| БрМЭЦМі: |
| БОЮФРДдДyunweipaiЃЌБОЮФНщЩмСЫMySQLЧЈвЦжСMariaDBЕФдвђвдМАMHAМмЙЙЁЂNewSQLЕШЯрЙиФкШнЁЃ |
|
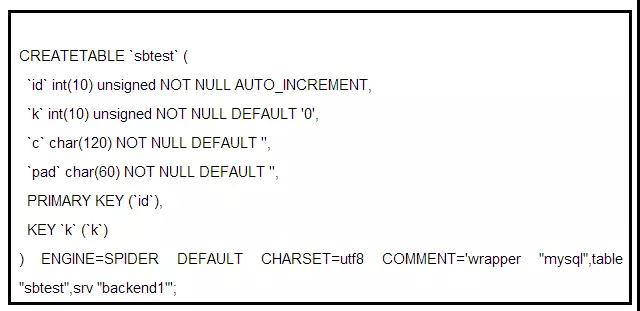
ЮЊЪВУДбЁдёСЫMariaDBЃП
ИцБ№MySQLвЦВНMariaDBЕФдвђ
1ЁЂ вЕЮёЩЯзгВщбЏSQLЙ§ЖрЃЌашвЊДѓСПИФаДЮЊjoinЙиСЊВщбЏгяОфЃЌПЊЗЂашвЊИќИФДњТы
дкMariaDB 5.3АцБОРяЃЌОЭвбОЖдзгВщбЏНјааСЫгХЛЏЃЌВЂВЩгУsemi joinАыСЌНгЗНЪННЋSQLИФаДЮЊСЫБэЙиСЊjoinЃЌДгЖјЬсИпСЫВщбЏЫйЖШЁЃ
ЭЈГЃЧщПіЯТЃЌЮвУЧЯЃЭћгЩФкЕНЭтЃЌМДЯШЭъГЩФкБэРяЕФВщбЏНсЙћЃЌШЛКѓЧ§ЖЏЭтВщбЏЕФБэЃЌЭъГЩзюжеВщбЏЃЌЕЋЪЧMySQL
5.5ЛсЯШЩЈУшЭтБэжаЕФЫљгаЪ§ОнЃЌУПЬѕЪ§ОнНЋЛсДЋЕНФкБэжагыжЎЙиСЊЃЌШчЙћЭтБэКмДѓЕФЛАЃЌФЧУДадФмЩЯНЋЛсКмВюЁЃ
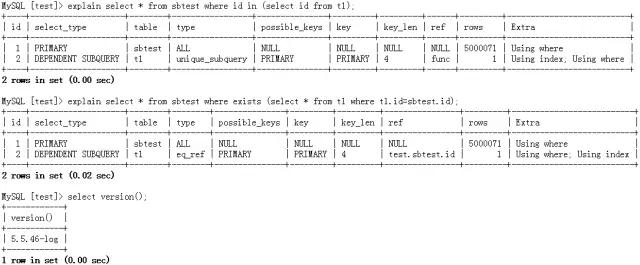
АИР§ЃКMySQL 5.5ЕФзгВщбЏжДааМЦЛЎЃЌЪЧНЋinжиаДЮЊexists
ЮвУЧПДвЛЯТетСНИіжДааМЦЛЎЃЌЕБЭтБэБШНЯДѓЪБЃЌЕквЛааЛсЩЈУш5000071ааЃЌИФЮЊexistsаДЗЈЃЌЫќЕФжДааМЦЛЎКЭinЪЧЭъШЋвЛбљЕФЁЃШчЙћФуЭтБэБШНЯДѓЕФЛАЃЌВщбЏадФмЛсЪЧЗЧГЃВюЕФЁЃ

АИР§ЃКMariaDB 10.0ЕФзгВщбЏжДааМЦЛЎЃЌЪЧНЋin/existsжиаДЮЊjoin
MariaDB 10.0ЯрЕБгкMySQL5.6АцБОЃЌетРяInКЭexistsЃЌЫќЛсжБНгжиаДЮЊjoinЙиСЊВщбЏЃЌетРягаШ§ИіВЛЭЌЕФаДЗЈЃЌжДааМЦЛЎЪЧЭъШЋвЛбљЕФЁЃИФаДjoinвдКѓЪЧгЩаЁБэЙиСЊДѓБэЃЌПЩвдПДЯТЩЈУшЕФааЪ§ЮЊ10ааЃЌжДаааЇТЪОЭЪЧЗЧГЃПьЕФЁЃ
2ЁЂгЩгкЪ§ОнСПЩЯTBЃЌжБНгЩ§МЖMySQL5.6ЃЌВЛФмЦНЛЌЩ§МЖЃЌашвЊНјаавЛДЮmysqldumpдйЕМШыЃЌКФЗбЙ§ЖрЕФЪБМфЁЃ
вдMySQL5.5АцБОЮЊР§ЃЌШєвЊЩ§МЖЕНMySQL5.6ЃЌашвЊНјаавЛДЮШЋПтmysqldumpЕМГідйЕМШыЃЌЕБЪ§ОнПтКмДѓЪБЃЌБШШч100GBЃЌЩ§МЖЦ№РДЛсЗЧГЃРЇФбЁЃЕЋШчЙћЩ§МЖЮЊMariaDB10ЃЌЛсЗЧГЃЧсЫЩЃЌАДееЙйЗНЮФЕЕВћЪіЃЌжЛашАбMySQLаЖдиЕєЃЌВЂгУMariaDBЦєЖЏЃЌШЛКѓЭЈЙ§mysql_upgradeУќСюЩ§МЖМДПЩЭъГЩЁЃ
MariaDBИњMySQLдкОјДѓЖрЪ§ЗНУцЪЧМцШнЕФЃЌЖдгкЧАЖЫгІгУЃЈБШШчPHPЁЂPerlЁЂPythonЁЂJavaЁЂ.NETЁЂMyODBCЁЂRubyЁЂMySQL
C connectorЃЉРДЫЕЃЌМИКѕИаОѕВЛЕНШЮКЮВЛЭЌЁЃ
Щ§МЖЕНMariaDB10зЂвтЪТЯю
дкДІРэФкВПЕФСйЪББэЃЌMariaDB 5.5/10.0гУAriaв§ЧцДњЬцСЫMyISAMв§ЧцЃЌетНЋЪЙФГаЉGROUP
BYКЭDISTINCTЧыЧѓЫйЖШИќПьЃЌвђЮЊAriaгаБШMyISAMИќКУЕФЛКДцЛњжЦЁЃШчЙћФуЕФСйЪББэКмЖрЕФЛАЃЌвЊдіМгaria_pagecache_buffer_sizeВЮЪ§ЕФжЕЃЈЛКДцЪ§ОнКЭЫїв§ЃЉЃЌФЌШЯЪЧ128MBЃЈ
ЖјВЛЪЧtmp_table_size ВЮЪ§ЃЉЁЃШчЙћФуУЛгаMyISAMБэЕФЛАЃЌНЈвщАбkey_buffer_sizeЕїЕЭЃЌР§Шч64KBЃЌНіНіЬсЙЉИјMySQLПтРяУцЕФЯЕЭГБэЪЙгУЁЃ
ЙйЗНЭЦМіЪЙгУjemallocФкДцЙмРэЦїЛёШЁИќКУЕФадФмЁЃ
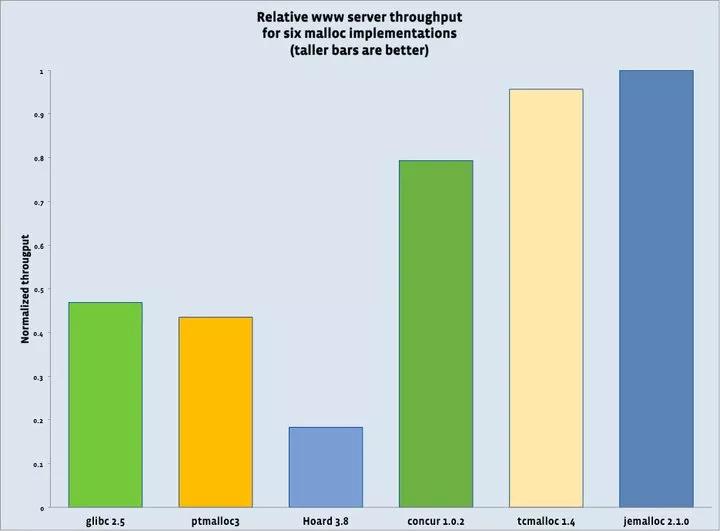
JemallocФкДцЙмРэЦїадФм
ЩЯЭМЪЧЙйЗНЕФбЙСІВтЪдБЈИцЃЌПЩвдПДГіJemallocФкДцЙмРэЦїЕФадФмЪЧзюКУЕФЁЃ

етЪЧжЎЧАЮвИјMariaDBзїепаДЕФвЛЗтаХЃЌЫћЛиД№ЃЌЩ§МЖЕНMariaDBЪЧУЛгаЮЪЬтЕФЃЌЯждкКмЖрДѓЙЋЫОЖМгУMariaDBЃЌР§ШчGoogleЁЂWikipediaЁЃжївЊдвђЮвзмНсШчЯТЃК
дкOracleПижЦЯТЕФMySQLгаСНИіЮЪЬтЃК
MySQLКЫаФПЊЗЂЭХЖгЪЧЗтБеЕФЃЌЭъШЋУЛгаOracleжЎЭтЕФГЩдБВЮМгЁЃКмЖрИпЪжМДЪЙгааФзіЙБЯзЃЌвВУЛАьЗЈзіЕНЁЃ
MySQLаТАцБОЕФЗЂВМЫйЖШЃЌдкOracleЪеЙКSunжЎКѓДѓЮЊМѕЛКЁЃ

