| 通过合并非结构化文本和空间数据改进搜索应用程序
不管是通过支持 GPS 的智能手机查找最近的咖啡馆,还是通过社交站点查找附近的朋友,或是查看特定城市中运输某种商品的所有货车,越来越多的人和企业都使用位置感知的搜索服务。创建位置感知搜索服务通常属于昂贵的专用解决方案的一部分,并且一般由地理空间专家完成。不过,很流行的开源搜索库
Apache Lucene 和强大的 Lucene 搜索服务器 Apache Solr 最近添加了空间位置功能。Lucene
和 Solr 专家 Grant Ingersoll 将逐步向您介绍空间搜索的基础知识,并演示如何利用这些功能来增强您的下一个位置感知应用程序。
地理位置在空间搜索中至关重要!地理位置不仅在地产中至尊为王,将其用在搜索中还能帮助位于特定位置的用户快速找到有用的信息。例如,如果您是企业名录提供商(比如一个
“黄页” 站点),当用户需要找一位水管维修员时,该站点必须返回在用户住所附近的维修员。如果您运营的是一个旅游站点,那么您必须让旅游者能够搜索到他们所在的位置附近的名胜,从而帮助他们丰富旅游行程。如果您要构建一个社交网络站点,那么最好使用位置信息来帮助用户与朋友联系。位置感知设备(比如汽车导航系统和支持
GPS 的摄像机)和大量免费地图数据的普及为构建能够为终端用户搜索高级结果的 Geographical
Information Systems (GIS) 提供了各种机会。
空间信息还可以被利用到搜索领域之外,但在本文中我将主要关注如何通过 Apache
Lucene 和 Apache Solr 利用空间信息来改进搜索应用程序。为什么要使用搜索引擎?并不是因为它是许多很好(甚至免费)的
GIS 工具中的必要组成部分。不过,将应用程序构建在搜索引擎的基础上能够提供几个强大的功能,这是其他传统途径无法实现的。搜索系统在合并结构化和非结构化方面非常强劲,这允许用户输入自由形式的查询,比如在搜索免费文本的描述和标题的同时根据地理位置数据限制或修改结果。例如,旅游站点可以实现这样一个特性,它让用户能够在一秒之内找到马萨诸塞州波士顿市的所有
24 小时提供服务并且配有舒适床具的四星级宾馆。有些搜索系统(比如 Apache Solr)还提供对结果集进行分类(参考资料
部分提供关于 Solr 和分类的信息)、突出显示和拼写检查的功能,从而让应用程序能够帮助用户高效地查找所需的结果。
我首先简单介绍 Lucene 的一些关键概念,深入的细节留给读者自己探索。接下来,我将介绍一些基础的地理空间搜索概念。GIS
是一个广泛的领域,本文难以对其进行详尽的描述,因此我仅关注一些查找服务、人和其他日常事项所需的基础概念。本文的末尾是关于使用
Lucene 和 Solr 索引和搜索空间信息的方法的讨论。我将通过一个真实但很简单的例子来阐述这些概念,并且使用来自
OpenStreetMap (OSM) 项目的数据(参见 参考资料)。
回顾关键的 Lucene 概念
Apache Lucene 是一个基于 Java? 的高性能搜索库。Apache
Solr 是一个使用 Lucene 通过 HTTP 来提供搜索、分类等功能的搜索服务器。它们都使用价格适中的
Apache Software License。参见 参考资料 了解更多关于每个产品提供的特性和 API
的信息。
从本质上看,Solr 和 Lucene 都将内容表示为文档。文档由一个或多个字段
和一个表明文档的重要性的可选增强(boost)值 组成。字段由需要索引和储存的实际内容、告诉 Lucene
如何处理该内容的元数据和表明该字段的重要性的增强值组成。由您决定以何种方式将内容表示为文档和字段,这取决于您希望怎样搜索或访问文档中的信息。在每个内容单元中,您可以使用一对一的关系,也可以使用一对多的关系。例如,我可以选择用一个包含几个字段(比如
title、keywords 和 body)的文档来表示一个 Web 页面。如果是一本书,我则选择将它的每一页表示为一个独立的文档。稍后您将看到,这一区分在为搜索编码空间数据时非常重要。可以为字段中的内容建立索引,或者原样储存供应用程序使用。如果为内容建立了索引,应用程序就可以使用它。还可以分析建立了索引的内容来生成词汇(通常称为令牌)。词汇是在搜索过程中查找和使用的基础。词汇通常是一个词,但这不是必要的。我建议您通过
参考资料 部分了解所有这些概念。
在查询方面,Lucene 和 Solr 为表达用户查询(从基础的关键字查询到短语和通配符查询)提供丰富的功能。Lucene
