дкаэЖраавЕгІгУжаЃЌашвЊЙмРэЫцвЕЮёашвЊВЛЖЯБфЛЏЕФЪ§ОнЃЌЬсЙЉЫљМћМДЫљЕУЕФдіЩОИФВщЁЂЭМБэЗжЮіЁЂЙиСЊЪ§ОнМЦЫуЙиЯЕЮЌГжЕШЙІФмЁЃБОЮФИјГіЛљгкЙиЯЕЪ§ОнПтИќаТЪгЭМЕФдРэКЭ
JDBCЁЂAppletЁЂServlet ЕШ Java ММЪѕЕФНтОіЗНАИЃЌВЂИјГіЙиМќДњТыЪЕЯжЁЃ
дкаэЖрЕфаЭаавЕгІгУжаЃЌашвЊДІРэАДееЕигђЁЂЪБМфЛђРрБ№ЕШЮЌЖШВњЩњВЂБЛЙмРэгыЮЌЛЄЕФЪ§ОнЁЃБЛЙмРэЕФЪ§ОнЗжРрЗНЪНЛљБОЮЌГжКуЖЈЃЌЖјЪ§ОнБОЩэЕФФкШнЃЈзжЖЮЃЉдђашвЊИљОнвЕЮёашвЊВЛЖЯБфЛЏЁЃвЛЗНУцЃЌБЛЙмРэЕФЪ§ОнБиаыжЇГжАДееШЈЯоНјаадіЩОИФВщВйзїЃЛСэвЛЗНУцЃЌЛЙашвЊФмЙЛНјааЫљМћМДЫљЕУЕФЭМБэЗжЮіЃЌШчВЛЭЌЕигђжЎМфЪ§ОнЕФЖдБШЁЂЪБМфЮЌЖШЪ§ОнБфЛЏЙцТЩЕФЗжЮіЁЂВЛЭЌРрБ№Ъ§ОнЕФЗжРрЛузмЁЂЩѕжСАќРЈЙиСЊЪ§ОнжЎМфЕФЭГМЦЙиЯЕЮЌГжЕШЁЃ
Р§ШчдкЕчСІаавЕЃЌЕчЭјЙЋЫОАДееЕигђНјааЛЎЗжЃЌЦфвдЕчСПЁЂИККЩЮЊДњБэЕФКЫаФвЕЮёЪ§ОнАДееЪБМфЗЂЩњВЂБЛМЦСПЁЃетаЉБЛЙмРэЕФЪ§ОнОпгавЛЖЈЕФЙВадЃКЪ§ОнЫљЪєЕигђЁЂЪ§ОнЕФЪБМфЛЎЗжЁЂЪ§ОнЕФЭГМЦПкОЖЕШЪ§ОнЕФЮЌЖШЛљБОЮЌГжВЛБфЃЌЕЋЪ§ОнЕФРрБ№ШДЫцзХОМУаЮЪЦЗЂеЙБфЛЏЁЂВЛЭЌЕиЧјВњвЕНсЙЙЁЂЩѕжСЪЧЕиЗНеўВпЕШОГЃЗЂЩњБфЛЏЁЃвдЕиЧјЕФдТЖШгУЕчСПЮЊР§ЃЌЫфШЛЕчСІаавЕгагУЕчЗжРрБъзМгУвдЭГвЛИїЕиЧјЕФгУЕчЗжРрКЭРрБ№УћГЦЃЌЕЋЪЧОМУЗЂеЙЕФВЛОљКтКЭВњвЕНсЙЙЕФВювьЃЌЪЙЕУВЛЭЌЕиЧјЪЕМЪашвЊЙизЂЕФгУЕчЗжРрДѓЭЌаЁвьЃЌетвЊЧѓЯЕЭГЬсЙЉЕФЪ§ОнЙмРэЗжЮіЙІФмФмЙЛЖдКѓЬЈЙиЯЕЪ§ОнПтжаЪ§ОнБэСаЕФБфЛЏгаНЯЧПЕФЪЪгІФмСІЃЛСэвЛЗНУцЃЌЕиЧјВювьадЛЙЕМжТСЫВЛЭЌЕчЭјЙЋЫОЙизЂЕФЪ§ОнМЏКЯБОЩэОЭгаВюБ№ЃЌетгжвЊЧѓЯЕЭГЬсЙЉЕФЪ§ОнЙмРэЗжЮіЙІФмФмЙЛЪЪгІдіМѕЪ§ОнПтБэЕФИіадЛЏашЧѓЁЃ
днЧвАбБОЮФашвЊЪЕЯжЕФФПБъЙІФмГЦЮЊЪ§ОнЙмРэЗжЮіЦНЬЈЃЌЫќашвЊОпБИШчЯТЬиЕуЃК
- етЪЧвЛИігУдкВњЦЗжаЕФЙІФмЃЌЭЈгУадКЭПЩЮЌЛЄадЪЧЕквЛЮЛЕФЁЃ
- етЪЧвЛИі B/S гІгУЃЌгУЛЇЪЙгУфЏРРЦїЗУЮЪЯЕЭГЁЃ
- гУЛЇдкНчУцЩЯПЩвдЖдЪ§ОнНјаадіЩОИФВщЁЃ
- ВЛЭЌЪ§ОнжЎМфЕФМЦЫуЙиЯЕЮЌГжЖдгУЛЇЭИУїЁЃ
- гУЛЇПЩвдЖдВщбЏЕНЕФЪ§ОнНјаазїЭМЗжЮіЁЃ
- ПчЪ§ОнПтЦНЬЈЁЃ
гЩгкЦкЭћетИіЪ§ОнЙмРэЗжЮіЦНЬЈФмЙЛдкВЛЭЌЕФВњЦЗжаИДгУЃЌвђДЫБОЗНАИгІеыЖдЪ§ОнДцДЂдкЙиЯЕЪ§ОнПтжаЕФЙВЭЌЬиеїНјааГщЯѓЃЌЖјВЛЪЧеыЖдЬиЖЈВњЦЗЕФвЕЮёТпМНјааГщЯѓЁЃЛЛОфЛАЫЕЃЌгІИУеыЖдЙиЯЕЪ§ОнПтЕФБэКЭзжЖЮНјааГщЯѓЃЌЖјВЛЪЧИљОнЬиЖЈВњЦЗЕФвЕЮёЪ§ОнЖдЯѓНјааГщЯѓЁЃетдЪаэзюжеЪЕЯжФмЙЛЭЈЙ§МђЕЅХфжУРДЪЕЯждіМгКЭМѕЩйБЛЙмРэЪ§ОнРрБ№ЃЈБЛЙмРэБэЕФРЉеЙЃЉЃЌвдМАЖдЬиЖЈЪ§ОнРрБ№ЕФдіМгКЭМѕЩйБЛЙмРэЪ§ОнзжЖЮЃЈБЛЙмРэСаЕФРЉеЙЃЉЁЃ
