| БрМЭЦМі: |
| БОЮФРДздгкЮЂаХЃЌ
БОЮФеЙЪОСЫвЛИіОпЬхЕФЮФЕЕЪОР§ЃЌбнЪОШчКЮЪЙгУЩюЖШбЇЯАКЭ Computer Vision
System Toolbox бЕСЗгявхЗжИюЭјТчЁЃ |
|

ЮЊСЫЫЕУїбЕСЗЙ§ГЬЃЌБОЪОР§НЋбЕСЗ SegNetЃЌвЛжжгУгкЭМЯёгявхЗжИюЕФОэЛ§ЩёОЭјТч
(CNN)ЁЃгУгкгявхЗжИюЕФЦфЫћРраЭЭјТчАќРЈШЋОэЛ§ЭјТч (FCN) КЭ U-NetЁЃвдЯТЫљЪОбЕСЗЙ§ГЬвВПЩгІгУгкетаЉЭјТчЁЃ
БОЪОР§ЪЙгУРДздНЃЧХДѓбЇЕФ CamVid Ъ§ОнМЏеЙПЊбЕСЗЁЃДЫЪ§ОнМЏЪЧАќКЌМнЪЛЪБЫљЛёЕУЕФНжЕРМЖЪгЭМЕФЭМЯёМЏКЯЁЃИУЪ§ОнМЏЮЊ
32 жжгявхРрЬсЙЉСЫЯёЫиМЖБъЧЉЃЌАќРЈГЕСОЁЂааШЫКЭЕРТЗЁЃ
НЈСЂ
БОЪОР§ДДНЈСЫ SegNet ЭјТчЃЌЦфШЈжиДг VGG-16 ЭјТчГѕЪМЛЏЁЃвЊЛёШЁ VGG-16ЃЌЧыАВзАNeural Network Toolbox? Model for VGG-16 NetworkЃК
https://cn.mathworks.com/matlabcentral/fileexchange/61733-neural-network-toolbox-model-for-vgg-16-network"
АВзАЭъГЩКѓЃЌдЫаавдЯТДњТывдбщжЄЪЧЗёАВзАе§ШЗЁЃ
ДЫЭтЃЌЧыЯТдидЄбЕСЗАц SegNetЁЃдЄбЕСЗФЃаЭПЩжЇГжФњдЫааећИіЪОР§ЃЌЖјЮоашЕШД§бЕСЗЭъГЩЁЃ

ЧПСвНЈвщВЩгУМЦЫуФмСІЮЊ 3.0 ЛђИќИпМЖБ№ЃЌжЇГж CUDA ЕФ NVIDIA? GPU РДдЫааБОЪОР§ЁЃЪЙгУ GPU ашвЊ Parallel Computing Toolbox?ЁЃ
ЯТди CamVid Ъ§ОнМЏ
ДгвдЯТ URL жаЯТди CamVid Ъ§ОнМЏЁЃ
зЂвтЃКЪ§ОнЯТдиЪБМфШЁОігкФњЕФ Internet СЌНгЧщПіЁЃдкЯТдиЭъГЩжЎЧАЃЌЩЯУцЪЙгУЕФУќСюЛсзшжЙЗУЮЪ MATLABЁЃЛђепЃЌФњПЩвдЪЙгУ Web фЏРРЦїЯШНЋЪ§ОнМЏЯТдиЕНБОЕиДХХЬЁЃвЊЪЙгУДг Web жаЯТдиЕФЮФМўЃЌЧыНЋЩЯЪі outputFolder БфСПИќИФЮЊЯТдиЮФМўЕФЮЛжУЁЃ
Мгди CamVid ЭМЯё
гУгкМгди CamVid ЭМЯёЁЃНшжњ imageDatastoreЃЌПЩвдИпаЇЕиМгдиДХХЬЩЯЕФДѓСПЭМЯёЪ§ОнЁЃ
imgDir = fullfile(outputFolder,'images','701_StillsRaw_full');
imds = imageDatastore(imgDir); |
ЯдЪОЦфжавЛИіЭМЯёЁЃ
I = readimage(imds,1);
I = histeq(I);
imshow(I) |

