| 编辑推荐: |
本文将探讨一下使用协程后究竟可以为我们现在的Java应用解决什么问题,以及现在成熟的协程实现(Kotlin/Go),在最后会基于JDK20的协程实现分析下JDK部分的源码。希望能对遇到类似问题的同学有所帮助。
本文来自于阿里云,由火龙果软件Linda编辑、推荐。 |
|
今年9月份,Java会最新的LTS版本的发布会带来一项重磅更新:协程
在此之前,在JDK19中协程已经作为一个预览版的功能被放在了JDK中,本文将探讨一下使用协程后究竟可以为我们现在的Java应用解决什么问题,以及现在成熟的协程实现(Kotlin/Go),在最后会基于JDK20的协程实现分析下JDK部分的源码。
协程是什么
协程其实是很古老的概念,1963年就被提出。协程是一种协作式的程序执行流,只有当协程主动让出控制权才会切换,并且可以在适当的时间点协作式的被切换回来。
协作式的程序执行流,指的是在一个线程中,协程可以主动挂起,转而执行另一个协程,而无需像使用多线程一样需要操作系统调度,进行线程上下文的切换。
多线程有什么问题?
关于多线程开销的讨论:https://ata.alibaba-inc.com/articles/147345?spm=ata.23639746.0.0.3286f6368pc31e
结论:多线程真正的开销来源于线程阻塞唤醒调度。
减少线程上下文切换的次数,其实就是减少线程阻塞唤醒的调度次数。
但是协程的挂起与恢复仍然是需要保存协程调用栈的,但是因为协程本身是应用层面实现的,一个协程默认只会占用几k、几十k的内存,相比线程是很轻量级的,我们下面的讨论都是基于协程的挂起/恢复操作远比线程的调度轻量的共识。
协程的线程模型
当前Java的线程模型为1:1的模式,即一个Java线程对应一个操作系统线程。
协程是实现在操作系统线程上的一种用户级线程,是一种M:N的线程模型(M为协程数量,N为操作系统内核线程数量)。
协程栈切换的操作(来源网络):每个协程有独立的栈,而栈既保留了变量的值,也保留了函数的调用关系、参数和返回值,CPU中的栈寄存器SP指向了当前协程的栈,而指令寄存器IP保存着下一条要执行的指令地址。因此,从协程1切换到协程2时,首先要把SP、IP寄存器的值为线程1保存下来,再从内存中找出协程2上一次切换前保存好的寄存器值,写入CPU的寄存器,这样就完成了协程切换。
一般情况:
使用协程后应用线程数=cpu核数
一个协程创建的子协程由父协程所在的线程进行调度
要保证协程 非阻塞
长时间运行的协程需要有切出机制,否则一直占用cpu
协程最适合的应用场景:(网络)IO密集型
协程带来的好处:用写同步代码的方式写异步非阻塞程序
其实,协程的调度我理解和Reactor模型是有些相似之处的,都是为了解决多线程IO(阻塞)问题。因此我将先从Reactor模型讲起,以及使用协程后相比我们现在使用的Reactor模型有哪些优化。