ЮЊКЮЪЙгУ JDBC
ШчЙћАбБЛЙмРэЕФЪ§ОнЃЌАДееЪ§ОнПтБэгГЩфЮЊ POJOЃЌдйеыЖд POJO ЪЕЯжКѓајЕФеЙЯжКЭ Persistence
ВйзїЃЌМДЪЙ DIY ГівЛИіЯё Hibernate вЛбљЭъећЕФ Persistence ЙЄОпРДЃЌашвЊдіМгБЛЙмРэЕФЪ§ОнРрБ№ЪБЃЌШдШЛашвЊИљОнетИіЪ§ОнРрБ№ЖдгІЕФЙиЯЕЪ§ОнПтБэЃЌгГЩфГівЛИі
POJO РрЁЃетИіЙ§ГЬВњЩњСЫаТЕФ Java ДњТыЃЌвтЮЖзХбаЗЂЁЂВтЪдЁЂЗЂВМЁЂЪЕЪЉЕШећИіШэМўЙЄГЬЙ§ГЬБЛЦєЖЏСЫЃЌАбетИіЙ§ГЬНазіХфжУЪЧУїЯдВЛКЯЪЪЕФЁЃ
ЕБШЛЃЌB/S МмЙЙгІгУжаГЃгУЕФЭЈЙ§БэЕЅЬсНЛЗНЪНЪЕЯж CRUD ЕФЗНАИОЭИќВЛПЩШЁСЫЃЌвдСїааЕФ SSHЃЈStrutsЁЂSpringЁЂHibernateЃЉФЃЪНЮЊР§ЃЌдіМгаТЕФБЛЮЌЛЄЪ§ОнЃЌвтЮЖзХжСЩйашвЊдіМгвЛИі
JSP вГУцгУРДЩњГЩгУЛЇНчУцЃЌвЛИі ActionFormBean гУРДНгЪеБэЕЅЕФЪ§ОнЃЌвЛИі Hibernate
ЕФБэгГЩф POJO ЖдЯѓЃЌВЛНіЭЌбљвтЮЖзХЦєЖЏвЛИіЭъећЕФШэМўЙЄГЬЙЄГЬЃЌЖјЧвЙЄзїСПЪЧЫцзХаТдіЪ§ОнРрБ№ЕФЪ§ФПЯпаддіГЄЕФЁЃ
ЫЕЕНетРяЃЌПЩФмФњвбОЯыЕНСЫЪ§ОнПтПЭЛЇЖЫЃЌУЛДэЃЌЪ§ОнПтПЭЛЇЖЫОЭЪЧвЛИіЕфаЭЕФЫљМћМДЫљЕУТњзугУЛЇЖдЪ§ОнНјаадіЩОИФВщашЧѓЕФЪЕЯжЁЃШчЙћЮвУЧЖдвЛИіЪ§ОнПтПЭЛЇЖЫНјааИФдьЃЌШУЫќНЋВщбЏНсЙћвдгУЛЇЕФвЕЮёЪгНЧНјааеЙЯжЃЌЭЌЪБШУЫќдкфЏРРЦїжадЫааЃЌЬсЙЉЖдЫљЯдЪОЪ§ОнНјаазїЭМЗжЮіЕФЙІФмЃЌВЂЧвФмЙЛЮЌГжЙиСЊЪ§ОнЕФМЦЫуЙиЯЕЃЌФЧОЭдВТњСЫЁЃ
ПЩЯЇЕФЪЧЃЌЮвУЧВЛФмЯёЪ§ОнПтПЭЛЇЖЫФЧбљЃЌШУзюжегУЛЇжБНгУцСйДцДЂвЕЮёЪ§ОнЕФЮяРэБэЃЌдквЛИіЪ§ОнПтБэЕФжБНгВщбЏНсЙћЩЯНјаадіЩОИФВщВйзїЁЃвђЮЊдкТњзуЪ§ОнПтЩшМЦЗЖЪНЕФЧАЬсЯТЃЌЪ§ОнБэжагаКмЖрЮвУЧГЦжЎЮЊ
ID ЕФзжЖЮЁЃР§ШчЃЌвЛИіАДЕиЧјДцДЂФГжжЪ§ОнЕФБэжаЃЌБэЪОЕиЧјЕФзжЖЮжаЃЌвЛЖЈЪЧДцДЂСЫвЛИіДњБэЕиЧјЕФ ID КЭСэвЛИіДцДЂЕиЧјаХЯЂЕФЪ§ОнБэзіЭтМќЙиСЊЃЌдкВщбЏЪБЃЌашвЊзіЖрБэСЌНгВХФмЛёЕУЕиЧј
ID ЖдгІЕФПЩвдШУзюжегУЛЇЖСЖЎЕФЕиЧјУшЪіаХЯЂЁЃ
вђДЫЃЌЮвУЧЕФЪ§ОнЙмРэЗжЮіЦНЬЈЃЌжСЩйгІИУгаФмСІЯђгУЛЇЬсЙЉвЛИіПЩвдаоИФЕФЖрБэСЌНгВщбЏНсЙћМЏЁЃШчЙћФуЯыЕНСЫЪгЭМЃЌФЧКмКУЃЌвђЮЊШЗЪЕКмЖрЙиЯЕЪ§ОнПтЖМжЇГжЪгЭМЕФИќаТЃЌЖјЧвздДђ
JDK1.4 вдКѓЃЌJDBC ЕФ RowSet РЉеЙвВе§ЪНГЩЮЊСЫ JDK БъзМ API ЕФвЛВПЗжЃЌдЪаэЭЈЙ§
