| БрМЭЦМі: |
БОЮФРДдДcsdnЃЌЮФеТдЫгУАИР§в§ГіЫМТЗЃЌНВНтгіЕНЕФЮЪЬтЃЌгжЪЧдѕУДНтОіЕФЃЌИЩЛѕТњТњЯЃЭћЖдДѓМвгаАяжњЁЃ
|
|
БОЮФФкШнАќРЈЛљгкЛњЦїбЇЯАЕФжЧФмдЫЮЌЕФАИР§ЁЂЬєеНКЭЫМТЗЁЃЯТУцЯШНВвЛЯТЪЕМЪЕФШ§ИіАйЖШАИР§ЁЃ
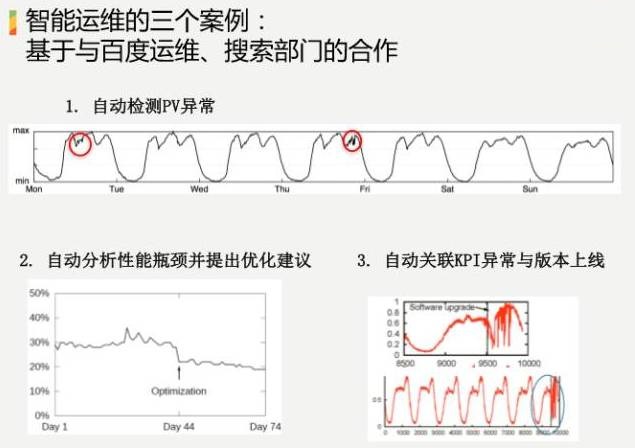
ЕквЛИіГЁОАЃЌКсжсЪЧЪБМфЃЌзнжсЪЧАйЖШЕФЫбЫїСїСПЃЌДѓИХЪЧвЛЬьМИвкЬѕЕФМЖБ№ЃЌЫцзХЪБМфЕФБфЛЏЃЌУПЬьдчЩЯЕНжаЮчЩЯЩ§ЃЌЕНЯТЮчЕНЭэЩЯЯТШЅЃЌЮвУЧвЊдкетИіЧњЯпРяУцевЕНЫќЕФвьГЃЕуЃЌвЊдкетбљвЛИіБОЩэОЭдкБфЛЏЕФЧњЯпРяУцЃЌФмЙЛздЖЏЛЏЕФевЕНЫќЕФПгЃЌВЂЧвНјааИцОЏЁЃФЧУДЖрЫуЗЈЃЌШчКЮЬєбЁЫуЗЈЃПШчКЮАбуажЕздЖЏЩшГіРДЃПетЪЧЕквЛИіГЁОАЁЃ
ЕкЖўИіГЁОАЃЌЮвУЧвЊУыМЖЁЃЖдгкЫбЫїв§ЧцРДЫЕЃЌОЭЪЧвЊ1УыЕФжИБъЃЌетИіЪБКђга30%ГЌЙ§1УыЃЌЮвУЧЕФФПБъЪЧвЊНЕЕН20%МАвдЯТЃЌШчКЮевЕНОпЬхЕФгХЛЏЗНЗЈАбЫќНЕЯТРДЃПЮвУЧгаКмЖргХЛЏЙЄОпЃЌЕЋЪЧВЛжЊЕРЕНЕзгУФФИіЃЌвђЮЊЪ§ОнЬЋИДдгСЫЃЌетЪЧЕкЖўИігІгУГЁОАЁЃ
ЕкШ§ИіГЁОАЃЌздЖЏЙиСЊKPIвьГЃгыАцБОЩЯЯпЁЃЩЯЯпЕФЙ§ГЬжаЃЌЫцЪБЖМгаПЩФмЗЂЩњЮЪЬтЃЌЗЂЩњЮЪЬтЕФЪБКђЃЌШчКЮбИЫйХаЖЯГіРДЪЧФуетДЮЩЯЯпЕМжТЗЂЩњЕФЮЪЬтЃПгаПЩФмЪЧФуЩЯЯпЕМжТЕФЃЌвВгаПЩФмВЛЪЧЃЌФЧУДЖрвђЫиЃЌИеВХЫЕСЫМИЪЎЭђЬЈЛњЦїЃЌФудѕУДХаЖЯГіРДЃПетЪЧАйЖШЪЕМЪЫбЫїЙуИцЕФЪеШыЃЌЮвУЧПДЕНгавЛИіЩЯЯпЪТМўЃЌЪеШыдкЩЯЯпжЎКѓЕєЯТРДСЫЁЃ
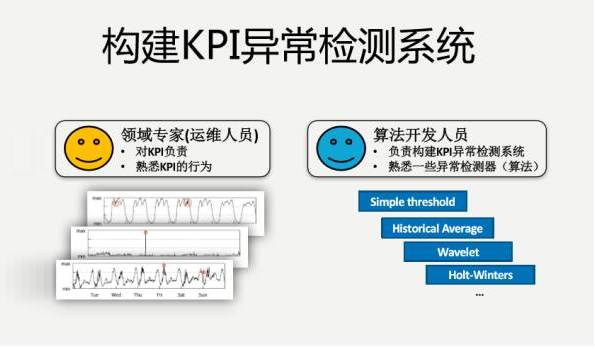
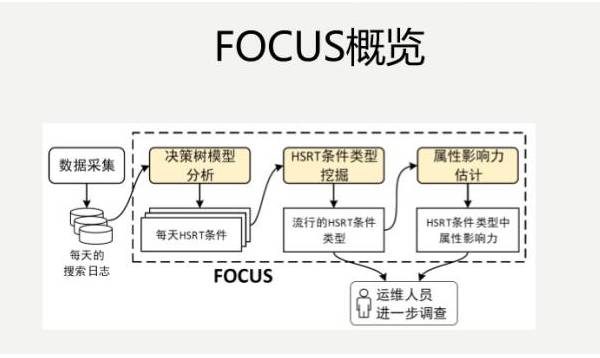
ЯТУцетИіЪЧЮвУЧвЛИібЇЩњдкАйЖШЪЕЯАЕФЪБКђзіГіРДЕФвЛИіЗНАИЃЌЛљгкЛњЦїбЇЯАЕФKPIздЖЏЛЏвьГЃМьВтЁЃ

КсжсЪЧЪБМфЃЌзнжсЪЧСїСПЃЌвЊевЕНвьГЃЁЃЮвУЧвЊбИЫйЪЖБ№ГіРДЃЌВЂЧвзМШЗЪЖБ№ГіРДЃЌАяжњЮвУЧбИЫйНјааеяЖЯКЭаоИДЃЌНјвЛВНзшжЙЧБдкЗчЯеЁЃ
