| БрМЭЦМі: |
| БОЮФРДдДcsdnЃЌБОЮФжївЊНщЩмСЫКЃСПЪ§ОнЪЕЪБOLAPГЁОАЕФРЇОГЃЌвдМАЮЈЦЗЛсДѓЪ§ОнЪЕЪБOLAPЩ§МЖЙ§ГЬЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ |
|
КЃСПЪ§ОнЪЕЪБOLAPГЁОАЕФРЇОГ
ДѓЪ§Он
ЪзЯШРДПДвЛЯТЮвУЧдкзюГѕМИФъгіЕНЕФЮЪЬтЁЃЕквЛОЭЪЧДѓЪ§ОнЃЌЬ§Ц№РДКУЯёТљЮоСФЕФЃЌЕЋДѓЪ§ОнЕНЕзЪЧжИЪВУДФиЃПзюжївЊЕФЮЪЬтОЭЪЧЪ§ОнДѓЃЌЮЈЦЗЛсдкетМИФъПьЫйЗЂеЙЃЌгУЛЇСїСПЪ§ОнДгИеПЊЪМЕФМИАйЭђЁЂМИЧЇЭђЗЂеЙЕНЯждкЕФМИИівкЃЌГЪЯжСЫ100БЖвдЩЯЕФдіГЄЁЃ
ЖдЮвУЧЖјбдЃЌЫљЮНЕФДѓЪ§ОнОЭЪЧЪ§ОнСПЕФПьЫйХђеЭЃЌДјРДЕФЮЪЬтзюжївЊЕФОЭЪЧДЋЭГRDBMSЮоЗЈТњзуДцДЂЕФашЧѓЃЌМЬЖјЪЧМЦЫуЕФашЧѓЃЌЮвУЧЕФЬєеНБуЪЧШчКЮПЫЗўетИіЮЪЬтЁЃ
Т§ВщбЏ
ЕкЖўИіЮЪЬтЪЧТ§ВщбЏЃЌгаСНИіЗНУцЃКвЛЪЧOLAPВщбЏЕФЫйЖШБфТ§ЃЛЖўЪЧETLЪ§ОнДІРэаЇТЪНЕЕЭЁЃ
ЗжЮіЯТетСНИіЮЪЬтЃКЪзЯШЃЌгУЛЇЪЙгУOLAPЗжЮіЯЕЭГЪБЛсгаетбљЕФдЄЦкЃЌЕБЮвЕуЛїВщбЏАДХЅЪБЯЃЭћЫљгаЕФЪ§ОнФмЙЛУыГіЃЌЖјВЛЪЧЮвГщЩэШЅХнИіВшЃЌЛиРДвЛПДЪ§ОнВХХмСЫ10%ЃЌетЪЧЮоЗЈНгЪмЕФЁЃгЩгкЪ§ОнСПДѓЃЌЮвУЧвВПЩвдбЁдёдЄЯШМЦЫуКУЃЌЕБгУЛЇВщбЏЪБжБНгДгМЦЫуНсЙћжаевЕНЖдгІЕФжЕЗЕЛиЃЌФЧУДВщбЏОЭЪЧУыГіЕФЁЃЪ§ОнСПДѓЖддЄМЦЫуЖјбдвВгаЭЌбљЕФЮЪЬтЃЌОЭЪЧETLЕФадФмвВЯТНЕСЫЃЌБОРДзМБИетИіЪ§ОнПЩФмжЛаш40ЗжжгЛђвЛИіаЁЪБЃЌЯждкЪ§ОнСПЗСЫвЛАйБЖЃЌашвЊШ§ИіаЁЪБЃЌетЪБКђЪ§ОнЗжЮіЪІЩЯАрЪБОЭЛсБЇдЙЪ§ОнУЛгазМБИКУЃЌЕУЕШЕНжаЮчЗжЮіжЎРрЕФЃЌЛсЬ§ЕНРДздЭЌЪТВЛЖЯЕФБЇдЙЁЃ
ГЄЕќДњ
Ъ§ОнСПБфДѓДјРДЕФЕкШ§ИіУЋВЁЃЌОЭЪЧПЊЗЂжмЦкБфГЄЁЃСНИіНЧЖШЃКЕквЛЃЌаТвЕЮёЩЯЯпЃЌгУЛЇЛсЫЕЮвФмВЛФмдкетИіаТЕФНЧЖШЩЯЯпЧАЃЌПДПДРњЪЗЪ§ОнЃЌвЊПДвЛФъЕФЃЌетЪБОЭвЊЫЂЪ§ОнСЫЁЃЫЂЪ§ОнетМўЪТЧщДѓМвжЊЕРЃЌУПДЮЫЂЭЗЖМКмДѓЃЌЛЈЕФЪБМфКмГЄЁЃОЩвЕЮёвВвЛбљЃЌМгаТЕФжИБъЃЌУЛгаРњЪЗЧїЪЦвВВЛааЃЌвВвЊЫЂЪ§ОнЃЌПЊЗЂОЭВЛЖЯЕиЫЂЪ§ОнЁЃвђЮЊЪ§ОнСПДѓЃЌЫЂЪ§ОнЕФЪБМфЗЧГЃГЄЃЌЪ§ОнбщжЄвВашвЊЛЈКмЖрЕФЪБМфЃЌТ§Т§ЕФЃЌПЊЗЂжмЦкБфТ§ЃЌвЕЮёКмМБдъЃЌОѕЕУВЛОЭЪЧМгИізжЖЮТ№ЃЌдѕУДетУДТ§ЁЃетбљвЛРДЃЌЪ§ОнЕФЕќДњГЄЃЌжмЦкБфТ§ЃЌЖМШУвЕЮёВПУХЖдДѓЪ§ОнвЕЮёЬсГіКмЖрЕФжЪвЩЃЌЮвУЧашвЊИФНјРДНтОіетаЉЮЪЬтЁЃ
вЕЮёВПУХЕФЯыЗЈЪЧЃЌВЛЙмФуЪЧЪВУДвЕЮёЃЌВЛЙмЯждкгУЕФЪЧЪВУДЗНЗЈЃЌЫћУЧжЛЙиаФШ§ЕуЃКЕквЛЃЌЬсЕФашЧѓвЊКмПьТњзуЃЛЕкЖўЃЌЪ§ОнвЊКмПьзМБИКУЃЛЕкШ§ЃЌЪ§ОнзМБИКУжЎКѓЃЌЕБЮвРДзіЗжЮіЪБЪ§ОнФмЙЛКмПьЕиЗЕЛиЁЃвЕЮёвЊЕФЪЧПьПьПьЃЌЕЋЯждкЕФФмСІЪЧТ§Т§Т§ЃЌЮЊДЫЃЌЮвУЧМБашНтОівЕЮёВПУХЕФашЧѓКЭЯжзДжЎМфЕФГхЭЛЁЃ