和 Solr 还通过应用一个或多个对空间搜索非常重要的过滤器来提供限制空间的能力。范围查询 和范围过滤器
是限制空间的关键机制。在范围查询(或过滤器)中,用户声明需要将所有搜索到的文档限制在使用自然排序的两个值之间。例如,通常使用范围查询来查找发生在过去一年或上一个月的所有文档。在处理过程中,Lucene
必须枚举文档中的词汇以识别在范围之内的所有文档。如我在稍后展示的一样,正确地设置范围查询是提升空间搜索应用程序的查询性能的关键因素之一。
Lucene 和 Solr 还提供函数查询 的概念,它允许您使用字段的值(比如经度和纬度)作为记录机制的一部分,而不是仅仅使用组成主要的记录机制的内部数据集合。该功能在后文我演示使用
Solr 的一些基于距离的函数时用到。
地理空间搜索概念
在构建空间搜索应用程序时,最重要的是识别需要添加到应用程序中的空间数据。这些数据通常以某些地理编码的形式出现,比如纬度、经度和海拔,或以邮政编码或街道地址的形式出现。编码系统的格式越规范,它在您的系统中的使用就越容易。例如,民歌
“Over the River and Through the Woods”(其中有这样的歌词:“to
Grandmother's house we go”)就将很多空间信息编码到了歌词中(参见 参考资料)。但这些信息在
GIS 系统中就没有多大用处,因为我们不知道小河和森林的位置。该信息与到外婆家的详细方向(包含出发地址和到达地址的)相比,您将了解到为什么正确编码地址如此重要。(有趣的是,能够提取和编码更常用的方向和地理实体
―― 比如渡过小河 或在棕色房子附近 ―― 并根据它们进行推断的系统也是非常有用的,但这不属于本文的讨论范围)。
除了用于识别地理位置的原始地理编码数据之外,许多 GIS 系统还可以添加与实际位置相关的信息。例如,导航系统可以使用在地图上按顺序列出的一系列位置来创建一条从
A 点到 B 点的路线。或者气象学家可以将降雨或恶劣的天气数据添加到特定区域的地图上,从而允许用户搜索到特定区域的降雨量。居住地点相邻的人通常将小的区域合并起来,从而形成
ZIP 编码、地区编码,甚至是城镇、市或州。例如在 OSM 中,用户可以编辑和覆盖地图顶层的信息,比如旅游景点或街道。通过合并各层的信息建立它们之间的关系并进行跟踪,可以生成更加动态和强大的应用程序。
表示空间数据
不管与一个或多个位置相关的信息是什么,搜索应用程序都需要通过一种高效的方式来表示这些数据。尽管可以通过几种方式来表示位置信息,但我仅关注与
Lucene 相关的方式。首先需要注意的是,许多类型的地理空间数据都可以用它们的 “原始” 格式表示,并且能够在搜索应用程序中很好地发挥作用。例如,Syracuse
表示城市 Syracuse 的完美方式,用户只要在搜索栏中输入 Syracuse 就可以找到包含 Syracuse
的所有文档,输入其他搜索关键词也将取得类似的结果。实际上,原始格式是用于表示带名称的位置,比如城市、州和
ZIP 编码的最常用方法。不过要注意,尽管我使用了术语原始表示,您仍然可以先对数据进行转换或格式化。例如,将
New York 转换成 NY 通常是一种合理的做法。
在我介绍 Lucene 能够使用的表示方式之前,您一定要理解所有表示方式都必须考虑到生成它们的空间引用(参见
参考资料)。在美国,最常见的是 World Geodetic System,它通常缩写为 WGS 84(参见
参考资料)。尽管在某些系统之间允许进行转换,但最好用一个系统来表示您的所有数据。本文假设使用同一个系统表示数据。
使用 Lucene 和 Solr 进行搜索时,纬度和经度(缩写为 lat/lon)等数字空间信息的表示方式是最有趣的。纬度和经度通常使用与本初子午线(位于英国的格林威治)相距的度、分和秒来表示,并且通常需要使用
double(或更高的精度)来表示。例如,对于我的例子中使用的数据 ―― 美国纽约州的 Syracuse
市 ―― 它的经度为东经 76.150026(如果没有指定东方,则为 -76.150026)和北纬 43.049648。
编码每个纬度和经度可能导致索引大量唯一的词汇,这取决于应用程序。这会显著减慢搜索速度,并且您将在本文的后面看到,这通常是不必要的。事实上,许多地图应用程序将搜索与特定领域关联起来,因此储存关于特定区域的适当信息会生成更少的词汇,并且不对搜索结果产生很大的负面影响。这种在精确度上采取折衷的方法通常将纬度和经度封装到层中。您可以将每个层看作是地图的特定部分的缩放级别,比如位于美国中央上方的第