етРядйЫЕвЛЯТMariaDBЦѓвЕАцКЭЩчЧјАцЕФЧјБ№ЃК
ЦѓвЕАцИќзЂжиbugЕФаоИДЃЌЩчЧјАцдђЖдаТЙІФмИќаТБШНЯПьЁЃMariaDBЩчЧјАцКЭЦѓвЕАцЕФдДДњТыЖМЪЧПЊдДЕФЃЌВЂЧвЫљгаЙІФмЖМЪЧУтЗбПЊЗХЃЌВЛгУЕЃаФЙІФмЩЯгабЫИюЃЌЕЋМзЙЧЮФMySQLЦѓвЕАцбгЩьЬзМўВЩШЁЗтБедДДњТыЧвашвЊИЖЗбЁЃ
ДЫЭтЃЌMariaDBЯрБШMySQLгЕгаИќЖрЕФЙІФмЁЂИќПьЁЂИќЮШЖЈЁЂBUGаоИДИќПьЁЃ
3ЁЂНтОіИДжЦбгГйЃЌПЊЦєЖрЯпГЬВЂааИДжЦЃЈMariaDB 10.0.XЛљгкБэЃЉ
Н№ШкЙЋЫОЖдЪ§ОнвЛжТадвЊЧѓНЯИпЃЌжїДгЭЌВНбгГйЮЪЬтЪЧВЛФмНгЪмЕФЁЃMySQL5.6гЩгкЪЧЛљгкПтМЖБ№ЕФВЂааИДжЦЃЌдкЪЕМЪЩњВњжагУДІВЂВЛДѓЃЌЖјжЛга5.7ВХжЇГжЛљгкБэЕФВЂааИДжЦЁЃMariaDBЕФВЂааИДжЦгаСНжжЪЕЯжФЃЪНЃК
ЕквЛжжЃКConservative mode of in-order parallel replicationЃЈБЃЪиФЃЪНЕФЫГађВЂааИДжЦЃЉ
MariaDB 10 ЭЈЙ§ЛљгкБэЕФЖрЯпГЬВЂааИДжЦММЪѕЃЌШчЙћжїПтЩЯ1УыФкга10ИіЪТЮёЃЌФЧУДКЯВЂвЛИіIOЬсНЛвЛДЮЃЌВЂдкbinlogРядіМгвЛИіcid
= XX БъМЧЃЌЕБcidЕФжЕЪЧвЛбљЕФЛАЃЌSlaveОЭПЩвдНјааВЂааИДжЦЃЌЭЈЙ§ЩшжУЖрИіsql_threadЯпГЬЪЕЯжЁЃ

ЩЯЪіcidЮЊ630ЕФЪТЮёга2ИіЃЌБэЪОзщЬсНЛЪБЬсНЛСЫ2ИіЪТЮёЃЌМйШчЩшжУslave_parallel_threads
=24ЃЈВЂааИДжЦЯпГЬЪ§ЃЌИљОнCPUКЫЪ§ЩшжУЃЉЃЌФЧУДет2ИіЪТЮёдкslaveДгПтЩЯЭЈЙ§24Иіsql_threadЯпГЬНјааВЂааЛжИДЁЃжЛгаФЧаЉБЛздЖЏШЗШЯЮЊВЛЛсв§Ц№ГхЭЛЕФЪТЮёВХЛсБЛВЂаажДааЃЌвдШЗБЃДгПтЩЯЪТЮёЬсНЛКЭжїПтЩЯЪТЮёЬсНЛЫГађвЛжТЁЃетаЉВйзїЭъШЋЪЧЭИУїЕФЃЌЮоаыDBAИЩЩцЁЃ
ШчЙћЯыПижЦbinlogзщЬсНЛЪ§СПЃЌПЩвдЭЈЙ§ЯТЭМСНИіВЮЪ§ЩшжУЁЃ

ЕкЖўжжФЃЪНЃКOut-of-order parallel replicationЃЈЮоађВЂааИДжЦЃЉ

ЩшжУSET SESSION gtid_domain_id=99ОпгаВЛЭЌgtid_domain_idгђЪЖБ№ЗћПЩВЂааИДжЦЃЌЩњВњЪЙгУГЁОАЭЈГЃЪЧгУдкдіМгЫїв§ЁЂдіМгзжЖЮЩЯЁЃ

ЪЕЯжЮоађВЂааИДжЦЃЌашвЊАбGTIDПЊЦєВХПЩвдЪЕЯжЃЌжДааЩЯЭМЫљЪОЕФУќСюЁЃ
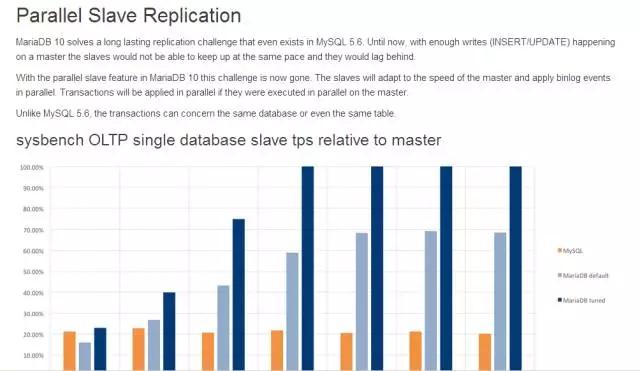
ЖрЯпГЬВЂааИДжЦЁЊбЙСІВтЪд
ЮвУЧПЩвдПДЕНЃЌЫцзХВЂааИДжЦЯпГЬЕФдіМгЃЌslaveДгПтЕФTPSУПУыаДШыЫйЖШНгНќжїПтЁЃ
4ЁЂЧАЦкЙЋЫОДѓЪ§ОнВПУХИеЦ№ВНЃЌЮДГЩЪьЃЌашвЊНшжњЖрдДИДжЦММЪѕЃЈЛузмЧАУцЖрИівЕЮёПтЃЉЃЌЬсЙЉИјBIВПУХЁЂВњЦЗPOЁЂН№ШкЗжЮіЪІBA/MAНјааЗжЮіЁЃ
ЃЈзЂЃКетИіЙІФмжЛгаMySQL5.7ВХгаЃЌ2015Фъ7дТЮДGAЃЉ

ЪЪгУГЁОАЃКЪЕЯжЪ§ОнЗжЮіВПУХЕФашЧѓЃЌНЋЖрИіЯЕЭГЕФЪ§ОнЛуОлЕНвЛЬЈЗўЮёЦїЩЯНјааOLAPЗжЮіМЦЫуЁЃ
MariaDB10ЖрдДИДжЦЕФДюНЈЗНЗЈШчЯТЁЃ
https://mariadb.com/kb/en/mariadb/multi-source-replication/
Ђй ДДНЈЭЈЕР
SET @@default_master_connection = ${connect_name};
Ђк НЈСЂЭЌВНИДжЦ
CHANGE MASTER ${connect_name} TO
MASTER_HOST=ЁЏ192.168.1.10Ёф,MASTER_USER=ЁЏreplЁЏ
,MASTER_PASSWORD=ЁЏreplЁЏ
,MASTER_PORT=3306,MASTER_LOG_FILE==ЁЏmysql-bin.000001Ёф,MASTER_LOG_POS=4,MASTER_CONNECT_RETRY=10;
Ђл ЦєЖЏ
START SLAVE ${connect_name};
START ALL SLAVES;
Ђм ЭЃжЙ
STOP SLAVE ${connect_name};
STOP ALL SLAVES;
Ђн ВщПДзДЬЌ
SHOW SLAVE ${connect_name} STATUS;
SHOW ALL SLAVES STATUS;
Ђо ЧхПеЭЌВНаХЯЂКЭШежО
RESET SLAVE ${connect_name} ALL;
Ђп ЫЂаТRelay logs
FLUSH RELAY LOGS ${connect_name}; |
5ЁЂMariaDB ColumnStoreЃЈInfiniDB 4.6.2ЃЉЪ§ОнВжПтЃЌгУгкДѓЪ§ОнРыЯпЗжЮіМЦЫу
ЕкЮхИідвђОЭЪЧЪ§ОнСПж№ШедіГЄЃЌдкInnoDBРяНјааИДдгSQLВщбЏЗжЮіЪЧвЛМўЗЧГЃЭДПрЕФЪТЧщЃЌКѓРДЮвбЁдёСЫMariaDB
ColumnStoreЪ§ОнВжПтЃЌзЈЮЊЗжВМЪНДѓЙцФЃВЂааДІРэMassively Parallel ProcessingЃЈMPPЃЉЩшМЦЕФСаЪНДцДЂв§ЧцЃЌгУЫќзіДѓЪ§ОнРыЯпЗжЮіOLAPЯЕЭГЃЌНшжњETLЙЄОпcanalЃЌЪЕЯжГщШЁbinlogВЂНтЮіЮЊдЩњЬЌSQLЮФМўШыПтЕНColumnstoreРяЁЃ
ColumnstoreММЪѕЬиад
БъзМSQLавщжЇГжNavicat/SQLyog/WebSQLЕШПЭЛЇЖЫЙЄОп
Ъ§ОнЗжВМЪНДцДЂЃЈБОЕиЛЏЃЉShard NothingМмЙЙ
ЗжВМЪНВЂааМЦЫуШЮЮёВЂаажДаа
КсЯђРЉеЙ
ColumnstoreММЪѕМмЙЙ
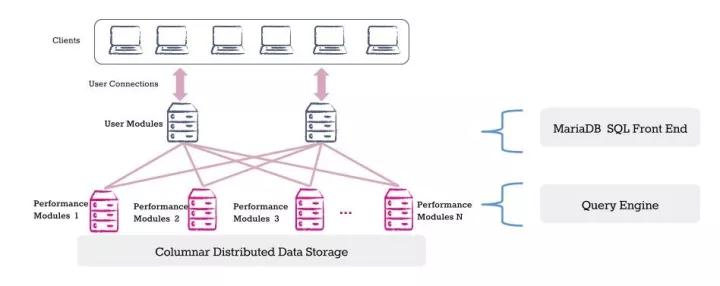
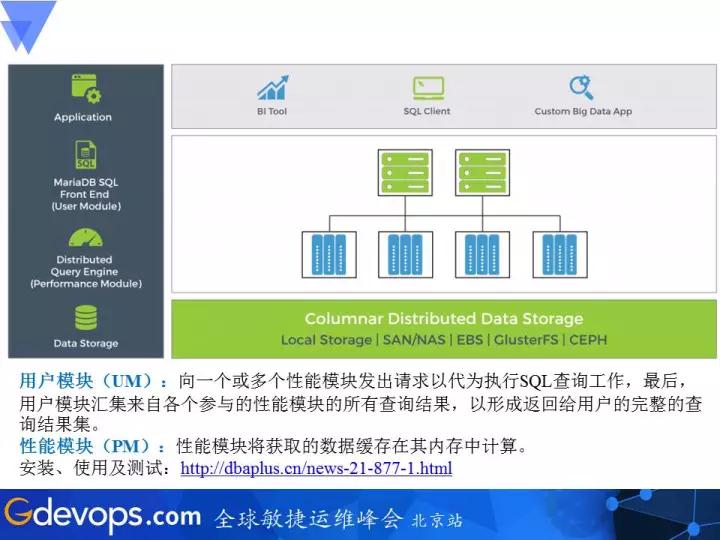
UMФЃПщЃКSQLавщНгПкЃЌНгЪеПЭЛЇЖЫСЌНгЗУЮЪЃЌЭЦЫЭSQLЧыЧѓИјPMадФмФЃПщДњЮЊжДааЃЌзюКѓЪеМЏадФмФЃПщЕФДІРэНсЙћзіЪ§ОнЛузмЃЌВЂЗЕЛиИјПЭЛЇЖЫзюжеВщбЏНсЙћЁЃ
PMФЃПщЃКИКд№Ъ§ОнЕФСаЪНДцДЂЃЌДІРэВщбЏЧыЧѓЃЌНЋЪ§ОнЬсШЁЕНФкДцжаМЦЫуЁЃ
6ЁЂЩѓМЦШежОAudit Log
ЛЅСЊЭјН№ШкЙЋЫОЖдЪ§ОнКмУєИаЃЌвЕЮёДгПтЬсЙЉИјПЊЗЂЕШШЫдБЪЙгУЁЃDBAЭЈЙ§ЩѓМЦШежОМЧТМЫћУЧВйзїЕФНсЙћЁЃ
АВзАЩѓМЦAudit PluginВхМўЃК

