MatplotlibЪЧPythonжазюГЃгУЕФПЩЪгЛЏЙЄОпжЎвЛ,ПЩвдЗЧГЃЗНБуЕиДДНЈКЃСПРраЭЕФ2DЭМБэКЭвЛаЉЛљБОЕФ3DЭМБэЁЃБОЮФжївЊНщЩмСЫдкбЇЯАMatplotlibЪБУцСйЕФвЛаЉЬєеНЃЌЮЊЪВУДвЊЪЙгУMatplotlibЃЌВЂЭЦМіСЫвЛИібЇЯАЪЙгУMatplotlibЕФВНжшЁЃ
МђНщ
ЖдгкаТЪжРДЫЕЃЌНјШыPythonПЩЪгЛЏСьгђгаЪБПЩФмЛсСюШЫИаЕНОкЩЅЁЃPythonгаКмЖрВЛЭЌЕФПЩЪгЛЏЙЄОпЃЌбЁдёвЛИіе§ШЗЕФЙЄОпгаЪБЪЧвЛжжЬєеНЁЃ
Р§ШчЃЌМДЪЙСНФъЙ§ШЅСЫЃЌетЦЊЁЖOverview of Python Visualization ToolsЁЗЪЧв§ЕМШЫУЧЕНетИіЭјеОЕФЖЅМЖЬћзгжЎвЛЁЃ
дкФЧЦЊЮФеТжаЃЌЮвЖдmatplotlibСєЯТСЫвЛаЉвѕгАЃЌВЂдкЗжЮіЙ§ГЬжаВЛдйЪЙгУЁЃ ШЛЖјЃЌдкЪЙгУжюШчpandasЃЌscikit-learnЃЌseabornКЭЦфЫћЪ§ОнПЦбЇММЪѕеЛЕФpythonЙЄОпКѓЃЌОѕЕУЖЊЦњmatplotlibгаЕуЙ§дчСЫЁЃЫЕЪЕЛАЃЌжЎЧАЮвВЛЬЋСЫНтmatplotlibЃЌвВВЛжЊЕРШчКЮдкЙЄзїСїГЬжагааЇЕиЪЙгУЁЃ
ЯждкЮвЛЈЪБМфбЇЯАСЫЦфжаЕФвЛаЉЙЄОпЃЌвдМАШчКЮЪЙгУmatplotlibЃЌвбОПЊЪМНЋmatplotlibПДзїЪЧВЛПЩЛђШБЕФЙЄОпСЫЁЃетЦЊЮФеТНЋеЙЪОЮвЪЧШчКЮЪЙгУmatplotlibЕФЃЌВЂЮЊИеШыУХЕФгУЛЇЛђепУЛЪБМфбЇЯАmatplotlibЕФгУЛЇЬсЙЉвЛаЉНЈвщЁЃЮвМсаХmatplotlibЪЧpythonЪ§ОнПЦбЇММЪѕеЛЕФживЊзщГЩВПЗжЃЌЯЃЭћБОЮФФмАяжњДѓМвСЫНтШчКЮНЋmatplotlibгУгкздМКЕФПЩЪгЛЏЁЃ
ЮЊЪВУДЖдmatplotlibЖМЪЧИКУцЦРМлЃП
дкЮвПДРДЃЌаТгУЛЇбЇЯАmatplotlibжЎЫљвдЛсУцСйвЛЖЈЕФЬєеНЃЌжївЊгавдЯТМИИідвђЁЃ
ЪзЯШЃЌmatplotlibгаСНжжНгПкЁЃЕквЛжжЪЧЛљгкMATLABВЂЪЙгУЛљгкзДЬЌЕФНгПкЁЃЕкЖўжжЪЧУцЯђЖдЯѓЕФНгПкЁЃЮЊЪВУДЪЧетСНжжНгПкВЛдкБОЮФЬжТлЕФЗЖЮЇжЎФкЃЌЕЋЪЧжЊЕРгаСНжжЗНЗЈдкЪЙгУmatplotlibНјааЛцЭМЪБЗЧГЃживЊЁЃ
СНжжНгПкв§Ц№ЛьЯ§ЕФдвђдкгкЃЌдкstack overflowЩчЧјКЭЙШИшЫбЫїПЩвдЛёЕУДѓСПаХЯЂЕФЧщПіЯТЃЌаТгУЛЇЖдФЧаЉПДЦ№РДгааЉЯрЫЦЕЋВЛвЛбљЕФЮЪЬтЃЌУцЖдЖрИіНтОіЗНАИЛсИаЕНРЇЛѓЁЃДгЮвздМКЕФОРњЫЕЦ№ЁЃЛиЙЫвЛЯТЮвЕФОЩДњТыЃЌвЛЖбmatplotlibДњТыЕФЛьКЯЁЊЁЊетЖдЮвРДЫЕЗЧГЃЛьТвЃЈМДЪЙЪЧЮваДЕФЃЉЁЃ
