简介:
Facebook 介绍了一个名为 BigPipe 的技术,这项技术可使 Facebook 站点的访问速度提升一倍。目前,也有一小部分文章介绍了该技术在
JSP 中的实现,但是这些文章只是基于 Servlet 的理论实现,对于 Java Web 开发者来说并不存在实际意义。本文基于
BigPipe 的思想,开发了 BigPipe 的 JSP 实现,该技术可以实现 JSP 页面的快速加载,增强用户体验,读者不仅可以从本文了解
BigPipe 原理,还可以使用开发的 Struts2 标签进行实际的开发,相信对读者的学习和开发有很大的好处。
引言
Facebook 创立了一项技术名为 BigPipe。该技术改善了 Facebook
用户的用户体验,减少页面加载等待时间,它的原理简单、合理。本文借鉴 BigPipe 的思想,针对 Struts2
和 JSP 技术的特点,实现了单线程与多线程版的 BigPipe。两种版本的实现各有优缺点,它们与 Facebook
的 BigPipe 不尽相同,其中多线程版的 BigPipe 实现与 Facebook 较为类似。单线程与多线程实现方式都可以明显改善用户体验,文章之所以要介绍两种实现,是笔者认为二者都有更加适用的情境,在很多情况下,单线程的使用情况更多、更简单。文章将用实际的使用实例,对两种实现进行详细的介绍。在阅读文章之前,读者最好先了解一下
Struts2 自定义标签的开发方法、Java 的 Concurrent 多线程框架以及 FreeMarker
模板引擎,这将帮助你更好的理解文章的 BigPipe 实现方式。
技术简介
现在的浏览器,显示网页时需要经历连续的几个步骤,分别是请求网页 ->
服务器端的页面生成 -> 返回全部内容 -> 浏览器渲染,在这一过程中,“服务器的页面生成”到“返回全部内容”阶段,浏览器什么也不做,大部分浏览器就直接显示空白。可想而知,如果页面庞大,那么等待的时间就很长,这很可能导致大量的用户丢失。Facebook
提出的 BigPipe 技术就是为了解决这个问题,它是基于多线程实现,原理大致可以分为以下两点。
将一个页面分为多个的 PageLet,每个的 PageLet 实际上就是一个 HTML 片段,每个 PageLet
的页面内容由单独的线程生成与处理。
由于使用了多线程,PageLet 内容的返回顺序无法确定,因此如果将内容直接写回 HTML 文档内,它的位置是无法确定的,因此需要借助
JavaScript 将内容插入到正确的位置,因为脚本代码的位置无关紧要。
实现了以上两点,最终的效果将是网页中首先出现网页结构和基本的、简单的信息,然后才会在网页的各个 PageLet
位置出现具体内容,这些 PageLet 没有按流模型从上到下从左到右出现,而是“并行出现”,加载页面速度加快。从以上的分析,这种技术至少有两种好处。
首先出现的结构和基本信息,告诉用户页面正在加载,是有希望的。
并行加载的机制使得某个 PageLet 的缓慢不会影响到别的 PageLet 的加载。
所有的 PageLet 在同一个 HTTP 请求内处理。
接下来,文章先进行示例程序的展示与分析,给出各种实现方式的对比,然后讲解了基于
Struts2 的 BigPipe 标签开发,最后总结了单线程与多线程实现方式的优缺点。
示例展示
为了让读者对本文所讲内容有一个实际的印象,提升您对该技术的兴趣,本文以一个例子,采用三种实现方式来实现。该例子实现了一个
2*3 的表格,按从左到右、从上到下的顺序(也就是文档流模型的加载顺序),标明了序号。每个单元格的内容,都使用
Thread.sleep 方法模拟了加载时间较长的 HTML 内容。按照文档流顺序,每个单元格的线程等待时间分别是
1、2、3、4、5、6 秒。我们观察三种实现方式:普通实现、单线程 BigPipe、多线程 BigPipe,看它们对结果的影响。
示例程序在附件部分,它是一个 JEE Eclipse 工程,读者可以到
Eclipse 官方网站下载 JEE Eclipse,下载后导入工程。另外运行示例程序需要 Tomcat
6+ 的支持。
普通方式
打开附件,查看 WebContent 下的 normal.jsp 源码,如清单 1 所示。
清单 1. normal.jsp 源码
<%@ page language="java" contentType="text/html;
charset=utf-8"
pageEncoding="utf-8"%>
<%long pstart = System.currentTimeMillis();%>
<table border="1" width="100%"
height="500">
<caption> 普通例子 </caption>
<tr>
<td>
<%
long start = System.currentTimeMillis();
Thread.sleep(1000);
long seconds = System.currentTimeMillis() - start;
%>
1 秒的内容 <br>
加载耗时:<%=seconds%> 毫秒 ;
</td>
// 中间的省略
//...
