介绍
最近我开始使用Eclipse作为我的开发环境,部分原因是因为在我进行开发的许多平台上都可以使用Eclipse来工作,还有部分原因是因为Eclipse是展示人人皆可作出贡献的开放、可扩展环境的优势的一个极好的例子。我开始研究其他人提供的对Eclipse的扩展。例如,当用到xml文件时,我使用XMLBuddy插件。该插件对于我的工作很有助益。因为最近一直在写Developer's
Notebook,所以我很想知道是不是已经有人写了关于Hibernate的插件,事实上,有好几个这样的插件正在开发。在这篇文章中,我们将探索其中之一:Hibernate
Synchronizer.
Hibernate Synchronizer
在我找的和Hibernate有关的插件中,Hibernate Synchronizer最令我感兴趣,因为它为我在Developer's
Notebook书中采用的以映射为中心的工作流(mapping-centric workflow)提供了最好的支持。(可以用多种方法使用Hibernate,你可能会试试其它一些插件,它们提供的方法可能正是你自己特定环境所要求的)。事实上,当使用Hibernate
Synchronizer时,如果你改变了映射文件,你不需要为更新相应的java文件而劳心费神。当你编辑映射文件时,和Eclipse采取的方法类似,该插件自动更新你的java代码。还不止于此,还提供了比Hibernate内建的代码生成工具更多的功能:它为每个映射对象创建一对类(
a pair of classes),其中一个是基础类,当你改变映射内容时,它可以随意重写这个类;另一个类作为该基础类的子类,在子类中,你可以添加具体的商业逻辑和另一些代码。使用这个插件生成java代码时,不用象使用Hibernate内置的代码生成工具那样,担心其它代码(如商业逻辑的代码)会在你的眼皮底下消失。
对于以Hibernate影射文档为基础的方法,还有一些其它的好处,Hibernate Synchronizer有一个新编辑器,当编辑这类文件时,为Eclipse添加了智能辅助和自动完成功能。一个比较好的、以DTD驱动的XML编辑器,如以前提及的XMLBuddy,也可以完成部分功能。与此相比,Hibernate
Synchronizer利用对影射文档语义的了解,提供了更进一步的功能。例如,提供了对属性和影射关系的可视化显示,创建新元素的向导界面,象以上提及的一样,缺省设置情况下,当你编辑影射文档时,编辑器会自动生成数据访问类(data-access
class).
当然还有其它一些功能,在Eclipse的新建(New)菜单中,提供了一个向导,可以用来创建Hibernate配置文件和映射文件,在包资源浏览器(package
explorer)和其它一些合适的地方增加了上下文菜单,方便调用和Hibernate相关的功能。
好了,在这些抽象的描述之后,到了开始做实事的时候,当然,这正是你兴趣所在,不然你就不会读这篇文章。怎么安装和使用呢?下边一一解释。
安装
Hibernate Synchronizer可以用Eclipse内置的更新管理器(Update
Manager)来安装。对Eclipse 2.1和即将发布的Eclipse 3的用户提供了不同的更新站点。(因为用Eclipse作关键性的工作,我仍使用作为产品发行的2.1版。当我写这篇文章的时候,Eclipse
3已经进入了“候选发布”阶段。我希望当我今夏晚些时候从JavaOne回来时,我可以更新到版本3的产品发行版。提及这个的主要原因是因为我想强调一下,这些指南是以Eclipse
2的角度的来讲解,毫无疑问,一些命令和窗口会在版本3中发生变化,因此,当你使用Eclipse
3时,你应当做一些相应的调整。我印象中Hibernate
Synchronizer自己的install instructions是针对Eclipse 3,也许这对你有所帮助。
启动Eclipse,顺次单击帮助(Help) ->软件更新(Software Updates) -> 更新管理器(Update
Manager)来打开更新管理器,当安装/更新(Install/Update)透视图打开之后,在功能更新视图(Feature Updates)中用右键单击(如果你用的单键,你需要control-click)。选择新建(New)
-> 站点书签(Site Bookmark),如图1中所示。
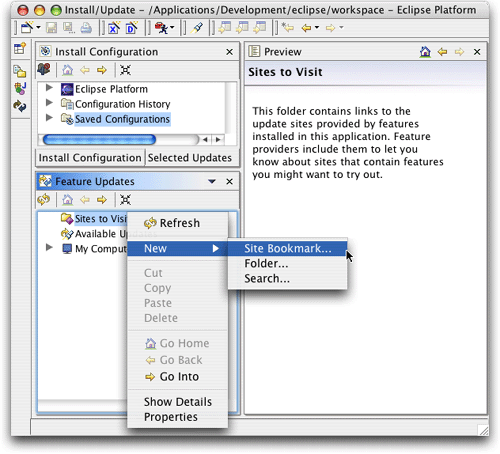
图 1 在更新管理器中添加Hibernate Synchronizer插件的更新地址
|
在弹出对话框中,输入适合你的Eclipse版本的插件地址:
・Eclipse 2.1: http://www.binamics.com/hibernatesync/eclipse2.1
・Eclipse 3: http://www.binamics.com/hibernatesync
还需要为新建的书签命名,"Hibernate
Synchronizer"就是个很贴切的名字。图2中显示的是在Eclipse
2.1.2中填完所有需要的信息后的对话框。填完之后,你可单击完成(Finish)按钮来完成增加书签。
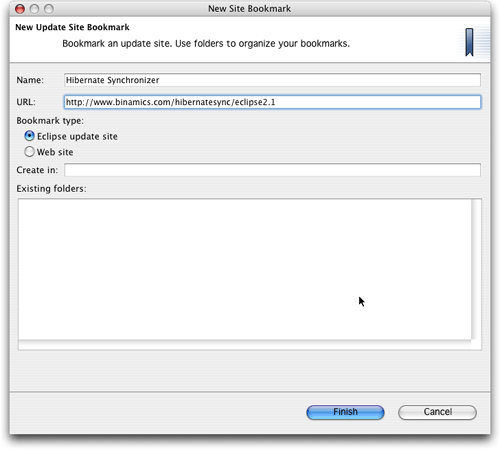
图 2. Hibernate Synchronizer插件更新站点书签
|
单击完成(Finish)后,新建的书签就会出现在功能更新(Feature
Updates) 视图中,如图3中所示.
