| БрМЭЦМі: |
| БОЮФРДздгкЬкбЖдЦЃЌНщЩмСЫгУЛЇЛЯёЦРВтЕФМђвЊЛиЙЫКЭзмНсЃЌpythonДѓЪ§ОнДІРэЩёЦїpandasЕФећЬхНщЩмЁЃ |
|
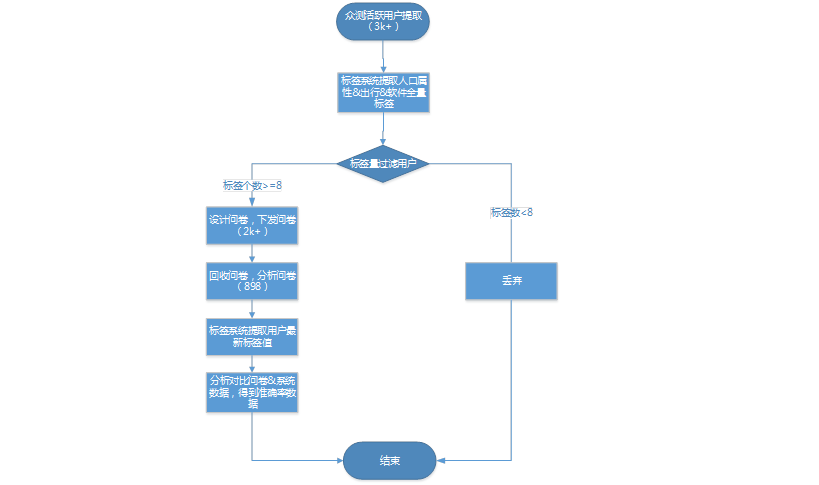
Part1 гУЛЇЛЯёЦРВтЛиЙЫгызмНс
1ЁЂЮЊЪВУДзігУЛЇЛЯёЦРВтЃП
НЋЪБжгВІЛиЕН2018ФъГѕЃЌДѓМвЦШЧаЯыДђЦЦвдЭљзЪбЖЭЦМіЮоеТПЩбЕФОжУцЃЌЖјНёШеЕФЭЦМіЫуЗЈвВЫЦКѕбнГЩСЫЩёЛАЃЌгУЛЇвтЭМетИіДЪдкWiFiЙмМвЭХЖгБЛвЛдйЬсМАЃЌМЬЖјAIЭЦМіВМОжБЛЭЦЕНСЫЧАЬЈЁЃ
гУЛЇвтЭМЪЖБ№ЕФгХСгШЁОігкЖдгУЛЇЪЕЪБашЧѓЕФСЫНтГЬЖШЃЌДЫЪТЙХРДФбЁЃAIЭХЖгТЪЯШзіЕФГЂЪдЪЧдквЛаЉЬиЖЈГЁОАЯТВТВтгУЛЇвтЭМЃЌНјаавтЭМЯрЙиЭЦМіЃЌШчзЁОЦЕъгУЛЇЃЌЕиЬњЩЯгУЛЇЕШЃЌетЪЧЫуЗЈПЩвдзіЕФЪТЧщЃЌФЧВтЪддкетИіЙ§ГЬжаПЩвдзіаЉЪВУДФиЃПЫуЗЈбщжЄЯрЖджЭКѓЃЌгаЪВУДПЩвдЯШааЕФФиЃПгУЛЇвтЭМЪЖБ№ЪзвЊЪЖБ№ЖдгУЛЇГЁОАЃЌШчЙћГЁОАДэСЫЃЌКѓУцЕФЙЄзїОЭЮоЗЈЙиСЊЦ№РДЁЃШчЃЌзЁОЦЕъЃЌЪЧИіЖЏЬЌГЁОАЃЌГЂЪдНјвЛВНВ№ЗжГЩПЩКтСПЕФОВЬЌГЁОАЃЌШчЃЌЪВУДШЫЃЈадБ№ЃЌЙЄзїЃЌЦЋКУЕШЃЉЃПЪВУДЪБМфЃЈГіааЪБМфЃЉзЁЪВУДОЦЕъЃЈОЦЕъЮЛжУЃЌМЖБ№ЕШЃЉЃПетаЉЮвУЧЪЧгаКѓЬзБъЧЉЯЕЭГЕФЃЌОЙ§СЫНтетаЉБъЧЉЯЕЭГвбОгааЉГЂЪдгІгУЃЌЕЋЪЧБъЧЉБОЩэзМШЗадШДЮоДгЦРЙРЃЌвђДЫЃЌгУЛЇБъЧЉзМШЗадЦРВтОЭдкуТЖЎжаГяБИПЊЪМСЫЁЃ