<td>
<%
start = System.currentTimeMillis();
Thread.sleep(6000);
seconds = System.currentTimeMillis() - start;
%>
6 秒的内容 <br>
加载耗时:<%=seconds%> 毫秒 ;
</td>
</tr>
</table>
<%seconds = System.currentTimeMillis() - pstart;%>
整个页面加载耗费了:<%=seconds%> 毫秒
这是一个再普通不过的 JSP 文件,用 Thread.sleep 模拟长时间的
HTML 加载。运行附件工程,打开 http://localhost:{your port}/BigPipeImpl/normal.jsp。接下来等待我们的就是一个很长时间的等待,浏览器一直处于白屏的状态,最终会出现如图
1 的结果。
图 1. 普通实现方式的结果

普通方式的实现缺点明显,从这个例子我们就可以知道,如果你的网页很大,这将直接导致用户无法等待。为了给出更加准确的用户等待时间,使用
Firebug 的网络监测功能,查看网页的加载时间,结果如图 2 所示。
图 2. 普通实现的加载时间

可以看到,该页面的加载时间是 21.02 秒,试问有哪个用户会忍受这么长时间的页面空白呢?
该实现方式的效果也在预料之内,表格按照文档流的顺序进行加载,也就是按照单元格的编号顺序逐个加载,直到页面全部加载完才一口气写回到浏览器,这样用户必须等待较长的时间。
单线程方式
普通方式的用户体验很差,要想增强用户体验就可以用到单线程 BigPipe
技术。单线程的实现方式,本质上与普通方式一样,但是不一样的是它可以将优先级高的区域提前加载,并且可以先将网页结构写回客户端,然后再显示内容,增强用户体验。本文的单线程示例程序,单元格内容的加载顺序是可以编程设置的,不一定需要按照文档流的顺序。由于增加了客户端的
JavaScript 处理,在总时间上会略微多于普通方式,但是在用户体验效果却远远优于普通方式。当我们编程设置单元格显示顺序按照
1-6 显示时(后半部分为展示如何设置顺序),打开 http://localhost:{your
port}/BigPipeImpl/single.action,效果如图 3 所示。
图 3. 单元格 1-6 顺序的单线程加载结果

可以看到,打开不久,表格的框架就显示了出来,接下来,就会逐个的显示单元格的内容,其他的单元格则显示加载状态,等到他加载完毕,我们再通过
Firebug 查看它的加载时间,如图 4 所示。
图 4. 单元格 1-6 顺序的单线程加载时间

可以看到,网页的加载时间与普通实现方式一样,但是却带来了普通实现方式不可比拟的用户体验,有时候用户只希望网页及时的给他回馈,让用户充满希望。有人说,这用
Ajax 一样可以实现,但是请再看图 4,我们看到,浏览器发出的请求只有一个 single.action,再没有别的请求,这大大减轻了服务器端的压力。又有人说,可以在每加载一个内容完毕的时候,执行
flush 操作。的确,这样可以实现图 3 的效果,但是,如果我想实现 6-1 的显示顺序呢,flush
就无能为力了,而用单线程 BigPipe,却可以通过简单的调整代码顺序,来改变加载顺序,6-1 顺序的显示结果如图
5 所示。
图 5. 单元格 6-1 顺序的单线程加载结果

从上图我们看到,这次的加载顺序,是按照 6-1 的显示顺序,总时间不变。这个功能很重要,有时候,重要的内容在文档流的后方,而我们想让它显示的优先级变高,那么单线程的实现方式将非常实用。
多线程方式
不管是单线程还是普通实现方式,它们加载页面所需的总时间没有减少,对于非常大的页面,缩短加载时间才是最重要的,那么就可以使用本文介绍的多线程
BigPipe 技术了。多线程实现方式与 Facebook 的实现方式基本一致,在本文的例子中,将每个单元格视为一个
PageLet,每个 PageLet 的内容交给单独的线程进行生成和处理,也就是说,六个 PageLet
的内容并行处理,无需按照文档流顺序进行处理。我们打开 http://localhost:{your
port}/BigPipeImpl/multi.action, 我们再次查看页面的内容加载时间,结果如图
6 所示。
图 6. 多线程实现方式的加载时间

看到了吗?总共的加载时间变为了 6 秒,是不是很神奇,针对本文的例子,提高了
3 倍多,同时也只在一个请求内完成(另外两个请求是请求 JavaScript 文件和图片文件的)。而实际上,这个
6 秒,是加载时间最长的 PageLet 所需要的时间,因为各个 PageLet 的加载是并行的,页面加载时间以最晚的那个
PageLet 为准。本文例子的加载原理如图 7 所示。
图 7. 多线程 BigPipe 原理
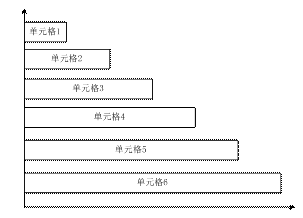
