|
可用性测试的权衡之道(一)
对于可用性测试,业内人士存在一些普遍认可的原则。它们神圣地如同自然科学里的理论,似乎我们只能对其言听计从、俯首称臣才能践行出“好的可用性测试”。其实,即便是科学,它的一个特征也是“可证伪性”――理论的正确性总是存在前提条件的。真理再向前一步就成为谬误!
可用性测试中的原则同样如此,需要根据目的、资源、环境的不同,灵活把握、权衡取舍,而非一味恪守某一个或某几个原则,也许这才是可用性从业人员经验重要性的体现。
一.任务设置:精细 VS 宽泛
制定的任务过于精细,一般原则上是反对的。理由很清楚,如果你的任务精细到一步一步“引导”用户进行操作,那太不符合用户现实中的使用情境,平时没有人在旁边“引导”用户的每一步操作;而且过于控制用户的操作步骤,用户缺乏真实使用时的灵活性。
是不是我们设置的任务只能是宽泛的,不能细化呢?这就必须根据研究的目的来做抉择。如果产品处在设计的初期,我们需要关注一些宏大的问题(如:网站的整体架构、导航和分类的合理性、页面的逻辑关系),此时就需要通过宽泛而有弹性的任务,来查找宏观层面的问题。如果产品的设计已经非常完善,开始进行细节的修改迭代,此时就需要通过设置相对具体的任务来查找特定的细节问题(如:对某个命名的理解、按钮的使用、链接的点击、表单的填写)。按照《Don’t
make me think》一书的观点:一般用户使用互联网产品时满足于能用就行,不会寻求最好的使用方法;只扫描网页,不会仔细阅读。所以,如果完全宽泛有弹性地设置任务,虽然更吻合实际使用情况,但是很可能用户直接跳过你想考察的细节。
实际工作中,由于时间和资源的限制,无法做到每个产品从设计初期到上线前后进行多次可用性测试。可能在一次的可用性测试中即需要同时关注宏观方面和细节上的问题。此时,还是需要和产品经理、交互设计师反复沟通,确认测试的主要目的,同时通过对任务设置精细程度的权衡把握,使次要目的也尽量得以满足。
不过,即便是想考察细节的任务,也要尽量避免“直接指导操作”式的语言描述方式,这样能让任务与真实使用情境不会相距太远。例如:想考察豆瓣读书页面【想要】按钮是否能被看到、是否具备可点击感。下面列出两种表述方式,以作对比:
A.请找到您喜欢的那本书,并在该页面点击【想要】。(×)
B.请找到您喜欢的那本书,并在该页面对其作个标记。(√)
二.任务数量:多VS少
任务数量的多少与可用性测试考察范围有关,与任务的精细程度也有关。如果对网站全站进行考察和只对其中某个页面、某个操作流程进行考察,所需的任务数量自然不一样。在同样的考察范围下,如果任务设置得越精细,所需任务数量也就越多。
Lindgaard和Chattratichart(2007)的研究发现任务数量与发现可用性问题比例存在显著的相关关系(r=0.82,p<0.01)。为了尽可能多地发现可用性问题,我们就尽量多地设置任务给用户吗?
此时要考虑任务数量过多可能带来的弊端:学习效应和疲劳效应,尤其是靠后的任务更可能会受影响。心理学实验中处理此问题的方法是顺序平衡,抵消影响。但是可用性测试中设置的场景和任务存在特定的先后次序,不适合采用顺序平衡的方法。基于我们的经验,还是通过对测试的任务数量进行控制,确保正式测试环节最多不超过1小时,加上前后的欢迎语、访谈、问答等,整个过程不超过1.5小时。
此外,任务数量的多少还会间接影响到测试所需参与者数量的多少。
三.用户人数:5个足够VS 5个不够
Nielsen的研究发现,5个用户可以发现80%以上的可用性问题。这个结论得到许多人的推崇,因此称之为“魔法数字5”。这个结论的来源依据是每个用户平均可以发现30%的可用性问题,且假设所有问题都有同等被发现的概率。不过,当设置的任务数量过多,且任务的精细程度和难度多种多样时,这个前提有可能不成立。
Lindgaard和Chattratichart(2007)的研究发现测试用户数量与发现的可用性问题比例并不存在显著的相关关系。这个结论似乎又支持我们选择少量用户进行测试即可。
其实,在用户招募阶段,比用户数量更需要重视是用户的代表性的问题。能否招募到有代表性的用户将直接影响可用性测试的成败。如测试一个医疗软件产品,招募到医护人员和患者作为测试用户,那5个用户可能就足够了;但如果只招募到医学实习生来测试,就必须超过5个以上的用户(即便这样,也未必能推论到整个产品的用户群)。
由此看来,招募用户的人数和任务的数量、精细程度、用户的代表性也是息息相关的。参考Tom
Tullis(2009)和本人经验:当可用性测试范围限定在一定的范围(20个任务内、或30个网页之内),且招募到很强代表性的用户,那么5个足够了。如果存在着差别较大的亚群体,争取做到每个亚群组有5个左右的代表性的用户(当然,目标用户的特征及分类应该是在可用性测试之前的用户调研阶段就解决的问题);一次测试最多不会超过12个用户。