2ЁЂгУЛЇЛЯёзМШЗаддѕУДзіЃП
ИааЛЯШааепфЏРРЦїЭХЖгЃЌЬсЙЉСЫзюГѕЕФЦРВтЫМТЗЃЌЫћУЧЕФПМТЧКмжмШЋЁЃЖјЮвдкОпЬхЕФЪЕМљЙ§ГЬжаЃЌИљОнвЕЮёЕФЪЕМЪЧщПіжЦЖЈСЫзюжеЕФЦРВтЗНАИЃЈЯТЭМЃЉЃЌДгЕквЛТжБъЧЉЬсШЁПЊЪМЃЌОЭБЉТЖГіИїжжЯИНкЮЪЬтЃЌКУдкЖМвЛвЛНтОіСЫЁЃ
МђЕЅСаЯТПЩЙЉКѓРДепНшМјЕФМИИізЂвтЯюЃК
ЃЈ1ЃЉ ЮЪОэЩшМЦЕФддђЃКУПвЛИіЮЪОэЬтФПгыКѓЬЈБъЧЉЖдгІЙиЯЕЬсЧАПМТЧКУЃЌгаЕФвЛЖдвЛгаЕФвЛЖдЖрЁЃЮЪОэЕФУПвЛИібЁЯювЊгыЖдгІБъЧЉЕФШЁжЕЖдгІКУЙиЯЕЃЌетЛсДѓДѓМђЛЏКѓЦкНХБОДІРэЙЄзїЁЃ
ЃЈ2ЃЉ ЮЪОэЯТЗЂЛиЪеЃКзюГѕЯТЗЂСЫlabelЪ§СП>9ЕФгУЛЇЃЌгУ>8ЕФгУЛЇВЙСЫ1kЃЌНсЙћЪЕМЪЛиЪеТЪВЛЕН50%ЃЌгкЪЧзЗМгСЫ>8ЕФШЋСПгУЛЇЃЌзмЙВ4kЖрИіЃЌЪЕМЪЛиЪевРШЛВЛзу1kЃЌЖјДЫМфКФЗбСЫНЋНќ2жмЕФЪБМфЁЃ
ЃЈ3ЃЉ ЙиМќзжбЁШЁЃКећИіЙ§ГЬЙиМќзжЪЧimeiЃЌЕЋЯТЗЂЮЪОэЪБЃЌжкВтЦНЬЈЙиМќзжШДЪЧqqЃЌетОЭдкЪ§ОнДІРэЩЯгжашвЊЖрвЛВузЊЛЛДІРэСЫЁЃ
ЃЈ4ЃЉ БъЧЉЯЕЭГЬсЪ§ЃКБъЧЉЯЕЭГЕФЪ§ОнЪЧжмЦкадИќаТЃЌИќаТЦЕТЪИпЃЌНЈвщЮЪОэЛиЪеКѓНјааЖўДЮЬсЪ§ЃЌОЁПЩФмМѕЩйЪБМфВюдьГЩЕФЪ§ОнВЛвЛжТЁЃ
ЃЈ5ЃЉ НХБОДІРэЃКвђЮЊЩцМАЕФЪ§ОнСПБШНЯДѓЃЌЩцМАЕНБШНЯЖрЮФМўЕФДІРэЃЌЧПСвНЈвщзАСНИіПтЃЌjupyter