MariaDBЩѓМЦШежОВЮЪ§ЃК
server_audit_events
= ЁЎCONNECT,QUERY,TABLEЁЏ
server_audit_logging = ON
server_audit_incl_users = ЁЎhechunyangЁЏ
server_audit_excl_users = ЁЎsys_pmm,nagiosЁЏ
server_audit_file_rotate_size = 10G
server_audit_file_rotations = 500
server_audit_file_path = /data/audit/server_audit.log |

НЋЩѓМЦШежОГщЕНБэРяЃЌгУPHPеЙЪОГіРДЗжЮіЁЃ
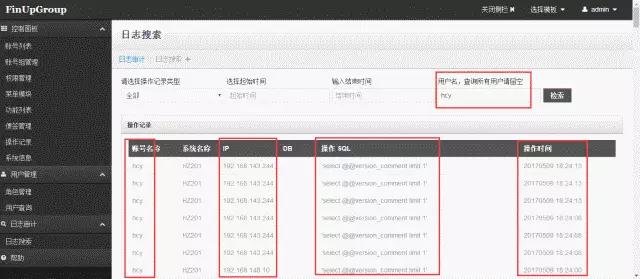
БОНкаЁНс
гЩгкMySQLЙІФмЩЯЕќДњЫйЖШЬЋТ§ЃЌвЦВНMariaDBКѓЃЌГХЙ§СЫвЕЮёЗЂеЙИпЗхЦк2015-2016ФъЁЃ
НшжњЁЖИпадФмШ§ЁЗвЛЪщЕФдЛАЃК

MariaDBКЭPerconaгаЪВУДВЛЭЌЃП

ИпПЩгУМмЙЙЕБЪБбЁаЭгаСНИіЗНАИЃЌвЛИіЪЧMHAЃЌвЛИіЪЧPXCЃЌЮЊЪВУДУЛгабЁдёPXCФиЃПгавдЯТМИИіВЛПЩПЙСІвђЫиЃК
ЃЈ1ЃЉЭјТчЖЖЖЏЛђепЛњЗПБЛARPЙЅЛїЃЌЕМжТNODEНкЕуЪЇСЊЃЌГіЯжСЫФдСбЃЌдѕУДДІРэЃПзюБЏОчЕФЪЧШ§ЗнНкЕуЖМЭЌЪБаДЃЌЖјЧвЛЙУЛИДжЦЙ§РДЃЌЕНЕзвдФФЗнЪ§ОнЮЊзМЃП
ЃЈ2ЃЉгВХЬЛЕСЫвЛПщЃЌЕМжТRAID10адФмЯТНЕЃЌЛсЕМжТМЏШКЯоСїЃЌЯоСїЕФВЮЪ§ЪЧwsrep_provider_options=gcs.fc_limitЃКД§жДааЖгСаГЄЖШГЌЙ§ИУжЕЪБЃЌflow
controlБЛДЅЗЂЃЌФЌШЯЪЧ16ЁЃДЫЪБе§ДІгкДйЯњЛюЖЏЧщаЮЃЌгЩгкPXCЕФадФмШЁОігкзюШѕЕФвЛИіNODEНкЕуЃЌЪ§ОнПтСЌНгЪ§КмШнвзБЛДђТњЃЌжБНгЙвСЫЁЃ
ЃЈ3ЃЉвЕЮёШчЙћгаДѓЪТЮёЃЌГЌЙ§СЫwsrep_max_ws_rowsЁЂwsrep_max_ws_sizeетСНИіжЕЃЌНкЕужЎМфЮоЗЈИДжЦЃЌдьГЩЪ§ОнВЛвЛжТЃЌдѕУДАьЃП
гЩгкМЏШКЪЧРжЙлЫјВЂЗЂПижЦЃЌЪТЮёГхЭЛЕФЧщПіЛсдкcommitНзЖЮЗЂЩњЁЃШчЙћгаСНИіЪТЮёдкМЏШКжаВЛЭЌЕФНкЕуЩЯЖдЭЌвЛаааДШыВЂЬсНЛЃЌЪЇАмЕФНкЕуНЋЛиЙіЃЌгІгУЖЫJAVA/PHPЗЕЛиБЈДэЃЌжБНггАЯьгУЛЇЬхбщЁЃ
ПЩВЮПМPerconaжЎЧАЗжЯэЕФPPTЁЊЁЊОоДѓЕФЧБСІдкPXCМмЙЙЃЌУВЫЦНтОіСЫвЛжТадЕФЮЪЬтЃЌЕЋОрРыГЩЪьЛЙгавЛЖЮОрРыЁЃ

ЯТЭМЪЧGroup ReplicationвдМАGalera ClusterМЏШКДЅЗЂЯоСїКѓЃЌадФмгАЯьЩѕДѓЁЃ

дкУЛгаСїСППижЦЕФЧщПіЯТЃЌWriterЛсдкгаЯоЕФЪБМфФкДІРэДѓСПааЃЈРДзд8ИіПЭЛЇЖЫЃЌ8ИіЯпГЬЃЌ50ИіВЂЗЂХњСПВхШыЃЉЁЃЫцзХСїСППижЦЃЌЧщПіМБОчБфЛЏЁЃWriterашвЊКмГЄЪБМфВХФмДІРэУїЯдИќаЁЕФааЪ§/УыЁЃзмжЎЃЌадФмЯджјЯТНЕЁЃ
Group Replication: The Sweet and the Sour
ЃЈ4ЃЉзюжївЊЕФвђЫиЁЊЁЊадФмЮЪЬт
гЩгкPXC/MariaDB Galera ClusterздЩэВЛжЇГжVIPЙІФмЃЌMariaDBЕФНтОіЗНАИЪЧгУMaxScaleзіЦпВуИКдиОљКтProxyЃЌгЩгкБОЩэадФмОЭВЛШчжїДгИДжЦЃЌдйЙ§вЛВуДњРэЃЌадФмОЭИќВюЁЃПЩВЮПМЯТЭМЙйЗНЕФНтОіЗНАИЁЃ
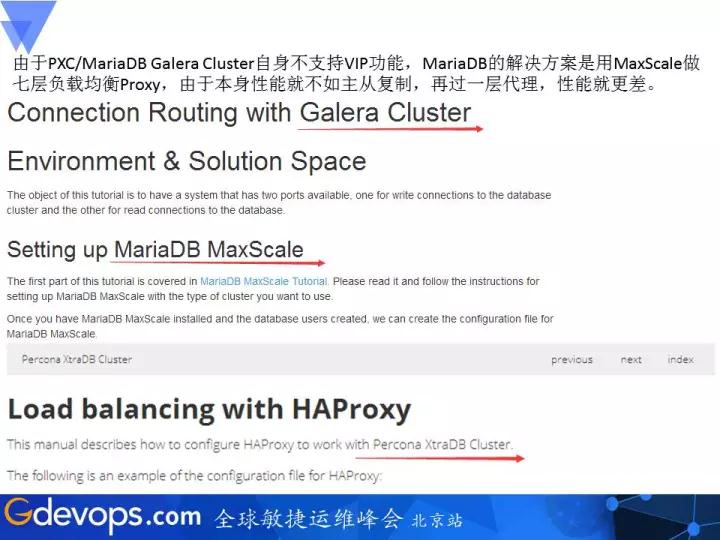
Galera ClusterећЬхМмЙЙЭМШчЯТЃК
аХШЮPerconaзЈвЕЭХЖгЕФбЁдё

