| БрМЭЦМі: |
| РДдДгкcsdnЃЌЙВНВНтСЫ16ИіФЃПщЃЌЗжБ№ДњТыЯъЯИУшЪіЃЌЯЃЭћЖдДѓМвЙЄзїгаАяжњЁЃ |
|
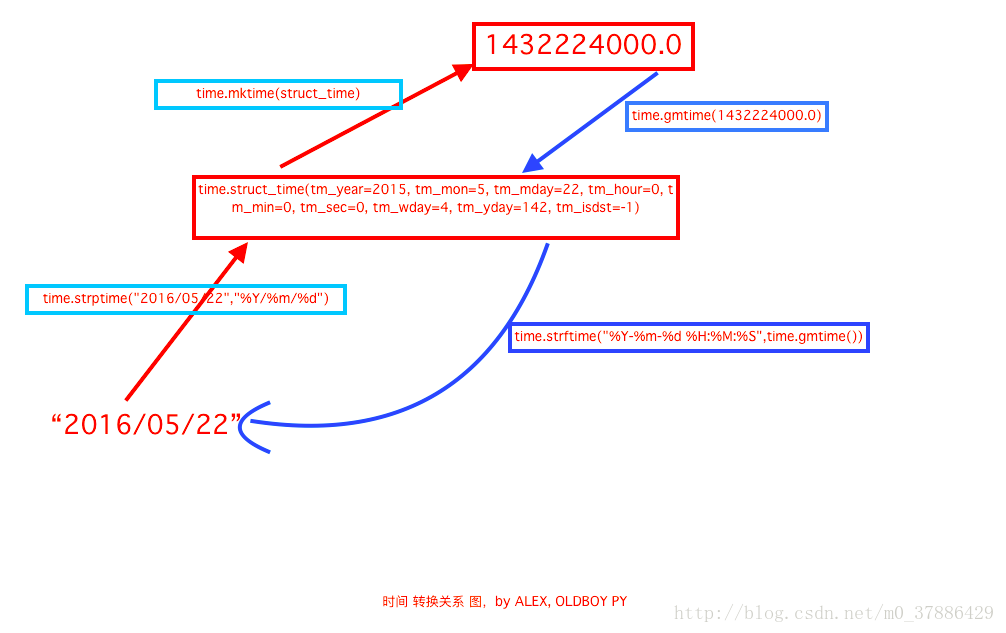
1ЁЂtime & datetimeФЃПщ
ЪБМфЯрЙиЕФВйзїЃЌЪБМфгаШ§жжБэЪОЗНЪНЃК
ЪБМфДС 1970Фъ1дТ1ШежЎКѓЕФУыЃЌМДЃКtime.time()
ИёЪНЛЏЕФзжЗћДЎ 2014-11-11 11:11ЃЌ МДЃКtime.strftime('%Y-%m-%d')
НсЙЙЛЏЪБМф дЊзщАќКЌСЫЃКФъЁЂШеЁЂаЧЦкЕШ...time.struct_time МДЃКtime.localtime()
print(time.time())
print(time.mktime(time.localtime()))
print(time.gmtime()) #ПЩМгЪБМфДСВЮЪ§
print(time.localtime()) #ПЩМгЪБМфДСВЮЪ§
print(time.strptime('2014-11-11', '%Y-%m-%d'))
print(time.strftime('%Y-%m-%d %X')) #ФЌШЯЕБЧАЪБМф
print(time.strftime('%Y-%m-%d %X',time.localtime()))
#ФЌШЯЕБЧАЪБМф
print(time.asctime())
print(time.asctime(time.localtime()))
print(time.ctime(time.time())) #ctimeКѓУцМгЕФЪЧЪБМфДС
import datetime
"""
datetime.dateЃКБэЪОШеЦкЕФРрЁЃГЃгУЕФЪєадгаyear, month, day
datetime.timeЃКБэЪОЪБМфЕФРрЁЃГЃгУЕФЪєадгаhour, minute, second,
microsecond
datetime.datetimeЃКБэЪОШеЦкЪБМф
datetime.timedeltaЃКБэЪОЪБМфМфИєЃЌМДСНИіЪБМфЕужЎМфЕФГЄЖШ
timedelta([days[, seconds[, microseconds[, milliseconds[,
minutes[, hours[, weeks]]]]]]])
strftime("%Y-%m-%d")
"""
import datetime
print(datetime.datetime.now())
print(datetime.datetime.now() - datetime.timedelta(days=5)) |
2ЁЂrandomФЃПщ
#ЫцЛњЪ§
import random
print(random.random())
print(random.randint(1,8)) #АќРЈ8
print(random.randrange(1,10)) #ВЛАќРЈ10
print(random.choice([1,2,3,4]))
print(random.sample([1,2,3,4],1)) #КѓУцЕФ1БэЪОДгађСажаШЁМИИіжЕ
#ЩњГЩЫцЛњбщжЄТы
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current != i:
temp = chr(random.randint(65,90)) #65-90ЭЈЙ§зЊЛЛЮЊДѓаДзжФИЃЌ97-122ЭЈЙ§зЊЛЛЮЊаЁаДзжФИ
else:
temp = random.randint(0,9)
checkcode += str(temp)
print(checkcode) |
3ЁЂOSФЃПщ
ЬсЙЉЖдВйзїЯЕЭГНјааЕїгУЕФНгПк
os.getcwd() ЛёШЁЕБЧАЙЄзїФПТМЃЌМДЕБЧАpythonНХБОЙЄзїЕФФПТМТЗОЖ
os.chdir("dirname") ИФБфЕБЧАНХБОЙЄзїФПТМЃЛЯрЕБгкshellЯТcd
os.curdir ЗЕЛиЕБЧАФПТМ: ('.')
os.pardir ЛёШЁЕБЧАФПТМЕФИИФПТМзжЗћДЎУћЃК('..')
os.makedirs('dirname1/dirname2') ПЩЩњГЩЖрВуЕнЙщФПТМ
os.removedirs('dirname1') ШєФПТМЮЊПеЃЌдђЩОГ§ЃЌВЂЕнЙщЕНЩЯвЛМЖФПТМЃЌШчШєвВЮЊПеЃЌдђЩОГ§ЃЌвРДЫРрЭЦ
os.mkdir('dirname') ЩњГЩЕЅМЖФПТМЃЛЯрЕБгкshellжаmkdir dirname
os.rmdir('dirname') ЩОГ§ЕЅМЖПеФПТМЃЌШєФПТМВЛЮЊПедђЮоЗЈЩОГ§ЃЌБЈДэЃЛЯрЕБгкshellжаrmdir
dirname
os.listdir('dirname') СаГіжИЖЈФПТМЯТЕФЫљгаЮФМўКЭзгФПТМЃЌАќРЈвўВиЮФМўЃЌВЂвдСаБэЗНЪНДђгЁ
os.remove() ЩОГ§вЛИіЮФМў
os.rename("oldname","newname")
жиУќУћЮФМў/ФПТМ
os.stat('path/filename') ЛёШЁЮФМў/ФПТМаХЯЂ
os.sep ЪфГіВйзїЯЕЭГЬиЖЈЕФТЗОЖЗжИєЗћЃЌwinЯТЮЊ"\\",LinuxЯТЮЊ"/"
os.linesep ЪфГіЕБЧАЦНЬЈЪЙгУЕФаажежЙЗћЃЌwinЯТЮЊ"\t\n",LinuxЯТЮЊ"\n"
os.pathsep ЪфГігУгкЗжИюЮФМўТЗОЖЕФзжЗћДЎ
os.name ЪфГізжЗћДЎжИЪОЕБЧАЪЙгУЦНЬЈЁЃwin->'nt'; Linux->'posix'
os.system("bash command") дЫааshellУќСюЃЌжБНгЯдЪО
os.environ ЛёШЁЯЕЭГЛЗОГБфСП
os.path.abspath(path) ЗЕЛиpathЙцЗЖЛЏЕФОјЖдТЗОЖ
os.path.split(path) НЋpathЗжИюГЩФПТМКЭЮФМўУћЖўдЊзщЗЕЛи
os.path.dirname(path) ЗЕЛиpathЕФФПТМЁЃЦфЪЕОЭЪЧos.path.split(path)ЕФЕквЛИідЊЫи
os.path.basename(path) ЗЕЛиpathзюКѓЕФЮФМўУћЁЃШчКЮpathвдЃЏЛђ\НсЮВЃЌФЧУДОЭЛсЗЕЛиПежЕЁЃМДos.path.split(path)ЕФЕкЖўИідЊЫи
os.path.exists(path) ШчЙћpathДцдкЃЌЗЕЛиTrueЃЛШчЙћpathВЛДцдкЃЌЗЕЛиFalse
os.path.isabs(path) ШчЙћpathЪЧОјЖдТЗОЖЃЌЗЕЛиTrue
os.path.isfile(path) ШчЙћpathЪЧвЛИіДцдкЕФЮФМўЃЌЗЕЛиTrueЁЃЗёдђЗЕЛиFalse
os.path.isdir(path) ШчЙћpathЪЧвЛИіДцдкЕФФПТМЃЌдђЗЕЛиTrueЁЃЗёдђЗЕЛиFalse
os.path.join(path1[, path2[, ...]]) НЋЖрИіТЗОЖзщКЯКѓЗЕЛиЃЌЕквЛИіОјЖдТЗОЖжЎЧАЕФВЮЪ§НЋБЛКіТд
os.path.getatime(path) ЗЕЛиpathЫљжИЯђЕФЮФМўЛђепФПТМЕФзюКѓДцШЁЪБМф
os.path.getmtime(path) ЗЕЛиpathЫљжИЯђЕФЮФМўЛђепФПТМЕФзюКѓаоИФЪБМф
os.popen(path) Р§ШчЃКдЫааa = os.popen('dir').read()
print(a)ЃЌПЩвдЯдЪОdirЯТЕФЫљгаФкШн |
4ЁЂsysФЃПщ
sys.argv УќСюааВЮЪ§ListЃЌЕквЛИідЊЫиЪЧГЬађБОЩэТЗОЖ
sys.exit(n) ЭЫГіГЬађЃЌе§ГЃЭЫГіЪБexit(0)
sys.version ЛёШЁPythonНтЪЭГЬађЕФАцБОаХЯЂ
sys.maxint зюДѓЕФIntжЕ
sys.path ЗЕЛиФЃПщЕФЫбЫїТЗОЖЃЌГѕЪМЛЏЪБЪЙгУPYTHONPATHЛЗОГБфСПЕФжЕ
sys.platform ЗЕЛиВйзїЯЕЭГЦНЬЈУћГЦ
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1] |
5ЁЂshutilФЃПщ
ИпМЖЕФ ЮФМўЁЂЮФМўМаЁЂбЙЫѕАќ ДІРэФЃПщ
shutil.copyfileobj(fsrc,
fdst[, length]) НЋЮФМўФкШн(ЛђепНаЮФМўЖдЯѓ)ПНБДЕНСэвЛИіЮФМўжаЃЌПЩвдВПЗжФкШн
shutil.copyfile(src, dst) ПНБДЮФМў
shutil.copymode(src, dst) НіПНБДШЈЯоЁЃФкШнЁЂзщЁЂгУЛЇОљВЛБф
shutil.copystat(src, dst) ПНБДзДЬЌЕФаХЯЂЃЌАќРЈЃКmode bits,
atime, mtime, flags
shutil.copy(src, dst) ПНБДЮФМўКЭШЈЯо
