| БрМЭЦМі: |
РДдДгкcnblogsЃЌНщЩмСЫЪ§ОнНсЙЙЃЌЪ§ОнЫїв§
index ЃЌ РћгУpandasВщбЏЪ§ОнЃЌЭГМЦЗжЮіЕШЁЃ |
|

вЛЁЂЪ§ОнНсЙЙНщЩм
дкpandasжагаСНРрЗЧГЃживЊЕФЪ§ОнНсЙЙЃЌМДађСаSeriesКЭЪ§ОнПђDataFrameЁЃSeriesРрЫЦгкnumpyжаЕФвЛЮЌЪ§зщЃЌГ§СЫЭЈГдвЛЮЌЪ§зщПЩгУЕФКЏЪ§ЛђЗНЗЈЃЌЖјЧвЦфПЩЭЈЙ§Ыїв§БъЧЉЕФЗНЪНЛёШЁЪ§ОнЃЌЛЙОпгаЫїв§ЕФздЖЏЖдЦыЙІФмЃЛDataFrameРрЫЦгкnumpyжаЕФЖўЮЌЪ§зщЃЌЭЌбљПЩвдЭЈгУnumpyЪ§зщЕФКЏЪ§КЭЗНЗЈЃЌЖјЧвЛЙОпгаЦфЫћСщЛюгІгУЃЌКѓајЛсНщЩмЕНЁЃ
1ЁЂSeriesЕФДДНЈ
ађСаЕФДДНЈжївЊгаШ§жжЗНЪНЃК
1ЃЉЭЈЙ§вЛЮЌЪ§зщДДНЈађСа
1.import numpy as np, pandas as pd
2.arr1 = np.arange(10)
3.arr1
4.type(arr1)
5.s1 = pd.Series(arr1)
6.s1
7.type(s1)
2ЃЉЭЈЙ§зжЕфЕФЗНЪНДДНЈађСа
1.dic1 = {'a':10,'b':20,'c':30,'d':40,'e':50}
2.dic1
3.type(dic1)
4.s2 = pd.Series(dic1)
5.s2
6.type(s2)
3ЃЉЭЈЙ§DataFrameжаЕФФГвЛааЛђФГвЛСаДДНЈађСа
етВПЗжФкШнЮвУЧЗХдкКѓУцНВЃЌвђЮЊЯТУцОЭПЊЪМНЋDataFrameЕФДДНЈЁЃ
2ЁЂDataFrameЕФДДНЈ
Ъ§ОнПђЕФДДНЈжївЊгаШ§жжЗНЪНЃК
1ЃЉЭЈЙ§ЖўЮЌЪ§зщДДНЈЪ§ОнПђ
1.arr2 = np.array(np.arange(12)).reshape(4,3)
2.arr2
3.type(arr2)
4.df1 = pd.DataFrame(arr2)
5.df1
6.type(df1)
2ЃЉЭЈЙ§зжЕфЕФЗНЪНДДНЈЪ§ОнПђ
вдЯТвдСНжжзжЕфРДДДНЈЪ§ОнПђЃЌвЛИіЪЧзжЕфСаБэЃЌвЛИіЪЧЧЖЬззжЕфЁЃ
1.dic2 = {'a':[1,2,3,4],'b':[5,6,7,8],
2.'c':[9,10,11,12],'d':[13,14,15,16]}
3.dic2
4.type(dic2)
5.df2 = pd.DataFrame(dic2)
6.df2
7.type(df2)
8.dic3 = {'one':{'a':1,'b':2,'c':3,'d':4},
9.'two':{'a':5,'b':6,'c':7,'d':8},
10.'three':{'a':9,'b':10,'c':11,'d':12}}
11.dic3
12.type(dic3)
13.df3 = pd.DataFrame(dic3)
14.df3
15.type(df3)
3ЃЉЭЈЙ§Ъ§ОнПђЕФЗНЪНДДНЈЪ§ОнПђ
1.df4 = df3[['one','three']]
2.df4
3.type(df4)
4.s3 = df3['one']
5.s3
6.type(s3)
ЖўЁЂЪ§ОнЫїв§index
ЯИжТЕФХѓгбПЩФмЛсЗЂЯжвЛИіЯжЯѓЃЌВЛТлЪЧађСавВКУЃЌЛЙЪЧЪ§ОнПђвВКУЃЌЖдЯѓЕФзюзѓБпзмгавЛИіЗЧдЪМЪ§ОнЖдЯѓЃЌетИіЪЧЪВУДФиЃПВЛДэЃЌОЭЪЧЮвУЧНгЯТРДвЊНщЩмЕФЫїв§ЁЃ