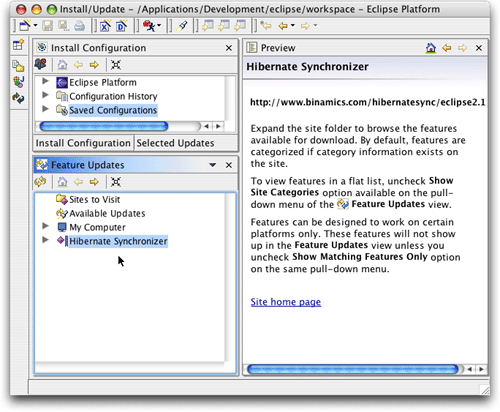
图 3. Hibernate Synchronizer站点已经可以使用
|
为了实际安装该插件,单击该书签左边的三角形符号,然后再次单击在书签下边出现的条目左边的三角形符号,继续这个过程,一直到书签下边出现的条目中出现该插件的图标。单击该条目,就会出现一个可以让你安装的界面,如图4所示。
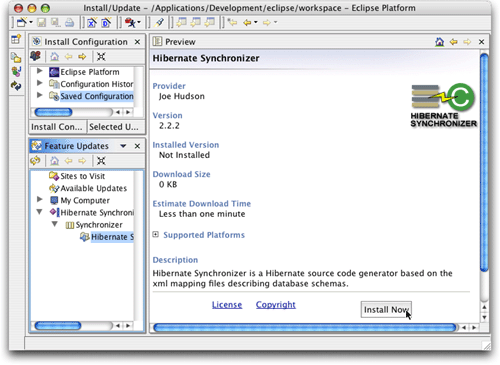
图 4. 准备开始安装插件
|
单击Install Now,让Eclipse引导你完成安装(如图5-10).
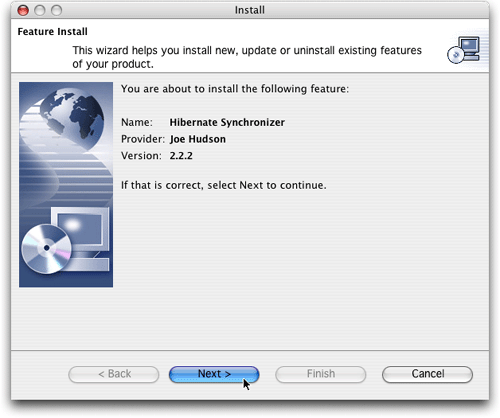
图 5. 安装Hibernate Synchronizer
图 6. 许可协议
|
你可以看看下边Trade-Offs部分对许可协议的一些讨论。当你打算在实际的项目中使用该插件时,想必你会仔细研究该协议。我认为也许好一点,不过该插件基于GPL协议,而不是开放源代码,令人迷惑。
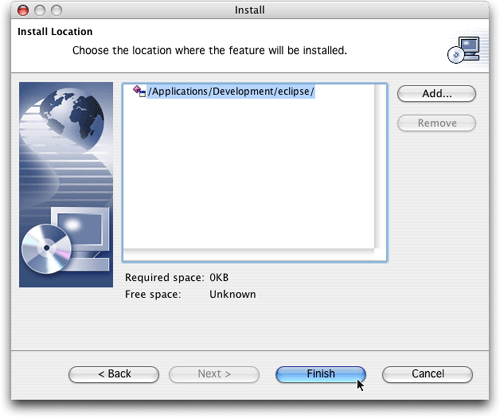
图 7. 选择安装位置,缺省的已经很好了
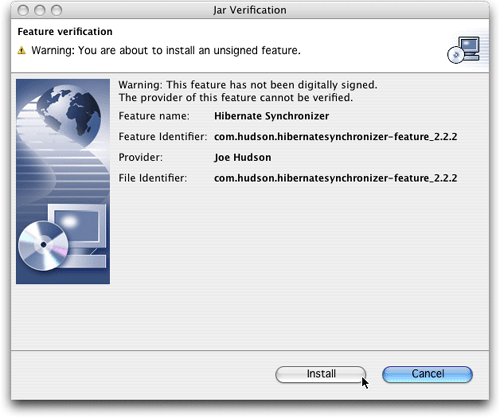
图 8. 安装没有签名插件时的标准警告
图 9 正在进行安装
图 10. 完成安装
|
现在已经完成安装,你需要退出,然后重新启动Eclipse以使所做的更改生效。看上边的对话框好像说能够自动重新启动Eclipse。,以我的经验,Eclipse只会退出,还是需要你自己手工重新启动。这可能是Max
OS X平台上Eclipse 2.1的一个局限。Eclipse 3已经许诺把对OS
X的支持列入第一级别。无论如何,这只是个小问题。如果你需要重新启动Eclipse,现在就可以这样做。安装完之后,接着需要对其对其进行配置,以便在项目中使用。
配置
重新启动Eclipse后,关闭安装/更新透视图。打开一个使用Hibernate的Java工程.如果你已经完成了Developer's
Notebook,一书中的例子,那么就有几个目录可供你选择,这里以书中第三章中的例子来说明。第三章是可以在线免费获得的样章,你还可以从该书的站点下载所有例子的源代码。
如果你打算使用其中的一个例子来新建一个Eclipse工程,选择文件(File)
->新建( New )-> 工程(Project),选定工程类型,然后单击下一步(Next),填入该工程名(我填的是"Hibernate
Ch3",如图11所示),不要复选使用缺省检查框(Use
