| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫSpring
BatchМмЙЙЁЂSpring BatchКЫаФИХЁЂХњДІРэВйзїжИФЯЁЂШчКЮФЌШЯВЛЦєЖЏjobЕШЯрЙиФкШнЁЃ
БОЮФРДздгкМмЙЙЪІЩчЧјЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
spring batchМђНщ
spring batchЪЧspringЬсЙЉЕФвЛИіЪ§ОнДІРэПђМмЁЃЦѓвЕгђжаЕФаэЖргІгУГЬађашвЊХњСПДІРэВХФмдкЙиМќШЮЮёЛЗОГжажДаавЕЮёВйзїЁЃетаЉвЕЮёдЫгЊАќРЈЃК
ЮоашгУЛЇНЛЛЅМДПЩзюгааЇЕиДІРэДѓСПаХЯЂЕФздЖЏЛЏЃЌИДдгДІРэЁЃетаЉВйзїЭЈГЃАќРЈЛљгкЪБМфЕФЪТМўЃЈР§ШчдТФЉМЦЫуЃЌЭЈжЊЛђЭЈаХЃЉЁЃ
дкЗЧГЃДѓЕФЪ§ОнМЏжажиИДДІРэИДдгвЕЮёЙцдђЕФЖЈЦкгІгУЃЈР§ШчЃЌБЃЯеРћвцШЗЖЈЛђЗбТЪЕїећЃЉЁЃ
МЏГЩДгФкВПКЭЭтВПЯЕЭГНгЪеЕФаХЯЂЃЌетаЉаХЯЂЭЈГЃашвЊвдЪТЮёЗНЪНИёЪНЛЏЃЌбщжЄКЭДІРэЕНМЧТМЯЕЭГжаЁЃХњДІРэгУгкУПЬьЮЊЦѓвЕДІРэЪ§ЪЎвкЕФНЛвзЁЃ
Spring BatchЪЧвЛИіЧсСПМЖЃЌШЋУцЕФХњДІРэПђМмЃЌжМдкПЊЗЂЖдЦѓвЕЯЕЭГШеГЃдЫгЊжСЙиживЊЕФЧПДѓХњДІРэгІгУГЬађЁЃSpring
BatchЙЙНЈСЫШЫУЧЦкЭћЕФSpring FrameworkЬиадЃЈЩњВњСІЃЌЛљгкPOJOЕФПЊЗЂЗНЗЈКЭвЛАувзгУадЃЉЃЌЭЌЪБЪЙПЊЗЂШЫдБПЩвддкБивЊЪБЧсЫЩЗУЮЪКЭРћгУИќИпМЖЕФЦѓвЕЗўЮёЁЃSpring
BatchВЛЪЧвЛИіschuedlingЕФПђМмЁЃ
Spring BatchЬсЙЉСЫПЩжигУЕФЙІФмЃЌетаЉЙІФмЖдгкДІРэДѓСПЕФЪ§ОнжСЙиживЊЃЌАќРЈМЧТМ/ИњзйЃЌЪТЮёЙмРэЃЌзївЕДІРэЭГМЦЃЌзївЕжиЦєЃЌЬјЙ§КЭзЪдДЙмРэЁЃЫќЛЙЬсЙЉИќИпМЖЕФММЪѕЗўЮёКЭЙІФмЃЌЭЈЙ§гХЛЏКЭЗжЧјММЪѕЪЕЯжМЋИпШнСПКЭИпадФмЕФХњДІРэзївЕЁЃ
Spring BatchПЩгУгкСНжжМђЕЅЕФгУР§ЃЈР§ШчНЋЮФМўЖСШыЪ§ОнПтЛђдЫааДцДЂЙ§ГЬЃЉвдМАИДдгЕФДѓСПгУР§ЃЈР§ШчдкЪ§ОнПтжЎМфвЦЖЏДѓСПЪ§ОнЃЌзЊЛЛЫќЕШЕШЃЉ
ЩЯЃЉЁЃДѓХњСПХњДІРэзївЕПЩвдИпЖШПЩРЉеЙЕФЗНЪНРћгУИУПђМмРДДІРэДѓСПаХЯЂЁЃ
Spring BatchМмЙЙНщЩм
вЛИіЕфаЭЕФХњДІРэгІгУГЬађДѓжТШчЯТЃК
ДгЪ§ОнПтЃЌЮФМўЛђЖгСажаЖСШЁДѓСПМЧТМЁЃ
вдФГжжЗНЪНДІРэЪ§ОнЁЃ
вдаоИФжЎКѓЕФаЮЪНаДЛиЪ§ОнЁЃ
ЦфЖдгІЕФЪОвтЭМШчЯТЃК

spring batchЕФвЛИізмЬхЕФМмЙЙШчЯТЃК
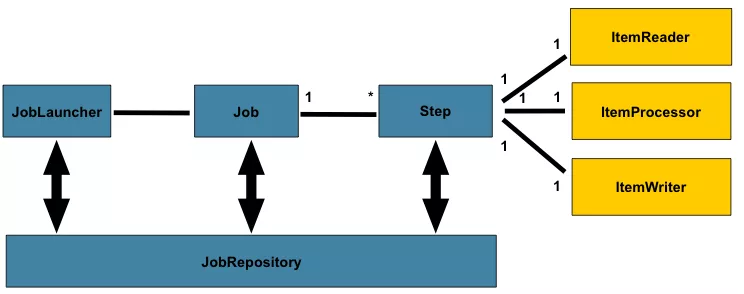
дкspring batchжавЛИіjobПЩвдЖЈвхКмЖрЕФВНжшstepЃЌдкУПвЛИіstepРяУцПЩвдЖЈвхЦфзЈЪєЕФItemReaderгУгкЖСШЁЪ§ОнЃЌItemProcesseorгУгкДІРэЪ§ОнЃЌItemWriterгУгкаДЪ§ОнЃЌЖјУПвЛИіЖЈвхЕФjobдђЖМдкJobRepositoryРяУцЃЌЮвУЧПЩвдЭЈЙ§JobLauncherРДЦєЖЏФГвЛИіjobЁЃ
