| БОЮФвЊЕу
1.ЕБЪфШыБфСПКЭЮвУЧГЂЪдШЅдЄВтЕФЪфГіБфСПжЎМфЪЧЯпадЯрЙиЪБЃЌЛђепЕБНтЪЭФЃаЭЕФФмСІКмживЊЪБЃЈР§ШчЃЌИєРыШЮКЮвЛИіЪфШыБфСПЖдгкдЄВтЕФгАЯьЃЉЃЌТпМЛиЙщЖдгкЖўНјжЦЗжРрЪЧБШНЯКЯЪЪЕФбЁдёЁЃ
2.ОіВпЪїКЭЫцЛњЩСжЪЧЗЧЯпадФЃаЭЃЌПЩвдБЛгУРДКмКУЕиМЦЫуИќИДдгЕФЙиЯЕЃЌЕЋЪЧЫќВЛЬЋЪЪгУгкДІРэШЫРрааЮЊРэНтЁЃ
3.ЪЪЕБЕиЦРЙРФЃаЭадФмКмживЊЃЌбщжЄФуЕФФЃаЭдкжЎЧАЮДМћЙ§ЕФЪ§ОнЩЯБэЯжЪЧЗёСМКУЁЃ
4.ВњЦЗЛЏвЛИіЛњЦїбЇЯАФЃаЭЧЃЩцаэЖрПМТЧвђЫиЃЌВЛЭЌгкФЃаЭПЊЗЂЙ§ГЬжаЕФФЧаЉПМТЧвђЫиЃКР§ШчЃЌШчКЮЭЌВНЕиМЦЫуФЃаЭЪфШыЃПУПДЮЕУЗжЪБФуашвЊМЧТМЪВУДаХЯЂЃПФуШчКЮШЗЖЈЩњВњЛЗОГЯТФЃаЭЕФадФмЃП
ЛњЦїбЇЯАЪЧЮвУЧШеГЃНгДЅЕНЕФаэЖрВњЦЗЕФГЄЦкЗЂеЙЖЏСІЃЌДгРрЫЦгкAppleЕФSiriКЭGoogleЕФжЧФмжњЪжЃЌЕНРрЫЦгкбЧТэбЗЕФНЈвщФуТђаТВњЦЗЕФЭЦМів§ЧцЃЌдйЕНGoogleКЭFacebookЪЙгУЕФЙуИцХХУћЯЕЭГЁЃзюНќЃЌЛњЦїбЇЯАгжгЩгкЁАЩюЖШбЇЯАЁБЕФЗЂеЙПЊЪМНјШыЙЋжкЪгЯпЃЌАќРЈAlphaGoЛїАмКЋЙњЮЇЦхДѓЪІРюЪРЪЏЃЌВЂЧвдкЭМЯёЪЖБ№КЭЛњЦїЗвыСьгђЗЂВМСЫСюШЫгЁЯѓЩюПЬЕФаТВњЦЗЁЃ
дкБОЯЕЭГжаЃЌЮвУЧНЋНщЩмвЛаЉЧПДѓЕФЃЌЕЋЪЧдкЛњЦїбЇЯАжаЦеБщЪЪгУЕФММЪѕЁЃетаЉММЪѕМШАќРЈЩюЖШбЇЯАЃЌвВАќРЈЯжДњЦѓвЕашвЊЕФаэЖрДЋЭГЫуЗЈЁЃдФЖСЯЕЭГЮФеТжЎКѓЃЌФугІИУОпБИдкФуздМКЕФСьгђзХЪжНјааОпЬхЛњЦїбЇЯАЪЕбщЕФЯргІжЊЪЖЁЃ
InfoQЕФетЦЊЮФеТЪЧЁАЛњЦїбЇЯАНщЩмЁБЯЕСаЕФвЛВПЗжЁЃФуПЩвдЭЈЙ§ЖЉдФRSSЪеЕНКѓајЭЈжЊЁЃ
БОЯЕСаНЋЬНЬжИїжжЙигкЛњЦїбЇЯАЕФжїЬтКЭММЪѕЃЌЛњЦїбЇЯАПЩвдЫЕЪЧзюНќМИФъзюгаЬжТлМлжЕЕФММЪѕКЭМЦЫуЛњПЦбЇСьгђЁЃдкInfoQЗЂБэЕФвЛаЉЮФеТжавбОЩцМАЕНСЫИпВуЕФЛњЦїбЇЯАЃЈР§ШчЃЌGetting
a Handle on Data ScienceЯЕСаЮФеТжЎвЛGetting Started with
Machine LearningЃЉЃЌБОЦЊЮФеТМАКѓајвЛЦЊЮФеТЮвУЧЛсЯъЯИНщЩмжЎЧАЬжТлЕФИХФюКЭЗНЗЈЃЌЭЛГіОпЬхЪОР§ЃЌВЂЧвГЂЪдНјШыаТСьгђЃЌАќРЈЩёОЭјТчКЭЩюЖШбЇЯАЁЃ