可以看到,六个单元格并行加载,整个页面的加载时间由最长的单元格 6 决定。按照图
7 的分析,单元格是按照 1-6 的顺序显示,同时每个单元格之间相差接近 1 秒。经验证,单元格显示的顺序的确是
1-6,结果如图 8 所示。
图 8. 多线程显示结果

在每个单元格(也就是 PageLet)显示出内容的瞬间,Firebug
的网络监控部分,就会显示出当时网页所消耗的时间,结果如图 9 所示。
图 9. 每个 PageLet 显示的时间

可以看到,每个 PageLet 的显示间隔正好一秒,与 图 7的分析完全一致。这也证实了多线程加载
PageLet 的实现是正确的。
多种实现方式的对比
从以上的示例展示和结果分析,不难看出普通实现方式、单线程 BigPipe、多线程 BigPipe 以及
Ajax 之间的差异,我们不防用一个表格来展示,对比结果如表 1 所示,注意:我们使用本文的示例程序作为评价背景,因为对于不同网页有可能出现不同的结果。
表 1. 四种实现方式对比
| 类型 |
请求数 |
服务器端压力 |
用户体验 |
网页加载速度 |
模块加载顺序 |
实现难度 |
| 普通 |
1 |
小 |
差 |
慢 |
文档流顺序 |
简单 |
| Ajax |
多 |
大 |
好 |
快 |
不确定 |
困难 |
| 单线程 BigPipe |
1 |
小 |
好 |
慢 |
自定义 |
一般 |
| 多线程 BigPipe |
1 |
一般(线程池引起) |
好 |
最快 |
不确定 |
最困难 |
针对本文的例子,给出了上表的评价结果,这些结果并不是绝对的,它是针对网页较大、内容模块较多情况下给出的结果,从中可以很容易看出各个实现方式的差异所在。读者可以从中找到符合自己需求的实现方式。
基于 Struts2 的标签开发
根据前面的分析,读者应该可以领略到 BigPipe 技术的优点了,为了让单线程和多线程版本更加实用,文章结合
Struts2 的标签技术,开发实现 BigPipe 技术,这样就可以让 Java 开发人员可以真正的将该技术用于实际。因此,这部分需要大致讲解一下
Struts2 自定义标签的开发方法。
实现基于 Struts2 的标签,需要重载两个类,org.apache.struts2.views.jsp.ComponentTagSupport
和 org.apache.struts2.components.Component,实现 ComponentTagSupport
类的 getBean 方法和 populateParams 方法,getBean 方法返回自定义 Component
的实例,populateParams 则是负责将页面传递的参数装配到 Component 里。在 Component
类里,需要重写 start 和 end 方法(也可以不重写),这两个方法分别代表标签的起始和标签的结束。最后再新建一个
tld 文件,来配置这个标签,由于篇幅限制,本文对 Struts2 的标签开发不多加解释,读者可以自行上网搜索相关资料。
单线程实现
还记得单线程 BigPipe 的实现效果吗?它可以自定义页面模块的显示顺序。普通的 JSP 文档 , 它显示页面的顺序
, 是按照文档流的顺序 , 也就是从上到下 , 从左到右的生成。但是页面中的一些元素,我们希望它早点显示出来,但是往往它又在文档流的后半部分,前半部分耽误了很多时间,这可能直接导致用户因为看不到重要信息而不再等候,离开页面。有一些应用,用户只希望能看到希望(页面出现内容),而我们正文的内容需要访问数据库,可能稍微慢点,因此我们可以将文档的结构先显示给用户,文档内容再慢慢填充,这听起来像
Ajax,然而这不是,在 BigPipe 技术里,文档内容的填充只在一个请求内完成,而 Ajax 则可能发出多个请求,对服务器的压力较大,这在前面也已经多次提到,读者要谨记这个不同点。
单线程实现的原理是:网页的布局仍然是不重要的在上方,重要的在下方,但是对要显示的内容进行重新排序,重要的放在文档流上方,不重要的放在后方。当重要内容加载完之后,再使用
JavaScript 将内容移到原有的位置。因此,单线程需要两个标签,一个名为 bigPipeTo,是一个占位标签,在原有的位置。一个是
bigPipeFrom,它包含了需要显示的内容,它的原理图如图 10 所示。
图 10. 单线程原理图
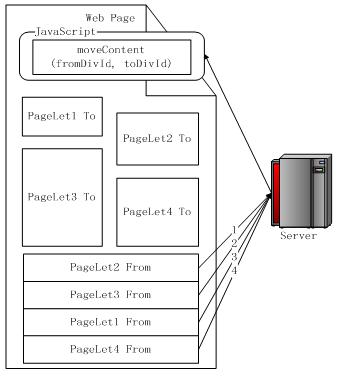
可以看到,如果按照普通的实现方式,网页是按照 PageLet1 To->PageLet2
To->PageLet3 To->PageLet4 To 的顺序加载内容。但是由于我们将内容放在了网页结构的下方,初始化为不可见,经过重新排序,顺序则变为了
2->3->1->4。bigPipeFrom 标签的内容,会经过 moveContent
