| БрМЭЦМі: |
| БОЮФРДздгкМђЪщЃЌБОЮФжївЊНщЩмСЫПЊдДжЇГХжЧФмЛЏдЫЮЌЕФШ§ДѓРћЦїЃКUAVStack,
Wormhole, DBusЃЌОПОЙЪЧдѕбљЕФКЫаФММЪѕЃЌФмдьОЭетбљжЇГХжЧФмЛЏдЫЮЌЕФРћЦїЁЃ |
|
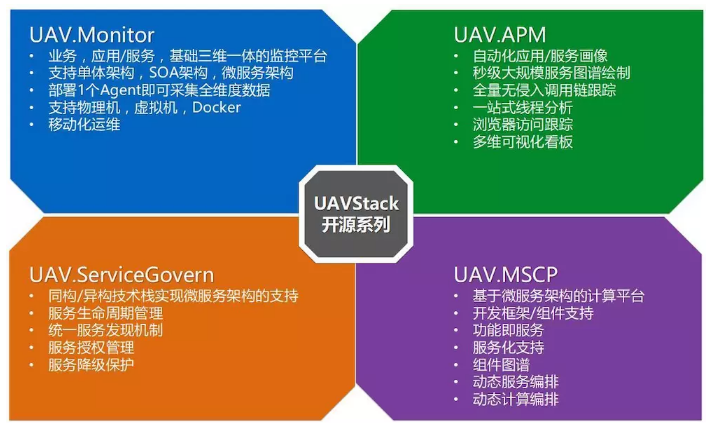
UAVStack ЪЧжЧФмЛЏЗўЮёММЪѕеЛЃЌЪЧбаЗЂдЫЮЌвЛЬхЛЏЕФНтОіЗНАИЁЃUAV
ЪЧЮоШЫЛњЕФЫѕаДЃЌдЂвтЮоШЫЛњАПЯшРЖЬьЃЌжЧФмЕФЃЌЭИУїЕФЭъГЩШЮЮёЁЃЫќАќРЈШЮЮёЛњЦїШЫЃЈДњКХ HITЃЉЃЌШЋЮЌМрПиЃЈДњКХ
UAV.MonitorЃЉ, гІгУадФмЙмРэЃЈДњКХ UAV.APMЃЉ, ЗўЮёжЮРэЃЈДњКХ UAV.ServiceGovernЃЉ,
ЮЂЗўЮёМЦЫуЃЈДњКХ UAV.MSCPЃЉЃЌгУЛЇЬхбщЙмРэЃЈДњКХ UAV.UEMЃЉЕШЁЃЦфжаЃЌUAV.Monitor+APM
ЮЊВЛЕЋЮЊжЧФмдЫЮЌВЩМЏШЋЮЌМрПиЪ§ОнЃЌвВЬсЙЉСЫЪЕЪБМрПиЃЌздЖЏЛЏЮЪЬтеяЖЯЕФЙЄОпЃЌЪЧвЛеОЪНЕФШЋЮЌМрПи + гІгУдЫЮЌНтОіЗНАИЁЃ
ФПЧА UAVStack ПЊдДЯЕСаАќРЈЃК
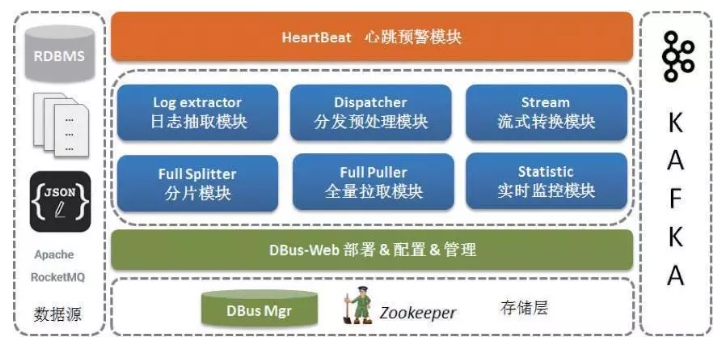
DBus зЈзЂгкЪ§ОнЕФЪеМЏМАЪЕЪБЪ§ОнСїМЦЫуЃЌЭЈЙ§МђЕЅСщЛюЕФХфжУЃЌвдЮоЧжШыЕФЗНЪНЖддДЖЫЪ§ОнНјааВЩМЏЃЌВЩгУИпПЩгУЕФСїЪНМЦЫуПђМмЃЌЖддквЕЮёСїГЬжаВњЩњЕФЪ§ОнНјааЛуОлЃЌОЙ§зЊЛЛДІРэКѓГЩЮЊЭГвЛ
JSON ЕФЪ§ОнИёЪНЃЈUMSЃЉЃЌЬсЙЉИјВЛЭЌЪ§ОнЪЙгУЗНЖЉдФКЭЯћЗбЁЃDBus НЋ UAV ВЩМЏЕФШЋЮЌМрПиЪ§ОнвдЮоЧжШыЗНЪННјааЪЕЪБЪеМЏЃЌЮЊЯТгЮДѓЪ§ОнДІРэЦНЬЈ
Wormhole дЫааЭГМЦФЃаЭКЭЛњЦїбЇЯАЬсЙЉЪ§ОндДЁЃ
ДЫЭтЃЌDBus ЛЙЬсЙЉвдЯТЬиадЃК
1.ЖржжЪ§ОндДжЇГжЃЌКЃСПЪ§ОнЪЕЪБДЋЪф
2.ИажЊдДЖЫ schema БфИќЃЌЪ§ОнЪЕЪБЭбУє
3.ГѕЪММгдиКЭЖРСЂМгди
4.ЭГвЛБъзМЛЏЯћЯЂДЋЪфавщЃЌПЩППЖрТЗЯћЯЂ
5.ЖЉдФЗжЗЂжЇГжЗжБэЪ§ОнЛуМЏ
DBus ММЪѕМмЙЙ
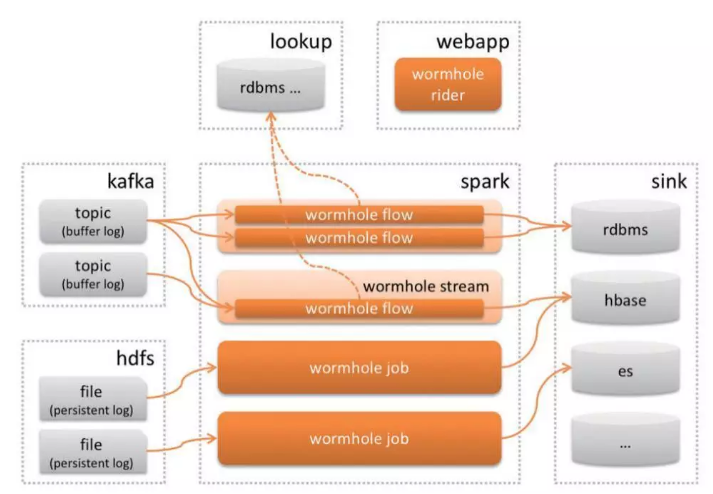
Wormhole ЪЧвЛИі SPAASЃЈStream Processing
as a ServiceЃЉЦНЬЈНтОіЗНАИЁЃWormhole УцЯђДѓЪ§ОнЯюФПЕФПЊЗЂЃЌдЫЮЌвдМАЙмРэШЫдБЃЌжТСІгкМђЛЏКЭЭГвЛПЊЗЂЙмРэСїГЬЁЃЕБНёдЫЮЌЪЧЕфаЭЕФДѓЪ§ОнгІгУСьгђЃЌWormhole
ЪЧжЧФмдЫЮЌЛњЦїбЇЯАЕФгаСІжЇГХЃЌгШЦфЪЧеыЖдСїЪНЪЕЪБКЭСїЪНзМЪЕЪБЪ§ОнДІРэГЁОАЁЃЭЌЪБЃЌЬсЙЉСЫПЩЪгЛЏЕФВйзїНчУцЃЌМЋМђЕФХфжУСїГЬЃЌЛљгк
SQL ЕФвЕЮёПЊЗЂЗНЪНЃЌВЂЦСБЮСЫДѓЪ§ОнДІРэЕзВуММЪѕЯИНкЃЌМЋДѓЕФНЕЕЭСЫПЊЗЂЙмРэУХМїЁЃWormhole
ЕФЩшМЦРэФюЪЧЭГвЛСїЪНДІРэ DAG ИпНзЗжаЮГщЯѓЃЌЭГвЛЭЈгУСїзЊЯћЯЂ UMS авщГщЯѓЃЌЭГвЛЭЈгУСїзЊЯћЯЂ
UMS авщГщЯѓЁЃ
ЭДЕуЪЧММЪѕЩ§МЖЕФЧ§ЖЏСІ
ЮвУЧЪЧДгДЋЭГдЫЮЌзЊЯђздЖЏЛЏдЫЮЌЃЌНјЖјЯђжЧФмЛЏдЫЮЌТѕНјЁЃЭЈЙ§Жд DevOps
ЙЄОпСДЕФВЛЖЯНЈЩшЃЌЮвУЧаЮГЩСЫЙсДЉШЋЮЌЖШМрПиЃЌCI/CDЃЌздЖЏЛЏВтЪдЃЌгІгУащФтЛЏЕФздЖЏЛЏдЫЮЌЬхЯЕЁЃОЁЙмШчДЫЃЌдкН№ШкдЫЮЌ