shutil.copy2(src, dst) ПНБДЮФМўКЭзДЬЌаХЯЂ
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
ЕнЙщЕФШЅПНБДЮФМў
Р§ШчЃКcopytree(source, destination, ignore=ignore_patterns('*.pyc',
'tmp*'))
shutil.rmtree(path[, ignore_errors[, onerror]])
ЕнЙщЕФШЅЩОГ§ЮФМў
shutil.move(src, dst) ЕнЙщЕФШЅвЦЖЏЮФМў
shutil.make_archive(base_name, format,...)
ДДНЈбЙЫѕАќВЂЗЕЛиЮФМўТЗОЖЃЌР§ШчЃКzipЁЂtar
base_nameЃКбЙЫѕАќЕФЮФМўУћЃЌвВПЩвдЪЧбЙЫѕАќЕФТЗОЖЁЃжЛЪЧЮФМўУћЪБЃЌдђБЃДцжСЕБЧАФПТМЃЌЗёдђБЃДцжСжИЖЈТЗОЖЃЌШчЃКbackup=>БЃДцжСЕБЧАТЗОЖЃЛШчЃК/home/www/backup
=>БЃДцжС/home/www/
formatЃКбЙЫѕАќжжРрЃЌЁАzipЁБ, ЁАtarЁБ, ЁАbztarЁБЃЌЁАgztarЁБ
root_dirЃКвЊбЙЫѕЕФЮФМўМаТЗОЖЃЈФЌШЯЕБЧАФПТМЃЉ
ownerЃКгУЛЇЃЌФЌШЯЕБЧАгУЛЇ
groupЃКзщЃЌФЌШЯЕБЧАзщ
loggerЃКгУгкМЧТМШежОЃЌЭЈГЃЪЧlogging.LoggerЖдЯѓ |
#НЋ /home/www/Downloads/test
ЯТЕФЮФМўДђАќЗХжУЕБЧАГЬађФПТМ
import shutil
ret = shutil.make_archive("test", 'gztar',
root_dir='/home/www/Downloads/test')
```
#НЋ/home/www/Downloads/test ЯТЕФЮФМўДђАќЗХжУ /home/www/ФПТМ
import shutil
ret = shutil.make_archive("/home/www/test",
'gztar', root_dir='/home/www/Downloads/test') |
shutil ЖдбЙЫѕАќЕФДІРэЪЧЕїгУ ZipFile КЭ TarFile СНИіФЃПщРДНјааЕФЃЌЯъЯИ
zipfile бЙЫѕНтбЙ
| import zipfile
# бЙЫѕ
z = zipfile.ZipFile('test.zip', 'w')
z.write('a.log')
z.write('data.data')
z.close()
# НтбЙ
z = zipfile.ZipFile('test.zip', 'r')
z.extractall()
z.close() |
tarfile бЙЫѕНтбЙ
| import tarfile
# бЙЫѕ
tar = tarfile.open('test.tar','w')
tar.add('/home/www/bbs2.zip', arcname='bbs2.zip')
tar.add('/home/www/cmdb.zip', arcname='cmdb.zip')
tar.close()
# НтбЙ
tar = tarfile.open(test.tar','r')
tar.extractall() # ПЩЩшжУНтбЙЕижЗ
tar.close() |
БИзЂЃК
1ЁЂshutil.copymode(src, dst) ЕФдДДњТы
def copymode(src,
dst):
"""Copy mode bits from
src to dst"""
if hasattr(os, 'chmod'):
st = os.stat(src)
mode = stat.S_IMODE(st.st_mode)
os.chmod(dst, mode) |
6ЁЂjson & pickle ФЃПщ
гУгкађСаЛЏЕФСНИіФЃПщ
jsonЃЌгУгкзжЗћДЎ КЭ pythonЪ§ОнРраЭМфНјаазЊЛЛ
pickleЃЌгУгкpythonЬигаЕФРраЭ КЭ pythonЕФЪ§ОнРраЭМфНјаазЊЛЛ
jsonФЃПщЬсЙЉСЫЫФИіЙІФмЃКdumpsЁЂdumpЁЂloadsЁЂload
pickleФЃПщЬсЙЉСЫЫФИіЙІФмЃКdumpsЁЂdumpЁЂloadsЁЂload
import pickle
data = {'k1':123,'k2':'hello'}
#pickle.dumps НЋЪ§ОнЭЈЙ§ЬиЪтЕФаЮЪНзЊЛЛЮЊжЛгаpythonгябдЪЖБ№ЕФзжЗћДЎ
p_str = pickle.dumps(data)
print(p_str)
#pickle.dump НЋЪ§ОнЭЈЙ§ЬиЪтЕФаЮЪНзЊЛЛЮЊжЛгаpythonгябдЪЖБ№ЕФзжЗћДЎЃЌВЂаДШыЮФМў
with open('D:/result.pk','w') as fp:
pickle.dump(data,fp)
import json
#json.dumps НЋЪ§ОнЭЈЙ§ЬиЪтЕФаЮЪНзЊЛЛЮЊЫљгаГЬађгябдЪЖБ№ЕФзжЗћДЎ
j_str = json.dumps(data)
print(j_str)
#json.dump НЋЪ§ОнЭЈЙ§ЬиЪтЕФаЮЪНзЊЛЛЮЊЫљгаГЬађгябдЪЖБ№ЕФзжЗћДЎЃЌВЂаДШыЮФМў
with open('D:/result.json','w') as fp:
json.dump(data,fp) |
7ЁЂshelve ФЃПщ
shelveФЃПщЪЧвЛИіМђЕЅЕФk,vНЋФкДцЪ§ОнЭЈЙ§ЮФМўГжОУЛЏЕФФЃПщЃЌПЩвдГжОУЛЏШЮКЮpickleПЩжЇГжЕФpythonЪ§ОнИёЪН
import shelve
d = shelve.open('shelve_test') #ДђПЊвЛИіЮФМў
class Test(object):
def __init__(self,n):
self.n = n
t = Test(123)
t2 = Test(123334)
name = ["alex","rain","test"]
d["test"] = name #ГжОУЛЏСаБэ
d["t1"] = t #ГжОУЛЏРр
d["t2"] = t2
d.close() |
8ЁЂxmlДІРэФЃПщ
xmlЪЧЪЕЯжВЛЭЌгябдЛђГЬађжЎМфНјааЪ§ОнНЛЛЛЕФавщЃЌИњjsonВюВЛЖрЃЌЕЋjsonЪЙгУЦ№РДИќМђЕЅЃЌВЛЙ§ЃЌдкjsonЛЙУЛЕЎЩњЕФКкАЕФъДњЃЌДѓМвжЛФмбЁдёгУxmlбНЃЌжСНёКмЖрДЋЭГЙЋЫОШчН№ШкаавЕЕФКмЖрЯЕЭГЕФНгПкЛЙжївЊЪЧxmlЁЃ
xmlЕФИёЪНШчЯТЃЌОЭЪЧЭЈЙ§<>НкЕуРДЧјБ№Ъ§ОнНсЙЙЕФ:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data> |
(1)НтЮіXML
ЂйРћгУElementTree.XMLНЋзжЗћДЎНтЮіГЩxmlЖдЯѓ
from xml.etree import ElementTree as ET
# ДђПЊЮФМўЃЌЖСШЁXMLФкШн
str_xml = open('xo.xml', 'r').read()
# НЋзжЗћДЎНтЮіГЩxmlЬиЪтЖдЯѓЃЌrootДњжИxmlЮФМўЕФИљНкЕу
root = ET.XML(str_xml)
ЂкРћгУElementTree.parseНЋЮФМўжБНгНтЮіГЩxmlЖдЯѓ
from xml.etree import ElementTree as ET
# жБНгНтЮіxmlЮФМў
tree = ET.parse("xo.xml")
# ЛёШЁxmlЮФМўЕФИљНкЕу
root = tree.getroot() |
(2)ВйзїXML
XMLИёЪНРраЭЪЧНкЕуЧЖЬзНкЕуЃЌЖдгкУПвЛИіНкЕуОљгавдЯТЙІФмЃЌвдБуЖдЕБЧАНкЕуНјааВйзї
гЩгк УПИіНкЕу ЖМОпгавдЩЯЕФЗНЗЈЃЌВЂЧвдкЩЯвЛВНжшжаНтЮіЪБОљЕУЕНСЫrootЃЈxmlЮФМўЕФИљНкЕуЃЉ,ПЩвдРћгУвдЩЯЗНЗЈНјааВйзїxmlЮФМўЁЃ
aЁЂБщРњXMLЮФЕЕЕФЫљгаФкШн
from xml.etree
import ElementTree as ET
############ НтЮіЗНЪНвЛ ############
# ДђПЊЮФМўЃЌЖСШЁXMLФкШн
str_xml = open('xo.xml', 'r').read()
# НЋзжЗћДЎНтЮіГЩxmlЬиЪтЖдЯѓЃЌrootДњжИxmlЮФМўЕФИљНкЕу
root = ET.XML(str_xml)
############ НтЮіЗНЪНЖў ############
# жБНгНтЮіxmlЮФМў
#tree = ET.parse("xo.xml")
# ЛёШЁxmlЮФМўЕФИљНкЕу
#root = tree.getroot()
