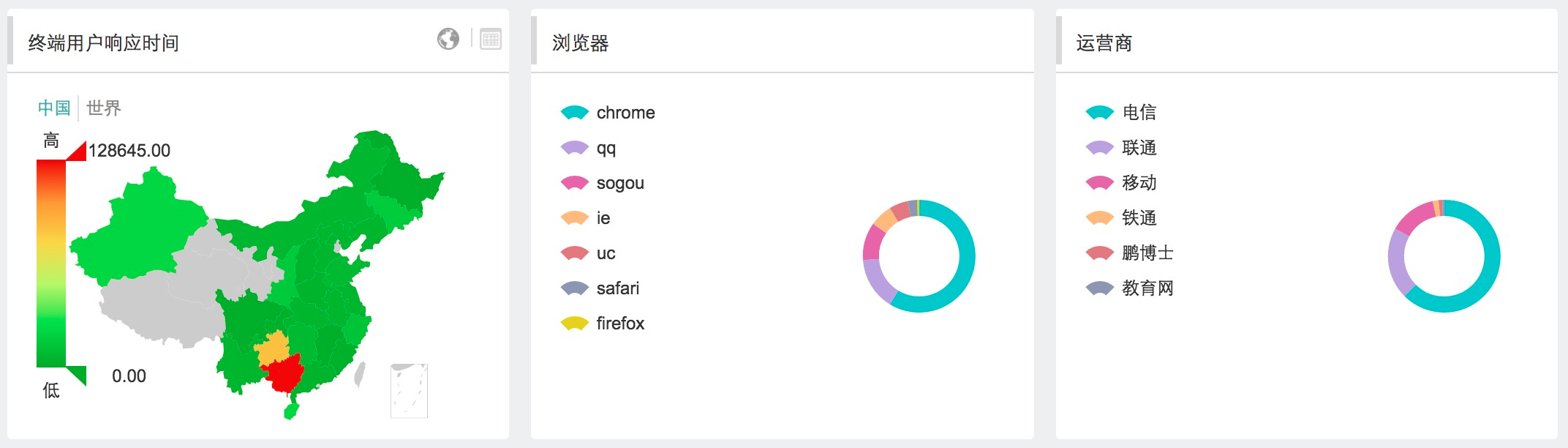
| БрМЭЦМі: |
БОЮФНщЩмСЫМрПиећИіЬхЯЕЃЌАќКЌМрПиЕФживЊадвдМАФПБъЁЂМрПиЕФКЫаФЁЂМрПиСїГЬЁЂЙЪеЯБЈОЏЕШЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњ
БОЮФРДздгк51CTOЃЌгЩЛ№СњЙћШэМўLucaБрМЁЂЭЦМіЁЃ |
|
ЧАбдНщЩм
МрПиЪЧећИідЫЮЌФЫжСећИіВњЦЗЩњУќжмЦкжазюживЊЕФвЛЛЗЃЌЪТЧАМАЪБдЄОЏЗЂЯжЙЪеЯЃЌЪТКѓЬсЙЉЯъЪЕЕФЪ§ОнгУгкзЗВщЖЈЮЛЮЪЬтЁЃ
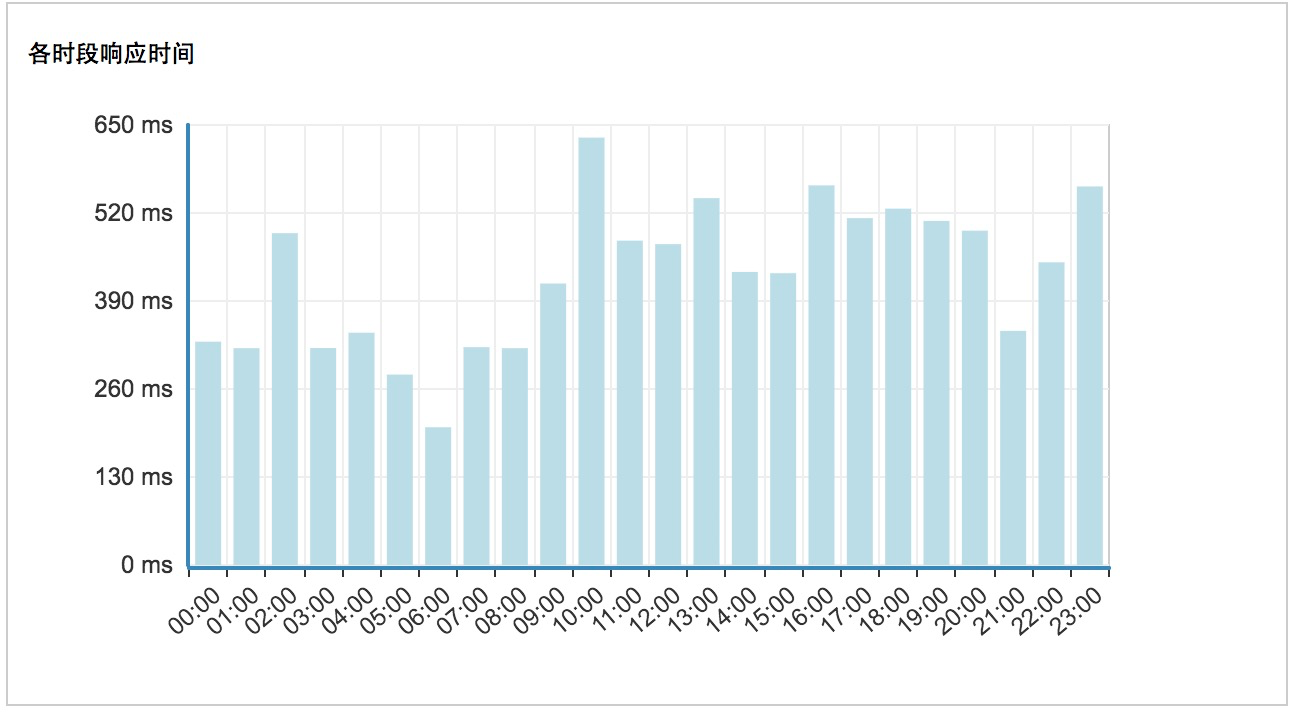
ФПЧАвЕНчгаКмЖрВЛДэЕФПЊдДВњЦЗПЩЙЉбЁдёЁЃбЁдёвЛПюПЊдДЕФМрПиЯЕЭГЃЌЪЧвЛИіЪЁЪБЪЁСІЃЌаЇТЪзюИпЕФЗНАИЁЃЕБШЛЖдМрПиВЛЪЧКмУїАзЕФХѓгбУЧЃЌПДСЫвдЯТЮФеТПЩФмЛсЖдМрПиећИіЬхЯЕгаБШНЯЩюПЬЕФШЯЪЖЁЃ
0 МрПиФПБъ
ЮвУЧЯШРДСЫНтЪВУДЪЧМрПиЃЌМрПиЕФживЊадвдМАМрПиЕФФПБъЃЌЕБШЛУПИіШЫЫљдкЕФаавЕВЛЭЌЁЂЙЋЫОВЛЭЌЁЂвЕЮёВЛЭЌЁЂИкЮЛВЛЭЌЁЂЖдМрПиЕФРэНтвВВЛЭЌЃЌЕЋЪЧЮвУЧашвЊзЂвтЃЌМрПиЪЧашвЊеОдкЙЋЫОЕФвЕЮёНЧЖШШЅПМТЧЃЌЖјВЛЪЧеыЖдФГИіМрПиММЪѕЕФЪЙгУЁЃ

МрПиФПБъ
1.ЖдЯЕЭГВЛМфЖЯЪЕЪБМрПи:ЪЕМЪЩЯЪЧЖдЯЕЭГВЛМфЖЯЕФЪЕЪБМрПи(етОЭЪЧМрПи)
2.ЪЕЪБЗДРЁЯЕЭГЕБЧАзДЬЌ:ЮвУЧМрПиФГИігВМўЁЂЛђепФГИіЯЕЭГЃЌЖМЪЧашвЊФмЪЕЪБПДЕНЕБЧАЯЕЭГЕФзДЬЌЃЌЪЧе§ГЃЁЂвьГЃЁЂЛђепЙЪеЯ
3.БЃжЄЗўЮёПЩППадАВШЋад:ЮвУЧМрПиЕФФПЕФОЭЪЧвЊБЃжЄЯЕЭГЁЂЗўЮёЁЂвЕЮёе§ГЃдЫаа
4.БЃжЄвЕЮёГжајЮШЖЈдЫаа:ШчЙћЮвУЧЕФМрПизіЕУКмЭъЩЦЃЌМДЪЙГіЯжЙЪеЯЃЌФмЕквЛЪБМфНгЪеЕНЙЪеЯБЈОЏЃЌдкЕквЛЪБМфДІРэНтОіЃЌДгЖјБЃжЄвЕЮёГжајадЕФЮШЖЈдЫааЁЃ
1 МрПиЗНЗЈ
МШШЛЮвУЧСЫНтЕНСЫМрПиЕФживЊадЁЂвдМАМрПиЕФФПЕФЃЌФЧУДЯТУцЮвУЧашвЊСЫНтЯТМрПигаФФаЉЗНЗЈЁЃ

МрПиЗНЗЈ
1.СЫНтМрПиЖдЯѓ:ЮвУЧвЊМрПиЕФЖдЯѓФуЪЧЗёСЫНтФиЃПБШШчCPUЕНЕзЪЧШчКЮЙЄзїЕФЃП
2.адФмЛљзМжИБъ:ЮвУЧвЊМрПиетИіЖЋЮїЕФЪВУДЪєадЃПБШШчCPUЕФЪЙгУТЪЁЂИКдиЁЂгУЛЇЬЌЁЂФкКЫЬЌЁЂЩЯЯТЮФЧаЛЛЁЃ
3.БЈОЏуажЕЖЈвх:дѕУДбљВХЫуЪЧЙЪеЯЃЌвЊБЈОЏФиЃПБШШчCPUЕФИКдиЕНЕзЖрЩйЫуИпЃЌгУЛЇЬЌЁЂФкКЫЬЌЗжБ№ХмЖрЩйЫуИпЃП
4.ЙЪеЯДІРэСїГЬ:ЪеЕНСЫЙЪеЯБЈОЏЃЌФЧУДЮвУЧдѕУДДІРэФиЃПгаЪВУДИќИпаЇЕФДІРэСїГЬТ№ЃП
2 МрПиКЫаФ
ЮвУЧСЫНтСЫМрПиЕФЗНЗЈЁЂМрПиЖдЯѓЁЂадФмжИБъЁЂБЈОЏуажЕЖЈвхЁЂвдМАЙЪеЯДІРэСїГЬМИВНжшЃЌЕБШЛЮвУЧИќашвЊжЊЕРМрПиЕФКЫаФЪЧЪВУДЃП
МрПиКЫаФ
1.ЗЂЯжЮЪЬт:ЕБЯЕЭГЗЂЩњЙЪеЯБЈОЏЃЌЮвУЧЛсЪеЕНЙЪеЯБЈОЏЕФаХЯЂ
2.ЖЈЮЛЮЪЬт:ЙЪеЯгЪМўвЛАуЖМЛсаДФГФГжїЛњЙЪеЯЁЂОпЬхЙЪеЯЕФФкШнЃЌЮвУЧашвЊЖдБЈОЏФкШнНјааЗжЮіЃЌБШШчвЛЬЈЗўЮёЦїСЌВЛЩЯ:ЮвУЧОЭашвЊПМТЧЪЧЭјТчЮЪЬтЁЂЛЙЪЧИКдиЬЋИпЕМжТГЄЪБМфЮоЗЈСЌНгЃЌгжЛђепФГПЊЗЂДЅЗЂСЫЗРЛ№ЧННћжЙЕФЯрЙиВпТдЕШЕШЃЌЮвУЧОЭашвЊШЅЗжЮіЙЪеЯОпЬхдвђЁЃ
3.НтОіЮЪЬт:ЕБШЛЮвУЧСЫНтЕНЙЪеЯЕФдвђКѓЃЌОЭашвЊЭЈЙ§ЙЪеЯНтОіЕФгХЯШМЖШЅНтОіИУЙЪеЯЁЃ
4.змНсЮЪЬт:ЕБЮвУЧНтОіЭъжиДѓЙЪеЯКѓЃЌашвЊЖдЙЪеЯдвђвдМАЗРЗЖНјаазмНсЙщФЩЃЌБмУтвдКѓжиИДГіЯжЁЃ
3 МрПиЙЄОп
ЯТУцЮвУЧашвЊбЁдёвЛПюКЯЪЪЙЋЫОвЕЮёЕФМрПиЙЄОпНјааМрПи,етРяЮвЖдМрПиЙЄОпНјааСЫМђЕЅЕФЗжРр

