随着 Ron Bodkin 介绍如何把 AspectJ 和 JMX 组合成灵活而且模块化的性能监视方式,就可以对散乱而纠缠不清的代码说再见了。在这篇文章(共分两部分)的第一部分中,Ron
用来自开放源码项目 Glassbox Inspector 的代码和想法帮助您构建一个监视系统,它提供的相关信息可以识别出特定问题,但是在生产环境中使用的开销却足够低。
现代的 Java™ 应用程序通常是采用许多第三方组件的复杂的、多线程的、分布式的系统。在这样的系统上,很难检测(或者分离出)性能问题或可靠性问题的根本原因,尤其是生产中的问题。对于问题容易重现的情况来说,profiler
这类传统工具可能有用,但是这类工具带来的开销造成在生产环境、甚至负载测试环境中使用它们是不现实的。
监视和检查应用程序和故障常见的一个备选策略是,为性能的关键代码提供有关调用,记录使用情况、计时以及错误情况。但是,这种方式要求在许多地方分散重复的代码,而且要测量哪些代码也需要经过许多试验和错误才能确定。当系统变化时,这种方式既难维护,也很难深入进去。这造成日后要求对性能需求有更好理解的时候,添加或修改应用程序的代码变得很困难。简单地说,系统监视是经典的横切关注点,因此任何非模块化的实现都会让它混乱。
学习这篇分两部分的文章就会知道,面向方面编程(AOP)很自然地适合解决系统监视问题。AOP 允许定义切入点,与要监视性能的许多连接点进行匹配。然后可以编写建议,更新性能统计,而在进入或退出任何一个连接点时,都会自动调用建议。
在本文的这半部分,我将介绍如何用 AspectJ 和 JMX 创建灵活的、面向方面的监视基础设施。我要使用的监视基础设施是开放源码的
Glassbox Inspector 监视框架(请参阅 参考资料)的核心。它提供了相关的信息,可以帮助识别特定的问题,但是在生产环境中使用的开销却足够小。它允许捕捉请求的总数、总时间以及最差情况性能之类的统计值,还允许深入请求中数据库调用的信息。而它做的所有这些,仅仅是在一个中等规模的代码基础内完成的!
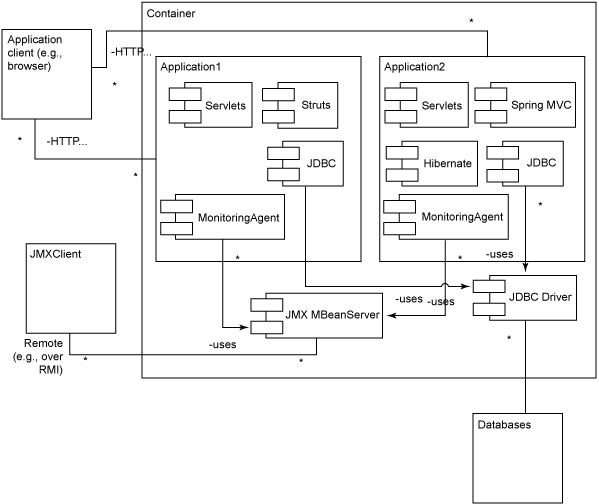
在这篇文章和下一篇文章中,我将从构建一个简单的 Glassbox Inspector 实现开始,并逐渐添加功能。图
1 提供了这个递增开发过程的最终系统的概貌。请注意这个系统的设计是为了同时监视多个 Web 应用程序,并提供合并的统计结果。
图 1. 带有 JConsole JMX 客户端的 Glassbox
Inspector

图 2 是监视系统架构的概貌。方面与容器内的一个或多个应用程序交互,捕捉性能数据,然后用 JMX Remote
标准把数据提出来。从架构的角度来看,Glassbox Inspector 与许多性能监视系统类似,区别在于它拥有定义良好的实现了关键监视功能的模块。
图 2. Glassbox Inspector 架构
Java 管理扩展(JMX)是通过查看受管理对象的属性来管理 Java 应用程序的标准 API。JMX
Remote 标准扩展了 JMX,允许外部客户进程管理应用程序。JMX 管理是 Java 企业容器中的标准特性。现有多个成熟的第三方
JMX 库和工具,而且 JMX 支持在 Java 5 中也已经集成进核心 Java 运行时。Sun 公司的
Java 5 虚拟机包含 JConsole JMX 客户端。
在继续本文之前,应当下载 AspectJ、JMX 和 JMX Remote 的当前版本以及本文的源代码包(请参阅
参考资料 获得技术内容,参阅下载
获得代码)。如果正在使用 Java 5 虚拟机,那么内置了 JMX。请注意源代码包包含开放源码的 Glassbox
Inspector 性能监视基础设施 1.0 alpha 发行版的完整最终代码。
我将从一个基本的面向方面的性能监视系统开始。这个系统可以捕捉处理 Web 请求的不同 servlet
的时间和计数。清单 1 显示了一个捕捉这个性能信息的简单方面:
清单 1. 捕捉 servlet 时间和计数的方面
/**
* Monitors performance timing and execution counts for
* <code>HttpServlet</code> operations
*/
public aspect HttpServletMonitor {
/** Execution of any Servlet request methods. */
public pointcut monitoredOperation(Object operation) :
execution(void HttpServlet.do*(..)) && this(operation);
/** Advice that records statistics for each monitored operation. */
void around(Object operation) : monitoredOperation(operation) {
long start = getTime();
proceed(operation);
PerfStats stats = lookupStats(operation);
stats.recordExecution(getTime(), start);
}
/**
* Find the appropriate statistics collector object for this
* operation.