JDBC ЖдВщбЏНсЙћМЏНјааЪ§ОнИќаТВйзїЁЃШчЙћЮвУЧЕФЪ§ОнЙмРэЗжЮіЦНЬЈЪЧАѓЖЈдкЬиЖЈЪ§ОнПтЦНЬЈжЎЩЯЕФЃЌФЧУДзаЯИбаОПвЛЯТЖдгІЕФЪ§ОнПтЦНЬЈЖдЪгЭМИќаТЕФжЇГжЧщПіЃЌзаЯИЙцдМГівЛЬзПЩааадЪгЭМЩшМЦЗНАИвВаэРэТлЩЯЪЧПЩФмЕФЁЃЕЋЪЧЃЌЮвУЧЕФЪ§ОнЙмРэЗжЮіЦНЬЈЪЧЯЃЭћФмЙЛПчЪ§ОнПтЦНЬЈЕФЃЌгЩгкВЛЭЌЕФЪ§ОнПтдкЪгЭМИќаТЩЯИїгаЬиЕуЃЌВЩгУетИіЗНАИЃЌНЋЛсДѓДѓНЕЕЭНтОіЗНАИЕФЪ§ОнПтЮоЙиадЁЃ
МШШЛШчДЫЃЌВЛЗСБЇзЁ JDBC ЕФДѓЭШдйКУКУЯыЯыЁЃдк Java ЪРНчРяЃЌЮвУЧЪЙгУ JDBC РДЭъГЩЖдвЛааЪ§ОнЕФдіЩОИФВщВйзїЃЌгаСНИіБивЊЬѕМўЃКвЛЪЧФмЛёЕУЪ§ОнБэЕФУћГЦЃЌЖўЪЧЮЈвЛЖЈЮЛЪ§ОнааЕФЬѕМўЃЌЭЈГЃЪЧжїМќжЕЁЃвђДЫЃЌЖдгквЛИіСЌНгВщбЏЕФНсЙћМЏЃЌжЛвЊФмЙЛШЗШЯБЛаоИФЪ§ОнСаЖдгІЕФБэЃЌвдМАИУСаЫљдкааЖдгІЕФжїМќжЕЃЌЪЙгУБъзМ
SQLЃЌНшжњ JDBC ОЭФмЪЕЯжЪ§ОнЕФИќаТВйзїЁЃ
вдЙњМвЭГМЦОжЕФФъЖШШЫПкЭГМЦЪ§ОнЮЊР§ЃЌгУЛЇПДЕНЕФеЙЯжаЮЪНШчЯТЃК
Бэ 1. ФъЖШШЫПкЪ§ОнЕФгУЛЇНчУц
ЁЁ
|
ЕиЧј |
ФъЗн |
змШЫПк |
Фа |
ХЎ |
ГЧеђ |
ЯчДх |
|
ШЋЙњ |
1999 |
125786 |
64692 |
61094 |
43748 |
82038 |
|
ШЋЙњ |
2000 |
126743 |
65437 |
61306 |
45906 |
80837 |
|
ШЋЙњ |
2001 |
127627 |
65672 |
61955 |
48064 |
79563 |
|
ШЋЙњ |
2002 |
128453 |
66115 |
62338 |
50212 |
78241 |
|
ШЋЙњ |
2003 |
129227 |
66556 |
62671 |
52376 |
76851 |
|
ШЋЙњ |
2004 |
129988 |
66976 |
63012 |
54283 |
75705 |
|
ШЋЙњ |
2005 |
130756 |
67375 |
63381 |
56212 |
74544 |
|
ШЋЙњ |
2006 |
131448 |
67728 |
63720 |
57706 |
73742 |
|
ШЋЙњ |
2007 |
132129 |
68048 |
64081 |
59379 |
72750 |
етРяЕФЪ§ОнЃЌгІИУРДздЙиЯЕЪ§ОнПтжаЕФСНИіБэЃЌЫќУЧЪЧЃК
Бэ 2. ЕиЧјБэЃЈAREAЃЉ
ЁЁ
|
Name |
Type |
Comments |
|
AREAID |
VARCHAR2(10) |
ЕиЧј IDЃЌжїМќ |
|
AREANAME |
VARCHAR2(20) |
ЕиЧјУћГЦ |
Бэ 3. ШЫПкБэЃЈPOPULATIONЃЉ
ЁЁ
|
Name |
Type |
Comments |
|
AREAID |
VARCHAR2(10) |
ЕиЧј IDЃЌжїМќЃЌЭтМќ |
|
YEAR |
VARCHAR2(4) |
ФъЗнЃЌжїМќ |
|
TOTAL |
NUMBER |
змШЫПк |
|
MEN |
NUMBER |
Фа |
|
WOMEN |
NUMBER |
ХЎ |
|
CITY |
NUMBER |
ГЧеђ |
|
COUNTRY |
NUMBER |
ЯчДх |
Бэ 1 ЫљЪОЕФЪ§ОнЃЌгІИУРДздБэ 2 КЭБэ 3 ЕФСЌНгВщбЏЃК
ДњТы 1. SQL ЪОР§
ЁЁ
Select
A.AREANAME,B.AREAID,B.YEAR,B.TOTAL,B.MEN,B.WOMEN,B.CITY,B.COUNTRY
from
AREA A, POPULATION B
where
A.AREAID = B.AREAID
|
ШчЧАЫљЪіЃЌВщбЏНсЙћМЏжаАќКЌСЫ AREA БэЕФ AREANAME СаЃЌТњзуСЫгУЛЇвЕЮёТпМЪгНЧЕФеЙЪОашвЊЃЛАќКЌСЫ