四.用户表现:行为VS言语
在可用性测试中强调对用户操作行为的关注,是毋庸置疑的。因为:
1.用户的行为指标更明确、具体、客观,易观察和记录。
2.如果完全把关注点放在用户的操作行为上,那么就无需跟用户进行多余的(指导语之外的)语言交流。类似于心理学研究规范,对实验或测试中的指导语进行统一,对一切无关变量(包括主试的语言、体态表情)进行控制,以减少对研究过程的干扰。
3.即便你直接询问用户某些问题,也极可能得到错误的答案。30年前Richard
Nisbett和Timothy Wilson的实验、2年前Peter Johansson在《science》的文章,都证实了某些情况下人们无法解释清楚自己行为的真正原因。另外,用户还可能揣摩主试的喜好,回答他们认为主试期望的答案。
因此,有必要强调在可用性测试过程中关注的重点永远应该是用户的操作行为,而且尽量减少任何无关变量的干扰。但这个原则被有些人引申到极端,认为只有观察用户的操作行为才有意义,其他信息都是无需关注的,甚至轻率地怀疑用户的话都是不可信的。
可用性测试的主要目的虽然是发现问题,但也需要了解问题背后的原因,而仅仅依靠观察用户的操作行为是无法获悉所有问题背后的原因的,此时,我们就希望用户能采用“出声思维法”,出声思维就是集中于如何与产品进行交互的意识流。如果测试中的氛围比较平等、自然、融洽,用户又特别愿意表达,那么用户就会在进行任务操作同时,表达他们想做什么、打算如何做、背后的原因是什么。此时,不仅是操作行为、用户表达出来的想法和原因、以及语言中透露出的疑惑、失望、不满、惊讶、犹豫等情绪同样是需要我们加以关注的。但是,有些用户比较内向,不善于主动表达自己的想法,此时就需要主试跟他进行简单的交流,以引导用户说出背后的原因(注:不是引导用户说出你期望得到答案)。
所以,在实际的可用性测试,基本应该以关注用户的行为为主,少量、适时地进行询问交流也是需要的。但这个度如何把握呢?
1.当用户出现犹豫、惊讶、任务失败(过程节点上出现自然而然地稍微中断/暂停)的时候才进行简单的询问。
2.询问采用一般疑问句的句式,重复用户刚才的行为表现(要具体客观):“你刚才没有……,是吗?”――虽然没有直接问“为什么”,但暗示了希望听到他进一步的解释。
3.如果用户没有自己主动说出原因,可以“顺便”问一下“为什么?”或通过身体前倾、目光注视等非语言方式来暗示用户你希望能听到更多内容。若用户很快、坚定地说出原因,则该理由的可信度较高;如果用户犹豫、或难以说出原因,就不要继续追问。
除了上述的语言、情绪、行为都需要得到关注,还有一种特殊情况是需要听懂用户“没有说的”语言。例如,我们预计网站的某二级导航标签和一级导航标签存在分类逻辑上的不合理;但用户在测试中,导航相关的操作步骤进行得很流畅,用户也什么都没说。这通常表明用户认为这些是理所当然的、不影响操作的――此时你需要听懂用户“没有说的”语言。如果你简单粗暴地打断用户并询问:“你觉得这两个导航标签如何?”,则变成了一种诱导性地提问。
总结一下关于此部分内容的实践应用:
1.用户的操作行为永远是可用性测试的重点。
2.鼓励用户采用“出声思维法”。
3.适时、少量地向用户提问,禁止对同一个问题反复追问“为什么”。
4.采用真正地“倾听”技术保持和用户的交流状态,而非通过过多的话语。
5.开放、不预设立场地观察、倾听用户“没有说的”语言。
在可用性测试中考虑需要遵循的原则时,一定要理解它的适用条件,以及它和其它原则之间的互相影响,并结合本次用户研究的目的、资源、环境综合考虑,以尽可能形成一个最优方案。由于博文长度所限,先总结这么多,在下次的文章中会继续总结其它几方面的原则。
可用性测试的权衡之道(二)
继续讨论可用性测试中各种原则的灵活运用和注意事项。
五.发现问题:真的 VS 假的
判断发现问题的真假,初看上去似乎不是个困难。多数或全部参与者都遇到的问题毫无疑问是明显的可用性问题。或许有人会建议,根据参与者中发现该问题的人数比例来判断:比例高是真问题,比例低是假问题。前半句话可以接受,后半句话则有待商榷。
虽然可用性测试是相对严谨的用户研究方法,但是其对无关变量控制的严格程度和真正的心理学实验还是有一定的差距;并且心理学实验对每组参与者数量的最低要求是30人,这样得出的结论(数量比例)才具有推论至一般的意义。而可用性测试一般才8人左右的参与人数(尽管招募的参与者在质的方面非常具有代表性),但却无法把可用性测试中出现的所有数量比例简单推论至一般。8个参与者中有1人发现某个问题,不代表现实中出现同样问题的真实用户只有12.5%,更不代表这个问题不是真正的/严重的可用性问题。
问题的真假除了根据问题出现的次数比例,还有很重要的考虑点是:用户“错误行为”背后的认知/思考方式是否合乎逻辑?