### Вйзї
# ЖЅВуБъЧЉprint(root.tag)
# БщРњXMLЮФЕЕЕФЕкЖўВуfor child in root:
# ЕкЖўВуНкЕуЕФБъЧЉУћГЦКЭБъЧЉЪєад
print(child.tag, child.attrib)
# БщРњXMLЮФЕЕЕФЕкШ§Ву
for i in child:
# ЕкЖўВуНкЕуЕФБъЧЉУћГЦКЭФкШн
print(i.tag,i.text) |
bЁЂБщРњXMLжажИЖЈЕФНкЕу
from xml.etree
import ElementTree as ET
############ НтЮіЗНЪНвЛ ############
# ДђПЊЮФМўЃЌЖСШЁXMLФкШн
#str_xml = open('xo.xml', 'r').read()
# НЋзжЗћДЎНтЮіГЩxmlЬиЪтЖдЯѓЃЌrootДњжИxmlЮФМўЕФИљНкЕу
#root = ET.XML(str_xml)
############ НтЮіЗНЪНЖў ############
# жБНгНтЮіxmlЮФМў
tree = ET.parse("xo.xml")
# ЛёШЁxmlЮФМўЕФИљНкЕу
root = tree.getroot()
### Вйзї
# ЖЅВуБъЧЉ print(root.tag)
# БщРњXMLжаЫљгаЕФyearНкЕуfor node in root.iter('year'):
# НкЕуЕФБъЧЉУћГЦКЭФкШн
print(node.tag, node.text) |
cЁЂаоИФНкЕуФкШн
гЩгкаоИФЕФНкЕуЪБЃЌОљЪЧдкФкДцжаНјааЃЌЦфВЛЛсгАЯьЮФМўжаЕФФкШнЁЃЫљвдЃЌШчЙћЯывЊаоИФЃЌдђашвЊжиаТНЋФкДцжаЕФФкШнаДЕНЮФМўЁЃ
ЂйНтЮізжЗћДЎЗНЪНЃЌаоИФЃЌБЃДц
from xml.etree
import ElementTree as ET
############ НтЮіЗНЪНвЛ ############
# ДђПЊЮФМўЃЌЖСШЁXMLФкШн
str_xml = open('xo.xml', 'r').read()
# НЋзжЗћДЎНтЮіГЩxmlЬиЪтЖдЯѓЃЌrootДњжИxmlЮФМўЕФИљНкЕу
root = ET.XML(str_xml)
############ Вйзї ############
# ЖЅВуБъЧЉprint(root.tag)
# бЛЗЫљгаЕФyearНкЕуfor node in root.iter('year'):
# НЋyearНкЕужаЕФФкШнзддівЛ
new_year = int(node.text) + 1
node.text = str(new_year)
# ЩшжУЪєад
node.set('name', 'alex')
node.set('age', '18')
# ЩОГ§Ъєад
del node.attrib['name']
############ БЃДцЮФМў ############
tree = ET.ElementTree(root)
tree.write("newnew.xml", encoding='utf-8') |
ЂкНтЮіЮФМўЗНЪНЃЌаоИФЃЌБЃДц
from xml.etree
import ElementTree as ET
############ НтЮіЗНЪНЖў ############
# жБНгНтЮіxmlЮФМў
tree = ET.parse("xo.xml")
# ЛёШЁxmlЮФМўЕФИљНкЕу
root = tree.getroot()
############ Вйзї ############
# ЖЅВуБъЧЉprint(root.tag)
# бЛЗЫљгаЕФyearНкЕуfor node in root.iter('year'):
# НЋyearНкЕужаЕФФкШнзддівЛ
new_year = int(node.text) + 1
node.text = str(new_year)
# ЩшжУЪєад
node.set('name', 'alex')
node.set('age', '18')
# ЩОГ§Ъєад
del node.attrib['name']
############ БЃДцЮФМў ############
tree.write("newnew.xml", encoding='utf-8') |
dЁЂЩОГ§НкЕу
ЂйНтЮізжЗћДЎЗНЪНДђПЊЃЌЩОГ§ЃЌБЃДц
from xml.etree
import ElementTree as ET
############ НтЮізжЗћДЎЗНЪНДђПЊ ############
# ДђПЊЮФМўЃЌЖСШЁXMLФкШн
str_xml = open('xo.xml', 'r').read()
# НЋзжЗћДЎНтЮіГЩxmlЬиЪтЖдЯѓЃЌrootДњжИxmlЮФМўЕФИљНкЕу
root = ET.XML(str_xml)
############ Вйзї ############
# ЖЅВуБъЧЉprint(root.tag)
# БщРњdataЯТЕФЫљгаcountryНкЕуfor country in root.findall('country'):
# ЛёШЁУПвЛИіcountryНкЕуЯТrankНкЕуЕФФкШн
rank = int(country.find('rank').text)
if rank > 50:
# ЩОГ§жИЖЈcountryНкЕу root.remove(country)
############ БЃДцЮФМў ############
tree = ET.ElementTree(root)
tree.write("newnew.xml", encoding='utf-8') |
ЂкНтЮіЮФМўЗНЪНДђПЊЃЌЩОГ§ЃЌБЃДц
from xml.etree
import ElementTree as ET
############ НтЮіЮФМўЗНЪН ############
# жБНгНтЮіxmlЮФМў
tree = ET.parse("xo.xml")
# ЛёШЁxmlЮФМўЕФИљНкЕу
root = tree.getroot()
############ Вйзї ############
# ЖЅВуБъЧЉprint(root.tag)
# БщРњdataЯТЕФЫљгаcountryНкЕуfor country in root.findall('country'):
# ЛёШЁУПвЛИіcountryНкЕуЯТrankНкЕуЕФФкШн
rank = int(country.find('rank').text)
if rank > 50:
# ЩОГ§жИЖЈcountryНкЕу root.remove(country)
############ БЃДцЮФМў ############
tree.write("newnew.xml", encoding='utf-8') |
(3)ДДНЈXMLЮФЕЕ
aЁЂЗНЪНЃЈвЛЃЉ
from xml.etree
import ElementTree as ET
# ДДНЈИљНкЕу
root = ET.Element("famliy")
# ДДНЈНкЕуДѓЖљзг
son1 = ET.Element('son', {'name': 'Жљ1'})# ДДНЈаЁЖљзг
son2 = ET.Element('son', {"name": 'Жљ2'})
# дкДѓЖљзгжаДДНЈСНИіЫязг
grandson1 = ET.Element('grandson', {'name': 'Жљ11'})
grandson2 = ET.Element('grandson', {'name': 'Жљ12'})
son1.append(grandson1)
son1.append(grandson2)
# АбЖљзгЬэМгЕНИљНкЕужаroot.append(son1)
root.append(son1)
tree = ET.ElementTree(root)
tree.write('oooo.xml',encoding='utf-8', short_empty_elements=False) |
bЁЂДДНЈЗНЪНЃЈЖўЃЉ
from xml.etree
import ElementTree as ET
# ДДНЈИљНкЕу
root = ET.Element("famliy")
# ДДНЈДѓЖљзг
# son1 = ET.Element('son', {'name': 'Жљ1'})
son1 = root.makeelement('son', {'name': 'Жљ1'})#
ДДНЈаЁЖљзг
# son2 = ET.Element('son', {"name":
'Жљ2'})
son2 = root.makeelement('son', {"name":
'Жљ2'})
# дкДѓЖљзгжаДДНЈСНИіЫязг
# grandson1 = ET.Element('grandson', {'name':
'Жљ11'})
grandson1 = son1.makeelement('grandson', {'name':
'Жљ11'})# grandson2 = ET.Element('grandson',
{'name': 'Жљ12'})
grandson2 = son1.makeelement('grandson', {'name':
'Жљ12'})
son1.append(grandson1)
son1.append(grandson2)
