测试只是测试驱动开发(TDD)的意外结果之一;如果正确地应用,TDD 能够改进代码的整体设计。
演化架构与紧急设计 系列的这一期文章将介绍一个进一步扩展的示例,演示如何根据测试中显现的关注点进行设计。
本文是分两部分的文章的第二部分,讨论如何使用 TDD 在编写代码之前编写测试,并通过这个过程形成更好的设计。在
第
1 部分 中,我采用后测试开发方法(在编写代码之后编写测试)编写了完全数查找程序的一个版本。然后,使用
TDD(在编写代码之前编写测试,这样就可以用测试驱动代码的设计)编写了另一个版本。在第 1 部分的末尾,我发现我在用来保存完全数列表的数据结构类型方面犯了一个根本性错误:我最初根据直觉选用了
ArrayList,但是后来发现 Set
更合适。我将以这个问题为起点,讨论如何改进测试的质量和检查最终代码的质量。
使用更好的 Set 抽象的测试见清单 1:
清单 1. 使用更好的 Set 抽象的单元测试
_@Test public void add_factors() {
Set<Integer> expected =
new HashSet<Integer>(Arrays.asList(1, 2, 3, 6));
Classifier4 c = new Classifier4(6);
c.addFactor(2);
c.addFactor(3);
assertThat(c.getFactors(), is(expected));
}
|
这段代码测试我的问题领域中最关键的部分之一:获取数字的因子。我希望彻底地测试这个步骤,因为它是问题中最复杂的部分,所以也是最容易出现错误的。但是,它包含一个笨重的构造:new
HashSet(Arrays.asList(1, 2, 3, 6));。即使有了现代 IDE
支持,这行代码编写起来也很别扭:输入 new,输入 Has,执行代码探察;输入
<Int,再次执行代码探察,真是太麻烦了。我要让它容易些。
潮湿的测试
Andy Hunt 和 Dave Thomas 所著的 The Pragmatic Programmer(见
参考资料)提出了许多良好的编程实践,其中之一是
DRY(Don't Repeat Yourself,不要重复自己)原则。这条原则主张从代码中消除所有重复,因为重复常常会导致错误。但是,DRY
不适用于单元测试。单元测试常常需要测试有细微差异的代码行为,因此涉及到相似和重复的情况。例如,为了在不同的测试中测试各种情况,常常需要复制粘贴代码,以得出
清单 1 中预期的结果
(new HashSet(Arrays.asList(1, 2, 3, 6)))。
对于 TDD,我的经验规则是测试应该是潮湿的,但是不要湿透。也就是说,测试中可以有一些重复(而且这是不可避免的),但是不应该创建笨拙的重复结构。因此,我要重构测试,提供一个
private 辅助方法,用它处理这个常用的创建语句,见清单 2:
清单 2. 保持测试适当潮湿的辅助方法
private Set<Integer> expectationSetWith(Integer... numbers) {
return new HashSet<Integer>(Arrays.asList(numbers));
}
|
清单 2 中的代码能够让对因子的所有测试更加简洁,清单
1 中的测试可以改写为清单 3 这样:
清单 3. 更潮湿的数字因子测试
@Test public void factors_for_6() {
Set<Integer> expected = expectationSetWith(1, 2, 3, 6);
Classifier4 c = new Classifier4(6);
c.calculateFactors();
assertThat(c.getFactors(), is(expected));
}
|
在编写测试时,也应该遵守良好的设计原则。测试也是代码,良好的原则也适用于测试(尽管原则有所差异)。
边界条件
在为一些新功能编写第一个测试时,TDD 鼓励开发人员编写失败的测试。这可以防止测试意外地通过所有情况,也就是说,测试实际上没有测试任何东西(同义反复
测试)。测试还可以检查您认为正确,但是没有经过充分测试的行为。这些测试不一定需要首先采用失败测试的形式(但是,如果在认为测试应该通过时测试却失败了,这是很有价值的,因为这意味着找到了一个潜在的
bug)。考虑测试会引导您考虑哪些东西是可测试的。
