| БрМЭЦМі: |
БОЮФЖд
Prometheus ЕФзщГЩЃЌМмЙЙКЭЛљБОИХФюНјааСЫНщЩмЃЌВЂЪЕР§бнЪОСЫ node
exporter, Prometheus КЭ Alermanager ЕФХфжУКЭдЫааЁЃ
БОЮФРДздгкibmЃЌгЩЛ№СњЙћШэМўLucaБрМЁЂЭЦМіЁЃ |
|
ЫцзХШнЦїММЪѕЕФбИЫйЗЂеЙЃЌKubernetes вбШЛГЩЮЊДѓМвзЗХѕЕФШнЦїМЏШКЙмРэЯЕЭГЁЃPrometheus
зїЮЊЩњЬЌШІ Cloud Native Computing FoundationЃЈМђГЦЃКCNCFЃЉжаЕФживЊвЛдБ,ЦфЛюдОЖШНіДЮгк
Kubernetes, ЯжвбЙуЗКгУгк Kubernetes МЏШКЕФМрПиЯЕЭГжаЁЃБОЮФНЋМђвЊНщЩм Prometheus
ЕФзщГЩКЭЯрЙиИХФюЃЌВЂЪЕР§бнЪО Prometheus ЕФАВзАЃЌХфжУМАЪЙгУЃЌвдБуПЊЗЂШЫдБКЭдЦЦНЬЈдЫЮЌШЫдБПЩвдПьЫйЕФеЦЮе
PrometheusЁЃ
Prometheus МђНщ
Prometheus ЪЧвЛЬзПЊдДЕФЯЕЭГМрПиБЈОЏПђМмЁЃЫќЦєЗЂгк Google ЕФ borgmon МрПиЯЕЭГЃЌгЩЙЄзїдк
SoundCloud ЕФ google ЧАдБЙЄдк 2012 ФъДДНЈЃЌзїЮЊЩчЧјПЊдДЯюФПНјааПЊЗЂЃЌВЂгк
2015 Фъе§ЪНЗЂВМЁЃ2016 ФъЃЌPrometheus е§ЪНМгШы Cloud Native Computing
FoundationЃЌГЩЮЊЪмЛЖгЖШНіДЮгк Kubernetes ЕФЯюФПЁЃ
зїЮЊаТвЛДњЕФМрПиПђМмЃЌPrometheus ОпгавдЯТЬиЕуЃК
ЧПДѓЕФЖрЮЌЖШЪ§ОнФЃаЭЃК
ЪБМфађСаЪ§ОнЭЈЙ§ metric УћКЭМќжЕЖдРДЧјЗжЁЃ
ЫљгаЕФ metrics ЖМПЩвдЩшжУШЮвтЕФЖрЮЌБъЧЉЁЃ
Ъ§ОнФЃаЭИќЫцвтЃЌВЛашвЊПЬвтЩшжУЮЊвдЕуЗжИєЕФзжЗћДЎЁЃ
ПЩвдЖдЪ§ОнФЃаЭНјааОлКЯЃЌЧаИюКЭЧаЦЌВйзїЁЃ
жЇГжЫЋОЋЖШИЁЕуРраЭЃЌБъЧЉПЩвдЩшЮЊШЋ unicodeЁЃ
СщЛюЖјЧПДѓЕФВщбЏгяОфЃЈPromQLЃЉЃКдкЭЌвЛИіВщбЏгяОфЃЌПЩвдЖдЖрИі metrics НјааГЫЗЈЁЂМгЗЈЁЂСЌНгЁЂШЁЗжЪ§ЮЛЕШВйзїЁЃ
взгкЙмРэЃК Prometheus server ЪЧвЛИіЕЅЖРЕФЖўНјжЦЮФМўЃЌПЩжБНгдкБОЕиЙЄзїЃЌВЛвРРЕгкЗжВМЪНДцДЂЁЃ
ИпаЇЃКЦНОљУПИіВЩбљЕуНіеМ 3.5 bytesЃЌЧввЛИі Prometheus server ПЩвдДІРэЪ§АйЭђЕФ
metricsЁЃ
ЪЙгУ pull ФЃЪНВЩМЏЪБМфађСаЪ§ОнЃЌетбљВЛНігаРћгкБОЛњВтЪдЖјЧвПЩвдБмУтгаЮЪЬтЕФЗўЮёЦїЭЦЫЭЛЕЕФ metricsЁЃ
ПЩвдВЩгУ push gateway ЕФЗНЪНАбЪБМфађСаЪ§ОнЭЦЫЭжС Prometheus server
ЖЫЁЃ
ПЩвдЭЈЙ§ЗўЮёЗЂЯжЛђепОВЬЌХфжУШЅЛёШЁМрПиЕФ targetsЁЃ
гаЖржжПЩЪгЛЏЭМаЮНчУцЁЃ
взгкЩьЫѕЁЃ
ашвЊжИГіЕФЪЧЃЌгЩгкЪ§ОнВЩМЏПЩФмЛсгаЖЊЪЇЃЌЫљвд Prometheus ВЛЪЪгУЖдВЩМЏЪ§ОнвЊ 100% зМШЗЕФЧщаЮЁЃЕЋШчЙћгУгкМЧТМЪБМфађСаЪ§ОнЃЌPrometheus
ОпгаКмДѓЕФВщбЏгХЪЦЃЌДЫЭтЃЌPrometheus ЪЪгУгкЮЂЗўЮёЕФЬхЯЕМмЙЙЁЃ
Prometheus зщГЩМАМмЙЙ
Prometheus ЩњЬЌШІжаАќКЌСЫЖрИізщМўЃЌЦфжааэЖрзщМўЪЧПЩбЁЕФЃК
Prometheus Server: гУгкЪеМЏКЭДцДЂЪБМфађСаЪ§ОнЁЃ
Client Library: ПЭЛЇЖЫПтЃЌЮЊашвЊМрПиЕФЗўЮёЩњГЩЯргІЕФ metrics ВЂБЉТЖИј Prometheus
serverЁЃЕБ Prometheus server РД pull ЪБЃЌжБНгЗЕЛиЪЕЪБзДЬЌЕФ metricsЁЃ
Push Gateway: жївЊгУгкЖЬЦкЕФ jobsЁЃгЩгкетРр jobs ДцдкЪБМфНЯЖЬЃЌПЩФмдк Prometheus
РД pull жЎЧАОЭЯћЪЇСЫЁЃЮЊДЫЃЌетДЮ jobs ПЩвджБНгЯђ Prometheus server ЖЫЭЦЫЭЫќУЧЕФ
metricsЁЃетжжЗНЪНжївЊгУгкЗўЮёВуУцЕФ metricsЃЌЖдгкЛњЦїВуУцЕФ metricesЃЌашвЊЪЙгУ
node exporterЁЃ
Exporters: гУгкБЉТЖвбгаЕФЕкШ§ЗНЗўЮёЕФ metrics Иј PrometheusЁЃ
Alertmanager: Дг Prometheus server ЖЫНгЪеЕН alerts КѓЃЌЛсНјааШЅГ§жиИДЪ§ОнЃЌЗжзщЃЌВЂТЗгЩЕНЖдЪеЕФНгЪмЗНЪНЃЌЗЂГіБЈОЏЁЃГЃМћЕФНгЪеЗНЪНгаЃКЕчзггЪМўЃЌpagerdutyЃЌOpsGenie,
webhook ЕШЁЃ