ЩњВњЪ§ОнПтHAМмЙЙ

MHAЙмРэЖрзщМЏШКЃЈЖрЪЕР§ЃЉ
ЮвУЧЙЋЫОФПЧАЮЊвЛжїДјШ§ДгЃЈЦфжавЛИіДгПтЪЧзіЕФбгГйИДжЦ12аЁЪБЃЌгУpt-slave-delayЙЄОпЪЕЯжЃЉЃЌИпПЩгУМмЙЙВЩгУПЊдДMHA+АыЭЌВНИДжЦsemi
replicationЁЃ
бгГйИДжЦЕФФПЕФХТЭђвЛПЊЗЂЪжЖЖЃЌЛђепДњТыаДСЫвЛИіBUGЃЌЛђепАбвЛИіБэИјЩОСЫЃЌЭЈЙ§бгГйЛЙФмЛиРДЁЃ
ЩЯУцЪЧвЛИіМрПиЭМЃЌБЈДэЕФОЭЪЧбгЪБИДжЦДгПтЁЃ
ЩњВњПтMariaDBПЊЦєЕФВЮЪ§
sync_binlog = 1
innodb_flush_log_at_trx_commit = 1
innodb_support_xa = 1 ЃЈЪТЮёЕФСННзЖЮЬсНЛЃЉ
MHAМмЙЙКЭMMMМмЙЙгаЪВУДЧјБ№ФиЃПзюДѓЕФЧјБ№дкгкЃКMHAЛсАбЖЊЪЇЕФЪ§ОнЃЌдкУПИіSlaveНкЕуЩЯВЙЦыЁЃЯТУцЭЈЙ§вЛЗљЭМРДСЫНтЫќЕФЙЄзїдРэЁЃ
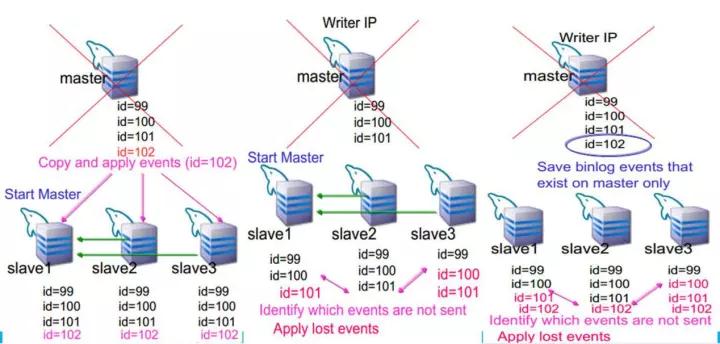
ЮвУЧПЩвдПДЕНЃЌЕБmasterхДЛњЪБЃЌMHAЙмРэЛњЛсЪдЭМscpЖЊЪЇЕФФЧвЛВПЗжbinlogЃЌШЛКѓАбИУbinlogПНБДЕНзюаТЕФslaveЛњЦїЩЯЃЌВЙЦыВювьЕФbinlogВЂгІгУЁЃЕБзюаТЕФslaveВЙЦыЪ§ОнКѓЃЌАбЫќЕФrelay-logПНБДЕНЦфЫћЕФslaveЩЯЃЌЪЖБ№ВювьВЂгІгУЁЃжСДЫЃЌећИіЛжИДЙ§ГЬНсЪјЃЌДгЖјБЃжЄЧаЛЛКѓЕФЪ§ОнЪЧвЛжТЕФЁЃ
дйЭЈЙ§ЯТЭМЃЌПЩвдИќШнвзШЅРэНтећИіЛжИДЙ§ГЬЁЃ
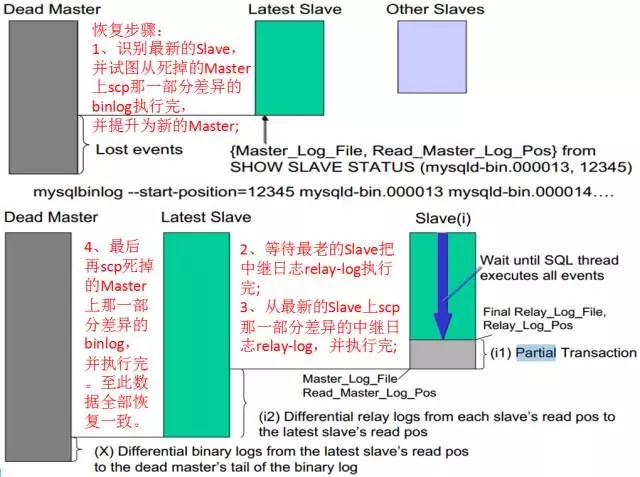
MHAМмЙЙзЂвтЪТЯю
1ЁЂЗРжЙЭјТчЖЖЖЏЮѓЧаЛЛЃЌдьГЩЪ§ОнВЛвЛжТ
ЦфЪЕЯждРэЮЊЃКЭЖЦБЛњжЦЃЌЕБМрПиЙмРэЛњЮоЗЈpingЭЈКЭЮоЗЈСЌНгMySQLжїПтЃЌЛсЪдЭМДгМрПиБИЛњЩЯШЅpingКЭСЌНгMySQLжїПтЃЌжЛгаЫЋЗНЖМСЌНгЪЇАмЃЌВХШЯЖЈMySQLжїПтхДЛњЁЃМйШчгавЛЗНПЩвдСЌНгMySQLжїПтЃЌЖМВЛЛсЧаЛЛЁЃ

ВЮЪ§ЃК
secondary_check_script=/usr/local/bin/
masterha_secondary_check
-s 192.168.111.76 -s 192.168.111.79 ЈCuser=root
ЈCmaster_host=QCZJ-dbm
ЈCmaster_ip=192.168.111.77 ЈCmaster_port=3306 |
ДгЧаЛЛШежОРяПДЃЌЫќЯШЪдЭМгУДгПт111.76КЭ111.79ЃЌШЅЭЌЪБping 111.77жїПтЃЌСНИіЖМpingВЛЭЈЕФЛАЃЌВХШЯЖЈжїПтхДЛњЃЌДЫЪБВХПЩвдНјааЙЪеЯЧаЛЛЁЃШчЙћгавЛИіДгПтФмpingЭЈжїПтЖМВЛЛсНјааЙЪеЯЧаЛЛЁЃ
ашвЊСєвтЕФЕиЗНЃКгЩгкmasterha_secondary_checkНХБОаДЫРСЫЖЫПкЃЌЫљвдвЊЪжЙЄаоИФsshЖЫПк
$ssh_user =
ЁАrootЁБ unless ($ssh_user);
$ssh_port = 62222 unless ($ssh_port);
$master_port = 3306 unless ($master_port); |
2ЁЂVIPУЛгаВЩгУkeepalivedЃЌОЭЪЧХТЭјТчЖЖЖЏЮЪЬтЁЃ
етРяЮваоИФСЫвдЯТСНИіНХБОЃЌздДјVIPЃЌДѓМвПЩвдЯТдиЪдгУ
master_ip_failover_script=/usr/local
/bin/master_ip_failover
master_ip_online_change_script=
/usr/local/bin/master_ip_online_change
КьЩЋЕФВПЗжЪЧаоИФЕФЕиЗНЁЃ
ЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊ-# Hardcode stuff now
until the next MHA release passes SSH info in
here
MHA::ManagerUtil::exec_ssh_cmd
( $new_master_ip,
ЁЎ62222ЁЏ,
ЁАip addr add 192.168.111.83/32 dev em2;arping
-q -c 2 -U -I em2 192.168.111.83ЁБ, undef );
ЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊЁЊ |

Ъ§ОнПтМмЙЙбнНј
ЫцзХЭјеОзГДѓЃЌЪ§ОнПтМмЙЙвЛАуЛсОРњШчЯТбнНјЃК

ЮЊЪВУДвЊЗжПтЗжБэЃПЃЈадФм+ДцДЂРЉШнЃЉ
ЕЅИіПтЪ§ОнШнСПЬЋДѓЃЌЕЅИіDBДцДЂПеМфВЛЙЛ
ЕЅИіПтБэЬЋЖрЃЌВщбЏЕФЪБКђЃЌДђПЊБэВйзївВЯћКФЯЕЭГзЪдД
ЕЅИіБэШнСПЬЋДѓЃЌВщбЏЕФЪБКђЃЌЩЈУшааЪ§Й§ЖрЃЌДХХЬIOДѓЃЌВщбЏЛКТ§
ЕЅИіПтФмГадиЕФЗУЮЪСПгаЯоЃЌдйИпЕФЗУЮЪСПжЛФмЭЈЙ§ЗжПтЗжБэЪЕЯж
еыЖдХРГцвЕЮёЃЌВЂЗЂЖСаДЦЕТЪКмИпЧвЖдЪТЮёвЊЧѓадВЛИпЃЌУЛгаСЊБэЙиСЊВщбЏЃЌФЧУДОЭВЛашвЊПМТЧЗХШыMySQLРяЃЌжБНгДцШыNOSQLЁЊЁЊMongoDBРяИќЪЪКЯЁЃ
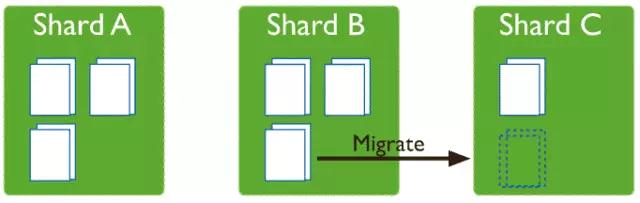
РћгУMongoDBздЩэЕФAuto-ShardingЗжЦЌММЪѕЪЕЯжЃЌЭЈЙ§етжжММЪѕПЩвдЪЙЮвУЧЗЧГЃЗНБуЕФРЉеЙЪ§ОнЃЌДгЖјВЛгУШУПЊЗЂИќИФвЛааДњТыМДПЩЧсЫЩЪЕЯжЪ§ОнВ№ЗжЁЃ
ЮвУЧетРязіСЫЗжВМЪНЃЌМЏШКзмЙВЪЧ9ЬЈЛњЦїЗжСНзщShardЃЌСНИіShardзщРДзіЕФЁЃЭЈЙ§етИіздЖЏЗжЦЌЃЌНтОіСЫПЊЗЂВЛгУИФБфдДњТыСЫЃЌМѕЩйШеГЃЙЄзїЁЃ

ЦЌМќЕФбЁдё

Hash based partitioningПЩвдШЗБЃЪ§ОнЦНОљЗжВМЃЌЕЋЪЧетбљЛсЕМжТОЙ§ЙўЯЃДІРэЕФжЕдкИїИіЪ§ОнПщКЭshardЩЯЫцЛњЗжВМЃЌНјЖјЪЙжЦЖЈЕФЗЖЮЇВщбЏrange
queryВЛФмЖЈЮЛЕНФГаЉshardЖјЪЧдкУПИіshardЩЯНјааБщРњВщбЏЁЃМјгквЕЮёЕФЪЕМЪЧщПіЃЌУЛгаЗЖЮЇВщбЏЃЌЮвУЧЪЧвдuserIdЃЈВщбЏзюЦЕЗБЕФЃЉзжЖЮзіЕФHashВ№ЗжЁЃ
дйЫЕЫЕЦЌМќЕФзЂвтЪТЯюЁЃ
ЕквЛЃЌдкЖдЮФЕЕИіБ№зжЖЮupdateЪБЃЌШчЙћqueryВПЗжУЛгаДјЩЯshard keyЃЌадФмЛсКмВюЃЌвђЮЊmongosашвЊАбетЬѕupdateгяОфХЩЗЂИјЫљгаЕФshard
ЪЕР§ЃЌПчЖрИіЭјТчадФмОЭЛсЯТНЕЁЃ
ЕкЖўЃЌЕБupdate ЕФupsertВЮЪ§ЮЊtrueЪБЃЌqueryВПЗжБиаыДјЩЯ shard keyЃЌЗёдђгяОфжДааГіДэЁЃР§ЃКdb.t1.update({},{cid:7,name:ЁБDЁБ},{upsert:1})
ЕкШ§ЃЌshard keyЕФжЕВЛФмБЛИќИФЁЃ
зюКѓдйЫЕвЛЯТЪ§ОнОљКтBalanceзЂвтЪТЯюЁЃ