Мгди CamVid ЯёЫиБъЧЉЭМЯё
ЪЙгУ imageDatastore Мгди CamVid ЯёЫиБъЧЉЭМЯёЁЃpixelLabelDatastore НЋЯёЫиБъЧЉЪ§ОнКЭБъЧЉ ID ЗтзАЕНРрУћгГЩфжаЁЃ
АДее SegNet дДДТлЮФЃЈBadrinarayananЁЂVijayЁЂAlex Kendall КЭ Roberto CipollaЃКЁЖSegNetЃКгУгкЭМЯёЗжИюЕФвЛжжЩюЖШОэЛ§БрТыЦї-НтТыЦїМмЙЙЁЗ(SegNet: A Deep Convolutional Encoder-Decoder Architecture for ImageSegmentation)ЁЃarXiv дЄгЁБОЃК1511.00561ЃЌ201ЃЉжаВЩгУЕФВНжшНјааВйзїЃЌНЋ CamVid жаЕФ 32 ИідЪМРрЗжзщЮЊ 11 ИіРрЁЃжИЖЈетаЉРрЁЃ
classes = [
"Sky"
"Building"
"Pole"
"Road"
"Pavement"
"Tree"
"SignSymbol"
"Fence"
"Car"
"Pedestrian"
"Bicyclist"
]; |
вЊНЋ 32 ИіРрМѕЩйЮЊ 11 ИіЃЌЧыНЋдЪМЪ§ОнМЏжаЕФЖрИіРрзщКЯдквЛЦ№ЁЃР§ШчЃЌЁАCarЁБ ЪЧ ЁАCarЁБ ЁЂ ЁАSUVPickupTruckЁБ ЁЂ ЁАTruck_BusЁБ ЁЂ ЁАTrainЁБ КЭ ЁАOtherMovingЁБ ЕФзщКЯЁЃЪЙгУжЇГжКЏЪ§ camvidPixelLabelIDs ЗЕЛивбЗжзщЕФБъЧЉ IDЃЌИУКЏЪ§ЛсдкБОЪОР§ЕФФЉЮВСаГіЁЃ
| labelIDs = camvidPixelLabelIDs(); |
ЪЙгУетаЉРрКЭБъЧЉ ID ДДНЈ pixelLabelDatastoreЁЃ
labelDir = fullfile(outputFolder,'labels');
pxds = pixelLabelDatastore(labelDir,classes,labelIDs); |
ЖСШЁВЂдквЛЗљЭМЯёЩЯЕўМгЯдЪОЯёЫиБъЧЉЭМЯёЁЃ
C = readimage(pxds,1);
cmap = camvidColorMap;
B = labeloverlay(I,C,'ColorMap',cmap);
imshow(B)
pixelLabelColorbar(cmap,classes); |

УЛгабеЩЋЕўМгЕФЧјгђУЛгаЯёЫиБъЧЉЃЌдкбЕСЗЦкМфВЛЛсЪЙгУетаЉЧјгђЁЃ
ЗжЮіЪ§ОнМЏЭГМЦаХЯЂ
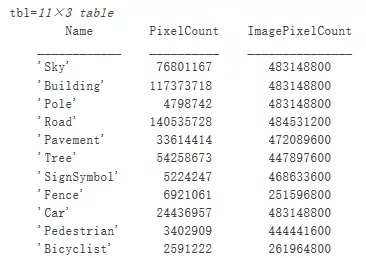
вЊВщПД CamVid Ъ§ОнМЏжаРрБъЧЉЕФЗжВМЧщПіЃЌЧыЪЙгУ countEachLabelЁЃДЫКЏЪ§ЛсАДРрБъЧЉМЦЫуЯёЫиЪ§ЁЃ
| tbl = countEachLabel(pxds) |
АДРрПЩЪгЛЏЯёЫиМЦЪ§ЁЃ
frequency =
tbl.PixelCount/sum(tbl.PixelCount);
bar(1:numel(classes),frequency)
xticks(1:numel(classes))
xticklabels(tbl.Name)
xtickangle(45)
ylabel('Frequency') |
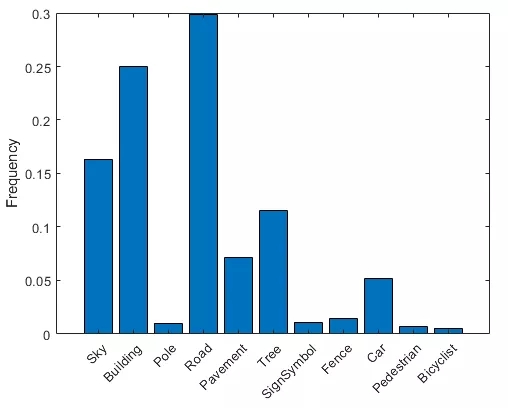
РэЯыЧщПіЯТЃЌЫљгаРрЖМгаЯрЭЌЪ§СПЕФЙлВьНсЙћЁЃЕЋЪЧЃЌCamVid жаЕФетаЉРрБШР§ЪЇКтЃЌетЪЧНжЕРГЁОАЦћГЕЪ§ОнМЏжаЕФГЃМћЮЪЬтЁЃгЩгкЬьПеЁЂНЈжўЮяКЭЕРТЗИВИЧСЫЭМЯёжаЕФИќЖрЧјгђЃЌвђДЫЯрБШааШЫКЭЦяздааГЕепЯёЫиЃЌетаЉГЁОАгЕгаИќЖрЕФЬьПеЁЂНЈжўЮяКЭЕРТЗЯёЫиЁЃШчЙћДІРэВЛЕБЃЌетжжЪЇКтПЩФмгАЯьбЇЯАЙ§ГЬЃЌвђЮЊбЇЯАЙ§ГЬЦЋЯђжїЕМРрЁЃдкБОЪОР§жаЃЌФњЩдКѓНЋЪЙгУРрШЈжиРДДІРэДЫЮЪЬтЁЃ
Еїећ CamVid Ъ§ОнЕФДѓаЁ
CamVid Ъ§ОнМЏжаЕФЭМЯёДѓаЁЮЊ 720 x 960ЁЃвЊМѕЩйбЕСЗЪБМфКЭФкДцЪЙгУСПЃЌЧыНЋЭМЯёКЭЯёЫиБъМЧЭМЯёЕФДѓаЁЕїећЮЊ 360 x 480ЁЃresizeCamVidImages КЭ resizeCamVidPixelLabels ЪЧБОЪОР§ФЉЮВЫљСаГіЕФжЇГжКЏЪ§ЁЃ