ЮвУЧЛсДгБОЮФПЊЪМЃЌНсКЯвЛИіPythonРЉеЙЕФЁААИР§баОПЁБЃКЮвУЧПЩвдШчКЮЙЙНЈгУгкМьВтаХгУПЈеЉЦЕФЛњЦїбЇЯАФЃаЭЃПЃЈЫфШЛЮвУЧЛсЪЙгУеЉЦМьВтгябдЃЌЫљзіЕФДѓВПЙЄзїЪЧдкЮЂаЁаоИФЛљДЁЩЯЪЪгУгкЦфЫћЗжРрЮЪЬтЃЌР§ШчЃЌЙуИцЕуЛїдЄВтЁЃЃЉЫцзХЪБМфЕФЭЦвЦЃЌЮвУЧЛсгіЕНаэЖрЛњЦїбЇЯАЕФЙиМќЫМЯыКЭЪѕгяЃЌАќРЈТпМЛиЙщЁЂОіВпЪїЁЂЫцЛњЩСжЁЂе§ЯђдЄВтЃЈTrue
PositiveЃЉКЭИКЯђдЄВтЃЈFalse PositiveЃЉЁЂНЛВцбщжЄЃЈcross-validationЃЉЃЌвдМАЪмЪдепЙЄзїЬиеїЃЈReceiver
Operating CharacteristicЃЌМђГЦROCЃЉЧњЯпКЭЧњЯпвдЯТЧјгђЃЈArea Under
the CurveЃЌМђГЦAUCЃЉЧњЯпЁЃ
ФПБъЃКаХгУПЈеЉЦ
дкЯпЯњЪлВњЦЗЕФЦѓвЕВЛПЩБмУтЕиашвЊгІЖдЦлеЉааЮЊЁЃвЛИіЕфаЭЕФЦлеЉНЛвзЃЌеЉЦепЪЙгУЭЕРДЕФаХгУПЈКХТыШЅдкЯпЭјеОЙКТђЩЬЦЗЁЃЦлеЉепЩдКѓЛсдкЦфЫћЕиЗНвдДђелаЮЪНЯњЪлетаЉЩЬЦЗЃЌжаБЅЫНФвЃЌШЛЖјЦѓвЕБиаыГаЕЃЁАЭЫПюЁБГЩБОЁЃФуПЩвдДгетРяЛёШЁаХгУПЈеЉЦЕФЯъЯИФкШнЁЃ
ШУЮвУЧМйЩшздМКЪЧвЛИіЕчзгЩЬЮёЦѓвЕЃЌВЂЧввбОгІЖдеЉЦгавЛаЉЪБМфСЫЃЌЮвУЧЯывЊЪЙгУЛњЦїбЇЯААяжњНтОіЮЪЬтЁЃИќОпЬхЕиЫЕЃЌУПДЮНЛвзНјааЪБЃЌЮвУЧЯывЊШЅдЄВтЪЧЗёПЩвджЄУїЪЧеЉЦепЃЈР§ШчЃЌЪЧЗёЪкШЈЕФГжПЈШЫВЛЪЧНЛвзШЫЃЉЃЌетбљЮвУЧПЩвдЯргІЕиВЩШЁааЖЏЁЃетРрЛњЦїбЇЯАЮЪЬтБЛГЦЮЊЗжРрЃЌвђЮЊЮвУЧе§дкзіЕФОЭЪЧАбУПБЪЪеШыЙщШыЦлеЉЛђЗЧЦлеЉетСНРржаЕФЦфжавЛРрЁЃ
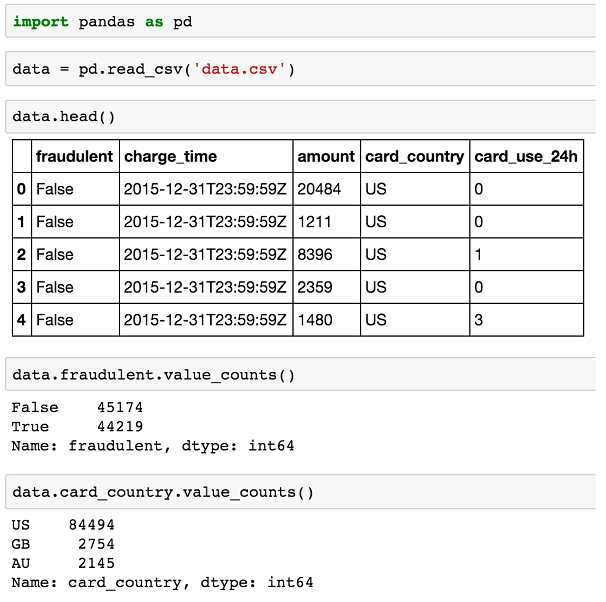
ЖдгкУПвЛБЪРњЪЗИЖПюЃЌЮвУЧгавЛИіВМЖћжЕжИЪОБэУїетБЪНЛвзЪЧЗёЦлеЉЃЈfraudulentЃЉЃЌвдМАвЛаЉЮвУЧШЯЮЊПЩФмБэУїЦлеЉЕФЦфЫћЪєадЃЌР§ШчЃЌвдУРдЊжЇИЖЕФН№ЖюЃЈamountЃЉЁЂПЈЦЌПЊПЈЙњМвЃЈcard_countryЃЉЃЌвдМАетеХПЈЦЌЭЌвЛЬьФкдкЮвУЧЦѓвЕЕФжЇИЖДЮЪ§ЃЈcard_use_24hЃЉЁЃвђДЫЃЌМЋгаПЩФмЮвУЧНЈСЂдЄВтФЃаЭЕФЪ§ОнПДЦ№РДШчвдЯТCSVЫљЪОЃК
| fraudulent,charge_time, amount,card_country, card_use_24h
False,2015-12-31T23:59:59Z, 20484,US,0
False,2015-12-31T23:59:59Z, 1211,US,0
False,2015-12-31T23:59:59Z, 8396,US,1
False,2015-12-31T23:59:59Z, 2359,US,0
False,2015-12-31T23:59:59Z, 1480,US,3
False,2015-12-31T23:59:59Z, 535,US,3