Spring BatchКЫаФИХФюНщЩм
ЯТУцЪЧвЛаЉИХФюЪЧSpring batchПђМмжаЕФКЫаФИХФюЁЃ
ЪВУДЪЧJob
JobКЭStepЪЧspring batchжДааХњДІРэШЮЮёзюЮЊКЫаФЕФСНИіИХФюЁЃ
ЦфжаJobЪЧвЛИіЗтзАећИіХњДІРэЙ§ГЬЕФвЛИіИХФюЁЃJobдкspring batchЕФЬхЯЕЕБжажЛЪЧвЛИізюЖЅВуЕФвЛИіГщЯѓИХФюЃЌЬхЯждкДњТыЕБжадђЫќжЛЪЧвЛИізюЩЯВуЕФНгПкЃЌЦфДњТыШчЯТ:
/**
* Batch domain object representing a job. Job is
an explicit abstraction
* representing the configuration of a job specified
by a developer. It should
* be noted that restart policy is applied to the
job as a whole and not to a
* step.
*/
public interface Job {
String getName();
boolean isRestartable();
void execute(JobExecution execution);
JobParametersIncrementer getJobParametersIncrementer();
JobParametersValidator getJobParametersValidator();
} |
дкJobетИіНгПкЕБжаЖЈвхСЫЮхИіЗНЗЈЃЌЫќЕФЪЕЯжРржївЊгаСНжжРраЭЕФjobЃЌвЛИіЪЧsimplejobЃЌСэвЛИіЪЧflowjobЁЃдкspring
batchЕБжаЃЌjobЪЧзюЖЅВуЕФГщЯѓЃЌГ§jobжЎЭтЮвУЧЛЙгаJobInstanceвдМАJobExecutionетСНИіИќМгЕзВуЕФГщЯѓЁЃ
вЛИіjobЪЧЮвУЧдЫааЕФЛљБОЕЅЮЛЃЌЫќФкВПгЩstepзщГЩЁЃjobБОжЪЩЯПЩвдПДГЩstepЕФвЛИіШнЦїЁЃвЛИіjobПЩвдАДеежИЖЈЕФТпМЫГађзщКЯstepЃЌВЂЬсЙЉСЫЮвУЧИјЫљгаstepЩшжУЯрЭЌЪєадЕФЗНЗЈЃЌР§ШчвЛаЉЪТМўМрЬ§ЃЌЬјЙ§ВпТдЁЃ
Spring BatchвдSimpleJobРрЕФаЮЪНЬсЙЉСЫJobНгПкЕФФЌШЯМђЕЅЪЕЯжЃЌЫќдкJobжЎЩЯДДНЈСЫвЛаЉБъзМЙІФмЁЃвЛИіЪЙгУjava
configЕФР§згДњТыШчЯТЃК
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.end()
.build();
} |
етИіХфжУЕФвтЫМЪЧЃКЪзЯШИјетИіjobЦ№СЫвЛИіУћзжНаfootballJobЃЌНгзХжИЖЈСЫетИіjobЕФШ§ИіstepЃЌЫћУЧЗжБ№гЩЗНЗЈЃЌplayerLoad,gameLoad, playerSummarizationЪЕЯжЁЃ
ЪВУДЪЧJobInstance
ЮвУЧдкЩЯЮФвбОЬсЕНСЫJobInstanceЃЌЫћЪЧJobЕФИќМгЕзВуЕФвЛИіГщЯѓЃЌЫћЕФЖЈвхШчЯТЃК
public interface JobInstance {
/**
* Get unique id for this JobInstance.
