| БрМЭЦМі: |
| БОЮФРДдДsohuЃЌБОЮФЪЧИљОнзїепЕФРэНтЃЌГЂЪдДгЯжЪЕЕФНЧЖШЃЌШЅЬИAIOps
дкТфЕиЙ§ГЬжаШнвзВњЩњЕФЮѓНтЃЌЬєеНвдМАвЛаЉНЈвщЁЃ |
|
БГОАИХФюЕФНјЛЏЃКITOA -> AIOps -> AIOps
ШУЮвУЧЛиЕН2013ФъЃЌжјУћЕФ Buzz word (ЪБїжгУгя) жЦдьЩЬ Gartner дквЛЗнБЈИцжаЬсМАСЫITOAЃЌЕБЪБЕФЖЈвхЪЧЃЌITдЫгЊЗжЮі(IT
Operations Analytics)ЃЌ ЭЈЙ§ММЪѕгыЗўЮёЪжЖЮЃЌВЩМЏЁЂДцДЂЁЂеЙЯжКЃСПЕФITдЫЮЌЪ§ОнЃЌВЂНјаагааЇЕФЭЦРэгыЙщФЩЕУГіЗжЮіНсТлЁЃ
ЖјЫцзХЪБМфЭЦвЦЃЌдк2016ФъЃЌGartner НЋITOA ИХФюЩ§МЖЮЊСЫ AIOpsЃЌдБОЕФКЌвхЛљгкЫуЗЈЕФITдЫЮЌ(Algorithmic
IT Operations)ЃЌМДЃЌЦНЬЈРћгУДѓЪ§ОнЃЌЯжДњЕФЛњЦїбЇЯАММЪѕКЭЦфЫћИпМЖЗжЮіММЪѕЃЌЭЈЙ§жїЖЏЃЌИіадЛЏКЭЖЏЬЌЕФЖДВьСІжБНгЛђМфНгЕиЃЌГжајЕидіЧПITВйзїЃЈМрПиЃЌздЖЏЛЏКЭЗўЮёЬЈЃЉЙІФмЁЃ
AIOpsЦНЬЈПЩвдЭЌЪБЪЙгУЖрИіЪ§ОндДЃЌЖржжЪ§ОнЪеМЏЗНЗЈЃЌЪЕЪБЗжЮіММЪѕЃЌЩюВуЗжЮіММЪѕвдМАеЙЪОММЪѕЁЃ
ЫцзХAIдкЖрИіСьгђдНРДдНЛ№БЌЃЌGartnerжегкАДорВЛзЁСЫЃЌдкЫќЕФ2017ФъФъжавЛЗнБЈИцжаЃЌЫГгІУёвтНЋAIOpsЕФКЌвхЖЈвхЮЊСЫЃЌArtificial
Intelligence for IT OperationsЃЌ вВОЭЪЧЯждкДѓМвЖМдкЫЕЕФжЧФмдЫЮЌЁЃ
дкЖЬЖЬЕФВЛЕН1ФъЪБМфжаЃЌАщЫцзХAIЕФШШГДЃЌвдМАдкИїИіСьгђЕФТфЕиЃЌдЫЮЌНчЕФЭЌШЪЛљБОЩЯАбAIOps ПДГЩЪЧЮДРДНтОідЫЮЌЮЪЬтЕФБиШЛЗНЯђЁЃ
ИіШЫШЯЮЊЃЌдкЦѓвЕФкВПЙЙНЈAIOpsЃЌЭЈЙ§ШкКЯITЪ§ОнЃЌеце§ДђЦЦЪ§ОнбЬДбЃЌЖдМрПиЃЌздЖЏЛЏЃЌЗўЮёЬЈНјаажЇГжЃЌЪЙЕУITФмЙЛИќКУЕФжЇГХвЕЮёЃЌРћгУДѓЪ§ОнММЪѕвдМАЛњЦїбЇЯАММЪѕЃЌЛиД№вдЧАКмЖрЕЅДгвЕЮёПкОЖЃЌЛђепЕЅДгITПкОЖЮоЗЈЛиД№ЕФЮЪЬтЁЃШчЃЌСЊЭЈЃЌЕчаХЃЌвЦЖЏЃЌЕчаХЕФгУЛЇЃЌФФжжгУЛЇзЊЛЏТЪНЯИпЁЃAIOpsвдДДдьЩЬвЕМлжЕЮЊЕМЯђЃЌЖдIT
дЫгЊвдМАвЕЮёдЫгЊВњЩњГжајЖДВьЃЌЮЊDevOps ЬсЙЉГжајЗДРЁЃЌМгПьЦѓвЕдкОКељШеЧїМЄСвЪаГЁЛЗОГжаЃЌЪ§зжЛЏзЊаЭЕФВНЗЅЁЃ
вђДЫЃЌGartner дЄВтЕН2022ФъЃЌДѓаЭЦѓвЕжаЕФЕФ40%НЋЛсВПЪ№AIOpsЦНЬЈЁЃ
ОпЬхЙигкAIOpsЕФИХФюЃЌМлжЕЃЌGartner КмЖрЖМвбОЫЕЕФКмЧхГўЃЌВЛЪЧБОЮФЕФжиЕуЃЌБОЮФЪЧИљОнЮвЕФРэНтЃЌГЂЪдДгЯжЪЕЕФНЧЖШЃЌШЅЬИAIOps
дкТфЕиЙ§ГЬжаШнвзВњЩњЕФЮѓНтЃЌЬєеНвдМАвЛаЉНЈвщЁЃ
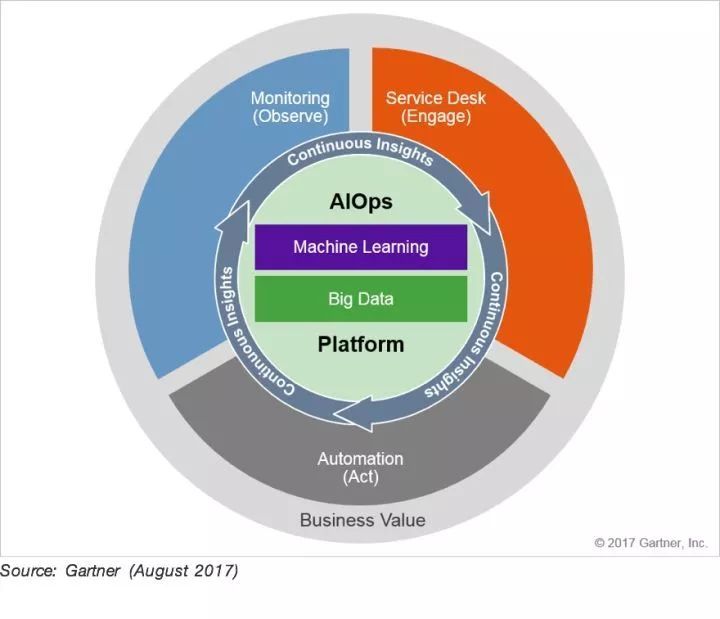

AIOps ЫљгІОпБИММЪѕФмСІЗжЮі
ИіШЫШЯЮЊЃЌAIOpsЃЌБОжЪЩЯЪЧITOA ЕФЩ§МЖАцЃЌШУЮвУЧРДПДвЛЯТ Garnter дк2015ФъЖдITOA
ЕФЫљгІИУгаЕФФмСІЖЈвхЁЃ

ML/SPDR: ЛњЦїбЇЯА/ЭГМЦФЃЪНЗЂЯжгыЪЖБ№
UTISI: ЗЧНсЙЙЛЏЮФБОЫїв§ЃЌЫбЫївдМАЭЦЖЯ
Topological Analysis: ЭиЦЫЗжЮі
Multi-dimensional Database Search and Analysis:ЖрЮЌЪ§ОнПтЫбЫїгыЗжЮі
Complex Operations Event Processing: ИДдгдЫЮЌЪТМўДІРэ
ШЛКѓЃЌ ЮвУЧЖдБШвЛЯТЃЌGartner ЖдAIOps ЕФФмСІЖЈвх
Historical data management РњЪЗЪ§ОнЙмРэ