False,2015-12-31T23:59:59Z, 1632,US,0
False,2015-12-31T23:59:59Z, 10305,US,1
False,2015-12-31T23:59:59Z, 2783,US,0 |
гаСНИіживЊЕФЯИНкЮвУЧЛсдкЬжТлРяЬјЙ§ЃЌЕЋЪЧЮвУЧашвЊРЮМЧгкаФЃЌвђЮЊЫќУЧЭЌбљживЊЃЌЩѕжСГЌЙ§ЮвУЧдкетРяНщЩмЕФФЃаЭЙЙНЈЮЪЬтЁЃ
ЪзЯШЃЌШЗЖЈЮвУЧШЯЮЊДцдкеЉЦааЮЊЕФЬиеїЪЧвЛИіЪ§ОнПЦбЇЮЪЬтЁЃдкЮвУЧЕФР§згжаЃЌЮвУЧвбОШЗШЯжЇИЖЕФН№ЖюЁЂетеХПЈЦЌЪЧдкФФИіЙњМвЗЂааЕФЃЌвдМАЙ§ШЅвЛЬьРяЮвУЧЪеЕНЕФПЈЦЌНЛвзДЮЪ§ЕШзїЮЊЬиеїЃЌЮвУЧШЯЮЊетаЉЬиеїПЩФмПЩвдгааЇдЄВтеЉЦЁЃвЛАуРДЫЕЃЌФуНЋашвЊЛЈЗбаэЖрЪБМфВщПДетаЉЪ§ОнЃЌвдОіЖЈЪВУДЪЧгагУЕФЃЌЪВУДЪЧУЛгагУЕФЁЃ
ЦфДЮЃЌМЦЫуЬиеїжЕЕФЪБКђДцдкЪ§ОнЛљзМЮЪЬтЃКЮвУЧашвЊЫљгаРњЪЗбљБОжЕгУгкбЕСЗФЃаЭЃЌЕЋЪЧЮвУЧвВашвЊАбЫћУЧЕФЪЕЪБИЖПюжЕМгНјРДЃЌгУвде§ШЗЕиЖдаТЕФНЛвзМгШыбЕСЗЁЃЕБФуПЊЪМЕЃгЧеЉЦжЎЧАЃЌФувбОЮЌГжКЭМЧТМСЫЙ§ШЅ24аЁЪБЙіЖЏМЧТМЕФаХгУПЈЪЙгУДЮЪ§ЃЌетбљШчЙћФуЗЂЯжЬиеїЪЧгаРћгкеЉЦМьВтЕФЃЌФуНЋЛсашвЊдкЩњВњЛЗОГКЭХњСПЛЗОГжаЗжБ№дкМЦЫужаЪЙгУЫќУЧЁЃвРРЕгкЖЈвхЕФВЛЭЌЬиеїЃЌНсЙћКмгаПЩФмЪЧВЛвЛбљЕФЁЃ
етаЉЮЪЬтКЯдквЛЦ№ЭЈГЃБЛШЯЮЊЪЧЬиеїЙЄГЬЃЌВЂЧвЭЈГЃЪЧЙЄвЕМЖЛњЦїбЇЯАСьгђзюГЃЩцМАЃЈгагАЯьЃЉЕФВПЗжЁЃ
ТпМЛиЙщ
ШУЮвУЧвдвЛИізюЛљБОЕФФЃаЭПЊЪМЃЌвЛИіЯпадФЃаЭЁЃЮвУЧНЋЛсЗЂЯжЯЕЪ§aЁЂbЁЂ...ЁЂzЃЌШчЯТ
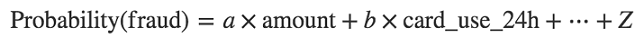
ЖдгкУПвЛБЪжЇИЖЃЌЮвУЧЛсНЋamountЁЂcard_countryКЭcard_use_24hЕФжЕДњШыЕНЩЯУцЕФЙЋЪНжаЃЌШчЙћИХТЪДѓгк0.5ЃЌЮвУЧЛсЁАдЄВтЁБетБЪжЇИЖЪЧЦлеЉЕФЃЌЗДжЎЮвУЧНЋЛсдЄВтЫќЪЧКЯЗЈЕФЁЃ
дкЮвУЧЬжТлШчКЮМЦЫуaЁЂbЁЂ...ЁЂzжЎЧАЃЌЮвУЧашвЊНтОіСНИіЕБЧАЮЪЬтЃК
ИХТЪЃЈЦлеЉЃЉашвЊдк0КЭ1жЎМфЕФвЛИіЪ§зжЃЌЕЋЪЧгвВрЕФЪ§СППЩвдШЮвтДѓЃЈОјЖджЕЃЉЃЌШЁОігкamountКЭ
card_use_24hЕФжЕЃЈШчЙћФЧаЉЬиеїЕФжЕзуЙЛДѓЃЌВЂЧвaЛђепbжСЩйгавЛИіЗЧСуЃЉЁЃ
card_countryВЛЪЧвЛИіЪ§зжЃЌЫќДгаэЖржЕжаШЁЦфвЛЃЈР§ШчUSЁЂAUЁЂGBЃЌвдМАЕШЕШЃЉЁЃетаЉЬиеїБЛГЦЮЊЗжРрЕФЃЌВЂЧвашвЊдкЮвУЧПЩвдбЕСЗФЃаЭжЎЧАНјааЪЪЕБЕиЁАБрТыЁБЁЃ