МрПиЙЄОп
РЯХЦМрПи:
MRTGЃЈMulti Route Trffic GrapherЃЉЪЧвЛЬзПЩгУРДЛцжЦЭјТчСїСПЭМЕФШэМўЃЌгЩШ№ЪПАТЖћыјЕФTobias
OetikerгыDave RandЫљПЊЗЂЃЌвдGPLЪкШЈЁЃ
MRTGзюКУЕФАцБОЪЧ1995ФъЭЦГіЕФЃЌгУperlгябдаДГЩЃЌПЩПчЦНЬЈЪЙгУЃЌЪ§ОнВЩМЏгУSNMPавщЃЌMRTGНЋЪжЛњЕНЕФЪ§ОнЭЈЙ§WebвГУцвдGIFЛђепPNGИёЪНЛцжЦГіЭМЯёЁЃ
GrngliaЪЧвЛИіПчЦНЬЈЕФЁЂПЩРЉеЙЕФЁЂИпадФмЕФЗжВМЪНМрПиЯЕЭГЃЌШчМЏШККЭЭјИёЁЃЫќЛљгкЗжВуЩшМЦЃЌЪЙгУЙуЗКЕФММЪѕЃЌгУRRDtoolДцДЂЪ§ОнЁЃОпгаПЩЪгЛЏНчУцЃЌЪЪКЯЖдМЏШКЯЕЭГЕФздЖЏЛЏМрПиЁЃЦфОЋаФЩшМЦЕФЪ§ОнНсЙЙКЭЫуЗЈЪЙЕУМрПиЖЫЕНБЛМрПиЖЫЕФСЌНгПЊЯњЗЧГЃЕЭЁЃФПЧАвбОгаГЩЧЇЩЯЭђЕФМЏШКе§дкЪЙгУетИіМрПиЯЕЭГЃЌПЩвдЧсЫЩЕФДІРэ2000ИіНкЕуЕФМЏШКЛЗОГЁЃ
CactiЃЈгЂЮФКЌвхЮЊЯЩШЫеЦЃЉЪЧвЛЬзЛљгкPHPЁЂMySQLЁЂSNMPКЭRRDtoolПЊЗЂЕФЭјТчСїСПМрВтЭМаЮЗжЮіЙЄОпЃЌЫќЭЈЙ§snmpgetРДЛёШЁЪ§ОнЪЙгУRRDtoolЛцЭМЃЌЕЋЪЙгУепЮоаыСЫНтRRDtoolИДдгЕФВЮЪ§ЁЃЬсЙЉСЫЗЧГЃЧПДѓЕФЪ§ОнКЭгУЛЇЙмРэЙІФмЃЌПЩвджИЖЈУПвЛИігУЛЇФмВщПДЪїзДНсЙЙЁЂжїЛњЩшБИвдМАШЮКЮвЛеХЭМЃЌЛЙПЩвдгыLDAPНсКЯНјаагУЛЇШЯжЄЃЌЭЌЪБвВФмздЖЈвхФЃАхЁЃдкРњЪЗЪ§ОнеЙЪОМрПиЗНУцЃЌЦфЙІФмЯрЕБВЛДэЁЃ
CactiЭЈЙ§ЬэМгФЃАхЃЌЪЙВЛЭЌЩшБИЕФМрПиЬэМгОпгаПЩИДгУадЃЌВЂЧвОпБИПЩздЖЈвхЛцЭМЕФЙІФмЃЌОпгаЧПДѓЕФдЫЫуФмСІЃЈЪ§ОнЕФЕўМгЙІФмЃЉ
NagiosЪЧвЛИіЦѓвЕМЖМрПиЯЕЭГЃЌПЩМрПиЗўЮёЕФдЫаазДЬЌКЭЭјТчаХЯЂЕШЃЌВЂФмМрЪгЫљжИЖЈЕФБОЕиЛђдЖГЬжїЛњзДЬЌвдМАЗўЮёЃЌЭЌЪБЬсЙЉвьГЃИцОЏЭЈжЊЙІФмЕШЁЃ
NagiosПЩдЫаадкLinuxКЭUNIXЦНЬЈЩЯЁЃЭЌЪБЬсЙЉWebНчУцЃЌвдЗНБуЯЕЭГЙмРэШЫдБВщПДЭјТчзДЬЌЁЂИїжжЯЕЭГЮЪЬтЁЂвдМАЯЕЭГЯрЙиШежОЕШ
NagiosЕФЙІФмВржигкМрПиЗўЮёЕФПЩгУадЃЌФмИљОнМрПижИБъзДЬЌДЅЗЂИцОЏЁЃ
ФПЧАNagiosвВеМСьСЫвЛЖЈЕФЪаГЁЗнЖюЃЌВЛЙ§NagiosВЂУЛгагыЪБОуНјЃЌвбОВЛФмТњзугкЖрБфЕФМрПиашЧѓЃЌМмЙЙЕФРЉеЙадКЭЪЙгУЕФБуНнадгаД§діЧПЃЌЦфИпМЖЙІФмМЏГЩдкЩЬвЕАцNagios
XIжаЁЃ
SmokepingжївЊгУгкМрЪгЭјТчадФмЃЌАќРЈГЃЙцЕФpingЁЂwwwЗўЮёЦїадФмЁЂDNSВщбЏадФмЁЂSSHадФмЕШЁЃЕзВувВЪЧгУRRDtoolзіжЇГжЃЌЬиЕуЪЧЛцжЦЭМЗЧГЃЦЏССЃЌЭјТчЖЊАќКЭбгГйгУбеЩЋКЭвѕгАРДБъЪОЃЌжЇГжНЋЖреХЭМЕўЗХдквЛЦ№ЃЌЦфзїепЛЙПЊЗЂСЫMRTGКЭRRDtllЕШЙЄОпЁЃ
SmokepingЕФеОЕуЮЊЃКhttp://tobi.oetiker.cn/hp
ПЊдДМрПиЯЕЭГOpenTSDBгУHbaseДцДЂЫљгаЪБађЃЈЮоаыВЩбљЃЉЕФЪ§ОнЃЌРДЙЙНЈвЛИіЗжВМЪНЁЂПЩЩьЫѕЕФЪБМфађСаЪ§ОнПтЁЃЫќжЇГжУыМЖЪ§ОнВЩМЏЃЌжЇГжгРОУДцДЂЃЌПЩвдзіШнСПЙцЛЎЃЌВЂКмШнвзЕиНгШыЕНЯжгаЕФИцОЏЯЕЭГРяЁЃ
OpenTSDBПЩвдДгДѓЙцФЃЕФМЏШКЃЈАќРЈМЏШКжаЕФЭјТчЩшБИЁЂВйзїЯЕЭГЁЂгІгУГЬађЃЉжаЛёШЁЯргІЕФВЩМЏжИБъЃЌВЂНјааДцДЂЁЂЫїв§КЭЗўЮёЃЌДгЖјЪЙетаЉЪ§ОнИќШнвзШУШЫРэНтЃЌШчWebЛЏЁЂЭМаЮЛЏЕШЁЃ
ЭѕХЦМрПи
ZabbixЪЧвЛИіЗжВМЪНМрПиЯЕЭГЃЌжЇГжЖржжВЩМЏЗНЪНКЭВЩМЏПЭЛЇЖЫЃЌгазЈгУЕФAgentДњРэЃЌвВжЇГжSNMPЁЂIPMIЁЂJMXЁЂTelnetЁЂSSHЕШЖржжавщЃЌЫќНЋВЩМЏЕНЕФЪ§ОнДцЗХЕНЪ§ОнПтЃЌШЛКѓЖдЦфНјааЗжЮіећРэЃЌДяЕНЬѕМўДЅЗЂИцОЏЁЃЦфСщЛюЕФРЉеЙадКЭЗсИЛЕФЙІФмЪЧЦфЫћМрПиЯЕЭГЫљВЛФмБШЕФЁЃЯрЖдРДЫЕЃЌЫќЕФзмЬхЙІФмзіЕФЗЧГЃгХауЁЃ
ДгвдЩЯИїжжМрПиЯЕЭГЕФЖдБШРДПДЃЌZabbixЖМЪЧОпгагХЪЦЕФЃЌЦфЗсИЛЕФЙІФмЁЂПЩРЉеЙЕФФмСІЁЂЖўДЮПЊЗЂЕФФмСІКЭМђЕЅвзгУЕФЬиЕуЃЌЖСепжЛвЊЩдМгбЇЯАЃЌМДПЩЙЙНЈздМКЕФМрПиЯЕЭГЁЃ
аЁУзЕФМрПиЯЕЭГЃКopen-falconЁЃopen-falconЕФФПБъЪЧзізюПЊЗХЁЂзюКУгУЕФЛЅСЊЭјЦѓвЕМЖМрПиВњЦЗЁЃ
OWLЪЧTalkingDataЙЋЫОЭЦГіЕФвЛПюПЊдДЗжВМЪНМрПиЯЕЭГOWLgithubЕижЗ
Ш§ЗНМрПи:
ЯждкЪаГЁЩЯгаКмЖрВЛДэЕФЕкШ§ЗНМрПиЃЌБШШчЃКМрПиБІЁЂМрПивзЁЂЬ§дЦЁЂЛЙгаКмЖрдЦГЇЩЬздДјМрПиЃЌЕЋЪЧдкетРяЮвУЧВЛДђЫузХжиНщЩмЃЌШчЙћЯыСЫНтШ§ЗНМрПиПЩздааЩЯЙйЭјзЩбЏЁЃЃЈБмУтЫЕЙуИцжВШыЃЉ
4 МрПиСїГЬ
ЩЯУцНщЩмСЫетУДЖрЃЌФЧУДЕНЕзбЁдёЪВУДМрПиЙЄОпзюКЯЪЪФиЃЌЮветРяЭЦМіМИПюПЊдДМрПиЙЄОп:zabbixЁЂOpen-FalconЁЂLEPUSЬьЭУ(зЈгУгкМрПиЪ§ОнПт)ЁЃ
ЕЋЪЧБОЮФЛЙЪЧЛљгкzabbixРДЙЙНЈећИіМрПиЬхЯЕЩњЬЌШІЁЃ
ФЧУДЯТУцЮвУЧОЭРДСФСФЃЌzabbixЕФећИіСїГЬЃК

МрПиСїГЬ
1.Ъ§ОнВЩМЏ: ZabbixЭЈЙ§SNMPЁЂAgentЁЂICMPЁЂSSHЁЂIPMIЕШЖдЯЕЭГНјааЪ§ОнВЩМЏ
2.Ъ§ОнДцДЂ: ZabbixДцДЂдкMySQLЩЯЃЌвВПЩвдДцДЂдкЦфЫћЪ§ОнПтЗўЮё
3.Ъ§ОнЗжЮі: ЕБЮвУЧЪТКѓашвЊИДХЬЗжЮіЙЪеЯЪБЃЌzabbixФмИјЮвУЧЬсЙЉЭМаЮвдМАЪБМфЕШЯрЙиаХЯЂЃЌЗНУцЮвУЧШЗЖЈЙЪеЯЫљдкЁЃ
4.Ъ§ОнеЙЪО: webНчУцеЙЪОЁЂ(вЦЖЏAPPЁЂjava_phpПЊЗЂвЛИіwebНчУцвВПЩвд)
5.МрПиБЈОЏ:ЕчЛАБЈОЏЁЂгЪМўБЈОЏЁЂЮЂаХБЈОЏЁЂЖЬаХБЈОЏЁЂБЈОЏЩ§МЖЛњжЦЕШЃЈЮоТлЪВУДБЈОЏЖМПЩвдЃЉ
6.БЈОЏДІРэ:ЕБНгЪеЕНБЈОЏЃЌЮвУЧашвЊИљОнЙЪеЯЕФМЖБ№НјааДІРэЃЌБШШч:живЊНєМБЁЂживЊВЛНєМБЃЌЕШЁЃИљОнЙЪеЯЕФМЖБ№ЃЌХфКЯЯрЙиЕФШЫдБНјааПьЫйДІРэЁЃ
5 МрПижИБъ
ЮвУЧЩЯУцСЫНтСЫМрПиЗНЗЈЁЂФПБъЁЂСїГЬЁЂвВСЫНтСЫМрПигаФФаЉЙЄОпЃЌПЩФмгаШЫЛсвЩЛѓЃЌЮвУЧОпЬхвЊМрПиаДЪВУДЖЋЮїЃЌФЧУДЮвдкетРяНјааСЫЗжРрећРэ:
гВМўМрПи
ЯЕЭГМрПи
гІгУМрПи
ЭјТчМрПи
СїСПЗжЮі
ШежОМрПи
АВШЋМрПи
APIМрПи
адФмМрПи
вЕЮёМрПи
5.1 гВМўМрПи
дчЦкЮвУЧЭЈЙ§ЛњЗПбВМьЕФЗНЪНЃЌВщПДгВМўЩшБИЕЦЙтЩСЫИЧщПіХаЖЯЪЧЗёЙЪеЯЃЌетбљЗЧГЃРЫЗбШЫСІЃЌВЂЧвЪЧжиИДадЮоММЪѕКЌСПЕФЙЄзїЃЌДѓМвЖЎЕУЁЃ