* @return instance id
*/
public long getInstanceId();
/**
* Get job name.
* @return value of 'id' attribute from <job>
*/
public String getJobName();
} |
ЫћЕФЗНЗЈКмМђЕЅЃЌвЛИіЪЧЗЕЛиJobЕФidЃЌСэвЛИіЪЧЗЕЛиJobЕФУћзжЁЃ
JobInstanceжИЕФЪЧjobдЫааЕБжаЃЌзївЕжДааЙ§ГЬЕБжаЕФИХФюЁЃInstanceБООЭЪЧЪЕР§ЕФвтЫМЁЃ
БШШчЫЕЯждкгавЛИіХњДІРэЕФjobЃЌЫќЕФЙІФмЪЧдквЛЬьНсЪјЪБжДаааавЛДЮЁЃЮвУЧМйЖЈетИіХњДІРэjobЕФУћзжЮЊ'EndOfDay'ЁЃдкетИіЧщПіЯТЃЌФЧУДУПЬьОЭЛсгавЛИіТпМвтвхЩЯЕФJobInstance,
ЖјЮвУЧБиаыМЧТМjobЕФУПДЮдЫааЕФЧщПіЁЃ
ЪВУДЪЧJobParameters
дкЩЯЮФЕБжаЮвУЧЬсЕНСЫЃЌЭЌвЛИіjobУПЬьдЫаавЛДЮЕФЛАЃЌФЧУДУПЬьЖМгавЛИіjobIntsanceЃЌЕЋЫћУЧЕФjobЖЈвхЖМЪЧвЛбљЕФЃЌФЧУДЮвУЧдѕУДРДЧјБ№вЛИіjobЕФВЛЭЌjobinstanceСЫЁЃВЛЗСЯШзіИіВТЯыЃЌЫфШЛjobinstanceЕФjobЖЈвхвЛбљЃЌЕЋЪЧЫћУЧгаЕФЖЋЮїОЭВЛвЛбљЃЌР§ШчдЫааЪБМфЁЃ
spring batchжаЬсЙЉЕФгУРДБъЪЖвЛИіjobinstanceЕФЖЋЮїЪЧЃКJobParametersЁЃJobParametersЖдЯѓАќКЌвЛзщгУгкЦєЖЏХњДІРэзївЕЕФВЮЪ§ЃЌЫќПЩвддкдЫааЦкМфгУгкЪЖБ№ЛђЩѕжСгУзїВЮПМЪ§ОнЁЃЮвУЧМйЩшЕФдЫааЪБМфЃЌОЭПЩвдзїЮЊвЛИіJobParametersЁЃ
Р§Шч, ЮвУЧЧАУцЕФ'EndOfDay'ЕФjobЯждквбОгаСЫСНИіЪЕР§ЃЌвЛИіВњЩњгк1дТ1ШеЃЌСэвЛИіВњЩњгк1дТ2ШеЃЌФЧУДЮвУЧОЭПЩвдЖЈвхСНИіJobParameterЖдЯѓЃКвЛИіЕФВЮЪ§ЪЧ01-01,
СэвЛИіЕФВЮЪ§ЪЧ01-02ЁЃвђДЫЃЌЪЖБ№вЛИіJobInstanceЕФЗНЗЈПЩвдЖЈвхЮЊЃК

вђДЫЃЌЮвУДПЩвдЭЈЙ§JobparameterРДВйзїе§ШЗЕФJobInstance
ЪВУДЪЧJobExecution
JobExecutionжИЕФЪЧЕЅДЮГЂЪддЫаавЛИіЮвУЧЖЈвхКУЕФJobЕФДњТыВуУцЕФИХФюЁЃjobЕФвЛДЮжДааПЩФмвдЪЇАмвВПЩФмГЩЙІЁЃжЛгаЕБжДааГЩЙІЭъГЩЪБЃЌИјЖЈЕФгыжДааЯрЖдгІЕФJobInstanceВХвВБЛЪгЮЊЭъГЩЁЃ
ЛЙЪЧвдЧАУцУшЪіЕФEndOfDayЕФjobзїЮЊЪОР§ЃЌМйЩшЕквЛДЮдЫаа01-01-2019ЕФJobInstanceНсЙћЪЧЪЇАмЁЃФЧУДДЫЪБШчЙћЪЙгУгыЕквЛДЮдЫааЯрЭЌЕФJobparameterВЮЪ§ЃЈМД01-01-2019ЃЉзївЕВЮЪ§дйДЮдЫааЃЌФЧУДОЭЛсДДНЈвЛИіЖдгІгкжЎЧАjobInstanceЕФвЛИіаТЕФJobExecutionЪЕР§,JobInstanceШдШЛжЛгавЛИіЁЃ
JobExecutionЕФНгПкЖЈвхШчЯТЃК
public interface JobExecution {
/**
* Get unique id for this JobExecution.
