|
|
|
|
eBay开源新数据库技术Kylin,支持TB到PB级数据量 |
| |
|
作者 Derrick Harris 火龙果软件 发布于 2014-10-27 |

|
|
|
eBay已经开源了一种数据库技术—— Kylin,它利用了分布式处理和HBase数据存储技术,目的是让Hadoop的SQL查询返回更快的结果。
eBay开源了一种名为Kylin的数据库技术,eBay在周三的一篇博客上分享了Kylin 的诸多细节,基于 Hadoop 提供 SQL 接口和 OLAP 接口,支持 TB 到 PB 级别的数据量,Kylin旨在减少Hadoop在10亿行以上数据级别的情况下的查询延迟。这些都表明eBay在使用Hadoop技术等方面取得了不俗的成绩。
以下为译文:
在线拍卖网站eBay开源了一种名为Kylin的数据库技术,该公司宣称这项技术能够在Hadoop上支持PB级数据存储的快速查询。eBay并不是像Google和Facebook那样的大数据公司,但它运用Hadoop等技术已经达到了一个相当大的规模,Kylin就是一个很好的例子,这说明它在该领域的创新已经走在前头。
eBay在周三的一篇博客上分享了Kylin的细节,包括REST API、ANSI-SQL兼容性、连接分析工具Tableau和Excel,以及在一些查询上低于秒级的延迟。然而, Kylin最独特的特性是它如何处理scale。eBay表示,它可以查询数十亿行数据——在高达14TB的数据集上,速度比使用传统的Apache Hive工具快得多。
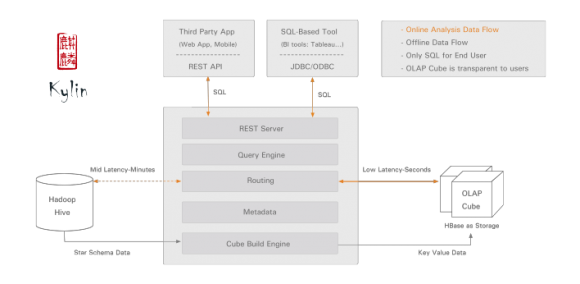
Kylin工作在一个很高级别上,它从Hive取数据;使用MapReduce预处理大型查询;然后将这些结果作为键值cuboids存储在HBase上。当用户用一组特定的变量值运行一个Kylin查询,结果已经准备就绪,不需要再重新处理,这和已经使用多年的分析型数据库完全不同。
下面是eBay分享的Kylin如何在公司内部的使用情况:
开放Kylin的时候,我们已经有一些eBay业务单元在生产中使用它。我们最大的用例是120+亿源记录生成的14 +TB cube。它的90%查询延迟小于5秒。现在,我们的用例瞄准分析师和业务用户,他们可以轻松的通过Tableau分析并且得到结果——不再需要Hive查询,shell命令等等。
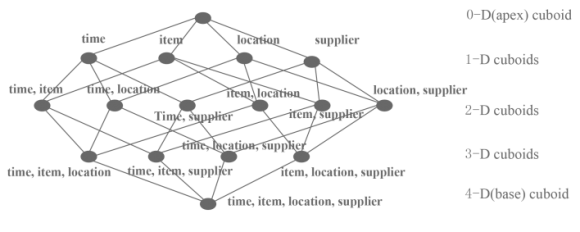
想要知道Kylin在与下一版本的Hive、Spark SQL以及Hadoop SQL分析的其他选项较量中谁会胜出,将是一件非常有趣的事情,Kylin作为YARN资源管理器一部分可以在Apache Hadoop的最新版本上获得。我猜它会慢一点,但比内存选项或那些不需要MapReduce处理的更具扩展性,不过这对于那些仍然在运行更早软件版本的用户可能是一个可靠的选择。
|
|
|