的 JavaScript 方法移动到对应的 bigPipeTo 标签的位置。在本文的例子中,单线程的 JSP
使用代码如清单 2 所示。
清单 2. 单线程的 JSP
<%@ page language="java" contentType="text/html;
charset=utf-8"
pageEncoding="utf-8"%>
<%@ taglib prefix="s" uri="/struts-tags"%>
<%@ taglib prefix="b" uri="/WEB-INF/bigpipe.tld"%>
<%long pstart = System.currentTimeMillis();%>
<table border="1" width="100%"
height="500">
<caption> 单线程例子 </caption>
<tr>
<td><b:bigPipeTo name="index1">
编号:1
<img src="images/loading.gif"/></b:bigPipeTo></td>
<td><b:bigPipeTo name="index2">
编号:2
<img src="images/loading.gif"/></b:bigPipeTo></td>
<td><b:bigPipeTo name="index3">
编号:3
<img src="images/loading.gif"/></b:bigPipeTo></td>
</tr>
<tr>
<td><b:bigPipeTo name="index4">
编号:4
<img src="images/loading.gif"/></b:bigPipeTo></td>
<td><b:bigPipeTo name="index5">
编号:5
<img src="images/loading.gif"/></b:bigPipeTo></td>
<td><b:bigPipeTo name="index6">
编号:6
<img src="images/loading.gif"/></b:bigPipeTo></td>
</tr>
</table>
<b:bigPipeFrom name="index6"
bigPipeJSPath="js/bigpipe.js">
<%
long start = System.currentTimeMillis();
Thread.sleep(6000);
long seconds = System.currentTimeMillis() - start;
%>
6 秒的内容 <br>
加载耗时:<%=seconds%> 毫秒 ;
</b:bigPipeFrom>
// 中间的 4 个由于篇幅限制,省略…
<b:bigPipeFrom name="index1"
bigPipeJSPath="js/bigpipe.js">
<%
long start = System.currentTimeMillis();
Thread.sleep(1000);
long seconds = System.currentTimeMillis() - start;
%>
1 秒的内容 <br>
加载耗时:<%=seconds%> 毫秒 ;
</b:bigPipeFrom> …
从清单 2 可以看出,bigPipeFrom 标签的 name 属性和
bigPipeTo 标签的 name 是一一对应的,这样在 bigPipeFrom 标签里的内容加载完以后,会准确的将内容移到对应
bigPipeTo 标签的位置。bigPipeFrom 标签对应类 BigPipeFrom 的关键代码如清单
3 所示。
清单 3. BigPipeFrom 关键代码
@Override
public boolean start(final Writer writer) {
boolean result = super.start(writer);
try {
writer.flush();// 刷新显示网页结构
// 用 DIV 包围内容
if (visiable)
{
writer.write("<div style='display:none' id='"
+ name + "_from'>");
} else {
writer.write("<div id='" + name + "_from'>");
}
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
@Override
public boolean end(Writer writer, String body) {
boolean end = super.end(writer, body);
try {
//DIV 的结束,也就是该标签里的内容加载完毕
writer.write("</div>");
// 引入移动内容的 JavaScript 文件,就是 <script src=”…”></script>