* @return execution id
*/
public long getExecutionId();
/**
* Get job name.
* @return value of 'id' attribute from <job>
*/
public String getJobName();
/**
* Get batch status of this execution.
* @return batch status value.
*/
public BatchStatus getBatchStatus();
/**
* Get time execution entered STARTED status.
* @return date (time)
*/
public Date getStartTime();
/**
* Get time execution entered end status: COMPLETED,
STOPPED, FAILED
* @return date (time)
*/
public Date getEndTime();
/**
* Get execution exit status.
* @return exit status.
*/
public String getExitStatus();
/**
* Get time execution was created.
* @return date (time)
*/
public Date getCreateTime();
/**
* Get time execution was last updated updated.
* @return date (time)
*/
public Date getLastUpdatedTime();
/**
* Get job parameters for this execution.
* @return job parameters
*/
public Properties getJobParameters();
} |
УПвЛИіЗНЗЈЕФзЂЪЭвбОНтЪЭЕФКмЧхГўЃЌетРяВЛдйЖрзіНтЪЭЁЃжЛЬсвЛЯТBatchStatusЃЌJobExecutionЕБжаЬсЙЉСЫвЛИіЗНЗЈgetBatchStatusгУгкЛёШЁвЛИіjobФГвЛДЮЬиЕижДааЕФвЛИізДЬЌЁЃBatchStatusЪЧвЛИіДњБэjobзДЬЌЕФУЖОйРрЃЌЦфЖЈвхШчЯТЃК
public enum BatchStatus {STARTING, STARTED,
STOPPING,
STOPPED, FAILED, COMPLETED, ABANDONED } |
етаЉЪєадЖдгквЛИіjobЕФжДааРДЫЕЪЧЗЧГЃЙиМќЕФаХЯЂЃЌВЂЧвspring batchЛсНЋЫћУЧГжОУЕНЪ§ОнПтЕБжа.
дкЪЙгУSpring batchЕФЙ§ГЬЕБжаspring batchЛсздЖЏДДНЈвЛаЉБэгУгкДцДЂвЛаЉjobЯрЙиЕФаХЯЂЃЌгУгкДцДЂJobExecutionЕФБэЮЊbatch_job_execution,ЯТУцЪЧвЛИіДгЪ§ОнПтЕБжаНиЭМЕФЪЕР§ЃК

ЪВУДЪЧStep
УПвЛИіStepЖдЯѓЖМЗтзАСЫХњДІРэзївЕЕФвЛИіЖРСЂЕФНзЖЮЁЃЪТЪЕЩЯЃЌУПвЛИіJobБОжЪЩЯЖМЪЧгЩвЛИіЛђЖрИіВНжшзщГЩЁЃУПвЛИіstepАќКЌЖЈвхКЭПижЦЪЕМЪХњДІРэЫљашЕФЫљгааХЯЂЁЃШЮКЮЬиЖЈЕФФкШнЖМгЩБраДJobЕФПЊЗЂШЫдБздааОіЖЈЁЃ
вЛИіstepПЩвдЗЧГЃМђЕЅвВПЩвдЗЧГЃИДдгЁЃР§ШчЃЌвЛИіstepЕФЙІФмЪЧНЋЮФМўжаЕФЪ§ОнМгдиЕНЪ§ОнПтжаЃЌФЧУДЛљгкЯждкspring
batchЕФжЇГждђМИКѕВЛашвЊаДДњТыЁЃИќИДдгЕФstepПЩФмОпгаИДдгЕФвЕЮёТпМЃЌетаЉТпМзїЮЊДІРэЕФвЛВПЗжЁЃ
гыJobвЛбљЃЌStepОпгагыJobExecutionРрЫЦЕФStepExecutionЃЌШчЯТЭМЫљЪОЃК

ЪВУДЪЧStepExecution
StepExecutionБэЪОвЛДЮжДааStep, УПДЮдЫаавЛИіStepЪБЖМЛсДДНЈвЛИіаТЕФStepExecutionЃЌРрЫЦгкJobExecutionЁЃЕЋЪЧЃЌФГИіВНжшПЩФмгЩгкЦфжЎЧАЕФВНжшЪЇАмЖјЮоЗЈжДааЁЃЧвНіЕБStepЪЕМЪЦєЖЏЪБВХЛсДДНЈStepExecutionЁЃ