гВМўМрПи
ЕБШЛЮвУЧЯждкПЩвдЭЈЙ§IPMIЖдгВМўЯъЯИЧщПіНјааМрПиЃЌВЂЖдCPUЁЂФкДцЁЂДХХЬЁЂЮТЖШЁЂЗчЩШЁЂЕчбЙЕШЩшжУБЈОЏЩшжУБЈОЏуажЕ(здааЖдМрПиБЈОЏФкШнБраДКЯРэЕФБЈОЏЗЖЮЇ)

IPMIЙЄОпЮоЗЈЛёШЁЕНгВМўЕФзДЬЌЃЌПЩвдНшжњMegaCliЙЄОпЬНВтRaidДХХЬЖгСазДЬЌ
zabbixЬсЙЉIPMIМрПиФЃАхЃКZabbix IPMI Interface
ЯЕЭГздДјЕФIPMIФЃАхжЛФмМрПиЃЌЗчЩШЃЌЕчдДЃЌКЭВПЗжЮТЖШ
5.2 ЯЕЭГМрПи
жааЁаЭЦѓвЕЛљБОШЋЪЧLinuxЗўЮёЦїЃЌФЧУДЮвУЧПЯЖЈЪЧвЊМрПиЦ№ЯЕЭГзЪдДЕФЪЙгУЧщПіЃЌЯЕЭГМрПиЪЧМрПиЬхЯЕЕФЛљДЁЁЃ
МрПижївЊЖдЯѓ:

CPUгаМИИіживЊЕФИХФю:ЩЯЯТЮФЧаЛЛЁЂдЫааЖгСаКЭЪЙгУТЪЁЃ
етвВЪЧЮвУЧCPUМрПиЕФМИИіжиЕужИБъЁЃ
ЭЈГЃЧщПіЃЌУПИіДІРэЦїЕФдЫааЖгСаВЛвЊИпгк3ЃЌCPU РћгУТЪжагУЁАЛЇЬЌ/ФкКЫЬЌЁББШР§ЮЌГждк70/30ЃЌПеЯазДЬЌЮЌГждк50%ЃЌЩЯЯТЮФЧаЛЛвЊИљОнЯЕЭГЗБУІГЬЖШРДзлКЯПМСПЁЃ
еыЖдCPUГЃгУЕФЙЄОпга:htopЁЂtopЁЂvmstatЁЂmpstatЁЂdstatЁЂglances
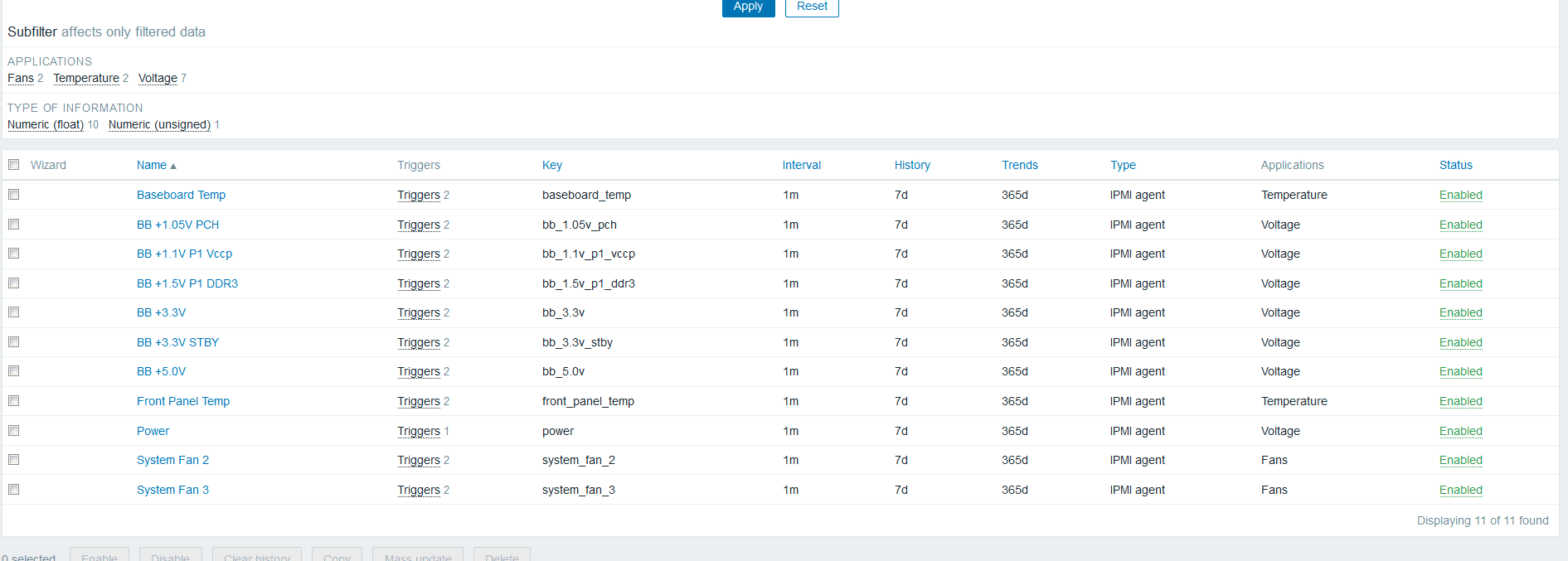
zabbixЬсЙЉЯЕЭГМрПиФЃАхЃКZabbix Agent Interface

CPUећЬхзДЬЌ
ЩЯЯТЮФЧаЛЛ

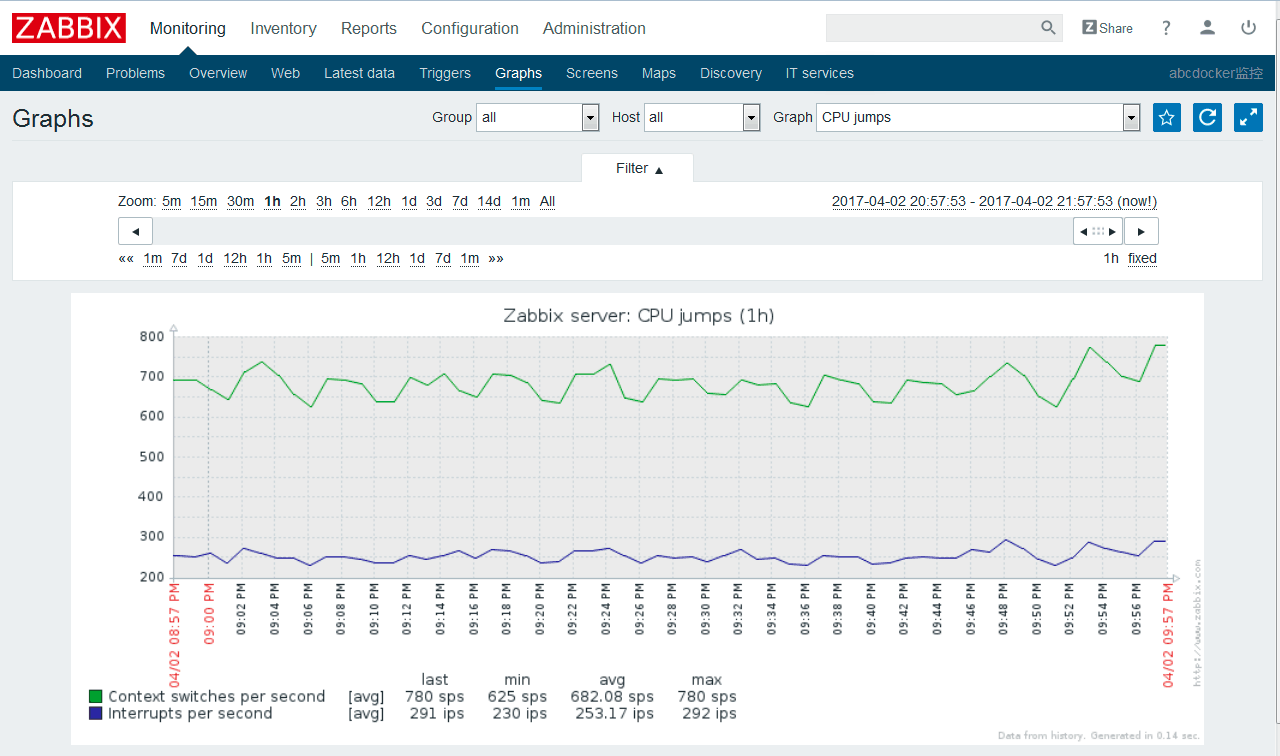
ИКдизДЬЌ
ФкДцЃКЭЈГЃЮвУЧашвЊМрПиФкДцЕФЪЙгУТЪЁЂSWAPЪЙгУТЪЁЂЭЌЪБПЩвдЭЈЙ§zabbixУшЛцФкДцЪЙгУТЪЕФЧњЯпЭМаЮЗЂЯжФГЗўЮёФкДцвчГіЕШЁЃ
еыЖдФкДцГЃгУЕФЙЄОпга: freeЁЂtopЁЂvmstatЁЂglances
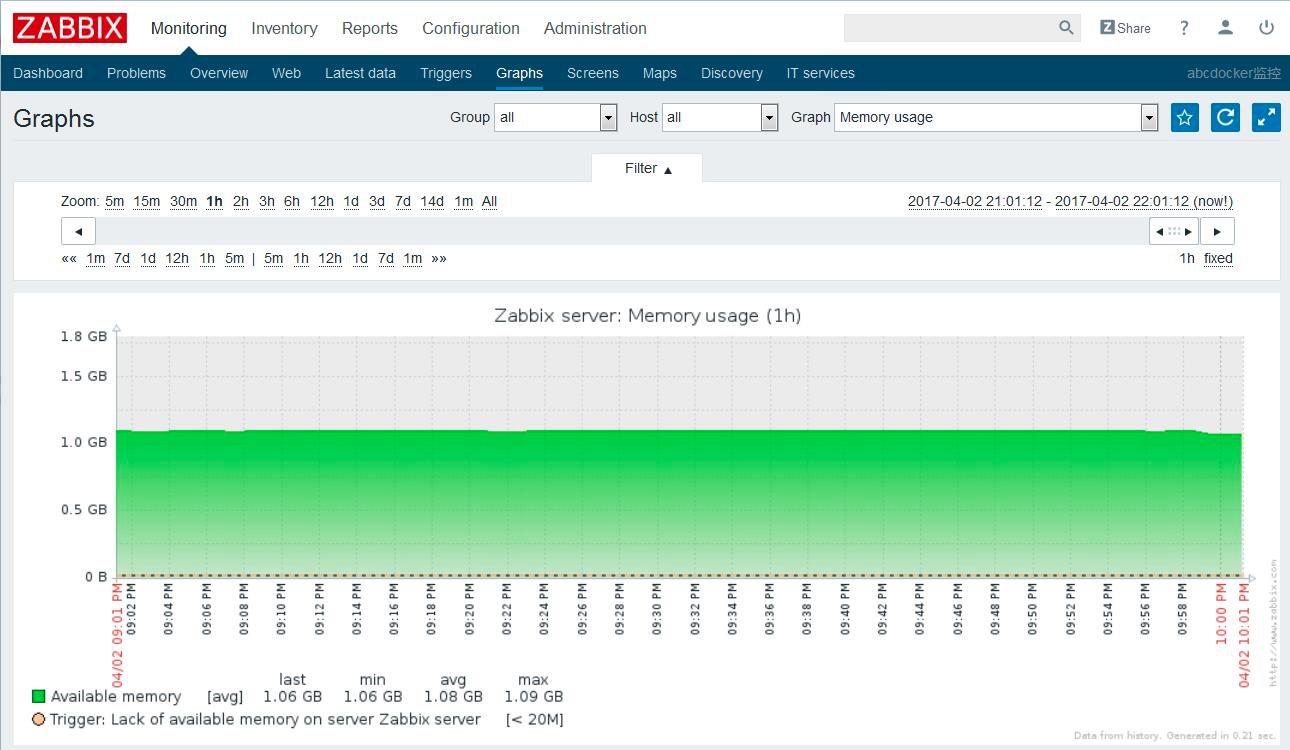
ФкДцЪЙгУТЪ
IOЗжЮЊДХХЬIOКЭЭјТчIOЁЃГ§СЫдкзіадФмЕїгХЮвУЧвЊМрПиИќЯъЯИЕФЪ§ОнЭтЃЌФЧУДШеГЃМрПиЃЌжЛЙизЂДХХЬЪЙгУТЪЁЂДХХЬЭЬЭТСПЁЂДХХЬаДШыЗБУІГЬЖШЃЌЭјТчвВЪЧМрПиЭјПЈСїСПМДПЩЁЃ
ГЃгУЙЄОпгаЃКiostatЁЂiotopЁЂdfЁЂiftopЁЂsarЁЂglances 
ДХХЬЪЙгУТЪ
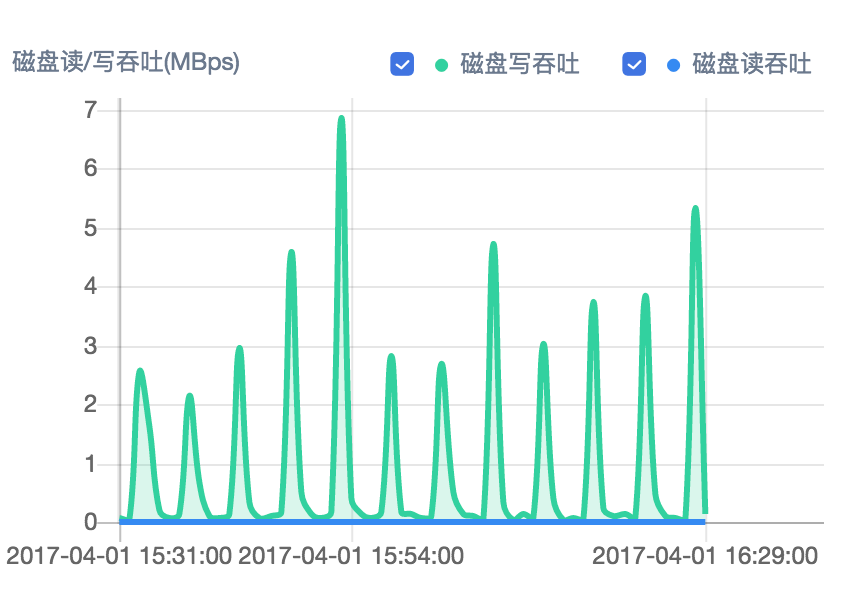
ДХХЬЖС/аДЭЬЭТ