ЮвУЧбЇЪѕНчЃЌАќРЈЦфЫћЕФСьгђЃЌАќРЈЙЩЦБЪаГЁЃЌвбОбаОПМИЪЎФъСЫЃЌШчКЮИљОнГжајЕФЧњЯпдЄВтЕНЯТвЛИіжЕЪЧЖрЩйЃПгаКмЖрЫуЗЈЁЃЮвУЧЕФдЫЮЌШЫдБЃЌОЭЪЧЮвУЧЕФСьгђзЈМвЃЌЛсЖдздМКМьВтЕФKPIНјааИКд№ЃЌЕЋЪЧЮвУЧгаКЃСПЕФЪ§ОнЃЌетKPIгжЪЧЧЇБфЭђЛЏИїжжИїбљЕФЃЌШ§ИіЧњЯпОЭКмВЛвЛбљЃЌШчКЮдкетаЉОпЬхЕФKPIЧњЯпРяШЁЕУСМКУЕФЦЅХфЃПетЪЧЗЧГЃФбЕФвЛМўЪТЧщЁЃ
ЮвУЧПДПДЮЊЪВУДЪЧетбљЕФЃПгавЛИідЫЮЌШЫдБИКд№МьВтетбљЕФЧњЯпЃЌМйШчЫЕвЊЪдгУвЛЯТЫуЗЈЃЌбЇЪѕНчЕФГЃЙцЫуЗЈЃЌвЊИњЫуЗЈПЊЗЂШЫдБНјаавЛаЉУшЪіЁЃЫуЗЈПЊЗЂШЫдБЫЕЃЌФуПДЮветЖљгаШ§ИіВЮЪ§ЃЌАбФуЕФвьГЃАДееЮвЕФШ§ИіВЮЪ§УшЪівЛЯТЃЌдЫЮЌШЫдБПЯЖЈВЛИЩетИіЪТЧщЁЃПЊЗЂШЫдБЛЙВЛСЫНтKPIЕФзЈвЕжЊЪЖЃЌОЭЯыВюВЛЖрзівЛзіАЩЃЌзіЭъСЫжЎКѓЫЕФуПДПДаЇЙћдѕУДбљЃПЭљЭљаЇЙћВюЧПШЫвтЃЌдйРДЕќДњвЛЯТЃЌПЩФмМИИідТОЭЙ§ШЅСЫЁЃ

дЫЮЌШЫдБФбвдЪТЯШИјГізМШЗЁЂСПЛЏЕФвьГЃЖЈвхЃЛЖдгкПЊЗЂШЫдБРДЫЕЃЌбЁдёКЭзлКЯВЛЭЌЕФМьВтЦїашвЊКмЖрШЫСІЃЛМьВтЦїЫуЗЈИДдгЃЌВЮЪ§ЕїНкВЛжБЙлЃЌетаЉЖМЪЧДцдкЕФЮЪЬтЁЃ
ЫљвдЮвУЧЗНЗЈЕФжївЊЫМЯыЪЧЃЌзівЛИіЛњЦїбЇЯАЕФЙЄОпЁЃЮвУЧИњзХдЫЮЌШЫдБбЇЃЌзівЛИіАИР§бЇвЛИіЃЌАбЫћЕФжЊЪЖбЇЯТРДЃЌВЛашвЊЬєОпЬхЕФМьВтЫуЗЈЃЌАбетИіЪТЧщзіГіРДЃЌИљОнРњЪЗЕФЪ§ОнвдМАЫќЕФвьГЃбЇЕНетИіЖЋЮїЁЃ
дЫЮЌШЫдБашвЊзіЪВУДЪТЧщЃПЮвПДзХетаЉKPIЕФЧњЯпЃЌетЖЮЪЧвьГЃЃЌБъзЂГіРДЃЌОЭгаСЫБъзЂЪ§ОнЁЃБОЩэОЭЪЧгаЬиеїЪ§ОнЕФЃЌЬсЙЉвЛЯТЃЌЫЕФуетИіаЁЭНЕмЃЌФувЊЯыАбЫќзіКУЃЌЮвгавЛИівЊЧѓЃЌзМШЗТЪвЊГЌЙ§80%ЃЌаЁЭНЕмОЭЦДУќЕФИњЪІИЕбЇЁЃ

ОпЬхзіЕФЪБКђЃЌБШШчЫЕKPIЕФОпЬхЧњЯпЃЌМйШчЫЕетРягавЛИівьГЃЕуЃЌЮвУЧАбФмФУЕНЕФРэТлНчЩЯЃЌбЇЪѕНчЩЯЕФИїжжЫуЗЈЖМвбОЪЕЯжСЫЃЌЫќЛЙгаИїжжВЮЪ§ЃЌАбВЮЪ§ПеМфЩЈвЛБщЃЌДѓИХ100ЖржжЃЌгУМЏЬхЕФжЧЛлАбKPIЕНЕзЪЧВЛЪЧвьГЃЃЌЭЈЙ§ИњдЫЮЌШЫдБШЅбЇЃЌАбетИібЇГіРДЁЃ
