| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫХњДІРэЕфаЭГЁОАЁЂХњДІРэЙиМќСьгђФЃаЭМАЙиМќМмЙЙЁЂЪЕЯжзївЕЕФНЁзГадгыРЉеЙадЁЂХњДІРэПђМмЕФВЛзугыдіЧПЕШЯрЙиФкШнЁЃ
БОЮФРДздгкМЋПЭЪБМфЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ШчНёЮЂЗўЮёМмЙЙЬжТлЕФШчЛ№ШчнБЁЃЕЋдкЦѓвЕМмЙЙРяГ§СЫДѓСПЕФOLTPНЛвзЭтЃЌЛЙДцдкКЃСПЕФХњДІРэНЛвзЁЃдкжюШчвјааЕФН№ШкЛњЙЙжаЃЌУПЬьга3-4ЭђБЪЕФХњДІРэзївЕашвЊДІРэЁЃеыЖдOLTPЃЌвЕНчгаДѓСПЕФПЊдДПђМмЁЂгХауЕФМмЙЙЩшМЦИјгшжЇГХЃЛЕЋХњДІРэСьгђЕФПђМмШЗЗяУЋїыНЧЁЃЪЧЪБКђКЭЮвУЧвЛЦ№РДСЫНтЯТХњДІРэЕФЪРНчФФаЉгХауЕФПђМмКЭЩшМЦСЫЃЌНёЬьЮвНЋвдSpring
BatchЮЊР§ЃЌКЭДѓМввЛЦ№ЬНУиХњДІРэЕФЪРНчЁЃ
ЁЄГѕЪЖХњДІРэЕфаЭГЁОА
ЁЄЬНУиСьгђФЃаЭМАЙиМќМмЙЙ
ЁЄЪЕЯжзївЕНЁзГадгыРЉеЙад
ЁЄХњДІРэПђМмЕФВЛзугыдіЧП
ХњДІРэЕфаЭвЕЮёГЁОА
ЖдеЫЪЧЕфаЭЕФХњДІРэвЕЮёДІРэГЁОАЃЌИїИіН№ШкЛњЙЙЕФЭљРДвЕЮёКЭПчжїЛњЯЕЭГЕФвЕЮёЖМЛсЩцМАЕНЖдеЫЕФЙ§ГЬЃЌШчДѓаЁЖюжЇИЖЁЂвјСЊНЛвзЁЂШЫааЭљРДЁЂЯжН№ЙмРэЁЂPOSвЕЮёЁЂATMвЕЮёЁЂжЄШЏЙЋЫОзЪН№еЫЛЇЁЂжЄШЏЙЋЫОгыжЄШЏНсЫуЙЋЫОЁЃ

ЯТУцЪЧФГааЭјвјЕФВПЗжШежеХмХњЪЕЧèОАашЧѓЁЃ

ЩцМАЕНЕФашЧѓЕуАќРЈЃК
1.ХњСПЕФУПИіЕЅдЊЖМашвЊДэЮѓДІРэКЭЛиЭЫЃЛ
2.УПИіЕЅдЊдкВЛЭЌЦНЬЈжадЫааЃЛ
3.ашвЊгаЗжжЇбЁдёЃЛ
4.УПИіЕЅдЊашвЊМрПиКЭЛёШЁЕЅдЊДІРэШежОЃЛ
5.ЬсЙЉЖржжДЅЗЂЙцдђЃЌАДШеЦкЃЌШеРњЃЌжмЦкДЅЗЂЃЛ
Г§ДЫжЎЭтЕфаЭЕФХњДІРэЪЪгУгкШчЯТЕФвЕЮёГЁОАЃК
1.ЖЈЦкЬсНЛХњДІРэШЮЮёЃЈШежеДІРэЃЉ
2.ВЂааХњДІРэЃКВЂааДІРэШЮЮё
3.ЦѓвЕЯћЯЂЧ§ЖЏДІРэ
4.ДѓЙцФЃЕФВЂааДІРэ
5.ЪжЖЏЛђЖЈЪБжиЦє
6.АДЫГађДІРэвРРЕЕФШЮЮё(ПЩРЉеЙЮЊЙЄзїСїЧ§ЖЏЕФХњДІРэ)
7.ВПЗжДІРэЃККіТдМЧТМ(Р§ШчдкЛиЙіЪБ)
8.ЭъећЕФХњДІРэЪТЮё
гыOLTPРраЭНЛвзВЛЭЌЃЌХњДІРэзївЕСНИіЕфаЭЬиеїЪЧХњСПжДаагыздЖЏжДааЃЈашвЊЮоШЫжЕЪиЃЉЃКЧАепФмЙЛДІРэДѓХњСПЪ§ОнЕФЕМШыЁЂЕМГіКЭвЕЮёТпММЦЫуЃЛКѓепЮоашШЫЙЄИЩдЄЃЌФмЙЛздЖЏЛЏжДааХњСПШЮЮёЁЃ

