|
|
|
|
GitHub迁移数据库,借助MySQL大行其道! |
| |
作者 伍昆 火龙果软件 发布于 2014-9-10 |

|
|
GitHub,作为广泛使用的开源代码库以及版本控制系统,其数据库MySQL性能的优劣对整个网站平台有着举足轻重的影响。接下来我们一起跟随GitHub基础架构团队的步伐,来重温去年8月做的一次重大MySQL更新,看是如何使得GitHub运行得更畅顺的。
任务简述
自去年开始,我们陆续地把GitHub主体架构迁移到新的数据中心,与之配套的是世界级的硬件和网络环境。我们十分希望这次升迁对后端系统基石MySQL的性能也有所提高。不过在一个新环境重新建立一个新的服务器集群和硬件平台,并不是件轻易的事情,我们必须做好计划与测试,确保迁移工作顺利完成。
准备工作
每当要进行类似的重大升级工作,对每个测量和指标量度步骤都会提出严格的要求。为新机器安装好操作系统后,接下来需要根据不同的配置来进行测试。为了得到真实的负载测试数据,我们使用了tcpdump对从旧集群系统到新系统执行的SELECT查询进行抓包分析。
MySQL性能调整可谓是细节决定成败,例如众所周知的innodb_buffer_pool_size的设置,对整体有着举足轻重的影响。为了尽更全面地管控升级过程,我们把 innodb_thread_concurrency、innodb_io_capacity、innodb_buffer_pool_instances等参数也一并进行分析和研究。
每次测试时我们都只改变某一个参数,然后让系统连续运行至少12小时。在这过程中不断观察SHOW ENGINE INNODB STATUS带来的统计信息,其中SEMAPHORES栏目,能很好地反映工作负荷竞争情况。当相关设置测试通过后,接下来我们将尝试把其中一个最大的数据表迁移到一个单独的集群上。作为前期测试的一部分,这样的迁移工作能为日后更大更核心的变更带来指引。
除了对基础硬件部分进行了升级,我们还对流程和拓扑进行了优化。例如:延后复制,更快速和高频的备份,提高备带读取能力。一切就绪后,将进入最后的升级阶段。
制定升级项目清单,进行二次检查
作为每天服务上百万用户的平台,任何差错都将是毁灭性的。我们在进行真实切换前,列出了一个任务清单,确保各项工作有序执行:
- 确保缓冲池在新集群中成功预热
- 在推特等社交平台公告维护开始