ЮЊЪВУДФмЙЛЙЄзїЃПОЭЪЧвђЮЊЫќЕФЛљБОЙЄзїдРэЃЌОЭЪЧЮвЛсбЇРњЪЗаХЯЂЃЌбЇЕНСЫжЎКѓЩњГЩвЛаЉаХКХЃЌЖдгкЭЌбљЕФвьГЃЛсгадЄВтжЕЃЌКьЩЋЪЧМьВтГіРДЕФаХКХЁЃМьВтГіРДЕФаХКХТдгаВЛЭЌЃЌЕЋЪЧЮвУЧОѕЕУМЏЬхЕФжЧЛлЃЌФмЙЛзюКѓИјГівЛИіЗЧГЃКУЕФаЇЙћЃЌетОЭЪЧвЛИіЛљБОЕФЫМТЗЁЃ
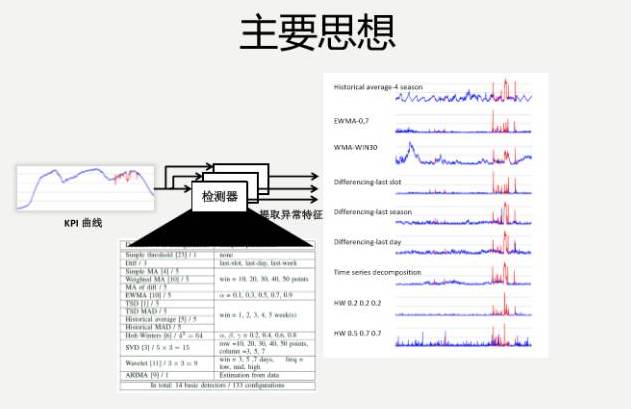
ШчКЮАбЫќзЊЛЏГЩЛњЦїбЇЯАЕФЮЪЬтЃПЮвУЧгаЬиеїЪ§ОнЁЂгаБъзЂЃЌЯывЊЕФОЭЪЧЫќЪЧвьГЃЛЙЪЧЗЧвьГЃЃЌОЭЪЧвЛИіМђЕЅЕФМрЖНЛњЦїбЇЯАЗжРрЕФЮЪЬтЁЃдЫЮЌШЫдБНјааБъзЂЃЌВњЩњИїжжЬиеїЪ§ОнЃЌетОЭЪЧИеВХ100ЖржжМьВтЦїИјГіЕФЬиеїЪ§ОнЃЌШЛКѓНјааЗжРрЃЌаЇЙћЛЙЪЧБШНЯРэЯыЕФЁЃ

ЕЋЪЧЃЌЛЙЪЧгаКмЖрЪЕМЪЕФЬєеНЃЌЮвУЧМђЕЅЬсвЛИіЬєеНЁЃЕквЛИіЬєеНЃЌЮвУЧдЫЮЌШЫдБашвЊБъзЂЃЌЮвЕУЛЈЖрГЄЪБМфШЅБъзЂЃПдкЪЕМЪдЫЮЌЙ§ГЬжаЃЌФЧаЉеце§ЕФвьГЃВЂУЛгаФЧУДЖрЃЌБОЩэЪ§СПЯрЖдБШНЯЩйЁЃШчЙћФмзіГівЛаЉБШНЯИпаЇЕФБъМЧЙЄОпЃЌЪЧФмЙЛКмКУЕФАяжњЮвУЧЕФЁЃ
ШчЙћАбетИіБъзЂЙЄОпЯёзівЛИіЛЅСЊЭјВњЦЗвЛбљЃЌзіЕУЗЧГЃКУЃЌФмЙЛНкЪЁБъзЂШЫдБКмЖрЕФЪБМфЁЃЮвУЧзіСЫКмЖрЙЄзїЃЌЪѓБъМгМќХЬЃЌфЏРРЭЌБШЁЂЛЗБШЕФЪ§ОнЃЌЩЯУцгаЗХДѓЫѕаЁЃЌЯыБъзЂвЛИіЪ§ОнЃЌФУзХЪѓБъЭЯвЛЯТОЭOKСЫЁЃвЛИідТРяУцЕФвьГЃЪ§ОнЃЌзюКѓгЩдЫЮЌШЫдБЪЕМЪНјааБъзЂЃЌДѓИХвЛИідТвВОЭЛЈЮхСљЗжжгЕФЪБМфЃЌОЭИуЖЈСЫЁЃ

ЛЙгаКмЖрЦфЫћЕФЬєеНЃЌБШШчЫЕРњЪЗЪ§ОнжавьГЃжжРрБШНЯЩйЃЌРрБ№ВЛОљКтЮЪЬтЃЌЛЙгаШпгрКЭЮоЙиЬиеїЕШЁЃ
ЯТУцЪЧвЛИіећЬхЕФЩшМЦЁЃФЧУДЃЌФУЪЕМЪдЫЮЌЕФЪ§ОнНјааМьВтЕФЪБКђаЇЙћдѕУДбљФиЃП

