| 编辑推荐: |
文章首先对Solr进行了简单的介绍和安装,然后针对Solr的配置及目录结构进行了详细说明。最后通过一个简单的示例来介绍了如何使用Solr。
本文来自于csdn,由火龙果软件Luca编辑、推荐。
|
|
Solr简介
官网:https://lucene.apache.org/solr/
Solr是基于Apache Lucene™构建的流行,快速,开源的企业搜索平台。
Solr是一个Java Web应用,可以运行在任何主流Java Servlet引擎中。下面来看一个Solr服务器的主要软件构成:
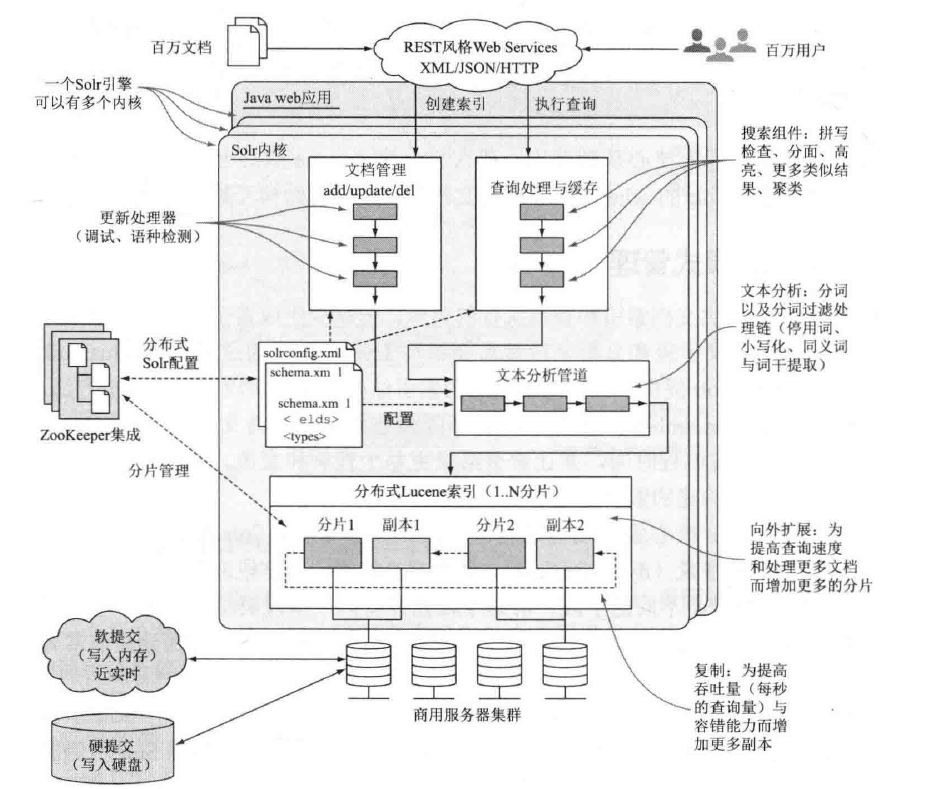
Solr基于已有的XML、JSON和HTTP标准,提供简单的类似REST的服务,这使得Solr可以被不同编程语言的应用访问。
Solr可以使用Zookeeper实现简易分片和复制,统一配置。
为了提高查询速度和处理更多的文档,Solr可以通过索引分片来实现分布式查询。
为了提高吞吐量和容错能力,可以为每个索引分片增加副本,同时,把所有的索引复制到其他的服务器搭建成一个服务器集群,提高吞吐量。
可通过缓存来提高查询速度,达到近实时查询。并写入到硬盘以达到持久化索引。
Solr具有高可靠性,可扩展性和容错性,可提供分布式索引,复制和负载均衡查询,自动故障转移和恢复,集中配置等。Solr为世界上许多最大的互联网站点的搜索和导航功能提供支持。
高可靠性
Solr有三个主要的子系统:文档管理、查询处理和文本分析。每一个子系统,都是由模块化的“管道”构成的,通过插件方式实现新功能,这意味着,我们可以根据特定的应用需求实现定制。
可扩展性
Lucene是一个执行速度相当快的搜索类库,Solr汲取了Lucene速度方面的所有优点。但因CPU的I/O原则,单台服务器终会达到并发请求的处理上限。为了解决这个问题,一,Solr提供灵活的缓存管理功能,帮助服务器重用运算量大的数据扩容。二,可以通过增加服务器实现增容。
Solr伸缩性有两个常用的维度:查询吞吐量和文档索引量。查询吞吐量是指搜索引擎每秒支持的查询数量,在多台服务器都复制一份索引,当有大量查询请求进入时,可以减轻每台服务器的压力。文档索引量是指索引文档的大小,当数量规模很大时,单个实例会因容纳太多文档而达到极限,查询性能也会受影响。为了处理更多文档,可以将索引拆分为很小的索引分片,然后在索引分片中进行分布式搜索。
容错性
当线上运行Solr时,如果索引分片中其中一个分片的服务器断电了,就会导致Solr无法继续索引文档和提供查询服务,因此,为了避免此种情况出现,应该对每一个分片添加副本,当其中一台分片服务器发生故障时,可以启用副本来索引和处理查询。
Solr安装
安装之前,确保已安装了正确的Java版本,一般为1.6以上版本。
下载Solr压缩包,前行http://www.apache.org/dyn
/closer.lua/lucene/solr/7.6.0下载7.6.0版本Solr,根据自己的系统下载对应的压缩包,我的是windows,所以下载solr-7.6.0.zip。
解压缩后添加环境变量SOLR_HOME,指向Solr解压缩的目录。
SOLR_INSTALL=D:\solr-7.6.0
PATH=%SOLR_INSTALL%\bin |
目录说明:
bin/,该目录包含几个重要的脚本,可以轻松使用solr。
solr和solr.cmd,这是 solr的控制脚本,用于启动和停止solr的服务器。在slorCloud模式下运行时,可以创建集合或内核,配置身份验证以及使用配置文件。
post,post工具,它提供了用于发布内容到solr的一个简单的命令行界面。
solr.in.sh和solr.in.cmd,此处配置Java,Jetty和solr的系统级属性,即全局属性。
install_solr_services.sh,在unix系统上用于将solr安装为服务。
contrib/,该目录包含solr专用功能的附加插件。
dist/,包含主要的solr.jar文件。
docs/,solr javadoc。
example/,包括几种演示各种solr功能的示例。
licenses/,包含solr使用的第三方库的所有许可证
server/,此目录包含了运行Solr服务器的Jetty Servlet容器设置,此目录中的README文件提供了详细的概述。
Solr的管理员UI(server/solr-webapp)
Jetty libraries(server/lib)
日志文件(server/logs)和日志配置(server/resources)
示例配置集(server/solr/configsets)
solr主目录(server/solr)
solr start启动solr服务器,solr stop停止solr服务器,服务器端口为8983:
Solr部署模式
Solr服务器有两种部署模式,分别为单机模式(Standalone Server)和分布式集群模式(SolrCloud)
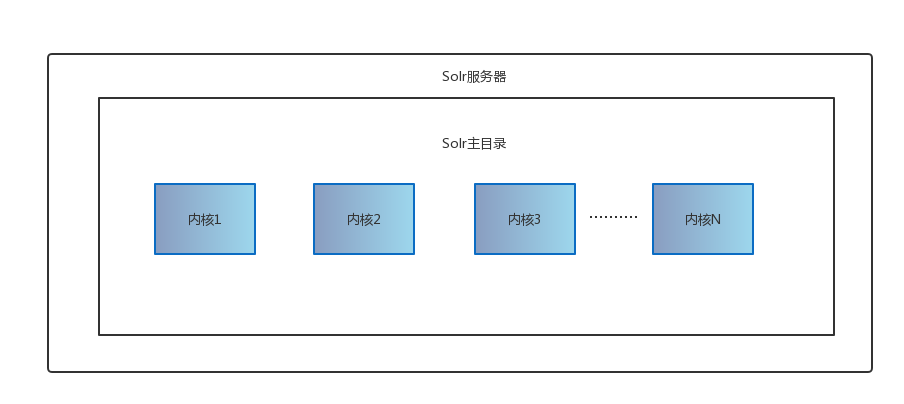
内核VS集合
Solr的内核是运行在Solr服务器中的具有唯一命名的、可管理的和可配置的索引。一台Solr服务器可以托管一个或多个内核。内核典型的用途是为了区分不同模式的文档。单机模式下,内核可以理解为一个索引库。
SolrCloud引入了集合的概念,集合将具有唯一命名的、可管理的和可配置的索引扩展成不同的分片,并且分配到多台服务器上。分布式索引的每一个分片都托管在一个Solr的内核中,即多个内核可以组成一个索引库。
目录结构
每个solr服务器进程都有一个solr主目录,系统变量名为solr.solr.home,默认为server/solr目录:

主目录的作用是在于存储服务器实例托管的内核的。
运行solr服务器实例的命令:

默认端口是8983。指定另一个主目录,主目录下必须要有一个solr.xml文件:
执行命令,-s是指定主目录的路径,-p是指定新启动的服务器实例监听的端口:
]
创建内核,需要指定solr服务器监听的端口,这样才能使内核存储在对应的主目录:
创建成功后,会在主目录下生成内核目录:

内核目录有三个文件:

(1)conf/:内核配置文件的文件夹,里面有个solrconfig.xml用于控制高级配置信息。
(2)data/:索引数据存放的目录,相当于lucene中定义IndexWriter对象的第一个Directory参数。
(3)core.preperties:内核的一些参数定义。
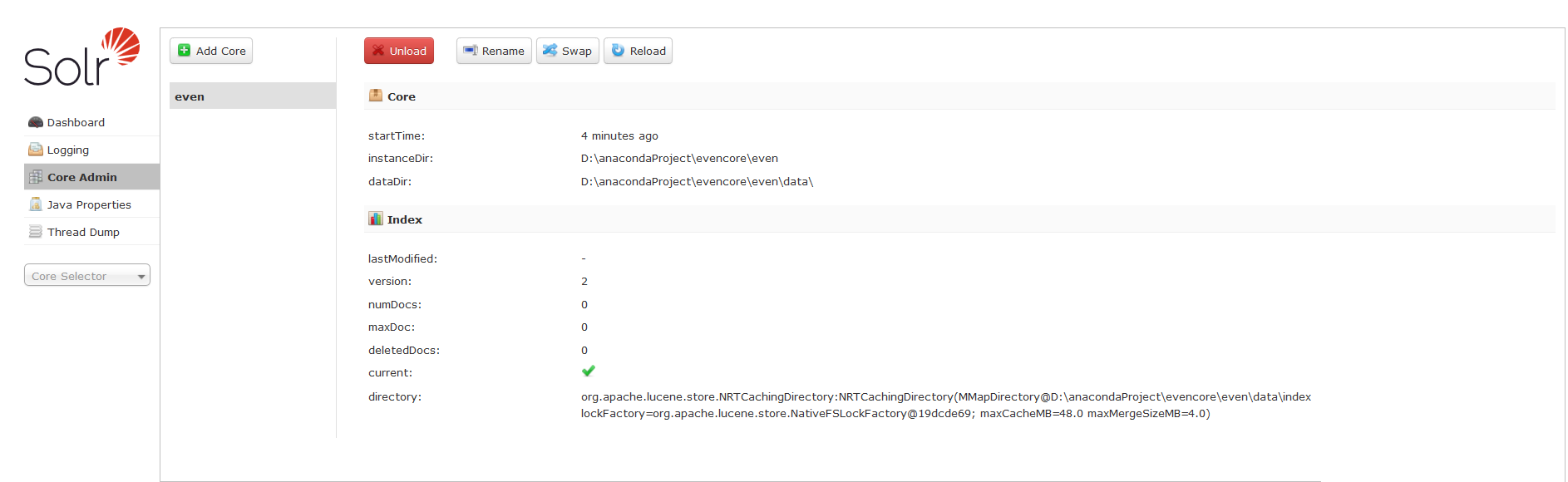
打开sorl admin ui可以看到关于内核的信息:
Solr配置文件
solr.xml
solr.xml文件定义了一些适用于所有或多个内核的全局配置选项。
在单机模式下,solr.xml是在$SOLR_HOME目录中,默认是(server/solr),而在SolrCloud运行时,是在Zookeeper中找到。默认的solr.xml文件如下:
<?xml version="1.0"
encoding="UTF-8" ?>
<solr>
<solrcloud>
<str
name="host">${host:}</str>
<int name="hostPort">${jetty.port:8983}</int>
<str name="hostContext">${hostContext:solr}</str>
<bool name="genericCoreNodeNames">
${genericCoreNodeNames:true}</bool>
<int name="zkClientTimeout"> ${zkClientTimeout:30000}</int>
<int name="distribUpdateSoTimeout"
>${distribUpdateSoTimeout:600000}</int>
<int name="distribUpdateConnTimeout">
${distribUpdateConnTimeout:60000}</int>
<str name="zkCredentialsProvider">
${zkCredentialsProvider:org.apache.solr.common.
cloud.DefaultZkCredentialsProvider}
</str>
<str name="zkACLProvider">${zkACLProvider:org.apache
.solr.common.cloud.DefaultZkACLProvider}</str>
</solrcloud>
<shardHandlerFactory
name="shardHandlerFactory"
class="HttpShardHandlerFactory">
<int name="socketTimeout">${socketTimeout:600000}</int>
<int name="connTimeout">${connTimeout:60000}</int>
</shardHandlerFactory>
</solr> |
配置中已有一些关于SolrCloud的配置,但是这并不意味着启动时是SolrCloud模式,需要在启动时指定参数-DzkHost或-DzkRun才是在SolrCloud模式下运行。
1.<solr>元素,该元素是solr.xml文件的根元素,不可以指定属性。
2. <solrcloud>元素,该元素定义了与SolrCloud相关的参数:
distribUpdateConnTimeout:用于设置集群内部更新的连接超时时间。
distribUpdateSoTimeout:用于设置集群内部更新的socket连接超时时间。
host:solr用于访问内核的主机号。
hostContext:url的上下文路径。
hostPort:solr用于访问内核的端口。默认${jetty.port:8983},表示使用Jetty中定义的solr端口,如果没有定义,就使用8983端口。
leaderVoteWait:当SolrCloud启动时,假定存在未报告的节点宕机了,每个Solr节点等待找到碎片的所有已知副本的时间。
leaderConflictResolveWait:当尝试为分片选择Leader时,该属性设置了副本等待查看解决的冲突状态信息的最长时间,在执行滚动重新启动时可能会发生状态信息中的临时冲突,尤其是在重新启动托管监视器的节点时。
zkClientTimeout:连接Zookeeper服务器的超时时间。
zkHost:zookeeper主机的url。
genericCoreNodeNames:如果为true,节点名称不是基于节点的地址,而是基于标识内核的通用名称(内核别名)。当一台不同的机器接管服务内核时,可以更易理解它。
zkCredentialsProvider&zkACLProvider:用于设置Zookeeper访问控制。
<logging>元素,log记录的一些配置:
class,用于记录的类。相应的JAR文件必须可用于Solr,也可以通过solrconfig.xml的<lib>指令使用。
enabled,true/false,是否启动日志记录
<logging><watcher>元素:
size,缓冲的日志事件数
threshold,日志级别,如DEBUG,WARN,INFO等
<shardHandlerFactory>元素,可以定义自定义分片处理程序。
<shardHandlerFactory name=“ShardHandlerFactory”
class=“qualified.class.name”>
由于是自定义分片处理程序,所以,子元素是在实现中指定。
而Solr提供了一个默认和唯一的分片处理程序——HttpShardHandlerFactory,在这种情况下,可以指定以下子元素:
socketTimeout:集群内查询和管理请求的读取超时。默认值与distribUpdateSoTimeout指定的默认值相同。
connTimeout:群集内查询和管理请求的连接超时,默认值与distribUpdateConnTimeout指定的默认值相同。
urlScheme:用于分布式搜索中使用的URL方案
maxConnectionsPerHost:每台主机允许的最大连接数,默认为10000.