# АбЖљзгЬэМгЕНИљНкЕужаroot.append(son1)
root.append(son1)
tree = ET.ElementTree(root)
tree.write('oooo.xml',encoding='utf-8', short_empty_elements=False) |
cЁЂДДНЈЗНЪНЃЈШ§ЃЉ
from xml.etree
import ElementTree as ET
# ДДНЈИљНкЕу
root = ET.Element("famliy")
# ДДНЈНкЕуДѓЖљзг
son1 = ET.SubElement(root, "son", attrib={'name':
'Жљ1'})# ДДНЈаЁЖљзг
son2 = ET.SubElement(root, "son", attrib={"name":
"Жљ2"})
# дкДѓЖљзгжаДДНЈвЛИіЫязг
grandson1 = ET.SubElement(son1, "age",
attrib={'name': 'Жљ11'})
grandson1.text = 'Ыязг'
et = ET.ElementTree(root) #ЩњГЩЮФЕЕЖдЯѓ
et.write("test.xml", encoding="utf-8",
xml_declaration=True, short_empty_elements=False) |
dЁЂгЩгкдЩњБЃДцЕФXMLЪБФЌШЯЮоЫѕНјЃЌШчЙћЯывЊЩшжУЫѕНјЕФЛАЃЌ ашвЊаоИФБЃДцЗНЪНЃК
| from xml.etree
import ElementTree as ETfrom xml.dom import minidom
def prettify(elem):
"""НЋНкЕузЊЛЛГЩзжЗћДЎЃЌВЂЬэМгЫѕНјЁЃ
"""
rough_string = ET.tostring(elem, 'utf-8')
reparsed = minidom.parseString(rough_string)
return reparsed.toprettyxml(indent="\t")
# ДДНЈИљНкЕу
root = ET.Element("famliy")
# ДДНЈДѓЖљзг
# son1 = ET.Element('son', {'name': 'Жљ1'})
son1 = root.makeelement('son', {'name': 'Жљ1'})#
ДДНЈаЁЖљзг
# son2 = ET.Element('son', {"name":
'Жљ2'})
son2 = root.makeelement('son', {"name":
'Жљ2'})
# дкДѓЖљзгжаДДНЈСНИіЫязг
# grandson1 = ET.Element('grandson', {'name':
'Жљ11'})
grandson1 = son1.makeelement('grandson', {'name':
'Жљ11'})# grandson2 = ET.Element('grandson',
{'name': 'Жљ12'})
grandson2 = son1.makeelement('grandson', {'name':
'Жљ12'})
son1.append(grandson1)
son1.append(grandson2)
# АбЖљзгЬэМгЕНИљНкЕужаroot.append(son1)
root.append(son1)
raw_str = prettify(root)
f = open("xxxoo.xml",'w',encoding='utf-8')
f.write(raw_str)
f.close() |
(4)УќУћПеМф
| from xml.etree
import ElementTree as ET
ET.register_namespace('com',"http://www.company.com")
#some name
# build a tree structure
root = ET.Element("{http://www.company.com}STUFF")
body = ET.SubElement(root, "{http://www.company.com}MORE_STUFF",
attrib={"{http://www.company.com}hhh":
"123"})
body.text = "STUFF EVERYWHERE!"
# wrap it in an ElementTree instance, and save
as XML
tree = ET.ElementTree(root)
tree.write("page.xml",
xml_declaration=True,
encoding='utf-8',
method="xml") |
(5)БШНЯЧхГўЕФВйзїЁЁЁЁ
import xml.etree.ElementTree
as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#БщРњxmlЮФЕЕ
for child in root:
print(child.tag, child.attrib)
for i in child:
print(i.tag,i.text)
#жЛБщРњyear НкЕу
for node in root.iter('year'):
print(node.tag,node.text)
#аоИФКЭЩОГ§xmlЮФЕЕФкШн
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#аоИФ
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated","yes")
tree.write("xmltest.xml")
#ЩОГ§node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
#здМКДДНЈxmlЮФЕЕ
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = '33'
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = '19'
et = ET.ElementTree(new_xml) #ЩњГЩЮФЕЕЖдЯѓ
et.write("test.xml", encoding="utf-8",xml_declaration=True)
ET.dump(new_xml) #ДђгЁЩњГЩЕФИёЪН
|
9ЁЂPyYAMLФЃПщ
PythonвВПЩвдКмШнвзЕФДІРэymalЮФЕЕИёЪНЃЌжЛВЛЙ§ашвЊАВзАвЛИіФЃПщЃЌВЮПМЮФЕЕЃКhttp://pyyaml.org/wiki/PyYAMLDocumentation
10ЁЂconfigparserФЃПщ
гУгкЩњГЩКЭаоИФГЃМћХфжУЮФЕЕЃЌЕБЧАФЃПщЕФУћГЦдк python 2.x АцБОжаЮЊ ConfigParserЁЃРДПДвЛИіКУЖрШэМўЕФГЃМћЮФЕЕИёЪНШчЯТ
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes
[bitbucket.org]
User = hg
[topsecret.server.com]
Port = 50022
ForwardX11 = no |
ШчЙћЯыгУpythonЩњГЩвЛИіетбљЕФЮФЕЕдѕУДзіФи
| import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval':
'45',
'Compression': 'yes',
'CompressionLevel': '9'}
config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '50022' # mutates the
parser
topsecret['ForwardX11'] = 'no' # same here
config['DEFAULT']['ForwardX11'] = 'yes'
with open('example.ini', 'w') as configfile:
config.write(configfile) |
аДЭъСЫЛЙПЩвддйЖСГіРД
>>> import
configparser
>>> config = configparser.ConfigParser()
>>> config.sections()
[]
>>> config.read('example.ini')
['example.ini']
>>> config.sections()
['bitbucket.org', 'topsecret.server.com']
>>> 'bitbucket.org' in config
True
>>> 'bytebong.com' in config
False
>>> config['bitbucket.org']['User']
'hg'
>>> config['DEFAULT']['Compression']
'yes'
>>> topsecret = config['topsecret.server.com']
>>> topsecret['ForwardX11']
'no'
>>> topsecret['Port']
'50022'
>>> for key in config['bitbucket.org']:
print(key)
...