вЛДЮstepжДааЕФЪЕР§гЩStepExecutionРрЕФЖдЯѓБэЪОЁЃУПИіStepExecutionЖМАќКЌЖдЦфЯргІВНжшЕФв§гУвдМАJobExecutionКЭЪТЮёЯрЙиЕФЪ§ОнЃЌР§ШчЬсНЛКЭЛиЙіМЦЪ§вдМАПЊЪМКЭНсЪјЪБМфЁЃ
ДЫЭтЃЌУПИіВНжшжДааЖМАќКЌвЛИіExecutionContextЃЌЦфжаАќКЌПЊЗЂШЫдБашвЊдкХњДІРэдЫаажаБЃСєЕФШЮКЮЪ§ОнЃЌР§ШчжиаТЦєЖЏЫљашЕФЭГМЦаХЯЂЛђзДЬЌаХЯЂЁЃЯТУцЪЧвЛИіДгЪ§ОнПтЕБжаНиЭМЕФЪЕР§ЃК

ЪВУДЪЧExecutionContext
ExecutionContextМДУПвЛИіStepExecution
ЕФжДааЛЗОГЁЃЫќАќКЌвЛЯЕСаЕФМќжЕЖдЁЃЮвУЧПЩвдгУШчЯТДњТыЛёШЁExecutionContext
ExecutionContext ecStep = stepExecution.getExecutionContext();
ExecutionContext ecJob = jobExecution.getExecutionContext(); |
ЪВУДЪЧJobRepository
JobRepositoryЪЧвЛИігУгкНЋЩЯЪіjobЃЌstepЕШИХФюНјааГжОУЛЏЕФвЛИіРрЁЃЫќЭЌЪБИјJobКЭStepвдМАЯТЮФЛсЬсЕНЕФJobLauncherЪЕЯжЬсЙЉCRUDВйзїЁЃ
ЪзДЮЦєЖЏJobЪБЃЌНЋДгrepositoryжаЛёШЁJobExecutionЃЌВЂЧвдкжДааХњДІРэЕФЙ§ГЬжаЃЌStepExecutionКЭJobExecutionНЋБЛДцДЂЕНrepositoryЕБжаЁЃ
@EnableBatchProcessingзЂНтПЩвдЮЊJobRepositoryЬсЙЉздЖЏХфжУЁЃ
ЪВУДЪЧJobLauncher
JobLauncherетИіНгПкЕФЙІФмЗЧГЃМђЕЅЃЌЫќЪЧгУгкЦєЖЏжИЖЈСЫJobParametersЕФJobЃЌЮЊЪВУДетРявЊЧПЕїжИЖЈСЫJobParameterЃЌдвђЦфЪЕЮвУЧдкЧАУцвбОЬсЕНСЫЃЌjobparameterКЭjobвЛЦ№ВХФмзщГЩвЛДЮjobЕФжДааЁЃЯТУцЪЧДњТыЪЕР§ЃК
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException,
JobInstanceAlreadyCompleteException, JobParametersInvalidException;
} |
ЩЯУцrunЗНЗЈЪЕЯжЕФЙІФмЪЧИљОнДЋШыЕФjobвдМАjobparamatersДгJobRepositoryЛёШЁвЛИіJobExecutionВЂжДааJobЁЃ
ЪВУДЪЧItem Reader
ItemReaderЪЧвЛИіЖСЪ§ОнЕФГщЯѓЃЌЫќЕФЙІФмЪЧЮЊУПвЛИіStepЬсЙЉЪ§ОнЪфШыЁЃЕБItemReaderвдМАЖСЭъЫљгаЪ§ОнЪБЃЌЫќЛсЗЕЛиnullРДИцЫпКѓајВйзїЪ§ОнвбОЖСЭъЁЃSpring
BatchЮЊItemReaderЬсЙЉСЫЗЧГЃЖрЕФгагУЕФЪЕЯжРрЃЌБШШчJdbcPagingItemReaderЃЌJdbcCursorItemReaderЕШЕШЁЃ
ItemReaderжЇГжЕФЖСШыЕФЪ§ОндДвВЪЧЗЧГЃЗсИЛЕФЃЌАќРЈИїжжРраЭЕФЪ§ОнПтЃЌЮФМўЃЌЪ§ОнСїЃЌЕШЕШЁЃМИКѕКИЧСЫЮвУЧЕФЫљгаГЁОАЁЃ
ЯТУцЪЧвЛИіJdbcPagingItemReaderЕФР§згДњТыЃК
@Bean
public JdbcPagingItemReader itemReader(DataSource dataSource,
PagingQueryProvider queryProvider) {
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("status", "NEW");
return new JdbcPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.dataSource(dataSource)