2 层几乎包含了整个北美,而第 19 层可能只是某户人家的后院。尤其是,每个层都将地图分成 2层 # 的箱子或网格。然后给每个箱子分配一个号码并添加到文档索引中。我将在下一小节解释如何利用该信息加快搜索速度。
Lucene 词汇中的纬度和经度通常表示为两个不同的字段,但是这在一些应用程序中可能会影响性能。如果希望使用一个字段,那么可以使用
Geohash 编码方式将纬度/经度编码到一个 String 中(参见 参考资料)。Geohash 的好处是能够通过切去散列码末尾的字符来实现任意的精度。在许多情况下,相邻的位置通常有相同的前缀。例如,在
geohash.org 中输入 Syracuse, NY 将生成散列码 dr9ughxjkrt4b,而输入
Syracuse 的郊区 Cicero, NY 生成散列码 dr9veggs4ptd3,它们的前缀都是
dr9。
到目前为止,我只是谈到几个单独的点,但是许多地理空间应用程序在图像、路线和数据中的其他关系方面都很有趣。Lucene
和 Solr 不具备这些功能;参见 参考资料 了解关于这些概念的更多信息。
在搜索中将空间数据与文本合并
一旦在索引中添加了数据之后,搜索应用程序在与数据交互时至少有 5 种基本要求:
距离计算:根据给定点计算它到其他点的距离。
限定框过滤器:查找某些特定区域内所有匹配项(文档)。
排序:根据到固定点的距离对搜索结果进行排序。
相关度改进:使用距离作为记录中的增强因素,同时允许其他因素发挥作用。
查询解析:在给出位置的地址或其他一些用户规定时,创建可用于根据索引数据进行搜索的编码表示。
这 5 个因素都可以在基于位置的应用程序中扮演重要的角色,但是我在这里主要关注距离计算、限定框过滤和查询解析。排序和相关度改进仅使用距离计算,我将在本文的后面介绍它们的实际应用。
距离计算
当计算用于 GIS 应用程序的距离时,一定要知道有许多不同的实现方法,并且每种方法都有其优缺点。距离计算可以划分成
3 个组,这取决于应用程序选择以什么方式对地球进行建模。在一些情况下,完全可以采用平面地球模型,通过牺牲一些精确性来获取速度。在平面地球模型中,大部分距离计算都是勾股定理的变体。在其他情况下使用球面模型,所使用的主要距离计算为大圆弧长(参见
参考资料)。大圆弧长计算球面两点之间的最短距离。当两点之间的距离相隔很远和要求更高的准确度时,需要使用球面模型。最后,可以使用椭圆的地球模型和
Vincenty 公式(参见 参考资料)来获取高度精确的距离(精确到 0.5 毫米),但是在许多应用程序中用不上这种复杂的模型。
当然,其他距离计算也是有用的,比如曼哈顿距离,它反映在由街区组成的城市中行走的距离(例如在一辆出租车中穿越纽约城的曼哈顿)。但是为了实现本文的目的,我将使用平面地球模型和大圆弧长距离来演示距离,其他方法留给读者探索。此外,本文不将海拔作为影响因素,但是一些应用程序可能需要考虑海拔。要获取更多关于地理距离的信息,请参见
参考资料。
差之毫厘,失之千里
在许多本地搜索应用程序中,精度的需求由应用程序本身决定。在某些情况下,偏离一公里问题并不大,而在另一些情况下,偏离几毫米就会导致严重的问题。例如,欧几里得距离计算对于跨度很长的距离(比如跨州)通常不够精确,即使是半正矢(大圆)方法也不足以为某些场合提供所需的精度,因为将地球建模成椭圆体比建模成球体更精确。对于这些情况,使用
Vincenty 公式将得到更加满意的结果。在其他应用程序中,唯一需要注意的事情是对结果的排序,因此可以使用
Squared Euclidean Distance(实际不是距离),从而避免平方根计算。
限定框过滤器
在许多基于位置的应用程序中,可以搜索到数百万条地址信息。遍历所有这些数据来查找既包含关键字又在用户指定的距离之内的文档集将需要花费大量时间。一种合理的做法是先缩小文档集的范围然后再计算相关的子集。如果仅储存了纬度和经度信息,那么缩小文档集的首选方法是传入包含指定位置的周边区域的范围。这可以通过
图 1 来表示,其中不完全透明的方框表示包含南卡罗来纳州的查尔斯顿(Charleston)市及其周边地区的限定框:
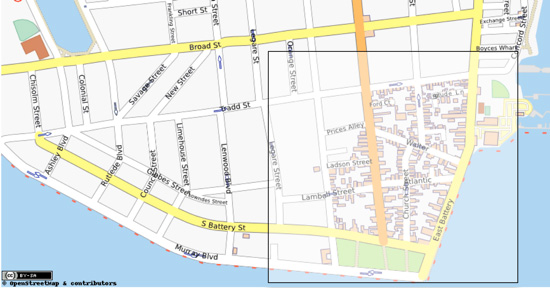
图 1. 位于 Charleston 中央上方的限定框
南卡罗来纳州查尔斯顿市市区,OpenStreetMap 提供