дкЮвПДРДЃЌађСаЛђЪ§ОнПђЕФЫїв§гаСНДѓгУДІЃЌвЛИіЪЧЭЈЙ§Ыїв§жЕЛђЫїв§БъЧЉЛёШЁФПБъЪ§ОнЃЌСэвЛИіЪЧЭЈЙ§Ыїв§ЃЌПЩвдЪЙађСаЛђЪ§ОнПђЕФМЦЫуЁЂВйзїЪЕЯжздЖЏЛЏЖдЦыЃЌЯТУцЮвУЧОЭРДПДПДетСНИіЙІФмЕФгІгУЁЃ
1ЁЂЭЈЙ§Ыїв§жЕЛђЫїв§БъЧЉЛёШЁЪ§Он
1.s4 = pd.Series(np.array([1,1,2,3,5,8]))
2.s4
ШчЙћВЛИјађСавЛИіжИЖЈЕФЫїв§жЕЃЌдђађСаздЖЏЩњГЩвЛИіДг0ПЊЪМЕФзддіЫїв§ЁЃПЩвдЭЈЙ§indexВщПДађСаЕФЫїв§ЃК
1.s4.index
ЯждкЮвУЧЮЊађСаЩшЖЈвЛИіздЖЈвхЕФЫїв§жЕЃК
1.s4.index = ['a','b','c','d','e','f']
2.s4
ађСагаСЫЫїв§ЃЌОЭПЩвдЭЈЙ§Ыїв§жЕЛђЫїв§БъЧЉНјааЪ§ОнЕФЛёШЁЃК
1.s4[3]
2.s4['e']
3.s4[[1,3,5]]
4.s4[['a','b','d','f']]
5.s4[:4]
6.s4['c':]
7.s4['b':'e']
ЧЇЭђзЂвтЃКШчЙћЭЈЙ§Ыїв§БъЧЉЛёШЁЪ§ОнЕФЛАЃЌФЉЖЫБъЧЉЫљЖдгІЕФжЕЪЧПЩвдЗЕЛиЕФЃЁдквЛЮЌЪ§зщжаЃЌОЭЮоЗЈЭЈЙ§Ыїв§БъЧЉЛёШЁЪ§ОнЃЌетвВЪЧађСаВЛЭЌгквЛЮЌЪ§зщЕФвЛИіЗНУцЁЃ
2ЁЂздЖЏЛЏЖдЦы
ШчЙћгаСНИіађСаЃЌашвЊЖдетСНИіађСаНјааЫуЪѕдЫЫуЃЌетЪБЫїв§ЕФДцдкОЭЬхЯжЕФЫќЕФМлжЕСЫЁЊздЖЏЛЏЖдЦы.
1.s5 = pd.Series(np.array([10,15,20,30,55,80]),
2.index = ['a','b','c','d','e','f'])
3.s5
4.s6 = pd.Series(np.array([12,11,13,15,14,16]),
5.index = ['a','c','g','b','d','f'])
6.s6
7.s5 + s6
8.s5/s6
гЩгкs5жаУЛгаЖдгІЕФgЫїв§ЃЌs6жаУЛгаЖдгІЕФeЫїв§ЃЌЫљвдЪ§ОнЕФдЫЫуЛсВњЩњСНИіШБЪЇжЕNaNЁЃзЂвтЃЌетРяЕФЫуЪѕНсЙћОЭЪЕЯжСЫСНИіађСаЫїв§ЕФздЖЏЖдЦыЃЌЖјЗЧМђЕЅЕФНЋСНИіађСаМгзмЛђЯрГ§ЁЃЖдгкЪ§ОнПђЕФЖдЦыЃЌВЛНіНіЪЧааЫїв§ЕФздЖЏЖдЦыЃЌЭЌЪБвВЛсздЖЏЖдЦыСаЫїв§ЃЈБфСПУћЃЉ
Ъ§ОнПђжаЭЌбљгаЫїв§ЃЌЖјЧвЪ§ОнПђЪЧЖўЮЌЪ§зщЕФЭЦЙуЃЌЫљвдЦфВЛНігаааЫїв§ЃЌЖјЧвЛЙДцдкСаЫїв§ЃЌЙигкЪ§ОнПђжаЕФЫїв§ЯрБШгкађСаЕФгІгУвЊЧПДѓЕФЖрЃЌетВПЗжФкШнНЋЗХдкЪ§ОнВщбЏжаНВНтЁЃ
Ш§ЁЂРћгУpandasВщбЏЪ§Он
етРяЕФВщбЏЪ§ОнЯрЕБгкRгябдРяЕФsubsetЙІФмЃЌПЩвдЭЈЙ§ВМЖћЫїв§гаеыЖдЕФбЁШЁдЪ§ОнЕФзгМЏЁЂжИЖЈааЁЂжИЖЈСаЕШЁЃЮвУЧЯШЕМШывЛИіstudentЪ§ОнМЏЃК
1.student = pd.io.parsers.read_csv
('C:\\Users\\ admin\\Desktop \\student.csv')
ВщбЏЪ§ОнЕФЧА5ааЛђФЉЮВ5аа
1.student.head()
2.student.tail()