етРяФУСЫЫФзщЪ§ОнЃЌШ§зщЪЧАйЖШЕФЃЌвЛзщЪЧЧхЛЊаЃдАЭјЕФЁЃвЛАуЕФВйзїЃЌЗжБ№ЖдетаЉЪ§ОнХфвЛзщуажЕЁЃЮвУЧВЛЙметИіЪ§ОнЪЧЪВУДбљЕФЃЌОЭЪЧгУвЛжжЫуЗЈАбЫќИуЖЈЃЌОЭФУИеВХИјГіЕФдЫЮЌаЁЭНЕметбљЕФЫуЗЈЃЌАб100ЖржжЦфЫћЕФЫуЗЈЖМХмСЫвЛБщЃЌБШНЯСЫвЛЯТЃЌдкЫФзщЪ§ОнРяУцЃЌЮвУЧЫуЗЈЕФзМШЗТЪВЛЪЧЕквЛОЭЪЧЕкЖўЃЌЖјЧвЮвУЧЕФКУДІЪЧВЛгУЕїВЮЪ§ЁЃГЌЙ§ЮвУЧетИіЫуЗЈЃЌЦеЭЈЕФПЩФмвЊАб100ЖржжЪдвЛЯТЃЌЮвУЧетИіВЛгУЪдЃЌжБНгОЭГіРДЁЃ

ЮЊСЫШУдЫЮЌИќИпаЇЃЌПЩвдШУИцОЏЙЄзїИќжЧФмЃЌЮоашШЫЙЄбЁдёЗБдгЕФМьВтЦїЃЌЮоашЕїВЮЃЌАбЫќзіЕУЯёвЛИіЛЅСЊЭјВњЦЗвЛбљКУЁЃетЪЧЕквЛИіАИР§ЃЌЙигкжЧФмИцОЏЕФЁЃРэТлЩЯбЇЪѕНчгаКмЖрЦЏССЕФЫуЗЈЃЌШчКЮдкЪЕМЪжаТфЕиЕФЮЪЬтЃЌдкетИіЙ§ГЬжаЮвУЧЪЙгУЕФЪЧЛњЦїбЇЯАЕФЗНАИЁЃЮвУЧПДвЛЯТЕкЖўИіАИР§ЃЌИеВХЫЕЕФУыМЖЁЃЯШПДвЛИіИХФюЃЌЫбЫїЯьгІЪБМфЁЃ

ЫбЫїЯьгІЪБМфЃЌетИіОЭЪЧЪзЦСЪБМфСЫЁЃЖдгкзлКЯЫбЫїРДЫЕЃЌгУЛЇдкфЏРРЦїЩЯЪфШывЛИіЙиМќзжЃЌЕувЛЯТАДХІЃЌжБЕНЪзЦСЫбЫїНсЙћЗЕЛиРДЃЌЕБШЛетРяУцгавЛаЉЙ§ГЬЁЃ
етИіЮЊЪВУДКмживЊЃПетОЭЪЧЧЎЁЃЖдгкбЧТэбЗРДЫЕЃЌШчЙћЯьгІЪБМфдіМг100КСУыЃЌЯњСПНЕЕЭ1%ЁЃЖдгкЙШИшРДЫЕЃЌУПдіМг100КСУыЕН400КСУыЫбЫїЃЌгУЛЇЪ§ОЭЛсЯТНЕ0.2%ЕН0.6%ЃЌЫљвдЗЧГЃживЊЁЃ
ПДвЛЯТдкЪЕМЪжаЫбЫїЯьгІЪБМфЪЧЪВУДбљЕФЃПКсжсЪЧЫбЫїЯьгІЪБМфЃЌзнжсЪЧCDFЁЃ70%ЕФЫбЫїЯьгІЪБМфЪЧЕЭгк1УыЃЌЪЧЗћКЯвЊЧѓЕФЁЃ30%ЕФЪБМфЪЧИпгк1УыЕФЃЌЪЧВЛДяБъЕФЁЃФЧдѕУДАьФиЃПДѓгк1УыЕФЫбЫїдвђЕНЕзЪЧЪВУДЃПШчКЮИФНјЃПетРяУцвВЪЧвЛИіЛњЦїбЇЯАЕФЮЪЬтЁЃИїжжШежОЗЧГЃЖрЃЌД№АИОЭВидкШежОРяУцЃЌЮЪЬтЪЧШчКЮФУЕНШежОЗжЮіГіРДЁЃЮвУЧПДвЛЯТШежОЕФаЮЪНЃК

