|
摘要:本文介绍了Java代码优化的过程,总结了优化Java程序的一些最佳实践,分析了进行优化的方法并解释了性能提升的原因。多角度分析导致性能低的原因并逐个进行优化使得程序性能得到极大提升,代码可读性、可扩展性更强。
作者通过经历的一个项目实例,介绍Java代码优化的过程,总结了优化Java程序的一些最佳实践,分析了进行优化的方法,并解释了性能提升的原因。作者从多个角度分析导致性能低的原因,并逐个进行优化,最终使得程序的性能得到极大提升,增强了代码的可读性、可扩展性
一、衡量程序的标准
衡量一个程序是否优质,可以从多个角度进行分析。其中,最常见的衡量标准是程序的时间复杂度、空间复杂度,以及代码的可读性、可扩展性。针对程序的时间复杂度和空间复杂度,想要优化程序代码,需要对数据结构与算法有深入的理解,并且熟悉计算机系统的基本概念和原理;而针对代码的可读性和可扩展性,想要优化程序代码,需要深入理解软件架构设计,熟知并会应用合适的设计模式。
- 首先,如今计算机系统的存储空间已经足够大了,达到了 TB 级别,因此相比于空间复杂度,时间复杂度是程序员首要考虑的因素。为了追求高性能,在某些频繁操作执行时,甚至可以考虑用空间换取时间。
- 其次,由于受到处理器制造工艺的物理限制、成本限制,CPU主频的增长遇到了瓶颈,摩尔定律已渐渐失效,每隔18个月CPU主频即翻倍的时代已经过去了,程序员的编程方式发生了彻底的改变。在目前这个多核多处理器的时代,涌现了原生支持多线程的语言(如Java)以及分布式并行计算框架(如Hadoop)。为了使程序充分地利用多核CPU,简单地实现一个单线程的程序是远远不够的,程序员需要能够编写出并发或者并行的多线程程序。
- 最后,大型软件系统的代码行数达到了百万级,如果没有一个设计良好的软件架构,想在已有代码的基础上进行开发,开发代价和维护成本是无法想象的。一个设计良好的软件应该具有可读性和可扩展性,遵循“开闭原则”、“依赖倒置原则”、“面向接口编程”等。
二、项目介绍
本文将介绍笔者经历的一个项目中的一部分,通过这个实例剖析代码优化的过程。下面简要地介绍该系统的相关部分。
该系统的开发语言为Java,部署在共拥有4核CPU的Linux服务器上,相关部分主要有以下操作:通过某外部系统D提供的REST
API获取信息,从中提取出有效的信息,并通过JDBC 存储到某数据库系统S中,供系统其他部分使用,上述操作的执行频率为每天一次,一般在午夜当系统空闲时定时执行。为了实现高可用性(High
Availability),外部系统D部署在两台服务器上,因此需要分别从这两台服务器上获取信息并将信息插入数据库中,有效信息的条数达到了上千条,数据库插入操作次数则为有效信息条数的两倍。
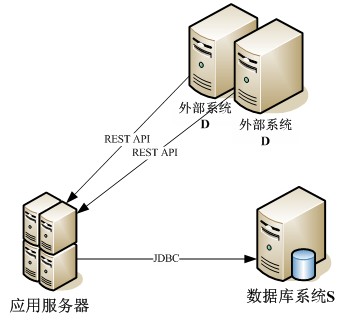
图 1.系统体系结构图
为了快速地实现预期效果,在最初的实现中优先考虑了功能的实现,而未考虑系统性能和代码可读性等。系统大致有以下的实现:
- REST API获取信息、数据库操作可能抛出的异常信息都被记录到日志文件中,作为调试用;
- 共有5次数据库连接操作,包括第一次清空数据库表,针对两个外部系统D各有两次数据库插入操作,这5个连接都是独立的,用完之后即释放;
- 所有的数据库插入语句都是使用java.sql.Statement类生成的;
- 所有的数据库插入语句,都是单条执行的,即生成一条执行一条;
- 整个过程都是在单个线程中执行的,包括数据库表清空操作,数据库插入操作,释放数据库连接;
- 数据库插入操作的JDBC代码散布在代码中。虽然这个版本的系统可以正常运行,达到了预期的效果,但是效率很低,从通过
REST API获取信息,到解析并提取有效信息,再到数据库插入操作,总共耗时100秒左右。而预期的时间应该在一分钟以内,这显然是不符合要求的。
三、代码优化过程
笔者开始分析整个过程有哪些耗时操作,以及如何提升效率,缩短程序执行的时间。通过REST
API获取信息,因为是使用外部系统提供的API,所以无法在此处提升效率;取得信息之后解析出有效部分,因为是对特定格式的信息进行解析,所以也无效率提升的空间。所以,效率可以大幅度提升的空间在数据库操作部分以及程序控制部分。下面,分条叙述对耗时操作的改进方法。
1. 针对日志记录的优化
关闭日志记录,或者更改日志输出级别。因为从两台服务器的外部系统D上获取到的信息是相同的,所以数据库插入操作会抛出异常,异常信息类似于“Attempt
to insert duplicate record”,这样的异常信息跟有效信息的条数相等,有上千条。这种情况是能预料到的,所以可以考虑关闭日志记录,或者不关闭日志记录而是更改日志输出
级别,只记录严重级别(severe level)的错误信息,并将此类操作的日志级别调整为警告级别(warning
level),这样就不会记录以上异常信息了。本项目使用的是 Java 自带的日志记录类,以下配置文件将日志输出级别设置为严重级别。
清单 1. log.properties 设置日志输出级别的片段
default file output is in user ’ s home directory.