ВщбЏжИЖЈЕФаа
1.student.ix[[0,2,4,5,7]] #етРяЕФixЫїв§БъЧЉКЏЪ§БиаыЪЧжаРЈКХ[]
ВщбЏжИЖЈЕФСа
1.student[['Name','Height','Weight']].head()
#ШчЙћЖрИіСаЕФЛАЃЌБиаыЪЙгУЫЋжижаРЈКХ
вВПЩвдЭЈЙ§ixЫїв§БъЧЉВщбЏжИЖЈЕФСа
1.student.ix[:,['Name','Height','Weight']].head()
ВщбЏжИЖЈЕФааКЭСа
1.student.ix[[0,2,4,5,7],['Name','Height','Weight']].head()
вдЩЯЪЧДгааЛђСаЕФНЧЖШВщбЏЪ§ОнЕФзгМЏЃЌЯждкЮвУЧРДПДПДШчКЮЭЈЙ§ВМЖћЫїв§ЪЕЯжЪ§ОнЕФзгМЏВщбЏЁЃ
ВщбЏЫљгаХЎЩњЕФаХЯЂ
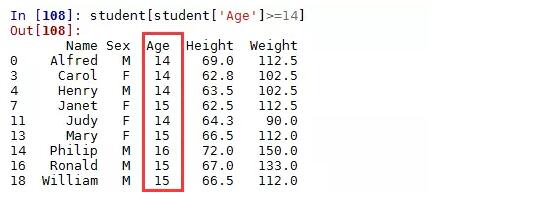
1.student[student['Sex']=='F']
ВщбЏГіЫљга12ЫъвдЩЯЕФХЎЩњаХЯЂ
1.student[(student['Sex']=='F') &
(student['Age']>12)]
ВщбЏГіЫљга12ЫъвдЩЯЕФХЎЩњаеУћЁЂЩэИпКЭЬхжи
1.student[(student['Sex']=='F') &
(student['Age']>12)][['Name','Height','Weight']]
ЩЯУцЕФВщбЏТпМЦфЪЕЗЧГЃЕФМђЕЅЃЌашвЊзЂвтЕФЪЧЃЌШчЙћЪЧЖрИіЬѕМўЕФВщбЏЃЌБиаыдк&ЃЈЧвЃЉЛђеп|ЃЈЛђЃЉЕФСНЖЫЬѕМўгУРЈКХРЈЦ№РДЁЃ
ЫФЁЂЭГМЦЗжЮі
pandasФЃПщЮЊЮвУЧЬсЙЉСЫЗЧГЃЖрЕФУшЪіадЭГМЦЗжЮіЕФжИБъКЏЪ§ЃЌШчзмКЭЁЂОљжЕЁЂзюаЁжЕЁЂзюДѓжЕЕШЃЌЮвУЧРДОпЬхПДПДетаЉКЏЪ§ЃК
ЪзЯШЫцЛњЩњГЩШ§зщЪ§Он
1.np.random.seed(1234)
2.d1 = pd.Series(2*np.random.normal(size
= 100)+3)
3.d2 = np.random.f(2,4,size = 100)
4.d3 = np.random.randint(1,100,size
= 100)
5.d1.count() #ЗЧПедЊЫиМЦЫу
6.d1.min() #зюаЁжЕ
7.d1.max() #зюДѓжЕ
8.d1.idxmin() #зюаЁжЕЕФЮЛжУЃЌРрЫЦгкRжаЕФwhich.minКЏЪ§
9.d1.idxmax() #зюДѓжЕЕФЮЛжУЃЌРрЫЦгкRжаЕФwhich.maxКЏЪ§
10.d1.quantile(0.1) #10%ЗжЮЛЪ§
11.d1.sum() #ЧѓКЭ
12.d1.mean() #ОљжЕ
13.d1.median() #жаЮЛЪ§
14.d1.mode() #жкЪ§
15.d1.var() #ЗНВю
16.d1.std() #БъзМВю
17.d1.mad() #ЦНОљОјЖдЦЋВю
18.d1.skew() #ЦЋЖШ
19.d1.kurt() #ЗхЖШ
20.d1.describe() #вЛДЮадЪфГіЖрИіУшЪіадЭГМЦжИБъ
БиаызЂвтЕФЪЧЃЌdescirbeЗНЗЈжЛФмеыЖдађСаЛђЪ§ОнПђЃЌвЛЮЌЪ§зщЪЧУЛгаетИіЗНЗЈЕФ
етРяздЖЈвхвЛИіКЏЪ§ЃЌНЋетаЉЭГМЦУшЪіжИБъШЋВПЛузмЕНвЛЦ№:
1.def stats(x):