user
compressionlevel
serveraliveinterval
compression
forwardx11
>>> config['bitbucket.org']['ForwardX11']
'yes' |
configparserдіЩОИФВщгяЗЈ
[section1]
k1 = v1
k2:v2
[section2]
k1 = v1
import ConfigParser
config = ConfigParser.ConfigParser()
config.read('i.cfg')
# ########## ЖС ##########
#secs = config.sections()
#print secs
#options = config.options('group2')
#print options
#item_list = config.items('group2')
#print item_list
#val = config.get('group1','key')
#val = config.getint('group1','key')
# ########## ИФаД ##########
#sec = config.remove_section('group1')
#config.write(open('i.cfg', "w"))
#sec = config.has_section('wupeiqi')
#sec = config.add_section('wupeiqi')
#config.write(open('i.cfg', "w"))
#config.set('group2','k1',11111)
#config.write(open('i.cfg', "w"))
#config.remove_option('group2','age')
#config.write(open('i.cfg', "w")) |
11ЁЂhashlibФЃПщ
гУгкМгУмЯрЙиЕФВйзїЃЌДњЬцСЫmd5ФЃПщКЭshaФЃПщЃЌжївЊЬсЙЉ SHA1, SHA224, SHA256,
SHA384, SHA512 ЃЌMD5 ЫуЗЈ
| import hashlib
# ######## md5 ########
hash = hashlib.md5()
hash.update('admin')
print(hash.hexdigest())
# ######## sha1 ########
hash = hashlib.sha1()
hash.update('admin')
print(hash.hexdigest())
# ######## sha256 ########
hash = hashlib.sha256()
hash.update('admin')
print(hash.hexdigest())
# ######## sha384 ########
hash = hashlib.sha384()
hash.update('admin')
print(hash.hexdigest())
# ######## sha512 ########
hash = hashlib.sha512()
hash.update('admin')
print(hash.hexdigest()) |
вдЩЯМгУмЫуЗЈЫфШЛвРШЛЗЧГЃРїКІЃЌЕЋЪБКђДцдкШБЯнЃЌМДЃКЭЈЙ§зВПтПЩвдЗДНтЁЃЫљвдЃЌгаБивЊЖдМгУмЫуЗЈжаЬэМгздЖЈвхkeyдйРДзіМгУмЁЃ
| import hashlib
# ######## md5 ########
hash = hashlib.md5('898oaFs09f')
hash.update('admin')
print(hash.hexdigest()) |
ЛЙВЛЙЛЕѕЃПpython ЛЙгавЛИі hmac ФЃПщЃЌЫќФкВПЖдЮвУЧДДНЈ key КЭ ФкШн дйНјааДІРэШЛКѓдйМгУм
import hmac
h = hmac.new('wueiqi')
h.update('hellowo')
print(hash.hexdigest()) |
БИзЂЃКдкpython3жаЃЌМгУмзжЗћДЎашвЊНЋзжЗћДЎзЊЛЛЮЊbytesРраЭЃЌзЊЛЛЗНЗЈ
| hash.update(b'admin')
Лђеп hash.update('admin'.encode('utf8')) |
12ЁЂloggingФЃПщ
КмЖрГЬађЖМгаМЧТМШежОЕФашЧѓЃЌВЂЧвШежОжаАќКЌЕФаХЯЂМДгае§ГЃЕФГЬађЗУЮЪШежОЃЌЛЙПЩФмгаДэЮѓЁЂОЏИцЕШаХЯЂЪфГіЃЌpythonЕФloggingФЃПщЬсЙЉСЫБъзМЕФШежОНгПкЃЌФуПЩвдЭЈЙ§ЫќДцДЂИїжжИёЪНЕФШежОЃЌloggingЕФШежОПЩвдЗжЮЊ
debug(), info(), warning(), error() and critical()
5ИіМЖБ№ЃЌЯТУцЮвУЧПДвЛЯТдѕУДгУЁЃ
ЂйзюМђЕЅгУЗЈ
import logging
logging.warning("user [tom] attempted wrong
password more than 3 times")
logging.critical("server is down")
#ЪфГі
WARNING:root:user [tom] attempted wrong password
more than 3 times
CRITICAL:root:server is down |
ЂкШчЙћЯыАбШежОаДЕНЮФМўРя
import logging
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d]
%(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='test.log',
filemode='a')
logging.debug('This message should go to the
log file')
logging.info('So should this')
logging.warning('And this, too') |
ЦфжаЯТУцетОфжаЕФlevel=loggin.INFOвтЫМЪЧЃЌАбШежОМЭТММЖБ№ЩшжУЮЊINFOЃЌвВОЭЪЧЫЕЃЌжЛгаБШШежОЪЧINFOЛђБШINFOМЖБ№ИќИпЕФШежОВХЛсБЛМЭТМЕНЮФМўРяЃЌдкетИіР§згЃЌ
ЕквЛЬѕШежОЪЧВЛЛсБЛМЭТМЕФЃЌШчЙћЯЃЭћМЭТМdebugЕФШежОЃЌФЧАбШежОМЖБ№ИФГЩDEBUGОЭааСЫЁЃ
| logging.basicConfig (filename='example.log', level=logging.INFO) |
ЖдгкИёЪНЃЌгаШчЯТЪєадПЩЪЧХфжУЃК
logging.basicConfigКЏЪ§ИїВЮЪ§ЃК
filename: жИЖЈШежОЮФМўУћ
filemode: КЭfileКЏЪ§втвхЯрЭЌЃЌжИЖЈШежОЮФМўЕФДђПЊФЃЪНЃЌ'w'Лђ'a'
format: жИЖЈЪфГіЕФИёЪНКЭФкШнЃЌformatПЩвдЪфГіКмЖргагУаХЯЂЃЌШчЩЯР§ЫљЪО:
%(levelno)s: ДђгЁШежОМЖБ№ЕФЪ§жЕ
%(levelname)s: ДђгЁШежОМЖБ№УћГЦ
%(pathname)s: ДђгЁЕБЧАжДааГЬађЕФТЗОЖЃЌЦфЪЕОЭЪЧsys.argv[0]
%(filename)s: ДђгЁЕБЧАжДааГЬађУћ
%(funcName)s: ДђгЁШежОЕФЕБЧАКЏЪ§
%(lineno)d: ДђгЁШежОЕФЕБЧАааКХ
%(asctime)s: ДђгЁШежОЕФЪБМф
%(thread)d: ДђгЁЯпГЬID
%(threadName)s: ДђгЁЯпГЬУћГЦ
%(process)d: ДђгЁНјГЬID
%(message)s: ДђгЁШежОаХЯЂ
datefmt: жИЖЈЪБМфИёЪНЃЌЭЌtime.strftime()
level: ЩшжУШежОМЖБ№ЃЌФЌШЯЮЊlogging.WARNING
stream: жИЖЈНЋШежОЕФЪфГіСїЃЌПЩвджИЖЈЪфГіЕНsys.stderr,sys.stdoutЛђепЮФМўЃЌФЌШЯЪфГіЕНsys.stderrЃЌЕБstreamКЭfilenameЭЌЪБжИЖЈЪБЃЌstreamБЛКіТд |

ЂлНЋШежОЭЌЪБЪфГіЕНЮФМўКЭЦСФЛ(БШНЯСщЛюЕФЗНЪН)
import logging
logger = logging.getLogger() #ДДНЈвЛИіloggerЖдЯѓ
fileoutput = logging.FileHandler('test.log') #ДДНЈвЛИіhandlerЃЌгУгкЪфГіЕНЮФМў
screenoutput = logging.StreamHandler() #ДДНЈвЛИіhandlerЃЌгУгкЪфГіЕНПижЦЬЈ
fmt = logging.Formatter(
'%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s
%(message)s'
) #ЪфГіИёЪН
fileoutput.setFormatter(fmt)
screenoutput.setFormatter(fmt)
logger.addHandler(fileoutput)
logger.addHandler(screenoutput)
logger.setLevel(logging.DEBUG) #ЩшжУШежОЕФМЖБ№
logging.debug('This message should go to the
log file')
logging.info('So should this')
logging.warning('And this, too')
ЦСФЛЩЯДђгЁ:
2017-5-12 10:35:48 bbb.py[line:21] DEBUG This
message should go to the log file
2017-5-12 10:35:48 bbb.py[line:22] INFO So should
this
2017-5-12 10:35:48 bbb.py[line:23] WARNING And
this, too
test.logЮФМўжаФкШнЮЊ:
2017-5-12 10:35:48 bbb.py[line:21] DEBUG This
message should go to the log file
2017-5-12 10:35:48 bbb.py[line:22] INFO So should
this
2017-5-12 10:35:48 bbb.py[line:23] WARNING And