ЖдгкгУЛЇУПвЛДЮЫбЫїЃЌЖМгаЫћРДздгкФФИідЫгЊЩЬЃЌфЏРРЦїФкКЫЪЧЪВУДЃЌЗЕЛиНсЙћРяУцЭМЦЌгаЖрЩйЃЌЗЕЛиНсЙћгаУЛгаЙуИцЃЌКѓЬЈИКдиШчКЮЕШаХЯЂЁЃетДЮЯьгІЃЌЫќЕФЯьгІЪБМфЪЧЖрЩйЃЌДѓгк1УыОЭЪЧВЛРэЯыЃЌаЁгк1УыОЭЪЧБШНЯРэЯыЃЌЮвУЧгазуЙЛЖрЕФЪ§ОнЃЌвЛЬьЩЯвкЃЌЛЙгаБъзЂЃЌетИіБъзЂБШНЯМђЕЅСЫЁЃ
ЮвУЧЯждкРДЛиД№МИИіЮЪЬтЃЌдкетУДЖрЮЌЖШЕФЪ§ОнРяБпЃЌШчКЮевГіЫќЯьгІЪБМфБШНЯИпЕФЪБКђЃЌИпЯьгІЪБМфШнвзЗЂЩњЕФЬѕМўЪЧЪВУДЃПФФаЉHSRTЬѕМўБШНЯСїааЃПШчЙћевГіСїааЕФЬѕМўЃЌЮвУЧОЭевЕНСЫвЛаЉЯпЫїЃЌОЭжЊЕРШчКЮШЅгХЛЏЁЃЮвУЧФмВЛФмдкЪЕМЪгХЛЏжЎЧАЃЌЪТЯШПДвЛЯТЃЌгаПЩФмгХЛЏЕФНсЙћЪЧЪВУДЃПЛљБОЩЯЯызіЕФОЭЪЧетУДвЛИіЪТЧщЁЃетРяУцгааЉЯИНкЮвУЧОЭЬјЙ§ЃЌЯыБэДяЕФвтЫМЪЧЫЕЖдгкЖрЮЌЖШЪ§ОнЃЌШчЙћжЛПДЕЅЮЌЖШЕФЪ§ОнЃЌЛсгаИїжжИїбљЕФЮЪЬтЁЃ
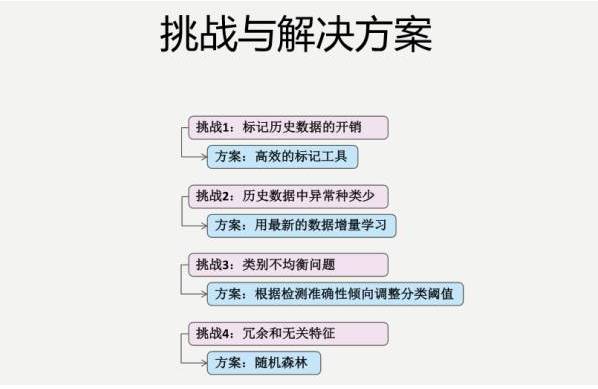
дкЗжЮіЖрЮЌЪєадЫбЫїШежОЕФЪБКђвВЛсгаКмЖрЬєеН
ЕквЛЃЌЕЅЮЌЖШЪєадЗжЮіЗНЗЈЮоЗЈНвЪОВЛЭЌЬѕМўЪєадЕФзщКЯДјРДЕФгАЯьЁЃ
ЕкЖўЃЌЪєаджЎМфЛЙДцдкзХЧБдкЕФвРРЕЙиЯЕЃЌЫљвдЕЅЮЌЖШЗжЮіЕФНсТлПЩФмЪЧЦЌУцЕФЁЃ
ЕкШ§ЃЌЕУЕНЕФHSRTЬѕМўПЩжиЕўЃЌУПДЮHSRTБЛМЦЫуЖрДЮЃЌВЛвзРэНтЁЃФуШчЙћЕЅЮЌЖШПДЃЌЭМЦЌЪ§СПДѓгк30%ЃЌЙБЯзСЫ50%ЕФЯьгІЪБМфЃЌПДвЛЯТЦфЫћЕФЮЌЖШЃЌМгЦ№РДЗЂЯж120%ЃЌетЖМЪЧЕЅЮЌЖШПДДцдкЕФЮЪЬтЁЃ
вђЮЊУПИіЮЌЖШгаИїжжИїбљЕФШЁжЕЃЌвЛЕЉзщКЯЃЌПеМфОЭБЌеЈСЫЃЌШЫЪЧВЛПЩФмзіЕФЃЌОЭЫуЪЧзіСЫПЩЪгЛЏЕФЙЄОпЃЌШЫЪЧВЛПЩФмвЛИіИіЪдРДЕУГіНсТлЃЌБиаыППЛњЦїбЇЯАЕФЗНЗЈЃЌЫљвдЮвУЧАбетИіЮЪЬтНЈФЃГЩЗжРрЮЪЬтЃЌРћгУМрЖНЛњЦїбЇЯАЫуЗЈЃЌОіВпЪїЕУЕНжБЙлЗжРрФЃаЭЁЃ
ЯТУцетИіЪЧЮвУЧЕБЪБЩшМЦЕФвЛИіМмЙЙЭМЃЌУПЬьШежОРДСЫжЎКѓЃЌЪфШыЕНЛњЦїбЇЯАОіВпЪїЕФФЃаЭРяУцЃЌЗжЮіГіУПЬьИпЯьгІЪБМфЕФЬѕМўЃЌПчЬьНјааЗжЮіЃЌжЎКѓдйШЅзівЛаЉзМЪЕбщЃЌзюКѓЕУГівЛаЉНсЙћЁЃ
