求知
文章
文库
Lib
视频
iPerson
课程
认证
咨询
工具
讲座
Modeler
Code
会员
分享到
利用Neo4j对电影评论进行深度学习情感分析
作者 Kenny Bastani 火龙果软件 发布于 2014-10-09
目前,国外一个电影网站允许用户提交关于他们针对某部电影是喜欢还是不喜欢相关信息的评论,随着这种类型评论的海量增加,依靠人工方法分析难以为继,情感分析技术被提到越来越重要的位置。
随着互联网的发展,用户从以前的“读”网页转变为“写”网页,互联网上产生了大量的用户参与的,对于诸如人物、事件、产品等有价值的评论信息,而随着网络上评论信息爆炸式的增长,以人工的方法很难应付海量评论信息的收集和处理,情感分析技术随之产生,本文以电影影评为例,利用Neo4j对电影评论进行深度学习的情感分析。
一个电影评论网站允许用户提交关于他们针对某部电影是喜欢还是不喜欢相关信息的评论。充分挖掘这些评论继而生成有价值的元数据(针对相关内容的)将给我们提供一个难得的机会,它可以让我们以一个大众化的方式来理解用户对于这部电影的情感,这是一件很酷的事情。我们可以对主观内容做出一个客观的分析,这样可以使我们能够更好地理解产品和服务的趋势,可以为消费者做出更好的决策。
情感分析的数据模型
实现这些的主要障碍是我们的结构和转换数据。当前最先进的技术包括Support Vector Machines以及Maximum Entropy。这些技术实施的挑战仍然是如何以最小的性能代价从文本中提取特征和结构化数据,这就是我决定要集中精力解决的问题。
我使用特征选择算法,利用图形数据库Neo4j来解决数据转换和可用性的挑战,而最先进的自然语言解析算法的重点是关注句子结构,我决定为自然语言Grammar induction设计一个统计方法,主要是针对巨大文本语料库的概括,生成新特性,使用深度学习预测当下特性左边或右边的概率最高的新特性。
基于图形的NLP实例
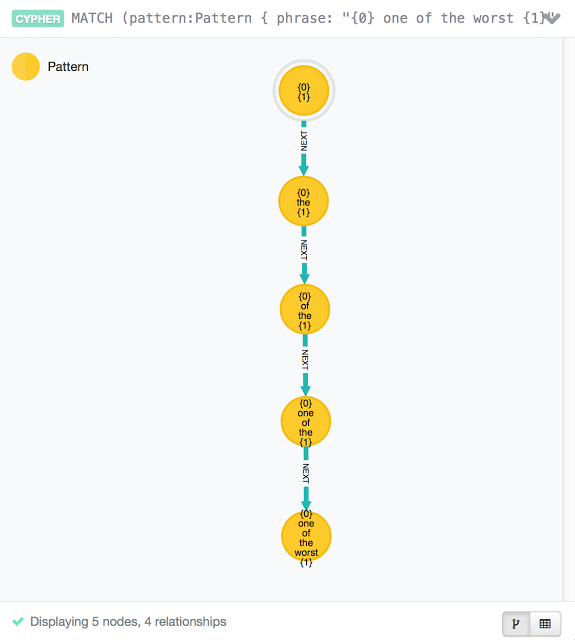
我假设短语“
one of the worst
”作为一组文本的特征已经被提取。这个词提取的原因是这个短语有最大的统计学相关性,这意味着这个短语在父短语之后有最佳的匹配机会。使用Neo4j我们可以确定产生这一词的继承特性。
从根节点开始,它被加上“{ 0 } { 1 }”,路径里面”
one of the worst
“将被解析为
(the)->(of the)->(one of the)->(one of the worst)
。
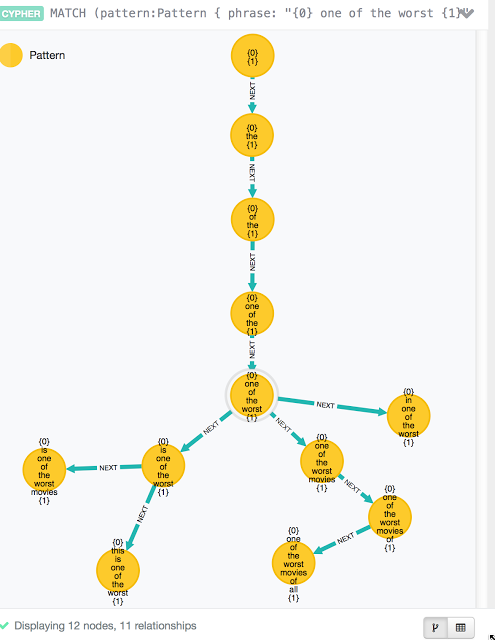
这样的层次结构将会扩展为更多的可能性,如下图显示:
这种特征选择算法可以在不到一秒钟的时间从文本语料库中选择提取概率最大的相关特性和短语。这种技术对于情感分析具有非常重要意义的原因是这些模式节点可以连接到他们训练过的文本标签上,如下所示。
该算法的结果是任何自然语言文本可以在秒级解析,生成一个可用于任何分类算法的子图。这在很大程度上要归功于Neo4j图遍历。
开放源码演示
针对电影评论的例子,我选择了500个影评,包括正面和负面的标签,使用Graphify训练一个自然语言解析模型。在下一篇博文中,我将向你介绍展示如何做到比人类更好地电影评论分类,人类分类错误率为30%。
分享到
相关新闻
利用Gitlab和Jenkins做CI
CPU深度学习推理部署优化
九种跨域方式实现原理
讲座
设计模式C语言
讲师:薛卫国
时间:2019-4-20
每天2个文档/视频
扫描微信二维码订阅
订阅技术月刊
获得每月300个技术资源
希望我们的资料可以帮助你学习,也欢迎投稿&提建议给我
频道编辑:winner
邮 件:winner@uml.net.cn
关于我们
|
联系我们
|
京ICP备10020922号 京公海网安备110108001071号