如果应用程序还使用层信息或 Geohash 信息,那么可以使用这些值来更好地缩小需要搜索的文档的范围。我将在讨论使用
Lucene 和 Solr 建立索引和搜索的细节时演示这点。
查询解析
查询解析的目的是确定查询的哪个部分包含所搜索的关键字,哪个部分包含位置信息。这个过程的后半部分称为地理编码(geocoding)(参见
参考资料)。尽管我在这里在查询解析的上下文中讨论地理编码,它在索引期间也非常有用。请考虑下面的用户查询例子:
1600 Pennsylvania Ave. Washington, DC
1 Washington Av. Philadelphia Pennsylvania
Mall of America, 60 East Broadway Bloomington, MN 55425
Restaurants near Mall of America
Restaurants in the Mall of America |
查看前两个查询可以发现一些有趣的东西:
词汇的顺序通常很重要,但是在纯文本搜索中,顺序可能不重要。
地名表和其他空间资源,比如 GeoNames(参见 参考资料)可能在将地址转换成位置时非常有用。这些资源通常包含旅游景点的列表
―― 例如,白宫等标志性建筑。
规范化缩写,比如 Ave. 和 DC,或使用同义词来包含用户输入地址信息的各种变体非常重要。
剩余的查询将展示几个微妙的地方。例如,在第三个查询中,用户指定了完整的地址;如果您要搜索每个字段以获得名称、地址、城市和
ZIP,那么就必须正确地解析这些属性。在最后两个查询中,用户选择 near 还是 in 是非常重要的。与
Mall 的距离在一定范围内的所有饭店都符合第四个查询的用户,而最后一个查询的用户仅对在 Mall 内部的饭店感兴趣。查询解析可能相差甚远,因为描述与位置的关系很复杂,更何况还存在拼写错误、语言歧义和不良数据等。
虽然地理编码很复杂,但是可以使用服务来将地址转换成位置。两种常用的服务为
Google Maps 公共 API 和 GeoNames(参见 参考资料)。不幸的是,使用这些 Web
服务必须遵循使用条款(通常带有某些限制)和网络流量。对于现实的生产系统,您最好自己实现这些功能。尽管实现这些功能超出了本文的范围,但一定要记住
GeoNames 数据和其他许多空间资源是可以完全免费下载的(参见 参考资料)。有了好的资源之后,最好从基础开始积累(地址、城市和州),然后再添加旅游景点和健壮的异常处理。随着时间的推移,您的查询记录将能够创建健壮的查询解析器,足以应付用户的各种输入。不管是什么搜索应用程序,良好的猜测和请求用户证实猜测结果都是好实践,如
图 2 的 Google Maps 截屏所示:
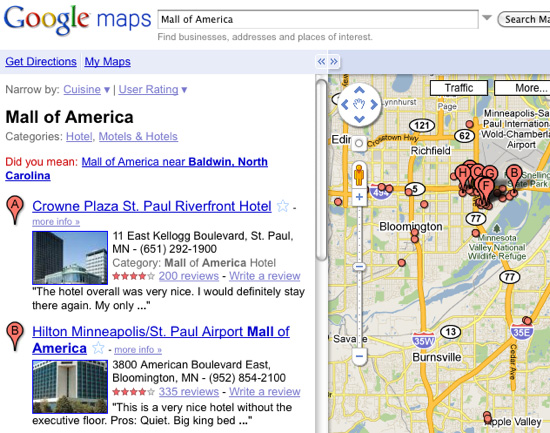
图 2. 在 Google Maps 上的良好猜测和请求用户证实猜测结果
对于本文,我将展示使用 GeoNames 服务并具有一些其他特性的基础查询解析器,但生成版本的解析器将留给用户实现。至此,您应该具备了足够的背景知识,可以进入主题了。本文后面的内容将关注如何使用
Lucene 和 Solr 为空间信息建立索引并搜索它们。
安装样例代码
要运行样例代码,您需要安装以下软件:
JDK 1.5 或更高版本
Ant 1.7 或更高版本
最新的 Web 浏览器,比如 Firefox
您还需要本文提供的样例代码(参见 下载),它包含 Apache Solr
及其所依赖的软件。遵循以下步骤安装样例代码:
1.unzip sample.zip
2.cd geospatial-examples
3.ant install
4.启动 Solr: ant start-solr(以后要停止 Solr,运行
ant stop-solr)
5.在浏览器中访问 http://localhost:8983/solr/admin
并确认 Solr 正常运行。您应该看到一个带有查询框的基础管理员界面。
安装好 Solr 并正常运行之后,就可以在 Lucene 中开始处理空间数据了。运行安装步骤将下载一些来自
OSM 项目的样例代码,我在 http://people.apache.org/~gsingers/spatial/
上介绍了该项目。对于本文,我包含了来自美国的 4 个位置的样例 OSM 数据(在文件中列出了到 OSM
的永久链接):
Syracuse, N.Y.