вЛаЉЦфЫћЕФЙЄОпЁЃ
ЭМ 1 ЮЊ Prometheus ЙйЗНЮФЕЕжаЕФМмЙЙЭМЃК
ЭМ 1. Prometheus МмЙЙЭМ
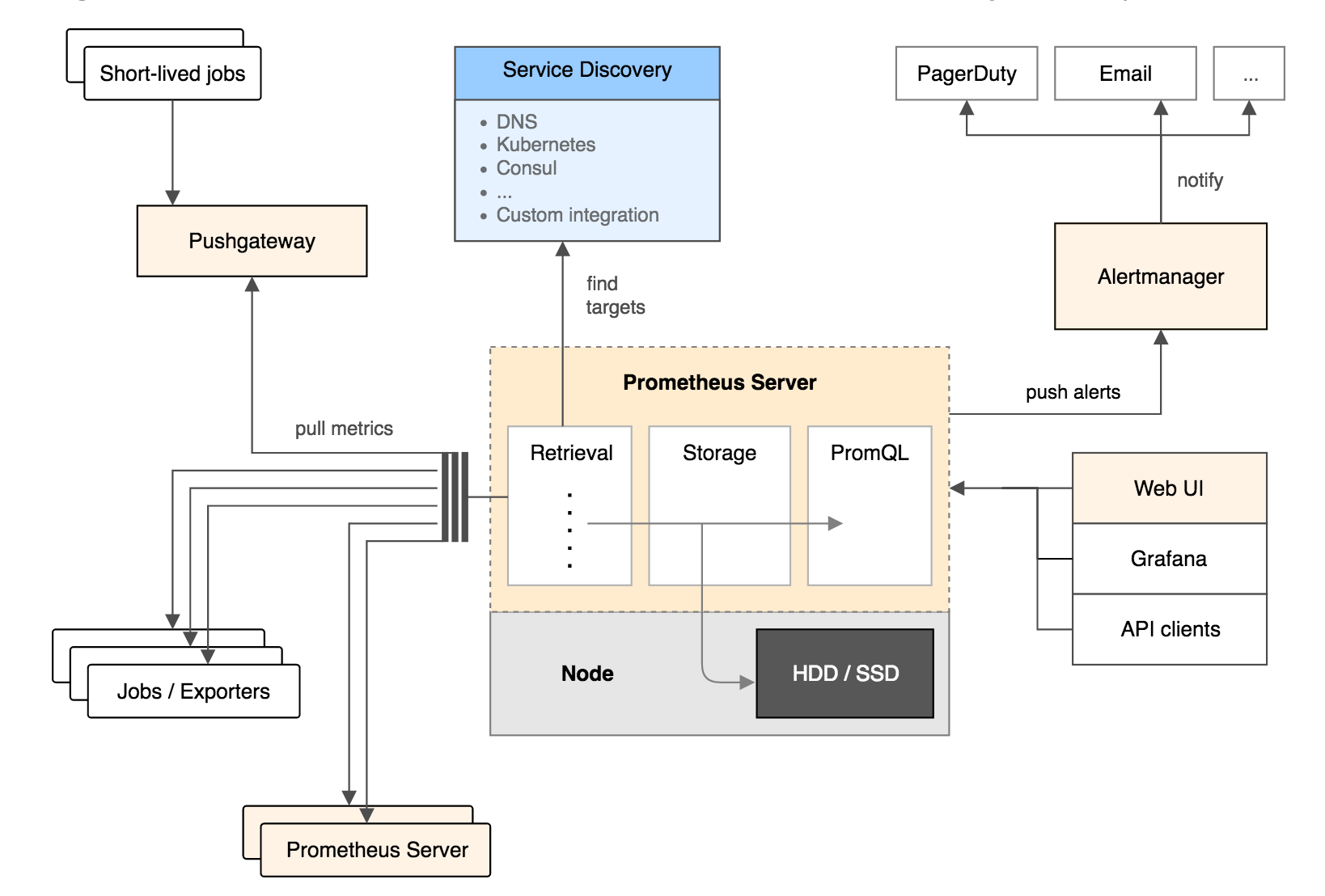
ДгЩЯЭМПЩвдПДГіЃЌPrometheus ЕФжївЊФЃПщАќРЈЃКPrometheus server, exporters,
Pushgateway, PromQL, Alertmanager вдМАЭМаЮНчУцЁЃ
ЦфДѓИХЕФЙЄзїСїГЬЪЧЃК
Prometheus server ЖЈЦкДгХфжУКУЕФ jobs Лђеп exporters жаР metricsЃЌЛђепНгЪеРДзд
Pushgateway ЗЂЙ§РДЕФ metricsЃЌЛђепДгЦфЫћЕФ Prometheus server
жаР metricsЁЃ
Prometheus server дкБОЕиДцДЂЪеМЏЕНЕФ metricsЃЌВЂдЫаавбЖЈвхКУЕФ alert.rulesЃЌМЧТМаТЕФЪБМфађСаЛђепЯђ
Alertmanager ЭЦЫЭОЏБЈЁЃ
Alertmanager ИљОнХфжУЮФМўЃЌЖдНгЪеЕНЕФОЏБЈНјааДІРэЃЌЗЂГіИцОЏЁЃ
дкЭМаЮНчУцжаЃЌПЩЪгЛЏВЩМЏЪ§ОнЁЃ
Prometheus ЯрЙиИХФю
ЯТУцНЋЖд Prometheus жаЕФЪ§ОнФЃаЭЃЌmetric РраЭвдМА instance КЭ job
ЕШИХФюНјааНщЩмЃЌвдБуЖСепдк Prometheus ЕФХфжУКЭЪЙгУжаПЩвдгавЛИіИќКУЕФРэНтЁЃ
Ъ§ОнФЃаЭ
Prometheus жаДцДЂЕФЪ§ОнЮЊЪБМфађСаЃЌЪЧгЩ metric ЕФУћзжКЭвЛЯЕСаЕФБъЧЉЃЈМќжЕЖдЃЉЮЈвЛБъЪЖЕФЃЌВЛЭЌЕФБъЧЉдђДњБэВЛЭЌЕФЪБМфађСаЁЃ
metric УћзжЃКИУУћзжгІИУОпгагявхЃЌвЛАугУгкБэЪО metric ЕФЙІФмЃЌР§ШчЃКhttp_requests_total,
БэЪО http ЧыЧѓЕФзмЪ§ЁЃЦфжаЃЌmetric УћзжгЩ ASCII зжЗћЃЌЪ§зжЃЌЯТЛЎЯпЃЌвдМАУАКХзщГЩЃЌЧвБиаыТњзуе§дђБэДяЪН
[a-zA-Z_:][a-zA-Z0-9_:]*ЁЃ
БъЧЉЃКЪЙЭЌвЛИіЪБМфађСагаСЫВЛЭЌЮЌЖШЕФЪЖБ№ЁЃР§Шч http_requests_total{method="Get"}
БэЪОЫљга http ЧыЧѓжаЕФ Get ЧыЧѓЁЃЕБ method="post" ЪБЃЌдђЮЊаТЕФвЛИі
metricЁЃБъЧЉжаЕФМќгЩ ASCII зжЗћЃЌЪ§зжЃЌвдМАЯТЛЎЯпзщГЩЃЌЧвБиаыТњзуе§дђБэДяЪН [a-zA-Z_:][a-zA-Z0-9_:]*ЁЃ
бљБОЃКЪЕМЪЕФЪБМфађСаЃЌУПИіађСаАќРЈвЛИі float64 ЕФжЕКЭвЛИіКСУыМЖЕФЪБМфДСЁЃ
ИёЪНЃК<metric name>{<label
name>=<label value>, Ё}ЃЌР§ШчЃКhttp_requests_total
{method="POST",endpoint="/api/tracks"}ЁЃ
ЫФжж Metric РраЭ
Prometheus ПЭЛЇЖЫПтжївЊЬсЙЉЫФжжжївЊЕФ metric РраЭЃК
Counter
вЛжжРлМгЕФ metricЃЌЕфаЭЕФгІгУШчЃКЧыЧѓЕФИіЪ§ЃЌНсЪјЕФШЮЮёЪ§ЃЌ ГіЯжЕФДэЮѓЪ§ЕШЕШЁЃ
Р§ШчЃЌВщбЏ http_requests_total{method="get",
job="Prometheus", handler="query"}
ЗЕЛи 8ЃЌ10 УыКѓЃЌдйДЮВщбЏЃЌдђЗЕЛи 14ЁЃ
Gauge
вЛжжГЃЙцЕФ metricЃЌЕфаЭЕФгІгУШчЃКЮТЖШЃЌдЫааЕФ goroutines ЕФИіЪ§ЁЃ
ПЩвдШЮвтМгМѕЁЃ
Р§ШчЃКgo_goroutines{instance="172.17.0.2",
job="Prometheus"} ЗЕЛижЕ 147ЃЌ10 УыКѓЗЕЛи 124ЁЃ
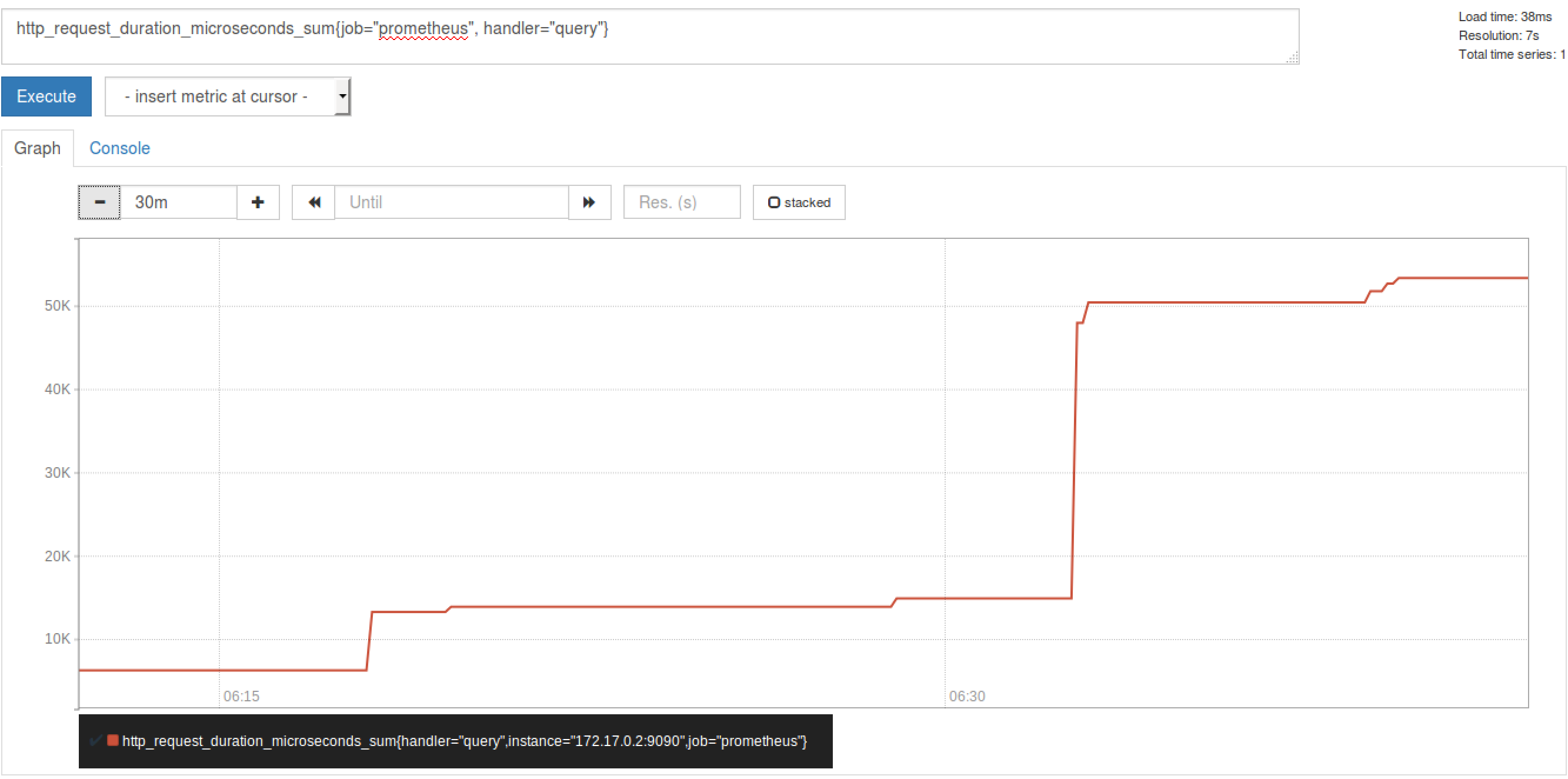
Histogram
ПЩвдРэНтЮЊжљзДЭМЃЌЕфаЭЕФгІгУШчЃКЧыЧѓГжајЪБМфЃЌЯьгІДѓаЁЁЃ
ПЩвдЖдЙлВьНсЙћВЩбљЃЌЗжзщМАЭГМЦЁЃ
Р§ШчЃЌВщбЏ http_request_duration_microseconds_sum
{job="Prometheus", handler="query"}
ЪБЃЌЗЕЛиНсЙћШчЯТЃК
ЭМ 2. Histogram metric ЗЕЛиНсЙћЭМ
Summary
РрЫЦгк Histogram, ЕфаЭЕФгІгУШчЃКЧыЧѓГжајЪБМфЃЌЯьгІДѓаЁЁЃ
ЬсЙЉЙлВтжЕЕФ count КЭ sum ЙІФмЁЃ
ЬсЙЉАйЗжЮЛЕФЙІФмЃЌМДПЩвдАДАйЗжБШЛЎЗжИњзйНсЙћЁЃ
instance КЭ jobs
instance: вЛИіЕЅЖР scrape ЕФФПБъЃЌ вЛАуЖдгІгквЛИіНјГЬЁЃ
jobs: вЛзщЭЌжжРраЭЕФ instancesЃЈжївЊгУгкБЃжЄПЩРЉеЙадКЭПЩППадЃЉЃЌР§ШчЃК
ЧхЕЅ 1. job КЭ instance ЕФЙиЯЕ