ЯТУцетИіЪЧЮвУЧЕквЛВНЭъГЩСЫжЎКѓЃЌЕУГіЕФвЛИіОіВпЪїЃЌЩњГЩОіВпЪїЕФЙ§ГЬЃЌЛљБОЩЯФУвЛаЉЯжГЩЕФЙЄОпЃЌАбЪ§ОнЕМНјШЅЃЌЕївЛаЉВЮЪ§ОЭПЩвдСЫЁЃ
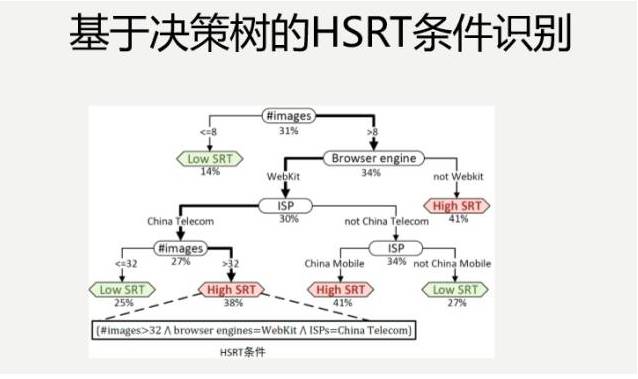
ЮвУЧЛсПДвЛИідТЕФЪБМфФкЃЌУПЬьЖМЛёЕУЕФЪ§ОнЃЌЮвУЧЕУГівЛИідТРяУцЃЌФФаЉЬѕМўБШНЯСїааЃЌШЛКѓЃЌдкДЫЛљДЁЩЯЃЌзівЛаЉзМЪЕбщЁЃВЛЪЧЫЕЗжЮіГіРДСЫжЎКѓЃЌОЭецЕФЩЯЯпЕїетаЉгХЛЏЬѕМўЃЌБШШчЫЕЕУГіетбљЕФзщКЯЃЌЕБЭМЦЌЪ§СПДѓгк10ЃЌЫќЕФфЏРРЦїв§ЧцВЛЪЧWebKitЃЌРяУцУЛгаДђЙуИцЃЌЫќЛсШнвзЯьгІЪБМфБШНЯИпЁЃ
ИјСЫЮвУЧвЛаЉЦєЪОЃЌОпЬхФФИіЬѕМўЕМжТЕФЃПгХЛЏФФИіЮЌЖШЛсВњЩњБШНЯКУЕФНсЙћЃПетВЛжЊЕРЁЃЮвШчЙћАбУПИіЬѕМўЕївЛЯТЃЌетИіДѓгк10ЃЌБфГЩаЁгк10ЃЌетИіЬѕМўЕФзщКЯЃЌдкЪЕМЪЕФШежОЪ§ОнРяУцОЭЪЧДцдкЕФЃЌАбетИіЪ§ОнШЁГіРДЃЌПДвЛЯТЫќЕФЯьгІбгГйЕНЕзЪЧИпЛЙЪЧЕЭЃЌетОЭЪЧзМЪЕбщЃЌжюШчДЫРрЖМзівЛаЉЃЌКмШнвзЕУГівЛаЉНсТлЁЃ
ЮвУЧеыЖдЕБЪБЕФГЁОАЃЌЭМЦЌЪ§СПЙ§ЖрЪЧЕМжТЯьгІЪБМфБШНЯГЄЕФжївЊЦПОБЃЌЪЧЕБЪБзюживЊЕФЦПОБЃЌОпЬхЖдетИіНјааСЫгХЛЏЃЌДѓМвПЩФмОЭБШНЯЪьЯЄСЫЃЌВПЪ№СЫbase64
encodingРДЬсИпЁАЪ§СПЖрЁЂЬхЛ§аЁЁБЕФЭМЦЌДЋЪфЫйЖШЁЃ
етРяЯыЧПЕївЛЕуЃЌетИігХЛЏЗНЪНЃЌДѓМвЖМжЊЕРЃЌЕЋЪЧдкУЛгаетбљЗжЮіЕФЧщПіЯТЃЌФуВЂУЛгаАбЮеЩЯЯпжЎКѓЃЌОЭгааЇЙћЁЃМйШчЫЕФудЫЮЌВПУХЕФKPIжИБъЃЌГЌЙ§20%ОЭВЛДяБъЃЌШчЙћЕЭгк20%ОЭДяБъСЫЃЌЩЯЯпетвЛИіОЭДяБъСЫЁЃИїжжБШНЯЖМКмЧхЮњЃЌОЭЪЧетбљЕФвЛИіЙЄОпЃЌгаКмЖрШежОЃЌФузівЛаЉЛљгкЛњЦїбЇЯАЕФЗжЮіЃЌевЕНФПЧАзюживЊЕФЦПОБЃЌАбетаЉЦПОБИњФУЕНЪжЕФИїжжгХЛЏЕФЗНЪНЗНЗЈЃЌгІгУвЛЯТЃЌОЭФмЕУЕНКмКУЕФаЇЙћЃЌетИіаЇЙћЪЧКмВЛДэЕФЃЌЭЈгУадвВБШНЯИпЁЃ
ЕкШ§ИіАИР§ЬјЙ§ШЅАЩЃЌДѓИХвтЫМЪЧЫЕздЖЏИќаТЛсВњЩњКмЖрЮЪЬтЃЌЮвМђЕЅжБНгАбАИР§ИјГіРДОЭКУСЫЁЃ