дкЙизЂЦфЛљБОЙІФмжЎЭтЃЌЛЙашвЊЙизЂШчЯТЕФМИЕуЃК
НЁзГадЃКВЛЛсвђЮЊЮоаЇЪ§ОнЛђДэЮѓЪ§ОнЕМжТГЬађБРРЃЃЛ
ПЩППадЃКЭЈЙ§ИњзйЁЂМрПиЁЂШежОМАЯрЙиЕФДІРэВпТдЃЈжиЪдЁЂЬјЙ§ЁЂжиЦєЃЉЪЕЯжХњзївЕЕФПЩППжДааЃЛ
РЉеЙадЃКЭЈЙ§ВЂЗЂЛђепВЂааММЪѕЪЕЯжгІгУЕФзнЯђКЭКсЯђРЉеЙЃЌТњзуКЃСПЪ§ОнДІРэЕФадФмашЧѓЃЛ
ПргквЕНчецЕФШБЩйБШНЯКУЕФХњДІРэПђМмЃЌSpring BatchЪЧвЕНчФПЧАЮЊЪ§ВЛЖрЕФгХауХњДІРэПђМмЃЈJavaгябдПЊЗЂЃЉЃЌSpringSourceКЭAccentureЃЈАЃЩемЃЉЙВЭЌЙБЯзСЫжЧЛлЁЃ

AccentureдкХњДІРэМмЙЙЩЯгазХЗсИЛЕФЙЄвЕМЖБ№ЕФОбщЃЌЙБЯзСЫжЎЧАзЈгУЕФХњДІРэЬхЯЕПђМмЃЈетаЉПђМмРњОЪ§ЪЎФъбаЗЂКЭЪЙгУЃЌЮЊSpring
BatchЬсЙЉСЫДѓСПЕФВЮПМОбщЃЉЁЃ
SpringSourceдђгазХЩюПЬЕФММЪѕШЯжЊКЭSpringПђМмБрГЬФЃаЭЃЌЭЌЪБНшМјСЫJCL(Job
Control Language)КЭCOBOLЕФгябдЬиадЁЃ2013ФъJSR-352НЋХњДІРэФЩШыЙцЗЖЬхЯЕЃЌВЂБЛАќКЌдкСЫJEE7жЎжаЁЃетвтЮЖзХЃЌЫљгаЕФJEE7гІгУЗўЮёЦїЖМЛсгаХњДІРэЕФФмСІЃЌФПЧАЕквЛИіЪЕЯжДЫЙцЗЖЕФгІгУЗўЮёЦїЪЧGlassfish
4ЁЃЕБШЛвВПЩвддкJava SEжаЪЙгУЁЃ

ЕЋзюЮЊЙиМќЕФвЛЕуЪЧЃКJSR-352ЙцЗЖДѓСПНшМјСЫSpring BatchПђМмЕФЩшМЦЫМТЗ,ДгЩЯЭМжаЕФКЫаФФЃаЭКЭИХФюжаПЩвдПДГіОПОЙЃЌКЫаФЕФИХФюФЃаЭЭъШЋвЛжТЁЃЭъећЕФJSR-252ЙцЗЖПЩвдДгhttps://jcp.org/aboutJava/communityprocess/final/jsr352/index.htmlЯТдиЁЃ
ЭЈЙ§Spring BatchПђМмПЩвдЙЙНЈГіЧсСПМЖЕФНЁзГЕФВЂааДІРэгІгУ,жЇГжЪТЮёЁЂВЂЗЂЁЂСїГЬЁЂМрПиЁЂзнЯђКЭКсЯђРЉеЙ,ЬсЙЉЭГвЛЕФНгПкЙмРэКЭШЮЮёЙмРэЁЃ

ПђМмЬсЙЉСЫжюШчвдЯТЕФКЫаФФмСІЃЌШУДѓМвИќЙизЂдквЕЮёДІРэЩЯЁЃИќЪЧЬсЙЉСЫШчЯТЕФЗсИЛФмСІЃК
1.УїШЗЗжРыХњДІРэЕФжДааЛЗОГКЭгІгУ
2.НЋЭЈгУКЫаФЕФЗўЮёвдНгПкаЮЪНЬсЙЉ
3.ЬсЙЉЁАПЊЯфМДгУЁБ ЕФМђЕЅЕФФЌШЯЕФКЫаФжДааНгПк
4.ЬсЙЉSpringПђМмжаХфжУЁЂздЖЈвхЁЂКЭРЉеЙЗўЮё
5.ЫљгаФЌШЯЪЕЯжЕФКЫаФЗўЮёФмЙЛШнвзЕФБЛРЉеЙгыЬцЛЛЃЌВЛЛсгАЯьЛљДЁВу
6.ЬсЙЉвЛИіМђЕЅЕФВПЪ№ФЃЪНЃЌЪЙгУMavenНјааБрвы
ХњДІРэЙиМќСьгђФЃаЭМАЙиМќМмЙЙ
ЯШРДИіHello WorldЪОР§ЃЌвЛИіЕфаЭЕФХњДІРэзївЕЁЃ

ЕфаЭЕФвЛИізївЕЗжЮЊ3ВПЗжЃКзївЕЖСЁЂзївЕДІРэЁЂзївЕаДЃЌвВЪЧЕфаЭЕФШ§ВНЪНМмЙЙЁЃећИіХњДІРэПђМмЛљБОЩЯЮЇШЦReadЁЂProcessЁЂWriterРДДІРэЁЃГ§ДЫжЎЭтЃЌПђМмЬсЙЉСЫзївЕЕїЖШЦїЁЂзївЕВжПтЃЈгУвдДцЗХJobЕФдЊЪ§ОнаХЯЂЃЌжЇГжФкДцЁЂDBСНжжФЃЪНЃЉЁЃ
ЭъећЕФСьгђИХФюФЃаЭВЮМгЯТЭМЃК