Reactor模型
常见的我们使用Netty时的线程模型如下:
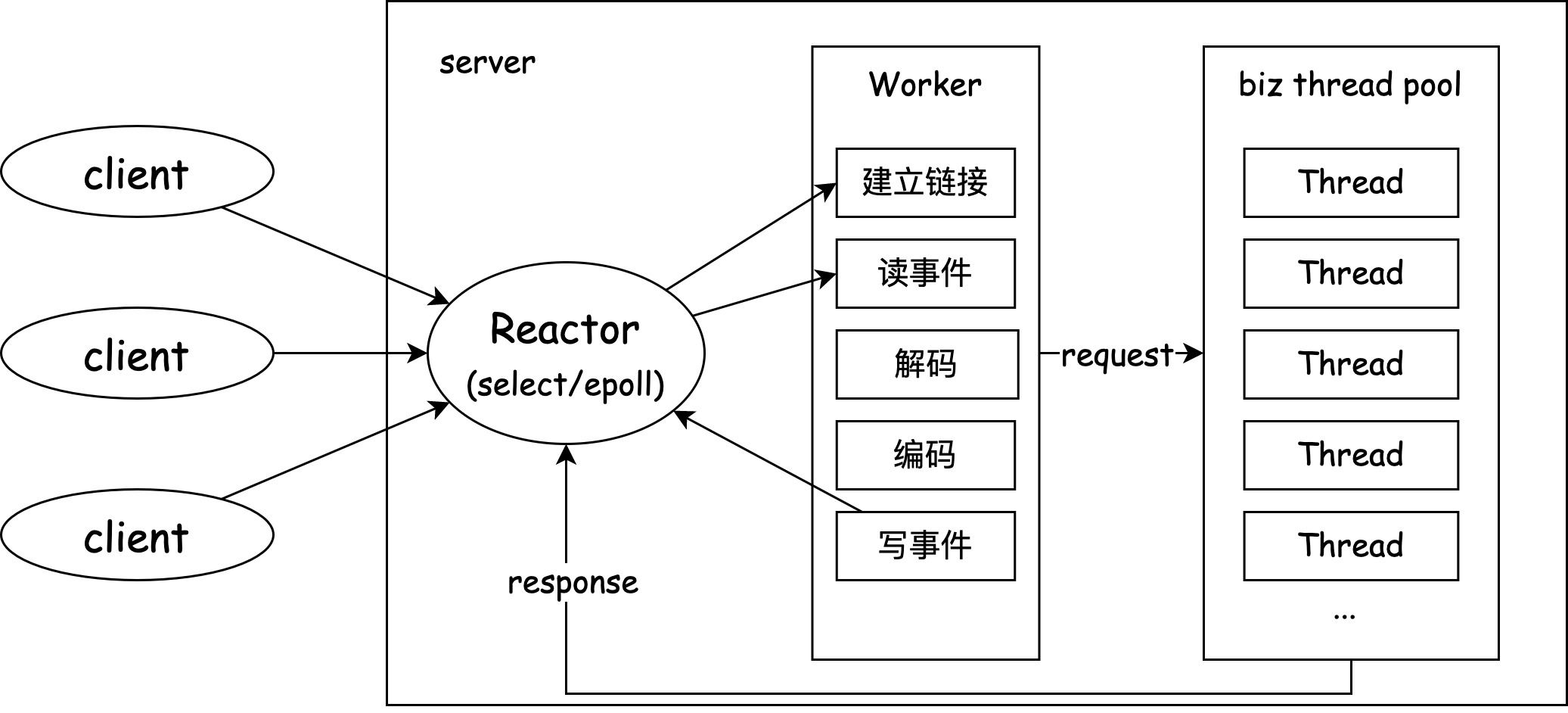
Reactor模型相比原始的一个请求一个线程的模型极大的降低了应用的线程数量的同时还极大的提高了应用可同时处理的并发请求数量。
痛点:Worker线程解析网络请求后需要向业务线程池提交任务,否则如果业务逻辑存在阻塞,Worker线程将进入阻塞状态,严重影响吞吐;而且在request
-> response的过程中会有至少两次线程的切换。
那么,前面提到协程可以让应用的线程数==CPU数量,这样在线程执行时理论上是不存在线程阻塞唤醒的,CPU和内存的利用率应该都会有一定程度的优化,体现在我们的应用中就是系统的吞吐量上升。
ps:之所以说协程与Reactor模型类型,就是因为,要想协程非阻塞,就需要有一个类似epoll的回调机制,挂起协程后,我们需要知道这个协程何时可以继续被执行,当原本的阻塞操作完成时,协程可以直接拿到返回结果,而这种挂起函数一般是由API提供者实现,因此在使用API时可以无感的使用写同步代码的方式编写异步非阻塞代码。
使用协程后
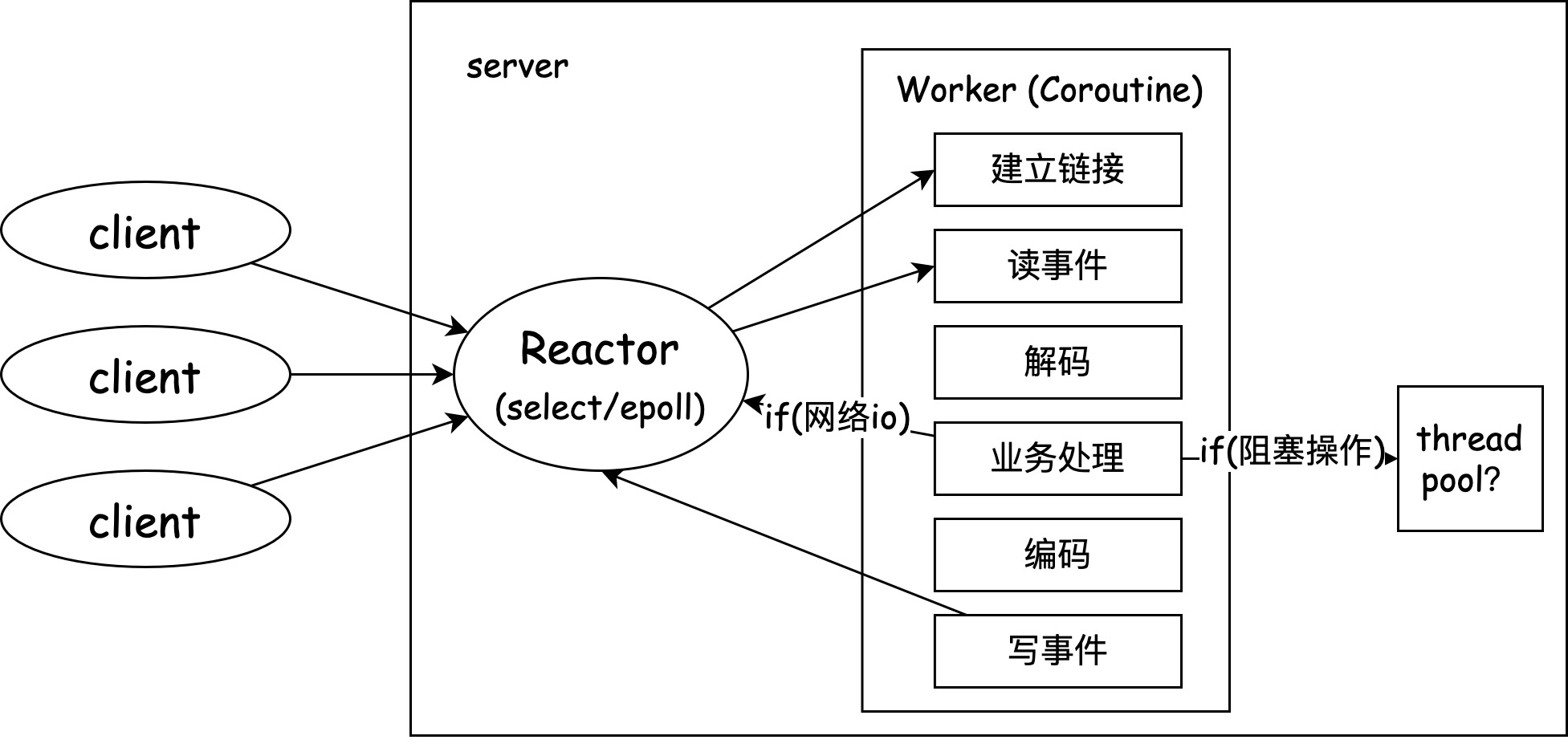
使用协程后最直接的就是可以优化我们应用中大量的RPC调用的线程池,历史存在的一些阻塞API,比如JDBC,则需要进行一定的重构来支持协程的非阻塞调用(NIO),或者使用线程池来处理,这样虽然背离了协程的本质,但是相比之前的模型可以尽量优化掉网络IO的阻塞操作。协程的发布后,越来越多的中间件一定也会支持协程。
RPC并发
以RPC场景为例,一般的RPC底层都是支持异步回调的(HSF、Dubbo),但是相关的异步操作都是被封装在二方库中的,提供出的API一般都是阻塞形式,在内部通过线程池+Future的形式实现,执行的代价是比较大的。
将线程池的实现切换到协程后,可以使多个RPC的调用在单个线程内创建多个协程来实现,减少线程上下文切换次数(线程数量),对于降低cpu使用率,降低系统load都是有效的。
在我们的应用中,一个应用有上千个线程是很常见的,而Java默认一个线程会占用1M(64位系统)的内存,因此在使用协程后,系统整体的内存占用也会有一定程度的优化。
IO阻塞
IO操作包括内存IO、磁盘IO和网络IO三种,我们平时说的IO一般是后两种,因为内存的操作是非常快的。
那么,如何解决阻塞IO就是使用协程编写代码的关键
网络IO
可以通过IO多路复用器解决(select/poll/epoll),使用Netty编写API
磁盘IO
在Linux中,磁盘IO是一定会阻塞调用线程的,因此只能通过线程池的方式解决(?)