зюКѓИјГівЛИіАИР§ЃЌетИіАИР§ОЭЪЧЫЕАйЖШЩЯЯпСЫвЛИіЗДЕуЛїзїБзЕФАцБОЃЌЩЯЯпжЎКѓЃЌЙуИцЪеШыОЭГіЯжСЫЯТНЕЃЌЪЕМЪЩЯгУЮвУЧетИіЯЕЭГзіСЫвЛЯТЃЌ10ЗжжгФмЙЛзМШЗМьВтГіЮЪЬтЁЃЖјШЫдкОпЬхзіЕФЪБКђЃЌвЊПЭЛЇЩъЪіЁЂМьВщKPIЁЂЖЈЮЛЮЪЬтЃЌвЊвЛИіАыаЁЪБЃЌВювьЛЙЪЧКмДѓЕФЁЃ
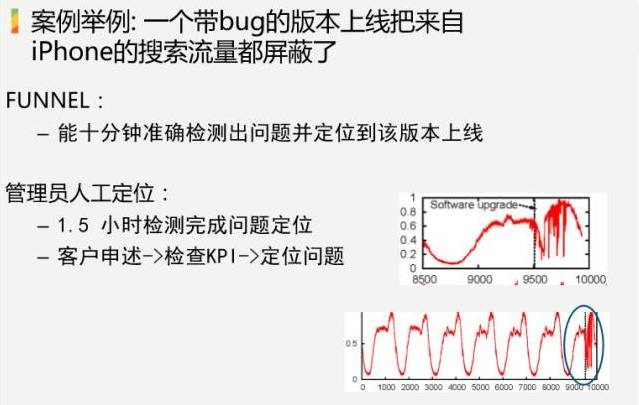
ИеВХОйСЫМИИіОпЬхЕФАИР§ЃЌЦфЪЕЛЙгаЦфЫћЕФКмЖрАИР§ЃЌШчвьГЃМьВтжЎКѓЕФЙЪеЯЖЈЮЛЁЂЙЪеЯжЙЫ№НЈвщЁЂЙЪеЯИљвђЗжЮіЁЂЪ§ОнжааФНЛЛЛЛњЙЪеЯдЄВтЁЂКЃСПSyslogШежОбЙЫѕГЩЩйСПгавтвхЕФЪТМўЁЂЛљгкЛњЦїбЇЯАЕФЯЕЭГгХЛЏ(ШчTCPдЫааВЮЪ§)ЁЃ

ЮвУЧдкбЇЪѕНчРДЫЕЃЌЮвУЧвВВЛзіВњЦЗЃЌЮвУЧЪЧеыЖдвЛЯпЩњВњЛЗОГжагіЕНЕФИїжжгаЬєеНадЕФЮЪЬтЃЌзівЛаЉОпЬхЕФЫуЗЈЁЃЮвУЧЕФФПБъОЭЪЧзівЛаЉжЧФмдЫЮЌЫуЗЈЕФМЏКЯЃЌдЫаадкдЦЩЯУцЃЌЫќЛсгавЛаЉБъзМЕФAPIЁЃБъзМЕФAPIжЇГжШЮвтЪБађЪ§ОнЃЌЫќгавЛИіЪБМфДСЃЌгавЛИіЙиМќжИБъЃЌетИіЙиМќжИБъеыЖдВЛЭЌГЁОАЛсВЛвЛбљЃЌгаЯњЪлЖюЁЂРћШѓЁЂЖЉЕЅЪ§ЁЂзЊЛЏТЪЕШЕШВЛЭЌЪєадЃЌОЙ§етбљЕФЗжЮіжЎКѓЃЌХмЕНдЦРяУцЃЌОЭФмЕУГівЛаЉЭЈгУадЕФНсЙћЁЃ
етРяЮвЯыИјДѓМввЛаЉОпЬхЕФЦєЪОЃЌАќРЈЮвУЧздМКЕФвЛаЉЫМПМЁЃжЧФмдЫЮЌЕНЕзгаФФаЉПЩааЕФФПБъЃПЮвУЧЕФВНзгВЛФмТѕЕУЬЋДѓЃЌгжВЛФмЬЋБЃЪиЃЌЮвУЧЕНЕзЯыДяЕНЪВУДбљЕФаЇЙћЃПЫФУзХЧЙЃЌЫОЭДІгкжїЕМЕиЮЛЁЃЯёR2-D2ЪЧдЫЮЌШЫдБЕФПЩППжњЪжЃЌзюКѓЛЙЪЧШЫРДЦ№жїЕМзїгУЁЃ
1ЁЂКмживЊЕФОЭШЁОігкШЫЙЄжЧФмБОЩэЗЂеЙЕНФФИіЕиВНЃЌШЫЙЄжЧФмНтОіСЫвЛаЉЮЪЬтЃЌжЊЦфШЛЃЌгжжЊЦфЫљвдШЛЁЃжЊЦфШЛЃЌВЛжЊЦфЫљвдШЛЃЌетИіЦфЮвжЊЕРЫќЯТЕФКУЃЌЕЋЪЧЮЊЪВУДКУЃЌМЦЫуЛњЫуГіРДЕФЃЌЮвВЂВЛжЊЕРЁЃШЫЙЄжЧФмЗЂеЙЕНЯждкЕФНзЖЮЃЌБШНЯПЩППЕФЪЧетИіЕиВНЃКжЊЦфШЛЃЌЖјВЛжЊЦфЫљвдШЛЃЌММЪѕЗНУцЃЌЭЈЙ§ЛњЦїбЇЯАЯрЖдГЩЪьЃЌдквЛЖЈЬѕМўЯТБШШЫКУЁЃЕНКѓУцМШВЛжЊЦфШЛЃЌгжВЛжЊЦфЫљвдШЛЃЌвдМАСЌЮЪЬтЖМВЛжЊЕРЃЌШЫЙЄжЧФмЛЙУЛгаЕНФЧИіЕиВНЁЃЮвУЧвЊздЖЏЛЏФЧаЉЁАжЊЦфШЛЖјВЛжЊЦфЫљвдШЛЁБЕФдЫЮЌШЮЮёЁЃ