default),这样你可以告诉Eclipse从哪里找到已经存在的工程目录,单击浏览按钮(Browse)来定位目录。选定工程目录后可以单击完成(Finish)来创建工程。不过,一般情况下我喜欢单击下一步(Next)来复查Eclipse为此工程所作的设置(当然,如果发现有些配置不对,总是可以选择回退来修改这些设置。不过,我总是发现,如果有一个库文件丢失或是其它一些原因,会有非常多的错误和警告信息)。
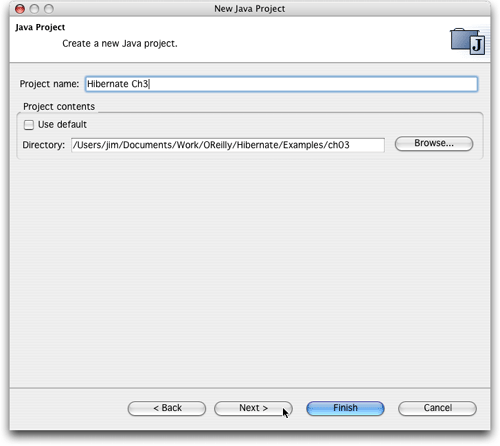
图 11. 创建一个需要使用Hibernate的新工程
|
在当前情况下,我的谨慎有点多余。Eclipse准确的算出了目录是如何组织以及是用来干什么的,找到我为使用Hibernate和
HSQLDB
数据库而下载的第三方库(下载和安装的详细过程可以参看书中第一章)。如此聪明的适应能力是Eclipse优点之一。图12显示新工程已经打开,准备好可以用来做实验。从这个图中也可以推断Eclipse不喜欢调整窗口大小使其小到形成合适的屏幕布局。从现在开始,显示的屏幕截图只显示窗口的一部分,而不是完整的窗口。
图 12. 使用Chapter 3例子的工程
|
下一个需要做的工作是创建一个Hibernate配置文件,提供给Hibernate
Synchronizer使用。在src目录中已经有了一个hibernate.properties文件,这是书中例子使用的配置。这里有个问题,坏消息是Hibernate
Synchronizer只能使用XML样式的Hibernate配置文件。这样,就需要把hibernate.properties中的内容移植到XML样式的配置文件hibernate.cfg.xml中。好消息是,这正是Hibernate
Synchronizer创建配置文件向导第一次大显身手的时候。选择文件(File)
->新建(New) -> 其它(Other),然后在弹出对话框选取刚可用的Hibernate类,选取
Hibernate Configuration File,然后单击下一步(Next).
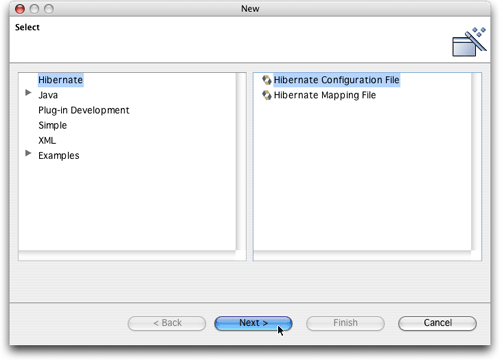
图13 打开Hibernate配置文件向导
|
打开向导时,保存文件的位置和在Eclipse中现在选择的文件有关。请确保把该文件保存在src
目录中。添加其余一些向导需要的信息,这些信息应该和配置文件的版本相一致,如图14中所示。值得注意的是,和用Ant来控制Hibernate的运行(书中使用就是这种方法)不同,这里你无法控制Hibernate运行时的当前工作目录,因此你需要在URL文件中使用路径的全称。我自己的添加的URL值(有点难看)为
jdbc:hsqldb:/Users/jim/Documents/Work/OReilly/Hibernate/Examples/ch03/data/music.