ФкВПЗжСбВЂздЖЏbalanceЃЌвЛЕЉЗЂЩњЪ§ОнЧЈвЦЛсдьГЩећИіЯЕЭГЕФЭЬЭТСПМБОчЯТНЕЁЃЮЊСЫгІЖдShardingЧЈвЦЕФВЛШЗЖЈадЃЌЮвУЧПЩвдЧПжЦжИЖЈShardingЧЈвЦЕФЪБМфЕуЃЌОпЬхЧЈвЦЪБМфЕувРОнвЕЮёЗУЮЪЕФЕЭЗхЦкЁЃ
ЮвУЧЕФСїСПЕЭЗхЦкЪЧдкСшГП1ЕуЕН6ЕуЃЌФЧУДЮвУЧПЩвддкетЖЮЪБМфФкЩшжУДАПкЦкПЊЦєShardingЧЈвЦЙІФмЃЌдЪаэЪ§ОнЕФЧЈвЦЃЌЦфЫћЕФЪБМфВЛНјааЪ§ОнЕФЧЈвЦЃЌДгЖјзіЕНЖдShardingЧЈвЦЕФЭъШЋеЦПиЃЌБмУтЕєЮДжЊЪБМфShardingЧЈвЦДјРДЕФвЛаЉЗчЯеЁЃ
ЩшжУДАПкЦкУќСюЃК
use config
db.settings.update({ _id : ЁАbalancerЁБ }, { $set
: { activeWindow : { start : ЁА1:00ЁБ, stop : ЁА6:00ЁБ
} } }, true ) |
Ъ§ОнОљКтBalanceМрПиЭМЈCPercona PMM
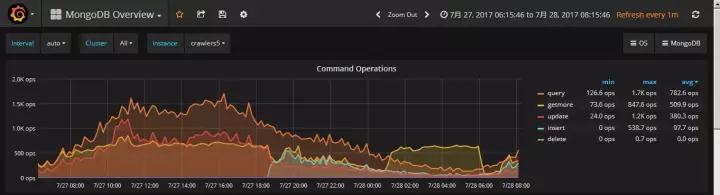
ЙлВьgetmoreЛЦбеЩЋЧњЯпЃЌ1:00-6:00ЕуЪБМфЖЮе§ЪЧзіЪ§ОнЧЈвЦЁЃ
ШчЙћВЛЩшжУДАПкЦкЃЌвдЮвУЧ7200зЊЕФsasгВХЬЃЌдкдчИпЗхзіЪ§ОнЧЈвЦЃЌЖЈНЋгАЯьвЕЮёЮШЖЈЁЃ
ХРГцећЬхШыПтМмЙЙЭМ
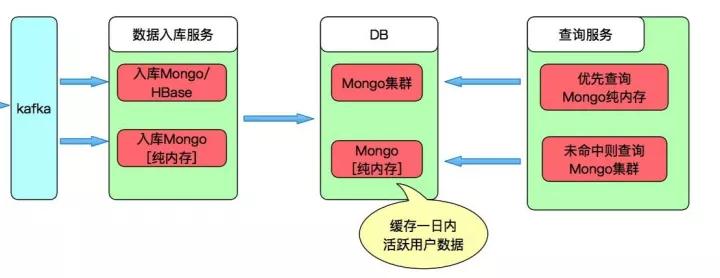
аТдіЪ§ОнЯШаДШыЪ§ОнПтWiredTigerРяЃЌШЛКѓТэЩЯИќаТЕНIn-Memoryв§ЧцЃЈinMemorySizeGB
= 180GЃЉЃЌЖСШЁЪБгХЯШдкIn-MemoryФкДцжаЖСШЁЃЌШчЙћЪ§ОнВЛдкдђДгКѓЖЫWiredTigerРяШЁЪ§ЁЃIn-MemoryжаЕФШШЪ§ОнЪЇаЇЪБМфЮЊвЛЬьЃЌЕШД§ЯТДЮЖСШЁЪБдйМгдиЁЃ
ЛКДцЪЇаЇЪБМфЩшжУ
дкДДНЈЫїв§ЪБЃЌашвЊжИЖЈЙ§ЦкЪБМфЃЌВЮПМЛКьЩЋЯпВПЗжЃЌЙ§ЦкКѓМЏКЯРяЕФетИіЮФЕЕОЭЛсздЖЏЩОГ§ЁЃетРягавЛИізЂвтЪТЯюОЭЪЧЃКзжЖЮБиаыЪЧЪБМфРраЭЕФЁЃ
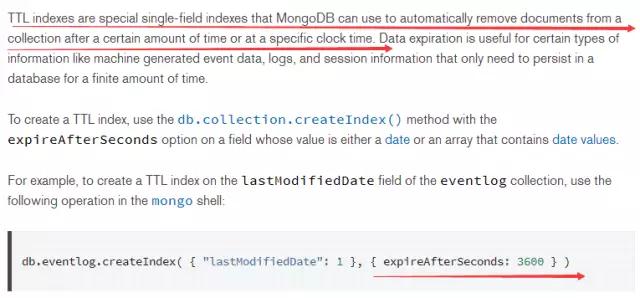
аДЙизЂЃЈWrite ConcernЃЉ
1ЁЂ MongoDBФЌШЯЮЊвьВНИДжЦЃЌБОЕиаДЭъКѓМДЗЕЛиПЭЛЇЖЫЧыЧѓЁЃ
2ЁЂПЩвдЭЈЙ§Ч§ЖЏЩшжУЮЊЃК
<?php
// Setting w=majority for update:
$collection->update($someDoc, $someUpdates,
array(ЁАwЁБ =>
ЁАmajorityЁБ,ЁБjЁБ => true));
?> |
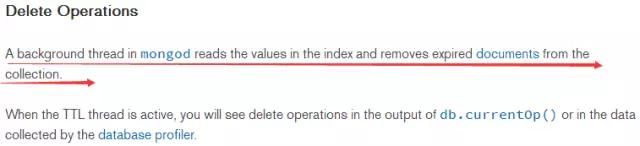
втЫМЮЊЭЌВНИДжЦЛњжЦЃЌжїПтЪ§ОнаДШыФкДцКѓЃЌЛЙвЊШЗБЃJournalжизіШежОЫЂШыДХХЬЃЌВЂБЃжЄвбИДжЦЕНДгНкЕуКѓЃЌВХЛсЗЕЛиИќаТГЩЙІЃЌНЋЧыЧѓЗЕЛиИјПЭЛЇЖЫЁЃ
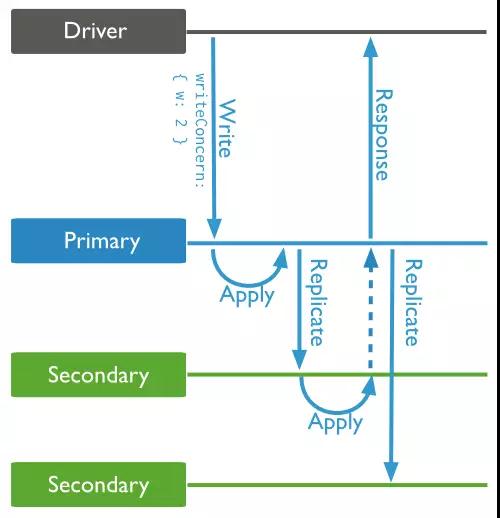
ЖСаДЗжРы
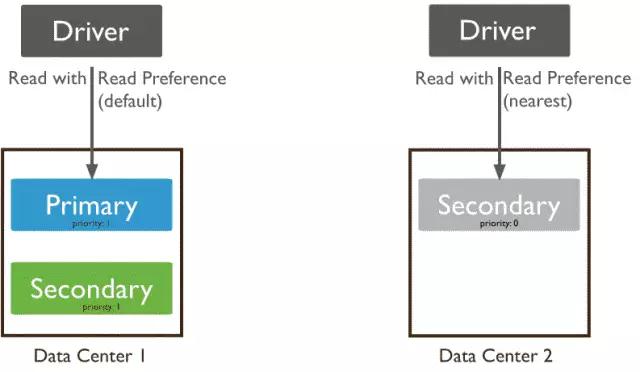

MongoDBЕФJavaЧ§ЖЏЃЌФЌШЯЖСаДЪЧдкPrimaryжїНкЕуЩЯЃЌШчЙћЯыЖСSecondaryДгНкЕуЃЌашвЊЭЈЙ§ЩшжУЧ§ЖЏЪЕЯжЁЃ
НкЕуЖЏЬЌРЉШн&вЛжТадЙўЯЃЫуЗЈ

НкЕуРЉШнЙ§ГЬЮЊЃКЪ§Он1ЁЂ2дкНкЕуAЩЯЃЌЪ§Он3ЁЂ4дкНкЕуCЩЯЁЃШчЙћдіМгвЛИіНкЕуBЃЌЪ§Он1ЁЂ2ЛЙдкAЩЯЃЌжЛашвЊАбЪ§Он3ЧЈЕНBЩЯЃЌЪ§Он4ШддкCЩЯЃЌЫљвджЛЪЧВПЗжЪ§ОнЧЈвЦЃЌВЂВЛЪЧећЬхЪ§ОнЧЈвЦЃЌетбљБмУтСЫбЉБРЕФЯжЯѓЁЃ
бгГйИДжЦНкЕуЕФБивЊад
двђЃК
1ЁЂПЊЗЂДњТыгаBUGЛђDBAЪжЖЖЃЌвЛЫВМфШУФуЕФвЕЮёЛиЕННтЗХЧА
2ЁЂЙ§TBЪ§ОнБИЗнЛжИДЮЪЬт
MariaDB 10.2ВХжЇГжбгГйИДжЦЃЈMySQL5.6дчвбжЇГжЃЉЃЌЙЬашвЊНшжњPercona PTЙЄОпЪЕЯж
shell > perl
/usr/local/bin/pt-slave-delay -S /tmp/mysql.sock
ЈCuser root
ЈCpassword 123456 ЈCdelay 43200 ЈClog /root/delay.log
ЈCdaemonize |
зЂЃКЕЅЮЛУыЃЌ43200УыЕШгк12аЁЪБ
MongoDB 3.2бгГйИДжЦЪЕЯж
Primary >
rs.add( { host:
ЁАqianzhan_delay.mongodb.dc.puhuifinance.com:27017ЁБ,
priority:0,hidden:1,slaveDelay:43200,votes:0 }
) |
зЂЃК
priorityШЈжиЩшжУЮЊ0ЃЌгРдЖВЛФмЧаЮЊPrimary
hiddenЩшжУЮЊвўВиНкЕу
slaveDelayбгГйЪБМфЃЌЕЅЮЛУыЃЌ43200УыЕШгк12аЁЪБ
votesШЁЯћЭЖЦБзЪИё

гУPercona MongoDBЬцЛЛдЩњАцЁЊЁЊШШБИЗнЙІФм
Percona MongoDB3.2АцБОФЌШЯжЇГжWiredTigerв§ЧцЕФдкЯпШШБИЗнЃЌНтОіСЫЙйЗНАцжЛФмЭЈЙ§mongodumpТпМБИЗнетвЛШБЯнЁЃЛжИДКмМђЕЅЃЌАбБИЗнФПТМРяЕФЪ§ОнЮФМўжБНгПНБДЕНФуЕФdbpathЯТЃЌШЛКѓЦєЖЏMongoDBМДПЩЁЃ
зЂЃКPercona server Mongodb 3.2.10гавЛИіbug
directoryperdb = true
wiredTigerDirectoryForIndexes = true
етСНИіВЮЪ§БиаызЂЯњЕєЃЌЗёдђБИЗнЪЇАмЁЃ
етЪЧЮвЬсНЛЕФbugЕижЗЃЌhttps://jira.percona.com/browse/PSMDB-123
PerconaВЩФЩСЫИУbugЃЌВЂдк3.2.12АцБОРяаоИДЁЃ
https://www.percona.com/doc/percona-server-for-mongodb/3.2/release_notes/3.2.12-3.2.html