job: api-server
instance 1: 1.2.3.4:5670
instance 2: 1.2.3.4:5671
instance 3: 5.6.7.8:5670
instance 4: 5.6.7.8:5671 |
ЕБ scrape ФПБъЪБЃЌPrometheus ЛсздЖЏИјетИі scrape ЕФЪБМфађСаИНМгвЛаЉБъЧЉвдБуИќКУЕФЗжБ№ЃЌР§ШчЃК
instanceЃЌjobЁЃ
ЯТУцвдЪЕМЪЕФ metric ЮЊР§ЃЌЖдЩЯЪіИХФюНјааЫЕУїЁЃ
ЭМ 3. Metrics ЪОР§

ШчЩЯЭМЫљЪОЃЌетШ§Иі metric ЕФУћзжЖМвЛбљЃЌЫћУЧНіЦО handler ВЛЭЌЖјБЛБъЪЖЮЊВЛЭЌЕФ metricsЁЃетРр
metrics жЛЛсЯђЩЯРлМгЃЌЪЧЪєгк Counter РраЭЕФ metricЃЌЧв metrics жаЖМКЌга
instance КЭ job етСНИіБъЧЉЁЃ
Node exporter АВзА
ЮЊСЫИќКУЕФбнЪО Prometheus ДгХфжУЃЌЕНМрПиЃЌЕНБЈОЏЕФЙІФмЃЌБОЪЕР§НЋв§ШыБОЛњ ubuntu
server ЕФМрПиЁЃгЩгк Prometheus жївЊгУгкМрПи web ЗўЮёЃЌШчЙћашвЊМрПи ubuntu
serverЃЌдђашвЊдкБОЛњЩЯАВзА node exporterЁЃ Node exporter жївЊгУгкБЉТЖ
metrics Иј PrometheusЃЌЦфжа metrics АќРЈЃКcpu ЕФИКдиЃЌФкДцЕФЪЙгУЧщПіЃЌЭјТчЕШЁЃ
АВзА node export ЪзЯШашвЊДг github жаЯТдизюаТЕФ node exporter
АќЃЌЗХдкжИЖЈЕФФПТМВЂНтбЙАВзААќЃЌдкБОЪЕР§жаЃЌЗХдк /home/lilly/prom/exporters/
жаЁЃ
ЧхЕЅ 2. АВзА Node exporter
cd /home/lilly/prom/exporters/
wget https://github.com/prometheus/node_exporter
/releases/download/v0.14.0/ node_exporter-0.14.0.linux-amd64.tar.gz
tar -xvzf node_exporter-0.14.0.linux-amd64.tar.gz
|
ЮЊСЫИќКУЕФЦєЖЏКЭЭЃжЙ node exporterЃЌПЩвдАб node exporter зЊЛЛЮЊвЛИіЗўЮёЁЃ
ЧхЕЅ 3. ХфжУ node exporter ЮЊЗўЮё
vim /etc/init/node_exporter.conf
#Prometheus Node Exporter Upstart script
start on startup
script
/home/lilly/prom/exporters/node_exporter/node_exporter
end script |
ДЫЪБЃЌnode exporter вбОЪЧвЛИіЗўЮёЃЌПЩвджБНггУ service УќСюНјааЦєЭЃКЭВщПДЁЃ
ЧхЕЅ 4. ВщПД node exporter зДЬЌ
root@ubuntu1404-dev:~/alertmanager#
service node_exporter start
node_exporter start/running, process 11017
root@ubuntu1404-dev:~/alertmanager# service node_exporter
status
node_exporter start/running, process 11017
ДЫЪБЃЌnode exporter вбОМрЬ§дк 9100 ЖЫПкЁЃ
root@ubuntu1404-dev:~/prom# netstat -anp | grep
9100
tcp6 0 0 :::9100 :::* LISTEN 155/node_exporter
|
ЕБ node exporter ЦєЖЏЪБЃЌПЩвдЭЈЙ§ curl http://localhost:9100/metrics
ЛђепдкфЏРРЦїжаВщПД ubuntu server РяУцЕФ metricsЃЌВПЗж metrics аХЯЂШчЯТЃК
ЧхЕЅ 5. бщжЄ node exporter
root@ubuntu1404-dev:~/prom#
curl http://localhost:9100/metrics
ЁЁ
# HELP node_cpu Seconds the cpus spent in each
mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="guest"}
0
node_cpu{cpu="cpu0",mode="idle"}
30.02
node_cpu{cpu="cpu0",mode="iowait"}
0.5
node_cpu{cpu="cpu0",mode="irq"}
0
node_cpu{cpu="cpu0",mode="nice"}
0
node_cpu{cpu="cpu0",mode="softirq"}
0.34
node_cpu{cpu="cpu0",mode="steal"}
0
node_cpu{cpu="cpu0",mode="system"}
5.38
node_cpu{cpu="cpu0",mode="user"}
11.34
# HELP node_disk_bytes_read The total number of
bytes read successfully.
