| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫдЫЮЌНјНзЁЂвЛЬхЛЏдЫЮЌЦНЬЈЁЂжиЕуНщЩмвЛЯТ
DataOps ЪЕМљЁЂзюКѓвЛВПЗжЪЧдк AIOps ЗНЯђЕФЬНЫїЕШЯрЙиФкШнЁЃ
БОЮФРДздгкЫбКќЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|

1. дЫЮЌНјНз
дЫЮЌЕФНзЖЮПЩФмКмЖрГЁКЯКмЖрШЫЖМНВЙ§ЃЌЕЋетРягавЛЕуВЛвЛбљЃЌДгШЫШтдЫЮЌЕНздЖЏЛЏдЫЮЌЃЌдйЕН AIOps
жаМфгІИУЛЙгаИіЙ§ЖЩНзЖЮЃЌЕБШЛДѓМввВПЩвдАбЫќРэНтЮЊ AIOps ЕФГѕМЖНзЖЮЁЃ
ФЧетИіКЭ AIOps жЎМфЕФЧјБ№ЪЧЪВУДЃПDataOps ДгРэТлЩЯРДНВвВЪЧвЛбљЃЌжївЊвРОнгкЪ§ОнМгИїжжЫуЗЈФЃаЭФмЙЛИјГівЛИіБШНЯжЧФмЕФНсЙћЁЃЫќЯрБШ
AIOps ИќЖрЪЧдкгкЫќИјГіЕФНсЙћЪЧвЛИіИЈжњОіВпЕФзїгУЃЌОЭФуВЛИвФУЫќЕФНсТлжБНгШЅЖдНгФуЕФздЖЏЛЏЦНЬЈЁЃ
AIOps ЪЕМЪдкШЫетИіОіВпЩЯЛсгаКмДѓЕФЧјБ№ЃЌжЛЪЧНјаавЛаЉвьГЃЕФЯьгІЃЌЦНГЃУЛЪТОЭВЛашвЊШЫЕФИЩдЄЁЃDataOps
ЛЙЪЧашвЊОЙ§ШЫЕФОіВпЙ§ГЬЃЌетЪЧСНепжЎМфзюДѓЕФЧјБ№ЃЌФПЧАЛЙЪЧжївЊДІдк DataOps ЕФНзЖЮЃЌРы AIOps
ЛЙЪЧгавЛЖЈОрРыЁЃ

2. вЛЬхЛЏдЫЮЌЦНЬЈ
етЪЧећИіАЂРяАЭАЭМЦЫуЦНЬЈЪТвЕВПЫљИКд№ЕФвЛаЉММЪѕМмЙЙЃЌЯТУцгаСНДѓЗжВМЪНМЦЫув§ЧцЃЌдкДЫжЎЩЯЛсгаКмЖрЕФДѓЪ§ОнМЦЫуЦНЬЈЃЌЯёИеИеЬсЕН
MaxCompute ЕШЕШЃЌИїжжРраЭЕФРыЯпМЦЫуЦНЬЈЁЂЪЕЪБМЦЫуЦНЬЈЁЂДцДЂЦНЬЈЁЂЪ§ОнЭЈЕРЕШЕШЖМЪЧЛљгкЯТУцСНИіДѓЕФМЦЫув§ЧцШЅЙЙНЈЕФЃЌетећЬхЕФЮяРэЬхСПдк10w+вдЩЯЁЃ
етРягаМИИіПЩФмДѓМвБШНЯЪьЯЄвЛЕуЕФЃЌGMV УНЬхДѓЦСЃЌетОЭЪЧЛљгкЪЕЪБМЦЫуЕФМЦЫуЦНЬЈзіЕФЛузмЁЃЩњвтВЮФБЃЌЬсЙЉаавЕФкЕФИїжжгЊЯњЪ§ОнЁЃ