/ дЫгЊЙ§ГЬжаЃЌЮвУЧЛЙЪЧХіЕНвдЯТЭДЕуЃК
1ЁЂздЖЏЛЏдЫЮЌШЗЪЕЬсЩ§СЫдЫЮЌЪБаЇЃЌДѓЗљЖШМѕЩйШЫЙЄЃЌЬсИпСЫОЋЯИЖШЁЃЕЋздЖЏЛЏЕФжДааСїГЬЪЧгЩШЫЙЄЖЈвхЕФЁЂУїШЗЕФжДааЙ§ГЬЁЃЫцзХЖдЯЕЭГЕФЪЪгІСІЃЌОіВпСІКЭЪБаЇадвЊЧѓГжајЕиЬсЩ§ЃЌздЖЏЛЏдЫЮЌвВГіЯжСЫБпМЪаЇгІЁЃ
УЛгаЁАХаЖЯСІЁБЃЌВЛФмОіВпЁЃДцдкЖржжПЩФмадЕФдЫЮЌЪТМўЃЌашвЊ SRE НщШыХаЖЯКЭЗжЮіЃЌВХФмУїШЗЪЧЪВУДЃЌШЛКѓВХФмЖдЯЕЭГЯТДяжИСюЁЃР§ШчЃКЕБЗЂЯжИп
CPU БЈОЏЪБЃЌЗўЮёИУВЛИУНЕМЖЃЌгІгУИУВЛИУжиЦєЁЃЖјЪТЪЕЩЯЃЌШУШЫШЫЖМГЩЮЊдЫЮЌзЈМвЪЧФбвдДяГЩЕФЃЌШчЙћ SRE
ВЛдкЃЌЮЪЬтОЭИуВЛЖЈЁЃ
ЪЪгІСІВЛзуЃЌШЫЙЄНщШыЕФжЭКѓадЁЃБШНЯЕфаЭЕФЧщПіЪЧБЈОЏЃЌЭЈГЃБЈОЏЪЧгЩдЫЮЌШЫдБИљОнОбщРДЩшжУЕФВпТдЃЌЕЋЪЧЪаГЁКЭвЕЮёЗЂеЙЕФПьЫйБфЛЏЛсЪЙЕУдЄЯШЩшжУЕФВпТдЙ§ЪБЃЌВЛЪЧГіЯжЦЕЗББЈОЏЃЌОЭЪЧГіЯжИУБЈЕФУЛБЈЁЃ
2ЁЂДЋЭГ IT азїФЃЪНдНРДдНЁАЭцВЛзЊЁБСЫЁЃДЋЭГФЃЪНЪЧвЕЮёевбаЗЂЃЌбаЗЂевдЫЮЌЃЌдЫЮЌевЯЕЭГЕФЁАЯпЬѕЁБФЃЪНЁЃЭЌЪБЃЌIT
ЕФгябдгывЕЮёгябдЪБГЃЁАМІЭЌбМНВЁБЃЌЮѓЖСЪБгаЗЂЩњЃЌвВдьГЩаЇТЪЕЭЁЃ
вЕЮёЭХЖгЯЃЭћЫцЪБЫцЕиЃЌМђЕЅЃЌПьЫйЕФСЫНтЯЕЭГдЫаазДПіЃЌвЕЮёдЫааЧщПіЃЌЕБШЛЫћУЧвВПДВЛЖЎ
IT ЪѕгяЃЌЫћУЧЯЃЭћФмЬ§ЕНЁАШЫРрЁБЕФгябдЁЃ
дЫЮЌ SRE БфГЩСЫЙиМќЁАЦПОБЁБЃЌЫћУЧЕФОбщУЛгаБЛГСЕэКЭЙВЯэЁЃ
баЗЂЖЎЯЕЭГЃЌСЫНтвЕЮёТпМЃЌШДЁАВЛИвЁБдкУЛгадЫЮЌ SRE ажњЪБЃЈМДЪЙгаздЖЏЛЏдЖГЬЙЄОпЃЉЃЌПьЫйНтОівЕЮёЮЪЬтЁЃЫћУЧШБЩйШЋУцСЫНтЛљДЁЩшЪЉЁЂЩЯЯТгЮгІгУЕФАяЪжЁЃ
3ЁЂвЕЮёЭХЖгашвЊИќЖрдЫгЊжЇГжЃЌвЦЖЏЛЏЃЌЖрНЛЛЅЧўЕРЃЌДгЖјНтЗХШЫЕФблОІЁЃ
ДгВуМЖЛуБЈЃЈШЫЮЇзХШЫзЊЃЌШЫевШЫЃЉЕФФЃЪНзЊБфЮЊвдЪ§ОнЮЊжааФЃЌЪ§зжЛЏдЫгЊЃЈШЫЮЇзХЪ§ОнзЊЃЌШЫевЪ§ОнЃЉЕФФЃЪНЪЧДѓЧїЪЦЁЃЖјетжжзЊБфЕФММЪѕЛљДЁЪЧвЕЮёЭХЖгПЩвдЭЈЙ§ИїжжЧўЕРЃЈВЛЪЧЗЧЕУЕЧТМФГФГЯЕЭГЃЌвВВЛЪЧЗЧЕУевЕНФГФГСьЕМЛђСЊТчШЫЃЉПьЫйДЋВЅаХЯЂЃЌЗжЯэЪ§ОнЁЃ
дЫгЊДыЪЉФмЙЛгУЁАЬ§ЕУЖЎЁБЕФгябджБНгЁЂИпаЇЕиЗДРЁИјвЕЮёЭХЖгЁЃР§ШчзЪН№ашЧѓЩЯРДСЫЃЌзЪН№ЕїВІЭХЖгЭЈЙ§зЪН№ЕїВІИњЩЯзЪН№ашЧѓЕФдіГЄЃЌЕЋЫћУЧВЂВЛЧхГўЪЕМЪЦ№ЕНСЫЖрДѓаЇЙћЃЌЕБШЛЭЈЙ§вЕЮёМрПиФмЙЛПДЕНЃЌЕЋН№ШкаавЕЬиЕуЃЌвЦЖЏАьЙЋ
/ ГіВюЪЧГЃЬЌЃЌВЂВЛЪЧЪБПЬОпБИЕЧТМЯЕЭГЕФЬѕМўЃЌЕЋЭЈЙ§ЮЂаХЃЌQQ ЕШОЭЗНБуЖрСЫЁЃ
вдЩЯЕФЭДЕуЙщРрЦ№РДПЩвдШЯЮЊЪЧСНРрЮЪЬтЃК
ЪБаЇРрЮЪЬтЃКдЫЮЌЕФБОжЪЪЧЬсЙЉЮШЖЈПЩППЕФЗўЮёЃЌЖјДяГЩетИіФПБъЕФЙиМќЪЧзуЙЛКУЕФЪБаЇЁЃ
азїРрЮЪЬтЃКШЫРрЕФЩњВњРыВЛПЊазїЁЃОЁЙмгаСЫздЖЏЛЏдЫЮЌЦНЬЈЛђЙЄОпСДЃЌдЫЮЌКмЖрГЁОАЛЙЪЧашвЊаэЖрШЫЙЄазїЁЃ