ЙиМќЕу
matplotlibЕФаТгУЛЇгІИУбЇЯАЪЙгУУцЯђЖдЯѓЕФНгПкЁЃ
matplotlibЕФСэвЛИіРњЪЗадЬєеНЪЧЃЌвЛаЉФЌШЯЗчИёбЁЯюЯрЕБУЛгаЮќв§СІЁЃ дкRгябдЪРНчРяЃЌПЩвдгУggplotЩњГЩвЛаЉЯрЕБПсЕФЛцЭМЃЌЯрБШжЎЯТЃЌmatplotlibЕФбЁЯюПДЦ№РДгаЕуГѓЁЃСюШЫаРЮПЕФЪЧmatplotlib
2.0ОпгаИќУРЙлЕФбљЪНЃЌвдМАЗЧГЃБуНнЖдПЩЪгЛЏЕФФкШнНјаажїЬтЛЏЕФФмСІЁЃ
ЪЙгУmatplotlibЮвШЯЮЊЕкШ§ИіЬєеНЪЧЃЌЕБЛцжЦФГаЉЖЋЮїЪБЃЌгІИУЕЅДПЪЙгУmatplotlibЛЙЪЧЪЙгУНЈСЂдкЦфжЎЩЯЕФРрЫЦpandasЛђепseabornетбљЕФЙЄОпЃЌФуЛсИаЕНРЇЛѓЁЃШЮКЮЪБКђЖМПЩвдгаЖржжЗНЪНРДзіЪТЃЌЖдгкаТЪжЛђВЛГЃгУmatplotlibЕФгУЛЇРДНВЃЌзёбе§ШЗЕФТЗОЖЪЧОпгаЬєеНадЕФЁЃНЋетжжРЇЛѓгыСНжжВЛЭЌЕФAPIСЊЯЕЦ№РДЃЌЪЧНтОіЮЪЬтЕФУиОїЁЃ
ЮЊЪВУДМсГжвЊгУmatplotlibЃП
ОЁЙмгаетаЉЮЪЬтЃЌЕЋЪЧЮвЧьавгаmatplotlibЃЌвђЮЊЫќЗЧГЃЧПДѓЁЃетИіПтдЪаэДДНЈМИКѕШЮКЮФуПЩвдЯыЯѓЕФПЩЪгЛЏЁЃДЫЭтЃЌЮЇШЦзХЫќЛЙгавЛИіЗсИЛЕФpythonЙЄОпЩњЬЌЯЕЭГЃЌаэЖрИќЯШНјЕФПЩЪгЛЏЙЄОпгУmatplotlibзїЮЊЛљДЁПтЁЃШчЙћдкpythonЪ§ОнПЦбЇеЛжаНјааШЮКЮЙЄзїЃЌЖМНЋашвЊЖдШчКЮЪЙгУmatplotlibгавЛИіЛљБОЕФСЫНтЁЃетЪЧБОЮФЕФЦфгрВПЗжЕФжиЕуЁЊЁЊНщЩмвЛжжгааЇЪЙгУmatplotlibЕФЛљБОЗНЗЈЁЃ
ЛљБОЧАЬс
ШчЙћФуГ§СЫБОЮФжЎЭтУЛгаШЮКЮЛљДЁЃЌНЈвщгУвдЯТМИИіВНжшбЇЯАШчКЮЪЙгУmatplotlibЃК
1.бЇЯАЛљБОЕФmatplotlibЪѕгяЃЌгШЦфЪЧЪВУДЪЧЭМКЭзјБъжс
2.ЪМжеЪЙгУУцЯђЖдЯѓЕФНгПкЃЌДгвЛПЊЪМОЭбјГЩЪЙгУЫќЕФЯАЙп
3.гУЛљДЁЕФpandasЛцЭМПЊЪМФуЕФПЩЪгЛЏбЇЯА
4.гУseabornНјааИќИДдгЕФЭГМЦПЩЪгЛЏ
5.гУmatplotlibРДЖЈжЦpandasЛђепseabornПЩЪгЛЏ
етЗљРДздmatplotlib faqЕФЭМЗЧГЃОЕфЃЌЗНБуСЫНтвЛЗљЭМЕФВЛЭЌЪѕгяЁЃ
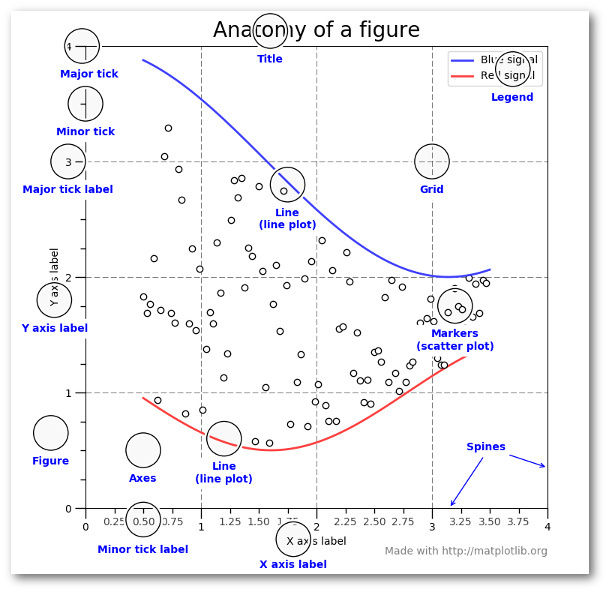
ДѓЖрЪ§ЪѕгяЖМЗЧГЃжБНгЃЌЕЋвЊМЧзЁЕФвЊЕуЪЧЃЌFigureЪЧзюжеЕФЭМЯёЃЌПЩФмАќКЌвЛИіЛђЖрИізјБъжсЁЃзјБъжсДњБэвЛИіЕЅЖРЕФЛЎЗжЁЃвЛЕЉФуСЫНтетаЉФкШнЃЌвдМАШчКЮЭЈЙ§УцЯђЖдЯѓЕФAPIЗУЮЪЫќУЧЃЌЯТУцЕФВНжшВХФмПЊЪМНјааЁЃ