ФЧЮЊСЫНтОіЛђепдЫЮЌКУЖрв§ЧцЖрЦНЬЈЕФгІгУЃЌЮвУЧЙЙНЈСЫетбљвЛИіЗжВуЕФдЫЮЌНтОіЗНАИЃЌећЬхРДНВЮвУЧАбдЫЮЌЦНЬЈвВГщЯѓГЩСЫШ§ВуЃК
дЫЮЌЕФ laaS ВуЃЌетаЉжївЊвРРЕгкМЏЭХЕФЛљДЁЩшЪЉЃЌВЛашвЊЮвУЧВПУХЭЖКмЖрЕФСІСПШЅНтОіЕФЁЃ
ЛљгкЫќжЎЩЯОЭгаЫљЮНЕФдЫЮЌ PaaS ВуЃЌвВАќРЈЙЋЙВЗўЮёЕФгУЛЇЙмРэЁЂНЧЩЋЙмРэЁЃ
ФЧдйЩЯвЛВу PaaSЃЌПЭЛЇЖдгкетаЉЦНЬЈЫљЯЃЭћЕУЕНЕФЙІФмЫпЧѓвВЪЧВЛвЛбљЕФЃЌЫљвдгІгУетвЛВуИіадЛЏЕФЃЌЛљгкЙЋЙВЕФЗўЮёВуПьЫйЙЙНЈздМКЕФгІгУеОЕуЁЃ

ЮвУЧПДвЛЯТЫљЮНЕФвЛеОЪНдЫЮЌЦНЬЈЕНЕздкНтОіЪВУДЮЪЬтЃЌвђЮЊВЛЭЌЙЋЫОЕФГЁОАВЛвЛбљЃЌЪЧВЛЪЧвЛЖЈвЊЕНФЧЗБдгЕФГЬЖШвВЪЧВЛвЛЖЈЕФЃЌФмНтОіздМКЕФЮЪЬтОЭКУЁЃФуПДПДдЫЮЌдкетНЧЩЋжаЕНЕзУПЬьдкУІЪВУДЃЌЪЧЪВУДбљЕФШЫРДевФуЃЌЫћУЧевФуЪЧвђЮЊЪВУДбљЕФЪТЧщЁЃ
ЪЕМЪЩЯетРяДѓЕФРрБ№РДНВОЭЪЧНтОіСНИіаХЯЂСїЕФЮЪЬтЃК
вЛЪЧаХЯЂСїгЩЯТЭљЩЯЃЌОЭЪЧПДЁАПДЁБЕФЮЪЬтЃЌЕНЕзЗўЮёЮШВЛЮШЖЈЁЂЗўЮёдЫаадѕУДбљЃЛ
ЖўЪЧУќСюСїЃЌДгЩЯЭљЯТЃЌАќРЈздМКЗўЮёЕФЩЯЯТЯпЕШЕШЃЌЫљвдздМКШЅЙцЛЎЕФЪБКђвЛАуЪЧдЫЮЌЦНЬЈвЊНтОіЕФЮЪЬтДгЁАПДЁБКЭЁАзіЁБСНЗНУцЃЌШЅзівЛаЉНтОіздМКЭДЕуЕФТфЕиЁЃ

ЫљЮНЕФздЖЏЛЏГЬЖШдкетРяЛсгавЛИіUIЪгЭМЃЌШЫПЩвдЭЈЙ§етИіЪгЭМШЅНтОіетСНИіДѓЕФЮЪЬтЃЌдйРїКІвЛЕуПЩФмСЌНгетСНИіаХЯЂСїжЎМфЕФЪЧAIММЪѕЃЌаЮГЩвЛИіаХЯЂСїЕФБеЛЗЃЌдкетИіНзЖЮПЩФмОЭЪЧЫљЮНЕФAI
OpsЃЌе§ГЃРДНВЪЧаХЯЂЪеМЏЁЂМгЙЄДІРэЁЂОіВпЃЌдйаХЯЂЛиСїПДЗДРЁЪЧЪВУДбљЕФЁЃ