2.return pd.Series([x.count(),x.min(),x.idxmin(),
3.x.quantile(.25),x.median(),
4.x.quantile(.75),x.mean(),
5.x.max(),x.idxmax(),
6.x.mad(),x.var(),
7.x.std(),x.skew(),x.kurt()],
8.index = ['Count','Min','Whicn_Min',
9.'Q1','Median','Q3','Mean',
10.'Max','Which_Max','Mad',
11.'Var','Std','Skew','Kurt'])
12.stats(d1)
дкЪЕМЪЕФЙЄзїжаЃЌЮвУЧПЩФмашвЊДІРэЕФЪЧвЛЯЕСаЕФЪ§жЕаЭЪ§ОнПђЃЌШчКЮНЋетИіКЏЪ§гІгУЕНЪ§ОнПђжаЕФУПвЛСаФиЃППЩвдЪЙгУapplyКЏЪ§ЃЌетИіЗЧГЃРрЫЦгкRжаЕФapplyЕФгІгУЗНЗЈЁЃ
НЋжЎЧАДДНЈЕФd1,d2,d3Ъ§ОнЙЙНЈЪ§ОнПђ:
1.df = pd.DataFrame(np.array([d1,d2,d3]).T,columns=['x1','x2','x3'])
2.df.head()
3.df.apply(stats)
ЗЧГЃЭъУРЃЌОЭетбљКмМђЕЅЕФДДНЈСЫЪ§жЕаЭЪ§ОнЕФЭГМЦадУшЪіЁЃШчЙћЪЧРыЩЂаЭЪ§ОнФиЃПОЭВЛФмгУетИіЭГМЦПкОЖСЫЃЌЮвУЧашвЊЭГМЦРыЩЂБфСПЕФЙлВтЪ§ЁЂЮЈвЛжЕИіЪ§ЁЂжкЪ§ЫЎЦНМАИіЪ§ЁЃФужЛашвЊЪЙгУdescribeЗНЗЈОЭПЩвдЪЕЯжетбљЕФЭГМЦСЫЁЃ
1.student['Sex'].describe()
Г§вдЩЯЕФМђЕЅУшЪіадЭГМЦжЎЭтЃЌЛЙЬсЙЉСЫСЌајБфСПЕФЯрЙиЯЕЪ§ЃЈcorrЃЉКЭаЗНВюОиеѓЃЈcovЃЉЕФЧѓНтЃЌетИіИњRгябдЪЧвЛжТЕФгУЗЈЁЃ
1.df.corr()
ЙигкЯрЙиЯЕЪ§ЕФМЦЫуПЩвдЕїгУpearsonЗНЗЈЛђkendellЗНЗЈЛђspearmanЗНЗЈЃЌФЌШЯЪЙгУpearsonЗНЗЈЁЃ
1.df.corr('spearman')
ШчЙћжЛЯыЙизЂФГвЛИіБфСПгыЦфгрБфСПЕФЯрЙиЯЕЪ§ЕФЛАЃЌПЩвдЪЙгУcorrwith,ШчЯТЗНжЛЙиаФx1гыЦфгрБфСПЕФЯрЙиЯЕЪ§:
1.df.corrwith(df['x1'])
Ъ§жЕаЭБфСПМфЕФаЗНВюОиеѓ
1.df.cov()
ЮхЁЂРрЫЦгкSQLЕФВйзї
дкSQLжаГЃМћЕФВйзїжївЊЪЧдіЁЂЩОЁЂИФЁЂВщМИИіЖЏзїЃЌФЧУДpandasФмЗёЪЕЯжЖдЪ§ОнЕФетМИЯюВйзїФиЃПД№АИЪЧOf
Course!
діЃКЬэМгаТааЛђдіМгаТСа
1.In [99]: dic = {'Name':['LiuShunxiang','Zhangshan'],
2....: 'Sex':['M','F'],'Age':[27,23],
3....: 'Height':[165.7,167.2],'Weight':[61,63]}
4.In [100]: student2 = pd.DataFrame(dic)
5.In [101]: student2
6.Out[101]:
7.Age Height Name Sex Weight
8.0 27 165.7 LiuShunxiang M 61
9.1 23 167.2 Zhangshan F 63
ЯждкНЋstudent2жаЕФЪ§ОнаТдіЕНstudentжаЃЌПЩвдЭЈЙ§concatКЏЪ§ЪЕЯжЃК

