|
|
|
|
如何创建一条可靠的实时数据流
|
| |
|
作者:TigerMee 来源:CSDN 发布于 2016-6-3 |

|
|
|
|
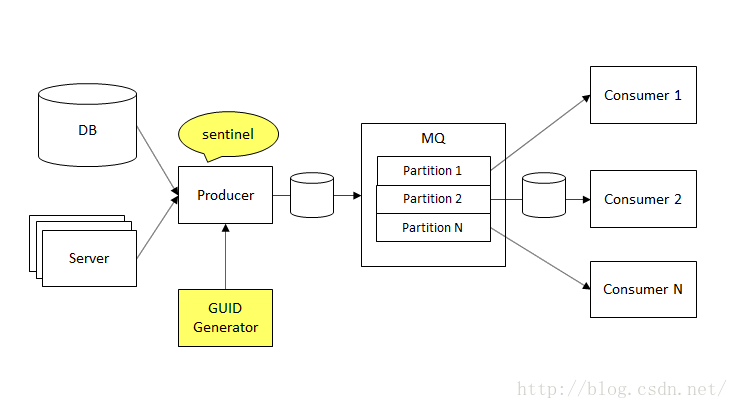
数据的生命周期一般包含“生成、传输、消费”三个阶段。在有些场景下,我们需要将数据的变化快速地反馈到在线服务中,因此出现了实时数据流的概念。如何衡量数据流是否“可靠”,不同的业务之间关注的指标差别很大。根据对大量业务场景的观察,我们发现对数据流要求最严格的业务场景往往和钱有关。
在广告平台业务中,广告的预算和消费数据。
广告主修改广告预算,投放系统首先将新的预算更新到数据库,然后需要将其同步到检索端。检索端将广告的预算和已消费金额作对比,重新决定广告是否有效。如果没有及时更新,会导致广告超预算消费或者没有及时上线,无论哪种情况,损失都将由广告平台承担。
广告的消费数据一般在广告发生特定事件的时候产生(展现,点击,转化等)。当产生消费数据时,需要将其同步到检索端,检索端更新广告的已消费金额,并和广告的预算做对比,重新决定广告是否有效。如果没有及时更新,会导致广告超预算消费,损失将由广告平台承担。
在电商业务中,商品的库存和价格。当商品库存变少时,如果没有及时同步到服务端,会使用户在结算时才发现商品已无货,伤害用户体验,甚至导致用户流失。一个极端的业务场景是秒杀。同样,如果商品的价格变高时没有及时同步到服务端,会导致用户在付款的时候发现价格变高,伤害用户体验,甚至导致用户流失。另外,如果库存增加或者价格降低时,没有及时同步到服务端,会流失可能带来的交易,带来的损失也只能是电商平台承担。
在电商业务中,用户的消费数据。有些电商业务中允许用户预充值,用户的账户可能会有余额。如果用户产生了消费,但订单和余额并没有及时更新,可想而知会导致用户产生很大的疑惑。
因此,本文重点讨论一下这些业务场景下对实时数据流的要求。相信在这些场景下都可以认为是可靠的实时数据流,可以很容易适应其他业务。在这些场景下的实时数据流中,往往最关心三个指标:可用性,准确性,实时性。
可用性
最基本的要求,可靠的实时数据流必须要高可用的。
准确性
准确性表示数据流的消费端接收的数据,和数据流发送端发送的数据保持严格一致。也就是常说的“不重不漏”。在有些场景下,如果消费端的操作满足“幂等性”,那么对“不重”的要求可以放宽。但是对“不漏”的要求往往一般是不能妥协的。
实时性
实时性表示数据的传输要满足低延时。延时一般定义为,一条数据从被发送端发送到被消费端接收之间的时间。不同的场景对实时性的要求不同,一般分为秒级和分钟级。
为了方便讨论,我们以一个最简单的实时数据流系统为例,其包含三个模块:生产者,传输模块,消费者。复杂的实时数据流系统可以认为是这三个模块的多次组合。一般来说,我们会使用 Message Queue 作为数据的传输模块,因此在下文中使用MQ来代替传输模块。接下来我们从三个方面讨论如何保证实时数据流的可靠。
可用性
成熟的 MQ 系统(例如kafka)都用保障高可用性的方案。生产者和消费者我们一般是使用集群来提高可用性。
在生产者端,对可用性的定义包含两重含义:
数据总是能被生成的。
数据总是能被发送到 MQ 的。
具体分两种情况。一种情况是数据量非常大,但是能容忍在极端情况,有很小一部分的丢失(例如广告的消费数据)。另一种情况是数据量不是特别大,但对准确性要求非常高,数据是严格不能丢失的(例如用户充值数据)。两种情况的处理方案有所不同。
第一种情况,在消息生成的时候,生产者一般都会先落地到本地磁盘,再由一个单独的程序从磁盘读取数据并发送到 MQ。这样有几个好处:
当生产者发生宕机的时候,并不影响数据的继续发送。生产者重启或者迁移到备用机器后,数据可以继续生成并发送。
避免因为网络抖动或者 MQ 性能出现问题时,影响生产者的对外服务质量。一般来说,数据是生产者在对外提供服务的过程中产生的。如果由生产者直接将数据写入 MQ,为了保证数据和对外响应结果的一致性,不能使用异步写的方式,需要同步写。因此在出现网络抖动或者 MQ 写延迟过长的时候,会导致生产者无法对外提供服务。
降低生产者代码复杂性。
这个将磁盘数据发送到 MQ 的程序一般仅仅是调用 MQ 的library,可以非常简单,减少了出错导致崩溃的可能性,其开源方案是 Flume。实战中,Flume + Kafka 已经有非常成熟的方案,而且非常稳定。
第二种情况,生产者一般是将数据直接写入一个可靠的存储系统中(例如数据库),再由一个单独的程序将数据从存储系统中读出并写入到 MQ。