常常被忽视的一种测试用例是边界条件:当遇到不正常的输入时,代码会做什么?围绕 getFactors()
方法编写一些测试,可以帮助我们考虑合理和不合理的输入可能导致什么情况。
因此,我要针对感兴趣的边界条件编写几个测试,见清单 4:
清单 4. 因子的边界条件
@Test public void factors_for_100() {
Classifier5 c = new Classifier5(100);
c.calculateFactors();
assertThat(c.getFactors(),
is(expectationSetWith(1, 100, 2, 50, 4, 25, 5, 20, 10)));
}
@Test(expected = InvalidNumberException.class)
public void cannot_classify_negative_numbers() {
new Classifier5(-20);
}
@Test public void factors_for_max_int() {
Classifier5 c = new Classifier5(Integer.MAX_VALUE);
c.calculateFactors();
assertThat(c.getFactors(), is(expectationSetWith(1, 2147483647)));
}
|
数字 100 看起来很有意思,因为它有许多因子。通过测试多个不同的数字,我认识到负数对于这个问题领域是没有意义的,所以编写了一个排除负数的测试(在我纠正它之前,这个测试确实会失败)。考虑到负数还让我想到了
MAX_INT:如果系统的用户需要 long 数字,我的解决方案应该怎么处理呢?我原来假设数字是整数,但是需要确保这是有效的假设。
测试边界条件会迫使开发人员明确考虑自己的假设。在编写解决方案时,很容易做出无效的假设。实际上,这正是传统的需求收集过程的缺点之一
― 无法收集足够的细节,所以无法消除不可避免的实现问题。需求收集是一种 有损压缩。
因为在定义 “软件必须做什么” 的过程中忽略了太多细节,所以必须通过某些机制帮助重现那些必须问的问题,从而充分地理解需求。凭空猜测业务用户实际上希望做什么是很危险的,很可能会猜错。使用测试研究边界条件有助于找到要问的问题,这对于理解需求非常重要。找到要问的问题会提供许多信息,有助于实现良好的设计。
肯定测试和否定测试
在开始研究完全数问题时,我把它分解为几个子任务。在编写测试时,我发现了另一个重要的子任务。下面是完整的列表:
- 我需要所求数字的因子。
- 我需要确定某个数字是不是因子。
- 我需要决定如何把因子添加到因子列表中。
- 我需要把因子加起来。
- 我需要确定某个数字是不是完全数。
还没有完成的两个任务是把因子加起来和判断完全数。这两个任务很简单;最后两个测试见清单 5:
清单 5. 完全数的最后两个测试
@Test public void sum() {
Classifier5 c = new Classifier5(20);
c.calculateFactors();
int expected = 1 + 2 + 4 + 5 + 10 + 20;
assertThat(c.sumOfFactors(), is(expected));
}
@Test public void perfection() {
int[] perfectNumbers =
new int[] {6, 28, 496, 8128, 33550336};
for (int number : perfectNumbers)
assertTrue(classifierFor(number).isPerfect());
}
|
在 Wikipedia 上查找到前几个完全数之后,我可以编写一个测试,它检查实际上是否可以找到完全数。但是,这还没有完。肯定测试只是工作的一半儿。还需要编写另一个测试,确保不会意外地把非完全数分类为完全数。因此,我编写了清单
6 所示的否定测试:
清单 6. 确保完全数分类正确的否定测试
@Test public void test_a_bunch_of_numbers() {
Set<Integer> expected = new HashSet<Integer>(
Arrays.asList(PERFECT_NUMS));
for (int i = 2; i < 33550340; i++) {
