| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫећЬхдЫЮЌЦНЬЈжївЊЕФЙІФмЁЂдѕУДНЈЩшФуЕФдЫЮЌЦНЬЈЃЌГЁОАЗжЮіЁЃ
БОЮФРДздгкЙЋжкКХЁИDevOps ЪБДњЁЙЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ЧАбд
БОЮФжївЊЗжЮЊСНДѓПщФкШнЃК
ЕквЛЃЌдѕУДШЅЫМПМЮвУЧетИідЫЮЌЦНЬЈЃЌгавЛаЉНсКЯдЫЮЌздЩэЕФРэНтЃЌНсКЯвЕЮёГЁОАЕФЗжЮіЃЌАќРЈвЕНчЕФЗНЗЈТлЕФвЛаЉЫМПМЃЌНсКЯЮвУЧздЩэЕФЮЪЬтЃЌЕУГіРДЕФвЛаЉзюМбЕФЪЕМљЁЃ
ЕкЖўЃЌНщЩмвЛЯТЮвУЧећЬхдЫЮЌЦНЬЈжївЊЕФЙІФмЁЃЯЃЭћДѓМвЬ§ЮвЕквЛПщЕФЪБКђОЭжЊЕРФудѕУДНЈЩшФуЕФдЫЮЌЦНЬЈЃЌЮвКѓУцзіЕФЃЌГЁОАЮЪЬтФуУЛгаБивЊАДееЮвУЧетбљШЅЩшМЦЁЃ
дЫЮЌЕФШ§ИіНзЖЮ
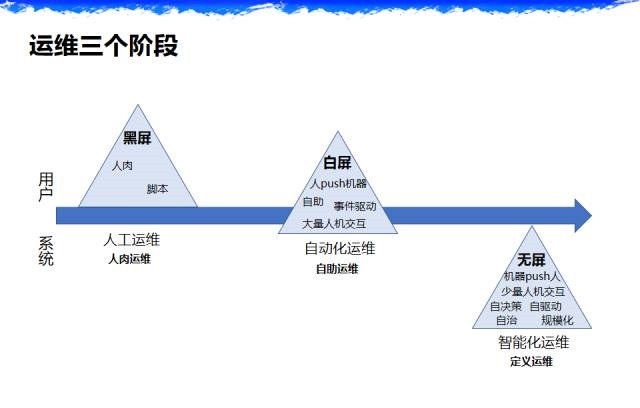
ЕквЛНзЖЮЃЌКкЦСЃЌШ§НЧаЮЮвЕФвтЫМЪЧДњБэећИідЫЮЌИјгУЛЇЕФвЛаЉЬхИаЛђепИјбаЗЂЕФЬхИаЃЌШЫЙЄдЫЮЌЃЌЦфЪЕКмЖрЦѓвЕРяУцгаПЩФмЛЙЪЧетбљЁЃ
ЕкЖўНзЖЮЃЌАзЦСЃЌЮвУЧзджњдЫЮЌЃЌвдЧААбНХБОзіГЩЙЄОпШЅХЊЃЌгаЪВУДЬиеїЃЌШЫpushЛњЦїШЅИЩЛюЃЌзджњдЫЮЌЁЃ
ЕкШ§НзЖЮЃЌгУЛЇЖддЫЮЌЬхИаКмЩйЃЌЕЋЪЧдЫЮЌетИіСьгђЪЧВЛБфЕФЁЃзюживЊЕФЪЧШЫЛњНЛЛЅБфЩйСЫЃЌЮоЦСЫфЫЕЪЧВЛПЩФмЕФЃЌЗЧГЃМЋЖЫЃЌЕЋЪЧЪЧвЛИіЧїЪЦЃЌЩйСПЕФШЫЛњНЛЛЅЃЌЫќгаздОіВпЁЂздЧ§ЖЏЁЃ
здЖЏЛЏдЫЮЌЛљДЁ
ЮвУЧзіздЖЏЛЏдЫЮЌЃЌЮвШЯЮЊгаЫФДѓЛљДЁЁЃзіетИіЪТЧщВЛзіЃЌЫќвЛжБЛсШУФуЭДЁЃ
ЕквЛЃЌдЫЮЌБъзМгыЙцЗЖ
ЮвУЧЕФБъзМгаЪВУДКУДІЃЌШУбаЗЂ follow етИіБъзМЃЌБъзМЛсдкЙЄОпРяЙЬЛЏЁЃ
ЕкЖўЃЌЗКМрПиЃЌдЫааЪБЃЌОВЬЌЃЌЪ§ОнЛЏЃЌПЩЪгЛЏ
ЗКМрПиЃЌВЛЪЧЫЕДЋЭГЕФМрПиЃЌЪЧАбЯпЩЯЯыжЊЕРЕФвЛЧаЖМЪ§ОнЛЏЃЌзюжеЪ§ОнВЛЪЧИјШЫПДЕФЃЌЪЧИјЛњЦїШЅЯћЗбЕФЃЌЪ§ОнЪЧЮвУЧЕФЩњВњзЪСЯЃЌВЛЪЧПЩЪгЛЏЃЌФЧВЛЪЧЮвУЧЕФФПБъЁЃ
ЕкШ§ЃЌCMDB
НёЬьЫЕЕУЬЋЖрСЫЃЌЗЧГЃживЊЃЌЮвЯыЛиД№СНИіЮЪЬтЃК
ЕквЛЃЌCMDB гІИУЗХЪВУДЃЌвЛАуЗХЗўЮёЦїЯрЙиЕФЁЂЭјТчЯрЙиЕФЁЂгІгУЯрЙиЕФетШ§ИіЮЌЖШЕФЯрЙиаХЯЂЁЃ