Job LauncherЃЈзївЕЕїЖШЦїЃЉЪЧSpring BatchПђМмЛљДЁЩшЪЉВуЬсЙЉЕФдЫааJobЕФФмСІЁЃЭЈЙ§ИјЖЈЕФJobУћГЦКЭзїJob
ParametersЃЌПЩвдЭЈЙ§Job LauncherжДааJobЁЃ
ЭЈЙ§Job LauncherПЩвддкJavaГЬађжаЕїгУХњДІРэШЮЮёЃЌвВПЩвддкЭЈЙ§УќСюааЛђепЦфЫќПђМмЃЈШчЖЈЪБЕїЖШПђМмQuartzЃЉжаЕїгУХњДІРэШЮЮёЁЃ
Job RepositoryРДДцДЂJobжДааЦкЕФдЊЪ§ОнЃЈетРяЕФдЊЪ§ОнЪЧжИJob InstanceЁЂJob
ExecutionЁЂJob ParametersЁЂStep ExecutionЁЂExecution
ContextЕШЪ§ОнЃЉЃЌВЂЬсЙЉСНжжФЌШЯЪЕЯжЁЃ
вЛжжЪЧДцЗХдкФкДцжаЃЛСэвЛжжНЋдЊЪ§ОнДцЗХдкЪ§ОнПтжаЁЃЭЈЙ§НЋдЊЪ§ОнДцЗХдкЪ§ОнПтжаЃЌПЩвдЫцЪБМрПиХњДІРэJobЕФжДаазДЬЌЁЃJobжДааНсЙћЪЧГЩЙІЛЙЪЧЪЇАмЃЌВЂЧвЪЙЕУдкJobЪЇАмЕФЧщПіЯТжиаТЦєЖЏJobГЩЮЊПЩФмЁЃStepБэЪОзївЕжаЕФвЛИіЭъећВНжшЃЌвЛИіJobПЩвдгавЛИіЛђепЖрИіStepзщГЩЁЃ
ХњДІРэПђМмдЫааЦкЕФФЃаЭвВЗЧГЃМђЕЅЃК

Job InstanceЃЈзївЕЪЕР§ЃЉЪЧвЛИідЫааЦкЕФИХФюЃЌJobУПжДаавЛДЮЖМЛсЩцМАЕНвЛИіJob InstanceЁЃ
Job InstanceРДдДПЩФмгаСНжжЃКвЛжжЪЧИљОнЩшжУЕФJob ParametersДгJob RepositoryЃЈзївЕВжПтЃЉжаЛёШЁвЛИіЃЛШчЙћИљОнJob
ParametersДгJob RepositoryУЛгаЛёШЁJob InstanceЃЌдђаТДДНЈвЛИіаТЕФJob
InstanceЁЃ
Job ExecutionБэЪОJobжДааЕФОфБњЃЌвЛДЮJobЕФжДааПЩФмГЩЙІвВПЩФмЪЇАмЁЃжЛгаJobжДааГЩЙІКѓЃЌЖдгІЕФJob
InstanceВХЛсБЛЭъГЩЁЃвђДЫдкJobжДааЪЇАмЕФЧщПіЯТЃЌЛсгавЛИіJob InstanceЖдгІЖрИіJob
ExecutionЕФГЁОАЗЂЩњЁЃ
змНсЯТХњДІРэЕФЕфаЭИХФюФЃаЭЃЌЦфЩшМЦЗЧГЃОЋМђЕФЪЎИіИХФюЃЌЭъећжЇГХСЫећИіПђМмЁЃ

JobЬсЙЉЕФКЫаФФмСІАќРЈзївЕЕФГщЯѓгыМЬГаЃЌРрЫЦУцЯђЖдЯѓжаЕФИХФюЁЃЖдгкжДаавьГЃЕФзївЕЃЌЬсЙЉжиЦєЕФФмСІЁЃ

ПђМмдкJobВуУцЃЌЭЌбљЬсЙЉСЫзївЕБрХХЕФИХФюЃЌАќРЈЫГађЁЂЬѕМўЁЂВЂаазївЕБрХХЁЃ

дквЛИіJobжаХфжУЖрИіStepЁЃВЛЭЌЕФStepМфПЩвдЫГађжДааЃЌвВПЩвдАДееВЛЭЌЕФЬѕМўгабЁдёЕФжДааЃЈЬѕМўЭЈГЃЪЙгУStepЕФЭЫГізДЬЌОіЖЈЃЉЃЌЭЈЙ§nextдЊЫиЛђепdecisionдЊЫиРДЖЈвхЬјзЊЙцдђЃЛ
ЮЊСЫЬсИпЖрИіStepЕФжДаааЇТЪЃЌПђМмЬсЙЉСЫStepВЂаажДааЕФФмСІЃЈЪЙгУsplitНјааЩљУїЃЌЭЈГЃИУЧщПіЯТашвЊStepжЎМфУЛгаШЮКЮЕФвРРЕЙиЯЕЃЌЗёдђШнвзв§Ц№вЕЮёЩЯЕФДэЮѓЃЉЁЃStepАќКЌСЫвЛИіЪЕМЪдЫааЕФХњДІРэШЮЮёжаЕФЫљгаБиашЕФаХЯЂЃЌЦфЪЕЯжПЩвдЪЧЗЧГЃМђЕЅЕФвЕЮёЪЕЯжЃЌвВПЩвдЪЧЗЧГЃИДдгЕФвЕЮёДІРэЃЌStepЕФИДдгГЬЖШЭЈГЃЪЧвЕЮёОіЖЈЕФЁЃ

