|
|
|
|
避免关注底层硬件,Nvidia将机器学习与GPU绑定 |
| |
作者 Derrick Harris 火龙果软件 发布于 2014-9-11 |

|
|
Nvidia释放的一组cuDNN的库,有效的实现了其与多种深度学习框架的整合。基于cuDNN,加速了代码的运行,同时让研究员避免去关心底层硬件性能。
Nvidia通过发布cuDNN库,将GPU和机器学习更加紧密的联系起来,同时实现了cuDNN与深度学习框架的直接整合,使得研究员能够在这些框架上无缝利用GPU,忽略深度学习系统中的底层优化,更多的关注于更高级的机器学习问题。
以下为译文
近日,通过释放一组名为cuDNN的库,Nvidia将GPU与机器学习联系的更加紧密。据悉,cuDNN可以与当下的流行深度学习框架直接整合。Nvidia承诺,cuDNN可以帮助用户更加聚焦深度神经网络,避免在硬件性能优化上的苦工。
当下,深度学习已经被越来越多的大型网络公司、研究员,甚至是创业公司用于提升AI能力,代表性的有计算机视觉、文本检索及语音识别。而包括计算机视觉等流行的领域都使用了图形处理单元(GPU),因为每个GPU都包含了上千的核心,它们可以加快计算密集型算法。
通过Nvidia了解到,cuDNN基于该公司的CUDA并行编程语言,可以在不涉及到模型的情况下与多种深度学习框架整合。Nvidia的一位发言人透露了更多消息:
通过在Caffe、Theano、Torch7等主流机器学习框架上的研究,cuDNN允许研究员可以在这些框架上无缝利用GPU的能力,并预留了未来的发展空间。举个例子:在Caffe中整合cuDNN对终端用户是不可见,只需要非常简单的设置就可以完成这个操作,即插即用是cuDNN的核心设计因素。
从更技术的角度看,cuDNN是一个低等级的库,无需任何CUDA代码就可以在host-code中调用,非常类似我们已经开发的CUDA cuBLAS和cuFFT库。通过cuDNN,用户不必再关心以往深度学习系统中的底层优化,他们可以将注意力集中在更高级的机器学习问题,推动机器学习的发展。同时基于cuDNN,代码将以更快的速度运行。
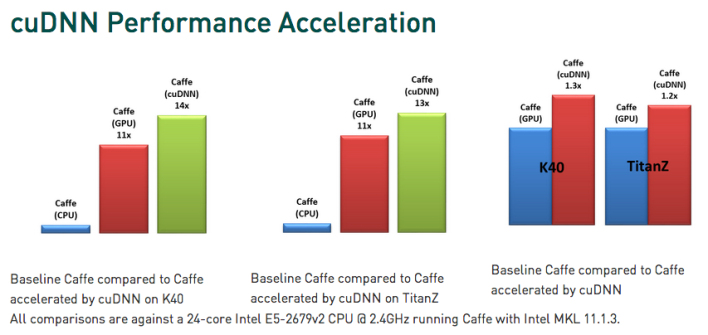
不管是为了未来增长,还是“GPU不只用于计算机图形渲染”这个长期目标,Nvidia在拥抱深度学习和机器学习上非常积极。当下GPU的使用已经非常广泛,机构使用它代替CPU以获得更高的速度及更低的成本。
但是,仍然存在一些特定的因素抑制了CPU的长期发展。其中一个就是替代架构,比如IBM的SyNAPSE和类似Nervana Systems一些初创公司的努力,比如,它们专门为神经网络和机器学习负载设计。另一个则是现有的处理器架构,包括CPUs和FPGAs已经让人们看到了未来机器学习负载上的能力。
虽然当下已经有很多云供应商通过服务的形式提供了深度学习能力,但是机器深度学习离进入主流仍然有很大的距离。
|
|
|