3. DataOps ЪЕМљ
МШШЛАбетИіНзЖЮНазі DataOpsЃЌПЯЖЈЪЧРыВЛПЊЪ§ОнЕФЃЌЪ§ОнЪЧЫќЕФЛљДЁЃЌдЫЮЌЕФЪ§ОнЪЧашвЊАДееБъзМЕФЪ§ВжддђНјааНЈЩшЁЃгвБпетеХЭМЯдЪОЕФЪЧећИіЪ§Оне§ГЃЕФВЩМЏЁЂДцДЂзюКѓЕНМгЙЄЁЂгІгУВуЕФГЃМћВНжшЃЌетЪЧДгЁЖДѓЪ§ОнжЎТЗЁЗжаФУРДЕФЁЃ
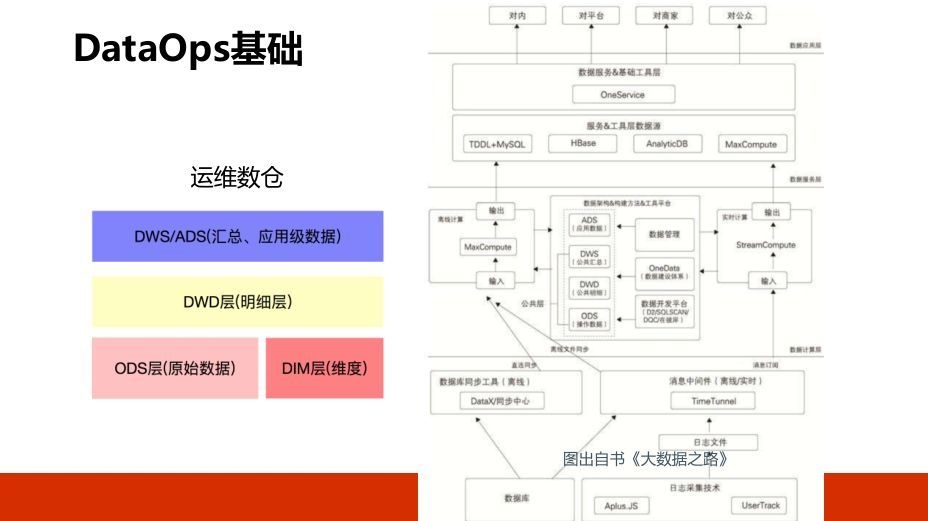
ГЃМћЕФдЫЮЌЪ§ОнЃЌЕквЛРрЪЧЮЌЖШЪ§ОнЃЈдЊЪ§ОнЃЉЃЌЗўЮёЦїЁЂЗўЮёЦїIPЪЧЪВУДЃЌРрЫЦгкетбљЕФвЛаЉОВЬЌаХЯЂЁЃСэвЛРрЪЧЖШСПЪ§ОнЃЈдЫааЪБЃЉЃЌвВОЭЪЧжИБъЛђепЪТМўРрЕФЃЌЛЙгавЛРрЪЧШежОРрЕФЁЃетЪЧдЫЮЌжазюживЊЕФМИДѓРраЭЪ§ОнЃЌвВЪЧзі
DataOpsЕФЛљДЁЁЃ

етИіИДдгЭМЪЧЕБЧАЮвУЧзі DataOps ЕФЪ§ОнМмЙЙЭМЃЌдкетРяФУГіРДКЭДѓМвНЛСївЛЯТЃЌЪзЯШзѓБпЛЙЪЧЬсЕНИеВХЕФддђЃЌЪ§ВжНЈЩшЕФЙцЗЖЁЃ
ЮвУЧЛсАбЪ§ОнзівЛИіГщЯѓЃЌЩЯУцгаКУМИИіДѓЪ§ОнЦНЬЈвЊЙмЃЌУПИіДѓЪ§ОнЦНЬЈЛсгаЖдгІаЁзщЕФШЫШЅИКд№ЫќЕФгІгУФЧвЛВудЫЮЌЃЌЫљвдЮвУЧЛсАбжиИДЕФЃЌЙЋЙВЕФЃЌИїИіВњЦЗЖМЛсгУЕНЕФЪ§ОнЃЌЯёЛњЦїЁЂжИБъЁЂШежОЁЂМрПиЁЂБЈОЏЕШЕФЙЋЙВаХЯЂШЋВПГщШЁдквЛЦ№ЃЌЗХдквЛЦ№ШЅзіЧхЯДМгЙЄДцДЂЁЃЫљвдЛсЗжЮЊЙЋЙВЪ§ОнКЭвЕЮёЪ§ОнСНДѓРраЭЃЌЛљгкетжЎЩЯдйШЅЙЙНЈИїжжИїбљЕФдЫЮЌГЁОАЃЌЯёЙЪеЯздгњЁЂвьГЃМьВтЁЃ