Downtown Minneapolis, Minn.
Around the Mall of America in Bloomington,
Minn.
Downtown Charleston, S.C.
为了演示本文介绍的许多概念,我编写代码来在 Solr 中为 OSM 建立索引,并将一些简单的事实与特定的位置相关联(例如,查看数据目录中的
syracuse.facts 文件)。这样做的目的是展示如何合并非结构化文本和空间数据,以创建高效的搜索应用程序。此外还要注意,我使用
Solr 1.5-dev 版本(Solr 的当前开发主干),而不是最近发布的 Solr 1.4。
在 Lucene 中为空间数据建立索引
Lucene 2.9 添加了两个在空间搜索方面起到重大作用的新特性。首先,Lucene
实现了更好的数字范围查询和过滤功能,它们通常用在限定框方法中。其次,Lucene 有一个新的贡献软件(contrib)模块,它包含以前称为
Local Lucene 的独立项目(参见 参考资料)。(该代码位于 Lucene 的 contrib/spatial;我已经在
样例代码 中包含了 JAR 文件)。空间贡献软件为创建笛卡儿层和 Geohash 代码提供工具,并且为创建
Lucene 查询和过滤器对象提供工具。
在查看为数据建立索引的代码之前,您需要评估如何与数据交互以及您的应用程序需要处理多少数据,这非常重要。例如,对于大多数拥有少量或中等程度文档数量(少于
1000 万)的人而言,为纬度和经度创建索引和使用简单的数字范围查询可以得到优异的性能。但是对于数据量更大的应用程序,就需要做更多的工作(比如添加笛卡尔层)来减少词汇的数量和需要过滤和记录的文档。此外,考虑使用什么格式储存信息也很重要。许多空间距离算法要求采用以弧度表示的数据,而其他算法则要求使用以度表示的数据。因此在建立索引时将纬度/经度值转换成弧度是值得的,从而避免在每次搜索都执行转换。当然,如果您需要保留两种格式的数据,则意味着需要更多的空间(磁盘,甚至内存)。最后,您是不是对位置特性进行分类、排序和记录,而不是仅将它们用于过滤?如果是这样,那么将需要交替使用不同的表示。
Lucene 和 Solr
尽管我使用 Solr 模式来展示需要建立索引的字段,这里的所有概念在 Lucene
中都是可用的。例如,Lucene 2.9.1 中的 tdouble 实际上就是精度为 8 的 NumericField。
因为本文仅演示概念而没有考虑生产使用,所以我将用一些 Java 代码在同一个地方显示如何为
Geohash、笛卡尔层创建索引。我已经在 Solr 模式中定义了许多值(模式的位置为 geospatial-examples/solr/conf/schema.xml)来捕捉
OSM 数据。清单 1 显示了用于表示位置的主要字段:
清单 1. 样例 Solr 模式
<!-- Latitude -->
<field name="lat" type="tdouble" indexed="true" stored="true"/>
<!-- Longitude -->
<field name="lon" type="tdouble" indexed="true" stored="true"/>
<!--
lat/lon in radians
In a real system, use a copy field for these instead of sending over the wire -->
<field name="lat_rad" type="tdouble" indexed="true" stored="true"/>
<field name="lon_rad" type="tdouble" indexed="true" stored="true"/>
<!-- Hmm, what about a special field type here? -->
<field name="geohash" type="string" indexed="true" stored="true"/>
<!-- Elevation data -->
<field name="ele" type="tfloat" indexed="true" stored="true"/>
<!-- Store Cartesian tier information -->
<dynamicField name="tier_*" type="double" indexed="true" stored="true"/> |