ЕкЖўЃЌОГЃгаШЫЛсЫЕ CMDB ВЛзМЃЌЪ§ОнВЛзМЪЧвђЮЊФуУЛгаАбЪ§ОнЩњВњКЭЪ§ОнЕФЯћЗбаЮГЩБеЛЗЃЌШчЙћФуаЮГЩСЫБеЛЗЃЌЪ§ОнВЛзМЃЌжЛЪЧФуВЛИвгУЃЌКмЖрШЫОЭЪЧетбљЕФЃЌвђЮЊФуЪ§ОнВЛзМЃЌЫљвдЮвВЛИвгУЁЃетВЛЪЧРэгЩЃЌФугУЃЌГіСЫЮЪЬтЃЌЪЧЫОЭИуЫЃЌCMDB
ОЭетУДИуЃЌЦфЪЕЗНЗЈКмЭСЃЌФуВЛгУетИіЪ§ОнгРдЖВЛзМЁЃ
ЕкЫФЃЌИпаЇЕФCI/CD/CD
зюКѓвЛИіЃЌЮвУЧвЛЖЈвЊОпБИПьЫйЕФНЛИЖФмСІЃЌжївЊЬхЯжетСНИіЗНУцЃЌЕквЛИіаТПЊЗЂЕФФмСІФмВЛФмПьЫйЩЯЯпЃЌЕкЖўЪЧЯыРЉШнвЛЬЈЛњЦїФмВЛФмПьЫйРЉГіРДЁЃетСНИіФмСІЮвГщЯѓГіРДЪЧШ§ИіЖЋЮїЁЃ
ГжајМЏГЩ(CI)ЃЌКмЖрШЫЫЕГжајМЏГЩЙЄОпВЛКУгУЃЌаЇТЪЕЭЃЌЦфЪЕГжајМЏГЩЕФБОжЪРяУцЪЧвЊздЖЏЛЏВтЪдЁЃШчЙћбаЗЂВПВЛОпБИздЖЏЛЏВтЪдЕФетИі
senseЃЌФуГжајМЏГЩдѕУДзіЖМЪЧЪЇАмЕФЁЃ
ГжајМЏГЩРязюживЊЕФвЛЕуОЭЪЧвЊЭЦааЮвУЧЕФВтЪдЕЅВтЁЂМЏГЩВтЪдЛЙгаЯЕЭГВтЪдЃЌЕЅВтЪЧБЃжЄздМКУЛЮЪЬтЃЌМЏГЩВтЪдЪЧБЃжЄИњЩЯгЮЯТгЮУЛЮЪЬтЃЌЯЕЭГВтЪдЪЧБЃжЄећИіЯЕЭГУЛЮЪЬтЁЃ
ГжајНЛИЖ(CD)ЃЌЯждкгаКмЖрШЫЫЕГжајНЛИЖБОжЪЪЧвЛИі PipelineЃЌCIЕФФПБъЪЧЪВУДЃЌПьЫйе§ШЗШЅДђвЛИіАќГіРДЃЌCDЕФФПБъЪЧЪВУДЃПЮвФмЙЛПьЫйАбвЛИіАќдкВЛЭЌЕФЛЗОГбщжЄЫќЪЧokЕФПЩвдЗХЕНЯпЩЯШЅЃЌетОЭЪЧГжајНЛИЖвЊИЩЕФЪТЁЃ
ГжајНЛИЖРяУцКмЙиМќЕФвЛЕуЃЌЮвУЧвЊШЅНтОіЕєЃЌОЭЪЧЫќЕФЛЗОГвЛжТадЁЂХфжУвЛжТадЁЃЛЗОГвЛжТадПЩвдгУDockerШЅНтОіЃЌDocker
ЦфЪЕБОЩэОЭЪЧвЛжжБъзМЛЏЕФЖЋЮїЁЃ
ЫљвдЫЕЕквЛЬѕгУ DockerЃЌПЯЖЈЪЧБъзМЛЏЕФЃЌСэЭтвЛИіЮЪЬтЃЌХфжУЪЧВЛЪЧвЛжТадЃЌЪЧВЛЪЧЖЏОВЗжРыЁЃ
ГжајВПЪ№(CD)ЃЌЪЧвЛжжФмСІЃЌетжжФмСІЗЧГЃживЊЃЌАбвЛИіАќПьЫйВПЪ№дкФуЯывЊЕФЕиЗНЁЃ
PSЃКГжајВПЪ№ЕФМИИіЭДЕуЁЃ
ЕквЛИіЃЌЖдФуАќЕФЮФМўЕФЗжЗЂЃЌДѓМвПЩвдПДПДЮвУЧАЂРяздМКзіЕФЃЌЪЧвЛИіЭЌбЇзіЕФвЛИіНађпђбЕФВњЦЗЃЌЫћЪЧзіСЫ
SP2PЃЌдк P2P ЕФЛљДЁЩЯМгСЫвЛИі SuperЃЌ
ЕкЖўИіЃЌЮвЕФгІгУЦєЖЏЃЌетИіЫЕЪЧЬєеНЃЌЦфЪЕЪЧЮввдЧАзіетИіВњЦЗЖдБ№ШЫЕФЬєеНЃЌКмЖргІгУЦєЖЏЕФЪБКђвЊСНШ§ЗжжгЃЌетЪЧКмгаЮЪЬтЕФЁЃ