Streaming data management СїЪ§ОнЙмРэ
Log data ingestion ШежОЪ§ОнећКЯ
Wire data ingestion ЭјТчЪ§ОнећКЯ
Metric data ingestion жИБъЪ§ОнећКЯ
Document text ingestion ЮФБОЪ§ОнећКЯ
Automated pattern discovery and prediction здЖЏЛЏФЃЪНЗЂЯжКЭдЄВт
Anomaly detection вьГЃМьВт
Root cause determination ИљвђЗжЮі
On-premises delivery ЬсЙЉЫНгаЛЏВПЪ№
Software as a service ЬсЙЉSaaSЗўЮё
Г§ШЅзюКѓСНИіЕФНЛИЖЗНЪНЃЌЖдБШЯТРДЃЌЮвШЯЮЊAIOps БШЦ№дРДЕФITOA гавдЯТЕФНјЛЏЃК
ЧПЕїРњЪЗЪ§ОнЕФЙмРэЃК
дЪаэВЩМЏЃЌЫїв§КЭГжајДцДЂШежОЪ§ОнЃЌЭјТчЪ§ОнЃЌжИБъвдМАЮФЕЕЪ§ОнЃЌЪ§ОнДѓВПЗжЪЧЗЧНсЙЙЛЏЛђепАыНсЙЙЛЏЕФЃЌЖјЧвЪ§ОнСПРлЛ§ЫйЖШКмПьЃЌИёЪНЖрбљЃЌЗЧГЃЗћКЯДѓЪ§ОнЕФЬиеїЁЃзмЫљжмжЊЃЌдкаТвЛТжвдCNN
, RNN ЫуЗЈЮЊДњБэЕФЫуЗЈжаЃЌЖМашвЊДѓСПгаБъзМЕФЪ§ОнРДНјаабЕСЗЃЌвђДЫЃЌ ЖдРњЪЗЪ§ОнЕФЙмРэЃЌГЩСЫжЧФмдЫЮЌЕФЕквЛжиЕуЁЃ
ЧПЕїЪЕЪБЕФСїЪ§ОнЙмРэЃК
вдKafka StreamsЃЌFlinkЃЌStormЃЌSpark Streaming ЮЊДњБэЕФСїМЦЫуДІРэММЪѕЃЌвбОГЩЮЊСЫИїДѓЪ§ОнЦНЬЈЕФБиБИзщМўЃЌЖјУцЖдIT
Ъ§ОнжаКЃСПЕФЪЕЪБСїЪНЪ§ОнЃЌФГаЉГЁОАРяЭЗЃЌдкЪ§ОнНјааГжОУЛЏЧАЃЌНјааЪЕЪБЗжЮіЃЌВщбЏЃЌМЏКЯЃЌДІРэЃЌНЕЕЭЪ§ОнПтЃЈSQL
or NosqlЃЉЕФИКдиЃЌГЩЮЊСЫЗЧГЃКЯРэЧвГЃЙцЕФбЁдёЃЌвђДЫAIOpsЦНЬЈжаЃЌКЌгаЪ§ОнСїЃЌЗЧГЃКЯРэЁЃ
ЧПЕїЖржжЪ§ОндДЕФећКЯ:
ЮвШЯЮЊЃЌетИіЪЧAIOpsЦНЬЈзюДѓЕФМлжЕЕуЃЌвђЮЊGartnerЕквЛДЮНЋЖржжЪ§ОндДећКЯЕФФмСІЃЌДјШыСЫITOM
ЙмРэЕФСьгђЃЌЮвУЧИудЫЮЌМрПиФЧУДЖрФъЃЌжегкЕквЛДЮПЩвдвдДѓЪ§ОнЕФЪгНЧЃЌЪ§ОнЧ§ЖЏЕФЪгНЧЃЌШЅЫМПМдЫЮЌМрПиетИіДЋЭГЕФааЕБЁЃ
Gartner етРяЬсМАЕНСЫЫФжжЪ§ОнЃЌLog Data, Wire Data, Metirc dataЃЌDocument
textЁЃ етбљЕФЗжРрЃЌЮвЪЧИіШЫГжгаБЃСєвтМћЃЌИаОѕКмЦцЙжЃЌЬиБ№ЪЧ Document text ЕФФЧПщЃЌашвЊгУЕНNLPЃЌжївЊЪЧгУгкДђЭЈITSM
ВњЦЗЃЌЗжЮіITSM ЙЄЕЅЁЃЮвЖдетИіГЁОАДцдкБивЊадЃЌвдМАЪЕЯжЕФROI БэЪОЛГвЩЁЃОпЬхдвђЮвПЩФмЩдКѓЛсаДвЛЦЊЮФеТЃЌНјааИќЯъЯИЕФНтЪЭЁЃ
ЮвШЯЮЊЃЌШчЙћДгКъЙлЕФРраЭРДЛЎЗжЃЌгІИУетбљЛЎЗж ЃЈЯТКЌВПЗжЮвЫОВњЦЗНщЩмЃЉ
ЛњЦїЪ§ОнЃЈMachine DataЃЉЃКЪЧITЯЕЭГздМКВњЩњЕФЪ§ОнЃЌАќРЈПЭЛЇЖЫЁЂЗўЮёЦїЁЂЭјТчЩшБИЁЂАВШЋЩшБИЁЂгІгУГЬађЁЂДЋИаЦїВњЩњЕФШежОЃЌМА
SNMPЁЂWMIЃЌМрПиНХБОЕШЪБМфађСаЪТМўЪ§ОнЃЈКЌCPU ФкДцБфЛЏЕФГЬЖШЃЉЃЌетаЉЪ§ОнЖМДјгаЪБМфДСЁЃетРявЊЧПЕїЃЌ
Machine Data ВЛЕШгкLog Data ЃЌвђЮЊжИБъЪ§ОнАќКЌЁЃдкЭЈГЃЕФвЕНчЪЕМљжаЃЌетаЉЪ§ОнЭЈГЃЭЈЙ§дЫаадкжїЛњЩЯЕФвЛИіAgentГЬађЃЌШчLogStashЃЌ
File beatЃЌZabbix agent ЕШЛёЕУЃЌШчЙћЮвУЧЕФLogInsightЃЌServer
Insight ВњЦЗЃЌОЭЪЧУцЯђДЫРраЭЪ§ОнЁЃ
ЭјТчЪ§ОнЃЈWire DataЃЉЃКЯЕЭГжЎМф2~7ВуЭјТчЭЈаХавщЕФЪ§ОнЃЌПЩЭЈЙ§ЭјТчЖЫПкОЕЯёСїСПЃЌНјааЩюЖШАќМьВт