ЮЈЦЗЛсДѓЪ§ОнЪЕЪБOLAPЩ§МЖЙ§ГЬ
Ек0НзЖЮ
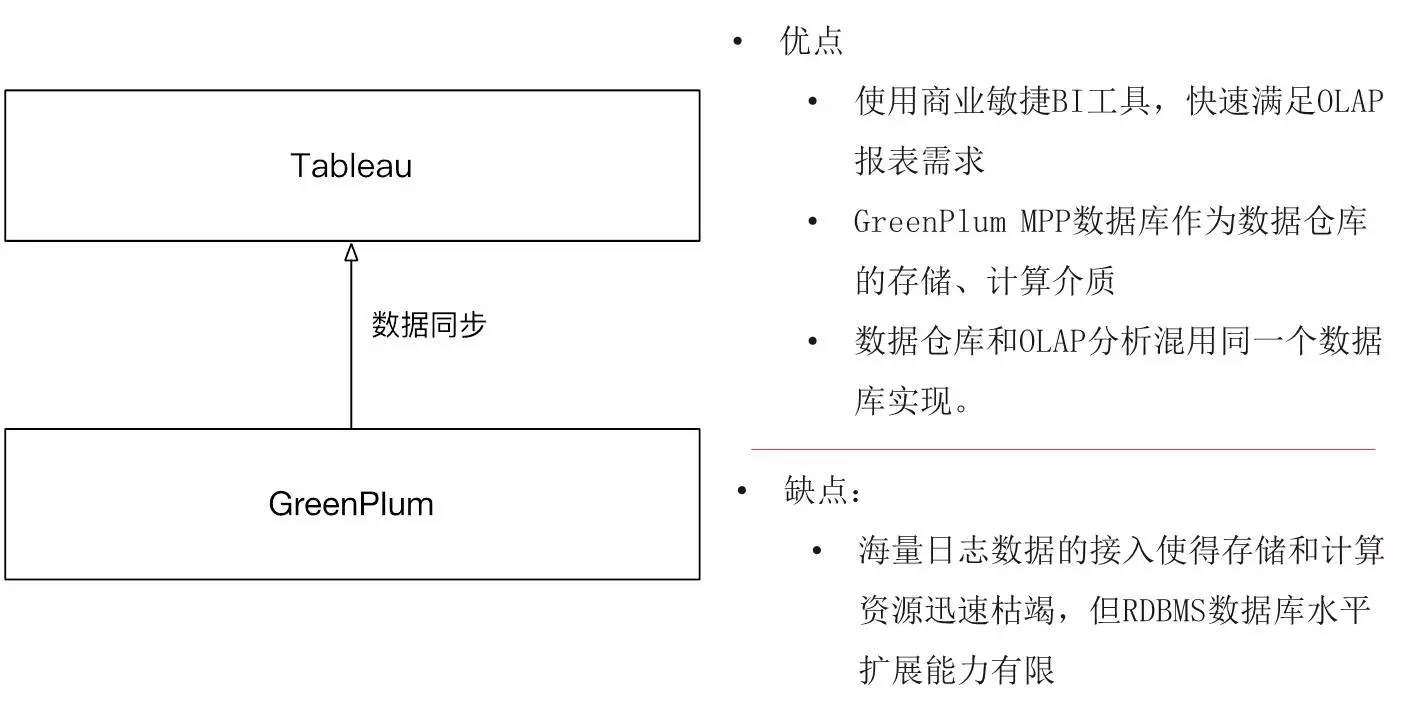
етЪЧЮвУЧЕФГѕЪМзДЬЌЃЌМмЙЙБШНЯМђЕЅЁЃЕзВуЕФМЦЫуЁЂДцДЂКЭOLAPЗжЮігУMDBЕФЪ§ОнВжПтНтОіЕФЃЌЩЯВугУTableauЕФBIЙЄОпЃЌПЊЗЂЫйЖШБШНЯПьЃЌЭЌЪБгаЪ§ОнПЩЪгЛЏаЇЙћЃЌвЕЮёВПУХЗЧГЃШЯПЩЁЃGreenPlumЪЧMPPЕФЗНАИЃЌЫќЕФИпВЂЗЂВщбЏЗЧГЃЪЪКЯЮвУЧетжжOLAPЕФВщбЏЃЌадФмЗЧГЃКУЁЃЫљвдЮвУЧдкетИіНзЖЮЃЌАбGreenPlumзїЮЊЪ§ОнВжПтКЭOLAPЛьгУЕФЪЕЯжЁЃ
етбљвЛИіМмЙЙЦфЪЕЪЧвЛИіЭЈгУЕФМмЙЙЃЌЯёTableauПЩвдЧсвзБЛЬцЛЛЃЌ
GreenPlumвВПЩвдЬцЛЛГЩOracleжЎРрЕФЃЌетбљвЛИіГЃгУЕФЙЄОпЁЂвЛИіМмЙЙЃЌЦфЪЕТњзуСЫВПЗжЕФашЧѓЃЌЕЋвВгаИіЮЪЬтЃЌОЭЪЧЯёGreenPlumетбљЕФRDBMSЪ§ОнПтЃЌдкУцЖдКЃСПЕФЪ§ОнаДШыЪБДцДЂКЭМЦЫуЕФзЪдДПьЫйЕиПнНпСЫЃЌ
GreenPlumЕФЫЎЦНРЉеЙгаЯоЃЌЫљвдЭЌбљХіЕНСЫДѓЪ§ОнЕФЮЪЬтЁЃ
Ек1НзЖЮ

ЫљвдКмПьЮвУЧОЭНјШыСЫЕквЛНзЖЮЁЃетИіНзЖЮЃЌЮвУЧв§ШыСЫHadoop/HiveЃЌЫљгаЕФМЦЫуНсЙћзідЄМЦЫужЎКѓЃЌЛсЭЌВНЕНGreenPlumРяУцЃЌНгЯТШЅвЛбљЃЌгУGreenPlumШЅзіЗжЮіЁЃOLAPНВОлКЯНВЕФAd-hocЃЌМЬајгЩGreenPlumГадиЃЌЪ§ОнВжПтНВУїЯИЪ§ОнНВBatchЃЌОЭНЛИјзЈЮЊХњСПЖјЩњЕФHiveРДзіЃЌетбљОЭФмАбOLAPКЭЪ§ОнВжПтетСНИіГЁОАгУСНИіВЛвЛбљММЪѕеЛЗжПЊЁЃетбљвЛИіММЪѕЗНАИНтОіСЫЪ§ОнСПДѓЕФЮЪЬтЃЌETLХњСПОЭВЛЛсЫЕХмВЛЖЏЛђепЪ§ОнУЛЗЈДцДЂЁЃ
ЕЋЮЪЬтЪЧдіМгСЫаТЕФЭЌВНЛњжЦЃЌашвЊдкСНИіВЛЭЌЕФDBжЎМфЭЌВНЪ§ОнЁЃЭЌВНЪ§ОнзюЯдЖјвзМћЕФЮЪЬтОЭЪЧГ§СЫЪ§ОнШпгрЭтЃЌШчЙћЪ§ОнВЛЭЌВНдѕУДАьЃПБШШчETLПЊЗЂдкHadoopЩЯИќаТЃЌЕЋУЛгаЭЌВНЕНGreenPlumЩЯЃЌгУЛЇЛсЗЂЯжЪ§ОнЛЙЪЧДэЮѓЕФЁЃЕкЖўЃЌЖдгУЛЇРДЫЕЃЌЕБЫћШЅзіOLAPЗжЮіЪБЃЌTablueaЪЧИќЪЪКЯзіБЈБэЕФЙЄОпЃЌЫцзХЮвУЧвЕЮёЕФРЉеЙКЭЪ§ОнЧ§ЖЏВЛЖЯЕФЩюШыЃЌвЕЮёВЛЙмЗжЮіЪІЛЙЪЧЩЬЮёЁЂдЫгЊЁЂЪаГЁЃЌЫћУЧЛсдНРДдНЖрЕиЯызщКЯВЛЭЌЕФжИБъКЭЮЌЖШШЅЙлВьздМКЕФЪ§ОнЃЌевздМКдЫгЊЕФЗжЮіЕуЁЃДЋЭГЕФTablueaБЈБэвбОВЛФмТњзуЫћУЧЁЃ
ЮвУЧашвЊвЛИіаТЕФBIНтОіЗНАИ
ЖдЮвУЧРДЫЕЪ§ОнВЛЭЌВНЛЙПЩвдНтОіЃЌБЯОЙЪЧХМШЛЗЂЩњЕФЃЌДІРэвЛЯТОЭПЩвдСЫЁЃЕЋЪЧBIЙЄОпгаКмДѓЕФЮЪЬтЃЌВЛФмТњзувЕЮёвбОНјЛЏЕФашЧѓЁЃЫљвдЮвУЧашвЊвЛИіаТЕФBIНтОіЗНАИЃК
ЪзЯШЫќвЊзуЙЛСщЛюЃЌВЛФмЗЂВМжЎКѓгУЛЇЪВУДЖМВЛФмзіЃЌжЛФмПДЃЌЮвУЧЯЃЭћЫќЕФЮЌЖШКЭжИБъПЩвдПьЫйећКЯЁЃ
ЕкЖўЃЌУХМївЊЕЭЃЌЮвУЧВЛПЩФмЯЃЭћвЕЮёЯёBIЙЄГЬЪІбЇЯАЫќЕФПЊЗЂЪЧдѕУДзіЕФЃЌЫљвдЫќвЊШыУХЗЧГЃМђЕЅЁЃЦфДЮЃЌвЊФмЙЛгУгябдУшЪіздМКЕФашЧѓЃЌЖјВЛЪЧгУSQLЃЌШУЩЬЮёетжжИаадЫМЮЌЕФШЫбЇSQLМђжБЪЧВЛПЩФмЕФЃЌЫљвдвЊФмгУгябдУшЪіЫћУЧздМКЯывЊЪВУДЁЃ