- 把网站转为维护等待模式
- 等候所有与旧MySQL服务器相关的通信终止
- 把旧服务器设为只读模式
- 从旧集群中移除主要和复制的VIPs数据
- 确认所有写入操作已经终止
- 终止cluster1的复制
- 获取cluster1复制的位置,并告知当前线程
- 重置cluster1的复制
- 关闭cluster1的只读模式
- 把旧集群连接到新的cluster1集群
- 按照cluster1连接配置进行应用程式部署
- 确保新连接能通过新集群
- 检查后台工具resque的任务(workers)
- 进行阶段检查并确保一切正常
- 把网站转为正常模式
- 在推特等社交平台公告维护结束
- 把https://github.com/github/xxxx/pull/xxx整合到主页面
迁移当天
在周六的上午5点太平洋时间),团队成员就位后,迁移工作正式开始。当用户在这段时间访问网站时,会收到如下的提示:
13分钟后,新集群即将开始正常运作。我们终止了网站的维护模式,并告知大众网站将回复正常。
效果评估
在接下来的几个星期,我们密切关注了整体性能和响应时间方面的变化。结果是令人欣喜的,页面载入时间减少了将近三分之二:
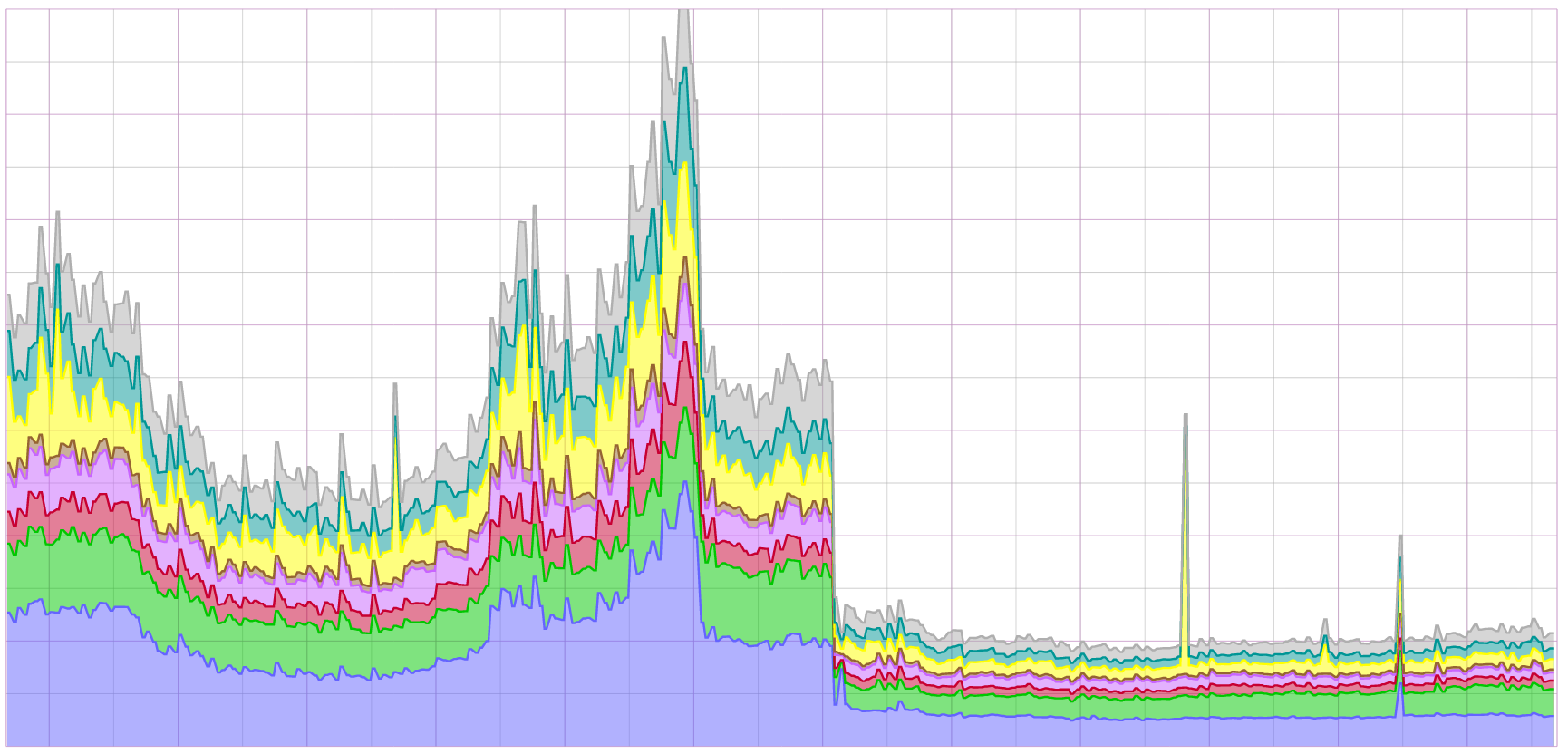
经验总结:
1. 功能划分
在本次操作中,我们把较大的历史数据记录表放入单独的集群,事后证明这是明智的做法—很好地释放了存储空间和缓冲池空间。同时,能够把更多资源放在活跃数据处理上,连接逻辑的划分也使得程序可以在多个集群间进行查询。以后我们还将采取该方法进行升级。
2. 不断测试
罗马非一天建成,整个过程需要不断进行验收和回归测试,避免意外的发生。
3. 团队的力量
如此重大的架构升级需要很多小伙伴协力工作,我们主要使用GitHub上的拉请求功能来进行互动交流。部署团队来自世界各地:
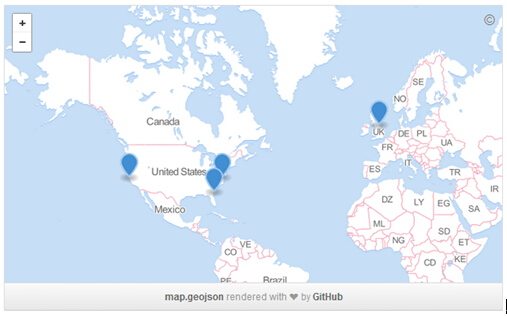
当开启一个拉请求后,我们将进行实时交流,例如:错误处理,回归处理等信息的交流。每个交流环节都生成一个URL,方便进行历史查询和反馈。
一年后……
路遥知马力,一年后,实践证明这是一次成功的操作。MySQL持续表现符合预期,系统可靠性进一步提高。还有个附加好处是:新系统的扩展性得到提升,将来可进行更大规模的升级和改造。
|
|
|
|
|