етаЉЪѕгяжЊЪЖгаСэвЛИіКУДІЃЌЕБФудкЭјЩЯПДФГаЉЖЋЮїЪБЃЌОЭгаСЫвЛИіЦ№ЕуЁЃШчЙћФуЛЈЪБМфСЫНтСЫетвЛЕуЃЌВХЛсРэНт matplotlib
APIЕФЦфгрВПЗжЁЃДЫЭтЃЌаэЖрpythonЕФИпМЖШэМўАќЃЌШчseabornКЭggplotЖМвРРЕгк matplotlib ЁЃвђДЫЃЌСЫНтетаЉЛљДЁжЊЪЖКѓдйбЇФЧаЉЙІФмИќЧПДѓЕФПђМмЛсШнвзвЛаЉЁЃ
зюКѓЃЌЮвВЛЪЧЫЕФугІИУБмУтбЁдёР§Шч ggplot ЃЈaka ggpyЃЉ ЃЌbokeh ЃЌplotly Лђеп altair ЕШЦфЫћИќКУЕФЙЄОпЁЃЮвжЛЪЧШЯЮЊФуашвЊДгЖд matplotlib
+ pandas + seaborn гавЛИіЛљБОСЫНтПЊЪМЁЃвЛЕЉРэНтСЫЛљБОЕФПЩЪгЛЏММЪѕЃЌОЭПЩвдЬНЫїЦфЫћЙЄОпЃЌВЂИљОнздМКЕФашвЊзіГіУїжЧЕФбЁдёЁЃ
ШыУХ
БОЮФЕФЦфгрВПЗжНЋзїЮЊвЛИіШыУХНЬГЬЃЌНщЩмШчКЮдкpandasжаНјааЛљБОЕФПЩЪгЛЏДДНЈЃЌВЂЪЙгУ matplotlibздЖЈвхзюГЃгУЕФЯюФПЁЃвЛЕЉФуСЫНтСЫЛљБОЙ§ГЬЃЌНјвЛВНЕФЖЈжЦЛЏДДНЈОЭЯрЖдБШНЯМђЕЅЁЃ
жиЕуНВвЛЯТЮвгіЕНЕФзюГЃМћЕФЛцЭМШЮЮёЃЌШчБъМЧжсЃЌЕїећЯожЦЃЌИќаТЛцЭМБъЬтЃЌБЃДцЭМЦЌКЭЕїећЭМР§ЁЃШчЙћФуЯыИњзХМЬајбЇЯАЃЌдкСДНгhttps : // github . com / chris1610 / pbpython / blob / master / notebooks / Effectively - Using - Matplotlib . ipynb
жаАќКЌИНМгЯИНкЕФБЪМЧЃЌгІИУЗЧГЃгагУЁЃ
зМБИПЊЪМЃЌЮвЯШв§ШыПтВЂЖСШывЛаЉЪ§ОнЃК
| import
pandas as pd
import matplotlib .pyplot as plt
from matplotlib.ticker import FuncFormatter
df = pd.read_excel("https://github.com/chris1610/
pbpython/blob/master/data/sample-salesv3.xlsx?raw=true")
df.head() |

етЪЧ2014ФъЕФЯњЪлНЛвзЪ§ОнЁЃЮЊСЫЪЙетаЉЪ§ОнМђЖЬвЛаЉЃЌЮвНЋЖдЪ§ОнНјааОлКЯЃЌвдБуЮвУЧПЩвдПДЕНЧАЪЎУћПЭЛЇЕФзмЙКТђСПКЭзмЯњЪлЖюЁЃЮЊСЫЧхГўЮвЛЙЛсдкЛцЭМжажиаТУќУћСаЁЃ
| top_10
= (df.groupby('name')['ext price',
'quantity'].agg({'ext
price': 'sum', 'quantity'
: 'count'})
.sort_values(by='ext price', ascending=False))
[:10].reset_index()
top_10.rename(columns={'name': 'Name', 'ext