DPIЃЈDeep Packet InspectionЃЉЁЂАќЭЗШЁбљ Netflow ЕШММЪѕЗжЮіЁЃвЛИі10GbpsЖЫПквЛЬьВњЩњЕФЪ§ОнПЩДя100TBЃЌАќКЌЕФаХЯЂЗЧГЃЖрЃЌЕЋвЛаЉадФмЁЂАВШЋЁЂвЕЮёЗжЮіЕФЪ§ОнЮДБиЭЈЙ§ЭјТчДЋЪфЃЌвЛаЉЪТМўЕФЗЂЩњвВЮДБЛДЅЗЂЭјТчЭЈаХЃЌДгЖјЮоЗЈЛёЕУЁЃЮвЫОЕФNetwork
Insight жївЊУцЯђЕФЪЧетаЉЪ§ОнЃЌЬсЙЉЙиМќгІгУЕФ 7 x 24 аЁЪБШЋЗНЮЛЪгЭМЁЃ
ДњРэЪ§ОнЃЈAgent DataЃЉЃКЪЧдк .NETЁЂPHPЁЂJava зжНкТыРяВхШыДњРэГЬађЃЌДгзжНкТыРяЭГМЦКЏЪ§ЕїгУЁЂЖбеЛЪЙгУЕШаХЯЂЃЌДгЖјНјааДњТыМЖБ№ЕФМрПиЁЃЮвЫОЕФApplication
InsightжївЊЪЧНтОіетИіЮЪЬтЖјЕЎЩњЃЌФмЛёЕУеце§гУЛЇЬхбщЪ§ОнвдМАгІгУадФмжИБъЁЃ
ЬНеыЪ§ОнЃЈProbe DataЃЉЃКвВОЭЪЧЫљЮНЕФВІВтЃЌЪЧФЃФтгУЛЇЧыЧѓЃЌЖдЯЕЭГНјааМьВтЛёЕУЕФЪ§ОнЃЌШч
ICMP pingЁЂHTTP GETЕШЃЌФмЙЛДгВЛЭЌЕиЕуФЃФтПЭЛЇЖЫЗЂЦ№ЃЌНјааАќРЈЭјТчКЭЗўЮёЦїЕФЖЫЕНЖЫШЋТЗОЖМьВтЃЌМАЪБЗЂЯжЮЪЬтЁЃ
ЮвЫОЕФCloud TestЃЌCloud Performance Test жївЊЪЧВњГіетаЉЪ§ОнЕФЃЌCTЕФВњЦЗФмДгБщВМШЋЧђЕФВІВтЕуЃЌЖдЭјеОЕФПЩгУадНјааШЋЬьКђЕФЗжВМЪНМрПиЁЃЦфжаЮвУЧЕФCPT
ИјФуДјРДДгЪ§АйЕНЪ§АйЭђЭъШЋЕЏадЕФбЙСІВтЪдФмСІЃЌЛёЕУгІгУдкИпбЙСІЕФЧщПіЯТЕФадФмБэЯжЧщПіЁЃ
вђЮЊIT МрПиММЪѕЗЂеЙЪЕдкЪЧЬЋХгдгЃЌвдЩЯЕФЛЎЗжВЛвЛЖЈЖдЃЌЕЋЪЧгІИУУЛгаЯджјЕФвХТЉЁЃ
ЕЋШчЙћДгЮЂЙлММЪѕЕФНЧЖШРДПДЃЌВЛПМТЧЪ§ОнЕФРДдДЃЌжЛПМТЧЪ§ОнБОЩэЕФЪєадЬиЕуЃЌЮвУЧПЩвдетбљЛЎЗжЃК
жИБъЪ§ОнЃЈ Metrics Data ЃЉ
УшЪіОпЬхФГИіЖдЯѓФГИіЪБМфЕуетИіОЭВЛгУЖрЫЕСЫЃЌ CPU АйЗжБШЕШЕШЃЌжИБъЪ§ОнЕШЕШ
ШежОЪ§Он ( Logging Data ЃЉ
УшЪіФГИіЖдЯѓЕФЪЧРыЩЂЕФЪТЧщЃЌР§ШчгаИігІгУГіДэЃЌХзГіСЫNullPointerExcepctionЃЌИіШЫШЯЮЊLogging
Data ДѓдМЕШЭЌгк Event DataЃЌЫљвдИцОЏаХЯЂдкЮвШЯЮЊЃЌвВЪЧвЛжжLogging DataЁЃ
ЕїгУСДЪ§ОнЃЈ Tracing Data ЃЉЃК
Tracing DataетДЪУВЫЦЯждкЛЙУЛгавЛИіШЈЭўЕФЗвыЗЖЪНЃЌгаШЫЗвыГЩИњзйЪ§ОнЃЌгаШЫЗвыГЩЕїгУЪ§ОнЃЌЮвОЁСПгУTracing
етИіДЪЁЃ TracingЕФЬиЕуОЭЪЧЃЌЫќдкЕЅДЮЧыЧѓЕФЗЖЮЇФкЃЌДІРэаХЯЂЁЃ ШЮКЮЕФЪ§ОнЁЂдЊЪ§ОнаХЯЂЖМБЛАѓЖЈЕНЯЕЭГжаЕФЕЅИіЪТЮёЩЯЁЃ
Р§ШчЃКвЛДЮЕїгУдЖГЬЗўЮёЕФRPCжДааЙ§ГЬЃЛвЛДЮЪЕМЪЕФSQLВщбЏгяОфЃЛвЛДЮHTTPЧыЧѓЕФвЕЮёадIDЁЃ ЭЈЙ§ЖдTracing
аХЯЂНјааЛЙдЃЌЮвУЧПЩвдЕУЕНЕїгУСД Call Chain ЕїгУСДЃЌЛђепЪЧ Call Tree ЕїгУЪ§ЁЃ

ЙйЗНOpenTracing жаЕФCall TreeР§згЁЃ
дкЪЕМљЕФЙ§ГЬжаЃЌКмЖрЕФШежОЃЌЖМЛсгаСїЫЎКХЃЌTrace IDЃЌ span IDЃЌ ChildOf,
FollowsFrom ЕШЯрЙиЕФаХЯЂЃЌШчЙћЭЈЙ§ММЪѕЪжЖЮЃЌНЋЦфДЎСЊдквЛЦ№ЃЌвВПЩвдНЋетаЉШежОЪгЮЊTracing
ЁЃ
TracingаХЯЂдНРДдНБЛжиЪгЃЌвђЮЊдквЛИіЗжВМЪНЛЗОГжаЃЌНјааЙЪеЯЖЈЮЛЃЌTracing Data ЪЧБиВЛПЩЩйЕФЁЃ