*
* @param operation
* the instance of the operation being monitored
*/
protected PerfStats lookupStats(Object operation) {
Class keyClass = operation.getClass();
synchronized(operations) {
stats = (PerfStats)operations.get(keyClass);
if (stats == null) {
stats = perfStatsFactory.
createTopLevelOperationStats(HttpServlet.class,
keyClass);
operations.put(keyClass, stats);
}
}
return stats;
}
/**
* Helper method to collect time in milliseconds. Could plug in
* nanotimer.
*/
public long getTime() {
return System.currentTimeMillis();
}
public void setPerfStatsFactory(PerfStatsFactory
perfStatsFactory) {
this.perfStatsFactory = perfStatsFactory;
}
public PerfStatsFactory getPerfStatsFactory() {
return perfStatsFactory;
}
/** Track top-level operations. */
private Map/*<Class,PerfStats>*/ operations =
new WeakIdentityHashMap();
private PerfStatsFactory perfStatsFactory;
}
/**
* Holds summary performance statistics for a
* given topic of interest
* (e.g., a subclass of Servlet).
*/
public interface PerfStats {
/**
* Record that a single execution occurred.
*
* @param start time in milliseconds
* @param end time in milliseconds
*/
void recordExecution(long start, long end);
/**
* Reset these statistics back to zero. Useful to track statistics
* during an interval.
*/
void reset();
/**
* @return total accumulated time in milliseconds from all
* executions (since last reset).
*/
int getAccumulatedTime();
/**
* @return the largest time for any single execution, in
* milliseconds (since last reset).
*/
int getMaxTime();
/**
* @return the number of executions recorded (since last reset).
*/
int getCount();
}
/**
* Implementation of the
*
* @link PerfStats interface.
*/
public class PerfStatsImpl implements PerfStats {
private int accumulatedTime=0L;
private int maxTime=0L;
private int count=0;
public void recordExecution(long start, long end) {
int time = (int)(getTime()-start);
accumulatedTime += time;
maxTime = Math.max(time, maxTime);
count++;
}
public void reset() {
accumulatedTime=0L;
maxTime=0L;
count=0;
}
int getAccumulatedTime() { return accumulatedTime; }
int getMaxTime() { return maxTime; }
int getCount() { return count; }
}
public interface PerfStatsFactory {
PerfStats
createTopLevelOperationStats(Object type, Object key);
}
|
可以看到,第一个版本相当基础。 HttpServletMonitor 定义了一个切入点,叫作
monitoredOperation,它匹配 HttpServlet
接口上任何名称以 do 开始的方法的执行。这些方法通常是 doGet()
和 doPost(),但是通过匹配 doHead()、 doDelete()、 doOptions()、 doPut()
和 doTrace(),它也可以捕捉不常用的 HTTP 请求选项。
每当其中一个操作执行的时候,系统都会执行 around 通知去监视性能。建议启动一个秒表,然后让原始请求继续进行。之后,通知停止秒表并查询与指定操作对应的性能统计对象。然后它再调用
PerfStats 接口的 recordExecution(),记录操作经历的时间。这仅仅更新指定操作的总时间、最大时间(如果适用)以及执行次数。自然也可以把这种方式扩展成计算额外的统计值,并在问题可能发生的地方保存单独的数据点。
我在方面中使用了一个哈希图为每种操作处理程序保存累计统计值。在这个版本中,操作处理程序是
HttpServlet 的子类,所以 servlet 的类被用作键。我还用术语 操作
表示 Web 请求,以便把它与应用程序可能产生的其他请求(例如,数据库请求)区分开。在这篇文章的第二部分,我将扩展这种方式,来解决更常见的在控制器中使用的基于类或方法的跟踪操作情况,例如
Apache Struts 的动作类或 Spring 的多动作控制器方法。
一旦捕捉到了性能数据,让它可以使用的方式就很多了。最简单的方式就是把信息定期地写入日志文件。也可以把信息装入数据库进行分析。由于不增加延迟、复杂性以及合计、日志及处理信息的开销,提供到即时系统数据的直接访问通常会更好。在下一节中我将介绍如何做到这一点。
我想使用一个现有管理工作能够显示和跟踪的标准协议,所以我将用 JMX API 来共享性能统计值。使用
JMX 意味着每个性能统计实例都会公开成一个管理 bean,从而提供详细的性能数据。标准的 JMX 客户端(像
Sun 公司的 JConsole)也能够显示这些信息。请参阅 参考资料
学习有关 JMX 的更多内容。
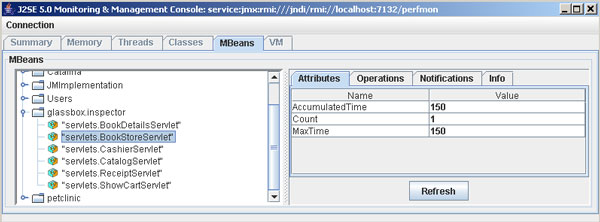
图 3 是一幅 JConsole 的截屏,显示了 Glassbox Inspector 监视 Duke
书店示例应用程序性能的情况。(请参阅 参考资料)。清单
2 显示了实现这个特性的代码。
图 3. 用 Glassbox Inspector 查看操作统计值
传统上,支持 JMX 包括用样本代码实现模式。在这种情况下,我将把 JMX 与 AspectJ 结合,这个结合可以让我独立地编写管理逻辑。
清单 2. 实现 JMX 管理特性
/** Reusable aspect that automatically registers
* beans for management
*/
public aspect JmxManagement {
/** Defines classes to be managed and
* defines basic management operation
*/
public interface ManagedBean {
/** Define a JMX operation name for this bean.