УПИіStepгЩItemReaderЁЂItemProcessorЁЂItemWriterзщГЩЃЌЕБШЛИљОнВЛЭЌЕФвЕЮёашЧѓЃЌItemProcessorПЩвдзіЪЪЕБЕФОЋМђЁЃЭЌЪБПђМмЬсЙЉСЫДѓСПЕФItemReaderЁЂItemWriterЕФЪЕЯжЃЌЬсЙЉСЫЖдFlatFileЁЂXMLЁЂJsonЁЂDataBaseЁЂMessageЕШЖржжЪ§ОнРраЭЕФжЇГжЁЃ
ПђМмЛЙЮЊStepЬсЙЉСЫжиЦєЁЂЪТЮёЁЂжиЦєДЮЪ§ЁЂВЂЗЂЪ§ЃЛвдМАЬсНЛМфИєЁЂвьГЃЬјЙ§ЁЂжиЪдЁЂЭъГЩВпТдЕШФмСІЁЃЛљгкStepЕФСщЛюХфжУЃЌПЩвдЭъГЩГЃМћЕФвЕЮёЙІФмашЧѓЁЃЦфжаШ§ВНзпЃЈReadЁЂProcessorЁЂWriterЃЉЪЧХњДІРэжаЕФОЕфГщЯѓЁЃ

зїЮЊУцЯђХњЕФДІРэЃЌдкStepВуЬсЙЉСЫЖрДЮЖСЁЂДІРэЃЌвЛДЮЬсНЛЕФФмСІЁЃ
дкChunkЕФВйзїжаЃЌПЩвдЭЈЙ§Ъєадcommit-intervalЩшжУreadЖрЩйЬѕМЧТМКѓНјаавЛДЮЬсНЛЁЃЭЈЙ§ЩшжУcommit-intervalЕФМфИєжЕЃЌМѕЩйЬсНЛЦЕДЮЃЌНЕЕЭзЪдДЪЙгУТЪЁЃStepЕФУПвЛДЮЬсНЛзїЮЊвЛИіЭъећЕФЪТЮёДцдкЁЃФЌШЯВЩгУSpringЬсЙЉЕФЩљУїЪНЪТЮёЙмРэФЃЪНЃЌЪТЮёБрХХЗЧГЃЗНБуЁЃШчЯТЪЧвЛИіЩљУїЪТЮёЕФЪОР§ЃК

ПђМмЖдгкЪТЮёЕФжЇГжФмСІАќРЈЃК
1.ChunkжЇГжЪТЮёЙмРэЃЌЭЈЙ§commit-intervalЩшжУУПДЮЬсНЛЕФМЧТМЪ§ЃЛ
2.жЇГжЖдУПИіTaskletЩшжУЯИСЃЖШЕФЪТЮёХфжУЃКИєРыНчБ№ЁЂДЋВЅааЮЊЁЂГЌЪБЃЛ
3.жЇГжrollbackКЭno rollbackЃЌЭЈЙ§skippable-exception-classesКЭno-rollback-exception-classesНјаажЇГХЃЛ
4.жЇГжJMS QueueЕФЪТЮёМЖБ№ХфжУЃЛ
СэЭтЃЌдкПђМмзЪЩюЕФФЃаЭГщЯѓЗНУцЃЌSpring BatchвВзіСЫМЋЮЊОЋМђЕФГщЯѓЁЃ
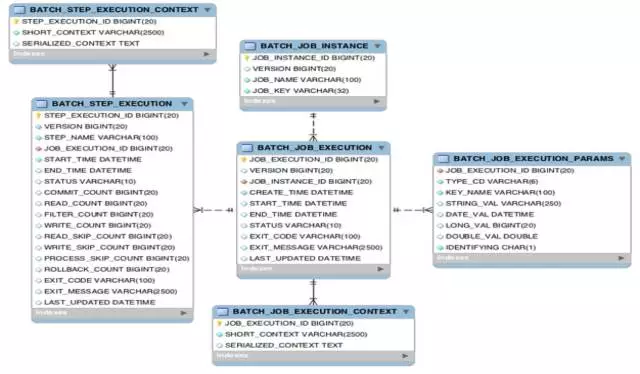
НіНіЪЙгУСљеХвЕЮёБэДцДЂСЫЫљгаЕФдЊЪ§ОнаХЯЂЃЈАќРЈJobЁЂStepЕФЪЕР§ЃЌЩЯЯТЮФЃЌжДааЦїаХЯЂЃЌЮЊКѓајЕФМрПиЁЂжиЦєЁЂжиЪдЁЂзДЬЌЛжИДЕШЬсЙЉСЫПЩФмЃЉЁЃ
BATCH_JOB_INSTANCEЃКзївЕЪЕР§БэЃЌгУгкДцЗХJobЕФЪЕР§аХЯЂ
BATCH_JOB_EXECUTION_PARAMSЃКзївЕВЮЪ§БэЃЌгУгкДцЗХУПИіJobжДааЪБКђЕФВЮЪ§аХЯЂЃЌИУВЮЪ§ЪЕМЪЖдгІJobЪЕР§ЕФЁЃ
BATCH_JOB_EXECUTIONЃКзївЕжДааЦїБэЃЌгУгкДцЗХЕБЧАзївЕЕФжДаааХЯЂЃЌБШШчДДНЈЪБМфЃЌжДааПЊЪМЪБМфЃЌжДааНсЪјЪБМфЃЌжДааЕФФЧИіJobЪЕР§ЃЌжДаазДЬЌЕШЁЃ
BATCH_JOB_EXECUTION_CONTEXTЃКзївЕжДааЩЯЯТЮФБэЃЌгУгкДцЗХзївЕжДааЦїЩЯЯТЮФЕФаХЯЂЁЃ
BATCH_STEP_EXECUTIONЃКзївЕВНжДааЦїБэЃЌгУгкДцЗХУПИіStepжДааЦїЕФаХЯЂЃЌБШШчзївЕВНПЊЪМжДааЪБМфЃЌжДааЭъГЩЪБМфЃЌжДаазДЬЌЃЌЖСаДДЮЪ§ЃЌЬјЙ§ДЮЪ§ЕШаХЯЂЁЃ
BATCH_STEP_EXECUTION_CONTEXTЃКзївЕВНжДааЩЯЯТЮФБэЃЌгУгкДцЗХУПИізївЕВНЩЯЯТЮФЕФаХЯЂЁЃ
ЪЕЯжзївЕЕФНЁзГадгыРЉеЙад
ХњДІРэвЊЧѓJobБиаыгаНЯЧПЕФНЁзГадЃЌЭЈГЃJobЪЧХњСПДІРэЪ§ОнЁЂЮоШЫжЕЪиЕФЃЌетвЊЧѓдкJobжДааЦкМфФмЙЛгІЖдИїжжЗЂЩњЕФвьГЃЁЂДэЮѓЃЌВЂЖдJobжДааНјаагааЇЕФИњзйЁЃ
вЛИіНЁзГЕФJobЭЈГЃашвЊОпБИШчЯТЕФМИИіЬиадЃК
1. ШнДэад
дкJobжДааЦкМфЗЧжТУќЕФвьГЃЃЌJobжДааПђМмгІФмЙЛНјаагааЇЕФШнДэДІРэЃЌЖјВЛЪЧШУећИіJobжДааЪЇАмЃЛЭЈГЃжЛгажТУќЕФЁЂЕМжТвЕЮёВЛе§ШЗЕФвьГЃВХПЩвджежЙJobЕФжДааЁЃ
2. ПЩзЗзйад
JobжДааЦкМфШЮКЮЗЂЩњДэЮѓЕФЕиЗНЖМашвЊНјаагааЇЕФМЧТМЃЌЗНБуКѓЦкЖдДэЮѓЕуНјаагааЇЕФДІРэЁЃР§ШчдкJobжДааЦкМфШЮКЮБЛКіТдДІРэЕФМЧТМааашвЊБЛгааЇЕФМЧТМЯТРДЃЌгІгУГЬађЮЌЛЄШЫдБПЩвдеыЖдБЛКіТдЕФМЧТМКѓајзігааЇЕФДІРэЁЃ
3. ПЩжиЦєад
JobжДааЦкМфШчЙћвђЮЊвьГЃЕМжТЪЇАмЃЌгІИУФмЙЛдкЪЇАмЕФЕужиаТЦєЖЏJobЃЛЖјВЛЪЧДгЭЗПЊЪМжиаТжДааJobЁЃ