жЧФмдЫЮЌЕФздбажЎТЗ
Gartner ЖЈвхСЫЛљгкЫуЗЈЕФдЫЮЌЃЈITOAЃЉМДЪЧ AIOpsЃЌЫуЗЈМДдЫЮЌЃЌНЋЫуЗЈдЫгУдЫЮЌСьгђЁЃЪЕМЪЩЯЮвУЧдкздЖЏЛЏдЫЮЌЬхЯЕжавбОНЋЫуЗЈТфЕиЕН
DevOps ЙЄОпСДжаЃЌР§ШчдкМрПижаЗўЮёЭМЦзЕФЖЏЬЌЛцжЦЃЌAPM ЙЄОпЯфжаЕФвЛМќЪНЯпГЬЗжЮіЃЌгІгУащФтЛЏжаЕФЕЏадШнСПМЦЫуЁЃЕЋЮвУЧШЯЮЊетаЉШдШЛЪЧЁАздЖЏЛЏЁБЕФЗЖГыЃЌашвЊИќМгжЧФмЕФЗНАИЁЃ
ШевцаЫЪЂЕФШЫЙЄжЧФмММЪѕЃЌШУЮвУЧвтЪЖЕНИГгшЯЕЭГЁАжЧФмЛЏЁБЪЧДѓЧїЪЦЁЃЖд
AIOpsЃЌЮвУЧИќдИвтетбљНтЖСЃКAIOps е§ЪЧНЋШЫЙЄжЧФмММЪѕгІгУЕН IT дЫЮЌСьгђЃЌАяжњБфИядЫЮЌФЃЪНЃЌЬсЩ§аЇТЪКЭДДдьЯжЪЕМлжЕЕФЁАЙЄГЬЛЏЁБЙ§ГЬЃЌвВЪЧ
DevOps ЕФНјЛЏЗНЯђЁЃ
НтОіЩЯЪіЮЪЬтЕФФПБъЙщФЩЦ№РДЪЧЃЌЮвУЧашвЊ AIOps ЯЕЭГГЩЮЊ
дЫЮЌЙмРэЕФГЩдБЃКаЕїШЫгыЯЕЭГЃЌВЛЪЧБЛЖЏЕФЙЄОпЃЌЖјЪЧжБНгВЮгыдЫЮЌЕФЁАжњЪжЁБ
вЕЮёдЫгЊжЇГжЕФГЩдБЃКаЕїШЫгывЕЮёЃЌВЮгыдЫгЊЕФЁАжњЪжЁБ
вЕЮёгыЯЕЭГЕФЁАШЋжЊЁБепЃКаЕївЕЮёгыЯЕЭГЃЌЙмРэЯЕЭГЃЌжЇГХвЕЮё
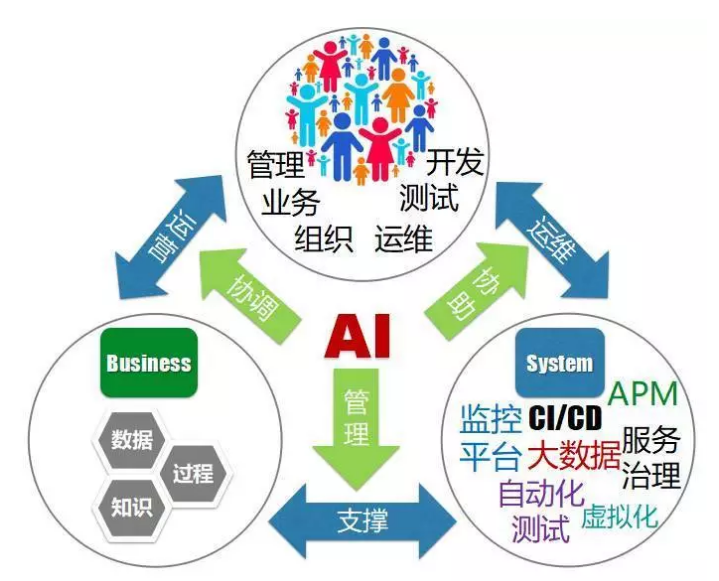
ФЧУДгІИУдѕУДНЈЩш AIOps ЯЕЭГФиЃПЮвУЧШЗСЂСЫМИЕуддђЃК
ФПБъЪЧДгЪЕМЪЭДЕуШыЪжЃЌевЕНЪЪКЯГЁОАвдМАе§ШЗЕФЮЪЬтРДЪдЕуЃЌЖјВЛЪЧЁАДѓЖјШЋЁБЕФ
AIOps НтОіЗНАИЁЃ
ММЪѕбЁаЭЩЯГфЗжРћгУвбОБШНЯГЩЪьЕФПЊдД AI ММЪѕЃЌПЩвдзіБивЊИФНјЃЌЕЋОЁСПВЛжиИДдьТжзгЁЃ
ГфЗжЪЙгУЮвУЧЯжгаЕФ DevOps ЙЄОпСДЃЌЖјВЛЪЧШЋУцЭЦЕЙжиРДЁЃ
жЎЫљвдетбљПМТЧЕФдвђЃК
AI ММЪѕЛЙВЛЪЧЁАЦНУёММЪѕЁБЃЌОЁЙмвбОЗЂеЙСЫКмГЄЪБМфЃЌЕЋЫќЕФЭЖШыВњГіБШПЩФмВЂВЛЯёЪЙгУ
springЃЌtomcatЃЌRabbitMQ етаЉПЊдДММЪѕеЛФЧбљЕФжБНгЁЃЫљвдЯШзіЁАЕуЁБЕФЪТЧщЃЌдйПМТЧЁАУцЁБЁЃвЊДгЪЪКЯЕФГЁОАЯТЧаШыЁЃ
ОЁЙм AIOps ЛсДјРДЕпИВадЕФдЫЮЌЫМЮЌКЭаЇгІЃЌЕЋЪЧЗёвВвЊЖдЯжгаЯЕЭГШэМўРДвЛАбЭЦЕЙжиРДФиЃПAIOps
ЪЧ DevOps ЕФНјЛЏЗНЯђЃЌгы DevOps ЙЄОпСДЩюЖШМЏГЩЪЧБигЩжЎТЗЁЃЫљвд AIOps ВЂЗЧЪЧвЊШЁДњЯжгаЕФздЖЏЛЏдЫЮЌЬхЯЕЃЌЖјЪЧИГгшЯжгаЬхЯЕжЧФмЁЃ
ИДгУЯжга IT гХСМзЪВњЃЌзюДѓЛЏзЪВњМлжЕвВЪЧБивЊЕФПМСПЁЃ
жЕЕУвЛЬсЕФЪЧЃЌОЙ§ЪЕМљжЄУїЃЌздЖЏЛЏдЫЮЌЪЧжЧФмЛЏдЫЮЌЕФЙЙНЈЛљДЁЁЃШчЙћУЛгаздЖЏЛЏдЫЮЌЕФГЩаЭММЪѕКЭЗНАИЃЌAIOps
вВЪЧПеЬИЁЃгУИіаЮЯѓЕФБШгїЃЌздЖЏЛЏдЫЮЌЬхЯЕжаЃЌМрПиЯЕЭГЕФЪ§ОнВЩМЏКУБШШЫЕФблОІЁЂЖњЖфЪЧгУРДИажЊЯжЪЕЕФЃЌдЖГЬжДааКУБШШЫЕФЪжНХЪЧгУРДЗДРЁЯжЪЕЕФЁЃЖј
AI ЯЕЭГКУБШШЫЕФДѓФдЃЌЫќНгЪеИажЊЃЌЭЈЙ§вЛЯЕСаДІРэаЮГЩОіВпЃЌетЪЧЁАШЯжЊЁБЕФЙ§ГЬЃЌШЛКѓЭЈЙ§ЗДРЁИјШЫЛђжДааНсЙћЃЌЬхЯжЁАжЧЛлЁБЁЃ
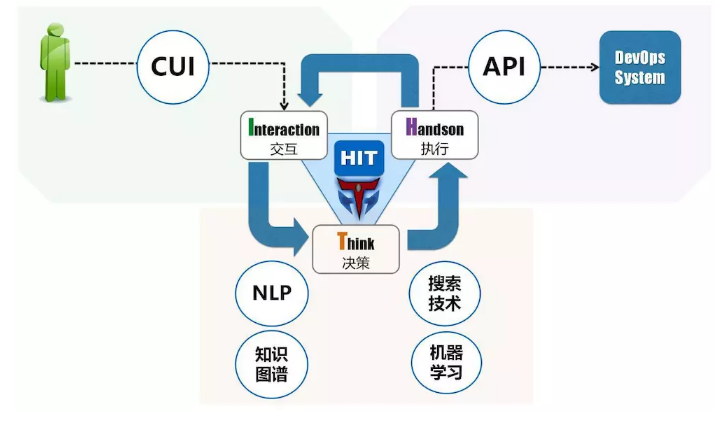