* Not to be confused with a Web request operation.
*/
String getOperationName();
/** Returns the underlying JMX MBean that
* provides management
* information for this bean (POJO).
*/
Object getMBean();
}
/** After constructing an instance of
* <code>ManagedBean</code>, register it
*/
after() returning (ManagedBean bean):
call(ManagedBean+.new(..)) {
String keyName = bean.getOperationName();
ObjectName objectName =
new
ObjectName("glassbox.inspector:" + keyName);
Object mBean = bean.getMBean();
if (mBean != null) {
server.registerMBean(mBean, objectName);
}
}
/**
* Utility method to encode a JMX key name,
* escaping illegal characters.
* @param jmxName unescaped string buffer of form
* JMX keyname=key
* @param attrPos position of key in String
*/
public static StringBuffer
jmxEncode(StringBuffer jmxName, int attrPos) {
for (int i=attrPos; i<jmxName.length(); i++) {
if (jmxName.charAt(i)==',' ) {
jmxName.setCharAt(i, ';');
} else if (jmxName.charAt(i)=='?'
|| jmxName.charAt(i)=='*' ||
jmxName.charAt(i)=='\\' ) {
jmxName.insert(i, '\\');
i++;
} else if (jmxName.charAt(i)=='\n') {
jmxName.insert(i, '\\');
i++;
jmxName.setCharAt(i, 'n');
}
}
return jmxName;
}
/** Defines the MBeanServer with which beans
* are auto-registered.
*/
private MBeanServer server;
public void setMBeanServer(MBeanServer server) {
this.server = server;
}
public MBeanServer getMBeanServer() {
return server;
}
}
|
可以看出这个第一个方面是可以重用的。利用它,我能够用 after 建议自动为任何实现
ManagedBean 接口的类登记对象实例。这与 AspectJ 标记器接口的理念类似(请参阅
参考资料):定义了实例应当通过 JMX 公开的类。但是,与真正的标记器接口不同的是,它还定义了两个方法
。
这个方面提供了一个设置器,定义应当用哪个 MBean 服务器管理对象。这是一个使用反转控制(IOC)模式进行配置的示例,因此很自然地适合方面。在最终代码的完整清单中,将会看到我用了一个简单的辅助方面对系统进行配置。在更大的系统中,我将用
Spring 框架这样的 IOC 容器来配置类和方面。请参阅 参考资料
获得关于 IOC 和 Spring 框架的更多信息,并获得关于使用 Spring 配置方面的介绍。
清单 3. 公开负责 JMX 管理的 bean
/** Applies JMX management to performance statistics beans. */
public aspect StatsJmxManagement {
/** Management interface for performance statistics.
* A subset of @link PerfStats
*/
public interface PerfStatsMBean extends ManagedBean {
int getAccumulatedTime();
int getMaxTime();
int getCount();
void reset();
}
/**
* Make the @link PerfStats interface
* implement @link PerfStatsMBean,
* so all instances can be managed
*/
declare parents: PerfStats implements PerfStatsMBean;
/** Creates a JMX MBean to represent this PerfStats instance. */
public DynamicMBean PerfStats.getMBean() {
try {
RequiredModelMBean mBean = new RequiredModelMBean();
mBean.setModelMBeanInfo
(assembler.getMBeanInfo(this, getOperationName()));
mBean.setManagedResource(this,
"ObjectReference");
return mBean;
} catch (Exception e) {
/* This is safe because @link ErrorHandling
* will resolve it. This is described later!
*/
throw new
AspectConfigurationException("can't
register bean ", e);
}
}
/** Determine JMX operation name for this
* performance statistics bean.
*/
public String PerfStats.getOperationName() {
StringBuffer keyStr =
new StringBuffer("operation=\"");
int pos = keyStr.length();
if (key instanceof Class) {
keyStr.append(((Class)key).getName());
} else {
keyStr.append(key.toString());
}
JmxManagement.jmxEncode(keyStr, pos);
keyStr.append("\"");
return keyStr.toString();
}
private static Class[] managedInterfaces =
{ PerfStatsMBean.class };
/**
* Spring JMX utility MBean Info Assembler.
* Allows @link PerfStatsMBean to serve
* as the management interface of all performance
* statistics implementors.