ПђМмЬсЙЉСЫжЇГжЩЯУцЫљгаФмСІЕФЬиадЃЌАќРЈSkipЃЈЬјЙ§МЧТМДІРэЃЉЁЂRetryЃЈжиЪдИјЖЈЕФВйзїЃЉЁЂRestartЃЈДгДэЮѓЕуПЊЪМжиаТЦєЖЏЪЇАмЕФJobЃЉЃК
SkipЃЌдкЖдЪ§ОнДІРэЦкМфЃЌШчЙћЪ§ОнЕФФГМИЬѕЕФИёЪНВЛФмТњзувЊЧѓЃЌПЩвдЭЈЙ§SkipЬјЙ§ИУааМЧТМЕФДІРэЃЌШУProcessorФмЙЛЫГРћЕФДІРэЦфгрЕФМЧТМааЁЃ
RetryЃЌНЋИјЖЈЕФВйзїНјааЖрДЮжиЪдЃЌдкФГаЉЧщПіЯТВйзївђЮЊЖЬднЕФвьГЃЕМжТжДааЪЇАмЃЌШчЭјТчСЌНгвьГЃЁЂВЂЗЂДІРэвьГЃЕШЃЌПЩвдЭЈЙ§жиЪдЕФЗНЪНБмУтЕЅДЮЕФЪЇАмЃЌЯТДЮжДааВйзїЪБКђЭјТчЛжИДе§ГЃЃЌВЛдйгаВЂЗЂЕФвьГЃЃЌетбљЭЈЙ§жиЪдЕФФмСІПЩвдгааЇЕФБмУтетРрЖЬднЕФвьГЃЁЃ
RestartЃЌдкJobжДааЪЇАмКѓЃЌПЩвдЭЈЙ§жиЦєЙІФмРДМЬајЭъГЩJobЕФжДааЁЃдкжиЦєЪБКђЃЌХњДІРэПђМмдЪаэдкЩЯДЮжДааЪЇАмЕФЕужиаТЦєЖЏJobЃЌЖјВЛЪЧДгЭЗПЊЪМжДааЃЌетбљПЩвдДѓЗљЬсИпJobжДааЕФаЇТЪЁЃ
ЖдгкРЉеЙадЃЌПђМмЬсЙЉЕФРЉеЙФмСІАќРЈШчЯТЕФЫФжжФЃЪН :
Multithreaded Step ЖрЯпГЬжДаавЛИіStep;
Parallel Step ЭЈЙ§ЖрЯпГЬВЂаажДааЖрИіStep;
Remote Chunking дкдЖЖЫНкЕуЩЯжДааЗжВМЪНChunkВйзї;
Partitioning Step ЖдЪ§ОнНјааЗжЧјЃЌВЂЗжПЊжДаа;
ЮвУЧЯШРДПДЕквЛжжЕФЪЕЯжMultithreaded StepЃК