notebookЃЈНЛЛЅЪНБЪМЧБОЃЌПЩМАЪББраДКЭЕїЪдДњТыЃЌКмКУгУЃЉЃЌЛЙгавЛИіДѓЪ§ОнДІРэЕФpandasЃЌЖдгкexcelЕФВйзїЪЕдкБуРћЬЋЖрЁЃ
ЃЈ6ЃЉ ОЮГЖШДІРэЃКОЮГЖШЪ§ОнУЛЗЈЯТЗЂЮЪОэЃЌвђДЫЮЪОэЬтФПЩшМЦГЩЮЪОпЬхЕижЗЃЌДѓТЅЃЌаЁЧјЕШЁЃЪ§ОнзЊЛЛНгШыСЫЕиЭМЕФФцЕижЗНтЮіНгПкЃЌШЛКѓдйЖдБШОпЬхЮЛжУаХЯЂЃЌетРяЕФЖдБШвВЪЧОРНсСЫ1ЬьЪБМфЃЌзюжеОЋШЗЕН2ИіжаЮФзжЗћЕФЮЌЖШЁЃ
3ЁЂгУЛЇЛЯёзМШЗаддѕУДЗжЮіЃП
жСЮЪОэЛиЪеЭъБЯЃЌЪЕМЪЙЄзїВХЭъГЩвЛАыЃЌНгЯТРДОЭЪЧдЖГЌдЄЙРЕФИДдгЗБЫіЕФЪ§ОнДІРэМАЗжЮіЙ§ГЬСЫЁЃЮвЯыгУЯТУцетеХЭМРДУшЪіећИіЗжЮіЙ§ГЬЁЃ
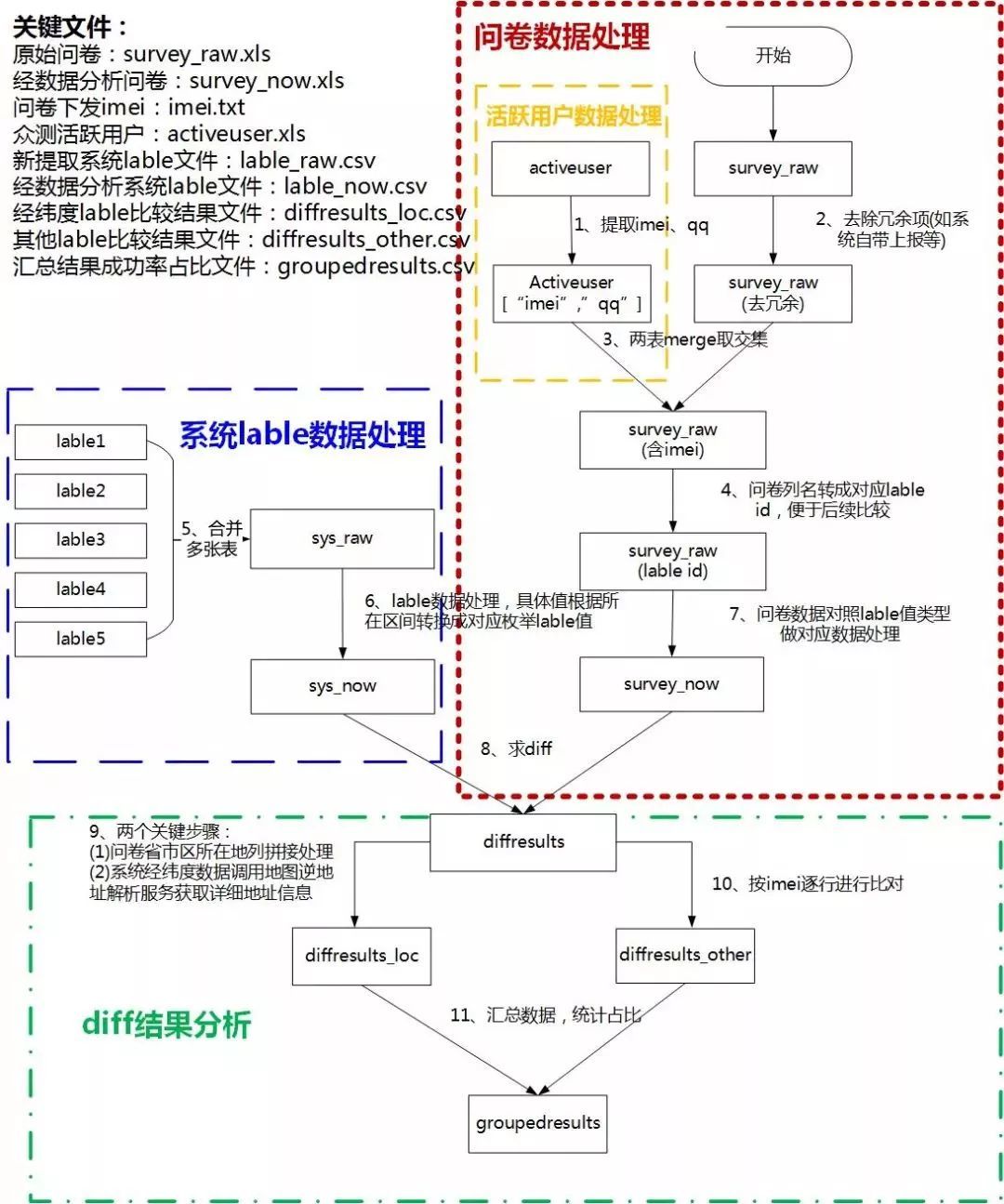
ећИіЗжЮіАќРЈЫФВПЗжЃК
ЃЈ1ЃЉ ЛЦПђЃКЛюдОгУЛЇЪ§ОнДІРэЁЃ
1.ЮЊЪВУДвЊзіЃП
ЛюдОгУЛЇжївЊЯТЗЂЮЪОэЧАгУЃЌетРяЮЊЪВУДЛЙашвЊзіЗжЮіФиЃПетРяЕФЗжЮіЙЄзїЪЧПЩвдЪЁЕєЕФЃЌЗНАИзюКѓЛсЫЕЃЌЯШРДПДетРяЕФФПБъЪЧЪВУДЁЃвђЮЊЮЪОэУЛгаЪеМЏimeiЪ§ОнЃЌЖјlableБъЧЉЪЧИљОнimeiНјааЭГМЦЕФЃЌвђДЫетРяашвЊЖрзівЛВуmergeДІРэЃЌвдЪЙЮЪОэПЩвдВЙзуШБЪЇЕФimeiаХЯЂЁЃ
2.ЪЧЗёПЩгХЛЏЃПЪЧЗёДцдкЗчЯеЃП