maxConnections:允许最大的总连接数。默认为10000
corePoolSize:线程池服务请求的初始内核大小,默认为0
maximumPoolSize:服务请求的线程池的最大数,默认无限制。
maxThreadIdleTime:在被kill之前,空闲线程在队列中持续存在的时间,以秒为单位,默认为5秒。
sizeOfQueue:如果线程池使用后备队列,则使用直接切换的最大大小是多少,默认使用SynchronousQueue。
fairnessPolicy:一个布尔值,用于配置线程池是否有利于吞吐量的公平性,默认值为false以支持吞吐量。
core.properties
core.properties文件是一个简单的Java Properties文件,每一行只是一个key=value对,core.properties的位置可以是在内核目录的任何位置,但是,一个内核目录中,只会识别目录深度最浅的文件。如下:

上面的示例中,只会枚举到core1,即只会识别第一个core.properties文件。一般情况都是把该文件放在内核的第一级目录中。
core.properties可以为空,创建内核时生成的core.properties会有一个kv对,表示内核的名称。
core.properties属性:
name,SolrCore的名称,在使用CoreAdminHandler运行命令时,将使用此名称来引用SolrCore。
config,给定内核的的配置文件名。默认为solrconfig.xml。
schema,给定内核的模式文件名,默认为schema.xml。
dataDir,内核的数据目录(存储索引),绝对路径或相对于instanceDir的路径。默认值是data
configSet,如果需要,用于配置内核的已定义配置集的名称。
properties,此内核的属性文件的名称,该值可以是绝对路径名或相对于instanceDir的路径。
transient,如果为true,则在Solr到达时transientCacheSize大小时,unload内核,如果未指定,那么内核会按照最近最少使用的顺序来unload。在SolrCloud不建议开启。
loadOnStartup,如果为true,则在Solr启动时将会加载内核,默认为true,在SolrCloud模式下不建议设置为false。
coreNodeName,仅在SolrCloud中使用,这是托管此副本的节点的唯一标识符。默认情况下,coreNodeName会自动生成。显式设置该属性,可以允许你手动分配新内核以替换现有的副本。例如,通过从具有新主机名或端口的新计算机上的备份进行恢复来替换出现硬件故障的计算机时,可以使用。
ulogDir,此内核的更新日志的绝对或相对目录。(SolrCloud模式下)
shard,分配此内核的分片。(SolrCloud模式下)
collection,该内核所属集合的名称。
roles,SolrCloud的未来参数或用户标记节点供自己使用的方法。
core.properties文件就是用于指定属性变量的。
solrconfig.xml
solrconfig.xml文件是影响solr本身的参数最多的配置文件。
在配置Solr时,你可以使用solrconfig.xml,也可以通过Config API来创建"configuration
overlays"(configoverlay.json)来重写solrconfig.xml的值。
solrconfig.xml可以配置的重要功能有:
请求处理程序,处理对solr的请求,例如向索引添加文档的请求或返回查询结果的请求。
监听器,“监听”特定查询相关事件的过程;监听器可用于触发特殊代码的执行,例如调用一些常见查询来预热缓存
Request Dispatcher用于管理HTTP通信
Admin Web界面
与复制和副本相关的参数,详情请查看https://lucene.apache.org/solr/guide/7_6
/config-api.html#config-api
下面详细介绍solrconfig.xml的几个部分:
DataDir和DirectoryFactory
为索引指定存储的位置
dataDir参数用于指定索引数据的位置,默认情况下,solr将其索引数据存储在/data目录中,如果需要指定其他目录用于存储索引,可以在core.properties中配置dataDir,或在solrconfig.xml中配置<dataDir>参数。可以使用绝对路径或相对于Solr
内核的instanceDir路径名来指定另一个目录。
为索引指定DirectoryFactory,即生成的目录类型
默认是solr.NRTCachingDirectoryFactory,是基于文件系统,并深度为当前JVM和平台选择最佳实现。可以通过强制指定一个实现或者是配置选项为solr.MMapDirectoryFactory
,solr.NIOFSDirectoryFactory或solr.SimpleFSDirectoryFactory。
如:
<directoryFactory
name="DirectoryFactory"
class="solr.MMapDirectoryFactory">
<bool name="preload">true</bool>
</directoryFactory> |
还有两种较常用的,一种是org.apache.solr.core.RAMDirectoryFactory,它是基于内存的,不适用于持久化和副本的。另一种是将索引存储在HDFS中,需要使用solr.HdfsDirectoryFactory。
Resource and Plugin Loading
Resource:可以通过配置来调用资源:存储在外部的文件数据。
这些数据可以以与位置无关的方式引用,如停止过滤器的停用词列表,学习排名的机器学习模型等。
Plugin:可以在solrconfig.xml配置,是一个Java类,通过打包在.jar文件中。Solr附带了许多内置的插件,也可以配置使用自定义插件。
资源和插件可以存储在:
在zookeeper服务器中的一个collection的configset节点下。
在solr可访问的文件系统中。
在solr的Blob 商店
其中1,3都需要在SolrCloud模式下才可以使用。
资源和插件的加载顺序
在SolrCloud下,首先在Zookeeper的collection的configset节点下查找要加载的资源和插件。如果在那里找不到资源或插件,solr将回退到从文件系统中加载。
如果需要从Blod 商店加载,需要额外配置,因为用得少,此处不作介绍,有兴趣的可以查看官方文档。
Zookeeper上的ConfigSet