ХњДІРэПђМмдкJobжДааЪБФЌШЯЪЙгУЕЅИіЯпГЬЭъГЩШЮЮёЕФжДааЃЌЭЌЪБПђМмЬсЙЉСЫЯпГЬГиЕФжЇГжЃЈMultithreaded
StepФЃЪНЃЉЃЌПЩвддкStepжДааЪБКђНјааВЂааДІРэЃЌетРяЕФВЂааЪЧжИЭЌвЛИіStepЪЙгУЯпГЬГиНјаажДааЃЌЭЌвЛИіStepБЛВЂааЕФжДааЁЃЪЙгУtaskletЕФЪєадtask-executorПЩвдЗЧГЃШнвзЕФНЋЦеЭЈЕФStepБфГЩЖрЯпГЬStepЁЃ
Multithreaded StepЕФЪЕЯжЪОР§ЃК

ашвЊзЂвтЕФЪЧSpring BatchПђМмЬсЙЉЕФДѓВПЗжЕФItemReaderЁЂItemWriterЕШВйзїЖМЪЧЯпГЬВЛАВШЋЕФЁЃ
ПЩвдЭЈЙ§РЉеЙЕФЗНЪНЯдЯжЯпГЬАВШЋЕФStepЁЃ
ЯТУцЮЊДѓМвеЙЪОвЛИіРЉеЙЕФЪЕЯжЃК

ашЧѓЃКеыЖдЪ§ОнБэЕФХњСПДІРэЃЌЪЕЯжЯпГЬАВШЋЕФStepЃЌВЂЧвжЇГжжиЦєФмСІЃЌМДдкжДааЪЇАмЕуПЩвдМЧТМХњДІРэЕФзДЬЌЁЃ
ЖдгкЪОР§жаЕФЪ§ОнПтЖСШЁзщМўJdbcCursorItemReaderЃЌдкЩшМЦЪ§ОнПтБэЪБЃЌдкБэжадіМгвЛИізжЖЮFlagЃЌгУгкБъЪЖЕБЧАЕФМЧТМЪЧЗёвбОЖСШЁВЂДІРэГЩЙІЃЌШчЙћДІРэГЩЙІдђБъЪЖFlag=trueЃЌЕШЯТДЮжиаТЖСШЁЕФЪБКђЃЌЖдгквбОГЩЙІЖСШЁЧвДІРэГЩЙІЕФМЧТМжБНгЬјЙ§ДІРэЁЃ
Multithreaded StepЃЈЖрЯпГЬВНЃЉЬсЙЉСЫЖрИіЯпГЬжДаавЛИіStepЕФФмСІЃЌЕЋетжжГЁОАдкЪЕМЪЕФвЕЮёжаЪЙгУЕФВЂВЛЪЧЗЧГЃЖрЁЃ
ИќЖрЕФвЕЮёГЁОАЪЧJobжаВЛЭЌЕФStepУЛгаУїШЗЕФЯШКѓЫГађЃЌПЩвддкжДааЦкВЂааЕФжДааЁЃ
Parallel StepЃКЬсЙЉЕЅИіНкЕуКсЯђРЉеЙЕФФмСІ

ЪЙгУГЁОАЃКStep AЁЂStep BСНИізївЕВНгЩВЛЭЌЕФЯпГЬжДааЃЌСНепОљжДааЭъБЯКѓЃЌStep CВХЛсБЛжДааЁЃ
ПђМмЬсЙЉСЫВЂааStepЕФФмСІЁЃПЩвдЭЈЙ§SplitдЊЫиРДЖЈвхВЂааЕФзївЕСїЃЌВЂжЦЖЈЪЙгУЕФЯпГЬГиЁЃ
Parallel StepФЃЪНЕФжДаааЇЙћШчЯТЃК

УПИізївЕВНВЂааДІРэВЛЭЌЕФМЧТМЃЌЪОР§жаШ§ИізївЕВНЃЌДІРэЭЌвЛеХБэжаЕФВЛЭЌЪ§ОнЁЃ
ВЂааStepЬсЙЉСЫдквЛИіНкЕуЩЯКсЯђДІРэЃЌЕЋЫцзХзївЕДІРэСПЕФдіМгЃЌгаПЩФмвЛЬЈНкЕуЮоЗЈТњзуJobЕФДІРэЃЌДЫЪБЮвУЧПЩвдВЩгУдЖГЬStepЕФЗНЪННЋЖрИіЛњЦїНкЕузщКЯЦ№РДЭъГЩвЛИіJobЕФДІРэЁЃ
Remote ChunkingЃКдЖГЬStepММЪѕБОжЪЩЯЪЧНЋЖдItemЖСЁЂаДЕФДІРэТпМНјааЗжРыЃЛЭЈГЃЧщПіЯТЖСЕФТпМЗХдквЛИіНкЕуНјааВйзїЃЌНЋаДВйзїЗжЗЂЕНСэЭтЕФНкЕужДааЁЃ