ЕкШ§ОЭЪЧПЊЗЂжмЦкЖЬЃЌвЕЮёЯыПДЪВУДЃЌЫљгаЕФЪ§ОнЖМашвЊЬсашЧѓЃЌашЧѓЗжЮіЃЌХХЦкЪЕЪЉЃЌЬсБфИќгжвЊХХЦкЪЕЪЉЃЌетЪБКђЫфШЛЫЕвЕЮёЗЂеЙВЛЪЧвЛЬьвЛБфЃЌЕЋКмЖрвЕЮёЪдДэЕФЪБМфЗЧГЃПьЃЌЪ§ОнПЊЗЂГіРДЛЦЛЈВЫЖМСЙСЫЁЃЫљвдЯЃЭћгавЛИіаТЕФBIЗНАИНтОіетШ§ИіЮЪЬтЁЃ
ЮвУЧПДСЫвЛЯТЪаУцЩЯЕФЩЬвЕЙЄОпВЂВЛЪЪКЯЃЌВЂЧветбљСщЛюЕФЗНАИашвЊЮвУЧгаИќЧПЕФеЦПиадЃЌгкЪЧЮвУЧОЭПЊЪМзпЯђСЫздбаЕФЕРТЗЁЃ
Ек2НзЖЮ
ЮвУЧНјШыСЫOLAPЗжЮіЕФЕкЖўИіНзЖЮЃЌетЪБЧАЖЫПЊЗЂСЫвЛИіВњЦЗНазджњЗжЮіЦНЬЈЃЌетИіЦНЬЈЩЯгУЛЇПЩвдЭЈЙ§ЭЯРзЇАбзѓБпЕФЮЌЖШжИБъздМКзщКЯЭЯЕНЩЯУцЃЌзщГЩздМКЯыПДЕФНсЙћЁЃНсЙћВщбЏГіРДКѓПЩвдгУБэИёвВПЩвдЭМаЮНјааеЙЪОЃЌАќРЈелЯпЁЂжљзДЁЂЬѕаЮЭМЃЌетРяУцЫљгаЕФЗжЮіНсЙћЖМЪЧПЩБЃДцЁЂПЩЗжЯэЁЂПЩЯТдиЕФЁЃ
РћгУетбљЕФЙЄОпПЩвдАяжњЗжЮіЪІЛђепвЕЮёШЫдБИќКУЕиздгЩЕФзщКЯИеВХЮвУЧЫљЫЕЕФвЛЧаЃЌВЂЧвСщЛюадЁЂУХМїЕЭЕФЮЪЬтЦфЪЕвВЖМгШаЖјНтСЫЁЃЖјЧвЯёетбљЭЯРзЇЪЧЗЧГЃШнвзбЇЯАЕФЃЌжЛвЊШЅбЇЯАдѕУДАбвЕЮёТпМзЊЛЏГЩвЛИіЪ§ОнЕФТпМУшЪіЃЌИуЖЎвЊдѕУДзЊЛЏГЩЪВУДаЮЪНЃЌааРяУцЯдЪОЪВУДЃЌСаЯдЪОЪВУДЃЌЖШСПЪЧЪВУДОЭПЩвдСЫЃЌЫфШЛгавЛЕуЕФбЇЯАЧњЯпЃЌЕЋБШЦ№бЇЯАЭъећЕФBIЙЄОпЃЌУХМїНЕЕЭСЫКмЖрЁЃ

ЧАЖЫЪЧетбљЕФВњЦЗЃЌКѓЖЫвВвЊИњзХЫќвЛЦ№БфЁЃЪзЯШЧАЖЫЪЧвЛИіЭЯРзЇЕФUIзщМўЃЌетИізщМўвтЮЖзХгУДЋЭГЕФбЁдёSQLЃЌжБНгаЮГЩБЈБэЕФЗНЪНвбОВЛПЩааСЫЃЌвђЮЊЫљгаЕФвЛЧаВЛЙмЪЧЮЌЖШжИБъЖМЪЧгУЛЇздМКзщКЯЕФЃЌЫљвдЮвУЧашвЊвЛИіSQL
ParserАяжњгУЛЇАбЫќЕФЪ§ОнЕФУшЪізЊЛЏГЩSQLЃЌЛЙвЊНјааадФмЕФЕїгХЃЌБЃжЄвдвЛИіБШНЯИпЕФадФмЗДРЁЪ§ОнЁЃ
ЫљвдЮвУЧОЭПЊЗЂСЫвЛИіSQL ParserгУРДГаНгзщМўЩњГЩЕФЪ§ОнНсЙЙЃЌЭЌЪБгУSQL ParserжБНгШЅOLAPЪ§ОнЁЃЛЙЪЧЭЈЙ§дЄМЦЫуЕФЗНЪНЃЌАбЮвУЧашвЊЕФжИБъЮЌЖШЫуКУЭЌВНЕНSQL
ParserЁЃетбљЕФФЃаЭвЛЕЉНЈСЂЃЌПЩвдЖрДЮИДгУЁЃ
ЕЋЮвУЧжЊЕРетИіМЦЫуЗНАИгаМИИіУїЯдЕФШБЕуЃКЕквЛЃЌЫљгаЕФЪ§ОнБиаыОЙ§МЦЫуЃЌМЦЫуЗЖЮЇжЎЭтЕФВЛФмзщКЯЃЛЕкЖўЃЌЛЙЪЧгаЪ§ОнЭЌВНЕФЮЪЬтЃЌЕкШ§ЪЧЪВУДЃПЦфЪЕдЄМЦЫуЕФЪБКђДѓМвЛсОГЃЗЂЯжЮвУЧШЯЮЊетаЉзщКЯЪЧгааЇЕФЃЌгУЛЇПЩФмВЛЛсВщЃЌЕЋВЛШЅВщетДЮМЦЫуОЭРЫЗбЕєСЫЁЃЪЧВЛЪЧгаИќКУЕФАьЗЈШЅНтОіетжжЯжзДЃП
ЮвУЧашвЊвЛИіаТЕФOLAPМЦЫув§Чц
ДгетИіНЧЖШРДПДGreenPlumвбОВЛФмТњзуЮвУЧСЫЃЌОЭЫудЄЯШМЦЫуКУвВВЛФмТњзуЃЌашвЊвЛИіаТЕФOLAPМЦЫув§ЧцЁЃетИіаТЕФв§ЧцашвЊТњзуШ§ИіЬѕМўЃК