(如果有人知道怎么让Eclipse或是Hibernate
Synchronizer使用一个工程特定的目录,你可以告诉我,我很想知道。因为我才开始使用Eclipse,是个新手。如果有人告诉我这是可能的,只是因为我不知道怎么做而已,我一点也不会感到吃惊)
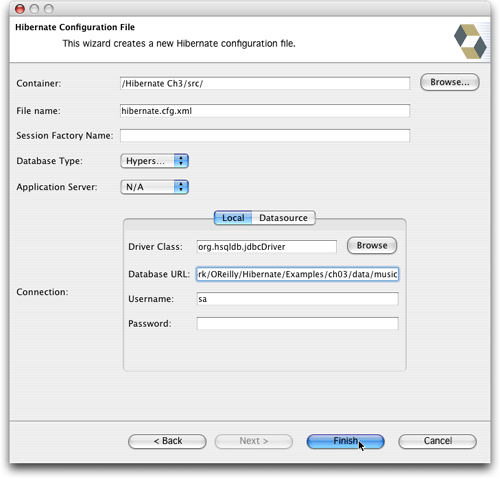
图14 添加配置文件信息
|
添加Driver Class 的方法有点奇怪,你需要单击Browse按钮,然后开始输入driver的类名(译者注:你需要确定该driver类在该工程的类路径中)。如果你输入"jdbcD",窗口就会出现这个选择,很容易就可以从中选取一个。具体如图15所示。
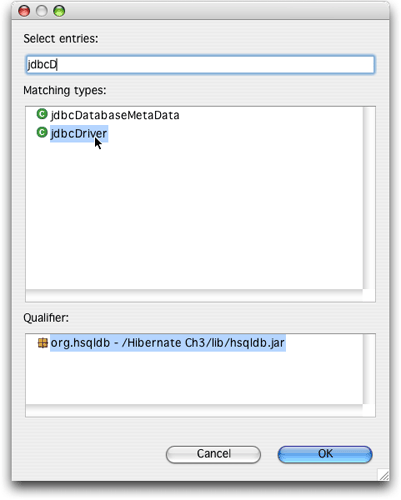
图15 指定HSQLDB的driver类
|
只要添加如图14中那些属性值就可以。完成后单击Finish来完成创建配置文件。Hibernate
Synchronizer
现在已经可以开始使用了。完成创建文件后,配置文件会打开,这时候你就可以看看Hibernate
XML格式的配置文件的结构和细节。
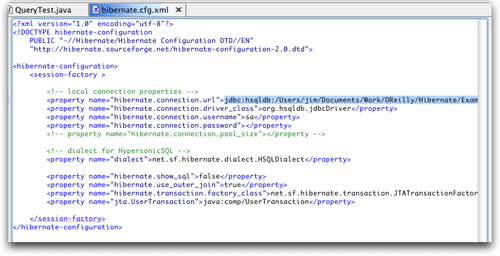
图16 生成的配置文件
|
要想测试配置文件是否可用,有一个又快又简单的方法:使用向导来创建一个影射文件。选择文件(File)
-> 新建(New) -> 其它(Other),选取Hibernate类别,然后再选Hibernate
影射文件,单击下一步(Next)。向导出现的时候,其中有些属性已经自动填入了在配置文件中相应属性的值,单击Refresh(确保可以通过这些信息和你的数据库相连)。和数据库连接后,会显示库中的表,这里只有一个TRACK表。第一次使用的时候,不知什么原因,需要你指定包含HSQLDB驱动的.jar文件的路径。好在你只需要指定一次。只要你认为工作正常(译者注:显示了数据库中有权限访问的表),单击Cancel。试验中使用已有的影射文件,不需要实际创建一个。
生成代码
这可能是你一直在等待的部分。我们能用这个插件来做什么?好,马上就开始。为Hibernate影射文档提供一个新的菜单条目。
右击(如果是单键鼠标,在按住Control键的同时点鼠标键)一个影射文档,菜单条目中会显示几个和Hibernate相关的选择(如图17所示),其中有一个和synchronize有关,这是一个手工方法,可以让Hibernate
Synchronizer产生和该影射文档相对应的数据访问对象。
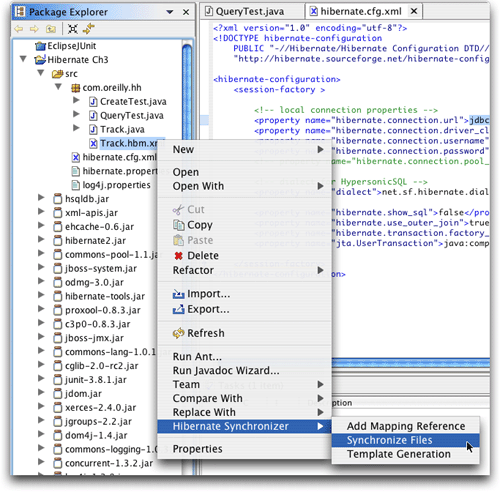
图17 Synchronizer插件为影射文档提供的几个菜单项
|
Add Mapping Reference
选项也很有用,当你单击该项时,会把相应的影射文件增加到Hibernate配置文件中,表明该文件是影射文档,因此你不需要在源代码中增加任何信息要求相应的影射文件进行设置。现在让我们看看选取Synchronize
Files后的结果。
事情开始变得有趣,出现了两个子包,一个是“base”的DAO,Hibernate
Synchronizer所有,可以在任何时候重写,一个是继承那些DAO类的商业对象,不会被覆盖,也就给了我们一个机会,可以在其中加入商业逻辑(具体如图18中所示)。
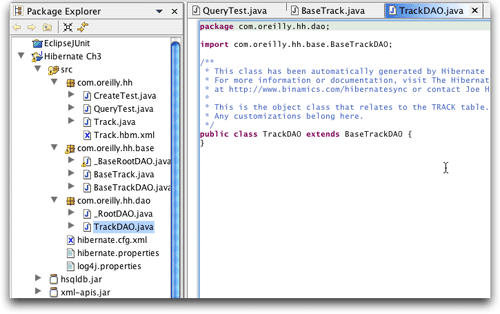
图18 同步后的DAO,图中显示的是我们可以编辑的子类
|
和Hibernate的代码生成工具相比,用该插件生成了更多的类。这是优点,也可能是一些潜在的缺点,将在Trade-Offs
部分进行讨论。你可以在工程配置文件中选取要生成的类和它们所在的包的结构。我可以证明这点,但现在的发行版有个bug
,,无法访问Mac OS X上的配置界面。针对该bug的一个补丁已经做好了,但仍没有发布。
基于Hibernate Synchronizer网页上的例子,和以下这个类一起,用那些新的数据访问对象来试着把一些数据放入数据库中。看起来和标准的Hibernate代码生成工具生成的版本(在Hibernate:
A Developer's Notebook一书的39-40页)很相似,甚至更简单一些。因为Hibernate
Synchronizer生成的类为你的每个数据库操作都创建和提交一个新事务,因此在与此类似的简单情况下,你不需要自己来设置事务(当然,如果你需要把一组操作作为一个单独事务,有很多方法可以做到这点)这里是新版本的代码。
package com.oreilly.hh;
import java.sql.Time;
import java.util.Date;
import net.sf.hibernate.HibernateException;
import com.oreilly.hh.dao.TrackDAO;
import com.oreilly.hh.dao._RootDAO;
/**
* Try creating some data using the Hibernate Synchronizer approach.