.queryProvider(queryProvider)
.parameterValues(parameterValues)
.rowMapper(customerCreditMapper())
.pageSize(1000)
.build();
}
@Bean
public SqlPagingQueryProviderFactoryBean queryProvider()
{
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setSelectClause("select id, name, credit");
provider.setFromClause("from customer");
provider.setWhereClause("where status=:status");
provider.setSortKey("id");
return provider;
} |
JdbcPagingItemReaderБиаыжИЖЈвЛИіPagingQueryProviderЃЌИКд№ЬсЙЉSQLВщбЏгяОфРДАДЗжвГЗЕЛиЪ§ОнЁЃ
ЯТУцЪЧвЛИіJdbcCursorItemReaderЕФР§згДњТы:
private JdbcCursorItemReader<Map<String,
Object>> buildItemReader(final DataSource
dataSource, String tableName,
String tenant) {
JdbcCursorItemReader<Map<String, Object>>
itemReader = new JdbcCursorItemReader<>();
itemReader.setDataSource(dataSource);
itemReader.setSql("sql here");
itemReader.setRowMapper(new RowMapper());
return itemReader;
} |
ЪВУДЪЧItem Writer
МШШЛItemReaderЪЧЖСЪ§ОнЕФвЛИіГщЯѓЃЌФЧУДItemWriterздШЛОЭЪЧвЛИіаДЪ§ОнЕФГщЯѓЃЌЫќЪЧЮЊУПвЛИіstepЬсЙЉЪ§ОнаДГіЕФЙІФмЁЃаДЕФЕЅЮЛЪЧПЩвдХфжУЕФЃЌЮвУЧПЩвдвЛДЮаДвЛЬѕЪ§ОнЃЌвВПЩвдвЛДЮаДвЛИіchunkЕФЪ§ОнЃЌЙигкchunkЯТЮФЛсгазЈУХЕФНщЩмЁЃItemWriterЖдгкЖСШыЕФЪ§ОнЪЧВЛФмзіШЮКЮВйзїЕФЁЃ
Spring BatchЮЊItemWriterвВЬсЙЉСЫЗЧГЃЖрЕФгагУЕФЪЕЯжРрЃЌЕБШЛЮвУЧвВПЩвдШЅЪЕЯжздМКЕФwriterЙІФмЁЃ
ЪВУДЪЧItem Processor
ItemProcessorЖдЯюФПЕФвЕЮёТпМДІРэЕФвЛИіГщЯѓ, ЕБItemReaderЖСШЁЕНвЛЬѕМЧТМжЎКѓЃЌItemWriterЛЙЮДаДШыетЬѕМЧТМжЎЧАЃЌIЮвУЧПЩвдНшжњtemProcessorЬсЙЉвЛИіДІРэвЕЮёТпМЕФЙІФмЃЌВЂЖдЪ§ОнНјааЯргІВйзїЁЃШчЙћЮвУЧдкItemProcessorЗЂЯжвЛЬѕЪ§ОнВЛгІИУБЛаДШыЃЌПЩвдЭЈЙ§ЗЕЛиnullРДБэЪОЁЃItemProcessorКЭItemReaderвдМАItemWriterПЩвдЗЧГЃКУЕФНсКЯдквЛЦ№ЙЄзїЃЌЫћУЧжЎМфЕФЪ§ОнДЋЪфвВЗЧГЃЗНБуЁЃЮвУЧжБНгЪЙгУМДПЩЁЃ
chunk ДІРэСїГЬ
spring batchЬсЙЉСЫШУЮвУЧАДееchunkДІРэЪ§ОнЕФФмСІЃЌвЛИіchunkЕФЪОвтЭМШчЯТЃК

ЫќЕФвтЫМОЭКЭЭМЪОЕФвЛбљЃЌгЩгкЮвУЧвЛДЮbatchЕФШЮЮёПЩФмЛсгаКмЖрЕФЪ§ОнЖСаДВйзїЃЌвђДЫвЛЬѕвЛЬѕЕФДІРэВЂЯђЪ§ОнПтЬсНЛЕФЛАаЇТЪВЛЛсКмИпЃЌвђДЫspring
batchЬсЙЉСЫchunkетИіИХФюЃЌЮвУЧПЩвдЩшЖЈвЛИіchunk sizeЃЌspring batch
НЋвЛЬѕвЛЬѕДІРэЪ§ОнЃЌЕЋВЛЬсНЛЕНЪ§ОнПтЃЌжЛгаЕБДІРэЕФЪ§ОнЪ§СПДяЕНchunk sizeЩшЖЈЕФжЕЕУЪБКђЃЌВХвЛЦ№ШЅcommit.