LogitКЏЪ§
ЮЊСЫНтОіЮЪЬтЃЈ1ЃЉЃЌЮвУЧЛсНЈСЂвЛИіГЦЮЊеЉЦепЕФlog-oddsФЃаЭЃЌЖјВЛЪЧжБНгЭЈЙ§p
= Probability(fraud)ЙЙНЈФЃаЭЃЌЫљвдЮвУЧЕФФЃаЭОЭБфГЩ
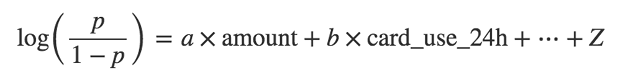
ШчЙћвЛИіЪТМўЗЂЩњЕФИХТЪЮЊpЃЌЫќЕФПЩФмадЪЧp / (1 - p)ЃЌетОЭЪЧЮЊЪВУДЮвУЧГЦЙЋЪНзѓБпЮЊЁАЖдЪ§МИТЪЃЈlog
oddsЃЉЁБЛђепЁАlogitЁБЁЃ
ПМТЧЕНaЁЂbЁЂ...ЁЂzетаЉжЕКЭЬиеїЃЌЮвУЧПЩвдЭЈЙ§ЗДзЊЩЯУцИјГіЕФЙЋЪНМЦЫудЄВтеЉЦИХТЪЃЌЕУЕНвдЯТЙЋЪН
еЉЦpЕФИХТЪЪЧЯпадКЏЪ§ЕФзЊЛЛКЏЪ§L=a x amount + b x
card_use_24h + ЁЃЌПДЦ№РДШчЯТЫљЪОЃК
ВЛПМТЧЯпадКЏЪ§ЕФжЕЃЌsigmoidгГЩфЮЊвЛИідк0КЭ1жЎМфЕФЪ§зжЃЌетЪЧвЛИіКЯЗЈЕФИХТЪЁЃ
ЗжРрБфСП
ЮЊСЫНтОіЮЪЬтЃЈ2ЃЉЃЌЮвУЧЛсЪЙгУЗжРрБфСП card_countryЃЈФУNИіВЛЭЌжЕжаЕФ1ИіЃЉВЂЧвРЉеЙЕНN-1ЁАащФтЁББфСПЁЃетаЉаТЕФЬиеїЪЧВМЖћаЭИёЪНЃЌcard_country
= AUЁЂcard_country = GBЕШЕШЁЃЮвУЧжЛЪЧашвЊN-1ЁАащФтЁБЃЌвђЮЊЕБN-1ащФтжЕЖМЪЧfalseЕФЪБКђNжЕЪЧБиШЛАќКЌЕФЁЃЮЊСЫМђЕЅЦ№МћЃЌШУЮвУЧМйЩшcard_countryПЩвдНіНіЪЙгУAUЁЂGBКЭUSШ§ИіжЕжаЕФвЛИіЁЃШЛКѓЮвУЧашвЊСНИіащФтБфСПШЅЖдетИіжЕНјааБрТыЃЌВЂЧвЮвУЧЯывЊШЅЪЪХфЕФФЃаЭЃЈР§ШчЃЌЗЂЯжЯЕЪ§жЕЃЉЪЧЃК
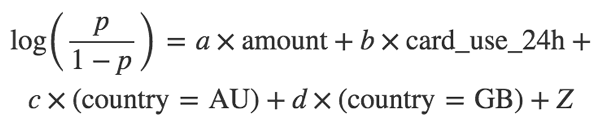
ФЃаЭРраЭБЛГЦЮЊвЛИіТпМЛиЙщЁЃ
ФтКЯФЃаЭ
ЮвУЧШчКЮШЗЖЈaЁЂbЁЂcЁЂdКЭZЕФжЕЃПШУЮвУЧвдЫцЛњбЁдёaЁЂbЁЂcЁЂdКЭZЕФЗНЪНПЊЪМЁЃЮвУЧПЩвдЖЈвхетЬзВТВтЕФПЩФмадШчЃК
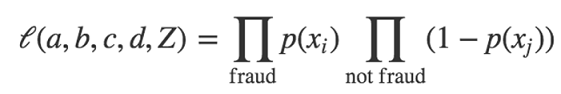
вВОЭЪЧЫЕЃЌДгЮвУЧЕФЪ§ОнМЏРяШЁГіУПвЛИібљБОЃЌВЂЧвМЦЫуеЉЦpЕФдЄВтИХТЪЃЌЬсЙЉИјВТВтaЁЂbЁЂcЁЂdКЭZЃЈУПИібљБОЕФЬиеїжЕЃЉЕФжЕЪЙгУЃК
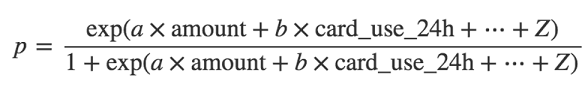