*/
public class CreateTest2 {
public static void main(String[] args) throws HibernateException {
// Load the configuration file
_RootDAO.initialize();
// Create some sample data
TrackDAO dao = new TrackDAO();
Track track = new Track("Russian Trance", "vol2/album610/track02.mp3",
Time.valueOf("00:03:30"), new Date(), (short)0);
dao.save(track);
track = new Track("Video Killed the Radio Star",
"vol2/album611/track12.mp3", Time.valueOf("00:03:49"), new Date(),
(short)0);
dao.save(track);
// We don't even need a track variable, of course:
dao.save(new Track("Gravity's Angel", "/vol2/album175/track03.mp3",
Time.valueOf("00:06:06"), new Date(), (short)0));
}
}
|
当我写这个的时候,有Eclipse在手边真是太好了
,我已经忘了当写书中例子的时候多么想念智能代码完成功能,有另外几件事情JDT也发挥了作用。
为了在Eclipse中运行这个简单的程序,需要设置一个新的运行配置。用CreateTest2.java作为当前文件,选择运行(Run
)-> 运行...(Run...)。然后单击新建(New),因为该类有一个main()
方法,Eclipse推断出要运行该工程的当前类。Eclipse为新的运行配置取的名字,CreateTest2,很合适。屏幕窗口看起来如图19中所示,单击运行来在数据库中创建一些数据。

图19 准备在Eclipse中运行创建数据的测试程序
|
如果你确实按照上边说的来做,你会发现第一次的尝试运行失败。Hibernate抱怨配置文件中连一个映射文件都没有参考,为了运行程序,至少需要一个这样的文件。这也是为什么XMLBuddy在图16底部用黄色下划线发出警告。可以很容易修改该错误,你只要在包资源浏览器(Package
Explorer)中的Track.hbm.xml这个影射文档上单击右键,在Hibernate
Synchronizer子菜单中选取Add Mapping Reference(如图17中所示),这样XMLBuddy就不会再抱怨XML文件有错误,程序也可以继续向前。不幸的是,没有向前推进我们所愿的那样远,下一个问题又出来了。Eclipse中显示的下一个错误是“不能在JNDI中找到JTA
UserTransaction initial context”。不止我一个人犯这种错误,因为在a
forum thread中有这样的讨论,而且到目前为止仍然没有找到一个解决方法。
既然我知道不需要使用JTA,我倒是很想知道为什么Hibernate竟然会使用JTA?打开Hibernate配置文件,如图16所示,看看是不是Hibernate
Synchronizer在其中加入了可疑的内容。看了配置文件后,可以确定,有一些行看起来是罪魁祸首:
<property name="hibernate.transaction.factory_class">
net.sf.hibernate.transaction.JTATransactionFactory
</property>
<property name="jta.UserTransaction">
java:comp/UserTransaction
</property>
|
一旦把那些行变成注释后,再次运行程序。这次,也就是第三次运行成功。我在自己计算机上运行没有一点错误,数据已经保存到数据库中。运行
ant db 这个target(在Developer's Notebook一书的第一章有相应的解释)可以把表中所有的数据显示出来(不可否认,这也许有点简单),如图20中所示。如果你跟着这篇文章中顺序来做的,而不是跟着书中步骤一步一步来的,你需要先运行ant
schema来创建数据库中的表,或是删除以前试验留下的数据。
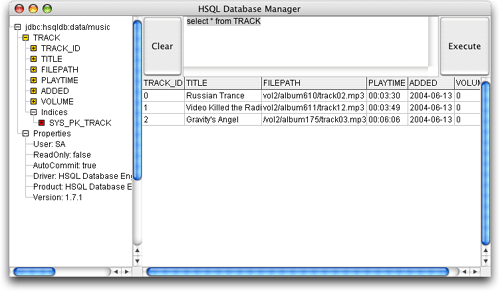
图20 在Eclipse中运行Ant
|
你可以在Eclipse内运行Ant的target,方法是用右键单击包资源浏览器(Package
Explorer)中的build.xml 文件,选择菜单中的运行Ant(Run
Ant),然后在弹出对话框中选择你要运行的target,如图21所示。这个功能很cool。
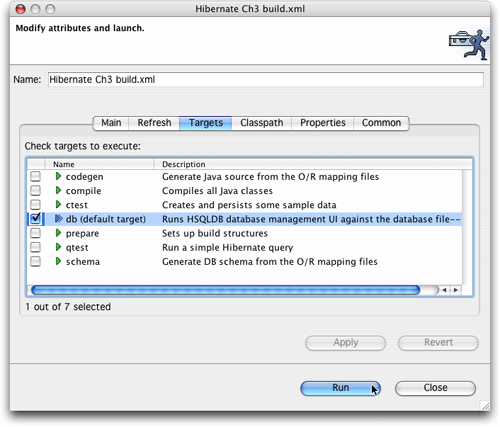
图21 在Eclipse中运行Ant
|
查询数据相当简单、直白,即使Hibernate
Synchronizer产生了很多辅助方法来使用指定查询,我认为这些没有什么用处,都是运行查询,然后返回包含结果的列表,而不是返回一个Query对象,让你直接使用该对象。这使你不能使用任何Query提供的、方便的、类型安全(type-safe)的参数设置方法,因为这个,我打算让_RootDAO对象提供一个Session对象,可以用“老式”的方法来使用Hibernate。公平来说,我认为如果编辑Hibernate