资源和插件可以作为配置集的一部分上传到Zookeeper,可以通过Configsets API或bin/solr
zk upload
要将资源或插件上传到已存储在Zookeeper的配置集,可以使用bin/solr zk cp。
注意:Zookeeper的默认大小是1MB,如果大于此值,需要设置。
在单机模式下,当要查找插件或资源时,Solr资源加载器将首先查看<instanceDir>/conf/目录下的内容,如果找不到,就会遵循lib指令。
lib指令,首先会让资源加载器查看solr_home/lib的内容,然后再查看solrconfig.xml中lib参数指定的目录。
总结:<instanceDir>/conf/?>?solr_home/lib?>?solrconfig.xml中lib参数指定的目录
solrconfig.xml关于lib参数的例子,其中,如果存在依赖关系,需要把最低级别的依赖列在前面
<lib dir="../../../contrib/extraction/lib"
regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-cell-\d.*\.jar"
/>
<lib dir="../../../contrib/clustering/lib/"
regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-clustering-\d.*\.jar"
/>
<lib dir="../../../contrib/langid/lib/"
regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-langid-\d.*\.jar"
/>
<lib dir="../../../contrib/velocity/lib"
regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-velocity-\d.*\.jar"
/> |
SolrConfig中的Schema Factory定义
Solr的Schema API可以使远程客户端能够通过REST接口访问Schema信息进行Schema修改。
managed-schema概览(schema.xml)
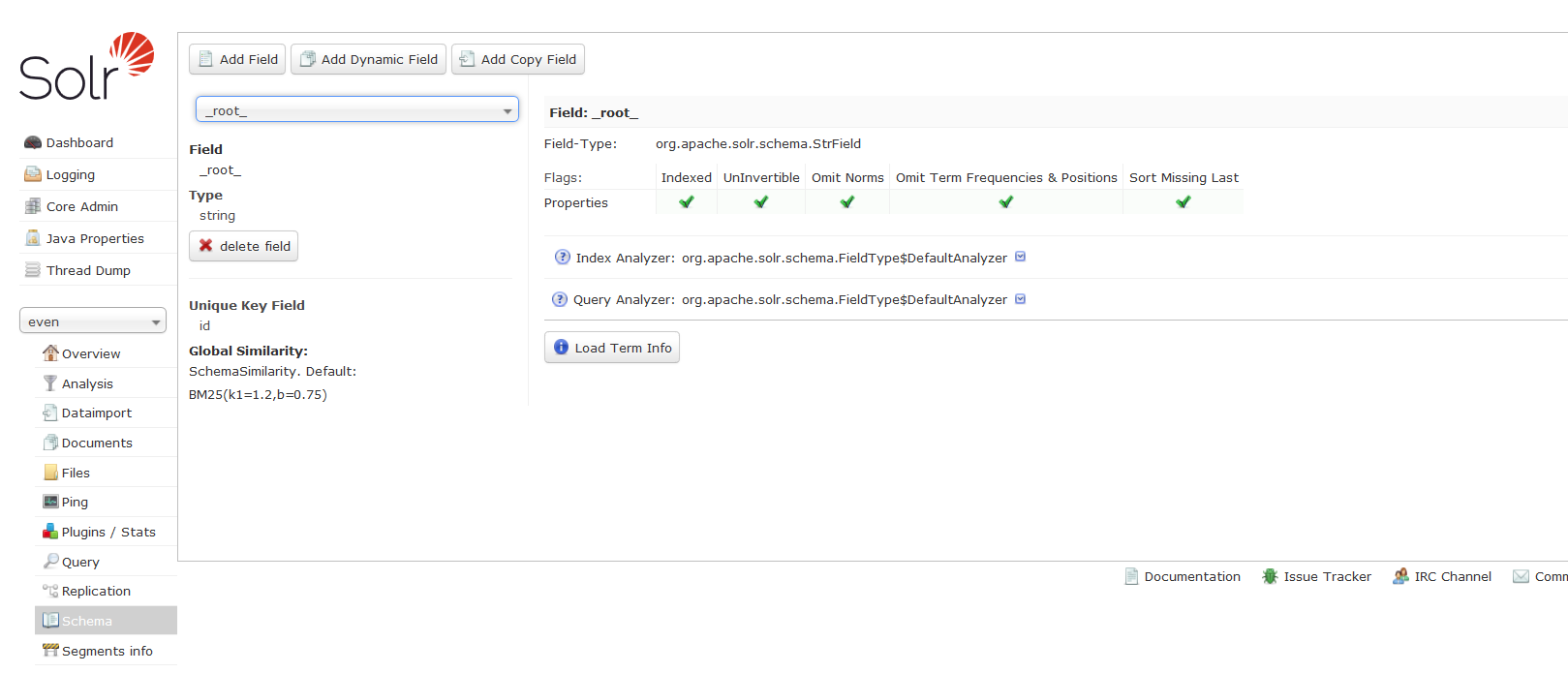
managed-schema定义了索引库的数据类型,同时指明某个类型的字段是不是要进行索引,是不是要进行保存到索引库里等等。类似传统数据库的Schema。旧版本(不知从哪一版本开始)用的是schema.xml,现在新版本的是用managed-schema,文件位于内核目录的conf文件夹中。可以通过solr
admin ui内核的schema查看。solr的schema的作用与lucene定义Document的fieldType作用类似。
Solr默认使用托管模式
当solrconfig.xml中的<schemaFactory>文件没有显式声明时,Solr隐式使用ManagedIndexSchemaFactory,默认开启“mutable”,且把schema的信息保存到managed-schema文件中。
<schemaFactory
class="ManagedIndexSchemaFactory">
<!--控制是否可以对Schema数据进行更改,必须将其设置为true才能允许使用schema
api进行编辑-->
<bool name="mutable">true</bool>
<!--可选参数,默认为“maanged-schema”,为模式文件定义一个新名称,该名称可以定义除schema.xml之外的任何名称-->
<str name="managedSchemaResourceName">managed-schema</str>
</schemaFactory> |
使用上面显示的默认配置,可以根据需要使用Schema API修改架构。
经典schema.xml
管理模式的另一种做法是显示配置ClassicIndexSchemaFactory,ClassicIndexSchemaFactory需要使用schema.xml文件,且不允许在运行时对schema进行任何编程更改。schema.xml必须手动编辑并且仅在加载集合时才会加载该文件
<schemaFactory class=“ClassicIndexSchemaFactory”/>
两种模式的切换
一,从schema.xml到托管模式:
把ClassicIndexSchemaFactory改为ManagedIndexSchemaFactory,并把“mutable”设置为true,当重新启动solr时并检测到schema.xml时,但是managedSchemaResourcename文件不存在时,现在的schema.xml文件将重命名为schema.xml.bak并且内容将重新写入managed-schema文件。
二,从托管模式到schema.xml:
1,将managed-schema重命名为schema.xml;2,修改schemaFactory类;3,重新加载内核。
schema的相应配置请查看官方文档
schema.xml中的字段类型定义
字段类型定义分析发生在索引文档或将查询发送到索引时。
字段类型定义可以包括四种类型的信息:
字段类型的名称(必需)
实现类名称(必需)
如果字段是TextField,需要关于字段类型的字段分析描述
字段类型属性,根据不同的实现类,某些属性是必须的
样例:
<fieldType
name="text_general" class="solr.TextField"
positionIncrementGap="100">
<analyzer type="index">
<tokenizer
class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="stopwords.txt"
/>
<!-- in this example, we will only
use synonyms at query time
<filter class="solr.SynonymFilterFactory"
synonyms="index_synonyms.txt" ignoreCase="true"
expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true" words="stopwords.txt"
/>
<filter class="solr.SynonymFilterFactory"
synonyms="synonyms.txt" ignoreCase="true"
expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType> |
其中“solr”这个字符串表示org.apache.solr.schema或org.apache.solr.analysis。
字段类型属性
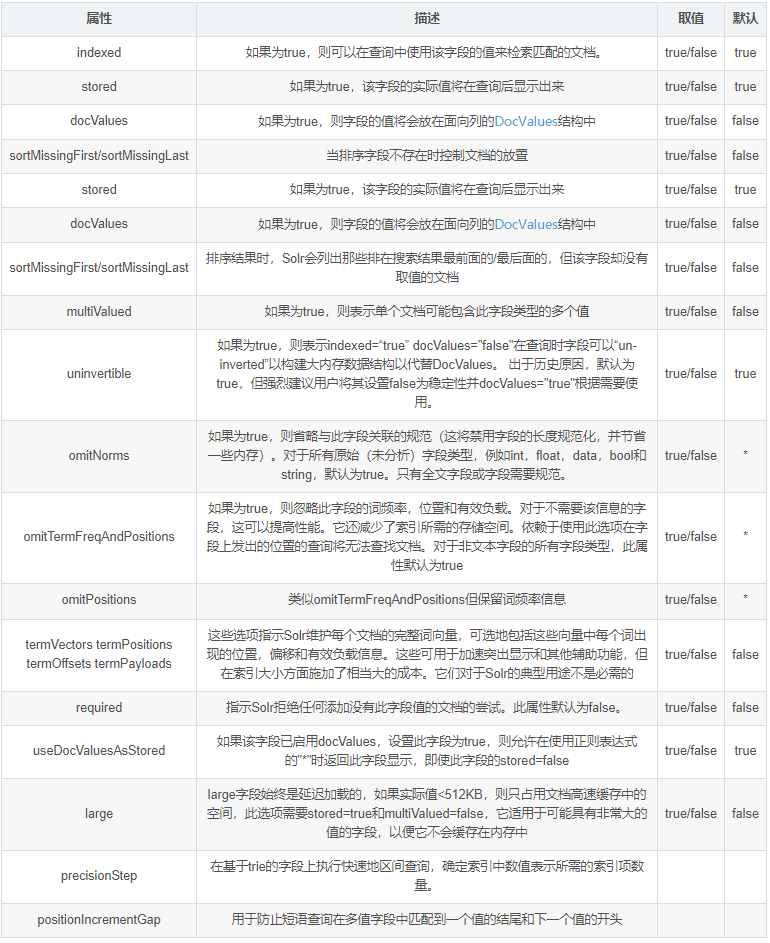
字段类型class确定字段类型的大多数行为,但有一些可选属性可以自定义。如下,sortMissingLast和omitNorms为可选属性:
<fieldType
name="date" class="solr.DatePointField"
sortMissingLast="true" omitNorms="true"/> |
可以为给定字段类型指定的属性为分三大类:
特定于字段类型的类型属性
常规属性,solr支持任何字段类型
字段默认属性,可以在字段类型上指定,将由使用此类型的字段而不是默认行为继承
常规属性
name:fieldType的名称。
class:用于存储和索引此类型数据的类名。
positionIncreamentGap:对于多值字段,指定多个值之间的距离,以防止虚拟短语匹配。
autoGeneratePhraseQueries:对于文本字段,如果true,Solr自动为相邻术语生成短语查询。如果为false,术语必须用双引号括起来作为短语。
synonymQueryStyle:用于组合重叠查询项(即同义词)的分类的查询。
字段默认属性
这些属性可以在字段类型上指定,也可以在单个字段上指定,以覆盖字段类型的默认值。
Solr命令
启动停止Solr
#后台启动Solr服务器,默认端口8983,默认主目录server/solr
solr start
#前台启动Solr服务器
solr start -f
#SolrCloud模式启动Solr,如果-z没有指明或ZK_HOST没有在solr.in.cmd中定义,默认使用一个端口为Solr
port+1000的嵌入式Zookeeper实例。
solr start -c 或者 solr start -cloud
#指定Solr服务器实例的host名
solr start -h mysolr
#指定solr http监听端口,
solr start -p 8984
#指明Solr服务的目录,默认是server
solr start -d dir/
#指明Zookeeper的Host
solr start -z 192.168.1.198:22222
#指定内存的最大和最小使用量。如-m 4g代表-Xms4g -Xmx4g
solr start -m 4g
#指定主目录路径
solr start -s evendir/
#指定索引存储路径
solr start -t dir/
#停止solr服务器
solr stop -p port
#停止所有solr服务器
solr stop -all |
创建内核
#创建内核
solr create -c corename
#指定配置文件目录
solr create -c corename -d confdir/
#指定solr服务器的监听端口
solr create -c corename -p 8983
#支持详细输出级别
solr create -c corename -v info |
删除内核
#删除内核
solr delete -c corename
#删除内核时把Zookeeper上的配置也一起删除,布尔类型,默认为true
solr delete -c corename -deleteConfig 0
#删除指定端口的内核,如果没有指定,则会搜索本地系统正在运行的solr实例,用第一个找到的实例的端口
solr delete -c corename -p 8985
#打印详细信息
solr delete -c corename -v info |
Solr示例
下面以一个微博搜索作为示例来了解如何使用Solr。
一,面向搜索的内容表示
下面是虚构的一段微博。
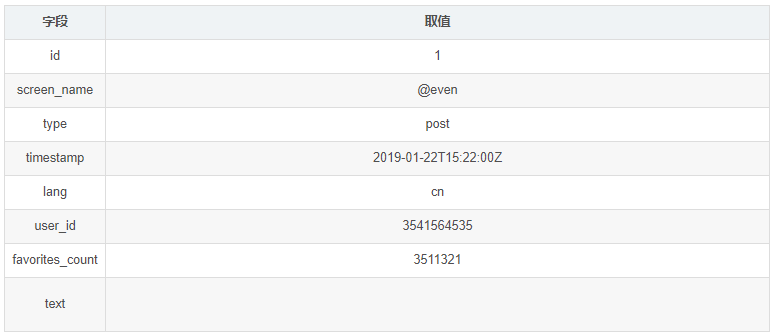
在Solr索引中,每个文档由字段组成,每个字段拥有具体的类型,字段类型决定了文档将如果被存储、搜索与分析。在上表中,微博文档有8个字段,但是,从搜索角度来说用户并不会使用所有的这些字段来寻找微博。现在假设,用户可能会用到screen_name、type、timestamp、lang和text这些字段来搜索微博,例如,一个用户可能想要查看特定用户(screen_name)在特定时间(timestamp)以后的所有中文(lang)微博(text)。
实际应用也可以索引所有的字段,但是,在一个千万级别文档与高查询量的大规模系统中,如果对一些没有必要的字段也一起索引,会增加索引的体积,影响查询的效率。如id,user_id这些系统内部定义的字段,用户是不会用到的,如favorites_count这个表示粉丝数量的字段,用户在查询时一般也不会关注,所以都可以不加入到索引中。
二,Solr索引构建概览
从宏观层面看,Solr的索引构建可分解为三个主要任务:
将文档从原始格式转换成Solr支持的格式,例如XML或JSON
选择一种接口方法,通常使用HTTP POST,将文档添加到Solr
在索引中,通过配置Solr,对文档的文本进行转换。
如下图所示:
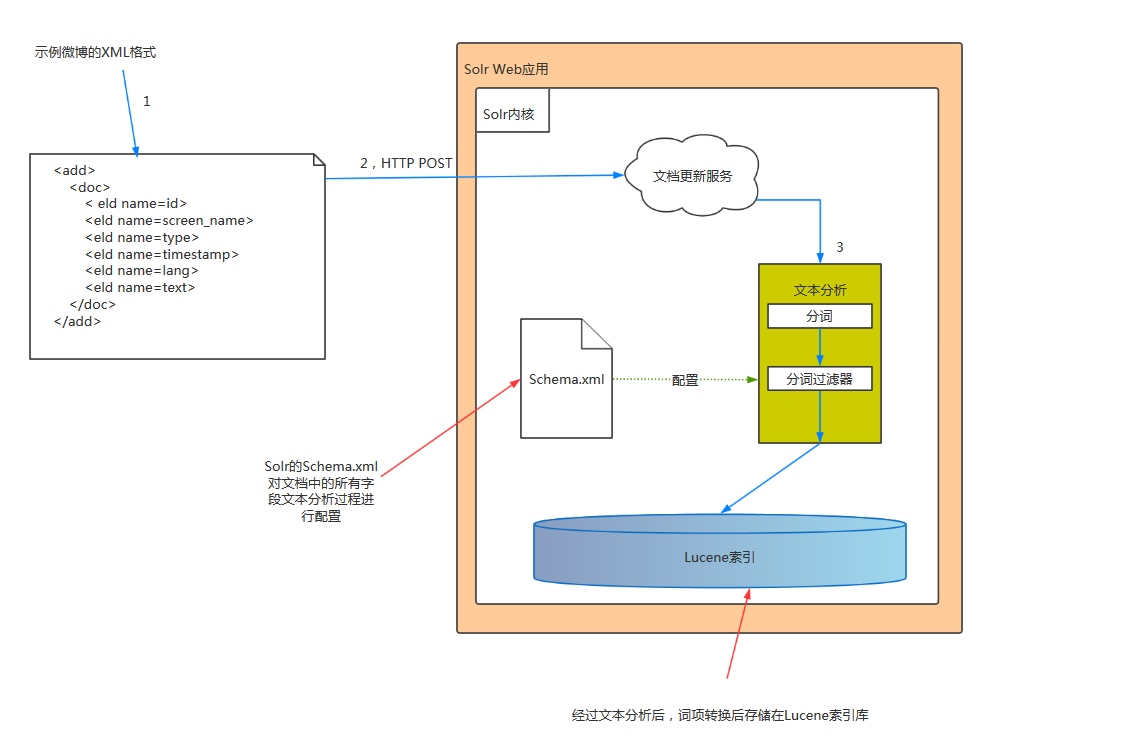
通过HTTP POST方式把XML格式的内容发送到Solr文档更新服务,文档更新服务主要是用于验证文档中每个字段的内容,之后进入文本分析阶段。每个字段经过分析后的结果文本将被添加到索引中,这样文档就可以用于搜索了。
示例微博的XML格式:
<!--add告诉Solr要创建索引-->
<add>
<!--doc表示文档,可以添加多个doc-->
<doc>
<!--文档的字段,由name和value组成-->
<field
name="id">1</field>
<field
name="screen_name">@even</field>
<field name="type">post</field>
<field name="timestamp">2019-01-22T15:22:00Z</field>
<field name="lang">cn</field>
<field name="user_id">3541564535</field>
<field name="favorites_count">3511321</field>
<field name="text"> </field>
</doc>
</add> |
三,设计自己的Schema
索引中的文档内容有哪些?