зМБИбЕСЗМЏКЭВтЪдМЏ
ЪЙгУЪ§ОнМЏжа 60% ЕФЭМЯёбЕСЗ SegNetЁЃЦфгрЭМЯёгУгкВтЪдЁЃвдЯТДњТыЛсНЋЭМЯёКЭЯёЫиБъМЧЪ§ОнЫцЛњЗжГЩбЕСЗМЏКЭВтЪдМЏЁЃ
| [imdsTrain,imdsTest,pxdsTrain,pxdsTest]
= partitionCamVidData(imds,pxds); |
60/40 В№ЗжЛсЩњВњвдЯТЪ§СПЕФбЕСЗЭМЯёКЭВтЪдЭМЯёЃК
| numTrainingImages
= numel(imdsTrain.Files) |
numTrainingImages =
421
| numTestingImages = numel(imdsTest.Files) |
numTestingImages =
280
ДДНЈЭјТч
ЪЙгУ segnetLayers ДДНЈРћгУ VGG-16 ШЈжиГѕЪМЛЏЕФ SegNet ЭјТчЁЃsegnetLayers ЛсздЖЏжДааДЋЪф VGG-16 жаЕФШЈжиЫљашЕФЭјТчВйзїЃЌВЂЬэМггявхЗжИюЫљашЦфЫћЭјТчВуЁЃ
imageSize =
[360 480 3];
numClasses = numel(classes);
lgraph = segnetLayers(imageSize,numClasses,'vgg16'); |
ЮЊСЫБугкЙлВьШШЫ№ЕФгАЯьЃЌЖдЩГзгбљЦЗНјааСЫгаШШЫ№ЧщПіЯТЕФФЃФтЗТецМЦЫуЃЌНсЙћШчЭМ5-2ЫљЪОЁЃДгЭМ5-2жаПЩвдПДГіЃЌЕБгаВрЯђШШЫ№ДцдкЪБЃЌбљЦЗДяЕНШШЦНКтКѓЃЌьЪжЕЫцЪБМфЕФБфЛЏВЂЮДГЪЫЎЦНЗНЯђЕФЧњЯпаЮЪНЃЌЖјЪЧЯђЩЯЧуаБЃЌЖјЧвьЪжЕвЊБШЮоШШЫ№ЪБвЊДѓЃЈЮѓВюНЋНќ10%зѓгвЃЉЃЌетжЄУїЦфжагавЛВПШШСПБЛВрЯђШШЫ№ДјзпЃЌвђДЫдкЪЕМЪВтЪджавЊЖдВтЪдЧњЯпНјааВрЯђШШЫ№аое§ЁЃ
ИљОнЪ§ОнМЏжаЭМЯёЕФДѓаЁбЁдёЭМЯёДѓаЁЁЃИљОн CamVid жаЕФРрбЁдёРрЕФЪ§СПЁЃ
ЪЙгУРрШЈжиЦНКтРр
ШчЧАЫљЪОЃЌCamVid жаЕФетаЉРрБШР§ЪЇКтЁЃвЊИФНјбЕСЗЧщПіЃЌПЩвдЪЙгУРрШЈжиРДЦНКтетаЉРрЁЃЪЙгУжЎЧАЭЈЙ§ countEachLayer МЦЫуЕФЯёЫиБъЧЉМЦЪ§ЃЌВЂМЦЫужажЕЦЕТЪРрШЈжиЁЃ
imageFreq =
tbl.PixelCount ./ tbl.ImagePixelCount;
classWeights = median(imageFreq) ./ imageFreq |