гЩгкTracing ЯрЖдгкLogging вдМА Metircs ЯрЖдБШНЯИДдгвЛЕуЃЌЯыЩюШыСЫНтЕФЛАЃЌПЩвдВЮПМ
ЃК
ЁЖDapper, a Large-Scale Distributed Systems Tracing
InfrastructureЁЗ bigbully.github.io/Dapp/
Opentracing ЕФММЪѕЙцЗЖЮФЕЕ github.com/opentracing/ШчЙћЮвУЧНЋвдЩЯЪ§ОнРраЭзіГЩвЛИіОиеѓПДПДЃЌЮвУЧПЩвдЕУЕНетбљвЛИіБэИёЃЌБШНЯКУЕФЫЕЧхГўСЫЯрЙиЙиЯЕЁЃ
ОйР§ОЭЪЧЃЌЮвУЧЕФServer Insight ЛљДЁМрПиВњЦЗЃЌФмВЩМЏМАДІРэжИБъЪ§ОнЃЌМАШежОЃЌЕЋЪЧЛљДЁМрПиВњЦЗЃЌВЛЛсДІРэTracing
DataЃЌЖјЮвУЧЕФApplication Insight ВњЦЗФмДгJVM ащФтЛњжаЃЌЭЈЙ§ВхТыЃЌЛёЕУгІгУЕФЯьгІЪБМфЃЈMetrisЃЉЃЌJavaвьГЃЃЈ
Logging ЃЉЃЌгІгУМфЕФЕїгУЭиЦЫЙиЯЕЃЌвдМАЕїгУЕФЯьгІЪБМфЃЈTracingЃЉЁЃ


ЮвЫОAI ЦНЬЈгІгУЭиЦЫНиЭМ
ЛиЕНGarnert ЕФAIOps ФмСІЖЈвхЃЌ ОгШЛУЛгаАб Tracing Data ФЩШыЕНЪ§ОнећКЯЕФЗЖЮЇжЎжаЃЌИіШЫШЯЮЊВЛЬЋКЯРэЃЌвђЮЊвЊШЅзіИљвђЗжЮіЃЌШчЙћВЛжЊЕРЗўЮёКЭжИБъжЎМфЕФЙиСЊЙиЯЕЃЌЦфЪЕЪЧБШНЯФбзіЕНЙЪеЯЕФИљБОЖЈЮЛЕФЁЃ
ЫуЗЈВПЗж
ЦфЪЕПЩвдПДЕНЃЌGartner дкITOA ЖЈвхЕФЫуЗЈВПЗжЃЌШчФЃЪНЗЂЯжЃЌЛњЦїбЇЯАЕШММЪѕЖЈвхЃЌЖМБЛБШНЯЫГЛЌЕФЙ§ЖЩЕНAIOPS
жаРДЃЌвЛИіЗНУцПЩвдПДГіGartner дкЖЈвхITOA ЕФЪБКђгазуЙЛЕФЧАеАадЃЌСэЭтвЛИіЗНУцПЩвдПДЕНЃЌЯрЙиЕФЫуЗЈЮЪЬтЃЌНтОіМАбнНјЕФЫйЖШЃЌЪЧЯрЖдгкЛљДЁДѓЪ§ОнМмЙЙЯрЖдвЊТ§ЩЯВЛЩйЁЃ
аЁНс
AIOPS ИХФюгы ITOA ИХФюЯрБШЃЌдкДѓЪ§ОнММЪѕВПЗжНјааСЫИќЯИЃЌИќгажИЕМадЕФВћЪіЃЌЫљвдЮвШЯЮЊЃЌAIOps
ЪзЯШЪЧДѓЪ§ОнЃЌШЛКѓВХЪЧЫуЗЈЁЃ
ЮѓНтЃКAIOps ЕШгкПЩвдМѕЩйШЫСІзЪдДЕФЭЖШы
AIOps ВЛЕШгкЮоШЫжЕЪи
AIOps ВЛЕШгк NoOps
AIOps ВЛЕШгкПЩвдМѕЩйШЫзЈМвЕФВЮгы
AIOps ПЩвдНЕЕЭШЫСІГЩБО
AIOps дкЯжНзЖЮВЛЕШгкПЩвдЪЁЧЎ
AI ЕФШЗЪЧвЛИіЗЧГЃадИаЕФДЪЛуЃЌДѓМвШЯЮЊжЛвЊЪЕЯжСЫжЧФмЛЏЃЌОЭФмЙЛЧсЧсЫЩЫЩЃЌВЛашвЊШЫЕФИЩдЄЃЌетЕБШЛЪЧвЛИіЗЧГЃРэЯыЕФзДПіЃЌЕЋЪЧЃЌдкЖЬЪБМфФкЃЌетИіВЛФмЪЕЯжЁЃетИіЕФЪЕЯжФбЖШЃЌИіШЫШЯЮЊЃЌгыздЖЏЮоШЫМнЪЛЃЌФмЪЕЯжЕкЮхЕШМЖЪЧЭЌбљЕФФбЖШЃЌвВОЭЫЕЃЌПЩФмЦ№ТыашвЊ10ФъзѓгвЕФЪБМфЃЌЩѕжСПЩФмИќГЄЪБМфЁЃ
AIOpsЦНЬЈБОжЪЩЯЛЙЪЧвЛИіЙЄОпЃЌдкЙЙНЈКѓЃЌШдШЛашвЊШЫЕФВЮгыЃЌЖјЧвдкФПЧАЕФЬНЫїЗЂеЙЕФЭЖШыНзЖЮЃЌгаДѓСПЕФЙЄашвЊШЅзіЃЌашвЊдЫЮЌзЈМвЃЌДѓЪ§ОнЙЄГЬЪІЃЌЫуЗЈПЦбЇМвЃЌвЕЮёзЈМвЃЌднЪБПДВЛЕНФмЯїМѕШЫСІГЩБОЕФПЩФмадЃЌЖјЧвЯрЙиЕФЭЖШыПЩФмашвЊЖрФъЕФЪБМфЁЃ
дкЦНЬЈНЈСЂКѓЃЌдкГжајИФНјЕФЧщПіЯТЃЌШдШЛашвЊзЈМвЛђепЗжЮіЪІЃЌДгВЛЭЌЕФЮЌЖШЃЌДгВЛЭЌЕФвЕЮёПкОЖЃЌзщКЯКЯЪЪЕФПЩЪгЛЏММЪѕЃЌЛњЦїбЇЯАММЪѕЃЌДѓЪ§ОнЗжЮіММЪѕЃЌжЦЖЈЗжЮіГЁОАЃЌЦНЬЈВХФмЙЛЮЊITдЫЮЌЃЌвЕЮёЗжЮіВњЩњГжајЕФЖДВьЃЌЬсЙЉЩЬвЕМлжЕЁЃ
ЫљвдЃЌAIOps ВЛФмШЁДњШЫЃЌдкЯжНзЖЮВЛПЩФмМѕЩйШЫСІЭЖШыЃЌЕЋдкЮДРДПЩФмФмДйНјВПЗждЫЮЌШЫдБзЊаЭЮЊЭЈЯўвЕЮёЃЌеЦЮедЫЮЌжЊЪЖЕФЪ§ОнЗжЮіЪІЁЃ