# TYPE node_disk_bytes_read counter
node_disk_bytes_read{device="sda"} 5.50009856e+08
node_disk_bytes_read{device="sr0"} 67584
# HELP node_disk_bytes_written The total number
of bytes written successfully.
# TYPE node_disk_bytes_written counter
node_disk_bytes_written{device="sda"}
2.0160512e+07
node_disk_bytes_written{device="sr0"}
0
# HELP node_disk_io_now The number of I/Os currently
in progress.
# TYPE node_disk_io_now gauge
node_disk_io_now{device="sda"} 0
node_disk_io_now{device="sr0"} 0
# HELP node_disk_io_time_ms Total Milliseconds
spent doing I/Os.
# TYPE node_disk_io_time_ms counter
node_disk_io_time_ms{device="sda"} 3484
node_disk_io_time_ms{device="sr0"} 12
ЁЁ
# HELP node_memory_MemAvailable Memory information
field MemAvailable.
# TYPE node_memory_MemAvailable gauge
node_memory_MemAvailable 1.373270016e+09
# HELP node_memory_MemFree Memory information
field MemFree.
# TYPE node_memory_MemFree gauge
node_memory_MemFree 9.2403712e+08
# HELP node_memory_MemTotal Memory information
field MemTotal.
# TYPE node_memory_MemTotal gauge
node_memory_MemTotal 2.098388992e+09
ЁЁ
# HELP node_network_receive_drop Network device
statistic receive_drop.
# TYPE node_network_receive_drop gauge
node_network_receive_drop{device="docker0"}
0
node_network_receive_drop{device="eth0"}
0
node_network_receive_drop{device="eth1"}
0
node_network_receive_drop{device="lo"}
0 |
Prometheus АВзАКЭХфжУ
Prometheus ПЩвдВЩгУЖржжЗНЪНАВзАЃЌБОЮФжБНггУЙйЭјЕФ docker imageЃЈprom/prometheusЃЉЦєЖЏвЛИі
Prometheus server, ВЂХфжУЯргІЕФОВЬЌМрПи targetsЃЌjobs КЭ alert.rules
ЮФМўЁЃ
ЦєЖЏ Prometheus ШнЦїЃЌВЂАбЗўЮёАѓЖЈдкБОЛњЕФ 9090 ЖЫПкЁЃУќСюШчЯТЃК
ЧхЕЅ 6. АВзА Prometheus
docker run -d
-p 9090:9090 \
-v $PWD/prometheus.yml:/etc/prometheus/prometheus.yml
\
-v $PWD/alert.rules:/etc/prometheus/alert.rules
\
--name prometheus \
prom/prometheus \
-config.file=/etc/prometheus/prometheus.yml \
-alertmanager.url=http://10.0.2.15:9093 |
Цфжа Prometheus ЕФХфжУЮФМў prometheus.yml ФкШнЮЊЃК
ЧхЕЅ 7. Prometheus.yml ХфжУЮФМў
global: # ШЋОжЩшжУЃЌПЩвдБЛИВИЧ
scrape_interval: 15s # ФЌШЯжЕЮЊ 15sЃЌгУгкЩшжУУПДЮЪ§ОнЪеМЏЕФМфИє
external_labels: # ЫљгаЪБМфађСаКЭОЏИцгыЭтВПЭЈаХЪБгУЕФЭтВПБъЧЉ
monitor: 'codelab-monitor'
rule_files: # ОЏИцЙцдђЩшжУЮФМў
- '/etc/prometheus/alert.rules'
# гУгкХфжУ scrape ЕФ endpoint ХфжУашвЊ scrape ЕФ targets
вдМАЯргІЕФВЮЪ§
scrape_configs:
# The job name is added as a label `job=<job_name>`
to any timeseries scraped from this config.
- job_name: 'prometheus' # вЛЖЈвЊШЋОжЮЈвЛ, ВЩМЏ Prometheus
здЩэЕФ metrics
# ИВИЧШЋОжЕФ scrape_interval
scrape_interval: 5s
static_configs: # ОВЬЌФПБъЕФХфжУ
- targets: ['172.17.0.2:9090']
- job_name: 'node' # вЛЖЈвЊШЋОжЮЈвЛ, ВЩМЏБОЛњЕФ metricsЃЌашвЊдкБОЛњАВзА
node_exporter
scrape_interval: 10s
static_configs:
- targets: ['10.0.2.15:9100'] # БОЛњ node_exporter
ЕФ endpoint |
alert ЙцдђЮФМўЕФФкШнШчЯТЃК
ЧхЕЅ 8. alert.rules ХфжУЮФМў
# Alert for
any instance that is unreachable for >5 minutes.
ALERT InstanceDown # alert Ућзж
IF up == 0 # ХаЖЯЬѕМў
FOR 5m # ЬѕМўБЃГж 5m ВХЛсЗЂГі alert
LABELS { severity = "critical" } # ЩшжУ
alert ЕФБъЧЉ
ANNOTATIONS { # alert ЕФЦфЫћБъЧЉЃЌЕЋВЛгУгкБъЪЖ alert
summary = "Instance {{ $labels.instance }}
down",
description = "{{ $labels.instance }} of
job {{ $labels.job }} has been down for more than
5 minutes.",
} |
ЕБ Prometheus server Ц№РДЪБЃЌПЩвддк Prometheus ШнЦїЕФШежОжаПДЕНЃК
ЧхЕЅ 9. Prometheus ШежО
time="2017-09-05T08:18:02Z"
level=info msg="Starting prometheus (version=1.7.1,
branch=master,
revision=3afb3fffa3a29c3de865e1172fb740442e9d0133)"
source="main.go:88"
time="2017-09-05T08:18:02Z" level=info
msg="Build context (go=go1.8.3, user=root@0aa1b7fc430d,
date=20170612-
11:44:05)" source="main.go:89"
time="2017-09-05T08:18:02Z" level=info
msg="Host details (Linux 3.19.0-75-generic
#83~14.04.1-Ubuntu SMP Thu Nov
10 10:51:40 UTC 2016 x86_64 71984d75e6a1 (none))"
source="main.go:90"
time="2017-09-05T08:18:02Z" level=info
msg="Loading configuration file /etc/prometheus/prometheus.yml"
source="main.go:252"
time="2017-09-05T08:18:03Z" level=info
msg="Loading series map and head chunks..."