ЯИаФЕФЖСепПЩФмвбОЗЂЯжЃЌетРяДцдквЛИівўЛМЃЁПЩФмЕМжТбљБОЪ§СПМѕЩйЃЌвђЮЊгУЛЇЕФqqКЭimeiЦфЪЕВЛЪЧвЛвЛЖдгІЕФЃЌПЩФмДцдквЛЖдвЛЛђвЛЖдЖрЧщПіЃЌШчЙћЯТЗЂimeiгУЛЇИќЛЛqqЭъГЩСЫЮЪОэЃЌетРяЕФmergeОЭЛсЕМжТВПЗжбљБОЪ§ОнЗДВщВЛЕНimeiЪ§ОнДгЖјЖЊЪЇбљБОЁЃЧьавЕФЪЧБОДЮВтЪдЖЊЪЇбљБОЪ§ВЛЕН10ИіЃЌЗёдђЮвПЩФмвЊДгЭЗдйРДСЫЁЃ
3.ШчКЮЙцБмЃП
дкгУЛЇЮЪОэЩшМЦжаШУгУЛЇжїЖЏЗДРЁimeiаХЯЂЁЃЧАЦкЩшМЦУЛгаПМТЧЧхГўkeyжЕЕФЩшМЦдьГЩСЫетИівўЛМЃЌЭЌЪБЛЙдіМгСЫЗжЮіЕФЙЄзїСПЁЃ
ЃЈ2ЃЉ РЖПђЃКЯЕЭГlableЪ§ОнДІРэЁЃ
1.ЮЊЪВУДвЊзіЃП
ЯИаФЕФЖСепЛсЗЂЯжЃЌЯЕЭГlableдкзюГѕвбОЬсШЁСЫЃЌгУгкзіЕЅИігУЛЇlableЪ§СПЕФЙ§ТЫЗжЮіЃЌетРяЛЙПЩвджБНггУдРДЕФЪ§ОнУДЃП
Д№АИЪЧЗЧГЃВЛНЈвщЃЁвђЮЊКѓЬЈЪ§ОнЛсжмЦкадИќаТЃЌзюГѕЬсШЁЕФЪ§ОнвбОВЛФмБэеїЮЪОэгУЛЇЕБЧАЕФЩЯБЈЪ§ОнСЫЁЃЫљвдlableЪ§ОнжиаТЬсШЁетвЛВНВЛФмЪЁЁЃ
ЃЈ3ЃЉ КьПђЃКЮЪОэЪ§ОнДІРэЁЃ
1.ЮЊЪВУДвЊзіЃП
ЮЪОэЩшМЦЕФддђЪЧБугкгУЛЇРэНтбЁдёЃЌгыДњТыЪ§ОнЩЯБЈЪЕЯжВювьКмДѓЃЌЫљвдетРяЕФЪ§ОнНтЮіЪЧБиаыЕФЃЌвВЪЧНсЙћЗжЮізюКЫаФЕФВПЗжЁЃ
2.зіСЫЪВУДЃП
етРяЮвЛЈЗбСЫДѓСПЕФЪБМфаДНХБОЁЂЕїЪдЃЌетРяДѓСПВЩгУpandasЃЌИааЛЫќДѓДѓМђЛЏСЫЮвЕФДњТыСПЁЃЮЊСЫБугкДѓМвЪьЯЄСЫНтpandasЕФгУЗЈЃЌЮветРяЛсНиШЁВПЗжДњТыРДПДЁЃ
Action1ЃКdropШпгрЪ§Он
ОбщЃКИааЛpandasЃЌЖЈвхdroplistЃЌЭЈЙ§dataframeЕФdropЗНЗЈЃЌСНааДњТыЃК