зЂвтЕНСЫТ№ЃПдкЪ§ОнПтжаunionБиаывЊЧѓСНеХБэЕФСаЫГађвЛжТЃЌЖјетРяconcatКЏЪ§ПЩвдздЖЏЖдЦыСНИіЪ§ОнПђЕФБфСПЃЁ
аТдіСаЕФЛАЃЌЦфЪЕдкpandasжаОЭИќМђЕЅСЫЃЌР§Шчдкstudent2жааТдівЛСабЇЩњГЩМЈЃК

ЖдгкаТдіЕФСаУЛгаИГжЕЃЌОЭЛсГіЯжПеNaNЕФаЮЪНЁЃ
ЩОЃКЩОГ§БэЁЂЙлВтааЛђБфСПСа
ЩОГ§Ъ§ОнПђstudent2,ЭЈЙ§delУќСюЪЕЯжЃЌИУУќСюПЩвдЩОГ§PythonЕФЫљгаЖдЯѓЁЃ

ЩОГ§жИЖЈЕФаа

дЪ§ОнжаЕФЕк1,2,4,7ааЕФЪ§ОнвбОБЛЩОГ§СЫЁЃ
ИљОнВМЖћЫїв§ЩОГ§ааЪ§ОнЃЌЦфЪЕетИіЩОГ§ОЭЪЧБЃСєЩОГ§ЬѕМўЕФЗДУцЪ§ОнЃЌР§ШчЩОГ§Ыљга14ЫъвдЯТЕФбЇЩњЃК
ЩОГ§жИЖЈЕФСа

ЮвУЧЗЂЯжЃЌВЛТлЪЧЩОГ§ааЛЙЪЧЩОГ§СаЃЌЖМПЩвдЭЈЙ§dropЗНЗЈЪЕЯжЃЌжЛашвЊЩшЖЈКУЩОГ§ЕФжсМДПЩЃЌМДЕїећdropЗНЗЈжаЕФaxisВЮЪ§ЁЃФЌШЯИУВЮЪ§ЮЊ0ЃЌБэЪОЩОГ§ааЙлВтЃЌШчЙћашвЊЩОГ§СаБфСПЃЌдђашЩшжУЮЊ1ЁЃ
ИФЃКаоИФдЪММЧТМЕФжЕ
ШчЙћЗЂЯжБэжаЕФФГаЉЪ§ОнДэЮѓСЫЃЌШчКЮИќИФдРДЕФжЕФиЃПЮвУЧЪдЪдНсКЯВМЖћЫїв§КЭИГжЕЕФЗНЗЈЃК
Р§ШчЗЂЯжstudent3жааеУћЮЊLiushunxiangЕФбЇЩњЩэИпДэСЫЃЌгІИУЪЧ173ЃЌШчКЮИФФиЃП

етбљОЭПЩвдАбдРДЕФЩэИпаоИФЮЊЯждкЕФ170СЫЁЃ
ПДЃЌЙигкЫїв§ЕФВйзїЗЧГЃСщЛюЁЂЗНБуАЩЃЌОЭетбљЧсЫЩИуЖЈЪ§ОнЕФИќИФЁЃ
ВщЃКгаЙиЪ§ОнВщбЏВПЗжЃЌЩЯУцвбОНщЩмЙ§ЃЌЯТУцжиЕуНВНВОлКЯЁЂХХађКЭЖрБэСЌНгВйзїЁЃ
ОлКЯЃКpandasФЃПщжаПЩвдЭЈЙ§groupby()КЏЪ§ЪЕЯжЪ§ОнЕФОлКЯВйзї
ИљОнадБ№ЗжзщЃЌМЦЫуИїзщБ№жабЇЩњЩэИпКЭЬхжиЕФЦНОљжЕЃК

ШчЙћВЛЖддЪМЪ§ОнзїЯожЦЕФЛАЃЌОлКЯКЏЪ§ЛсздЖЏбЁдёЪ§жЕаЭЪ§ОнНјааОлКЯМЦЫуЁЃШчЙћВЛЯыЖдФъСфМЦЫуЦНОљжЕЕФЛАЃЌОЭашвЊЬоГ§ИФБфСПЃК

groupbyЛЙПЩвдЪЙгУЖрИіЗжзщБфСПЃЌР§ШчИљБОФъСфКЭадБ№ЗжзщЃЌМЦЫуЩэИпгыЬхжиЕФЦНОљжЕЃК

ЕБШЛЃЌЛЙПЩвдЖдУПИіЗжзщМЦЫуЖрИіЭГМЦСПЃК

ЪЧВЛЪЧКмМђЕЅЃЌжЛашвЛОфОЭФмЭъГЩSQLжаЕФSELECTЁFROMЁGROUP BYЁЙІФмЃЌКЮРжЖјВЛЮЊФиЃП
ХХађЃК
ХХађдкШеГЃЕФЭГМЦЗжЮіжаЛЙЪЧБШНЯГЃМћЕФВйзїЃЌЮвУЧПЩвдЪЙгУorderЁЂsort_indexКЭsort_
values ЪЕЯжађСаКЭЪ§ОнПђЕФХХађЙЄзїЃК

ЮвУЧдйЪдЪдНЕађХХађЕФЩшжУЃК

ЩЯУцСНИіНсЙћЦфЪЕЖМЪЧАДжЕХХађЃЌВЂЧвНсЙћжаЖМИјГіСЫОЏИцаХЯЂЃЌМДНЈвщЪЙгУsort_values()КЏЪ§НјааАДжЕХХађЁЃ
дкЪ§ОнПђжавЛАуЖМЪЧАДжЕХХађЃЌР§ШчЃК