ДХХЬЖС/аДДЮЪ§
ЭјПЈНјГіПкСїСП
TCPМрПиЃКдкКмЖрЧщПіЯТгаБивЊМрПиTCPЕФзДЬЌЃЌПЩвдЪЙгУnetstatЛђепssРДЛёШЁЫљгаЕФTCPСЌНгЃЌРДеЙЯж11жжВЛЭЌЕФTCPСЌНгзДЬЌЕФЪ§СПЃЌПЩвддкДѓВЂЗЂжаМАЪБЗЂЯжTCPЕФЯрЙиЙЪеЯЁЃ

TCP11жжзДЬЌаХЯЂ
ЦфЫќЕФЯЕЭГМрПиЛЙгадЫааЕФНјГЬЖЫПкЁЂНјГЬЪ§ЁЂЕЧТНгУЛЇЁЂOpen FileЕШЃЈЯъЯИВщПДzabbixздДјOS
LinuxФЃАхЃЉ 
ЦфЫћЯрЙиМрПи
5.3 гІгУМрПи
АбгВМўМрПиКЭЯЕЭГМрПибаОПУїАзКѓЃЌЮвУЧНјвЛВНВйзїЪЧашвЊЕЧТНЕНЗўЮёЦїЩЯВщПДЗўЮёЦїдЫааСЫФФаЉЗўЮёЃЌЖМашвЊМрПиЦ№РДЁЃ
гІгУЗўЮёМрПивВЪЧМрПиЬхЯЕжаБШНЯживЊЕФФкШнЃЌР§ШчЃК
LVSЁЂHaproxyЁЂDockerЁЂNginxЁЂPHPЁЂMemcachedЁЂRedisЁЂMySQLЁЂRabbitmqЕШЕШЃЌЯрЙиЕФЗўЮёЖМашвЊЪЙгУzabbixМрПиЦ№РДЁЃ
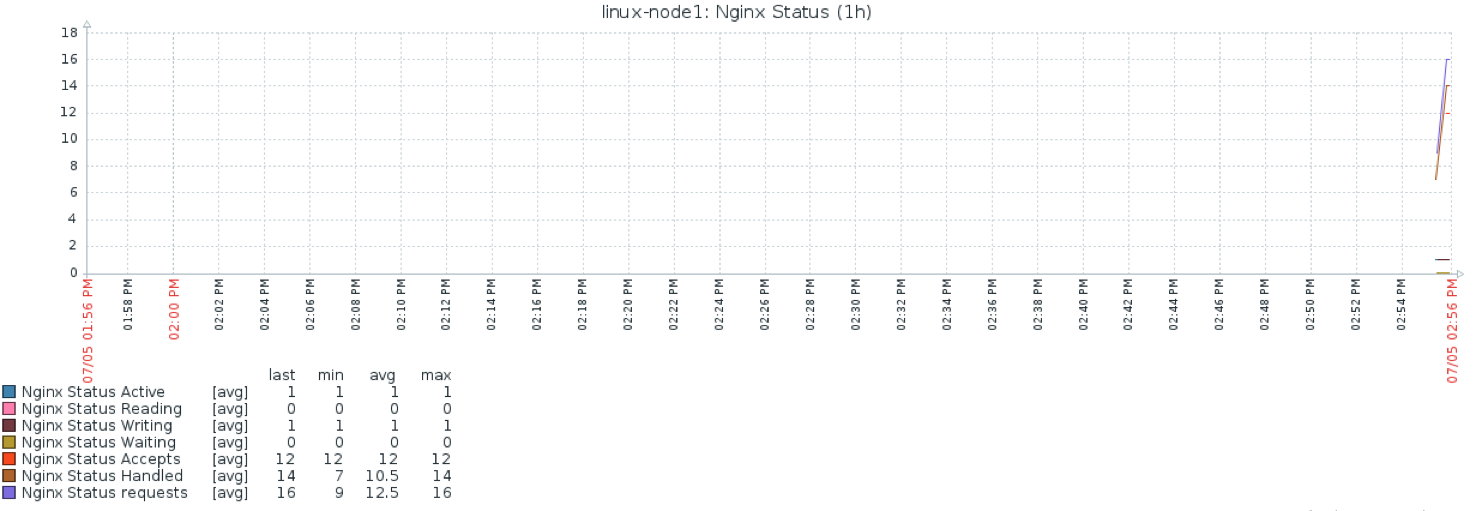
nginx_status
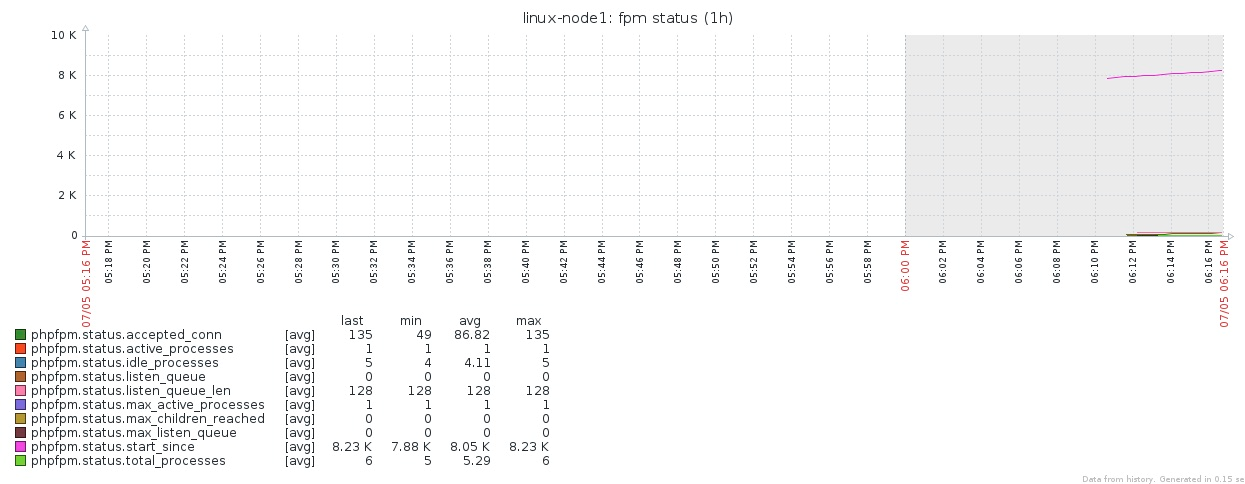
PHP-FPM_status
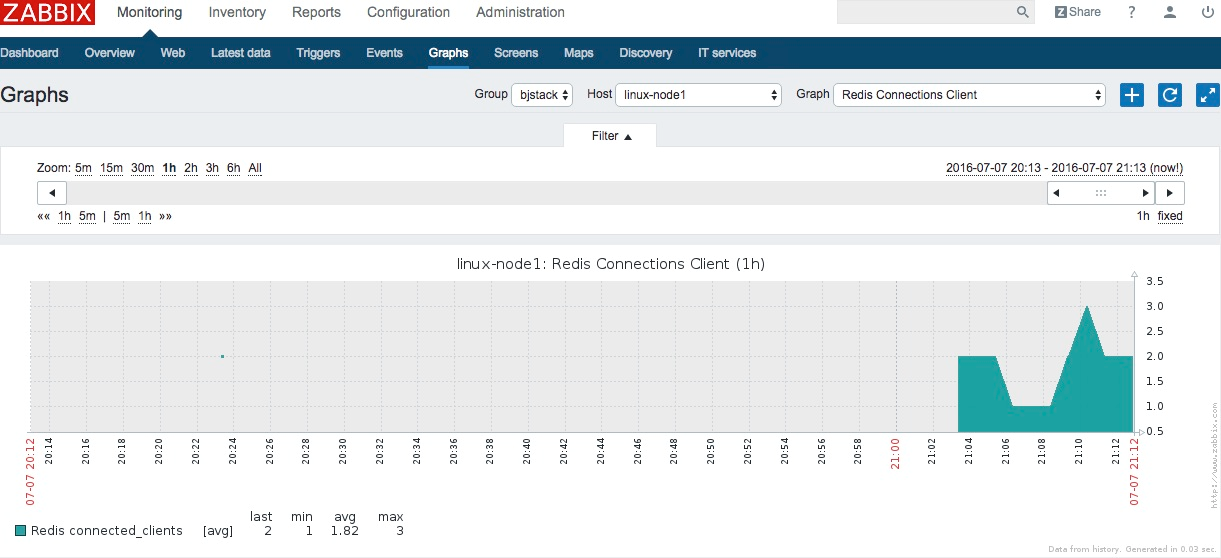
Redis_status
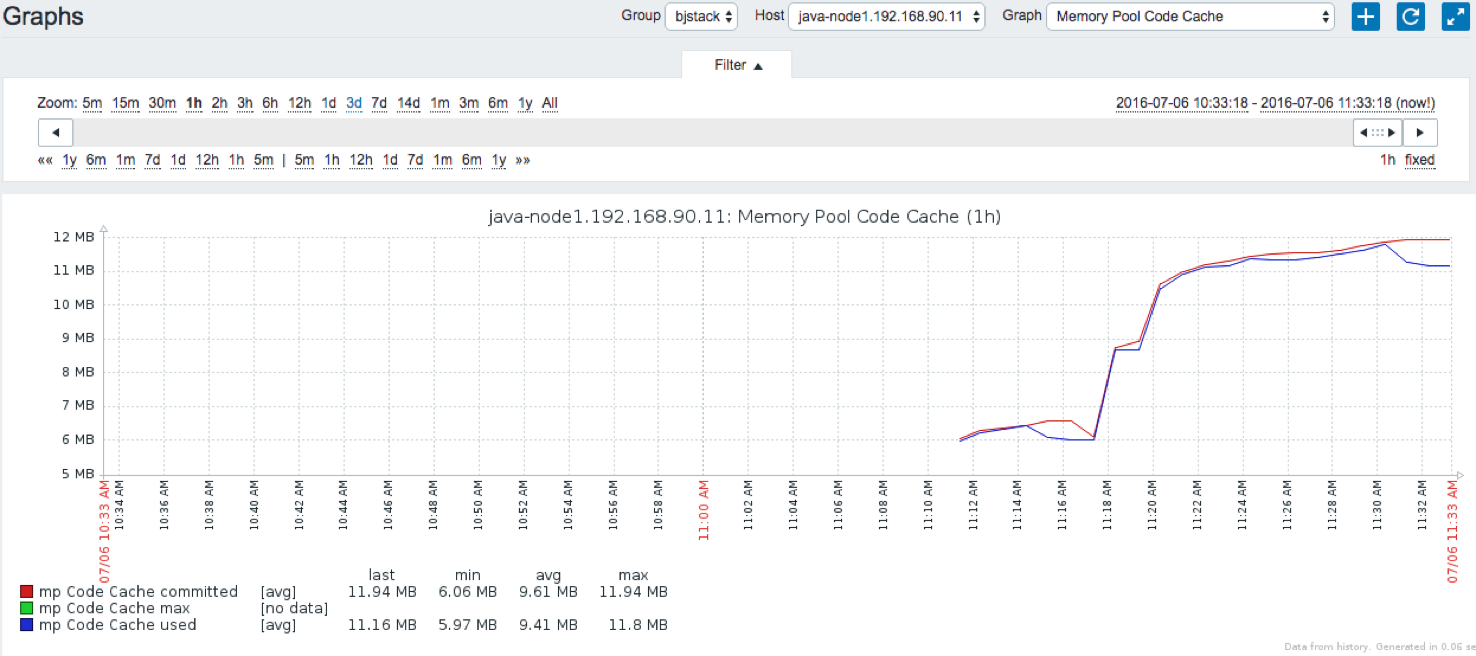
JVMМрПи
БЪепжЎЧАаДЙ§ЗўЮёМрПиЯъЯИЕФВйзїЙ§ГЬЃЌетРяОЭВЛвЛвЛеЙЪОЃЌЯъЧщЗУЮЪЃКzabbixМрПиИїжжгІгУЗўЮё
zabbixЬсЙЉгІгУЗўЮёМрПиЃКZabbix Agent UserParameter
zabbixЬсЙЉЕФJavaМрПиЃКZabbix JMX Interface
perconaЬсЙЉMySQLЪ§ОнПтМрПиЃКpercona-monitoring-plulgins
5.4 ЭјТчМрПи
зїЮЊвЛИіеыЖдШЋЙњгУЛЇЕФЕчЩЬЭјеОЃЌЪБПЬеЦЮеИїЕиЕНЛњЗПЕФЭјТчзДЬЌвВЪЧБиаыЕФЁЃ
ЭјТчМрПиЪЧЮвУЧЙЙНЈМрПиЦНЬЈЪЧБиаывЊПМТЧЕФЃЌгШЦфЪЧеыЖдгаЖрИіЛњЗПЕФГЁОАЃЌИїИіЛњЗПжЎМфЕФЭјТчзДЬЌЃЌЛњЗПКЭШЋЙњИїЕиЕФЭјТчзДЬЌЖМЪЧЮвУЧашвЊжиЕуЙизЂЕФЖдЯѓЃЌФЧУДШчКЮеЦЮеетаЉзДЬЌаХЯЂФиЃПЮвУЧашвЊНшжњгкЭјТчМрПиЙЄОпSmokepingЁЃ
Smokeping ЪЧrrdtoolЕФзїепTobi OetikerЕФзїЦЗЃЌЪЧгУPerlаДЕФЃЌжївЊЪЧМрЪгЭјТчадФмЃЌwww
ЗўЮёЦїадФмЃЌdnsВщбЏадФмЕШЃЌЪЙгУrrdtoolЛцЭМЃЌЖјЧвжЇГжЗжВМЪНЃЌжБНгДгЖрИіagentНјааЪ§ОнЕФЛузмЁЃ
ЭЌЪБЃЌгЩгкздМКМрПиЕуБШНЯЩйЃЌЛЙПЩвдНшжњКмЖрЩЬвЕЕФМрПиЙЄОпЃЌБШШчМрПиБІЁЂЬ§дЦЁЂЛљЕїЁЂВЉШ№ЕШЁЃЭЌЪБетаЉЗўЮёЬсЙЉЩЬЛЙПЩвдАяжњФуМрПиCDNЕФзДЬЌЁЃ