ЯТУцОЭетРяЕФвЛаЉГЁОАИјДѓМвОйаЉР§згЁЃ
ЕквЛИіР§згЪЧдЫЮЌЫбЫїЕФЃЌМђЕЅНВвЛЯТжЊЪЖЭМЦзЃЌдЫЮЌЪРНчРяИќЖрЪЧЪЕЬхгыЪЕЬхМфЕФЙиЯЕЃЌгУжЊЪЖЭМЦзЕФБэДяЗНЪНЛђепЪ§ОнЕФДцДЂаЮЪНШЅБэДяЛсИќКЯЪЪвЛаЉЃЌгШЦфЪЧдкКѓУцНВЕНЕФЫбЫїГЁОАРяЃЌгаЦфЖРЬиЕФгХЪЦЁЃ

ЛљгкжЊЪЖЭМЦзЕФдЫЮЌЫбЫїЃЌЧАУцПДЕНвЛеОЪНЕФдЫЮЌЬхЯЕЃЌетИіЦНЬЈЪЧБШНЯХгДѓЕФЃЌБШНЯИДдгЃЌФЧгУЛЇНјРДвдКѓДѓМвЖМЛсУцСйвЛИіЮЪЬтЃЌзмгааЉШЫВЛТњвтЫЕевВЛЕНЕуЃЌЫљвдЮвУЧЛсгаИівЛеОЪНЕФЫбЫїШыПкЃЌФудкЫбЫїПђРяЧУЯывЊЪВУДЯыИЩЪВУДЃЌБШШчЫЕгаШЫЯызіИіЖгСаРЉШнЃЌФЧжЛвЊЪфШыЖгСаЃЌОЭЛсАбЖгСаЯрЙиЕФЪЕЬхЁЂЖЏзїЃЌАќРЈЪєадгаФФаЉШЋВПСадкетРяЃЌФЧПЯЖЈгавЛИіЪЧЫћЯыИЩЕФЁЃ
ЕБШЛФувВПЩвджБНгЪфШыетИіЖгСаЕФУћГЦЃЌШЛКѓвВФмИјГіРДетИіЖгСаЯрЙиЕФЁЃгУЦ№РДЛЙЪЧКмКУгУЃЌеОЕуЙ§гкХгдгЃЌУцЖдЕФгУЛЇгжКмЖрЃЌКмФбТњзуЫљгаШЫЕФЮИПкЃЌФЧШУЫћУЧЗНБуЕФРДЪЙгУетИіЦНЬЈЁЃ

ЛљгкетИіЛЙПЩвдШЅзі ChatOpsЃЌБШШчЫЕФуЪфвЛИіЛњЦїЃЌЛњЦїЯждкЕФзДЬЌдѕбљЃЌФФИіЗжзщЃЌФФИіЛњЗПЃЌвВПЩвдгааЉЛљДЁЕФЛљгкЮФЕЕГЃМћЮЪЬтЕФЮЪД№ЃЌЛђепЫЕШУЫќПЊвЛИіШБЯнГіРДЃЌРрЫЦетбљЁЃ
ЕБЧАChatOpsзіЕФЛЙЪЧБШНЯМђЕЅвЛЕуЃЌЛЙЪЧвдВщбЏЪНЕФЮЊжїЃЌОЭжївЊЪЧНтОіжиИДЕФвЛаЉМђЕЅЕФД№вЩРрЕФВйзїЁЃвВОЭЫЕеце§жДааУќСюВйзїРрЕФЛљгкChatOpsЕФФПЧАзіЕФЛЙЩйвЛЕуЁЃ

ЯТвЛИіГЁОАЪЧЙигкзївЕеяЖЯЃЌФЧУДЖрЕФгУЛЇЛсРДЮЪетИізївЕХмЕФгаЕуТ§ЃЌФуРДАяЮвПДПДдѕУДСЫЃЌетЪЧКмЗГШЫЕФвЛИіЪТЧщЁЃЮЊСЫНтОіетИіЮЪЬтОЭЬсЙЉЖЫЕНЖЫЕФзївЕеяЖЯЃЌгУЛЇЪфШызївЕвдКѓЫќЛсШЅеяЖЯЃЌИњзХетИізївЕШЋЩњУќжмЦкЕФСїГЬЃЌЮветРяНВЕФЫљгаЖМЪЧЛљгкЫЕгаФмСІЧввбОЪеМЏКУФЧаЉаХЯЂЃЌЖјЧвгаСЫЪЕЪБадВХФмШЅзіЕФЁЃ
етРяЛсШЅПДЫЕетИізївЕЗжЙЄдкФФаЉЛњЦїЩЯЃЌЛсАбЯрЙиЕФЛњЦїРГіРДЃЌетаЉЛњЦїБОЩэгжгаУЛгаЮЪЬтЃЌгаСЫетИівдКѓЛљБОЩЯГѕМЖЕФЮЪЬтОЭВЛгУдйРДЮЪЁЃ