Percona MongoDB3.2 HotBackup Perl Scripts
ЪЙгУЫЕУїЃКЧыдкБОЕиadminЪ§ОнПтЃЌвдЙмРэдБЩэЗндЫааcreateBackupУќСюЃЌВЂжИЖЈБИЗнФПТМЁЃ
здЖЏБИЗнНХБО
# perl -MCPAN
-e ЁАinstall MongoDBЁБ
#!/usr/bin/perl
use MongoDB;
use File::Path
use POSIX qw(strftime);
my $mc = MongoDB::MongoClient->new(
host => ЁАmongodb://localhost:37019/ЁБ,
username => ЁАadminЁБ,
password => ЁА123456ЁБ,
);
my $db = $mc->get_database(ЁАadminЁБ);
$year = strftime ЁА%YЁБ,localtime;
$month = strftime ЁА%mЁБ,localtime;
$time = strftime ЁА%Y-%m-%d-%H-%M-%SЁБ, localtime;
$BAKDB = ЁАyourdbЁБ;
$BAKDIR = ЁА/data/bak/hcy/$year/$month/$BAKDB_$timeЁБ;
my $user = getpwnam ЁАmongodbЁБ or die ЁАbad userЁБ;
my $group = getgrnam ЁАmongodbЁБ or die ЁАbad groupЁБ;
mkpath($BAKDIR) or die ЁАФПТМвбДцдк. $!ЁБ;
chown $user, $group, $BAKDIR;
my $cmd = [
createBackup => 1,
backupDir => $BAKDIR
];
$db->run_command($cmd);
if($! == 0){
print ЁАbackup is success.ЁБ;
}else{
print ЁАbackup is failure.ЁБ;
} |
MongoDB Т§ВщбЏгЪМўБЈОЏВЂздЖЏKILL Perl Scripts

ЭЈЙ§ВщПДЕБЧАВйзїdb.currentOp()ЃЌДѓгкжИЖЈжДааЪБМфЃЌЗЂгЪМўБЈОЏЃЌВЂЭЈЙ§db.killOp(opid)ЩБЕєНјГЬЁЃ

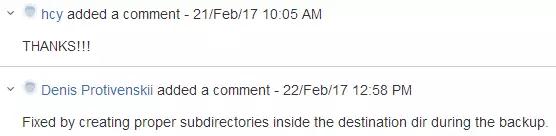
OplogИЧзгМЏКЯ(Capped Collections)зЂвтЪТЯюЃЈПЩвдРэНтЮЊMySQL BinlogЃЉ
ФЌШЯЪЃгрПеМфЕФ5%
ЕБФуДюНЈИББОМЏЕФЪБКђЃЌвЛЖЈвЊАбOplogЩшжУЕУБШНЯДѓЃЌФЌШЯЪЧЪЃгрДХХЬПеМфЕФ5%ЃЌЮвУЧЯпЩЯЩшжУЮЊ100GЁЃOplogИњbinlogДцДЂЗНЪНВЛЬЋвЛбљЃЌbinlogЪЧаДТњвЛИіЮФМўЛсдйЩњГЩвЛИіаТЕФЮФМўМЬајаДЃЌЖјOplogдђЪЧИВИЧаДЁЃЮвУЧПДЩЯЭМЃЌДгПтЙвЕєвдКѓдйДЮМгШыМЏШКЪБЃЌЫќЛсЯШЗЂЫЭвЛИіЮЛжУЕуИјжїПтЃЌБШШчЯждкЗЂЫЭвЛИіЮЛжУЕуЪЧ27ЃЌжїПтгаЕФЛАЛсАб27жЎКѓЕФЪ§ОнЭЦЙ§РДЁЃШчжїПтУЛгаЛсИцжЊДгПтЮветРяУЛгаевЕНЃЌДгПтЛсАбБОЕиЪ§ОнШЋВПЩОГ§ЃЌДгжїПтЩЯШЋСПГщЪ§ОнЃЌбЇУћЮЊinitial
syncЁЃ
ЩёЦїЃЁMongoDBгяЗЈдкЯпЩњГЩЦї
http://www.querymongo.com/ПЩвдНЋSQLгяЗЈзЊЛЛГЩMongoDBгяЗЈЃЌР§згЃК
MySQL ЗжПтЗжБэжаМфМўбЁдё
MariaDB SpiderЗжПтЗжБэДцДЂв§Чц
https://mariadb.com/kb/en/mariadb/spider-storage-engine-overview/
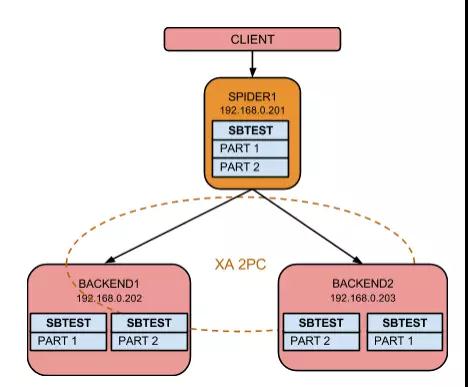
SpiderЪЧMariaDBФкжУЕФвЛИіПЩВхАЮгУгкMariaDB/MySQLЪ§ОнПтЗжЦЌЕФДцДЂв§ЧцЃЌГфЕБгІгУЗўЮёЦїКЭдЖГЬКѓЖЫDBжЎМфЕФДњРэЃЈжаМфМўЃЉЃЌЫќПЩвдЧсЫЩЪЕЯжMySQLЕФКсЯђКЭзнЯђРЉеЙЃЌЭЛЦЦЕЅЬЈMySQLЕФЯожЦЃЌжЇГжЗЖЮЇЗжЧјЁЂСаБэЗжЧјЁЂЙўЯЃЗжЧјЃЌжЇГжXAЗжВМЪНЪТЮёЃЌжЇГжПчПтjoinЁЃЭЈЙ§SpiderЃЌФњПЩвдПчЖрИіЪ§ОнПтКѓЖЫгааЇЗУЮЪЪ§ОнЃЌШУФњЕФгІгУГЬађвЛааДњТыВЛИФЃЌМДПЩЧсЫЩЪЕЯжЗжПтЗжБэЃЁ
ПЊЗЂЮоашЕїећДњТыЃЌгІгУВуИњЗУЮЪЕЅЛњMySQLвЛбљЁЃ
DBAВПЪ№МђЕЅЃЌгЩгкMariaDB10 ФЌШЯвбОРІАѓСЫSpiderв§ЧцЃЌЮоашБрвыАВзАЁЃ
жЇГжБъзМSQLгяЗЈЃЌДцДЂЙ§ГЬЃЌКЏЪ§ЃЌПчПтJoinЃЌУЛгаAtlasФЧУДЖрЕФЯожЦЁЃ
КѓЖЫDBПЩвдЪЧШЮвЛАцБОЃЌMySQL/MariaDB/Percona
ЮоЮЌЛЄГЩБО
ЩњВњГЩЪьАИР§-ЬкбЖЙЋЫО
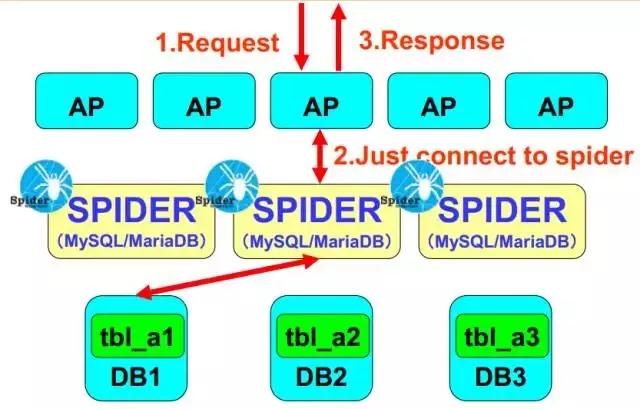
етИіЪЧЫќЕФећЬхЕФМмЙЙЭМЃЌ гІгУГЬађСЌНгSpiderЃЌSpiderГфЕБжаМфМўДњРэЃЌНЋПЭЛЇЖЫВщбЏЕФЧыЧѓЃЌАДееЪТЯШЖЈвхКУЕФЗжЦЌЙцдђЃЌЗжЗЂИјКѓЖЫЪ§ОнПтЃЌжЎКѓЗЕЛиЕФЪ§ОнЛузмдкSpiderФкДцРязіОлКЯЃЌзюжеЗЕЛиПЭЛЇЖЫЧыЧѓЃЌЖдгкгІгУГЬађЖјбдЪЧЭИУїЕФЁЃ
адФмбЙСІВтЪдsysbench
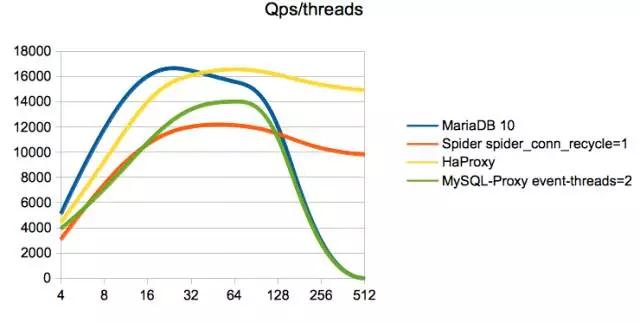
дкЮвЕФбЙВтНсЙћЩЯЃЌЗжБэЕФадФмЛсНЕЕЭ70%ЃЌДЙжБВ№ЗжадФмЛсНЕЕЭ40%ЃЌадФмЫ№КФЕФдвђЪЧдкЗжВМЪНГЁОАЯТЃЌвЊБЃжЄ2PCвЛжТадКЭПЩгУадЖСаДЕФБэЯжОЭВюЃЌСэЭтОЭЪЧПчЖрИіЭјТчДЋЪфетСНЗНУцв§Ц№ЕФЁЃ
дкЩњВњЛЗОГжаЃЌЮвЭЈЙ§SpiderЪЕЯжСЫБэЕФДЙжБВ№ЗжЃЌУЛгазіЗжПтЗжБэЁЃ
ЪЙгУГЁОАНщЩм
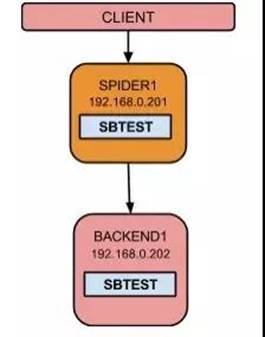
ЃЈМмЙЙЭМЃЉ
1ЁЂНЛвзСїЫЎБэЮвЪЧАыФъвЛЧаБэЃЌРЯБэИФУћЃЌдйДДаТвЛеХаТБэЃЌШЛКѓЭЈжЊПЊЗЂЪжЙЄИФДњТыРяЕФSQLЃЌгУunion
allЕФЗНЪНЙиСЊВщбЏЁЃШчЃКselect * from t1 where apply_no = ЁЎXXXXЁЏ
union all select * from t1_20170630 where apply_no
= ЁЎXXXXЁЏ
2ЁЂгЩгкРњЪЗБэУЛгааДВйзїЃЌжЛгагУЛЇЕФВщбЏЃЌЧвВщбЏЦЕТЪВЂВЛЪЧКмИпЃЌНЋРњЪЗБэвЦЕНБИЗнЛњЃЌдйЭЈЙ§spiderзівЛИігГЩфЃЈШэСЌНгЃЉЪЕЯжБэЕФДЙжБВ№ЗжЃЌНтОіДХХЬПеМфРЉеЙЮЪЬтЁЃ
3ЁЂЪЕЪЉетИіЗНАИЃЌбЁдёSpiderв§ЧцЪЧгагХЪЦЕФЃК
SQLНтЮіКЭВщбЏгХЛЏЪЧИіЗЧГЃИДдгЧвКмФбзіКУЕФЙЄзїЃЌЦфЫќЬцДњВњЦЗЖМЪЧздМКЪЕЯжЃЌгЩгкИДдгадЃЌетаЉВњЦЗЖМДјРДСЫвЛаЉЯожЦЃЌБШШчВЛжЇГжДцДЂЙ§ГЬЁЂКЏЪ§ЁЂЪгЭМЕШЃЌИјЪЙгУКЭЪЕЪЉДјРДСЫРЇФбЁЃЖјзїЮЊвЛИіДцДЂв§ЧцЃЌетаЉЙЄзїЖМгЩMariaDBздЩэЭъГЩСЫЃЌПЩвдЗНБуЕиНЋДѓБэзіЗжВМЪНВ№ЗжЃЌЫќЕФКУДІЪЧЖдвЕЮёЗНЪЙгУЪЧЭИУїЕФЃЌSQLгяЗЈУЛгаШЮКЮЯожЦЃЌдкВЛИФБфЯжгаDBМмЙЙЕФЗНАИжаЃЌЧжШыадзюаЁЁЃ
ЬсЩ§адФмЕФЙиМќ
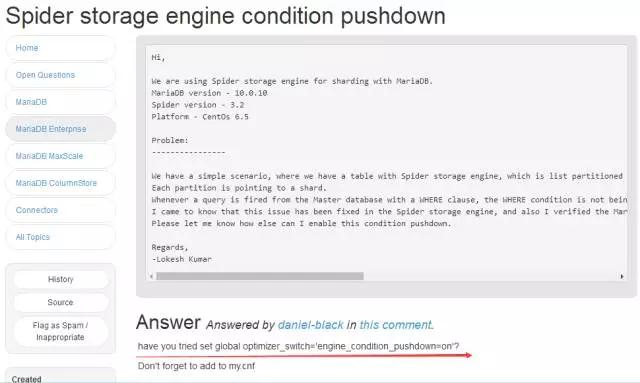
optimizer_switch= ЁЎengine_condition_pushdown=onЁЏ
в§ЧцЯТЭЦЃЌВщбЏЭЦЫЭЕНКѓЖЫЪ§ОнПтЃЌНЋВщбЏНсЙћЗЕЛиИјSpiderзіОлКЯЃЌРрЫЦMap-ReduceЁЃдчЦкЕФАцБОЪЧДгКѓЖЫРШЁЫљашЕФЪ§ОнЕНБОЕиСйЪББэЃЌШЛКѓдйзіДІРэЁЃ
Spiderв§ЧцАВзА
shell > mysql -uroot -p < /usr/local/mysql/share/install_spider.sql
SELECT engine, support, transactions, xa FROM
information_schema.engines;