我将纬度/经度值存储为 tdouble 字段。一个 tdouble 就是在内部使用
Trie 结构表示的一个 double。Lucene 可以使用它来大大减少在范围计算期间需要计算的词汇的数量,尽管实际上它向索引添加了更多词汇。我将
Geohash 储存为一个简单的 string(未分析)因为我仅需要它的精确匹配。严格而言,我进行的这些计算用不到海拔,但我将它储存为
tfloat,它是存储在 Trie 结构中的 float。最后,tier_* 动态字段允许应用程序动态地添加笛卡尔层字段,而不需要提前声明它们。至于索引过程捕捉的其他元数据字段,我将留给读者探索。
负责为数据创建索引的代码位于 sample.zip 的 source 树中。Driver
类是一个用于启动索引过程的命令行实用程序,但实际的索引过程发生在名为 OSMHandler 的实现的 SAX
ContentHandler 部分。在 OSMHandler 代码内部,最关键的代码行是 startElement()
方法。我将它分成 3 个部分。第一个例子(见清单 2)以 double 的形式为纬度和经度建立索引,并将它们转换成可以索引的弧度:
清单 2. 纬度/经度的样例索引
//... current is a SolrInputDocument
double latitude = Double.parseDouble(attributes.getValue("lat"));
double longitude = Double.parseDouble(attributes.getValue("lon"));
current.addField("lat", latitude);
current.addField("lon", longitude);
current.addField("lat_rad", latitude * TO_RADS);
current.addField("lon_rad", longitude * TO_RADS); |
为纬度/经度建立索引非常简单。接下来,我为纬度/经度对索引 Geohash
值,如清单 3 所示:
清单 3. 样例 Geohash 索引
//...
//See http://en.wikipedia.org/wiki/Geohash
String geoHash = GeoHashUtils.encode(latitude, longitude);
current.addField("geohash", geoHash); |
在清单 3 的 Geohash 代码中,我使用随 Lucene 空间 contrib
包附带的 GeoHashUtils.encode()(有一个等效的 decode() 方法)方法将纬度/经度对转换成一个
Geohash 字符串,然后再把该字符串添加到 Solr。最后,为了添加笛卡尔层,我在 OSMHandler
代码中完成了两件事情:
我在构造器中创建 CartesianTierPlotter 类的 n 个实例,每个需要建立索引的层一个。
在 startElement() 方法中,我遍历所有 n 个描绘器,并为每个包含当前
OSM 元素的纬度和经度的每个网格元素获取标识符。该代码如清单 4 所示:
清单 4. 笛卡尔层的样例索引
//...
//Cartesian Tiers
int tier = START_TIER; //4
//Create a bunch of tiers, each deeper level has more precision
for (CartesianTierPlotter plotter : plotters)
{current.addField("tier_" + tier, plotter.getTierBoxId(latitude, longitude));
tier++;
} |
一般情况下,查询一次仅需搜索一个层,因此拥有多个层通常不会造成任何问题。您应该根据搜索所需的粒度来选择层数。如果您花时间查看剩余的索引代码,将看到我添加了许多与
OSM 文件中的数据点相关的其他元数据值。我现在仅为两种 OSM 数据类型建立索引:界点(node) 和路线(way)。界点是特定的纬度和经度上的一个点,而路线是所有在某种程度上相关的界点的集合,比如街道(参见
参考资料 中的 OSM Data Primitives 链接更多地了解 OSM 文件)。
什么是 CartesianTierPlotter?