КѓУцдйРДЩюШыеЙПЊвЛЯТЛњЦїеяЖЯЃЌШчЙћЫќгаfoverОЭИјГіРэгЩЁЃДѓМвПЩвдПДЪзЯШЛњЦїЪЧВЛЪЧе§ГЃЃЌетОЭЪЧЛњЦїгВМўМЖБ№ЕФМьВтЃЌгВМўУЛгаЮЪЬтЕФЛАЛсгавЛИіIOеяЖЯЃЌетБпЛсИјГіРДЫЕЗжЧјЩЯЕФЮФМўЃЌДЮЪ§ЪЧдѕУДбљЕФЃЌЪЧдкЖСЁЃ
ЛЙгаЭјТчЕФеяЖЯЃЌеыЖдЭјТчСїСПТњЕФЧщПіЯТЃЌФФИіНјГЬСїСПеМСЫЖрЩйЁЃетбљРДНтОігУЛЇОГЃЮЪЕФЛљгкзївЕдЫааЧщПіЕФД№вЩЁЃ

ЯТУцНщЩмСНИівьГЃМьВтЕФР§згЃЌПЩФметСНЬьЯТРДДѓМвдкКмЖрГЁЬ§СЫКмЖрЃЌзюЖрЕФОЭЪЧЛљгкЪБађЕФЃЌЫљвдЮвУЧНВЕуВЛвЛбљЕФЁЃ
Г§СЫЪБађЕФЛЙгаЛљгкОлРрЕФЃЌЪЪгУЕФГЁОАЪЧгаКмЖрДѓСПЭЌжЪЕФжїЛњЃЌЩЯУцХмЕФШЮЮёЖМЪЧРрЫЦЕФЃЌЖјЧвзЪдДЕїЖШЦївВЪЧБШНЯИпаЇЕФЃЌФмЙЋЦНЕФШЅЕїЖШетаЉзївЕЃЌРэТлЩЯетаЉЛњЦїЕФИКдиЛљБОЩЯЪЧОљКтЕФЃЌЫљвдПЩвдЛљгкЫќЕФCPUЁЂЯЕЭГЕФИДдгЁЂЭјТчЕШШЅзіОлРрЃЌПДПДгаУЛгаФГаЉЛњЦїКЭБ№ШЫБэЯжВЛвЛбљЃЌВЛвЛбљЕФЛАетаЉЛњЦїПЯЖЈЪЧгаЫќЕФИїжждвђЁЃ
ИљОнетИіОлРрФУЕНвьГЃзщжЎКѓдйШЅПДЫќУЧгаУЛгаЪВУДЙВадЃЌБШШчЫЕЪЧВЛЪЧЭЌвЛЬьПЊЛњЕФЃЌЩЯУцЪЧВЛЪЧдЫааЭЌвЛИізївЕЕШЕШЁЃDBScanЕФКУДІЪЧВЛОаФргкОлРрзщЕФЪ§СПЃЌШчЙћОѕЕУжЛвЊФмЙЛЗЂЯжвьГЃЕФЮЪЬтОЭЕїЕФДжсювЛЕуЁЃ

ЕкЖўИіЪЧЛљгкШежОЕФШеГЃМьВтЃЌетИіДѓМвНВЕФПЩФмЛсЩдЮЂЩйвЛЕуЁЃЮвУЧИќЖрЕФЪЧАбШежОНјааФЃЪНЕФЬсШЁЃЌФЃЪНЬсШЁЕФЫуЗЈгаКмЖрЃЌЭјЩЯвВгаКмЖрВщЕНЕФЃЌБШШчЫЕЮФБОжЎМфЕФЯрЫЦЖШЃЌОЭгаКмЖрЕФЗНЪНШЅевШежОжЎМфЕФЯрЫЦЖШЛђепЫЕЫќУЧЪЧВЛЪЧЭГвЛРрЕФЃЌгаСЫетИіЪ§ОнжЎКѓОЭПЩвдЧаУцЃЌЮвУЧзіЕФЪБКђЪЧАбШежОЕФвьГЃМьВтБфГЩжИБъРрЕФЁЃ