BigPipeWriter.instance().writeJavaScript(bigPipeJSPath,
writer);
// 调用 moveContent 方法的脚本代码
BigPipeWriter.instance().writeFromToTo(name, writer,
copy);
} catch (Exception e) {
e.printStackTrace();
}
return end;
}
在清单 3 的 start 方法里,执行 flush,将已经加载的内容先写回浏览器,使用一个
div 包含主体内容。在 end 方法里,不仅要写回 div 的后半部分,还要将移动内容的 JavaScript
代码写回去。实际上就是 <script src=” js/bigpipe.js”></script><script>moveContent(fromDiv,
toDiv);</script>。其中 moveContent 方法就是在 bigpipe.js
里定义的。为了让 bigPipeFrom 的内容知道要移动到什么位置,所以在 bigPipeTo 标签对应的
BigPipeTo 类里,需要用一个 div 包围,BigPipeTo 的代码如清单 4 所示。
清单 4. BigPipeTo 关键代码
public boolean start(final Writer writer) {
boolean result = super.start(writer);
try {
writer.write("<div id='"+name+"'>");
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
@Override
public boolean end(Writer writer, String body) {
boolean end = super.end(writer, body);
try {
writer.write("</div>");
} catch (IOException e) {
e.printStackTrace();
}
return end;
}
最后,只要将 bigPipeFrom 标签里的 div 内容,移动到 bigPipeTo
的 div 里,就完成了。移动 div 内容的 JavaScript 代码非常简单,代码如清单 5 所示。
清单 5. JavaScript 移动内容的代码
function moveContent(fromId, toId)
{
document.getElementById(toId).innerHTML = document.getElementById(fromId).innerHTML;
document.getElementById(fromId).innerHTML = "";
}
基于以上的代码实现,bigPipeFrom 使用的顺序,就是网页模块 PageLet
加载并显示的顺序,调整代码就等同于调整了加载顺序。达到了重要在前,次要在后的效果。
多线程实现
从单线程 BigPipe 的实现方式可以看出,单线程并不能解决总时间加载慢的问题,它更适合对文档内容显示按照优先级排序的需求。
而要是总体时间过慢,就要考虑多线程的实现方式。Java 中提供了 Concurrent 框架可以很轻松的实现多线程技术。先将页面内容分为多个的
PageLet,这里我们将每个单元格的内容定义为一个 PageLet。多线程的实现原理图如图 11 所示。
图 11. 多线程原理图
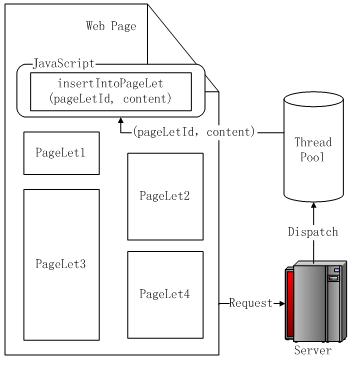
服务器接受到网页请求时,就开始按照文档流顺序处理 PageLet。每处理到一个
PageLet,服务器端程序会将其交给线程池里的线程处理,线程池处理完请求后,就将内容包含在 JavaScript
代码里,写回客户端。客户端执行这段代码将内容插入到正确的位置(这和单线程是一样的),由于借助 JavaScript
执行内容的插入,因此只要网页结构先加载,那么线程池处理的内容在任何时候返回,都可以执行正确的插入,无需关心
JavaScript 代码的位置。
从技术实现上,由于将内容交给其他线程处理,那么处理页面的主线程在所有 PageLet 处理完之前不能结束,因为只要主线程处理结束,那么网页输出流就会被关闭,线程池的处理结果也就无法被写回。这里可以采用
Concurrent 框架里的 CountDownLatch,这个类就像比赛结束的哨声,处理 PageLet
的线程就像赛跑员,当所有的赛跑员都跑到终点线(countDown),那么裁判就可以吹响结束的哨声(await),也就是当所有的
PageLet 都生成完毕时,主线程就可以结束。
