|
Fork/Join框架在不同配置下的表现如何?
正如即将上映的星球大战那样,Java 8的并行流也是毁誉参半。并行流(Parallel Stream)的语法糖就像预告片里的新型光剑一样令人兴奋不已。现在Java中实现并发编程存在多种方式,我们希望了解这么做所带来的性能提升及风险是什么。从经过260多次测试之后拿到的数据来看,还是增加了不少新的见解的,这里我们想和大家分享一下。

ExecutorService vs. Fork/Join框架 vs. 并行流
在很久很久以前,在一个遥远的星球上。。好吧,其实我只是想说,在10年前,Java的并发还只能通过第三方库来实现。然后Java 5到来了,并引入了java.util.concurrent包,上面带有深深的Doug Lea的烙印。ExecutorService为我们提供了一种简单的操作线程池的方式。当然了,java.util.concurrent包也在不断完善,Java 7中还引入了基于ExecutorService线程池实现的Fork/Join框架。对很多开发人员来说,Fork/Join框架仍然显得非常神秘,因此Java 8的stream提供了一种更为方便地使用它的方法。我们来看下这几种方式有什么不同之处。
我们来通过两个任务来进行测试,一个是CPU密集型的,一个是IO密集型的,同样的功能,分别在4种场景下进行测试。不同实现中线程的数量也是一个非常重要的因素,因此这个也是我们测试的目标之一。测试机器共有8个核,因此我们分别使用4,8,16,32个线程来进行测试。对每个任务而言,我们还会测试下单线程的版本,不过这个在图中并没有标出来,因为它的时间要长得多。如果想了解这些测试用例是如何运行的,你可以看一下最后的基础库一节。我们开始吧。
给一段580万行6GB大小的文本建立索引
在本次测试中我们生成了一个超大的文本文件,并通过相同的方法来建立索引。我们来看下结果如何:
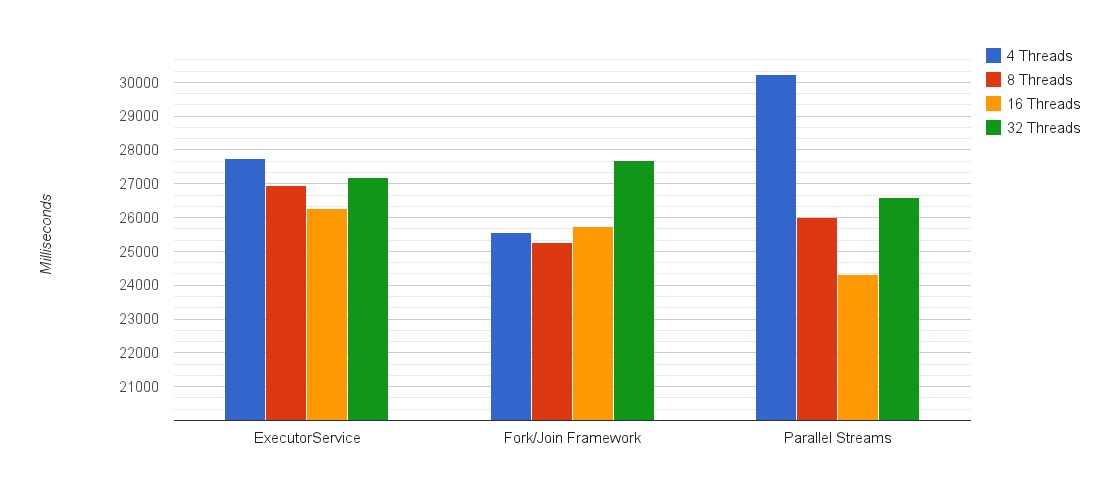
单线程执行时间:176,267毫秒,大约3分钟。 注意,上图是从20000毫秒开始的。
1. 线程过少会浪费CPU,而过多则会增加负载
从图中第一个容易注意到的就是柱状图的形状――光从这4个数据就能大概了解到各个实现的表现是怎样的了。8个线程到16个线程这里有所倾斜,这是因为某些线程阻塞在了文件IO这里,因此增加线程能更好地使用CPU资源。而当加到32个线程时,由于增加了额外的开销,性能又开始会变差。
2.并行流表现最佳。与直接使用Fork/Join相比要快1秒左右
并行流所提供的可不止是语法糖(这里指的并不是lambda表达式),而且它的性能也比Fork/Join框架以及ExecutorService要更好。索引完6GB大小的文件只需要24.33秒。请相信Java,它的性能也能做到很好。
3. 但是。。并行流的表现也是最糟糕的:唯独它是超过了30秒的
并行流为什么会影响性能,这里也给你上了一课。这在本来就运行着多线程应用的机器上是有可能的。由于可用的线程本身就很少了,直接使用Fork/Join框架要比使用并行流更好一些――两者的结果相差5秒,大约是18%的性能损耗。
4. 如果涉及到IO操作的话,不要使用默认的线程池大小
测试中使用默认线程池大小(默认值是机器的CPU核数,在这里是8)的并行流,跟使用16个线程相比要慢上2秒。也就是说使用默认的池大小则要慢了7%。这是由于阻塞的IO线程导致的。由于有很多线程处于等待状态,因此引入更多的线程能够更好地利用CPU资源,当其它线程在等待调度时不至于让它们闲着。
如果改变并行流的默认的Fork/Join池的大小?你可以通过一个JVM参数来修改公用的Fork/Join线程池的大小:
-Djava.util.concurrent.ForkJoinPool.common.parallelism=16 |