етЪЧШежОвьГЃМьВтЕФЪЕМЪР§згЃЌДѓМвПЩвдЗЂЯжЫЕКіШЛФГвЛРрФЃЪНЕФШежОБфЖрСЫЃЌПЩвдПДЕНФГИіЪБМфЖЮФкГіЯжЕФШежОЪ§СПДяЕНетУДЖрЃЌвВОЭЫЕДѓСПЕФзївЕдкФГвЛИіЪБМфЕуГіЯжЭЌРраЭЕФШежОЃЌКмгаПЩФмЪЧЦНЬЈЕФЮЪЬтЃЌвђЮЊЖдгкЮвУЧзіЦНЬЈРДНВЃЌИќЙизЂЕФЪЧЦНЬЈЮЊжїЕФЮЪЬтЃЌЮвУЧПЩвдИјЫќЬсЙЉетбљЕФЧўЕРШЅЬсабЫќЁЃ
етЪБКђЮвУЧПЩФмЛсЛГвЩЪЧВЛЪЧЦНЬЈгаЮЪЬтСЫЃЌФЧПЩвддкШежОЯъЧщРяШЅПДЕНЕзЪЧФФРрШежОЃЌетИіР§згЦфЪЕНВЕФЪЧЪЕЪБМЦЫуЕФЩЯгЮФЧРяГіСЫЮЪЬтЁЃ

DataOps ЛЙгавЛИіКмДѓЕФЗжжЇОЭЪЧдЫГягХЛЏЃЌПЩФмдЫЮЌЕФЁАдЫЁББОРДОЭАќКЌСЫдЫГяЕФвтЫМЁЃдЫГягХЛЏЕФР§згБШНЯЖрЃЌЖрИіМЏШКжЎМфШнСПЕФОљКтЃЌХфжУЕФгХЛЏЕШЕШЁЃ

ЯТУцОйвЛИіР§згЃЌЙигкЭЌВНШЮЮёЕФгХЛЏЃЌетИіР§згБШНЯМђЕЅЃЌЖдДѓМвЕФРэНтЗНУцЁЂЦєЗЂЗНУцКУРэНтвЛЕуЁЃЭЌВНШЮЮёОЭЪЧЫЕдкETLРыЯпДІРэЕФЕквЛВНЃЌДгВЛЭЌЕФЕквЛРяУцАбЪ§ОнЭГвЛЙ§РДЁЃ
ЮвУЧПЩвдПДЕНетаЉЭЌВНШЮЮёAКЭBЪЧАЂРяВЛЭЌЕФСНИіBUЃЌаДЕФЭЌВНзївЕЕФЫйЖШЭъШЋВЛвЛбљЃЌABUЦНОљЫйЖШФмЙЛДяЕН4езЖрЃЌЖјBBUЦНОљжЛга1.8МИезЃЌдкУПИіВЛЭЌЕФЫйЖШЧјМфзівЛИіЗжВМвВЪЧЭъШЋВЛвЛбљЕФЃЌдвђЪЧвђЮЊABUЕФШЫБШНЯгаОбщвЛЕуЛђепЫћУЧзіЕФЪБМфИќОУвЛЕуЁЃ
ЮвУЧФмзіЕФЪТЧщЪЧдѕУДбљАбABUЕФОбщПьЫйЕиИДжЦЕНBBUЃЌЖјВЛашвЊBBUЕФПЊЗЂепдйШЅбЇвЛБщЃЌетИіГЁОАдкДѓМвЕФЙЄзїжавВгІИУЪЧФмКмШнвзевЕНТфЕиЕуЁЃ