ЕкШ§ИіЃЌЮвУЧВПЪ№Ц№РДвдКѓетИівЕЮёЪЧВЛЪЧе§ШЗЕФЃЌДѓМввЛЖЈвЊзівЛИі HealthCheckЃЌВЛЪЧЮвУЧдЫЮЌРДзіЃЌЪЧPEРДзіЃЌвЛЖЈвЊАбетИівЊЧѓЫЕГіРДЃЌжДаа
HealthCheck етИіНХБОЁЃ
дЫЮЌЯЕЭГЕФживЊЬиад
ЮвУЧЕФжаМфМўбаЗЂЙизЂЮШЖЈадЃЌЦфЖўЪЧаЇТЪЃЌЦфШ§ЪЧвзРЉеЙЃЌЪВУДЪЧжаМфМўЃЌДѓМвгІИУЖМжЊЕРЃЌдЫЮЌбаЗЂРяУцЮвЫЕЕФетСљИіЖЋЮїЃЌЦфЪЕУПвЛИіЖМЪЧЗЧГЃживЊЕФЃЌШчЙћФуУЛзіКУЃЌецЕФПЩвдв§Ц№джФбадЕФЮЪЬтЃЌЕЋЪЧЛЙЪЧЧПЕїМИИіЮвИаДЅБШНЯЩюЕФЁЃ
ЕквЛЃЌИпПЩгУ
ЮвУЧдкзіЭЌГЧШнджбнСЗЕФЪБКђЃЌЮвАбЭјвЛЧаЃЌНсЙћЗЂЯждЫЮЌЯЕЭГЙвСЫЃЌОШУќЕФЖЋЮїУЛгаСЫЃЌдѕУДИуЃЌЕБШЛетжжЧщПіЮвУЧУЛгаЗЂЩњЙ§ЁЃЫљвдЫЕЮвУЧЕФдЫЮЌЯЕЭГвЛЖЈвЊЪЧИпПЩгУЃЌВЛвЛЖЈЪЧИпВЂЗЂЁЃ
ЕкЖўЃЌУнЕШад
УнЕШадЪЧЗжВМЪНЯЕЭГЩшМЦжаЪЎЗжживЊЕФИХФюЃЌетИівВЗЧГЃживЊЁЃ
ЕкШ§ЃЌПЩЛиЙі
етИіЪЧЮвУЧзідЫЮЌзюЛљБОЕФвЛИі senseЃЌФузіЕФШЮКЮВйзїЪЧВЛЪЧПЩПиЕФЃЌДѓМвзюНќжЊЕРКмЖрЙЪеЯЃЌАќРЈбЧТэбЗЕФЃЌЦфЪЕЖМЪЧвЛИіаЁЕФЮѓВйзїЁЃЮвУЧШчЙћеце§зіПЩЛиЙіЃЌЦфЪЕЪТЧщУЛгаетУДИДдгЁЃ
ЕкЫФЃЌИпаЇТЪ
ШчЙћФуЕФЦѓвЕЗЂеЙЗЧГЃПьЫйЃЌФуЕФЙцФЃадаЇгІвбОРДСЫЃЌФуЕФдЫЮЌЯЕЭГвЛЖЈвЊОпБИКмИпаЇТЪЃЌжївЊЬхЯждкЪВУДЕиЗНЃЌЦфЪЕдЫЮЌКмЖрЕиЗНВЛвЛЖЈвЊЧѓаЇТЪЗЧГЃИпЃЌЕЋЪЧгаМИИіЕиЗНвЊЧѓЗЧГЃИпЃЌПьЫйРЉШнЁЂПьЫйВПЪ№етИіаЇТЪЮвУЧвЊзЗЧѓМЋжТЁЃ
баЗЂЖЈвхдЫЮЌЃЌХфжУЧ§ЖЏБфИќ
ЦфЪЕЮвУЧгаЪБКђзіОіВпзюРЇФбЕФЪЧаХЯЂВЛЖдГЦЃЌШчЙћЮвШЅГДЙЩЃЌХдБпзјИізЈМвИњЮвГДЃЌШчЙћЮвжЊЕРФкФЛЯћЯЂЃЌЫћЫРЛюГДВЛгЎЮвЁЃ
вђЮЊЮвжЊЕРФкФЛЃЌОЭжЊЕРУїЬьвЊЪеЙКЃЌетОЭЪЧаХЯЂВЛЖдГЦЃЌЮвУЧНёЬьЕФЦѓвЕЃЌаХЯЂВЛЖдГЦЃЌВПУХгыВПУХжЎМфЃЌзгЙЋЫОжЎМфЃЌАќРЈЯЕЭГгыЯЕЭГжЎМфЃЌаХЯЂДѓВПЗжВЛЖдГЦЃЌетУДЖрВЛЖдГЦЃЌФугжВЛжЊЕРФуЕФЯжзДЃЌФугжВЛжЊЕРФуЕФФПБъЁЃ
етИіЪЧ2015Фъ11дТ4КХЃЌФЧИіЪБКђЫЋЪЎвЛИеИеИуЭъЃЌЮвШЅЫМПМЃЌОЭЪЧЮвЯызівЛжжФмСІЃЌетИіЕЙЯТЕФШУЫќОйЦ№РДЃЌетИіФмСІАбЫќИуЦ№РДЃЌОЭЪЧВЛЕЙЮЬдРэЃЌЮвЯыЕНетбљЕФМмЙЙЁЃ