另一方面,由于现有的 JSP 标签扩展机制,使得我们无法将标签里的内容直接丢到线程池里执行。因此标签里的内容,需要使用新的模板文件,程序将模板生成的内容插入到主页面对应的位置,生成内容的过程在单独的线程中执行,模板就使用
Struts2 支持的 FreeMarker 模板。
使用多线程实现的代码如清单 6 所示。
清单 6. 多线程使用代码
<%@ taglib prefix="b" uri="/WEB-INF/bigpipe.tld"%>
<%long pstart = System.currentTimeMillis();%>
<b:multiThread pageLetNum="6" bigPipeJSPath="js/bigpipeMulti.js">
<table border="1" width="100%"
height="500">
<caption> 多线程例子 </caption>
<tr>
<td><b:pageLet dealClass="com.bigpipe.tag.Index1"
name="index1">
编号:1<img src="images/loading.gif"/>
</b:pageLet></td>
<td><b:pageLet dealClass="com.bigpipe.tag.Index2"
name="index2">
编号:2<img src="images/loading.gif"/>
</b:pageLet></td>
<td><b:pageLet dealClass="com.bigpipe.tag.Index3"
name="index3">
编号:3<img src="images/loading.gif"/>
</b:pageLet></td>
</tr>
<tr>
<td><b:pageLet dealClass="com.bigpipe.tag.Index4"
name="index4">
编号:4<img src="images/loading.gif"/>
</b:pageLet></td>
<td><b:pageLet dealClass="com.bigpipe.tag.Index5"
name="index5">
编号:5<img src="images/loading.gif"/>
</b:pageLet></td>
<td><b:pageLet dealClass="com.bigpipe.tag.Index6"
name="index6">
编号:6<img src="images/loading.gif"/>
</b:pageLet></td>
</tr>
</table>
</b:multiThread>
<%long secs = System.currentTimeMillis() - pstart;%>
整个页面加载耗费了:<%=secs%> 毫秒
使用 multiThread 标签包围所有的 pageLet 标签 ,
在 multiThread 里的所有 PageLet 是并行加载的。multiThread 标签有一个
pageLetNum 属性,它代表 multiThread 包围的 pageLet 标签数,它必须与实际包围的
pageLet 标签数一致。每个 pageLet 标签都有一个 dealClass,它是类的全路径,该类实现
IPageLetDealer 接口,该接口只有一个方法:public PageAndModel<String,
Object> deal(ValueStack vs, HttpServletRequest request,
HttpServletResponse response) throws Exception,这个接口返回的是一个
PageAndModel<String, Object> 对象,String 代表 FreeMarker
模板的地址(WEB-INFO 下 template 文件夹的相对地址),Object 代表这个模板的模型对象,它的实例是根据业务逻辑由程序员实现。查看
multiThread 标签对应类 MultiThread 类的代码,它的关键代码如清单 7 所示。
清单 7. MultiThread 关键代码
@Override
public boolean start(Writer writer) {
boolean start = super.start(writer);
try {
writer.write("<script type='text/javascript'
src='" + bigPipeJSPath
+ "'></script>");
} catch (IOException e) {
e.printStackTrace();
}
return start;
}
@Override
public boolean end(Writer writer, String body) {
boolean end = super.end(writer, body);