if (expected.contains(i))
assertTrue(classifierFor(i).isPerfect());
else
assertFalse(classifierFor(i).isPerfect());
}
}
|
这段代码报告我的完全数算法工作正常,但是它非常慢。通过查看 calculateFactors()
方法(清单 7),我可以猜出原因。
清单 7. 最初的 getFactors()
方法
public void calculateFactors() {
for (int i = 2; i < _number; i++)
if (isFactor(i))
addFactor(i);
}
|
清单 7 中出现的问题与
第
1 部分 中后测试版本中的问题相同:寻找因子的代码会一直循环到数字本身。可以通过成对地寻找因子来改进此代码,这样就只需要循环到数字的平方根,重构的版本见清单
8:
清单 8. calculateFactors()
方法的性能更好的重构版本
public void calculateFactors() {
for (int i = 2; i < sqrt(_number) + 1; i++)
if (isFactor(i))
addFactor(i);
}
public void addFactor(int factor) {
_factors.add(factor);
_factors.add(_number / factor);
}
|
这与在后测试版本中做过的重构相似(见 第
1 部分),但是这一次要修改两个不同的方法。这里的修改更简单,因为我已经把 addFactors()
功能放在一个单独的方法中了,而且这个版本使用 Set 抽象,这样就不需要通过测试确保没有出现在后测试版本中曾经出现的重复。
优化的指导原则应该总是先确保它正确,然后加快它的运行速度。全面的单元测试集能够轻松地检查行为是否正确,让开发人员能够专心地优化代码,而不必担心是否会破坏代码的正常行为。
最后,完成了完全数查找程序的测试驱动版本;完整的类见清单 9:
清单 9. 数字分类程序的完整 TDD 版本
public class Classifier6 {
private Set<Integer> _factors;
private int _number;
public Classifier6(int number) {
if (number < 1)
throw new InvalidNumberException(
"Can't classify negative numbers");
_number = number;
_factors = new HashSet<Integer>();
_factors.add(1);
_factors.add(_number);
}
private boolean isFactor(int factor) {
return _number % factor == 0;
}
public Set<Integer> getFactors() {
return _factors;
}
private void calculateFactors() {
for (int i = 2; i < sqrt(_number) + 1; i++)
if (isFactor(i))
addFactor(i);
}
private void addFactor(int factor) {
_factors.add(factor);
_factors.add(_number / factor);
}
private int sumOfFactors() {
int sum = 0;
for (int i : _factors)
sum += i;
return sum;
}
public boolean isPerfect() {
calculateFactors();
return sumOfFactors() - _number == _number;
}
}
|
可组合的方法
第
1 部分 中提到的测试驱动开发的好处之一是可组合性,也就是采用 Kent Beck
提出的组合方法模式(见 参考资料)。组合方法可以用许多内聚的方法构建软件。TDD
能够促进这种做法,因为为了进行测试,必须把软件分解为小的功能块。组合方法生成可重用的构建块,有助于产生更好的设计。