每个文档如何做到唯一确定?
用户会搜索文档中的哪些字段?
在搜索结果中应该向用户显示哪些字段?
针对特定的搜索应用,下面需要设计特定的schema。
文档粒度
schema的设计过程实际是确定文档如何表征为Solr索引的过程。
举例:
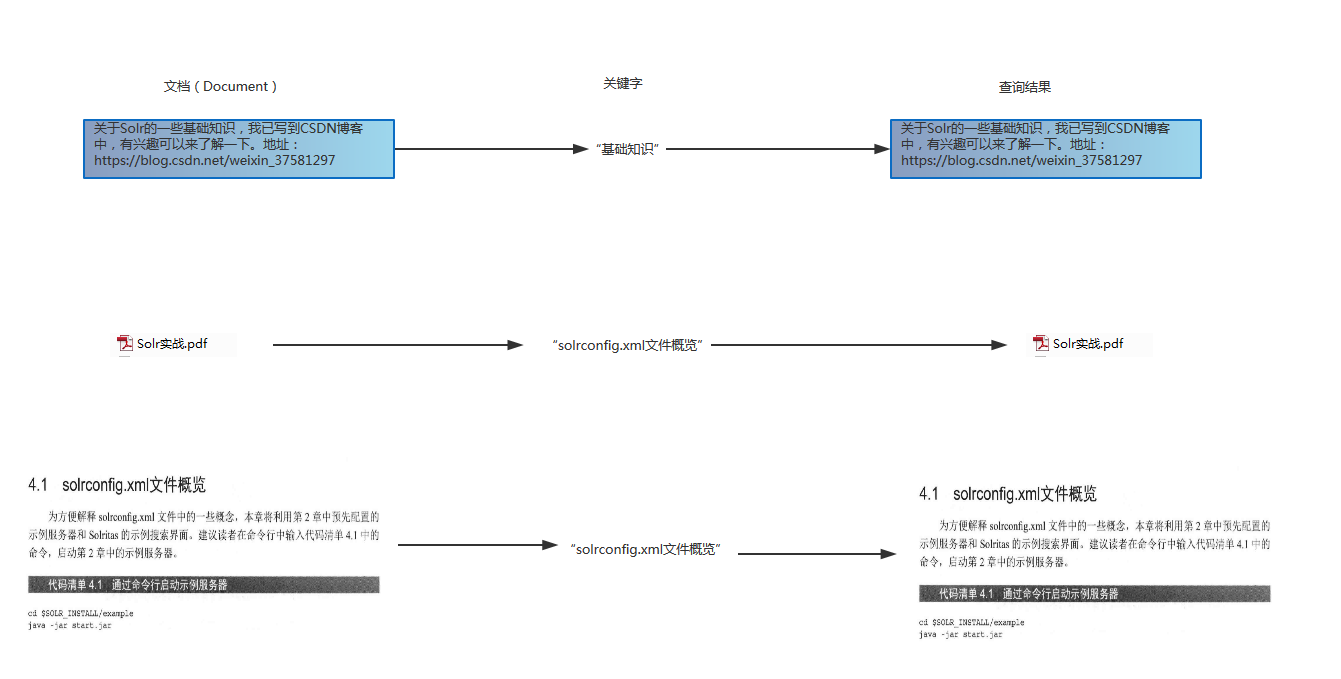
当把一段文字作为文档时,输入字查询,得到的结果是这段文字;当把一个书籍作为文档时,输入书籍内的一段文字,会返回整个书籍;当使用书籍中的一个章节作为文档时,返回的结果就是此章节内容。
上图中,以章节为文档,就是文件粒度细;以整本书籍为文档,就是文件粒度粗。通常情况下,文件粒度细的,搜索出来的结果就会很多,文件粒度粗的,返回的结果就会很少。因此,需要我们根据用户的需求来确定文件粒度,schema就是用于确定文档表征为Solr索引。
唯一键
一旦确定了待索引的文档构成,就需要确定如何在索引中唯一识别每个文档,相当于主键。如果把相同主键的文档添加到索引,Solr会用最新的文档覆盖已在的文档。上面的微博搜索应用只,id就是唯一键,如果还要区别是哪个社交媒体的内容,还需要在id前加上前缀以便区分。
索引字段
确定了索引文档的构成以及文档唯一识别符后,接下来确定文档中的索引字段。索引字段,其实就是用户可能输入的关键字。正常情况下,如果用户需要搜索某一篇书籍,一般会输入书名和作者,这里书名和作者就可以作为索引字段。而书籍中的编辑的名字,一般用户是不会作为关键字搜索的,因此可以不使用编辑的名字作为索引字段。
索引字段的选择需要根据具体的业务场景以及用户需求来确定。
存储字段
存储字段是指那些需要显示在搜索结果的内容字段。当用户想要在搜索结果中显示某些字段,但又不想通过这些字段来进行搜索,如,一本书籍的编辑,正常情况下用户是不会用编辑名字来搜索书籍的,但是,在显示书籍内容时,需要显示书籍的编辑。这种情况,就可以把书籍的编辑名字设为存储字段。一个字段可以同时是存储字段和索引字段。
索引的大小会影响到搜索的效率,而索引中每一个存储字段都需要占用磁盘空间,CPU和I/O资源,因此,在使用Solr时,需要谨慎选择存储字段。
以上是设计搜索应用时需要认真思考所需的字段类型。下面来看一下schema.xml的字段定义。
四,在schema.xml中定义字段
schema.xml文档由三个主要部分组成:
1, <fields>元素包含<field>和<dynamicFiedl>,用于定义文档的基本结构。
2,其他元素,如<uniqueKey>和<copyField>,位于field元素之后。
3,<types>元素下的字段类型包括Solr能够处理的日期、数字和文本字段。
<?xml version="1.0"
encoding="UTF-8"?>
<schema name="default-config" version="1.6">
<fields>
<!--该字段是索引中文档的唯一识别符-->
<field name="id" type="string"
indexed="true" stored="true"
required="true"/>
<field name="screen_name"
type="string" indexed="true"
stored="true"/>
<field name="type"
type="string" indexed="true"
stored="true"/>
<field name="timestamp"
type="string" indexed="true"
stored="true"/>
<field name="lang"
type="string" indexed="true"
stored="true"/>
<!--该字段索引是为了排序,存储是为了显示-->
<field name="favorites_count" type="int"
indexed="true" stored="true"/>
<!--该字段使用自定义的类型进行分析-->
<field name="text"
type="text_microblog" indexed="true"
stored="true"/>
</fields>
</schema> |
4,设置唯一键字段,唯一键字段应使用字符串类型或其他基本字段类型。
<uniqueKey>id</uniqueKey>
五,结构化非文本字段类型
示例中除了文本外,其他字段都是Solr常用的字段类型,下面对这些常用的字段类型进行讲解。
Solr最常用的字段类型的类图:
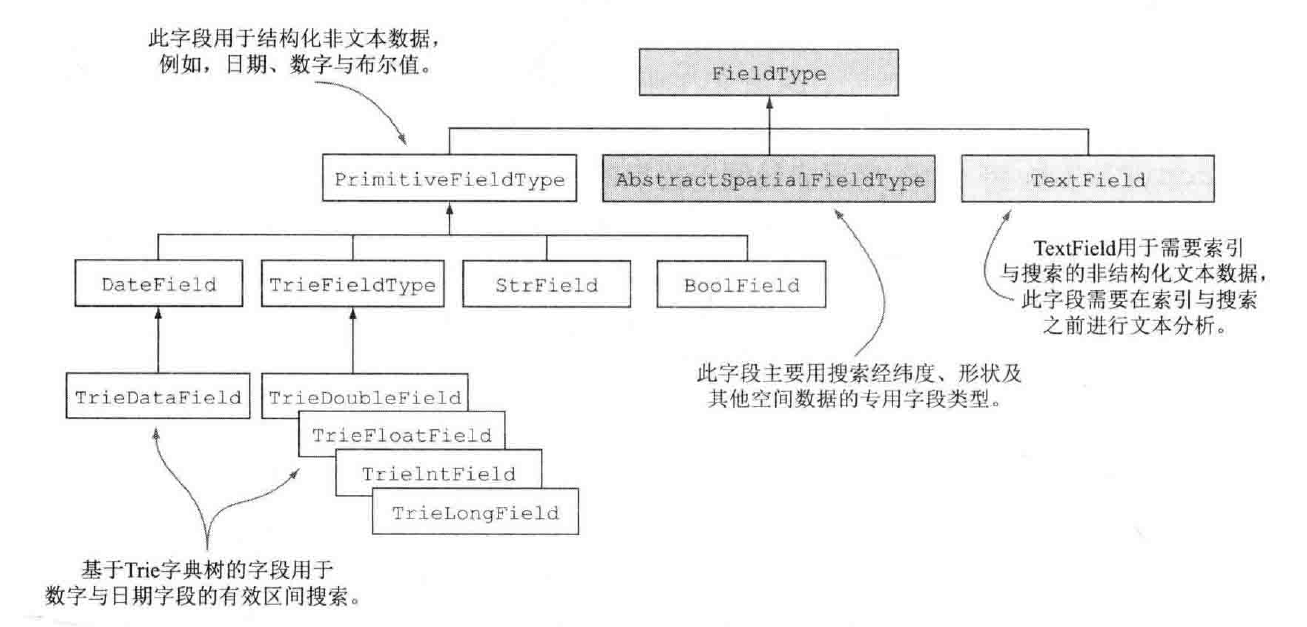
1,字符串字段
Solr对于一些不需要变更的值提供了string字段类型。string字段类型在schema.xml中的定义:
| <fieldType
name="string" class="solr.StrField"
sortMissingLast="true" docValues="true"
/> |
它使用了solr.StrField类。如果把索引字段设置为字符串类型,Solr会把字段的取值存储在索引中,并作为不变的持久索引。查询时需要传递准确值才能匹配出结果。对于一些固定不变的值,如类型和账号一般都是设置了就不会变,可以使用字符串类型。跟Java中对String的定义类似,即如果字符不变,使用string
2,日期字段
Solr提供了一个优化的内置<fieldType>,tdate类型:
| <fieldType
name="tdate" class="solr.TrieDateField"
omitNorms="true" precisionStep="6"