ДгзюЯТУцНВЃЌетЪЧЮвУЧЛљДЁЩшЪЉЃЌЬсЙЉШ§жжФмСІЃЌМЏЩЂЁЂДцДЂЁЂЭјТчЁЂЮоТлФуЪЧдѕУДбљИуЃЌОЭЪЧЬсЙЉетШ§жжФмСІЁЃДггвЯТНЧЕФЮЛжУЩЯЃЌЮвЯШЛЕФЪЧвЛИіЗКМрПиЃЌЫќЛсжЊЕРЯЕЭГЁЂгІгУЕШЕШЃЌЮвАбЫќХдБпБъСЫвЛИізжЃЌЯжзДЃЌЮввЊЭЈЙ§етИіЯжзДАбЯпЩЯЕФЯЕЭГШЋВПЪ§ОнЛЏЃЌШЛКѓЮвЗХЕНОіВпжааФЁЃ
зѓЩЯНЧга CMDBЃЌЮвУЧЯждкКмЖрБфИќЯЕЭГЃЌКмЖрЧПЕїСїГЬЃЌЫЕЪЕдкЕФЃЌЦфЪЕЮвБОШЫЪЧзібаЗЂГіЩэЕФЃЌЮвЗЧГЃЕжДЅСїГЬЃЌСїГЬВЛЪЧвЛИіаЇТЪЙЄОпЃЌЫќЪЧзшАаЇТЪЕФЁЃ
ЮвжИЕФСїГЬОЭЪЧЫЕЃЌЮвУЧЙЪеЯИуЭъвдКѓОЭЪЧвЛЖбЕФСїГЬЃЌСїГЬЗЧГЃзшАаЇТЪЃЌЪЧжЪСППижЦЕФвЛИіЙЄОпЁЃСїГЬВЛЪЧВЛвЊЃЌЪЧАбСїГЬзіЕНЯЕЭГРяУцШЅЃЌШУЯЕЭГШЅАяШЫзіОіВпЃЌЖјВЛЪЧШЫдкФЧРяЕуЃЌЬьЬьДђИіЕчЛАШУФуШЅЕуЃЌШЛКѓЮвУЧЛЙвЊзіЕНЪТКѓЩѓМЦЁЃ
CMDB ЖЈвхСЫЮвИеВХЫЕЕФФПБъЃЌЮвЕФЯжзДЭЈЙ§МрПиФУЕНСЫЃЌФПБъвВжЊЕРСЫЃЌетИіЪБКђФуОѕЕУетИіЪТЧщКмИДдгТ№ЃЌЮвШЯЮЊетПДФудѕУДШЅзіЃЌШчЙћФуЯызіГЩШЫЙЄЛЙЪЧзіГЩздЖЏЛЙЪЧзіГЩжЧФмЃЌЖМШЁОігкетИіЕиЗНЁЃ
ЫљвдЮвУЧжЧФмРявЛЖЈвЊОпгаЪ§ОнЕФЃЌФужЊВЛжЊЕРФуЕФФПБъЪЧЪВУДЃЌЫљвджЧФмЖдДѓМвРДЫЕОЭЪЧЮвЫЕЕФОіВпжааФРяИУИЩЕФЪТЧщЃЌАбФПБъЕФЪ§ОнФУЕНСЫЃЌОЭФмПьЫйНјааОіВпЁЃ
ЫЕИізюМђЕЅЕФР§згЃЌЭЈЙ§жЧФмЗжЮіГіФПБъзДЬЌЪЧЪЙетИігІгУга100ИіVMЃЌЕЋЪЧЯждкзДЬЌжЛга80ИіЃЌвЛПДетСНИіВЛвЛбљЃЌвЊРЉШн20ЬЈЃЌШчЙћЯЕЭГзіЕУИќжЧФмвЛЕуЃЌЭЈЙ§ЭМЩЯзѓБпЕФЪТМўжааФЬсЪОЮв20ЬЈИКдиНЯЧсЕФЗХдкФФЃЌОЭПЩвдЕїЖШЙ§ШЅЃЌШЛКѓШЅзіжДааБфИќЁЃ
ЮвЛљгкетаЉЖЋЮїЕУГіРДСНИіНсТлЃЌЁАбаЗЂЖЈвхдЫЮЌЁБЃЌЁАХфжУЧ§ЖЏБфИќЁБЁЃ
ЮЊЪВУДЪЧбаЗЂЖЈвхдЫЮЌЃП
Ювдк2015Фъ11дТЪБЫЕбаЗЂЖЈвхдЫЮЌЃЌЮвШЁСЫИіУћзжЃЌDDOЃЌЮЊЪВУДЪЧбаЗЂЖЈвхдЫЮЌЃЌбаЗЂзюЬљНќвЕЮёЃЌзюгІИУЧхГўетИівЕЮёгІИУОпБИЪВУДбљЕФФмСІЃЌЫљвдЫЕжЛгабаЗЂВХФмЙЛжЊЕРетИівЕЮёKPSгІИУЪЧЖрЩйЃЌЮвКѓУцЛЙЛсНВШЅзіШнСПдЄВтЕШЕШетаЉЪТЧщЃЌЕЋЪЧвЛАуРДЫЕЃЌЫќЕФФПБъзДЬЌЪЧбаЗЂЛсШЅЫЕЕФЃЌетЪЧЮветИіЗўЮёЩЯРДЬсЙЉЖрЩйЕФЗўЮёФмСІЁЃ
ЮЊЪВУДЪЧХфжУЧ§ЖЏБфИќ?