ЪЙгУ pixelClassificationLayer жИЖЈРрШЈжиЁЃ
| pxLayer = pixelClassificationLayer('Name','labels',
'ClassNames',tbl.Name,'ClassWeights',classWeights) |

ЭЈЙ§ЩОГ§ЕБЧА pixelClassificationLayer ВЂЬэМгаТВуЃЌЪЙгУаТЕФ pixelClassificationLayer ИќаТ SegNet ЭјТчЁЃЕБЧА pixelClassificationLayer УћЮЊЁАpixelLabelsЁБЁЃЪЙгУ removeLayers ЩОГ§ИУВуЃЌЪЙгУ addLayers ЬэМгаТВуЃЌШЛКѓЪЙгУ connectLayers НЋаТВуСЌНгЕНЭјТчЕФЦфгрВПЗжЁЃ

бЁдёбЕСЗбЁЯю
гУгкбЕСЗЕФгХЛЏЫуЗЈЪЧв§ШыЖЏСПЕФЫцЛњЬнЖШЯТНЕ (SGDM) ЫуЗЈЁЃЪЙгУ trainingOptions жИЖЈгУгк SGDM ЕФГЌВЮЪ§ЁЃ
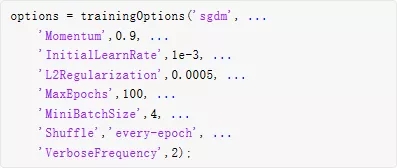
ДѓаЁЮЊ 4 ЕФ minimatch гУгкМѕЩйбЕСЗЪБЕФФкДцЪЙгУСПЁЃФњПЩвдИљОнЯЕЭГжаЕФ GPU ФкДцСПдіМгЛђМѕЩйДЫжЕЁЃ
Ъ§ОнРЉГф
дкбЕСЗЦкМфЪЙгУЪ§ОнРЉГфЯђЭјТчЬсЙЉИќЖрЪОР§ЃЌвдБуЬсИпЭјТчЕФзМШЗадЁЃДЫДІЃЌЫцЛњзѓ/гвЗДЩфвдМА +/- 10 ЯёЫиЕФЫцЛњ X/Y ЦНвЦгУгкЪ§ОнРЉГфЁЃгУгкжИЖЈетаЉЪ§ОнРЉГфВЮЪ§ЁЃ

imageDataAugmenter жЇГжЦфЫћМИжжРраЭЕФЪ§ОнРЉГфЁЃбЁдёЫќУЧашвЊОбщЗжЮіЃЌВЂЧветЪЧСэвЛИіВуДЮЕФГЌВЮЪ§ЕїећЁЃ
ПЊЪМбЕСЗ
ЪЙгУ pixelLabelImageDatastore зщКЯбЕСЗЪ§ОнКЭЪ§ОнРЉГфбЁдёЁЃpixelLabelImageDatastore ЛсЖСШЁХњСПбЕСЗЪ§ОнЃЌгІгУЪ§ОнРЉГфЃЌВЂНЋвбРЉГфЕФЪ§ОнЗЂЫЭжСбЕСЗЫуЗЈЁЃ

ШчЙћ doTraining БъжОЮЊ trueЃЌдђЛсПЊЪМбЕСЗЁЃЗёдђЃЌЛсМгдидЄбЕСЗЭјТчЁЃзЂвтЃКNVIDIA? Titan X ЩЯЕФбЕСЗДѓдМашвЊ 5 ИіаЁЪБЃЌИљОнФњЕФ GPU гВМўОпЬхЧщПіЃЌПЩФмЛсашвЊИќГЄЕФЪБМфЁЃ

дкЭМЯёЩЯВтЪдЭјТч
зїЮЊПьЫйЭъећадМьВщЃЌНЋдкВтЪдЭМЯёЩЯдЫаавббЕСЗЕФЭјТчЁЃ
| I = read(imdsTest);
C = semanticseg(I, net); |
ЯдЪОНсЙћЁЃ


НЋ C жаЕФНсЙћгы pxdsTest жаЕФдЄЦкецжЕНјааБШНЯЁЃТЬЩЋКЭбѓКьЩЋЧјгђЭЛГіЯдЪОСЫЗжИюНсЙћгыдЄЦкецжЕВЛЭЌЕФЧјгђЁЃ
expectedResult
= read(pxdsTest);
actual = uint8(C);
expected = uint8(expectedResult);
imshowpair(actual, expected) |