positionIncrementGap="0"/> |
通常情况下,Solr默认采用ISO-8601日期/时间格式(YYYY-MM-DDTHH:MM:SSZ),如果向Solr提交其他日期格式,创建索引时会得到验证错误信息。
日期粒度
日期的粒度也是可以确认的。如果用户只希望按时天来查询,就不需要对日期索引精确到秒或毫秒,如果是按日期对文档排序,那么小时级别的粒度就不需要。举例,当索引时,日期按小时级别的粒度,应当在提交XML文档时设置,在value后加上/HOUE。
| <field name="timestamp">2019-01-22T15:22:00Z/HOUR</field> |
上面的示例等价于2019-01-22T15:00:00Z。Solr还支持NOW关键字,表示当前系统时间。通过数学运算可以对日期计算。如NOW/DAY表示当前日的午夜,NOW/DAY+1DAY表示明天的午夜。
3,数值字段
Solr的int字段类型定义如下:
| <fieldType
name="int" class="solr.TrieintField"
precisionStep="0" positionIncrementGap="0"/> |
由于默认不需要在int字段进行区间查询,所以设定precisionStep=“0”。
六,发送文档到Solr进行索引
使用bin/post脚本来发送文档到Solr
把上面的示例微博内容另存为一个xml文件,然后输入命令:
结果:
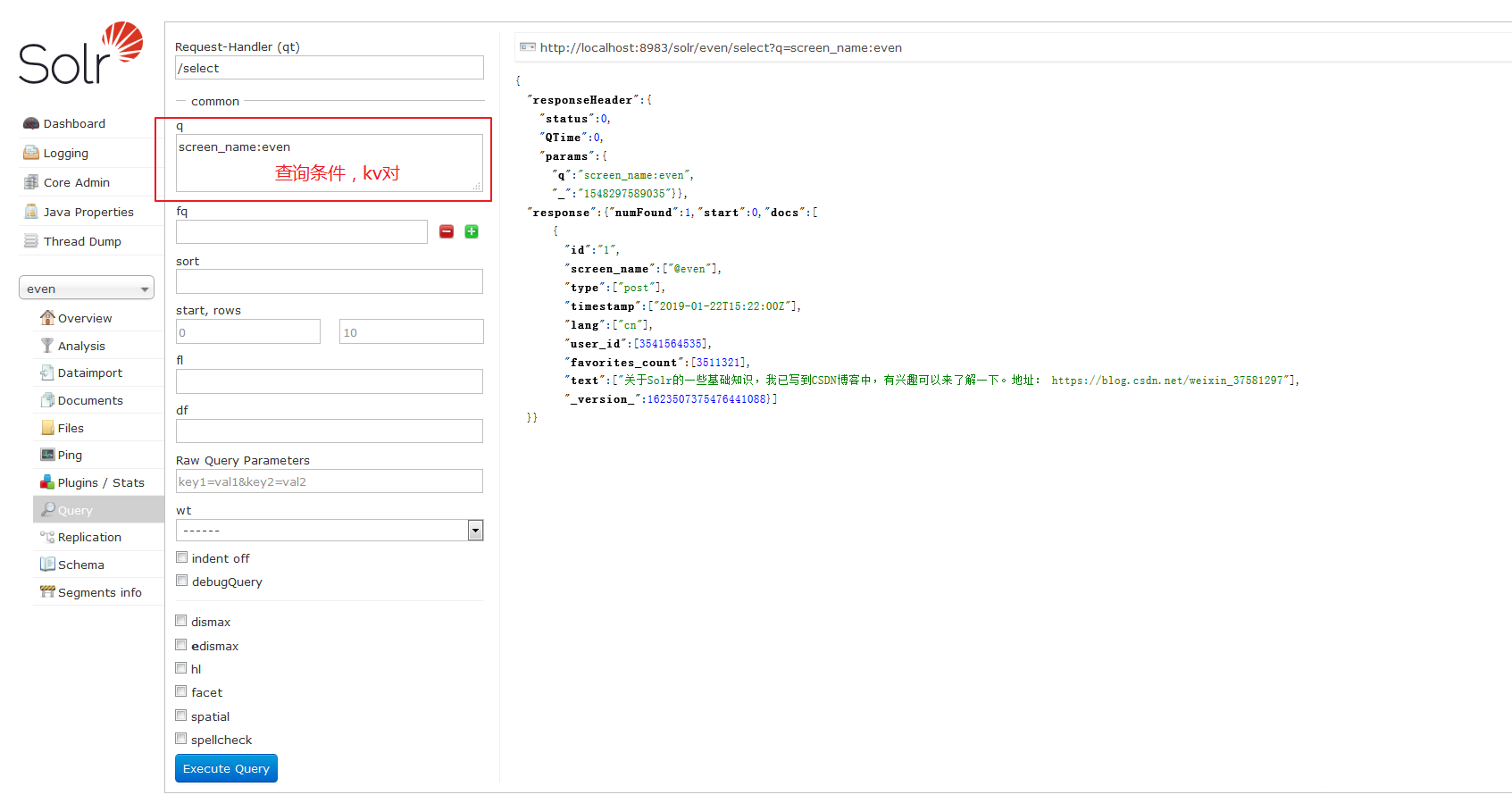
response是响应数据,numFound表示匹配的数量。
SolrJ客户端库
SolrJ是一个Solr项目提供的基于Java的客户端库,用于Java程序与Solr服务器进行通信。下面来看一下如何简单使用SolrJ。
1,建立一个maven项目,配置pom.xml
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>7.6.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/ org.apache.solr/solr-core
-->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-core</artifactId>
<version>7.6.0</version>
</dependency> |
2,连接Solr服务器:
String serverUrl
= "http://localhost:8983/solr";
String coreName = "even";//创建的内核名
HttpSolrClient solrClient = new HttpSolrClient.Builder(serverUrl).
withConnectionTimeout(10000) .withSocketTimeout(60000).build(); |
3,使用SolrInputDocument对象构造一个要被索引的文档
SolrInputDocument
doc = new SolrInputDocument();
doc.addField("id", "2");
doc.addField("screen_name", "elina");
doc.addField("type", "post");
doc.addField("timestamp", "2019-01-22T15:22:00Z/HOUR");
doc.addField("lang", "cn");
doc.addField("user_id", "32134");
doc.addField("favorites_count", "6513515321");
doc.addField("text", " "); |
4,通过HTTP发送SolrInputDocument到Solr更新请求处理器,并提交
try {
solrClient.add(coreName, doc);
solrClient.commit(coreName, true,true);//第一个是waitFlush,第二个是waitSearcher
} catch (SolrServerException | IOException e)
{
e.printStackTrace();
} |
5,创建SolrJ查询方法
public static
void queryIndex(SolrClient solrClient, Map<String,
String> queryParamMap, String coreName) throws
IOException, SolrServerException {
MapSolrParams solrParams = new MapSolrParams(queryParamMap);
QueryResponse response = solrClient.query(coreName,
solrParams);
SolrDocumentList results = response.getResults();
System.out.println("查询到" + results.getNumFound()
+ "个文档!");
for (SolrDocument document : results) {
String id = (String) document.getFirstValue("id");