Spiderв§ЧцЪЙгУ
ЖЈвхКѓЖЫЗўЮёЦїКЭЪ§ОнПтУћзж

етИіЪЧЖЈвхКѓЖЫЗўЮёЦїКЭЪ§ОнПтУћзжЁЃетРяКѓЖЫЗўЮёЦїЕФУћзжЮЊbackend1ЃЌЪ§ОнПтУћзжЮЊtestЃЌжїЛњIPЕижЗЮЊ192.168.143.205ЃЌгУЛЇУћЮЊuser_readonlyЃЌУмТыЮЊ123456ЃЌЖЫПкЮЊ3306ЁЃ
зЂЃКШчХфжУДэЮѓЃЌПЩжБНгDROP SERVER backend1; жиаТДДНЈМДПЩЁЃ
ДЙжБВ№ЗжЃЈгГЩфЁЂШэСЌНгЃЉ
етИіЪЧЖЈвхДЙжБВ№ЗжЃЌвВОЭЪЧгГЩфКЭШэСЌНгЃЌзівЛИіГЌСДНгЁЃSpiderздЩэВЛБЃДцЪ§ОнЃЌжЛБЃДцТЗгЩаХЯЂЁЃетРяЭЈЙ§ЩшжУCOMMENTзЂЪЭРДЕїгУКѓЖЫЕФБэЃЌШЛКѓФуОЭПЩвдВщПДsbtestБэСЫЃЌЪЧВЛЪЧКмМђЕЅЃП
MariaDB 10.3& Spider GA

ВЮПМhttps://mariadb.org/embrace-community-fly-open-source-dream/
МрПиТ§SQLЁЊPercona Query Analytics
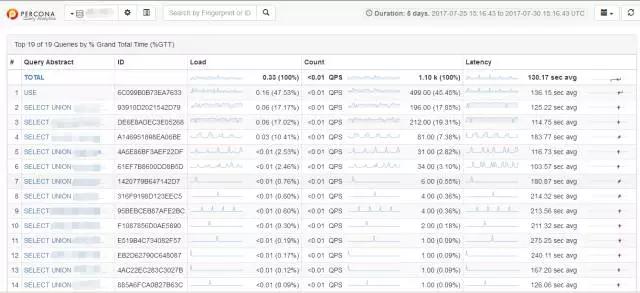
Т§ВщбЏМрПивВЪЧгУЕФЪЧPerconaРДзіЃЌетРяЪЧМЏГЩСЫПЩЪгЛЏЦНЬЈЁЃ

MySQL Т§ВщбЏгЪМўБЈОЏВЂздЖЏKILL

ЃЈPercona PT-killОЋМђАцЃЉ
ЖрдіМгЗЂЫЭkillЕєКѓЕФТ§SQLгЪМўБЈОЏЙІФм
зЂЃКЙйЗНдАцФЌШЯБЛkillЕєЕФSQLВЛЛсЗЂгЪМўГіРДЃЌетЛсдьГЩВЛФмМАЪБЭЈжЊПЊЗЂЃЌЖдХХВщЮЪЬтДјРДРЇЛѓЁЃ
ЯТвЛДњЙиЯЕаЭЪ§ОнПтNewSQL

зюКѓЫЕвЛЯТЯТвЛДњЙиЯЕаЭЪ§ОнПтNewSQLЃКCockroachDBКЭTiDBЁЃ
CockroachDBЪЧвЛИіЗжВМЪНSQLЪ§ОнПтЁЃЦфжївЊЩшМЦФПБъЪЧРЉеЙадЁЂЧПвЛжТадКЭЩњДцадЃЈCockroachDBѓЏђыЪ§ОнПтгЩДЫЕУУћЃЉЁЃ
CockroachDBЕФФПБъЪЧШнШЬДХХЬЁЂЛњЦїЁЂЛњМмЃЌЩѕжСЪ§ОнжааФЙЪеЯЃЌдкЮоашШЫЙЄИЩдЄЕФЧщПіЯТЃЌзюаЁЛЏетаЉбгГйжаЖЯЕФгАЯьЁЃ
CockroachDBИїНкЕуЪЧЖдЕШЕФЃЌЩшМЦФПБъЪЧЭЌжЪЛЏВПЪ№ЃЈвЛИіЖўНјжЦАќЃЉЃЌзюаЁЛЏХфжУЃЌвВВЛашвЊЭтВПвРРЕЯюЁЃCockroachDBМЏШКжаЕФУПИіНкЕуЖМПЩвдАчбнвЛИіПЭЛЇЖЫSQLЭјЙиНЧЩЋЃЌSQLЭјЙиНЋПЭЛЇЖЫSQLгяОфзЊЛЛГЩKVВйзїЃЌЗжЗЂЕНЫљашЕФНкЕужДааВЂЗЕЛиНсЙћИјПЭЛЇЖЫЁЃЦфЩшМЦСщИаЃЌРДздЙШИшSpannerКЭF1ТлЮФЁЃ
https://github.com/cockroachdb/cockroach
https://www.cockroachlabs.com/docs/stable/
ЧјБ№
TiDBЕФSQLНтЮіавщЪЧЛљгкMySQLЃЌЖјCockroachDBЪЧЛљгкPostgreSQLЁЃ
ФкВПМмЙЙЬхЯЕ
CockroachDBВЩгУЗжВуМмЙЙЃЌЦфзюИпГщЯёВуЮЊSQLВуЃЌCockroachDBжБНгЭЈЙ§SQLВуЬсЙЉЪьЯЄЕФЙиЯЕИХФюЃЌ
ШчЃКФЃЪНschemaЁЂБэtableЁЂСаcolumnКЭЫїв§indexЃЌ НгЯТРДSQLВувРРЕгкЗжВМЪНKVДцДЂЃЌИУДцДЂЙмРэrangeДІРэЕФЯИНквдЬсЙЉвЛИіЕЅвЛШЋОжKVДцДЂЕФГщЯѓЁЃЗжВМЪНKVДцДЂгыШЮвтЪ§СПЕФCockroachDBЮяРэНкЕуЭЈаХЃЌУПИіЮяРэНкЕуАќКЌвЛИіЛђепЖрИіДцДЂЁЃ