УЛгадЄМЦЫуЕФФЃаЭЁЃвђЮЊдЄМЦЫуЕФШБЕуЪЧУЛгаДЋЭГвтвхЩЯЕФЪ§ОнЛузмВуЃЌжБНгДгDWВуУїЯИЪ§ОнЩЯЕФжБНгМЦЫуЁЃЖјЧвЮвУЧЫљгаЕФвЕЮёГЁОАЛЏЃЌжЛвЊDWВугаетИіЪ§ОнОЭВЛгУдйПЊЗЂСЫЃЌжБНгФУРДгУОЭПЩвдСЫЁЃжЎЧАЮвУЧНВЕНЪ§ОнЯШЛузмЃЌгааЉЛКТ§БфЛЏЪЧашвЊЫЂЪ§ОнЕФЃЌетИіЭЗКмЬлЃЌвВвЊНтОіЁЃ
ЫйЖШвЊзуЙЛПьЁЃЪ§ОнЦНОљ10УыЗЕЛиЃЌПДЩЯШЅЭІТ§ЕФЃЌВЛЪЧУыГіЃЌЮЊЪВУДЕБЪБЖЈетбљЕФФПБъЃПвђЮЊИеВХНВЕНжЎЧАЕФПЊЗЂЗНЪНвЕЮёвЊХХЦкЕШЃЌетИіжмЦкЗЧГЃГЄЃЌШчЙћЯждкЭЈЙ§вЛИіПЩвдЫцвтзщКЯЕФЗНЪНШЅТњзуЫќ90%вдЩЯЕФашЧѓЃЌЦфЪЕЫќдкеце§зіЕФЪБКђЖдадФмЕФвЊЧѓВЂУЛгаФЧУДбЯПСЁЃЮвУЧвВВЛЯЃЭћетБпВщбЏЕФЪБКђвђЮЊЕШД§Ъ§ОнАбздМКЗжЮіЕФЫМТЗЛђепШеГЬДђТвСЫЃЌ10УыПЩФмЪЧБШНЯКЯЪЪЕФЁЃШЛКѓЃЌвђЮЊЮвУЧЕФЪ§ОнВжПтDWВугУЮЌЖШНЈФЃЃЌЫљвдетИіOLAPв§ЧцБиаыжЇГжJoinЁЃ
зюКѓЪЧжЇГжКсЯђРЉеЙЃЌМЦЫуФмСІПЩЭЈЙ§МЦЫуНкЕуРЉШнЛёЕУЬсИпЃЌЭЌЪБУЛгаDBЭЌВНЕФЮЪЬтЁЃетРяУцЖЋЮїЛЙЪЧЭІЖрЕФЃЌдѕУДНтОіетИіЮЪЬтФиЃПЮвУЧАбашЧѓЗжНтСЫвЛЯТЁЃ

ЪзЯШВщбЏЫйЖШвЊПьЃЌЮвУЧашвЊвЛИіSQLФкдкЕФИпВЂЗЂЁЃЦфДЮгУДПФкДцМЦЫуДњЬцФкДц+гВХЬЕФМЦЫуЃЌФкДц+гВХЬЕФМЦЫуНВЕФОЭЪЧHiveЃЌHiveвЛИіSQLЦєЖЏвЛЯТЃЌАќРЈЪЕМЪМЦЫуЙ§ГЬЖМЪЧКмТ§ЕФЁЃЕкЖўИіЪЧЪ§ОнФЃаЭЃЌИеВХНВЕНЪ§ОнВжПтВХЪЧЮЌЖШНЈФЃЕФЃЌБиаыжЇГжJoinЃЌЯёЭтУцБШНЯСїааЕФDruidЛђепESЕФЗНАИЦфЪЕВЛЪЪгУСЫЁЃЕкШ§ИіОЭЪЧЪ§ОнВЛашвЊЭЌВНЃЌвтЮЖзХашвЊЪ§ОнДцдкHDFSЩЯЃЌМЦЫув§ЧцвЊФмЙЛИажЊЕНHiveЕФMetadataЁЃЕкЫФИіЪЧЭЈЙ§РЉШнЬсИпМЦЫуФмСІЃЌШчЙћЯызіЕНЭъШЋУЛгаЗўЮёНЕМЖЕФРЉШнЃЌвЛИіМЦЫув§ЧцУЛгазДЬЌЪЧзюКУЕФЃЌЭЌЪБМЦЫуЕФНкЕуЛЅЯрЮовРРЕЁЃзюКѓвЛЕуЪЧЗНАИГЩЪьЮШЖЈЃЌвђЮЊетЪЧдкГЂЪдаТЕФOLAPЗНАИЃЌШчЙћетИіOLAPЗНАИВЛЮШЖЈЃЌжБНггАЯьЕНСЫгУЛЇЬхбщЃЌЮвУЧЯЃЭћЯпЩЯГіЮЪЬтЪБЮвУЧВЛжСгкЪжУІНХТвЕНУЛАьЗЈПьЫйНтОіЁЃ
PrestoЃКFacebookЙБЯзЕФПЊдДMPP OLAPв§Чц
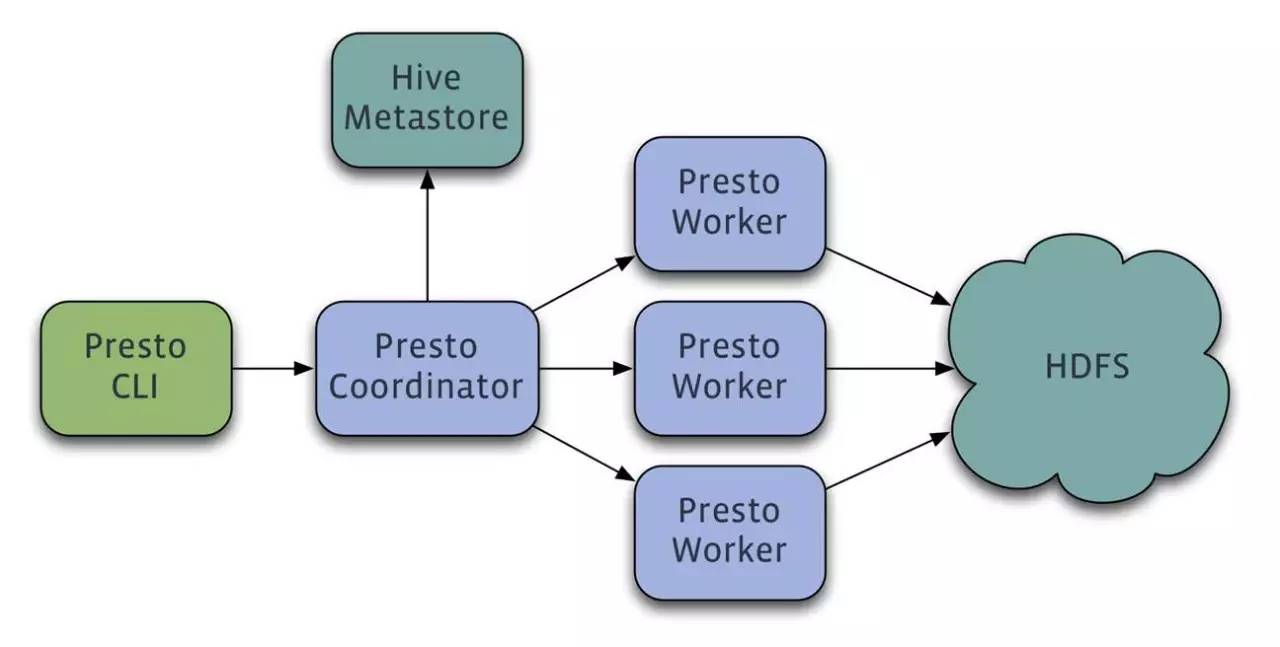
етЪБКђPrestoНјШыЮвУЧЕФЪгвАЃЌЫќЪЧFacebookЙБЯзЕФПЊдДMPP OLAPв§ЧцЁЃетЪЧвЛИіКьОЦЕФУћзжЃЌвђЮЊПЊЗЂзщЫљгаЕФШЫЖМЯВЛЖКШетИіХЦзгЕФКьОЦЃЌЫљвдАбЫќУќУћЮЊетИіУћзжЁЃзїЮЊMPPв§ЧцЃЌЫќЕФДІРэЗНЪНЪЧАбЫљгаЕФЪ§ОнScanГіРДЃЌЭЈЙ§HashЕФЗНЗЈАбЪ§ОнБфГЩИќаЁЕФПщЃЌШУВЛЭЌЕФНкЕуВЂЗЂЃЌДІРэЭъНсЙћКѓПьЫйЕиЗЕЛиИјгУЛЇЁЃЮвУЧПДЕНЫќЕФТпММмЙЙвВЪЧетбљЃЌЗЂЦ№вЛИіSQLЃЌШЛКѓеветаЉЪ§ОндкФФаЉHDFSНкЕуЩЯЃЌШЛКѓЗжХфКѓзіОпЬхЕФДІРэЃЌзюКѓдйАбЪ§ОнЗЕЛиЁЃ
ЮЊЪВУДЪЧPresto
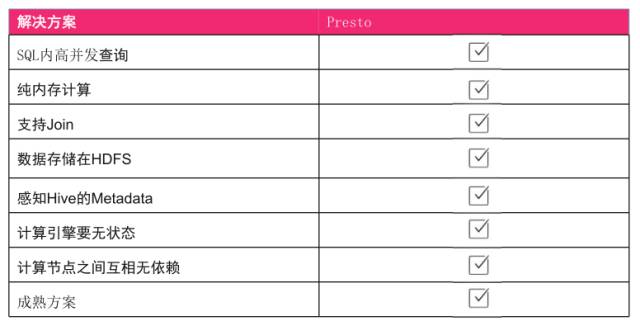