Synchronizer
用来生成代码所使用的模板,就可以生成想要的任何方法,如果有一个项目,要用到该插件,可以肯定我会试着这么做。
实际上,进一步考虑,当你得到一个活动的Session时,你只能使用Query,而这些DAO对象已经提供为相应功能最佳的实现。如果你和我在例子中使用查询的方法一样,那就需要你自己来实现session管理。你能够把session管理内嵌于你自己所写的那一半DAO中,这样可以给你提供两方面的好处。(译者注:和有base的java
POJO对象一样,对于DAO,该插件也生成一对类,一个base
DAO给该插件用,一个是继承该base DAO的自定义DAO,你可以在其中添加商业逻辑)。这也是Hibernate
Synchronizer把类分隔开来如此有用的另一个原因。对该插件的远见在下边做了一点研究
不管怎么说,下边是我第一次使用的代码,和书中48-49页上的代码功能基本一致:
package com.oreilly.hh;
import java.sql.Time;
import java.util.ListIterator;
import net.sf.hibernate.HibernateException;
import net.sf.hibernate.Query;
import net.sf.hibernate.Session;
import com.oreilly.hh.dao.TrackDAO;
import com.oreilly.hh.dao._RootDAO;
/**
* Use Hibernate Synchronizer's DAOs to run a query
*/
public class QueryTest3 {
public static void main(String[] args) throws HibernateException {
// Load the configuration file and get a session
_RootDAO.initialize();
Session session = _RootDAO.createSession();
try {
// Print the tracks that will fit in five minutes
Query query = session.getNamedQuery(
TrackDAO.QUERY_COM_OREILLY_HH_TRACKS_NO_LONGER_THAN);
query.setTime("length", Time.valueOf("00:05:00"));
for (ListIterator iter = query.list().listIterator() ;
iter.hasNext() ; ) {
Track aTrack = (Track)iter.next();
System.out.println("Track: \"" + aTrack.getTitle() +
"\", " + aTrack.getPlayTime());
}
} finally {
// No matter what, close the session
session.close();
}
}
}
|
TrackDAO为我们提供了一个很好的功能:静态常数,使用这个功能,可以用来进行指定查询(named
query),这就消除了由于输入问题而导致运行时错误的任何机会。我欣赏这个功能。为该测试类设定运行配置,然后运行,输出结果正和我想的一样,如图22所示。
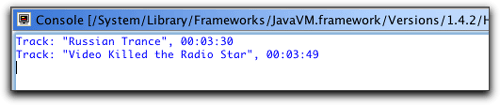
图22 Eclipse控制台窗口显示的查询结果
|
如上所述,这个类运行后,借助于Hibernate
Synchronizer提供的模型,我想到有一个更好的方法可以实现这个功能。把查询放到TrackDAO中去,这里才是查询方法真正属于的地方,指定查询(named
query)是和该DAO关联的映射文件的一个功能。
package com.oreilly.hh.dao;
import java.sql.Time;
import java.util.List;
import net.sf.hibernate.HibernateException;
import net.sf.hibernate.Query;
import net.sf.hibernate.Session;
import com.oreilly.hh.base.BaseTrackDAO;
/**
* This class has been automatically generated by Hibernate Synchronizer.
* For more information or documentation, visit The Hibernate Synchronizer page
* at http://www.binamics.com/hibernatesync or contact Joe Hudson at joe@binamics.com.
*
* This is the object class that relates to the TRACK table.
* Any customizations belong here.