*/
static InterfaceBasedMBeanInfoAssembler assembler;
static {
assembler = new InterfaceBasedMBeanInfoAssembler();
assembler.setManagedInterfaces(managedInterfaces);
}
}
|
清单 3 包含 StatsJmxManagement 方面,它具体地定义了哪个对象应当公开管理
bean。它描述了一个接口 PerfStatsMBean,这个接口定义了用于任何性能统计实现的管理接口。其中包括计数、总时间、最大时间的统计值,还有重设操作,这个接口是
PerfStats 接口的子集。
PerfStatsMBean 本身扩展了 ManagedBean,所以它的任何实现都会自动被
JmxManagement 方面登记成进行管理。我采用 AspectJ 的 declare
parents 格式让 PerfStats 接口扩展了一个特殊的管理接口
PerfStatsMBean。结果是 JMX Dynamic MBean 技术会管理这些对象,与使用
JMX 的标准 MBean 相比,我更喜欢这种方式。
使用标准 MBean 会要求定义一个管理接口,接口名称基于每个性能统计的实现类,例如 PerfStatsImplMBean。后来,当我向
Glassbox Inspector 添加 PerfStats 的子类时,情况变糟了,因为我被要求创建对应的接口(例如
OperationPerfStatsImpl)。标准 MBean 的约定使得接口依赖于实现,而且代表这个系统的继承层次出现不必要的重复。
这个方面剩下的部分负责用 JMX 创建正确的 MBean 和对象名称。我重用了来自 Spring 框架的
JMX 工具 InterfaceBasedMBeanInfoAssembler,用它可以更容易地创建
JMX DynamicMBean(用 PerfStatsMBean 接口管理
PerfStats 实例)。在这个阶段,我只公开了 PerfStats
实现。这个方面还用受管理 bean 类上的类型间声明定义了辅助方法。如果这些类中的任何一个的子类需要覆盖默认行为,那么可以通过覆盖这个方法实现。
您可能想知道为什么我用方面进行管理而不是直接把支持添加到 PerfStatsImpl
的实现类中。虽然把管理添加到这个类中不会把代码分散,但是它会把性能监视系统的实现与 JMX 混杂在一起。所以,如果我想把这个系统用在一个
没有 JMX 的系统中,就要被迫包含 JMX 的库,还要禁止有关服务。而且,当扩展系统的管理功能时,我还要公开更多的类用
JMX 进行管理。使用方面可以让系统的管理策略保持模块化。
分布式调用是应用程序性能低和出错误的一个常见源头。多数基于 Web 的应用程序要做相当数量的数据库工作,所以对查询和其他数据库请求进行监视就成为性能监视中特别重要的领域。常见的问题包括编写得有毛病的查询、遗漏了索引以及每个操作中过量的数据库请求。在这一节,我将对监视系统进行扩展,跟踪数据库中与操作相关的活动。
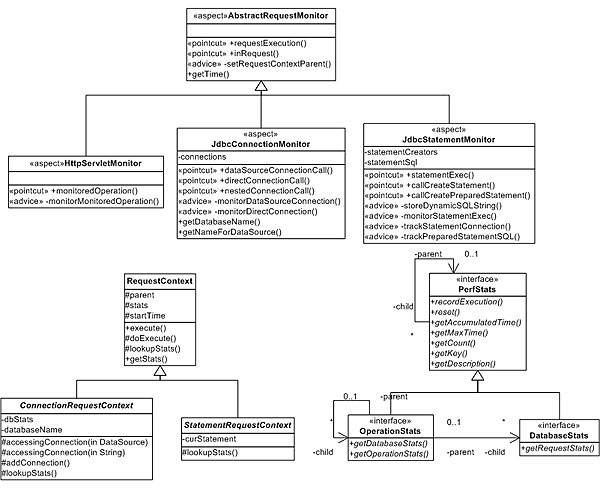
开始时,我将监视数据库的连接次数和数据库语句的执行。为了有效地支持这个要求,我需要归纳性能监视信息,并允许跟踪嵌套在一个操作中的性能。我想把性能的公共元素提取到一个抽象基类。每个基类负责跟踪某项操作前后的性能,还需要更新系统范围内这条信息的性能统计值。这样我就能跟踪嵌套的
servlet 请求,对于在 Web 应用程序中支持对控制器的跟踪,这也会很重要(在第二部分讨论)。
因为我想根据请求更新数据库的性能,所以我将采用 composite pattern 跟踪由其他统计值持有的统计值。这样,操作(例如
servelt)的统计值就持有每个数据库的性能统计。数据库的统计值持有有关连接次数的信息,并聚合每个单独语句的额外统计值。图
4 显示整体设计是如何结合在一起的。清单 4 拥有新的基监视方面,它支持对不同的请求进行监视。
图 4. 一般化后的监视设计
清单 4. 基监视方面
/** Base aspect for monitoring functionality.
* Uses the worker object pattern.
*/
public abstract aspect AbstractRequestMonitor {
/** Matches execution of the worker object
* for a monitored request.
*/
public pointcut
requestExecution(RequestContext requestContext) :
execution(* RequestContext.execute(..))
&& this(requestContext);
/** In the control flow of a monitored request,
* i.e., of the execution of a worker object.
*/
public pointcut inRequest(RequestContext requestContext) :
cflow(requestExecution(requestContext));
/** establish parent relationships
* for request context objects.
*/
// use of call is cleaner since constructors are called
// once but executed many times
after(RequestContext parentContext)
returning (RequestContext childContext) :
call(RequestContext+.new(..)) &&
inRequest(parentContext) {
childContext.setParent(parentContext);
}
public long getTime() {
return System.currentTimeMillis();
}
/** Worker object that holds context information
* for a monitored request.
*/
public abstract class RequestContext {
/** Containing request context, if any.
* Maintained by @link AbstractRequestMonitor
*/
protected RequestContext parent = null;
/** Associated performance statistics.
* Used to cache results of @link #lookupStats()
*/
protected PerfStats stats;
/** Start time for monitored request. */
protected long startTime;
/**
* Record execution and elapsed time
* for each monitored request.
* Relies on @link #doExecute() to proceed
* with original request.