epoll为什么不支持磁盘io?
epoll本质其实是监听io操作是否可读可写,而磁盘io始终是出于就绪状态的,实际进行读取的时候还是会“阻塞”住等在io操作的执行完成,因此就算使用了epoll也是没有意义的。
ps:windows、mac(kqueue)支持磁盘io的非阻塞
Kotlin与Go的协程
Go
使用
package main
import (
"time"
"fmt"
)
func say(s string) {
for i := 0; i < 3; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Println(s)
}
}
func main() {
go say("hello world")
time.Sleep(1000 * time.Millisecond)
fmt.Println("over!")
}
|
go的协程是使用起来最简单的,也是最无感的,只需要一个关键词go就可以开启一个协程。
Go的协程调度(GPM模型)
G(协程) P(协程调度器,存储协程) M(内核线程)
在Go中,线程是运行goroutine的实体,调度器的功能是把可运行的goroutine分配到工作线程上。
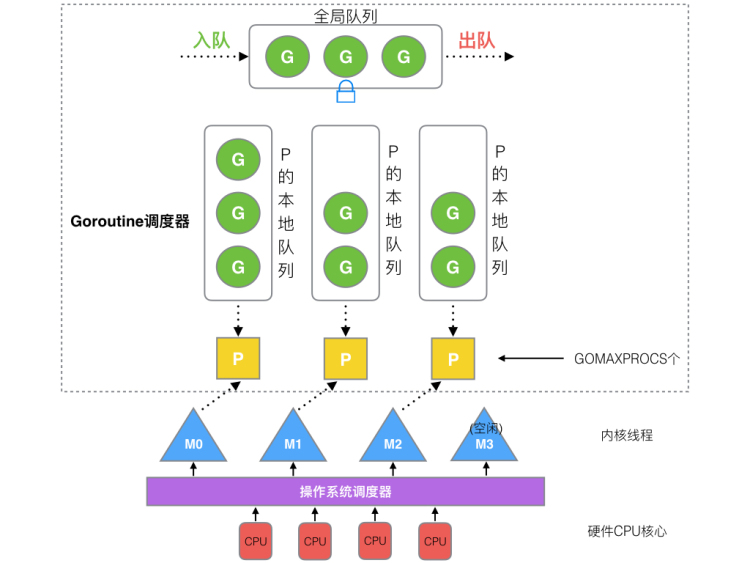
全局队列(Global Queue):存放等待运行的G。
P的本地队列:同全局队列类似,存放的也是等待运行的G,存的数量有限,不超过256个。新建G时,G优先加入到P的本地队列,如果队列满了,则会把本地队列中一半的G移动到全局队列。
P列表:所有的P都在程序启动时创建,并保存在数组中,最多有GOMAXPROCS(可配置)个。
M:线程想运行任务就得获取P,从P的本地队列获取G,P队列为空时,M也会尝试从全局队列拿一批G放到P的本地队列,或从其他P的本地队列偷一半放到自己P的本地队列。M运行G,G执行之后,M会从P获取下一个G,不断重复下去。
特点:
work stealing机制:当本线程无可运行的G时,尝试从其他线程绑定的P偷取G,而不是销毁线程。
hand off机制:当本线程因为G进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程执行。
缺点:Go协程在执行系统调用时,会在阻塞一段时间后,调度器发现线程阻塞,才会进行hand off,当进行不恰当的代码编写时,可能导致系统最后创建过量线程,Go过于“廉价”的协程可能会“惯坏”一些对IO理解不深的开发者。(实际上只有磁盘io才会有系统阻塞,GO有全局的网络io调度器)
Kotlin
相比Kotlin,我觉得Go的协程实现相对“丐版”,Kotlin的协程库更加丰富,但同时也带来了理解和使用上的复杂度。(不得不说,Go的上手速度,即使作为Java开发,Go的上手速度也要快于Kotlin)
使用
使用挂起函数launch
fun main() = runBlocking {
launch {
delay(1000L)
println("World!")