String screen_name = (String) document.getFirstValue("screen_name");
System.out.println("id:" + id + ",name:"
+ screen_name);
}
} |
6,调用查询方法
Map<String,
String> queryParamMap = new HashMap<>();
queryParamMap.put("q", "*:*");//表示查询条件
queryParamMap.put("fl", "id,screen_name");//要显示的内容
queryParamMap.put("sort", "id asc");//排序方式
try {
queryIndex(solrClient, queryParamMap, coreName);
} catch (IOException e) {
e.printStackTrace();
} catch (SolrServerException e) {
e.printStackTrace();
} |
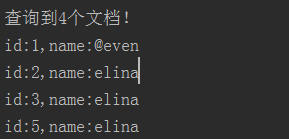
7,结果,都是我之前添加的文档:
SolrParams除了上面通过Map对象来生成的方法外,Solr还提供了另一个方便的方法:
SolrQuery solrParams
= new SolrQuery("*:*");
solrParams.addField("id");
solrParams.addField("screen_name");
solrParams.addSort("id", SolrQuery.ORDER.asc);
solrParams.setRows(10);//返回的数量 |
通过SolrInputDocument对象来添加文档的方式,需要调用多次addField方法,这样会影响代码美观,有时也难以理解。因此,Solr提供了Field注释,可以把Field注释对Java对象中的每个变量映射到相应的Solr字段。
Info.java:
public static
class Info {
@Field
public String id;
@Field
public String screen_name;
@Field
public String type;
@Field
public String timestamp;
@Field
public String lang;
@Field
public String user_id;
@Field
public int favorites_count;
@Field
public String text;
public Info(String id, String screen_name, String
type, String timestamp, String lang, String user_id,
int favorites_count, String text) {
this.id = id;
this.screen_name = screen_name;
this.type = type;
this.timestamp = timestamp;
this.lang = lang;
this.user_id = user_id;
this.favorites_count = favorites_count;
this.text = text;
}
} |
构造Info对象提交到solr:
Info info = new
Info("4", "lala", "post",
"2019-01-22T15:22:00Z/HOUR", "cn",
"16542314560", 154354,
"关于Solr的一些基础知识,我已写到CSDN博客中,有兴趣可以来了解一下。地址:
https://blog.csdn.net/weixin_37581297");
solrClient.addBean(coreName, info);
solrClient.commit(coreName, true, true); |
同样,查询时也可以使用此对象:
SolrQuery solrParams
= new SolrQuery("*:*");
solrParams.addField("id");
solrParams.addField("screen_name");
solrParams.addSort("id", SolrQuery.ORDER.asc);
solrParams.setRows(10);//返回的数量
QueryResponse response = solrClient.query(coreName,
solrParams);
List<Info> beans = response.getBeans(Info.class); |
总结
本文首先对Solr进行了简单的介绍和安装,然后针对Solr的配置及目录结构进行了详细说明。最后通过一个简单的示例来介绍了如何使用Solr。
示例中,我们介绍了Solr的创建索引和查询索引的两种方法,一种是使用post集合上传xml文件(相对应的查询没有这个命令。),另一种是使用SolrJ客户端来创建和查询文档。其中SolrJ客户端方式也分了简单方式和注释方法。
另外还介绍了通过schema.xml方式来指定各字段的类型,较新版本的是使用managed-schema文件。也介绍了schema.xml和managed-schema两种方式的切换。
对Solr的常用类型也进行了一些概述,详细说明请参看官方文档。
参考文献
Apache Solr参考指南 | 