*/
public final Object execute() {
startTime = getTime();
Object result = doExecute();
PerfStats stats = getStats();
if (stats != null) {
stats.recordExecution(startTime, getTime());
}
return result;
}
/** template method: proceed with original request */
public abstract Object doExecute();
/** template method: determines appropriate performance
* statistics for this request
*/
protected abstract PerfStats lookupStats();
/** returns performance statistics for this method */
public PerfStats getStats() {
if (stats == null) {
stats = lookupStats(); // get from cache if available
}
return stats;
}
public RequestContext getParent() {
return parent;
}
public void setParent(RequestContext parent) {
this.parent = parent;
}
}
}
|
不出所料,对于如何存储共享的性能统计值和基方面的每请求状态,有许多选择。例如,我可以用带有更底层机制的单体(例如
ThreadLocal)持有一堆统计值和上下文。但是,我选用了工人对象(Worker
Object)模式(请参阅 参考资料),因为它支持更加模块化、更简洁的表达。虽然这会带来一些额外的开销,但是分配单一对象并执行建议所需要的额外时间,比起为
Web 和数据库请求提供服务来说,通常是微不足道的。换句话说,我可以在不增加开销的情况下,在监视代码中做一些处理工作,因为它运行的频繁相对很低,而且比起在通过网络发送信息和等候磁盘
I/O 上花费的时间来说,通常就微不足道了。对于 profiler 来说,这可能是个糟糕的设计,因为在
profiler 中可能想要跟踪每个请求中的许多操作(和方法)的数据。但是,我是在做请求的统计汇总,所以这个选择是合理的。
在上面的基方面中,我把当前被监视请求的中间状态保存在匿名内部类中。这个工人对象用来包装被监视请求的执行。工人对象
RequestContext 是在基类中定义的,提供的 final execute
方法定义了对请求进行监视的流程。execute 方法委托抽象的模板方法 doExecute()
负责继续处理原始的连接点。在 doExecute() 方法中也适合在根据上下文信息(例如正在连接的数据源)继续处理被监视的连接点之前设置统计值,并在连接点返回之后关联返回的值(例如数据库连接)。
每个监视方面还负责提供抽象方法 lookupStats() 的实现,用来确定为指定请求更新哪个统计对象。 lookupStats()
需要根据被监视的连接点访问信息。一般来说,捕捉的上下文对于每个监视方面都应当各不相同。例如,在
HttpServletMonitor 中,需要的上下文就是目前执行操作对象的类。对于 JDBC
连接,需要的上下文就是得到的数据源。因为要求根据上下文而不同,所以设置工人对象的建议最好是包含在每个子方面中,而不是在抽象的基方面中。这种安排更清楚,它支持类型检测,而且也比在基类中编写一个建议,再把
JoinPoint 传递给所有孩子执行得更好。
AbstractRequestMonitor 确实包含一个具体的 after
建议,负责跟踪请求上下文的双亲上下文。这就让我可以把嵌套请求的操作统计值与它们双亲的统计值关联起来(例如,哪个
servlet 请求造成了这个数据库访问)。对于示例监视系统来说,我明确地 需要 嵌套的工人对象,而
不想 把自己限制在只能处理顶级请求上。例如,所有的 Duke 书店 servlet 都把调用
BannerServlet 作为显示页面的一部分。所以能把这些调用的次数分开是有用的,如清单
5 所示。在这里,我没有显示在操作统计值中查询嵌套统计值的支持代码(可以在本文的源代码中看到它)。在第二部分,我将重新回到这个主题,介绍如何更新
JMX 支持来显示像这样的嵌套统计值。
清单 5. 更新的 servlet 监视
清单 5 should now read
public aspect HttpServletMonitor extends AbstractRequestMonitor {
/** Monitor Servlet requests using the worker object pattern */
Object around(final Object operation) :
monitoredOperation(operation) {
RequestContext requestContext = new RequestContext() {
public Object doExecute() {
return proceed(operation);
}
public PerfStats lookupStats() {
if (getParent() != null) {
// nested operation
OperationStats parentStats =
(OperationStats)getParent().getStats();
return
parentStats.getOperationStats(operation.getClass());
}
return lookupStats(operation.getClass());
}
};
return requestContext.execute();
}
...
|
清单 5 显示了修订后进行 serverlet 请求跟踪的监视建议。余下的全部代码与
清单 1 相同:或者推入基方面 AbstractRequestMonitor
方面,或者保持一致。
设置好性能监视框架后,我现在准备跟踪数据库的连接次数以及数据库语句的时间。而且,我还希望能够把数据库语句和实际连接的数据库关联起来(在
lookupStats() 方法中)。为了做到这一点,我创建了两个跟踪
JDBC 语句和连接信息的方面: JdbcConnectionMonitor
和 JdbcStatementMonitor。
这些方面的一个关键职责是跟踪对象引用的链。我想根据我用来连接数据库的 URI 跟踪请求,或者至少根据数据库名称来跟踪。这就要求跟踪用来获得连接的数据源。我还想进一步根据
SQL 字符串跟踪预备语句(在执行之前就已经准备就绪)。最后,我需要跟踪与正在执行的语句关联的 JDBC
连接。您会注意到:JDBC 语句 确实 为它们的连接提供了存取器;但是,应用程序服务器和
Web 应用程序框架频繁地使用修饰器模式包装 JDBC 连接。我想确保自己能够把语句与我拥有句柄的连接关联起来,而不是与包装的连接关联起来。
JdbcConnectionMonitor 负责测量数据库连接的性能统计值,它也把连接与它们来自数据源或连接
URL 的元数据(例如 JDBC URL 或数据库名称)关联在一起。 JdbcStatementMonitor
负责测量执行语句的性能统计值,跟踪用来取得语句的连接,跟踪与预备(和可调用)语句关联的 SQL 字符串。清单
6 显示了 JdbcConnectionMonitor 方面。
清单 6. JdbcConnectionMonitor 方面
/**
* Monitor performance for JDBC connections,
* and track database connection information associated with them.