CountDownLatch c =
(CountDownLatch)request.getAttribute(MultiThreadTag.COUNT_DOWN);
try {
//等待所有的PageLet结束
c.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
return end;
}
在 end 方法里,执行 CountDownLatch 的 await,这个方法只有当 pageLetNum
个 pageLet 都调用了 countDown 方法,await 以后的代码才会继续执行,这就确保输出流在所有
PagetLet 加载完毕前不被关闭。countDown 方法会在模板生成内容,并且 flush 到客户端后
pageLet 才会执行,pageLet 标签对应类 PageLet 的关键代码如清单 8 所示。
清单 8. PageLet 关键代码
public boolean start(final Writer writer) {
boolean result = super.start(writer);
try {
writer.write("<div id='"+name+"'>");
} catch (IOException e1) {
e1.printStackTrace();
}
return result;
}
@Override
public boolean end(final Writer writer, String body)
{
boolean end = super.end(writer, body);
try {
writer.write("</div>");
writer.flush();
} catch (IOException e1) {
e1.printStackTrace();
}
// MultiThreadTag.exe是定义的线程池对象
MultiThreadTag.exe.execute(new Runnable() {
@Override
public void run() {
//从request中获得计数器
CountDownLatch attribute =
(CountDownLatch)request.getAttribute(MultiThreadTag.COUNT_DOWN);
try
{
if (null != dealClass && !"".equals(dealClass))
{
IPageLetDealer pld =
(IPageLetDealer)Class.forName(dealClass).newInstance();
PageAndModel<String, Object> deal =
pld.deal(getStack(), request, response);
StringWriter sw = new StringWriter();
//使用FreeMarker引擎生成内容
FreeMarkerInstance.instance(request).getConfiguration()
.getTemplate(deal.getPage())
.process(deal.getModel(), sw);
//将插入内容的JavaScript代码写回。
writer.write("
<script
type='text/javascript'>ii('
"+name+"','"+sw.getBuffer().toString()+"');</script>");
}
}catch (Exception e) {
e.printStackTrace();
} finally {
try {
writer.flush();
//生成内容后,告诉线程池,执行countDown
attribute.countDown();
} catch (IOException e) {
e.printStackTrace();
}
}
}
});
return end;
}
上面的清单使用反射机制生成了 IPageLetDealer 对象,调用它的 deal 方法获得 PageAndModel<String,
Object> deal。然后再调用 FreeMarkerInstance.instance(request).getConfiguration().getTemplate(deal.getPage()).process(deal.getModel(),
sw),其中 sw 是一个 StringWriter,将 PageLet 的内容写入到 sw。最后将 sw
里的 PageLet 内容取出,签入到 JavaScript 里返回给客户端。
上面的清单还提到了 MultiThreadTag.exe,它是 concurrent 技术的线程池,是一个精简的做法。在