ДгдРэЩЯРДПДЃЌИпВЂЗЂВщбЏвђЮЊЪЧMPPв§ЧцЕФжЇГжЁЃДПФкДцМЦЫуЃЌЫќЪЧДПФкДцЕФЃЌИњгВХЬУЛгаШЮКЮНЛЛЅЁЃЕкШ§ЃЌвђЮЊЫќЪЧвЛИіSQLв§ЧцЃЌЫљвджЇГжJoinЁЃСэЭтЪ§ОнУЛгаДцДЂЃЌЪ§ОнжБНгДцДЂдкHDFSЩЯЁЃМЦЫув§ЧцУЛгазДЬЌЃЌМЦЫуНкЕуЛЅЯрЮовРРЕЖМЪЧТњзуЕФЁЃСэЭтЫќвВЪЧвЛИіГЩЪьЗНАИЃЌFacebookБОЩэвВЪЧДѓГЇЃЌЙњЭтгаЙШИшдкгУЃЌЙњФкОЉЖЋвВгаздМКЕФАцБОЃЌЫљвдетИіЖЋЮїЦфЪЕЛЙЪЧТњзуЮвУЧашЧѓЕФЁЃ
PrestoадФмВтЪд
ЮвУЧдкгУжЎЧАзіСЫPOCЁЃЮвУЧзіСЫвЛИіГЂЪдЃЌАбдкЮвУЧЦНЬЈЩЯГЃгУЕФSQLЃЈВЛгУTPCHЕФдвђЪЧЮвУЧЦНЬЈЕФSQLИќЪЪКЯЮвУЧЕФГЁОАЃЉЃЌдкGPКЭPrestoСНИіМЦЫув§ЧцЩЯЃЌгУЯрЭЌЕФЛњЦїХфжУКЭНкЕуЪ§ЭЌЪБзіСЫвЛДЮЛљзМадФмВтЪдЃЌПЩвдПДЕННсЙћЪЧЗЧГЃСюШЫЛЖЯВЕФЁЃ
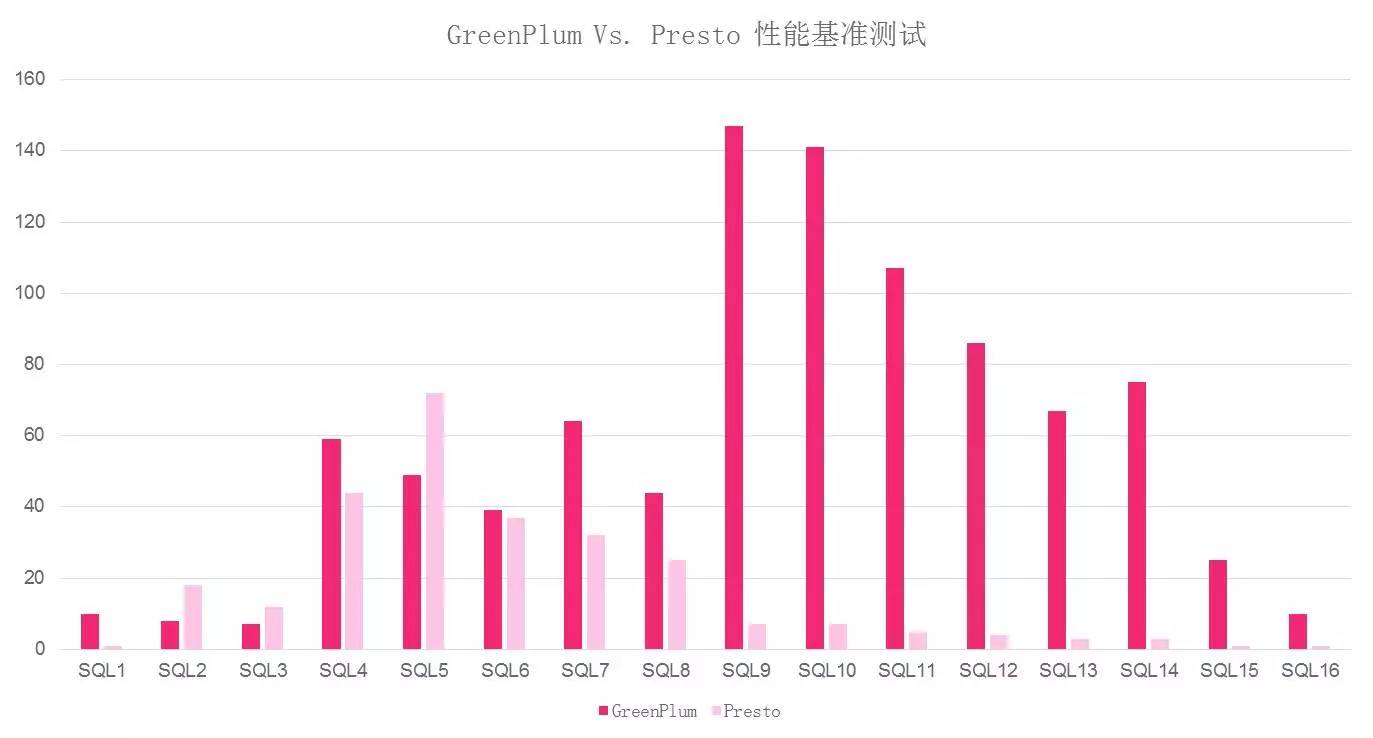
ећЬхЖјбдЯрЭЌНкЕуЕФPrestoБШGreenPlumЕФадФмЬсЩ§70%ЃЌЖјЧвSQL9ЕНSQL16ЖМДг100ЖрУыЯТНЕЕН10УыЃЌПЩМћЫќЕФЬсЩ§ЪЧЗЧГЃУїЯдЕФЁЃ
ЕБЮвУЧзіЭъадФмВтЪдЪБЃЌЮвУЧвЛИізЈУХзів§ЧцПЊЗЂЕФЭЌбЇНаСЫЦ№РДЃЌЫЕОЭФуСЫЃЌгУPrestoЬцДњGreenPlumЁЃ
Ек3НзЖЮ
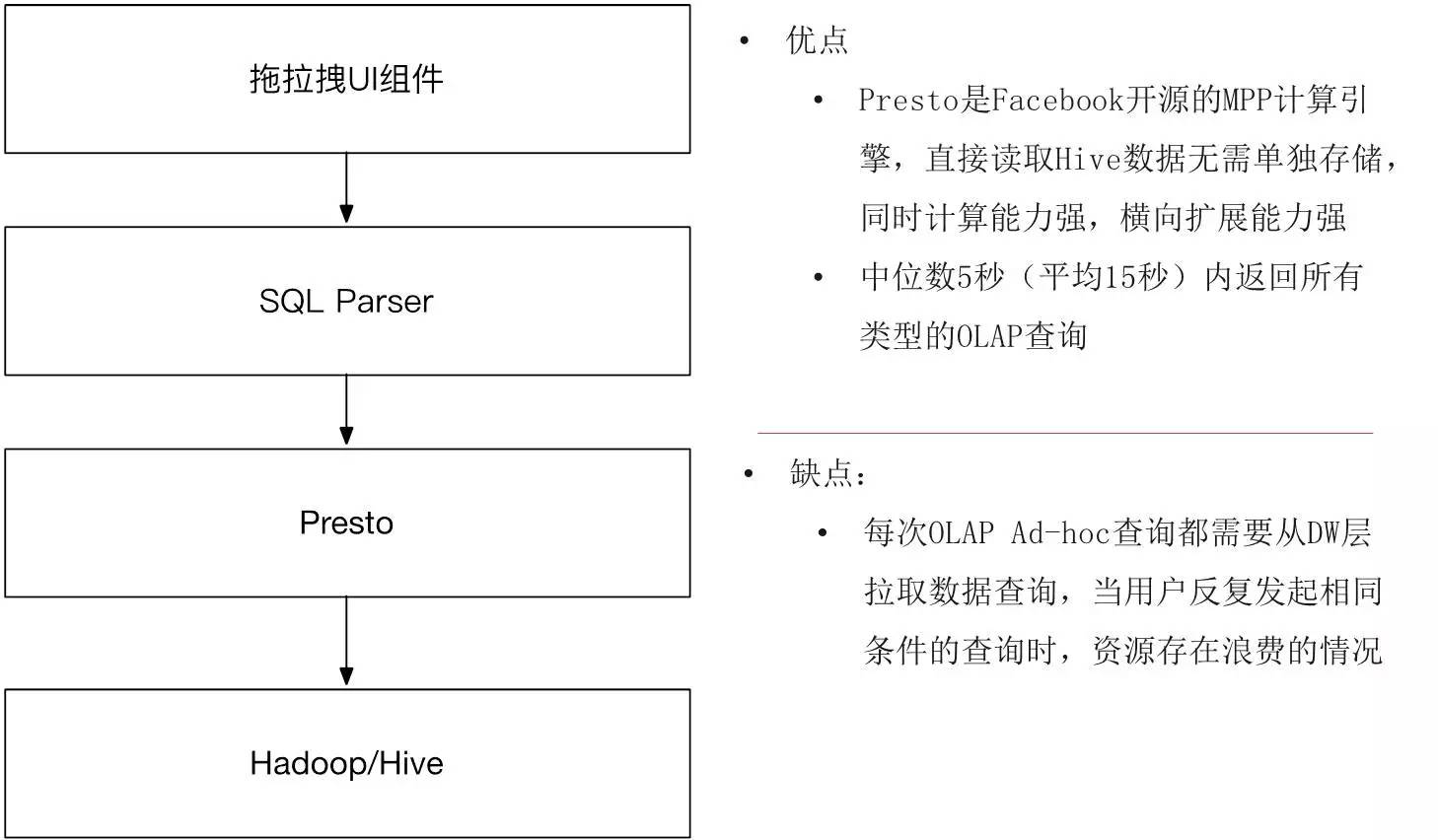
дкPrestoв§НјРДжЎКѓЃЌЮвУЧЗЂЯжећИіЪ§ОнМмЙЙБфЕУЗЧГЃЫГГЉЃЌЩЯВугУЭЯРзЇЕФUIзщМўЩњГЩДЋИјSQLЕНParserЃЌШЛКѓДЋИјPrestoжДааЁЃВЛЙмЪЧСїСПЪ§ОнЃЌЛЙЪЧТёЕуЃЌЛЙЪЧЦиЙтЪ§ОнЗЕЛиЗЧГЃПьЃЌЭЌЪБЮвУЧвВАбГЁОАРЉеЙЕНАќРЈЖЉЕЅЁЂЯњЪлжЎРрЕФЪТЮёаЭЗжЮіЩЯЁЃгУСЫжЎКѓжаЮЛЪ§ЗЕЛиЪБМф5УыжгЃЌЦНОљЗЕЛиЪБМф15УыЃЌЛљБОЩЯетЖЮЪБМфПЩвдЗЕЛиЫљгаЕФOLAPВщбЏЁЃвђЮЊгУСЫDWЪ§ОнЃЌЮЌЖШИќЗсИЛЃЌДѓЖрЪ§ЕФашЧѓЮЪЬтБЛНтОіЁЃ
гУСЫPrestoжЎКѓгУЛЇЕФЕквЛЗДгІЪЧЮЊЪВУДЛсетУДПьЃЌЕНЕзгУСЫЪВУДКкПЦММЁЃЕЋЪЧдЫааСЫвЛЖЮЪБМфКѓЮвУЧЙлВьСЫгУЛЇЕФааЮЊЪЧЪВУДбљЕФЃЌЕНЕздкВщбЏЪВУДбљЕФSQLЃЌЪВУДЮЌЖШКЭжИБъЕФзщКЯЃЌЯЃЭћЛЙФмдйзівЛаЉгХЛЏЁЃ
зюПьЕФМЦЫуЗНЗЈЪЧВЛМЦЫу
дкетИіЪБКђЮвУЧЭЛШЛЗЂЯжЃЌМДЪЙЪЧгУЛЇздгЩзщКЯЕФжИБъвВЛсЗЂЯжВЛЭЌвЕЮёдкЯрЭЌвЕЮёГЁОАЯТЛсШЅВщЭъШЋЯрЭЌЕФЪ§ОнзщКЯЁЃБШШчКмЖргУЛЇЛсВщЭЌвЛЧўЕРЕФЯњЪлСїСПзЊЛЏЃЌЯждкЕФЗНАИЛсгаЪВУДЮЪЬтФиЃПЭъШЋЯрЭЌЕФВщбЏвВашвЊЕНЩЯУцеце§жДаавЛБщЃЌЪЕМЪЩЯШчЙћЭъШЋЯрЭЌЕФПЩвджБНгЗЕЛиНсЙћВЛгУМЦЫуСЫЁЃЫљвдЮвУЧОЭдкЯыдѕУДНтОіетИіЮЪЬтЃПЪЕМЪетРягавЛИіЫљЮНЕФРэТлЁЊЁЊОЭЪЧзюПьЕФМЦЫуОЭЪЧВЛМЦЫуЃЌдѕУДзіФиЃПШчЙћЮвУЧФмЙЛФЃЗТOracleЕФBGAЃЌАбМЦЫуНсЙћДцДЂЯТРДЃЌгУЛЇВщбЏЯрЭЌЪБПЩвдАбЪ§ОнШЁГіРДИјгУЛЇжБНгЗЕЛиОЭКУСЫЁЃ