*/
public aspect JdbcConnectionMonitor extends AbstractRequestMonitor {
/** A call to establish a connection using a
* <code>DataSource</code>
*/
public pointcut dataSourceConnectionCall(DataSource dataSource) :
call(Connection+ DataSource.getConnection(..))
&& target(dataSource);
/** A call to establish a connection using a URL string */
public pointcut directConnectionCall(String url) :
(call(Connection+ Driver.connect(..)) || call(Connection+
DriverManager.getConnection(..))) &&
args(url, ..);
/** A database connection call nested beneath another one
* (common with proxies).
*/
public pointcut nestedConnectionCall() :
cflowbelow(dataSourceConnectionCall(*) ||
directConnectionCall(*));
/** Monitor data source connections using
* the worker object pattern
*/
Connection around(final DataSource dataSource) :
dataSourceConnectionCall(dataSource)
&& !nestedConnectionCall() {
RequestContext requestContext =
new ConnectionRequestContext() {
public Object doExecute() {
accessingConnection(dataSource);
// set up stats early in case needed
Connection connection = proceed(dataSource);
return addConnection(connection);
}
};
return (Connection)requestContext.execute();
}
/** Monitor url connections using the worker object pattern */
Connection around(final String url) : directConnectionCall(url)
&& !nestedConnectionCall() {
RequestContext requestContext =
new ConnectionRequestContext() {
public Object doExecute() {
accessingConnection(url);
Connection connection = proceed(url);
return addConnection(connection);
}
};
return (Connection)requestContext.execute();
}
/** Get stored name associated with this data source. */
public String getDatabaseName(Connection connection) {
synchronized (connections) {
return (String)connections.get(connection);
}
}
/** Use common accessors to return meaningful name
* for the resource accessed by this data source.
*/
public String getNameForDataSource(DataSource ds) {
// methods used to get names are listed in descending
// preference order
String possibleNames[] =
{ "getDatabaseName",
"getDatabasename",
"getUrl", "getURL",
"getDataSourceName",
"getDescription" };
String name = null;
for (int i=0; name == null &&
i<possibleNames.length; i++) {
try {
Method method =
ds.getClass().getMethod(possibleNames[i], null);
name = (String)method.invoke(ds, null);
} catch (Exception e) {
// keep trying
}
}
return (name != null) ? name : "unknown";
}
/** Holds JDBC connection-specific context information:
* a database name and statistics
*/
protected abstract class ConnectionRequestContext
extends RequestContext {
private ResourceStats dbStats;
/** set up context statistics for accessing
* this data source
*/
protected void
accessingConnection(final DataSource dataSource) {
addConnection(getNameForDataSource(dataSource),
connection);
}
/** set up context statistics for accessing this database */
protected void accessingConnection(String databaseName) {
this.databaseName = databaseName;
// might be null if there is database access
// caused from a request I'm not tracking...
if (getParent() != null) {
OperationStats opStats =
(OperationStats)getParent().getStats();
dbStats = opStats.getDatabaseStats(databaseName);
}
}
/** record the database name for this database connection */
protected Connection
addConnection(final Connection connection) {
synchronized(connections) {
connections.put(connection, databaseName);
}
return connection;
}
protected PerfStats lookupStats() {
return dbStats;
}
};
/** Associates connections with their database names */
private Map/*<Connection,String>*/ connections =
new WeakIdentityHashMap();
}
|
清单 6 显示了利用 AspectJ 和 JDBC API 跟踪数据库连接的方面。它用一个图来关联数据库名称和每个
JDBC 连接。
在 jdbcConnectionMonitor
内部
在清单 6 显示的 JdbcConnectionMonitor 内部,我定义了切入点,捕捉连接数据库的两种不同方式:通过数据源或直接通过
JDBC URL。连接监视器包含针对每种情况的监视建议,两种情况都设置一个工人对象。 doExecute()
方法启动时处理原始连接,然后把返回的连接传递给两个辅助方法中名为 addConnection
的一个。在两种情况下,被建议的切入点会排除来自另一个连接的连接调用(例如,如果要连接到数据源,会造成建立
JDBC 连接)。
数据源的 addConnection() 委托辅助方法 getNameForDataSource()
从数据源确定数据库的名称。 DataSource 接口不提供任何这类机制,但是几乎每个实现都提供了
getDatabaseName() 方法。 getNameForDataSource()
用反射来尝试完成这项工作和其他少数常见(和不太常见)的方法,为数据库源提供一个有用的标识。 addConnection()
方法然后委托给 addConnection() 方法,这个方法用字符串参数作为名称。
被委托的 addConnection() 方法从父请求的上下文中检索可以操作的统计值,并根据与指定连接关联的数据库名称(或其他描述字符串)查询数据库的统计值。然后它把这条信息保存在请求上下文对象的
dbStats 字段中,更新关于获得连接的性能信息。这样就可以跟踪连接数据库需要的时间(通常这实际是从池中得到连接所需要的时间)。 addConnection()
方法也更新到数据库名称的连接的连接图。随后在执行 JDBC 语句更新对应请求的统计值时,会使用这个图。 JdbcConnectionMonitor
还提供了一个辅助方法 getDatabaseName(),它从连接图中查询字符串名称找到连接。
弱标识图和方面
JDBC 监视方面使用 弱标识 哈希图。这些图持有 弱 引用,允许连接这样的被跟踪对象在只有方面引用它们的时候,被垃圾收集掉。这一点很重要,因为单体的方面通常
不会 被垃圾收集。如果引用不弱,那么应用程序会有内存泄漏。方面用 标识 图来避免调用连接或语句的 hashCode
或 equals 方法。这很重要,因为我想跟踪连接和语句,而不理会它们的状态:我不想遇到来自
hashCode 方法的异常,也不想在对象的内部状态已经改变时(例如关闭时),指望对象的哈希码保持不变。我在处理动态的基于代理的
JDBC 对象(就像来自 iBatis 的那些对象)时遇到了这个问题:在连接已经关闭之后调用对象上的方法就会抛出异常。在完成操作之后还想记录统计值时会造成错误。
从这里可以学到的教训是:把对第三方代码的假设最小化。使用标识图是避免对接受建议的代码的实现逻辑进行猜测的好方法。在这种情况下,我使用了来自
DCL Java 工具的 WeakIdentityHashMap 开放源码实现(请参阅
参考资料)。跟踪连接或语句的元数据信息让我可以跨越请求,针对连接或语句把统计值分组。这意味着可以只根据对象实例进行跟踪,而不需要使用对象等价性来跟踪这些
JDBC 对象。另一个要记住的教训是:不同的对象经常用不同的修饰器包装(越来越多地采用动态代理) JDBC
对象。所以假设要处理的是这类接口的简单而原始的实现,可不是一个好主意!