source="storage.go:428"
time="2017-09-05T08:18:03Z" level=info
msg="0 series loaded." source="storage.go:439"
time="2017-09-05T08:18:03Z" level=info
msg="Starting target manager..." source="targetmanager.go:63"
time="2017-09-05T08:18:03Z" level=info
msg="Listening on :9090" source="web.go:259" |
дкфЏРРЦїжаЗУЮЪ Prometheus ЕФжївГ http://localhost:9091, ПЩвдПДЕН
Prometheus ЕФаХЯЂШчЯТЃК
ЭМ 4. Prometheus зДЬЌаХЯЂ
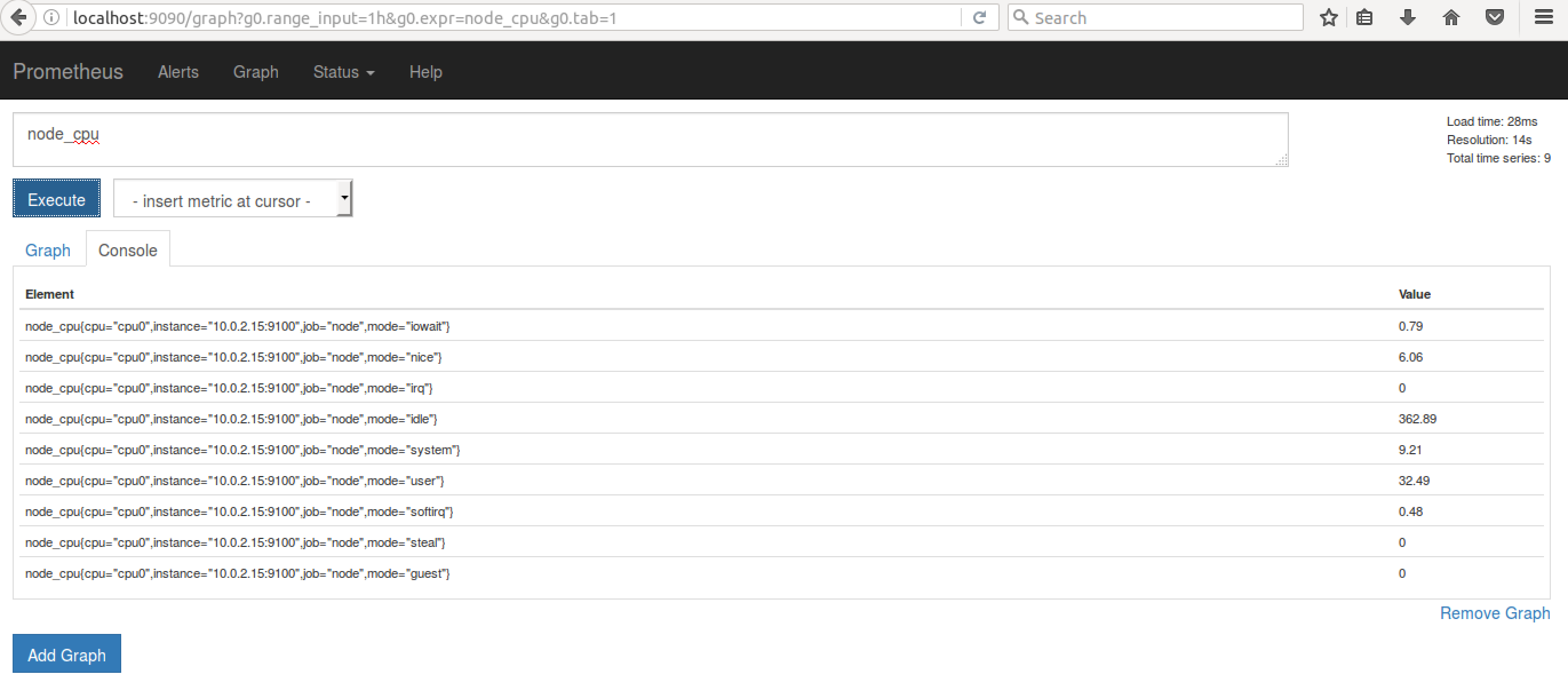
ЮЊСЫБЃжЄ Prometheus ШЗЪЕДг node exporter жаЪеМЏЪ§ОнЃЌПЩвддк Graph
вГУцжаЫбЫї metric УћзжЃЌШч node_cpu ВЂЕуЛї ExecuteЃЌПЩвддк console
жаПДЕН metric ШчЯТЁЃ
ЭМ 5. Prometheus жа metric ВщбЏНсЙћ console ЪфГіЪОР§
ЦфжаЕквЛЬѕЮЊРДзд node exporter ЕФ metricЃЌДЫЪБ ubuntu server
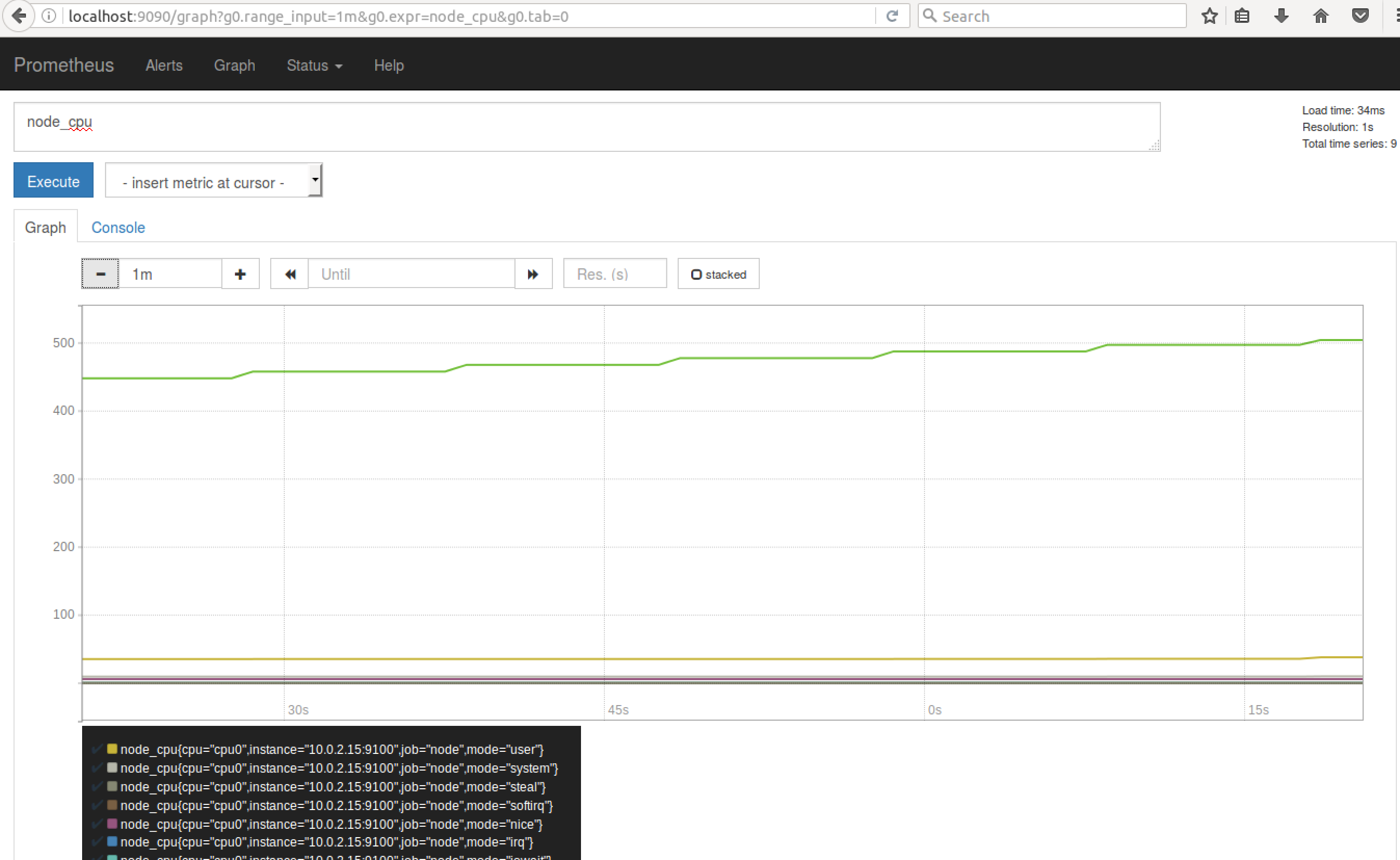
ЩЯ goroutines ЕФИіЪ§ЮЊ 13ЁЃЕуЛї Graph ПЩвдЙлВь metrics ЕФРњЪЗЪ§ОнЁЃШчЯТЭМЫљЪОЃК
ЭМ 6. Prometheus жа metric ВщбЏНсЙћ Graph ЪфГіЪОР§
Alertmanager АВзАКЭХфжУ
ЕБНгЪеЕН Prometheus ЖЫЗЂЫЭЙ§РДЕФ alerts ЪБЃЌAlertmanager ЛсЖд alerts
НјааШЅжиИДЃЌЗжзщЃЌТЗгЩЕНЖдгІМЏГЩЕФНгЪмЖЫЃЌАќРЈЃКslackЃЌЕчзггЪМўЃЌpagerdutyЃЌhitchatЃЌwebhookЁЃ
дк Alertmanager ЕФХфжУЮФМўжаЃЌашвЊНјааШчЯТХфжУЃК
ЧхЕЅ 10. Alermanager жа config.yml ЮФМў
root@ubuntu1404-dev:~/alertmanager#