这里顺便借用一下诺曼《设计心理学》里谈到的理论:概念模型――系统表象――心理模型。概念模型可认为是产品设计人员对产品的设计思想;系统表象可认为是产品展现出的交互界面;而心理模型则是用户按照既往经验对如何操作该产品的设想。从这个角度来认识,可用性问题则是“概念模型、系统表象、心理模型”三者的不吻合或矛盾。

通过分析用户行为背后的认知是否符合逻辑,来判断发现的问题的真假,主要体现在以下几点:
1.“概念模型、系统表象”的不一致
产品设计人员突然发现,界面的交互形式根本没有反映出他原先的设计思想!
2.“系统表象、心理模型”的不一致
(1)用户的思维方式受已有的同类产品的影响,并内化接受,而新产品的“系统表象”和已有同类产品并不一致。
(2)用户在日常生活经验中形成了许多并不科学地通俗理解世界的方式(比如通俗物理学、通俗心理学),但产品设计人员没有意识到用户在以这样一种“自认正确”的错误方式来理解和使用产品。
如果发现的可用性问题属于以上情况,那么即使只有一个参与者碰到,它也非常可能是一个真正的可用性问题。
例如:让用户登录购彩网站,查看自己上次购彩结果。大多数用户点击【个人中心】去查看,有2个用户点击【开奖公告】去查看,发现只有开奖号码,没有任何购彩结果信息后,再去点击【个人中心】。仅2个人出现了稍微的偏差,而且很快就找到了正确的页面,这貌似应该不算什么问题。
但若追究其行为背后的逻辑,并与其他用户的反馈(“我上次买的号码没有直接显示出来?”“这里看不到开奖的号码啊?”)联系起来,可以判断用户的心理模型和产品的系统表象不一致。用户希望能同时对照着开奖号码和自己买的号码很方便地核对,而网站却割裂两部分放在不同的页面,因此需要将这2个用户碰到的问题当作真正的可用性问题来对待。
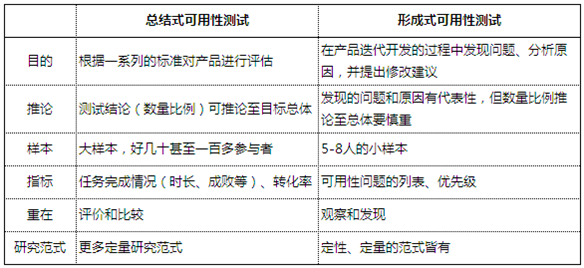
六.研究方法:定性 VS 定量
可用性测试,很多时候被认为是一种定性研究方法;但也有人说它是一种定量研究方法。究竟是怎么回事呢?