*/
public class TrackDAO extends BaseTrackDAO {
// Return the tracks that fit within a particular length of time
public static List getTracksNoLongerThan(Time time)
throws HibernateException
{
Session session = _RootDAO.createSession();
try {
// Print the tracks that will fit in five minutes
Query query = session.getNamedQuery(
QUERY_COM_OREILLY_HH_TRACKS_NO_LONGER_THAN);
query.setTime("length", time);
return query.list();
} finally {
// No matter what, close the session
session.close();
}
}
}
|
以上代码,看起来更好(nice)、更为清晰(clean),QueryTest3中的main()方法更是得到了大大简化
public static void main(String[] args) throws HibernateException {
// Load the configuration file and get a session
_RootDAO.initialize();
// Print the tracks that fit in five minutes
List tracks = TrackDAO.getTracksNoLongerThan(Time.valueOf("00:05:00"));
for (ListIterator iter = tracks.listIterator() ;
iter.hasNext() ; ) {
Track aTrack = (Track)iter.next();
System.out.println("Track: \"" + aTrack.getTitle() +
"\", " + aTrack.getPlayTime());
}
}
|
很清楚,这是在Hibernate Synchronizer中用到指定查询(named
query)时所应采取的方法。很快测试一下就可以证实以上的代码输出同样的结果,而且这里的代码更好。
编辑映射文件
Hibernate Synchronizer一个主要
引人之处是为映射文件提供的有专业水平的编辑器,你可以配置该编辑器,这样当你保存文件的时候,可以自动重新生成相应的数据对象,.这只是你最后才会用到的功能。即使不使用该插件的代码生成器,可能你还是会用这个编辑器。当你编辑影射文档时,它可以为映射文档中的元素提供智能完成功能,还有一个你可以操作的映射文档的大纲视图。
如果你从Developer's Notebook下载的源代码,然后想用该插件的映射文档编辑器来编辑该文件,需要耍一个小花招。在下载文件中,影射文档的扩展名是".hbm.xml",而该插件仅仅对以"hbm"为扩展名的文件才调用影射文档编辑器。理论上,你可以在Eclipse中配置扩展名映射,以便两个扩展名都可以用该插件的编辑器,不过,我没有成功过,我在支持论坛上看到别人有同样的问题。因此,暂时来看,最好的办法就是重命名文件(如果用Ant来生成代码,确保修改build.xml文件的codegen这个target,使其也使用新扩展名)。
当我把Track.hbm.xml改名为Track.hbm时,包资源浏览器中该文件的图标更新为象Hibernate的logo。该文件的默认编辑器变为该插件的影射文档编辑器,如图23中所示。不知道什么原因,对这两个扩展名的文件,其它的Hibernate
Synchronizer选项都可用,令人奇怪的是,只有“hbm”结尾的文件可以用其编辑器。
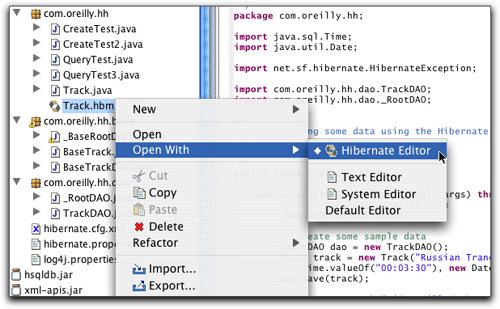
图23 Hibernate影射文档(扩展名为".hbm")的上下文菜单
|
编辑器对于你要在影射文档中增加的所有元素提供了上下文敏感的自动完成功能,图24举了两个例子。虽然如此,没有一个屏幕抓图能够真正显示如此功能的细节和有用之处。我鼓励你自己安装该插件,然后自己来试试这个编辑器.你很快就会发现当使用影射文档的时候,这个编辑器是多么有帮助。
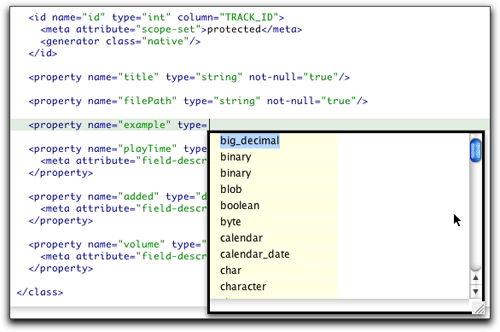

图24,25 影射文档编辑器中的自动完成功能
|
大纲视图,象图26中所示,可以用图形的方式显示类的结构,被影射的元素,指定查询和其它一些出现在影射文档中内容,同时也提供了几个向导,帮助你创建新项

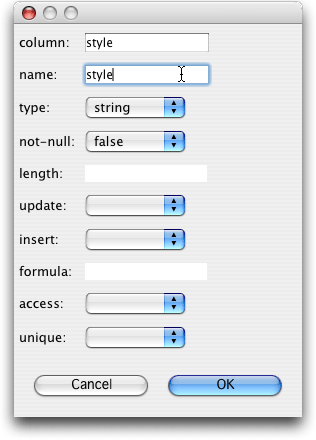
图26,27 影射编辑器的大纲视图以及“Add
property”向导
|
编辑器内的上下文菜单中有一项是Format Source Code,你可以用来对文档进行清洁和改变文档结构。编辑器内也有很多灵巧和有用的功能,看看它如何“成长”是一件有趣的事情。对我来说,唯一的不满是当你完成XML属性的时候,该编辑器用非常不同于JDT在java代码中使用的方法来帮助你管理引号,在它们之间切换有时令人迷失(JDT采用的方法可能只适于它自己,但一旦你信任它,这个方法看起来就有点魔力)