price': 'Sales',
'quantity': 'Purchases'},
|
ЯТУцЪЧЪ§ОнЕФДІРэНсЙћЁЃ
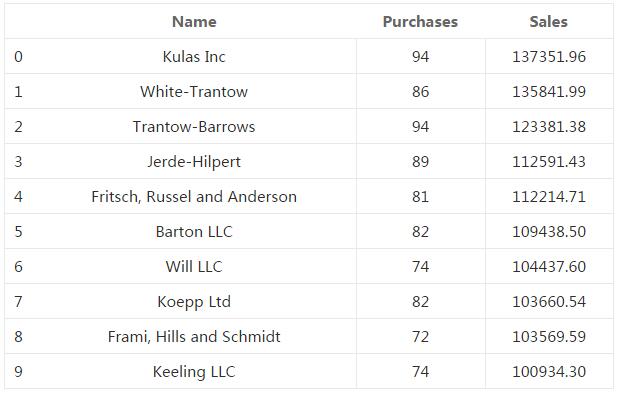
ЯждкЃЌЪ§ОнБЛИёЪНЛЏГЩвЛИіМђЕЅЕФБэИёЃЌЮвУЧРДПДШчКЮНЋетаЉНсЙћЛцжЦГЩЬѕаЮЭМЁЃ
ШчЧАЫљЪіЃЌmatplotlibгааэЖрВЛЭЌЕФбљЪНПЩгУгкфжШОЛцЭМЃЌПЩвдгУ plt . style . available ВщПДЯЕЭГжагааЉПЩгУЕФбљЪНЁЃ
| ['seaborn-dark',
'seaborn-dark-palette',
'fivethirtyeight',
'seaborn-whitegrid',
'seaborn-darkgrid',
'seaborn',
'bmh',
'classic',
'seaborn-colorblind',
'seaborn-muted',
'seaborn-white',
'seaborn-talk',
'grayscale',
'dark_background',
'seaborn-deep',
'seaborn-bright',
'ggplot',
'seaborn-paper',
'seaborn-notebook',
'seaborn-poster',
'seaborn-ticks',
'seaborn-pastel'] |
етбљМђЕЅЪЙгУвЛИібљЪНЃК
ЮвЙФРјДѓМвГЂЪдВЛЭЌЕФЗчИёЃЌПДПДФуЯВЛЖФФаЉЁЃ
ЯждкЮвУЧзМБИКУСЫвЛИіИќУРЙлЕФбљЪНЃЌЕквЛВНЪЧЪЙгУБъзМЕФpandasЛцЭМЙІФмЛцжЦЪ§ОнЃК
top_10.plot(kind='barh', y="Sales",
x="Name") |
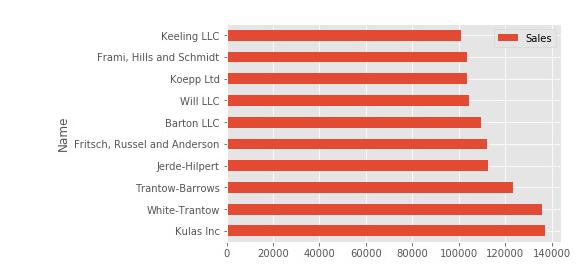
ЮвЭЦМіЯШЪЙгУpandasЛцЭМЃЌЪЧвђЮЊЫќЪЧвЛжжПьЫйМђБуЙЙНЈПЩЪгЛЏЕФЗНЗЈЁЃ гЩгкДѓЖрЪ§ШЫПЩФмвбОдкpandasжаНјааЙ§вЛаЉЪ§ОнДІРэ/ЗжЮіЃЌЫљвдЧыЯШДгЛљБОЕФЛцЭМПЊЪМЁЃ
ЖЈжЦЛЏЛцЭМ
МйЩшФуЖдетИіЛцЭМЕФвЊЕуКмТњвтЃЌЯТвЛВНОЭЪЧЖЈжЦЫќЁЃЪЙгУpandasЛцЭМЙІФмЖЈжЦЃЈШчЬэМгБъЬтКЭБъЧЉЃЉЗЧГЃМђЕЅЁЃЕЋЪЧЃЌФуПЩФмЛсЗЂЯжздМКЕФашЧѓдкФГжжГЬЖШЩЯГЌдНИУЙІФмЁЃетОЭЪЧЮвНЈвщбјГЩетбљзіЕФЯАЙпЕФдвђЃК
| fig,
ax = plt.subplots()
top_10.plot(kind='barh', y="Sales",
x="Name", ax=ax) |
ЕУЕНЕФЭМПДЦ№РДгыдЪМЭМПДЦ№РДЯрЭЌЃЌЕЋЪЧЮвУЧЯђ plt.subplots () ЬэМгСЫвЛИіЖюЭтЕФЕїгУЃЌВЂНЋaxДЋЕнИјЛцЭМКЏЪ§ЁЃЮЊЪВУДвЊетбљзіЃП
МЧЕУЕБЮвЫЕдк matplotlib жавЊЗУЮЪзјБъжсКЭЪ§зжжСЙиживЊТ№ЃПетОЭЪЧЮвУЧдкетРяЭъГЩЕФЙЄзїЁЃНЋРДШЮКЮЖЈжЦЛЏЖМНЋЭЈЙ§axЛђfigЖдЯѓЭъГЩЁЃ