Action2ЃКАДlableidжиаТЖЈвхСаУћ
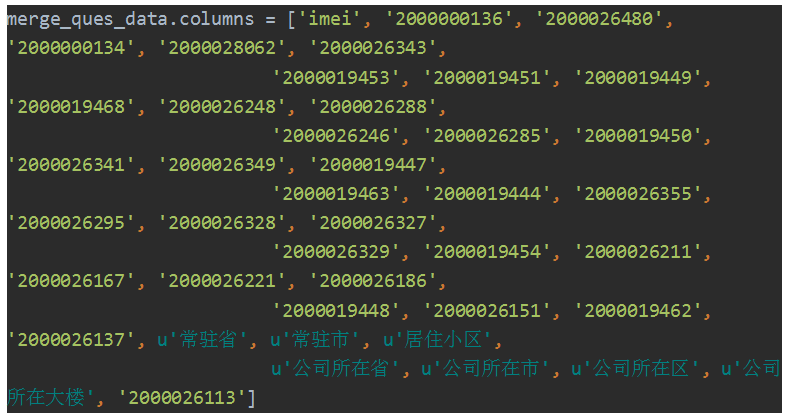
Action3ЃКГЃЙцИїСаЪ§ОнДІРэЃЈОйИіРѕзгЃЉ