POPULATION БэЕФ AREAID КЭ YEAR СНСаЃЌТњзуСЫдк POPULATION БэжаЖЈЮЛЪ§ОнааНјааЪ§ОнИќаТЕФашвЊЁЃ
ВЩгУ Applet
ЃЋ JSP
ШчЙћНіНіжЛашвЊТњзуБэ 1 ЫљЪОЕФЭМаЮНчУцЁЊЁЊвЛИіеЙЯжЪ§ОнЕФБэИёЃЌФЧУДБэЯжВуЕФбЁдёУЛгаШЮКЮдМЪјЃЌПЩвдгУдк
Java EE ЦНЬЈЯТЕФШЮКЮБэЯжВуММЪѕЖМФмТњзуЁЃБэИёжаЕФЪ§ОнашвЊФмЙЛаоИФЃЛШчЕиЧјетбљЕФСаашжЇГжЯТРСаБэбЁдёЬюаДЃЛБэИёжаЕФЪ§ОнПЩвджЇГжИДжЦЁЂеГЬљЃЛБиаыдЪаэгУЛЇИљОнБэИёжаЕФЪ§ОнжЦзїЭМБэЃЛЭМБэПЩвдЗХДѓЫѕаЁЃЛЭМБэПЩвдДђгЁЃЛЭМБэПЩвдЕМГіГЩЭМЦЌЃЛЁЁ
ЫцзХвЊЧѓЕФНјвЛВНдіЖрЃЌПЩбЁЗЖЮЇбИЫйМѕаЁЃЌЕЋЪЧПЩвдПЯЖЈЕФЪЧЃЌJava Swing ЃЋ JFreeChart
ВюВЛЖрПЩвдТњзуЫљгавЊЧѓЁЃПМТЧЕНетИіЙІФмЪЧгУгк B/S МмЙЙЯЕЭГжаЕФЃЌбЁдёЧЖШы JSP вГУцЕФ Applet
зїЮЊБэЯжВуВпТдЃЌЪЧКЯЪЪЕФЁЃ
вЛЕЉБэЯжВуШЗЖЈЮЊ JSP ЃЋ Applet ЕФЗНЪНЃЌвтЮЖзХПЭЛЇЖЫЛёШЁЕНСЫзюДѓЕФПЩНЛЛЅадЁЃдкЗўЮёЦїЖЫВщбЏЕФНсЙћМЏЃЌНјааМђЕЅЗтзАЃЌВЩгУЖдЯѓађСаЛЏЗНЪНЃЌНЋЦфДЋЫЭЕН
Applet ЖЫЃЌApplet ЖЫЪЙгУ Java Swing ЙЙдьЯдЪОЕФЭМаЮНчУцЃЌВЂДІРэгУЛЇЕФВйзїЁЃ
ЪЙгУФЃАх SQL
ЪЕЯжВщбЏ
дкгУЛЇНчУцжаЃЌЯёЪБМфКЭЕиЧјетбљЕФЪ§ОнЩИбЁЬѕМўЃЌПЩФмЗжБ№гУЯТРСаБэбЁдёКЭЪїаЮНсЙЙЪЕЯжЃЌвддіЧПжБЙлЖШКЭвзгУадЁЃЛЛОфЛАЫЕЃЌДњТы
1 ЫљЪОЕФ SQL гяОфжаЃЌашвЊИљОнгУЛЇдкНчУцЩЯЕФбЁдёНсЙћЃЌЩњГЩЪЪЕБЕФ where згОфвдЯьгІЩИбЁЬѕМўЁЃМйЩшИљОнашЧѓЃЌЙЙдьСЫШчЯТЭМЫљЪОЕФ
UIЃК
ЭМ 1. UI ЪОвтЭМ
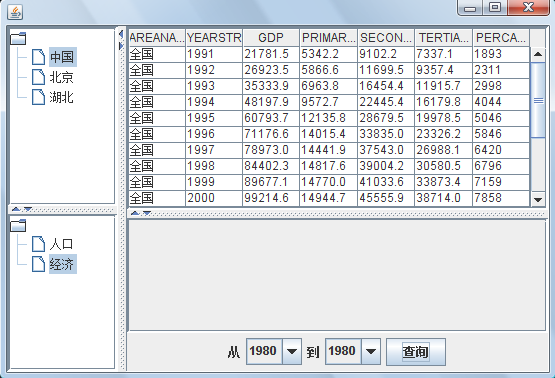
ФЧУДЃЌЭМЪОЕФ UI жаЃЌЕиЧјЕФбЁдёЃЌдкДњТы 1 ЖдгІЕФ SQL жаЃЌЖдгІЬэМг B.AREAID=? ЕФ
where згОфбЁЃЛСНИіФъЗнЕФбЁдёЃЌЖдгІЬэМг B.YEAR between ? and ? ЕФзгОфЃЛЖјЪ§ОнРрБ№ЕФбЁдёЃЌдђЪЧгУРДШЗЖЈБЛВщбЏЕФЪ§ОнРрБ№ЕФЁЃПМТЧЪЙгУШчДњТы
2 ЫљЪОЕФ SQL гяОфЃК
ДњТы 2. SQL ЪОР§
ЁЁ
Select
A.AREANAME,B.AREAID,B.YEAR,B.TOTAL,B.MEN,B.WOMEN,B.CITY,B.COUNTRY
from
AREA A, POPULATION B
where
A.AREAID = B.AREAID and B.@area and B.@year
|
ЩЯЪіДњТыжаЃЌ@area КЭ @year ЪЧашвЊИљОнгУЛЇЫљбЁдёжЎЬѕМўНјааЬцЛЛЕФЬцЛЛБъЪЖЁЃ
ВЛвЊаЁПДетвЛЕуЕуаЁЪжЖЮЃЌЭГМЦОжЕФДѓЖрЪ§Ъ§ОнЖМЪЧАДееЕиЧјКЭЪБМфНјааЗжРрКЭЭГМЦЕФЃЌвђДЫЩЯУцЕФМђЕЅЗНАИвбОПЩвдДІРэДѓЖрЪ§ЭГМЦЪ§ОнЕФВщбЏашЧѓСЫЁЃЖјЧв
@area етИіЬцЛЛБъЪЖЃЌМШПЩвдгУ AREAID=? ЕФзгОфЬцЛЛЃЌвВПЩвдгУ AREAID in (?,?)