}
println("Hello,")
delay(2000L)
}
|
runBlocking可以保证块内协程执行结束后再结束当前协程(即主线程)
launch定义
fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job
|
当kotlin方法只有一个参数或者只有一个参数没有默认参数时,可以实现Java中类似关键字的操作,虽然只是一种语法糖,但是很酷。
通过使用这个特性,可以实现很多其他语言的原升关键词的特性,比如js中的async与await
使用async
val time = measureTimeMillis {
val one = async { doSomethingUsefulOne() }
val two = async { doSomethingUsefulTwo() }
println("The answer is ${one.await() + two.await()}")
}
println("Completed in $time ms")
|
async可以异步执行一个挂起函数,await可以等待该协程执行结束,类似Java的CompletableFuture
Kotlin协程调度
Kotlin协程运行在⼀些以 CoroutineContext 类型为代表的上下文中,它们被定义在了
Kotlin 的标准库里。协程上下文是各种元素的集合,其中主要元素是协程中的Job(前面提到lanch和async都会返回一个job)
协程上下文包含⼀个协程调度器(参见 CoroutineDispatcher)它确定了相关的协程在哪个线程或哪些线程上执行。协程调度器可以将协程限制在⼀个特定的线程执行,或将它分派到⼀个线程池,亦或是让它不受限地运行。
几种调度器 :
Dispatchers.Unconfined 调度器:默认执行在启动线程,无线程切换;
Dispatchers.IO 调度器:在 子线程中运行,处理文件操作和网络IO操作;使用场景如:数据库增删查改,文件读写处理,网络数据处理;(io线程池)