дЖГЬЗжПщЪЧвЛИіАбstepНјааММЪѕЗжИюЕФЙЄзїЃЌВЛашвЊЖдДІРэЪ§ОнЕФНсЙЙгаУїШЗСЫНтЁЃ
ШЮКЮЪфШыдДФмЙЛЪЙгУЕЅНјГЬЖСШЁВЂдкЖЏЬЌЗжИюКѓзїЮЊ"Пщ"ЗЂЫЭИјдЖГЬЕФЙЄзїНјГЬЁЃ
дЖГЬНјГЬЪЕЯжСЫМрЬ§епФЃЪНЃЌЗДРЁЧыЧѓЁЂДІРэЪ§ОнзюжеНЋДІРэНсЙћвьВНЗЕЛиЁЃЧыЧѓКЭЗЕЛижЎМфЕФДЋЪфЛсБЛШЗБЃдкЗЂЫЭепКЭЕЅИіЯћЗбепжЎМфЁЃ
дкMasterНкЕуЃЌзївЕВНИКд№ЖСШЁЪ§ОнЃЌВЂНЋЖСШЁЕФЪ§ОнЭЈЙ§дЖГЬММЪѕЗЂЫЭЕНжИЖЈЕФдЖЖЫНкЕуЩЯЃЌНјааДІРэЃЌДІРэЭъБЯКѓMasterИКд№ЛиЪеRemoteЖЫжДааЕФЧщПіЁЃ
дкSpring BatchПђМмжаЭЈЙ§СНИіКЫаФЕФНгПкРДЭъГЩдЖГЬStepЕФШЮЮёЃЌЗжБ№ЪЧChunkProviderгыChunkProcessorЁЃ
ChunkProviderЃКИљОнИјЖЈЕФItemReaderВйзїВњЩњХњСПЕФChunkВйзїЃЛ
ChunkProcessorЃКИКд№ЛёШЁChunkProviderВњЩњЕФChunkВйзїЃЌжДааОпЬхЕФаДТпМЃЛ
Spring BatchжаЖддЖГЬStepУЛгаФЌШЯЕФЪЕЯжЃЌЕЋЮвУЧПЩвдНшжњSIЛђепAMQPЪЕЯжРДЪЕЯждЖГЬЭЈбЖФмСІЁЃ
ЛљгкSIЪЕЯжRemote ChunkingФЃЪНЕФЪОР§ЃК

StepБОЕиНкЕуИКд№ЖСШЁЪ§ОнЃЌВЂЭЈЙ§MessagingGatewayНЋЧыЧѓЗЂЫЭЕНдЖГЬStepЩЯЃЛдЖГЬStepЬсЙЉСЫЖгСаЕФМрЬ§ЦїЃЌЕБЧыЧѓЖгСажагаЯћЯЂЪБКђЛёШЁЧыЧѓаХЯЂВЂНЛИјChunkHanderИКд№ДІРэЁЃ
НгЯТРДЮвУЧПДЯТзюКѓвЛжжЗжЧјФЃЪНЃЛPartitioning StepЃКЗжЧјФЃЪНашвЊЖдЪ§ОнЕФНсЙЙгавЛЖЈЕФСЫНтЃЌШчжїМќЕФЗЖЮЇЁЂД§ДІРэЕФЮФМўЕФУћзжЕШЁЃ

етжжФЃЪНЕФгХЕудкгкЗжЧјжаУПвЛИідЊЫиЕФДІРэЦїЖМФмЙЛЯёвЛИіЦеЭЈSpring BatchШЮЮёЕФЕЅВНвЛбљдЫааЃЌвВВЛБиШЅЪЕЯжШЮКЮЬиЪтЕФЛђЪЧаТЕФФЃЪНЃЌРДШУЫћУЧФмЙЛИќШнвзХфжУгыВтЪдЁЃ
ЭЈЙ§ЗжЧјПЩвдЪЕЯжвдЯТЕФгХЕуЃК
ЗжЧјЪЕЯжСЫИќЯИСЃЖШЕФРЉеЙЃЛ
ЛљгкЗжЧјПЩвдЪЕЯжИпадФмЕФЪ§ОнЧаЗжЃЛ
ЗжЧјБШдЖГЬЭЈГЃОпгаИќИпЕФРЉеЙадЃЛ
ЗжЧјКѓЕФДІРэТпМЃЌжЇГжБОЕигыдЖГЬСНжжФЃЪНЃЛ
ЗжЧјзївЕЕфаЭЕФПЩвдЗжГЩСНИіДІРэНзЖЮЃЌЪ§ОнЗжЧјЁЂЗжЧјДІРэЃЛ
Ъ§ОнЗжЧјЃКИљОнЬиЪтЕФЙцдђЃЈР§ШчЃКИљОнЮФМўУћГЦЃЌЪ§ОнЕФЮЈвЛадБъЪЖЃЌЛђепЙўЯЃЫуЗЈЃЉНЋЪ§ОнНјааКЯРэЕФЪ§ОнЧаЦЌЃЌЮЊВЛЭЌЕФЧаЦЌЩњГЩЪ§ОнжДааЩЯЯТЮФExecution
ContextЁЂзївЕВНжДааЦїStep ExecutionЁЃПЩвдЭЈЙ§НгПкPartitionerЩњГЩздЖЈвхЕФЗжЧјТпМЃЌSpring
BatchХњДІРэПђМмФЌШЯЪЕЯжСЫЖдЖрЮФМўЕФЪЕЯжorg.springframework.batch.core.partition.support.MultiResourcePartitionerЃЛвВПЩвдздааРЉеЙНгПкPartitionerРДЪЕЯжздЖЈвхЕФЗжЧјТпМЁЃ
ЗжЧјДІРэЃКЭЈЙ§Ъ§ОнЗжЧјКѓЃЌВЛЭЌЕФЪ§ОнвбОБЛЗжХфЕНВЛЭЌЕФзївЕВНжДааЦїжаЃЌНгЯТРДашвЊНЛИјЗжЧјДІРэЦїНјаазївЕЃЌЗжЧјДІРэЦїПЩвдБОЕижДаавВПЩвддЖГЬжДааБЛЛЎЗжЕФзївЕЁЃНгПкPartitionHandlerЖЈвхСЫЗжЧјДІРэЕФТпМЃЌSpring
BatchХњДІРэПђМмФЌШЯЪЕЯжСЫБОЕиЖрЯпГЬЕФЗжЧјДІРэorg.springframework.batch.core.partition.support.TaskExecutorPartitionHandlerЃЛвВПЩвдздааРЉеЙНгПкPartitionHandlerРДЪЕЯжздЖЈвхЕФЗжЧјДІРэТпМЁЃ