this, too |
ЂмloggingжЎШежОЛиЙі
import logging
from logging.handlers import RotatingFileHandler
#ЖЈвхвЛИіRotatingFileHandlerЃЌзюЖрБИЗн5ИіШежОЮФМўЃЌУПИіШежОЮФМўзюДѓ10M
Rthandler = RotatingFileHandler('myapp.log', maxBytes=10*1024*1024,backupCount=5)
Rthandler.setLevel(logging.INFO)
formatter = logging.Formatter('%(name)-12s: %(levelname)-8s
%(message)s')
Rthandler.setFormatter(formatter)
logging.getLogger('').addHandler(Rthandler)
|
ДгЩЯР§КЭБОР§ПЩвдПДГіЃЌloggingгавЛИіШежОДІРэЕФжїЖдЯѓЃЌЦфЫќДІРэЗНЪНЖМЪЧЭЈЙ§addHandlerЬэМгНјШЅЕФЁЃ
loggingЕФМИжжhandleЗНЪНШчЯТЃК
logging.StreamHandler:
ШежОЪфГіЕНСїЃЌПЩвдЪЧsys.stderrЁЂsys.stdoutЛђепЮФМў
logging.FileHandler: ШежОЪфГіЕНЮФМў
ШежОЛиЙіЗНЪНЃЌЪЕМЪЪЙгУЪБгУRotatingFileHandlerКЭTimedRotatingFileHandler
logging.handlers.BaseRotatingHandler
logging.handlers.RotatingFileHandler
logging.handlers.TimedRotatingFileHandler
logging.handlers.SocketHandler: дЖГЬЪфГіШежОЕНTCP/IP
sockets
logging.handlers.DatagramHandler: дЖГЬЪфГіШежОЕНUDP sockets
logging.handlers.SMTPHandler: дЖГЬЪфГіШежОЕНгЪМўЕижЗ
logging.handlers.SysLogHandler: ШежОЪфГіЕНsyslog
logging.handlers.NTEventLogHandler: дЖГЬЪфГіШежОЕНWindows
NT/2000/XPЕФЪТМўШежО
logging.handlers.MemoryHandler: ШежОЪфГіЕНФкДцжаЕФжЦЖЈbuffer
logging.handlers.HTTPHandler: ЭЈЙ§"GET"Лђ"POST"дЖГЬЪфГіЕНHTTPЗўЮёЦї |
ЂнЭЈЙ§logging.configФЃПщХфжУШежО
#logger.conf
###############################################
[loggers]
keys=root,example01,example02
[logger_root]
level=DEBUG
handlers=hand01,hand02
[logger_example01]
handlers=hand01,hand02
qualname=example01
propagate=0
[logger_example02]
handlers=hand01,hand03
qualname=example02
propagate=0
###############################################
[handlers]
keys=hand01,hand02,hand03
[handler_hand01]
class=StreamHandler
level=INFO
formatter=form02
args=(sys.stderr,)
[handler_hand02]
class=FileHandler
level=DEBUG
formatter=form01
args=('myapp.log', 'a')
[handler_hand03]
class=handlers.RotatingFileHandler
level=INFO
formatter=form02
args=('myapp.log', 'a', 10*1024*1024, 5)
###############################################
[formatters]
keys=form01,form02
[formatter_form01]
format=%(asctime)s %(filename)s[line:%(lineno)d]
%(levelname)s %(message)s
datefmt=%a, %d %b %Y %H:%M:%S
[formatter_form02]
format=%(name)-12s: %(levelname)-8s %(message)s
datefmt= |
import logging
import logging.config
logging.config.fileConfig("logger.conf")
logger = logging.getLogger("example01")
logger.debug('This is debug message')
logger.info('This is info message')
logger.warning('This is warning message') |
ЖдгкЕШМЖЃК
CRITICAL = 50
FATAL = CRITICAL
ERROR = 40
WARNING = 30
WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0 |
13ЁЂreФЃПщ
ГЃгУе§дђБэДяЪНЗћКХ
'.' ФЌШЯЦЅХфГ§\nжЎЭтЕФШЮвтвЛИізжЗћЃЌШєжИЖЈflag
DOTALL,дђЦЅХфШЮвтзжЗћЃЌАќРЈЛЛаа
'^' ЦЅХфзжЗћПЊЭЗЃЌШєжИЖЈflags MULTILINE,етжжвВПЩвдЦЅХфЩЯ(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' ЦЅХфзжЗћНсЮВЃЌЛђe.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()вВПЩвд
'*' ЦЅХф*КХЧАЕФзжЗћ0ДЮЛђЖрДЮ(АќРЈ0ДЮ)ЃЌre.findall("ab*","cabb3abcbbac")
НсЙћЮЊ['abb', 'ab', 'a'] #ШчЙћbЮЊ0ДЮвВПЩвдЦЅХфЕН
'+' ЦЅХфЧАвЛИізжЗћ1ДЮЛђЖрДЮ(зюЩй1ДЮ)ЃЌre.findall("ab+","ab+cd+abb+bba")
НсЙћ['ab', 'abb']
'?' ЦЅХфЧАвЛИізжЗћ0ДЮЛђ1ДЮ
'{m}' ЦЅХфЧАвЛИізжЗћmДЮ
'{n,m}' ЦЅХфЧАвЛИізжЗћnЕНmДЮЃЌre.findall("ab{1,3}","abb
abc abbcbbb") НсЙћ'abb', 'ab', 'abb']
'|' ЦЅХф|зѓЛђ|гвЕФзжЗћЃЌre.search("abc|ABC","ABCBabcCD").group()
НсЙћ'ABC'
'(...)' ЗжзщЦЅХфЃЌre.search("(abc){2}a(123|456)c",
"abcabca456c").group() НсЙћ abcabca456c
'\A' жЛДгзжЗћПЊЭЗЦЅХфЃЌre.search("\Aabc","alexabc")
ЪЧЦЅХфВЛЕНЕФ
'\Z' ЦЅХфзжЗћНсЮВЃЌЭЌ$
'\d' ЦЅХфЪ§зж0-9
'\D' ЦЅХфЗЧЪ§зж
'\w' ЦЅХф[A-Za-z0-9]
'\W' ЦЅХфЗЧ[A-Za-z0-9]
'\s' ЦЅХфПеАззжЗћЁЂ\tЁЂ\nЁЂ\r , re.search("\s+","ab\tc1\n3").group()
НсЙћ '\t'
'(?P<name>...)' ЗжзщЦЅХф re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city")
НсЙћ{'province': '3714', 'city': '81', 'birthday':
'1993'} |
#IPЃК
^(25[0-5]|2[0-4]\d|[0-1]?\d?\d)(\.(25[0-5]|2[0-4]\d|[0-1]?\d?\d)){3}$
#ЪжЛњКХЃК
^1[3|4|5|8][0-9]\d{8}$
import re
ret = re.search('(?P<id>\d{3})/(?P<name>\w{3})','negbhgao123/gna')
print(ret.group())
print(ret.group('id'))
print(ret.group('name')) |
зюГЃгУЕФЦЅХфгяЗЈ
re.match ДгЭЗПЊЪМЦЅХф
re.search АќКЌЦЅХф
re.findall АбЫљгаЦЅХфЕНЕФзжЗћЗХЕНвдСаБэжаЕФдЊЫиЗЕЛи
re.splitall вдЦЅХфЕНЕФзжЗћЕБзіСаБэЗжИєЗћ
re.sub ЦЅХфзжЗћВЂЬцЛЛ |
ЗДаБИмЕФРЇШХ
| гыДѓЖрЪ§БрГЬгябдЯрЭЌЃЌе§дђБэДяЪНРяЪЙгУ"\"зїЮЊзЊвхзжЗћЃЌетОЭПЩФмдьГЩЗДаБИмРЇШХЁЃМйШчФуашвЊЦЅХфЮФБОжаЕФзжЗћ"\"ЃЌФЧУДЪЙгУБрГЬгябдБэЪОЕФе§дђБэДяЪНРяНЋашвЊ4ИіЗДаБИм"\\\\"ЃКЧАСНИіКЭКѓСНИіЗжБ№гУгкдкБрГЬгябдРязЊвхГЩЗДаБИмЃЌзЊЛЛГЩСНИіЗДаБИмКѓдйдке§дђБэДяЪНРязЊвхГЩвЛИіЗДаБИмЁЃPythonРяЕФдЩњзжЗћДЎКмКУЕиНтОіСЫетИіЮЪЬтЃЌетИіР§згжаЕФе§дђБэДяЪНПЩвдЪЙгУr"\\"БэЪОЁЃЭЌбљЃЌЦЅХфвЛИіЪ§зжЕФ"\\d"ПЩвдаДГЩr"\d"ЁЃгаСЫдЩњзжЗћДЎЃЌФудйвВВЛгУЕЃаФЪЧВЛЪЧТЉаДСЫЗДаБИмЃЌаДГіРДЕФБэДяЪНвВИќжБЙлЁЃ |
ЧсЧсжЊЕРЕФМИИіЦЅХфФЃЪН
re.I(re.IGNORECASE):
КіТдДѓаЁаДЃЈРЈКХФкЪЧЭъећаДЗЈЃЌЯТЭЌЃЉ
M(MULTILINE): ЖрааФЃЪНЃЌИФБф'^'КЭ'$'ЕФааЮЊ
S(DOTALL): ЕуШЮвтЦЅХфФЃЪНЃЌИФБф'.'ЕФааЮЊ |
БИзЂЃК