Dispatchers.Default 调度器:在 子线程中运行,处理CPU耗时任务,主要侧重算法消耗;使用场景:数据排序,数据解析,数据对比等耗时算法操作;(cpu密集型任务线程池)
Dispatchers.Main 调度器:在 主线程中运行,处理UI交互任务;使用场景如:调用挂起suspend函数,更新
UI,更新 LiveData ;(客户端场景)
特点:kotlin协程更加灵活,同时也可以使用Java丰富的类库
阿里Wisp协程
通过将Java的Thread替换为Wisp实现的协程,将Java原生的阻塞方法全部代理掉的方式,实现了用户无感知的协程,可以直接通过升级ajdk接入。实现了高压力下qps/RT10%~20%的优化。
不适用有JNI调用阻塞代码的程序。
具体的实现没有去下载代码查看,推测是通过在ajdk做了一些改造,在类加载时将Java一些api替换成了wisp的实现
可以参考梁希大佬的两篇文章:
Wisp协程
Wisp2: 开箱即用的Java协程
Java预览版协程
Java现在的最新版jdk19、20,也实现了预览版协程的支持,我们可以下载最新的jdk进行试用
使用
使用Thread.ofVirtual().name("coroutine-",
0).factory();可以创建一个协程Factory,后续可以threadFactory.newThread方法创建一个协程。
使用Thread.startVirtualThread()方法也可以直接创建一个没有名字的协程
首先我在代码中创建了20w个协程(在我的电脑上不修改jvm参数的情况下,使用线程在创建4000多个线程的时候就直接OOM了),实验了协程对lock的支持,实验结果是synchronized目前还不支持协程(wisp已支持)
在试用协程时需要打开启动参数--enable-preview
public class LockTest {
public static void main(String[] args) throws InterruptedException {