ЮвУЧПЩвдАбЭЌВНШЮЮёЕФЪєадФУГіРДЃЌАбЫќУЧЗжЮЊЙЬЖЈЪєадКЭПЩХфЪєадЃЌЫљЮНЙЬЖЈЪєадЪЧжИБОЩэзївЕЙЬгаЕФЪєадЃЌЖдЭЌВНШЮЮёРДНВгадДРраЭЃЌАќРЈЫќЕФЫоРраЭЃЌЛЙгавЛаЉдкдЫаажаПЩвдХфжУЕФЃЌБШШчЫЕВЂЗЂадЁЂjvmВЮЪ§ЪЧЖрЩйЕШЁЃ
ЙЬЖЈЪєадK-meansОлРрЃЌШЅевЕНЮвУЧетУДЖрЕФЭЌВНзївЕЕНЕзгаЖрЩйжжРраЭЃЌевЕНвЛИіЗжРрЃЌОЁПЩФмРраЭВюВЛЖрЕФЗждкЭЌвЛРраЭРяУцЁЃ
ЭъГЩетИівдКѓдйдкЭЌвЛРрРяУцШЅевЕНвЛИіБШШчЫЕЕЅзЪдДЧщОАЯТЕФЭЌВНЫйЖШзюИпЕФзївЕЃЌзїЮЊетвЛРрзївЕЕФзюМбЪЕР§ЃЌАбетИізюМбЪЕР§ЕФХфжУгІгУЕНЭЌРраЭРяЕФЦфЫћзївЕЃЌетИіЮЪЬтОЭНтОіСЫЃЌЦфЪЕЪЧвЛИіздЖЏЕФОлРрЁЂЗжРрЃЌШЛКѓдйдкРяУцеввЛИізюМбЪЕР§ЁЃ

етЪЧетИіХфжУНтОіЕФзюКѓаЇЙћЃЌЛљБОЩЯЦНОљЫйЖШга7БЖЕФЬсЩ§ЃЌЪевцЛЙЪЧТљДѓЕФЃЌВЛгУвЛИіИіШЫдйШЅЕїзївЕзігХЛЏЁЃ

4. AIOps ЯрЙи
AIOps ЮвИіШЫШЯЮЊРыЫќЛЙЪЧТљдЖЕФЃЌЕЋВЂВЛЪЧвЃВЛПЩМАЃЌAIOps жЛвЊТњзуЫќЕФвЛИіФЃЪНЕФЖЈвхЃЌОЭПЩвдГЦжЎЮЊ
AIOpsЃЌЩѕжСгавЛаЉдРДдкздЖЏЛЏдЫЮЌГЁОАОЭвбОЪЕЯжЕФСЫЃЌетЪЧЮвИіШЫвЛаЉЧГТЉЕФРэНтЁЃЮвЕФИХФюРяжЛвЊЪЧЫЕЫќФмжаМфРћгУЪ§ОнЁЂЫуТыФЃаЭзівЛаЉОіВпЃЌЧветаЉОіВпФмЙЛздЖЏЕФШЅгІгУЕНЯпГЄЃЌаЮГЩетбљвЛИіБеЛЗЃЌВЛашвЊШЫИЩдЄЕФЃЌЮвШЯЮЊетИіГЁОАОЭПЩвдГЦжЎЮЊAIOpsЁЃ
4.1 AIOpsЕФМрПиздгњ
зюЭЗЬлЕФЪЧАывЙЪеЕНИцОЏЁЂжмФЉЪеЕНИцОЏЁЂПДЕчгАЪБЪеЕНИцОЏЃЌетРяУцАбЫќгУAI OpsЕФПђМмдйШЅЪсРэвЛЯТЃЌЬсЩ§ЫќЕФаЇЙћЁЃ
жївЊЪЧШ§ДѓВПЗжЃК
ЕквЛВПЗжЪЧИажЊЃЌдѕУДШЅИажЊЕНвьГЃЪТМўЕФЗЂЩњЃЌШчЙћзіМрПиздгњЕФЛАРДдДОЭБШНЯМђЕЅ
ЕкЖўВПЗжЪЧОіВпЃЌзіЪЕЪБЕФОіВпДІРэЁЃ
ЕкШ§ВПЗжЪЧздгњЃЌЭЌЪБЛЙвЊдйШЅЙизЂвЛЯТЪЧЗёЖМНтОіСЫ
зївЕЦНЬЈЭЦИјСїГЬЦНЬЈЃЌСїГЬЦНЬЈжаЛсОЭШЫНщШызівЛИіЩѓКЫЃЌПЩФмгааЉживЊЕФЛњЦїЪЧВЛФмжиЦєЕФЃЌЛђепдкФГаЉИцОЏЧщПіЯТВЛЪЪКЯзіЯТЯпЃЌетПЩвдЗжНзЖЮШЅзіЁЃ