ЕФзгОфЬцЛЛЁЃЖдгІЕНВйзїжаЃЌОЭЪЧПЩвдЪЕЯжВЛЭЌЕиЧјЪ§ОнЕФЖдБШВщбЏЃЌдйЪЙгУ JFreeChart ЬсЙЉЭМБэжЇГжЃЌОЭПЩвдЪЕЯжвЛЯЕСагаМлжЕЕФЪ§ОнЗжЮіЙІФмЁЃ
СэЭтЃЌДњТы 2 ЕФ SQL ЪОР§ВщбЏЕФНсЙћМЏжаЃЌPOPULATION БэЕФ AREAID зжЖЮЫфШЛЪЧВщбЏНсЙћМЏЕФвЛВПЗжЃЌЕЋЪЧетИізжЖЮВЂВЛгІИУЯдЪОдкзюжегУЛЇНчУцжаЃЌВщбЏГіетИізжЖЮЪЧЮЊСЫТњзуНсЙћМЏПЩИќаТЕФБивЊЬѕМўЁЃвђДЫЃЌПЩвдЬсЙЉвЛИіЖюЭтЕФХфжУаХЯЂЃЌжИУїВщбЏНсЙћМЏжаЕФФФаЉзжЖЮдкДЋЪфЕНПЭЛЇЖЫ
Applet КѓашвЊБЛЁАвўВиЁБЦ№РДЃЌПЭЛЇЖЫ Applet ДІРэЯдЪОЪБЃЌВЛЯдЪОетаЉзжЖЮЃЌЕЋашЮЌГжетаЉзжЖЮКЭЪ§ОнаажЎМфЕФЙиСЊЙиЯЕВЛБЛЦЦЛЕЁЃ
ОпЬхЕФЪЕЯжЯИНкЃЌЧыВЮМћБОЮФИНДјЕФВЮПМЪЕЯжДњТыЁЃ
МЧТМгУЛЇЕФдіЩОИФВйзї
ШчКЮЪЕЯжВщбЏВйзїЃЌЧАУцЕФаЁНквбОБэЪіСЫЃЌБОНкЕФКЫаФЪЧНтОігУЛЇЕФЪ§ОнаоИФШчКЮБЃДцЕНЪ§ОнПтжаЁЃ
ЪзЯШжиИДвЛЯТЖдЙиЯЕЪ§ОнПтжаЕФвЛааМЧТМНјаааоИФЕФСНИіБивЊЬѕМўЃКвЛЪЧФмЛёЕУЪ§ОнБэЕФУћГЦЃЌЖўЪЧЮЈвЛЖЈЮЛЪ§ОнааЕФЬѕМўЃЌЭЈГЃЪЧжїМќжЕЁЃЭЈЙ§ЩЯвЛНкУшЪіЕФФЃАх
SQL жаВщбЏСаЕФдМЖЈЃЌПЩвдШЗБЃФПБъЪ§ОнБэЕФжїМќСаЖМБЛВщбЏЕНЪ§ОнНсЙћМЏжаЃЌВЂБЛЗтзАКѓДЋЫЭЕНПЭЛЇЖЫ Applet
вдЙЉЯдЪОЁЃвђДЫЃЌЖдЪ§ОндіЩОИФжЇГжЕФЪЕЯжЃЌЦфЪЕОЭЪЧашвЊЪЕЯжМЧТМгУЛЇЕФдіЩОИФВйзїЃЌВЂгЩЗўЮёЦїЖЫИљОнИУМЧТМЩњГЩЯЕСа
SQL гяОфВЂжДааЁЃ
аоИФВйзїЃЌПЩвдЗжЮЊСНжжЧщПіЃЌвЛжжЧщПіЪЧаоИФЗЧжїМќЪ§ОнСаЃЌСэвЛжжЧщПіЪЧаоИФжїМќЪ§ОнСаЁЃЧАепЪЧАВШЋЕФЃЌвВЪЧШнвзМЧТМЕФЃЛКѓепдђЛсДјРДвЛаЉЮЪЬтЃКвЛЪЧжїМќжиИДЮЪЬтЃЌВЛЙ§етИіЮоЗЈгЩГЬађЬцгУЛЇНтОіЃЌЖўЪЧжїМќБЛаоИФКѓЃЌЯрЕБгкЪ§ОнааЕФЮЈвЛЖЈЮЛЬѕМўЖЊЪЇЃЌШчЙћВЛФмевЛидРДЕФжїМќжЕЃЌдђЮоЗЈЭъГЩЯргІЕФ
Update ВйзїЃЌЛЙПЩФмИќаТДэЮѓЕФЪ§ОнааЁЃ
ЩОГ§ВйзїЃЌвВгаСНжжЧщПіЃЌвЛжжЧщПіЪЧЩОГ§ЪБЃЌИУааЪ§ОнЕФжїМќСаЮДБЛаоИФЃЌСэвЛжжЧщПіЪБЃЌЩОГ§ВйзїЪБЃЌжїМќСавбОБЛаоИФЙ§СЫЁЃНсКЯаоИФЧщПіПМТЧЃЌвВЛсГіЯжРрЫЦЕФЧщПіЃЌгЩгкжїМќСавбОБЛаоИФЖјдьГЩЩОГ§ВйзїЮоаЇЃЈжїМќЖдгІЕФМЧТМВЛДцдкЃЉЛђепЩОГ§СЫДэЮѓЕФМЧТМЃЈжїМќаоИФКѓЃЌгыСэвЛЬѕвбОДцдкЕФЪ§ОнМЧТМвЛжТЃЉЁЃ