ДгЪгОѕЩЯПДЃЌЕРТЗЁЂЬьПеЁЂНЈжўЮяЕШРрЕФгявхЗжИюНсЙћжиЕўЧщПіСМКУЁЃШЛЖјЃЌааШЫКЭГЕСОЕШНЯаЁЕФЖдЯѓдђВЛФЧУДзМШЗЁЃПЩвдЪЙгУНЛВцСЊКЯ (IoU) жИБъЃЈгжГЦ Jaccard ЯЕЪ§ЃЉРДВтСПУПИіРрЕФжиЕўСПЁЃЪЙгУ jaccard КЏЪ§ВтСП IoUЁЃ
iou = jaccard(C,
expectedResult);
table(classes,iou) |
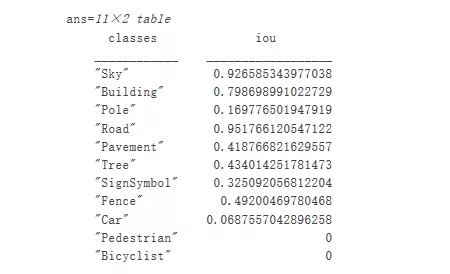
IoU жИБъПЩШЗШЯЪгОѕаЇЙћЁЃЕРТЗЁЂЬьПеКЭНЈжўЮяРрОпгаНЯИпЕФ IoU ЗжЪ§ЃЌЖјааШЫКЭГЕСОЕШРрЕФЗжЪ§НЯЕЭЁЃЦфЫћГЃМћЕФЗжИюжИБъАќРЈ Dice ЯЕЪ§ КЭ Boundary-F1 ТжРЊЦЅХфЗжЪ§ЁЃ
ЦРЙРвббЕСЗЕФЭјТч
вЊВтСПЖрИіВтЪдЭМЯёЕФзМШЗадЃЌЧыдкећИіВтЪдМЏжадЫаа semanticsegЁЃ
| pxdsResults
= semanticseg(imdsTest,net,'MiniBatchSize',4,'
WriteLocation',tempdir,'Verbose',false); |
semanticseg ЛсНЋВтЪдМЏЕФНсЙћзїЮЊ pixelLabelDatastore ЖдЯѓЗЕЛиЁЃimdsTest жаУПИіВтЪдЭМЯёЕФЪЕМЪЯёЫиБъЧЉЪ§ОнЛсдкЁАWriteLocationЁБВЮЪ§жИЖЈЕФЮЛжУаДШыДХХЬЁЃЪЙгУ evaluateSemanticSegmentation ВтСПВтЪдМЏНсЙћЕФгявхЗжИюжИБъЁЃ
| metrics = evaluateSemanticSegmentation
(pxdsResults,pxdsTest,'Verbose',false); |
evaluateSemanticSegmentationЗЕЛиећИіЪ§ОнМЏЁЂИїИіРрвдМАУПИіВтЪдЭМЯёЕФИїжжжИБъЁЃвЊВщПДЪ§ОнМЏМЖБ№жИБъЃЌЧыМьВщ metrics.DataSetMetricsЁЃ

Ъ§ОнМЏжИБъПЩЬсЙЉЭјТчадФмЕФИпМЖИХЪіЁЃвЊВщПДУПИіРрЖдећЬхадФмЕФгАЯьЃЌЧыЪЙгУ metrics.ClassMetrics МьВщУПИіРрЕФжИБъЁЃ
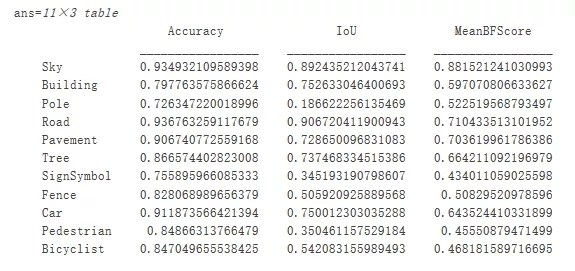
ОЁЙмЪ§ОнМЏећЬхадФмЗЧГЃИпЃЌЕЋРржИБъЯдЪОЃЌжюШч PedestrianЁЂBicyclist КЭ Car ЕШДњБэадВЛзуЕФРрЗжИюаЇЙћВЛШчRoadЁЂSky КЭ Building ЕШРрЁЃИНМгЪ§ОнЖрвЛаЉДњБэадВЛзуРрбљБОПЩФмЛсЬсЩ§ЗжИюаЇЙћЁЃ
|