在 TDD 驱动的解决方案中,方法的数量和名称反映了这种思想。下面是 TDD 完全数分类程序的最终版本中的方法:
isFactor() getFactors() calculateFactors() addFactor() sumOfFactors() isPerfect()
下面通过一个示例说明组合方法的好处。假设您已经编写了完全数查找程序的 TDD 版本,而您公司中的另一个开发组编写了完全数查找程序的后测试版本(第
1 部分 中有一个示例)。现在,您的用户慌慌张张地跑来说,“我们还必须判断盈数和亏数!” 盈数
的因子的总和大于数字本身,而亏数 的因子的总和小于数字本身。
在后测试版本中,所有逻辑都放在一个方法中,他们必须重写整个解决方案,把盈数、亏数和完全数都涉及的代码分离出来。但是,对于
TDD 版本,只需要编写两个新方法,见清单 10:
清单 10. 支持盈数和亏数
public boolean isAbundant() {
calculateFactors();
return sumOfFactors() - _number > _number;
}
public boolean isDeficient() {
calculateFactors();
return sumOfFactors() - _number < _number;
}
|
这两个方法所需的惟一任务是把 calculateFactors() 方法重构为类的构造函数。(这对于
isPerfect() 方法没有害处,但是现在它在所有三个方法中重复出现,因此应该重构)。
把代码编写成小的构建块会提高代码的可重用性,因此这是您应该遵守的主要设计原则之一。使用测试有助于编写可组合的方法,能够改进设计。
在 第
1 部分 开头,我指出代码的 TDD 版本比后测试版本更好。我已经给出了许多证据,但是能够进行客观的证明吗?当然,对于代码质量,没有纯粹客观的度量方法,但是有几个指标能够比较客观地反映代码质量;其中之一是圈复杂度(见
参考资料),这是由
Thomas McCabe 发明的度量代码复杂度的方法。公式非常简单:边数减去节点数,再加 2,这里的边代表执行路径,节点代表代码行数。请考虑清单
11 中的代码:
清单 11. 用于判断圈复杂度的简单 Java 方法
public void doit() {
if (c1) {
f1();
} else {
f2();
}
if (c2) {
f3();
} else {
f4();
}
}
|
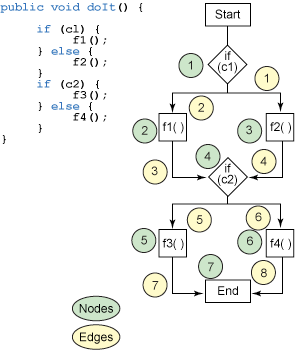
如果把 清单 11
所示的方法画成流程图(见图 1),就很容易算出边数和节点数并计算出圈复杂度。这个方法的圈复杂度是 3 (8
- 7 + 2)。
图 1. doit() 方法的节点和边
为了度量完全数代码的两个版本,我将使用开放源码的 Java 圈复杂度工具 JavaNCSS(“NCSS”
代表 “non-commenting source statements”,这意味着这个工具也度量非注释源代码语句)。下载信息见
参考资料。
对后测试代码运行 JavaNCSS 会产生图 2 所示的结果:
图 2. 后测试完全数查找程序的圈复杂度
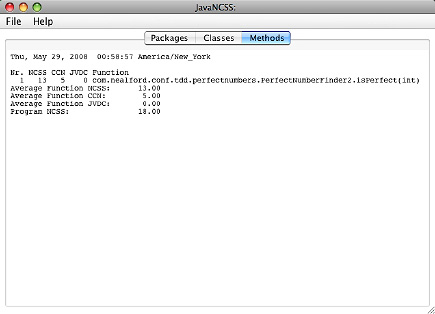
这个版本中只有一个方法,JavaNCSS 报告类的方法平均有 13 行代码,圈复杂度为 5.00。TDD
版本的结果见图 3:
图 3. 完全数查找程序的 TDD 版本的圈复杂度
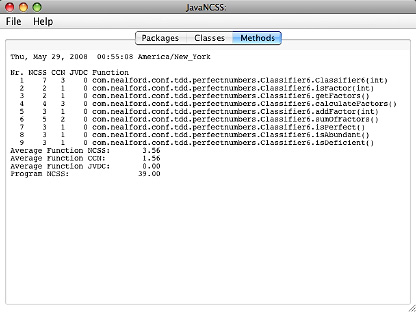
显然,代码的 TDD 版本包含更多方法,每个方法平均有 3.56 行代码,平均圈复杂度只有 1.56。根据这个指标,TDD
版本比后测试代码简单三倍。即使对于这个小问题,这也是很显著的差异。
在 演化架构与紧急设计
系列的最近两篇文章中,我深入讨论了在编写代码之前 编写测试的好处。TDD 能够产生更简单的方法,更好的抽象,可重用性更好的构建块。
测试可以引导开发人员沿着更好的设计路径前进,纠正可能出现的偏差。设计人员的主观臆断可能对设计产生严重损害。应该尽可能避免猜想,避免意外地做出错误的决策,但是这很困难。TDD
提供一种有效的习惯性方法,能够帮助开发人员跳出错误的猜想,克服各种困难顺利地设计出解决方案。
在下一篇文章中,我要暂时把测试放在一边,谈谈从 Smalltalk 领域借用的两个重要模式:组合方法和单一抽象层
原则。
学习
获得产品和技术
讨论
| 