smokeping
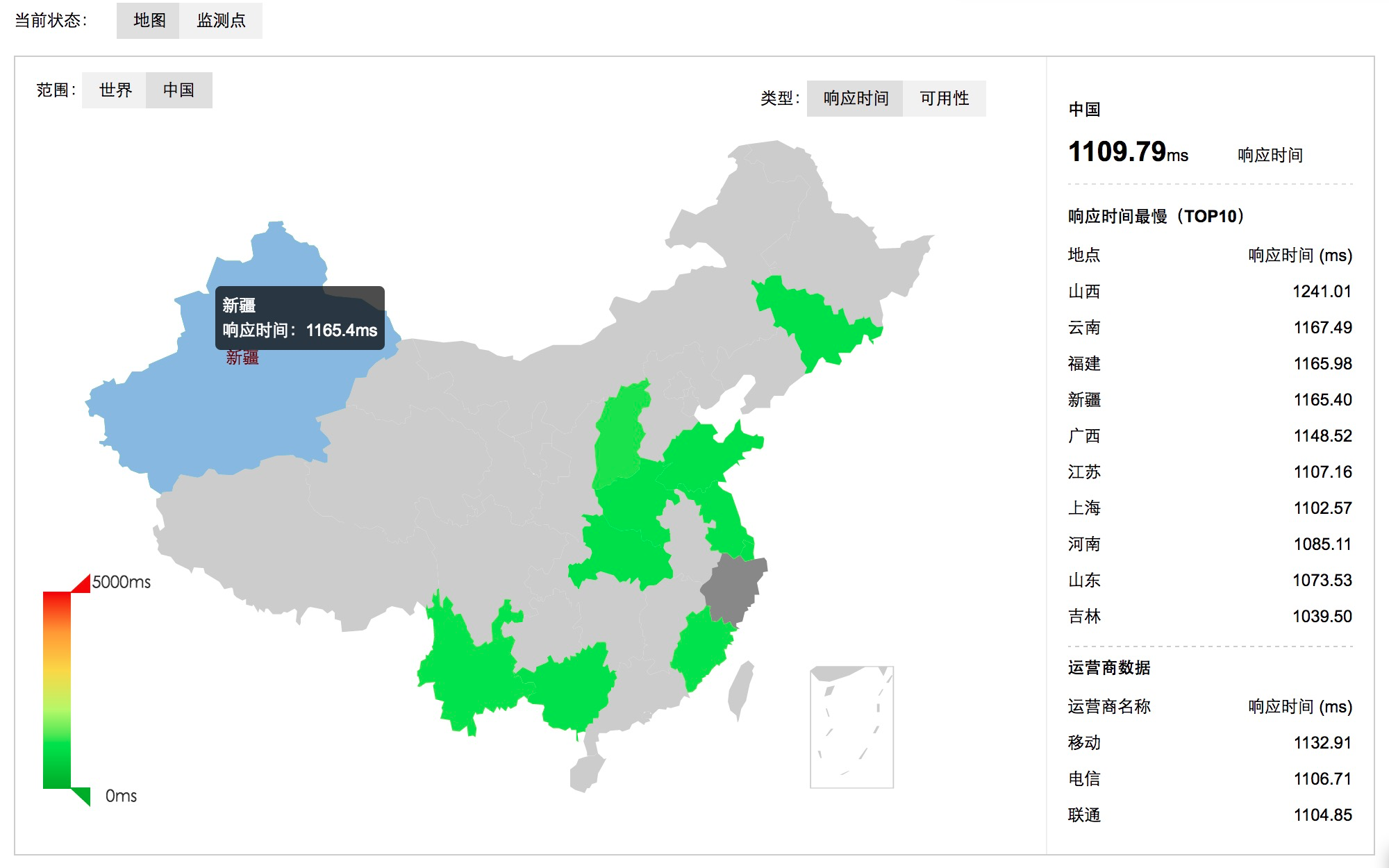

МрПиБІ
5.5 СїСПЗжЮі
ЭјеОСїСПЗжЮіЖдгкдЫЮЌШЫдБРДЫЕЃЌИќЪЧвЛУХБиаыеЦЮеЕФжЊЪЖСЫЁЃБШШчЖдгквЛМвЕчЩЬЙЋЫОРДЫЕЃК
ЭЈЙ§ЖдЖЉЕЅРДдДЕФЭГМЦКЭЗжЮіЃЌПЩвдСЫНтЮвУЧдкФГИіЭјеОЩЯЕФЙуИцЭЖШыгаУЛгаЪеЕНдЄЦкЕФаЇЙћЁЃ
ПЩвдЧјЗжВЛЭЌЕиЧјЕФЗУЮЪШЫЪ§ЁЂЩѕжСЩЬЦЗНЛвзЖюЕШЁЃ
АйЖШЭГМЦЁЂgoogleЗжЮіЁЂеОГЄЙЄОпЕШЕШЃЌжЛашвЊдквГУцЧЖШывЛИіjsМДПЩЁЃ
ЕЋЪЧЃЌЪ§ОнЪМжеЪЧдкЖдЗНЪжжаЃЌИіадЛЏЖЈжЦВЛЗНБуЃЌгкЪЧgoogleГівЛИіНаpiwikЕФПЊдДЗжЮіЙЄОп