ЃЈ4ЃЉТЬПђЃКdiffНсЙћЗжЮі
1.зіСЫЪВУДЃП
дкНХБОДІРэЩЯОЮГЖШЛсИќИДдгЃЌЕЋЫМТЗДѓЭЌаЁвьЃЌБугкНтЫЕЃЌетРявдГЃЙцЪ§ОнОйР§ЁЃ
ЙиМќЕу1ЃКРћгУdataframeНЋвЛааШЁГіРДДцГЩarrayЃК

ЙиМќЕу2ЃКЖЈвхdiffresultЮФМўСаУћЃК

ЙиМќЕу3ЃКБщРњУПвЛСаЪ§ОнЃЌЙ§ТЫЕєВЛДцдкlableЃК

ЙиМќЕу4ЃКбЛЗБщРњБШНЯЯЕЭГЪ§ОнКЭгУЛЇЪ§ОнЃК
дкБОpartзюКѓЃЌдйзмНсЯТВЛзуЃЌжївЊгаШчЯТШ§ЗНУцЃК
ЃЈ1ЃЉ бљБОИВИЧШЋУцадВЛЙЛЃКИВИЧОпгаОжЯоадЃЌВЛФмДњБэЫљгаЕФгУЛЇЃЛ
ЃЈ2ЃЉ ЮоЗЈШЋздЖЏЛЏМрПиЃКЮЪОэЩшМЦМАЬсЪ§днЪБЮоЗЈздЖЏЛЏЃЌвВОЭНіЯогквЛДЮУўЕзЃЛ
ЃЈ3ЃЉ бљБОЪ§СПВЛзуЃКЕЅИігУЛЇЕФБъЧЉВЛШЋЃЌЕМжТБъЧЉећЬхЪ§СПЦЋЩйЁЃ
Part2 pandasЪЙгУзмНс
1ЁЂjupyterЛЗОГзМБИЃЈwebНЛЛЅЪНБЪМЧБОЃЌpythonПьЫйБрТыдЫааЕїЪдЩёЦїЃЉЁЃ
ЃЈ1ЃЉpip install jupyter

НтОіЃКЯТдиipython-5.7.0-py2-none-any.whlЃЌnotebook-5.5.0-py2.py3-none-any.whlЗХЕНpythonЕФScriptsФПТМЯТЃЌpip
install xxx.whlЁЃ
ЃЈ2ЃЉдйДЮpipinstall jupyter
ЃЈ3ЃЉЪЙгУjupyter notebook
new-бЁдёЖдгІРраЭПЩДђПЊНЛЛЅЪНБЪМЧБОНчУцЁЃ
2ЁЂPandasЩУГЄзіЪВУДЃП
ЃЈ1ЃЉПьЫйЖСаДcsvЁЂexcelЁЂsqlЃЌвддБэЪ§ОнНсЙЙДцДЂЃЌБуНнВйзїДІРэааЁЂСаЪ§ОнЃЛ
ЃЈ2ЃЉЪ§ОнЮФЕЕааСаЫїв§ПьЫйвЛМќжиЖЈвхЃЛ
ЃЈ3ЃЉЧПДѓЕФКЏЪ§жЇГжДѓЪ§ОнЮФМўЕФПьЫйЭГМЦЗжЮіЃЛ
ЃЈ4ЃЉПЩвдЖдећИіЪ§ОнНсЙЙНјааВйзїЃЌВЛБивЛаааабЛЗЖСШЁЁЁ
ШчЙћФњгаЩЯЪіашЧѓЃЌВЛЗСМЬајЭљЯТПДЁЃ
3ЁЂpandasАВзА
ЃЈ1ЃЉАВзАЃКвЛАугУpipЃЌАВзАЕкШ§ЗНПтЧАВЛЗСЯШИќаТЯТpipЁЃ
python -m pip install -U pip
pip install pandas
ЃЈ2ЃЉЕМШы
import pandas as pd
ЃЈ3ЃЉ Аяжњ
ВщПДpythonЕкШ§ЗНПтАяжњЃЌРћгУpythonздДјpydocЮФЕЕЩњГЩЙЄОп
Step1ЃКХфжУpydocЗўЮё
CmdЯТpython ЈCm pydoc ЈCp 1234