ХфжУОЭАбФПБъИФБфвЛЯТЃЌФуЫцБуИњЮвЫЕвЛИідЫЮЌГЁОАЃЌЮвПЩвдИјФудкетИіЭМРяУц run Ц№РДЃЌЮвУЧХфжУжЛашвЊИФФуЕФФПБъзДЬЌЃЌЮвАбФуЕФзДЬЌ10VM
БфГЩ15ИіVMЁЃетОЭЪЧЮвЫЕЕФбаЗЂЖЈвхдЫЮЌЃЌХфжУЧ§ЖЏБфИќЃЌЧАвђКѓЙћЕФЫМПМОЭЪЧетбљЕФЁЃ
дЫЮЌЙЄОпгыЗНЗЈТл
ОЋвцЗЂЯжМлжЕ
ЮвПДЕНЕФзюДѓЕФИаДЅЪЧМлжЕЃЌМлжЕРДдДгкгУЛЇЕФашЧѓЃЌЮвУЧМлжЕКмЖрЪБКђЪЧРДдДгкздМКЕФYYЃЌЮвУЧЕФМлжЕРДдДгкгУЛЇЁЃ
ОЋвцЖдЮвзюДѓЕФИаДЅОЭЪЧЮвУЧвЊЗЂЯжМлжЕЁЃЮвЗЂЯжСЫМлжЕЃЌЮвУЧзіЕФФПБъЃЌКмЖрШЫдкЖЈ KPI ЕФЪБКђИњЮвНВЮвзіСЫ
AЁЂBЁЂCЁЂD ЙІФмЃЌЮвЫЕШ§ИізжЃЌШЛКѓФиЃП
ЮЊЪВУДвЊв§Шы DockerЁЂkubernetesЁЂJenkinsЃПФужЊЕРЯждкЕФЭДЕуЪЧЪВУДТ№ЃПШчЙћФуВЛФмОЭВЛвЊзіетаЉЖЋЮїЃЌЮвУЧЭљЭљПДБ№ШЫЪЧПДЕУзюЧхГўЕФЃЌПДздМКПДЕУВЛЧхГўЁЃ
НёЬьвВгаШЫЮЪЮвЃЌDevOps ЭХЖгЪЧИУВ№ЛЙЪЧИУКЯЃЌЮвЫЕФуУцЖдЪВУДбљЕФЮЪЬтФужЊВЛжЊЕРЃЌФуЫМПМЙ§УЛгаЃЌФуЕФЮЪЬтгХЯШМЖЪЧЪВУДЃЌШчЙћжЛИјФуНтОівЛИіЮЪЬтЪЧФФИіЃЌвВаэВЂВЛЪЧ
DevOps ЭХЖгВ№ВЛВ№ЕФЮЪЬтЁЃ
ОЋвцЫМЯыЃЌЪВУДЖЋЮїЪЧгаМлжЕЕФЃЌФмЙЛЖдгУЛЇДјРДЮяжЪЩЯЕФЛђепЩэЬхЩЯЕФгфдУЕФЖЋЮїОЭЪЧгаМлжЕЕФЁЃ
УєНнНЛИЖМлжЕ
УєНнвВЪЧЖдЮвгАЯьКмЖрЕФЃЌКмЖрШЫЬИУєНнЃЌЮвЭХЖгРявВИуУєНнЃЌУєНнетжждЫЖЏетжжЗНЗЈЪЧЗЧГЃППЦзЕФЃЌЫќЪЧвЛЯЕСаЕФЗНЗЈТлЁЃЕЋЪЧдкФув§ШыЕФЪБКђЃЌЧЇЭђвЊзЂвтЃЌБ№ШЫааЕФЖЋЮїФуВЛвЛЖЈааЃЌФуашвЊЕФЖЋЮїВЂВЛвЛЖЈЪЧУєНнЁЃ