ЖдгкУПИіЪЕМЪЩЯЪЧЦлеЉЕФбљБОЃЌЮвУЧЯЃЭћpБШНЯНгНќ1ЃЌЖјЖдгкУПвЛИіВЛЪЧеЉЦЕФбљБОЃЌЮвУЧЯЃЭћpНгНќ0ЃЈЫљвд1-pгІИУНгНќ1ЃЉЁЃвђДЫЃЌЮвУЧЖдгкЫљгаЦлеЉбљБОВЩгУpВњЦЗЃЌЖдгкЫљгаЗЧЦлеЉбљБОВЩгУ1-pВњЦЗЃЌгУвдЕУЕНЦРЙРЃЌВТВтaЁЂbЁЂcЁЂdКЭZгаЖрКУЁЃЮвУЧЯыШУЫЦШЛКЏЪ§ОЁПЩФмДѓЃЈР§ШчЃЌОЁПЩФмЕиНгНќ1ЃЉЁЃПЊЪМЮвУЧЕФВТВтЃЌЮвУЧЕќДњЕиЕїећaЁЂbЁЂcЁЂdКЭZЃЌЬсИпПЩФмадЃЌжБЕНЮвУЧЗЂЯжВЛПЩвддйЭЈЙ§ШХЖЏЯЕЪ§ЬсЩ§ЫќЕФжЕЁЃвЛжжГЃгУЕФгХЛЏЗНЪНЪЧЫцЛњЬнЖШЯТНЕЁЃ
PythonЪЕЯж
ЯждкЮвУЧНЋЛсЪЙгУБъзМЕФPythonПЊдДЙЄОпЪЕМљЮвУЧИеИеЬжТлЭъЕФдРэЁЃЮвУЧНЋЛсЪЙгУpandasЃЌЫќИјPythonДјРДСЫРрЫЦгкRгябдЕФДѓЙцФЃЪ§ОнПЦбЇЕФAPIЃЈR-like
data framesЃЉЃЌвдМАscikit-learnЃЌЫќЪЧвЛИіШШУХЕФЛњЦїбЇЯААќЁЃШУЮвУЧЖджЎЧАУшЪіЙ§ЕФCSVЮФМўУќУћЮЊЁАdata.csvЁБЃЛЮвУЧПЩвдЩЯДЋЪ§ОнВЂПДвЛЯТЯТУцЕФДњТыЃК
ЮвУЧПЩвдЪЙгУШчЯТДњТыБрТыcard_countryГЩЮЊКЯЪЪЕФащФтБфСП
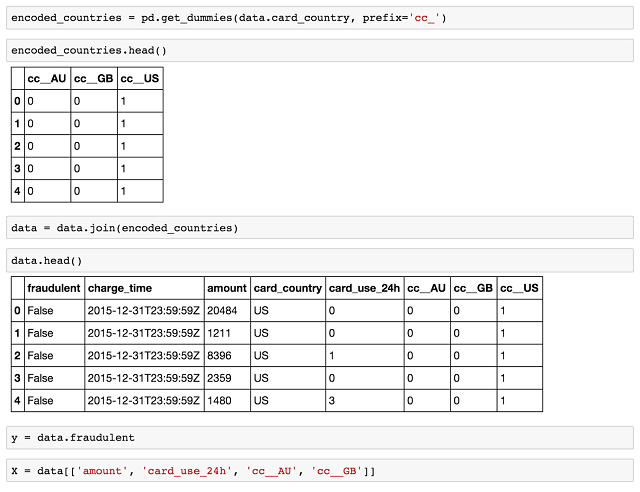
ЯждкДѓЙцФЃЪ§ОнжЁЪ§ОнгЕгаСЫЫљгаЮвУЧашвЊЕФЪ§ОнЁЂащФтБфСПвдМАЫљгагУгкбЕСЗЮвУЧЕФФЃаЭЕФЪ§ОнЁЃЮвУЧЖдФПБъНјааЧаЗжЃЈдкетжжЦлеЉЧщПіЯТГЂЪддЄВтБфСПЃЉвдМАгУscikitашвЊЕФЪєадзїЮЊВЛЭЌЕФЪфШыВЮЪ§ЁЃ
дкНјааФЃаЭбЕСЗжЎЧАЃЌЮвУЧЛЙгавЛИіЮЪЬташвЊЬжТлЁЃЮвУЧЯЃЭћЮвУЧЕФФЃаЭЙщФЩГфЗжЃЌР§ШчЃЌЕБЖдИЖПюНјааЗжРрЪБгІИУЪЧзМШЗЕФЃЌЫќгІИУЪЧЮвУЧжЎЧАУЛгаМћЙ§ЕФЗНЪНЃЌЖјВЛгІИУНіНіЪЧжЎЧАМћЙ§ФЧаЉдкжЇИЖЪБМЦЫуЕФЬиЪтФЃЪНЁЃЮЊСЫШЗБЃВЛЛсдкЯжгаЕФЪ§ОнжаЙ§ЖШФтКЯФЃаЭГЩЮЊдыЩљЃЌЮвУЧНЋЛсЗжИюЪ§ОнЮЊСНИібЕСЗМЏЃЌвЛИібЕСЗМЏЛсБЛгУРДЦРЙРФЃаЭВЮЪ§ЃЈaЁЂbЁЂcЁЂdКЭZЃЉвдМАбщжЄМЏЃЈвВБЛНазіВтЪдМЏЃЉЃЌСэвЛИіЪ§ОнМЏЛсБЛгУРДМЦЫуФЃаЭадФмжИБъЃЈЯТвЛеТЮвУЧЛсНщЩмЃЉЁЃШчЙћвЛИіФЃаЭЪЧЙ§ЖШФтКЯЕФЃЌЫќЛсдкбЕСЗМЏЩЯБэЯжСМКУЃЈвђЮЊЫќЛсдкИУМЏКЯжабЇЯАФЃЪНЃЉЃЌЕЋЪЧдкбщжЄМЏЩЯБэЯжНЯВюЁЃЛЙгаЦфЫћЕФНЛВцбщжЄЗНЪНЃЈР§ШчЃЌk-foldНЛВцбщжЄЃЉЃЌЕЋЪЧЁАВтЪдбЕСЗЁБЗжРыЛсЪЪКЯЮвУЧетРяЕФФПЕФЁЃ
ЮвУЧЪЙгУsckitПЩвдКмЧсЫЩЕиЗжИюЪ§ОнЮЊбЕСЗКЭВтЪдМЏЃЌШчЯТЃК

дкетРяР§згжаЃЌЮвУЧЛсЪЙгУЪ§ОнЕФ2/3гУгкбЕСЗФЃаЭЃЌЪ§ОнЕФ1/3гУгкбщжЄФЃаЭЁЃЮвУЧЯждкзМБИШЅбЕСЗФЃаЭЃЌдкДЫЫќжЛЪЧИіЫіЫщаЁЪТЃК
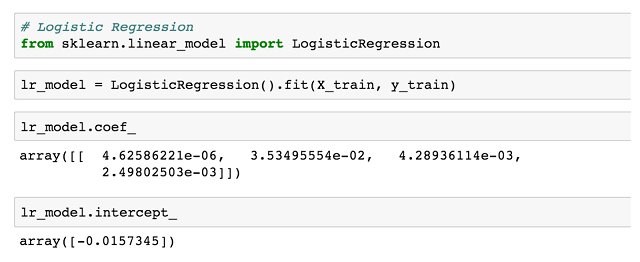