ЖрБэСЌНг:
ЖрБэжЎМфЕФСЌНгвВЪЧЗЧГЃГЃМћЕФЪ§ОнПтВйзїЃЌСЌНгЗжФкСЌНгКЭЭтСЌНгЃЌдкЪ§ОнПтгябджаЭЈЙ§joinЙиМќзжЪЕЯжЃЌpandasЮвБШНЯНЈвщЪЙгУmergerКЏЪ§ЪЕЯжЪ§ОнЕФИїжжСЌНгВйзїЁЃ
ШчЯТЪЧЙЙдьвЛеХбЇЩњЕФГЩМЈБэЃК

ЯждкЯыАббЇЩњБэstudentгыбЇЩњГЩМЈБэscoreзівЛИіЙиСЊЃЌИУШчКЮВйзїФиЃП

зЂвтЃЌФЌШЯЧщПіЯТЃЌmergeКЏЪ§ЪЕЯжЕФЪЧСНИіБэжЎМфЕФФкСЌНгЃЌМДЗЕЛиСНеХБэжаЙВЭЌВПЗжЕФЪ§ОнЁЃПЩвдЭЈЙ§howВЮЪ§ЩшжУСЌНгЕФЗНЪНЃЌleftЮЊзѓСЌНгЃЛrightЮЊгвСЌНгЃЛouterЮЊЭтСЌНгЁЃ

зѓСЌНгЪЕЯжЕФЪЧБЃСєstudentБэжаЕФЫљгааХЯЂЃЌЭЌЪБНЋscoreБэЕФаХЯЂгыжЎХфЖдЃЌФмХфЖрЩйХфЖрЩйЃЌЖдгкУЛгаХфЖдЩЯЕФNameЃЌНЋЛсЯдЪОГЩМЈЮЊNaNЁЃ
СљЁЂШБЪЇжЕДІРэ
ЯжЪЕЩњЛюжаЕФЪ§ОнЪЧЗЧГЃдгТвЕФЃЌЦфжаШБЪЇжЕвВЪЧЗЧГЃГЃМћЕФЃЌЖдгкШБЪЇжЕЕФДцдкПЩФмЛсгАЯьЕНКѓЦкЕФЪ§ОнЗжЮіЛђЭкОђЙЄзїЃЌФЧУДЮвУЧИУШчКЮДІРэетаЉШБЪЇжЕФиЃПГЃгУЕФгаШ§ДѓРрЗНЗЈЃЌМДЩОГ§ЗЈЁЂЬюВЙЗЈКЭВхжЕЗЈЁЃ
ЩОГ§ЗЈЃКЕБЪ§ОнжаЕФФГИіБфСПДѓВПЗжжЕЖМЪЧШБЪЇжЕЃЌПЩвдПМТЧЩОГ§ИФБфСПЃЛЕБШБЪЇжЕЪЧЫцЛњЗжВМЕФЃЌЧвШБЪЇЕФЪ§СПВЂВЛЪЧКмЖрЪЧЃЌвВПЩвдЩОГ§етаЉШБЪЇЕФЙлВтЁЃ
ЬцВЙЗЈЃКЖдгкСЌајаЭБфСПЃЌШчЙћБфСПЕФЗжВМНќЫЦЛђОЭЪЧе§ЬЌЗжВМЕФЛАЃЌПЩвдгУОљжЕЬцДњФЧаЉШБЪЇжЕЃЛШчЙћБфСПЪЧгаЦЋЕФЃЌПЩвдЪЙгУжаЮЛЪ§РДДњЬцФЧаЉШБЪЇжЕЃЛЖдгкРыЩЂаЭБфСПЃЌЮвУЧвЛАугУжкЪ§ШЅЬцЛЛФЧаЉДцдкШБЪЇЕФЙлВтЁЃ
ВхВЙЗЈЃКВхВЙЗЈЪЧЛљгкУЩЬиПЈТхФЃФтЗЈЃЌНсКЯЯпадФЃаЭЁЂЙувхЯпадФЃаЭЁЂОіВпЪїЕШЗНЗЈМЦЫуГіРДЕФдЄВтжЕЬцЛЛШБЪЇжЕЁЃ
ЮвУЧетРяОЭНщЩмМђЕЅЕФЩОГ§ЗЈКЭЬцВЙЗЈЃК

етЪЧвЛзщКЌгаШБЪЇжЕЕФађСаЃЌЮвУЧПЩвдНсКЯsumКЏЪ§КЭisnullКЏЪ§РДМьВтЪ§ОнжаКЌгаЖрЩйШБЪЇжЕЃК
1.In [130]: sum(pd.isnull(s))
2.Out[130]: 9
жБНгЩОГ§ШБЪЇжЕ