гкЪЧетРяОЭНВЕНСЫЛКДцИДгУЁЃЕквЛИіНзЖЮЭъШЋЯрЭЌЕФжБНгЗЕЛиЃЌЕкЖўИіНзЖЮИќНјвЛВНЃЌЯрЖдРДЫЕИќИДдгвЛаЉЃЌШчЙћЫЕЬсГівЛИіаТЕФSQLЃЌНсЙћЪЧЩЯвЛИіЕФЃЌЮвУЧвВВЛНсЫуЃЌДгЩЯвЛИіНсЙћРяУцжБНгзіЖўДЮДІРэЃЌАбЛКДцЕФЪ§ОнФУГіРДЗДРЁИјгУЛЇЁЃГ§СЫетИіССЕужЎЭтЃЌЦфЪЕЛКДцКмживЊЕФОЭЪЧЩњУќжмЦкЙмРэЃЌЗЧГЃИДдгЃЌвђЮЊЪ§ОнВЛЖЯЕиИќаТЃЌЛКДцШчЙћВЛИќаТПЩФмВщГіРДЕФЪ§ОнВЛЖдЃЌдкЪ§ОнПтЛсЫЕетЪЧдрЖСЛђепЛУгАЖСЃЌЮвУЧЯЃЭћЛКДцЕФЩњУќжмЦкПЩвдздМКЙмРэЃЌВЛЯЃЭћЪЧЭЈЙ§ГЌЪБРДЙмРэЛКДцЃЌЮвУЧИќЯЃЭћЛКДцПЩвдЙмРэздМКЕФЩњУќжмЦкЃЌИњдДЪ§ОнЭЌВНЩњУќжмЦкЃЌетбљЛКДцЪЙгУаЇТЪЛсЪЧзюКУЕФЁЃ
RedisЃКГЩЪьЕФЛКДцЗНАИ
ЫЕЕНЛКДцвЊЬсЕНRedisЃЌетЪЧКмЖрЩњВњЯЕЭГЩЯДѓСПЪЙгУЕФЃЌЫќвВЗЧГЃЪЪКЯOLAPЁЃ
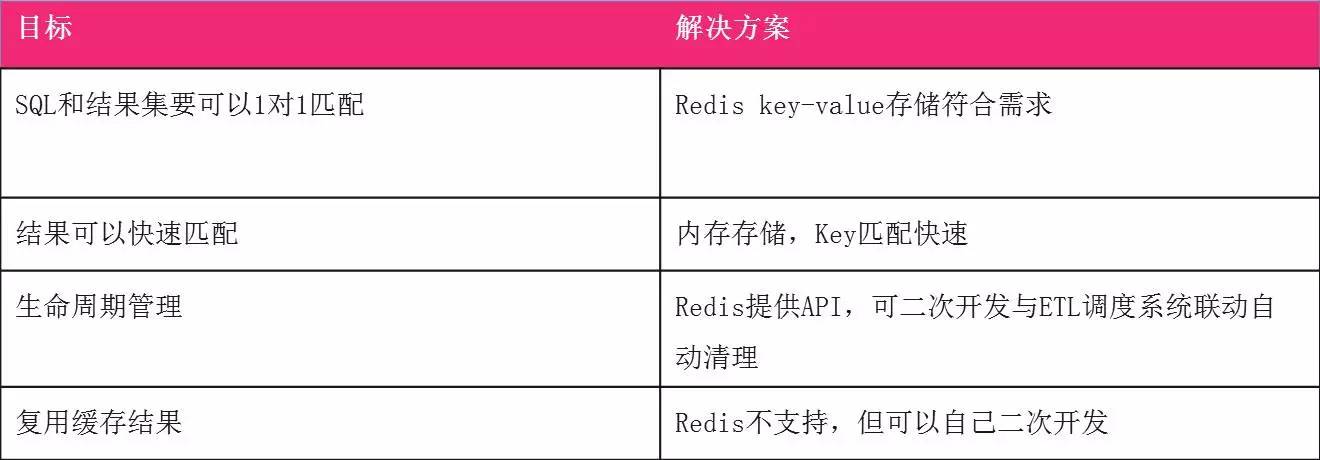
ЪзЯШЮвУЧЯывЊЕФЪЧSQLИњНсЙћвЛЖдвЛЦЅХфЃЌЫќЪЧЗЧГЃЗћКЯетИіашЧѓЕФЁЃЦфДЮЮвУЧЯЃЭћЛКДцИќПьЕФЗЕЛиЃЌRedisЪЧДПФкДцЕФДцДЂЃЌЗЕЛиЫйЖШЗЧГЃПьЃЌвЛАуЪЧКСУыМЖЁЃЕкШ§ИіЩњУќжмЦкЙмРэЃЌЫќЬсЙЉAPIЃЌЮвУЧзіЖўДЮПЊЗЂЃЌИњЮвУЧETLЕїЖШЯЕЭГДђЭЈЃЌДІРэИќаТЪБОЭПЩвдЭЈжЊЪВУДбљЕФЪ§ОнПЩвдБЛгУЕНЁЃЖјЛКДцИДгУЪЧВЛжЇГжЕФЃЌЮвУЧПЩвдздМКРДзіЁЃ
Ек3.5НзЖЮ
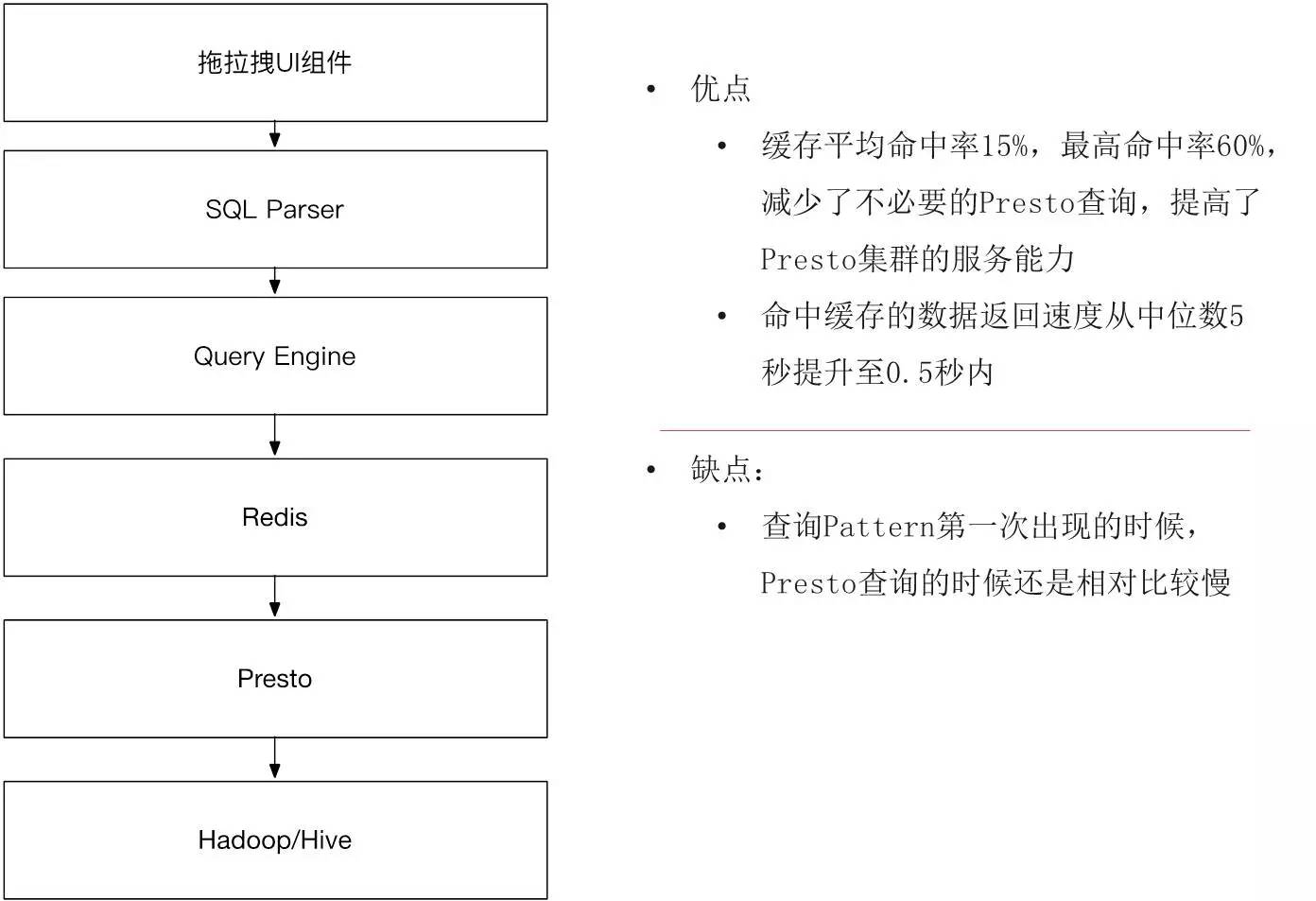
гкЪЧетЪБОЭАбRedisЕФЗНАИв§ШыНјРДЁЃ
в§ШыRedisжЎКѓДјРДвЛИіаТЕФЬєеНЃЌЮвУЧВЛЪЧжЛгавЛИіМЦЫув§ЧцЃЌЮвУЧднЪБЯШАбRedisГЦЮЊвЛИіМЦЫув§ЧцЃЌвђЮЊЪ§ОнПЩФмдкRedisЃЌвВПЩФмашвЊЭЈЙ§PrestoШЅАбЪ§ОнЖСГіРДЃЌетЪБЮвУЧдкИеВХЩњГЩSQLжЎКѓЛЙМгШыСЫаТЕФвЛИізщМўЃЌQuery
EngineЕФФПЕФОЭЪЧдкВЛЭЌЕФв§ЧцжЎМфзіТЗгЩЃЌевЕНзюПьЗЕЛиЪ§ОнЕФЦЅХфЁЃБШШчЫЕЮвУЧвЛИіSQLЗЂЯТРДЃЌЫќЛсЯШШЅевRedisЃЌПДдкRedisевгаУЛгаетИіSQLЛКДцЕФМЧТМЃЌгаОЭжБНгЗЕЛиИјгУЛЇЃЌУЛгадйЕНPrestoЩЯУцВщбЏЁЃЩЯЯпСЫжЎКѓЃЌЮвУЧЙлВьСЫНсЙћЃЌНсЙћвВЪЧЗЧГЃВЛДэЕФЃЌЗЂЯжЦНОљЕФЛКДцУќжаТЪДяЕН15%ЃЌвтЮЖзХет15%ЕФВщбЏЖМЪЧУыГіЁЃ
вђЮЊЮвУЧгаВЛЭЌЕФжїЬтЃЌСїСПжїЬтЁЂЯњЪлЁЂЪеВиЁЂПЭЛЇЃЌРрЫЦВЛЭЌЕФжїЬтЃЌгУЛЇВщбЏЕФзщКЯВЛвЛбљЃЌЬиЪтЕФГЁОАЯТЃЌУќжаТЪДяЕН60%ЃЌетбљГ§ШЅЛКДцЕФЗЕЛиЫйЖШЗЧГЃПьжЎЭтЃЌЛКДцвВгаКУДІЃЌОЭЪЧЪЭЗХСЫPrestoЕФМЦЫуФмСІЃЌдЯШашвЊХмвЛДЮЕФВщбЏБуВЛашвЊСЫЁЃЪЭЗХГіРДЕФФкДцКЭCPUОЭПЩвдИјЦфЫќЕФВщбЏЬсЙЉМЦЫуФмСІСЫЁЃ
ПеМфЛЛЪБМфЃКOLAPЗжЮіЕФСэвЛЬѕЭООЖ
ЛКДцЕФЗНАИЪЕЪЉжЎКѓЃЌПДЩЯШЅКмВЛДэСЫЃЌетЪБКђЮвУЧгжв§Ц№СЫСэвЛДЮЫМПМЃЌЛКДцЯждкЪЧдкзіЕкЖўДЮВщбЏЕФЬсЫйЃЌЕЋЮвУЧЯыШУЕквЛДЮЕФЫйЖШвВПЩвдИќПьвЛаЉЁЃЫЕЕНЕквЛДЮЕФВщбЏЃЌЮвУЧвЊзпЛиРЯТЗСЫЃЌЮвУЧЫЕПеМфЛЛЪБМфЃЌЪЧЬсЩ§ЕквЛДЮВщбЏвЛИізюЯдЖјвзМћЕФАьЗЈЁЃ