jdbcStatementMonitor
内部
清单 7 显示了 JdbcStatementMonitor 方面。这个方面有两个主要职责:跟踪与创建和准备语句有关的信息,然后监视
JDBC 语句执行的性能统计值。
清单 7. JdbcStatementMonitor 方面
/**
* Monitor performance for executing JDBC statements,
* and track the connections used to create them,
* and the SQL used to prepare them (if appropriate).
*/
public aspect JdbcStatementMonitor extends AbstractRequestMonitor {
/** Matches any execution of a JDBC statement */
public pointcut statementExec(Statement statement) :
call(* java.sql..*.execute*(..)) &&
target(statement);
/**
* Store the sanitized SQL for dynamic statements.
*/
before(Statement statement, String sql,
RequestContext parentContext):
statementExec(statement) && args(sql, ..)
&& inRequest(parentContext) {
sql = stripAfterWhere(sql);
setUpStatement(statement, sql, parentContext);
}
/** Monitor performance for executing a JDBC statement. */
Object around(final Statement statement) :
statementExec(statement) {
RequestContext requestContext =
new StatementRequestContext() {
public Object doExecute() {
return proceed(statement);
}
};
return requestContext.execute();
}
/**
* Call to create a Statement.
* @param connection the connection called to
* create the statement, which is bound to
* track the statement's origin
*/
public pointcut callCreateStatement(Connection connection):
call(Statement+ Connection.*(..))
&& target(connection);
/**
* Track origin of statements, to properly
* associate statistics even in
* the presence of wrapped connections
*/
after(Connection connection) returning (Statement statement):
callCreateStatement(connection) {
synchronized (JdbcStatementMonitor.this) {
statementCreators.put(statement, connection);
}
}
/**
* A call to prepare a statement.
* @param sql The SQL string prepared by the statement.
*/
public pointcut callCreatePreparedStatement(String sql):
call(PreparedStatement+ Connection.*(String, ..))
&& args(sql, ..);
/** Track SQL used to prepare a prepared statement */
after(String sql) returning (PreparedStatement statement):
callCreatePreparedStatement(sql) {
setUpStatement(statement, sql);
}
protected abstract class StatementRequestContext
extends RequestContext {
/**
* Find statistics for this statement, looking for its
* SQL string in the parent request's statistics context
*/
protected PerfStats lookupStats() {
if (getParent() != null) {
Connection connection = null;
String sql = null;
synchronized (JdbcStatementMonitor.this) {
connection =
(Connection) statementCreators.get(statement);
sql = (String) statementSql.get(statement);
}
if (connection != null) {
String databaseName =
JdbcConnectionMonitor.aspectOf().
getDatabaseName(connection);
if (databaseName != null && sql != null) {
OperationStats opStats =
(OperationStats) getParent().getStats();
if (opStats != null) {
ResourceStats dbStats =
opStats.getDatabaseStats(databaseName);
return dbStats.getRequestStats(sql);
}
}
}
}
return null;
}
}
/**
* To group sensibly and to avoid recording sensitive data,
* I don't record the where clause (only used for dynamic
* SQL since parameters aren't included
* in prepared statements)
* @return subset of passed SQL up to the where clause