ФЌШЯЧщПіЯТЃЌdropnaЛсЩОГ§ШЮКЮКЌгаШБЪЇжЕЕФааЃЌЮвУЧдйЙЙдьвЛИіЪ§ОнПђЪдЪдЃК

ЗЕЛиНсЙћБэУїЃЌЪ§ОнжажЛвЊКЌгаШБЪЇжЕNaN,ИУЪ§ОнааОЭЛсБЛЩОГ§ЃЌШчЙћЪЙгУВЮЪ§how=ЁЏallЁЏЃЌдђБэУїжЛЩОГ§ЫљгаааЮЊШБЪЇжЕЕФЙлВтЁЃ

ЪЙгУвЛИіГЃСПРДЬюВЙШБЪЇжЕЃЌПЩвдЪЙгУfillnaКЏЪ§ЪЕЯжМђЕЅЕФЬюВЙЙЄзїЃК
1ЃЉгУ0ЬюВЙЫљгаШБЪЇжЕ

2)ВЩгУЧАЯюЬюГфЛђКѓЯђЬюГф

3)ЪЙгУГЃСПЬюГфВЛЭЌЕФСа

4)гУОљжЕЛђжаЮЛЪ§ЬюГфИїздЕФСа

КмЯдШЛЃЌдкЪЙгУЬюГфЗЈЪБЃЌЯрЖдгкГЃЪ§ЬюГфЛђЧАЯюЁЂКѓЯюЬюГфЃЌЪЙгУИїСаЕФжкЪ§ЁЂОљжЕЛђжаЮЛЪ§ЬюГфвЊИќМгКЯРэвЛЕуЃЌетвВЪЧЙЄзїжаГЃгУЕФвЛИіПьНнЪжЖЮЁЃ
ЦпЁЂЪ§ОнЭИЪгБэ
дкExcelжагавЛИіЗЧГЃЧПДѓЕФЙІФмОЭЪЧЪ§ОнЭИЪгБэЃЌЭЈЙ§ЭаРзЇЕФЗНЪНПЩвдбИЫйЕФВщПДЪ§ОнЕФОлКЯЧщПіЃЌетРяЕФОлКЯПЩвдЪЧМЦЪ§ЁЂЧѓКЭЁЂОљжЕЁЂБъзМВюЕШЁЃ
pandasЮЊЮвУЧЬсЙЉСЫЗЧГЃЧПДѓЕФКЏЪ§pivot_table()ЃЌИУКЏЪ§ОЭЪЧЪЕЯжЪ§ОнЭИЪгБэЙІФмЕФЁЃЖдгкЩЯУцЫљЫЕЕФвЛаЉОлКЯКЏЪ§ЃЌПЩвдЭЈЙ§ВЮЪ§aggfuncЩшЖЈЁЃЮвУЧЯШПДПДетИіКЏЪ§ЕФгяЗЈКЭВЮЪ§АЩЃК
1.pivot_table(data,values=None,
2.index=None,
3.columns=None,
4.aggfunc='mean',
5.fill_value=None,
6.margins=False,
7.dropna=True,
8.margins_name='All')
9.dataЃКашвЊНјааЪ§ОнЭИЪгБэВйзїЕФЪ§ОнПђ
10.valuesЃКжИЖЈашвЊОлКЯЕФзжЖЮ
11.indexЃКжИЖЈФГаЉдЪМБфСПзїЮЊааЫїв§
12.columnsЃКжИЖЈФФаЉРыЩЂЕФЗжзщБфСП
13.aggfuncЃКжИЖЈЯргІЕФОлКЯКЏЪ§
14.fill_valueЃКЪЙгУвЛИіГЃЪ§ЬцДњШБЪЇжЕЃЌФЌШЯВЛЬцЛЛ
15.marginsЃКЪЧЗёНјааааЛђСаЕФЛузмЃЌФЌШЯВЛЛузм
16.dropnaЃКФЌШЯЫљгаЙлВтЮЊШБЪЇЕФСа
17.margins_nameЃКФЌШЯааЛузмЛђСаЛузмЕФУћГЦЮЊ'All'
ЮвУЧШдШЛвдstudentБэЮЊР§ЃЌРДШЯЪЖвЛЯТЪ§ОнЭИЪгБэpivot_tableКЏЪ§ЕФгУЗЈЃК
ЖдвЛИіЗжзщБфСПЃЈSexЃЉЃЌвЛИіЪ§жЕБфСПЃЈHeightЃЉзїЭГМЦЛузм

ЖдвЛИіЗжзщБфСПЃЈSexЃЉЃЌСНИіЪ§жЕБфСПЃЈHeight,WeightЃЉзїЭГМЦЛузм

ЖдСНИіЗжзщБфСПЃЈSexЃЌAge)ЃЌСНИіЪ§жЕБфСПЃЈHeight,WeightЃЉзїЭГМЦЛузм

КмЯдШЛетбљЕФНсЙћВЂВЛЯёExcelжадЄЦкЕФФЧбљЃЌИУШчКЮБфГЩСаСЊБэЕФаЮЪНЕФЃПКмМђЕЅЃЌжЛашНЋНсЙћНјааЗЧЖбЕўВйзїЃЈunstackЃЉМДПЩЃК