УєНнРяУцЃЌЮвУЧПьЫйШЅНЛИЖМлжЕЃЌдкв§ШыУєНнЕФЪБКђЃЌвЛЖЈвЊПДЃЌвђЭХЖгЖјвьЃЌИњЭХЖгЕФГЩЪьЖШВЛвЛбљЃЌЫќЕФЗНЗЈвВВЛвЛбљЃЌШчЙћвЛИіЗЧГЃГЩЪьЕФЭХЖгЃЌШЮКЮИњЫћНВЖМЪЧгАЯьЫћаЇТЪЕФЁЃ
ШчЙћвЛИіВЛГЩЪьЕФЭХЖгЃЌФуОЭвЊИцЫпЫћЃЌвЛПЊЪМЦєЖЏЛсвщЃЌШЛКѓеОЛсЃЌбЯИёАДзХетИіЖЏзїРДЁЃЮфЙІзюИпОГНчгаСНжжЃЌвЛЙВЪЧЬьЯТЮфЙІЮЈПьВЛЦЦЃЌЛЙгавЛжжЪЧЮоеаЪЄгаеаЃЌБ№ШЫзіетИіЪТЧщЖзТэВНСЫМИЪЎФъЃЌФуЩЯРДОЭЫЕЮоеаЪЄгаеаЁЃУєНнРяЮвУЧвЊаЮГЩвЛИіЛЗЃЌГжајЗДРЁЁЃ
OODAЛЗ
OODA ЛЗЃЌвЛЖЈвЊаЮГЩЛЗЁЃЮвПДСЫетаЉЖЋЮїЃЌЮвЫљПДЕНЕФЖЋЮїЪЧЪВУДЃЌОЭЪЧаЮГЩБеЛЗЃЌШУМлжЕПьЫйСїЖЏЁЃ
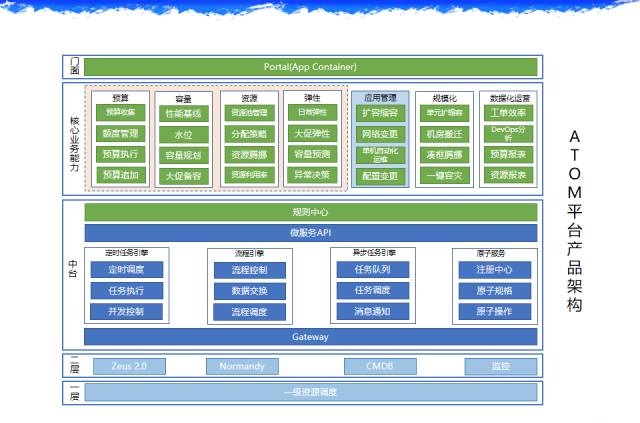
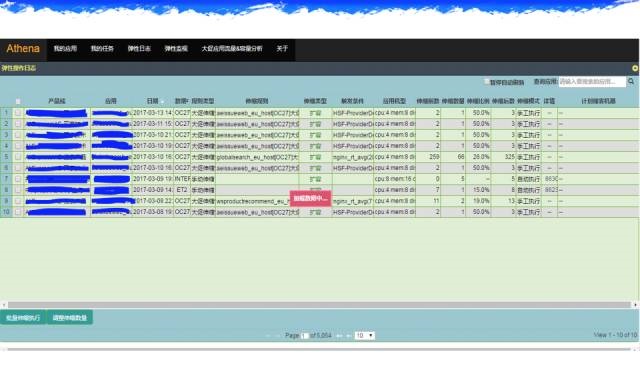
гІгУдЫЮЌЦНЬЈATOM
етЪЧМмЙЙЭМЃЌвђЮЊФуЕФЦѓвЕПЩФмВЛвЛбљЃЌЮвУЧетИіЯЕЭГУПвЛИіаЁПщПЩФмОЭЪЧвЛИіЯЕЭГЁЃ
ЮвУЧЕФЛљДЁЩшЪЉЪЧвЛВуЃЌЖўВуЪЧдЫЮЌжаЬЈЃЌзюЩЯУцвЛПщЪЧвЊзіЕФ PaaS ЦНЬЈЃЌетИіЦНЬЈЮвЗжСЫМИВНЁЃ
ЕквЛПщЃЌдЄЫуЁЂШнСПЁЂзЪдДЁЂЕЏад
етаЉЖЋЮїМгдквЛЦ№ЪЧИЩЪВУДЃЌЦфЪЕОЭЪЧвЊШУзЪдДПьЫйСїЖЏЦ№РДЃЌСїЯђе§ШЗЕФЗНЯђРДВњ ЩњМлжЕЃЌФуЕФзЪдДШчЙћГЃФъВЛдіВЛМѕЃЌетЪЧгаЮЪЬтЕФЁЃетИідкЮвЕФ
PaaS ЦНЬЈЪЧЗЧГЃживЊЕФвЛПщЃЌФПЕФОЭЪЧШУФуЕФзЪдДПьЫйСїЖЏЦ№РДЁЃ
ЕкЖўПщЃЌгІгУЙмРэ
ЮвУЧвЊзіШеГЃЕФВйзїЃЌетИіЖЋЮїШЋВПЪЧШУбаЗЂШЅзіЃЌОЭВЛШЅзіСЫЁЃетЪЧЙцФЃЛЏЃЌАЂРяЕФГЁОАКмДѓЃЌвЊПьЫйЖдвЛИіЕЅдЊНЈеОЁЂРЉШнЁЂЫѕШнЁЃ