ThreadFactory threadFactory = Thread.ofVirtual().name("coroutine-", 0).factory();
Lock lock = new ReentrantLock();
IntStream.range(0, 10_000).forEach(i -> threadFactory.newThread(() -> {
lock.lock();
try {
Thread.sleep(Duration.ofMillis(1));
System.out.println(Thread.currentThread().getName());
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}).start());
IntStream.range(10_000, 20_000).forEach(i -> threadFactory.newThread(() -> {
try {
Thread.sleep(Duration.ofSeconds(10));
System.out.println(Thread.currentThread().getName());
} catch (Exception e) {
throw new RuntimeException(e);
}
}).start());
Thread.sleep((Duration.ofSeconds(100)));
}
}
|
新增结构化编程支持,可以在一个StructuredTaskScope执行多个协程,等待全部执行完/取第一个成功/失败
但我感觉目前的api比较鸡肋
public class StructuredTaskScopeTest {
public static void main(String[] args) throws Exception {
try (var scope = new StructuredTaskScope<String>()) {
IntStream.range(0, 10_000).forEach(i -> scope.fork(() -> {
try {
Thread.sleep(Duration.ofSeconds(10));
System.out.println(Thread.currentThread().getName() + " " + i);
} catch (Exception e) {
throw new RuntimeException(e);
}
return null;
}));
scope.join();
}
System.out.println("success");
}
}
|
值得一提的是在使用这个api的过程中,由于这个api由于是预览版,所在的模块(module)没有被JDK默认引用,实际学习操作了一下JDK9新增的module功能
源码分析(JDK层面)
协程的挂起/执行
第一个引起我注意的就是Thread.sleep方法,会判断如果是协程的话

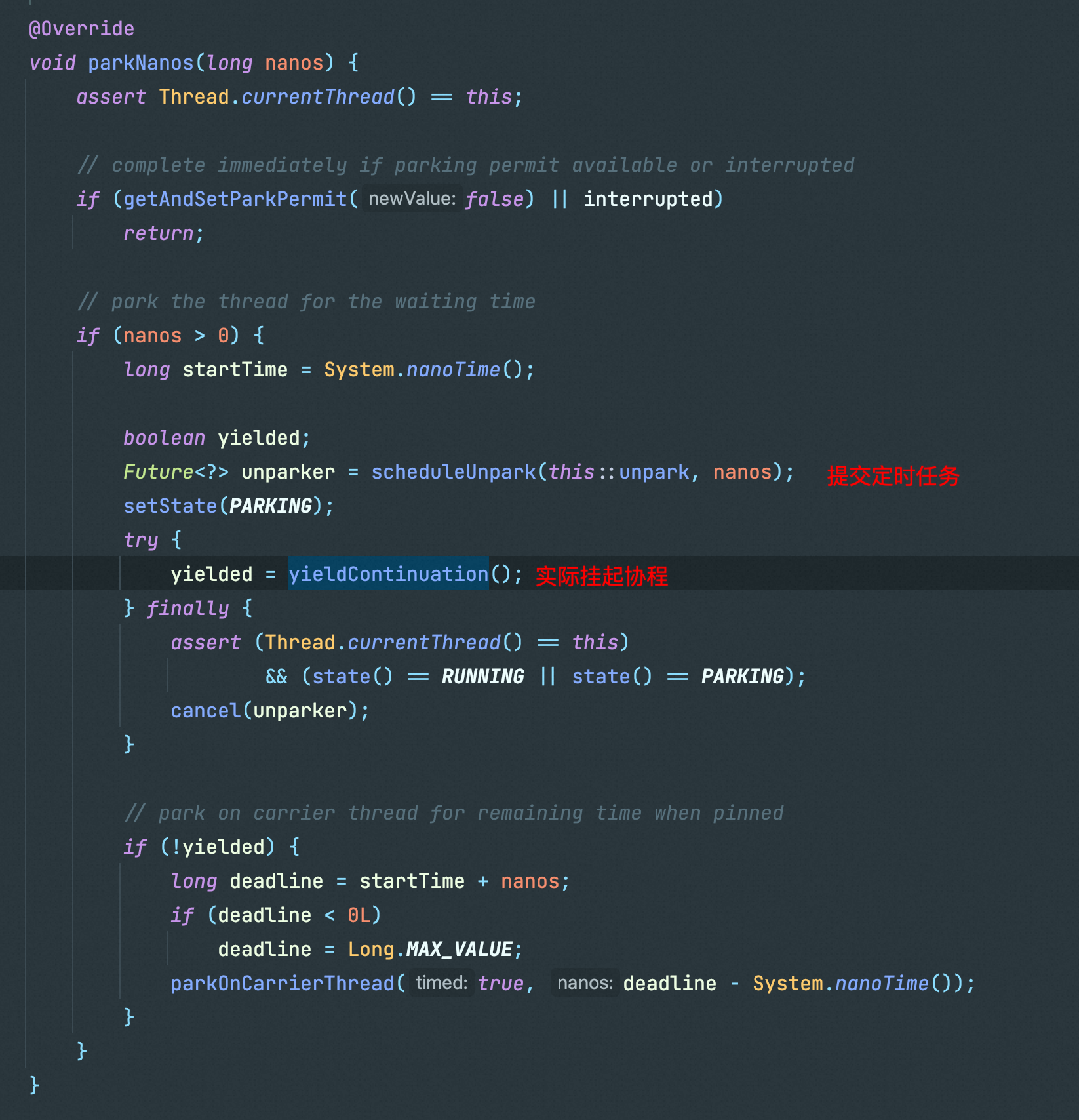
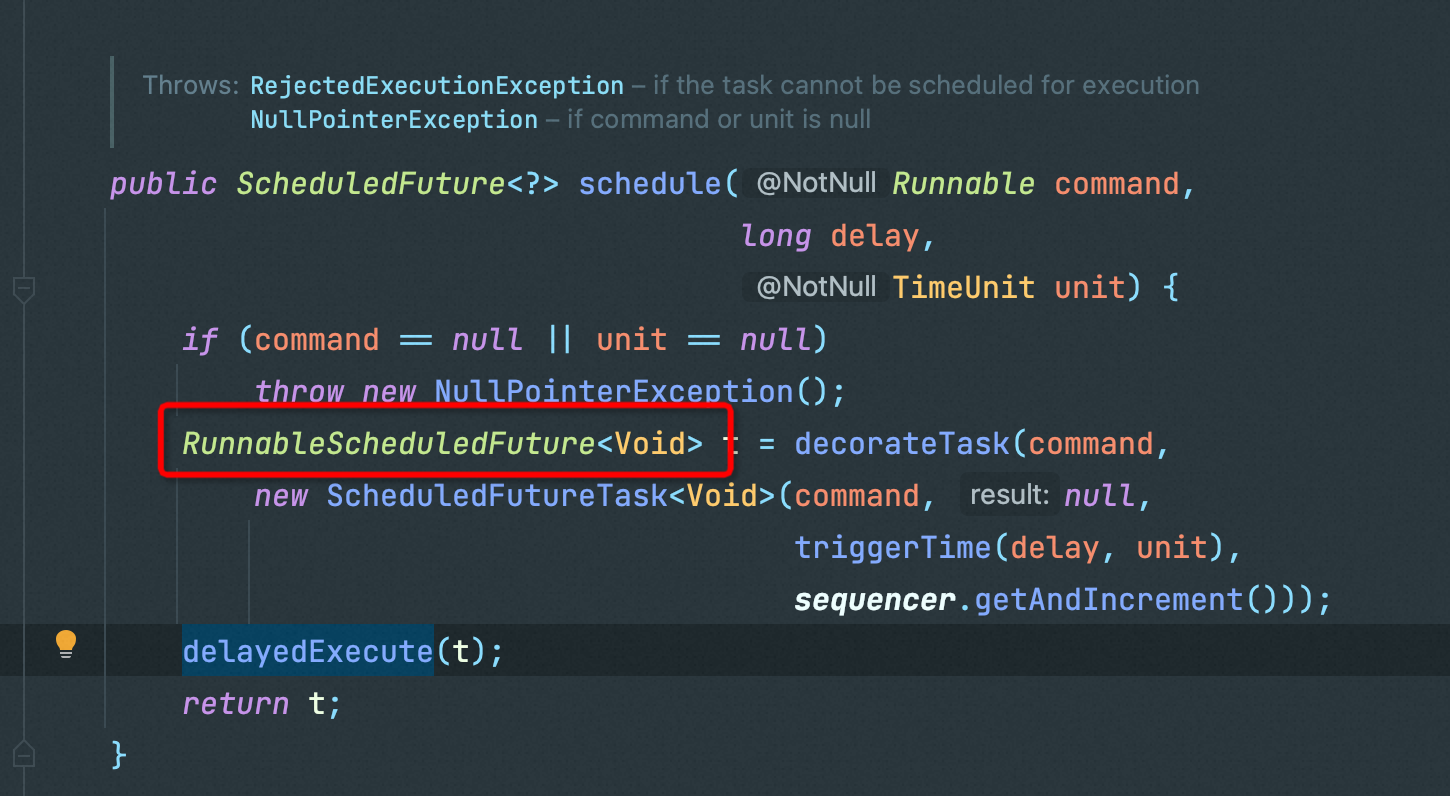
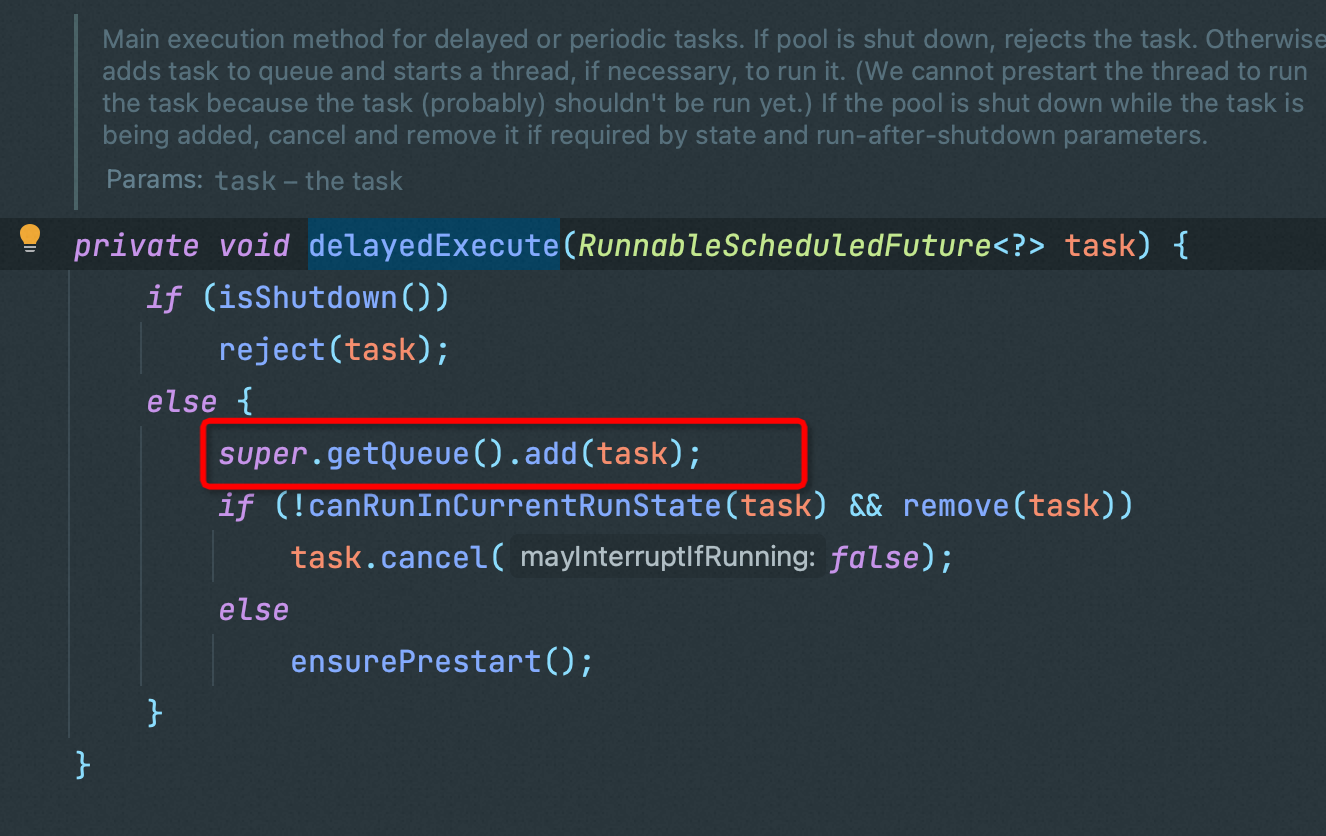
最终会把协程作为一个延迟任务放进一个BlockingQueue中,然后通过yieldContinuation挂起当前协程,在yieldContinuation会调用Continuation.yield(VTHREAD_SCOPE)

在unmount(卸载)中会重置当前协程和载体线程的关联关系,然后调用Continuation.yield方法挂起当前协程
挂起结束后会重新mount(挂载)协程到平台线程上,以执行后续操作
Continuation.yield会将当前虚拟线程的堆栈由平台线程的堆栈转移到Java堆内存,然后将其他就绪虚拟线程的堆栈由Java堆中拷贝到当前平台线程的堆栈中继续执行。