cat config.yml
global:
resolve_timeout: 5m
route:
receiver: 'default-receiver'
group_wait: 30s
group_interval: 1m
repeat_interval: 1m
group_by: ['alertname']
routes:
- match:
severity: critical
receiver: my-slack
receivers:
- name: 'my-slack'
slack_configs:
- send_resolved: true
api_url: https://hooks.slack.com/services/***
channel: '#alertmanager-critical'
text: "{{ .CommonAnnotations.description
}}"
- name: 'default-receiver'
slack_configs:
- send_resolved: true
api_url: https://hooks.slack.com/services/***
channel: '#alertmanager-default'
text: "{{ .CommonAnnotations.description
}}" |
ДДНЈКУ config.yml ЮФМўКѓЃЌПЩвджБНггУ docker ЦєЖЏвЛИі Alertmanager
ЕФШнЦїЃЌШчЯТЃК
ЧхЕЅ 11. АВзА Alertmanager
docker run -d
-p 9093:9093
ЈCv /home/lilly/alertmanager/config.yml:/etc /alertmanager/config.yml
\
--name alertmanager \
prom/alertmanager
docker ps | grep alert
d1b7a753a688 prom/alertmanager "/bin /alertmanager
-c" 25 hours ago Up 25 hours
0.0.0.0:9093->9093/tcp alertmanager |
ЕБ Alertmanager ЗўЮёЦ№РДЪБЃЌПЩвдЭЈЙ§фЏРРЦїЗУ Alertmanager ЕФжївГ http://localhost:9093ЃЌЦфзДЬЌаХЯЂШчЯТЃК
ЭМ 7. Alertmanager зДЬЌаХЯЂ
дк alerts ЕФвГУцжаЃЌЮвУЧПЩвдПДЕНДг Prometheus sever ЖЫЗЂЙ§РДЕФ alertsЃЌДЫЭтЃЌЛЙПЩвдзі
