PodҲ��ȫ�����٣������������������Ⱥ�ĸ��¡�
��һ�ַ����Dz�ʹ�������ļ���ֱ����kubectl rolling-update�������--image����ָ���°澵�����������Pod�Ĺ���������
kubectl rolling-update redis-master --image=redis-master:2.0 |
��ʹ�������ļ��ķ�ʽ��ͬ��ִ�еĽ���Ǿɵ�RC��ɾ�����µ�RC�Խ�ʹ�þɵ�RC�����֡�
Kubectl��ִ�й������£�

���Կ�����Kubectlͨ���½�һ���°汾Pod��ͣ��һ���ɰ汾Pod���������������RC�ĸ��¡�
������ɺ鿴RC��

���Կ�����Kubectl��RC������һ��keyΪ��deployment����Label�����key�����ֿ�ͨ��--deployment-label-key���������ģ���Label��ֵ��RC�����ݽ���Hash������ֵ���൱��ǩ�����������ܷܺ���رȽ�RC���Image���ּ�������Ϣ�Ƿ����˱仯�����ľ������ÿ��Բμ���6�µ�Դ�������
����ڸ��¹����з��������������û������жϸ��²�������ͨ��ִ��Kubectl rolling-update
�Crollback���Pod�汾�Ļع���
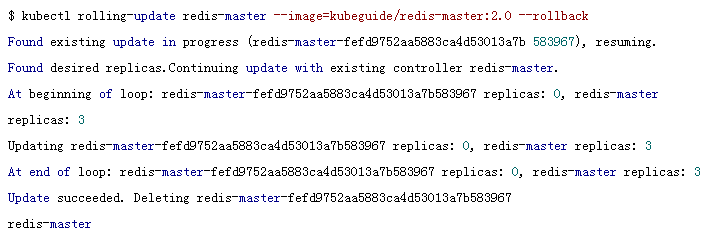
���ˣ����Կ���Pod�ָ�������ǰ�İ汾�ˡ�
Kubernetes��Ⱥ�߿��÷���
Kubernetes��Ϊ����Ӧ�õĹ������ģ�ͨ����Pod���������м�أ����Ҹ�������������ʧЧ��״̬���µ�Pod���ȵ�����Node�ϣ�ʵ����Ӧ�ò�ĸ߿����ԡ����Kubernetes��Ⱥ���߿����Ի�Ӧ����������������Ŀ��ǣ�etcd���ݴ洢�ĸ߿����Ժ�Kubernetes
Master����ĸ߿����ԡ�
1��etcd�߿����Է���
etcd������Kubernetes��Ⱥ�д����������ݿ�ĵ�λ��Ϊ��֤Kubernetes��Ⱥ�ĸ߿����ԣ�������Ҫ��֤���ݿⲻ�ǵ����ϵ㡣һ���棬etcd��Ҫ�Լ�Ⱥ�ķ�ʽ���в�����ʵ��etcd���ݴ洢�����ࡢ������߿����ԣ���һ���棬etcd�洢�����ݱ���ҲӦ����ʹ�ÿɿ��Ĵ洢�豸��
etcd��Ⱥ�IJ������ʹ�þ�̬���ã�Ҳ����ͨ��etcd�ṩ��REST API������ʱ��̬���ӡ��Ļ�ɾ����Ⱥ�еij�Ա�����ڽ���etcd��Ⱥ�ľ�̬���ý���˵�������ڶ�̬�ĵIJ���������ο�etcd�ٷ��ĵ���˵����
���ȣ��滮һ������3̨���������ڵ㣩��etcd��Ⱥ����ÿ̨�������ϰ�װ��etcd��
����һ����3̨��������ɵ�etcd��Ⱥ�����������1��ʾ���伯Ⱥ����ʵ����ͼ2��ʾ��
��1 etcd��Ⱥ������ 
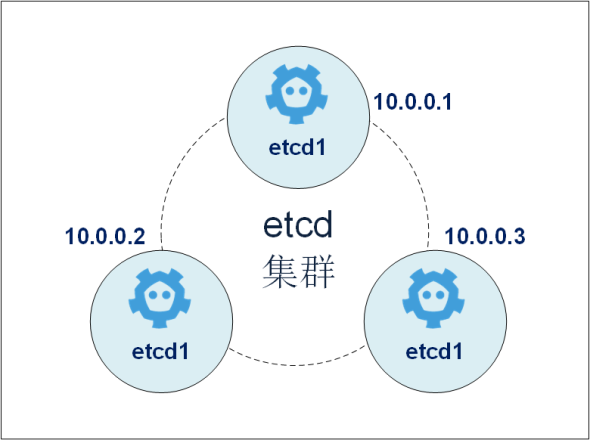
ͼ2 etcd��Ⱥ����ʵ��
Ȼ����ÿ̨��������etcd�������ļ�/etc/etcd/etcd.conf��
��etcd1Ϊ������Ⱥ��ʵ������Ҫ����ETCD_INITIAL_CLUSTER_STATE����Ϊ��new����etcd1�������������£� 
����etcd1�������ϵ�etcd����
������ɺʹ�����һ����Ϊetcd-cluster�ļ�Ⱥ��
etcd2��etcd3Ϊ����etcd-cluster��Ⱥ��ʵ������Ҫ����ETCD_INITIAL_CLUSTER_STATE����Ϊ��exist����etcd2�������������£�etcd3�������ԣ���

����etcd2��etcd3�������ϵ�etcd����
������ɺ�������etcd�ڵ�ִ��etcdctl cluster-health��������ѯ��Ⱥ������״̬��
$ etcdctl cluster-health
cluster is healthy
member ce2a822cea30bfca is healthy
member acda82ba1cf790fc is healthy
member eba209cd0012cd2 is healthy |
������etcd�ڵ���ִ��etcdctl member list��������ѯ��Ⱥ�ij�Ա�б���

���ˣ�һ��etcd��Ⱥ�ʹ����ɹ��ˡ�
��kube-apiserverΪ����������etcd��Ⱥ�IJ�������Ϊ��
--etcd-servers=http://10.0.0.1:4001,http://10.0.0.2:4001,http://10.0.0.3:4001 |
��etcd��Ⱥ�ɹ�����֮�������Ҫ�Լ�Ⱥ��Ա�����ģ�����ο��ٷ��ĵ�����ϸ˵��������˴�
����etcd����Ҫ��������ݵĿɿ��ԣ����Կ���ʹ��RAID�������С������ܴ洢�豸��NFS�����ļ�ϵͳ������ʹ���Ʒ������ṩ������ϵͳ����ʵ�֡�
2.Kubernetes Master����ĸ߿����Է���
��Kubernetes��ϵ�У�Master����������ܿ����ĵĽ�ɫ����Ҫ����������kube-apiserver��kube-controller-mansger��kube-schedulerͨ�������빤���ڵ��ϵ�Kubelet��kube-proxy����ͨ����ά��������Ⱥ�Ľ�������״̬�����Master�ķ��������ʵ�ij��Node����Ὣ��Node���Ϊ�����ã�������������½���Pod������Master��������Ҫ���ж���ļ�أ�ʹMaster����Ϊ��Ⱥ�ĵ����ϵ㣬���Զ�Master����Ҳ��Ҫ���и߿��÷�ʽ�IJ���
��Master��kube-apiserver��kube-controller-mansger��kube-scheduler����������Ϊһ������Ԫ��������etcd��Ⱥ�ĵ��Ͳ������á�ʹ��������̨��������װMaster������ʹ��Active-Standby-Standbyģʽ����֤�κ�ʱ������һ��Master�ܹ�����������
���й����ڵ��ϵ�Kubelet��kube-proxy��������Ҫ����Master��Ⱥ��ͳһ������ڵ�ַ���������ʹ��pacemaker�ȹ�����ʵ�֡�ͼ3չʾ��һ�ֵ��͵IJ���ʽ�� 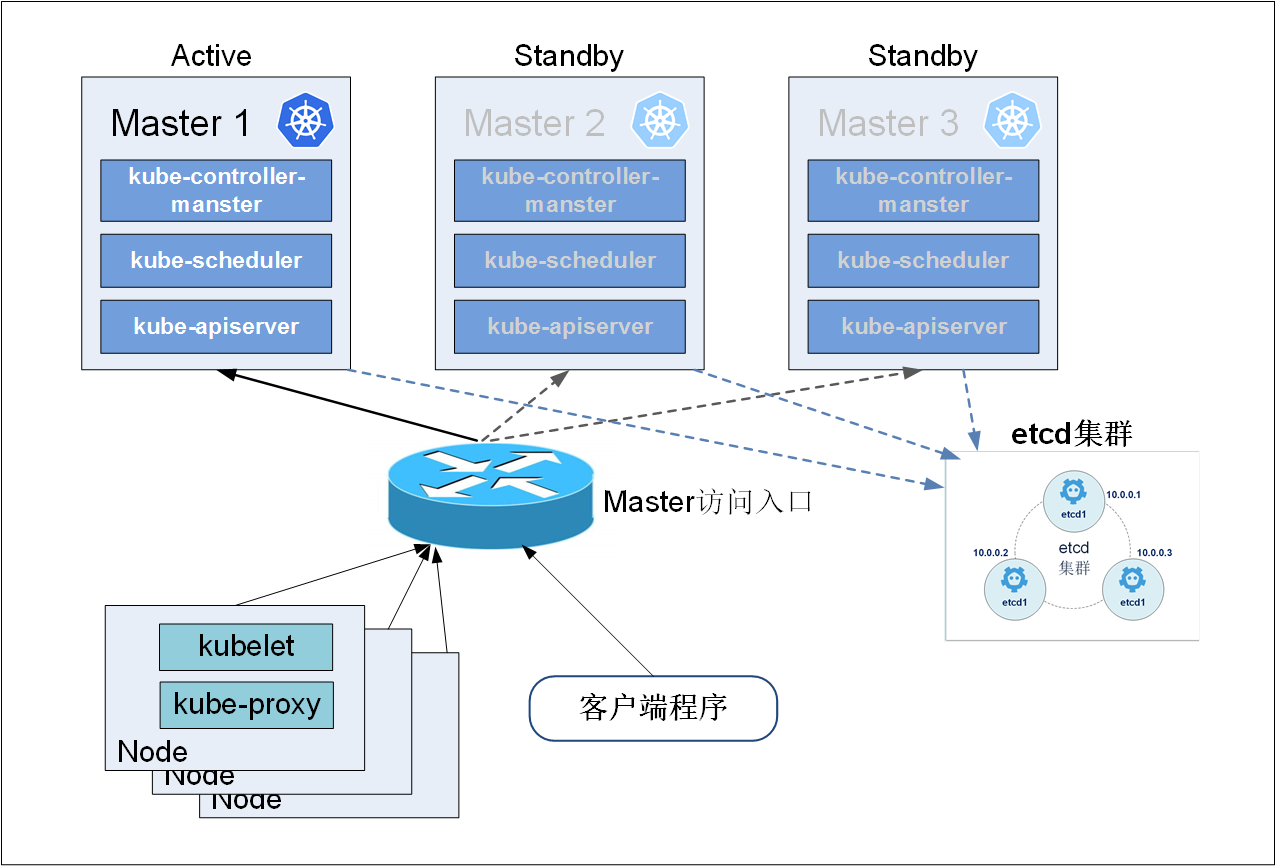
ͼ3 Kubernetes Master�߿��ò���ܹ� |