ЬиЕу
дкдгаNoSQLЪ§ОнПтЃЈFacebook RocksDBЃЉЛљДЁЩЯЃЌдіМгСЫЗжВМЪНЪТЮёЃЌНтОіСЫЪ§ОнЧПвЛжТадЁЃ
жЇГжДЋЭГSQLгяЗЈЃЌЗтзАСЫвЛВуPostgreSQLавщЁЃ
ВЩгУMongoDBЕФRaftавщзіЙЪеЯЧаЛЛЃЈДѓЖрЪ§ЭЖЦБЛњжЦЃЉЃЌФЌШЯ3ИіНкЕуЙв1ИіНкЕуВЛгАЯьвЕЮёЖСаДЁЃ
НкЕуЖЏЬЌШШРЉШнЃЌНкЕуМфЕФЪ§ОнздЖЏЧЈвЦЁЃ
ФкВПздЖЏЗжСбЪ§ОнПщЃЈДяЕН64MЃЉЃЌздЖЏbalanceОљКтЃЈЪ§ОнЧЈвЦЃЉЁЃ
ШЋЭЌВНЛњжЦЃЈЧПвЛжТадЃЉЃЌЪ§ОнаДШыБиаыжСЩй2ИіИББОЃЈФЌШЯ3ИіИББОЃЉТфЕиЃЌПЭЛЇЖЫВХПЩвдЗЕЛиЬсНЛГЩЙІЧыЧѓЁЃ
ШЮвтвЛИіНкЕужЇГжЖСаДВйзїЁЃ
ЪЙгУГЁОА

етИіЪЧPerconaжЎЧАдкетИіЮФеТРязіЕФЦРВт
WhatЁЏs Next for SQL Databases?
адФмЩЯЃЌВЛМАMySQLЃЌЩњВњЛЗОГжїПтЬцДњMySQLЮЊЪБЩадчЃЌЦфЙЄвЕЦЗжЪКЭMySQLЩагаВюОрЁЃ
Both CockroachDB and TiDB, at the moment of this
writing, still have rough edges and canЁЏt be used
in serious deployments (from my experience). I expect
both projects will makea big progress in 2017.
выЃКВЛФмгУгкбЯжиВПЪ№(ИљОнЮвЕФОбщ)ЃЌЮвдЄМЦетСНИіЯюФПНЋдк2017ФъШЁЕУжиДѓНјеЙЁЃ
ВЛФмгУгкOLAP КЭжиЖШЪ§ОнЗжЮі
JOINЙиСЊВщбЏадФмНЯВю
БШНЯЪЪКЯЕФГЁОАЃЌОЭЪЧЖЉЕЅРњЪЗСїЫЎБэЃЌЮяСїРњЪЗБэЃЌТлЬГЬћзгРњЪЗБэетжжЃЌЕЭВЂЗЂМђЕЅSQLЖСаДЃЌЭЈЙ§CockroachDBздЖЏРЉШн
ЮвУЧЙЋЫОЯждкАбРњЪЗБэЕМШыЕНCockroachDBРяУцЃЌХфКЯДѓЪ§ОнВПУХЃЌШУЫћУЧДгетРяжБНгГщЪ§ОнЁЃ
адФмВюЕФдвђ

вЛИіЪЧШЋЭЌВНЛњжЦЃЌЧПвЛжТадЃЌЪ§ОнжСЩйаДШыСНИіНкЕуВХПЩвдЁЃ
ЕкЖўОЭЪЧФЌШЯађСаЛЏЃЌЪТЮёжЛФмвЛИівЛИіжДааЃЌВЛФмВЂаажДааЁЃ
ЕкШ§ЗжВМЪНЪТЮёЬсНЛЃЌашвЊПчЖрИіЭјТчЃЌЭјТчIOПЊЯњДѓЁЃ
The long transactions (letЁЏs say changing 100000 or
more rows) also will
be problematic. There is just too much network round-trips
and
housekeeping work on each node, making long transactions
an issue for
distributed systems.
WhatЁЏs Next for SQL Databases?
выЃКДѓЪТЮёЃЈР§ШчИќИФ10ЭђааЛђИќЖрЃЉвВЪЧгаЮЪЬтЕФЁЃУПИіНкЕуЖМгаЬЋЖрЕФЭјТчЭљЗЕЃЌЪЙЕУГЄЪБМфЕФДѓЪТЮёГЩЮЊЗжВМЪНЯЕЭГЕФвЛИіЦПОБЁЃ
ФЌШЯШ§ИіИББОЃЌУПИіНкЕуЖМПЩвдЖСаДЃК
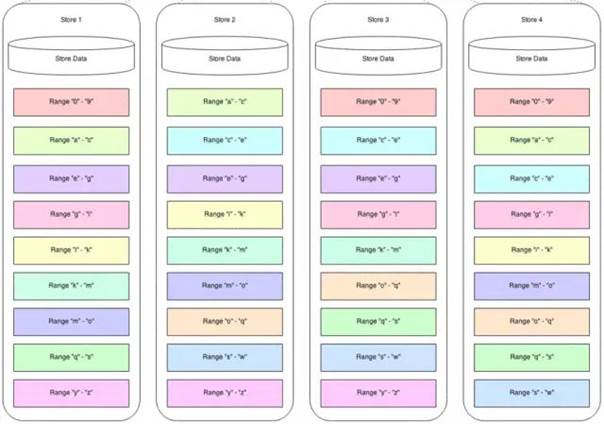
дЫЮЌВПЪ№

ВЮЪ§НтЪЭЃК
ЈCcacheЮЊФкДцЛКДцЕФЪ§ОнЃЌЭЈГЃЮЊЮяРэФкДцЕФ70%
ЈCjoinЮЊМгШыШКМЏНкЕу
ВПЪ№ЗЧГЃМђЕЅЃЌжЛашвЊЬэМгНкЕуЃЌЪ§ОнЛсздЖЏЧЈвЦРЉШнЁЃ
CockroachDBПЭЛЇЖЫ Postico for Mac

УќСюааЙЄОп
# psql -h 192.168.1.1 -U dev -p 26257 ЈCpassword
здДјМрПи http://192.168.155.46:8080

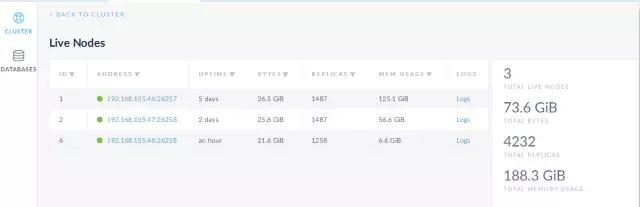
етИіЪЧздДјЕФМрПиЦНЬЈЃЌПЩвдПДЕНдЫааЧщПіЁЃ
ДгMySQLЧЈвЦРњЪЗЪ§ОнЕНCockroachDB
гЩгкВЩгУPostgreSQLавщЃЌMySQLБэНсЙЙгяЗЈЛсБЈДэЃЌашвЊЮЂЕїЁЃ
ВЛжЇГжCOMMENTзЂЪЭЃЌашзЂЯњЕєЁЃ
AUTO_INCREMENT PRIMARY KEYжїМќзддіЃЌашИФГЩSERIAL
int(11)ИФЮЊintЃЌУЛгаtinyintЃЌгУsmallintДњЬц
ВЛжЇГжdoubleЃЌгУdecimalДњЬц
ВЛжЇГж`ЗДв§КХЃЌашзЂЯњЕє
ДДНЈБэНсЙЙЪБЃЌВЛжЇГжаДЖўМЖЫїв§ЃЌашвЊЕЅЖРгУУќСюДДНЈ
ФЌШЯUTF-8зжЗћМЏ
timestampФЌШЯUTCИёСжЭўжЮЪБМф
ИќЖрЧыВЮПМhttps://www.cockroachlabs.com/docs/stable/data-types.html
1ЁЂЕМГіMySQLБэНсЙЙ
# mysqldump ЈCxml ЈCcompact test t1 > t1_schema.sql
2ЁЂзЊГЩPostgreSQLБэНсЙЙ
# php convertor.php -i t1_schema.sql -o t1_schema.sql.pg
https://github.com/mihailShumilov/mysql2postgresql
3ЁЂЕМГіMySQLЪ§Он
# mysqldump ЈCsingle-transaction ЈCcompact
ЈCdefault-character-set=utf8 ЈCset-charset -c -t -q
ЈCextended-insert
-uroot -p123456 ЈCcompatible=postgresql test t1 >
t1.sql
4ЁЂШчЙћSQLЮФМўРягазЊвхЗћЃЌашвЊНјаавЛДЮИёЪНЛЏЃЌPostgreSQLдкЗДаБИмзЊвхЗћжЎЧАашвЊЬэМгЁЏEЁЏЧАзКЁЃ
# sed -i ЁАs/,ЁЏ/,eЁЏ/gЁБ t1.sql
ЕМШыЕНCockroachDBРя
# psql -h 192.168.155.249 -U root -p 26257 -d test
< t1.sql

ПЊЦєТ§ВщбЏ
# ЖЈвхТ§SQLжДааЪБМф
> SET CLUSTER SETTING sql.trace.txn.enable_threshold
= ЁЎ1sЁЏ;
# ПЊЦєТ§ШежОМЧТМ
> SET CLUSTER SETTING sql.trace.log_statement_execute
= true;
аЇЙћШчЯТЃК

1.1аТАцБОЬиад
1ЁЂжЇГжВщПДSQLдЫаазДЬЌЃЌРрЫЦMySQL show processlistУќСю

2ЁЂжЇГжkill Т§SQLЯпГЬidЃЌРрЫЦMySQL kill thread_id
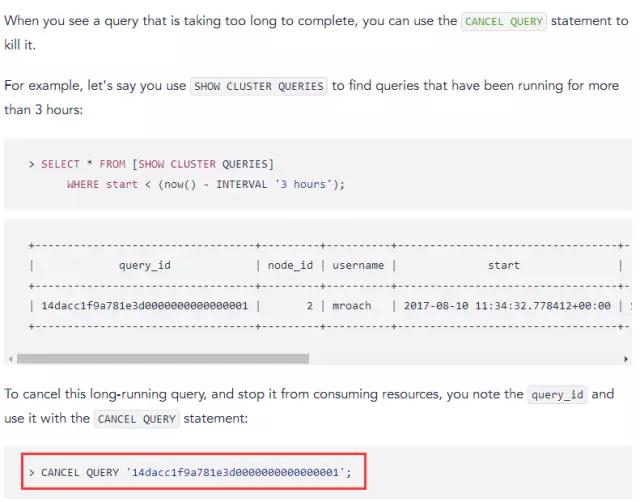
жДааЪБМфГЌЙ§10УыЕФselectВщбЏШЋВПИЩЕє
CANCEL QUERY (SELECT query_id FROM [SHOW CLUSTER
QUERIES] WHERE start < (now() ЈC INTERVAL ЁЏ10 secondsЁЏ)
AND query ~* ЁЎselectЁЏ);
ПЊЗЂЪжВс
1ЁЂЯТдиPostgrepSQLЧ§ЖЏ
https://jdbc.postgresql.org/
2ЁЂСЌНгCockroachDBЗЖР§For JDBC
етОЭЪЧЮвНёЬьНВЕФШ§ИіЪ§ОнПтЃЌаЛаЛДѓМвЃЁ |








