Android核心分析(25)------Android GDI之共享缓冲区机制
1 native_handle_t对private_handle_t
的包裹
private_handle_t是gralloc.so使用的本地缓冲区私有的数据结构,而Native_handle_t是上层抽象的可以在进程间传递的数据结构。在客户端是如何还原所传递的数据结构呢?首先看看native_handle_t对private_handle_t的抽象包装。

numFds= sNumFds=1;
numInts= sNumInts=8;
这个是Parcel中描述句柄的抽象模式。实际上是指的Native_handle所指向句柄对象的具体内容:
numFds=1表示有一个文件句柄:fd/
numInts= 8表示后面跟了8个INT型的数据:magic,flags,size,offset,base,lockState,writeOwner,pid;
由于在上层系统不要关心buffer_handle_t中data的具体内容。在进程间传递buffer_handle_t(native_handle_t)句柄是其实是将这个句柄内容传递到Client端。在客户端通过Binder读取readNativeHandle
@Parcel.cpp新生成一个native_handle。
native_handle* Parcel::readNativeHandle()
const {
…
native_handle* h = native_handle_create(numFds,
numInts);
for (int i=0 ; err==NO_ERROR
&& i<="" font="">
h->data[i] = dup(readFileDescriptor());
if (h->data[i] < 0) err = BAD_VALUE;
}
err = read(h->data
+ numFds, sizeof(int)*numInts);
….
return h;
}
这里需要提到的是为在构造客户端的native_handle时,对于对方传递过来的文件句柄的处理。由于不是在同一个进程中,所以需要dup(…)一下为客户端使用。这样就将Native_handle句柄中的,客户端感兴趣的从服务端复制过来。这样就将Private_native_t的数据:magic,flags,size,offset,base,lockState,writeOwner,pid;复制到了客户端。
客户端利用这个新的Native_buffer被Mapper传回到gralloc.xxx.so中,获取到native_handle关联的共享缓冲区映射地址,从而获取到了该缓冲区的控制权,达到了客服端和Server间的内存共享。从SurfaceFlinger来看就是作图区域的共享。
2 Graphic Mapper是干什么的?
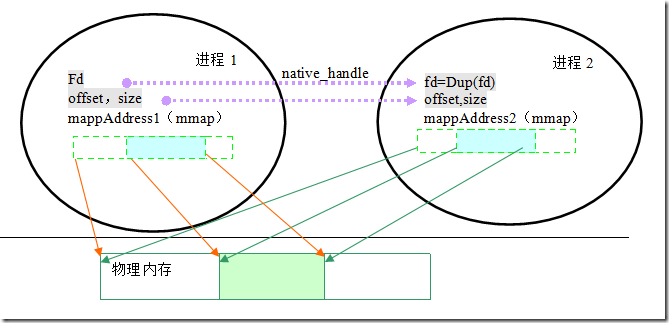
服务端(SurfaceFlinger)分配了一段内存作为Surface的作图缓冲,客户端怎样在这个作图缓冲区上工作呢?这个就是Mapper(GraphicBufferMapper)y要干的事情。两个进程间如何共享内存,如何获取到共享内存?Mapper就是干这个得。需要利用到两个信息:共享缓冲区设备句柄,分配时的偏移量。Mapper利用这样的原理:
客户端只有lock,unlock,实质上就是mmap和ummap的操作。对于同样一个共享缓冲区,偏移量才是总要的,起始地址不重要。实际上他们操作了同一物理地址的内存块。我们在上面讨论了native_handle_t对private_handle_t
的包裹过程,从中知道服务端给客户端传递了什么东西。
进程1在共享内存设备上预分配了8M的内存。以后所有的分配都是在这个8M的空间进行。对以该文件设备来讲,8M物理内存提交后,就实实在在的占用了8M内存。每个每个进程都可以同个该内存设备共享该8M的内存,他们使用的工具就会mmap。由于在mmap都是用0开始获取映射地址,所以所有的客户端进程都是有了同一个物理其实地址,所以此时偏移量和size就可以标识一段内存。而这个偏移量和size是个数值,从服务进程传递到客户端直接就可以使用。
3 GraphicBuffer(缓冲区代理对象)
typedef struct android_native_buffer_t
{
struct android_native_base_t
common;
int width;
int height;
int stride;
int format;
int usage;
…
buffer_handle_t
handle;
…
} android_native_buffer_t;
关系图表:
GraphicBuffer :EGLNativeBase :android_native_buffer_t
GraphicBuffer(parcel &)建立本地的GraphicBuffer的数据native_buffer_t。在通过接收对方的传递的native_buffer_t
构建GraphicBuffer。我们来看看在客户端Surface::lock获取操作缓冲区的函数调用:
Surface::lock(SurfaceInfo* other, Region*
dirtyIn, bool blocking)
{int Surface::dequeueBuffer(android_native_buffer_t**
buffer)(Surface)
{status_t Surface::getBufferLocked(int index, int usage)
{
sp buffer = s->requestBuffer(index,
usage);
{
virtual sp requestBuffer(int
bufferIdx, int usage)
{ remote()->transact(REQUEST_BUFFER,
data, &reply);
sp buffer = new GraphicBuffer(reply);
Surface::Lock建立一个在Client端建立了一个新的GraphicBuffer
对象,该对象通过(1)描述的原理将SurfaceFlinger的buffer_handle_t相关数据构成新的客户端buffer_handle_t数据。在客户端的Surface对象就可以使用GraphicMapper对客户端buffer_handle_t进行mmap从而获取到共享缓冲区的开始地址了。
4 总结
Android在该节使用了共享内存的方式来管理与显示相关的缓冲区,他设计成了两层,上层是缓冲区管理的代理机构GraphicBuffer,及其相关的native_buffer_t,下层是具体的缓冲区的分配管理及其缓冲区本身。上层的对象是可以在经常间通过Binder传递的,而在进程间并不是传递缓冲区本身,而是使用mmap来获取指向共同物理内存的映射地址。
| 