javaЕФЪЕР§ЖЈвхДњТыШчЯТЃК

дкЩЯУцетИіstepРяУцЃЌchunk sizeБЛЩшЮЊСЫ10ЃЌЕБItemReaderЖСЕФЪ§ОнЪ§СПДяЕН10ЕФЪБКђЃЌетвЛХњДЮЕФЪ§ОнОЭвЛЦ№БЛДЋЕНitemWriterЃЌЭЌЪБtransactionБЛЬсНЛЁЃ
skipВпТдКЭЪЇАмДІРэ
вЛИіbatchЕФjobЕФstepЃЌПЩФмЛсДІРэЗЧГЃДѓЪ§СПЕФЪ§ОнЃЌФбУтЛсгіЕНГіДэЕФЧщПіЃЌГіДэЕФЧщПіЫфГіЯжЕФИХТЪНЯаЁЃЌЕЋЪЧЮвУЧВЛЕУВЛПМТЧетаЉЧщПіЃЌвђЮЊЮвУЧзіЪ§ОнЧЈвЦзюживЊЕФЪЧвЊБЃжЄЪ§ОнЕФзюжевЛжТадЁЃspring
batchЕБШЛвВПМТЧЕНСЫетжжЧщПіЃЌВЂЧвЮЊЮвУЧЬсЙЉСЫЯрЙиЕФММЪѕжЇГжЃЌЧыПДШчЯТbeanЕФХфжУЃК

ЮвУЧашвЊСєвтетШ§ИіЗНЗЈЃЌЗжБ№ЪЧskipLimit(),skip(),noSkip(),
skipLimitЗНЗЈЕФвтЫМЪЧЮвУЧПЩвдЩшЖЈвЛИіЮвУЧдЪаэЕФетИіstepПЩвдЬјЙ§ЕФвьГЃЪ§СПЃЌМйШчЮвУЧЩшЖЈЮЊ10ЃЌдђЕБетИіstepдЫааЪБЃЌжЛвЊГіЯжЕФвьГЃЪ§ФПВЛГЌЙ§10ЃЌећИіstepЖМВЛЛсfailЁЃзЂвтЃЌШєВЛЩшЖЈskipLimitЃЌдђЦфФЌШЯжЕЪЧ0.
skipЗНЗЈЮвУЧПЩвджИЖЈЮвУЧПЩвдЬјЙ§ЕФвьГЃЃЌвђЮЊгааЉвьГЃЕФГіЯжЃЌЮвУЧЪЧПЩвдКіТдЕФЁЃ
noSkipЗНЗЈЕФвтЫМдђЪЧжИГіЯжетИівьГЃЮвУЧВЛЯыЬјЙ§ЃЌвВОЭЪЧДгskipЕФЫљвдexceptionЕБжаХХГ§етИіexceptionЃЌДгЩЯУцЕФР§згРДЫЕЃЌвВОЭЪЧЬјЙ§ЫљгаГ§FileNotFoundExceptionЕФexceptionЁЃ
ФЧУДЖдгкетИіstepРДЫЕЃЌFileNotFoundExceptionОЭЪЧвЛИіfatalЕФexceptionЃЌХзГіетИіexceptionЕФЪБКђstepОЭЛсжБНгfail
ХњДІРэВйзїжИФЯ
БОВПЗжЪЧвЛаЉЪЙгУspring batchЪБЕФжЕЕУзЂвтЕФЕу
ХњДІРэддђ
дкЙЙНЈХњДІРэНтОіЗНАИЪБЃЌгІПМТЧвдЯТЙиМќддђКЭзЂвтЪТЯюЁЃ
ХњДІРэЬхЯЕНсЙЙЭЈГЃЛсгАЯьЬхЯЕНсЙЙ
ОЁПЩФмМђЛЏВЂБмУтдкЕЅХњгІгУГЬађжаЙЙНЈИДдгЕФТпМНсЙЙ
БЃГжЪ§ОнЕФДІРэКЭДцДЂдкЮяРэЩЯППЕУКмНќЃЈЛЛОфЛАЫЕЃЌНЋЪ§ОнБЃДцдкДІРэЙ§ГЬжаЃЉЁЃ
зюДѓЯоЖШЕиМѕЩйЯЕЭГзЪдДЕФЪЙгУЃЌгШЦфЪЧI / O. дкinternal memoryжажДааОЁПЩФмЖрЕФВйзїЁЃ
ВщПДгІгУГЬађI / OЃЈЗжЮіSQLгяОфЃЉвдШЗБЃБмУтВЛБивЊЕФЮяРэI / O. ЬиБ№ЪЧЃЌашвЊбАеввдЯТЫФИіГЃМћШБЯнЃК
- ЕБЪ§ОнПЩвдБЛЖСШЁвЛДЮВЂЛКДцЛђБЃДцдкЙЄзїДцДЂжаЪБЃЌЖСШЁУПИіЪТЮёЕФЪ§ОнЁЃ
- жиаТЖСШЁЯШЧАдкЭЌвЛЪТЮёжаЖСШЁЪ§ОнЕФЪТЮёЕФЪ§ОнЁЃ
- ЕМжТВЛБивЊЕФБэЛђЫїв§ЩЈУшЁЃ