ЕкШ§ПщЃЌЪ§ОнЛЏдЫгЊ
вЛЖЈвЊНВЪ§ОнЃЌЪ§ОнвЛЖЈВЛЪЧПЩЪгЛЏГіРДвЛаЉБЈБэЃЌвЛЖЈвЊИјНсТлЃЌИцЫпгУЛЇФуетИіЪ§ОнЭъСЫвдКѓгІИУЪЧЪВУДЁЃЙцдђжааФЪЧЪВУДЃЌОЭЪЧЮвУЧЫљгадЫЮЌЭЌбЇШеГЃЕФдЫЮЌОбщЕФГСЕэЃЌФудкЯпЩЯЯЃЭћЪЧЪВУДбљзгЕФЃЌгІИУАбФуЕФОбщШЋВПЙЬЛЏЕНЙцдђжааФШЅЁЃ
ХњСПЬкХВЙЄОп 
етИіЙЄОпВЛЖЈЫљгаШЫЖМашвЊЃЌПЩвдНтОіЪВУДЮЪЬтЃЌЛњЗПЕФАсЧЈЃЌДеПђЧЈвЦЁЃ
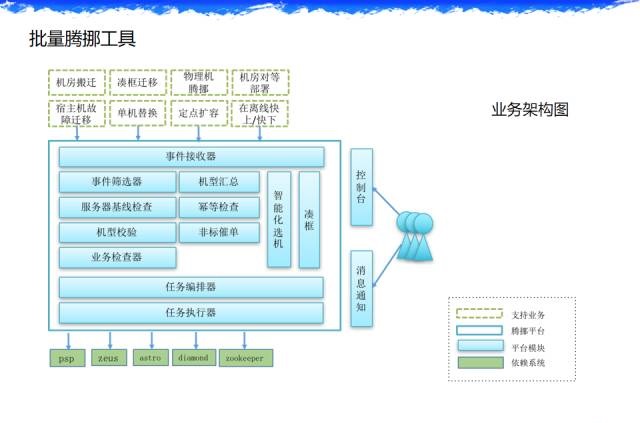
ЮвУЧЛЙзіСЫЕЅЛњБеЛЗЃЌетЪЧЬкХВЙЄОпЕФЙиМќЃЌШчЙћЦѓвЕЗЂЩњСЫвЛЖЈЙцФЃЃЌетИіЖЋЮївЛЖЈЪЧЛсашвЊЕФЁЃ
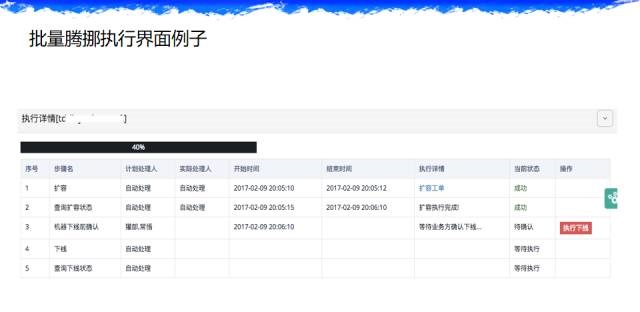
ЕЏадЩьЫѕЙЄОп 
ШЛКѓЪЧЕЏадЩьЫѕЃЌОЭЪЧЮвУЧЕФОіВпжааФЃЌНтОіЪВУДЭДЕуЃЌШУФуЕФзЪдДСїЖЏЦ№РДЕФОіВпЃЌЫќОіЖЈФуЕФзЪдДдѕУДШЅСїЃЌЭљФФИіЕиЗНСїЃЌетИіЖЋЮїЗЧГЃЙиМќЁЃ

зюКѓЫќвВЪЧЫЕдЫЮЌСьгђРяУцММЪѕКЌСПзюЩюЕФвЛИіЕиЗНЃЌвЊИуЛњЦїбЇЯАЁЂЩюЖШбЇЯАЁЂЧПЛЏбЇЯАЕШЕШЃЌЫуЗЈвЛЖбЕФЖЋЮїЃЌЮвУЧдкетРяШЅХЊЁЃ
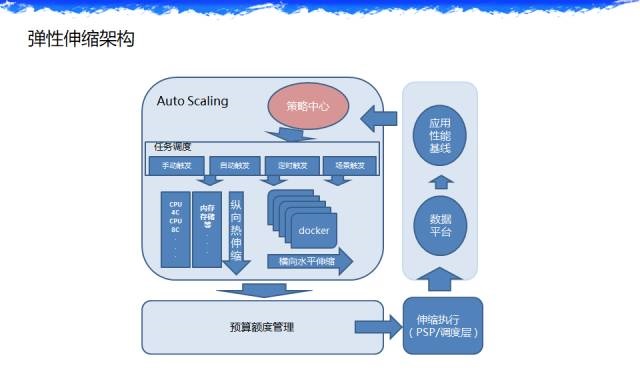
ЕЏадЦНЬЈжївЊНтОіЪВУДЮЪЬтЃЌетЪЧЮвУЧЕФМмЙЙЃЌетИіЦНЬЈВЛвЛЖЈКмЖрЦѓвЕЖМашвЊЃЌЕЋЪЧЮвЯыНВИігІгУГЁОАОЭЪЧдкЫЋЪЎвЛЕФЪБКђЪЧдѕУДгУЕФЁЃ
ЮвУЧНЈвЛИіеОЕуЦ№РДжЛга5000ЕФНЛвзФмСІЃЌПЩвдЭЈЙ§10ЗжжгЪБМфШУЫќОпга30000ЭђЕФФмСІЃЌПьЫйОіВпЃЌПьЫйЕїЖЏЦ№РДЁЃЕЏадРяУцОЭЪЧвЛИі
OODA ЛЗЃЌФУЫћЕФЪ§ОнЃЌИњгІгУМЋЯозіБШНЯЃЌЕУГіРДвЛИіВпТджааФЁЃ