1ЁЂmatch(pattern, string, flags=0) ДгЦ№ЪМЮЛжУПЊЪМИљОнФЃаЭШЅзжЗћДЎжаЦЅХфжИЖЈФкШнЃЌЦЅХфЕЅИі
е§дђБэДяЪН
вЊЦЅХфЕФзжЗћДЎ
БъжОЮЛЃЌгУгкПижЦе§дђБэДяЪНЕФЦЅХфЗНЪН
import re
obj = re.match('\d+', '123uuasf')
if obj:
print(obj.group()) |
2ЁЂsearch(pattern, string, flags=0) ИљОнФЃаЭШЅзжЗћДЎжаЦЅХфжИЖЈФкШнЃЌЦЅХфЕЅИі
import re
obj = re.search('\d+', 'u123uu888asf')
if obj:
print(obj.group() |
3ЁЂgroupКЭgroups
a = "123abc456"
print(re.search("([0-9]*)([a-z]*)([0-9]*)",
a).group())
print(re.search("([0-9]*)([a-z]*)([0-9]*)",
a).group(0))
print(re.search("([0-9]*)([a-z]*)([0-9]*)",
a).group(1))
print(re.search("([0-9]*)([a-z]*)([0-9]*)",
a).group(2))
print(re.search("([0-9]*)([a-z]*)([0-9]*)",
a).groups()) |
4ЁЂfindall(pattern, string, flags=0)
ЩЯЪіСНжаЗНЪНОљгУгкЦЅХфЕЅжЕЃЌМДЃКжЛФмЦЅХфзжЗћДЎжаЕФвЛИіЃЌШчЙћЯывЊЦЅХфЕНзжЗћДЎжаЫљгаЗћКЯЬѕМўЕФдЊЫиЃЌдђашвЊЪЙгУ
findallЁЃ
import re
obj = re.findall('\d+', 'fa123uu888asf')
print(obj) |
5ЁЂsub(pattern, repl, string, count=0, flags=0)
гУгкЬцЛЛЦЅХфЕФзжЗћДЎ
content = "123abc456"
new_content = re.sub('\d+', 'sb', content)
# new_content = re.sub('\d+', 'sb', content, 1)
print(new_content) |
ЯрБШгкstr.replaceЙІФмИќМгЧПДѓ
6ЁЂsplit(pattern, string, maxsplit=0, flags=0) ИљОнжИЖЈЦЅХфНјааЗжзщ
content = "'1
- 2 * ((60-30+1*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2)
)'"
new_content = re.split('\*', content)
# new_content = re.split('\*', content, 1)
print(new_content) |
content = "'1
- 2 * ((60-30+1*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2)
)'"
new_content = re.split('[\+\-\*\/]+', content)
# new_content = re.split('\*', content, 1)
print(new_content) |
inpp = '1-2*((60-30
+(-40-5)*(9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14
)) - (-4*3)/ (16-3*2))'
inpp = re.sub('\s*','',inpp)
new_content = re.split('\(([\+\-\*\/]?\d+[\+\-\*\/]?\d+){1}\)',
inpp, 1)
print(new_content) |
ЯрБШгкstr.splitИќМгЧПДѓ
7ЁЂЦЅХфurlЕижЗ
res = re.findall('www.(?:\w+).com','www.baidu.com')
print(res) #['www.baidu.com'] |
14ЁЂparamiko
paramikoЪЧвЛИігУгкзідЖГЬПижЦЕФФЃПщЃЌЪЙгУИУФЃПщПЩвдЖддЖГЬЗўЮёЦїНјааУќСюЛђЮФМўВйзїЃЌжЕЕУвЛЫЕЕФЪЧЃЌfabricКЭansibleФкВПЕФдЖГЬЙмРэОЭЪЧЪЙгУЕФparamikoРДЯжЪЕЁЃ
(1)ЯТдиАВзА
pycryptoЃЌгЩгк paramiko ФЃПщФкВПвРРЕpycryptoЃЌЫљвдЯШЯТдиАВзАpycrypto
pip3 install pycrypto
pip3 install paramiko |
(2)ФЃПщЪЙгУ
aЁЂжДааУќСю - гУЛЇУћ+УмТы
#!/usr/bin/env
python
#coding:utf-8
import paramiko
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy (paramiko.AutoAddPolicy())
ssh.connect (hostname='192.168.88.136', port=22, username='test', password='123')
stdin, stdout, stderr = ssh.exec_command('df
-h')
print(stdout.read())
ssh.close() |
bЁЂжДааУќСю - УмдП
| import paramiko
private_key_path = '/home/auto/.ssh/id_rsa'
key = paramiko.RSAKey.from _private_key_file (private_key_path)
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy (paramiko.AutoAddPolicy())
ssh.connect (hostname='192.168.88.136', port=22,username= 'test', password=key)
stdin, stdout, stderr = ssh.exec_command('df
-h')
print(stdout.read())
ssh.close() |
cЁЂЩЯДЋЛђЯТдиЮФМў - гУЛЇУћ+УмТы
#ЩЯДЋ
import os,sysimport paramiko
t = paramiko.Transport(('192.168.88.136',22))
t.connect(username='test',password='123')
sftp = paramiko.SFTPClient.from_transport(t)
sftp.put('/tmp/test1.py','/tmp/test2.py')
t.close()
#ЯТди
import os,sysimport paramiko
t = paramiko.Transport(('192.168.88.136',22))
t.connect(username='test',password='123')
sftp = paramiko.SFTPClient.from_transport(t)
sftp.get('/tmp/test1.py','/tmp/test2.py')
t.close() |
dЁЂЩЯДЋЛђЯТдиЮФМў - УмдП
#ЩЯДЋ
import paramiko
pravie_key_path = '/home/auto/.ssh/id_rsa'
key = paramiko.RSAKey.from_private_key_file(pravie_key_path)
t = paramiko.Transport(('192.168.88.136',22))
t.connect(username='wupeiqi',pkey=key)
sftp = paramiko.SFTPClient.from_transport(t)
sftp.put('/tmp/test3.py','/tmp/test4.py')
t.close()
#ЯТди
import paramiko
pravie_key_path = '/home/auto/.ssh/id_rsa'
key = paramiko.RSAKey.from_private_key_file(pravie_key_path)
t = paramiko.Transport(('192.168.88.136',22))
t.connect(username='test',pkey=key)
sftp = paramiko.SFTPClient.from_transport(t)
sftp.get('/tmp/test3.py','/tmp/test4.py')
t.close() |
15ЁЂrequests
PythonБъзМПтжаЬсЙЉСЫЃКurllibЕШФЃПщвдЙЉHttpЧыЧѓЃЌЕЋЪЧЃЌЫќЕФ API ЬЋдќСЫЁЃЫќЪЧЮЊСэвЛИіЪБДњЁЂСэвЛИіЛЅСЊЭјЫљДДНЈЕФЁЃЫќашвЊОоСПЕФЙЄзїЃЌЩѕжСАќРЈИїжжЗНЗЈИВИЧЃЌРДЭъГЩзюМђЕЅЕФШЮЮёЁЃ
(1)ЗЂЫЭGETЧыЧѓ
import urllib.request
f = urllib.request.urlopen('http:// www.webxml.com.cn// webservices/ qqOnlineWebService.asmx/ qqCheckOnline? qqCode=424662508')
result = f.read().decode('utf-8') |
(2)ЗЂЫЭаЏДјЧыЧѓЭЗЕФGETЧыЧѓ
import urllib.request
req = urllib.request.Request('http://www.example.com/')
req.add_header('Referer', 'http://www.python.org/')
r = urllib.request.urlopen(req)
result = f.read().decode('utf-8') |
БИзЂЃК
ИќЖрМћPythonЙйЗНЮФЕЕЃКhttps://docs.python.org/3.5/library/urllib.request.html#module-urllib.request
Requests ЪЧЪЙгУ Apache2 Licensed аэПЩжЄЕФ ЛљгкPythonПЊЗЂЕФHTTP
ПтЃЌЦфдкPythonФкжУФЃПщЕФЛљДЁЩЯНјааСЫИпЖШЕФЗтзАЃЌДгЖјЪЙЕУPythonerНјааЭјТчЧыЧѓЪБЃЌБфЕУУРКУСЫаэЖрЃЌЪЙгУRequestsПЩвдЧсЖјвзОйЕФЭъГЩфЏРРЦїПЩгаЕФШЮКЮВйзїЁЃ