ЮвУЧЕУвцгкpandasПьЫйЛцЭМЃЌЛёЕУСЫЗУЮЪ matplotlib ЕФЫљгаШЈЯоЁЃЮвУЧЯждкПЩвдзіЪВУДФиЃПгУвЛИіР§згРДеЙЪОЁЃСэЭтЃЌЭЈЙ§УќУћдМЖЈЃЌПЩвдЗЧГЃМђЕЅЕиАбБ№ШЫЕФНтОіЗНАИИФГЩЪЪКЯздМКЖРЬиашЧѓЕФЗНАИЁЃ
МйЩшЮвУЧвЊЕїећxЯожЦВЂИќИФвЛаЉзјБъжсЕФБъЧЉЃПЯждкзјБъжсБЃДцдкaxБфСПжаЃЌЮвУЧгаКмЖрЕФПижЦШЈЃК
fig, ax = plt.subplots()
top_10.plot(kind='barh', y="Sales",
x="Name", ax=ax)
ax.set_xlim([-10000, 140000])
ax.set_xlabel('Total Revenue')
ax.set_ylabel('Customer'); |
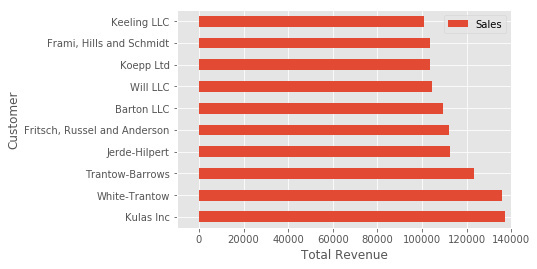
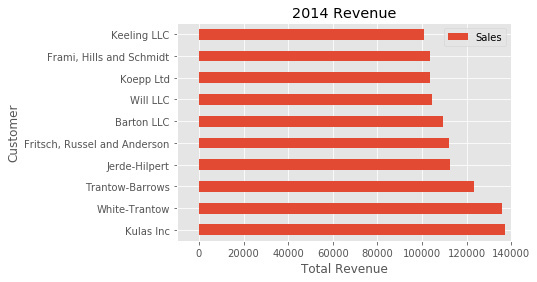
ЯТУцЪЧвЛИіПьНнЗНЪНЃЌПЩвдгУРДИќИФБъЬтКЭСНИіБъЧЉЃК
| Python
fig, ax = plt.subplots()
top_10.plot(kind='barh', y="Sales",
x="Name", ax=ax)
ax.set_xlim([-10000, 140000])
ax.set(title='2014 Revenue', xlabel='Total Revenue',
ylabel='Customer')
fig, ax = plt.subplots()
top_10.plot(kind='barh', y="Sales",
x="Name", ax=ax)
ax.set_xlim([-10000, 140000])
ax.set(title='2014 Revenue', xlabel='Total Revenue',
ylabel='Customer') |
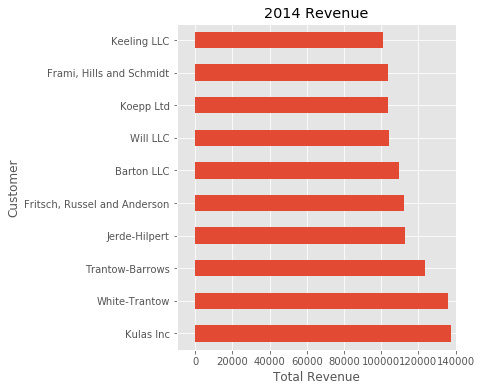
ЮЊСЫНјвЛВНбщжЄетжжЗНЗЈЃЌЛЙПЩвдЕїећЭМЯёЕФДѓаЁЁЃЭЈЙ§plt.subplots() КЏЪ§ЃЌПЩвдгУгЂДчЖЈвхfigsizeЁЃвВПЩвдгУax.legend().set_visibleЃЈFalseЃЉРДЩОГ§ЭМР§ЁЃ
fig, ax = plt.subplots(figsize=(5, 6))
top_10.plot(kind='barh', y="Sales",
x="Name", ax=ax)
ax.set_xlim([-10000, 140000])
ax.set(title='2014 Revenue', xlabel='Total Revenue')
ax.legend().set_visible(False) |
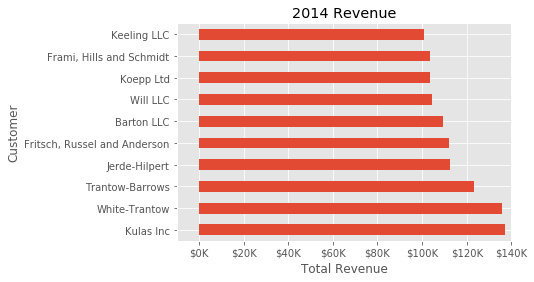
ЛљгкКмЖрдвђФуПЩФмЯывЊЕїећвЛЯТетИіЭМЁЃПДзХзюБ№ХЄЕФЕиЗНЪЧзмЪеШыЪ§зжЕФИёЪНЁЃ MatplotlibПЩвдЭЈЙ§FuncFormatterРДАяЮвУЧЪЕЯжЁЃетИіЙІФмПЩвдНЋгУЛЇЖЈвхЕФКЏЪ§гІгУгкжЕЃЌВЂЗЕЛивЛИіИёЪНећЦыЕФзжЗћДЎЗХжУдкзјБъжсЩЯЁЃ