CartesianTierPlotter 的工作是对地球进行投影(在我的例子中,我使用正弦曲线投影;参见
参考资料)和纬度/经度信息,将其转换成层系统所使用的网格,并且给每个网格一个唯一的号码。在搜索时,应用程序就可以通过指定网格
ID 来限制搜索范围。
您已经了解创建包含空间信息的 Solr 文档的基础知识,接下来将进行实践。Driver
类接收数据和事实文件以及运行 Solr 的 URL,并将该工作转交给 OSM2Solr 类。OSM2Solr
类将使用 Solr 的 Java 客户端 SolrJ 来接收 OSMHandler SAX 解析器创建的文档,并将它们批量发送到
Solr 服务器。您可以在命令行运行 Driver 类,或者只需运行 ant index,让 Ant 完成运行驱动程序所需的工作。完成该步骤之后,在浏览器中访问
http://localhost:8983/solr/select/?q=*:* 并确认 Solr 找到
68,945 个文档。花些时间细读返回到结果,熟悉其中包含的内容。
处理 OSM 数据的方法非常多,我在这里仅介绍了一些,不过,我们应该讨论如何在应用程序中使用这些数据了。
根据位置进行搜索
在把数据添加到索引中之后,我们将重温使用数据的各种方式。我将演示如何根据索引中的空间信息对文档进行排序、增强和过滤。
与距离相关的计算
根据距离增强文档和对文档进行排序是许多空间应用程序的常见要求。为了实现该目的,Lucene
和 Solr 包含几个用于计算距离的功能(参见 参考资料)。Lucene 包含根据大圆(Haversine)公式计算距离的工具(参见
DistanceUtils 和 DistanceFieldComparatorSource),而 Solr
包含几个用于计算距离的 FunctionQuery 函数:
大圆(Haversine 和 Geohash Haversine)
Euclidean 和 Squared Euclidean
Manhattan 和其他 p-norm
使用 Solr 的距离函数根据距离增强数据是非常容易的。我将关注 Solr
的函数查询,因为它们是最容易使用的并且不需要编程。可以在 Lucene 中轻松地使用它们,或者轻松地将它们移植到
Lucene。
如前所述,我设置了几个字段来储存 OSM 数据,包括 lat/lon、lat_rad/lon_rad
和 geohash。然后,我就可以搜索和增强这些值:
hsin(大圆):http://localhost:8983/solr/select/?q=name:Minneapolis
AND _val_:"recip(hsin(0.78, -1.6, lat_rad, lon_rad, 3963.205), 1, 1, 0)"^100
dist(Euclidean,Manhattan,p-norm):
http://localhost:8983/solr/select/?q=name:Minneapolis AND _val_:"recip(dist(2, lat, lon, 44.794, -93.2696), 1, 1, 0)"^100
sqedist(Squared Euclidean):
http://localhost:8983/solr/select/?q=name:Minneapolis AND _val_:"recip(sqedist(lat, lon, 44.794, -93.2696), 1, 1, 0)"^100
ghhdist(Geohash Haversine):
http://localhost:8983/solr/select/?q=_val_:"recip (ghhsin(geohash(44.79, -93), geohash, 3963.205), 1, 1, 0)"^100 |
对于以上每种情况,我将一个关键字查询与一个基于距离的 FunctionQuery
结合起来,生成一个包含关键字记录和距离记录的结果集。要查看这些部分的效果,请为每个查询添加一个 &debugQuery=true
并花些时间来检查 Solr 生成的解释。这些仅是它们的用例。要查看完整的签名和文档以及其他 FunctionQuery
函数,请参见 参考资料。当然,您可以选择增强某些部分,或者根据您的需求进行更改。
至于根据距离进行排序,Solr 提供一个主要选项,这实际上是一个弥补方法,因为
Solr 没有根据函数进行排序的功能,也没有定义定制的 FieldType。不过,这种措施非常简单。如果要根据函数进行排序,需要像上面一样创建查询,但在关键字子句后面添加
0,如 q=name:Minneapolis^0 AND _val_:... 所示。这将导致关键字记录为
0(但仍然返回匹配的结果),并且函数值将是记录的唯一组成部分。从长远看,希望 Solr 添加 FieldType
来更好地支持排序,而不需清零主要查询。
完成了排序和记录之后,我们将探讨过滤。
过滤
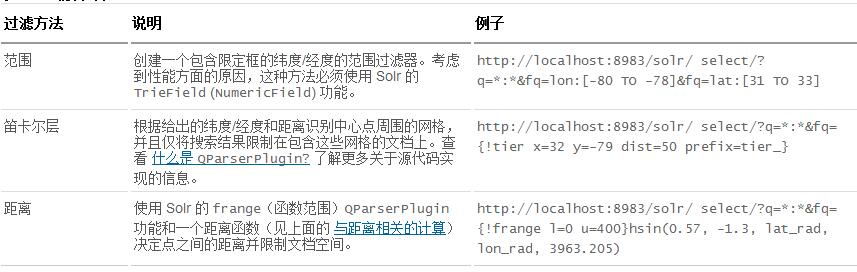
为了使用 Solr 根据位置进行过滤,表 1 为应用程序的记录器提供了
3 种主要的机制来限制文档空间:
表 1. 过滤方法
关于密度的简要说明
特定范围的点密度在用户的搜索体验方面扮演着重要的角色。例如,为纽约的曼哈顿提供商业搜索的应用程序的点密度比为明尼苏达州的布法罗提供搜索的应用程序的点密度大(参见
参考资料)。事实上,将该信息包含到过滤函数中是非常有用的,这让应用程序能够挑选一个最合适的距离,从而确保搜索结果是良好的。不过,演示如何实现该过程超出了本文的讨论范围。
什么是 QParserPlugin?