piwik 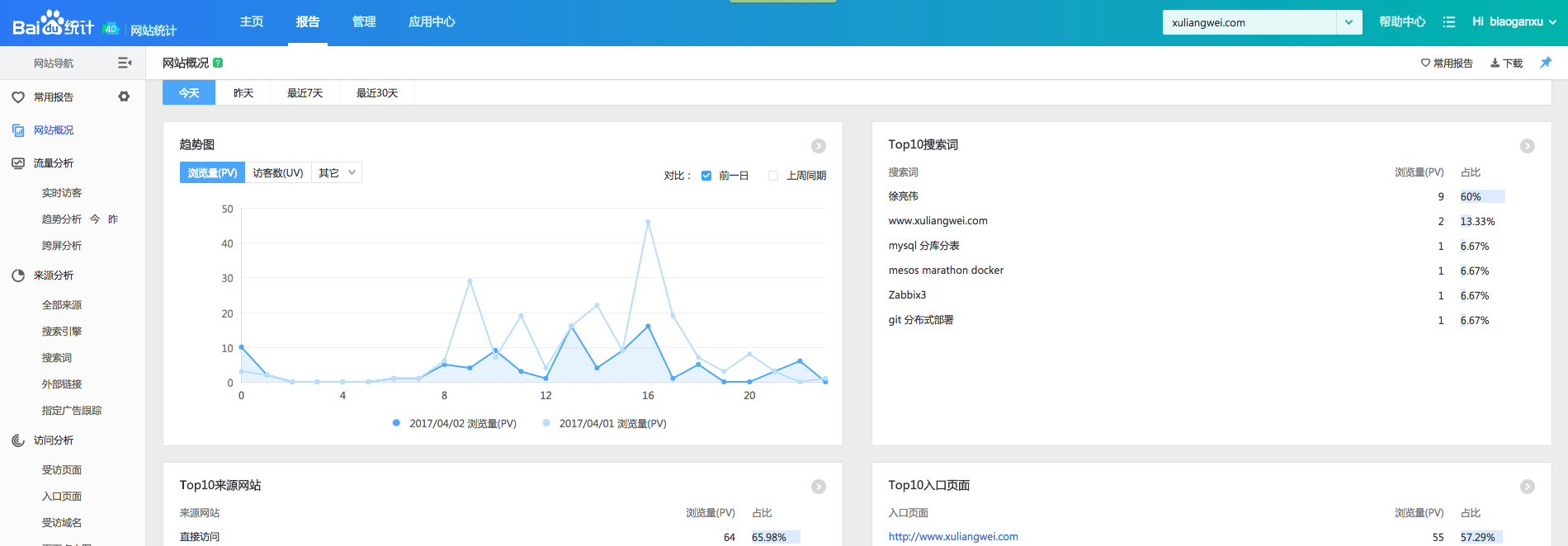
АйЖШЭГМЦ
5.6 ШежОМрПи
ЭЈГЃЧщПіЯТЃЌЫцзХЯЕЭГЕФдЫааЃЌВйзїЯЕЭГЛсВњЩњЯЕЭГШежОЃЌгІгУГЬађЛсВњЩњгІгУГЬађЕФЗУЮЪШежОЁЂДэЮѓШежОЃЌдЫааШежОЃЌЭјТчШежОЃЌЮвУЧПЩвдЪЙгУELKРДНјааШежОМрПиЁЃ
ЖдгкШежОМрПиРДЫЕЃЌзюМћЕФашЧѓОЭЪЧЪеМЏЁЂДцДЂЁЂВщбЏЁЂеЙЪОЃЌПЊдДЩчЧје§КУгаЯрЖдгІЕФПЊдДЯюФПЃК
logstashЃЈЪеМЏЃЉ + elasticsearchЃЈДцДЂ+ЫбЫїЃЉ + kibanaЃЈеЙЪОЃЉ
ЮвУЧНЋетШ§ИізщКЯЦ№РДЕФММЪѕГЦжЎЮЊELK StackЃЌЫљвдЫЕELK StackжИЕФЪЧElasticsearchЁЂLogstashЁЂKibanaММЪѕеЛЕФНсКЯЁЃ
ШчЙћЪеМЏСЫШежОаХЯЂЃЌФЧУДШчЙћВПЪ№ИќаТгавьГЃГіЯжЃЌПЩвдСЂМДдкkibanaЩЯПДЕНЁЃ 
ElkШежОеЙЪО
ЕБШЛвВПЩвдЭЈЙ§ZabbixЙ§ТЫДэЮѓШежОРДНјааИцОЏЁЃ 
zabbixШежОеЙЪО
5.7 АВШЋМрПи
ЫфШЛLinuxПЊдДЕФАВШЋВњЦЗВЛЩйЃЌБШШчЫФВуiptablesЃЌЦпВуWEBЗРЛЄnginx+luaЪЕЯжWAFЃЌзюКѓНЋЯрЙиЕФШежОЖМЪежСElkstackЃЌЭЈЙ§ЭМаЮЛЏНјааВЛЭЌЕФЙЅЛїРраЭеЙЪОЁЃЕЋЪЧЪМжеЪЧвЛМўБШНЯКФЗбЪБМфЃЌВЂЧвИіШЫаЇЙћВЂВЛЪЧКмКУЁЃетИіЪБКђЮвУЧПЩвдбЁдёНгШыЕкШ§ЗНЗўЮёГЇЩЬЁЃ
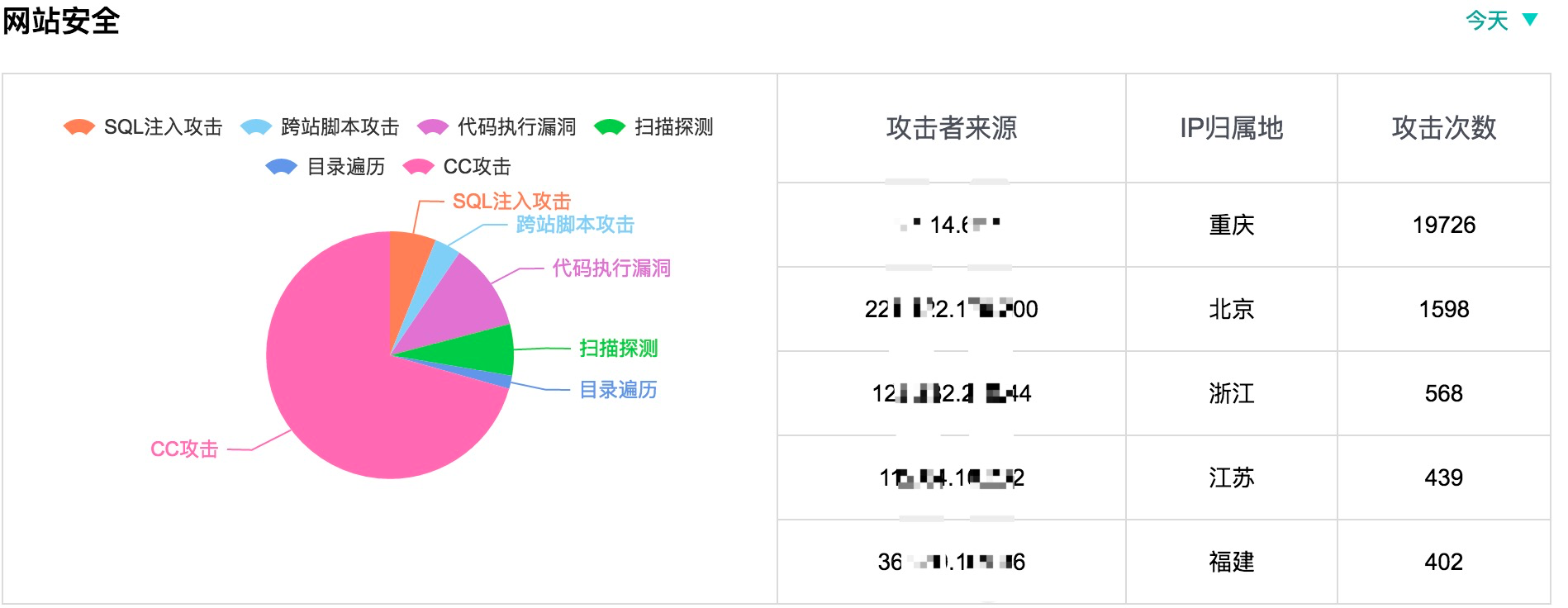
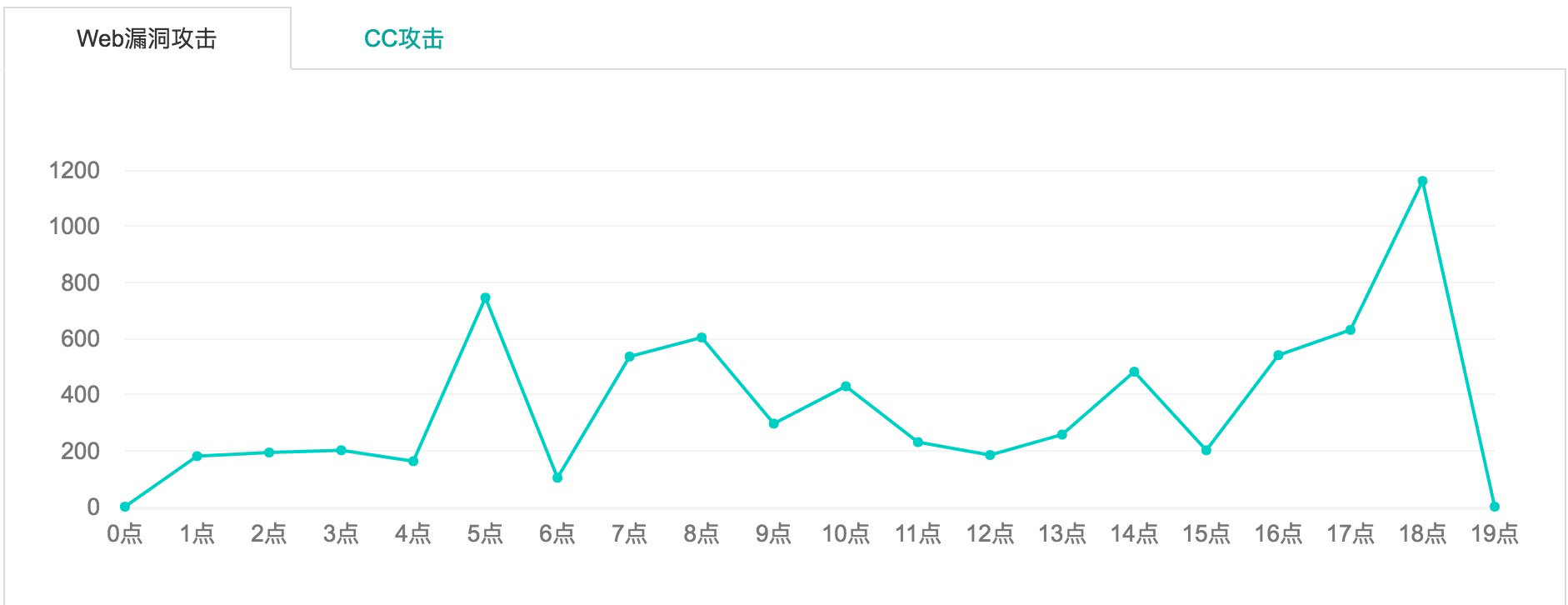

ФГФГШ§ЗНАВШЋ
Ш§ЗНГЇЩЬЬсЙЉШЋУцЕФТЉЖДПтЃЌКИЧЗўЮёЁЂКѓУХЁЂЪ§ОнПтЁЂХфжУМьВтЁЂCGIЁЂSMTPЕШЖржжРраЭ
ШЋУцМьВтжїЛњЁЂWebгІгУТЉЖДзджїЭкОђКЭаавЕЙВЯэЯрНсКЯЕквЛЪБМфИќаТ0dayТЉЖДЃЌЖХОјзюаТАВШЋвўЛМ
5.8 APIМрПи
гЩгкAPIБфЕУдНРДдНживЊЃЌКмЯдШЛЮвУЧвВашвЊетбљЕФЪ§ОнРДЗжБцЮвУЧЬсЙЉЕФ APIЪЧЗёФмЙЛе§ГЃдЫзїЁЃ
МрПиAPIНгПкGETЁЂPOSTЁЂPUTЁЂDELETEЁЂHEADЁЂOPTIONSЕФЧыЧѓ
ПЩгУадЁЂе§ШЗадЁЂЯьгІЪБМфЮЊШ§ДѓжиадФмжИБъ