- ЮДдкSQLгяОфЕФWHEREзгОфжажИЖЈМќжЕЁЃ
дкХњДІРэдЫаажаВЛвЊзіСНДЮвЛбљЕФЪТЧщЁЃР§ШчЃЌШчЙћашвЊЪ§ОнЛузмвдгУгкБЈИцФПЕФЃЌдђгІИУЃЈШчЙћПЩФмЃЉдкзюГѕДІРэЪ§ОнЪБЕндіДцДЂЕФзмМЦЃЌвђДЫФњЕФБЈИцгІгУГЬађВЛБижиаТДІРэЯрЭЌЕФЪ§ОнЁЃ
дкХњДІРэгІгУГЬађПЊЪМЪБЗжХфзуЙЛЕФФкДцЃЌвдБмУтдкДЫЙ§ГЬжаНјааКФЪБЕФжиаТЗжХфЁЃ
змЪЧМйЩшЪ§ОнЭъећадзюВюЁЃВхШыЪЪЕБЕФМьВщКЭМЧТМбщжЄвдЮЌЛЄЪ§ОнЭъећадЁЃ
ОЁПЩФмЪЕЪЉаЃбщКЭвдНјааФкВПбщжЄЁЃР§ШчЃЌЖдгквЛИіЮФМўРяЕФЪ§ОнгІИУгавЛИіЪ§ОнЬѕЪ§МЭТМЃЌИцЫпЮФМўжаЕФМЧТМзмЪ§вдМАЙиМќзжЖЮЕФЛузмЁЃ
дкОпгаецЪЕЪ§ОнСПЕФРрЫЦЩњВњЛЗОГжаОЁдчМЦЛЎКЭжДаабЙСІВтЪдЁЃ
дкДѓХњСПЯЕЭГжаЃЌЪ§ОнБИЗнПЩФмОпгаЬєеНадЃЌЬиБ№ЪЧШчЙћЯЕЭГвд24-7дкЯпЕФЧщПідЫааЁЃЪ§ОнПтБИЗнЭЈГЃдкдкЯпЩшМЦжаЕУЕНКмКУЕФДІРэЃЌЕЋЮФМўБИЗнгІИУБЛЪгЮЊЭЌбљживЊЁЃШчЙћЯЕЭГвРРЕгкЮФМўЃЌдђЮФМўБИЗнЙ§ГЬВЛНігІИУЕНЮЛВЂМЧТМдкАИЃЌЛЙгІЖЈЦкНјааВтЪдЁЃ
ШчКЮФЌШЯВЛЦєЖЏjob
дкЪЙгУjava configЪЙгУspring batchЕФjobЪБЃЌШчЙћВЛзіШЮКЮХфжУЃЌЯюФПдкЦєЖЏЪБОЭЛсФЌШЯШЅХмЮвУЧЖЈвхКУЕФХњДІРэjobЁЃФЧУДШчКЮШУЯюФПдкЦєЖЏЪБВЛздЖЏШЅХмjobФиЃП
spring batchЕФjobЛсдкЯюФПЦєЖЏЪБздЖЏrunЃЌШчЙћЮвУЧВЛЯыШУЫћдкЦєЖЏЪБrunЕФЛАЃЌПЩвддкapplication.propertiesжаЬэМгШчЯТЪєадЃК
| spring.batch.job.enabled=false |
дкЖСЪ§ОнЪБФкДцВЛЙЛ
дкЪЙгУspring batchзіЪ§ОнЧЈвЦЪБЃЌЗЂЯждкjobЦєЖЏКѓЃЌжДааЕНвЛЖЈЪБМфЕуЪБОЭПЈдквЛИіЕиЗНВЛЖЏСЫЃЌЧвlogвВВЛдйДђгЁЃЌЕШД§вЛЖЮЪБМфжЎКѓЃЌЕУЕНШчЯТДэЮѓЃК

КьзжЕФаХЯЂЮЊЃКResource exhaustion eventЃКthe JVM was unable
to allocate memory from the heap.
ЗвыЙ§РДЕФвтЫМОЭЪЧЯюФПЗЂГіСЫвЛИізЪдДКФОЁЕФЪТМўЃЌИцЫпЮвУЧjavaащФтЛњЮоЗЈдйЮЊЖбЗжХфФкДцЁЃ
дьГЩетИіДэЮѓЕФдвђЪЧ: етИіЯюФПРяЕФbatch jobЕФreaderЪЧвЛДЮадФУЛиСЫЪ§ОнПтРяЕФЫљгаЪ§ОнЃЌВЂУЛгаНјааЗжвГЃЌЕБетИіЪ§ОнСПЬЋДѓЪБЃЌОЭЛсЕМжТФкДцВЛЙЛгУЁЃНтОіЕФАьЗЈгаСНИі:
ЕїећreaderЖСЪ§ОнТпМЃЌАДЗжвГЖСШЁЃЌЕЋЪЕЯжЩЯЛсТщЗГвЛаЉЃЌЧвдЫаааЇТЪЛсЯТНЕ
діДѓserviceФкДц
| 