QParserPlugin 是 Solr 对查询解析器插件模块的称呼。和许多
Solr 部分一样,查询解析器实现也是可插拔的。对于本文,我使用 3 中不同的查询解析器插件,其中一个是随
Solr 附带的( FunctionRangeQParserPlugin ({!frange})),有两个是我自己编写的:CartesianTierQParserPlugin
({!tier}) 和 GeonamesQParserPlugin。这两个插件的源代码位于样例代码下载的
src 树中。这两个插件已经使用 solrconfig.xml 文件在 Solr 中进行了配置:在查询中通过指定
{!parserName [parameters]}[query](参数和查询可能是可选的)来调用 QParserPlugin,就像在
{!tier x=32 y=-79 dist=50 prefix=tier_} 和 {!frange l=0
u=400}hsin(0.57, -1.3, lat_rad, lon_rad, 3963.205) 中一样。
哪种方法适合您呢?这取决于点的密度(参见 关于密度的简要说明),但是我们建议首先采用简单的范围方法,然后在需要的时候提升到层方法。关键因素是每次计算范围时需要计算的词汇数量,因为这个数量直接控制
Lucene 需要做多少工作来限制结果集。
一个简单的 geonames.org 查询解析器
为空间应用程序构建功能齐全的查询解析器超出了本文的范围,反之,我将构建一个简单的
QParserPlugin,它将负责从来自 GeoNames 的位置信息获取结果。这个解析器假设应用程序能够提前将用户输入分成两部分:关键字查询和空间查询。事实上,许多本地查询应用程序都要求用户通过两个输入框输入信息。
解析器可以接受以下几个参数:
topo:toponym 的缩写(参见 GeoNames 文档)。在 GeoNames
中搜索的位置。必需。
rows:从 GeoNames 获取到的行数。可选。默认值为 1。
start:从其开始的结果。默认值为 0。
lat:在 FunctionQuery 中用作 ValueSource
的纬度字段名。如果指定了它,必须也设置 lon。
lon:在 FunctionQuery 中用作 ValueSource
的经度字段名。如果指定了它,必须也设置 lat。
gh:在 FunctionQuery 中用作 ValueSource 的
Geohash 字段名。如果指定了它,就不能 设置 lat/lon。
dist:需要使用的距离函数。String。[hsin, 0-Integer.MAX_VALUE,
ghhsin] 之一。如果指定了一个 geohash 字段,那么将忽略该字段。ghhsin 是自动的。2-norm
(Euclidean) 的默认值为 2。
unit - KM|M:需要使用的单位,KM 表示公制,M 表示英制。默认值为
M。
boost - float:增强函数查询的量。默认值为 1。
这个例子的代码包含在样例代码下载的 GeonamesQParserPlugin.java
文件中。(下载中包含的 Solr 版本中的 Solr 服务器已经配置好)。调用它与调用上面的 CartesianTierQParserPlugin
类似。例如,要在索引中搜索明尼苏达州 Bloomington 附近的购物中心,我将使用 http://localhost:8983/solr/select/?q=text:mall
AND _query_:"{!geo topo='Bloomington, MN' lat=lat_rad
lon=lon_rad dist=hsin}"。
通过采用 QParserPlugin 方法,我能够关注对我而言非常重要的语法,而且在位置方面仍然允许继续使用所有基于文本的查询解析功能。
从现在开始,可以大大地扩展 GeonamesQParserPlugin,将其与邮政编码和许多其他位置规范一起使用。当然,它还需要更多的错误处理,并且很可能需要转换为使用
GeoNames 数据集(参见 参考资料),从而使其不依赖于 Web 服务。Solr 在为问题跟踪器获取更多的空间查询解析器支持方面还存在开源问题(参见
参考资料)。
结束语
至此,我已经演示了 Lucene 和 Solr 根据基于点的位置模型搜索、排序和过滤文本文档的功能。接下来,将要实现一个真实的位置搜索应用程序来处理用户查询和呈现搜索结果。部分关于应用程序的伸缩性的问题可以从创建限定框过滤器时需要计算的词汇量找到答案。除了关于伸缩性的过滤器问题之外,还需要考虑其他与搜索相关的因素,比如是分发索引还是仅复制索引。请参见
Lucene 和 Solr 参考资料。
如果您对构建更加高级的 GIS 应用程序感兴趣,您将需要为路线查找、形状交叉等添加更加复杂的功能。如果您需要构建一个可靠搜索应用程序,用于合并基于点的位置的结构和非结构化文本,那么关注
Lucene 和 Solr 就足够了。
|