代码注释:// TODO: ugly
Continuation.yield可以让程序代码中断,然后再次调用Continuation.run可以从上一个中断位置继续执行

之前的JUC包中的锁和并发类都是使用LockSupport进行线程的阻塞和唤起,协程既然能用,那说明必有玄机

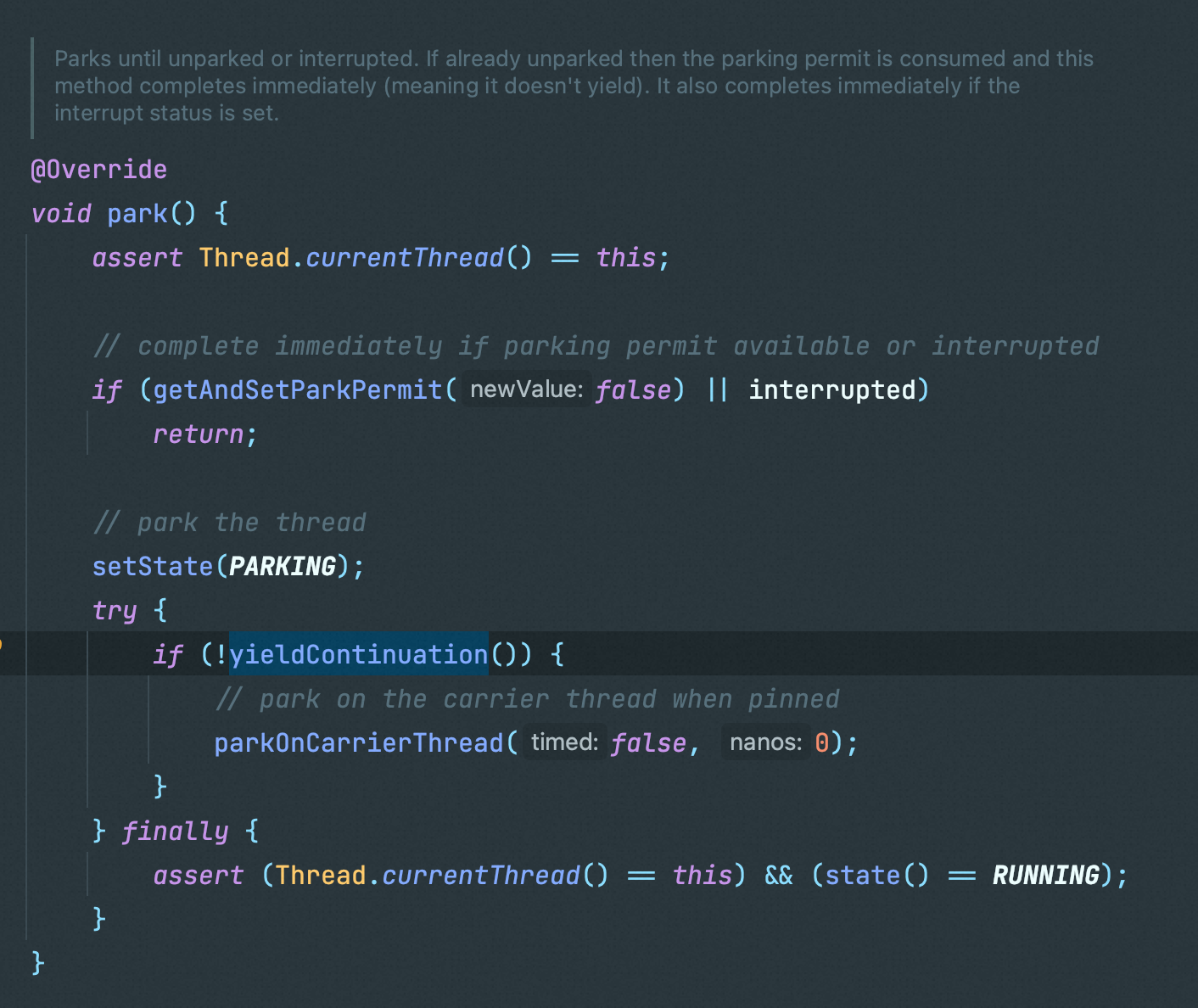
可以看到在LockSupport中最终也是通过yieldContinuation挂起的协程
磁盘io
磁盘io目前就简单看了下FileInputStream的read方法,旧版jdk的实现是直接调用read0的
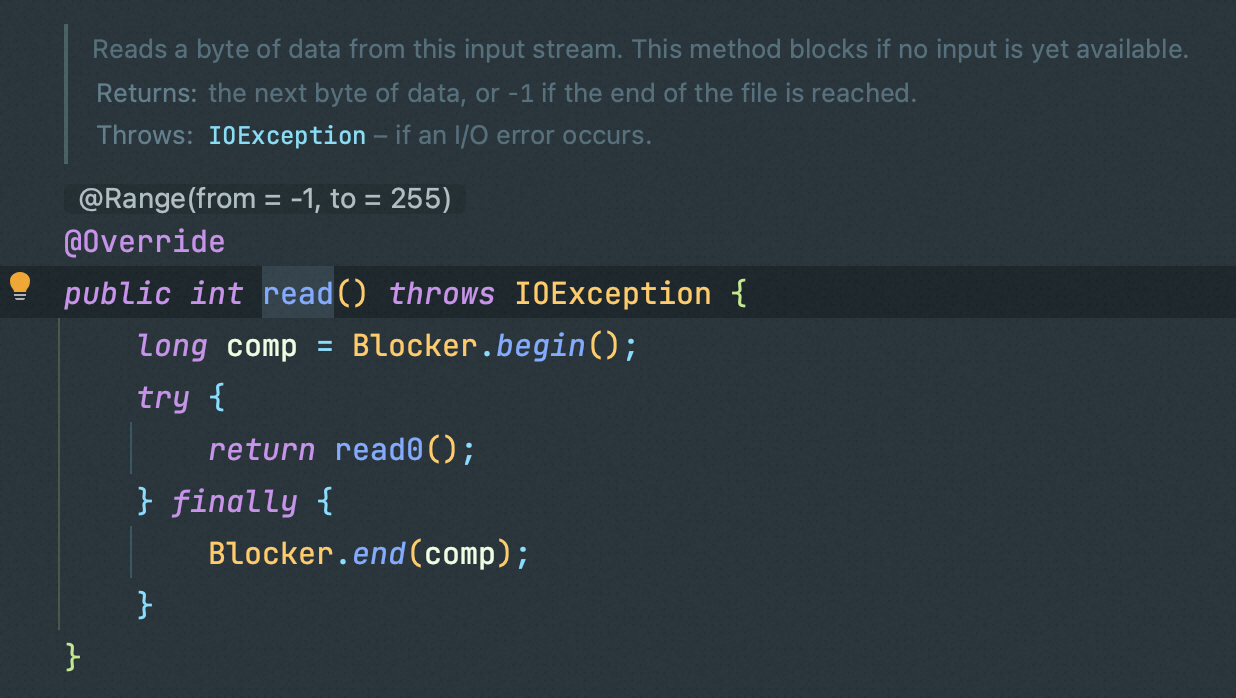
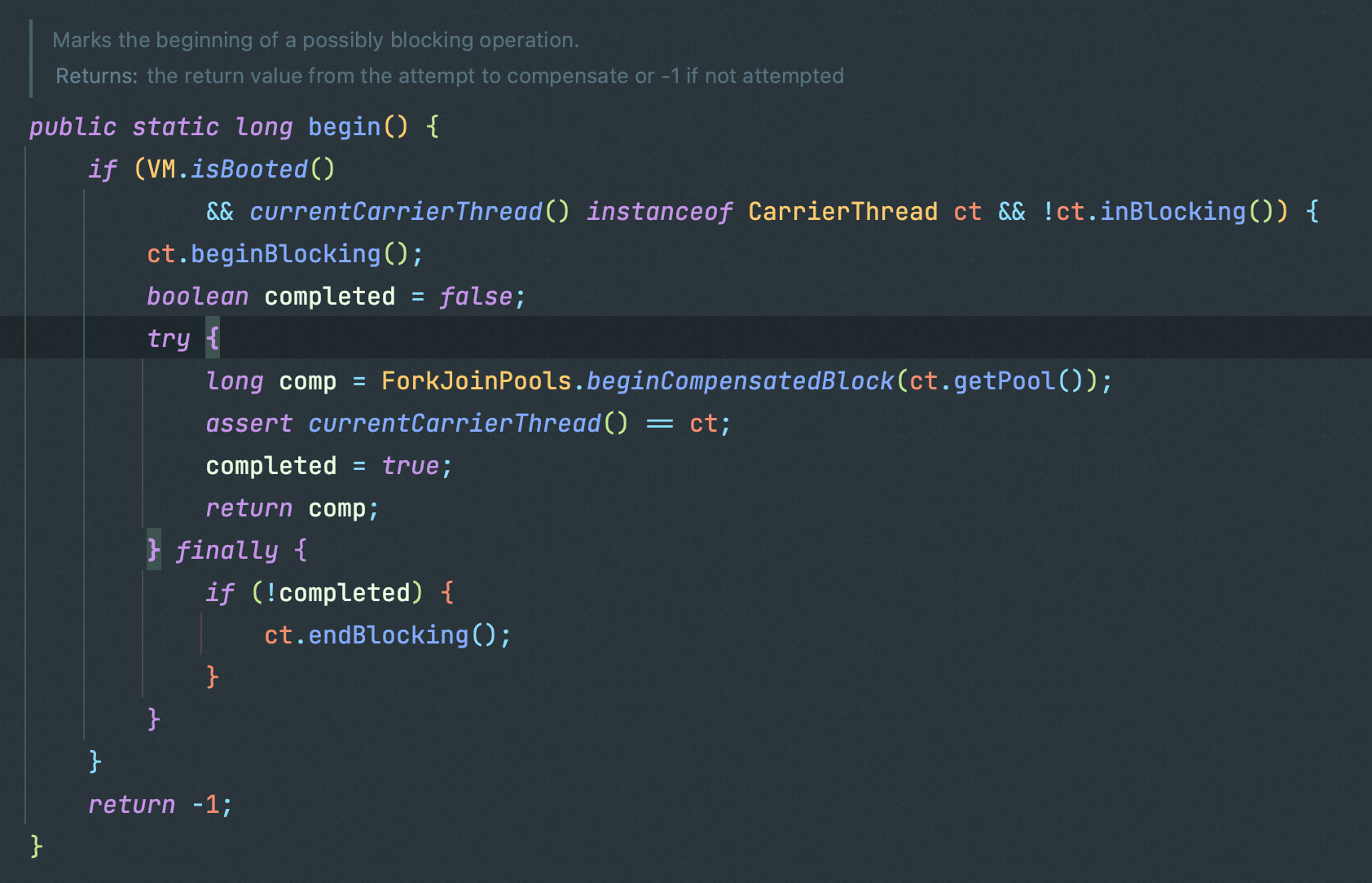
ForkJoinPools.beginCompensatedBlock会通过tryCompensate方法创建并激活一个备用线程,来执行阻塞操作
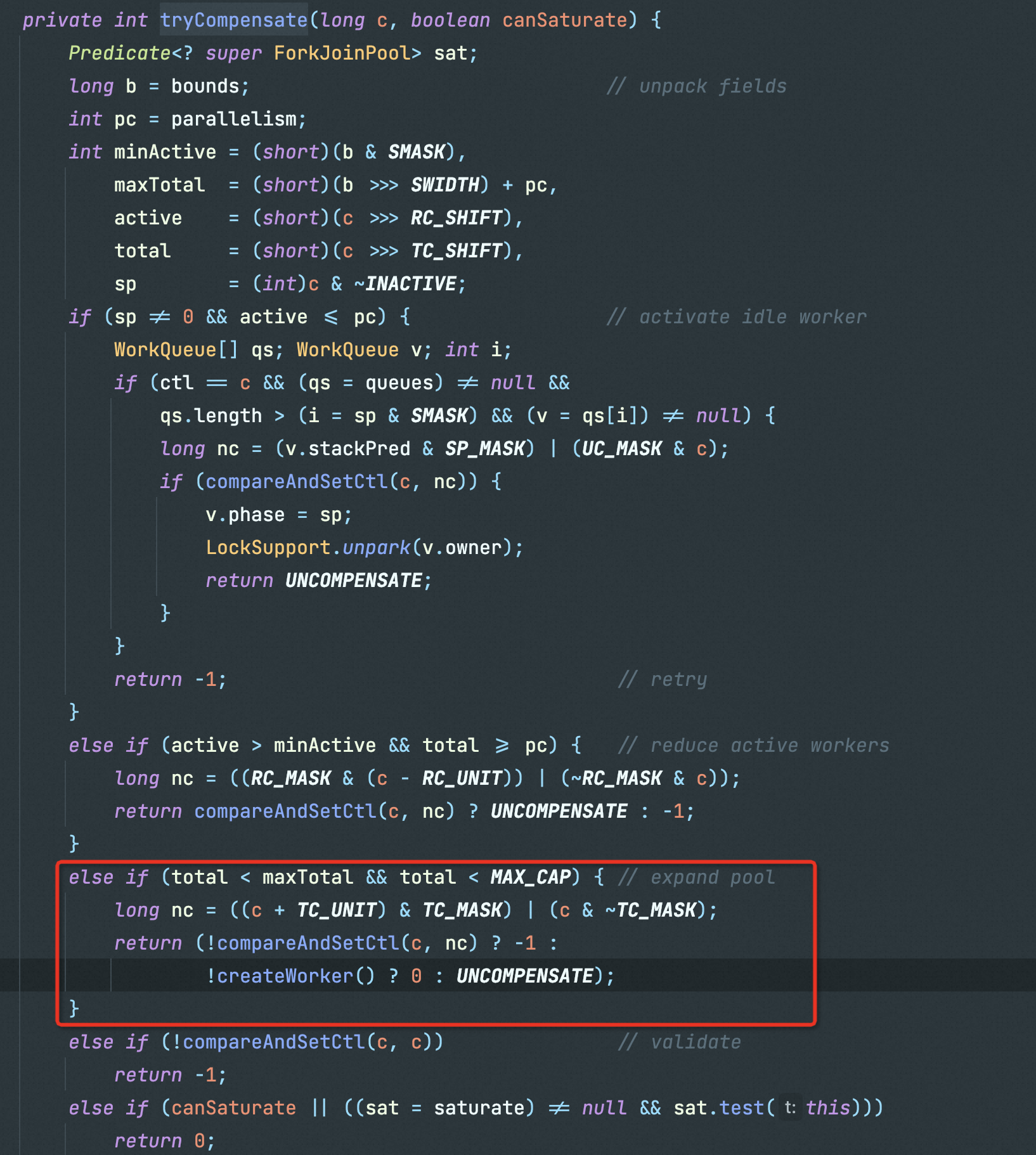
Java协程的调度是通过ForkJoinPool来实现的,因此也是具有work stealing机制的
总结
协程主要提供了两种新的能力:
用写同步代码的方式编写异步非阻塞代码
轻量级的“线程”切换方式,减少阻塞线程唤醒带来的开销
协程减少了使用线程池的心智负担的同时,对开发者对异步、阻塞的了解要求更高
对于协程,我们应该以一种拥抱新技术的态度来面对,协程作为这些年JDK的重量级更新,我相信后续也会越来越多的被用到生产环境中,我们要随时做好这个准备。同时对于JDK的其他更新(比如ZGC),相信随着后续各个团队升级JDK也会有被用在生产环境的机会。
还有很重要的一点(笑),我们在面对Go等其他语言开发者吐槽Java不支持协程时,也要有与其“论剑”的能力,协程究竟为开发带来了什么,而不是谈起协程就是泛泛而谈的轻量、快... | 





 订阅
订阅