ИУФтКЯКЏЪ§дЫааФтКЯГЬађЃЈзюДѓЛЏЩЯУцЬсЕНЕФЫЦШЛКЏЪ§ЃЉЃЌШЛКѓЮвУЧПЩвдеыЖдaЁЂbЁЂcЁЂdЃЈдкcoef_ЃЉКЭZЃЈдкintercept_ЃЉЕФжЕВщбЏЗЕЛиЕФЖдЯѓЁЃвђДЫЮвУЧЕФзюжеФЃаЭЪЧ
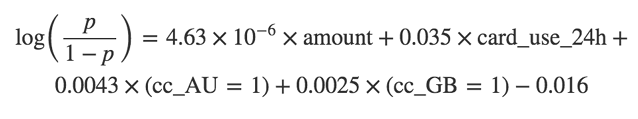
ЦРМлФЃаЭБэЯж
вЛЕЉбЕСЗСЫФЃаЭжЎКѓЃЌЮвУЧОЭашвЊШЅШЗЖЈетИіФЃаЭдкдЄВтИааЫШЄЕФБфСПЩЯОПОЙгаЖрКУСЫЃЈдкБОР§згжаЃЌИУВМЖћжЕБэУїИУжЇИЖЪЧЗёДцдкЦлеЉЃЉЁЃЛиЯывЛЯТЮвУЧдјОЫЕЙ§ЯЃЭћЖджЇИЖАДееЦлеЉНјааЗжРрЃЌШчЙћИХТЪЃЈЦлеЉЃЉДѓгк0.5ЃЌЮвУЧЯЃЭћНЋЦфЙщРрЮЊКЯЗЈЕФЁЃеыЖдвЛИіФЃаЭКЭвЛИіЗжРрЙцдђЕФадФмЦРЖЈЗНЪНЃЌЭЈГЃЪЙгУСНИіБфСПЃЌШчЯТЫљЪОЃК
МйбєадТЪЃКЫљгаКЯЗЈЗбгУжаБЛДэЮѓЕиЗжРрЮЊЦлеЉЕФФЧВПЗжЃЌвдМА
ецбєе§ТЪЃЈвВБЛГЦЮЊейЛиТЪЛђепУєИааджИБъЃЉЃЌЫљгаЦлеЉЪеШыжаБЛе§ШЗЕиЗжРрЮЊЦлеЉЕФФЧВПЗжЁЃ
ЦРЙРЗжРрадФмгаКмЖрЗНЪНЃЌЮвУЧЛсЫјЖЈетСНИіБфСПЁЃ
РэЯыЧщПіЯТЃЌМйбєадТЪНЋЛсНгНќ0ВЂЧвецбєе§ТЪЛсНгНќ1ЁЃЕБЮвУЧИФБфИХТЪуажЕЪБЮвУЧАбвЛБЪЗбгУЗжРрЮЊЦлеЉЕФЃЈЩЯУцЮвУЧЫЕЪЧ0.5ЃЌЕЋЪЧЮвУЧПЩвдбЁдё0КЭ1жЎМфЕФШЮКЮжЕЃЌдНаЁЕФжЕвтЮЖзХЮвУЧИќМгЛ§МЋЕиБъМЧжЇИЖЮЊЦлеЉЕФЃЌЖјИпЕФжЕвтЮЖзХЮвУЧИќМгБЃЪиЃЉЃЌМйбєадТЪКЭецбєе§ТЪЙДЛСЫвЛИіЧњЯпЃЌетИіЧњЯпвРРЕгкЮвУЧЕФФЃаЭгаЖрКУЁЃЮвУЧГЦжЎЮЊЪмЪдепЙЄзїЬиеїЧњЯпЃЈROCЧњЯпЃЉЃЌПЩвдЪЙгУscikitКмШнвзМЦЫуГіРДЃК
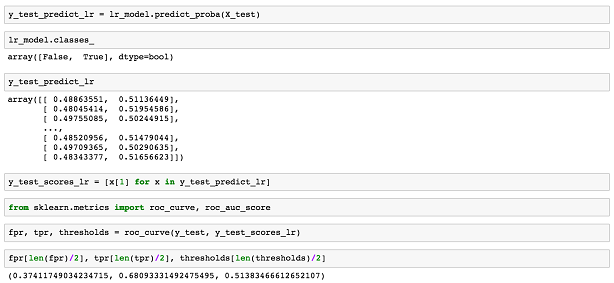
БфСПfprЁЂtprКЭуажЕАќКЌСЫЫљгаROCЧњЯпЕФЪ§ОнЃЌЕЋЪЧЮвУЧЬєбЁСЫвЛаЉгаеыЖдадЕФбљБОЃКШчЙћИХТЪЃЈЦлеЉЃЉДѓгк0.514ЃЌЖјМйбєадТЪЪЧ0.374ЃЌецбєадТЪЪЧ0.681ЪБЃЌЮвУЧМйЖЈИУЗбгУЮЊЦлеЉЁЃЮвУЧЫљбЁЕФROCЧњЯпМАУшЛцЕуЮЊЃК
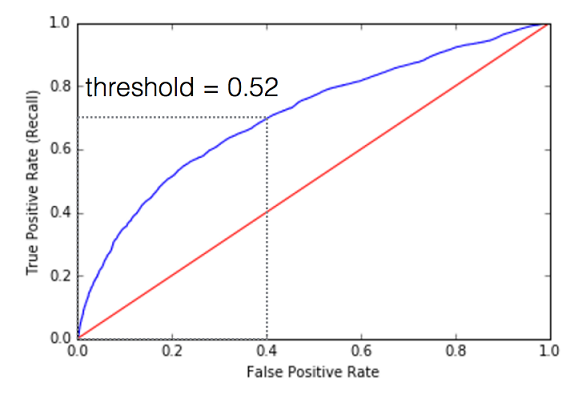
ФЃаЭадФмНЯКУЃЌдННгНќROCЧњЯпЃЈЩЯУцРЖЩЋЕФЯпЃЉЃЌдНЛсНєППЭМаЮзѓЩЯЗНЕФБпПђЁЃзЂвтROCЧњЯпПЩвдИцЫпФуФЃаЭгаЖрКУЃЌПЩвдЪЙгУвЛИіAUCЪ§МЦЫуЃЌЛђепВщПДЧњЯпЯТЕФУцЛ§ЁЃAUCжЕдННгНќгк1ЃЌФЃаЭадФмдНКУЁЃ