ЖдгкдіМгЃЌЧщПіЩдЮЂИДдгвЛЕуЃЌвЛРДЪЧЯёБэ 1 ЫљЪОЕФЕиЧјСаЃЌЪЧЪєгкЭтМќЙиСЊЪ§ОнЃЌвЊЧѓгУЛЇМЧзЁУшЪізжЖЮРДЬюаДЪЧВЛКЯРэЕФЃЌРэгІЬсЙЉЯТРСаБэЙЉгУЛЇбЁдёЃЛЖўРДЪ§ОнБэжаПЩФмгаБъЪЖадЕФ
ID зжЖЮзїЮЊжїМќЃЌР§ШчздЖЏдіМгЕФ ID жїМќЃЌПЩФмгЩЪ§ОнПтЮЌЛЄЃЌвВПЩФмгЩГЬађЮЌЛЄЃЌашвЊЬиБ№ДІРэЁЃПМТЧЕНашвЊЪЪгІВЛЭЌЪ§ОнПтЦНЬЈЕФЯожЦЃЌБЃЯеЦ№МћЃЌПЩвддМЖЈЖМЪЙгУГЬађЮЌЛЄЁЃ
ЮЌГжЙиСЊЪ§ОнЕФвЛжТад
вЛЕЉЩцМАЕНЪ§ОнаоИФЃЌОЭгаПЩФмЩцМАЕНЪ§ОнвЛжТадЮЪЬтЃЌР§ШчЧАУцСаОйЕФ POPULATION БэМЧТМСЫШЫПкЪ§ОнЃЌБОЮФИНМўЕФВЮПМЪЕЯжжаЃЌЛЙгавЛИі
ECONOMIC БэМЧТМСЫОМУЪ§ОнЃЌЦфжаЕФШЫОљ GDP Ъ§ОнЪЧКЭ POPULATION БэжаЕФзмШЫПквдМА
ECONOMIC БэжаЕФ GDP гаТпММЦЫуЙиЯЕЕФЁЃШчЙћгУЛЇаоИФСЫзмШЫПкЪ§ОнЃЌФЧУДШЫОљ GDP РэгІвЛВЂБЛаоИФЃЌШчЙћгУЛЇаоИФСЫ
GDP змжЕЪ§ОнЃЌФЧУДШЫОљ GDP ЭЌбљвВгІжиаТМЦЫуЁЃ
Ъ§ОнПтДЅЗЂЦїРэТлЩЯЪЧвЛжжбЁдёЃЌЕЋдкБОЮФЕФГЁОАЯТЃЌЫќжСЩйгаСНЗНУцШБЕуЁЃЪзЯШЃЌЫќЪЧЪ§ОнПтЦНЬЈЯрЙиЕФЃЌБраДЕФДЅЗЂЦїКЭДцДЂЙ§ГЬгавЦжВДњМлЃЛЦфДЮЃЌЪ§ОнжЎМфЕФМЦЫуЙиЯЕЃЌЪєгквЕЮёТпМЃЌдкЕБЧАЗжВуЖјжЮЕФжїСїМмЙЙЫМЯыЯТЃЌдкЪ§ОнПтжаДІРэВПЗжвЕЮёТпМЃЌетЪєгквЕЮёТпМЕФВЛКЯРэТћбгЁЃ
жЛвЊЛЛжжЫМТЗЃЌЪТЧщОЭБфЕУМђЕЅСЫЁЃЮЌГжЙиСЊЪ§ОнвЛжТадЕФТпМЃЌдк Java РржаЪЕЯжЃЛЕБЖдгІЕФЪ§ОнБЛаоИФКѓЃЌжЛвЊФмЙЛГіЗЂЯргІ
Java РрЕФЕїгУОЭааСЫЁЃЖдгкЭМ 1 ЫљЪОЕФвЛИіБЛЙмРэЕФЪ§ОнРрБ№ЃЌЪ§ОнБЛаоИФКѓЃЌПЩФмГіЗЂЕФЙиСЊЪ§ОнМЦЫуЪЧМШЖЈЕФЁЃдкХфжУЪБЃЌдіМгвЛИіаТЕФХфжУЯюЃЌМДЪ§ОнаоИФКѓашвЊЕїгУЕФЭГМЦЪЕЯж
Java РрОЭПЩвдСЫЁЃХфжУЯюЕФФкШнПЩвджБНгЪЙгУ Java ЕФРрУћЃЌдМЖЈЬсЙЉФЌШЯЮоВЮЪ§ЙЙдьКЏЪ§ЃЌЪЕЯжЭГвЛНгПкЃЌБугкНјаа
reflect ЕїгУОЭааСЫЁЃ
ИљОнЧАУцеТНкЕФЗжЮіЃЌШЗЖЈЪЙгУ Applet зїЮЊБэЯжЖЫЃЌЗўЮёЦїЖЫдђВЩгУ Servlet гы Applet
НјааЭЈаХЃЌНгЪеРДзд Applet ЕФгУЛЇЧыЧѓЃЌВЂНЋДІРэКѓЕФНсЙћЗЕЛиИјПЭЛЇЖЫЁЃШчЯТЭМЫљЪОЃК