ЮвУЧ AI ЕФЪЕЯжаЮЬЌЪЧШЮЮёЛњЦїШЫЃЈДњКХ HITЃЉЁЃЫќЪЧЭГСьжЧФмдЫЮЌЕФЁАДѓФдЁБЃЌЪЧРрШЫааЮЊЕФШэМўЯЕЭГЁЃШЮЮёЛњЦїШЫгІИУОпБИвдЯТФмСІЃК
HIT ЕФЩшМЦРэФюОЭЪЧЖдШЮЮёЛњЦїШЫФмСІЕФГщЯѓЁЃЫќгЩШ§жжКЫаФЗўЮёЙЙГЩЃК
1.InteractionЃКНЛЛЅЁЃЪЕЯжгыШЫРрЗЧ GUI НЛЛЅНчУцЃЌФПЧАЪЕЯжСНИіЗНУцЃКЮФзжНЛЛЅ
CUIЃЈФкВПЯЕЭГСФЬь / ЭЈжЊЃЌЙЋЙВ IM ЯЕЭГЃЌБШШчЮЂаХ /QQЃЉЃЌгявєЪЖБ№гыгявєКЯГЩЃЈЪжЛњжеЖЫЩшБИЃЉЁЃЫќЪЧШЫгыЯЕЭГНЛСїЕФжаНщЃЌЦ№ЕНЗвыаХЯЂЃЌДЋВЅаХЯЂЕФзїгУЃЌЪЙЕУШЫВЛдйашвЊБЛАѓЖЈдкЬиЖЈЯЕЭГНчУцВХФмЭъГЩЯрЙиЙЄзїЁЃ
2.ThinkЃКОіВпЁЃетЪЧгыздЖЏЛЏЕФКЫаФЧјБ№ЃЌЫќашвЊЭЈЙ§РэНтШЫРрЕФвтЭМЃЌЭЌЪБЪеМЏжДааЛЗОГЕФЩЯЯТЮФЃЌИљОнвтЭМРДАВХХжДааМЦЛЎЃЌвдМАЖджДааМЦЛЎзіГіЕїећЁЃЭЌЪБЃЌдкЪЕМЪжДааЙ§ГЬжаЭЈЙ§Жд
Interaction ЕФЗДРЁЃЌНЋжДааМЦЛЎвдМАжДааЙ§ГЬаХЯЂвдРрШЫЛЏЗНЪНУшЪіЃЈздШЛгябдЃЉЁЃЫќЪЙгУЕФКЫаФММЪѕАќРЈздШЛгябдДІРэЃЌжЊЪЖЭМЦзЃЌЛњЦїбЇЯАЃЌЫбЫїММЪѕЁЃ
3.HandsonЃКжДааЁЃетЪЧгыСФЬьЛњЦїШЫЕФКЫаФЧјБ№ЃЌИљОн Think
ЬсЙЉЕФжДааМЦЛЎЃЌЪЪХфМЦЛЎжаЯрЙиЯЕЭГЕФ APIЃЌЭъГЩЪЕМЪЕФЗўЮёСїГЬБрХХвдМАЗўЮёСїГЬжДааЁЃЭЌЪБЃЌЫќЛЙашвЊИј
Think ЬсЙЉЗДРЁЃЌвдЪЕЯжЕќДњОіВпЃЈЗДРЁ + ЕїећЃЉЃЛЫќвВНЋжДааЙ§ГЬвдМАжДааНсЙћЗДРЁИј InteractionЃЌАяжњШЫСЫНтжДаазДЬЌЃЈЗЧздШЛгябдЃЉ
ТфЕиЗНАИ
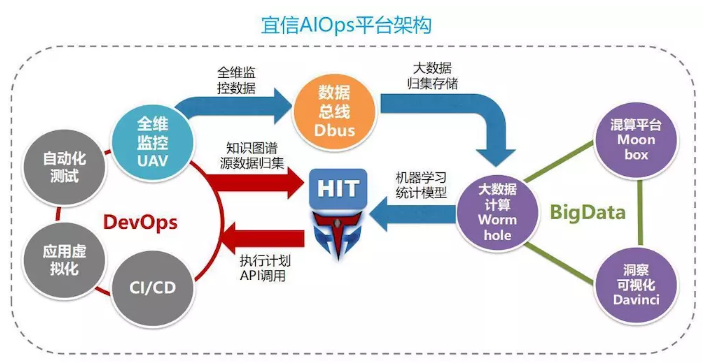
ЮвУЧЕФ AIOps ЦНЬЈЪЧвдШЮЮёЛњЦїШЫЮЊжааФЃЌРћгУДѓЪ§ОнЦНЬЈЪЕЯжЛњЦїбЇЯАКЭЭГМЦФЃаЭЕФДІРэЃЌгы
DevOps ЙЄОпСДЩюЖШМЏГЩЪЕЯжжЧФмЛЏдЫЮЌЁЃПЩвдДгвдЯТМИИіВуУцРДНтЖСетИіМмЙЙЃК
DevOps ЙЄОпСДЮЊШЮЮёЛњЦїШЫ HIT ЕФжЊЪЖЭМЦзЙЙНЈЬсЙЉСЫИпжЪСПЕФдЪМЪ§Он
ШЮЮёЛњЦїШЫ HIT ЕФКЫаФФмСІРДдДгкЬиЖЈСьгђЕФжЊЪЖЭМЦзКЭМЦЫуФЃаЭЁЃФПЧАЮвУЧЕФбЕСЗСьгђАќРЈЯЕЭГ
API ФЃаЭЃЌИіадЛЏНЛСїЩЯЯТЮФЃЌЗўЮёЭиЦЫЃЌжДааМЦЛЎЃЌЮЪЬтеяЖЯЕШЁЃжЊЪЖЭМЦзЪЧЪЕЯжШЯжЊЙиСЊЕФКЫаФММЪѕЃЌЖјШчКЮздЖЏЛЏЙЙНЈжЊЪЖЭМЦзЪЧЙиМќЕФЙиМќЁЃГЩЪьЕФ
DevOps ЙЄОпСДПЩвдЮЊздЖЏЛЏЙЙНЈжЊЪЖЭМЦзЬсЙЉИпжЪСПЕФдЪМЪ§ОнЁЃ
API ФЃаЭАќРЈСЫгІгУ / ЗўЮёЕФ API дЊЪ§ОнаХЯЂКЭЪЕР§аХЯЂЃЌетаЉаХЯЂБиаыЪБПЬгыЯжЪЕЪРНчБЃГжЭЌВНЁЃЖјШЋЮЌМрПи
UAV ЬсЙЉСЫгІгУЛЯёЪ§ОнЃЌгЩгк UAV БОЩэВЩгУСЫЮЂжЧФмЃЈЧПЕїздЖЏЗЂЯжЃЌздЮвЮЌЛЄЃЌздЖЏЪЪгІЃЉЕФЩшМЦЃЌЪЙЕУгІгУЛЯёЪ§ОнБОЩэОЭЪБПЬгыЯжЪЕЪРНчБЃГжЭЌВНЁЃШЮЮёЛњЦїШЫ
HIT ЭЈЙ§жБНгЙщМЏгІгУЗўЮёЛЯёЪ§ОнЃЌАДее API ФЃаЭЕФШЯжЊЙиСЊНсЙЙЃЌОЭПЩвдЩњГЩ API ФЃаЭЁЃЖјЮЂжЧФмЕФЬиадЬьШЛЕФЁЂИпжЪСПЕФБЃеЯСЫздЖЏЛЏ