ПеМфЛЛЪБМфЃЌШчЙћЫЕOLAP ad-hocВщбЏДгЪТЯШМЦЫуКУЕФНсЙћРяВщбЏЃЌФЧЪЧВЛЪЧЗЕЛиЫйЖШвВЛсКмПьЃПЦфДЮЃЌПеМфЛЛЪБМфвЊжЇГжЮЌЖШНЈФЃЃЌЫќвВвЊжЇГжJoinЁЃзюКѓЯЃЭћЪ§ОнЙмРэМђЕЅвЛаЉЃЌжЎЧАНВЕНЮЊЪВУДЬдЬСЫGreenPlumЃЌЪЧвђЮЊЪ§ОнЭЌВНИДдгЃЌЪ§ОнЕФдЄМЦЫуВЛКУПижЦЃЌЫљвдЯЃЭћЪ§ОнЙмРэПЩвдИќМђЕЅвЛаЉЁЃдЄМЦЫуЕФЙ§ГЬКЭНсЙћЕФЭЌВНВЛашвЊЖўДЮПЊЗЂЃЌзюКУгЩOLAPМЦЫув§ЧцздМКЙмРэЁЃЭЌЪБжЎЧАНВЕНЮвУЧЛсгавЛИідЄЯШЩшМЦДцдкЙ§ЖШЩшМЦЕФЮЪЬтЃЌетИіЮЪЬтдѕУДНтОіЃПЮвУЧФПЧАЕФГЁОАЪЧгаPrestoРДЖЕЕзЕФЃЌШчЙћУЛгаУќжаCUBEЃЌФЧЖЕЕзЕФКУДІОЭЪЧЫЕЮвУЧЛЙПЩвдгУPrestoРДГадиМЦЫуЃЌетШУЩшМЦдЄМЦЫуВщбЏЕФЪБКђЫќЕФбЁдёгрЕиЛсИќЖрЁЃЫќВЛашвЊЭъШЋИљОнгУЛЇЕФашЧѓЛђепвЕЮёашЧѓАбЫљгаЕФЩшМЦдкРяУцЃЌжЛвЊЬєздМККЯЪЪЕФОЭПЩвдЃЌЖдгкФЧаЉУЛгаУќжаЕФSQLЃЌЫфШЛТ§СЫвЛЕуЃЌЕЋИјЮвУЧДјРДЕФКУДІОЭЪЧЙмРэЕФГЩБОДѓДѓНЕЕЭСЫЁЃ
KylinЃКeBayЙБЯзЕФПЊдДMOLAPв§Чц
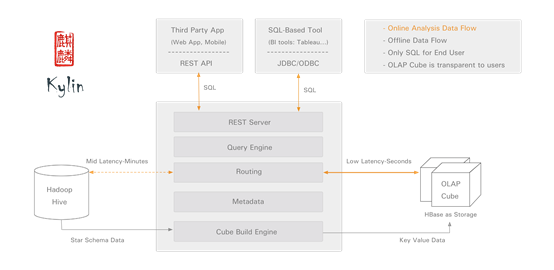
KylinЪЧгЩeBayПЊдДЕФвЛИів§ЧцЃЌKylinАбЪ§ОнЖСГіРДзіМЦЫуЃЌНсЫуЕФНсЙћЛсБЛДцдкHBaseРяЃЌЭЈЙ§HBaseзіAd-hocЕФЙІФмЁЃHBaseЕФКУДІЪЧгаЫїв§ЕФЃЌЫљвдзіAd-hocЕФадФмЗЧГЃКУЁЃ
ЮЊЪВУДЪЧKylin
ЪзЯШПеМфЛЛЪБМфЃЌЮвУЧдкИеПЊЪМв§ШыKylinЪБИњKylinПЊЗЂСФЙ§ЃЌЫћУЧНшМјСЫOracle
CUBEЕФИХФюЃЌЖдДЋЭГЪ§ОнПтПЊЗЂЕФШЫРДЫЕКмШнвзРэНтИХФюКЭЪЙгУЁЃжЇГжЮЌЖШНЈФЃздШЛжЇГжвВJoinЁЃдЄМЦЫуЕФЙ§ГЬЪЧгЩKylinздМКЙмРэЕФЃЌвВПЊЗХСЫAPIЃЌгыЕїЖШЯЕЭГДђЭЈзіЪ§ОнЫЂаТЁЃСэЭтKylinЪЧдкeBayЩЯКмДѓЕФЁЂУРЭХвВЪЧЭЖШыСЫКмДѓЕФОЋСІЕФгаГЩЙІОбщЕФВњЦЗЃЌЫљвдКмШнвзЕив§НјРДСЫЁЃ
Ек4НзЖЮ
гкЪЧЃЌЮвУЧНјШыСЫЮЈЦЗЛсOLAPЗжЮіМмЙЙЕФЕкЫФНзЖЮЃКHybirdЃКPrestoЕФROLAPКЭKylinЕФMOLAPНсКЯЗЂЛгИїздгХЪЦЃЌRedisЛКДцНјвЛВНЬсЩ§аЇТЪЁЃ
ВщбЏдкQuery EngineИљОнRedis-> KylinдйЕНPrestoЕФгХЯШМЖНјааТЗгЩЬНВщЃЌдкевЕНЕквЛИіПЩУќжаЕФТЗОЖжЎКѓЃЌзЊЯђЖдгІЕФв§ЧцНјааМЦЫуВЂИјгУЛЇЗЕЛиНсЙћЁЃKylinЕФв§ШыжївЊгУгкЬсЩ§КЫаФжИБъЕФOLAPЗжЮіЕФЪзДЮЯьгІЫйЖШЁЃетИізДЬЌПЩвдПДЕНKylinЕФВщбЏИВИЧТЪЦНОљ15%ЃЌзюИп25%ЃЌДѓЗљЬсЩ§КЫаФЪ§ОнЕФВщбЏЁЃЭЌЪБСїСПМИЪЎвкЁЂМИАйвкЕФЪ§ОнДгKylinзпвВДѓДѓЕиМѕЧсСЫPrestoЁЃЫфШЛЫЕетбљЕФМмЙЙПДЦ№РДЭІИДдгЕФЃЌЕЋетбљЕФвЛИіМмЙЙГіРДжЎКѓЃЌЛљБОЩЯТњзуСЫ90%ЕФOLAPЗжЮіСЫЁЃ
OLAPЗжЮіЕФММЪѕНјЛЏЪЧвЛИіУдЙЌЖјВЛЪЧН№зжЫў
ОЙ§етУДГЄвЛЖЮЪБМфЕФбнНјКЭвЛаЉУўЫїжЎКѓЃЌЮвУЧОѕЕУOLAPЗжЮіЕФММЪѕЪЧЫќЕФНјЛЏЪЧвЛИіУдЙЌЃЌВЛЪЧвЛИіН№зжЫўЁЃЙ§ШЅЫЕЩ§МЖЃЌЯёН№зжЫўЭљЩЯХЪЕЧЃЌЕЋЪЕМЪЩЯдкИеВХЕФЙ§ГЬДѓМвЗЂЯжЪЕМЪЩЯЫќИќЪЧЯёзпУдЙЌЃЌУПИізЊНЧЦфЪЕЪЧЖМХіЕНСЫЮЪЬтЃЌдкетИізЊНЧЃЌдкЕБЪБЕФЧщПіЯТевзюМбЕФЗНАИЁЃ