Step2ЃКфЏРРЦїДђПЊhttp://localhost:1234/
4ЁЂPandasЪ§ОнНсЙЙ
seriesЃКДјБъЧЉЕФвЛЮЌЪ§зщЃЌБъЧЉПЩвджиЖЈвхЁЃ
dataframeЃКЖўЮЌБэИёадЪ§зщЃЌЕМШыЖСШЁЕФcsvЁЂexcelОЭЪЧетжжНсЙЙЃЌПЩвджБНгЖдааСазіВйзїЁЃ
ОйИіР§згЃК


ЖСШЁБэИёЁЊЁЊЕУЕНРраЭЪЧDataFrameЕФЖўЮЌЪ§зщquestion_dataЃК

ЦфжаЕФвЛСаdf[ЁЎnumЁЏ]ОЭЪЧвЛЮЌЪ§зщseriesЃЌЯёИіЪњЦ№РДЕФlistЁЃ
5ЁЂpandasЕФЪ§ОнДІРэ
ЃЈ1ЃЉЪ§ОнМьЫїДІРэЁЃ
ЃЈaЃЉВщбЏЪзЮВЃЛ

ЃЈbЃЉВщбЏФГааЃЌСаЃЛ
зЂвтЃКilocЁЂlocЁЂixЃЈОЁСПгУixЃЌБмУтИуВЛЧхГўindexКЭааКХЃЉЁЃ

locЃКжївЊЭЈЙ§indexЫїв§ааЪ§ОнЁЃdf.loc[1:]ПЩЛёШЁЖрааЃЌdf.loc[[1],[ЁЎnameЁЏ,ЁЏscoreЁЏ]]вВПЩЛёШЁФГааФГСаilocЃКжївЊЭЈЙ§ааКХЫїв§ааЪ§ОнЁЃгыlocЕФЧјБ№ЃЌindexПЩвдЖЈвхЃЌааКХЙЬЖЈВЛБфЃЌindexУЛгажиаТЖЈвхЕФЛАЃЌindexгыааКХЯрЭЌЁЃ
ixЃКНсКЯlocКЭilocЕФЛьКЯЫїв§ЁЃdf.ix[1]ЃЌdf.ix[ЁЎ1ЁЏ]ЁЃ