(1)АВзАФЃПщ
(2)ЪЙгУФЃПщ
aЁЂGETЧыЧѓ
ЂйЮоВЮЪ§ЪЕР§
import requests
ret = requests.get('https://github.com/timeline.json')
print(ret.url)
print(ret.text)
ЂкгаВЮЪ§ЪЕР§
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
ret = requests.get("http://httpbin.org/get",
params=payload)
print(ret.url)
print(ret.text) |
bЁЂPOSTЧыЧѓ
ЂйЛљБОPOSTЪЕР§
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
ret = requests.post("http://httpbin.org/post",
data=payload)
print(ret.text)
ЂкЗЂЫЭЧыЧѓЭЗКЭЪ§ОнЪЕР§
import requests
import json
url = 'https://api.github.com/some/endpoint'
payload = {'some': 'data'}
headers = {'content-type': 'application/json'}
ret = requests.post(url, data=json.dumps(payload),
headers=headers)
print(ret.text)
print(ret.cookies) |
cЁЂЦфЫћЧыЧѓ
requests.get(url,
params=None, **kwargs)
requests.post(url, data=None, json=None, **kwargs)
requests.put(url, data=None, **kwargs)
requests.head(url, **kwargs)
requests.delete(url, **kwargs)
requests.patch(url, data=None, **kwargs)
requests.options(url, **kwargs) |
БИзЂЃК
вдЩЯЗНЗЈОљЪЧдкДЫЗНЗЈЕФЛљДЁЩЯЙЙНЈ requests.request(method, url, **kwargs)
ИќЖрrequestsФЃПщЯрЙиЕФЮФЕЕМћЃКhttp://cn.python-requests.org/zh_CN/latest/
(3)HttpЧыЧѓКЭXMLЪЕР§
ЪЕР§1ЃКМьВтQQеЫКХЪЧЗёдкЯп
import urllib
import requests
from xml.etree import ElementTree as ET
# ЪЙгУФкжУФЃПщurllibЗЂЫЭHTTPЧыЧѓЃЌЛђепXMLИёЪНФкШн"""
f = urllib.request.urlopen('http://www.webxml.com.cn//
webservices/qqOnlineWebService.asmx/ qqCheckOnline? qqCode=424662508')
result = f.read().decode('utf-8')
# ЪЙгУЕкШ§ЗНФЃПщrequestsЗЂЫЭHTTPЧыЧѓЃЌЛђепXMLИёЪНФкШн
r = requests.get('http://www.webxml.com.cn //webservices/
qqOnlineWebService.asmx/ qqCheckOnline? qqCode=424662508')
result = r.text
# НтЮіXMLИёЪНФкШн
node = ET.XML(result)
# ЛёШЁФкШн
if node.text == "Y":
print("дкЯп")
else:
print("РыЯп") |
ЪЕР§2ЃКВщПДЛ№ГЕЭЃППаХЯЂ
import urllib
import requests
from xml.etree import ElementTree as ET
# ЪЙгУФкжУФЃПщurllibЗЂЫЭHTTPЧыЧѓЃЌЛђепXMLИёЪНФкШн
f = urllib.request.urlopen ('http://www.webxml.com.cn/ WebServices
/TrainTimeWebService.asmx / getDetailInfoByTrainCode?
TrainCode= G666&UserID=')
result = f.read().decode()
# ЪЙгУЕкШ§ЗНФЃПщrequestsЗЂЫЭHTTPЧыЧѓЃЌЛђепXMLИёЪНФкШн
r = requests.get ('http://www.webxml.com.cn/
WebServices/ TrainTimeWebService.asmx/ getDetailInfoByTrainCode?
TrainCode =G666&UserID=')
result = r.text
# НтЮіXMLИёЪНФкШн
root = ET.XML(result)
for node in root.iter ('TrainDetailInfo'):
print(node.find ('TrainStation').text, node.find('StartTime').text, node.tag,node.attrib) |
16ЁЂsubprocess
(1)call #жДааУќСюЃЌЗЕЛизДЬЌТы
subprocess.call("ls
-l", shell=False)
subprocess.call("ls -l", shell=True) |
(2)check_call #жДааУќСюЃЌШчЙћжДаазДЬЌТыЪЧ 0 ЃЌдђЗЕЛи0ЃЌЗёдђХзвьГЃ
subprocess.check_call("ls
-l")
subprocess.check_call("ls -l", shell=True) |
(3)check_output #жДааУќСюЃЌШчЙћзДЬЌТыЪЧ 0 ЃЌдђЗЕЛижДааНсЙћЃЌЗёдђХзвьГЃ
subprocess.check_output(["echo",
"Hello World!"])
subprocess.check_output("ls -l", shell=True) |
(4)subprocess.Popen(Ё) #гУгкжДааИДдгЕФЯЕЭГУќСю
argsЃКshellУќСюЃЌПЩвдЪЧзжЗћДЎЛђепађСаРраЭЃЈШчЃКlistЃЌдЊзщЃЉ
bufsizeЃКжИЖЈЛКГхЁЃ0 ЮоЛКГх,1 ааЛКГх,ЦфЫћ ЛКГхЧјДѓаЁ,ИКжЕ ЯЕЭГЛКГх
stdin, stdout, stderrЃКЗжБ№БэЪОГЬађЕФБъзМЪфШыЁЂЪфГіЁЂДэЮѓОфБњ
preexec_fnЃКжЛдкUnixЦНЬЈЯТгааЇЃЌгУгкжИЖЈвЛИіПЩжДааЖдЯѓЃЈcallable objectЃЉЃЌЫќНЋдкзгНјГЬдЫаажЎЧАБЛЕїгУ
close_sfsЃКдкwindowsЦНЬЈЯТЃЌШчЙћclose_fdsБЛЩшжУЮЊTrueЃЌдђаТДДНЈЕФзгНјГЬНЋВЛЛсМЬГаИИНјГЬЕФЪфШыЁЂЪфГіЁЂДэЮѓЙмЕРЁЃЫљвдВЛФмНЋclose_fdsЩшжУЮЊTrueЭЌЪБжиЖЈЯђзгНјГЬЕФБъзМЪфШыЁЂЪфГігыДэЮѓ(stdin,
stdout, stderr)ЁЃ
shellЃКЭЌЩЯ
cwdЃКгУгкЩшжУзгНјГЬЕФЕБЧАФПТМ
envЃКгУгкжИЖЈзгНјГЬЕФЛЗОГБфСПЁЃШчЙћenv = NoneЃЌзгНјГЬЕФЛЗОГБфСПНЋДгИИНјГЬжаМЬГаЁЃ
universal_newlinesЃКВЛЭЌЯЕЭГЕФЛЛааЗћВЛЭЌЃЌTrue -> ЭЌвтЪЙгУ
startupinfoгыcreateionflagsжЛдкwindowsЯТгааЇ,НЋБЛДЋЕнИјЕзВуЕФCreateProcess()КЏЪ§ЃЌгУгкЩшжУзгНјГЬЕФвЛаЉЪєадЃЌШчЃКжїДАПкЕФЭтЙлЃЌНјГЬЕФгХЯШМЖЕШЕШ
|
aЁЂжДааЦеЭЈУќСю
import subprocess
ret1 = subprocess.Popen(["mkdir","t1"])
ret2 = subprocess.Popen("mkdir t2",
shell=True) |
bЁЂжеЖЫЪфШыЕФУќСюЗжЮЊСНжжЃК
ЪфШыМДПЩЕУЕНЪфГіЃЌШчЃКifconfig
ЪфШыНјааФГЛЗОГЃЌвРРЕдйЪфШыЃЌШчЃКpython
import subprocess
obj = subprocess.Popen("mkdir test",
shell=True, cwd='/home/',) |
import subprocess
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE,
stdout=subprocess.PIPE, stderr=subprocess.PIPE,
universal_newlines=True)
obj.stdin.write("print(1)\n")
obj.stdin.write("print(2)")
obj.stdin.close()
cmd_out = obj.stdout.read()
obj.stdout.close()
cmd_error = obj.stderr.read()
obj.stderr.close()
print(cmd_out)print(cmd_error) |
| import subprocess
obj = subprocess.Popen(["python"],
stdin=subprocess.PIPE, stdout=subprocess.PIPE,
stderr=subprocess.PIPE, universal_newlines=True)
obj.stdin.write("print(1)\n")
obj.stdin.write("print(2)")
out_error_list = obj.communicate()
print(out_error_list) |
import subprocess
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE,
stdout=subprocess.PIPE, stderr=subprocess.PIPE,
universal_newlines=True)
out_error_list = obj.communicate('print("hello")')
print(out_error_list) |
|