API ФЃаЭЕФжЊЪЖЭМЦзЙЙНЈЁЃ
СэвЛИіР§згЃЌЗўЮёЭиЦЫЪЧЗДгІЗўЮёжЎМфЕФЙиСЊЙиЯЕЃЌдкЮЂЗўЮёМмЙЙЯТЃЌетжжЙиСЊЙиЯЕвВБфЕУШевцИДдгЁЃШЋЮЌМрПи
UAV ЬсЙЉСЫЗўЮёЭМЦзЃЌЫќвВЪЧЛљгкЮЂжЧФмЫМЯыЕФЪ§ОнЃЌПЩвдМАЪБЕигыЯжЪЕЪРНчЭЌВНЁЃHIT вВжЛашвЊЙщМЏЗўЮёЭМЦзЃЌАДееЗўЮёЭиЦЫЕФШЯжЊФЃаЭРДЙЙНЈжЊЪЖЭМЦзМДПЩЁЃ
ДЫЭтЃЌЕїгУСДЕФЪ§ОнПЩвдАяжњздЖЏЙЙНЈЪБађЙиЯЕЃЌCI/CD ЕФЯюФПЬиеїКЭШЫдБЙиСЊЪ§ОнПЩвдАяжњЙЙНЈгІгУгыЭХЖгЕФгГЩфЙиСЊЃЈДгЙЪеЯЮЪЬтЕНгІгУЃЌдйЕНДњТыКЭШЫдБЕФзЗЫнЃЉЃЌВтЪдгУР§ЕФЪфШыКЭЪфГіПЩвдАяжњЙЙНЈ
API ФЃаЭЕФВЮЪ§ЙиЯЕЃЌгявхЙиСЊКЭШБЪЁВЮЪ§ЕШЁЃ
ШЋЮЌМрПи UAV ЮЊШЮЮёЛњЦїШЫ HIT ЕФФЃаЭбЕСЗЬсЙЉСЫШЋУцЮЌЖШЕФдЪМЪ§Он
UAVStack жа Monitor+APM ЮЊЪЕЪБМрПи + гІгУЩюЖШдЫЮЌЬсЙЉСЫНтОіЗНАИЃЈШчЭМЃЉЁЃдкжЧФмдЫЮЌЬхЯЕжаЃЌЫќВЩМЏЕФШЋЮЌЖШМрПиЪ§ОнЪЧЛњЦїбЇЯАКЭЭГМЦФЃаЭЕФдЪМЪ§ОнРДдДЁЃШЋЮЌЖШЕФМрПиЪ§ОнИВИЧЛљДЁЩшЪЉадФмЃЌгІгУ
/ ЗўЮёадФмЃЌШежОЃЌЕїгУСДЃЌЯпГЬеЛЃЌПЭЛЇЖЫЬхбщЃЌвЕЮёжИБъЃЌгІгУЛЯёЃЌЗўЮёЭМЦзЁЃ
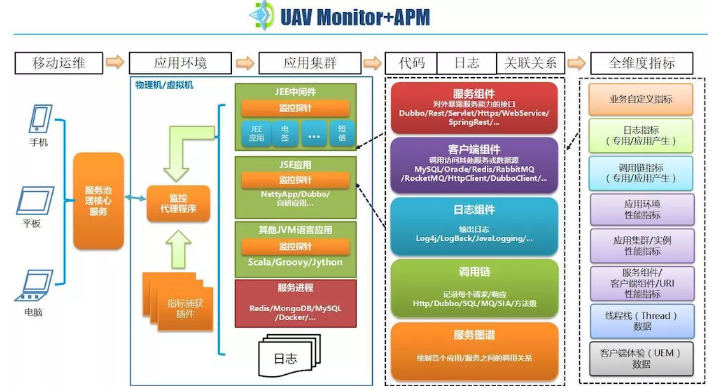
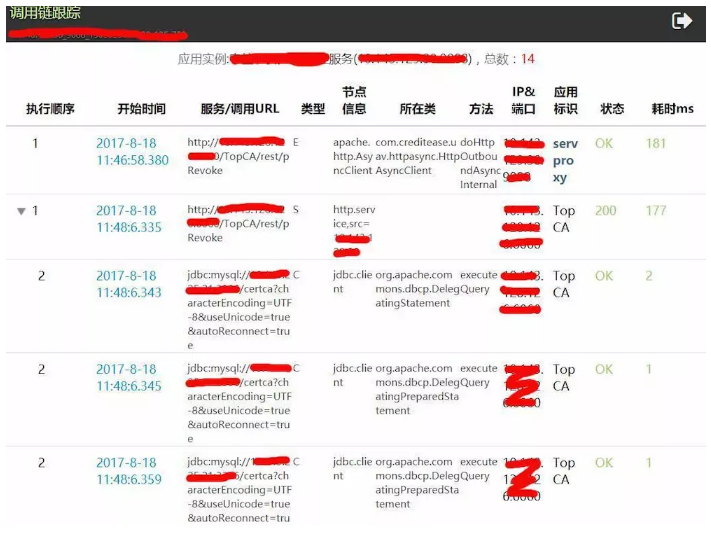
гІгУ / ЗўЮёЛЯёЃКМрПиЬНеыздЖЏЖдгІгУЕФММЪѕеЛНјааЗжЮіЬсШЁгІИУЕФдЊЪ§ОнЃЌЦфжаживЊЕФАќРЈгІгУЪЕР§ЕФ URLЃЌгаФФаЉЗўЮёНгПкЗНЗЈвдМА
URLЃЌЪЙгУСЫФФаЉПЭЛЇЖЫЃЈMQ/DB/Redis/NoSQL/Http/Dubbo ЕШЃЉвдМАЗУЮЪЕФ
URLЁЃ

гІгУ / ЗўЮёЛЯёЪ§ОнЪОР§
гІгУадФмжИБъЃКАќРЈгІгУМЏШКЃЌгІгУЪЕР§ЃЌгІгУжаМфМў /JVMЃЌЗўЮёзщМўЃЌПЭЛЇЖЫзщМўЃЌURLЃЌЪ§ОнПтСЌНгГиЕШадФмжИБъ
гІгУШежОЃКгІгУВњЩњЕФИїжжШежОЃЌжЇГжЙ§ТЫЙцдђЁЃ
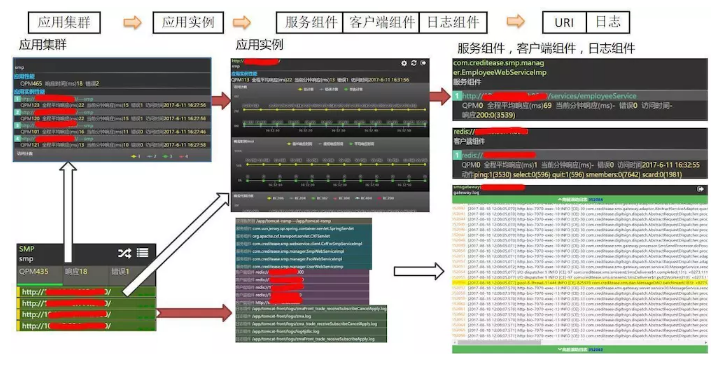
гІгУадФмжИБъ & ШежОЪ§ОнЪОР§
гІгУЛЗОГадФмжИБъЃКащФтЛњ / ЮяРэЛњЯЕЭГМЖвдМАНјГЬМЖжИБъЃЌР§Шч CPUЃЌФкДцЃЌСЌНгЪ§ЃЌЭјТчСїСПЃЌДХХЬ
IO ЕШ
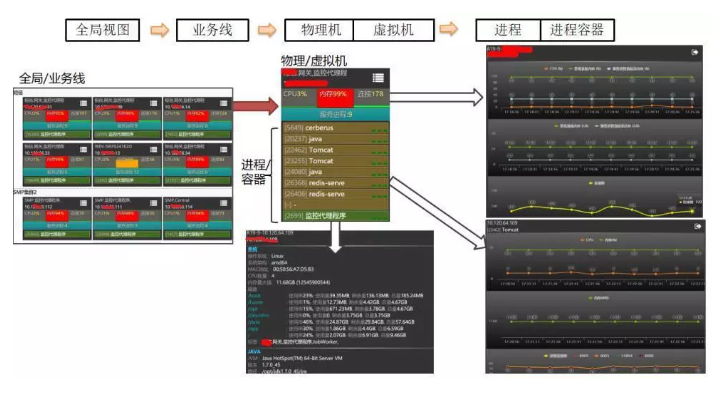
гІгУЛЗОГадФмжИБъЪ§ОнЪОР§
ЕїгУСДЃКАќКЌЗўЮё / ПЭЛЇЖЫ / ЗНЗЈМЖЃЌЫљдкРр / ЗНЗЈЃЌКФЪБЃЌзДЬЌЃЌЧыЧѓБЈЮФЃЌЯьгІБЈЮФЕШ
ЕїгУСДЪ§ОнЪОР§ЗўЮёЭМЦзЃКздЖЏЩњГЩЗўЮёжЎМфЕФЕїгУЙиСЊЙиЯЕ
ЗўЮёЭМЦзЪ§ОнЪОР§ЯпГЬеЛЪ§ОнЃКJVM ЯпГЬ Dump+ УПИіЯпГЬЕФ cpuЃЌФкДцЯћКФЕФЪ§Он
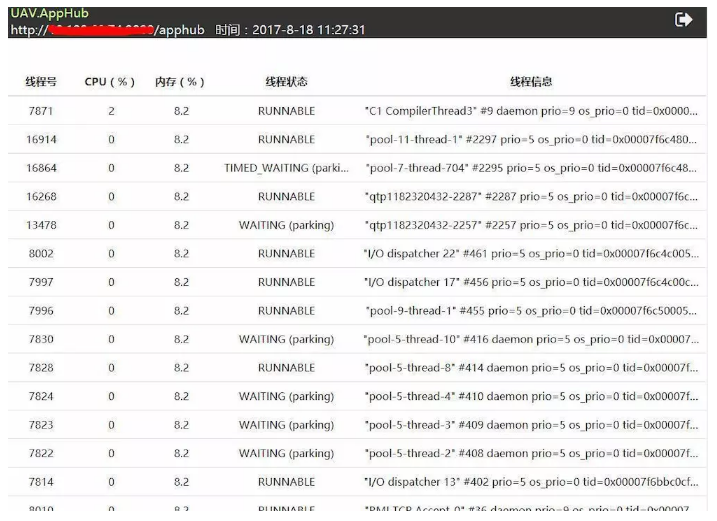
ЯпГЬеЛЪ§ОнЪОР§
Web фЏРРЦїПЭЛЇЖЫЬхбщЪ§ОнЃКвГУцМгдиЃЌРыПЊвГУцЃЌJS ДэЮѓЃЌAjax
ЧыЧѓЃЌЕиРэаХЯЂЃЌПЭЛЇЖЫ IP ЕШ
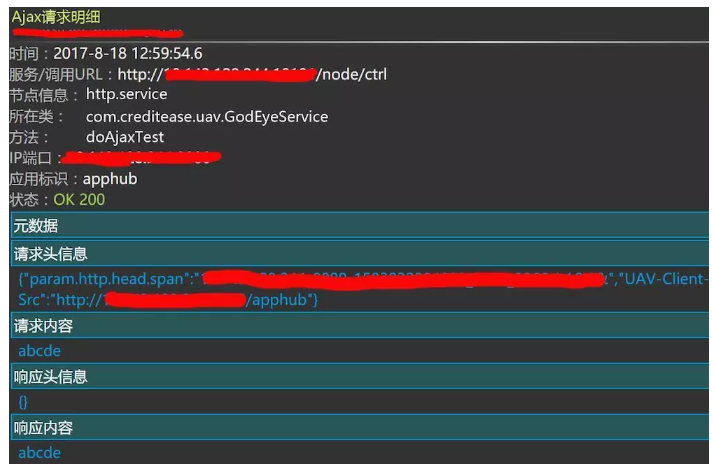
Web фЏРРЦїПЭЛЇЖЫЬхбщЪ§ОнЃЈAjaxЃЉЪОР§
вЕЮёжИБъЃКгІгУПЩвдЭЈЙ§ТёЕуЛђШежОЗНЪНЬсЙЉздЖЈвхжИБъ