ПДЃЌетбљЕФНсЙћЪЧВЛЪЧБШЩЯУцФЧжжПДЦ№РДИќЪцЗўвЛЕуЃП
ЪЙгУЖрИіОлКЯКЏЪ§

гаЙиИќЖрЪ§ОнЭИЪгБэЕФВйзїЃЌПЩВЮПМЁЖPandasЭИЪгБэЃЈpivot_tableЃЉЯъНтЁЗвЛЮФЃЌСДНгЕижЗЃКhttp:
//python.jobbole.com /81212/
АЫЁЂЖрВуЫїв§ЕФЪЙгУ
зюКѓЮвУЧдйРДНВНВpandasжаЕФвЛИіживЊЙІФмЃЌФЧОЭЪЧЖрВуЫїв§ЁЃдкађСажаЫќПЩвдЪЕЯждквЛИіжсЩЯгЕгаЖрИіЫїв§ЃЌОЭРрЫЦгкExcelжаГЃМћЕФетжжаЮЪНЃК
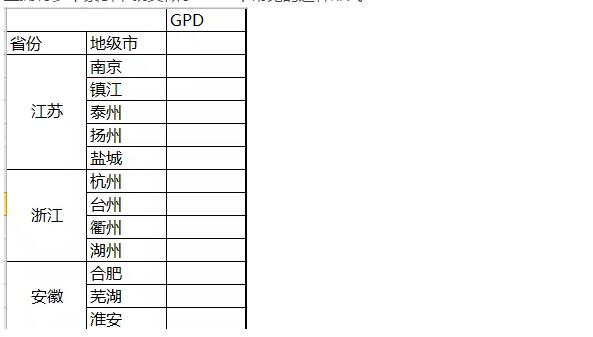
ЖдгкетбљЕФЪ§ОнИёЪНгаЪВУДКУДІФиЃПpandasПЩвдАяЮвУЧЪЕЯжгУЕЭЮЌЖШаЮЪНДІРэИпЮЌЪ§Ъ§ОнЃЌетРяОйИіР§згвВаэФуОЭФмУїАзСЫЃК

ЖдгкетжжЖрВуДЮЫїв§ЕФађСаЃЌШЁЪ§ОнОЭЯдЕУЗЧГЃМђЕЅСЫЃК

ЖдгкетжжЖрВуДЮЫїв§ЕФађСаЃЌЮвУЧЛЙПЩвдЗЧГЃЗНБуЕФНЋЦфзЊЛЛЮЊЪ§ОнПђЕФаЮЪНЃК

вдЩЯеыЖдЕФЪЧађСаЕФЖрВуДЮЫїв§ЃЌЪ§ОнПђвВЭЌбљгаЖрВуДЮЕФЫїв§ЃЌЖјЧвУПЬѕжсЩЯЖМПЩвдгаетбљЕФЫїв§ЃЌОЭРрЫЦгкExcelжаГЃМћЕФетжжаЮЪНЃК

ЮвУЧВЛЗСЙЙдьвЛИіРрЫЦЕФИпЮЌЪ§ОнПђЃК

ЭЌбљЃЌЪ§ОнПђжаЕФЖрВуЫїв§вВПЩвдЗЧГЃБуНнЕФШЁГіДѓПщЪ§ОнЃК

дкЪ§ОнПђжаЪЙгУЖрВуЫїв§ЃЌПЩвдНЋећИіЪ§ОнМЏПижЦдкЖўЮЌБэНсЙЙжаЃЌетЖдгкЪ§ОнжиЫмКЭЛљгкЗжзщЕФВйзїЃЈШчЪ§ОнЭИЪгБэЕФЩњГЩЃЉБШНЯгаАяжњЁЃ
ОЭФУstudentЖўЮЌЪ§ОнПђЮЊР§ЃЌЮвУЧЙЙдьвЛИіЖрВуЫїв§Ъ§ОнМЏЃК

НВЕНетРяЃЌЮвУЧЙигкpandasФЃПщЕФбЇЯАЛљБОЭъГЩЃЌЦфЪЕдкеЦЮеСЫpandasет8ИіжївЊЕФгІгУЗНЗЈОЭПЩвдСщЛюЕФНтОіКмЖрЙЄзїжаЕФЪ§ОнДІРэЁЂЭГМЦЗжЮіЕШШЮЮёЁЃгаЙиИќЖрЕФpandasНщЩмЃЌПЩВЮПМpandas
ЙйЗНЮФЕЕЃКhttp: //pandas.pydata.org /pandas-docs /version
/0.17.0 / whatsnew .html ЁЃ |