ЫуЗЈКЭжЧФмЛЏЪЧAIOpsзюживЊЕФЪТЧщ
ЫуЗЈКмживЊЃЌЕЋЪЧЮвИіШЫШЯЮЊЃЌдкДЫНзЖЮЃЌДѓВПЗжЦѓвЕВЛгІИУвдЫуЗЈЮЊЕквЛзХблЕуЁЃ
етИігІИУЪЧБШНЯгаељвщЃЌЛђепЃЌЛђепЫЕДѓМвШЯжЊВЛЬЋвЛжТЕФВПЗжЁЃвдЯТетеХЭМЪЧGartnert дк AIOpsЛЙдкНаITOA
ЪБКђЃЌИјЖЈвхЕФЫФИіНзЖЮЃК
Data ingestion, indexing, storage and access
Visualization and basic statistical summary
Pattern discovery and anomaly detection
True causal path discovery
Gartner дкБЈИцжаЧПЕїЃЌеЦЮеКѓУцНзЖЮЕФЧАЬсЪЧгЕгаЧАвЛНзЖЮЕФФмСІЃЌШчЙћВЛгЕгаГфЗжЕФЧАвЛНзЖЮФмСІЃЌНЋЛсгАЯьITOA
ЕФТфЕиаЇЙћЁЃвђДЫетЫФИіНзЖЮБиаывЛИіВНвЛНХгЁЃЌЕкШ§вдМАЕкЫФВПЪБЃЌВХЯджјЕив§ШыСЫЛњЦїЫуЗЈЃЌЛђепAIЕФБивЊЁЃ
ДѓМвЖМжЊЕРЃЌЫљЮНЕФЛњЦїбЇЯАЫуЗЈЃЌЭГМЦЫуЗЈЃЌЩюЖШбЇЯАЫуЗЈетаЉAI ЕФЗжРрЃЌЦфЪЕЪЧИпЖШвРРЕгкЪ§ОнЕФЁЃУЛгаЖржжЪ§ОндДЃЌЪ§ОнЕФВЩМЏЃЌЪ§ОнДцДЂЃЌЪ§ОнЭГМЦЃЌЪ§ОнПЩЪгЛЏЃЌвЛЧаЖМжЛЪЧПежаТЅЬнЁЃ

РДдДЃК Gartner Report ЁАOrganizations Must Sequentially
Implement the Four Phases of ITOA to Maximize Investment
ЁБ 2015.2.18
вђДЫЃЌAIOpsЕФЦНЬЈЕФНЈЩшЪзЯШгІИУЪЧзХблЕугІИУЪЧДѓЪ§ОнЃЌШЛКѓВХЪЧЫуЗЈЃЌДгЖјЪЕЯжГжајЖДВьКЭИФНјЕФФПБъЁЃ
вЛЖЈвЊЩЯЩюЖШбЇЯАВХНаAIOps
ЮвУЧПЩвдЯШПДПДAI , Machine Learning , Deep Learning ЕФЙиЯЕЃЌЫћУЧЕФЙиЯЕДѓИХШчЯТЭМЁЃ

бЇЪѕНчгаВЛЩйбЇепЃЌдкЬНЫїВПЗжЩюЖШбЇЯАЫуЗЈжЧФмдЫЮЌжаЕФгІгУЃЌШчгЬЫћжнДѓбЇЕФЁЖDeepLog: Anomaly
Detection and Diagnosis from System Logs through Deep
LearningЁЗ жаРћгУ Long Short-Term Memory (LSTM)РДЪЕЯжШежОФЃЪНЕФЗЂЯжЃЌДгЖјЪЕЯжвьГЃМьВтЁЃЕЋЪЧЃЌЦфЪЕжЧФмдЫЮЌЫљашвЊЕФДѓВПЗжЫуЗЈЃЌОіВпЪїбЇЯАЃЈdecision
tree learningЃЉЁЂОлРрЃЈclusteringЃЉЁЂSVMЃЈSupport Vector MachineЃЉКЭБДвЖЫЙЭјТчЃЈBayesian
networksЃЉЕШЕШЫуЗЈЃЌОљЪЧЪєгкДЋЭГЕФЛњЦїбЇЯАЗЖГыЕФЃЌвђДЫ ЮвУЧВЛгІИУНЋЩюЖШбЇЯАгыAIOps ЙвЩЯБиШЛЕФСЊЯЕЁЃ
ЩѕжСгкЃЌЮвУЧВЛгУОаФргкИХФюЃЌДгНтОіЮЪЬтЕФНЧЖШГіЗЂЃЌдкЬиЖЈЕФГЁОАЃЌРћгУДЋЭГЕФЙцдђМЏЃЌЩшЖЈвЛаЉЙцдђЃЌНЕЕЭСЫдЫЮЌШЫдБЕФЙЄзїЧПЖШЃЌЬсИпСЫаЇТЪЃЌвВФмНажЧФмдЫЮЌЁЃЩѕжСдкGartner
ЕФБЈИцжаЃЌЖдAIOps ТфЕиЕФЕквЛВНЃЌЪЧЭГМЦЗжЮіЃЌПЩЪгЛЏЃЌЖјВЛЪЧШЮКЮЕФЛњЦїбЇЯАЫуЗЈЁЃ
ЫќЪЪКЯЯжНзЖЮЫљгагаЙцФЃЕФгУЛЇ
етИіБШНЯКУРэНтЃЌОЭФПЧАРДПДЃЌAIOps жЛЪЪКЯДѓаЭЕФПЭЛЇЃЌдвђШчЯТ:
жааЁаЭЕФПЭЛЇШБЗІЖржжЪ§ОндД
жааЁаЭПЭЛЇвЕЮёашЧѓУЛгаФЧУДИДдг
КмЖрЫуЗЈЃЌЦфЪЕЪЧЮЊСЫДѓЙцФЃдЫЮЌЕФЪБКђВХгУЕФЩЯЕФЃЌдкЙцФЃаЁЕФЪБКђЃЌФбвдВњЩњаЇЙћ
дЫЮЌздЖЏЛЏЪЧжЧФмдЫЮЌЕФЧАЬс