APIМрПи 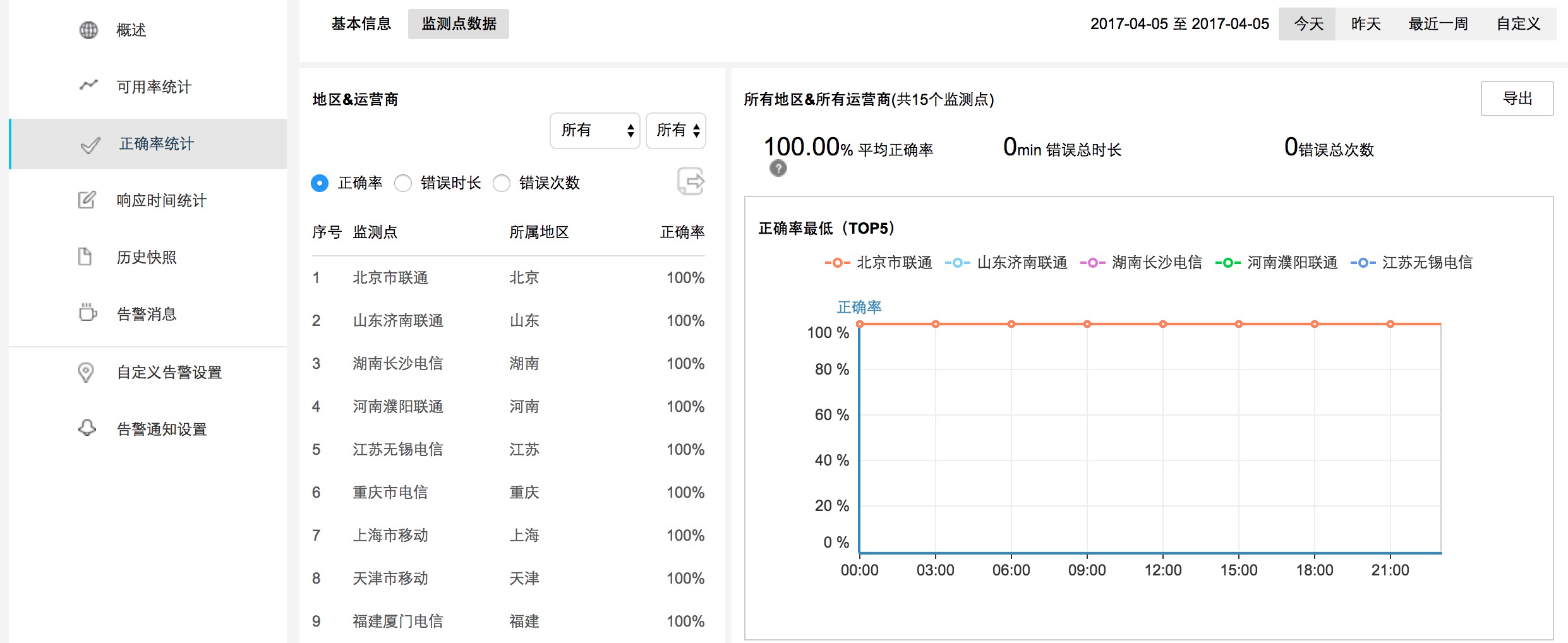
Ш§ЗНAPIМрПи

ЯьгІЪБМф
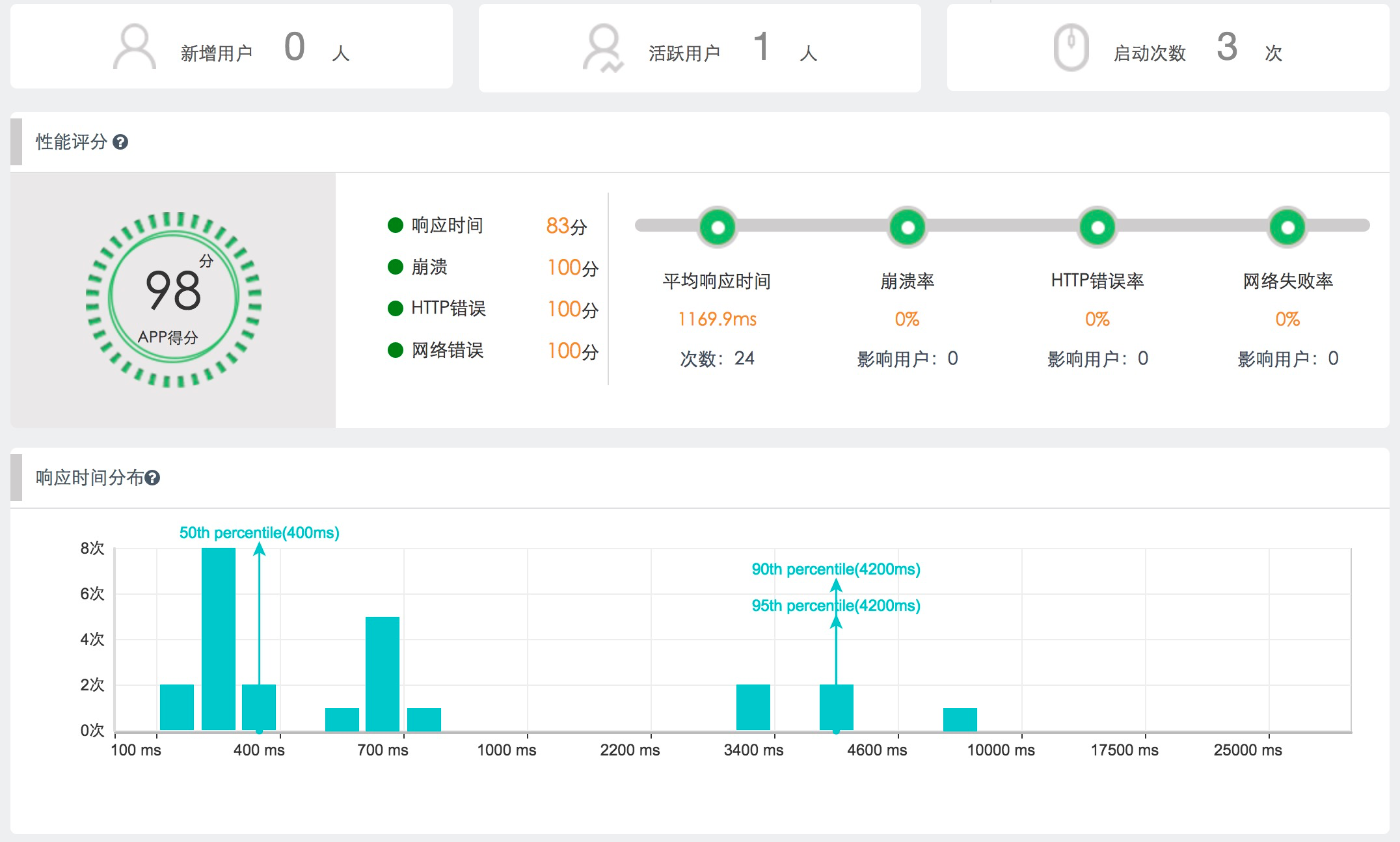
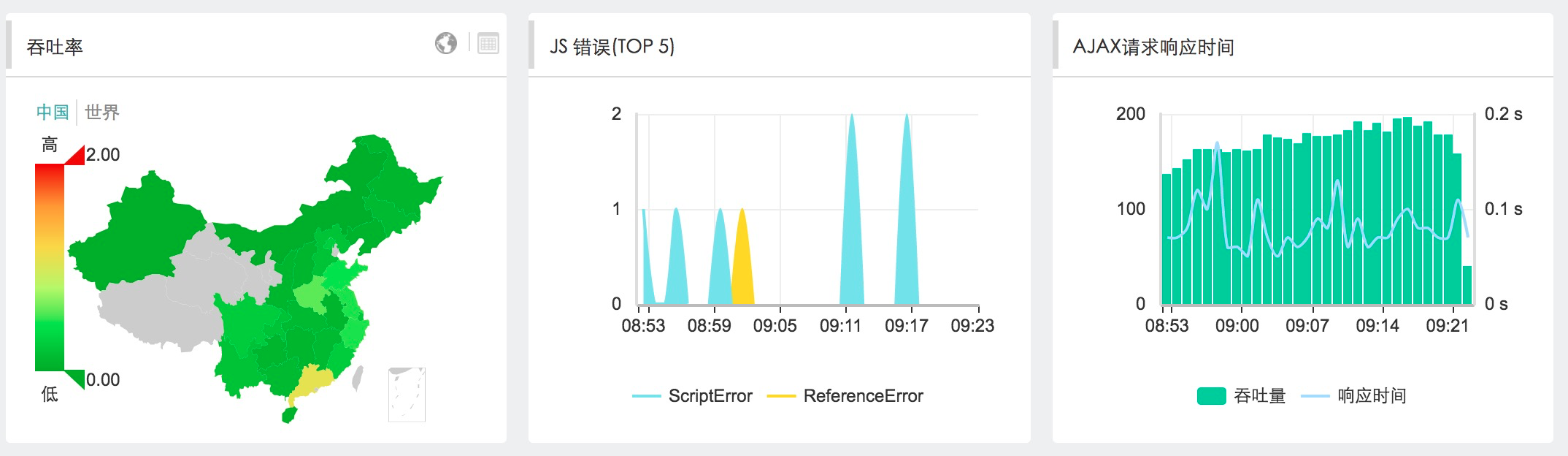
5.9 адФмМрПи
ШЋУцМрПиЭјвГадФмЃЌDNSЯьгІЪБМфЁЂHTTPНЈСЂСЌНгЪБМфЁЂвГУцадФмжИЪ§ЁЂЯьгІЪБМфЁЂПЩгУТЪЁЂдЊЫиДѓаЁЕШ
zabbixЬсЙЉURLМрПиЃКZabbix Web МрПи 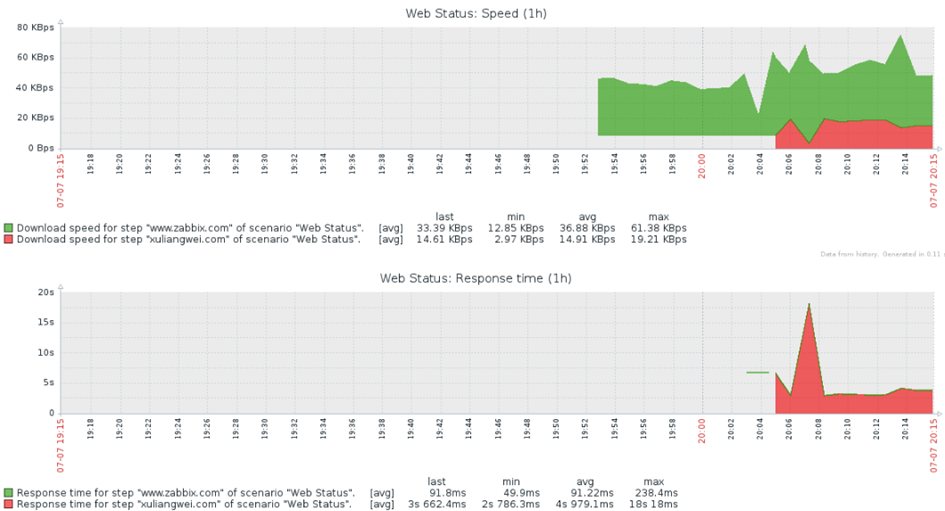
ZabbixеОЕуМрПи

жеЖЫЯьгІЪБМф
ЕкШ§ЗНМрПиМрПиДѓХЬЁЃИїРрЭМБэвЛФПСЫШЛЃЌШЋУцЬхЯжЭјвГадФмНЁПЕзДПіЁЃ
5.10 вЕЮёМрПи
УЛгавЕЮёжИБъМрПиЕФМрПиЦНЬЈЃЌВЛЪЧвЛИіЭъЩЦЕФМрПиЦНЬЈЃЌЭЈГЃдкЮвУЧЕФМрПиЯЕЭГжаЃЌБиаыНЋЮвУЧживЊЕФвЕЮёжИБъНјааМрПиЃЌВЂЩшжУуажЕНјааИцОЏЭЈжЊЁЃБШШчЕчЩЬаавЕЃК
УПЗжжгВњЩњЖрЩйЖЉЕЅЃЌ
УПЗжжгзЂВсЖрЩйгУЛЇЃЌ
УПЬьгаЖрЩйЛюдОгУЛЇЃЌ
УПЬьгаЖрЩйЭЦЙуЛюЖЏЃЌ
ЭЦЙуЛюЖЏв§ШыЖрЩйгУЛЇЃЌ
ЭЦЙуЛюЖЏв§ШыЖрЩйСїСПЃЌ
ЭЦЙуЛюЖЏв§ШыЖрЩйРћШѓЃЌ
НёЬьЩЬЦЗДђАќГіПтЖрЩйЃЌ
НёЬьЭЫЛѕЩЬЦЗгаЖрЩйЃЌ
ЕШЕШ живЊжИБъЖМПЩвдМгШыzabbixЩЯЃЌШЛКѓЭЈЙ§screenеЙЪОЁЃ
зЂЃКгЩгквЕЮёМрПиЭМБэЃЌЩцМАЕНвўЫНЕФЪ§ОнЬЋЖрЃЌОЭВЛНиЭМЁЃ
6 МрПиБЈОЏ
ЙЪеЯБЈОЏЭЈжЊЕФЗНЪНгаКмЖржжЃЌЕБШЛЮвУЧзюГЃгУЕФЛЙЪЧЖЬаХЃЌгЪМў
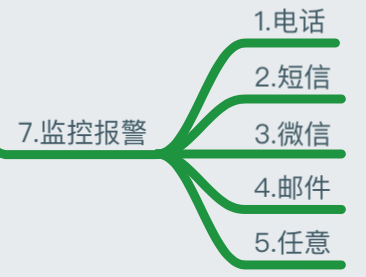
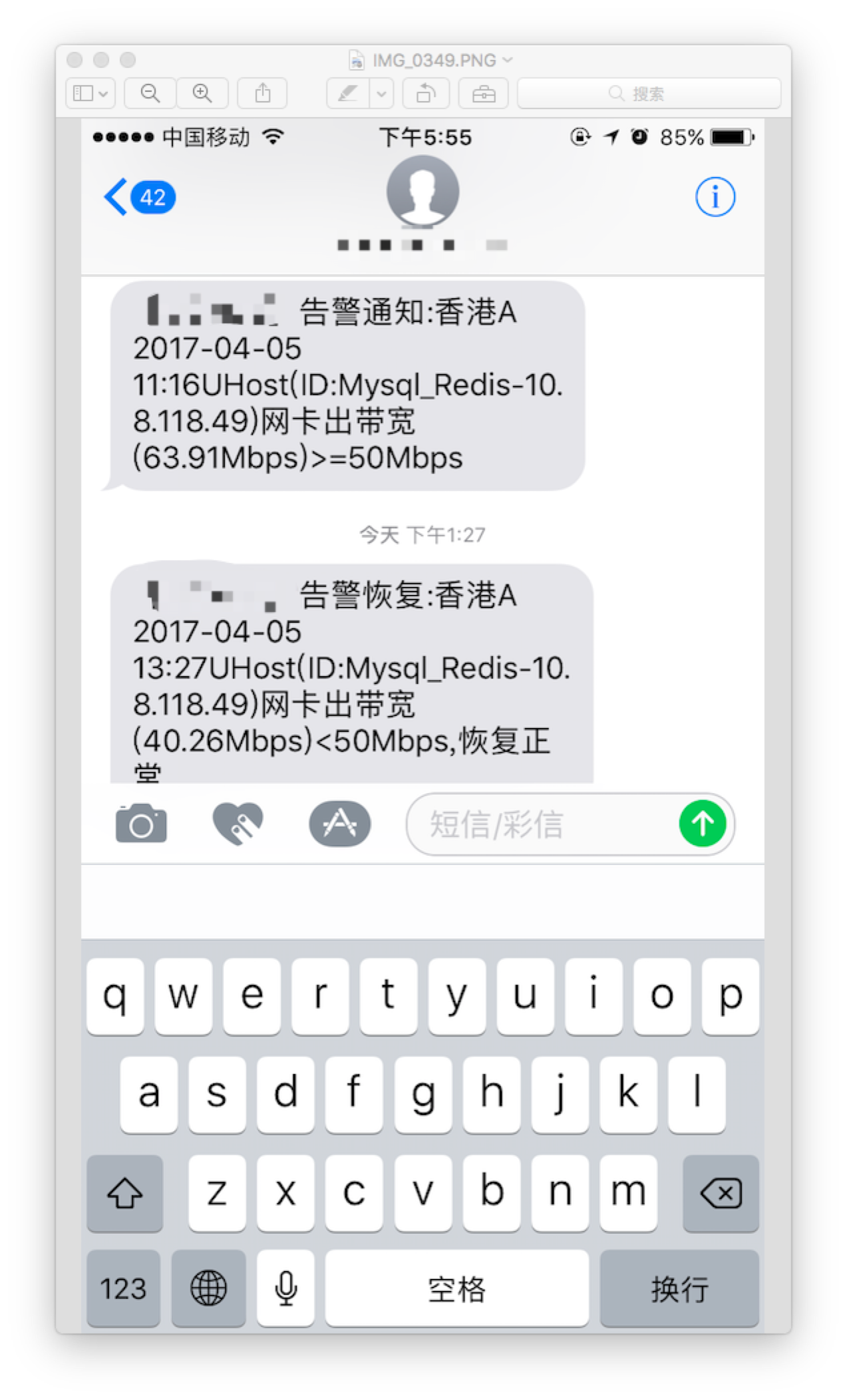
ЖЬаХБЈОЏ
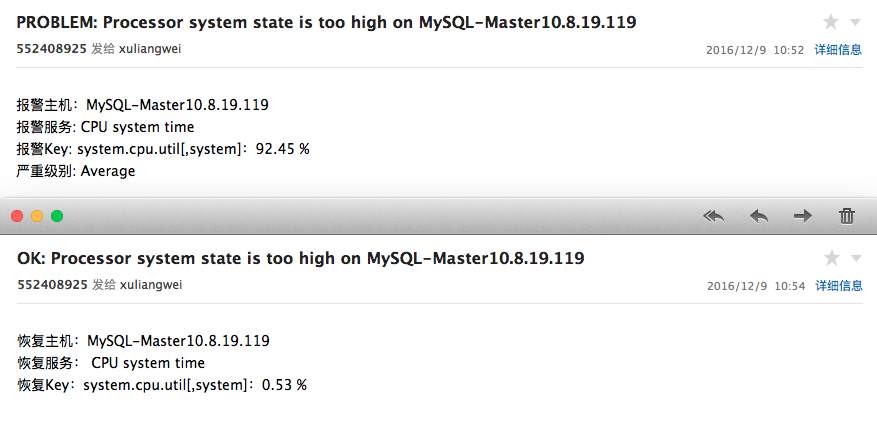
гЪМўБЈОЏ
7 БЈОЏДІРэ
вЛАуБЈОЏКѓЮвУЧЙЪеЯШчКЮДІРэЃЌЪзЯШЃЌЮвУЧПЩвдЭЈЙ§ИцОЏЩ§МЖЛњжЦЯШздЖЏДІРэЃЌБШШчnginxЗўЮёdownСЫЃЌПЩвдЩшжУИцОЏЩ§МЖздЖЏЦєЖЏnginxЁЃ
ЕЋЪЧШчЙћвЛАувЕЮёГіЯжСЫбЯжиЙЪеЯЃЌЮвУЧЭЈГЃИљОнЙЪеЯЕФМЖБ№ЃЌЙЪеЯЕФвЕЮёЃЌРДжИХЩВЛЭЌЕФдЫЮЌШЫдБНјааДІРэЁЃ
ЕБШЛВЛЭЌвЕЮёаЮЬЌЁЂВЛЭЌМмЙЙЁЂВЛЭЌЗўЮёПЩФмВЩгУЕФЗНЪНЖМВЛЭЌЃЌетИіУЛгавЛИіЙЬЖЈЕФФЃЪНЬзгУЁЃ