2ЁЂШчКЮИќЯЕЭГЕФгІгУЛњЦїбЇЯАММЪѕЁЃЛњЦїбЇЯАЗзЗБИДдгЃЌМђЕЅЫЕвЛЯТЁЃЬиеїбЁШЁЕФЪБКђЃЌдчЦкПЩвдгУвЛаЉШЋВПЪ§Он
ШнШЬЖШИпЕФЫуЗЈЃЌШчЫцЛњЩСжЃЌЛЙгаЬиеїЙЄГЬЁЂздЖЏбЁШЁ(ЩюЖШбЇЯА)ЃЛВЛЭЌЛњЦїбЇЯАЫуЗЈЪЪгУВЛЭЌЕФЮЪЬтЃЛвЛИіБШНЯаажЎгааЇЕФЗНЗЈЃЌДѓМвзіШеГЃдЫЮЌЙ§ГЬжаЃЌПЩвдИњбЇЪѕНчНјааОпЬхЬНЬжЃЌеыЖдблЧАЮЪЬтвЛЦ№ЬНЬжвЛЯТЃЌПЩФмБШНЯШнвзевЕНЪЪКЯЕФЦ№ЕуЁЃЙЄвЕНчИњбЇЪѕНчеыЖдОпЬхЮЪЬтНјааУмЧаКЯзїЪЧвЛИігааЇЕФВпТдЁЃ
3ЁЂШчКЮДгЯжгаticketЪ§ОнжаЬсШЁгаМлжЕаХЯЂЁЃЮвУЧПЩвдАбticketingЯЕЭГзїЮЊжЧФмдЫЮЌЕФвЛВПЗжРДЩшМЦЁЃ
4ЁЂШчКЮАбжЧФмдЫЮЌбгЩьЕНжЧФмдЫгЊЃПЮвУЧгаИїжжИїбљЕФЪ§ОнЃЌЪ§ОнЖМдкФЧЖљЃЌЦѓвЕЕФЭДЕуЪЧЃЌЙтгаКЃСПЪ§ОнЃЌШБЗІеце§ОЋзМЕФдЫгЊКЭааЖЏжЎМфгааЇзЊЛЏЕФЙЄОпЁЃЦфЪЕЮвУЧЫМПМвЛЯТЃЌЮвУЧПДЕФФЧаЉKPIЃЌШчЙћГщЯѓГЩЪБађЪ§ОнЃЌИњЕчЩЬЕФЯњЪлЪ§ОнЃЌИњгЮЯЗЕФKPIжИБъУЛгаБОжЪЕФЧјБ№ЁЃШчЙћГщЯѓГЩЫуЗЈВуУцЃЌПЩФмЖМгаКмКУЕФгІгУГЁОАЃЌОпЬхЛЙЛсгавЛаЉЖюЭтЕФЬєеНЃЌЕЋЪЧШчЙћдкЫуЗЈВуУцНјааИќЖрЭЖШыЃЌПЩвдЬјГідЫЮЌБОЩэЕНжЧФмдЫгЊетПщЁЃ
змНсвЛЯТНёЬьЕФФкШнЃЌЛљгкЛњЦїбЇЯАЕФжЧФмдЫЮЌЃЌдкНёКѓМИФъЛсгаЗЩЫйЕФЗЂеЙЃЌвђЮЊЫќгаЕУЬьЖРКёЕФЪ§ОнЁЂБъзЂКЭгІгУЁЃжЧФмдЫЮЌЕФжеМЋПЩааФПБъЃЌЪЧдЫЮЌШЫдБИпаЇПЩППЕФжњЪжЁЃжЧФмдЫЮЌФмЙЛИќЯЕЭГгІгУЛњЦїбЇЯАММЪѕЃЌбЇЪѕНчКЭЙЄвЕНчгІФмЙЛдквЛаЉОпЬхЮЪЬтЩЯУмЧаКЯзїЁЃИќЯЕЭГЕФЪ§ОнВЩМЏКЭБъзЂЛсАяжњжЧФмдЫЮЌИќПьЗЂеЙЁЃЯТвЛВНАбжЧФмдЫЮЌЕФММЪѕбгЩьЕНжЧФмдЫгЊРяУцЁЃ |