ЕЏадвЛАугаЫЎЦНЩьЫѕЁЂДЙжБЩьЫѕЃЌЖдЯпЩЯШЅзіЙмРэЃЌЕБШЛЮвУЧгаЖюЖШЃЌетЪЧБШНЯОЋЯИЛЏЕФЙмРэЃЌНёЬьПЩФмУЛФЧУДЖрЪБМфЗжЯэЁЃЕЏадгаЙлВьепФЃЪНЛЙгаздЖЏЛЏжДааЃЌУПДЮЕЏадЭъвдКѓгавЛИіПижЦЬЈЃЌвђЮЊЫЋЪЎвЛзіШЋФъбЙВтЕФЪБКђвЛАуЧщПіЯТВЛПДетИіЖЋЮїЁЃ

ЮвИеВХНВЕФКмЖрЖЋЮїЃЌУЛгаЫЕдѕУДзіГЩБОЃЌдѕУДзіаЇТЪЃЌЕШЕШетаЉЖЋЮїЃЌЕЋЪЧЮвУЧзіСЫетаЉЪТЧщЃЌЕФШЗЪЧЮЊЙЋЫОЪЁСЫЧЎЃЌДјРДвЛаЉЪевцЁЃ
ЮвУЧЕФеЙЭћЃЌPE зЊаЭвдКѓЃЌЮвУЧЪЧЯЃЭћШУбаЗЂРДЪЙгУЮвУЧЕФдЫЮЌЃЌНЕЕЭЫћдЫЮЌЕФИДдгЖШЃЌНЕЕЭдЫЮЌЕФУХМїЃЌЮвУЧЪЧЭЈЙ§ЯЕЭГЛЏЕФЗНЪНРДзіЃЌбаЗЂжЛашвЊАбЫћЕФФПБъаДГіРДЃЌШУдЫЮЌетИіЖЋЮїЯёЩНвЛбљГСЯТШЅЃЌИажЊВЛЕНЁЃ
ШЛКѓЪЧзЪдДЕФБеЛЗЁЃЙцФЃЛЏЃЌЯждкPEзіСНДѓПщЃЌЕквЛЪЧЙцФЃЛЏдЫЮЌЃЌШЛКѓЪЧЕЅгІгадЫЮЌЃЌКмЖрШЫРэНтАбЯпЩЯЯЕЭГЗЂВМЕНЯпЩЯШЅЃЌРЉШнМИЬЈЃЌетОЭЪЧЕЅгІгУдЫЮЌЁЃЦфЪЕЮвУЧгІгУЕФРЖКЃЪЧЙцФЃЛЏдЫЮЌЃЌетЛсЩцМАЕНЗНЗНУцУцЕФЪТЧщЁЃ
аЁНс
БОЮФНВЕФЫФЬѕЃЌЯЃЭћДѓМвецЕФФмЙЛРэНтЃК
ЪзЯШЃКЮЊЪВУД CMDB КмживЊЃЌЮЊЪВУДМрПиКмживЊЃЌЮЊЪВУДБъзМКмживЊЃЛ
ЕкЖўЃКбаЗЂЖЈвхдЫЮЌЃЌХфжУЧ§ЖЏБфИќЃЌетЪЧЮвУЧзіетИіЯЕЭГЕФвЛИізюЛљДЁЕФРэФюЃЛ
ЕкШ§ЃКЛљгкФПБъЙмРэЃЌФуВњЦЗгаУЛгаРэФюЃЌШчЙћУЛгаЃЌЮвШЯЮЊетжЛЪЧЙІФмЕФЖбЦіЃЛ
ЕкЫФЃКаЮГЩБеЛЗЃЌШУзЪдДСїЖЏЦ№РДЃЌШУФуЕФ CMDB РяЕФЪ§ОнСїЖЏЦ№РДЃЌШУФуЕФзЪдДСїЖЏЦ№РДЁЃ |