8 УцЪдМрПи
дкдЫЮЌУцЪджаЃЌГЃГЃЛсБЛЮЪЬтМрПиЯрЙиЕФЮЪЬтЃЌФЧУДетИіЮЪЬтЕНЕзИУШчКЮРДЛиД№ЃЌЮвеыЖдБОЮФИјДѓМвЬсЙЉСЫвЛИіМђЕЅЕФЛиД№ЫМТЗЁЃ
1.гВМўМрПиЁЃ
ЭЈЙ§SNMPРДНјааТЗгЩЦїНЛЛЛЛњЕФМрПи(етаЉПЩвдИњвЛаЉГЇЩЬЙЕЭЈРДСЫНтШчКЮзі)ЁЂЗўЮёЦїЕФЮТЖШвдМАЦфЫћЃЌПЩвдЭЈЙ§IPMIРДЪЕЯжЁЃЕБШЛШчЙћУЛгагВМўШЋЖМЪЧдЦЃЌжБНгЬјЙ§етвЛВНжшЁЃ
2.ЯЕЭГМрПиЁЃ
ШчCPUЕФИКдиЃЌЩЯЯТЮФЧаЛЛЁЂФкДцЪЙгУТЪЁЂДХХЬЖСаДЁЂДХХЬЪЙгУТЪЁЂДХХЬinodeЪЙгУТЪЁЃЕБШЛетаЉЖМЪЧашвЊХфжУДЅЗЂЦїЃЌвђЮЊФЌШЯЬЋЕЭЛсЦЕЗББЈОЏЁЃ
3.ЗўЮёМрПиЁЃ
БШШчЙЋЫОгУЕФLNMPМмЙЙЃЌnginxздДјStatusФЃПщЁЂPHPвВгаЯрЙиЕФStatusЁЂMySQLЕФЛАПЩвдЭЈЙ§perconaЙйЗНЙЄОпРДНјааМрПиЁЃRedisетаЉЭЈЙ§здЩэЕФinfoЛёШЁаХЯЂНјааЙ§ТЫЕШЁЃЗНЗЈЖМРрЫЦЁЃвЊУДЗўЮёздДјЁЃвЊУДЭЈЙ§НХБОРДЪЕЯжЯыМрПиЕФФкШнЃЌвдМАБЈОЏКЭЭМаЮЙІФмЁЃ
4.ЭјТчМрПиЁЃ
ШчЙћЪЧдЦжїЛњгжВЛЪЧПчЛњЗПЃЌФЧУДПЩвдбЁдёВЛМрПиЭјТчЁЃЕБШЛФуЫЕЮвУЧЪЧПчЛњЗПвдМАШчКЮШчКЮЁЃЭЦМіЪЙгУsmokepingРДзіЭјТчЯрЙиЕФМрПиЁЃЛђепжБНгНЛИјФуУЧЕФЭјТчЙЄГЬЪІРДзіЃЌвђЮЊЪѕвЕгазЈЙЅЁЃ
5.АВШЋМрПиЁЃ
ШчЙћЪЧдЦжїЛњПЩвдПМТЧЪЙгУздДјЕФАВШЋЗРЛЄЁЃЕБШЛвВПЩвдЪЙгУiptablesЁЃШчЙћЪЧгВМўЃЌФЧУДЭЦМіЪЙгУгВМўЗРЛ№ЧНЁЃЪЙгУдЦПЩвдЙКТђЗРDDOSЃЌБмУтГіЯжЙЪеЯЕМжТdownЛњвЛЬьЁЃШчЙћЪЧЯЕЭГЃЌФЧУДШЈЯоЁЂУмТыЁЂБИЗнЁЂЛжИДЕШЛљДЁЗНАИвЊзіКУЁЃwebЭЌЪБвВПЩвдЪЙгУNginx+LuaРДЪЕЯжвЛИіwebВуУцЕФЗРЛ№ЧНЁЃЕБШЛвВПЩвдЪЙгУМЏГЩКУЕФopenrestyЁЃ
6.WebМрПиЁЃ
webМрПиЕФЛАЬтЦфЪЕЛЙЪЧКмЖрЁЃБШШчПЩвдЪЙгУздДјЕФwebМрПиРДМрПивГУцЯрЙиЕФбгГйЁЂjsЯьгІЪБМфЁЂЯТдиЪБМфЁЂЕШЕШЁЃетРяЮвЭЦМіЪЙгУзЈвЕЕФЩЬвЕШэМў,МрПиБІЛђЬ§дЦРДЪЕЯжЁЃБЯОЙШЫМвШЋЙњИїЕиЖМгаЛњЗПЁЃЃЈШчЙћБОЩэЪЧЖрЛњЗПФЧОЭСэЫЕСЫЃЉ
7.ШежОМрПиЁЃ
ШчЙћЪЧwebЕФЛАПЩвдЪЙгУМрПиNginxЕФ50xЁЂ40xЕФДэЮѓШежОЃЌPHPЕФERRORШежОЁЃЦфЪЕетаЉашЧѓЮоЗЧЪЧЃЌЪеМЏЁЂДцДЂЁЂВщбЏЁЂеЙЪОЃЌЮвУЧЦфЪЕПЩвдЪЙгУПЊдДЕФELKstackРДЪЕЯжЁЃLogstashЃЈЪеМЏЃЉЁЂelasticsearchЃЈДцДЂ+ЫбЫїЃЉЁЂkibanaЃЈеЙЪОЃЉ
8.вЕЮёМрПиЁЃ
ЮвУЧЩЯУцзіСЫФЧУДЖрЃЌЦфЪЕзюжеЛЙЪЧБЃжЄвЕЮёЕФдЫааЁЃетбљЮвУЧзіЕФМрПиВХгавтвхЁЃЫљвдвЕЮёВуУцетПщЕФМрПиашвЊКЭПЊЗЂвдМАзмМрПЊЛсЬжТлЃЌМрПиБШНЯживЊЕФвЕЮёжИБъЃЌЃЈашвЊПЊЛсШЗШЯЃЉШЛКѓЭЈЙ§МђЕЅЕФНХБООЭПЩвдЪЕЯжЃЌзюКѓЩшжУДЅЗЂЦїМДПЩ
9.СїСПЗжЮіЁЃ
ЦНЪБЮвУЧЗжЮіШежОЖМЪЧФУawk sed xxxвЛЖбЙЄОпРДЪЕЯжЁЃетбљЖдЮвУЧЭГМЦipЁЂpvЁЂuvВЛЪЧКмЗНБуЁЃФЧУДПЩвдЪЙгУАйЖШЭГМЦЁЂgoogleЭГМЦЁЂЩЬвЕЃЌШУПЊЗЂЧЖШыДњТыМДПЩЁЃЮЊСЫБмУтвўЫНвВПЩвдЪЙгУpiwikРДзіЯрЙиЕФСїСПЗжЮіЁЃ
10.ПЩЪгЛЏЁЃ
ЭЈЙ§screenвдМАв§ШывЛаЉЕкШ§ЗНЕФПтРДУРЛЏНчУцЃЌЭЌЪБЮвУЧвВашвЊжЊЕРЃЌЖЉЕЅСПЭЛШЛдіМгЁЂЭЛШЛМѕЩйЁЃЛђепЫЕЭЛШЛРДСЫвЛДѓВЈСїСПЃЌетСїСПДгФФЖљРДЃЌЪЧВЛЪЧЭЦЙуСЫЃЌЛЙЪЧБЛЙЅЛїСЫЁЃПЩвдНсКЯМрПиЦНРДЪсРэИїИіЯЕЭГжЎМфЕФвЕЮёЙиЯЕЁЃ
11.здЖЏЛЏМрПиЁЃ
ШчЩЯЮвУЧзіСЫФЧУДЖрЕФЙЄзїЃЌЕБШЛВЛФмЪЧвЛЬЈвЛЬЈЕФРДМгkeyЪЕЯжЁЃПЩвдЭЈЙ§ZabbixЕФжїЖЏФЃЪНвдМАБЛЖЏФЃЪНРДЪЕЯжЁЃЕБШЛзюКУЛЙЪЧЭЈЙ§APIРДЪЕЯжЁЃ
12.ЗжВМЪНМрПи
9 МрПизмНс
еце§ЯызіЕНИќЭъећЕФМрПиЬхЯЕЃЌФПЧАЕФПЊдДШэМўЃЌШЗЪЕЮоЗЈКмКУЕФТњзуЃЌгаЬѕМўЕФЙЋЫОЖМПЊЪМздМКПЊЗЂздМКЕФМрПиЯЕЭГЃЌБШШчаЁУзПЊдДЕФOpen-FalconЁЃ
вВгаБШНЯКУЕФПЊдДЕФМрПиПђМмШчSensuЕШЃЌдйМгЩЯinfluxdbЁЂgrafanaПЩвдгУРДЖЈжЦЗћКЯздМКЦѓвЕЕФМрПиЦНЬЈЁЃ
ЕБШЛЮвЫЕЕФЛЙЪЧКмМђЕЅЃЌОбщгаЯоЁЂЫМТЗвВНіФмЬсЙЉетУДЖрЁЃ
вдЩЯОЭЪЧЮвЗжЯэЖдМрПиЕФвЛаЉЗНЗЈКЭаФЕУЁЃ |