ЃЈcЃЉАДЬѕМўВщбЏжИЖЈааКЭСаЃЛ

ЃЈdЃЉЖрЬѕМўВщбЏЃЛ

ЃЈ2ЃЉЪ§ОндіЩОИФДІРэЁЃ
ЃЈaЃЉдіЩОааЃЛ


ЃЈbЃЉдіЩОСаЃЛ

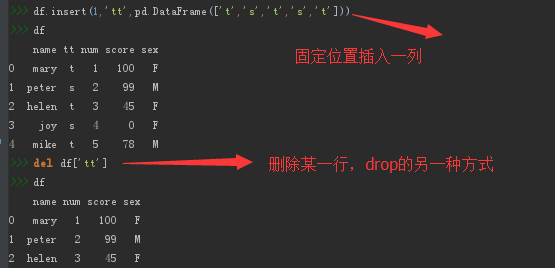
ЃЈcЃЉааСаЪ§ОнЯрСЌЃКВЮПДЃЈ3ЃЉЃЈcЃЉЁЃ
ЃЈ3ЃЉЖрБэЪ§ОнДІРэЃЛ
ЃЈaЃЉmergeЃЛ
eg:КЯВЂСНеХБэЃК
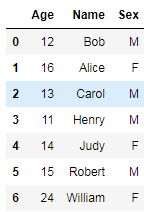
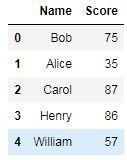
stu_score1 = pd.merge(df_student, df_score, on='Name')ЁЊЁЊФкСЌНгЃЌНЛМЏЁЃ
stu_score1
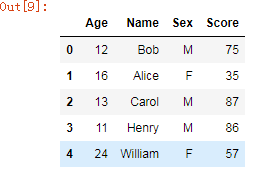
stu_score2 =pd.merge(df_student, df_score, on='Name',how='left')ЁЊЁЊзѓСЌНгЃЌвдзѓБпЮЊзМЁЃ
stu_score2
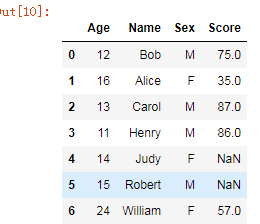
howВЮЪ§ЃКinner(ФЌШЯ)ЃЌleftЃЌrightЃЌouterЃЌЗжБ№ЮЊФкЁЂзѓЁЂгвЁЂЭтСЌНгЃЌinnerЮЊНЛМЏЃЌouterЮЊВЂМЏЁЃ
ЃЈbЃЉjoinЁЊЁЊhowддђЭЌmergeЃЌФЌШЯhow=ЁЎleftЁЏ
жїгУгкЫїв§ЦДНгСаЃЌСНеХБэВЛЭЌСаЫїв§КЯВЂГЩвЛИіDataFramЃЌБШНЯЩйгУЁЃ
ЃЈcЃЉconcatЁЊЁЊaxis=0ЃЌАДааКЯВЂЃЌaxis=1ЃЌАДСаКЯВЂ
stu_score2 = pd.concat([df_student,df_score], axis=0)ЁЃ
stu_score2
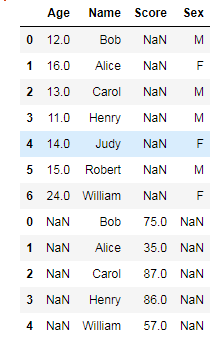
ЃЈ4ЃЉЪ§ОнЭГМЦДІРэЃЛ
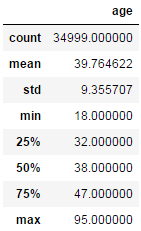
ЃЈaЃЉdf.describe()
ИљОнФГСаМЦЫувЛЯЕСаЭГМЦжЕЃЌdf[ЁЎxxxЁЏ].describe()ЃЌЗЕЛиШчЯТЪ§ОнБэЃК
ЃЈbЃЉdf.set_index(ЁЎСаaЁЏ)гыdf.reset_index(ЁЎСаaЁЏ)
ашвЊЖдФГСаЪ§ОнДІРэЪБПЩвдЭЈЙ§set_index()ЩшЮЊЫїв§ЃЌдйгУdf.sort_index()НјааХХађЃЌШЛКѓдйЭЈЙ§reset_index()ЩшЛиЪ§ОнЁЃ
ЃЈ5ЃЉЮФМўЖСаДДІРэЃЛ
вдcsvЮЊР§
df = pd.read_csv("D:/pandas_test.csv",
encoding='utf-8')
df.to_csv(r"D:\test.csv", index=False,sep=',',
encoding='utf_8_sig')
аДЮФМўЪБЩшжУencoding='utf_8_sig'ПЩНтОіжаЮФТвТыЮЪЬтЁЃ
ЃЈ6ЃЉЪ§ОнМЏХњСПДІРэЁЃ
ЃЈaЃЉapplyКЭapplymap
df[ЁЎЁЏ].apply(КЏЪ§)ЖдФГСаЪ§ОнгІгУКЏЪ§ЃЌdf.applymap(КЏЪ§)ЖдећИіБэгІгУКЏЪ§ЁЃ
ЃЈbЃЉgroupby
ИљОнФГСаЛђФГМИСаЗжзщЃЌБОЩэУЛгаШЮКЮМЦЫуЃЌЗЕЛиЃЌгУгкзіЗжзщКѓЕФЪ§ОнЭГМЦЃЌШчЃК
group_results = total_result.groupby(['lable', 'diff_value']).size()ЗЕЛиУПИіЗжзщЕФИіЪ§ЃЌГЃгУЕФгаmax()ЃЌmin()ЃЌmean()
ШчЩЯЪЧБОДЮНХБОЗжЮіЩцМАЕНЕФЙІФмЃЌДЫЭтЃЌpandasЛЙгазїЭМЙІФмЃЌетДЮднЮДгУЕНЃЌОЭВЛеЙПЊЫЕРВЁЃ |