ЭМ 2. МмЙЙМђЭМ
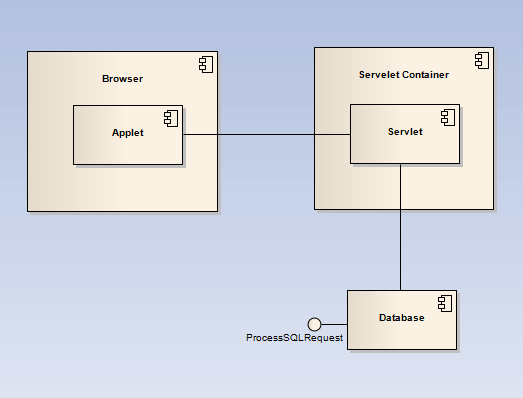
ЦфжаЃЌApplet КЭ Servlet жЎМфЕФЭЈаХЪЙгУ java.net.URLConnection
КЭЖдЯѓађСаЛЏЪЕЯжЃЌServlet КЭ Database ЕБШЛЪЧЭЈЙ§ JDBC жДаа SQL гяОфРДЭъГЩНЛЛЅЁЃ
ЭМ 3. РрЭМ
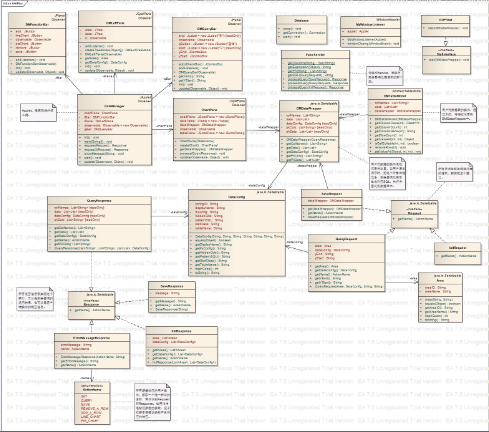
етИіЭМПДВЛЬЋЧхГўЃЌЕуЛїетРя
ВщПДДѓЭМЁЃЮЊСЫАяжњРэНтЃЌРрЭМжаЛЙЬэМгСЫвЛЯЕСазЂЪЭЁЃ
гааЫжТЕФЖСепПЩвдЯТдиБОЮФИНДјЕФИНМўЃЌMellonDataManager.jarЃЌЫќАќКЌвЛИігЩ NetBeans6.5
ДђАќЕФПЩжДаа jar ЮФМўЃКDataAnalyse.jarЁЃЛЙгавЛИі lib ФПТМЃЌРяУцгІИУЗХжУЪОР§ДњТыЕФжДааЫљашвЊЕФ
3 Иі jar ЮФМўЃЌderby.jarЃЈJava DBЃЉЃЌПЩвддк JDK1.6 жаЛёЕУЃЌвВПЩвдЕН
http://developers.sun.com/javadb/downloads/index.jsp
ЯТдиЃЛjcommon-1.0.16.jarЃЈJFreeChart ашвЊЕФжЇГжАќЃЉКЭ jfreechart-1.0.13.jarЃЌетСНИіАќПЩвдЕН
http://www.jfree.org/jfreechart/download.html ЯТдиЁЃвдМАвЛИі
src ФПТМЃЌЪЧЫљгаЕФдДЮФМўЁЃ
cn.mellon.Database РрЃЌИКд№ГѕЪМЛЏЪ§ОнПтКЭЬсЙЉЪ§ОнПтСЌНгЁЃ
cn.mellon.FakeServlet РрЃЌвђЮЊБОЮФЫљУшЪіЕФгІгУгІИУЪЧвЛИі Web ApplicationЃЌЮЊСЫЪЙГЬађФмЙЛзїЮЊЖРСЂ
Application жДааЃЌЪЙгУБОРрЮБзА Servlet РДНгЪе Applet ЗЂЫЭЕФЧыЧѓЃЌЦфЪЕЪЧ Applet
жБНгдкЭЌвЛИі JVM жаЕїгУЕФЃЌВЛЙ§НЋЦфИФЮЊ ServletЃЌВЂШУећИігІгУдЫаадк Tomcat жаЃЌвВЪЧЗЧГЃШнвзЕФЪТЧщЁЃ
cn.mellon.DataManager РрЃЌЪЧКЫаФЕФ Applet ЪЕЯжЃЌЭЌбљЕФЃЌЮЊСЫЗНБуГЬађзїЮЊЖРСЂ
Application дЫааЃЌетИі Applet БЛЬэМгСЫ main ЗНЗЈЃЌвђДЫЫќМцОп Applet КЭ
Application ЫЋжиЩэЗнЁЃ
ЕБФњЯТдиЕНШ§ИіБиаыЕФ jar АќЃЌВЂНЋЦ№ЗХжУдкжИЖЈЕФ lib ФПТМКѓЃЌФњПЩвдЪЙгУУќСюаа java ЈC
jar DataAnalyse.jar РДдЫааетИіЪОЗЖЪЕЯжЃЌГЬађЪзЯШГѕЪМЛЏЪ§ОнПтЃЌДДНЈМИИіЪОР§ЕФБэВЂЮДЖдгІБэВхШывЛЖЈЪ§СПЕФЪ§ОнЁЃ
ГЬађЕФдЫаааЇЙћЃЌШчЯТЭМЫљЪОЃК
ЭМ 4. ВЮПМЪЕЯждЫаааЇЙћ