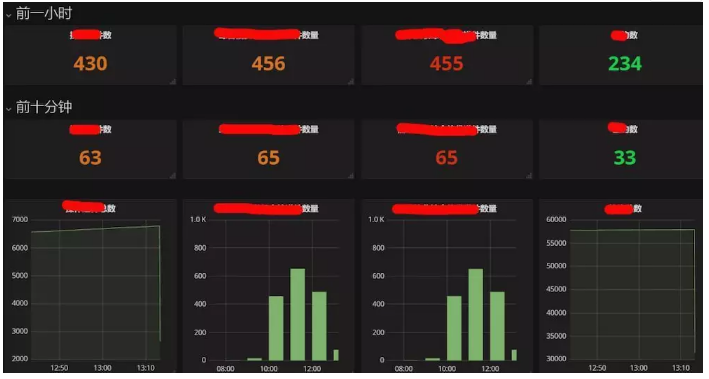
вЕЮёжИБъЪ§ОнЪОР§
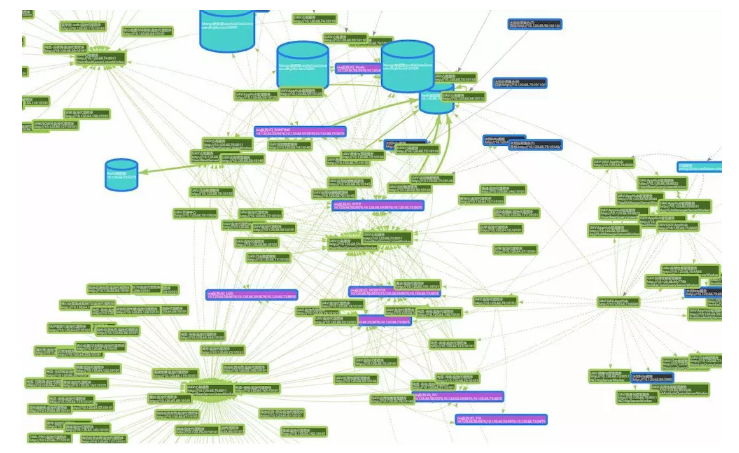
Ъ§ОнзмЯп DBus ГжајЕФЃЌздЪЪгІЕФНЋШЋЮЌМрПиЪ§ОнЕМШыДѓЪ§Он
ДцДЂОЁЙмЭЈЙ§ UAV ВЩМЏЕНСЫШЋЮЌЖШЕФМрПиЪ§ОнЃЌЕЋЪЧЛЙВЛФмжБНгЪЙгУетаЉЪ§ОнРДзіЛњЦїбЇЯАКЭЭГМЦФЃаЭЁЃЦфдвђЪЧгЩгкЫќУЧЕФДцДЂКЭВщбЏашЧѓЪЧИљОнЪЕЪБМрПиСьгђЕФашвЊРДЖЈвхЕФЃЌвђДЫЫќУЧгавдЯТЬиЕуЃК
1.БЛДцДЂдкВЛЭЌЕФДцДЂдДжаЃЌР§ШчЗўЮёЛЯёЪ§ОнДцДЂдк MongoDBЃЌгІгУШежОКЭЕїгУСДДцДЂдк
Elastic Search жаЃЌгІгУадФмжИБъКЭЛљДЁадФмжИБъЪ§ОнДцдк RocketMQ жаЕШЃЛ
2.газХИїздВЛЭЌЕФ schema ЖЈвхЃЌР§Шч BIN ШежОИёЪНЃЌJSON
ИёЪНЃЌPlain ШежОИёЪН, адФмжИБъЕФ schema гыЕїгУСДЕФ schema ЪЧВЛЭЌЕФЁЃ
3.ВЛЭЌЕФБфИќВпТдЃЌР§ШчЗўЮёЛЯёЪ§ОнЪЧИљОнгІгУЩ§МЖВЛЖЈЦкБфЛЏЕФЃЌШежОЪ§ОнвВПЩФмЪЧетбљЁЃ
4.Ъ§ОнзмЯп DBus е§ЪЧНтОіетШ§ИіЮЪЬтЕФСМЗНЁЃ
5.DBus ФмЙЛжЇГжЖржжЪ§ОндДЃЌжЛашЭЈЙ§ХфжУОЭПЩЪЕЯжЮоЧжШыЖдНгЁЃВЩМЏЖЫАќКЌСЫЪ§ОнПтЕФШежОВЩМЏЖЫЁЂШежОВЩМЏЖЫЁЂИїжжЛљгк
Flume здЖЈвхВхМўЕФВЩМЏЖЫЕШЃЌетаЉВЩМЏЖЫНЋЪ§ОнЪЕЪБЕФЭЌВНЕН Kafka жаЃЌЭъГЩЪ§ОнВЩМЏЙЄзїЁЃ
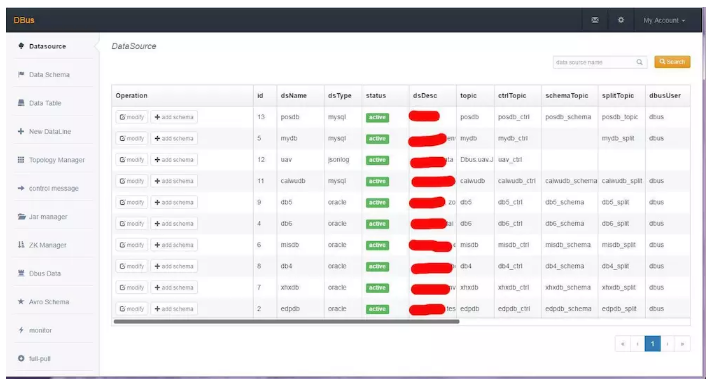
Dbus ЖрЪ§ОндДжЇГж
DBus ФмЙЛНЋВЛЭЌЕФИёЪНзЊЛЛГЩБъзМИёЪНЃЈUMS ИёЪНЃЉЁЃЫќЛсИљОнВЛЭЌЕФИёЪНКЭЖдЪ§ОнзЊЛЛКЭГщШЁЕФЯрЙиХфжУЃЌЖдЪ§ОнНјааЪЕЪБНтЮіКЭМЦЫуЁЃвдгІгУадФмжИБъКЭвЕЮёжИБъЮЊР§ЃКЪ§ОнИёЪНЪЧВЩгУ
MDF ЮФМўИёЪНЃЈUAV ЕФвЛжжИёЪНЃЉЃЌЫќЪЧвЛжж JSON ИёЪНЕФВуДЮЛЏЪ§ОнЃЌЖј DBus зюжеЪфГіЕФ
UMS Ъ§ОнИёЪНЪЧвЛжжвдБэЮЊЛљБОЕЅЮЛЕФЪ§ОнЃЌвђДЫашвЊНЋЪ§ОнНјааБтЦНЛЏЃЌвЛЬѕ MDF ШежОЖдгІЕФЖрЬѕ
UMS Ъ§ОнЁЃ
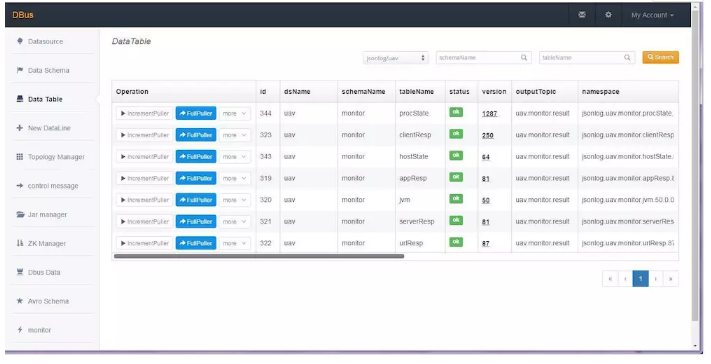
DBus жЇГжВЛЭЌИёЪНЕФБъзМЛЏ
DBus газдЖЏЪЪгІЕФФмСІЃЌЦЅХфетаЉРраЭКЭИёЪНЕФБфЛЏЁЃЫќжЇГжжИБъЖЏЬЌЬэМгЃЌОЭЫуУПДЮРДзд
UAV ЕФ MDF Ъ§ОнЖМДјРДаТЕФжИБъРраЭЃЌетаЉаТдіЕФжИБъвВВЂВЛЛсгАЯьНтЮіБОЩэЪ§ОнБОЩэЃЛЭЌЪБЃЌЫќЛЙжЇГжЖЏЬЌ
schema БфИќЃЌМДздЖЏИажЊЪ§ОнЕФСаУћКЭЪ§ОнРраЭЃЌUMS ИёЪНМЧТМСЫЪ§ОнЕФАцБОКЭСааХЯЂЕШЃЌвЛЕЉЗЂЯжВЛЪєгкЭЌвЛИіАцБОЕФЪ§ОнОЭЛсздЖЏЩ§МЖАцБОКХЃЌЩњГЩаТАцБОЕФЪ§ОнЁЃР§ШчШчЯТЕФаТАцБОБШОЩАцБОЖрСЫвЛИізжЖЮ
RC406ЃЈвЛжжгІгУадФмжИБъЃЌHttp ЯьгІТыЃЉЁЃ
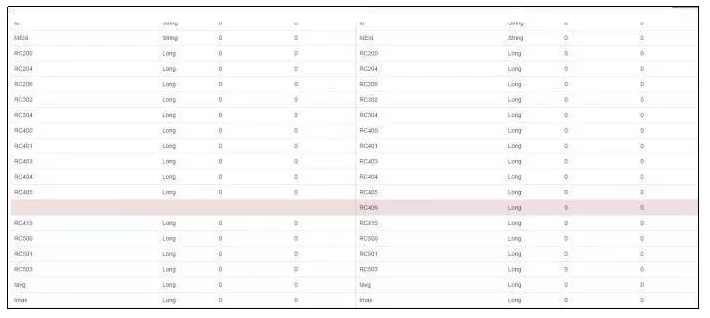
DBus здЖЏЪЪгІИёЪНАцБОБфИќ
ДѓЪ§ОнДІРэ Wormhole еыЖдФПБъГЁОАЃЌЛљгкШЋЮЌМрПиЪ§ОнНјааЛњЦїбЇЯАКЭЭГМЦФЃаЭДІРэ