4.2 AIOps гВМўздгњ
ећИіМЦЫуЦНЬЈЮяРэЛњетПщЗЧГЃЖрЃЌШчЙћШЫШЅзігВМўЙЪеЯЗЂЯжЁЂБЃаоЃЌжСЩйвЊЭЖвЛИіШЫШЋжАдкетМўЪТЧщЩЯЁЃдкетаЉЗўЮёЦїЩЯЛсзАЩЯвЛИіЯЕЭГЃЌЫќЛсШЅВЩМЏгВМўЙЪеЯХаЖЯЯрЙиЕФР§згЃЌВЩМЏЭъвдКѓЭЈЙ§SLSЪ§ОнЭЈЕРЃЌдйЭЈЙ§СїМЦЫузіЗжЮіОлКЯЃЌзюКѓЗХЕНOLAPРяУцЃЌНсКЯЫќдгаЕФФЃаЭШЅзівЛИіХаЖЯЃЌЫЕетЬЈЛњЦїЪЧВЛЪЧгаЮЪЬтСЫЃЌЭЌЪБвВЛсЪмвЕЮёАВШЋФЃаЭЕФжЦдМЁЃ
зюКѓЫќЛсВњЩњЖЏзїЃЌЛсАбетИіЖЏзїШгЕНЪТМўжааФЃЌОЭВњЩњЯТЯпЛђепжиЦєЕШЁЃвВе§ЪЧЛљгкетбљвЛЬзЯЕЭГПЩвдАяЮвУЧАбетЗНУцЕФШЫСІЪЁЯТРДЃЌвЛФъДІРэ20ЭђДЮздгњЪТМўЃЌЗўЮёЦїПЩгУТЪ99%вдЩЯЁЃ

4.3 AIOps ЕФзЪдДгХЛЏ
дѕУДИјМЏШКЕФзївЕЛЎЗжquotaзщзюКЯРэЃПЪзЯШвЊНЈСЂзЪдДЛЎЗжЕФТњвтЖШФЃаЭЃЌвђЮЊФуВЛПЩФмШУЫљЮНЕФAIФЃПщздМКШЅХаЖЯЫЕетгУЛЇгУЕФЫЌВЛЫЌЃЌетВЛПЩФмЕФЁЃ

ФЧзЪдДТњвтЖШФЃаЭПЩвдИљОнздМКЕФвЕЮёЬиЕуШЅНЈЃЌвЛЬззлКЯЦРМлЬхЯЕжївЊАќКЌгУЛЇзЪдДЧРеМЁЂЕШД§ЗжХфЪБМфЁЂзЪдДТњзуТЪЕШЃЌгУTdataЪБађвьГЃМьВтФЃаЭИњзйгУЛЇТњвтЖШБфЛЏЧщПіЁЃгаТњвтЖШФЃаЭЧвФмЙЛЗЂЯжвьГЃвдКѓЃЌФЧОЭШЅзіжЧФмЕФзЪдДЕїХфЕФЪТЧщЃЌбЁвЛИіФЃаЭЖдЮДРДвЛжмЕФгУЛЇзщЕФзЪдДзівЛИідЄВтЃЌЕБШЛетЗНУцЕФФЃаЭБШНЯЖрЮввВВЛЯъЯИЕиеЙПЊСЫЁЃ

зюКѓЛљгкУПИіХфЖюзщЮДРДвЛжмЕФзЪдДЯћКФдЄВтжЕНсКЯИУХфЖюзщЕФРњЪЗгУЛЇТњвтЖШЪ§ОнКЭЫљдкгУЛЇЕШМЖЕФЗўЮёSLAЃЌИљОнетШ§ЯюНсКЯЃЌзюКѓИјГіетИізЪдДзщХфжУЕФЭЦМіжЕЁЃ

ЕБШЛетИіжЕЙ§ШЅвдКѓЛЙЛсаЮГЩвЛИіБеЛЗЃЌвђЮЊгУЛЇТњвтЖШЕФвьГЃМьВтЪЧЪЕЪБвЛжБдкЯпЩЯХмЕФЃЌШчЙћКіШЛЗЂЯжФГИігУЛЇВЛТњвтЕФЛАЛсМАЪБЕїећЁЃ

|