ЮвПДЕНЙ§ВЛЩйЕФЮФеТЃЌНЋдЫЮЌЗжГЩСЫЫФИіНзЖЮЃЌНЋздЖЏЛЏдЫЮЌЗХдкжЧФмдЫЮЌЕФЧАвЛИіНзЖЮЃЌАбжЧФмЃЌгжЛђепдкжЧФмдЫЮЌетИіЬхЯЕРяЭЗЃЌгВЪЧШћСЫКмЖрздЖЏЛЏдЫЮЌЃЌХњСПВйзїЃЌХњСПЙцЛЎЕФЙІФмдкРяЭЗЃЌЮвОѕЕУЖМЪЧВЛЖдЕФЁЃздЖЏЛЏдЫЮЌИќЯёЪЧЪжЃЌжЧФмдЫЮЌИќЯёЪЧблОЕМАДѓФдЃЌгаСЫИќШЋУцЪ§ОнЃЌИќГфТњЕФЗжЮіКѓЃЌДѓФдФмИќКУЕФжИЛгЪжНјааВйзїЁЃ

вђДЫЃЌЦѓвЕгІИУНЋздЖЏЛЏдЫЮЌКЭжЧФмЛЏдЫЮЌПДГЩСЫСНИігаЙиСЊЕФЬхЯЕЃЌЕЋЪЧВЛгІИУЛьвЛЬИЃЌдьГЩИќЖрЕФЮѓНтЁЃ
ЬєеНЬєеН1ЃКГЌдНЕБЧАММЪѕЫЎЦНЕФЦкЭћ
вдЯТЪЧЦфжавЛР§ЃЌЕБгУЛЇЦкЭћГЌдНЕБЧАММЪѕЫЎЦНЕФвЛИіЕфаЭЕФР§згЃЌГЕЛйШЫЭіЁЃ

УРЙњМгжнЭхЧјИпЫйЩЯЕФвЛЦ№жТУќГЕЛіЃЌЁЃвЛСОМлжЕ$79,500ЕФTesla Model XЃЌдкааЪЛжСЩНОАГЧЖЮ101КЭ85ИпЫйНЛНчЪБЃЌЭЛШЛзВЩЯИєРыДјЃЌЫцКѓБЌеЈЦ№Л№ЁЃ
ЖдДЫЃЌгіФбЛЊвсЫОЛњЕФвХцзSevonne HuangЃЈЯТЮФМђГЦSevonneЃЉЪзДЮЙЋПЊЗЂЩљЭИТЖЃЌеЩЗђЩњЧАдјБЇдЙЙ§ЃЌЬиЫЙРЕФздЖЏЕМКНвЧЃЌКУМИДЮШУГЕзгПЊЯђГхЩЯЗРзВРИЁЃSevonneЫЕЃЌНЋЦ№ЫпЬиЫЙРЁЃ
здЖЏМнЪЛЕФАВШЋадЮЪЬтЃЌдйДЮАбЬиЫЙРЭЦЕНЗчПкРЫМтЩЯЁЃШЛЖјЪТКѓЃЌЫфШЛЬиЫЙРЗЂЩљУїГЦЃЌБЇЧИЗЂЩњетбљЕФБЏОчЃЌЕЋЭЌЪБвВНЋд№ШЮжИЯђСЫЫРепЃЌЁАГЕСОдйШ§ЗЂГіОЏИцЃЌЬсабЫОЛњВйПиГЕзгЃЌЕЋЪТЗЂЧАЃЌЫОЛњВЂУЛгаАбЪжЗХдкЗНЯђХЬЩЯЁЃздЖЏМнЪЛвЧВЂВЛФмБмУтШЮКЮЪТЙЪЁЃЁБ
ЫОЛњЖдгкЬиЫЙРЕФAutoPilot Й§ЖШЯраХЃЌзюжеЕМжТСЫБЏОчСЫЗЂЩњЁЃ
ЫфШЛФПЧАЕФжЧФмдЫЮЌЃЌЫљдьГЩЕФНсЙћПЩФмВЛЛсФЧУДбЯжиЃЌЕЋЪЧАДееGartner ММЪѕГЩЪьЖШЧњЯпРДПДЃЌAIOps
ЛЙДІгкЗЧГЃГѕЦкЕФНзЖЮЃЈзѓЯТНЧЃЉЃЌГЌдНЯжНзЖЮЕФЦкЭћЃЌЪЧAIOpsзюДѓЕФЗчЯеЁЃ

жаЙњЕФЦѓвЕгУЛЇЭљЭљгаДѓЖјШЋЕФНЈЩшЗНАИЃЌШчКЮДгЦѓвЕЕФЪЕМЪЧщПіГіЗЂЃЌжЦЖЈНкзрКЯЪЪЕФЙцЛЎЃЌЮвШЯЮЊЪЧвЛИіКмДѓЕФЬєеНЁЃ
ЬєеН2ЃКЫуЗЈгІгУГЁОАЗжЩЂЃЌГЩЪьЖШВЛвЛжТЃЌЭЈгУадВюЃЌВњЦЗЛЏЃЌЙЄГЬЛЏРЇФбЃЌДѓВПЗжГЁОАОрРыЪЕМЪгІгУгавЛЖЈЕФОрРы
ДгФПЧАРДПДЃЌДѓМвЦкЭћРћгУЫуЗЈНтОіЕФГЁОААќРЈЃК
ЕЅжИБъвьГЃМьВт
ЖржИБъвьГЃМьВт
ШежОФЃЪНвьГЃМьВтЃЈВЮее Log CompareЃЉ
ЙЪеЯИљвђЗжЮі
ШнСПдЄЙР
ИцОЏжЧФмбЙЫѕ ЃЈЛљгкИљвђЃЌЛљгкЪТМўШежОФЃЪНЃЉ
ЙЪеЯдЄВтЃЈНЯЮЊГЃгУЕФГЁОАЮЊгВХЬЕФЙЪеЯЖЈЮЛЃЉ
ЛљгкжЊЪЖЭМЦзЃЈдЫЮЌОбщЃЉЙЪеЯЖЈЮЛ
вдЩЯЕФУПИіжЧФмГЁОАЃЌУПИіГЁОАЫљашвЊгУЕНЕФЫуЗЈЖМВЛвЛбљЃЌЖјЧвГЩЪьЖШвВВЛвЛбљЁЃ
вдзюЮЊМђЕЅЃЌЕЋгІгУзюЮЊЙуЗКЃЌГЩЪьЖШзюИпЕФЕЅжИБъвьГЃМьВтРДОйР§ЃЌДгбЇЪѕЕФНЧЖШРДПДЃЌШчЙћФуЕНGoogleРяЭЗШЅЫбЫїЃЌФуЛсЗЂЯжгаДѓдМ60000ЖрЬѕЕФМЧТМЃЌЪБМфПчЖШДгЩЯЪРМЭ90ФъДњЕНМИЬьЧАЕФЖМЛсгаЁЃ
ДгЩЬвЕЛЏЕФНЧЖШРДПДЃЌФПЧАДгЮвПДЕНЃЌБШНЯГЩЪьЕФвВжЛгаElasticЙЋЫОЫљЪеЙКЕФ Prelert ЕФвьГЃМьВтММЪѕЃЌЪЧВњЦЗЛЏЕФБШНЯКУЕФЃЌЦеЭЈЕФгУЛЇЪЧШнвзРэНтЃЌШнвзЪЙгУЕФЁЃ

етвбОЪЧ30ФъРДЃЌМЏКЯСЫФЧУДЖрЖЅМтЕФжЧЛлЃЌЫљФмДяЕНЕФВњЦЗЛЏГЬЖШзюИпЃЌЭЈгУадзюЧПЕФГЁОАСЫЁЃЦфЫћЕФГЁОАЃЌГЩЪьЖШЃЌЛђепЭЈгУадПЯЖЈЪЧВЛШчБОГЁОАЁЃ