(默认情况下,所有的Fork/Join任务都会共用同一个线程池,线程的数量等于CPU的核数。好处就是当线程空闲下来时可以收来处理其它任务。)
或者,你还可以用下这个小技巧,用一个自定义的Fork/Join池来运行并行流。它会覆盖掉默认的公用的Fork/Join池并让你能够使用自己配置好的线程池。手段有点卑劣。测试中我们使用的是公用的线程池。
5.单线程的性能跟最快的结果相比要慢7.25倍 并发能够提升7.25倍的性能,考虑到机器是8核的,也就是说接近是8倍的提升!还差的那点应该是消耗在线程的开销上了。不仅如此,即便是测试中表现最差的并行版本,也就是4个线程的并行流实现(30.23秒),也比单线程的版本(176.27秒)要快5.8倍。
如果不考虑IO的话呢?比如判断某个数是否是素数
对这次测试而言,我们将去除掉IO的部分,来测试下判断一个大整数是否是素数要花多长时间。这个数有多大?19位,1,530,692,068,127,007,263,换句话说,一百五十三万零六百九十二兆零六百八十一亿两千万七千二百六十三。好吧,让我透透气先。我们也没有做任何的优化,而是直接运算到它的平方根,为此我们还检查了所有的偶数,尽管这个大数并不能被2整除,这只是为了让运算的时间更久一些。先剧透一下:这的确是一个素数。每个实现运算的次数也都是一样的。
下面是测试的结果:
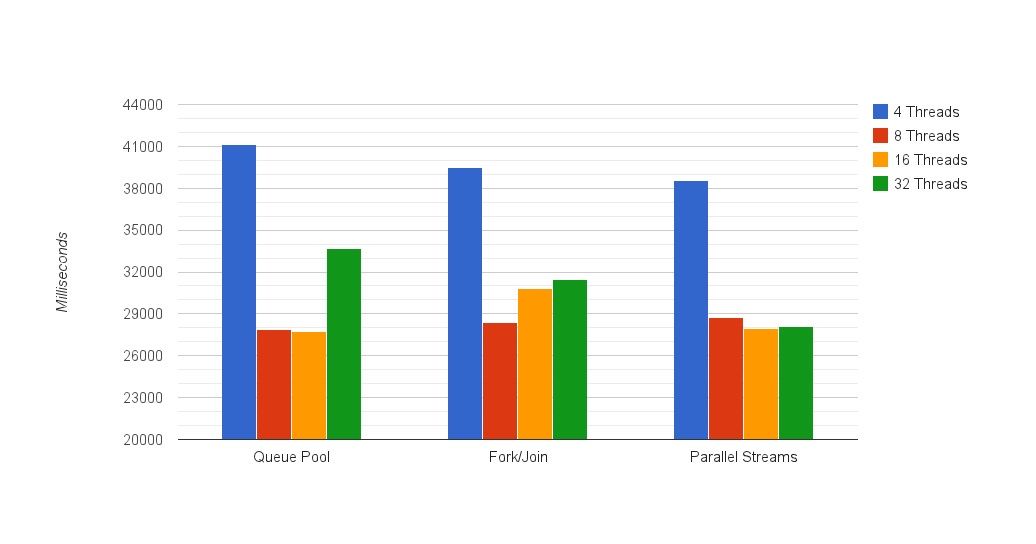
单线程执行时间:118,127毫秒,大约2分钟 注意,上图是从20000毫秒开始的
1.8个线程与16个线程相差不大
和IO测试中不同,这里并没有IO调用,因此8个线程和16个线程的差别并不大,Fork/Join的版本例外。由于它的反常表现,我们还多运行了好几组测试以确保得到的结果是正确的,但事实表明,结果仍是一样。希望你能在下方的评论一栏说一下你对这个的看法。
2. 不同实现的最好结果都很接近
我们看到,不同的实现版本最快的结果都是一样的,大约是28秒左右。不管实现的方法如何,结果都大同小异。但这并不意味着使用哪种方法都一样。请看下面这点。
3. 并行流的线程处理开销要优于其它实现
这点非常有意思。在本次测试中,我们发现,并行流的16个线程的再次胜出。不止如此,在这次测试中,不管线程数是多少,并行流的表现都是最好的。
4. 单线程的版本比最快的结果要慢4.2倍
除此之外,在运行计算密集型任务时,并行版本的优势要比带有IO的测试要减少了2倍。由于这是个CPU密集型的测试,这个结果倒也说得过去,不像前面那个测试中那样,减少CPU的等待IO的时间能获得额外的收益。
结论
之前我也建议过大家读一下源码,了解下何时应该使用并行流,并且在Java中进行并发编程时,不要武断地下结论。最好的检验方式就是在演示环境中多跑跑类似的测试用例。需要特别注意的因素包括你所运行的硬件环境 (以及测试的硬件环境),还有应用程序的总线程数。包括公用Fork/Join的线程池以及团队中其它开发人员所写的代码中包含的线程。在你编写自己的并发逻辑前,最好先检查下上述这些情况,对你的应用程序有一个整体的了解。
基础库
我们是在EC2的c3.2xlarge实例上运行的本次测试,它有8个vCPU核以及15GB的内存。vCPU是因为这里用到了超线程技术,因此实际上只有4个物理核,但每个核模拟成了两个。对操作系统的调度器而言,认为我们一共有8个核。为了尽可能的公平,每个实现都运行了10遍,并选择了第2次到第9次的平均运行时间。也就是一共运行了260次!处理时长也非常重要。我们所选择的任务的运行时间都会超过20秒,因此时间差异能很容易看出来,而不太受外部因素的影响。
最后
原始的测试结果在这里,代码放在Github上。欢迎进行修改,并告诉我们你的测试结果。如果发现了什么我们这里没有讲到的有意思的新的见解或者现象,欢迎告诉我们,我们很希望能把它们追加到本文中。 |