同样,在消费者端,也是先使用 Flume 将数据落地到本地磁盘。如果消费者发生了宕机,也并不影响 Flume 继续从 MQ 读取数据。在消费者重启或者迁移到备用机器以后,可以继续之前的工作。
这样,生产者和消费者都可以认为是在使用磁盘作为介质和 MQ 在通信,而不是网络,而磁盘的可靠性往往比网络更高。另一方面,生产者和消费者可以更专注于其本职工作,使用 Flume -> Kafka -> Flume 的开源方案,也避免重复开发。
虽然 Flume 在使用过程中非常稳定,但如果是对可用性要求非常高的系统,我们仍然要考虑在 Flume 程序崩溃甚至磁盘损坏时的恢复方案。尤其在磁盘发生损坏时,我们往往无法准确定位生产者哪些已经生产的数据没有被发送到 MQ。一个典型的方案是重做,即将我们无法确定是否已经发送到 MQ 的数据全部重发一次。因此,在消费者端,保证操作的幂等性是非常重要的。
准确性
准确性可以简单表述为“不重不漏”。“不重”的保证比较困难,在上文已经讨论,在数据流发生异常的某些情况下,我们是无法或者相当麻烦才能定位哪些数据已经发送到 MQ 中,因此需要批量重做,这就会导致 MQ 中有重复的数据。因此,一般的方案往往都是将消费者设计成操作幂等性的,这样就能够容忍数据重复的情况。
“不漏”在设计到财务的系统中往往不能妥协,可以延迟,但不能遗漏。
基于防御性编程的思想,我们做好任何上下游交互的模块都可能出错的准备,并提供更高层次的协议保证业务的正确性。例如,在向 MQ 写入数据时,我们要假定及时 MQ API 返回成功状态,数据在 MQ 中仍然是可能被丢失的,message id 机制也不是100%可靠的。 那么,我们如何验证生产者发送的数据,经过 MQ 之后一定能够到达消费者?我们需要在生产者和消费者之间建立新的协议。
协议的第一步是为每条数据做一个唯一的标示,即 GUID。更进一步,我们希望 GUID 能够可读,并且能表示数据的先后顺序。为了满足这个需求,我们需要一个高可用的能够产生严格递增的 ID 的服务。这是另一个很大的话题,在这里不展开。有了这个服务,在生产者发送数据前,先向这个服务请求一个 ID,附加到一条数据上,然后再传输。
在消费者端,有两个方案进行验证。一个方案是生产者要保证发送到数据 ID 是严格递增的。消费者验证前后两条数据的 ID 是否连续。如果不连续,即认为是数据有丢失,停止继续消费,通知生产者进行到错误恢复流程。待生产者恢复后,通知消费者继续消费。
另一个方案生产者在发送数据时,除了给每条数据附加上自己的 ID,还要附加上其前一条数据的 ID。这样消费者通过两个 ID 可以验证数据是否有丢失。这个方案的好处是,不需要生产者保证数据的 ID 是连续的。
在实战中,生产者往往将数据写入到一个 Topic 的多个 Partition,每个消费者只消费指定 Partition 的数据,因此同一个 Partition 内的数据 ID 往往是不连续的。因此,这种方案更多的被采纳。
实时性
实时性对系统带来的影响往往弱于准确性。从文章开头的案例讨论可以看出,实时性不好往往也导致业务上的经济损失,尤其在一些流水很大的系统中,可能导致非常可观的经济损失。
为了提高实时性,我们一般通过几个手段:
减少网络通信
上下游服务尽量同机房甚至同机架部署
如果一定出现跨机房(尤其是异地机房)的通信,在机房间使用专线
尽可能少地拆分服务是最有效的方法。这需要在系统的扩展性、伸缩性和成本之间做好权衡,根据业务需要设计方案,避免过度优化。
实时性的另一个问题是我们如何监控数据的延迟,并在延迟过高的能及时发现并处理。一个常见的方案是使用“哨兵数据”。生产者定期(例如每5分钟)向 MQ 写入一条固定格式的数据,这条数据必须包含的字段是数据生成的时间,这条数据成为哨兵数据。消费者需要监控,是否在经过一个指定的时间间隔能接收到“哨兵数据”。如果接收不到,说明生产者或者 MQ 出现了问题。如果接收到了,将数据的生成时间和接收时间做对比,如果时间间隔超出阈值,说明延迟过大。无论哪种情况,都应该触发报警,甚至有些依赖于数据流实时性的服务都要同时停止服务。
对绝大多数实时数据流系统来说,可用性、准确性、实时性,三个指标考虑的是优先级依次降低,实现的代价也是依次增长。在不同的业务场景中,对“可靠”的定义也有所不同。可能有些系统数据丢失1%对业务的影响不大,如果要保证100%准确带来的成本会大幅增加;也可能有些系统分钟级实时和秒级实时对业务的影响不大,但如果从分钟级提高到秒级成本会大幅增加。因此,在架构设计中,一定要结合具体业务场景,综合考虑和权衡服务质量、用户体验、系统成本等多方面因素。
|
|
|
|
|