ЯТУцЪЧвЛИіЛѕБвИёЪНЛЏКЏЪ§ЃЌПЩвдгХбХЕиДІРэМИЪЎЭђЗЖЮЇФкЕФУРдЊИёЪНЃК
|
def currency(x, pos):
'The two args are the value and tick position'
if x >= 1000000:
return '${:1.1f}M'.format(x*1e-6)
return '${:1.0f}K'.format(x*1e-3)
|
ЯждкЮвУЧгавЛИіИёЪНЛЏКЏЪ§ЃЌашвЊЖЈвхЫќВЂНЋЦфгІгУЕНxжсЁЃвдЯТЪЧЭъећЕФДњТыЃК
|
fig, ax = plt.subplots()
top_10.plot(kind='barh', y="Sales",
x="Name", ax=ax)
ax.set_xlim([-10000, 140000])
ax.set(title='2014 Revenue', xlabel='Total Revenue',
ylabel='Customer')
formatter = FuncFormatter(currency)
ax.xaxis.set_major_formatter(formatter)
ax.legend().set_visible(False)
|
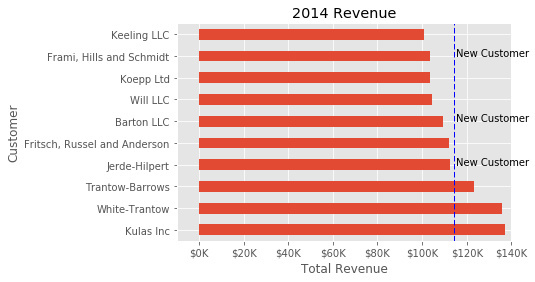
етбљИќУРЙлЃЌвВЪЧвЛИіКмКУЕФР§згЃЌеЙЪОШчКЮСщЛюЕиЖЈвхздМКЕФЮЪЬтНтОіЗНАИЁЃ
ЮвУЧзюКѓвЊШЅЬНЫїЕФвЛИіздЖЈвхЙІФмЪЧЭЈЙ§ЬэМгзЂЪЭЕНЛцЭМЁЃЛцжЦвЛЬѕДЙжБЯпЃЌПЩвдгУax.axvline()ЁЃЬэМгздЖЈвхЮФБОЃЌПЩвдгУax.text()ЁЃ
дкетИіР§згжаЃЌЮвУЧНЋЛцжЦвЛЬѕЦНОљЯпЃЌВЂЯдЪОШ§ИіаТПЭЛЇЕФБъЧЉЁЃ ЯТУцЪЧЭъећЕФДњТыКЭзЂЪЭЃЌАбЫќУЧЗХдквЛЦ№ЁЃ
| Python
# Create the figure and the axes
fig, ax = plt.subplots()
# Plot the data and get the averaged
top_10.plot(kind='barh', y="Sales",
x="Name", ax=ax)
avg = top_10['Sales'].mean()
# Set limits and labels
ax.set_xlim([-10000, 140000])
ax.set(title='2014 Revenue', xlabel='Total Revenue',
ylabel='Customer')
# Add a line for the average
ax.axvline(x=avg, color='b', label='Average',
linestyle='--', linewidth=1)
# Annotate the new customers
for cust in [3, 5, 8]:
ax.text(115000, cust, "New Customer")
# Format the currency
formatter = FuncFormatter(currency)
ax.xaxis.set_major_formatter(formatter)