ЕБШЛЃЌЕБФуАбФЃаЭжЕЗХШыЩњВњЛЗОГВЂЪЙгУЫќЪБЃЌФуЭЈГЃЛсашвЊШЅЭЈЙ§ЮвУЧЩЯУцВЩгУЕФЗНЪНЃЌМДБШНЯЫћУЧЕФуажЕЗНЪНВЩШЁааЖЏЪфГіИХТЪФЃаЭЃЌШчЙћИХТЪЃЈЦлеЉЃЉ>0.5ЃЌЮвУЧШЯЮЊвЛБЪЗбгУБЛМйЩшЮЊЪЧЦлеЉЕФЁЃвђДЫЃЌЖдгквЛИіЬиЖЈЕФгІгУГЬађЃЌФЃаЭадФмЖдгІгкROCЧњЯпЩЯЕФвЛИіЕуЃЌЧњЯпећЬхдйвЛДЮНіНіПижЦСЫМйбєадТЪКЭецбєе§ТЪжЎМфЕФНЛвзЦНКтЃЌР§ШчЃЌеўВпбЁдёЗЖЮЇФкЕФДІжУЗНЪНВЛЭЌЁЃ
ОіВпЪїгыЫцЛњЩСж
ЩЯЪіЕФТпМЛиЙщФЃаЭЪЧЯпадЛњЦїбЇЯАФЃаЭЕФвЛИіЪОР§ЁЃЯыЯѓвЛЯТЃЌЮвУЧгаЕФУПвЛБЪжЇИЖЪОР§ЪЧПеМфРяЕФвЛИіЕуЃЌетИіЕуЕФзјБъОЭЪЧЬиеїжЕЁЃШчЙћЮвУЧНіНігаСНИіЬиеїжЕЃЌУПИіЪОР§ЕуЛсЪЧX-YЦНУцЩЯЕФвЛИіЕуЁЃШчЙћдкЮвУЧПЩвдЪЙгУЯпадКЏЪ§АбЮоЦлеЉбљБОКЭЦлеЉепбљБОЧјЗжПЊЪБЃЌЭЈГЃРрЫЦгкТпМЛиЙщЕФЯпадФЃаЭОЭФмНЯКУЕидЫааЃЌетвтЮЖзХМИКѕЫљгаЦлеЉбљБОДІгквЛЬѕЯпЕФвЛБпЃЌЖјМИКѕЫљгаЕФЗЧЦлеЉбљБОДІгкетЬѕЯпЕФСэвЛБпЁЃ
ЭЈГЃЧщПіЯТЃЌдЄВтЬиеїКЭФПБъБфСПжЎМфЕФЙиЯЕЃЌЮвУЧЪдЭМдЄВтетИіЙиЯЕЪЧЗЧЯпадЕФЃЌдкетжжЧщПіЯТЃЌЮвУЧашвЊЪЙгУЗЧЯпадФЃаЭМЦЫуЙиЯЕЁЃвЛИіЧПгаСІЕФЁЂНЯЮЊжБЙлЕФЗЧЯпадФЃаЭЪЧОіВпЪїЃЌШчЯТЫљЪОЃК
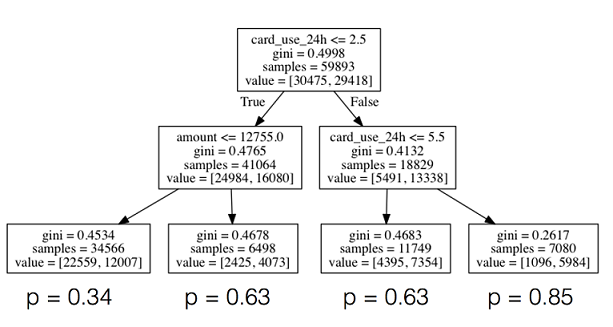
ЖдгкУПИіНкЕуЃЌЮвУЧНЋЬиЖЈЬиеїЕФжЕКЭвЛаЉуажЕНјааБШНЯЃЌИљОнБШНЯНсЙћЗжГіЯђзѓЛЙЪЧЯђгвЁЃЮвУЧМЬајвдетжжЗНЪНЃЈРрЫЦвЛИігкЖўЪЎЮЪЕФгЮЯЗЃЌЫфШЛЪ§ФПВЛашвЊЖўЪЎВуЩюЖШЃЉЃЌжБЕНЮвУЧЕНДяЪїФОЕФЪївЖЁЃЪївЖгЩЮвУЧбЕСЗМЏРяЕФЫљгаЕФбљБОзщГЩЃЌБШНЯетПУЪїЩЯЕФУПвЛИіНкЕуЕФТњвтТЗОЖЃЌЪОР§ЪївЖЩЯЦлеЉФЧвЛВПЗжБЛФЃаЭБЈИцдЄВтЕФИХТЪХаЖЈЮЊЦлеЉЁЃЕБЮвУЧгааТЕФбљБОашвЊБЛЗжРрЪБЃЌжБЕНЕНДяЪївЖжЎЧАЃЌЮвУЧЩњГЩЫќЕФЬиеїВЂЧвПЊЪМЭцЁАЖўЪЎЮЪЕФгЮЯЗЁБЃЌШЛКѓдЄВтЦлеЉЕФПЩФмадЃЌВЂУшЪіШчЯТЁЃ
ЫфШЛЮвУЧВЛЛсШЅЩюОПЪїЪЧШчКЮЩњГЩЕФЯИНкФкШнЃЈЫфШЛЃЌМђЕЅРДЫЕЮвУЧОЭЪЧЮЊУПвЛИіНкЕубЁдёЬиеїКЭуажЕЃЌзюДѓЛЏаХЯЂдівцЛђепБцБ№СІИХФюЃЌМДЩЯЪіЭМБэжаБЈИцЕФЛљФсЯЕЪ§ЃЌВЂдкДяЕНдЄЯШжИЖЈЕФвЛаЉЭЃжЙБъзМЧАвЛжБНјааЕнЙщЃЉЃЌЪЙгУscikitбЕСЗОіВпЪїФЃаЭОЭЯёбЕСЗТпМЛиЙщвЛбљШнвзЃЈЛђепЪТЪЕЩЯдкШЮКЮЦфЫћФЃаЭЩЯЃЉЃК