Spring BatchПђМмЬсЙЉСЫЖдЮФМўЗжЧјЕФжЇГжЃЌЪЕЯжРрorg.springframework.batch.core.partition.support.MultiResourcePartitionerЬсЙЉСЫЖдЮФМўЗжЧјЕФФЌШЯжЇГжЃЌИљОнЮФМўУћНЋВЛЭЌЕФЮФМўДІРэНјааЗжЧјЃЌЬсЩ§ДІРэЕФЫйЖШКЭаЇТЪЃЌЪЪКЯгаДѓСПаЁЮФМўашвЊДІРэЕФГЁОАЁЃ

ЪОР§еЙЪОСЫНЋВЛЭЌЮФМўЗжХфЕНВЛЭЌЕФзївЕВНжаЃЌЪЙгУMultiResourcePartitionerНјааЗжЧјЃЌвтЮЖзХУПИіЮФМўЛсБЛЗжХфЕНвЛИіВЛЭЌЕФЗжЧјжаЁЃШчЙћгаЦфЫќЕФЗжЧјЙцдђЃЌПЩвдЭЈЙ§ЪЕЯжНгПкPartitionerРДНјааздЖЈвхЕФРЉеЙЁЃгааЫШЄЕФTXЃЌПЩвдздМКЪЕЯжЛљгкЪ§ОнПтЕФЗжЧјФмСІХЖЁЃ
змНсвЛЯТЃЌХњДІРэПђМмдкРЉеЙадЩЯЬсЙЉСЫ4жаВЛЭЌФмСІЃЌУПжжЖМЪЧИїздЕФЪЙгУГЁОАЃЌЮвУЧПЩвдИљОнЪЕМЪЕФвЕЮёашвЊНјаабЁдёЁЃ

ХњДІРэПђМмЕФВЛзугыдіЧП
Spring BatchХњДІРэПђМмЫфШЛЬсЙЉСЫ4жжВЛЭЌЕФМрПиЗНЪНЃЌЕЋДгФПЧАЕФЪЙгУЧщПіРДПДЃЌЖМВЛЪЧЗЧГЃЕФгбКУЁЃ

ЭЈЙ§DBжБНгВщПДЃЌЖдгкЙмРэШЫдБРДНВЃЌецЕФВЛШЬжБЪгЃЛ
ЭЈЙ§APIЪЕЯжздЖЈвхЕФВщбЏЃЌетЪЧГЬађдБЕФЬьЬУЃЌШЗЪЕдЫЮЌШЫдБЕФЕигќЃЛ
ЬсЙЉСЫWebПижЦЬЈЃЌНјааJobЕФМрПиКЭВйзїЃЌФПЧАЬсЙЉЕФЙІФмЬЋТуТЖЃЌЮоЗЈжБНггУгкЩњВњЃЛ
ЬсЙЉJMXВщбЏЗНЪНЃЌЖдгкЗЧПЊЗЂШЫдБЬЋВЛгбКУЃЛ
ЕЋдкЦѓвЕМЖгІгУжаУцЖдХњСПЪ§ОнДІРэЃЌНіНіЬсЙЉХњДІРэПђМмНіФмТњзуХњДІРэзївЕЕФПьЫйПЊЗЂЁЂжДааФмСІЁЃ
ЦѓвЕашвЊЭГвЛЕФХњДІРэЦНЬЈРДДІРэИДдгЕФЦѓвЕХњДІРэгІгУЃЌХњДІРэЦНЬЈашвЊНтОізївЕЕФЭГвЛЕїЖШЁЂХњДІРэзївЕЕФМЏжаЙмРэКЭЙмПиЁЂХњДІРэзївЕЕФЭГвЛМрПиЕШФмСІЁЃ
ФЧЭъУРЕФНтОіЗНАИЪЧЪВУДФиЃП
ЦѓвЕМЖХњДІРэЦНЬЈашвЊдкSpring BatchХњДІРэПђМмЕФЛљДЁЩЯЃЌМЏГЩЕїЖШПђМмЃЌЭЈЙ§ЕїЖШПђМмПЩвдНЋШЮЮёАДееЦѓвЕЕФашЧѓНјааШЮЮёЕФЖЈЦкжДааЃЛ
ЗсИЛФПЧАSpring Batch AdminЃЈSpring BatchЕФЙмРэМрПиЦНЬЈЃЌФПЧАФмСІБШНЯБЁШѕЃЉПђМмЃЌЬсЙЉЖдJobЕФЭГвЛЙмРэЙІФмЃЌдіЧПJobзївЕЕФМрПиЁЂдЄОЏЕШФмСІЃЛ
ЭЈЙ§гыЦѓвЕЕФзщжЏЛњЙЙЁЂШЈЯоЙмРэЁЂШЯжЄЯЕЭГНјааКЯРэЕФМЏГЩЃЌдіЧПЦНЬЈЖдJobзївЕЕФШЈЯоПижЦЁЂАВШЋЙмРэФмСІЁЃ
гЩгкЪБМфЙиЯЕЃЌНёЬьЕФЗжЯэОЭЕНетРяЃЌКмЖрФкШнЮДФмеЙПЊЬжТлЁЃЛЖгДѓМвдкЪЕМЪвЕЮёжаЪЙгУSpring BatchПђМмЁЃ | 