个人认为,可用性测试实质上结合了定性和定量两种方法的特点,到底哪种成分更多,要看你的使用目的以及细节上如何操作。
定量研究的思路是基于对一定数量样本的测量,以将研究所得的结论推广至总体。除了强调样本的代表性,还对样本的数量有具体的要求,同时会考虑抽样误差、置信度、置信区间的度量。并且定量研究过程中非常注重对某些自变量操控、及无关变量的控制。
而定性研究重视对主观意义的理解(如背后隐藏的原因),采用解释建构的方法,比如访谈法等。
平时工作中以“形成式可用性”测试为主,即便它稍微偏向于定性研究,但在允许的范围内,我个人还是尽可能地遵循着定量研究的方法去实施。这样整个测试过程的严谨性能得到保证,结论的客观程度相对更高(近几个世纪来,量化研究一直是科学研究的主要范式,也正是这个原因)。具体做法如下:
1.在任务的设置上:因为参与者可能存在差别较大的亚群体,不可能要求完成完全相同的任务。但必定会设置大部分基本的、都需要完成的公共任务,再针对不同亚群体设置少量的特殊任务。在后期统计分析的时候,基本的公共任务则可以进行数量化的统计,并横向比较。
2.在测试过程中:关注参与者完成任务时的相关行为,用数字来记录(以0、0.5、1分别表示失败、帮助/提示下成功、成功)。主试尽量少地言语及体态姿势的干扰,只在必要时进行适当地言语交流。
3.在报告呈现:对任务完成情况(效率、完成率)统计呈现,对不同任务的完成情况进行比较,对亚群体间的任务完成情况进行比较,对所有可用性问题按数量化指标进行排序等。或者比较迭代前后独特问题的频次是否减少,以及严重程度高的等级里面可用性问题数量的变化情况。
4.测试过后,我们通常还会收集用户自我报告式的数据,作为“感知可用性”的一个总体反映。
(1)推荐使用系统可用性量表(SUS),因为有研究表明SUS在少量样本时即可产生较为一致的评分结果。
(2)为减少用户在填写这些量表时的反应心向,不要求填写任何个人信息,且主试最好暂时回避。
(3)只统计分析所有参与者SUS量表总分的平均值,切勿再拆分比较亚群体之间的差异,因为即便信效度再高的量表,当样本量极小时都会变得很不靠谱!
七.问题优先级:单指标 VS 多指标
除了在可用性测试过程中,最终报告也必须体现出量化、客观地特点。例如,报告发现的可用性问题的列表,我也会以量化的方式排列出问题的优先级别。
这样做的好处在于:首先,发现的可用性问题肯定有一些比另一些更严重;其次,考虑到产品和设计人员的精力和资源总是有限的,必须帮助他们梳理出最亟需整改的问题。站在别人的角度考虑问题,这样他们才能更“友好地”接受我们的报告。
可用性问题列表的排序,涉及到采用单指标还是多指标、以及指标分为几级的问题。

先就量化的客观性而言,“出现频率”指标是最客观、最易量化的;而其它三个指标都需分析人员的主观判断。
就指标的代表意义而言,“严重程度”、“出现频率”与用户体验最相关,与用研人员的职责也最相关。另两个指标可能更多地是产品人员的职责。
就指标的价值而言,多个指标的综合显然比单一指标更有价值。
基于上述考虑,实际工作中我会选择“严重程度”和“出现频率”两个指标的综合,作为可用性问题的优先级指标。“严重程度”分为3级,而不是5级(分析人员主观判断时,3级指标的误差率要低于5级指标);“出现频率”采用计算的具体数值,而非4级分类。这两个指标合并时,采用1:1的权重,具体公式为:
问题优先级=严重程度的级别+出现频率的具体值×3
八.报告呈现:优点 VS 问题 VS 建议
当产品设计人员辛辛苦苦做出的产品却被你报告上罗列的各种问题批评得一无是处时,即便理智上认可你的成果,情感上也很难接受。因此报告中列出哪怕一条最重要的优点,也会让产品设计人员感到欣慰、感受到你中立的态度,增加对报告的接纳程度。列出优点的另一个好处是,在测试中被参与者多次自发提及的优点确实带给用户某种惊喜;当你在报告中再次强调时,可以避免在后期迭代开发中丢失掉原本的优点。
问题的列举肯定是报告中非常重要的部分,但切勿罗列出清单就草草了事,因为:
1.某个(些)问题和另一个(些)问题是有关联的,但是报告中的问题列表部分却割裂了这些联系。
2.产品设计人员无法一直参与旁听/观察可用性测试的过程,导致对报告中文字描述的问题缺乏感性认识。
3.只提问题却不提供解决方案,就不是“建设性地提问”!
因此,我们需要在可用性测试报告的后半部分提出针对重要问题的解决方案。其目标并非是强迫产品设计人员一定要采纳我们提出方案,而是:(1)把一些相关问题联系起来看,(2)加深报告阅读者对于问题的感性认识和背后原因的理解,(3)使整个报告的思路更清晰、完整,(4)我们还可学到一些交互设计和产品的知识。
总之,可用性测试施行起来既简单又复杂。简单是因为不管你如何施行,终究能发现一些问题;复杂则在于发现可用性问题的质量、重要性、对测试的利用效率、对产品设计人员的帮助程度可能相距甚远。一次成功的可用性测试体现在从前期策划、测试过程、后期报告等整个过程中是否遵循了这些原则,并在某些难以两全的原则面前做到合理的权衡取舍。 | 