MultiThreadTag 的 getBean 方法里,会将 CountDownLatch 对象放到
request 对象里,这可以保证所有同一请求的 PageLet 都可以获得 CountDownLatch
对象。将 CountDownLatch 对象放入 request,声明简单的线程池,它们的代码都放在了
MultiThreadTag 类里,它继承于 ComponentTagSupport,该类顾名思义,是对标签的执行起到支持的作用,因此初始化、配置的工作在这个类里执行。它的关键代码如清单
9 所示。
清单 9. MultiThreadTag 的关键代码
public class MultiThreadTag extends ComponentTagSupport
{
public static final String COUNT_DOWN
= "countDown";
private static final long serialVersionUID
= 1L;
// 初始大小为 20 的线程池
public static ExecutorService exe = Executors.newFixedThreadPool(20);
// 传递的 pageLetNum 属性值
private String pageLetNum;
private String bigPipeJSPath;
//get/set 方法省略
@Override
public Component getBean(ValueStack vs, HttpServletRequest
request,
HttpServletResponse response) {
// 声明计数器,并且放入 request 中
CountDownLatch cdl = new CountDownLatch(Integer.parseInt(pageLetNum));
arg1.setAttribute(COUNT_DOWN, cdl);
return new MultiThread(vs, request, response);
}
protected void populateParams() {
super.populateParams();
// 装配参数
MultiThread pages = (MultiThread)component;
pages.setPageLetNum(pageLetNum);
pages.setBigPipeJSPath(bigPipeJSPath);
}
}
可以看到在 MultiThreadTag 类的 getBean 方法里声明了计数器
CountDownLatch,并将其存放到 request 对象中。getBean 方法在标签执行前会执行。
执行完 multiThread 的开始标签后,接下来每遇到一个 pageLet
标签,就将生成内容的过程放入 MultiThreadTag.exe 这个线程池里,生成 PageLet
的内容就需要用到定义好的 FreeMarker 模板,生成的内容嵌入到 JavaScript 中,返回给浏览器。MultiThread
的 end 方法,也就是 multiThread 的结束标签位置,调用 CountDownLatch 的
await 等待所有的 PageLet 加载完毕,每个 PageLet 加载完毕,就调用 CountDownLatch
的 countDown,通知计数器减一。最后所有的 PageLet 执行完毕,await 后面的代码继续执行,这时网页的内容已经显示完毕了,因此需要注意
pageLetNum 属性值必须与实际的 pageLet 标签数量一直,否则网页会一直阻塞。
优缺点
从示例展示部分,就可以看出单线程和多线程的优缺点,在这里再总结一下。
单线程:
优点:对流模型不多加干预,单线程对服务器的压力较小,用户体验较好
缺点:某个 PageLet 阻塞,会导致后面的 PageLet 阻塞
特点:PageLet 显示的顺序就是 pageFrom 标签排列的顺率 .
多线程:
优点:用户体验最好,多线程未阻塞时加载快速,保持程序员的正常编码习惯,不会因为一个 PageLet 的缓慢引起其他
PageLet 的失败。
缺点:线程池大小的选取是关键,太大导致服务器压力过大,资源占用太多,太小则导致网页处理的阻塞。
特点 :PageLet 内容出现的顺序不一定。
总结
本文根据 BigPipe 的思想,使用单线程与多线程技术对 BigPipe 进行了相似实现,可能与 Facebook
的 BigPipe 实现不尽相同,但却实现了相同的增强用户体验的目的。文章对两种实现效果和优缺点进行了详细分析,通过文章中的实际例子,相信读者不仅可以掌握
BigPipe 技术,还可以尝试将该技术运用到实际开发中。笔者就将单线程实现应用到实际开发中,得到了不错的反馈。由于笔者能力有限,如果有错误的地方,欢迎读者联系我批评指正。 | 