产生数据库中的表
和我的第一印象-一切都可以通过影射文档得到-不同,Hibernate
Synchronizer现在没有为创建或更新数据库提供任何支持。支持论坛上已经张贴了一个这样的功能要求,如果我们将来看到这些功能,我不会感到惊奇。这种功能应该不是很难。暂时,你不得不采用其他方法,如果你想从影射文档生成数据库,你可以象Hibernate:
A Developer's Notebook 一书中使用Ant一样来做到。下边描述的Hibernator插件支持在Eclipse中更新数据库。或许,我应该研究一下是否能够同时安装这两个插件。
好了,我当然希望这个简单介绍的指南能够让你对这个插件的功能有一个大致的了解,当然,我没有提及它的所有功能。如果文中有些内容激起了你的兴趣,那就下载,安装,自己试试。
Trade-Offs
很清楚,你可以用Hibernate Synchronizer来做灵巧的事情。我会在我自己的Hibernate项目中使用该插件吗?这个想法有其它一些优缺点需要考虑,可能现在还不是做决定的时候,直到需要用Hibernate来取代自家酿(当然非常简单)的、已经在工作的轻量级O/R工具时才能做出决定。这是个足够重要的改变,我们一直推迟做出决定,直到有其它原因出现。下边的因素在我的决定中占有重要分量。
在安装部分已经提及,有几个涉及到许可证的问题,该插件的论坛对这个也有些讨论。现在所采用的许可证是作了适合自己的修改后的GNU
GPL,删除了关于源代码共享的规定,保留了"copyleft"保护的其它方面。关于这个的合法性有些问题,作者正在找另外一个可用来替代的许可证。它的确切意图是保护该插件,不妨碍使用该插件生成代码的其它一些项目。不过还是值得仔细读一下现在的许可证,看看你是否相信该许可证已经达到其本来意图。否则,对你来说,会有很多风险
同样的讨论显示,作者本来想把该插件作为开源软件,但临时改变了主意,因为他觉得该插件还没有“琢磨”到足够给其他人以作为一个优秀的开源软件的程度。此后,他通过电子邮件和一些性急的人进行了交流,这些人的电子邮件非常讨厌,最终使他没有兴趣再分享整个源代码,真是令人感到悲哀。当然,和我们分享什么是他的权力。对于世界来说,这个插件是个礼物,作者不欠我们什么。但我希望其它用户的积极影响或许可以帮助说服他重新实行原来的计划-分享源代码。我真正重视可以得到源代码的工具,不仅是因为这是个很好的学习机会,而且意味着有了源代码,如果有需要,我(或其他人)可以马上修改出现的一些小问题。到目前为止,该插件的作者一直非常积极的回应用户的问题,但是没有人能够一个人做的象一个团队一样好,我们有些时候很忙,筋疲力尽,或是心情烦乱
Hibernate Synchronizer用它自己的模版和一套机制来生成你的数据访问类,这个事情有好的一面,也有坏的一面。好的一面在于它为你提供了比标准的Hibernate代码生成工具更多的功能。在自动产生的你所定义的数据对象的子类中嵌入商业逻辑,而不用害怕重新生成代码的时候有关商业逻辑的代码被覆盖,这是一个很大的额外好处。该插件生成的、使许多简单的类更简单的类提供了其它一些优秀的功能。
另一方面,这并不意味着当这个平台添加新功能或是有其它一些变化的时候,Hibernate
Synchronizer生成的代码会滞后。这个插件的代码也很有可能在支持Hibernate很少用到的方式方面存在一些bug,因为使用该插件的用户群很小,仅有一个人对其进行更新,你可以从论坛中看到这种现象的证据。
和许多事情一样,由你决定是否潜在好处胜过风险。即使你没有使用代码生成器,或许你会发现影射文档编辑器极端有用。如果你只是使用编辑器的自动完成和协助功能,你可以关闭automatic
synchronization。
如果你真的采用了这个插件,而且发现它很有用,毫无疑问,我鼓励你和作者联系,表达你的谢意,如果可能,可以考虑捐些钱以支持该插件继续开发。
其它一些插件
在我搜寻插件的过程中,我发现了其它两个插件,可以为在Eclipse中使用Hibernate提供支持(如果你知道其它一些插件,或是在将来的某一天偶遇其它的插件,我很有兴趣了解这些插件)。也许将来我会写一些关于这些插件的文章。
HiberClipse
HiberClipse看起来是另一个非常有用的工具,该插件采取的是数据库驱动的工作流方法:你已经有了数据库,想用该插件构造Hibernate映射文件和Java类文件。这种事很常见,如果你面对这样的任务,我肯定会推荐你使用该插件。该插件提供了一个很cool的功能
:在Eclipse中提供给你一个正在使用的数据库的图形化显示的“关系视图”(应该指出,当你从一个现存的数据库开始工作时候,Hibernate
Synchronizer也没有使你处于孤立无援的境地,New
Mapping File Wizard
可以连接数据库,然后根据它找到的内容生成映射文件,如图28所示)
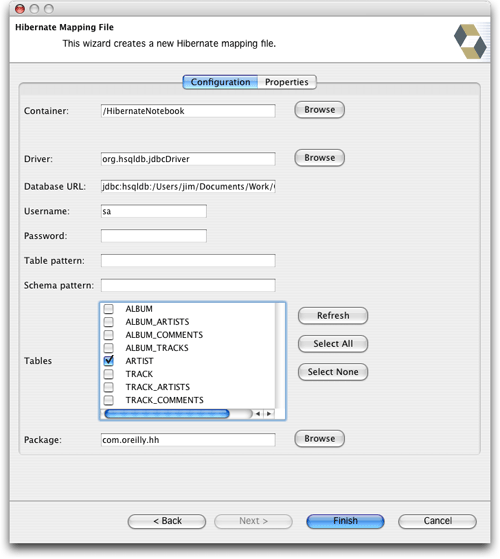
图28 Hibernate Synchronizer的创建映射文件向导
|
Hibernator
最后,Hibernator看起来向另一个方向倾斜,从你的Java代码来产生简单的Hibernate映射文档,然后可以由此创建(或是更新)数据库。另外,还提供了在Eclipse中进行数据库查询的能力。在这三个插件中,它处于开发的最早期,但是已经值得你时常关注,特别是该插件援引Hibernate开发小组的成员作为贡献者。