ВЛЪЧзіСЫДѓЪ§ОнжЎКѓЗХЦњСЫМЦЫуЃЌвВВЛЪЧзіСЫДѓЪ§ОнВЛдйПМТЧЪ§ОнЭЌВНЕФЮЪЬтЁЃЦфЪЕПЩвдЗЂЯжКмЖрДЋЭГЪ§ОнВжПтЛђепRBDMSЕФЫїв§ЁЂCUBEжЎРрЕФИХФюТ§Т§жиаТЛиЕНСЫДѓЪ§ОнЕФЪгвАРяУцЁЃЖдЮвУЧЖјбдЃЌЮвУЧШЯЮЊИќЖрЕФЪБКђЃЌЮвУЧдкзівЛаЉДѓЪ§ОнЕФаТММЪѕбнНјЪБИќЖрЕФЪЧгУИќгХауЕФММЪѕРДзіТфЕиКЭЪЕЯжЃЌЖјВЛЪЧШЅОмОјЙ§ШЅЕФвЛаЉДѓМвИаОѕКУЯёБШНЯГТОЩЕФЕФТпМЛђИХФюЁЃЫљвдЫЕЖдУПИіШЫРДЫЕЃЌЪЪКЯздМКвЕЮёЕФГЁОАЗНАИВХЪЧзюКУЕФЗНАИЁЃ
ЮЈЦЗЛсдкПЊдДМЦЫув§ЧцЩЯЫљзіЕФИФНј
НгЯТРДНВвЛЯТЮвУЧдкПЊдДМЦЫув§ЧцЩЯзіЕФИФНјЁЃPrestoКЭKylinЕФНЧЖШВЛвЛбљЃЌЫљвдЮвУЧдкгХЛЏЕФЗНЯђЩЯвВВЛЭЌЁЃPrestoжївЊзЂжиЬсЩ§ВщбЏадФмЃЌМѕЩйМЦЫуСПЃЌЬсЩ§ЪЕЪБадЁЃKylinзюжївЊгХЛЏЮЌБэВщевЃЌЬсИпCUBEЕФРћгУТЪЁЃ
PrestoЩЯЕФИФНј
дкЬсЩ§ВщбЏадФмЩЯЃК
аТдіHintгяЗЈЃЌЪзЯШзіЕФвВЪЧзюживЊЕФИФЖЏЪЧдкPrestoжадіМгСЫвЛИіHintЕФгяЗЈЃЌПЩвддкSQL
JoinМЖБ№ЖЏЬЌЩшжУВпТдЃЌЭЈЙ§БрвыЪБШУjoinдкreplicaКЭdistributeСНепжЎМфЩшжУЃЌЬсИпJoinаЇТЪЃЛ
МрПиИцОЏJOINЪ§ОнЧуаБЃЌЭЈЙ§МѕЩйЪ§ОнЧуаБЬсИпжДаааЇТЪЃЛ
діМгЖрМЏШКLOAD BALANCEЃЌПЩЦНКтВЛЭЌМЏШКМфМЦЫуСПЃЛ
ОЙ§ИФдьЃЌPrestoЕФВщбЏЪЕЪБадДѓЗљЬсЩ§ЁЃ
дкМѕЩйМЦЫуСПЩЯЃК
аТдіKylin ConnectorЃЌЭЈЙ§CUBEЬНасздЖЏЦЅХфSQLзгВщбЏжаПЩвдУќжаKylin CUBEЕФВПЗжЃЌДгKylinЬсШЁЪ§ОнКѓзіНјвЛВНЕФМЦЫуЃЌНЕЕЭВщбЏМЦЫуСПЃЛ
ОЙ§ИФдьЃЌPrestoЩ§МЖЮЊHybird OLAPв§ЧцЃЌЭЌЪБжЇГжROLAPКЭMOLAPСНжжФЃЪНЁЃ
дкЬсИпЪЕЪБадЩЯЃК
жиаДKafka ConnectorЃЌжЇГжШШИќаТKafkaжаTopicЁЂMessage КЭБэ/СаЕФгГЩфЖЈвхЃЛ
жЇГжKafkaАДoffsetЖСШЁЪ§ОнЃЌжЇГжPBИёЪНЃЌЬсИпKafkaЪ§ОндДЕФЖСШЁаЇТЪЃЛ
ОЙ§ИФдьЃЌPrestoВЛНіЪЧРыЯпOLAPв§ЧцЃЌзМЪЕЪБЪ§ОнДІРэЕФФмСІвВЕУЕНЬсИпЁЃ
KylinЩЯЕФИФНј
дкгХЛЏЮЌБэВщевЩЯЃК
ЭЈЙ§в§ШыPrestoНтОіKylinвкМЖЮЌБэЪЕЪБLookup OOMЕФЮЪЬтЃЌЭЈЙ§PrestoВщбЏЬцЛЛСЫдгаИДдгЕФЮЌБэгГЩфжЕВщевЛњжЦ;
ОЙ§ИФдьЃЌЮЈЦЗЛсАцЕФKylinЯрБШПЊдДАцБОМЋДѓЕФРЉеЙСЫЖдвЕЮёГЁОАЕФжЇГжГЬЖШ.
дкЬсЩ§CUBEРћгУТЪЩЯЃК
ПЊЗЂCUBE AdvisorЃЌЭЈЙ§ЭГМЦЗжЮізмНсКЯЪЪЕФЮЌЖШКЭжИБъзщКЯИЈжњПЊЗЂбЁдёХаЖЯаТНЈCUBEЕФВпТдЃЌМѕЩйШпгрКЭОбщХаЖЯЩЯЕФЮѓВю;
ЬсЙЉCUBEУќжаТЪМрПиЃЌаЮГЩCUBEаТНЈЁЂЪЙгУЕНзмНсЩ§МЖЕФБеЛЗ;
ОДЫИФдьЃЌCUBEУќжаТЪДѓЗљЬсИпЃЌМѕЩйСЫзЪдДЕФРЫЗбЬсЩ§СЫЯьгІЫйЖШЃЌОЙ§етбљЕФИФдьЃЌПЊЗЂВЛдйжЛЪЧИљОнздМКЕФОбщЛђепУЄФПНЈСЂЃЌЖјЪЧгаЪ§ОнПЩвРЁЃ |