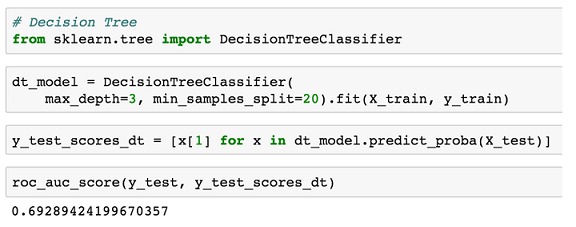
ОіВпЪїЕФвЛИіЮЪЬтЪЧЫќУЧКмШнвзБЛЙ§ЖШФтКЯЃЌвЛПУКмЩюЕФЪїЕФУПИівЖзгНіНіЪЧбЕСЗЪ§ОнРяЕФвЛИіЪОР§ЃЌЭЈГЃЛсМЦЫуУПИібљБОЕФдывєЃЌВЂЧвПЩФмВЛЪЧГЃМћЧїЪЦЃЌЕЋЪЧЫцЛњЩСжФЃаЭПЩвдАяжњНтОіетИіЮЪЬтЁЃдквЛИіЫцЛњЩСжжаЃЌЮвУЧбЕСЗДѓСПЕФОіВпЪїЃЌЕЋЪЧУППУЪїЕФбЕСЗНіНіЪЧЮвУЧЯжгаЕФЪ§ОнЕФвЛИізгМЏЃЌВЂЧвЕБЙЙНЈУППУЪїЪБЮвУЧНіНіПМТЧСЫЧаЗжЕФзгМЏЬиеїЁЃЫљдЄВтЕФЦлеЉЕФИХТЪЪЧЩСжРяЫљгаЪїЫљЩњВњЕФЦНОљИХТЪЁЃНіЛљгкЪ§ОнзгМЏЖдУППУЪїНјаабЕСЗЃЌНіНЋЬиеїЕФзгМЏзїЮЊУПИіНкЕуЕФЗжРыКђбЁРДПМТЧЃЌМѕЩйЪїФОжЎМфЕФЯрЙиадЃЌШУЙ§ЖШФтКЯИќЩйвЛаЉЁЃ
злЩЯЫљЪіЃЌЕБЬиеїКЭФПБъБфСПжЎМфЕФЙиЯЕЪЧЯпадЪБЃЌЯёТпМЛиЙщетбљЕФЯпадФЃаЭЪЧЪЪЕБЕФЃЌЛђепЕБФуЯЃЭћЗжРыШЮЮёЬиеїЖддЄВтЕФгАЯьЃЈвђЮЊетбљПЩвджБНгЖСШЁЛиЙщЯЕЪ§ЃЉЁЃСэвЛЗНУцЃЌЯёОіВпЪїетбљЕФЗЧЯпадФЃаЭКЭЫцЛњЩСжЪЧКмФбНтЪЭЕФЃЌЕЋЪЧЫћУЧПЩвдБЛгУРДМЦЫуИќИДдгЕФЙиЯЕЁЃ
ВњЦЗЛЏЛњЦїбЇЯАФЃаЭ
бЕСЗвЛИіЛњЦїбЇЯАФЃЪНПЩвдБЛШЯЮЊНіНіЪЧЪЙгУЛњЦїбЇЯАНтОівЕЮёЮЪЬтЙ§ГЬЕФЕквЛВНЁЃе§ШчЩЯУцУшЪіЕФЃЌФЃаЭбЕСЗЭЈГЃБиаыдкЬиеїЙЄГЬПЊЪМЙЄзїЧАЭъГЩЁЃвЛЕЉгаСЫФЃаЭОЭашвЊШЅВњЦЗЛЏЫќСЫЃЌвВОЭЪЧЫЕЃЌШУетИіФЃаЭПЩвдгУгкЩњВњЛЗОГВЂПЩвдВЩШЁЪЪЕБЕФааЖЏЃЈР§ШчЃЌзшжЙБЛЦРЙРЮЊЦлеЉЕФНЛвзЃЉЁЃ
ЫфШЛЮвУЧВЛЛсдкетРяЬИТлЯИНкЃЌЕЋЪЧВњЦЗЛЏЛсв§ШыаэЖрЬєеНЃЌР§ШчЃЌФуПЩвдЪЙгУPythonВПЪ№ФЃаЭЃЌЕЋЪЧФуЕФЩњВњЛЗОГШэМўеЛЪЙгУЕФЪЧRubyЁЃШчЙћГіЯжетжжЧщПіЃЌФуНЋЛсашвЊШУФуЕФФЃаЭЭЈЙ§вЛЖЈИёЪНЕФађСаЛЏаЮЪНДгPythonзЊЮЊRubyЃЌВЂЧвШУФуЩњВњЛЗОГЕФRubyДњТыЖСШЁађСаЛЏЃЌЛђепЪЙгУУцЯђЗўЮёЕФЯЕЭГМмЙЙЪЕЯжДгPythonЕНRubyЕФЗўЮёЧыЧѓЃЌЖўбЁвЛЁЃ
ЖдгкЭъШЋВЛЭЌаджЪЕФЮЪЬтЃЌФувВЛсЯывЊдкЩњВњЛЗОГЯТЮЌГжЖШСПФЃаЭадФмЃЈгыбщжЄЪ§ОнЕФДѓСПМЦЫуВЛЭЌЃЉЁЃвРРЕгкФуШчКЮЪЙгУФЃаЭЃЌетИіЙ§ГЬПЩФмБШНЯРЇФбЃЌвђЮЊНіНіЪЙгУФЃаЭШЅПижЦааЮЊЕФЗНЪНПЩвдЕМжТФуУЛгаЪ§ОнМЦЫуФуЕФЖШСПЁЃБОЯЕСаЕФЦфЫћЮФеТНЋЛсПМТЧвЛаЉетРрЮЪЬтЁЃ
|