alerts ЫбЫїЃЌЗжзщЃЌОВвєЕШВйзїЁЃ
ЭМ 8. Alertmanager БЈОЏвГУц
Prometheus ЪЕР§бнЪО
ЯТУцНЋЭЈЙ§вЛИіОпЬхЕФЪЕР§РДбнЪО Prometheus ЕФЪЙгУЁЃдк alert.ruels жаЖЈвхСЫ
alert ДЅЗЂЕФЬѕМўЪЧ up ЮЊ 0ЁЃЯТУцЃЌЪжЖЏЭЃжЙ node exporter ЗўЮёЁЃ
ЧхЕЅ 12. ЭЃжЙ node exporter ЗўЮё
root@ubuntu1404-dev:~/prom#
service node_exporter stop
node_exporter stop/waiting
root@ubuntu1404-dev:~/prom# service node_exporter
status
node_exporter stop/waiting |
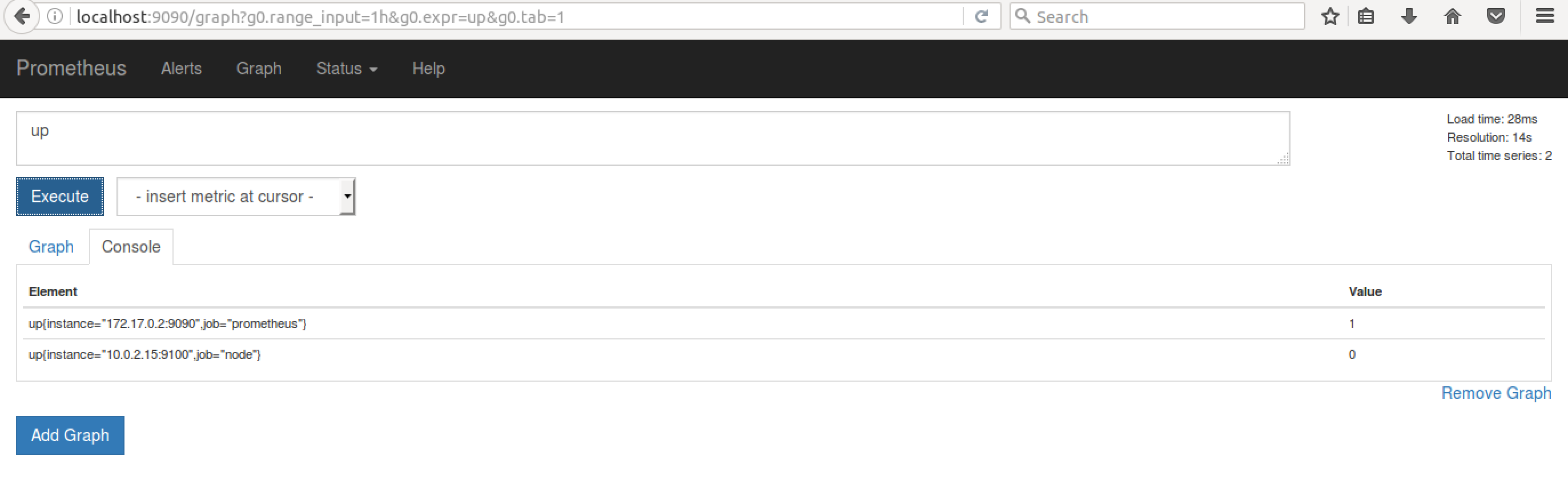
ДЫЪБЃЌPrometheus жаВщбЏ metric up,ПЩвдПДЕНДЫЪБ up{instance="10.0.2.15",job="node"}
ЕФжЕЮЊ 0ЃЌШчЯТЫљЪОЃК
ЭМ 9. Metric up ЕФЗЕЛижЕЃЈЭЃЃЉ
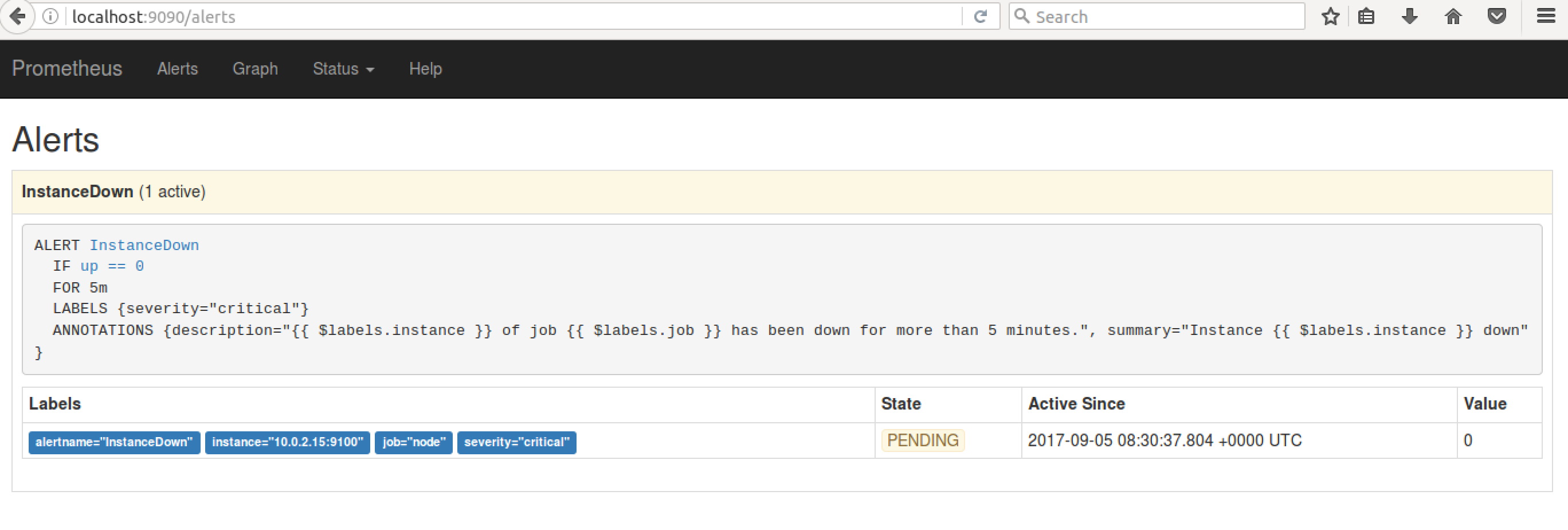
ДЫЪБЃЌAlerts вГУцжаЯдЪО InstanceDownЃЌзДЬЌЮЊ PENDINGЁЃвђЮЊ alert
ЙцдђжаЖЈвхашвЊБЃГж 5 ЗжжгЃЌЫљвддкетжЎЧАЃЌalerts ЛЙУЛгаЗЂЫЭжС AlertmanagerЁЃ
ЭМ 10. Alert Pending НчУц
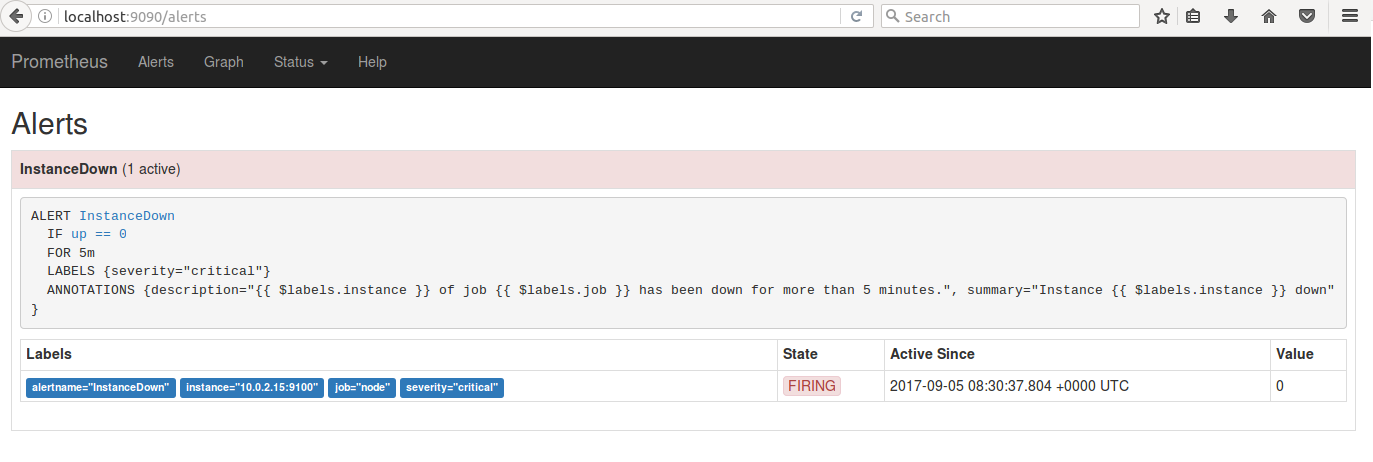
5 ЗжжгКѓЃЌзДЬЌгЩ PENDING БфЮЊ FIRINGЃЌгкДЫЭЌЪБЃЌдк Alertmanager жаПЩвдПДЕНгавЛИі
alertЁЃ
ЭМ 11. Alert Firing НчУц
ЭМ 12. Alertmanager ОЏБЈНчУц
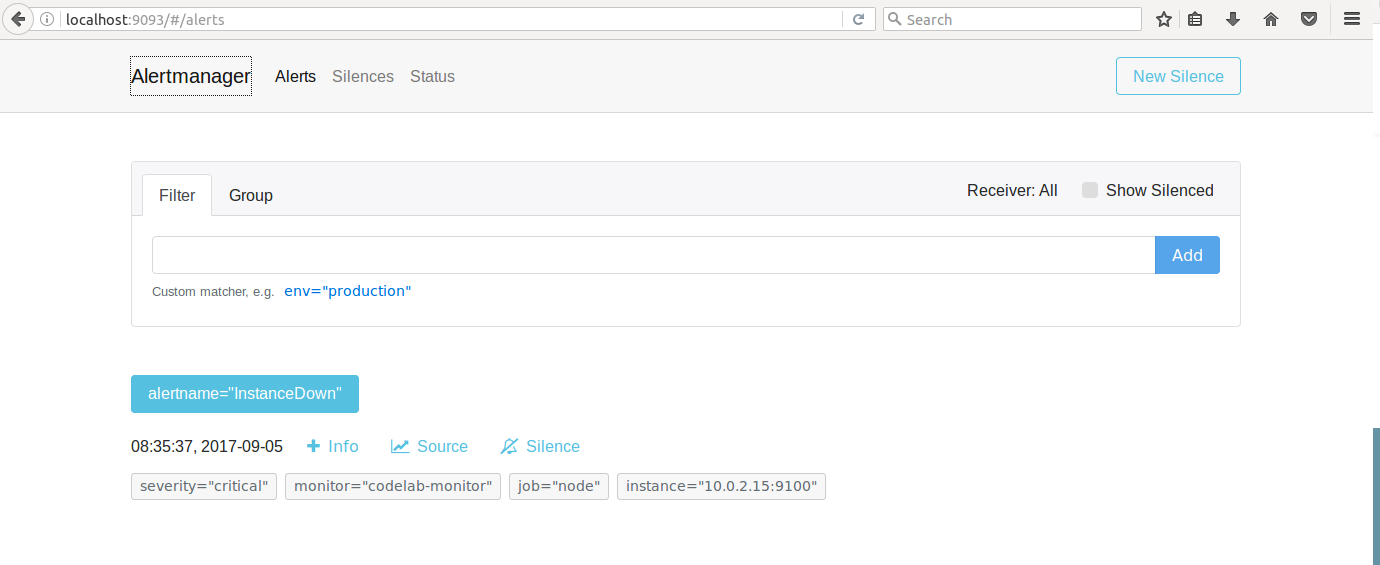
дк Alertmanager ЕФХфжУЮФМўжаЖЈвхЃЌЕГ severity ЮЊ critical ЕФЪБКђЃЌЭљ
Alertmanager-critical channel жаЗЂЫЭОЏИцЃЌЧвУПИєСНЗжжгжиИДЗЂЫЭЁЃШчЯТЭМЫљЪОЁЃ
ЭМ 13. Slack ИцОЏНчУц