*/
public static String stripAfterWhere(String sql) {
for (int i=0; i<sql.length()-4; i++) {
if (sql.charAt(i)=='w' || sql.charAt(i)==
'W') {
if (sql.substring(i+1, i+5).equalsIgnoreCase(
"here"))
{
sql = sql.substring(0, i);
}
}
}
return sql;
}
private synchronized void
setUpStatement(Statement statement, String sql) {
statementSql.put(statement, sql);
}
/** associate statements with the connections
* called to create them
*/
private Map/*<Statement,Connection>*/ statementCreators =
new WeakIdentityHashMap();
/** associate statements with the
* underlying string they execute
*/
private Map/*<Statement,String>*/ statementSql =
new WeakIdentityHashMap();
}
|
JdbcStatementMonitor 维护两个弱标识图: statementCreators
和 statementSql。第一个图跟踪用来创建语句的连接。正如前面提示过的,我不想依赖这条语句的
getConnection 方法,因为它会引用一个包装过的连接,而我没有这个连接的元数据。请注意
callCreateStatement 切入点,我建议它去监视 JDBC 语句的执行。这个建议匹配的方法调用是在
JDBC 连接上定义的,而且会返回 Statement 或任何子类。这个建议可以匹配
JDBC 中 12 种不同的可以创建或准备语句的方式,而且是为了适应 JDBC API 未来的扩展而设计的。
statementSql 图跟踪指定语句执行的 SQL 字符串。这个图用两种不同的方式更新。在创建预备语句(包括可调用语句)时,在创建时捕捉到
SQL 字符串参数。对于动态 SQL 语句,SQL 字符串参数在监视建议使用它之前,从语句执行调用中被捕捉。(建议的先后次序在这里没影响;虽然是在执行完成之后才用建议查询统计值,但字符串是在执行发生之前捕捉的。)
语句的性能监视由一个 around 建议处理,它在执行 JDBC 语句的时候设置工人对象。执行
JDBC 语句的 statementExec 切入点会捕捉 JDBC Statement(包括子类)实例上名称以
execute 开始的任何方法的调用,方法是在 JDBC API 中定义的(也就是说,在任何名称以
java.sql 开始的包中)。
工人对象上的 lookupStats() 方法使用双亲(servlet)的统计上下文来查询指定连接的数据库统计值,然后查询指定
SQL 字符串的 JDBC 语句统计值。直接的语句执行方法包括:SQL 语句中在 where
子句之后剥离数据的附加逻辑。这就避免了暴露敏感数据的风险,而且也允许把常见语句分组。更复杂的方式就是剥离查询参数而已。但是,多数应用程序使用预备语句而不是动态
SQL 语句,所以我不想深入这一部分。
在结束之前,关于监视方面如何解决跟踪 JDBC 信息的挑战,请静想一分钟。 JdbcConnectionMonitor
让我把数据库的文本描述(例如 JDBC URL)与用来访问数据库的连接关联起来。同样, JdbcStatementMonitor
中的 statementSql 映射跟踪 SQL 字符串(甚至是用于预备语句的字符串),从而确保可以用有意义的名称,把执行的查询分成有意义的组。最后, JdbcStatementMonitor
中的 statementCreators 映射让我把语句与我拥有句柄(而不是包装过)的连接关联。这种方式整合了多个建议,在把方面应用到现实问题时,更新内部状态非常有用。在许多情况下,需要跟踪来自
一系列 切入点的上下文信息,在单一公开上下文的 AspectJ 切入点中无法捕捉到这个信息。在出现这种情况时,一个切入点的跟踪状态可以在后一个切入点中使用这项技术就会非常有帮助。
这个信息可用之后, JdbcStatementMonitor 就能够很自然地监视性能了。在语句执行切入点上的实际建议只是遵循标准方法
,创建工人对象继续处理原始的计算。 lookupStats() 方法使用这三个不同的映射来查询与这条语句关联的连接和
SQL。然后它用它的双亲请求,根据连接的描述找到正确的数据库统计值,并根据 SQL 键字符串找到语句统计值。 lookupStats()
是防御性的,也就是说它在应用程序的使用违背预期的时候,会检查 null 值。在这篇文章的第二部分,我将介绍如何用
AOP 系统地保证监视代码不会在被监视的应用程序中造成问题。
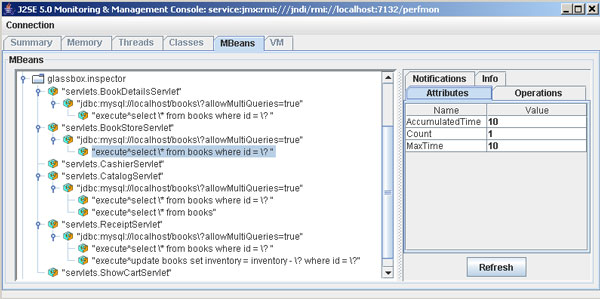
迄今为止,我构建了一个核心的监视基础设施,可以系统地跟踪应用程序的性能、测量 servlet 操作中的数据库活动。监视代码可以自然地插入
JMX 接口来公开结果,如图 5 所示。代码已经能够监视重要的应用程序逻辑,您也已经看到了扩展和更新监视方式有多容易。
图 5. 监视数据库结果
虽然这里提供的代码相当简单,但却是对传统方式的巨大修改。AspectJ 模块化的方式让我可以精确且一致地处理监视功能。比起在整个示例应用程序中用分散的调用更新统计值和跟踪上下文,这是一个重大的改进。即使使用对象来封装统计跟踪,传统的方式对于每个用户操作和每个资源访问,也都需要多个调用。实现这样的一致性会很繁琐,也很难一次实现,更不用说维护了。
在这篇文章的第二部分中,我将把重点放在开发和部署基于 AOP 的性能监视系统的编程问题上。我将介绍如何用
AspectJ 5 的装入时编织来监视运行在 Apache Tomcat 中的多个应用程序,包括在第三方库中进行监视。我将介绍如何测量监视的开销,如何选择性地在运行时启用监视,如何测量装入时编织的性能和内存影响。我还会介绍如何用方面防止监视代码中的错误造成应用程序错误。最后,我将扩展
Glassbox Inspector,让它支持 Web 服务和常见的 Web 应用程序框架(例如 Struts
和 Spring )并跟踪应用程序错误。欢迎继续阅读!
感谢 Ramnivas Laddad、Will Edwards、Matt Hutton、David Pickering、Rob
Harrop、Alex Vasseur、Paul Sutter、Mik Kersten 和 Eugene Kuleshov
审阅本文并给出非常深刻的评价。
| 描述 |
名字 |
大小 |
下载方法 |
Sample
code |
j-aopwork10-source.zip |
75 KB |
|
学习
获得产品和技术
讨论
| 