levels can be: SEVERE, WARNING, INFO, FINE, FINER, FINEST
java.util.logging.ConsoleHandler.level=SEVERE
java.util.logging.FileHandler.formatter=java.util.logging.SimpleFormatter
java.util.logging.FileHandler.append=true
|
通过上述的优化之后,性能有了大幅度的提升,从原来的 100 秒左右降到了
50 秒左右。为什么仅仅不记录日志就能有如此大幅度的性能提升呢?查阅资料,发现已经有人做了相关的研究与实验。经常听到
Java 程序比 C/C++ 程序慢的言论,但是运行速度慢的真正原因是什么,估计很多人并不清楚。对于 CPU
密集型的程序(即程序中包含大量计算),Java 程序可以达到 C/C++ 程序同等级别的速度,但是对于
I/O 密集型的程序(即程序中包含大量 I/O 操作),Java 程序的速度就远远慢于 C/C++ 程序了,很大程度上是因为
C/C++ 程序能直接访问底层的存储设备。因此,不记录日志而得到大幅度性能提升的原因是,Java 程序的
I/O 操作较慢,是一个很耗时的操作。
2. 针对数据库连接的优化
共享数据库连接。共有 5 次数据库连接操作,每次都需重新建立数据库连接,数据库插入操作完成之后又立即释放了,数据库连接没有被复用。为了做到共享数据库连接,可以通过单例模式
(Singleton Pattern)获得一个相同的数据库连接,每次数据库连接操作都共享这个数据库连接。这里没有使用数据库连接池(Database
Connection Pool)是因为在程序只有少量的数据库连接操作,只有在大量并发数据库连接的时候才需要连接池。
清单 2. 共享数据库连接的代码片段

public class JdbcUtil {
private static Connection con;
// 从配置文件读取连接数据库的信息
private static String driverClassName;
private static String url;
private static String username;
private static String password;
private static String currentSchema;
private static Properties properties = new Properties();
static {
// driverClassName, url, username, password, currentSchema 等从配置文件读取,代码略去
try {
Class.forName(driverClassName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
properties.setProperty("user", username);
properties.setProperty("password", password);
properties.setProperty("currentSchema", currentSchema);
try {
con = DriverManager.getConnection(url, properties);
} catch (SQLException e) {
e.printStackTrace();
}
}
private JdbcUtil() {}
// 获得一个单例的、共享的数据库连接
public static Connection getConnection() {
return con;
}
public static void close() throws SQLException {
if (con != null)
con.close();
}
} |
通过上述的优化之后,性能有了小幅度的提升,从 50 秒左右降到了 40
秒左右。共享数据库连接而得到的性能提升的原因是,数据库连接是一个耗时耗资源的操作,需要同远程计算机进行网络通信,建立
TCP 连接,还需要维护连接状态表,建立数据缓冲区。如果共享数据库连接,则只需要进行一次数据库连接操作,省去了多次重新建立数据库连接的时间。
3. 针对插入数据库记录的优化 - 1
使用预编译 SQL。具体做法是使用 java.sql.PreparedStatement
代替 java.sql.Statement 生成 SQL 语句。PreparedStatement 使得数据库预先编译好
SQL 语句,可以传入参数。而 Statement 生成的 SQL 语句在每次提交时,数据库都需进行编译。在执行大量类似的
SQL 语句时,可以使用 PreparedStatement 提高执行效率。使用 PreparedStatement
的另一个好处是不需要拼接 SQL 语句,代码的可读性更强。通过上述的优化之后,性能有了小幅度的提升,从
40 秒左右降到了 30~35 秒左右。
清单 3. 使用 Statement 的代码片段
// 需要拼接 SQL 语句,执行效率不高,代码可读性不强
StringBuilder sql = new StringBuilder();
sql.append("insert into table1(column1,column2) values('");
sql.append(column1Value);
sql.append("','");
sql.append(column2Value);
sql.append("');");
Statement st;