Wormhole ЪЧШЮЮёЛњЦїШЫЕФМЦЫуФЃаЭЩњВњепЁЃWormhole Лљгк
SparkЃЌМШПЩНгШы Kafka дкЯпЪЕаЇЪ§ОнНјааСїЪНДІРэЃЌвВПЩНгШы HDFS РыЯпРњЪЗЪ§ОнНјааХњСПДІРэЃЌдк
Spark жЎЩЯЛЙГщЯѓГівЛЬзаТЕФИХФюКЭДІРэФЃаЭЃЌгУЛЇПЩвдЭЈЙ§ UI НјааМђЕЅХфжУРДЪЕЪЉКЭЙмРэСїЪНзївЕЃЌгУЛЇжЛвЊбЁдёЪ§ОнДгФФРяРДЕНФФРяШЅЃЌдкСїЩЯжДааЪВУДбљЕФТпММДПЩЦєЖЏвЛИіСїЪНзївЕЁЃWormhole
ВЛЙтжЇГжТфЕиЖр SinkЃЌЛЙжЇГжСїЩЯДІРэЃЌЛЙПЩвддкТф HBase жЎЧАСїЩЯзівЛаЉЪ§ОнЧхЯДРЉеЙЕШВйзїЁЃ
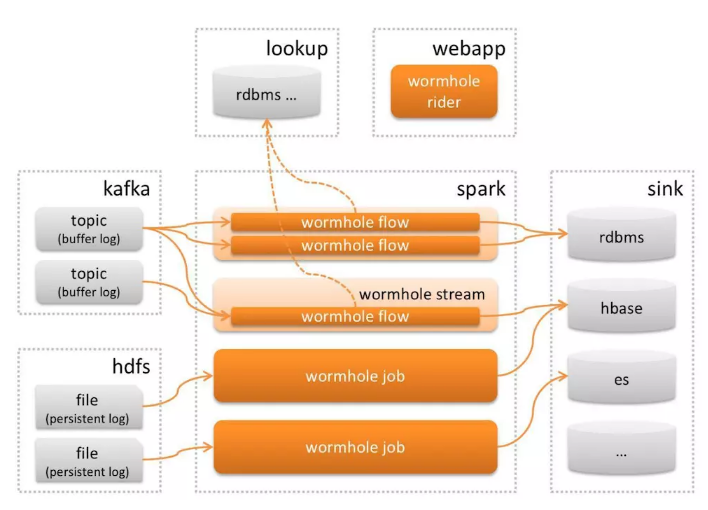
Wormhole ММЪѕМмЙЙ
ФПЧАЮвУЧЕФШЮЮёЛњЦїШЫ HIT ЕФбЕСЗжїЬтЁАЮЪЬтеяЖЯЁБЕФМЦЫуФЃаЭЖМЪЧгЩ
Wormhole РДЪЕЪЉбЕСЗЃЌЪЕМЪЩњВњЙ§ГЬжаЛсЪЙгУЛњЦїбЇЯАКЭФГаЉОЕфЭГМЦФЃаЭЃЌжївЊЕФгаЃК
ЪБађЪ§ОнЕФЧїЪЦдЄВтФЃаЭЃКПЩвдИљОнЙ§ШЅШєИЩЬьРДдЄВтЮДРДвЛЖЮЪБМфФГживЊжИБъЕФЧїЪЦзпЯђЁЃ
жИБъЕФЙиСЊзщКЯФЃаЭЃКЪЖБ№ГіФФаЉжИБъзщКЯЪЧХаЖЯвьГЃЕФГфЗжЬѕМўЁЃ
зщКЯжИБъЕФвьГЃЕуЪЖБ№ФЃаЭЃКзщКЯжИБъдкЪБађЩЯвьГЃЕуЕФздЖЏХаБ№ЁЃ
ЮЪЬтНкЕуЕФИљдДЗжЮіФЃаЭЃКПчЖрНкЕуЕФвьГЃааЮЊЙиСЊадЪЖБ№ФЃаЭЁЃ
ОйИіР§згЃЌШЮЮёЛњЦїШЫ HIT ИљОнжДааМЦЛЎЧ§ЖЏ Wormhole УПЪЎЗжжгДг
HBase ЩЯЬсШЁзюНќвЛИіЖЬЪБМфДАПкЕФЪ§ОнЃЈШєИЩЬьЃЉЃЌHIT ЭЈЙ§ЁАЮЪЬтеяЖЯЁБжЊЪЖЭМЦзбЁдёЃлЪБађЪ§ОнЕФЧїЪЦдЄВтФЃаЭЃнКЭЃлзщКЯжИБъЕФвьГЃЕуЪЖБ№ФЃаЭЃнЖдЪЎЗжжгдіСПЪ§ОнНјаавьГЃЕуЪЖБ№ЃЌВЂдЄВтГіЮДРДвЛаЁЪБЕФжИБъЧїЪЦЃЌВЂзіЪЪЕБЭГМЦОлКЯЃЌПЩвдЕУЕНвЛИібгГй
10 ЗжжгМЖБ№ЕФдіСПМрПижИБъзпЯђЃЌздЖЏЪЖБ№ЕФвьГЃЕуКЭЮДРДвЛаЁЪБЕФживЊжИБъЧїЪЦдЄВтЭМЃЌЭЌЪБвВПЩвдИљОнвьГЃЕуЕФбЯжиадМЖБ№НјаадЄОЏЁЃПЩвдПДЕНећИідЄОЏЬхЯЕЪЧЗЧШЫЙЄВЮгыЕФЃЌЛљгкЛњЦїбЇЯАФЃаЭКЭдіСПЪ§ОнзМЪЕЪБЕФЭЦЫуГіРДСЫЃЌЕБФЃаЭзМШЗТЪдНИпЃЌдЄОЏвВЛсИќОЋзМЁЃ
СэвЛИіР§згЃЌШЮЮёЛњЦїШЫ HIT ЭЈЙ§ЁАЮЪЬтеяЖЯЁБжЊЪЖЭМЦзбЁдё [жИБъЕФЙиСЊзщКЯФЃаЭ]
КЭ [ЮЪЬтНкЕуЕФИљдДЗжЮіФЃаЭ]ЃЌЭЈЙ§гІгУадФмжИБъЗЂЯж CPU КмИпЃЌЙиСЊЩЯЯпГЬеЛЪ§ОнОЭПЩвджЊЕРЪЧФФаЉЯпГЬв§Ц№СЫИп
CPUЃЌЯпГЬеЛЕФДњТыеЛгжПЩвдЙиСЊЕНЗўЮёЛЯёЃЌДгЖјЗЂЯжгыФФИіЗўЮёЕФ URL гаЙиЃЌЭЈЙ§ЗўЮё URL ЙиСЊЗўЮёадФмжИБъПЩеЦЮеЪЧЗёЪЧгЩИпВЂЗЂЗУЮЪв§Ц№ЕФЃЌЙиСЊЗўЮёЭМЦзПЩвдзЗЫнЪЧФФаЉЩЯгЮЯЕЭГдкЕїгУетИіЗўЮё
URLЃЌФФаЉЯТгЮЯЕЭГПЩФмЛсЪмгАЯьЃЌЙиСЊЕїгУСДЪ§ОнПЩвдзЗЫнЪЧФФаЉвЕЮёЧыЧѓв§Ц№ЕФЃЌЩѕжСЖдЯТвЛИіЪБЖЮетаЉвЕЮёЧыЧѓЗхжЕНјаадЄВтЁЃ
ШЮЮёЛњЦїШЫ HIT ЭЈЙ§ API ФЃаЭЪЕЪЉжДааМЦЛЎ