гЩЩЯПЩжЊЃЌЕБФПБъЪЇАмЪБЃЌВЛНіПЩвддк Prometheus ЕФжївГЩЯЪЕЪБЕФВщПДФПБъКЭ alerts
ЕФзДЬЌЃЌЛЙПЩвдЪЙгУ Alertmanager ЗЂЫЭОЏИцЃЌвдБудЫЮЌШЫдБОЁПьНтОіЮЪЬтЁЃ
ЕБЮЪЬтНтОіКѓЃЌPrometheus ВЛНіЛсЪЕЪБИќаТ metrics ЕФзДЬЌЃЌAlertmanager
вВЛсдк slack ЭЈжЊ resolved ЕФЯћЯЂЁЃвдЯТбнЪОЮЪЬтНтОіКѓЕФЃЌPrometheus ЕФВйзїЁЃ
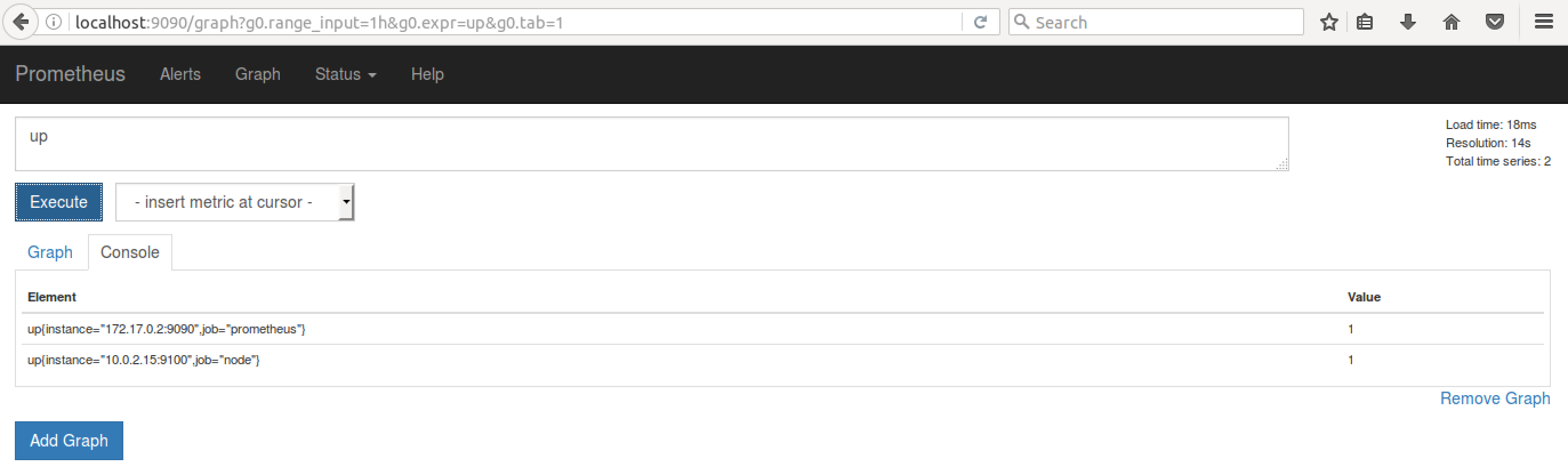
ЪжЖЏЦєЖЏ node exporterЁЃЪзЯШ metric дк Graph жаЛжИДжСе§ГЃжЕ 1ЁЃ
ЭМ 14. Metric up ЕФЗЕЛижЕЃЈЦєЃЉ
targets жаЯжЪЕ node етИі job ЪЧ up ЕФзДЬЌЁЃ
ЭМ 15. Targets НчУц
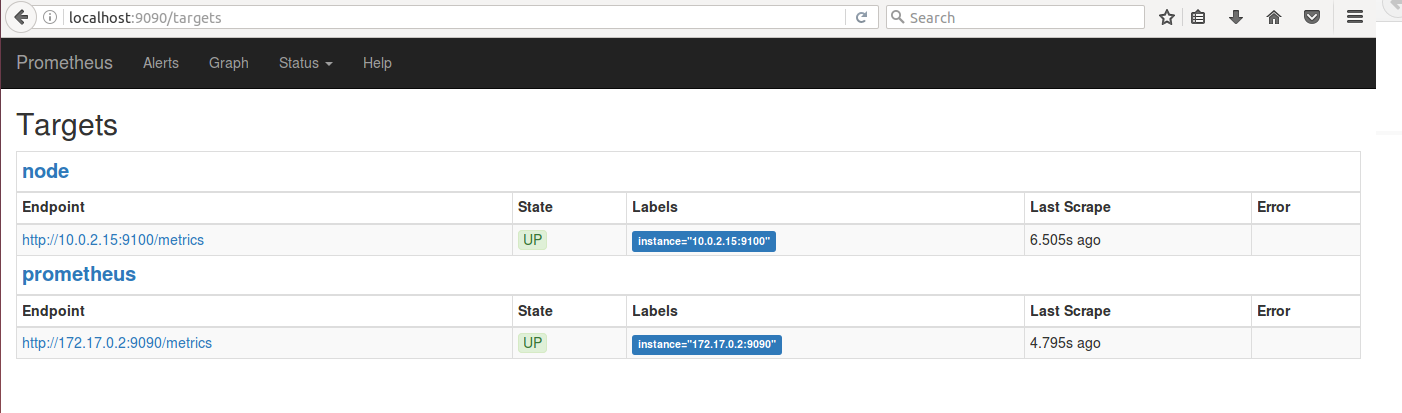
Alerts ЮЊТЬЩЋЃЌЯдЪОга 0 ИіМЄЛюЬЌЕФОЏИцЁЃ
ЭМ 16. Alers resolved НчУц
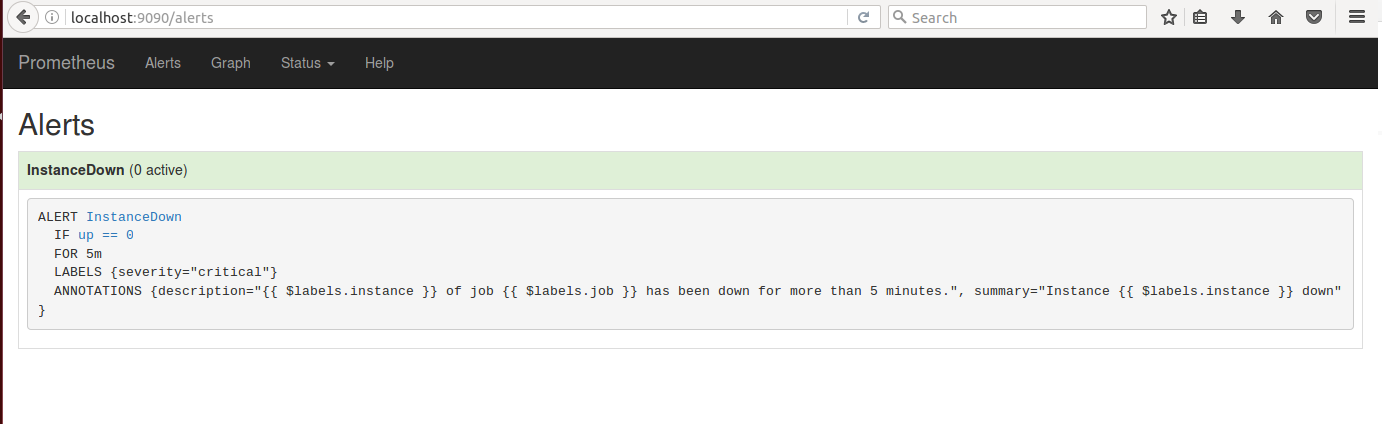
Жјдк Alertmanager ИеИеЕФ alert вВБЛЧхПеЃЌЯдЪО No alerts foundЁЃ
ЭМ 17. Alertmanager resolved НчУц
дк slack ЖЫЃЌдкЖрДЮКьЩЋ FRING БЈОЏКѓЃЌвВЪеЕНСЫТЬЩЋСЫ RESOLVED ЯћЯЂЁЃ
ЭМ 18. Slack resolved НчУц

змНс
БОЮФЖд Prometheus ЕФзщГЩЃЌМмЙЙКЭЛљБОИХФюНјааСЫНщЩмЃЌВЂЪЕР§бнЪОСЫ node exporter,
Prometheus КЭ Alermanager ЕФХфжУКЭдЫааЁЃзюКѓЃЌвдвЛИіМрПиЕФ target ЕФЦєЭЃЮЊР§ЃЌбнЪО
Prometheus ЕФвЛЯЕСаЯьгІвдМАШчКЮдк Prometheus КЭ Alertmanager жаВщПДЗўЮёЃЌОЏБЈКЭИцОЏЕФзДЬЌЁЃЖдгк
Prometheus жаИќИпМЖЕФЪЙгУЃЌШчВщбЏКЏЪ§ЕФЪЙгУЃЌИќЖрЭМаЮНчУцЕФМЏГЩЃЌЧыВЮПМЙйЗНЮФЕЕЁЃ |