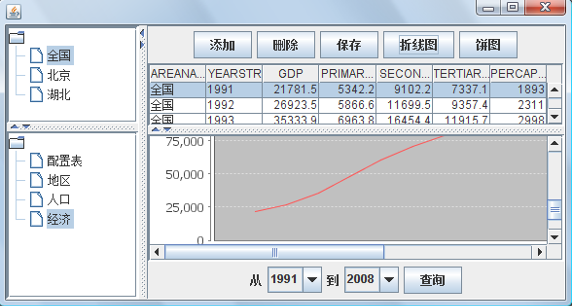
ЖдБэИёжаЪ§ОнЕФаоИФКЭЩОГ§ВйзїЃЌЖММЧТМдк cn.mellon.DMDataWrapper РржаЃЌcn.mellon.FakeServlet
ЭЈЙ§НтЮіетИіРрЃЌЩњГЩЯргІЕФ SQL гяОфКѓжДааЃЌДгЖјНЋЪ§ОнаоИФИќаТЕНЪ§ОнПтжаЁЃ
ЭМ 3 ЕФНчУцжаЃЌзѓЩЯЗНЕФЕиЧјбЁдёЪїФкШнРДздЕиЧјБэЃЌПЩвдаоИФЕиЧјБэЖдгІЕФЪ§ОнКѓЃЌжиаТЦєЖЏГЬађЙлВьаЇЙћЁЃХфжУБэЪЧБОЙІФмЪЕЯжЕФКЫаФХфжУЪ§ОнЫљдкЃЌБОВЮПМЪЕЯжвВвЛВЂНЋЦфБЉТЖвддЪаэдкНчУцжааоИФХфжУаХЯЂЃЌЙлВьаЇЙћЁЃЭЌбљЕФЃЌаоИФБЃДцКѓЃЌашвЊжиаТЦєЖЏГЬађЃЌЗНФмПДЕНаЇЙћЁЃвђЮЊХфжУаХЯЂКЭЕиЧјаХЯЂвЛбљЃЌЖМЪЧдк
Applet МгдиЪБЃЌДгЗўЮёЦїЖЫЛёШЁВЂБЛЛКДцдк Applet ЖЫЕФЁЃ
ЛЙгавЛаЉКЭБОЮФжїЬтЙиЯЕВЛДѓЕФЪЕЯжЯИНкЃЌЖСепПЩвдДгДњТыЛђзЂЪЭжадФЖСЕНЃЌШчЙћЯыНјвЛВННЛСїЃЌПЩвдЗЂгЪМўИјЮвЁЃ
БОЮФЫљЪіЕФЗНАИЪЧгІгУгк Web Application ЕФЃЌЖдгкОГЃашвЊЬэМгаТЕФЪ§ОнРрБ№ЕФгІгУЃЌПЩвдУтШЅеыЖдУПжжаТдіЪ§ОнжиИДПЊЗЂЖдгІЕФЧАЖЫвГУцКЭКѓЬЈДІРэРрЕШЗўЮёЦїЖЫГЬађЁЃЭЈЙ§МђЕЅХфжУМДПЩЖдаТдіЕФЪ§ОнБэЖдгІЕФЪ§ОнРрБ№ЭъГЩдіЩОИФВщЯЕСаВйзїЃЌвВЭЌЪБЛёЕУСЫЯрЙиЕФЭМБэЗжЮіЙІФмЃЌЯрЙиЕФЗжЮіЙІФмдНЖрЃЌетИіХфжУВњЩњЕФЪевцОЭдНДѓЁЃ
БОЗНАИвВгаОжЯоадЃЌгЩгкБОЗНАИЪЧЛљгк JDBC ЕФЃЌвђДЫЕББОЗНАИКЭЛљгк O/R Mapping ЪЕЯж Persistence
ВуЕФ Web Application ЙВДцЪБЃЌгы O/R Mapping ЕФЛКДцЛњжЦПжЮоЗЈМцШнЃЌвђЮЊБОЗНАИЯрЕБгкВЛО
O/R Mapping ВужБНгаоИФСЫЪ§ОнПтБэЁЃ
СэЭтЃЌБОЗНАИЕФЪ§ОнБЛВщбЏГіРДКѓЃЌДІдкРыЯпзДЬЌЃЌВЛЭЌгУЛЇдкЭЌвЛЪБМфЖдЯрЭЌЪ§ОнЕФаоИФЖЏзїЃЌЪЧЯрЛЅИВИЧЕФЃЌжСЩйдкЗўЮёЦїЖЫЪЕЯжЭЌВНДІРэжЎЧАЪЧетбљЕФЁЃШчЙћЪЙгУЯЕЭГЕФгУЛЇЪ§СПгаЯоЃЌЧвИїздЮЌЛЄЕФЪ§ОнУЛгажиЕўЃЌЛљБОЩЯЪЧАВШЋЕФЁЃШчЙћЪЙгУЯЕЭГЕФгУЛЇЪ§СПКмДѓЃЌБЫДЫЪ§ОнжиЕўЃЌдђашвЊПМТЧПижЦЭЌВНЮЪЬтЃЌКмУїЯдБОЗНАИЪЧВЛЪЪКЯгУдкВЂЗЂЗУЮЪЪ§СПЗЧГЃДѓЕФФфУћЗУЮЪЯЕЭГжаЕФЁЃ
| УшЪі |
Ућзж |
ДѓаЁ |
ЯТдиЗНЗЈ |
| БОЮФбљР§ДњТы |
DataAnalyse.jar |
68 KB |
|
бЇЯА
ЬжТл
|