# Hide the legend
ax.legend().set_visible(False)
# Create the figure and the axes
fig, ax = plt.subplots()
# Plot the data and get the averaged
top_10.plot(kind='barh', y="Sales",
x="Name", ax=ax)
avg = top_10['Sales'].mean()
# Set limits and labels
ax.set_xlim([-10000, 140000])
ax.set(title='2014 Revenue', xlabel='Total Revenue',
ylabel='Customer')
# Add a line for the average
ax.axvline(x=avg, color='b', label='Average',
linestyle='--', linewidth=1)
# Annotate the new customers
for cust in [3, 5, 8]:
ax.text(115000, cust, "New Customer")
# Format the currency
formatter = FuncFormatter(currency)
ax.xaxis.set_major_formatter(formatter)
# Hide the legend
ax.legend().set_visible(False) |
ЫфШЛетПЩФмВЛЪЧШУШЫИаЕНаЫЗмЃЈблЧАвЛССЃЉЕФЛцЭМЗНЪНЃЌЕЋЫќеЙЪОСЫФудкгУетжжЗНЗЈЪБгаЖрДѓШЈЯоЁЃ
ЭМаЮКЭЭМЯё
ЕНФПЧАЮЊжЙЃЌЮвУЧЫљзіЕФЫљгаИФБфЖМЪЧЕЅИіЭМаЮЁЃавдЫЕФЪЧЃЌЮвУЧвВгаФмСІдкЭМЩЯЬэМгЖрИіЭМаЮЃЌВЂЪЙгУИїжжбЁЯюБЃДцећИіЭМЯёЁЃ
ШчЙћОіЖЈвЊАбСНЗљЭМЗХдкЭЌвЛИіЭМЯёЩЯЃЌЮвУЧгІЖдШчКЮзіЕНетвЛЕугаЛљБОСЫНтЁЃ ЪзЯШЃЌДДНЈЭМаЮЃЌШЛКѓДДНЈзјБъжсЃЌШЛКѓНЋЦфШЋВПЛцжЦдквЛЦ№ЁЃЮвУЧПЩвдгУplt.subplots()РДЭъГЩЃК
| fig,
(ax0, ax1) = plt.subplots(nrows=1,
ncols=2, sharey=True,
figsize=(7, 4))
|
дкетИіР§згжаЃЌгУnrowsКЭncolsРДжИЖЈДѓаЁЃЌетбљЖдаТгУЛЇРДЫЕБШНЯЧхЮњЁЃдкЪОР§ДњТыжаЃЌОГЃПДЕНЯё1,2етбљЕФБфСПЁЃЮвОѕЕУЪЙгУУќУћЕФВЮЪ§ЃЌжЎКѓдкВщПДДњТыЪБИќШнвзРэНтЁЃ
гУsharey = TrueетИіВЮЪ§ЃЌвдБуyaxisЙВЯэЯрЭЌЕФБъЧЉЁЃ
етИіР§згвВКмКУЃЌвђЮЊИїИізјБъжсБЛНтбЙЫѕЕНax0КЭax1ЁЃгаетаЉзјБъжсжсЃЌФуПЩвдЯёЩЯУцЕФР§згвЛбљЛцжЦЭМаЮЃЌЕЋЪЧдкax0КЭax1ЩЯИїЗХвЛИіЭМЁЃ
|
# Get the figure and the axes
fig, (ax0, ax1) = plt.subplots(nrows=1,ncols=2,