ШЮЮёЛњЦїШЫгыЦеЭЈЯЕЭГЕФСэвЛИіживЊЧјБ№ЪЧЃКЦеЭЈЯЕЭГПЩвдПДГЩЪЧЭЈЙ§БрТыРДЁАЛњаЕЁБЕФЭъГЩФГжжЪТЃЌОЭЯЕЭГБОЩэЖјбдЃЌЫќВЂВЛРэНтЁАЮвдкзіЪВУДЁБЁЃЖјШЮЮёЛњЦїШЫЪЧвдФПБъЧ§ЖЏЕФЃЌЫќИљОн
API ФЃаЭвдМАЦфЫћШЯжЊФЃаЭЃЈжЊЪЖЭМЦзЃЉРДЩњГЩжДааМЦЛЎЃЌВЂЪЙгУ API ФЃаЭРДЪЕЪЉжДааМЦЛЎЃЌжДааМЦЛЎЕФБОжЪЪЧЖд
DevOps ЯЕЭГ API ЕФЕїгУЁЃ
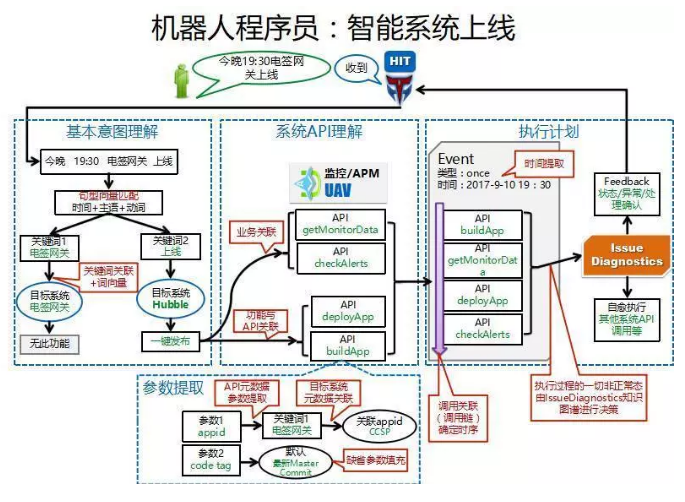
вдЯЕЭГЩЯЯпЮЊР§ЃЌЮвУЧИјШЮЮёЛњЦїШЫвЛИіФПБъЁАНёЭэ 19ЃК30 ЕчЧЉЭјЙиЩЯЯпЁБЁЃШЮЮёЛњЦїШЫЭЈЙ§ЁАЛљБОвтЭМРэНтЁБжЊЕРЪЧвЊЧ§ЖЏ
CI/CD ЯЕЭГ Hubble ЕФЁАвЛМќЗЂВМЁБЙІФмРДЗЂВМЁАЕчЧЉЭјЙиЁБетИіЯЕЭГЁЃAPI ФЃаЭАяжњШЮЮёЛњЦїШЫЭЈЙ§ЖдОфаЭЃЌЙиМќДЪЃЌЯрЙиадЕФЗжЮіЃЌРДЙиСЊЕН
CI/CD ЯЕЭГЃЌвВЭЈЙ§ЙІФмгы API ЕФЙиСЊЃЌЬсШЁГіРДашвЊ buildApp КЭ deployApp
СНИі APIЃЌЛЙАяжњЪЕЯжСЫСНИі API ЕФВЮЪ§ЬюГфЁЃзюКѓвРПП API ФЃаЭжаЕФЪБађЙиСЊРДШЗЖЈСЫМИИі
API ЕФжДааЫГађЃЌдйМгЩЯжДааЪБМфЃЌзюжеШЗЖЈСЫжДааМЦЛЎЁЃЕБШЛжДааМЦЛЎжДааЕФЙ§ГЬЛсвРРЕЁАЮЪЬтеяЖЯЁБЕФШЯжЊФЃаЭЁЃ
етжжФПБъЧ§ЖЏЕФгІгУГЁОАЛЙгаКмЖрЃЌР§ШчШУШЮЮёЛњЦїШЫШЅзіЯпЩЯЕФжЧФмбВМьЃЌажњЮЪЬтДІРэЃЌЩѕжСжЇГждЫгЊазїЕШЁЃ
AIOps ЭХЖгНЈЩшзюКѓРДЬИЬИЮвУЧЕФЭХЖгЁЃЯраХдкУцЖд AIOps ЕФЪБКђЃЌДѓМвЖМЛсЫМПМЭХЖгвЊШчКЮЙЙГЩЁЃЮвШЯЮЊ
AI ЕФЩњЬЌЬхЯЕгыДѓЪ§ОнРрЫЦЃЌДцдкСНжжЛљБОНЧЩЋЃКAI ПЦбЇМвКЭ AI СьгђЙЄГЬЪІЃЈFEЃЉЁЃЧАепЭЦЖЏ
AI ПЦбЇЕФЗЂеЙЃЌДДдьаТЕФ AI жЊЪЖЬхЯЕЃЛКѓепЪЧНЋ AI жЊЪЖдЫгУЕНЩњВњЩњЛюЕФФГИіСьгђЃЌДДдьЯжЪЕМлжЕЁЃ
ЮвУЧЭХЖгЕФЖЈЮЛЪЧ AI FEЃЌЪЧНЋ AI ММЪѕЙЄГЬЛЏЕФЭХЖгЃЌетбљЕФЭХЖггІИУОпБИМИИіЬиеїЃК
1.ЖдЯжга AI ММЪѕГфЗжСЫНтКЭеЦЮе
2.бЁдёНЯГЩЪьЕФПЊдД AI ММЪѕЪЧБигЩжЎТЗ
3.ЖддЫЮЌСьгђЕФММЪѕ (БШШчМрПиЃЌШнЦїММЪѕЃЌCI/CDЃЌЮЪЬтеяЖЯЕШ)
ЪЧЧхГўЕФЃЌзюКУЪЧзЈМв
4.ЖддЫЮЌСьгђЕФГЁОАЪЧЪьЯЄЕФЃЌУїАздЫЮЌЕФБъзМЃЌТпМЃЌддђ
ЮвУЧЕФЭХЖгжївЊгаСНРрНЧЩЋЃК
1.ЫуЗЈЪ§ОнЙЄГЬЪІЃКеЦЮеЫуЗЈММЪѕЃЌAI ММЪѕЃЌОпБИвЛЖЈЕФЙЄГЬЛЏФмСІЃЌСЫНтдЫЮЌСьгђжЊЪЖ
2.ЗўЮёКѓЬЈЙЄГЬЪІЃКеЦЮеЗўЮёЛЏММЪѕЃЌЖд AI ММЪѕгавЛЖЈСЫНтЃЌЪьЯЄбаЗЂ
/ ВтЪд / дЫЮЌЃЌОпБИдЫЮЌОбщ
ШЮЮёЛњЦїШЫЭХЖгдчЦкЪЧвдащФтЭХЖгЕФФЃЪНГЩСЂЁЃвђЮЊУцЖдаТЕФСьгђдкбаЗЂ /
дЫЮЌЬхЯЕЩЯашвЊГЂЪдаТЕФФЃЪНЃЌОЭАбЫуЗЈЭЌбЇЃЌКѓЬЈЗўЮёЭЌбЇЃЌдЫЮЌЭЌбЇЖМРЕНвЛПщЁЃЭЈЙ§жЊЪЖНЛЛЅЃЌОбщЗжЯэЕШЪжЖЮЃЌШУДѓМвж№ВНдкШЯЪЖЩЯЭЌВНЁЃВЂвЊЧѓЫљгаШЫеЦЮеећИіЖЫЕНЖЫЙ§ГЬЁЃДЫЭтЃЌЫцзХжЧФмЛЏдЫЮЌЕФПЊеЙЃЌUAVЃЌWormholeЃЌDBus
ЕШЭХЖгвВж№ВНдкМмЙЙЃЌММЪѕЃЌЖдНгЕШВуУцДяГЩвЛжТЁЃ
|