Р§ШчЙЪеЯдЄВтЃЌФПЧАБШНЯКУЕФАИР§ЪЧдЄВтгВХЬЙЪеЯЃЌЧАЬсЪЧФугЕгаДѓСПЭЌбљаЭКХЃЌЯрЭЌХњДЮЕФгВХЬЃЌЦфжаФГвЛаЉгВХЬГіЙЪеЯСЫЃЌДгS.M.A.R.T
аХЯЂжаЃЌФуВХФмЙЛЛёЕУбЕСЗМЏЃЌШЛКѓРћгУФЃаЭШЅдЄВтЭЌвЛИіХњДЮЕФЙЪеЯЁЃетжжЧАжУЬѕМўЃЌЭЈГЃжЛЛсдкЬиЖЈЕФгУЛЇЃЌР§ШчЬкбЖЃЌАйЖШЕФЪ§ОнжааФЃЌвЛДЮадЙКжУЩЯЧЇПщЕФЃЌВХФмГіЯж1ЕН15ПщЕФЙЪеЯгВХЬ
ЃЈОнЭГМЦЃЌгВХЬЕФЙЪеЯТЪдк0.1%~1.5% зѓгвЃЉЃЌЖјЧвОЭЫугагУЛЇИљОнгВХЬЕФЧщПіЃЌбЕСЗКУЕФФЃаЭвђЮЊУПИігУЛЇЕФЛњЗПЃЌЕчбЙЃЌЮТЖШЖМВЛвЛбљЃЌКмПЩФмУЛгаАьЗЈНјааИДЯжЃЌвђДЫЃЌДЫГЁОАЭЈгУадМЋВюЁЃ
ШчЙћвЊНЋгУгкдЄВтгВХЬЙЪеЯЕФЫуЗЈЃЌгУЕНФГвЛИіITвЕЮёЯЕЭГжЎЩЯЙЪеЯЩЯЃЌЛљБОЩЯвВЪЧВЛПЩФмЕФЃЌвђЮЊвЛИіЯЕЭГЃЌЯргІЕФВЮЪ§ЃЌБфСПЃЌПЩФмгАЯьЯЕЭГЦНЮШдЫаавђзгЬЋЖрЃЌвбОЪЧУЛгаАьЗЈЬзгУЕНдЄВтгВХЬЙЪеЯЕФЫуЗЈРяЭЗРДСЫЁЃ
ЛЙгаЃЌВПЗжЕФЫуЗЈЃЌдкЪЕбщЪвжаЕФаЇЙћЗЧГЃКУЃЌзМШЗТЪКЭейЛиТЪЖМКмИпЃЌЕЋЪЧЃЌЯћКФзЪдДОоДѓЃЌЪЕЪБадВюЃЌУЛгаАьЗЈЭЖШыеце§ЕФЩњВњЪЙгУЕФПЩФмадЁЃ
вђДЫЃЌдкЫуЗЈЩЯЃЌЮвУЧгІИУЯШШЅТфЕиГЩЪьЃЌROIЯджјЕФГЁОАЁЃ
ЬєеН3ЃКЯжгадЫЮЌМрПиЬхЯЕУЛгаЭъЩЦ
дкЮоШЫМнЪЛММЪѕСьгђЃЌзюКЫаФЕФвЛИізщМўЪЧLiDarЃЈМЄЙтРзДяЃЉЃЌвЛжждЫгУРзДядРэЃЌВЩгУЙтКЭМЄЙтзїЮЊжївЊДЋИаЦїЕФЦћГЕЪгОѕЯЕЭГЃЌLiDARДЋИаЦїИГгшСЫздЖЏМнЪЛЦћГЕФмЙЛПДЕНжмБпЛЗОГЕФЁАЫЋблЁБЁЃ
ЪРНчЩЯЃЌМИКѕЫљгаЕФЦћГЕГЇЩЬЃЈ Tesla Г§ЭтЃЌTesla гУЕФЪЧЭЈЙ§ЩуЯёЭЗЖјЪЕЯжЪгОѕЪЖБ№ММЪѕЃЌЫљвдЮвИіШЫИпЖШЛГвЩЬиЫЙРЕФЪТЙЪгыДЫгаЙиЃЉдкбаЗЂЮоШЫМнЪЛММЪѕЕФЪБКђЃЌЖМЛсИјГЕСОАВзАЩЯМЄЙтРзДяЁЃ
ЖјРрБШЕНдЫЮЌЕФГЁОАЃЌШчЙћблОІВЛЙЛЃЌЪ§ОнВЛзуЃЌЪТЧщПДВЛЧхГўЃЌЦфЪЕЪЧКмФбзіЕНУїШЗЕФОіВпЕФЃЌОпЬхБэЯжШчЯТЃК
ШБЗІзуЙЛЕФЪ§ОндДЃК гаЕФПЭЛЇЃЌУЛгаШежОЙмРэЯЕЭГЃЌвВУЛгаШЮКЮвЕЮёМрПиЕФЪжЖЮЃЌжЛгаCPU ФкДцЃЌгВХЬЕШЛљДЁМрПиЃЌетИіЪБКђЃЌЦфЪЕЮвИіШЫЩЯЪЧВЛНЈвщдкЯжНзЖЮзіAIOpsЕФЃЌвђЮЊAIOps
МрПижИБъЩюЖШЃЌзЈвЕЛЊГЬЖШВЛЙЛЃК етИіЮЪЬтКмЖрЪБКђЗДгІЕФЪ§ОнПтМрПиЩЯЃЌгЩгкЪ§ОнПтзЈвЕЛЏГЬЖШНЯИпЃЌвђДЫЖдЪ§ОнПтЕФКмЖрЙиМќЕФжИБъЮДФмЪЖБ№ЃЌЕМжТСЫЙиМќаХЯЂЕФвХТЉЃЌПЩФмЛсДѓДѓгАЯьAIOps
ЕФТфЕиаЇЙћЁЃ
ХфжУЙмРэВЛЭъЩЦЃК CMDB ШБЗІЮЌЛЄЃЌ ЮоЗЈЛёШЁЯЕЭГМфЙиЯЕЕФУшЪіЃЌЭиЦЫвРРЕЃЌЯрЙидЫЮЌМрПиЪ§ОндЊЪ§ОнШБЗІЙмРэЃЌЖМЛсНЕЕЭТфЕиаЇЙћЃЌЬиБ№ЪЧдкЙЪеЯИљвђЖЈЮЛжаЃЌШБЗІЙиЯЕУшЪіЫљаЮГЩЕФгаЯђЮоЛЗЭМЃЌОЭКмФбРћгУДЋВЅЙиЯЕЫуЗЈШЅАяжњЖЈЮЛИљвђЁЃЕБШЛЃЌетИіПЩвдЭЈЙ§гЩAPM
ЃЌЛђепNPM ЙЄОпЃЌЫљЩњГЩЕФгІгУЭиЦЫШЅВПЗжУжВЙЁЃ
ЬєеН4ЃКДѓЪ§ОнЛљДЁИДдгЃЌадФмМАЖрбљадвЊЧѓИпЃЌдЊЪ§ОнЙмРэ
ећИіAIOps ЦНЬЈзюКЫаФЪ§ОнЦНЬЈЕФВПЗжЃЌЪЧвЊТњзувдЯТЕФашЧѓЃК
ИпЭЬЭТСПЃЌФмЪЕЪБДІРэКЃСПЃЌВЛЭЌРраЭЕФЪ§ОнЃЈMetrics , Logging , TracingЃЉ
ОпБИЧПДѓЕФСїЪНМЦЫуФмСІ
Ъ§ОндкВхШыКѓЃЌФмБЛзМЪЕЪБЕФМьЫїЃЌОлКЯ
Ъ§ОнБфЛЏЖрбљЃЌЛсВЛЭЃЕиаТдіЖЏЬЌСаЃЌЪ§ОнДцДЂФЃаЭЫцЪБЛсИФБф