sharey=True, figsize=(7,
4))
top_10.plot(kind='barh', y="Sales",
x="Name", ax=ax0)
ax0.set_xlim([-10000, 140000])
ax0.set(title='Revenue', xlabel='Total Revenue',
ylabel='Customers')
# Plot the average as a vertical line
avg = top_10['Sales'].mean()
ax0.axvline(x=avg, color='b', label='Average',
linestyle='--',
linewidth=1)
# Repeat for the unit plot
top_10.plot(kind='barh', y="Purchases",
x="Name", ax=ax1)
avg = top_10['Purchases'].mean()
ax1.set(title='Units', xlabel='Total Units',
ylabel='')
ax1.axvline(x=avg, color='b', label='Average',
linestyle='--',
linewidth=1)
# Title the figure
fig.suptitle('2014 Sales Analysis', fontsize=14,
fontweight='bold');
# Hide the legends
ax1.legend().set_visible(False)
ax0.legend().set_visible(False) |
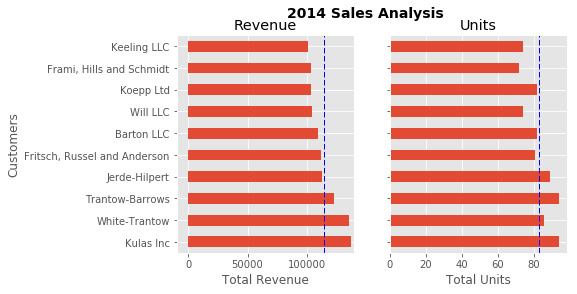
ЕНФПЧАЮЊжЙЃЌЮввЛжБгУjupyter notebookЃЌНшжњЃЅmatplotlibФкСЊжИСюРДЯдЪОЭМаЮЁЃЕЋЪЧКмЖрЪБКђЃЌашвЊвдЬиЖЈИёЪНБЃДцЪ§зжЃЌКЭЦфЫћФкШнвЛЦ№еЙЪОЁЃ
MatplotlibжЇГжаэЖрВЛЭЌИёЪНЮФМўЕФБЃДцЁЃ ФуПЩвдгУ fig . canvas . get _ supported _ filetypesЃЈЃЉВщПДЯЕЭГжЇГжЕФИёЪНЃК
гЩгкЮвУЧгаfigЖдЯѓЃЌЮвУЧПЩвдгУЖрИібЁЯюРДБЃДцЭМЯёЃК
| fig.savefig('sales.png',
transparent=False, dpi=80, bbox_inches="tight") |
ЩЯУцЕФДњТыАбЭМЯёБЃДцЮЊБГОАВЛЭИУїЕФpngЁЃЛЙжИЖЈСЫЗжБцТЪdpiКЭbbox_inches =ЁАtightЁБРДОЁСПМѕЩйЖргрЕФПеИёЁЃ
НсТл
ЯЃЭћетИіЙ§ГЬгажњгкФуСЫНтШчКЮдкШеГЃЕФЪ§ОнЗжЮіжаИќгааЇЕиЪЙгУmatplotlibЁЃ ШчЙћдкзіЗжЮіЪБбјГЩЪЙгУетжжЗНЗЈЕФЯАЙпЃЌФугІИУПЩвдПьЫйЖЈжЦГіШЮКЮФуашвЊЕФЭМЯёЁЃ
зїЮЊзюКѓЕФИЃРћЃЌЮвв§ШывЛИіПьЫйжИФЯРДзмНсЫљгаЕФИХФюЁЃЯЃЭћетгажњгкАбетЦЊЮФеТСЊЯЕЦ№РДЃЌВЂЮЊНёКѓЪЙгУВЮПМЬсЙЉЗНБуЁЃ

|