try {
st = con.createStatement();
st.executeUpdate(sql.toString());
} catch (SQLException e) {
e.printStackTrace();
}
|
清单 4. 使用 PreparedStatement 的代码片段
// 预编译 SQL 语句,执行效率高,可读性强
String sql = “insert into table1(column1,column2) values(?,?)”;
PreparedStatement pst = con.prepareStatement(sql);
pst.setString(1,column1Value);
pst.setString(2,column2Value);
pst.execute(); |
4. 针对插入数据库记录的优化 - 2
使用 SQL 批处理。通过 java.sql.PreparedStatement
的 addBatch 方法将 SQL 语句加入到批处理,这样在调用 execute 方法时,就会一次性地执行
SQL 批处理,而不是逐条执行。通过上述的优化之后,性能有了小幅度的提升,从 30~35 秒左右降到了
30 秒左右。
5. 针对多线程的优化
使用多线程实现并发 / 并行。清空数据库表的操作、把从 2 个外部系统
D 取得的数据插入数据库记录的操作,是相互独立的任务,可以给每个任务分配一个线程执行。清空数据库表的操作应该先于数据库插入操作完成,可以通过
java.lang.Thread 类的 join 方法控制线程执行的先后次序。在单核 CPU 时代,操作系统中某一时刻只有一个线程在运行,通过进程
/ 线程调度,给每个线程分配一小段执行的时间片,可以实现多个进程 / 线程的并发(concurrent)执行。而在目前的多核多处理器背景下,操作系统中同一时刻可以有多个线程并行(parallel)执行,大大地提高了
计算速度。
清单 5. 使用多线程的代码片段
Thread t0 = new Thread(new ClearTableTask());
Thread t1 = new Thread(new StoreServersTask(ADDRESS1));
Thread t2 = new Thread(new StoreServersTask(ADDRESS2));
try {
t0.start();
// 执行完清空操作后,再进行后续操作
t0.join();
t1.start();
t2.start();
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 断开数据库连接
try {
JdbcUtil.close();
} catch (SQLException e) {
e.printStackTrace();
} |
通过上述的优化之后,性能有了大幅度的提升,从 30 秒左右降到了 15
秒以下,10~15 秒之间。使用多线程而得到的性能提升的原因是,系统部署所在的服务器是多核多处理器的,使用多线程,给每个任务分配一个线程执行,可以充分地利用
CPU 计算资源。
笔者试着给每个任务分配两个线程执行,希望能使程序运行得更快,但是事与愿违,此时程序运行的时间反而比每个任务分配一个线程执行的慢,大约
20 秒。笔者推测,这是因为线程较多(相对于 CPU 的内核数),使得 CPU 忙于线程的上下文切换,过多的线程上下文切换使得程序的性能反而不如之前。因此,要根据实际的硬件环境,给任务分配适量的线程执行。
6. 针对设计模式的优化
使用 DAO 模式抽象出数据访问层。原来的代码中混杂着 JDBC 操作数据库的代码,代码结构显得十分凌乱。使用
DAO 模式(Data Access Object Pattern)可以抽象出数据访问层,这样使得程序可以独立于不同的数据库,即便访问数据库的代码发生了改变,上层调用数据访问的代码无需改变。并且程
序员可以摆脱单调繁琐的数据库代码的编写,专注于业务逻辑层面的代码的开发。通过上述的优化之后,性能并未有提升,但是代码的可读性、可扩展性大大地提高
了。
清单 6. 使用 DAO 模式的代码片段
// DeviceDAO.java,定义了 DAO 抽象,上层的业务逻辑代码引用该接口,面向接口编程
public interface DeviceDAO {
public void add(Device device);
}
// DeviceDAOImpl.java,DAO 实现,具体的 SQL 语句和数据库操作由该类实现
public class DeviceDAOImpl implements DeviceDAO {
private Connection con;
public DeviceDAOImpl() {
// 获得数据库连接,代码略去
}
@Override
public void add(Device device) {
// 使用 PreparedStatement 进行数据库插入记录操作,代码略去
}
} |
回顾以上代码优化过程:关闭日志记录、共享数据库连接、使用预编译 SQL、使用
SQL 批处理、使用多线程实现并发 / 并行、使用 DAO 模式抽象出数据访问层,程序运行时间从最初的
100 秒左右降低到 15 秒以下,在性能上得到了很大的提升,同时也具有了更好的可读性和可扩展性。
四、结束语
通过该项目实例,笔者深深地感到,想要写出一个性能优化、可读性可扩展性强的程序,需要对计算机系统的基本概念、原理,编程语言的特性,软件系统
架构设计都有较深入的理解。“纸上得来终觉浅,绝知此事要躬行”,想要将这些基本理论、编程技巧融会贯通,还需要不断地实践,并总结心得体会。
|