ГЌИпЕФЗжЮіОлКЯМЦЫуадФмЃЌашвЊЬсЙЉЖрЮЌСаЪНЪ§ОнПтЕФЗжЮіФмСІ
ЬсЙЉЧПДѓЕФЪЕЪБЫбЫїЗжЮіФмСІЃЌПЩвдЭЈЙ§ЙиМќзжЖдЪТМўаХЯЂНјааМьЫї
ОпБИвЛжжЛђЖржжЕФЪ§ОнВщбЏDSLЃЌБугкЪЕЯжВЛЭЌЕФЗжЮіГЁОА
ОпБИРњЪЗЪ§ОнКЭНќЯпЪ§ОнЕФЗжБ№ДІРэЕФФмСІ
Ъ§ОнДцДЂФмЖдНгЕНЖржжЕФMLПђМмжаЃЌзїЮЊЪ§ОндДЃЌбЕСЗФЃаЭ
Ъ§ОнвЊФмЪЕЯжЩЯОэдЄОлКЯЃЌдкНјааГЄЪБМфЗЖЮЇОлКЯЕФЪБКђЃЌШчдТБЈЕШТпМЪБЃЌПЩвдНкдММЦЫуЪБМф
ДѓЕФВщбЏНјШыЕНЦНЬЈЃЌЦНЬЈвЊгаздЮвБЃЛЄЛњжЦЃЌВЛЛсдьГЩЙЪеЯ
СМКУЕФдЊЪ§ОнЙмРэЕФФмСІЃЌАќРЈШчЙћДгФЧУДЖрЪ§ОнжаЃЌАДееФЃаЭЛЙдЯргІЕФжИБъЃЌвдМАжИБъМфЕФЙиСЊЙиЯЕ
ФмЙЛгыдкЯпЕФЫуЗЈФЃПщНјааМЏГЩ
вдЩЯЕФУшЪіЃЌЖМЪЧAIOps ЕФЪ§ОнФмСІвЊЧѓЃЌЭљЭљашвЊЖрИіДѓЪ§ОнДІРэЃЌДцДЂзщМўЃЌВХФмТњзуетжжПСПЬЕФвЊЧѓЃЌЖјЧвЛЙашвЊЮоЗьЕФећКЯЦ№РДЃЌЯргІЕФЙЄГЬММЪѕФбЖШЗЧГЃДѓЁЃ
ЬєеН5ЃКШЫВХибЗІ
ФПЧАдкЙњФкЃЌЮоТлЪЧЫуЗЈШЫВХЃЌЛЙЪЧДѓЪ§ОнШЫВХЃЌЖМЪЧБШНЯибЗІЕФМААКЙѓЕФЃЌдкШЫВХеаФМЃЌЯюФПдЄЫужЦЖЈЕФЪБКђЃЌвЊГфЗжПМТЧЯрЙивђЫиЁЃ
ДгШЫВХЕФвтдИРДПДЃЌДѓВПЗжЕФЫуЗЈЙЄГЬЪІМАДѓЪ§ОнЙЄГЬЪІЃЌИќдИвтШЅВЮгывЛаЉРыБфЯжБШНЯШнвзЕФГЁОАЃЌШчЭЦМіЯЕЭГЃЌЪгОѕЪЖБ№ЯЕЭГЕШЃЌШчКЮЮќв§ИќЖрЕФШЫВХЃЌЬиБ№ЪЧЫуЗЈПЦбЇМвЕШЃЌШУЫћУЧИааЫШЄЃЌМгШыЕНAIOpsЕФГЁОАжаРДЃЌвВЭЌЪБЛёЕУНЯКУЕФОМУЛиБЈЃЌЪЧећИівЕНчашвЊПМТЧЕФЕиЗНЁЃ
НЈвщ
ЦѓвЕНсКЯздЩэЕФЧщПіЃЌКЯРэПижЦЦкЭћЃЌЗжНзЖЮНјаабнНјЃЌВщТЉВЙШБ
НЈСЂвЛИіЭъећЕФдЫЮЌЪ§ОнДѓЪ§ОнЬхЯЕЪЧЯюФПдЫЮЌЕФЙиМќЃЌвВЪЧЮЊжЧФмЛЏДђЯТСМКУЕФЛљДЁ
вдНЋећКЯжИБъЪ§ОнЁЂШежОЪ§ОнзїЮЊЧаШыЕуЃЌТфЕиж№ВНећКЯИќЖрЕФЪ§ОндДЃЌВњЩњИќДѓЕФЪевц
жЧФмЛЏВПЗжЕФТфЕиГЁОАгХЯШОлНЙдкМрПиЕФвьГЃМьВтЃЌвдМАШежОЕФжЧФмОлРр
СЂзудЫЮЌЃЌУцЯђвЕЮёЃЌНЋOperationЕФКЌвхбнвяЮЊдЫгЊЃЌЮЊвЕЮёЬсЙЉЩЬвЕМлжЕ
змНс
AIOps ЕФШЗЪЧвЛИіЗЧГЃИяУќадЕФИХФюПђМмЃЌЫќДгДѓЪ§ОнКЭAI ЕФФмСІЪгНЧЃЌШЅЕпИВЛђепЭъЩЦЯждкЕФ ITOM
дЫЮЌЬхЯЕЃЌИјбЇЪѕНчЃЌЙЄвЕНчЃЌзюжегУЛЇЃЌжИУїСЫвЛИіУїШЗЃЌПЩГжајИпЫйЗЂеЙ5-10ФъЕФЗЂеЙЗНЯђЁЃПЩвддЄМЦЃЌдкЮДРД5-10ФъФкЃЌДѓСПЙигкAIOps
ЕФаТЫМЯыЃЌаТРэТлЃЌаТММЪѕЃЌНЋЛсЯёКЎЮфМЭЩњУќДѓБЌеЈЪБЃЌВЛЖЯЕФгПЯжЃЌДДаТдДдДВЛЖЯЃЌзїЮЊвЕНчЙЄзїепЃЌзїЮЊЦѓвЕЃЌзїЮЊГЇЩЬЃЌШчКЮдкетДЮЕФжмЦкжазЅзЁЪєгкздМКЕФЛњЛсЃЌетЪЧвЛИіКмжЕЕУЫМПМЕФУќЬтЁЃ
AIOps ШУдЫЮЌВПУХвЛЯТГЩСЫЙЋЫОВуУцгЕгаЪ§ОнзюЖрЕФВПУХЃЌдЫЮЌШЫШчКЮздЩэНјЛЏЃЌДгдЫЮЌЕНдЫгЊЃЌЖдДѓВПЗждЫЮЌШЫРДЫЕЃЌЖМЪЧвЛИіОоДѓЕФЛњЛсМАЬєеНЁЃ
ЫфШЛAIOpsЕФШЗИјЮвУЧДјРДКмЖрЕФЯыЯѓПеМфЃЌЕЋЪЧЮвУЧЛЙЪЧвЊвдЪЕМЪТфЕиЃЌЪЕМЪАяжњЦѓвЕВњЩњаЇТЪЮЊЕМЯђЃЌвЊБмУтЬјШыAI
Й§ШШЕФГДзїЗчЃЌвЛВНвЛНХгЁЃЌжБУцЬєеНЃЌГжајбнНјЃЌВЛЖЯЮќЪеЪРНчЯШНјЕФОбщМАЫМЯыЃЌДгЖјгНгЮДРДет10ФъЕФЛЦН№ЪБДњЁЃ |








